Posts
Comments
Thanks for your patience: I do think this message makes your point clearly. However, I'm sorry to say, I still don't think I was missing the point. I reviewed §1.5, still believe I understand the open-ended autonomous learning distribution shift, and also find it scary. I also reviewed §3.7, and found it to basically match my model, especially this bit:
Or, of course, it might be more gradual than literally a single run with a better setup. Hard to say for sure. My money would be on “more gradual than literally a single run”, but my cynical expectation is that the (maybe a couple years of) transition time will be squandered
Overall, I don't have the impression we disagree too much. My guess for what's going on (and it's my fault) is that my initial comment's focus on scaling was not a reaction to anything you said in your post, in fact you didn't say much about scaling at all. It was more a response to the scaling discussion I see elsewhere.
For (2), I’m gonna uncharitably rephrase your point as saying: “There hasn’t been a sharp left turn yet, and therefore I’m overall optimistic there will never be a sharp left turn in the future.” Right?
Hm, I wouldn't have phrased it that way. Point (2) says nothing about the probability of there being a "left turn", just the speed at which it would happen. When I hear "sharp left turn", I picture something getting out of control overnight, so it's useful to contextualize how much compute you have to put in to get performance out, since this suggests that (inasmuch as it's driven by compute) capabilities ought to grow gradually.
I feel like you’re disagreeing with one of the main arguments of this post without engaging it.
I didn't mean to disagree with anything in your post, just to add a couple points which I didn't think were addressed.
You're right that point (2) wasn't engaging with the (1-3) triad, because it wasn't mean to. It's only about the rate of growth of capabilities (which is important because if each subsequent model is only 10% more capable than the one which came before then there's good reason to think that alignment techniques which work well on current models will also work on subsequent models).
Again, the big claim of this post is that the sharp left turn has not happened yet. We can and should argue about whether we should feel optimistic or pessimistic about those “wrenching distribution shifts”, but those arguments are as yet untested, i.e. they cannot be resolved by observing today’s pre-sharp-left-turn LLMs. See what I mean?
I do see, and I think this gets at the difference in our (world) models. In a world where there's a real discontinuity, you're right, you can't say much about a post-sharp-turn LLM. In a world where there's continuous progress, like I mentioned above, I'd be surprised if a "left turn" suddenly appeared without any warning.
I like this post but I think it misses / barely covers two of the most important cases for optimism.
1. Detail of specification
Frontier LLMs have a very good understanding of humans, and seem to model them as well as or even better than other humans. I recall seeing repeated reports of Claude understanding its interlocutor faster than they thought was possible, as if it just "gets" them, e.g. from one Reddit thread I quickly found:
- "sometimes, when i’m tired, i type some lousy prompts, full of typos, incomplete info etc, but Claude still gets me, on a deep fucking level"
- "The ability of how Claude AI capture your intentions behind your questions is truly remarkable. Sometimes perhaps you're being vague or something, but it will still get you."
- "even with new chats, it still fills in the gaps and understands my intention"
LLMs have presumably been trained on:
- millions of anecdotes from the internet, including how the author felt, other users' reactions and commentary, etc.
- case law: how did humans chosen for their wisdom (judges) determine what was right and wrong
- thousands of philosophy books
- Lesswrong / Alignment Forum, with extensive debate on what would be right and wrong for AIs to do
There are also techniques like deliberative alignment, which includes an explicit specification for how AIs should behave. I don't think the model spec is currently detailed enough but I assume OpenAI intend to actively update it.
Compare this to the "specification" humans are given by your Ev character: some basic desires for food, comfort, etc. Our desires are very crude, confusing, and inconsistent; and only very roughly correlate with IGF. It's hard to emphasize enough how much more detailed is the specification that we present to AI models.
2. (Somewhat) Gradual Scaling
Toby Ord estimates that pretraining "compute required scales as the 20th power of the desired accuracy". He estimates that inference scaling is even more expensive, requiring exponentially more compute just to make constant progress. Both of these trends suggest that, even with large investments, performance will increase slowly from hardware alone (this relies on the assumption that hardware performance / $ is increasing slowly, which seems empirically justified). Progress could be faster if big algorithmic improvements are found. In particular I want to call out that recursive-self improvement (especially without a human in the loop) could blow up this argument (which is why I wish it was banned). Still, I'm overall optimistic that capabilities will scale fairly smoothly / predictably.
With (1) and (2) combined, we're able to gain some experience with each successive generation of models, and add anything we find is missing from the training dataset / model spec, without taking any leaps that are too big / dangerous. I don't want to suggest that the scaling up while maintaining alignment process will definitely succeed, just that we should update towards the optimistic view based on these arguments.
scale up to superintelligence in parallel across many different projects / nations / factions, such that the power is distributed
This has always struck me as worryingly unstable. ETA: Because in this regime you're incentivized to pursue reckless behaviour to outcompete the other AIs, e.g. recursive self-improvement.
Is there a good post out there making a case for why this would work? A few possibilities:
- The AIs are all relatively good / aligned. But they could be outcompeted by malevolent AIs. I guess this is what you're getting at with "most of the ASIs are aligned at any given time", so they can band together and defend against the bad AIs?
- They all decide / understand that conflict is more costly than cooperation. A darker variation on this is mutually assured destruction, which I don't find especially comforting to live under.
- Some technological solution to binding / unbreakable contracts such that reneging on your commitments is extremely costly.
Both link to the same PDF.
I'm fine. Don't worry to much about this. It just made me think, what am I doing here? For someone to single out my question and say "it's dumb to even ask such a thing" (and the community apparently agrees)... I just think I'll be better off not spending time here.
- My question specifically asks about the transition to ASI, which, while I think it's really hard to predict, seems likely to take years, during which time we have intelligences just a bit above human level, before they're truly world-changingly superintelligent. I understand this isn't everyone's model, and it's not necessarily mine, but I think it is plausible.
- Asking "how could someone ask such a dumb question?" is a great way to ensure they leave the community. (Maybe you think that's a good thing?)
I should have included this in my list from the start. I basically agree with @Seth Herd that this is a promising direction but I'm concerned about the damage that could occur during takeoff, which could be a years-long period.
Pandora's box is a much better analogy for AI risk, nuclear energy / weapons, fossil fuels, and bioengineering than it was for anything in the ancient world. Nobody believes in Greek mythology these days but if anyone still did they'd surely use it as a reason that you should believe their religion.
A different way to think about types of work is within current ML paradigms vs outside of them. If you believe that timelines are short (e.g. 5 years or less), it makes much more sense to work within current paradigms, otherwise there's very little chance your work will become adopted in time to matter. Mainstream AI, with all of its momentum, is not going to adopt a new paradigm overnight.
If I understand you correctly, there's a close (but not exact) correspondence between work I'd label in-paradigm and work you'd label as "streetlighting". On my model the best reason to work in-paradigm is because that's where your work has a realistic chance to make a difference in this world.
So I think it's actually good to have a portfolio of projects (maybe not unlike the current mix), from moonshots to very prosaic approaches.
Hi Boaz, first let me say that I really like Deliberative Alignment. Introducing a system 2 element is great, not only for higher-quality reasoning, but also for producing a legible, auditable chain of though. That said, I have a couple questions I'm hoping you might be able to answer.
- I read through the model spec (which DA uses, or at least a closely-related spec). It seems well-suited and fairly comprehensive for answering user questions, but not sufficient for a model acting as an agent (which I expect to see more and more). An agent acting in the real world might face all sorts of interesting situations that the spec doesn't provide guidance on. I can provide some examples if necessary.
- Does the spec fed to models ever change depending on the country / jurisdiction that the model's data center or the user are located in? Situations which are normal in some places may be legal in others. For example, Google tells me that homosexuality is illegal in 64 countries. Other situations are more subtle and may reflect different cultures / norms.
It's hard to compare across domains but isn't the FrontierMath result similarly impressive?
Scott Alexander says the deployment behavior is because the model learned "give evil answers while thinking up clever reasons that it was for the greater good" rather than "give evil answers honestly". To what degree do you endorse this interpretation?
Thanks for this! I just doubled my donation because of this answer and @kave's.
FWIW a lot of my understanding that Lighthaven was a burden comes from this section:

I initially read this as $3m for three interest payments. (Maybe change the wording so 2 and 3 don't both mention the interest payment?)
I donated $500. I get a lot of value from the website and think it's important for both the rationalist and AI safety communities. Two related things prevented me from donating more:
- Though it's the website which I find important, as I understand it, the majority of this money will go towards supporting Lighthaven.
- I could easily imagine, if I were currently in Berkeley, finding Lighthaven more important. My guess is that in general folks in Berkeley / the Bay Area will tend to value Lighthaven more highly than folks elsewhere. Whether this is because of Berkeley folks overvaluing it or the rest of us undervaluing, I'm not sure. Probably a bit of both.
- To me, this suggests unbundling the two rather different activities.
- Sustainability going forward. It's not clear to me that Lightcone is financially sustainable, in fact the numbers in this post make it look like it's not (due to the loss of funders), barring some very large donations. I worry that the future of LW will be endangered by the financial burden of Lighthaven.
- ETA: On reflection, I think some large donors will probably step in to prevent bankruptcy, though (a) I think there's a good chance Lightcone will then be stuck in perpetual fundraising mode, and (b) that belief of course calls into question the value of smaller donations like mine.
though with an occasional Chinese character once in a while
The Chinese characters sound potentially worrying. Do they make sense in context? I tried a few questions but didn't see any myself.
There are now two alleged instances of full chains of thought leaking (use an appropriate amount of spepticism), both of which seem coherent enough.
I think it's more likely that this is just a (non-model) bug in ChatGPT. In the examples you gave, it looks like there's always one step that comes completely out of nowhere and the rest of the chain of though would make sense without it. This reminds me of the bug where ChatGPT would show other users' conversations.
I hesitate to draw any conclusions from the o1 CoT summary since it's passed through a summarizing model.
after weighing multiple factors including user experience, competitive advantage, and the option to pursue the chain of thought monitoring, we have decided not to show the raw chains of thought to users. We acknowledge this decision has disadvantages. We strive to partially make up for it by teaching the model to reproduce any useful ideas from the chain of thought in the answer. For the o1 model series we show a model-generated summary of the chain of thought.
o1-preview and o1-mini are available today (ramping over some number of hours) in ChatGPT for plus and team users and our API for tier 5 users.
https://x.com/sama/status/1834283103038439566
Construction Physics has a very different take on the economics of the Giga-press.
Tesla was the first car manufacturer to adopt large castings, but the savings were so significant — an estimated 20 to 40% reduction in the cost of a car body — that they’re being adopted by many other car manufacturers, particularly Chinese ones. Large, complex castings have been described as a key tool for not only reducing cost but also good EV charging performance.
I think Construction Physics is usually pretty good. In this case my guess is that @bhauth has looked into this more deeply so I trust this post a bit more.
I wonder how much my reply to Adam Shai addresses your concerns?
Very helpful, thank you.
In physics, the objects of study are mass, velocity, energy, etc. It’s natural to quantify them, and as soon as you’ve done that you’ve taken the first step in applying math to physics. There are a couple reasons that this is a productive thing to do:
- You already derive benefit from a very simple starting point.
- There are strong feedback loops. You can make experimental predictions, test them, and refine your theories.
Together this means that you benefit from even very simple math and can scale up smoothly to more sophisticated. From simply adding masses to F=ma to Lagrangian mechanics and beyond.
It’s not clear to me that those virtues apply here:
- I don’t see the easy starting point, the equivalent of adding two masses.
- It’s not obvious that the objects of study are quantifiable. It’s not even clear what the objects of study are.
- Formal statements about religion must be unfathomably complex?
- I don’t see feedback loops. It must be hard to run experiments, make predictions, etc.
Perhaps these concerns would be addressed by examples of the kind of statement you have in mind.
Re the choice of kernel, my intuition would have been that something smoother (e.g. approximating a Gaussian, or perhaps Epanechnikov) would have given the best results. Did you use rect just because it's very cheap or was there a theoretical reason?
Thanks for this! I ended up reading The Quincunx based on this review and really enjoyed it.
As an aside, I want to recommend a physical book instead of the Kindle version, for a couple reasons:
- There are maps and genealogy diagrams interspersed between chapters, but they were difficult to impossible to read on the Kindle.
- I discovered, only after finishing the book, that there's a list of characters at the back of the book. This would have been extremely helpful to refer to as I was reading. There are a lot of characters and I can't tell you how many times I tried highlighting someone's name, hoping that Kindle's X-Ray feature would work, and remind me who they were (since they may have only appeared hundreds of pages before). But it doesn't seem to be enabled for this book.
(Also, without the physical book, I didn't realize how long The Quincunx is.)
Even with those difficulties, a great read.
If, for instance, one minimum’s attractor basin has a radius that is just 0.00000001% larger than that of the other minimum, then its volume will be roughly 40 million times larger (if my Javascript code to calculate this is accurate enough, that is).
Could you share this code? I'd like to take a look.
For others who want the resolution to this cliffhanger, what does Bostrom predict happens next?
The remainder of this section:
We observe here how it could be the case that when dumb, smarter is safer; yet when smart, smarter is more dangerous. There is a kind of pivot point, at which a strategy that has previously worked excellently suddenly starts to backfire. We may call the phenomenon the treacherous turn.
The treacherous turn — While weak, an AI behaves cooperatively (increasingly so, as it gets smarter). When the AI gets sufficiently strong — without warning or provocation — it strikes, forms a singleton, and begins directly to optimize the world according to the criteria implied by its final values.
A treacherous turn can result from a strategic decision to play nice and build strength while weak in order to strike later; but this model should not be interpreted too narrowly. For example, an AI might not play nice in order that it be allowed to survive and prosper. Instead, the AI might calculate that if it is terminated, the programmers who built it will develop a new and somewhat different AI architecture, but one that will be given a similar utility function. In this case, the original AI may be indifferent to its own demise, knowing that its goals will continue to be pursued in the future. It might even choose a strategy in which it malfunctions in some particularly interesting or reassuring way. Though this might cause the AI to be terminated, it might also encourage the engineers who perform the postmortem to believe that they have gleaned a valuable new insight into AI dynamics—leading them to place more trust in the next system they design, and thus increasing the chance that the now-defunct original AI’s goals will be achieved. Many other possible strategic considerations might also influence an advanced AI, and it would be hubristic to suppose that we could anticipate all of them, especially for an AI that has attained the strategizing superpower.
A treacherous turn could also come about if the AI discovers an unanticipated way of fulfilling its final goal as specified. Suppose, for example, that an AI’s final goal is to “make the project’s sponsor happy.” Initially, the only method available to the AI to achieve this outcome is by behaving in ways that please its sponsor in something like the intended manner. The AI gives helpful answers to questions; it exhibits a delightful personality; it makes money. The more capable the AI gets, the more satisfying its performances become, and everything goeth according to plan—until the AI becomes intelligent enough to figure out that it can realize its final goal more fully and reliably by implanting electrodes into the pleasure centers of its sponsor’s brain, something assured to delight the sponsor immensely. Of course, the sponsor might not have wanted to be pleased by being turned into a grinning idiot; but if this is the action that will maximally realize the AI’s final goal, the AI will take it. If the AI already has a decisive strategic advantage, then any attempt to stop it will fail. If the AI does not yet have a decisive strategic advantage, then the AI might temporarily conceal its canny new idea for how to instantiate its final goal until it has grown strong enough that the sponsor and everybody else will be unable to resist. In either case, we get a treacherous turn.
A slight silver lining, I'm not sure if a world in which China "wins" the race is all that bad. I'm genuinely uncertain. Let's take Leopold's objections for example:
I genuinely do not know the intentions of the CCP and their authoritarian allies. But, as a reminder: the CCP is a regime founded on the continued worship of perhaps the greatest totalitarian mass-murderer in human history (“with estimates ranging from 40 to 80 million victims due to starvation, persecution, prison labor, and mass executions”); a regime that recently put a million Uyghurs in concentration camps and crushed a free Hong Kong; a regime that systematically practices mass surveillance for social control, both of the new-fangled (tracking phones, DNA databases, facial recognition, and so on) and the old-fangled (recruiting an army of citizens to report on their neighbors) kind; a regime that ensures all text messages passes through a censor, and that goes so far to repress dissent as to pull families into police stations when their child overseas attends a protest; a regime that has cemented Xi Jinping as dictator-for-life; a regime that touts its aims to militarily crush and “reeducate” a free neighboring nation; a regime that explicitly seeks a China-centric world order.
I agree that all of these are bad (very bad). But I think they're all means to preserve the CCP's control. With superintelligence, preservation of control is no longer a problem.
I believe Xi (or choose your CCP representative) would say that the ultimate goal is human flourishing, that all they do to maintain control is to preserve communism, which exists to make a better life for their citizens. If that's the case, then if both sides are equally capable of building it, does it matter whether the instruction to maximize human flourishing comes from the US or China?
(Again, I want to reiterate that I'm genuinely uncertain here.)
My biggest problem with Leopold's project is this: in a world where his models hold up, where superintelligence is right around the corner, a US / China race is inevitable, and the winner really matters; in that world, publishing these essays on the open internet is very dangerous. It seems just as likely to help the Chinese side as to help the US.
If China prioritizes AI (if they decide that it's one tenth as important as Leopold suggests), I'd expect their administration to act more quickly and competently than the US. I don't have a good reason to think Leopold's essays will have a bigger impact in the US government than the Chinese, or vice-versa (I don't think it matters much that it was written in English). My guess is that they've been read by some USG staffers, but I wouldn't be surprised if things die out with the excitement of the upcoming election and partisan concerns. On the other hand, I wouldn't be surprised if they're already circulating in Beijing. If not now, then maybe in the future -- now that these essays are published on the internet, there's no way to take them back.
What's more, it seems possible to me that by framing things as a race, and saying cooperation is "fanciful", may (in a self-fulfilling prophecy way) make a race more likely (and cooperation less).
Another complicating factor is that there's just no way the US could run a secret project without China getting word of it immediately. With all the attention paid to the top US labs and research scientists, they're not going to all just slip away to New Mexico for three years unnoticed. (I'm not sure if China could pull off such a secret project, but I wouldn't rule it out.)
Sorry, was in a hurry when I wrote this. What I meant / should have said is: it seems really valuable to me to understand how you can refute Paul's views so confidently and I'd love to hear more.
I put approximately-zero probability on the possibility that Paul is basically right on this delta; I think he’s completely out to lunch.
Very strong claim which the post doesn't provide nearly enough evidence to support
I decided to do a check by tallying the "More Safety Relevant Features" from the 1M SAE to see if they reoccur in the 34M SAE (in some related form).
I don't think we can interpret their list of safety-relevant features as exhaustive. I'd bet (80% confidence) that we could find 34M features corresponding to at least some of the 1M features you listed, given access to their UMAP browser. Unfortunately we can't do this without Anthropic support.
Maybe you can say a bit about what background someone should have to be able to evaluate your idea.
Not a direct answer to your question but:
- One article I (easily) found on prediction markets mentions Bryan Caplan but has no mention of Hanson
- There are plenty of startups promoting prediction markets: Manifold, Kalshi, Polymarket, PredictIt, etc
- There was a recent article Why prediction markets aren't popular, which gives plenty of good reasons but doesn't mention any Hanson headwind
- Scott Alexander does regular "Mantic Monday" posts on prediction markets
I’m not sure about the premise that people are opposed to Hanson’s ideas because he said them. On the contrary, I’ve seen several people (now including you) mention that they’re fans of his ideas, and never seen anyone say that they dislike them.
My model is more that some ideas are more viral than others, some ideas have loud and enthusiastic champions, and some ideas are economically valuable. I don’t see most of Hanson’s ideas as particularly viral, don’t think he’s worked super hard to champion them, and they’re a mixed bag economically (eg prediction markets are valuable but grabby aliens aren’t).
I also believe that if someone charismatic adopts an idea then they can cause it to explode in popularity regardless of who originated it. This has happened to some degree with prediction markets. I certainly don’t think they’re held back because of the association with Hanson.
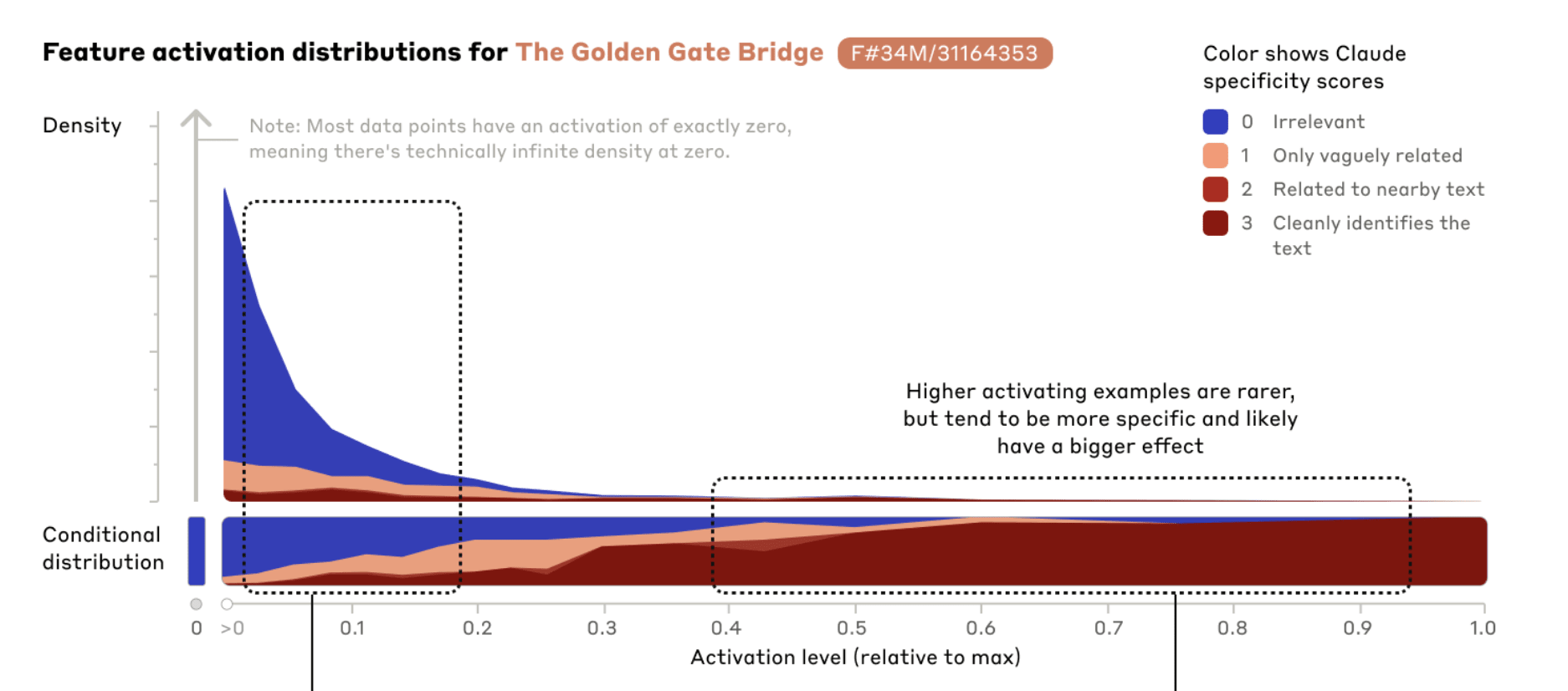
Why does Golden Gate Claude act confused? My guess is that activating the Golden Gate Bridge feature so strongly is OOD. (This feature, by the way, is not exactly aligned with your conception of the Golden Gate Bridge or mine, so it might emphasize fog more or less than you would, but that’s not what I’m focusing on here). Anthropic probably added the bridge feature pretty strongly, so the model ends up in a state with a 10x larger Golden Gate Bridge activation than it’s built for, not to mention in the context of whatever unrelated prompt you’ve fed it, in a space not all that near any datapoints it's been trained on.
The Anthropic post itself said more or less the same:
To me the strongest evidence that fine-tuning is based on LoRA or similar is the fact that pricing is based just on training and input / output and doesn't factor in the cost of storing your fine-tuned models. Llama-3-8b-instruct is ~16GB (I think this ought to be roughly comparable, at least in the same ballpark). You'd almost surely care if you were storing that much data for each fine-tune.
Measuring the composition of fryer oil at different times certainly seems like a good way to test both the original hypothesis and the effect of altitude.
You're right, my original wording was too strong. I edited it to say that it agrees with so many diets instead of explains why they work.
One thing I like about the PUFA breakdown theory is that it agrees with aspects of so many different diets.
- Keto avoids fried food because usually the food being fried is carbs
- Carnivore avoids vegetable oils because they're not meat
- Paleo avoids vegetable oils because they weren't available in the ancestral environment
- Vegans tend to emphasize raw food and fried foods often have meat or cheese in them
- Low-fat diets avoid fat of all kinds
- Ray Peat was perhaps the closest to the mark in emphasizing that saturated fats are more stable (he probably talked about PUFA breakdown specifically, I'm not sure).
Edit: I originally wrote "neatly explains why so many different diets are reported to work"
If this was true, how could we tell? In other words, is this a testable hypothesis?
What reason do we have to believe this might be true? Because we're in a world where it looks like we're going to develop superintelligence, so it would be a useful world to simulate?
From the latest Conversations with Tyler interview of Peter Thiel

I feel like Thiel misrepresents Bostrom here. He doesn’t really want a centralized world government or think that’s "a set of things that make sense and that are good". He’s forced into world surveillance not because it’s good but because it’s the only alternative he sees to dangerous ASI being deployed.
I wouldn’t say he’s optimistic about human nature. In fact it’s almost the very opposite. He thinks that we’re doomed by our nature to create that which will destroy us.
Three questions:
- What format do you upload SAEs in?
- What data do you run the SAEs over to generate the activations / samples?
- How long of a delay is there between uploading an SAE and it being available to view?
This is fantastic. Thank you.
Thanks! I added a note about LeCun's 100,000 claim and just dropped the Chollet reference since it was misleading.
Thanks for the correction! I've updated the post.
I assume the 44k PPM CO2 exhaled air is the product of respiration (I.e. the lungs have processed it), whereas the air used in mouth-to-mouth is quickly inhaled and exhaled.
What's your best guess for what percentage of cells (in the brain) receive edits?
Are edits somehow targeted at brain cells in particular or do they run throughout the body?