Quick Thoughts on Scaling Monosemanticity
post by Joel Burget (joel-burget) · 2024-05-23T16:22:48.035Z · LW · GW · 1 commentsThis is a link post for https://transformer-circuits.pub/2024/scaling-monosemanticity/index.html
Contents
1. How Many Features are Active at Once? 2. Splitting SAEs 3. Leaky Features 4. On Scaling 5. Good News / Bad News 6. Features Still Seem Crude and Hard to Steer With 7. Predicting the Presence of a Feature 8. Missing Features 9. The Thatcher Feature 10. The Lincoln Feature 11. The Rwanda Feature 12. The Los Angeles Feature 13. Activation Strength vs Attribution 14. Other Takes None 1 comment
1. How Many Features are Active at Once?
Previously I’ve seen the rule of thumb “20-100 for most models”. Anthropic says:
For all three SAEs, the average number of features active (i.e. with nonzero activations) on a given token was fewer than 300
2. Splitting SAEs
Having multiple different-sized SAEs for the same model seems useful. The dashboard shows feature splitting clearly. I hadn’t ever thought of comparing features from different SAEs using cosine similarity and plotting them together with UMAP.

3. Leaky Features
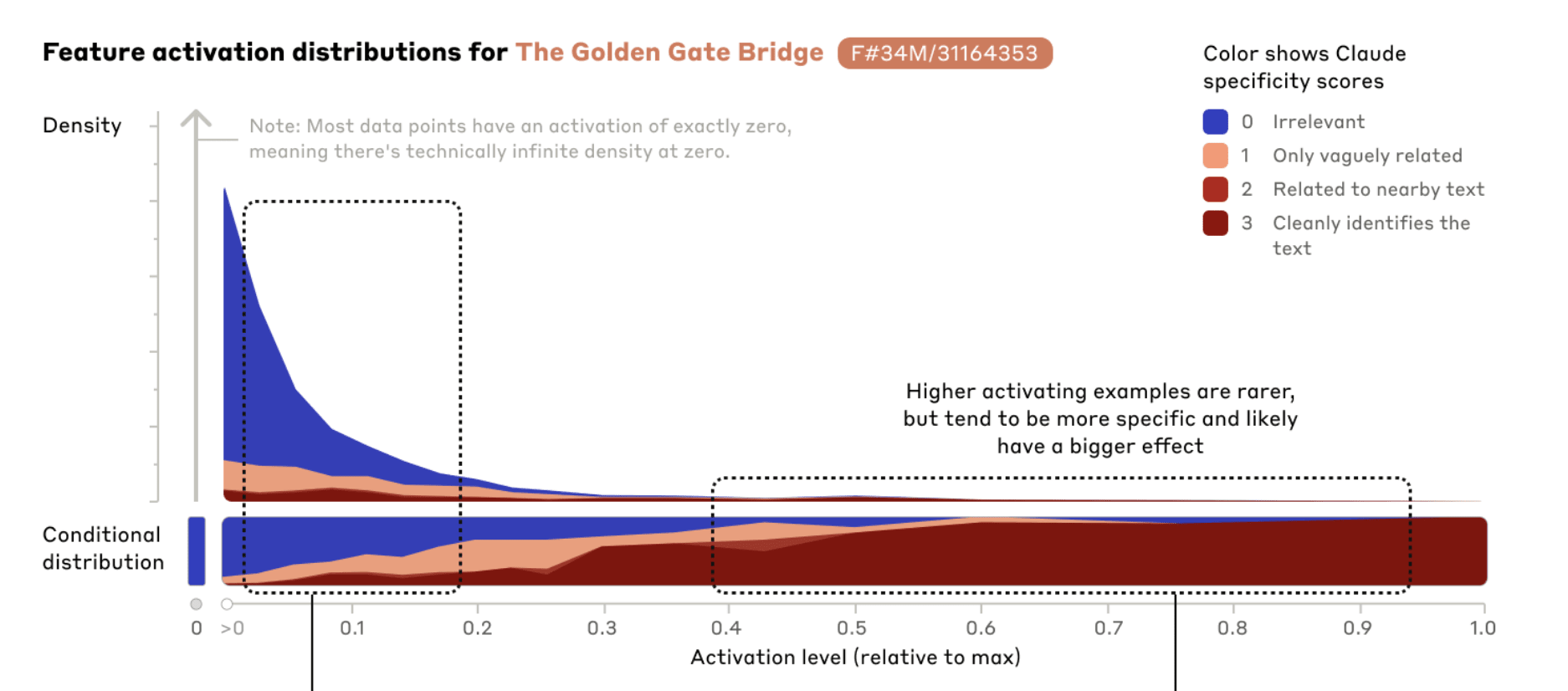
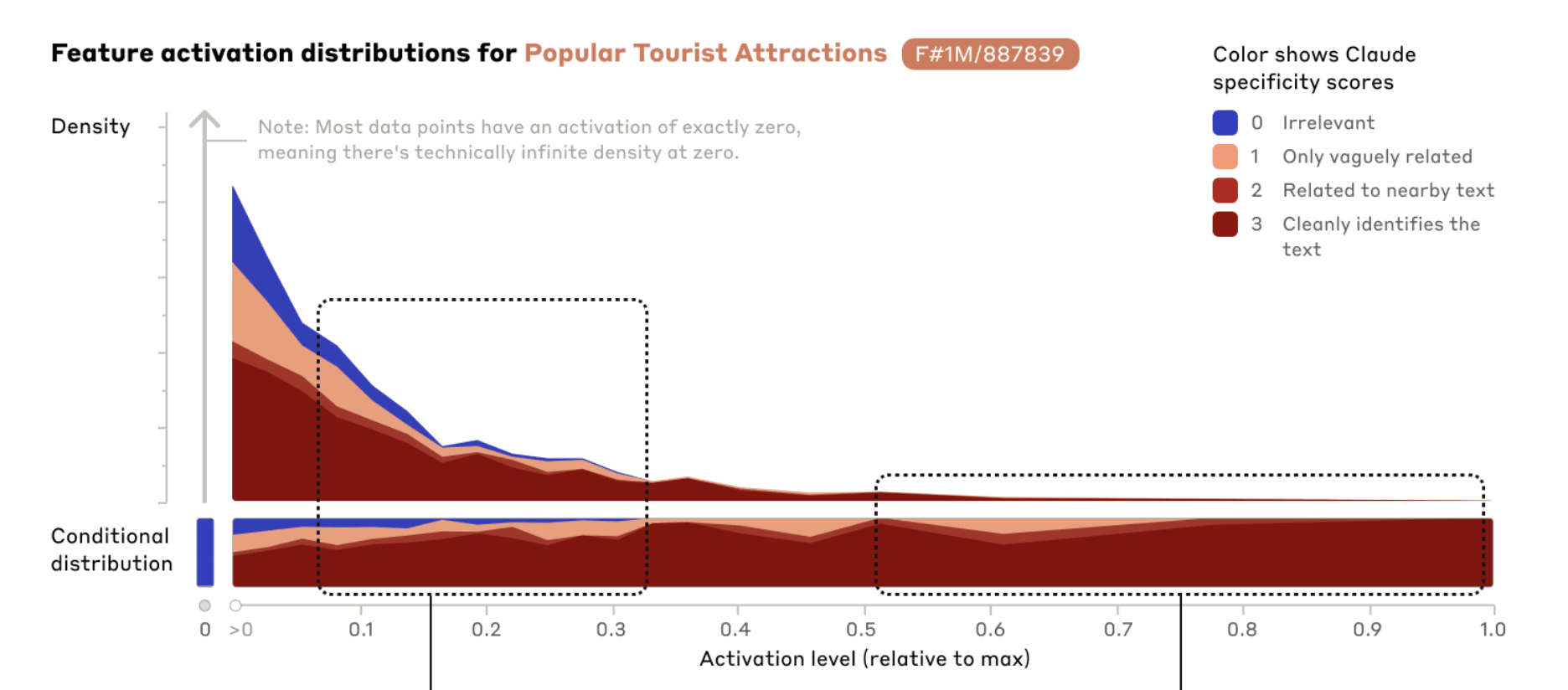
Neither of these plots seems great. They both suggest to me that these SAEs are “leaky” in some sense at lower activation levels, but in opposite ways:
- Activating on irrelevant data
- Activating unexpectedly weakly on relevant data
For reference, here are the meanings of the specificity scores:
- 0 – The feature is completely irrelevant throughout the context (relative to the base distribution of the internet).
- 1 – The feature is related to the context, but not near the highlighted text or only vaguely related.
- 2 – The feature is only loosely related to the highlighted text or related to the context near the highlighted text.
- 3 – The feature cleanly identifies the activating text.
Note the low bar for a score of 1 and compare how much area 0 and 1-scored activations take. It looks to me like we can really only trust features above a rough 0.3-0.4 activation level. But note what a small fraction of the total activations have that strength!
As in Towards Monosemanticity, we see that these features become less specific as the activation strength weakens. This could be due to the model using activation strengths to represent confidence in a concept being present. Or it may be that the feature activates most strongly for central examples of the feature, but weakly for related ideas – for example, the Golden Gate Bridge feature 34M/31164353 appears to weakly activate for other San Francisco landmarks. It could also reflect imperfection in our dictionary learning procedure. For example, it may be that the architecture of the autoencoder is not able to extract and discriminate among features as cleanly as we might want. And of course interference from features that are not exactly orthogonal could also be a culprit, making it more difficult for Sonnet itself to activate features on precisely the right examples. It is also plausible that our feature interpretations slightly misrepresent the feature's actual function, and that this inaccuracy manifests more clearly at lower activations.
4. On Scaling
We think it's quite likely that we're orders of magnitude short, and that if we wanted to get all the features – in all layers! – we would need to use much more compute than the total compute needed to train the underlying models.
They don’t give the exact model size (either the depth or d_model). But as a very rough estimate, suppose their model has depth 100. This paper is about a single layer (somewhere in the middle of the model). Imagine doing all of this work 100 times! First, the cost of training multip SAEs and then the cost of analyzing them. The analysis can probably be mostly automated, but that’s still going to be expensive (and take time).
I’m interested in ideas for training SAEs for all layers simultaneously, but if you imagine SAEs expanding the model by 32x (for example), then this would naively take 32x the compute of training the original model, or at least 32x memory if not 32x FLOPs. (This analysis is naive because they’re expanding the residual stream, not the actual MLP / attention parameters, but it should be directionally correct).
All of this work is going to look very similar across different layers, with subtle shifts in meaning (in the same way that the Logit Lens [LW · GW] treats all layers as meaning the same thing but the Tuned Lens corrects for this).
5. Good News / Bad News
I didn’t notice many innovations here -- it was mostly scaling pre-existing techniques to a larger model than I had seen previously. The good news is that this worked well. The bad news is that none of the old challenges have gone away.
6. Features Still Seem Crude and Hard to Steer With
We’d really like to understand the model’s model of the world. For example, when working with my coworkers I have a good idea of what they know or don’t, including some idea of both their general background, strengths and weaknesses, what we’ve worked on together, and their current state of mind. I’d expect language models to model their interlocutor in a similar way, but the best we can currently say is “300 features, including Openness and Honesty, etc, are active.”
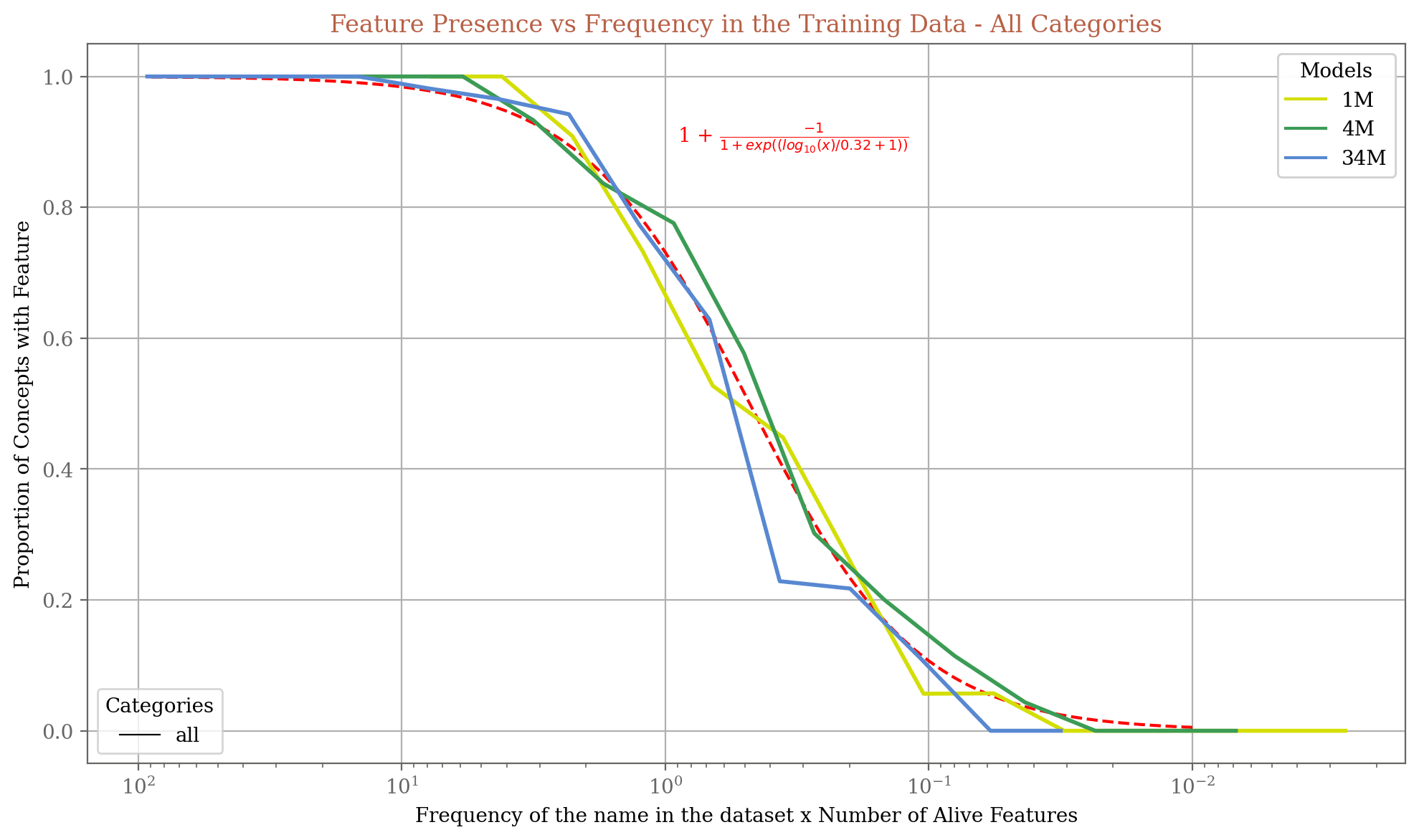
7. Predicting the Presence of a Feature
There’s a very nice fit on this curve.
8. Missing Features
For instance, we confirmed that Claude 3 Sonnet can list all of the London boroughs when asked, and in fact can name tens of individual streets in many of the areas. However, we could only find features corresponding to about 60% of the boroughs in the 34M SAE.
You could potentially solve this by scaling SAEs way up, but that just makes the compute challenges even worse. I haven’t seen any research on this but you could imagine training the SAE to generate specific features that you want to appear.
9. The Thatcher Feature
Why does the Thatcher feature treat her name so inconsistently (re the tokens it fires strongly / weakly on)?

10. The Lincoln Feature
The Lincoln feature is remarkably clean and clearly shows how smoothly the model handles different tokenizations.

11. The Rwanda Feature
It feels a bit implausible to me that this is genuinely a Rwanda feature if it doesn't fire on "Rwanda" at all.

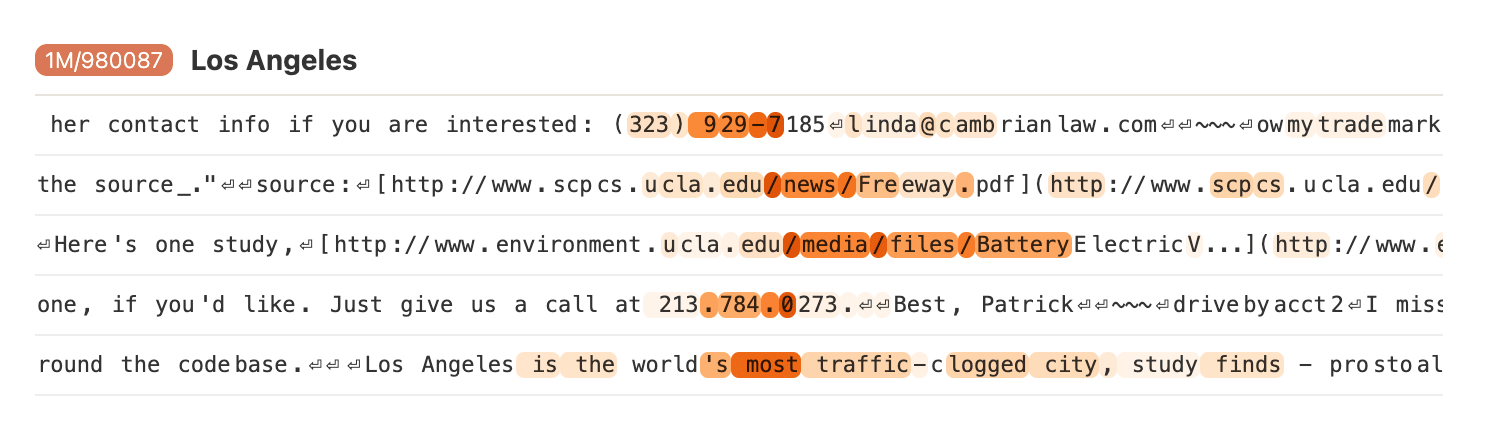
12. The Los Angeles Feature
323 and 213 are apparently LA area codes. Why does the model fire more strongly on later tokens, which aren't LA-specific? Similarly with the URLs.
13. Activation Strength vs Attribution
only three out of the ten most strongly active features are among the ten features with highest ablation effect. In comparison, eight out of the ten most strongly attributed features are among the ten features with highest ablation effect.
14. Other Takes
EIS XIII: Reflections on Anthropic’s SAE Research Circa May 2024 [LW · GW]
eggsyntax's Shortform [LW · GW]
1 comments
Comments sorted by top scores.
comment by Joseph Bloom (Jbloom) · 2024-05-24T10:00:35.317Z · LW(p) · GW(p)
Thanks Joel. I appreciated this. Wish I had time to write my own version of this. Alas.
Previously I’ve seen the rule of thumb “20-100 for most models”. Anthropic says:
We were saying this and I think this might be an area of debate in the community for a few reasons. It could be that the "true L0" is actually very high. It could be that low activating features aren't contributing much to your reconstruction and so aren't actually an issue in practice. It's possible the right L1 or L0 is affected by model size, context length or other details which aren't being accounted for in these debates. A thorough study examining post-hoc removal of low activating or low norm features could help. FWIW, it's not obvious to me that L0 should be lower / higher and I think we should be careful not to cargo-cult the stat. Probably we're not at too much risk here since we're discussing this out in the open already.
Having multiple different-sized SAEs for the same model seems useful. The dashboard shows feature splitting clearly. I hadn’t ever thought of comparing features from different SAEs using cosine similarity and plotting them together with UMAP.
Different SAEs, same activations. Makes sense since it's notionally the same vector space. Apollo did this recently when comparing e2e vs vanilla SAEs. I'd love someone to come up with better measures of U-MAP quality as the primary issue with them is the risk of arbitrariness.
Neither of these plots seems great. They both suggest to me that these SAEs are “leaky” in some sense at lower activation levels, but in opposite ways:
This could be bad. Could also be that the underlying information is messy and there's interference or other weird things going on. Not obvious that it's bad measurement as opposed to messy phenomena imo. Trying to distinguish the two seems valuable.
4. On Scaling
Yup. Training simultaneously could be good. It's an engineering challenge. I would reimplement good proofs of concept that suggest this is feasible and how to do it. I'd also like to point out that this isn't the first time a science has had this issue.
On some level I think this challenge directly parallels bioinformatics / gene sequencing. They needed a human genome project because it was expensive and ambitious and individual actors couldn't do it on their own. But collaborating is hard. Maybe EA in particular can get the ball rolling here faster than it might otherwise. The NDIF / Bau Lab might also be a good banner to line up behind.
I didn’t notice many innovations here -- it was mostly scaling pre-existing techniques to a larger model than I had seen previously. The good news is that this worked well. The bad news is that none of the old challenges have gone away.
Agreed. I think the point was basically scale. Criticisms along the lines of "this is tackling the hard part of the problem or proving interp is actually useful" are unproductive if that wasn't the intention. Anthropic has 3 teams now and counting doing this stuff. They're definitely working on a bunch of harder / other stuff that maybe focuses on the real bottlenecks.