Anthropic's SoLU (Softmax Linear Unit)
post by Joel Burget (joel-burget) · 2022-07-04T18:38:05.597Z · LW · GW · 1 commentsThis is a link post for https://transformer-circuits.pub/2022/solu/index.html
Contents
High-level Takeaways More Details SoLU How did they evaluate interpretability? More on LayerNorm Misc comments / questions None 1 comment
Anthropic continues their Transformer Circuits Thread. In previous work they were unable to make much progress interpreting MLP layers. This paper is focused on addressing that limitation.
High-level Takeaways
In this paper, we report an architectural change which appears to substantially increase the fraction of MLP neurons which appear to be "interpretable" (i.e. respond to an articulable property of the input), at little to no cost to ML performance. Specifically, we replace the activation function with a softmax linear unit (which we term SoLU) and show that this significantly increases the fraction of neurons in the MLP layers which seem to correspond to readily human-understandable concepts, phrases, or categories on quick investigation, as measured by randomized and blinded experiments. We then study our SoLU models and use them to gain several new insights about how information is processed in transformers. However, we also discover some evidence that the superposition hypothesis is true and there is no free lunch: SoLU may be making some features more interpretable by “hiding” others and thus making them even more deeply uninterpretable. Despite this, SoLU still seems like a net win, as in practical terms it substantially increases the fraction of neurons we are able to understand.
Although preliminary, we argue that these results show the potential for a general approach of designing architectures for mechanistic interpretability: there may exist many different models or architectures which all achieve roughly state-of-the-art performance, but which differ greatly in how easy they are to reverse engineer. Put another way, we are in the curious position of being both reverse engineers trying to understand the algorithms neural network parameters implement, and also the hardware designers deciding the network architecture they must run on: perhaps we can exploit this second role to support the first. If so, it may be possible to move the field in a positive direction by discovering (and advocating for) those architectures which are most amenable to reverse engineering.
Their Key Results:
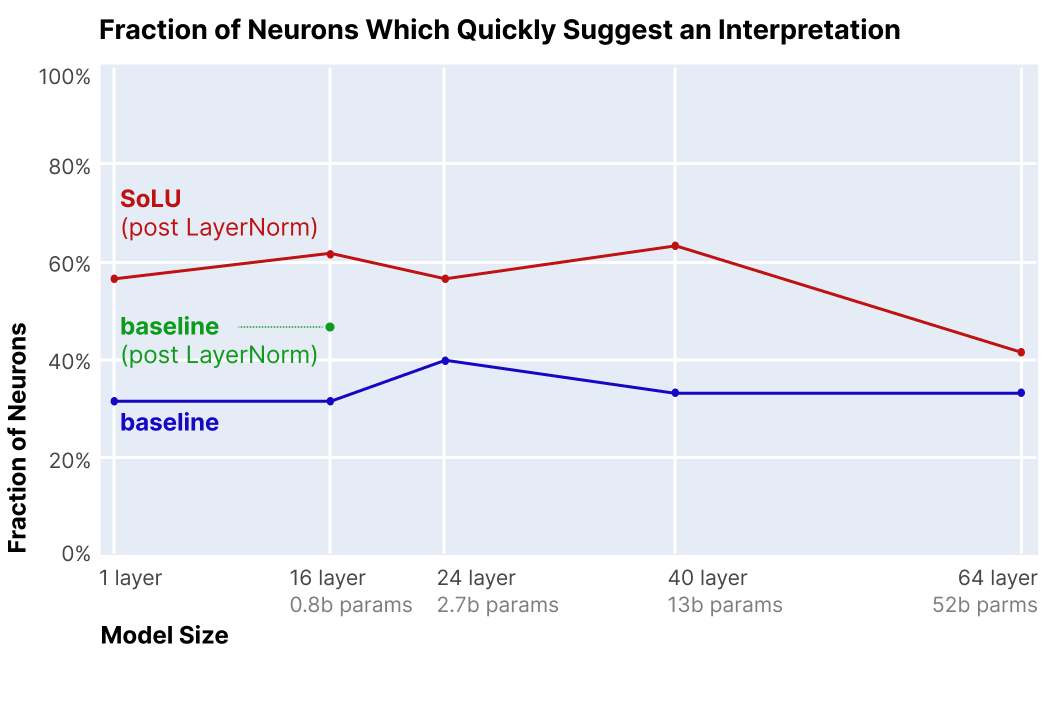
- SoLU increases the fraction of MLP neurons which appear to have clear interpretations, while preserving performance. Specifically, SoLU increases the fraction of MLP neurons for which a human can quickly find a clear hypothesis explaining its activations from 35% to 60%.
- SoLU’s benefits may come at the cost of “hiding” other features. In other words, SoLU causes some previously non-interpretable features to become interpretable, but it may also make it even harder to interpret some already non-interpretable features.
- Architecture affects polysemanticity and MLP interpretability. Although it isn't a perfect solution, SoLU is a proof of concept that architectural decisions can dramatically affect polysemanticity, making it more tractable to understand transformer MLP layers.
- An overview of the types of features which exist in MLP layers. SoLU seems to make some of the features in all layers easily interpretable.
- Evidence for the superposition hypothesis. Our SoLU results seem like moderate evidence for preferring the superposition hypothesis over alternatives.
More Details
SoLU
Anthropic use their new SoLU activation function (mean to discourage polysemanticity / superposition) in place of GeLU:
See the paper for intuition / examples for why this does what it says. I think this is brilliant and would not have thought of it myself. However...
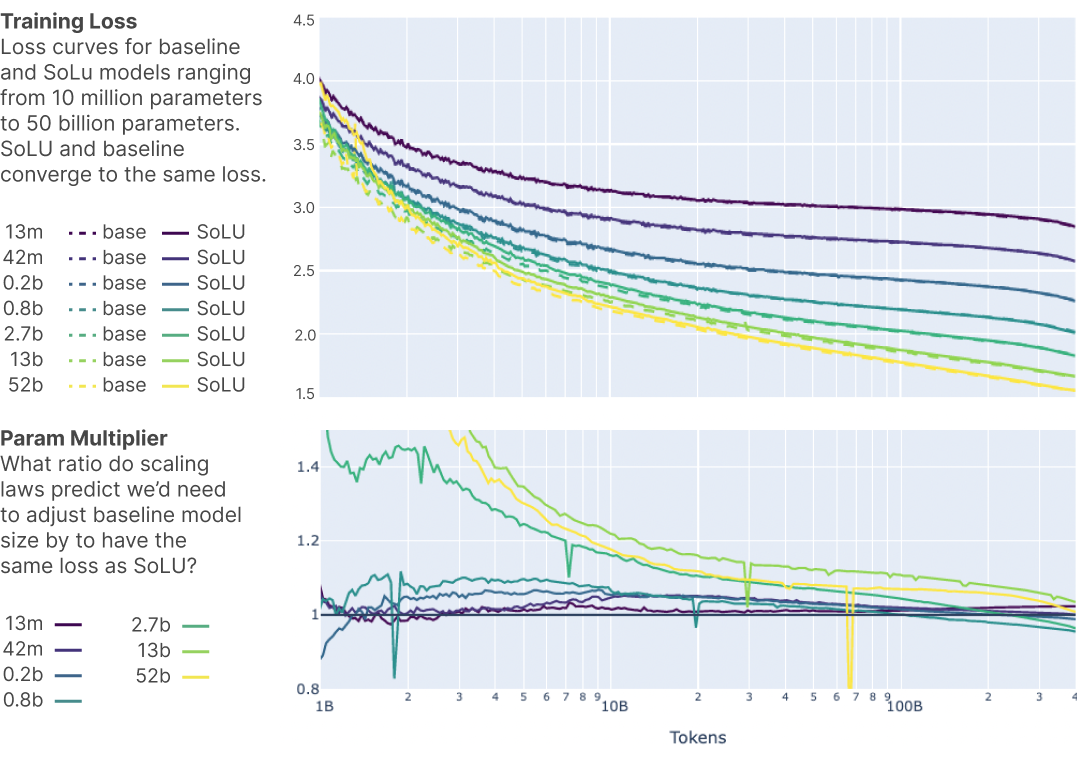
Our preliminary experiments found that simply using a SoLU activation function seemed to make neurons much more interpretable, but came at a major performance cost. Generally, SoLU models without any other changes had performance equivalent to a model 30-50% smaller than their actual size, with larger models being affected more. This is exactly what we’d expect to see if the superposition hypothesis was true – we can decrease polysemanticity, but doing so harms the network’s ML performance.
However, we found empirically that this performance penalty can be fixed, while also preserving the interpretability gains, by applying an extra LayerNorm after the SoLU [...]. This greatly improves ML performance.
Unfortunately, we now believe that at least part of the reason for the performance improvement is the extra LayerNorm may allow superposition to be smuggled through in smaller activations
SoLU penalizes superposition, but it's bad for performance, so they half allow superposition back in, and it kind of works? Surprisingly (to me) this allows their model to essentially match the vanilla GeLU model in performance while maintaining improved interpretability.
How did they evaluate interpretability?
To measure whether a neuron is “interpretable at first glance," we asked human evaluators (some of the authors) to examine a series of text snippets (typically 20 snippets of length a few paragraphs each) that include tokens where the neuron fires heavily. [...] We performed experiments on the 1 layer, 16 layer, 24 layer, 40 layer, and 64 layer (50 billion parameter) models. For each size of model, evaluators were presented with 60 neurons from the baseline model (without SoLU activation) and 60 neurons from the corresponding SoLU model – for a total of 60*2*5=600 neurons across all experiments. To prevent us from being biased in favor of our models, the neurons were presented to evaluators in a randomized and blinded manner (evaluators did not know which neurons came from which model).
From the appendix it looks like there were three evaluators. I would be very interested to see the experiment repeated with a larger sample size.
More on LayerNorm
Polysemanticity is so useful that it's unavoidable.
One hypothesis is that SoLU creates something like two tiers of features: neuron-aligned and non-neuron-aligned features. The neuron-aligned features are what we observe when we examine SoLU neurons, and if any are present they dominate the activations. The non-neuron-aligned features only have a large effect when no basis-aligned features are present, and LayerNorm rescales the activations which SoLU suppressed.
SoLU is a double-edged sword for interpretability. On the one hand, it makes it much easier to study a subset of MLP layer features which end up nicely aligned with neurons. On the other hand, we suspect that there are many other non-neuron-aligned features which are essential to the loss and arguably harder to study than in a regular model. Perhaps more concerningly, if one only looked at the SoLU activation, it would be easy for these features to be invisible and create a false sense that one understands all the features.
So, the SoLU trick privileges some features which become aligned with neurons. The model will still learn other features but they will become even harder to interpret that before.
Misc comments / questions
- Re LayerNorm: Which features become "privileged" (neuron-aligned)? Are they the most common / important features? If so, it makes me more confident in the SoLU trick.
- ELU, GELU, SoLU. All claim to be "linear units" but none are linear, right?
- "If one accepts the superposition hypothesis, the reason we have polysemanticity is that there aren't enough neurons for all the features the model would ideally like to represent. Unfortunately, naively making models bigger may not fix this, since more capable models may want to represent more features. Instead, we want to create more neurons without making models larger. Some architectural approaches may allow for this." I'm confused what the authors mean by the italicized phrase. How do you create more neurons without making the model larger?
- There is a companion video. In the video they're a little less careful about claims, and say things that make the result seem more powerful than the paper did: "everyone on the team independently agreed that these are just night and day different to look at".
- Michal Nielsen had an excellent Twitter thread exploring the paper.
1 comments
Comments sorted by top scores.
comment by gwern · 2022-07-05T01:17:27.613Z · LW(p) · GW(p)
I’m confused what the authors mean by the italicized phrase. How do you create more neurons without making the model larger?
I would assume various kinds of sparsity and modularization, and avoiding things which have many parameters but few neurons, such as fully-connected layers.
SoLU is a double-edged sword for interpretability. On the one hand, it makes it much easier to study a subset of MLP layer features which end up nicely aligned with neurons. On the other hand, we suspect that there are many other non-neuron-aligned features which are essential to the loss and arguably harder to study than in a regular model. Perhaps more concerningly, if one only looked at the SoLU activation, it would be easy for these features to be invisible and create a false sense that one understands all the features.
Extremely concerning for safety. The only thing more dangerous than an uninterpretable model is an 'interpretable' model. Is there an interpretability tax such that all interpretability methods wind up incentivizing covert algorithms, similar to how CycleGAN [LW · GW] is incentivized to learn steganography, and interpretability methods risk simply creating mesa-optimizers which optimize for a superficially-simple seeming 'surface' Potemkin-village network while it gets the real work done elsewhere out of sight?
(The field of interpretability research as a mesa-optimizer: the blackbox evolutionary search (citations, funding, tenure) of researchers optimizes for finding methods which yield 'interpretable' models and work almost as well as uninterpretable ones - but only because the methods are too weak to detect that the 'interpretable' models are actually just weird uninterpretable ones which evolved some protective camouflage, and thus just as dangerous as ever. The field already offers a lot of examples of interpretability methods which produce pretty pictures and convince their researchers as well as others, but which later turn out to not work as well or as thought, like salience maps. One might borrow a quote from cryptography: "any interpretability researcher can invent an interpretability method he personally is not smart enough to understand the uninterpretability thereof.")