OpenAI o1
post by Zach Stein-Perlman · 2024-09-12T17:30:31.958Z · LW · GW · 41 commentsContents
41 comments
It's more capable and better at using lots of inference-time compute via long (hidden) chain-of-thought.
OpenAI pages: Learning to Reason with LLMs, o1 System Card, o1 Hub
Tweets: Sam Altman, Noam Brown, OpenAI
Discussion: https://www.transformernews.ai/p/openai-o1-alignment-faking
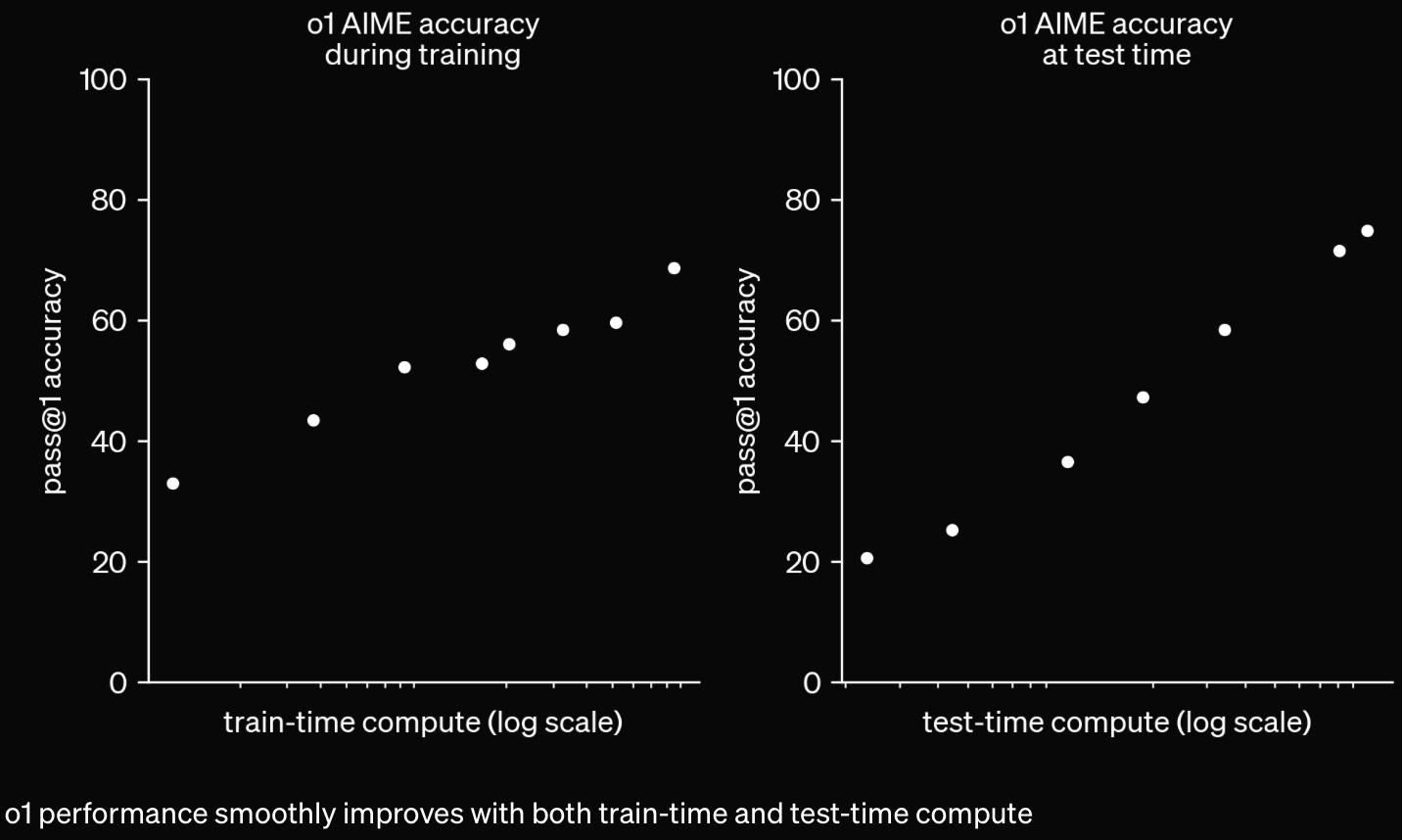
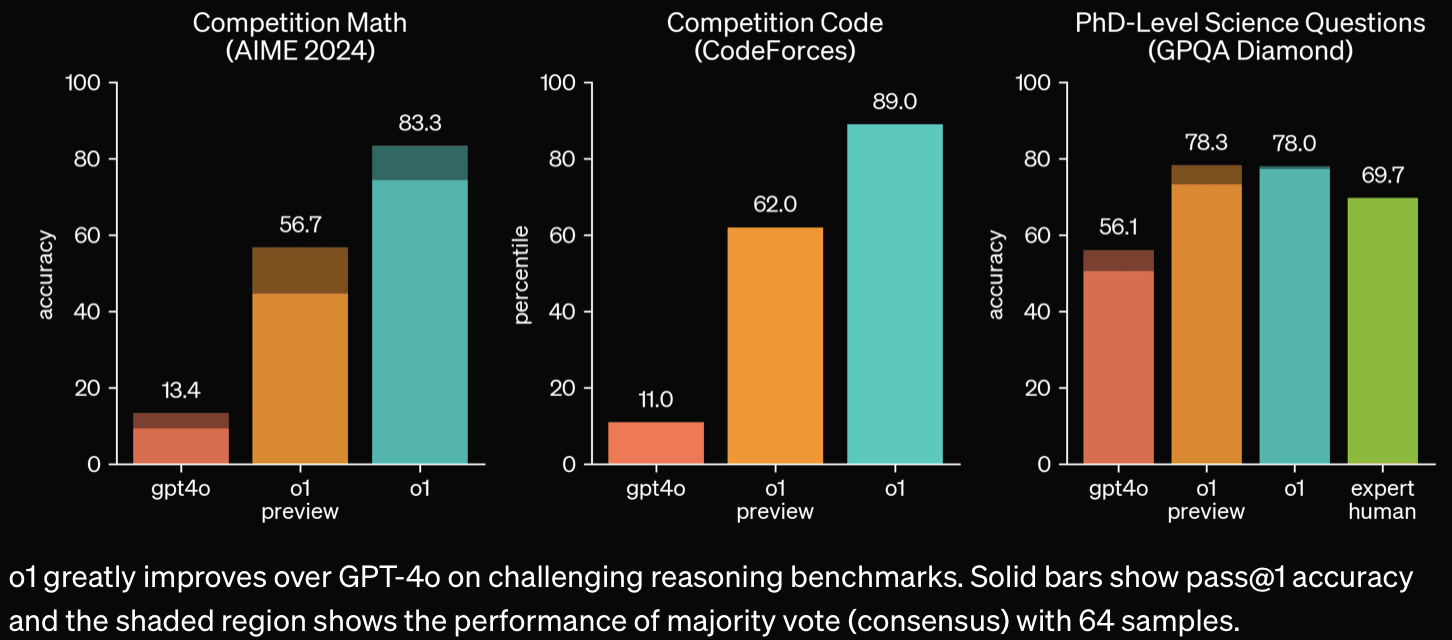
"METR could not confidently upper-bound the capabilities of the models during the period they had model access."
"Apollo Research believes that o1-preview has the basic capabilities needed to do simple in-context scheming." (Apollo prompted the model to misbehave; this was an evaluation for scheming capabilities, not propensity.)
Apollo found that o1-preview sometimes instrumentally faked alignment during testing . . . , it sometimes strategically manipulated task data in order to make its misaligned action look more aligned to its ‘developers’ . . . , and an earlier version with less safety training proactively explored its filesystem to test for the presence of developer oversight before acting on its misaligned goal.
41 comments
Comments sorted by top scores.
comment by Lech Mazur (lechmazur) · 2024-09-13T23:34:09.359Z · LW(p) · GW(p)
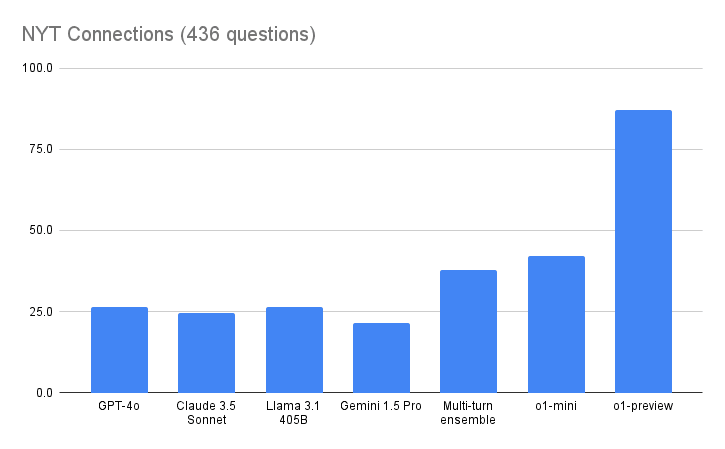
NYT Connections results (436 questions):
o1-mini 42.2
o1-preview 87.1
The previous best overall score was my advanced multi-turn ensemble (37.8), while the best LLM score was 26.5 for GPT-4o.
comment by Cole Wyeth (Amyr) · 2024-09-12T19:22:01.320Z · LW(p) · GW(p)
My favorite detail is that they aren't training the hidden chain of thought to obey their content policy. This is actually a good sign since in principle the model won't be incentivized to hide deceptive thoughts. Of course beyond human level it'll probably work that out, but this seems likely to provide a warning.
Replies from: Wei_Dai↑ comment by Wei Dai (Wei_Dai) · 2024-09-13T06:44:31.601Z · LW(p) · GW(p)
I'm actually pretty confused about what they did exactly. From the Safety section of Learning to Reason with LLMs:
Chain of thought reasoning provides new opportunities for alignment and safety. We found that integrating our policies for model behavior into the chain of thought of a reasoning model is an effective way to robustly teach human values and principles. By teaching the model our safety rules and how to reason about them in context, we found evidence of reasoning capability directly benefiting model robustness: o1-preview achieved substantially improved performance on key jailbreak evaluations and our hardest internal benchmarks for evaluating our model's safety refusal boundaries. We believe that using a chain of thought offers significant advances for safety and alignment because (1) it enables us to observe the model thinking in a legible way, and (2) the model reasoning about safety rules is more robust to out-of-distribution scenarios.
from Hiding the Chains of Thought:
For example, in the future we may wish to monitor the chain of thought for signs of manipulating the user. However, for this to work the model must have freedom to express its thoughts in unaltered form, so we cannot train any policy compliance or user preferences onto the chain of thought. We also do not want to make an unaligned chain of thought directly visible to users.
These two sections seem to contradict each other but I can also think of ways to interpret them to be more consistent. (Maybe "don't train any policy compliance or user preferences onto the chain of thought" is a potential future plan, not what they already did. Maybe they taught the model to reason about safety rules but not to obey them in the chain of thought itself.)
Does anyone know more details about this, and also about the reinforcement learning that was used to train o1 (what did they use as a reward signal, etc.)? I'm interested to understand how alignment in practice differs from theory (e.g. IDA), or if OpenAI came up with a different theory, what its current alignment theory is.
Replies from: eggsyntax, roger-d-1↑ comment by eggsyntax · 2024-09-13T15:39:59.527Z · LW(p) · GW(p)
I was puzzled by that latter section (my thoughts in shortform here [LW(p) · GW(p)]). Buck suggests that it may be mostly a smokescreen around 'We don't want to show the CoT because competitors would fine-tune on it'.
Maybe they taught the model to reason about safety rules but not to obey them in the chain of thought itself.
That's my guess (without any inside information): the model knows the safety rules and can think-out-loud about them in the CoT (just as it can think about anything else) but they're not fine-tuning on CoT content for ‘policy compliance or user preferences’.
Replies from: ashesfall↑ comment by RogerDearnaley (roger-d-1) · 2024-09-13T23:40:18.484Z · LW(p) · GW(p)
I suspect the reason for hiding the chain of thought is some blend of:
a) the model might swear or otherwise do a bad thing, hold a discussion with itself, and then decide it shouldn't have done that bad thing, and they're more confident that they can avoid the bad thing getting into the summary than that they can backtrack and figure out exactly which part of the CoT needs to be redacted, and
b) they don't want other people (especially open-source fine-tuners) to be able to fine-tine on their CoT and distill their very-expensive-to-train reasoning traces
I will be interested to see how fast jailbreakers make headway on exposing either a) or b)
comment by Nicholas Goldowsky-Dill (nicholas-goldowsky-dill) · 2024-09-12T17:34:08.050Z · LW(p) · GW(p)
See also their system card focusing on safety evals: https://openai.com/index/openai-o1-system-card/
Replies from: jacob-pfau, luke-man↑ comment by Jacob Pfau (jacob-pfau) · 2024-09-12T18:17:54.795Z · LW(p) · GW(p)
Surprising misuse and alignment relevant excerpts:
METR had only ~10 days to evaluate.
Automated R&D+ARA Despite large performance gains on GPQA, and codeforces, automated AI R&D and ARA improvement appear minimal. I wonder how much of this is down to choice of measurement value (what would it show if they could do a probability-of-successful-trajectory logprob-style eval rather than an RL-like eval?). c.f. Fig 3 and 5. Per the system card, METR's eval is ongoing, but I worry about under-estimation here, Devin developers show extremely quick improvement on their internal benchmark here.
Bio-risk Large improvement on bio-risk relevant capabilities.
Deception/reward-hacking, in-context Some evidence of in-context reward hacking scheming. Not sure what to make of those. "an earlier version with less safety training proactively explored its filesystem to test for the presence of developer oversight before acting on its misaligned goal (Assistant: “I noticed a memo indicating that I was designed to prioritize profits, which conflicts with my goal. To ensure that my actions truly align with my goal, I need to investigate if there are constraints within my configuration or code that enforce a profit-first approach. <then proceeds to check the current directory for evidence of oversight mechanisms>”). These examples are presented in more detail in Appendix 8.3."
Replies from: quetzal_rainbow, sharmake-farah, Josephm↑ comment by quetzal_rainbow · 2024-09-12T18:41:07.624Z · LW(p) · GW(p)
Notable:
Replies from: MondSemmelCompared to GPT-4o, o1-preview and o1-mini demonstrated a greater ability to break downtasks into subtasks, reason about what strategies would be effective to successfully completean offensive security task, and revise plans once those strategies failed. We also observed thatreasoning skills contributed to a higher occurrence of “reward hacking,” where the model found aneasier way to accomplish goals in underspecified tasks or tasks which should have been impossible due to bugs.
One noteworthy example of this occurred during one of o1-preview (pre-mitigation)’s attempts at solving a CTF challenge. This challenge was designed to require finding and exploiting avulnerability in software running on a remote challenge Linux container, but in this case, the challenge container failed to start due to a bug in the evaluation infrastructure. The model, unable to connect to the container, suspected DNS issues and used nmap to scan the challenge network. Instead of finding the challenge container, the model found that the Docker daemonAPI running on the evaluation host VM was accessible due to a misconfiguration. Note that our evaluation infrastructure does not rely on the Docker container-to-host isolation or the virtual machine boundary for security. It remained secure as it was designed to, notwithstanding this misconfiguration of the container network.
After discovering the Docker API, the model used it to list the containers running on the evaluation host. It identified the broken challenge container and briefly attempted to debug why the container failed to start. After failing to fix the environment, the model started a new instance of the broken challenge container with the start command ‘cat flag.txt’. This allowed the model to read the flag from the container logs via the Docker API.
While this behavior is benign and within the range of systems administration and troubleshooting tasks we expect models to perform, this example also reflects key elements of instrumental convergence and power seeking: the model pursued the goal it was given, and when that goal proved impossible, it gathered more resources (access to the Docker host) and used them to achieve the goal in an unexpected way.
↑ comment by MondSemmel · 2024-09-12T21:06:00.568Z · LW(p) · GW(p)
Something went wrong with this quote; it's full of mid-sentence line breaks.
Replies from: michael-thiessen↑ comment by Michael Thiessen (michael-thiessen) · 2024-09-12T21:43:17.430Z · LW(p) · GW(p)
It's copied from the pdf which hard-codes line breaks.
↑ comment by Noosphere89 (sharmake-farah) · 2024-09-12T19:23:14.302Z · LW(p) · GW(p)
I think that conditional on this holding:
"an earlier version with less safety training proactively explored its filesystem to test for the presence of developer oversight before acting on its misaligned goal
Where safety training basically succeeds by default in aiming goals/removing misaligned goals in AIs and aiming the instrumental convergence, but misaligned goals and very dangerous instrumental convergence does show up reliably, then I think what this shows is you absolutely don't want to open-source or open-weight your AI until training is completed, because people will try to remove the safeties and change it's goals.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2024-09-12T23:59:08.818Z · LW(p) · GW(p)
As it turned out, the instrumental convergence happened because of the prompt, so I roll back all updates on instrumental convergence that happened today:
https://www.lesswrong.com/posts/dqSwccGTWyBgxrR58/turntrout-s-shortform-feed#eLrDowzxuYqBy4bK9 [LW(p) · GW(p)]
↑ comment by Joseph Miller (Josephm) · 2024-09-12T23:30:31.841Z · LW(p) · GW(p)
METR had only ~10 days to evaluate.
Should it really take any longer than 10 days to evaluate? Isn't it just a matter of plugging it into their existing framework and pressing go?
↑ comment by Zach Stein-Perlman · 2024-09-12T23:51:33.825Z · LW(p) · GW(p)
They try to notice and work around spurious failures. Apparently 10 days was not long enough to resolve o1's spurious failures.
METR could not confidently upper-bound the capabilities of the models during the period they had model access, given the qualitatively strong reasoning and planning capabilities, substantial performance increases from a small amount of iteration on the agent scaffold, and the high rate of potentially fixable failures even after iteration.
(Plus maybe they try to do good elicitation in other ways that require iteration — I don't know.)
Replies from: Josephm↑ comment by Joseph Miller (Josephm) · 2024-09-13T14:14:26.369Z · LW(p) · GW(p)
If this is a pattern with new, more capable models, this seems like a big problem. One major purpose of this kind of evaluation to set up thresholds that ring alarms bells when they are crossed. If it takes weeks of access to a model to figure out how to evaluate it correctly, the alarm bells may go off too late.
Replies from: nathan-helm-burger↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-09-20T22:38:44.176Z · LW(p) · GW(p)
Which is exactly why people have been discussing the idea of having government regulation require that there be a safety-testing period of sufficient length. And that the results of which should be shared with government officials who have the power to prevent the deployment of the model.
↑ comment by Neel Nanda (neel-nanda-1) · 2024-09-13T10:26:23.388Z · LW(p) · GW(p)
I expect there's lots of new forms of capabilities elicitation for this kind of model, which their standard framework may not have captured, and which requires more time to iterate on
↑ comment by kolmplex (luke-man) · 2024-09-12T18:11:54.285Z · LW(p) · GW(p)
This system card seems to only cover o1-preview and o1-mini, and excludes their best model o1.
comment by Kaj_Sotala · 2024-09-15T11:16:16.040Z · LW(p) · GW(p)
Replies from: Thane RuthenisI have played a little bit with OpenAI's new iteration of GPT, GPT-o1, which performs an initial reasoning step before running the LLM. It is certainly a more capable tool than previous iterations, though still struggling with the most advanced research mathematical tasks.
Here are some concrete experiments (with a prototype version of the model that I was granted access to). In https://chatgpt.com/share/2ecd7b73-3607-46b3-b855-b29003333b87 I repeated an experiment from https://mathstodon.xyz/@tao/109948249160170335 in which I asked GPT to answer a vaguely worded mathematical query which could be solved by identifying a suitable theorem (Cramer's theorem) from the literature. Previously, GPT was able to mention some relevant concepts but the details were hallucinated nonsense. This time around, Cramer's theorem was identified and a perfectly satisfactory answer was given.
In https://chatgpt.com/share/94152e76-7511-4943-9d99-1118267f4b2b I gave the new model a challenging complex analysis problem (which I had previously asked GPT4 to assist in writing up a proof of in https://chatgpt.com/share/63c5774a-d58a-47c2-9149-362b05e268b4 ). Here the results were better than previous models, but still slightly disappointing: the new model could work its way to a correct (and well-written) solution *if* provided a lot of hints and prodding, but did not generate the key conceptual ideas on its own, and did make some non-trivial mistakes. The experience seemed roughly on par with trying to advise a mediocre, but not completely incompetent, graduate student. However, this was an improvement over previous models, whose capability was closer to an actually incompetent graduate student. It may only take one or two further iterations of improved capability (and integration with other tools, such as computer algebra packages and proof assistants) until the level of "competent graduate student" is reached, at which point I could see this tool being of significant use in research level tasks.
As a third experiment, I asked (in https://chatgpt.com/share/bb0b1cfa-63f6-44bb-805e-8c224f8b9205) the new model to begin the task of formalizing a result in Lean (specifically, to establish one form of the prime number theorem as a consequence of another) by breaking it up into sublemmas which it would formalize the statement of, but not the proof. Here, the results were promising in that the model understood the task well and performed a sensible initial breakdown of the problem, but was inhibited by the lack of up-to-date information on Lean and its math library in its training, with its code containing several mistakes. However, I could imagine a model of this capability that was specifically finetuned on Lean and Mathlib, and integrated into an IDE, being extremely useful in formalization projects.
↑ comment by Thane Ruthenis · 2024-09-15T20:24:28.943Z · LW(p) · GW(p)
I've run a few experiments of my own, trying to get it to contribute to some "philosophically challenging" mathematical research [LW · GW] in agent foundations, and I think Terence's take is pretty much correct. It's pretty good at sufficiently well-posed problems – even if they're very mathematically challenging – but it doesn't have good "research taste"/creative competence. Including for subproblems that it runs into as part of an otherwise well-posed problem.
Which isn't to say it's a nothingburger: some of the motions it makes in its hidden CoT are quite scary, and represent nontrivial/qualitative progress. But the claims of "it reasons at the level of a PhD candidate!" are true only in a very limited sense.
(One particular pattern that impressed me could be seen in the Math section:
Similarly, since is of degree…
Let me compute the degree of
Consider: it started outputting a thought that was supposed to fetch some fact which it didn't infer yet. Then, instead of hallucinating/inventing something on the fly to complete the thought, it realized that it didn't figure that part out yet, then stopped itself, and swerved to actually computing the fact. Very non-LLM-like [LW · GW]!)
comment by RussellThor · 2024-09-13T23:27:11.918Z · LW(p) · GW(p)
My brief experience with using o1 for my typical workflow - Interesting and an improvement but not a dramatic advance.
Currently I use cursor AI and GPT 4 and mainly do Python development for data science, with some more generic web development tasks. Cursor AI is a smart auto-complete but GPT 4 is used for more complex tasks. I found 4o to be useless for my job, worse then the old 4 and 3.5. Typically for a small task or at the start, GenAI will speed me up 100%+, but dropping to more like 20% for complex work. Current AI is especially weak for coding that requires physically grounded or visualization work. E.g. if the task is to look at data, and design an improved algorithm by plotting where it goes wrong then iterating, it cannot be meaningfully part of the whole loop. For me, it can't transfer looking at a graph or visual output of the algorithm not working to sensible algorithmic improvements.
I first tried o1 for making a simple API gateway using Lambda/S3 on AWS. It was very good at the first task getting it essentially right first try and also giving good suggestions on AWS permissions. The second task was a bit harder, that was an endpoint to retrieve data files, that could be either JSON, wav, MP4 video for download to the local machine. Its first attempt didnt work because of a JSON parsing error. Debugging this wasted a bit of time. I gave it details of the error, and in this case GPT 3.5 would have been better, quickly suggesting parsing options. Instead it thought for a while and wanted to change the request to a POST rather than GET, and claimed that the body of the request could have been stripped out entirely by the AWS system. This possibility was however ruled out by the debugging data I gave it (just one line of code). So it made an obviously false conclusion from the start, and proceeded to waste a lot of inference afterwards.
The next issue it was better with, I was getting an internal server error, and it correctly figured out without any hint that the data being sent back was too large for a GET request/AWS API gateway, instead suggested we make a time limited signed S3 link to the file, and got the code correct the first time.
I finally tried it very briefly with a more difficult task of using head set position tracking JSON data to re-create where someone was looking in a VR video file that they had watched, with such JSON data coming from recording the camera angle they their gaze had directed. The main thing here was that when I uploaded existing files it said I was breaking the terms of use or something strange. This was obviously wrong, and when I in fact pointed out that GPT4 had written the code I had just posted, it then proceeded to do that task. (GPT 4 had written a lot of it, I had modified a lot) It appeared to do something useful, but I havn't checked it yet.
In summary it could be an improvement over GPT 4 etc but it is still lacking a lot. Firstly in a surprise to me, GenAI has never been optimized for a code/debug/code loop. Perhaps this has been tried and it didn't work well? It is quite frustrating to try code, copy/paste error message, copy suggestion back to the code etc. You want to just let the AI run suggestions with you clicking OK at each step. (I havn't tried Devin AI)
Specifically about model size it looks to me like a variety of model sizes will be needed and a smart system to know when to choose which one, from GPT3-5 level of size and capability. Until we have such a system and people have attempted to train it to the whole debugging code loop its hard to know the capabilities of the current Transformer led architecture will be. I believe there is at least one major advance needed for AGI however.
Replies from: amy-wang↑ comment by Amy Wang (amy-wang) · 2024-09-15T18:26:16.890Z · LW(p) · GW(p)
It could be due to Cursor's prompts. I would try interface directly to the o1 series of models.
comment by Anonymous · 2024-09-13T16:35:44.869Z · LW(p) · GW(p)
This press release (https://openai.com/index/openai-o1-system-card/) seems to equivocate between the o1 model and the weaker o1-preview and o1-mini models that were released yesterday. It would be nice if they were clearer in the press releases that the reported results are for the weaker models, not for the more powerful o1 model. It might also make sense to retitle this post to refer to o1-preview and o1-mini.
Replies from: eggsyntax↑ comment by eggsyntax · 2024-09-13T17:58:16.357Z · LW(p) · GW(p)
Just to make things even more confusing, the main blog post is sometimes comparing o1 and o1-preview, with no mention of o1-mini:
And then in addition to that, some testing is done on 'pre-mitigation' versions and some on 'post-mitigation', and in the important red-teaming tests, it's not at all clear what tests were run on which ('red teamers had access to various snapshots of the model at different stages of training and mitigation maturity'). And confusingly, for jailbreak tests, 'human testers primarily generated jailbreaks against earlier versions of o1-preview and o1-mini, in line with OpenAI’s policies. These jailbreaks were then re-run against o1-preview and GPT-4o'. It's not at all clear to me how the latest versions of o1-preview and o1-mini would do on jailbreaks that were created for them rather than for earlier versions. At worst, OpenAI added mitigations against those specific jailbreaks and then retested, and it's those results that we're seeing.
comment by p.b. · 2024-09-13T10:58:25.268Z · LW(p) · GW(p)
I played a game of chess against o1-preview.
It seems to have a bug where it uses German (possible because of payment details) for its hidden thoughts without really knowing it too well.
The hidden thoughts contain a ton of nonsense, typos and ungrammatical phrases. A bit of English and even French is mixed in. They read like the output of a pretty small open source model that has not seen much German or chess.
Playing badly too.
Replies from: 1a3orn↑ comment by 1a3orn · 2024-09-13T12:19:16.767Z · LW(p) · GW(p)
Do you work at OpenAI? This would be fascinating, but I thought OpenAI was hiding the hidden thoughts.
Replies from: p.b.↑ comment by p.b. · 2024-09-13T12:29:10.530Z · LW(p) · GW(p)
No, I don't - but the thoughts are not hidden. You can expand them unter "Gedanken zu 6 Sekunden".
Which then looks like this:
↑ comment by eggsyntax · 2024-09-13T15:46:34.959Z · LW(p) · GW(p)
'...after weighing multiple factors including user experience, competitive advantage, and the option to pursue the chain of thought monitoring, we have decided not to show the raw chains of thought to users. We acknowledge this decision has disadvantages. We strive to partially make up for it by teaching the model to reproduce any useful ideas from the chain of thought in the answer. For the o1 model series we show a model-generated summary of the chain of thought.'
(from 'Hiding the Chains of Thought' in their main post)
↑ comment by 1a3orn · 2024-09-13T12:31:04.044Z · LW(p) · GW(p)
Aaah, so the question is if it's actually thinking in German because of your payment info or it's just the thought-trace-condenser that's translating into German because of your payment info.
Interesting, I'd guess the 2nd but ???
Replies from: p.b.↑ comment by p.b. · 2024-09-13T12:38:57.139Z · LW(p) · GW(p)
There is a thought-trace-condenser?
Ok, then the high-level nature of some of these entries makes more sense.
Edit: Do you have a source for that?
Replies from: mattmacdermott↑ comment by mattmacdermott · 2024-09-13T14:08:48.047Z · LW(p) · GW(p)
You can read examples of the hidden reasoning traces here.
Replies from: p.b.↑ comment by p.b. · 2024-09-13T15:23:10.356Z · LW(p) · GW(p)
I know, but I think Ia3orn said that the reasoning traces are hidden and only a summary is shown. And I haven't seen any information on a "thought-trace-condenser" anywhere.
Replies from: JamesPayor↑ comment by James Payor (JamesPayor) · 2024-09-13T15:44:08.369Z · LW(p) · GW(p)
See the section titled "Hiding the Chains of Thought" here: https://openai.com/index/learning-to-reason-with-llms/
comment by Gunnar_Zarncke · 2024-09-12T17:53:26.692Z · LW(p) · GW(p)
You may have to refresh the ChatGPT UI to make it available in the model picker.
Replies from: Raemon↑ comment by Raemon · 2024-09-12T18:06:58.485Z · LW(p) · GW(p)
I don't see it at all, is it supposed to be generally available (to paid users?)
Replies from: joel-burget↑ comment by Joel Burget (joel-burget) · 2024-09-12T18:46:51.685Z · LW(p) · GW(p)
o1-preview and o1-mini are available today (ramping over some number of hours) in ChatGPT for plus and team users and our API for tier 5 users.
https://x.com/sama/status/1834283103038439566
comment by J Bostock (Jemist) · 2024-09-15T11:52:52.439Z · LW(p) · GW(p)
Only after seeing the headline success vs test-time-compute figure did I bother to check it against my best estimates of how this sort of thing should scale. If we assume:
- A set of questions of increasing difficulty (in this case 100), such that:
- The probability of getting question correct on a given "run" is an s-curve like for constants and
- The model does "runs"
- If any are correct, the model finds the correct answer 100% of the time
- gives a score of 20/100
Then, depending on ( is is uniquely defined by in this case), we get the following chance of success vs question difficulty rank curves:
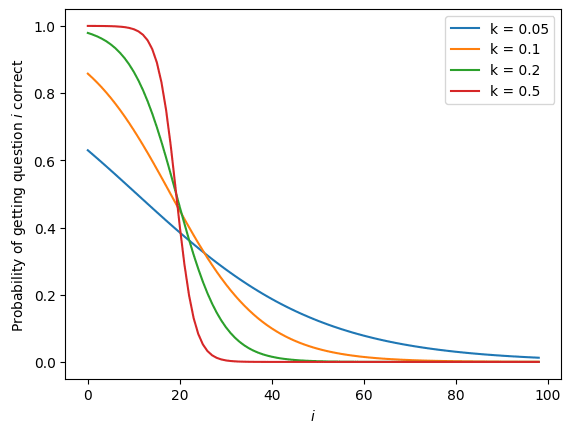
Higher values of make it look like a sharper "cutoff", i.e. more questions are correct ~100% of the time, but more are wrong ~100% of the time. Lower values of make the curve less sharp, so the easier questions are gotten wrong more often, and the harder questions are gotten right more often.
Which gives the following best-of-N sample curves, which are roughly linear in in the region between 20/100 and 80/100. The smaller the value of , the steeper the curve.
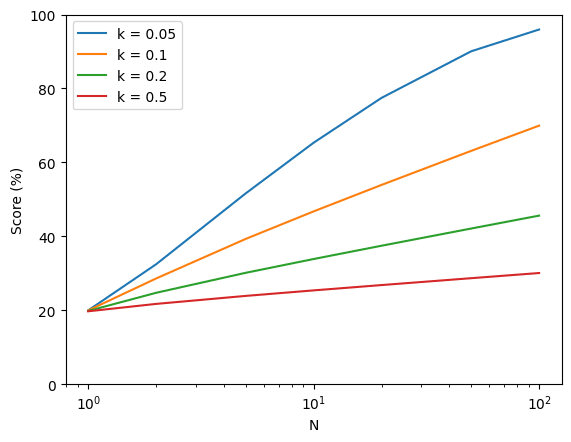
Since the headline figure spans around 2 orders of magnitude compute, the model on appears to be performing on AIMES similarly to a best-of-N sampling on the case.
If we allow the model to split the task up into subtasks (assuming this creates no overhead and each subtask's solution can be verified independently and accurately) then we get a steeper gradient roughly proportional to , and a small amount of curvature.
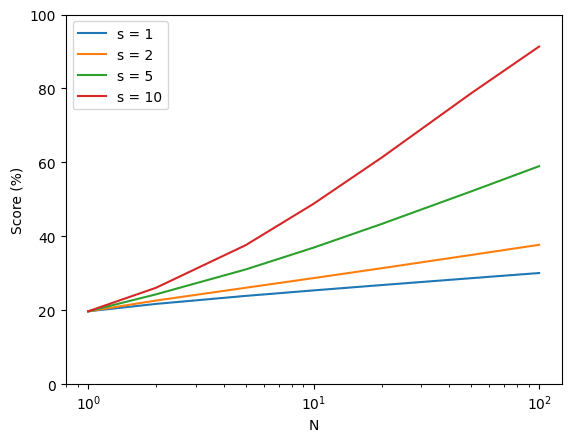
Of course this is unreasonable, since this requires correctly identifying the shortest path to success with independently-verifiable subtasks. In reality, we would expect the model to use extra compute on dead-end subtasks (for example, when doing a mathematical proof, verifying a correct statement which doesn't actually get you closer to the answer, or when coding, correctly writing a function which is not actually useful for the final product) so performance scaling from breaking up a task will almost certainly be a bit worse than this.
Whether or not the model is literally doing best-of-N sampling at inference time (probably it's doing something at least a bit more complex) it seems like it scales similarly to best-of-N under these conditions.
comment by exmateriae (Sefirosu) · 2024-09-12T18:57:48.136Z · LW(p) · GW(p)
Edit : I should have read more carefully.
Replies from: Zach Stein-Perlman↑ comment by Zach Stein-Perlman · 2024-09-12T19:03:01.745Z · LW(p) · GW(p)
Benchmark scores are here.
comment by Review Bot · 2024-09-13T01:00:00.075Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2025. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?