Posts
Comments
All of this sounds reasonable and it sounds like you may have insider info that I don’t. (Also, TBC I wasn’t trying to make a claim about which model is the base model for a particular o-series model, I was just naming models to be concrete, sorry to distract with that!)
Totally possible also that you’re right about more inference/search being the only reason o3 is more expensive than o1 — again it sounds like you know more than I do. But do you have a theory of why o3 is able to go on longer chains of thought without getting stuck, compared with o1? It’s possible that it’s just a grab bag of different improvements that make o3’s forward passes smarter, but to me it sounds like OAI think they’ve found a new, repeatable scaling paradigm, and I’m (perhaps over-)interpreting gwern as speculating that that paradigm does actually involve training larger models.
You noted that OAI is reluctant to release GPT-5 and is using it internally as a training model. FWIW I agree and I think this is consistent with what I’m suggesting. You develop the next-gen large parameter model (like GPT-5, say), not with the intent to actually release it, but rather to then do RL on it so it’s good at chain of thought, and then to use the best outputs of the resulting o model to make synthetic data to train the next base model with an even higher parameter count — all for internal use to push forward the frontier. None of these models ever need to be deployed to users — instead, you can distill either the best base model or the o-series model you have on hand into a smaller model that will be a bit worse (but only a bit) and way more efficient to deploy to lots of users.
The result is that the public need never see the massive internal models — we just happily use the smaller distilled versions that are surprisingly capable. But the company still has to train ever-bigger models.
Maybe what I said was already clear and I’m just repeating myself. Again you seem to be much closer to the action and I could easily be wrong, so I’m curious if you think I’m totally off-base here and in fact the companies aren’t developing massive models even for internal use to push forward the frontier.
Yeah sorry to be clear totally agree we (or at least I) don’t know the sizes of models, I was just naming specific models to be concrete.
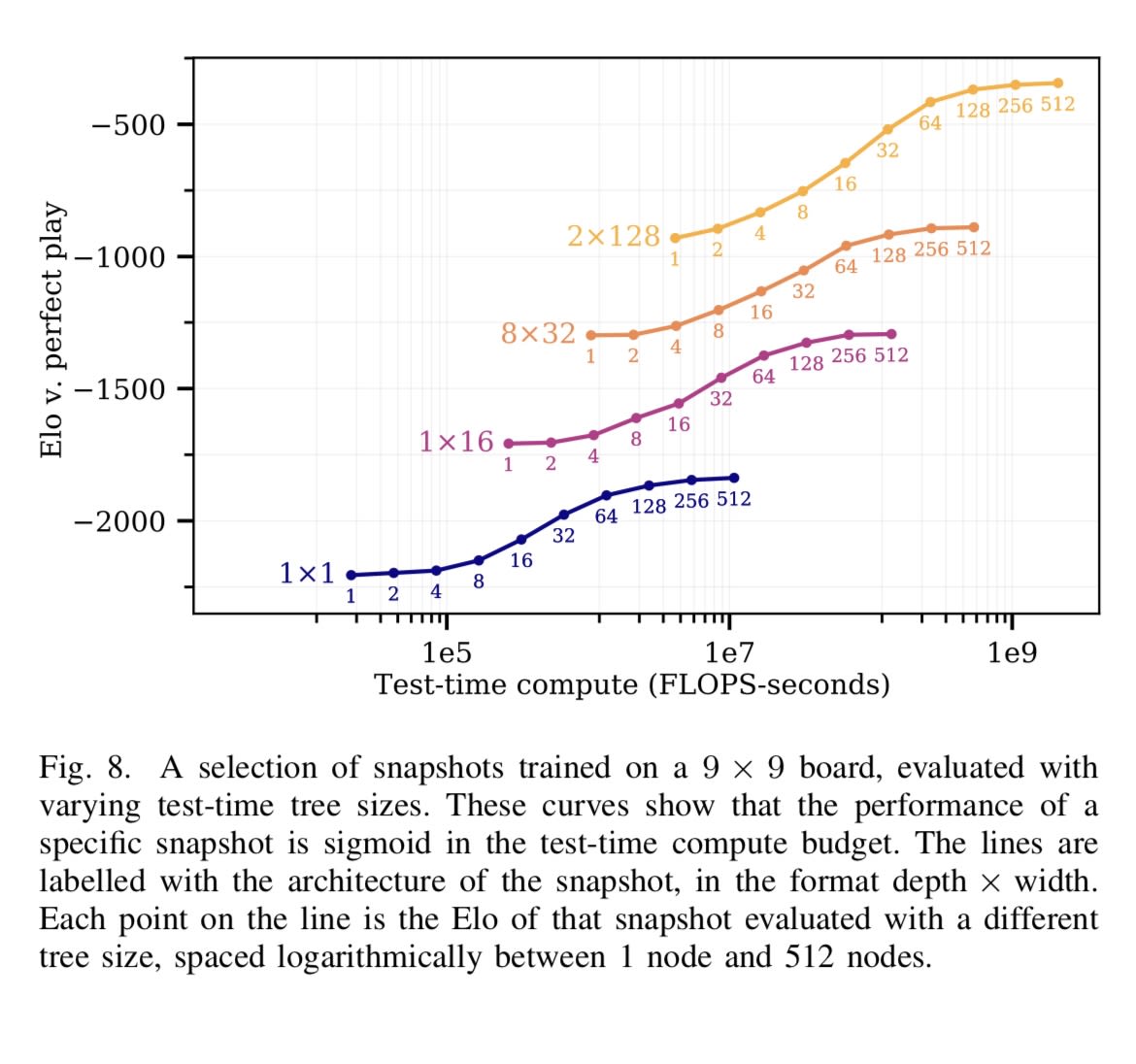
But anyway yes I think you got my point: the Jones chart illustrates (what I understood to be) gwern’s view that adding more inference/search does juice your performance to some degree, but then those gains taper off. To get to the next higher sigmoid-like curve in the Jones figure, you need to up your parameter count; and then to climb that new sigmoid, you need more search. What Jones didn’t suggest (but gwern seems to be saying) is that you can use your search-enhanced model to produce better quality synthetic data to train a larger model on.
When I hear “distillation” I think of a model with a smaller number of parameters that’s dumber than the base model. It seems like the word “bootstrapping” is more relevant here. You start with a base LLM (like GPT-4); then do RL for reasoning, and then do a ton of inference (this gets you o1-level outputs); then you train a base model with more parameters than GPT-4 (let’s call this GPT-5) on those outputs — each single forward pass of the resulting base model is going to be smarter than a single forward pass of GPT-4. And then you do RL and more inference (this gets you o3). And rinse and repeat.
I don’t think I’m really saying anything different from what you said, but the word “distill” doesn’t seem to capture the idea that you are training a larger, smarter base model (as opposed to a smaller, faster model). This also helps explain why o3 is so expensive. It’s not just doing more forward passes, it’s a much bigger base model that you’re running with each forward pass.
I think maybe the most relevant chart from the Jones paper gwern cites is this one:
This press release (https://openai.com/index/openai-o1-system-card/) seems to equivocate between the o1 model and the weaker o1-preview and o1-mini models that were released yesterday. It would be nice if they were clearer in the press releases that the reported results are for the weaker models, not for the more powerful o1 model. It might also make sense to retitle this post to refer to o1-preview and o1-mini.