JumpReLU SAEs + Early Access to Gemma 2 SAEs
post by Senthooran Rajamanoharan (SenR), Tom Lieberum (Frederik), nps29, Arthur Conmy (arthur-conmy), Vikrant Varma (amrav), János Kramár (janos-kramar), Neel Nanda (neel-nanda-1) · 2024-07-19T16:10:54.664Z · LW · GW · 10 commentsThis is a link post for https://storage.googleapis.com/jumprelu-saes-paper/JumpReLU_SAEs.pdf
Contents
10 comments
New paper from the Google DeepMind mechanistic interpretability team, led by Sen Rajamanoharan!
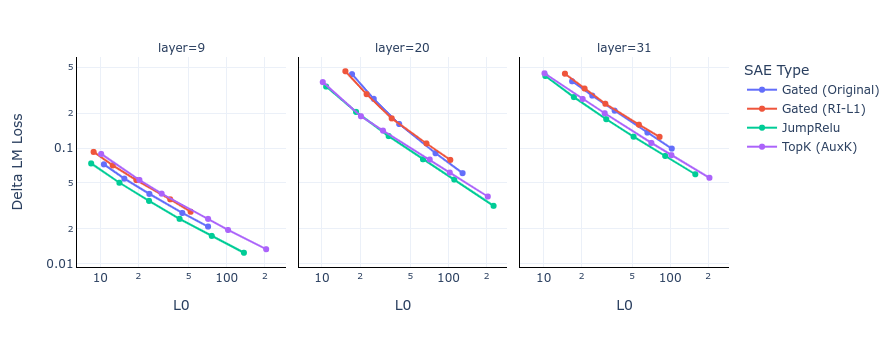
We introduce JumpReLU SAEs, a new SAE architecture that replaces the standard ReLUs with discontinuous JumpReLU activations, and seems to be (narrowly) state of the art over existing methods like TopK and Gated SAEs for achieving high reconstruction at a given sparsity level, without a hit to interpretability. We train through discontinuity with straight-through estimators, which also let us directly optimise the L0.
To accompany this, we will release the weights of hundreds of JumpReLU SAEs on every layer and sublayer of Gemma 2 2B and 9B in a few weeks. Apply now for early access to the 9B ones! We're keen to get feedback from the community, and to get these into the hands of researchers as fast as possible. There's a lot of great projects that we hope will be much easier with open SAEs on capable models!
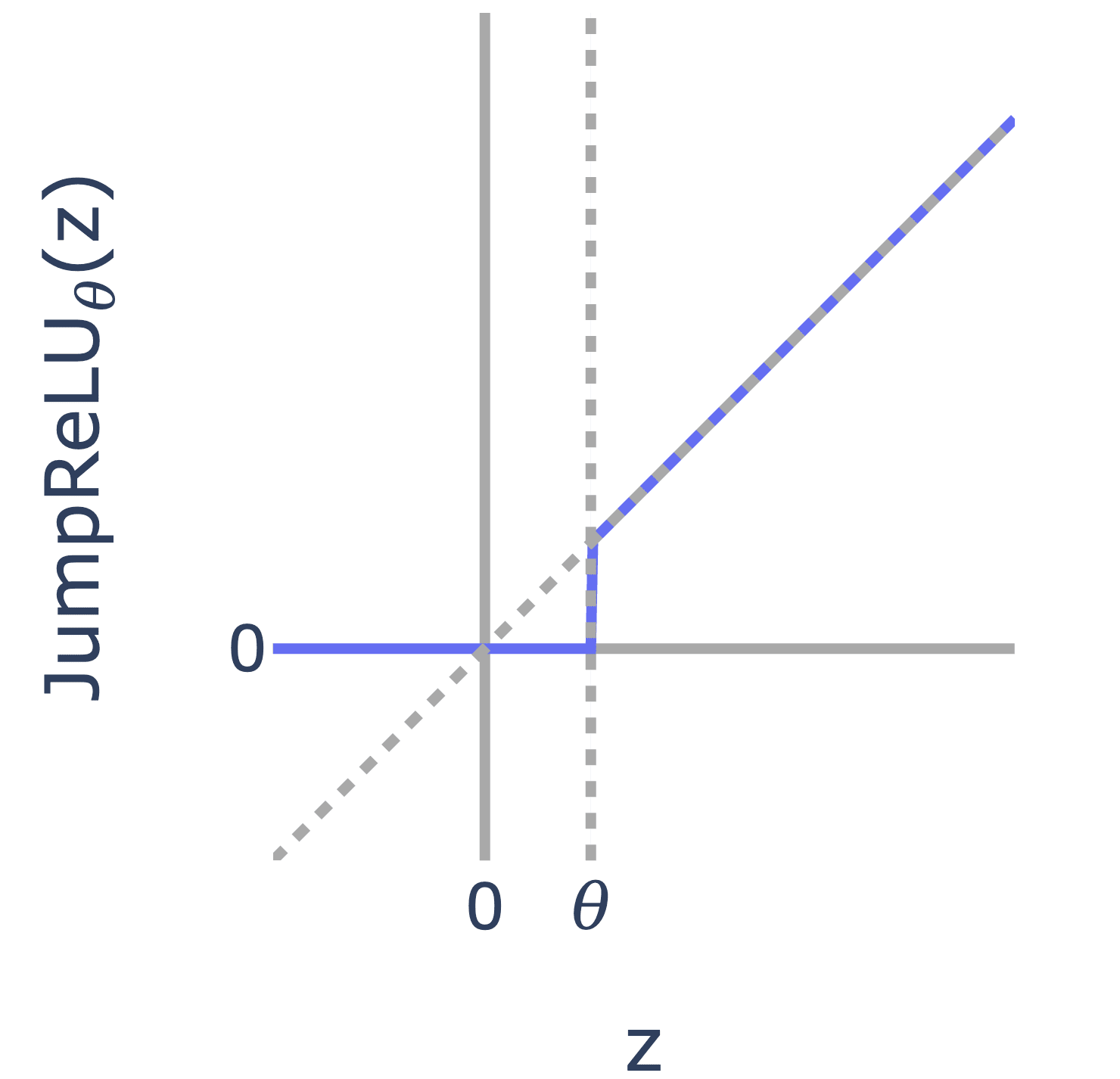

Gated SAEs already reduced to JumpReLU activations after weight tying, so this can be thought of as Gated SAEs++, but less computationally intensive to train, and better performing. They should be runnable in existing Gated implementations.
Abstract:
Sparse autoencoders (SAEs) are a promising unsupervised approach for identifying causally relevant and interpretable linear features in a language model’s (LM) activations. To be useful for downstream tasks, SAEs need to decompose LM activations faithfully; yet to be interpretable the decomposition must be sparse – two objectives that are in tension. In this paper, we introduce JumpReLU SAEs, which achieve state-of the-art reconstruction fidelity at a given sparsity level on Gemma 2 9B activations, compared to other recent advances such as Gated and TopK SAEs. We also show that this improvement does not come at the cost of interpretability through manual and automated interpretability studies. JumpReLU SAEs are a simple modification of vanilla (ReLU) SAEs – where we replace the ReLU with a discontinuous JumpReLU activation function – and are similarly efficient to train and run. By utilising straight-through-estimators (STEs) in a principled manner, we show how it is possible to train JumpReLU SAEs effectively despite the discontinuous JumpReLU function introduced in the SAE’s forward pass. Similarly, we use STEs to directly train L0 to be sparse, instead of training on proxies such as L1, avoiding problems like shrinkage.
10 comments
Comments sorted by top scores.
comment by leogao · 2024-07-20T01:18:47.505Z · LW(p) · GW(p)
Very exciting that JumpReLU works well with STE gradient estimation! I think this fixes one of the biggest flaws with TopK, which is that having a fixed number of latents k on each token is kind of wonky. I also like the argument in section 4 a lot - in particular the point about how this works because we're optimizing the expectation of the loss. Because of how sparse the features are, I wonder if it would reduce gradient noise substantially to use a KDE with state persisting across a few recent steps.
Replies from: SenR↑ comment by Senthooran Rajamanoharan (SenR) · 2024-07-20T15:22:49.727Z · LW(p) · GW(p)
Thanks! I was worried about how well KDE would work because of sparsity, but in practice it seems to work quite well. My intuition is that the penalty only matters for more frequent features (i.e. features that typically do fire, perhaps multiple times, within a 4096 batch), plus the threshold is only updated a small amount at each step (so the noise averages out reliably over many steps). In any case, we tried increasing batch size and turning on momentum (with the idea this would reduce noise), but neither seemed to particularly help performance (keeping the number of tokens constant). One thing I suspect would further improve things is to have a per-feature bandwidth parameter, as I imagine the constant bandwidth we use is too narrow for some features and too wide for others; but to do this we also need to find a reliable way to adapt the bandwidth during training.
comment by Logan Riggs (elriggs) · 2024-07-23T18:00:32.623Z · LW(p) · GW(p)
Did y'all do any ablations on your loss terms. For example:
1. JumpReLU() -> ReLU
2. L0 (w/ STE) -> L1
I'd be curious to see if the pareto improvements and high frequency features are due to one, the other, or both
↑ comment by Senthooran Rajamanoharan (SenR) · 2024-07-23T19:15:25.185Z · LW(p) · GW(p)
You can't do JumpReLU -> ReLU in the current setup, as there would be no threshold parameters to train with the STE (i.e. it would basically train a ReLU SAE with no sparsity penalty). In principle you should be able to train the other SAE parameters by adding more pseudo derivatives, but we found this didn't work as well as just training the threshold (so there was then no point in trying this ablation). L0 -> L1 leads to worse Pareto curves (I can't remember off the top of my head which side of Gated, but definitely not significantly better than Gated) - it's a good question whether this resolves the high frequency features; my guess is it would (as I think Gated SAEs basically approximate JumpReLU SAEs with a L1 loss) but we didn't check this.
comment by Joel Burget (joel-burget) · 2024-07-27T19:07:10.619Z · LW(p) · GW(p)
Re the choice of kernel, my intuition would have been that something smoother (e.g. approximating a Gaussian, or perhaps Epanechnikov) would have given the best results. Did you use rect just because it's very cheap or was there a theoretical reason?
↑ comment by Senthooran Rajamanoharan (SenR) · 2024-07-29T17:15:29.628Z · LW(p) · GW(p)
Good question! The short answer is that we tried the simplest thing and it happened to work well. (The additional computational cost of higher order kernels is negligible.) We did look at other kernels but my intuition, borne out by the results (to be included in a v2 shortly, along with some typos and bugfixes to the pseudo-code), was that this would not make much difference. This is because we're using KDE in a very high variance regime already, and yet the SAEs seem to train fine: given a batch size of 4096 and bandwidth of 0.001, hardly any activations (even for the most frequent features) end up having kernels that capture the threshold (i.e. that are included in the gradient estimate). So it's not obvious that improving the bias-variance trade-off slightly by switching to a different kernel is going to make that much difference. In this sense, the way we use KDE here is very different from e.g. using KDE to visualise empirical distributions, and so we need to be careful about how we transfer intuitions between these domains.
comment by Lennart Buerger · 2024-07-25T14:21:08.589Z · LW(p) · GW(p)
Nice work! I was wondering what context length you were using when you extracted the LLM activations to train the SAE. I could not find it in the paper but I might also have missed it. I know that OpenAI used a context length of 64 tokens in all their experiments which is probably not sufficient to elicit many interesting features. Do you use a variable context length or also a fixed value?
Replies from: Frederik↑ comment by Tom Lieberum (Frederik) · 2024-07-25T15:56:45.782Z · LW(p) · GW(p)
We use 1024, though often article snippets are shorter than that so they are separated by BOS.
comment by Boris Kashirin (boris-kashirin) · 2024-07-19T18:07:52.751Z · LW(p) · GW(p)
When I read about automated programming for robotics few month ago I wondered if it can be applied for ML. If it can, then there is good chance of seeing paper about modification for ReLU right about now. It seemed like possibly similar kind of research, case where perseverance is more important than intelligence. So at first I freaked out a bit at headline, but it is not it, right?
Replies from: neel-nanda-1↑ comment by Neel Nanda (neel-nanda-1) · 2024-07-20T00:35:43.881Z · LW(p) · GW(p)
Totally different