Posts
Comments
Sure, I agree that, as we point out in the post, this penalty may not be targeting the right thing, or could be targeting it in the wrong way. We shared this more as a proof of concept that others may like to build on and don't claim it's a superior solution to standard JumpReLU training.
A minor quibble on the ad-hoc point: while I completely agree about the pitfalls of ad-hoc definitions, I don't think the same arguments apply about ad-hoc training procedures. As long as your evaluation metrics measure the thing you actually care about, ML has a long history of ad-hoc approaches to optimising those metrics performing surprisingly well. Having said that though, I agree it would be great to see more research into what's really going on with these dense features, and this leading into a more principled approach to dealing with them! (Whether that turns out to be better understanding how to interpret them or improving SAE training to fix them.)
Thanks for copying this over!
For what it's worth, my current view on SAEs is that they remain a pretty neat unsupervised technique for making (partial) sense of activations, but they fit more into the general category of unsupervised learning techniques, e.g. clustering algorithms, than as a method that's going to discover the "true representational directions" used by the language model. And, as such, they share many of the pros and cons of unsupervised techniques in general:[1]
- (Pros) They may be useful / efficient for getting a first pass understanding of what's going in a model / with some data (indeed many of their success stories have this flavour).
- (Cons) They are hit and miss - often not carving up the data in the way you'd prefer, with weird omissions or gerrymandered boundaries you need to manually correct for. Once you have a hypothesis, a supervised method will likely give you better results.
I think this means SAEs could still be useful for generating hypotheses when trying to understand model behaviour, and and I really like the CLTs papers in this regard.[2] However, it's still unclear whether they are better for hypothesis generation than alternative techniques, particularly techniques that have other advantages, like the ability to be used with limited model access (i.e. black-box techniques) or techniques that don't require paying a large up-front cost before they can be used on a model.
I largely agree with your updates 1 and 2 above, although on 2 I still think it's plausible that while many "why is the model doing X?" type questions can be answered with black-box techniques today, this may not continue to hold into the future, which is why I still view interp as a worthwhile research direction. This does make it important though to always try strong baselines on any new project and only get excited when interp sheds light on problems that genuinely seem hard to solve using these baselines.[3]
When I say unsupervised learning, I'm using this term in its conventional sense, e.g. clustering algorithms, manifold learning, etc; not in the sense of tasks like language model pre-training which I sometimes see referred to as unsupervised. ↩︎
Particularly its emphasis on techniques to prune massive attribution graphs, improving tooling for making sense of the results, and accepting that some manual adjustment of the decompositions produced by CLTs may be necessary because we're giving up on the idea that CLTs / SAEs are uncovering a "true basis". ↩︎
And it does seem that black box methods often suffice (in the sense of giving "good enough explanations" for whatever we need these explanations for) when we try to do this. Though this could just be - as you say - because of bad judgement. I'd definitely appreciate suggestions for better downstream tasks we should try! ↩︎
Good question! The short answer is that we tried the simplest thing and it happened to work well. (The additional computational cost of higher order kernels is negligible.) We did look at other kernels but my intuition, borne out by the results (to be included in a v2 shortly, along with some typos and bugfixes to the pseudo-code), was that this would not make much difference. This is because we're using KDE in a very high variance regime already, and yet the SAEs seem to train fine: given a batch size of 4096 and bandwidth of 0.001, hardly any activations (even for the most frequent features) end up having kernels that capture the threshold (i.e. that are included in the gradient estimate). So it's not obvious that improving the bias-variance trade-off slightly by switching to a different kernel is going to make that much difference. In this sense, the way we use KDE here is very different from e.g. using KDE to visualise empirical distributions, and so we need to be careful about how we transfer intuitions between these domains.
You can't do JumpReLU -> ReLU in the current setup, as there would be no threshold parameters to train with the STE (i.e. it would basically train a ReLU SAE with no sparsity penalty). In principle you should be able to train the other SAE parameters by adding more pseudo derivatives, but we found this didn't work as well as just training the threshold (so there was then no point in trying this ablation). L0 -> L1 leads to worse Pareto curves (I can't remember off the top of my head which side of Gated, but definitely not significantly better than Gated) - it's a good question whether this resolves the high frequency features; my guess is it would (as I think Gated SAEs basically approximate JumpReLU SAEs with a L1 loss) but we didn't check this.
Thanks! I was worried about how well KDE would work because of sparsity, but in practice it seems to work quite well. My intuition is that the penalty only matters for more frequent features (i.e. features that typically do fire, perhaps multiple times, within a 4096 batch), plus the threshold is only updated a small amount at each step (so the noise averages out reliably over many steps). In any case, we tried increasing batch size and turning on momentum (with the idea this would reduce noise), but neither seemed to particularly help performance (keeping the number of tokens constant). One thing I suspect would further improve things is to have a per-feature bandwidth parameter, as I imagine the constant bandwidth we use is too narrow for some features and too wide for others; but to do this we also need to find a reliable way to adapt the bandwidth during training.
We found that exactly that form of sparsity penalty did improve shrinkage with standard (ungated) SAEs, and provide a decent boost to loss recovered at low L0. (We didn't evaluate interpretability though.) But then we hit upon Gated SAEs which looked even better, and for which modifying the sparsity penalty in this way feels less necessary, so we haven't experimented with combining the two.
Good question - we're planning to post an update on this point about combining the new sparsity penalty from Anthropic with Gated SAEs. The TL;DR is that you can replace the L1 term in the Gated SAE loss with the analogous (gated feature magnitudes dotted with decoder magnitudes) sparsity term introduced by Anthropic and thereby do away with the decoder norms constraint and resampling. If you're going to do this, you also need to either unfreeze the decoder in the auxiliary task, or freeze the decoder weights where they appear in the sparsity penalty; both attain reasonably similar performance, and are definitely better than having the decoder weights frozen in one place but not the other. Put together, this seems to a marginal hit (versus the original Gated loss with L1 penalty and resampling) when comparing Pareto curves, but may be worth to the extent it simplifies training (with this loss function, the SAE training loop just becomes a vanilla neural network training loop).
PS With either the original (L1-based) loss or the modified loss of the previous paragraph, some of the other improvements suggested in the Anthropic post -- in particular, initializing the encoder weights to the transpose of the decoder weights (only at initialisation, not tying them thereafter), and warming up lambda. My point about the new loss not being Pareto better than L1 applies only if you compare like with like -- i.e. apply these other improvements in both cases.
On , it's unclear what a "natural" choice would be for setting this parameter in order to simplify the architecture further. One natural reference point is to set it to , but this corresponds to getting rid of the discontinuity in the Jump ReLU (turning the magnitude encoder into a ReLU on multiplicatively rescaled gate encoder preactivations). Effectively (removing the now unnecessary auxiliary task), this would give results similar to the "baseline + rescale & shift" benchmark in section 5.2 of the paper, although probably worse, as we wouldn't have the shift.
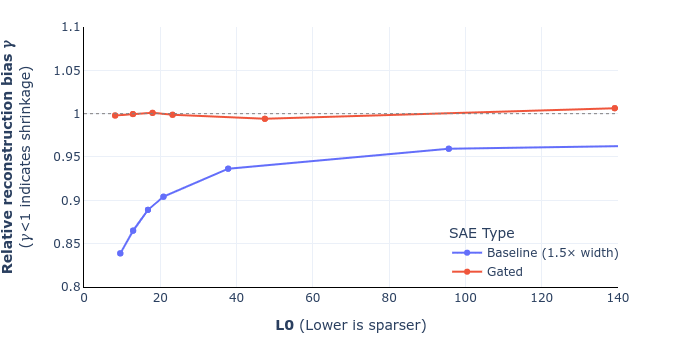
UPDATE: we've corrected equations 9 and 10 in the paper (screenshot of the draft below) and also added a footnote that hopefully helps clarify the derivation. I've also attached a revised figure 6, showing that this doesn't change the overall story (for the mathematical reasons I mentioned in my previous comment). These will go up on arXiv, along with some other minor changes (like remembering to mention SAEs' widths), likely some point next week. Thanks again Sam for pointing this out!
Updated equations (draft):

Updated figure 6 (shrinkage comparison for GELU-1L):
Yep, the intuition here indeed was that L1 penalised reconstruction seems to be okay for teaching a standard SAE's encoder to detect which features are on (even if features get shrunk as a result), so that is effectively what this auxiliary loss is teaching the gate sub-layer to do, alongside the sparsity penalty. (The key difference being we freeze the decoder in the auxiliary task, which the ablation study shows helps performance.) Maybe to put it another way, this was an auxiliary task that we had good evidence would teach the gate sublayer to detect active features reasonably well, and it turned out to give good results in practice. It's totally possible though that there are better auxiliary tasks (or even completely different loss functions) out there that we've not explored.
Hey Sam, thanks - you're right. The definition of reconstruction bias is actually the argmin of
which I'd (incorrectly) rearranged as the expression in the paper. As a result, the optimum is
That being said, the derivation we gave was not quite right, as I'd incorrectly substituted the optimised loss rather than the original reconstruction loss, which makes equation (10) incorrect. However the difference between the two is small exactly when gamma is close to one (and indeed vanishes when there is no shrinkage), which is probably why we didn't pick this up. Anyway, we plan to correct these two equations and update the graphs, and will submit a revised version.
Thanks for sharing your findings - this was an interesting idea to test out! I played around with the notebook you linked to on this and noticed that the logistic regression training accuracy is also pretty low for earlier layers when using the encoded hidden representations. This was initially surprising (surely it should be easy to overfit with such a high dimensional input space and only ~1000 examples?) until I noticed that the number of 'on' features is pretty low, especially for early layer SAEs.
For example, the layer 2 SAE only has (the same) 2 features on over all examples in the dataset, so effectively you're training a classifier after doing a dimensionality reduction down to 2 dimensions. This may be a tall order even if you used (say) PCA to choose those 2 dimensions, but in the case of the pretrained SAE those two dimensions were chosen to optimise reconstruction on the full data distribution (of which this dataset is rather unrepresentative). The upshot is that unless you're lucky (and the SAE happened to pick features that correspond to sentiment), it makes sense you lose a lot of classification performance.
In contrast, the final SAEs have hundreds of features that are 'on' over the dataset, so even if none of those features directly relate to sentiment, the chances are good that you have preserved enough of the structure in the original hidden state to be able to recover sentiment. On the other hand, even at this end of the spectrum, note you haven't really projected to a higher dimensional space - you've gone from ~1000 dimensions to a similar or fewer number of effective dimensions - so it's not so surprising performance still doesn't match training a classifier on the hidden states directly.
All in all, I think this gave me a couple of useful insights:
- It's important to have really, really high fidelity with SAEs if you want to keep L0 (number of on features) low while at the same time be able to use the SAE for very narrow distribution analysis. (E.g. in this case, if the layer 2 SAE really had encoded the concept of sentiment, then it wouldn't have mattered that only 2 features were on on average across the dataset.)
- I originally shared your initial hypothesis (about projecting to a higher dimensional space making concepts more separable), but have updated to thinking that I shouldn't think of sparse "high dimensional" projections in the same way as dense projections. My new mental model for sparse projections is that you're actually projecting down to a lower dimensional space, but where the projection is task dependent (i.e. the SAE's relu chooses which projections it thinks are relevant). (Think of it a bit like a mixture of experts dimensionality reduction algorithm.) So the act of projection will only help with classification performance if the dimensions chosen by the filter are actually relevant to the problem (which requires a really good SAE), otherwise you're likely to get worse performance than if you hadn't projected at all.