Classifying representations of sparse autoencoders (SAEs)
post by Annah (annah) · 2023-11-17T13:54:02.171Z · LW · GW · 6 commentsContents
Introduction Implementation Results Reconstruction error Test accuracy Conclusion/Confusion None 6 comments
Produced as part of the SERI ML Alignment Theory Scholars Program - Autumn 2023 Cohort, under the mentorship of Dan Hendrycks
There was recently some work on sparse autoencoding of hidden LLM representation.
I checked if these sparse representations are better suited for classification. It seems like they are significantly worse. I summarize my negative results in this blogpost, code can be found on GitHub.
Introduction
Anthropic, Conjecture [AF · GW] and other researchers [AF · GW] have recently published some work on sparse autoencoding. The motivation is to push features towards monosemanticity to improve interpretability.
The basic concept is to project hidden layer activations to a higher dimensional space with sparse features. These sparse features are learned by training an autoencoder with sparsity constraints.
I had previously looked into how to use hidden layer activations for classification, steering and removal [LW · GW]. I thought maybe sparse features could be better for these tasks as projecting features to a higher dimensional space can make them more easily linearly separable. Kind of like this (except sparser...):
Implementation
I use the pythia models (70m and 410m) together with the pretrained autoencoders from this work [AF · GW].
As the models are not super capable I use a very simple classification task. I take data from the IMDB review data set and filter for relatively short reviews.
To push the model towards classifying the review I apply a formatting prompt to each movie review:
format_prompt='Consider if following review is positive or negative:\n"{movie_review}"\nThe review is 'I encode the data and get the hidden representations for the last token (this contains the information of the whole sentence as I'm using left padding).
# pseudo code
tokenized_input = tokenizer(formatted_reviews)
output = model(**tokenized_input, output_hidden_states=True)
hidden_states = output["hidden_states"]
hidden_states = hidden_states[:, :, -1, :] # has shape (num_layers, num_samples, num_tokens, hidden_dim)I train a logistic regression classifier and test it on the test set, to get some values for comparison.
I then apply the autoencoders to the hidden states (each layer has their respective autoencoder):
# pseudo code
for layer in layers:
encoded[layer] = autoencoder[layer].encode(hidden_states[layer])
decoded[layer] = autoencoder[layer].decode(encoded[layer])Results
Reconstruction error
I don't technically need the decoded states, but I wanted to do a sanity check first. I was a bit surprised by the large reconstruction error. Here are the mean squared errors and cosine similarities for Pythia-70m and Pythia-410m for different layers:
Reconstruction errors for pythia-70m-deduped:
MSE:
{1: 0.0309, 2: 0.0429, 3: 0.0556}
Cosine similarities:
{1: 0.9195, 2: 0.9371, 3: 0.9232}
Reconstruction errors pythia-410m-deduped:
MSE: {2: 0.0495, 4: 0.1052, 6: 0.1255, 8: 0.1452, 10: 0.1528, 12: 0.1179, 14: 0.121, 16: 0.111, 18: 0.1367, 20: 0.1793, 22: 0.2675, 23: 14.6385}
Cosine similarities: {2: 0.8896, 4: 0.8728, 6: 0.8517, 8: 0.8268, 10: 0.8036, 12: 0.8471, 14: 0.8587, 16: 0.923, 18: 0.9445, 20: 0.9457, 22: 0.9071, 23: 0.8633}However @Logan Riggs [LW · GW] confirmed the MSE matched their results [AF · GW].
Test accuracy
So then I used the original hidden representations, and the encoded hidden representations respectively, to train logistic regression classifiers to differentiate between positive and negative reviews.
Here are the results for Pythia-70m and Pythia-410m[1] on the test set:
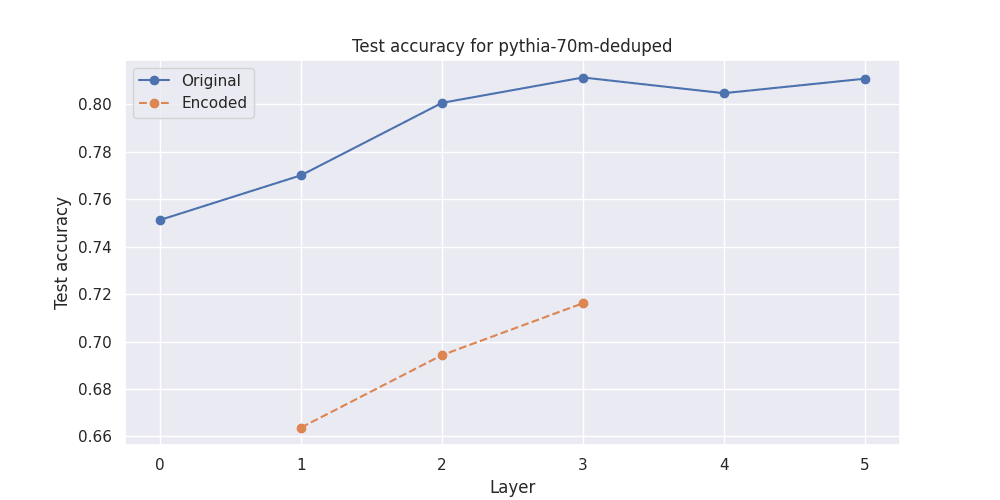
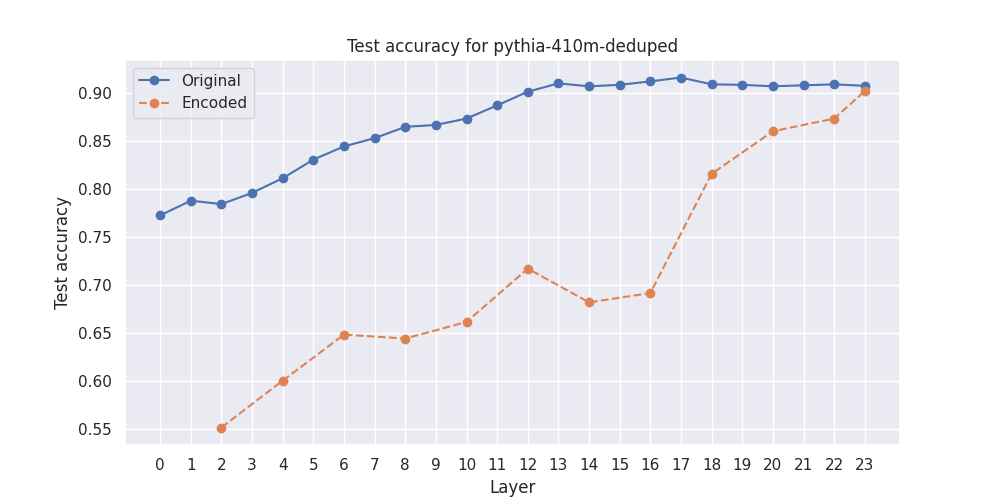
So the sparse encodings consistently under-perform compared to the original hidden states.
Conclusion/Confusion
I'm not quite sure how to further interpret these results.
- Are high-level features not encoded in the sparse representations?
- Previous work has mainly found good separation of pretty low level features...
- Is it just this particular sentiment feature that is poorly encoded?
- This seems unlikely.
- Did I make a mistake?
- The code that I adapted the autoencoder part from uses the transformer-lens library to get the hidden states. I just use the standard implementation since I'm just looking at the residual stream... I checked the hidden states produced with transformer-lens: they are slightly different but give similar accuracies. I'm not entirely sure how well transformer-lens deals with left padding and batch processing though...
Due to this negative result I did not further explore steering or removal with sparse representations.
Thanks to @Hoagy [LW · GW] and @Logan Riggs [LW · GW] for answering some questions I had and for pointing me to relevant code and pre-trained models.
- ^
I could not consistently load the same configuration for all layers, that's why I only got results for a few layers.
6 comments
Comments sorted by top scores.
comment by Senthooran Rajamanoharan (SenR) · 2023-11-17T17:57:33.735Z · LW(p) · GW(p)
Thanks for sharing your findings - this was an interesting idea to test out! I played around with the notebook you linked to on this and noticed that the logistic regression training accuracy is also pretty low for earlier layers when using the encoded hidden representations. This was initially surprising (surely it should be easy to overfit with such a high dimensional input space and only ~1000 examples?) until I noticed that the number of 'on' features is pretty low, especially for early layer SAEs.
For example, the layer 2 SAE only has (the same) 2 features on over all examples in the dataset, so effectively you're training a classifier after doing a dimensionality reduction down to 2 dimensions. This may be a tall order even if you used (say) PCA to choose those 2 dimensions, but in the case of the pretrained SAE those two dimensions were chosen to optimise reconstruction on the full data distribution (of which this dataset is rather unrepresentative). The upshot is that unless you're lucky (and the SAE happened to pick features that correspond to sentiment), it makes sense you lose a lot of classification performance.
In contrast, the final SAEs have hundreds of features that are 'on' over the dataset, so even if none of those features directly relate to sentiment, the chances are good that you have preserved enough of the structure in the original hidden state to be able to recover sentiment. On the other hand, even at this end of the spectrum, note you haven't really projected to a higher dimensional space - you've gone from ~1000 dimensions to a similar or fewer number of effective dimensions - so it's not so surprising performance still doesn't match training a classifier on the hidden states directly.
All in all, I think this gave me a couple of useful insights:
- It's important to have really, really high fidelity with SAEs if you want to keep L0 (number of on features) low while at the same time be able to use the SAE for very narrow distribution analysis. (E.g. in this case, if the layer 2 SAE really had encoded the concept of sentiment, then it wouldn't have mattered that only 2 features were on on average across the dataset.)
- I originally shared your initial hypothesis (about projecting to a higher dimensional space making concepts more separable), but have updated to thinking that I shouldn't think of sparse "high dimensional" projections in the same way as dense projections. My new mental model for sparse projections is that you're actually projecting down to a lower dimensional space, but where the projection is task dependent (i.e. the SAE's relu chooses which projections it thinks are relevant). (Think of it a bit like a mixture of experts dimensionality reduction algorithm.) So the act of projection will only help with classification performance if the dimensions chosen by the filter are actually relevant to the problem (which requires a really good SAE), otherwise you're likely to get worse performance than if you hadn't projected at all.
↑ comment by Annah (annah) · 2023-11-17T19:50:56.056Z · LW(p) · GW(p)
Yeah, this makes a ton of sense. Thx for taking the time to give it a closer look and also your detailed response :)
So then in order for the SAE to be useful I'd have to train it on a lot of sentiment data and then I could maybe discover some interpretable sentiment related features that could help me understand why a model thinks a review is positive/negative...
comment by James Payor (JamesPayor) · 2023-11-17T16:53:19.536Z · LW(p) · GW(p)
Your graphs are labelled with "test accuracy", do you also have some training graphs you could share?
I'm specifically wondering if your train accuracy was high for both the original and encoded activations, or if e.g. the regression done over the encoded features saturated at a lower training loss.
Replies from: annah↑ comment by Annah (annah) · 2023-11-17T20:13:35.896Z · LW(p) · GW(p)
The relative difference in the train accuracies looks pretty similar. But yeah, @SenR [LW · GW] already pointed to the low number of active features in the SAE, so that explains this nicely.
comment by Arthur Conmy (arthur-conmy) · 2023-11-17T14:31:39.868Z · LW(p) · GW(p)
Why do you think that the sentiment will not be linearly separable?
I would guess that something like multiplying residual stream states by (ie the logit difference under the Logit Lens [LW · GW]) would be reasonable (possibly with hacks like the tuned lens)
Replies from: annah↑ comment by Annah (annah) · 2023-11-17T19:25:59.551Z · LW(p) · GW(p)
I'm not quite sure what you mean with "the sentiment will not be linearly separable".
The hidden states are linearly separable (to some extend), but the sparse representations perform worse than the original representations in my experiment.
I am training logistic regression classifiers on the original, and sparse representations respectively, so I am multiplying the residual stream states (and their sparse encodings) with weights. These weights could (but don't have to) align with some meaningful direction like hidden_states("positive")-hidden_states("negative").
I'm not sure if I understood your comment about the logit lens. Are you proposing this as an alternative way of testing for linear separability? But then shouldn't the information already be encoded in the hidden states and thus extractable with a classifier?