Fact Finding: Attempting to Reverse-Engineer Factual Recall on the Neuron Level (Post 1)
post by Neel Nanda (neel-nanda-1), Senthooran Rajamanoharan (SenR), János Kramár (janos-kramar), Rohin Shah (rohinmshah) · 2023-12-23T02:44:24.270Z · LW · GW · 10 commentsContents
Executive Summary Our main contributions: Motivation Why Superposition Circuit Focused vs Representation Focused Interpretability Why Facts Our High-Level Takeaways How to think about facts? Is it surprising that we didn’t get much traction? Look for circuits building on factual representations, not computing them What We Learned What we learned about the circuit (Post 2 Summary) What we learned about the MLPs (Post 3 Summary) How to Think About Interpreting Memorisation (Post 4 Summary) Do Early Layers Specialise in Local Processing? (Post 5 Summary) Further Discussion Do sparse autoencoders make understanding factual recall easier? Future work Acknowledgements Author Contributions Citation None 10 comments
If you've come here via 3Blue1Brown, hi! If want to learn more about interpreting neural networks in general, here are some resources you might find useful:
- My getting started guide
- My paper reading list
- My Machine Learning Street Talk interview about the field
- Coding tutorials from ARENA
- An interactive demo of interpreting Gemma 2 2B via Neuronpedia
This is a write up of the Google DeepMind mechanistic interpretability team’s investigation of how language models represent facts. This is a sequence of 5 posts [? · GW], we recommend prioritising reading post 1, and thinking of it as the “main body” of our paper, and posts 2 to 5 as a series of appendices to be skimmed or dipped into in any order.
Executive Summary
Reverse-engineering circuits with superposition is a major unsolved problem in mechanistic interpretability: models use clever compression schemes to represent more features than they have dimensions/neurons, in a highly distributed and polysemantic way. Most existing mech interp work exploits the fact that certain circuits involve sparse sets of model components (e.g. a sparse set of heads), and we don’t know how to deal with distributed circuits, which especially holds back understanding of MLP layers. Our goal was to interpret a concrete case study of a distributed circuit, so we investigated how MLP layers implement a lookup table for factual recall: namely how early MLPs in Pythia 2.8B look up which of 3 different sports various athletes play. We consider ourselves to have fallen short of the main goal of a mechanistic understanding of computation in superposition, but did make some meaningful progress, including conceptual progress on why this was hard.
Our overall best guess is that an important role of early MLPs is to act as a “multi-token embedding”, that selects[1] the right unit of analysis from the most recent few tokens (e.g. a name) and converts this to a representation (i.e. some useful meaning encoded in an activation). We can recover different attributes of that unit (e.g. sport played) by taking linear projections, i.e. there are linear representations of attributes. Though we can’t rule it out, our guess is that there isn’t much more interpretable structure (e.g. sparsity or meaningful intermediate representations) to find in the internal mechanisms/parameters of these layers. For future mech interp work we think it likely suffices to focus on understanding how these attributes are represented in these multi-token embeddings (i.e. early-mid residual streams on a multi-token entity), using tools like probing and sparse autoencoders, and thinking of early MLPs similar to how we think of the token embeddings, where the embeddings produced may have structure (e.g. a “has space” or “positive sentiment” feature), but the internal mechanism is just a look-up table with no structure to interpret. Nonetheless, we consider this a downwards update on more ambitious forms of mech interp that hinge on fully reverse-engineering a model.
Our main contributions:
Post 2: Simplifying the circuit [AF · GW]
- We do a deep dive into the specific circuit of how Pythia 2.8B recalls the sports of different athletes. Mirroring prior work, we show that the circuit breaks down into 3 stages:
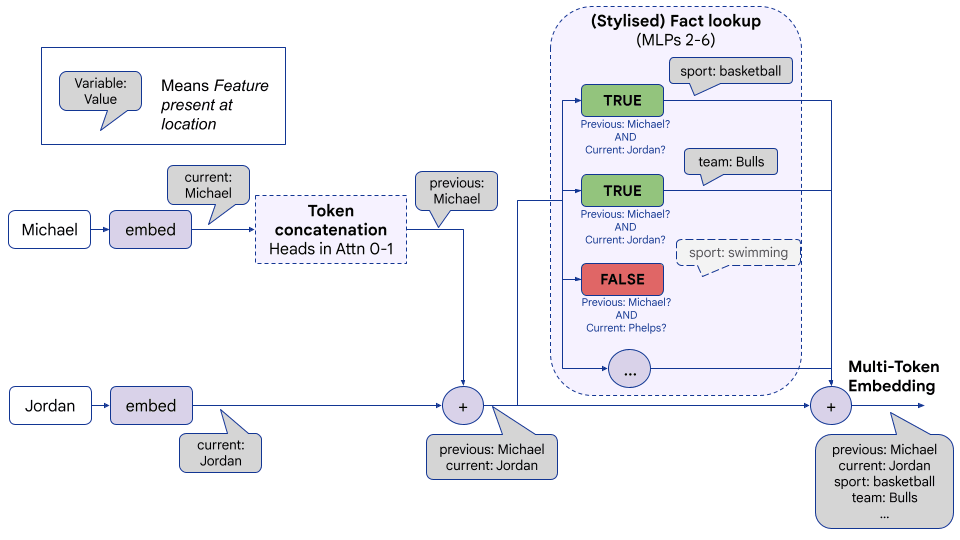
- Token concatenation: Attention layers 0 and 1 assemble the tokens of the athlete’s name on the final name token, as a sum of multiple different representations, one for each token.
- Fact lookup: MLPs 2 to 6 on the final name token map the concatenated tokens to a linear representation of the athlete’s sport - the multi-token embedding.
- Notably, this just depends on the name, not on the prior context.
- Attribute extraction: A sparse set of mid to late attention heads extract the sport subspace and move it to the final token, and directly connect with the output.
Post 3: Mechanistically understanding early MLP layers [? · GW]
- We zoom in on mechanistically understanding how MLPs 2 to 6 actually map the concatenated tokens to a linear representation of the sport.
- We explore evidence for and against different hypotheses of what’s going on mechanistically in these MLP layers.
- We falsify the naive hypothesis that there’s just a single step of detokenization, where the GELUs in specific neurons implement a Boolean AND on the raw tokens and directly output all known facts about the athlete.
- Our best guess for part of what’s going on is what we term the “hash and lookup” hypothesis [? · GW], but it’s messy, false in its strongest form and this is only part of the story. We give some evidence for and against the hypothesis.
Post 4: How to think about interpreting memorisation [? · GW]
- We take a step back to compare differences between MLPs that perform generalisation tasks and those that perform memorisation tasks (like fact recall) on toy datasets.
- We consider what representations are available at the inputs and within intermediate states of a network looking up memorised data and argue that (to the extent a task is accomplished by memorisation rather than generalisation) there is little reason to expect meaningful intermediate representations during pure lookup.
Post 5: Do Early Layers Specialise in Local Processing? [? · GW]
- We explore a stronger and somewhat tangential hypothesis that, in general, early layers specialise in processing recent tokens and only mid layers integrate the prior context.
- We find that this is somewhat but not perfectly true: early layers specialise in processing the local context, but that truncating the context still loses something, and that this effect gradually drops off between layers 0 and 10 (of 32).
We also exhibit a range of miscellaneous observations that we hope are useful to people building on this work.
Motivation
Why Superposition
Superposition is really annoying, really important, and terribly understood. Superposition is the phenomenon, studied most notably in Toy Models of Superposition, where models represent more features than they have neurons/dimensions[2]. We consider understanding how to reverse-engineer circuits in superposition to be one of the major open problems in mechanistic interpretability.
Why is it so annoying? Sometimes a circuit in a model is sparse, it only involves a small handful of components (heads, neurons, layers, etc) in the standard basis, and sometimes it’s distributed, involving many components. Approximately all existing mech interp works exploit sparsity, e.g. a standard workflow is identifying an important component (starting with the output logits), identifying the most important things composing with that, and recursing. And we don’t really know how to deal with distributed circuits, but these often happen (especially in non-cherry picked settings!)
Why is it so important? Because this seems to happen a bunch, and mech interp probably can’t get away with never understanding things involving superposition. We personally speculate that superposition is a key part of why scaling LLMs works so well[3], intuitively, the number of facts known by GPT-4 vs GPT-3.5 scales superlinearly in the number of neurons, let alone the residual stream dimension.[4]
Why is it poorly understood? There’s been fairly limited work on superposition so far. Toy Models of Superposition is a fantastic paper, but is purely looking at toy models, which can be highly misleading - your insights are only as good as your toy model is faithful to the underlying reality[5]. Neurons In A Haystack is the main paper studying superposition in real LLMs, and found evidence they matter significantly for detokenization (converting raw tokens into concepts), but fell short of a real mechanistic analysis on the neuron level.
This makes it hard to even define exactly what we mean when we say “our goal in this work was to study superposition in a real language model”. Our best operationalisation is that we tried to study a circuit that we expected to be highly distributed yet purposeful, and where we expected compression to happen. And a decent part of our goal was to better deconfuse what we’re even talking about when we say superposition in real models. See Toy Models of Superposition and Appendix A of Neurons In A Haystack for valuable previous discussion and articulation of some of these underlying concepts.
Circuit Focused vs Representation Focused Interpretability
To a first approximation, interpretability work often focuses either on representations (how properties of the input are represented internally) or circuits (understanding the algorithms encoded in the weights by which representations are computed and used). A full circuit-based understanding typically requires decent understanding of representations, and is often more rigorous and reliable and can fill in weak points of just studying representations.
For superposition, there has recently been a burst of exciting work focusing on representations, in the form of sparse autoencoders (e.g. Bricken et al, Cunningham et al). We think the success of sparse autoencoders at learning many interpretable features (which are often distributed and not aligned with the neuron basis) gives strong further evidence that superposition is the norm.
In this work, we wanted to learn general insights about the circuits underlying superposition, via the specific case study of factual recall, though it mostly didn’t pan out. In the specific case of factual recall, our recommendation is to focus on understanding fact representations without worrying about exactly how they’re computed.
Why Facts
We focused on understanding the role of early MLP layers to look up facts in factual recall. Namely, we studied one-shot prompts of the form “Fact: Michael Jordan plays the sport of” -> “basketball” for 1,500 athletes playing baseball, basketball or (American) football in Pythia 2.8B[6]. Factual recall circuitry has been widely studied before, we were influenced by Meng et al, Chughtai et al (forthcoming), Geva et al, Hernandez et al and Akyurek et al, though none of these focused on understanding early MLPs at the neuron level.
We think facts are intrinsically pretty interesting - it seems that a lot of what makes LLMs work so well are that they’ve memorised a ton of things about the world, but we also expected facts to exhibit significant superposition. The model wants to know as many facts as possible, so there’s an incentive to compress them, in contrast to more algorithmic tasks like indirect object identification where you can just learn them and be done - there’s always more facts to learn! Further, facts are easy to compress because they don’t interfere with each other (for a fixed type of attribute), the model never needs to inject the fact that “Michael Jordan plays basketball” and “Babe Ruth plays baseball” on the same token, it can just handle the tokens ‘ Jordan’ and ‘ Ruth’ differently[7] (see FAQ questions A.6 and A.7 here for more detailed discussion). We’d guess that a model like GPT-3 or GPT-4 knows more facts than it has neurons[8].
Further, prior work has shown that superposition seems to be involved in early MLP layers for detokenization, where raw tokens are combined into concepts, e.g. “social security” is a very different concept than “social” or “security” individually. Facts about people seemed particularly in need of detokenization, as often the same name tokens (e.g. a first name or surname) are shared between many unrelated people, and so the model couldn’t always store the fact in the token embeddings. E.g. “Adam Smith” means something very different to “Adam Driver” or “Will Smith”.[9]
Our High-Level Takeaways
How to think about facts?
(Figure from above repeated for convenience)
At a high-level, we recommend thinking about the recall of factual knowledge in the model as multi-token embeddings, which are largely formed by early layers (the first 10-20% of layers) from the raw tokens[10]. The model learns to recognise entities spread across several recent raw tokens, e.g. “| Michael| Jordan”, and produces a representation in the residual stream, with linear subspaces that store information about specific attributes of that entity[11][12].
We think that early attention layers perform token concatenation by assembling the raw tokens of these entities on the final token (the “ Jordan” position). And early MLP layers perform fact lookup, a Boolean AND (aka detokenization) on the raw tokens to output this multi-token embedding with information about the described entity.[13] Notably, we believe this lookup is implemented by several MLP layers, and was not localisable to specific neurons or even a single layer.
A significant caveat is that this is extrapolated from a detailed study of looking up athlete facts, rather than a broader range of factual recall tasks, though is broadly supported by the prior literature. Our speculative prediction is that factual recall of the form “recognise that some entity is mentioned in the context and recall attributes about them” looks like this, but more complex or sophisticated forms of factual recall may not (e.g. multi-hop reasoning, or recall with a richer or more hierarchical structure).
We didn’t make much progress on understanding the internal mechanisms of these early MLP layers. Our take is that it’s fine to just black box these early layers as “the thing that produces the multi-token embeddings” and to focus on understanding the meaningful subspaces in these embeddings and how they’re used by circuits in later layers, and not on exactly how they’re computed, i.e. focusing on the representations. This is similar to how we conventionally think of the token embeddings as a big look-up table. One major difference is that the input space to the token embeddings is a single token, d_vocab (normally about 50,000), while the input to the full model or other sub circuits are strings of tokens, which has a far larger input space. While you can technically think of language models as a massive lookup table, this isn’t very productive! This isn’t an issue here, because we focus on inputs that are the (tokenized) names of known entities, a far smaller set.
We think the goal of mech interp is to be useful for downstream tasks (i.e. understanding meaningful questions about model behaviour and cognition, especially alignment-relevant ones!) and we expect most of the interesting computation for downstream tasks to come in mid to late layers. Understanding these may require taking a dictionary of simpler representations as a given, but hopefully does not require understanding how the simpler representations were computed.
We take this lack of progress on understanding internal mechanisms as meaningful evidence against the goal of fully reverse-engineering everything in the model, but we think mech interp can be useful without achieving something that ambitious. Our vision for usefully doing mech interp looks more like reverse-engineering as much of the model as we can, zooming in on crucial areas, and leaving many circuits as smaller blackboxed submodules, so this doesn’t make us significantly more pessimistic on mech interp being relevant to alignment. Thus we think it is fine to leave this type of factual recall as one of these blackboxed submodules, but note that failing at any given task should make you more pessimistic about success at any future mech interp task.
Is it surprising that we didn’t get much traction?
In hindsight, we don’t find it very surprising that we failed to interpret the early MLP layers (though we’re glad we checked!). Conceptually, on an algorithmic level, factual recall is likely implemented as a giant lookup table. As many students can attest, there simply isn't much structure to capitalise on when memorising facts: knowing that "Tim Duncan" should be mapped to "basketball" doesn't have much to do with knowing that "George Brett" should be mapped to "baseball"; these have to be implemented separately.[14] (We deliberately focus on forms of factual recall without richer underlying structure.)
A giant lookup table has a high minimum description length, which suggests the implementation is going to involve a lot of parameters. This doesn’t necessarily imply it’s going to be hard to interpret: we can conceive of nice interpretable implementations like a neuron per entity, but these seem highly inefficient. In theory there could be interpretable schemes that are more efficient (we discuss, test and falsify some later on like single-step detokenization [? · GW]), but crucially there’s not a strong reason the model should use a nice and interpretable implementation, unlike with more algorithmic tasks like induction heads.
Mechanistically, training a neural network is a giant curve fitting problem, and there are likely many dense and uninterpretable ways to succeed at this. We should only expect interpretability when there is some structure to the problem that the training process can exploit. In the case of fact recall, the initial representation of each athlete is just a specific point in activation space[15], and there is (almost) no structure to exploit, so unsurprisingly we get a dense and uninterpretable result. In post 4, we also studied a toy model mapping pairs of integers to arbitrary labels where we knew all the data and could generate as much as we liked, and didn’t find the toy model any easier to interpret, in terms of finding internal sparsity or meaningful intermediate states.
Look for circuits building on factual representations, not computing them
In mechanistic interpretability, we can both study features and circuits. Features are properties of the input, which are represented in internal activations (eg, “projecting the residual stream onto direction v after layer 16 recovers the sentiment of the current sentence”). Circuits are algorithms inside the model, often taking simpler features and using them to compute more complex ones. Some works prioritise understanding features, others prioritise understanding circuits[16], we consider both to be valid approaches to mechanistic interpretability.
In the specific case of factual recall, we tried to understand the circuits by which attributes about an entity were looked up, and broadly failed. We think a reasonably halfway point is for future work to focus on understanding how these looked up attributes are represented, and how they are used by downstream circuits in later layers, treating the factual recall circuits of early layers as a small black-boxed submodule. Further, since the early residual stream is largely insensitive to context before the athlete’s name [? · GW], fact injection seems the only thing the early MLPs can be doing, suggesting that little is lost from not trying to interpret the early MLP layers (in this context).[17]
What We Learned
We split our investigation into four subsequent posts:
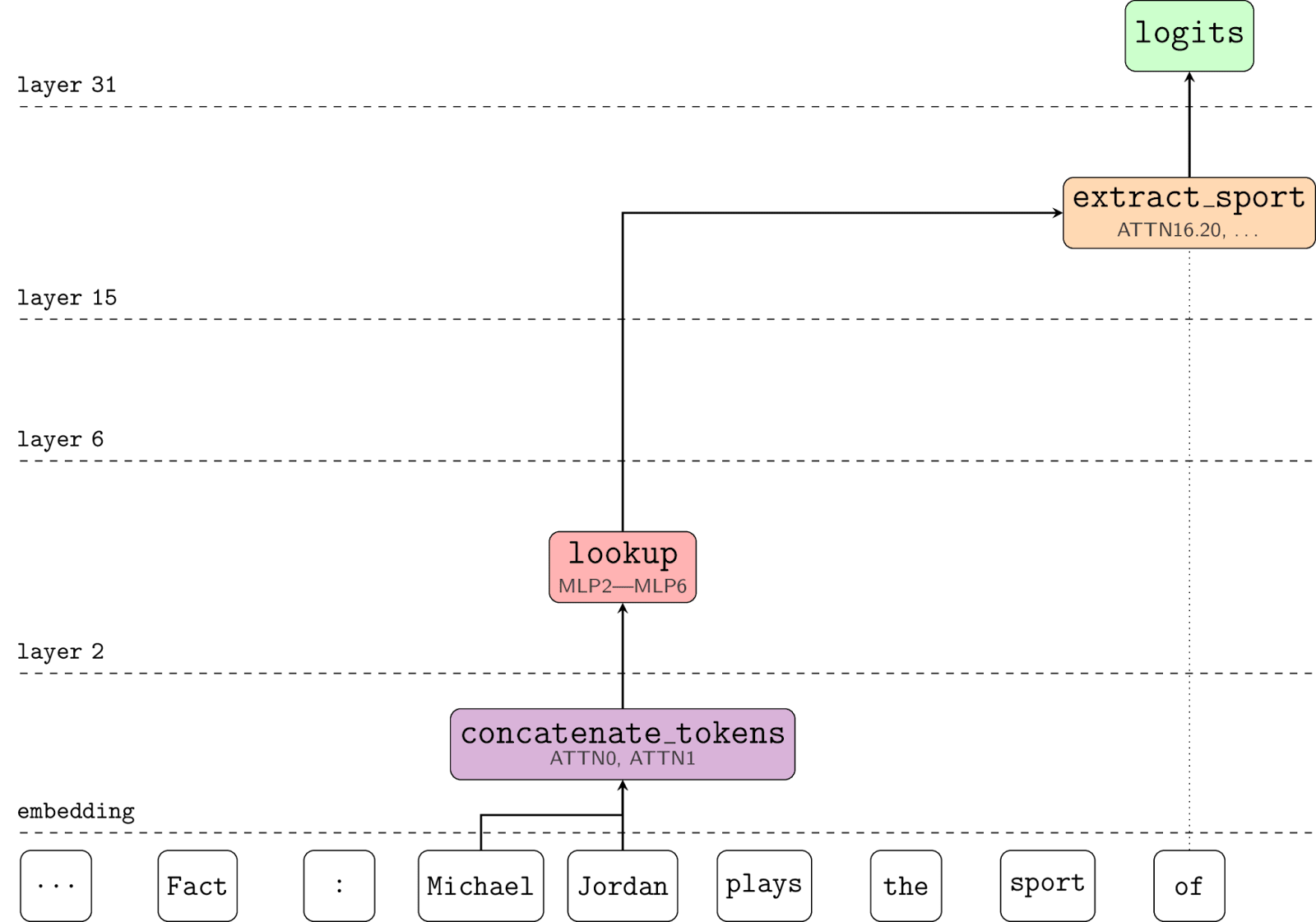
- A detailed analysis of the factual recall circuit with causal techniques, which localises the facts to MLPs 2 to 6 and understands a range of high-level facts about the circuit
- A deep dive into the internal mechanisms of these MLP layers that considers several hypotheses and collects evidence for and against, which attempts to (and largely fails to) achieve a mechanistic understanding from the weights.
- A shorter post exploring toy models of factual recall/memorisation, and how they seem similarly uninterpretable to Pythia, and how this supports conceptual arguments for how factual recall may not be interpretable in general
- A shorter post exploring a stronger and more general version of the multi-token embedding hypothesis: that in general residual streams in early layers are a function of recent tokens, and the further-back context only comes in at mid layers. There is a general tendency for this to happen, but some broader context is still used in early layers
What we learned about the circuit (Post 2 [? · GW] Summary)
-
The high-level picture from Geva et al mostly holds up: Given a prompt like “Fact: Michael Jordan plays the sport of”, the model detokenizes “Michael AND Jordan” on the Jordan token to represent every fact the model knows about Michael Jordan. After layer 6 the sport is clearly linearly represented on the Jordan token. There are mid to late layer fact extracting attention heads which attend from “of” to “Jordan” and map the sport to the output logits (see Chughtai et al (forthcoming) for a detailed investigation of these, notably finding that these heads still attend and extract the athlete’s sport even if the relationship asks for a non-sport attribute).
-
We simplified the fact extracting circuit down to what we call the effective model[18]. For two token athlete names, this consists of attention layers 0 and 1 retrieving the previous token embedding and adding it to the current token embedding. These summed token embeddings then go through MLP layers 2 to 6 and at the end the sport is linearly recoverable. Attention layers 2 onwards can be ablated, as can MLP layer 1.
- The linear classifier can be trained with logistic regression. We also found high performance (86% accuracy) by taking the directions that a certain attention head (Layer 16, Head 20) mapped to the output logits of the three sports: baseball, basketball, football[19].
-
We simplified our analysis to interpreting the effective model, where the “end” of the model is a linear classifier and softmax between the three sports.
- We think the insight of “once the feature is linearly recoverable, it suffices to interpret how the linear feature extraction happens, and the rest of the circuit can be ignored” may be useful in other circuit analyses, especially given how easy it is to train linear probes (given labelled data).
What we learned about the MLPs (Post 3 [? · GW] Summary)
- Once we’d zoomed in on the facts being stored in MLPs 2 to 6, we formed, tested and falsified a few hypotheses about what was going on:
- Note; These were fairly specific and detailed hypotheses, which were fairly idiosyncratic to my (Neel’s) gut feel about what might be going on. The space of all possible hypotheses is large.
- In fact, investigating these hypotheses made us think they were likely false, in ways that taught us about both how LLMs are working and the nature of the problem’s messiness.
- Single step detokenization hypothesis: There’s a bunch of “detokenization” neurons that directly compose with the raw token embeddings, use their GELU to simulate a Boolean AND for e.g. prev==Michael && curr==Jordan, and output a linear representation of all facts the model knows about Michael Jordan
- Importantly, this hypothesis claims that the same neurons matter for all facts about a given subject, and there’s no intermediate state between the raw tokens and the attributes.
- Prior work suggests that detokenization is done in superposition, suggesting a more complex mechanism than just one neuron per athlete. I hypothesised this was implemented by some combinatorial setup where each neuron detokenizing many strings, and each string is detokenized by many neurons, but each string corresponds to a unique subset of neurons firing above some threshold.
- We’re pretty confident the single step detokenization hypothesis is false (at least, in the strong version, though there may still be kernels of truth). Evidence:
- Path patching (noising) shows there’s meaningful composition between MLP layers, suggesting the existence of intermediate representations.
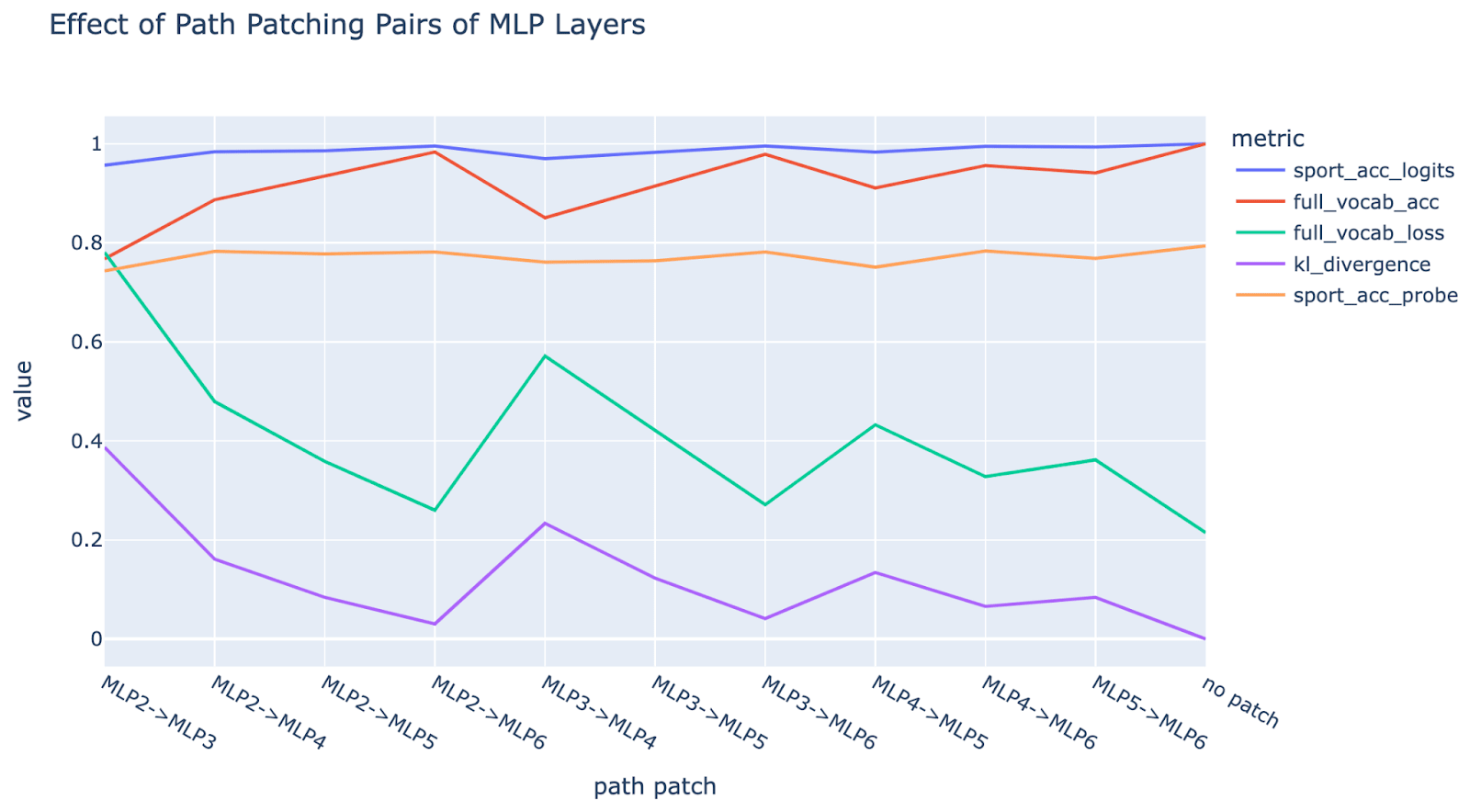
- We collect multiple facts the model knows about Michael Jordan. We then resample ablate[20] (patch) each neuron (one at a time), and measure its effect on outputting the correct answer. The single step detokenization hypothesis predicts that the same neurons will matter for each fact. We measure the correlation between the effect on each pair of facts, and observe little correlation, suggesting different mechanisms for each fact.

-
By measuring the non-linear effect of each neuron (how much it activates more for Michael Jordan than e.g. Keith Jordan or Michael Smith), we see that the neurons directly connecting with the probe already had a significant non-linear effect pre-GELU. This suggests that they compose with early neurons that compute the AND rather than the neurons with direct effect just computing the AND itself, i.e. that there are important intermediate states
-
Hash and lookup hypothesis: where the first few MLPs “hash” the raw tokens of the athlete into a gestalt representation of the name that’s almost orthogonal to other names, and then neurons in rest of the MLPs “look up” these hashed representations by acting as a lookup table mapping them to their specific sports.
- One role the hashing could serve is breaking linear structure between the raw tokens
- E.g. “Michael Jordan” and “Tim Duncan” play basketball, but we don’t want to think that “Michael Duncan” does
- In other words, this lets the model form a representation of “Michael Jordan” that is not necessarily similar to the representations of “Michael” or “Jordan”
- Importantly, hashing should work for any combination of tokens, not just ones the model has memorised in training, though looking up may not work for unknown names.
- One role the hashing could serve is breaking linear structure between the raw tokens
-
We’re pretty confident that the strong version of the hash and lookup hypothesis is false, though have found it a useful framework and think there may be some truth to it[21]. Unfortunately “there’s some truth to it, but it’s not the whole story” turned out to be very hard to prove or falsify. Evidence:
-
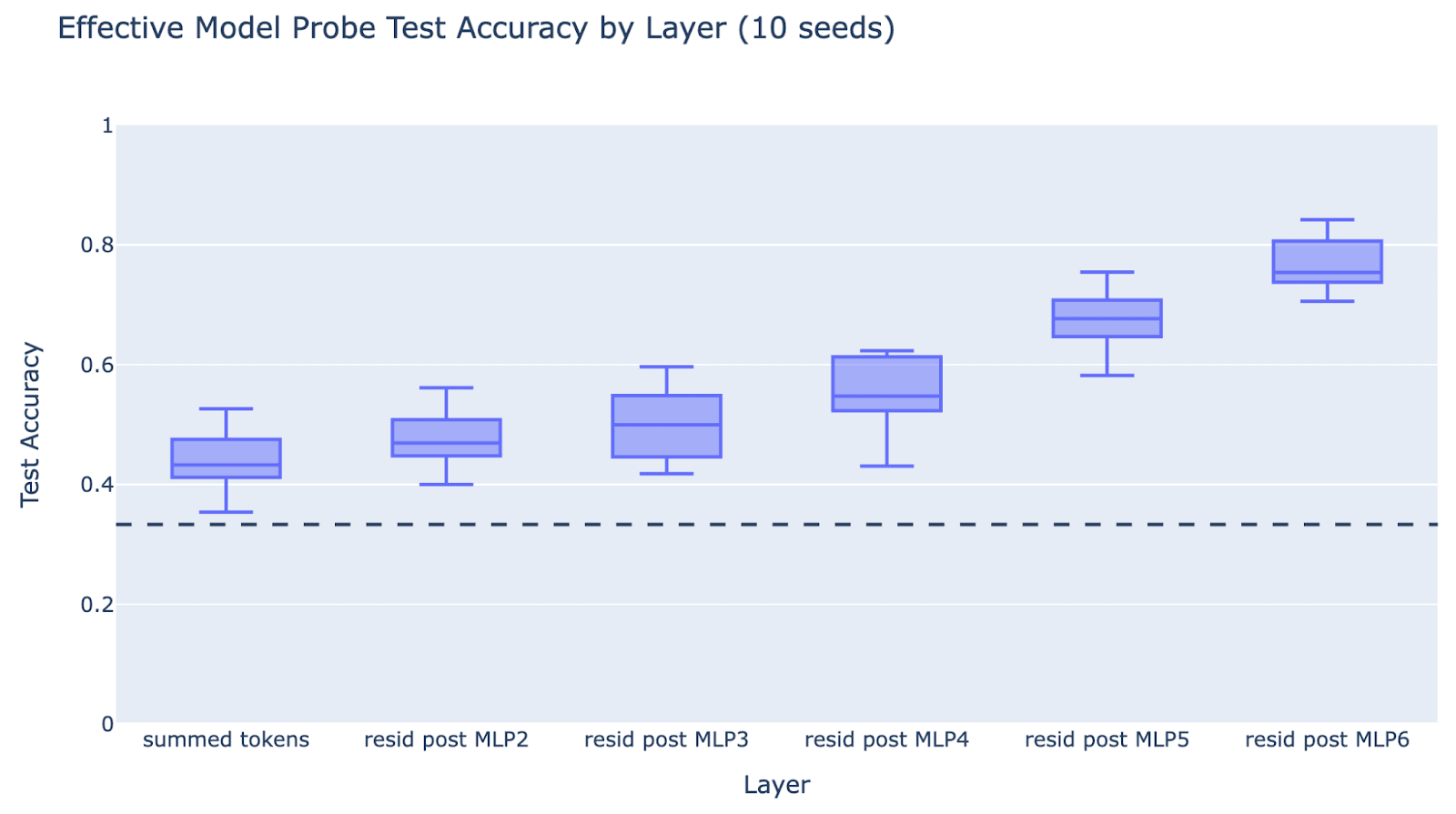
(Negative) If you linearly probe for sport on the residual stream, validation accuracy improves throughout the “hashing” layers (MLPs 2 to 4), showing there can’t be a clean layerwise separation between hashing and lookup. Pure hashing has no structure, so validation accuracy should be at random during the intermediate hashing layers.
- (Negative) Known names have higher MLP output norm than unknown names even at MLP1 and MLP2 - it doesn’t treat known and unknown names the same. MLP1 and MLP2 are hashing layers, so the model shouldn’t distinguish between known and unknown names this early. (This is weak evidence since there may e.g. be an amortised hash that has a more efficient subroutine for commonly-hashed terms, but still falsifies the strong version of the hypothesis, that hashing occurs with no regard for underlying meaning.)
- (Positive) The model does significantly break the linear structure between tokens. E.g. there’s a significant component on the residual for “Michael Jordan” that’s not captured by the average of names like “Michael Smith” or “John Jordan”. This is exactly what we expect hashing to do. * However, this is not strong evidence that the main role of MLP layers is to break linear structure, they may be doing a bunch of other stuff too. Though they do break linear structure significantly more than randomly initialised layers
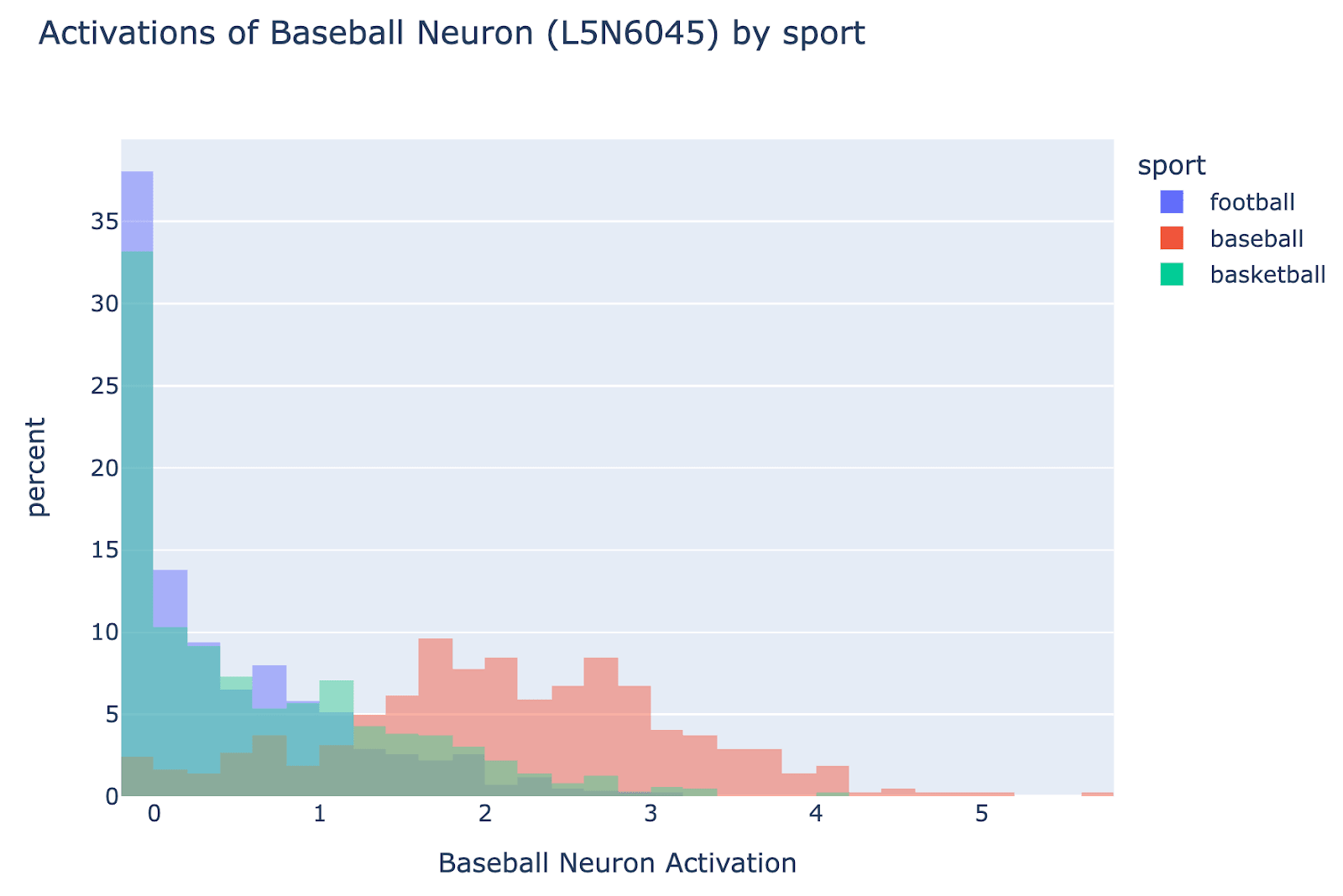
- We found a baseball neuron (L5N6045) which activated significantly more on the names of baseball playing athletes, and composed directly with the fact extracting head
- The input and output weights of the neuron have significant cosine sim with the head-mediated baseball direction (but it’s significantly less than 1): it’s partially just boosting an existing direction, but partially doing something more
- If you take the component of every athlete orthogonal to the other 1500 athletes, and project those onto the baseball neuron, it still fires more for baseball players than other players, maybe suggesting it is acting as a lookup table too.
- Looking on a broader data distribution than just athlete names, it often activates on sport-related things, but is not monosemantic.
- The input and output weights of the neuron have significant cosine sim with the head-mediated baseball direction (but it’s significantly less than 1): it’s partially just boosting an existing direction, but partially doing something more
How to Think About Interpreting Memorisation (Post 4 [? · GW] Summary)
This is a more philosophical and less rigorous post, thinking about memorisation and the modelling assumptions behind it, that was inspired by work with toy models, but has less in the way of rigorous empirical work.
-
Motivation:
- When we tried to understand mechanistically how the network does the “fact lookup” operation, we made very little progress.
- What should we take away from this failure about our ability to interpret MLPs in general when they compute distributed representations? In particular, what meaningful representations could we have expected to find in the intermediate activations of the subnetwork?
-
In post 4, we study toy models of memorisation (1-2 MLP layers mapping pairs of integers to fixed and random binary labels) to study memorisation in a more pure setting. The following is an attempt to distil our intuitions following this investigation, we do not believe this is fully rigorous, but hope it may be instructive.
-
We believe one important aspect of fact lookup, as opposed to most computations MLPs are trained to do, is that it mainly involves memorisation: there are no general rules that help you guess what sport an athlete plays from their name alone (at least, with any great accuracy[22]).
-
If a network solves a task by generalisation, we may expect to find representations in its intermediate state corresponding to inputs and intermediate values in the generalising algorithm that it has implemented to solve the task.[23]
-
On the other hand, if a network is unable to solve a task by generalisation (and hence has to memorise instead), this indicates that either no generalising algorithm exists, or at least that none of the features useful for implementing a possible generalising algorithm are accessible to the network.
-
Therefore, under the memorisation scenario, the only meaningful representations (relevant to the task under investigation) that we should find in the subnetwork’s inputs and intermediate representations are:
- Representations of the original inputs themselves (e.g. we can find features like “first name is George”).
- Noisy representations of the target concept being looked up: for example, the residual stream after the first couple of MLP layers contains a noisier, but still somewhat accurate, representation of the sport played, because it is a partial sum of the overall network’s output.[24] [25]
-
On the other hand, on any finite input domain – such as the Cartesian product of all first name / last name tokens – the output of any model component (neuron, layer of neurons, or multiple layers of neurons) can be interpreted as an embedding matrix: i.e. a lookup table individually mapping every first name / last name pair to a specific output vector. In this way, we could consider the sport lookup subnetwork (or any component in that network) as implementing a lookup table that maps name token pairs to sport representations.
-
In some sense, this perspective provides a trivial interpretation of the computation performed by the MLP subnetwork: the weights of the subnetwork are such that – within the domain of the athlete sport lookup task – the subnetwork implements exactly the lookup table required to correctly represent the sport of known athletes. And memorisation is, in a sense by definition, a task where there should not be interesting intermediate representations to interpret.
Do Early Layers Specialise in Local Processing? (Post 5 [? · GW] Summary)
- Motivation
-
The multi-token embedding hypothesis suggests that an important function of early layers is to gather together tokens that comprise a semantic unit (e.g.
[ George] [ Brett]) and “look up” an embedding for that unit, such that important features of that unit (e.g. “plays baseball”) are linearly recoverable. -
This got us thinking: to what extent is this all that early layers do?[26]
-
Certainly, it seems that many linguistic tasks require words / other multi-token entities to be looked up before language-level processing can begin. In particular, many words are split into multiple tokens but seem likely better thought of as a single unit. Such tasks can only be accomplished after lookup has happened, i.e. in later layers.
-
On the other hand, there is no reason to wait until multi-token lookup is finished for single-token level processing (e.g. simple induction behaviour) to proceed. So it’s conceivable that early layers aren’t all about multi-token embedding lookup either: they could be getting on with other token-level tasks in parallel to performing multi-token lookup.
-
If early layers only perform multi-token lookup, an observable consequence would be that early layers’ activations should primarily be a function of nearby context. For multi-token lookup to work, only the few most recent tokens matter.
-
- So, to measure the extent to which early layers perform multi-token lookup, we performed the following experiment:
- Collect residual stream activations across the layers of Pythia 2.8B for a sample of strings from the Pile.
- Collect activations for tokens from the same strings with differing lengths of truncated context: i.e. for each sampled token, we would collect activations for that token plus zero preceding tokens, one preceding token, etc, up to nine preceding tokens.
- Measure the similarity between the residual stream activations for tokens in their full context versus in the truncated contexts by computing the (mean centred) cosine similarities.
- If early layers only perform local processing, then the cosine similarities between truncated context activations and full context activations should be close to one (at least for a long-enough truncation window).
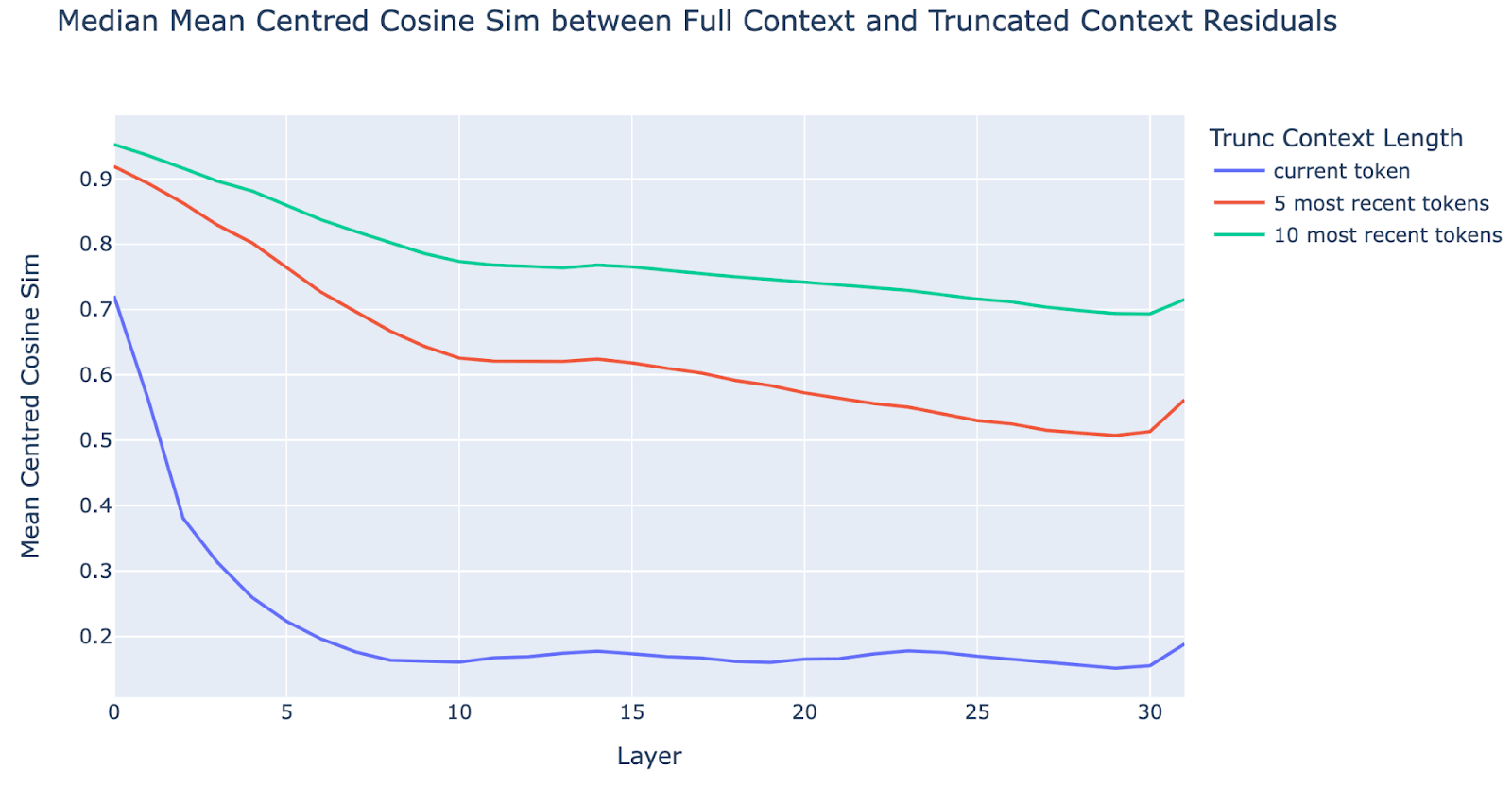
- Collecting the results, we made the following observations:
- Early layers do perform more local processing than later layers: cosine similarities between truncated and full contexts are clearly high in early layers and get lower in mid to late layers.
- There is a sharp difference though between cosine sims with zero prior context and with some prior context, showing that local layers are meaningfully dependent on nearby context (i.e. they aren’t simply processing the current token).
- However, even at layer 0, local layers do have some dependence on distant context: while cosine sims are high (above 0.9) they aren’t close to 1 (often <0.95)[27].
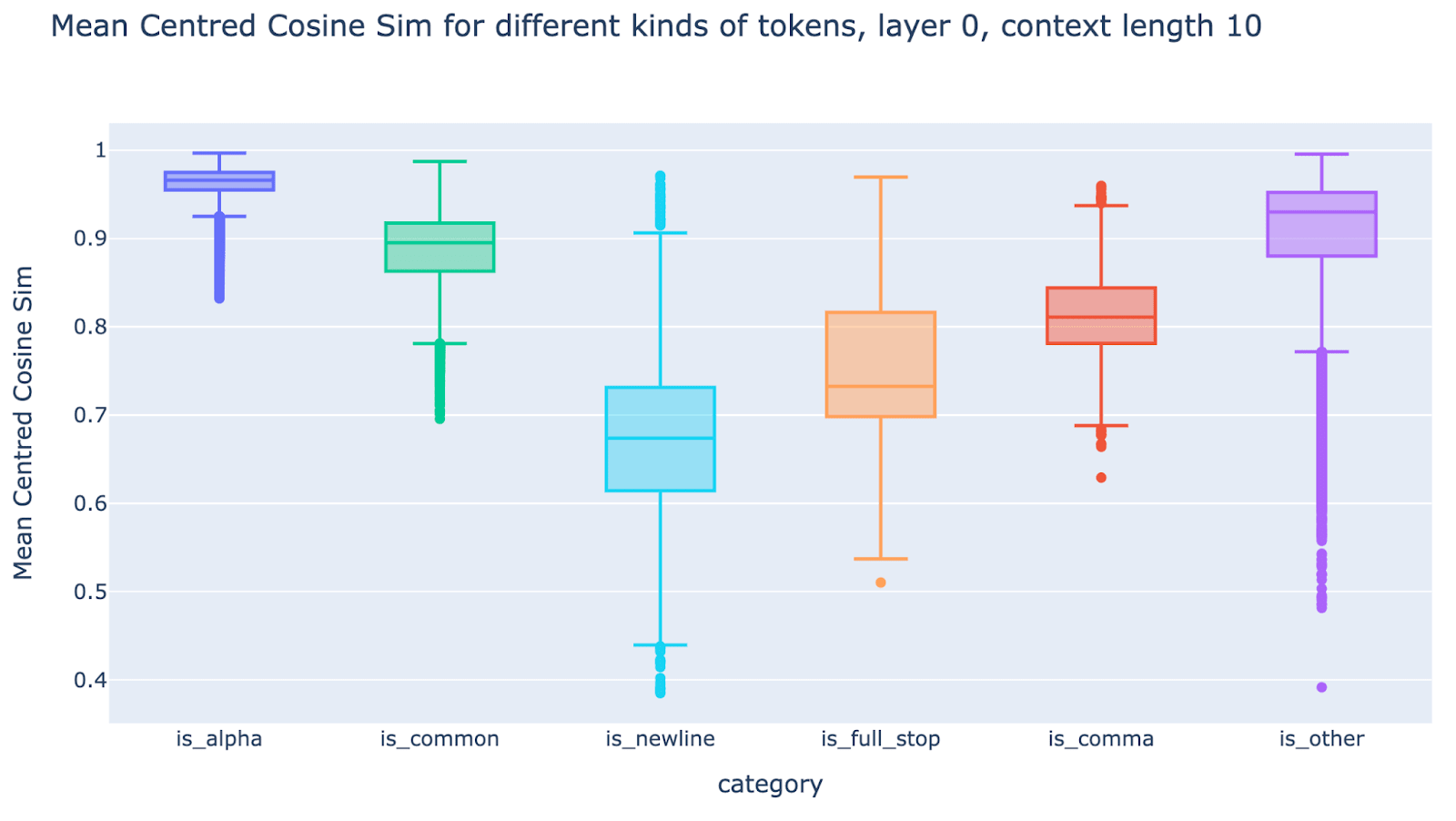
- Interestingly, we found that truncated vs full context cosine sims for early layers are particularly low on punctuation tokens (periods, commas, newlines, etc) and “stop words” (and, or, with, of, etc) – indicating that early layers perform highly non-local processing on these tokens.
- In retrospect, this isn’t so surprising, as the context immediately preceding such tokens often doesn’t add that much to their meaning, at least when compared to word fragment tokens like [ality], so processing them can start early (without waiting for a detokenisation step first).
- There are several other purposes that representations at these tokens might serve – e.g. summarisation, resting positions, counting delimiters – that could explain their dependence on longer range context.
Further Discussion
Do sparse autoencoders make understanding factual recall easier?
A promising recent direction has been to train Sparse Autoencoders (SAEs) to extract monosemantic features from superposition.[28] We haven’t explored SAEs ourselves[29] and so can’t be confident in this, but our guess is that SAEs don’t solve our problem of understanding the circuitry behind fact localisation, though may have helped to narrow down hypotheses.
The core issue is that SAEs are a tool to better understand representations by decomposing them into monosemantic features, while we wanted to understand the factual recall circuit: how do the parameters of the MLP layers implement the algorithm mapping tokens of the names to the sport played? The key missing piece in SAEs is that if meaningful features in MLP layers (pre and post GELU) are not basis aligned then we need (in theory) to understand the function of every neuron in the layer to understand the mapping. In contrast, basis aligned features (i.e. corresponding to a single neuron pre and post GELU) can be understood in terms of a single GELU, and the value of all other neurons is irrelevant.
Understanding representations better can be an extremely useful intermediate step that helps illuminates a circuit, but we expect this to be less useful here. The obvious features an SAE might learn are first name (e.g. “first name is Michael”), last name (e.g. “last name is Jordan”) and sport (e.g. “plays basketball”). It seems fairly likely that there’s an intermediate feature corresponding to each entity e.g. (“is Michael Jordan”) which may be learned by an extremely wide SAE (though it would need to be very wide! There are a lot of entities out there), though we don’t expect many meaningful features corresponding to groups of entities[30]. But having these intermediate representations isn’t obviously enough to understand how a given MLP layer works on the parameter level.
We can also learn useful things from what an SAE trained on the residual stream or MLP activations at different layers can learn. If we saw sharp transitions, where the sport only became a feature after layer 4 or something, this would be a major hint! But unfortunately, we don’t expect to see sharp transitions here, you can probe non-trivially for sport on even the token embeddings, and it smoothly gets better across the key MLP layers (MLPs 2 to 6).
Future work
In terms of overall implications for mech interp, we see our most important claims as that the early MLPs in factual recall implement “multi-token embeddings”, i.e. for known entities whose name consists of multiple tokens, the early MLPs produce a linear representation of known attributes, and more speculatively that we do not need to mechanistically understand how these multi-token embeddings are computed in order for mech interp to be useful (so long as we can understand what they represent, as argued above [? · GW]). In terms of future work, we would be excited for people to red-team and build on our claim that the mechanism of factual lookup is to form these multi-token embeddings. We would also be excited for work looking for concrete cases where we do need to understand tightly coupled computation in superposition (for factual recall or otherwise) in order for mech interp to be useful on a downstream task with real-world/alignment consequences, or just on tasks qualitatively different from factual recall.
In terms of whether there should be further work trying to reverse-engineer the mechanism behind factual recall, we’re not sure. We found this difficult, and have essentially given up after about 6-7 FTE months on this overall project, and through this project we have built intuitions that this may be fundamentally uninterpretable. But we’re nowhere near the point where we can confidently rule it out, and expect there’s many potentially fruitful perspectives and techniques we haven’t considered. If our above claims are true, we’re not sure if this problem needs to be solved for mech interp to be useful, but we would still be very excited to see progress here. If nothing else we expect it would teach us general lessons about computation in superposition which we expect to be widely applicable in models. And, aesthetically, we find it fairly unsatisfying that, though we have greater insight into how models recall facts, we didn’t form a full, parameter-level understanding.
Acknowledgements
We are grateful to Joseph Bloom, Callum McDougall, Stepan Shabalin, Pavan Katta and Stefan Heimersheim for valuable feedback. We are particularly grateful to Tom Lieberum and Sebastian Farquhar for the effort they invested in giving us detailed and insightful feedback that significantly improved the final write-up.
We are also extremely grateful to Tom Lieberum for being part of the initial research sprint that laid the seeds for this project and gave us the momentum we needed to get started.
This work benefited significantly from early discussions with Wes Gurnee, in particular for the suggestion to focus on detokenization of names, and athletes as a good category.
Author Contributions
Neel was research lead for the project, Sen was a core contributor throughout. Both contributed significantly to all aspects of the project, both technical contributions and writing. Sen led on the toy models focused work.
Janos participated in the two week sprint that helped start the project, and helped to write and maintain the underlying infrastructure we used to instrument Pythia. Rohin advised the project.
Citation
Please cite this work as follows
@misc{
nanda2023factfinding,
title={Fact Finding: Attempting to Reverse-Engineer Factual Recall on the Neuron Level},
url={https://www.alignmentforum.org/posts/iGuwZTHWb6DFY3sKB/fact-finding-attempting-to-reverse-engineer-factual-recall},
journal={Alignment Forum},
author={Nanda, Neel and Rajamanoharan, Senthooran and Kram\’ar, J\’anos and Shah, Rohin},
year={2023},
month={Dec}}
We use “select” because the number of tokens in the right “unit” can vary in a given context. E.g. in “On Friday, the athlete Michael Jordan”, the two tokens of ‘Michael Jordan’ is the right unit of analysis, while “On her coronation, Queen Elizabeth II”, the three tokens of “Queen Elizabeth II” are the right unit. ↩︎
It is closely related to the observed phenomenon of polysemanticity (where a neuron fires on multiple unrelated things) and distributed representations (where many neurons fire for the same thing), but crucially superposition is a mechanistic hypothesis that tries to explain why these observations emerge, not just an empirical observation itself. ↩︎
In particular, distributed representation seems particularly prevalent in language MLP layers: in image models, often individual neurons were monosemantic. This happens sometimes but seems qualitatively rarer in language models. ↩︎
Notably, almost all transformer circuit progress has been focused on attention heads rather than MLP layers (with some exceptions e.g. Hanna et al), despite MLPs being the majority of the parameters. We expect that part of this is that MLPs are more vulnerable to superposition than attention heads. Anecdotally, on a given narrow task, often a sparse set of attention heads matter, while a far larger and more diffuse set of MLP neurons matter, and Bricken et al suggests that there are many monosemantic directions in MLP activations that are sparse ↩︎
Though real models can also be difficult to study, as they may be full of messy confounders. Newtonian physics is particularly easy to reason about with billiard balls, but trying to learn about Newtonian physics by studying motion in a hurricane wouldn't be a good idea either. (Thanks to Joseph Bloom for this point!) ↩︎
A weakness in our analysis specifically is that we only studied 1,500 facts (the sports of 1,500 athletes) while the 5 MLP layers we studied each had 10,000 neurons, which was fairly under-determined! Note that we expect even Pythia 2.8B knows more than 50,000 facts total, athlete sports just happened to be a convenient subset to study. ↩︎
There are edge cases where e.g. famous people share the same name (e.g. Michael Jordan and Michael Jordan!), our guess is that the model either ignores the less famous duplicate, or it looks up a “combined” factual embedding that it later disambiguates from context. Either way, this is only relevant in a small fraction of factual recall cases. ↩︎
Note that models have many fewer neurons than parameters, e.g. GPT-3 has 4.7M neurons and 175B parameters, because each neuron has a separate vector of d_model input and output weights (and in GPT-3 d_model is 12288) ↩︎
Of course this is an imperfect abstraction, e.g. non-Western names are more likely to play internationally popular sports, and certain tokens may occur in exactly one athlete’s name. ↩︎
These are not the same as contextual word embeddings (as have been studied extensively with BERT-style models in the past). It has long been known that models enrich their representation of tokens as you go from layer to layer, using attention to add context to the (context-free) representations provided by the embedding layer. Here, however, we’re talking about how models represent linguistic units (e.g. names) that span multiple tokens independently of any additional context. Multi-token entities need to be represented somehow to aid downstream computation, but in a way that can’t easily be attributed back to individual tokens, similar to what’s been termed detokenization in the literature. In reality, models probably create contextual multi-token embeddings, where multi-token entities’ representations are further enriched by additional context, complicating the picture, but we still think multi-token embeddings are a useful concept for understanding models’ behaviour. ↩︎
For example, the model has a "plays basketball" direction in the residual stream. If we projected the multi-token representation for "| MIchael| Jordan" onto this direction, it would be unusually high ↩︎
This mirrors the findings in Hernandez et al, that looking up a relationship (e.g. “plays the sport of”) on an entity is a linear map. ↩︎
E.g. mapping “first name is Michael” and “last name is Jordan” to “is the entity Michael Jordan” with attributes like “plays basketball”, “is an athlete”, “plays for the Chicago Bulls” etc. ↩︎
Though there’s room for some heuristics, based on e.g. inferring the ethnicity of the name, or e.g. athletes with famous and unique single-token surnames where the sport may be stored in the token embedding. ↩︎
As argued in post 5 [? · GW], since early layers don’t integrate much prior context before the name. ↩︎
Which often implicitly involves understanding features. ↩︎
A caveat to this point is that without mechanistic understanding of the circuit it might be hard to verify that we have found all the facts that the MLPs inject -- though a countercounterpoint is that you can look at loss recovered from the facts you do know on a representative dataset ↩︎
i.e. showed that we can ablate everything else in the model without substantially affecting performance ↩︎
Each sport is a single token. ↩︎
I.e. we take another athlete (non-basketball playing), we take the neuron’s activation on that athlete, and we intervene on the “Michael Jordan” input to replace that neuron’s activation on the Jordan token with its activation on the final name token of the other athlete. We repeat this for 64 randomly selected other athletes. ↩︎
Note that it’s unsurprising to us that the strong form of hashing didn’t happen - even if at one point in training the early layers do pure hashing with no structure, future gradient updates will encourage early layers to bake in some known structure about the entities it’s hashing, lest the parameters be wasted. ↩︎
We suspect that generalisation probably does help a bit: the model is likely using correlations between features of names – e.g. cultural origin – and sports played to get some signal, and some first names or last names have sport (of famous athlete(s) with that name) encoded right in their token embeddings. But the key point is that these patterns alone would not allow you to get anywhere near decent accuracy when looking up sport; memorisation is key to being successful at this task. ↩︎
Note that we’re not saying that we would always succeed in finding these representations; the network may solve the task using a generalising algorithm we do not understand, or we may not be able to decode the relevant representations. The point we’re making is that, for generalising algorithms, we at least know that there must be meaningful intermediate states (useful to the algorithm) that we at least have a chance of finding represented within the network. ↩︎
Of course, there are many other representations in these subnetwork’s intermediate activations, because the subnetwork’s weights come from a language model trained to accomplish many tasks. But these representations cannot be decoded using just the task dataset (athlete names and corresponding sports). And, to the extent that these representations are truly task-irrelevant (because we assume the task can only be solved by memorisation – see the caveat in an earlier footnote), our blindness to these other representations shouldn’t impede our ability to understand how sport lookup is accomplished. ↩︎
Other representations we might find in a model in general include “clean” representations of the target concept (sport played), and functions of this concept (e.g. “plays basketball AND is over 6’8’’ tall”), but these should only appear following the lookup subnetwork, because we defined the subnetwork to end precisely where the target concept is first cleanly represented. ↩︎
Note that the answer to this question does not directly tell us anything (positive or negative) about the multi-token embedding hypothesis: it could be that early layers perform many local tasks, of which multi-token embeddings is just one; alternatively it could be the case that early layers do lots of non-local processing in addition to looking up multi-token embeddings. ↩︎
We note that it’s kind of ambiguous how best to quantify “how much damage did truncation do”. Arguably cosine sim squared might be a better metric, as it gives the fraction of the norm explained, and 0.9^2=0.81 looks less good. ↩︎
We note that by default SAEs get you representation sparsity but not circuit sparsity - if a SAE feature is distributed in the neuron basis then thanks to the per-neuron non-linearity any neuron can affect the output feature and can’t naively be analysed in isolation. ↩︎
We did the main work on this project before the recent flurry of work on SAEs. If we were doing this project again, we’d probably try using them! Though as noted, we don’t expect them to be a silver bullet solution. ↩︎
Beyond heuristics about e.g. certain ethnicities being inferrable from the name and more likely to play different sports, which we consider out of scope for this investigation. In some sense, we deliberately picked a problem where we did not expect intermediate representations to be important. ↩︎
10 comments
Comments sorted by top scores.
comment by LawrenceC (LawChan) · 2023-12-23T06:27:02.276Z · LW(p) · GW(p)
This is great work, even though you weren't able to understand the memorization mechanistically.
I agree that a big part of the reason to be pessimistic about ambitious mechanistic interp is that even very large neural networks are performing some amount of pure memorization. For example, existing LMs often can regurgitate some canary strings, which really seems like a case without any (to use your phrase) macrofeatures. Consequently, as you talk about in both posts 3 and 4, it's not clear that there even should be a good mechanistic understanding for how neural networks implement factual recall. In the pathological worst case, with the hash and lookup algorithm, there are actually no nontrivial, interpretable features to recover.
One hope here is no "interesting" cognition depends in large part on uninterpretable memorization[1]; maybe a understanding circuits is sufficient for understanding. It might be possible that for any dangerous capability a model could implement, we can't really understand how the facts it's using are mechanistically built up or even necessarily what all the facts are, but we can at least recognize the circuits building on factual representations, and do something with this level of understanding.
I also agree that SAEs are probably not a silver bullet to this problem. (Or at least, it's not clear.) In the case of common names like "Michael Jordan", it seems likely that a sufficiently wide SAE would recover that feature (it's a macrofeature, to use the terminology from post 4). But I'm not sure how an SAE would work in one-off cases without internal structure like predicting canary strings?
Absent substantial conceptual breakthroughs, my guess is the majority of my hope for ambitious mechanistic interp lies in use cases that don't require understanding factual recall. Given the negative results in this work despite significant effort, my best guess for how I'd study this problem would be to look at more toy models of memorization, perhaps building on Anthropic's prior work on this subject. If it's cheap and I had more familiarity with the SOTA on SAEs, I'd probably just throw some SAEs at the problem, to confirm that the obvious uses of SAEs wouldn't help.
Also, some comments on specific quotes from this post:
First, I'm curious why you think this is true:
intuitively, the number of facts known by GPT-4 vs GPT-3.5 scales superlinearly in the number of neurons, let alone the residual stream dimension.
Why specifically do you think this is intuitively true? (I think this is plausible, but don't think it's necessarily obvious.)
Second, a nitpick: you say in this post about post 4:
In post 4, we also studied a toy model mapping pairs of integers to arbitrary labels where we knew all the data and could generate as much as we liked, and didn’t find the toy model any easier to interpret, in terms of finding internal sparsity or meaningful intermediate states.
However, I'm not seeing any mention of trained models in post 4 -- is it primarily intended as a thought experiment to clarify the problem of memorization, or was part of the post missing?
(EDIT Jan 5 2024: in private correspondence with the authors, they've clarified that they have indeed done several toy experiments finding those results, but did not include them in post 4 because the results were uniformly negative.)
- ^
This reminds me about an old MIRI post distinguishing between interpretable top-level reasoning and uninterpretable subsystem reasoning [AF · GW], and while they imagined MCTS and SGD as examples of top-level reasoning (as opposed to the interpretable algorithms inside a neural network), this hope is similar to one of their paths to aligned AI:
Hope that top-level reasoning stays dominant on the default AI development path
Currently, it seems like most AI systems' consequentialist reasoning is explainable in terms of top-level algorithms. For example, AlphaGo's performance is mostly explained by MCTS and the way it's trained through self-play. The subsystem reasoning is subsumed by the top-level reasoning and does not overwhelm it.
comment by Neel Nanda (neel-nanda-1) · 2024-12-07T01:58:06.547Z · LW(p) · GW(p)
I'm not super sure what I think of this project. I endorse the seed of the idea re "let's try to properly reverse engineer what representing facts in superposition looks like" and think this was a good idea ex ante. Ex post, I consider our results fairly negative, and have mostly confused that this kind of thing is cursed and we should pursue alternate approaches to interpretability (eg transcoders). I think this is a fairly useful insight! But also something I made from various other bits of data. Overall I think this was a fairly useful conclusion re updating away from ambitious mech interp and has had a positive impact on my future research, though it's harder to say if this impacted others (beyond the general sphere of people I mentor/manage)
I think the circuit analysis here is great, a decent case study of what high quality circuit analysis looks like, one of studies of factual recall I trust most (though I'm biased), and introduced some new tricks that I think are widely useful, like using probes to understand when information is introduced Vs signal boosted, and using mechanistic probes to interpret activations without needing training data. However, I largely haven't seen much work build on this, beyond a few scattered examples, which suggests it hasn't been too impactful. I also think this project took much longer than it should have, which is a bit sad.
Though, this did get discussed in a 3Blue1Brown video, which is the most important kind of impact!
comment by Sodium · 2025-01-12T16:58:20.322Z · LW(p) · GW(p)
While this post didn't yield a comprehensive theory of how fact finding works in neural networks, it's filled with small experimental results that I find useful for building out my own intuitions [LW · GW] around neural network computation.
I think that's speaks to how well these experiments are scoped out that even a set of not-globally-coherent findings yield useful information.
comment by Roger Dearnaley · 2024-10-20T02:20:38.429Z · LW(p) · GW(p)
I think something that might be quite illuminating for this factual recall question (as well has having potential safety uses) is editing the facts. Suppose, for this case, you take just the layer 2-6 MLPs with frozen attention, you warm-start from the existing model, add a loss function term that penalizes changes to the model away from that initialization (perhaps using a combination of L1 and L2 norms), and train that model on a dataset that consists of your full set of athlete names embeddings and their sports (in a frequency ratio matching the original training data, so with more copies of data about more famous athletes), but with one factual edit to it to change the sport of one athlete. Train until it has memorized this slightly edited set of facts reasonably well, and then look at what the pattern of weights and neurons that changed significantly is. Repeat several times for the same athlete, and see how consistent/stochastic the results are. Repeat for many athlete/sport edit combinations. This should give you a lot of information on how widely distributed the representation of the data on a specific athlete is, and ought to give you enough information to distinguish between not only your single step vs hashing hypotheses, but also things like bagging and combinations of different algorithms. Even more interesting would be to do this not just for an athlete's sport, but also some independent fact about them like their number.
Of course, this is computationally somewhat expensive, and you do need to find metaparameters that don't make this too expensive, while encouraging the resulting change to be as localized as possible consistent with getting a good score on the altered fact.
↑ comment by Neel Nanda (neel-nanda-1) · 2024-10-21T14:40:54.408Z · LW(p) · GW(p)
This is somewhat similar to the approach of the ROME paper, which has been shown to not actually do fact editing, just inserting louder facts that drown out the old ones and maybe suppressing the old ones.
In general, the problem with optimising model behavior as a localisation technique is that you can't distinguish between something that truly edits the fact, and something which adds a new fact in another layer that cancels out the first fact and adds something new.
comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2024-05-09T11:37:31.801Z · LW(p) · GW(p)
Our overall best guess is that an important role of early MLPs is to act as a “multi-token embedding”, that selects[1] the right unit of analysis from the most recent few tokens (e.g. a name) and converts this to a representation (i.e. some useful meaning encoded in an activation). We can recover different attributes of that unit (e.g. sport played) by taking linear projections, i.e. there are linear representations of attributes. Though we can’t rule it out, our guess is that there isn’t much more interpretable structure (e.g. sparsity or meaningful intermediate representations) to find in the internal mechanisms/parameters of these layers. For future mech interp work we think it likely suffices to focus on understanding how these attributes are represented in these multi-token embeddings (i.e. early-mid residual streams on a multi-token entity), using tools like probing and sparse autoencoders, and thinking of early MLPs similar to how we think of the token embeddings, where the embeddings produced may have structure (e.g. a “has space” or “positive sentiment” feature), but the internal mechanism is just a look-up table with no structure to interpret.
You may be interested in works like REMEDI and Identifying Linear Relational Concepts in Large Language Models.
Replies from: neel-nanda-1↑ comment by Neel Nanda (neel-nanda-1) · 2024-05-09T15:57:21.522Z · LW(p) · GW(p)
I hadn't seen the latter, thanks for sharing!
comment by Review Bot · 2024-02-14T06:49:20.707Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
comment by WCargo (Wcargo) · 2024-02-09T13:40:42.093Z · LW(p) · GW(p)
Quick question: you say that the MLP 2-6 gradually improve the representation of the sport of the athlete, and that no single MLP do it in one go. Would you consider that the reason would be something like this post describes ? https://www.lesswrong.com/posts/8ms977XZ2uJ4LnwSR/decomposing-independent-generalizations-in-neural-networks [LW · GW]
So the MLP 2-6 basically do the same computations, but in a different superposition basis so that after several MLPs, the model is pretty confident about the answer ? Then would you think there is something more to say in the way the "basis are arranged", eg which concept interfere with which (i guess this could help answering questions like "how to change the lookup table name-surname-sport" which we are currently not able to do)
thks
Replies from: neel-nanda-1↑ comment by Neel Nanda (neel-nanda-1) · 2024-02-09T23:08:10.132Z · LW(p) · GW(p)
We dig into this in post 3. The layers compose importantly with each other and don't seem to be doing the same thing in parallel, path patching the internal connections will break things, so I don't think it's like what you're describing