Fact Finding: How to Think About Interpreting Memorisation (Post 4)
post by Senthooran Rajamanoharan (SenR), Neel Nanda (neel-nanda-1), János Kramár (janos-kramar), Rohin Shah (rohinmshah) · 2023-12-23T02:46:16.675Z · LW · GW · 0 commentsContents
Introduction Memorisation and generalisation How does learning to memorise differ from learning to generalise? Interpreting pure memorisation algorithms Limits on circuits-style interpretation of fact lookup Are any other styles of interpretation available? Memorisation with rules of thumb None No comments
This is the fourth post in the Google DeepMind mechanistic interpretability team’s investigation into how language models recall facts [? · GW]. In this post, we take a step back and consider the problem of fact lookup in general. We describe the features that distinguish memorisation problems from other learning problems and consider what constraints these place on the types of explanations that are possible for pure memorisation problems. This post can be read independently of the preceding posts in the series, though the introductory post may provide useful context on why we were interested in interpreting fact lookup circuits in the first place.
Introduction
In our previous posts, we described our attempt to understand mechanistically how Pythia 2.8B is able to accurately recall the sports of 1,500 real world athletes. Through ablation studies, we managed to isolate a subnetwork of 5 MLP layers (~50,000 neurons) that performs the sport lookup algorithm: given a pair of athlete name tokens, it could reliably lookup the sport played by that athlete. But we couldn’t give a fully mechanistic explanation of how the 5-layer MLP implements this algorithm.
In this post, we take a step back and wonder what we should take away from this failure. In particular, we ponder the following questions:
- What would it mean to understand “how” an algorithm performs fact lookup?
- What sets tasks involving fact lookup apart from other tasks that models can do?
- How do these distinguishing characteristics of fact lookup tasks limit the insights we can get into how an algorithm implementing lookup operates?
In response, we come up with the following high level takeaways, which we elaborate on in the rest of the post.
-
We distinguish between tasks that require pure memorisation and those that require generalisation. Fact lookup tasks fall into the first category.
-
By definition, the only features available in a pure memorisation task are “microfeatures” (features specific to a single example / small cluster of highly related examples[1]) or irrelevant “macrofeatures” (features shared by many examples, but not helpful for determining the correct output[2]). There are no relevant macrofeatures[3] because, if these existed, the task wouldn’t be a pure memorisation task in the first place[4].
-
This has two consequences for any model that correctly looks up facts in a pure memorisation task:
-
Intermediate states always have an interpretation in terms of combinations of microfeatures[5].
-
But, for memorisation tasks, these combinations of microfeatures will not be interpretable (even approximately) as macrofeatures[6] in their own right, because: (a) relevant macrofeatures do not exist for a pure memorisation task, and (b) the model has no need to represent irrelevant macrofeatures in its intermediate states to accomplish the task.
-
-
We argue that this rules out circuits-style interpretations – where an algorithm is decomposed into a graph of operations on interpretable intermediate representations – for algorithms implementing pure fact lookup, except in the limiting case where we “interpret” the entire algorithm by enumerating its input-output mapping, i.e. by writing out explicitly the lookup table the algorithm corresponds to.
-
We contend that this is not such a surprising result: since any pure memorisation task can essentially only be solved explicitly using a lookup table (which has no internal structure to interpret!), we shouldn’t be surprised that we only get the same degree of interpretability when another algorithm (e.g. an MLP) is used to perform the same function (though it would be nice if it were more interpretable!).
-
Finally, we consider how this analysis changes as we move from “pure” memorisation tasks to tasks where a limited amount of generalisation is possible. Many fact lookup tasks actually fall within this third “memorisation with rules of thumb” category, rather than being “pure” memorisation tasks.
Memorisation and generalisation
Formally, a “fact lookup” algorithm, is a map from a set of entities to the product of one or more sets of fact categories. For example, we could have a sports_facts function that maps an athlete’s name to a tuple representing the sport played by that athlete, the team they play for, etc, i.e.
On the face of it, this just looks like any other problem in unsupervised learning – learning a mapping given a dataset of examples. So what makes fact lookup special?
We contend that the key feature distinguishing factual recall from other supervised learning tasks is that, in its ideal form, it is purely about memorisation:
A memorisation ("pure'' factual recall) task admits no generalisation from previously seen examples to new examples. That is, when asked to look up facts for previously unseen entities, knowledge of the (and ability to fit to the) training data confers no advantage beyond knowledge of base rates of the outputs.
For example: knowing that LeBron James plays for the Los Angeles Lakers doesn’t help you much if you are actually asked which team Donovan Mitchell plays for.[7]
In contrast, a generalisation task is one where it is possible to learn general rules from previously seen examples that meaningfully help to make accurate inferences on unseen examples. This is the paradigm of classical computational learning theory.
How does learning to memorise differ from learning to generalise?
Consider the following two datasets. The objective is to learn a function that, given one of these points as the input, provides the point’s colour as its output.
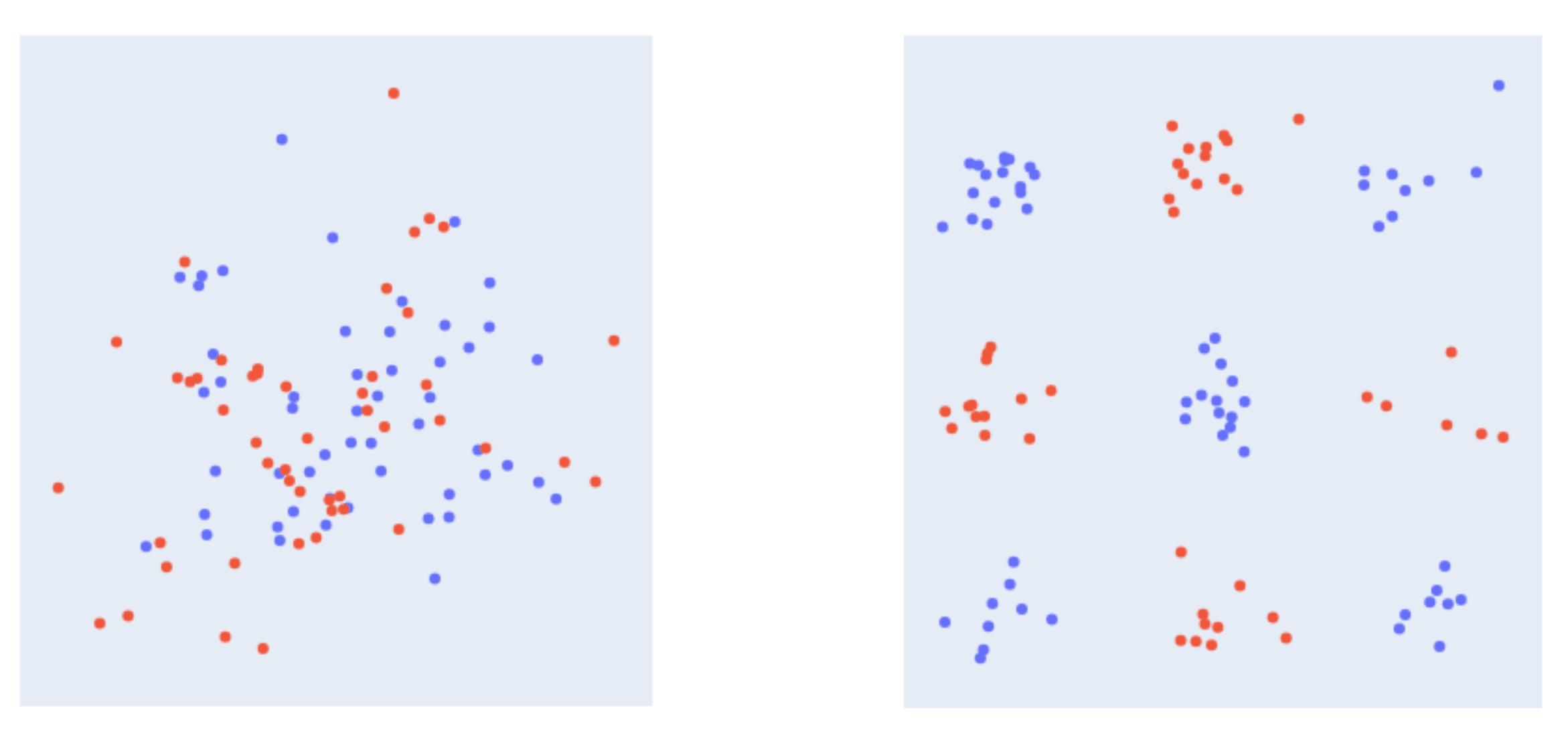
For the lefthand dataset, it seems that the only way to learn this point-to-colour mapping successfully is to literally memorise the colour of every point: there is no consistent rule or shortcut that can make learning the mapping easier. On the other hand, it’s fairly straightforward to come up with a geometric construction (perhaps one that can be translated into a neural network) that successfully distinguishes between blue and red points in the righthand dataset.
How can we best characterise the difference between the two datasets? One way, which we find useful in the context of this post, is to think in terms of microfeatures and macrofeatures of the inputs in each dataset. We characterise micro and macro features as follows:
- A microfeature is a feature that describes an input in highly specific terms, and is therefore not particularly useful for generalising.
- A macrofeature is a feature that describes an input in general terms, and could be useful for generalising (if it’s relevant to the task at hand).[8]
Both datasets have microfeatures: for example, if we (arbitrarily) assign an identifying integer to every point in the dataset, we can define microfeatures of the form
is_example_id_xxxfor any finite dataset.
But only the righthand dataset has macrofeatures: we could, for example, label each of the nine clusters in the “checkerboard” with an integer, and define macrofeatures of the form is_in_cluster_x. One possible lookup algorithm would then be to detect which of these clusters a new example is associated with, and then output the same colour as the majority of other examples in the same cluster.[9] On the other hand, the only macrofeature for the lefthand dataset is the label (“blue” or “red”) itself, which is precisely what the lookup algorithm needs to predict![10]
Interpreting pure memorisation algorithms
What insights can we gain into algorithms that solve pure memorisation tasks?
Limits on circuits-style interpretation of fact lookup
The canonical goal in mechanistic interpretability is to decompose an algorithm into a comprehensible graph (“circuit”), where each node is a “simple” operation (say, an operation that corresponds to a built-in function in a high level programming language) and the inputs and outputs to that operation can be interpreted in terms of “features” relevant to the domain of the problem.
In light of the discussion of micro- and macrofeatures in the previous section, it’s clear that pure memorisation tasks pose a challenge for circuits-style decomposition. Pure memorisation tasks are precisely those that don’t have macrofeatures that are relevant to solving the task. This means that any intermediate states in an algorithm performing pure fact lookup must either represent:
- Macrofeatures that are irrelevant, and hence do not determine the algorithm’s output;
- Unions, conjunctions, weighted combinations or other arbitrary functions of individual microfeatures that do not have an alternative interpretation as macrofeatures.
Taking the first bullet point, in fact we do find irrelevant macrofeatures within the MLP subnetwork of Pythia 2.8B that looks up sports facts: because of the residual stream connections between layers, macrofeatures like first_name_is_george are preserved all the way through to the network’s output. The point is though that these macrofeatures don’t tell us much about how the network is able to perform sport fact lookup.
Turning to the second bullet point, we note that for any finite dataset, we can actually trivially decompose a neural network into a computational graph involving weighted combinations of microfeatures. This is because each neuron in the network can be interpreted exactly as a weighted combination of microfeatures, where the weights correspond to its output on the example corresponding to that microfeatures. For example, a (hypothetical) neuron that outputs 3 on LeBron James, 1 on Aaron Judge, and so on, could be “interpreted” as representing the compound feature:
3 * is_LeBron_James + 1 * is_Aaron_Judge + ...
The output of each MLP layer is a sum of such features, which in turn has the same linear form – as does the output of the network. Note that this is equivalent to interpreting each individual neuron (and sum of neurons) as a lookup table.
In effect, this means that we always have access to the following “interpretation” of how a neural network performs fact lookup: each neuron in the network is a lookup table over the input space, and the output of the network is a sum of these lookup tables. By training the network, we have effectively solved a constraint satisfaction problem: that the summed lookup table should have high weights for one class and low weights for the other class.[11]
Notice that this microfeature (or lookup table) interpretation of a neural network applies equally to models that solve generalisation tasks (i.e. perform well on an unseen test set), as long as we restrict the space of inputs to a finite set.[12] The difference is that, for generalisation tasks, we might expect some of these “lookup table” representations to have better interpretations in terms of macrofeatures that are used by the model to generalise.
For example, a particular neuron in an image classification model may have weights corresponding to detecting a vertical edge on the lefthand side of the image, and hence its lookup table representation shows high activations for examples that contain this edge and low activations for examples that don’t. The point is that, although this lookup table representation is an exact representation of the neuron’s output, there is a more useful (to humans) interpretation of this activation pattern in terms of the presence of edges in the input image, which is only available because images have macrofeatures (like edges) that can be useful for a generalising task like image classification.
In contrast, we argue that for a pure memorisation task, these “lookup table” representations of neurons (or groups of neurons) are the only interpretations that are available.[13] In turn, this seems to preclude a standard circuits-style decomposition of the algorithm implemented by a pure fact lookup model, since the intermediate states do not have (macrofeature) interpretations.
Are any other styles of interpretation available?
Of course, we do not claim that the standard circuits approach to interpreting how a model performs a task is the only style of interpretation possible. Indeed, it may not even be the best way to interpret how a neuron performs fact lookup. In this section, we briefly discuss a couple of alternative directions that may be worth exploring further.
The first direction is to give up hope on intermediate states representing meaningful macrofeatures, but nonetheless to seek meaningful structure in how the lookup computation is organised. For example, we might explore the hypothesis that, when trained to perform pure memorisation, the trained neural network resembles a model learnt by bagging, where each individual neuron is an uncorrelated weak classifier for the fact to be learnt, and the overall neural network’s output is the sum of these classifiers. See also the hypotheses investigated in post 3.
The trouble with this approach is that we don’t know how to efficiently search the universe of hypotheses of this type. As we found in post three, for any seemingly concrete hypothesis that we falsify (e.g. the single-step detokenization hypothesis), there are many neighbouring hypotheses we could pivot towards that aren’t (yet) ruled out, and which are often themselves harder to falsify. Thus it’s unclear how to avoid an endless sequence of ad hoc hypotheses.[14]
Another direction is to look for non-mechanistic explanations for an algorithm, or – to put it another way – move from asking “how” a network behaves in a certain way to asking “why” it behaves that way. One area that we find interesting in this vein is the use of influence functions to explain a model’s behaviour in terms of its training data. This may seem uninteresting in the case of a model explicitly trained to memorise a dataset of facts[15], but could lead to non-trivial insights for models (like language models) that have implicitly memorised facts in order to satisfy a broader generalisation objective.
Memorisation with rules of thumb
Considering the tasks of memorising the following two datasets:
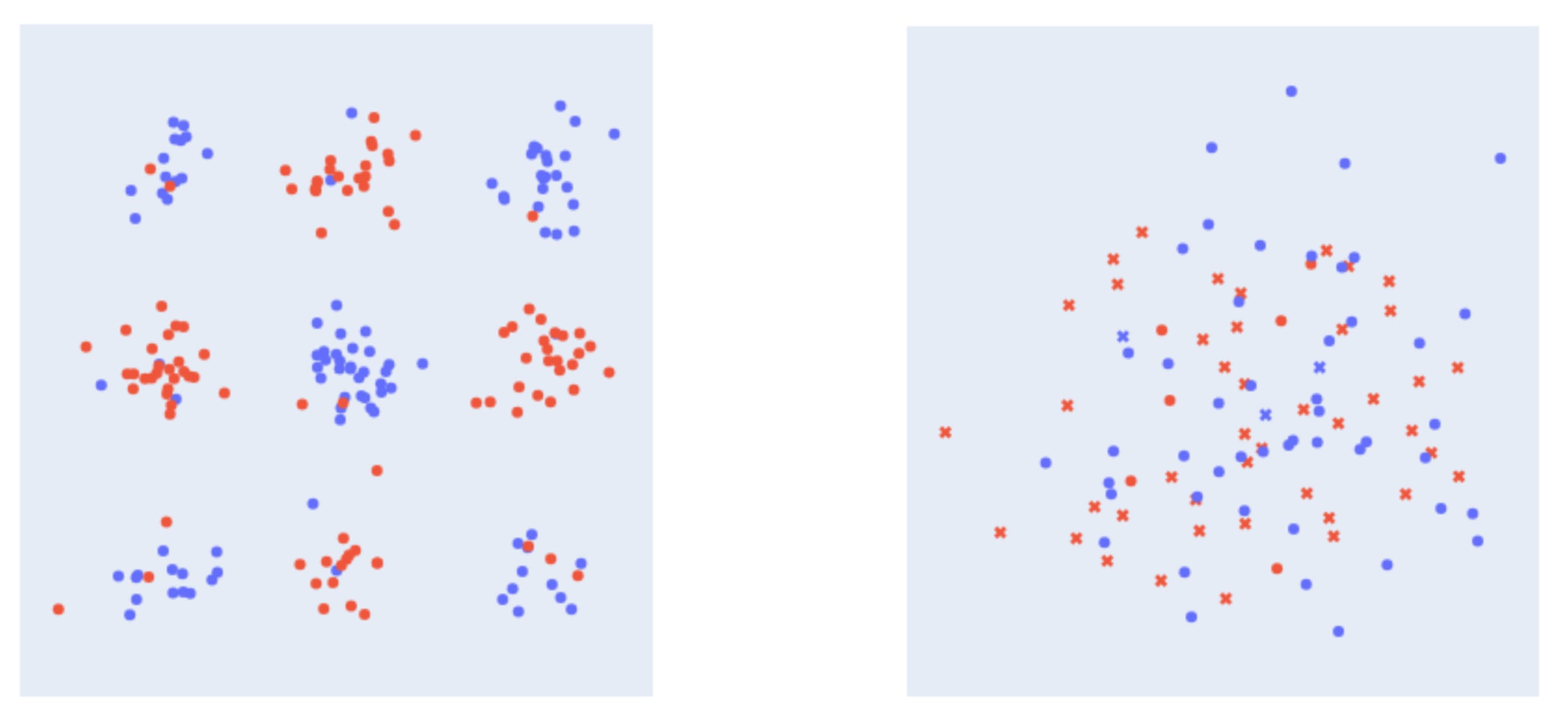
These are examples of memorisation tasks that do not fit our above characterisation of “pure” memorisation:
- In the lefthand dataset, perfect accuracy requires memorisation, but there are some helpful “rules of thumb” that can get you much of the way. A language modelling analogue of this type of task would be to predict the plural version of a singular noun in English: one gets the correct answer much of the time by simply adding “s” to the end of the singular version of the noun, but with some exceptions (e.g. “child”) that must be memorised to do the task perfectly.
- In the righthand dataset, each point is associated with two “facts” – represented by the point’s colour (blue or red) and its shape (cross or circle). Although there’s no systematic way to look up either colour or shape individually, notice that there is a high correlation between these two facts: blue points are nearly always circles whereas red points are nearly always crosses. This suggests it should be possible to memorise both shape and colour facts together more efficiently than by simply memorising each set of facts independently.
In general, we characterise these sorts of tasks as “memorisation with rules of thumb”. They differ from pure memorisation tasks in the sense that previous examples do help to a limited extent with inferring the correct outputs for new examples, but perfect performance does entail some degree of memorisation.[16]
Unlike pure memorisation, these rule-of-thumb memorisation tasks do have an element of generalisation to them and, consequently, there are macrofeatures that enable this generalisation. Therefore, it would be valid to look for these macrofeatures in the intermediate representations of a model that is able to perform these tasks. On the other hand, to the extent that the model does need to memorise the exceptions, we do not expect to be able to understand the algorithm perfectly: at least some portion of the algorithm must involve “pure lookup”, for which the limitations on interpretability discussed in this post would apply.
To what extent was the sport-fact lookup task pure memorisation, and to what extent was it memorisation with rules of thumb? As we discussed in post one, we picked this task because it seems close to pure memorisation: for many names, it seems unlikely that individual name tokens shed much light on the sport played by an athlete. Nevertheless, we do know that for some names, the last token does help determine the sport (because it’s possible to probe for sport with just the last token embedding and get better accuracy than an uninformed classifier). Furthermore, it’s conceivable that latent factors, like the cultural provenance of a name, is correlated with sport in ways that the model picks up on.
For example, the feature
is_Michael_Jordan, which is only true when the input is"Michael Jordan". ↩︎For example, the feature
first_name_is_George, which is shared by many athletes, but not particularly useful for predicting which sport an athlete plays. ↩︎We note that factual recall likely does have some somewhat relevant macrofeatures, like detecting a name’s ethnicity from the tokens and having heuristics for which ethnicities are likely to play different sports. But the model achieves significantly better performance than we expect possible from these heuristics, so for practical purposes we ignore them when discussing factual recall. One advantage of a toy model is that we can ensure such confounders don’t exist. ↩︎
Because, if they existed, we could use these relevant macrofeatures to help with fact lookup (make educated guesses to varying degrees of success), meaning the task would no longer entail pure memorisation. ↩︎
More precisely, weighted sums of microfeatures, e.g.
3 * is_Michael_Jordan + 0.5 * is_George_Brett. ↩︎We note that there are _un_available but useful macrofeatures - “plays basketball” is in some trivial sense a macrofeature useful for predicting whether an athlete plays basketball, as are downstream features like “plays basketball and is taller than 6’8”.” For the purposes of this analysis we focus on the features available to the model at the point it’s doing the lookup, ruling out potential macrofeatures that are downstream of the looked up labels. ↩︎
Of course, many factual recall tasks fall short of this ideal characterisation: it often pays off to make an “educated guess'' when participating in a trivia quiz, even when you don’t know the answer for sure. We discuss such “memorisation with rules of thumb” tasks further on [AF · GW]. ↩︎
We think of these concepts in analogy with the concepts of microstates and macrostates in statistical physics: a microstate describes a system in a highly precise way (e.g. specifying the positions and velocities of every molecule in a gas), whereas a macrostate describes a system in terms of properties that are readily measurable (e.g. pressure, volume, temperature), ignoring the details. For any “macroscopic” problem, there should be a solution solely in terms of macroscopic variables; the microscopic details shouldn’t matter. This is analogous to the idea of generalisation: any two examples that are alike in “ways that matter” (their macrofeatures) should be classified similarly, disregarding any differences in “ways that don’t matter” (their microfeatures). Under this analogy, memorisation problems are precisely those questions about a system that can only be answered with precise knowledge of its microstate. ↩︎
These are not the only macrofeatures that can solve this particular generalisation problem. If you train toy neural networks to perform this classification task, you will find (depending on hyperparameters like the number of neurons or random seed) a variety of ways to partition the space (in a coarse-grained, generalising manner) to successfully classify these points. ↩︎
We know this for sure with this dataset, because we generated it ourselves, by randomly assigning colours to points (which were themselves randomly sampled from a bivariate Gaussian distribution). Therefore the only relevant features in this dataset are the example IDs themselves and the output labels. ↩︎
This is the constraint satisfaction problem in the case of a binary fact lookup task, but it is trivial to generalise this interpretation to multi-class or continuous value fact lookup tasks. ↩︎
This can always be done for any practical ML task. For example, we could restrict the problem of classifying handwritten digits to classifying exactly the 70,000 examples found in the union of the MNIST train and test sets. (Or we could expand the task to classifying any of 280,000 possible corner crops of the combined MNIST dataset if we care about data augmentation.) We can arrange for the set of potential inputs to get as large as we wish, but still remain finite. ↩︎
Since there are (by definition) no relevant macrofeatures in a pure memorisation task (because if there were, then a model would be able to generalise). ↩︎
There is also the question of the usefulness of such an interpretation of a lookup algorithm. Even if we had uncovered some simple(ish) structure to how the lookup is accomplished – say, that it resembles bagging – it’s unclear, without meaningful intermediate representations, what this could help us with in terms of downstream uses for mechanistic interpretability. ↩︎
Because we already know precisely the correspondence between training data and model outputs if the model was trained explicitly to reproduce the memorisation dataset. ↩︎
Memorisation with rules of thumb should not be confused with generalisation tasks with aleatoric uncertainty. For example, the lefthand dataset could also be taken to represent a stochastic data generating process where points aren’t definitely blue or red, but are instead Bernoulli distributed – i.e. may be blue or red with some (input dependent) probability. In that case, a perfect generalising algorithm should output calibrated probabilities that are constant within each cluster. However, here we mean that blue points in the dataset really are blue and red points really are red – even where they look out of place – and that perfect performance corresponds to reproducing these idiosyncrasies, rather like the “pluralise this singular noun” task described in the main body of the text. ↩︎
0 comments
Comments sorted by top scores.