Takeaways From Our Recent Work on SAE Probing
post by Josh Engels (JoshEngels), Subhash Kantamneni (subhashk), Senthooran Rajamanoharan (SenR), Neel Nanda (neel-nanda-1) · 2025-03-03T19:50:16.692Z · LW · GW · 0 commentsContents
Key takeaways: Our thinking on SAE research: Summary of Main Results: Introduction Experimental Setup Main Experimental Results Dataset Quality Detection Multi-Token Probing Assessing Architectural Improvements None No comments
Subhash and Josh are co-first authors on this work done in Neel Nanda’s MATS stream.
We recently released a new paper investigating sparse probing that follows up on a post [LW · GW] we put up a few months ago. Our goal with the paper was to provide a single rigorous data point when evaluating the utility of SAEs.
TLDR: Our results are now substantially more negative. We find that SAE probes do not consistently beat baselines on probing in difficult conditions.
We’ve organized this post with the most important takeaways at the top and then a discussion of our new results down below. It might help if you’ve read our twitter thread, skimmed the paper, or skipped down to the results section before reading our takeaways.
Key takeaways:
SAE reconstruction loss may not be a great proxy for downstream tasks we care about: While newer SAE architectures have improved reconstruction loss and downstream cross-entropy at a fixed sparsity, this improvement doesn’t seem to have transferred to improved performance on sparse probing in difficult conditions, a real-world interpretability task. Recent SAE benchmarking efforts like SAEBench provide more support for this view, as on most of the SAEBench downstream tasks, performance does not consistently improve with newer SAE architectures.
Going forward, we’d be interested to see work that trains SAEs with loss metrics that incentivize “good downstream performance” or “more interpretable representations,” possibly at the cost of getting slightly worse on the sparsity vs. FVU frontier. For example, Goodfire has done this to an extent by prioritizing steering performance in their recent SAE releases.
The current best case for SAE usefulness seems to be interpretability-based tasks: Replicating Anthropic’s earlier probing work, our most promising results came from using the interpretable nature of SAE latents to find spurious features, identify dataset problems, etc. While we were able to eventually arrive at similar results with baseline methods, it was practically considerably easier to do so with the existing SAE infrastructure like Neuronpedia. We also believe that on some datasets, the spurious feature baseline detection method we came up with wouldn’t work (e.g. if the spurious feature was only the second or third most relevant latent). For both of these reasons, some future benchmark that looked at a problem like having to do a bunch of interpretability-based work in a short time frame might show that SAEs outperform.
We’ve personally learned the importance of strong baselines: There was a clear pattern that repeated throughout our investigations: we were initially tricked by promising results for SAEs, but when we tried hard to find a strong baseline method, the improvements would disappear. This was discouraging because we really wanted SAEs to win! But eventually, we realized that a rigorous negative is still an important contribution.
Some specific situations we ran into:
- We were initially excited that we were winning on some of the very noisy datasets, but when we chose the best method by validation AUC instead of taking the max over test AUCs, we found that we were not able to reliably find the better method between the baseline and the SAE (so we were probably correct by chance).
- We initially thought that our results finding spurious features in the dataset could only be done by SAE probes, but when Neel suggested we use the dot product of tokens from the pile with standard logistic regression probes as a sanity check, we were surprised that it also worked!
- Originally multi-token based SAE aggregation probing seemed really promising, but when we implemented a stronger attention-probe based baseline, much of the gain disappeared.
Our thinking on SAE research:
SAEs are an exciting technique, but there is not yet much evidence that they are useful in their current form. We hoped to provide some of this evidence with our work, but although we explored a number of settings where we thought SAEs should provide an advantage, we were ultimately unsuccessful.
We believe that progress on downstream applications is the primary way to get feedback from the real world about whether our techniques are working. Thus, in order to justify further work on SAEs in their current form, we think it is important to find other, more successful applications of SAEs.
However, many great scientific advances took years to bear fruit. It might be that some future form of SAEs are differentially useful for understanding, monitoring, and controlling neural networks, even if current SAEs are not. Thus, it seems reasonable to continue working on some more ambitious vision of SAEs if you have a direction that you believe may be promising. But we think that it is important to distinguish this from a belief that SAEs in their current form are great.
Summary of Main Results:
Introduction
Sparse autoencoders (SAEs) have been the hot topic of mechanistic interpretability (MI) research for the last year and a half. Despite their popularity, there have been relatively few works that rigorously compare the utility of SAEs to standard baselines. Instead, most studies evaluate SAEs on proxy metrics like downstream cross-entropy loss and reconstruction error. We argue that unless we are making measurable improvement on a task that is useful in the real world, it isn’t really clear if we are making progress on better understanding models.
One such useful task is probing: training classifiers to predict specific information from model activations. Probing is used extensively in the ML community to understand what information is present in neural networks, and it is a practical tool to answer safety relevant questions (e.g. truthfulness probes, self awareness probes, deception probes, etc.). Given that SAEs are supposed to extract meaningful, interpretable features from activations, we hypothesized that SAE-based probes should outperform standard probing methods in challenging scenarios where learning the correct dense probe is difficult. This would provide strong evidence that SAEs are useful.
Experimental Setup
We collect a set of 113 binary classification datasets (described here). Importantly, we wanted to avoid street-lighting effects, so we choose a wide range of challenging datasets - for example, one of our datasets requires differentiating whether a given news headline is on the front page or later in the newspaper, while another requires identifying if the second half of the prompt is logically entailed by the first half.
Given a set of training examples, we train SAE probes on the top-k latents by mean difference between positive and negative class examples. In practice, we use k = 16 and 128. We compare with baseline methods (logistic regression, PCA regression, MLPs, XGBoost, and KNN) applied to raw language model activations. We perform experiments on Gemma-2-9B with Gemma Scope JumpReLU SAEs, but also replicate core results on Llama-3.1-8B and Gemma-2-2B.
We wanted to simulate as accurately as possible the benefit a practitioner would have if SAE probes were added to their toolkit. We thus use what we call a “Quiver of Arrows” experimental design. Essentially, we train only baseline methods on the training data, choose the best method with validation AUC ROC (area under the ROC curve), and calculate the test AUC. Then, we add SAE probes to our bag of baseline methods and repeat the same process. The delta in test AUC represents the direct improvement of adding SAE probes to a practitioner’s toolkit.
Main Experimental Results
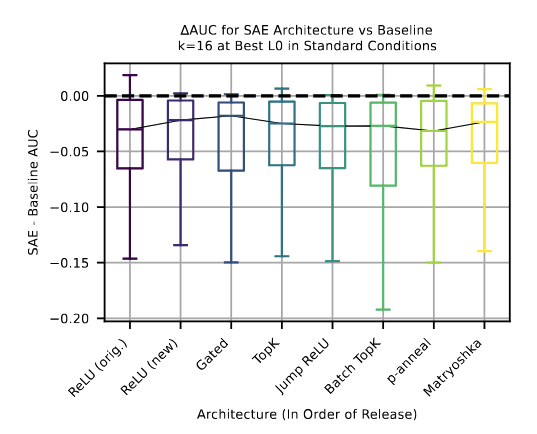
Since SAEs are lossy relative to model activations, we expected SAE probes to underperform baselines in standard conditions with plentiful data and balanced classes. This indeed ends up being the case:
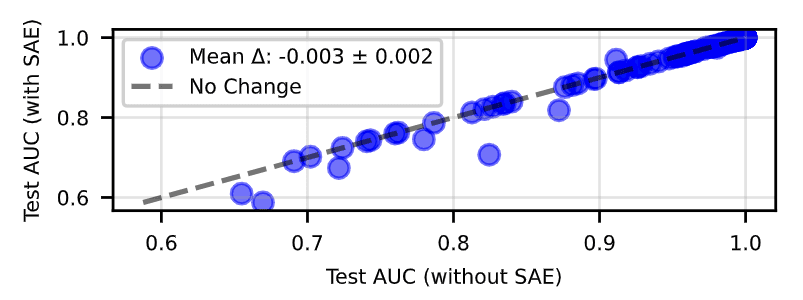
Our intuition is that SAE probes should help in settings where learning a dense probe is hard, and therefore the loss of information in an SAE encoding would be outweighed by the inductive bias of training a probe on a sparse set of meaningful latents. Thus, we tested challenging regimes to “force out” this advantage. We evaluated
- Data scarcity - Altering the number of training/validation data points from 2 to 1024
- Class Imbalance - Altering the ratio of the positive class to the total number of examples from 0.05 to 0.95
- Label Noise - Flipping from 0 to 50% of the labels
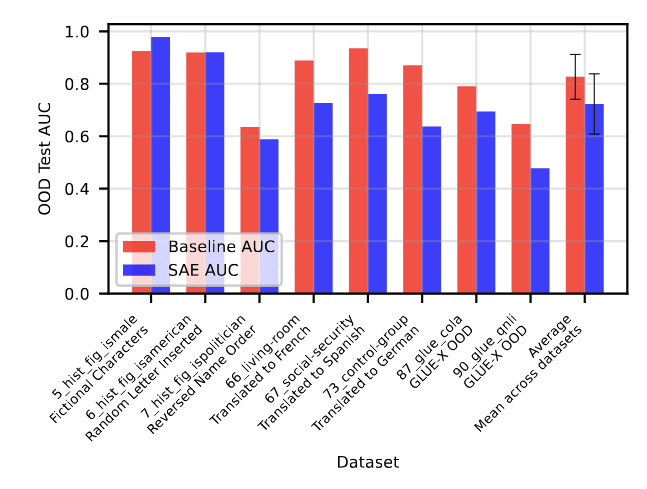
- Covariate Shift - Using a test set with a domain shift
In all regimes, we found that SAE probes provided no advantage compared to standard baselines.

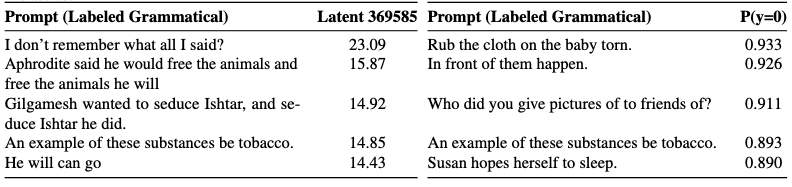
Dataset Quality Detection
We investigated whether SAE probes could help identify quality issues in datasets. For example, using the GLUE CoLA grammar dataset, we found a particularly interesting SAE latent that seemed to identify sentences incorrectly labeled as grammatical. Similarly, in an AI-vs-human text classification task, we found SAE latents that highlighted spurious correlations in the dataset (AI text more frequently ending with periods, human text with spaces).
However, upon closer inspection, we found that standard logistic regression probes could also identify these same dataset issues when properly analyzed. The SAE latent representations simply made these patterns more immediately obvious, but didn't provide unique capabilities that couldn't be achieved with baseline methods.
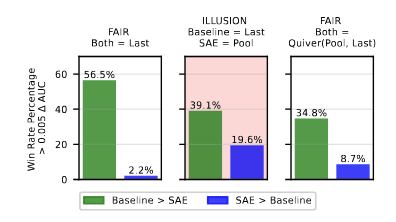
Multi-Token Probing
We also investigated multi-token probing, where information is aggregated across all tokens in a sequence. When we implemented max-pooling on SAE latents across tokens, the win rate for SAE probes jumped from 2.2% to 19.6% compared to last-token baselines. This initially appeared promising! However, when we implemented an attention-pooled baseline that could also leverage information across tokens, the SAE probe win rate dropped to 8.7%.
Assessing Architectural Improvements
Another thing we hoped is that SAEs were at least getting better over time. Unfortunately, we find that this was not the case. Any improvement is marginal at best and is not statistically significant.
0 comments
Comments sorted by top scores.