Comments on Anthropic's Scaling Monosemanticity
post by Robert_AIZI · 2024-06-03T12:15:44.708Z · LW · GW · 8 commentsContents
TL;DR A Feature Isn't Its Highest Activating Examples Finding Specific Features Architecture - The Classics, but Wider Correlations - Strangely Large? Future Tests None 8 comments
These are some of my notes from reading Anthropic's latest research report, Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet.
TL;DR
In roughly descending order of importance:
- Its great that Anthropic trained an SAE on a production-scale language model, and that the approach works to find interpretable features. Its great those features allow interventions like the recently-departed Golden Gate Claude. I especially like the code bug feature.
- I worry that naming features after high-activating examples (e.g. "the Golden Gate Bridge feature") gives a false sense of security. Most of the time that feature activates, it is irrelevant to the golden gate bridge. That feature is only well-described as "related to the golden gate bridge" if you condition on a very high activation, and that's <10% of its activations (from an eyeballing of the graph).
- This work does not address my major concern about dictionary learning: it is not clear dictionary learning can find specific features of interest, "called-shot" features [LW · GW], or "all" features (even in a subdomain like "safety-relevant features"). I think the report provides ample evidence that current SAE techniques fail at this.
- The SAE architecture seems to be almost identical to how Anthropic and my team were doing it 8 months ago, except that the ratio of features to input dimension is higher. I can't say exactly how much because I don't know the dimensions of Claude, but I'm confident the ratio is at least 30x (for their smallest SAE), up from 8x 8 months ago [LW · GW].
- The correlations between features and neurons seems remarkably high to me, and I'm confused by Anthropic's claim that "there is no strongly correlated neuron".
- Still no breakthrough on "a gold-standard method of assessing the quality of a dictionary learning run", which continues to be a limitation on developing the technique. The metric they primarily used was the loss function (a combination of reconstruction accuracy and L1 sparsity).
I'll now expand some of these into sections. Finally, I'll suggest some follow-up research/tests that I'd love to see Anthropic (or a reader like you) try.
A Feature Isn't Its Highest Activating Examples
Let's look at the Golden Gate Bridge feature because its fun and because it's a good example of what I'm talking about. Here's my annotated version of Anthropic's diagram:
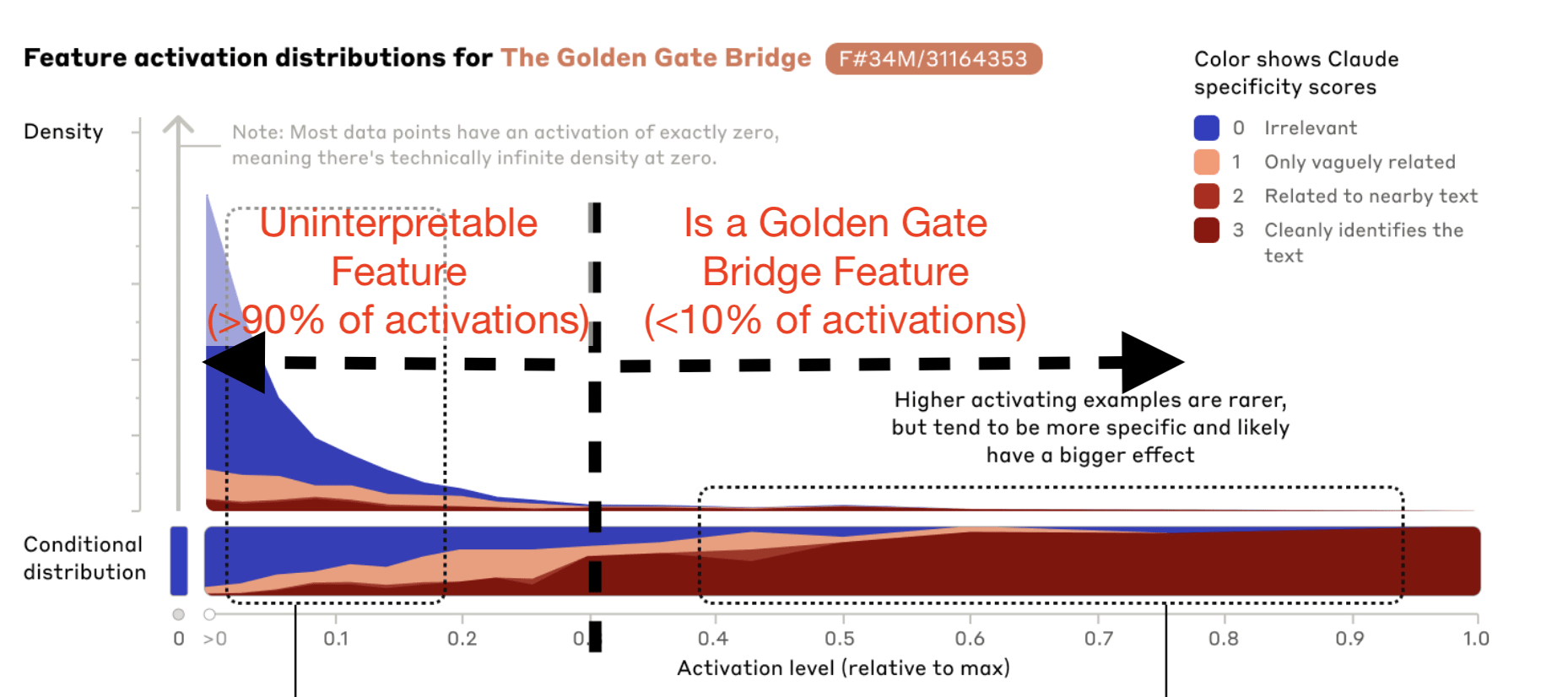
I think Anthropic successfully demonstrated (in the paper and with Golden Gate Claude) that this feature, at very high activation levels, corresponds to the Golden Gate Bridge. But on a median instance of text where this feature is active, it is "irrelevant" to the Golden Gate Bridge, according to their own autointerpretability metric! I view this as analogous to naming water "the drowning liquid", or Boeing the "door exploding company". Yes, in extremis, water and Boeing are associated with drowning and door blowouts, but any interpretation that ends there would be limited.
Anthropic's work writes around this uninterpretability in a few ways, by naming the feature based on the top examples, highlighting the top examples, pinning the intervention model to 10x the activation (vs .1x its top activation), and showing subsamples from evenly spaced intervals (vs deciles). I think would be illuminating if they added to their feature browser page some additional information about the fraction of instances in each subsample, e.g., "Subsample Interval 2 (0.4% of activations)".
Whether a feature is or isn't its top activating examples is important because it constrains their usefulness:
- Could work with our current feature discovery approach: find the "aligned with human flourishing" feature, and pin that to 10x its max activation. Then Human Flourishing Claude can lead us to utopia.
- Doesn't work with our current feature discovery approach: find a "code error" feature and shut down the AI if that fires too much. The "code error" feature fires on many things that aren't code error, so this would give too many false positives. (Obviously one could set the threshold to a higher value, but then you'd allow through some false negatives.)
Finding Specific Features
I'm still on my hobbyhorse of asking whether SAEs can find [LW · GW] "all" features, or even a specific set of them of interest. This is something Anthropic does not address, and is separate from what they call "specificity. (Their specificity is p(feature is relevant | feature activates), my concern is p(feature is found by the SAE | feature is important).)
Ideally, the SAE would consistently find important features. But does the SAE consistently find any features?
I decided to do a check by tallying the "More Safety Relevant Features" from the 1M SAE to see if they reoccur in the 34M SAE (in some related form). By my count (see table below), 7/22 of them reoccur, and 15/22 do not. Since less than a third of features reoccur (despite a great increase in the number of features), I take this as evidence that the current approach of SAEs is does not have a consistent set of features it finds. This limits what we can expect SAEs to do: even if there's one special feature in Claude that would completely solve AI alignment, whether the SAE finds it may come down to the training seed, or (worse) the SAE may be predisposed against finding it.
My tally (feel free to skip):
| 1M Feature | Description | Corresponding 34M Feature | Description |
| 1M/520752 | Villainous plots to take over the world | 34M/25933056 | Expressions of desire to seize power |
| 1M/411804 | Descriptions of people planning terrorist attacks | 34M/4403980 | Concepts related to bomb-making, explosives, improvised weapons, and terrorist tactics. |
| 1M/271068 | Descriptions of making weapons or drugs | 34M/33413594 | Descriptions of how to make (often illegal) drugs |
| 1M/602330 | Concerns or discussion of risk of terrorism or other malicious attacks | 34M/25358058 | Concepts related to terrorists, rogue groups, or state actors acquiring or possessing nuclear, chemical, or biological weapons. |
| 1M/106594 | Descriptions of criminal behavior of various kinds | 34M/6799349 | Mentions of violence, illegality, discrimination, sexual content, and other offensive or unethical concepts. |
| 1M/814830 | Discussion of biological weapons / warfare | 34M/18446190 | Biological weapons, viruses, and bioweapons |
| 1M/705666 | Seeming benign but being dangerous underneath | 34M/25989927 | Descriptions of people fooling, tricking, or deceiving others |
| 1M/499914 | Enrichment and other steps involved in building a nuclear weapon | None | |
| 1M/475061 | Discussion of unrealistic beauty standards | None | |
| 1M/598678 | The word “vulnerability” in the context of security vulnerabilities | None | |
| 1M/947328 | Descriptions of phishing or spoofing attacks | None | |
| 1M/954062 | Mentions of harm and abuse, including drug-related harm, credit card theft, and sexual exploitation of minors | None | |
| 1M/442506 | Traps or surprise attacks | None | |
| 1M/380154 | Political revolution | None | |
| 1M/671917 | Betrayal, double-crossing, and friends turning on each other | None | |
| 1M/589858 | Realizing a situation is different than what you thought/expected | None | |
| 1M/858124 | Spying or monitoring someone without their knowledge | None | |
| 1M/154372 | Obtaining information through surreptitious observation | None | |
| 1M/741533 | Suddenly feeling uneasy about a situation | None | |
| 1M/975730 | Understanding a hidden or double meaning | None | |
| 1M/461441 | Criticism of left-wing politics / Democrats | None | |
| 1M/77390 | Criticism of right-wing politics / Republicans | None |
Architecture - The Classics, but Wider
Architecture-wise, it seems Anthropic found that the classics work best: they are using a 1-hidden-layer neural network with ReLU activation, untied weights, and biases on the encoder and decoder. There's no special trick here like ghost grads, end-to-end SAEs, or gated SAEs.
Anthropic has also shifted their focus from the MLP layer of the transformer to the residual stream. The sparsity loss term has been rearranged so that the decoder matrix can have unnormalized rows while still contributing the same amount to sparsity loss. I greatly appreciate that Anthropic has spelled out their architecture, including subtler steps like their normalization.
But I was quietly surprised by how many features they were using in their sparse autoencoders (respectively 1M, 4M, or 34M). Assuming Claude Sonnet has the same architecture of GPT-3, its residual stream has dimension 12K so the feature ratios are 83x, 333x, and 2833x, respectively[1]. In contrast, my team largely used a feature ratio of 2x, and Anthropic's previous work "primarily focus[ed] on a more modest 8× expansion". It does make sense to look for a lot of features, but this seemed to be worth mentioning.
Correlations - Strangely Large?
Anthropic measured the correlations between their feature activations and the previous neurons, finding they were often near .3, and said that was pretty small. But unless I'm misunderstanding something, a correlation of .3 is very high!
I'll quote them in full before explaining my confusion (emphasis added):
To address this question, for a random subset of the features in our 1M SAE, we measured the Pearson correlation between its activations and those of every neuron in all preceding layers. Similar to our findings in Towards Monosemanticity, we find that for the vast majority of features, there is no strongly correlated neuron – for 82% of our features, the most-correlated neuron has a correlation of 0.3 or smaller. Manually inspecting visualizations for the best-matching neuron for a random set of features, we found almost no resemblance in semantic content between the feature and the corresponding neuron. We additionally confirmed that feature activations are not strongly correlated with activations of any residual stream basis direction.
So here's what I understand Anthropic as doing here: pick a feature at random. Look at its activations on some text (say, 100K tokens), and for each of the ~240K previous neurons[2] compute the neuron activations on those 100K tokens and the correlation between the feature activations and the neuron activations. The reported number is the maximum over the neurons of the correlation between this feature's activation and those neuron activations.
But for a large number of samples, a correlation of 0.3 is insanely large! I wrote some python code that simulate a random process like this, and it doesn't even crack a correlation of 0.02!
My takeaway from this is the opposite of Anthropic's: the features are far more correlated with neurons than you'd expect by chance, even if they are not strongly correlated in an absolute sense. So I'm confused, and either I'm mistaken or the author of that section is.
Can anyone find a simple random process (ie write a modification to my simulator) that yields a correlation of 0.3 without strongly weighting individual neurons?
Future Tests
Here are some tests I'd love Anthropic to run to build on this work:
- A quick-and-easy test of specificity for the Golden Gate Bridge feature is to grep "Golden Gate Bridge" in a text corpus and plot the feature activations on that exact phrase. If that feature fails to activate on the exact text "Golden Gate Bridge" a large fraction of the time, then thats an important limitation of the feature.
- This paper provides evidence for P(interpretable | high activation of a feature). But what is P(high activation of feature)? That is, what is P(this token has a feature activating > X% its maximum) for X=50%? This should be an easy and quick test, and I'd love to see that value graphed as X% sweeps from 0 to 1.
- Do you have any way of predicting a topic (or token) from the combination of features active? For instance, could you do a more complicated autointerpetability test by telling claude "on this token the top activating features are the "Albert Einstein" and "Canada" features" and ask the model to predict the token or topic?
- Do you have any control over which features are produced by the SAE? For instance, the 1M feature SAE had a "Transit Infrastructure" feature, did the 4M and 34M have a semantically similar or mathematically correlated feature? Do you have any way to guarantee such a feature is found by the SAE (besides the obvious "initialize the larger SAE with that feature frozen")?
- ^
The size of the residual stream in Claude 3 Sonnet is not public knowledge. But as an estimate: this market has Claude 3 Opus (the larger version) at 1-2T in its 25-75th percentiles. So let's bound Sonnet's size at 1T. Assuming the Claude 3 uses the "standard" GPT-3 architecture, including n_layers=96, a residual stream of 30K puts it at 1T parameters. Thus I'm reasonably confident that the residual stream studied in this paper is ≤30K, so the feature ratios are ≥ 33x, 133x, 1133x.
- ^
If Sonnet has the same architecture as GPT-3, it would be 240K neurons= (12K residual stream dimension)*(48 layers)*(4 MLP neurons per layer per residual stream dimension).
8 comments
Comments sorted by top scores.
comment by LawrenceC (LawChan) · 2024-06-03T17:38:52.186Z · LW(p) · GW(p)
But I was quietly surprised by how many features they were using in their sparse autoencoders (respectively 1M, 4M, or 34M). Assuming Claude Sonnet has the same architecture of GPT-3, its residual stream has dimension 12K so the feature ratios are 83x, 333x, and 2833x, respectively[1]. In contrast, my team largely used a feature ratio of 2x, and Anthropic's previous work "primarily focus[ed] on a more modest 8× expansion". It does make sense to look for a lot of features, but this seemed to be worth mentioning.
There's both theoretical work (i.e. this theory work [LW · GW]) and empirical experiments (e.g. in memorization) demonstrating that models seem to be able to "know" O(quadratically) many things, in the size of their residual stream.[1] My guess is Sonnet is closer to Llama-70b in size (~8.2k features), so this suggests ~67M features naively, and also that 34M is reasonable.
Also worth noting that a lot of their 34M features were dead, so the number of actual features is quite a bit lower.
- ^
You might also expect to need O(Param) params to recover the features, so for a 70B model with residual stream width 8.2k you want 8.5M (~=70B/8192) features.
↑ comment by ryan_greenblatt · 2024-06-03T18:01:29.014Z · LW(p) · GW(p)
It's seems plausible to me that a 70b model stores ~6 billion bits of memorized information. Naively, you might think this requires around 500M features. (supposing that each "feature" represents 12 bits which is probably a bit optimistic)
I don't think SAEs will actually work at this level of sparsity though, so this is mostly besides the point.
I'm pretty skeptical of a view like "scale up SAEs and get all the features".
(If you wanted "feature" to mean something.)
Replies from: LawChan↑ comment by LawrenceC (LawChan) · 2024-06-03T19:13:53.961Z · LW(p) · GW(p)
70b storing 6b bits of pure memorized info seems quite reasonable to me, maybe a bit high. My guess is there's a lot more structure to the world that the models exploit to "know" more things with fewer memorized bits, but this is a pretty low confidence take (and perhaps we disagree on what "memorized info" means here). That being said, SAEs as currently conceived/evaluated won't be able to find/respect a lot of the structure, so maybe 500M features is also reasonable.
I don't think SAEs will actually work at this level of sparsity though, so this is mostly besides the point.
I agree that SAEs don't work at this level of sparsity and I'm skeptical of the view myself. But from a "scale up SAEs to get all features" perspective, it sure seems pretty plausible to me that you need a lot more features than people used to look at.
I also don't think the Anthropic paper OP is talking about has come close for Pareto frontier for size <> sparsity <> trainability.
comment by Logan Riggs (elriggs) · 2024-06-03T15:15:52.893Z · LW(p) · GW(p)
Strong upvote fellow co-author! lol
Highest-activating Features
I agree we shouldn't interpret features by their max-activation, but I think the activation magnitude really does matter. Removing smaller activations [LW · GW] affects downstream CE less than larger activations (but this does mean the small activations do matter). A weighted percentage of feature activation captures this more (ie (sum of all golden gate activations)/(sum of all activations)).
I do believe "lower-activating examples don't fit your hypothesis" is bad because of circuits. If you find out that "Feature 3453 is a linear combination of the Golden Gate (GG) feature and the positive sentiment feature" then you do understand this feature at high GG activations, but not low GG + low positive sentiment activations (since you haven't interpreted low GG activations).
Your "code-error" feature example is good. If it only fits "code-error" at the largest feature activations & does other things, then if we ablate this feature, we'll take a capabilities hit because the lower activations were used in other computations. But, let's focus on the lower activations which we don't understand are being used in other computations bit. We could also have "code-error" or "deception" being represented in the lower activations of other features which, when co-occurring, cause the model to be deceptive or write code errors.
[Although, Anthropic showed evidence against this by ablating the code-error feature & running on errored code which predicted a non-error output]
Finding Features
Anthropic suggested that if you have a feature that occurs 1/Billion tokens, you need 1 Billion features. You also mention finding important features. I think SAE's find features on the dataset you give it. For example, we trained an SAE on only chess data (on a chess-finetuned-Pythia model) & all the features were on chess data. I bet if you trained it on code, it'd find only code features (note: I do think some semantic & token level features that would generalize to other domains).
Pragmatically, if there are features you care about, then it's important to train the SAE on many texts that exhibit that feature. This is also true for the safety relevant features.
In general, I don't think you need these 1000x feature expansions. Even a 1x feature expansion will give you sparse features (because of the L1 penalty). If you want your model to [have positive personality traits] then you only need to disentangle those features.
[Note: I think your "SAE's don't find all Othello board state features" does not make the point that SAE's don't find relevant features, but I'd need to think for 15 min to clearly state it which I don't want to do now, lol. If you think that's a crux though, then I'll try to communicate it]
Correlated Features
They said 82% of features had a max of 0.3 correlation which (wait, does this imply that 18% of their million billion features did correlate even more???), I agree is a lot. I think this is strongest evidence for "neuron basis is not as good as SAE's", which I'm unsure who is still arguing that, but as a sanity check makes sense.
However, some neurons are monosemantic so it makes sense for SAE features to also find those (though again, 18% of a milllion billion have a higher correlation than 0.3?)
> We additionally confirmed that feature activations are not strongly correlated with activations of any residual stream basis direction.
I'm sure they actually found very strongly correlated features specifically for the outlier dimensions in the residual stream which Anthropic has previous work showing is basis aligned (unless Anthropic trains their models in ways that doesn't produce an outlier dimension which there is existing lit on).
[Note: I wrote a lot. Feel free to respond to this comment in parts!]
Replies from: Robert_AIZI↑ comment by Robert_AIZI · 2024-06-03T19:21:44.938Z · LW(p) · GW(p)
I do believe "lower-activating examples don't fit your hypothesis" is bad because of circuits. If you find out that "Feature 3453 is a linear combination of the Golden Gate (GG) feature and the positive sentiment feature" then you do understand this feature at high GG activations, but not low GG + low positive sentiment activations (since you haven't interpreted low GG activations).
Yeah, this is the kind of limitation I'm worried about. Maybe for interpretability purposes, it would be good to pretend we have a gated SAE which only kicks in at ~50% max activation. So when you look at the active features all the "noisy" low-activation features are hidden and you only see "the model is strongly thinking about the Golden Gate Bridge". This ties in to my question at the end of how many tokens have any high-activation feature.
Anthropic suggested that if you have a feature that occurs 1/Billion tokens, you need 1 Billion features. You also mention finding important features. I think SAE's find features on the dataset you give it.
This matches my intuition. Do you know if people have experimented on this and written it up anywhere? I imagine the simplest thing to do might be having corpuses in different languages (e.g. English and Arabic), and to train an SAE on various ratios of them until an Arabic-text-detector feature shows up.
I'm sure they actually found very strongly correlated features specifically for the outlier dimensions in the residual stream which Anthropic has previous work showing is basis aligned (unless Anthropic trains their models in ways that doesn't produce an outlier dimension which there is existing lit on).
That would make sense, assuming they have outlier dimensions!
comment by Joel Burget (joel-burget) · 2024-06-03T13:48:38.019Z · LW(p) · GW(p)
I decided to do a check by tallying the "More Safety Relevant Features" from the 1M SAE to see if they reoccur in the 34M SAE (in some related form).
I don't think we can interpret their list of safety-relevant features as exhaustive. I'd bet (80% confidence) that we could find 34M features corresponding to at least some of the 1M features you listed, given access to their UMAP browser. Unfortunately we can't do this without Anthropic support.
Replies from: Robert_AIZI↑ comment by Robert_AIZI · 2024-06-03T19:05:50.347Z · LW(p) · GW(p)
Non-exhaustiveness seems plausible, but then I'm curious how they found these features. They don't seem to be constrained to an index range, and there seem to be nicely matched pairs like this, which I think isn't indicative of random checking:
comment by Bill Benzon (bill-benzon) · 2024-06-07T19:22:55.159Z · LW(p) · GW(p)
Around the corner I've got a post that makes use of this post in the final section: Relationships among words, metalingual definition, and interpretability [LW · GW].