Comparing Anthropic's Dictionary Learning to Ours
post by Robert_AIZI · 2023-10-07T23:30:32.402Z · LW · GW · 8 commentsContents
Target of Dictionary Learning/Sparse Autoencoding Language Model Used Sparse Autoencoder Architecture Sparse Autoencoder Training Checking Success None 8 comments
Readers may have noticed many similarities between Anthropic's recent publication Towards Monosemanticity: Decomposing Language Models With Dictionary Learning (LW post [LW · GW]) and my team's recent publication Sparse Autoencoders Find Highly Interpretable Directions in Language Models (LW post [LW · GW]). Here I want to compare our techniques and highlight what we did similarly or differently. My hope in writing this is to help readers understand the similarities and differences, and perhaps to lay the groundwork for a future synthesis approach.
First, let me note that we arrived at similar techniques in similar ways: both Anthropic and my team follow the lead of Lee Sharkey, Dan Braun, and beren's [Interim research report] Taking features out of superposition with sparse autoencoders [LW · GW], though I don't know how directly Anthropic was inspired by that post. I believe both our teams were pleasantly surprised to find out the other one was working on similar lines, serving as a form of replication.
Some disclaimers: This list may be incomplete. I didn't give Anthropic a chance to give feedback on this, so I may have misrepresented some of their work, including by omission. Any mistakes are my own fault.
Target of Dictionary Learning/Sparse Autoencoding
A primary difference is that we looked for language model features in different parts of the model. My team trained our sparse autoencoder on the residual stream of a language model, whereas Anthropic trained on the activations in the MLP layer.
These objects have some fundamental differences. For instance, the residual stream is (potentially) almost completely linear [LW · GW] whereas the MLP activations have just gotten activated, so their values will be positive-skewed. However, it's encouraging that this technique seems to work on both the MLP layer and residual stream. Additionally, my coauthor Logan Riggs successfully applied it to the output of the attention sublayer, so both in theory and in practice the dictionary learning approach seems to work well on each part of a language model.
Language Model Used
Another set of differences comes from which language model our teams used to train the autoencoders. My team used Pythia-70M and Pythia-410M, whereas Anthropic's language model was custom-trained for this study (I think). Some differences in the language model architectures:
- Layers: The Pythia models have 6 or 24 layers. The Anthropic language model had just 1 layer.
- Residual Stream Dimension: The Pythia models have 512- and 1024-dimensional residual streams. The Anthropic model has a 128-dimensional residual stream (but recall that they study their MLP layer, which has dimensionality 512).
- Parameters: As implied by the names, the Pythia models have 70M and 410M parameters. Anthropic does not specify the number of parameters in the language model, but from the information they give we can estimate their model had ~13M parameters (see calculations here and explanation of my estimation method here [LW · GW]). This estimate largely depends on assuming 1) they use untied embedding/unembedding weights and 2) they used a vocabulary size of ~50K (similar to Pythia and GPT-2/3), but this number isn't actually very important, because the more relevant statistic is...
- Non-Embedding Parameters: For language models of this size, most of the parameters are used for the word embedding/unembedding matrix, so for scaling laws its more important to measure non-embedding parameters. In particular, the Pythia models have only 19M and 300M non-embedding parameters, and for Anthropic's language model has only ~200K non-embedding parameters.
- Training Data: The Pythia models were trained on 300B tokens from The Pile, and Anthropic's was trained on 100B tokens also from The Pile. These are both significantly overtrained for this number of parameters per the scaling laws.
- Parallelization: The Pythia models apply their attention and MLP sublayers in parallel at the same time. Anthropic's model follows the more conventional approach of applying the attention sublayer before the MLP sublayer.
Sparse Autoencoder Architecture
Similarities:
- Both teams used an autoencoder with loss = (reconstruction loss)+(sparsity loss).
- Both teams used a single hidden layer which was wider than the input/output layers.
- Both teams used ReLU activations on the hidden layer.
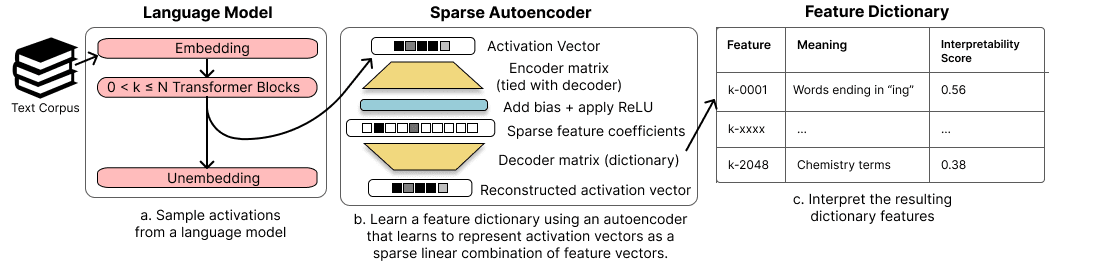
But some significant differences remain:
- We use a bias term on just the encoding step, Anthropic has a bias term on both their encoding and decoding steps.
- We use tied embeddings between our encoder and decoder, Anthropic uses untied embeddings.
In other words, we perform this calculation:
whereas Anthropic does this calculation:
more precisely, Anthropic writes their calculation in these terms:
which is equivalent to the above with etc.
Sparse Autoencoder Training
There are two main differences between how we trained our sparse autoencoders and how Anthropic trained theirs:
- Size of training set: We trained our autoencoders for 10M tokens. Anthropic trained theirs for much longer, 8B tokens.
- Dead Neurons and Reinitialization: A perennial problem with ReLU-activated neural networks is the presence of a dead neuron, i.e. a neuron that never activations and therefore does not get trained. Both teams encountered dead neurons, but Anthropic did something to address it: Anthropic resampled their dead neurons at checkpoints during training, while we did not.
Checking Success
[Epistemic status warning: I'm less sure I've fully capture Anthropic's work in this section.]
Finally, how did we decide the features were interpretable?
- Both teams did "manual inspection", i.e., one of the coauthors was able to better interpret the features.
- Both teams used the OpenAI autointerpretability technique, albeit with different models (we used GPT-3.5, Anthropic naturally used Claude 2).
- Both teams present individual features with data showing that tokens activating the feature follow a simple description. Our paper's Figure 4 (left) shows that we have a feature activating primarily apostrophes, while Anthropic's gorgeous "Feature Activation Distribution" graphic shows a feature activating primarily on Arabic text.
- Both teams measure how model predictions change by editing along a feature. In particular, in our Figure 4 (right), we show that editing the model activations to "turn off" the apostrophe feature decreases the model prediction of the "s" token, while Anthropic shows in their "Feature Downstream Effects" section that turning off the feature decreases the chance of predicting future tokens in Arabic, while "pinning" it to the on state makes the model produce text in Arabic.
Our team also performed these measures:
- Checking for human-understandable connections between features across layers of the language model (see our Figure 5).
- Measuring how many features need to be patched to change the model's behavior on a particular task (see our Section 4).
Anthropic also performed these measures:
- Confirmation that features are not neurons (in several places, including here)
- Checking for human-understandable connections between features across steps (token positions). For instance, in their "Finite State Automata" section they describe a feature activating on all-caps text and increasing predictions of underscores, and a second feature that activates on underscores and predicts all-caps text. These two features together aid the model in writing text in all-caps snake case.
- A second form of automatic interpretability, in which Claude is shown the feature description and then asked "would this feature predict [token X] is likely to come next?"
Thanks to Logan and Aidan for feedback on an earlier draft of this post.
8 comments
Comments sorted by top scores.
comment by Charlie Steiner · 2023-10-08T14:15:35.039Z · LW(p) · GW(p)
I'd definitely be interested if you have any takes on tied vs. untied weights.
It seems like the goal is to get the maximum expressive power for the autoencoder, while still learning features that are linear. So are untied weights good because they're more expressive, or are they bad because they encourage the model to start exploiting nonlinearity?
Replies from: baidicoot, Robert_AIZI↑ comment by Aidan Ewart (baidicoot) · 2023-10-08T17:00:13.663Z · LW(p) · GW(p)
Note: My take does not neccesarily represent the takes of my coauthors (Hoagy, Logan, Lee, Robert) etc etc. Or it might, but they may frame it differently. Take this as strictly my take.
My take is that the goal isn't strictly to get maximum expressive power under the assumptions detailed in Toy Models of Superposition; for instance, Anthropic found that FISTA-based dictionaries didn't work as well as sparse autoencoders, even though they are better in that they can achive lower reconstruction loss at the same level of sparsity. We might find that the sparsity-monosemanticity link breaks down at higher levels of autoencoder expressivity, although this needs to be rigourously tested.
To answer your question: I think Hoagy thinks that tied weights are more similar to how an MLP might use features during a forward pass, which would involve extracting the feature through a simple dot-product. I'm not sure I buy this, as having untied weights is equivalent to allowing the model to express simple linear computations like 'feature A activation = dot product along feature A direction - dot product along feature B direction', which could be a form of denoising if A and B were mutually exclusive but non-orthogonal features.
↑ comment by Robert_AIZI · 2023-10-09T13:18:49.067Z · LW(p) · GW(p)
Good question! I started writing and when I looked up I had a half-dozen takes, so sorry if these are rambly. Also let me give the caveat that I wasn't on the training side of the project so these are less informed than Hoagy, Logan, and Aidan's views:
- +1 to Aidan's answer.
- I wish we could resolve tied vs untied purely via "use whichever makes things more interpretable by metric X", but right now I don't think our interpretability metrics are fine-grained and reliable enough to make that decision for us yet.
- I expect a lot of future work will ask these architectural questions about the autoencoder architecture, and like transformers in general will settle on some guidelines of what works best.
- Tied weights are expressive enough to pass the test of "if you squint and ignore the nonlinearity, they should still work". In particular, (ignoring bias terms) we're trying to make , so we need "", and many matrices satisfy .
- Tied weights certainly make it easier to explain the autoencoder - "this vector was very far in the X direction, so in its reconstruction we add back in a term along the X direction" vs adding back a vector in a (potentially different) Y direction.
- Downstream of this, tied weights make ablations make more sense to me. Let's say you have some input A that activates direction X at a score of 5, so the autoencoder's reconstruction is A≈ 5X+[other stuff]. In the ablation, we replace A with A-5X, and if you feed A-5X into the sparse autoencoder, the X direction will activate 0 so the reconstruction will be A-5X≈0X+[different other stuff due to interference]. Therefore the only difference in the accuracy of your reconstruction will be how much the other feature activations are changed by interference. But if your reconstructions use the Y vector instead, then when you feed in A-5X, you'll replace A≈5Y+[other stuff] with A-5X≈0Y+[different other stuff], so you've also changed things by 5X-5Y.
- If we're abandoning the tied weights and just want to decompose the layer into any sparse code, why not just make the sparse autoencoder deeper, throw in smooth activations instead of ReLU, etc? That's not rhetorical, I honestly don't know... probably you'd still want ReLU at the end to clamp your activations to be positive. Probably you don't need too much nonlinearity because the model itself "reads out" of the residual stream via linear operations. I think the thing to try here is trying to make the sparse autoencoder architecture as similar to the language model architecture as possible, so that you can find the "real" "computational factors".
comment by wassname · 2023-12-09T00:54:52.843Z · LW(p) · GW(p)
This shows that we are in a period of Multiple_discovery.
I interpret this as a period when many teams are racing for low-hanging fruit, and it reinforces that we are in scientific race dynamics where no one team is critical, and slowing down research requires stopping all teams.
comment by research_prime_space · 2023-10-20T18:06:10.033Z · LW(p) · GW(p)
This is cool! These sparse features should be easily "extractable" by the transformer's key, query, and value weights in a single layer. Therefore, I'm wondering if these weights can somehow make it easier to "discover" the sparse features?
Replies from: Robert_AIZI↑ comment by Robert_AIZI · 2023-10-21T13:08:19.537Z · LW(p) · GW(p)
This is something we're planning to look into! From the paper:
Future efforts could also try to improve feature dictionary discovery by incorporating information about the weights of the model or dictionary features found in adjacent layers into the training process.
Exactly how to use them is something we're still working on...
comment by Review Bot · 2024-02-24T20:50:12.937Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?