Posts
Comments
One of my fascinations is when/how the Department of Defense starts using language models, and I can't help but read significance into this from that perspective. If OpenAI wants that sweet sweet defense money, having a general on your board is a good way to make inroads.
Sincere response: Could work, but I weep for the lost clarity caused by sen and ten rhyming. Our current digits are beautifully unambiguous this way, whereas our alphabet is a horrible lost cause which had to be completely replaced over low-fidelity audio channels.
Sarcastic response: I'll agree iff 10 becomes teven.
I do believe "lower-activating examples don't fit your hypothesis" is bad because of circuits. If you find out that "Feature 3453 is a linear combination of the Golden Gate (GG) feature and the positive sentiment feature" then you do understand this feature at high GG activations, but not low GG + low positive sentiment activations (since you haven't interpreted low GG activations).
Yeah, this is the kind of limitation I'm worried about. Maybe for interpretability purposes, it would be good to pretend we have a gated SAE which only kicks in at ~50% max activation. So when you look at the active features all the "noisy" low-activation features are hidden and you only see "the model is strongly thinking about the Golden Gate Bridge". This ties in to my question at the end of how many tokens have any high-activation feature.
Anthropic suggested that if you have a feature that occurs 1/Billion tokens, you need 1 Billion features. You also mention finding important features. I think SAE's find features on the dataset you give it.
This matches my intuition. Do you know if people have experimented on this and written it up anywhere? I imagine the simplest thing to do might be having corpuses in different languages (e.g. English and Arabic), and to train an SAE on various ratios of them until an Arabic-text-detector feature shows up.
I'm sure they actually found very strongly correlated features specifically for the outlier dimensions in the residual stream which Anthropic has previous work showing is basis aligned (unless Anthropic trains their models in ways that doesn't produce an outlier dimension which there is existing lit on).
That would make sense, assuming they have outlier dimensions!
Non-exhaustiveness seems plausible, but then I'm curious how they found these features. They don't seem to be constrained to an index range, and there seem to be nicely matched pairs like this, which I think isn't indicative of random checking:
Cool work! Some questions:
- Do you have any theory as to why the LLM did worse on guessing age/sexuality (relative to both other categories, and the baseline)?
- Thanks for including some writing samples in Appendix C! They seem to all be in lowercase, was that how they were shown to the LLM? I expect that may be helpful for tokenization reasons, but also obscure some "real" information about how people write depending on age/gender/etc. So perhaps a person or language model could do even better at identity-guessing if the text had its original capitalization.
- More of a comment than a question: I'd speculate that dating profiles, which are written to communicate things about the writer, make it easier to identify the writer's identity than other text (professional writing, tweets, etc). I appreciate the data availability problem (and thanks for explaining your choice of dataset), but do you have any ideas of other datasets you could test on?
Ah sorry, I skipped over that derivation! Here's how we'd approach this from first principals: to solve f=Df, we know we want to use the (1-x)=1+x+x^2+... trick, but now know that we need x=I instead of x=D. So that's why we want to switch to an integral equation, and we get
f=Df
If=IDf = f-f(0)
where the final equality is the fundamental theorem of calculus. Then we rearrange:
f-If=f(0)
(1-I)f=f(0)
and solve from there using the (1-I)=1+I+I^2+... trick! What's nice about this is it shows exactly how the initial condition of the DE shows up.
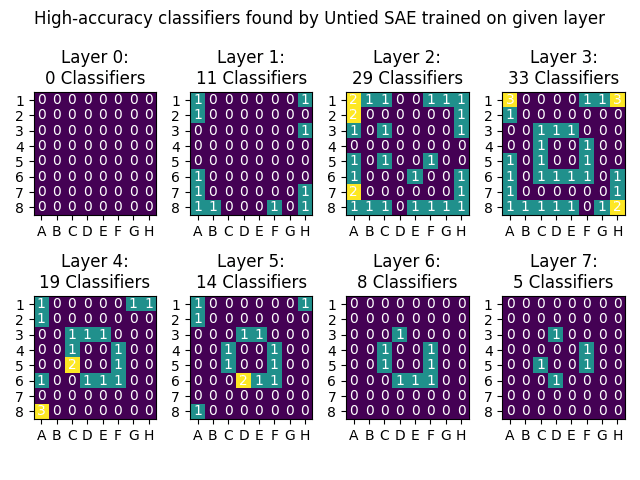
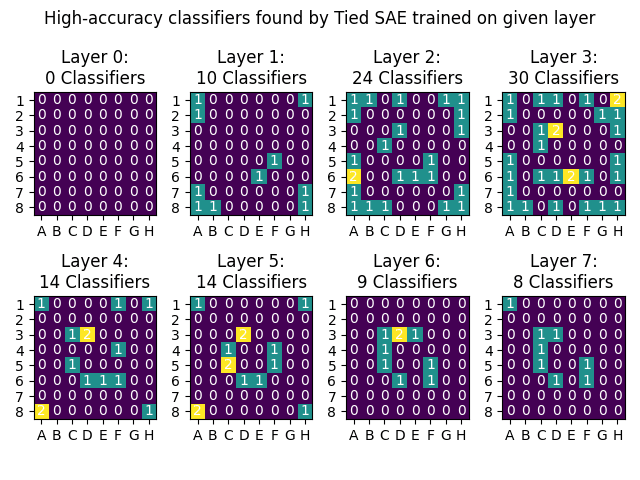
Followup on tied vs untied weights: it looks like untied makes a small improvement over tied, primarily in layers 2-4 which already have the most classifiers. Still missing the middle ring features though.
Next steps are using the Li et al model and training the SAE on more data.
Likewise, I'm glad to hear there was some confirmation from your team!
An option for you if you don't want to do a full writeup is to make a "diff" or comparison post, just listing where your methods and results were different (or the same). I think there's demnad for that, people liked Comparing Anthropic's Dictionary Learning to Ours
I've had a lot of conversations with people lately about OthelloGPT and I think it's been useful for creating consensus about what we expect sparse autoencoders to recover in language models.
I'm surprised how many people have turned up trying to do something like this!
What is the performance of the model when the SAE output is used in place of the activations?
I didn't test this.
What is the L0? You say 12% of features active so I assume that means 122 features are active.
That's correct. I was satisfied with 122 because if the SAEs "worked perfectly" (and in the assumed ontology etc) they'd decompose the activations into 64 features for [position X is empty/own/enemy], plus presumably other features. So that level of density was acceptable to me because it would allow the desired ontology to emerge. Worth trying other densities though!
In particular, can you point to predictions (maybe in the early game) where your model is effectively perfect and where it is also perfect with the SAE output in place of the activations at some layer? I think this is important to quantify as I don't think we have a good understanding of the relationship between explained variance of the SAE and model performance and so it's not clear what counts as a "good enough" SAE.
I did not test this either.
At a high level, you don't get to pick the ontology.
I agree, but that's part of what's interesting to me here - what if OthelloGPT has a copy of a human-understandable ontology, and also an alien ontology, and sparse autoencoders find a lot of features in OthelloGPT that are interpretable but miss the human-understandable ontology? Now what if all of that happens in an AGI we're trying to interpret? I'm trying to prove by example that "human-understandable ontology exists" and "SAEs find interpretable features" fail to imply "SAEs find the human-understandable ontology". (But if I'm wrong and there's a magic ingredient to make the SAE find the human-understandable ontology, lets find it and use it going forward!)
Separately, it's clear that sparse autoencoders should be biased toward local codes over semi-local / compositional codes due to the L1 sparsity penalty on activations. This means that even if we were sure that the model represented information in a particular way, it seems likely the SAE would create representations for variables like (A and B) and (A and B') in place of A even if the model represents A. However, the exciting thing about this intuition is it makes a very testable prediction about combinations of features likely combining to be effective classifiers over the board state. I'd be very excited to see an attempt to train neuron-in-a-haystack style sparse probes over SAE features in OthelloGPT for this reason.
I think that's a plausible failure mode, and someone should definitely test for it!
I found your bolded claims in the introduction jarring. In particular "This demonstrates that current techniques for sparse autoencoders may fail to find a large majority of the interesting, interpretable features in a language model".
I think our readings of that sentence are slightly different, where I wrote it with more emphasis on "may" than you took it. I really only mean this as an n=1 demonstration. But at the same time, if it turns out you need to untie your weights, or investigate one layer in particular, or some other small-but-important detail, that's important to know about!
Moreover, I think it would best to hold-off on proposing solutions here
I believe I do? The only call I intended to make was "We hope that these results will inspire more work to improve the architecture or training methods of sparse autoencoders to address this shortcoming." Personally I feel like SAEs have a ton of promise, but also could benefit from a battery of experimentation to figure out exactly what works best. I hope no one will read this post as saying "we need to throw out SAEs and start over".
Negative: I'm quite concerned that tieing the encoder / decoder weights and not having a decoder output bias results in worse SAEs.
That's plausible. I'll launch a training run of an untied SAE and hopefully will have results back later today!
Oh, and maybe you saw this already but an academic group put out this related work: https://arxiv.org/abs/2402.12201
I haven't seen this before! I'll check it out!
[Continuing our conversation from messages]
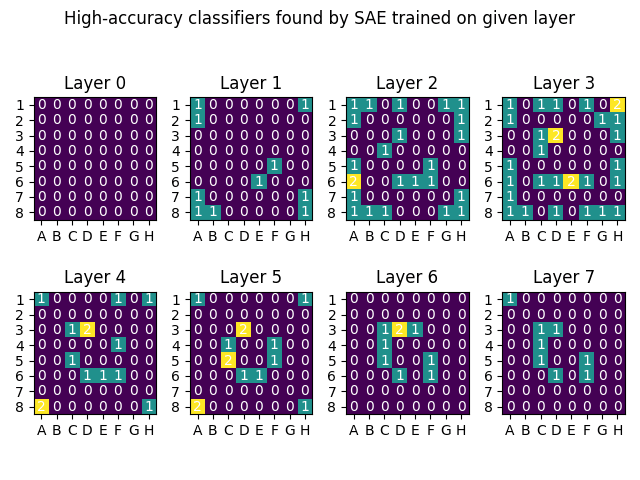
I just finished a training run of SAEs on the intermediate layer of my OthelloGPT. For me it seemed like the sweet spot was layers 2-3, and the SAE found up to 30 high-accuracy classifiers on Layer 3. They were located all in the "inner ring" and "outer ring", with only one in the "middle ring". (As before, I'm counting "high-accuracy" as AUROC>.9, which is an imperfect metric and threshold.)
Here were the full results. The numbers/colors indicate how many classes had a high-accuracy classifier for that position.
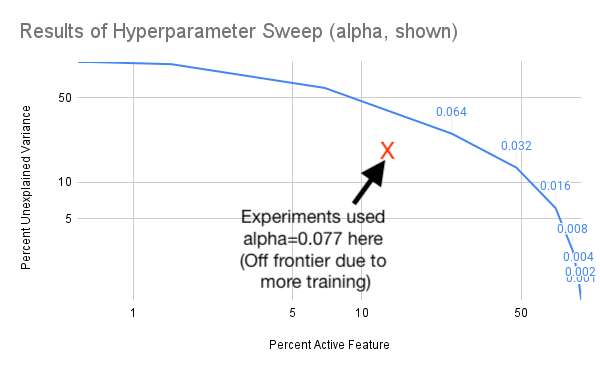
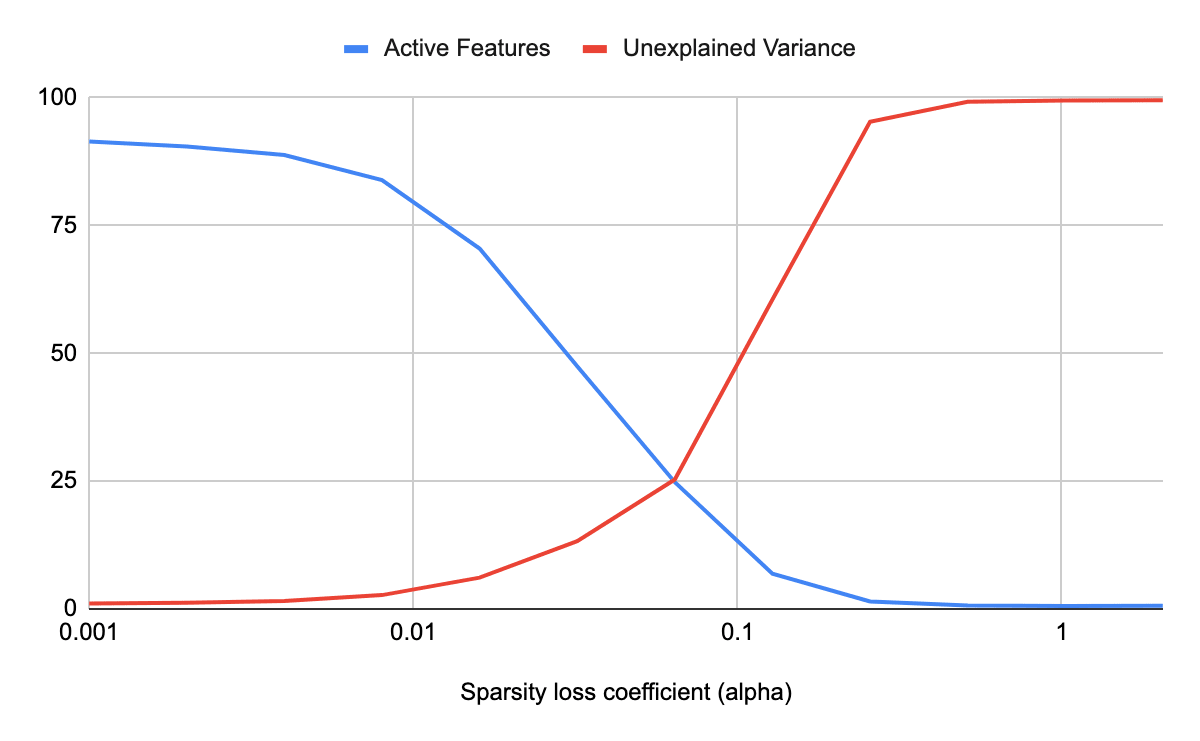
Good thinking, here's that graph! I also annotated it to show where the alpha value I ended up using for the experiment. Its improved over the pareto frontier shown on the graph, and I believe thats because the data in this sweep was from training for 1 epoch, and the real run I used for the SAE was 4 epochs.
Nope. I think they wouldn't make much difference - at the sparsity loss coefficient I was using, I had ~0% dead neurons (and iirc the ghost gradients only kick in if you've been dead for a while). However, it is on the list of things to try to see if it changes the results.
Cool! Do you know if they've written up results anywhere?
Here are the datasets, OthelloGPT model ("trained_model_full.pkl"), autoencoders (saes/), probes, and a lot of the cached results (it takes a while to compute AUROC for all position/feature pairs, so I found it easier to save those): https://drive.google.com/drive/folders/1CSzsq_mlNqRwwXNN50UOcK8sfbpU74MV
You should download all of these into the same level directory as the main repo.
Thanks for doing this -- could you share your code?
Just uploaded the code here: https://github.com/RobertHuben/othellogpt_sparse_autoencoders/. Apologies in advance, the code is kinda a mess since I've been writing for myself. I'll take the hour or so to add info to the readme about the files and how to replicate my experiments.
I'd be interested in running the code on the model used by Li et al, which he's hosted on Google drive:
https://drive.google.com/drive/folders/1bpnwJnccpr9W-N_hzXSm59hT7Lij4HxZ
Thanks for the link! I think replicating the experiment with Li et al's model is definite next step! Perhaps we can have a friendly competition to see who writes it up first :)
I have mixed feelings about whether the results will be different with the high-accuracy model from Li et al:
- On priors, if the features are more "unambiguous", they should be easier for the sparse autoencoder to find.
- But my hacky model was at least trained enough that those features do emerge from linear probes. If sparse autoencoders can't match linear probes, thats also worth knowing.
- If there is a difference, and sparse autoencoders work on a language model that's sufficiently trained, would LLMs meet that criteria?
Also, in addition to the future work you list, I'd be interested in running the SAEs with much larger Rs and with alternative hyperparameter selection criteria.
Agree that its worth experimenting with R, but the only other hyperparameter is the sparsity coefficient alpha, and I found that alpha had to be in a narrow range or the training would collapse to "all variance is unexplained" or "no active features". (Maybe you mean Adam hyperparameters, which I suppose might also be worth experimenting with.) Here's the result of my hyperparameter sweep for alpha:
In my accounting, the word "arbitrarily" saved me here. I do think I missed the middle ground of the sandboxed, limited programming environments like you.com and the current version of ChatGPT!
That's all correct
That link is broken for me, did you mean to link to this Lilian Weng tweet?
It was covered in Axios, who also link to it as a separate pdf with all 505 signatories.
I'm noticing my confusion about the level of support here. Kara Swisher says that these are 505/700 employees, but the OpenAI publication I'm most familiar with is the autointerpretability paper, and none (!) of the core research contributors to that paper signed this letter. Why is a large fraction of the company anti-board/pro-Sam except for 0/6 of this team (discounting Henk Tillman because he seems to work for Apple instead of OpenAI)? The only authors on that paper that signed the letter are Gabriel Goh and Ilya Sutskever. So is the alignment team unusually pro-board/anti-Sam, or are the 505 just not that large a faction in the company?
[Editing to add a link to the pdf of the letter, which is how I checked for who signed https://s3.documentcloud.org/documents/24172246/letter-to-the-openai-board-google-docs.pdf ]
I appreciate the joke, but I think that Sam Altman is pretty clearly "the biggest name in AI" as far as the public is concerned. His firing/hiring was the leading story in the New York Times for days in a row (and still is at time of writing)!
I hope this doesn't lead to everyone sorting into capabilities (microsoft) vs safety (openai). OpenAI's ownership was designed to preserve safety commitments against race dynamics, but microsoft has no such obligations, a bad track record (Sydney), and now the biggest name in AI. Those dynamics could lead to talent/funding/coverage going to capabilities unchecked by safety, which would increase my p(doom).
Two caveats:
- We don't know what the Altman/Brockman "advanced AI research team" will actually be doing at Microsoft, and how much independence they'll have.
- According to the new OpenAI CEO Emmett Shear, the split wasn't due to "any specific disagreement on safety", but I think that could be the end result.
This is something we're planning to look into! From the paper:
Future efforts could also try to improve feature dictionary discovery by incorporating information about the weights of the model or dictionary features found in adjacent layers into the training process.
Exactly how to use them is something we're still working on...
Good question! I started writing and when I looked up I had a half-dozen takes, so sorry if these are rambly. Also let me give the caveat that I wasn't on the training side of the project so these are less informed than Hoagy, Logan, and Aidan's views:
- +1 to Aidan's answer.
- I wish we could resolve tied vs untied purely via "use whichever makes things more interpretable by metric X", but right now I don't think our interpretability metrics are fine-grained and reliable enough to make that decision for us yet.
- I expect a lot of future work will ask these architectural questions about the autoencoder architecture, and like transformers in general will settle on some guidelines of what works best.
- Tied weights are expressive enough to pass the test of "if you squint and ignore the nonlinearity, they should still work". In particular, (ignoring bias terms) we're trying to make , so we need "", and many matrices satisfy .
- Tied weights certainly make it easier to explain the autoencoder - "this vector was very far in the X direction, so in its reconstruction we add back in a term along the X direction" vs adding back a vector in a (potentially different) Y direction.
- Downstream of this, tied weights make ablations make more sense to me. Let's say you have some input A that activates direction X at a score of 5, so the autoencoder's reconstruction is A≈ 5X+[other stuff]. In the ablation, we replace A with A-5X, and if you feed A-5X into the sparse autoencoder, the X direction will activate 0 so the reconstruction will be A-5X≈0X+[different other stuff due to interference]. Therefore the only difference in the accuracy of your reconstruction will be how much the other feature activations are changed by interference. But if your reconstructions use the Y vector instead, then when you feed in A-5X, you'll replace A≈5Y+[other stuff] with A-5X≈0Y+[different other stuff], so you've also changed things by 5X-5Y.
- If we're abandoning the tied weights and just want to decompose the layer into any sparse code, why not just make the sparse autoencoder deeper, throw in smooth activations instead of ReLU, etc? That's not rhetorical, I honestly don't know... probably you'd still want ReLU at the end to clamp your activations to be positive. Probably you don't need too much nonlinearity because the model itself "reads out" of the residual stream via linear operations. I think the thing to try here is trying to make the sparse autoencoder architecture as similar to the language model architecture as possible, so that you can find the "real" "computational factors".
Incidentally, maybe I missed this in the writeup, but this post is only providing an injective self-attention → MLP construction, right?
Either I'm misunderstanding you or you're misunderstanding me, but I think I've shown the opposite: any MLP layer can be converted to a self-attention layer. (Well, in this post I actually show how to convert the MLP layer to 3 self-attention layers, but in my follow-up I show how you can get it in one.) I don't claim that you can do a self-attention → MLP construction.
Converting an arbitrary MLP layer to a self-attention layer is presumably doable - at least with enough parameters - but remains unknown
This is what I think I show here! Let the unknown be known!
Unfortunate that the construction is so inefficient: 12 heads → 3,000 heads or 250x inflation is big enough to be practically irrelevant (maybe theoretically too).
Yes, this is definitely at an "interesting trivia" level of efficiency. Unfortunately, the construction is built around using 1 attention head per hidden dimension, so I don't see any obvious way to improve the number of heads. The only angle I have for this to be useful at current scale is that Anthropic (paraphrased) said "oh we can do interpretability on attention heads but not MLPs", so the conversion of the later into the former might supplement their techniques.
Calling fully-connected MLPs "feedforward networks" is common (e.g. in the original transformer paper https://arxiv.org/pdf/1706.03762.pdf), so I tried to use that language here for the sake of the transformer-background people. But yes, I think "Attention can implement fully-connected MLPs" is a correct and arguably more accurate way to describe this.
Thanks for the link! My read is that they describe an architecture where each attention head has some fixed "persistent memory vectors", and train a model under that architecture. In contrast, I'm showing how one can convert an existing attention+FFN model to an attention-only model (with only epsilon-scale differences in the output).
I think Yair is saying that the people putting in money randomly is what allows "beat the market" to be profitable. Isn't the return on beating the market proportional to the size of the market? In which case, if more people put money into the prediction markets suboptimally, this would be a moneymaking opportunity for professional forecasters, and you could get more/better information from the prediction markets.
This might not be the problem you're trying to solve, but I think if predictions markets are going to break into normal society they need to solve "why should a normie who is somewhat risk-averse, doesn't enjoy wagering for its own sake, and doesn't care about the information externalities, engage with prediction markets". That question for stock markets is solved via the stock market being overall positive-sum, because loaning money to a business is fundamentally capable of generating returns.
Now let me read your answer from that perspective:
users would not bet USD but instead something which appreciates over time or generates income (e.g. ETH, Gold, S&P 500 ETF, Treasury Notes, or liquid and safe USD-backed positions in some DeFi protocol)
Why not just hold Treasury Notes or my other favorite asset? What does the prediction market add?
use funds held in the market to invest in something profit-generating and distribute part of the income to users
Why wouldn't I just put my funds directly into something profit-generating?
positions are used to receive loans, so you can free your liquidity from long (timewise) markets and use it to e.g. leverage
I appreciate that less than 100% of my funds will be tied up in the prediction market, but why tie up any?
The practical problem is that the zero-sum monetary nature of prediction markets disincentives participation (especially in year+ long markets) because on average it's more profitable to invest in something else (e.g. S&P 500). It can be solved by allowing to bet other assets, so people would bet their S&P 500 shares and on average get the same expected value, so it will be not disincentivising anymore.
But once I have an S&P 500 share, why would I want to put it in a prediction market (again, assuming I'm a normie who is somewhat risk-averse, etc)
Surely, they would be more interested if they had free loans (of course they are not going to be actually free, but they can be much cheaper than ordinary uncollateralized loans).
So if I put $1000 into a prediction market, I can get a $1000 loan (or a larger loan using my $1000 EV wager as collateral)? But why wouldn't I just get a loan using my $1000 cash as collateral?
Overall I feel listed several mechanisms that mitigate potential downsides of prediction markets, but they still pull in a negative direction, and there's no solid upside to a regular person who doesn't want to wager money for wager's sake, doesn't think they can beat the market, and is somewhat risk averse (which I think is a huge portion of the public).
Also, there are many cases where positive externalities can be beneficial for some particular entity. For example, an investment company may want to know about the risk of a war in a particular country to decide if they want to invest in the country or not. In such cases, the company can provide rewards for market participants and make it a positive-sum game for them even from the monetary perspective.
This I see as workable, but runs into a scale issue and the tragedy of the commons. Let's make up a number and say the market needs a 1% return on average to make it worthwhile after transaction fees, time investment, risk, etc. Then $X of incentive could motivate $100X of prediction market. But I think the issue of free-riders makes it very hard to scale X so that $100X ≈ [the stock market].
Overall, in order to make prediction markets sustainably large, I feel like you'd need some way to internalize the positive information externalities generated by them. I think most prediction markets are not succeeding at that right now (judging from them not exploding in popularity), but maybe there would be better monetization options if they weren't basically regulated out of existence.
Cool to hear from someone at manifold about this! I agree the information and enjoyment value can make it worthwhile (and even pro-social), but if it's zero net monetary value, that surely limits their reach. I appreciate prediction markets from a perspective of "you know all that energy going into determining stock prices? That could be put towards something more useful!", but I worry they won't live up to that without a constant flow of money.
Subsidization doesn’t lead to increased activity in practice unless it makes the market among the top best trading opportunities.
That's really interesting! Is there a theory for why this happens? Maybe traders aren't fully rational in which markets they pursue, or small subsidies move markets to "not worth it" from "very not worth it"?
While it's true that they don't generate income and are zero-sum games in a strictly monetary sense, they do generate positive externalities.
...
The practical problem is that the zero-sum monetary nature of prediction markets disincentives participation
I think we're in agreement here. My concern is "prediction markets could be generating positive externalities for society, but if they aren't positive-sum for the typical user, they will be underinvested in (relative to what is societally optimal), and there may be insufficient market mechanisms to fix this". See my other comment here.
Thanks for the excellent answer!
On first blush, I'd respond with something like "but there's no way that's enough!" I think I see prediction markets as (potentially) providing a lot of useful information publicly, but needing a flow of money to compensate people for risk-aversion, the cost of research, and to overcome market friction. Of your answers:
- Negative-sum betting probably doesn't scale well, especially to more technical and less dramatic questions.
- Subsidies make sense, but could they run into a tragedy-of-the-commons scenario? For instance, if a group of businesses want to forecast something, they could pool their money to subsidize a prediction market. But there would be incentive to defect by not contributing to the pool, and getting the same exact information since the prediction market is public - or even to commission a classical market research study that you keep proprietary.
- Hedging seems fine.
If that reasoning is correct, prediction markets are doomed to stay small. Is that a common concern (and on which markets can wager on that? :P)
In a good prediction market design users would not bet USD but instead something which appreciates over time or generates income (e.g. ETH, Gold, S&P 500 ETF, Treasury Notes, or liquid and safe USD-backed positions in some DeFi protocol).
Isn't this just changing the denominator without changing the zero- or negative-sum nature? If everyone shows up to your prediction market with 1 ETH instead of $1k, the total amount of ETH in the market won't increase, just as the total amount of USD would not have increased. Maybe "buy ETH and gamble it" has a better expected return than holding USD, but why would it have a better expected return than "buy ETH"? Again, this is in contrast to a stock market, where "give a loan to invest in a long-term-profitable-but-short-term-underfunded business" is positive-sum in USD terms (as long as the business succeeds), and can remain positive sum when averaged over the whole stock market.
Also, Manifold solves it in a different way -- positions are used to receive loans, so you can free your liquidity from long (timewise) markets and use it to e.g. leverage.
I must confess I don't understand what you mean here. If 1000 people show up with $1000 each, and wager against each other on some predictions that resolve in 12 months, are you saying they can use those positions as capital to get loans and make more bets that resolve sooner? I can see how this would let the total value of the bets in the market sum to more than $1M, but once all the markets resolve, the total wealth would still be $1M, right? I guess if someone ends up with negative value and has to pay cash to pay off their loan, that brings more dollars into the market, but it doesn't increase the total wealth of the prediction market users.
GPT is decoder only. The part labeled as "Not in GPT" is decoder part.
I think both of these statements are true. Despite this, I think the architecture shown in "Not in GPT" is correct, because (as I understand it) "encoder" and "decoder" are interchangeable unless both are present. That's what I was trying to get at here:
4. GPT is called a “decoder only” architecture. Would “encoder only” be equally correct? From my reading of the original transformer paper, encoder and decoder blocks are the same except that decoder blocks attend to the final encoder block. Since GPT never attends to any previous block, if anything I feel like the correct term is “encoder only”.
See this comment for more discussion of the terminology.
Thanks, this is a useful corrective to the post! To shortcut safety to "would I trust my grandmother to use this without bad outcomes", I would trust a current-gen LLM to be helpful and friendly with her, but I would absolutely fear her "learning" factually untrue things from it. While I think it can be useful to have separate concepts for hallucinations and "intentional lies" (as another commenter argues), I think "behavioral safety" should preclude both, in which case our LLMs are not behaviorally safe.
I think I may have overlooked hallucinations because I've internalized that LLMs are factually unreliable, so I don't use LLMs where accuracy is critical, so I don't see many hallucinations (which is not much of an endorsement of LLMs).
Asking for some clarifications:
1. For both problems, should the solution work for an adversarially chosen set of m entries?
2. For both problems, can we read more entries of the matrix if it helps our solution? In particular can we WLOG assume we know the diagonal entries in case that helps in some way.
I agree my headline is an overclaim, but I wanted a title that captures the direction and magnitude of my update from fixing the data. On the bugged data, I thought the result was a real nail in the coffin for simulator theory - look, it can't even simulate an incorrect-answerer when that's clearly what's happening! But on the corrected data, the model is clearly "catching on to the pattern" of incorrectness, which is consistent with simulator theory (and several non-simulator-theory explanations). Now that I'm actually getting an effect I'll be running experiments to disentangle the possibilities!
Agreed! I was trying to get at something similar in my "masks all the way down" post. A framework I really like to explain why this happened is beren's "Direct Optimizer" vs "Amortised Optimizer". My summary of beren's post is that instead of being an explicit optimizing system, LLMs are made of heuristics developed during training, which are sufficient for next-token-prediction, and therefore don't need to have long-term goals.
Good post. Are you familiar with the pioneering work of BuzzFeed et al (2009-2014) indicated that prime numbered lists resulted in more engagement than round numbers?
I'm not surprised this idea was already in the water! I'm glad to hear ARC is already trying to design around this.
To use your analogy, I think this is like a study showing that wearing a blindfold does decrease sight capabilities. It's a proof of concept that you can make that change, even though the subject isn't truly made blind, could possibly remove their own blindfold, etc.
I think this is notable because it highlights that LLMs (as they exist now) are not the expected-utility-maximizing agents which have all the negative results. It's a very different landscape if we can make our AI act corrigible (but only in narrow ways which might be undone by prompt injection, etc, etc) versus if we're infinitely far away from an AI having "an intuitive sense to “understanding that it might be flawed”".
A few comments:
- Thanks for writing this! I've had some similar ideas kicking around my head but it's helpful to see someone write them up like this.
- I think token deletion is a good thing to keep in mind, but I think it's not correct to say you're always deleting the token in position 1. In the predict-next-token loop it would be trivial to keep some prefix around, e.g. 1,2,3,4 -> 1,2,4,5 -> 1, 2, 5, 6 -> etc. I assume that's what ChatGPT does, since they have a hidden prompt and if you could jailbreak it by just overflowing the dialogue box, the DAN people would presumably have found that exploit already. While this is on some level equivalent to rolling the static prefix into the next token prediction term, I think the distinction is important because it means we could actually be dealing with a range of dynamics depending on the prefix.
- Editing to provide an example: in your {F, U, N} example, add another token L (for Luigi), which is never produced by the LLM but if L is ever in the context window the AI behaves as Luigi and predicts F 100% of the time. If you trim the context window as you describe, any L will eventually fall out of the context window and the AI will then tend towards Waluigi as you describe. But if you trim from the second token, the sequence (L, F, F, F, F, ..., F) is stable. Perhaps the L token could be analogous to the <|good|> token described here.
- Nitpicking: Your "00000000000000000...." prompt doesn't actually max out the prompt window because sixteen 0s can combine into a single token. You can see this at the GPT tokenizer.
Thanks for compiling the Metaculus predictions! Seems like on 4/6 the community updated their timelines to be sooner. Also notable that Matthew Barnett just conceded a short timelines bet early! He says he actually updated his timelines a few months ago, partially due to ChatGPT.
Earlier this month PALM-E gives a hint of one way to incorporate vision into LLMs (statement, paper) though obviously its a different company so GPT-4 might have taken a different approach. Choice quote from the paper:
Inputs such as images and state estimates are embedded into the same latent embedding as language tokens and processed by the self-attention layers of a Transformer-based LLM in the same way as text
I object to such a [change in metric]/[change in time] calculation, in which case I'm still at fault for my phrasing using the terminology of speed. Maybe I should have said "is continuing without hitting a wall".
My main objection, as described by yourself in other comments, is that the choice of metric matters a great deal. In particular, even if log(KL divergence) continues (sub)linearly, the metrics we actually care about, like "is it smarter than a human" or "how much economic activity can be done by this AI" may be a nonlinear function of log(KL divergence) and may not be slowing down.
I think if I'm honest with myself, I made that statement based on the very non-rigorous metric "how many years do I feel like we have left until AGI", and my estimate of that has continued to decrease rapidly.
In transformers the compute cost for context length n of a part of the attention mechanism, which itself is only a part of the transformer architecture, grows at O(n^2), so for the transformer itself this is only true in the limit.
This is true, and a useful corrective. I'll edit the post to make this clear.
In fact, I think that as models are scaled, the attention mechanism becomes an ever smaller part of the overall compute cost (empirically, i.e. I saw a table to that effect, you could certainly scale differently), so with model scaling you get more and more leeway to increase the context length without impacting compute (both training and inference) cost too much.
I'd love to learn more about this, do you remember where you saw that table?
That's true, but for the long run behavior, the more expensive dense attention layers should still dominate, I think.
Yep, exactly as you explain in your edit!
This non-news seems like it might be the biggest news in the announcement? OpenAI is saying "oops publishing everything was too open, its gonna be more of a black box now".