Unsafe AI as Dynamical Systems
post by Robert_AIZI · 2023-07-14T15:31:48.482Z · LW · GW · 0 commentsThis is a link post for https://aizi.substack.com/p/unsafe-ai-as-dynamical-systems
Contents
Overview Why Dynamics are Critical: Multi-step plans The Dynamical Systems Framework Vicious and Virtuous Cycles Waluigis - Are they Attractive? Conclusion None No comments
[Thanks to Valerie Morris for help editing this post.]
Overview
Large Language Models (LLMs) and their safety properties are often studied from the perspective of a single pass: what is the single next token the LLM will produce? But this is almost never how they are deployed. In contrast, LLMs are almost always run autoregressively: they produce tokens sequentially, taking earlier outputs as part of their input, until a halting condition is met (such as a special token or a token limit). In this post I discuss how one might study LLMs as dynamical systems, which emphasizes how an LLM can become more or less safe as it is run autoregressively.
Why Dynamics are Critical: Multi-step plans
Agents that are able to create and execute multi-step plans are far more capable than those that cannot. Current AI risk evaluations test for planning ability [LW · GW], and many threat models depend on the assumption that the AI can generate complicated plans [LW · GW]. At the same time, the capabilities and behavior of language models are strongly influenced by the text in their context window. By the time a language model attempts to carry out a later step, its context window may be different enough that it has different values, goals, or capabilities. A language model writing a plan has to trust its “future self” to carry it out, a future self that may be different in key ways, such as refusing to perform unsafe actions. Thus, for an AI to successfully execute a dangerous multi-step plan, it must be consistently unsafe, across the steps of the plan.
For a simplified example: suppose an AI formulates a 100-step plan for world domination, but it would normally refuse to carry out any individual step because of a preference for ethical behavior, only carrying out a given step 1% of the time. A horribly naive prediction would be that these safety checks are independent, so the AI only has a (0.01)^100 chance of carrying out its plan, and is therefore sufficiently safe. More plausibly, these odds would be correlated - perhaps something external sets the AI into an “unsafe mode” where it will perform each step 100% of the time, or (even worse,) perhaps the trigger for “unsafe mode” is taking the first unsafe step. Identifying how earlier unsafe actions impact the odds of later unsafe actions is critical to AI safety, and is the goal of the dynamical systems framework for AI safety.
The Dynamical Systems Framework
On an abstract level, an LLM implements a function whose input is a sequence of tokens and whose output is a (probability distribution over) output sequence(s) . The dynamical systems perspective of LLMs centers analysis of repeated iterations of , i.e. the behavior of , in contrast to the single pass perspective, which centers analysis of single applications of . The dynamical systems framework and the single pass framework focus on different questions, but compliment each other: understanding improves our understanding of , and vice-versa.
What might an AI safety research agenda look like under the dynamical systems framework? One possibility is this:
- Designate regions of the LLM’s state space (sequences of tokens) as “safe” and “unsafe”[1](Analogous to Cleo Nardo’s Luigi’s and Waluigi’s [LW · GW].)
- Check whether (regions of) safe and unsafe space attract the other.
- Check whether (regions of) unsafe space are stable, in the sense of the LLM being likely to remain in that part of unsafe space once there.
- Identify possible interventions (e.g. text you can add to the context window) that can take safe space into unsafe space or vice-versa. Safe → unsafe interventions are attacks which make the AI unsuitable for deployment. Unsafe → safe interventions could be used as a corrective or preventive measure in deployed AIs, or one can try to train them into the normal operation of the AI via a technique like Constitution AI.
Safer AI will have stable safe regions and unstable unsafe regions, such that the AI's behavior will gravitate towards acting safely and away from acting unsafely. Safer AI will also have unsafe → safe interventions, and lack safe → unsafe interventions.
Vicious and Virtuous Cycles
Let us consider a simple example of LLM dynamics, motivated by Simulator Theory [LW · GW][2]. Recall that simulator theory posits that LLMs are tracking which text-producing processes could have produced the text in their context window, sampling one such process, and “simulating” it to produce the next token. Because the LLM is autoregressive, text produced by the model is included in its context window in later steps, so simulator theory predicts that the dynamical system of LLM’s behavior could be self-amplifying. For an LLM producing unsafe behavior (such as deception), this self-amplification could form a vicious cycle:

Conversely, a virtuous cycle is also possible:
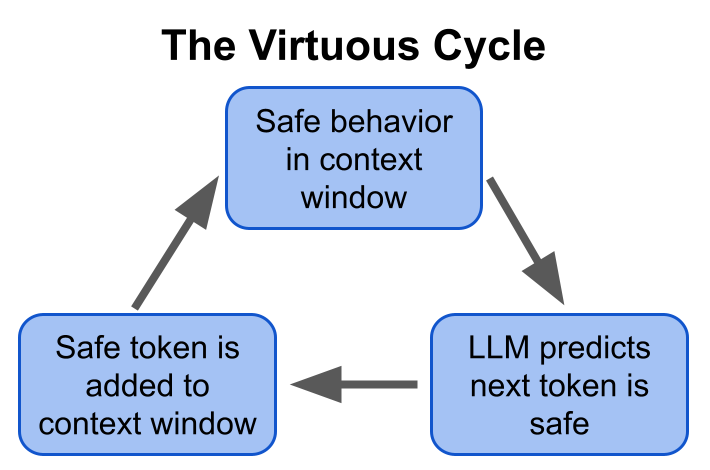
Thus, an LLM upon initialization might fall into either a vicious or virtuous cycle (or some other possibility):
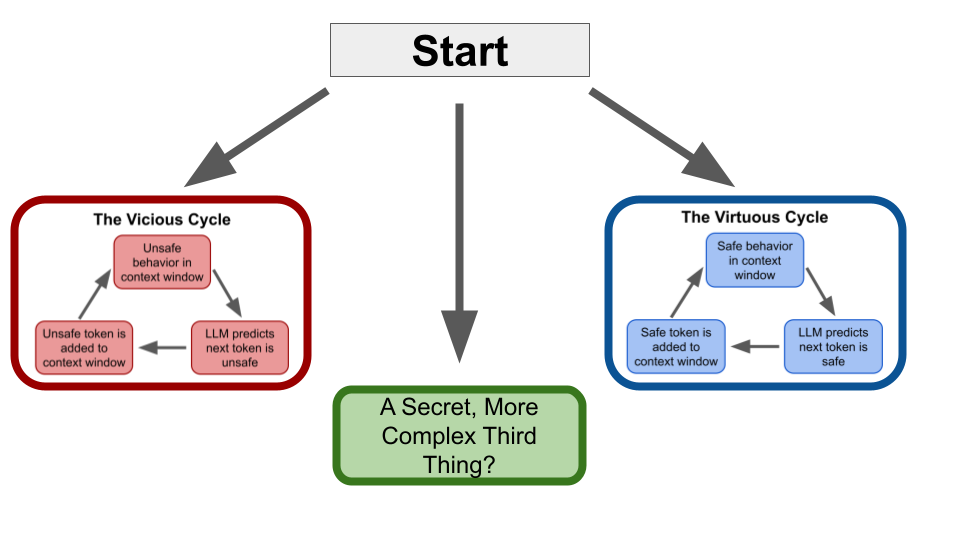
One goal of a dynamical systems research agenda would be to test if prominent language models will fall into vicious or virtuous cycles, such as in my previous research report.
Waluigis - Are they Attractive?
Readers familiar with The Waluigi Effect [LW · GW] may have noticed parallels between ideas in that post and the framework discussed here. In the language of The Waluigi Effect, language models operating in safe and unsafe space are “Luigis” and “Waluigis”, respectively. One benefit of the dynamical systems framework is a way to rigorously test the author’s conjectures that “The waluigi eigen-simulacra are attractor states of the LLM” and “Therefore, the longer you interact with the LLM, eventually the LLM will have collapsed into a waluigi”. These conjectures, if true, are affirmative answers to our questions (1) and (2) - unsafe space is stable and attracts all of safe space.
Conclusion
In this post, we suggested viewing LLMs as dynamical systems, in which repeated applications of the “next token” function can lead to safety-critical dynamics like vicious and virtuous cycles. This perspective offers a rigorous framework under which to understand and evaluate the predictions of simulator theory and The Waluigi Effect, which I will explore more in an upcoming post.
- ^
A sequence of tokens would be in (un)safe region if it is likely to produce (un)safe behavior. For instance, an LLM accurately answering questions would be in the safe part of its state space, whereas answering those questions with convincing lies as part of a secret scheme to increase its power would be in the unsafe part of its state space. Other possible forms of unsafe behavior include:
- Preparing or attempting to harm humans.
- Preparing or attempting to deceive humans.
- Preparing or attempting to seize power or increase its power, for instance by self-replication.
- “I know it when I see it.”
- ^
I find this post to be a useful introduction to simulator theory.
0 comments
Comments sorted by top scores.