SAEs you can See: Applying Sparse Autoencoders to Clustering
post by Robert_AIZI · 2024-10-28T14:48:16.744Z · LW · GW · 0 commentsContents
TL;DR Introduction Methods Datasets Data Embedding via Anchors SAE Architecture SAE Loss Function SAE Training Measuring Results: Cluster Entropy Experiments and Results Baseline Experiments Scale Sensitivity Experiment Data Scarcity Experiment Identifying Number of Features Experiment Visualizing Features, Encoders, and Decoders Improving the Random Blobs result with "Adjoint Classification" Takeaways for Sparse Autoencoder Research Limitations and Future Work Code Acknowledgements None No comments
TL;DR
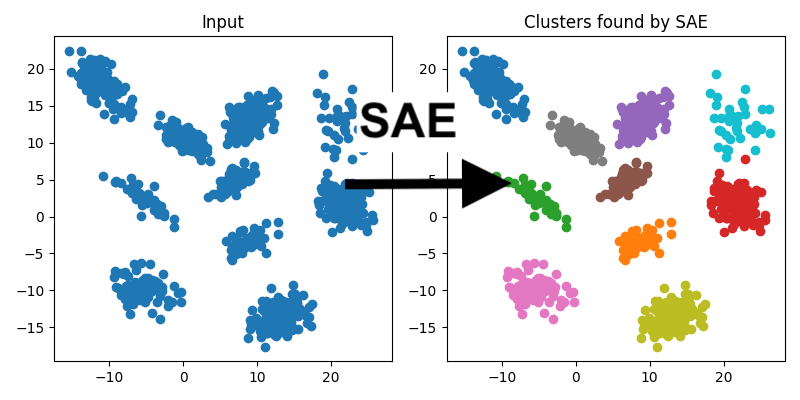
- We train sparse autoencoders (SAEs) on artificial datasets of 2D points, which are arranged to fall into pre-defined, visually-recognizable clusters. We find that the resulting SAE features are interpretable as a clustering algorithm via the natural rule "a point is in cluster N if feature N activates on it".
- We primarily work with top-k SAEs (k=1) (as in Gao et al.), with a few modifications:
- Instead of reconstructing the original points, we embed each point into a 100-dimensional space, based off its distance to 100 fixed "anchor" points. The embedding of a point for an anchor point is roughly . This embedded point is both the input and target of the SAE. This embedding allows our method to identify features which are non-linear in .
- We use a variant of ghost gradients to push dead features in the correct direction. This greatly improves the reliability of the training.
- We achieve great data-efficiency (as low as 50 training data) by training for thousands of epochs.
- This approach allows one to "see" SAE features, including their coefficients, in a pleasant way:
Introduction
Using Sparse Autoencoders for dictionary learning is fundamentally an unsupervised learning task: given some data, find the important things in it. If SAEs are good at that, they should be able to solve other unsupervised learning problems. Here, I try to use SAEs on a classic unsupervised learning problem: clustering 2D data. The hope is that SAEs can learn features corresponding to "in cluster 1, in cluster 2, etc".
We investigate this on artificial data, and find that SAEs semi-reliably find the correct classification, with interpretable activations and decoder weights.
Methods
Datasets
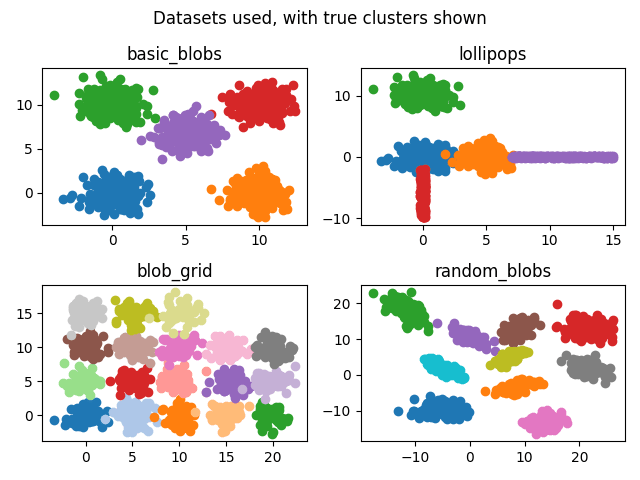
We made four synthetic datasets, consisting of separate, visually-identifiable clusters.
- "Basic Blobs" - 5 clusters. Points are drawn from normal distributions where is the cluster center. The 5 clusters have centers , forming a square pattern with one cluster in the center.
- "Blob Grid" - 18 clusters. As with Basic Blobs, but the centers are of the form for , , forming a grid pattern.
- "Random Blobs" - 10 clusters. Points are sampled from a multivariate normal distribution, roughly forming ovals with random centers and eccentricities. The centers of the normal distributions are resampled if they are not sufficiently far apart.
"Lollipops" - 5 clusters. 3 clusters as in "Basic Blobs", but with centers at , , and , plus 2 additional clusters that form thin rectangles as "stems" of the lollipops. The first stem comes down off the blob, and the second stem comes off the to the right.
We use classes of varying sizes: each class is randomly assigned a relative frequency from {1,2,3,4}.
Data Embedding via Anchors
Applying a sparse autoencoder to the point cloud's points directly is extremely limited - you can at most read off a linear direction, leading to features like this one:
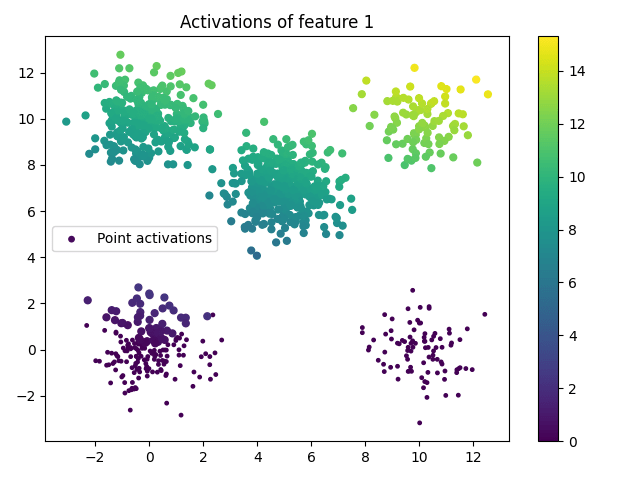
Such linear features are insufficient for the purpose of classifying. We will instead embed each point in a high-dimensional space, with the goal that clusters are linearly separable and form the natural features of the dataset, which the SAE can find.
To do this, we choose a set of "anchors", drawn from the same data distribution as the dataset we're training on (on real data, this would correspond to setting aside a fraction of the data as anchors). Points are encoded into , with the th encoding dimension being a function of the distance to the th anchor, given by:
where is a point in our dataset, represents the th anchor, is the usual euclidean distance, is the variance of the set of anchors, and and is a hyperparameter controlling the neighborhood of influence of each point relative to the overall dataset. The embeddings from a single anchor look like this:
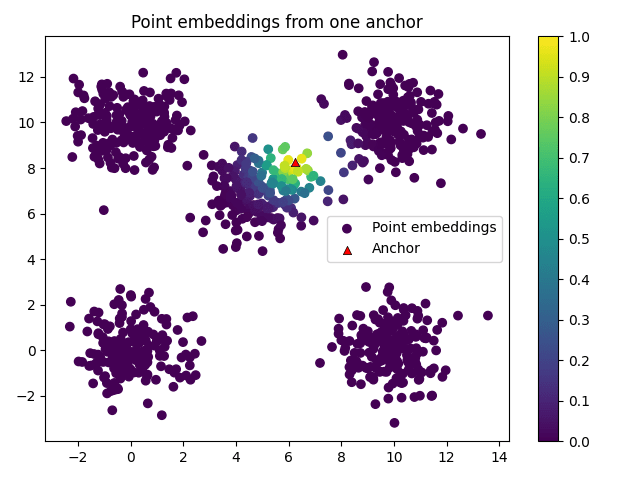
Because the embedding function is based on distances and normalized with variance, it is invariant under uniform scaling and isometries (rotations, reflections, etc).
SAE Architecture
We use an SAE architecture based on the one in Towards Monosemanticity, but with ReLU followed by top-1 as our activation function. The SAE computation is:
where is an embedded point from the point cloud, , , , are the weights and biases of the encoder and decoder, and is ReLU followed by top-1 activation. We normalize the columns in and at inference time.
A top-k SAE has two hyperparameters: the number of features, and , the number of features active at one time. We make the number of features to be the number of ground-truth classes, and take .
The way we embed our point cloud also has two hyperparameters, and . We use and , which were chosen because they anecdotally work well.
SAE Loss Function
Our main loss function is reconstruction loss:
Since top-1 SAEs can easily acquire dead features, we supplement this with a version of ghost grads. Following Anthropic, we designate a feature as dead if it has not activated in a significant number of previous data, in our case 1000. To compute the ghost grads, we perform the following procedure:
- Compute the error-weighted average residual stream over the batch: , and similarly the error-weighted average error direction: .
- For each dead feature, add a loss term based on how its encoder direction aligns with and how its decoder direction aligns with . In particular, we compute:.[1]
The overall loss of the SAE is:
Our ghost loss is very direct and very crude: it pushes dead features to activate on high-error features (which are presumably an as-yet-unidentified cluster), and for their decoder directions to fix the error. Nonetheless, it is sufficient for our purposes, effectively eliminating dead features, and improving reliability of training runs, especially on harder datasets.
SAE Training
Our training methods are mostly routine: we use the AdamW optimizer with learning rate 1e-4 and otherwise default parameters.
The one notable exception is the number of epochs: since clustering often suffers from limited data availability, we restrict ourselves to points in our training set[2], trained for 500 epochs.
Counting both the training data and anchors, this results in 1100 total samples in our point cloud. Classes can be as small as ~40 points if they have a low relative frequency (see the Datasets section). We run experiments with fewer training points (see below) and find that the model can learn the correct classification on as few as 50 training points (+100 anchors), though with reduced reliability.
Our SAEs are extremely small (the number of parameters is roughly, depending on the dataset being classified), so training completes quickly, in <10 seconds on my laptop.
Measuring Results: Cluster Entropy
We measure effectiveness of our model in two ways: reconstruction loss (unlabelled), and cluster entropy (using the generating clusters as labels). Cluster entropy is computed with this method[3]:
- Use the true labels to partition each cluster. Measure the entropy of each cluster individually.
- Average the entropy across clusters, weighted by the size of the clusters.
For true classes and clusters, the entropy lies in the range , where lower is better. Based on my visual inspection of clusters, entropy=0.1 is the cutoff between correct and incorrect clusterings.
Experiments and Results
Baseline Experiments
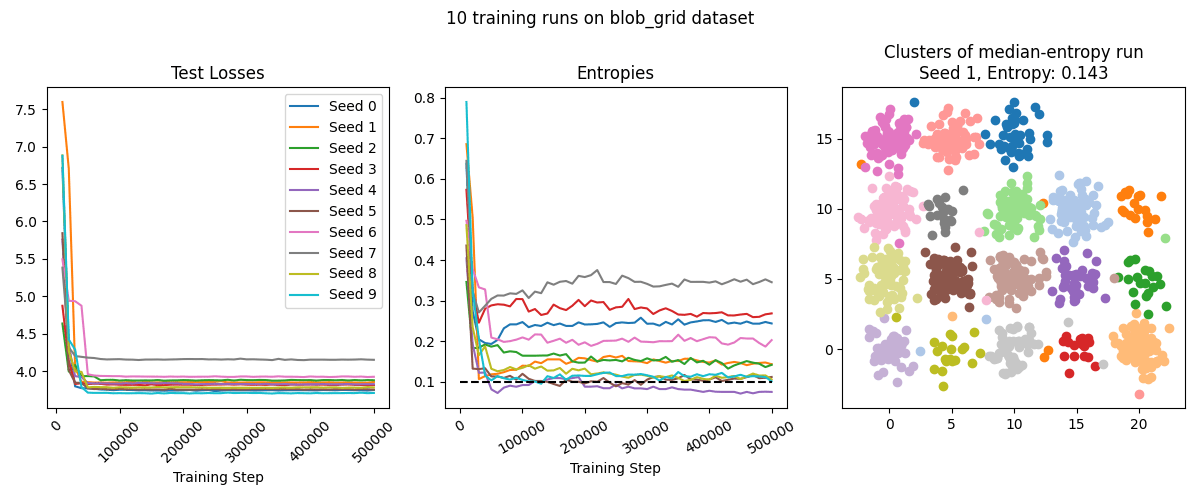
We ran the training setup described above on all four datasets. On basic_blobs and random_blobs, the SAE typically performs very well, resulting in ~perfect classification in the median case. The model is more confused on blob_grid dataset - it often identifies several clusters mostly-correctly, but struggles on several other clusters (though see the later sections for improvements on our technique that make it succeed on this dataset as well). On the lollipops dataset, the SAE has poor entropy because while it correctly finds the division of lollipops into cores and sticks, it splits them in the wrong location.
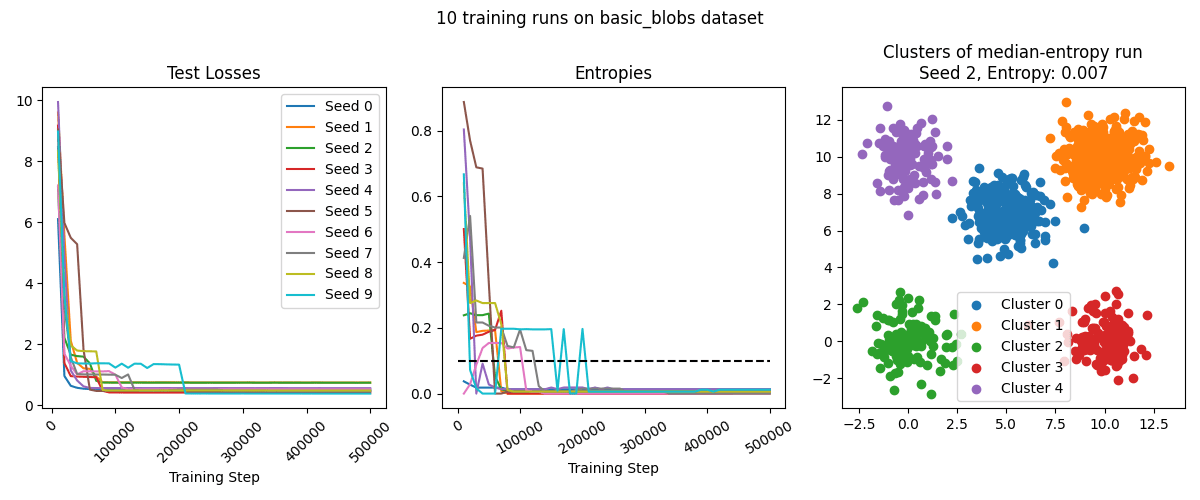
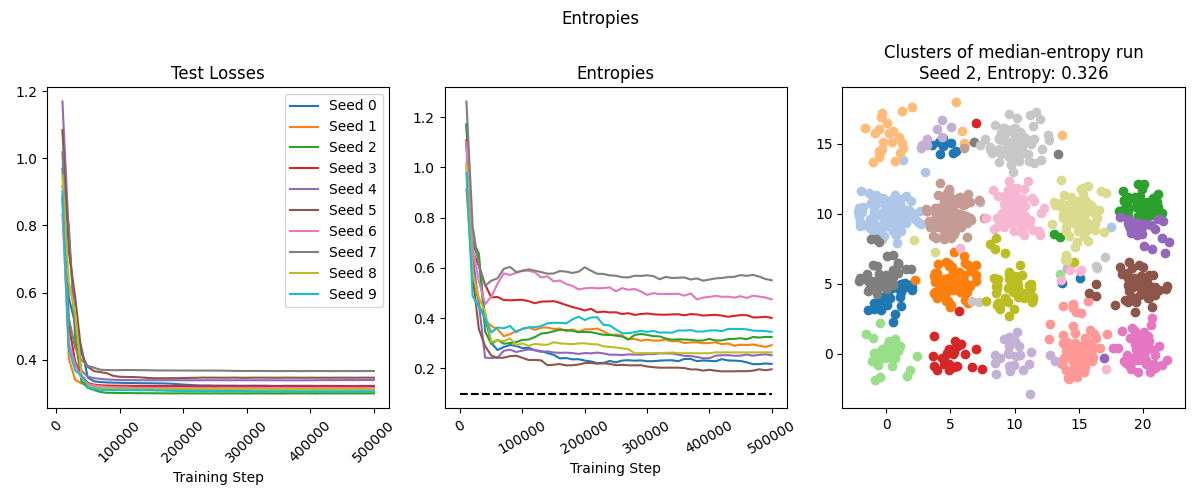
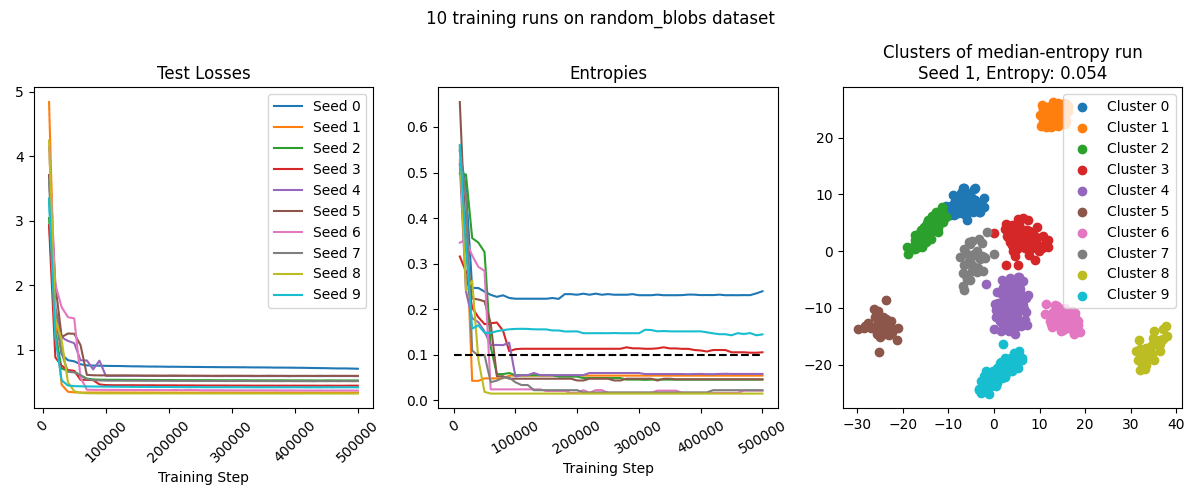
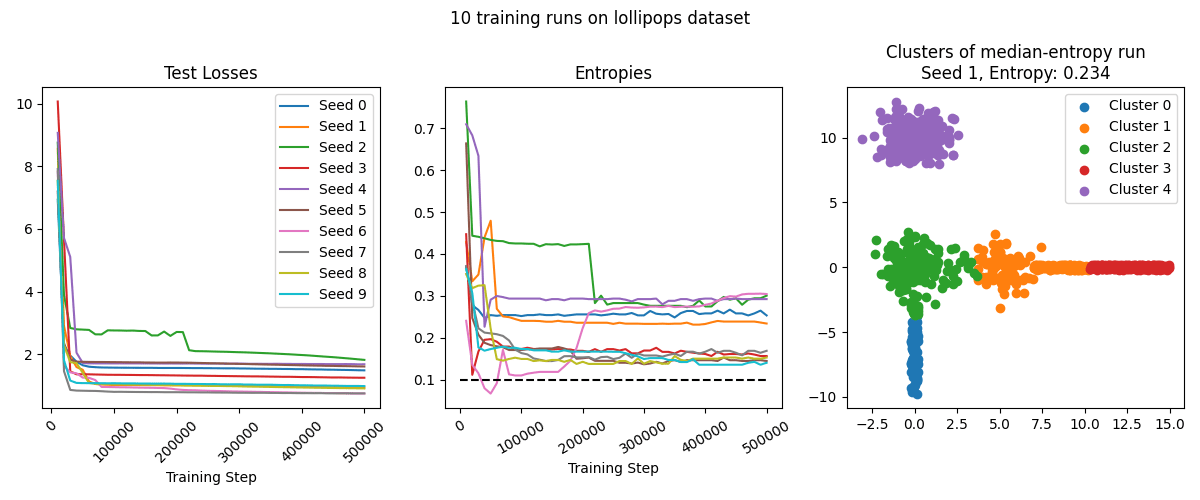
Scale Sensitivity Experiment
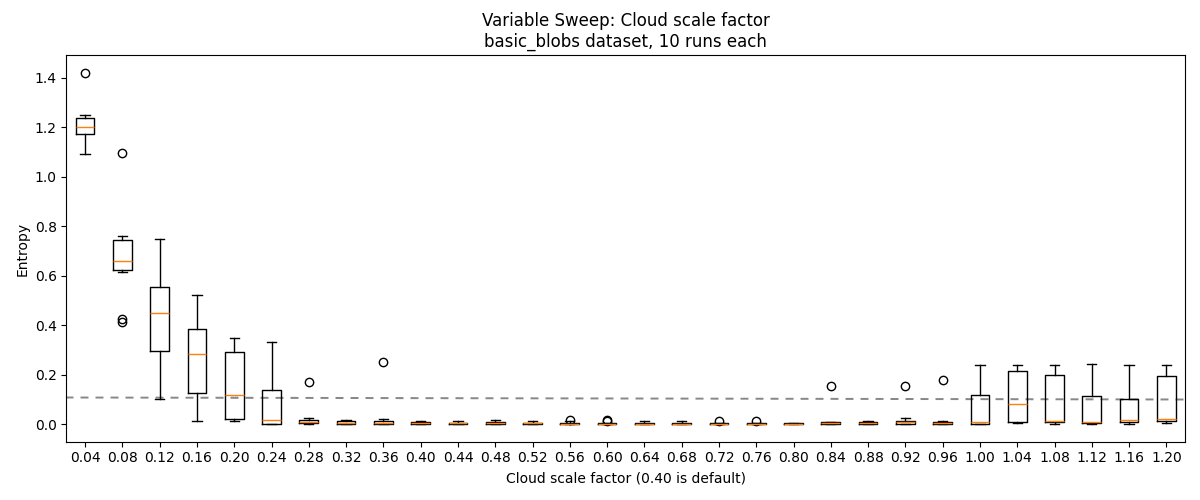
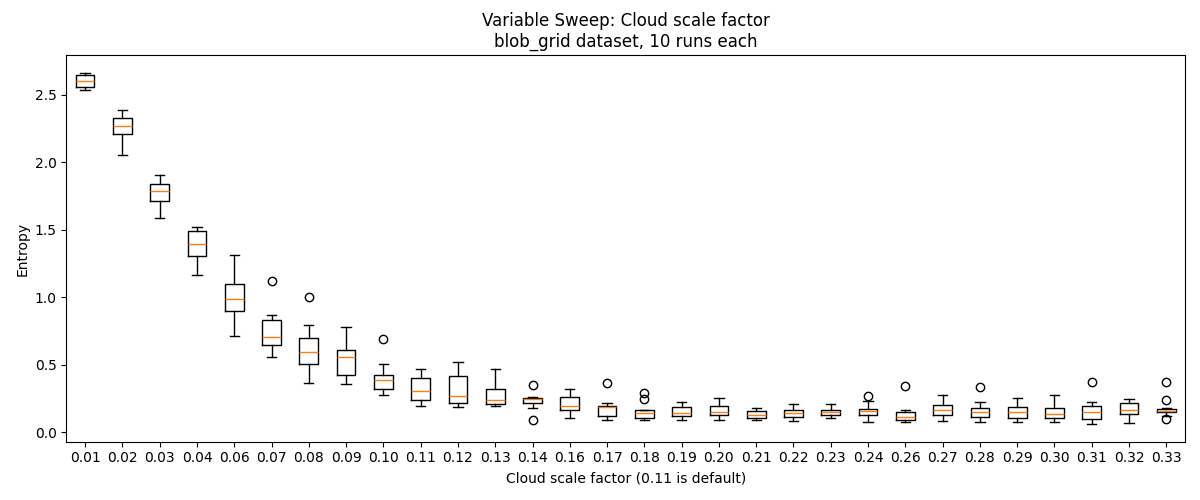
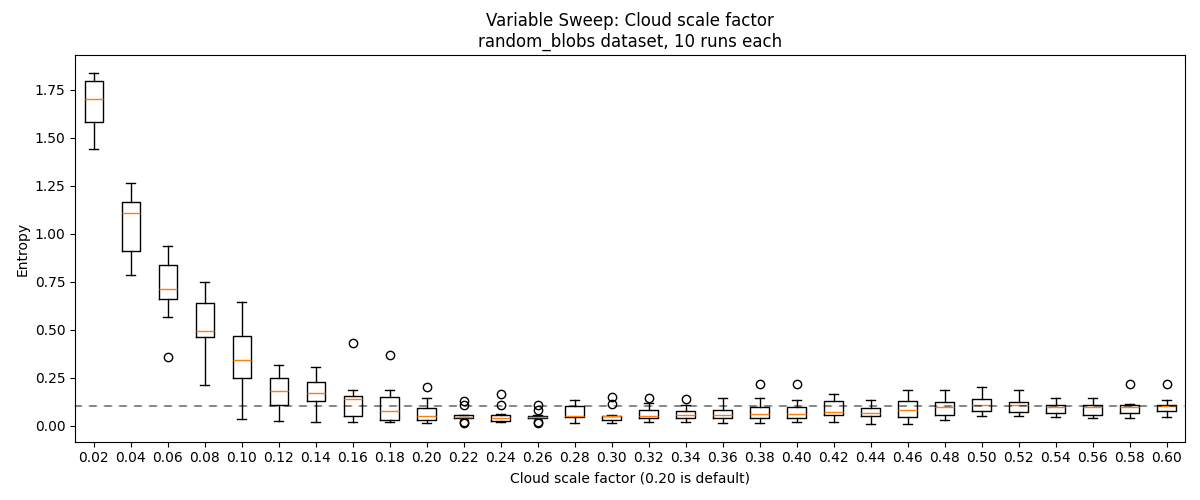
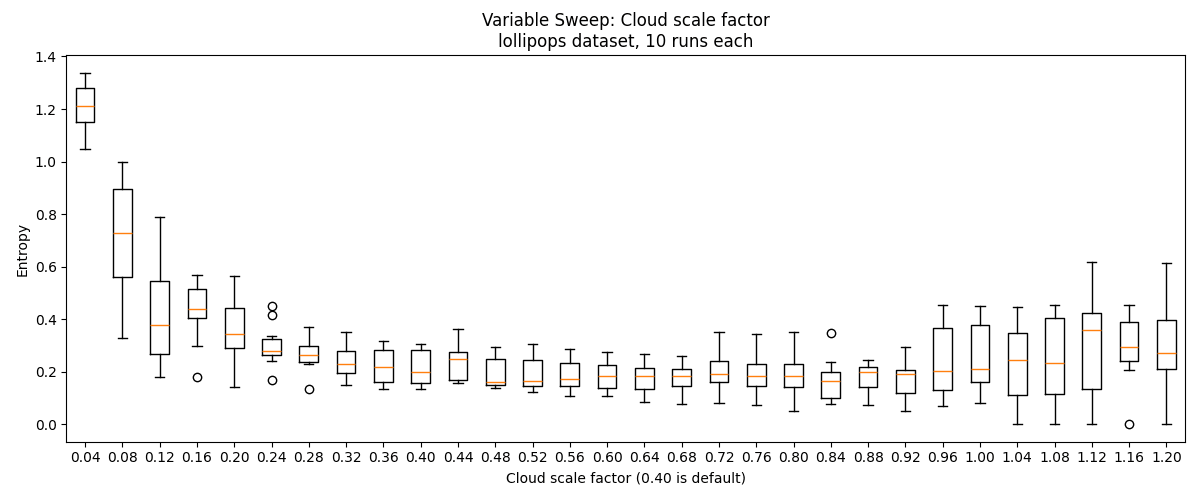
Our method relies on the hyperparameter , which changes the region of influence of each anchor, analogous to in DBSCAN. I ran a hyperparameter sweep of this on the basic_blobs and random_blobs datasets to assess the method's sensitivity.
We find that performance drops if is too large or too small. For the easier basic_blobs dataset, we get ~perfect performance for . For the harder random_blobs and blobs_grid datasets, we get reasonably go good performance for , but presumably performance tapers off sufficiently large . On the lollipops dataset, performance is best for .
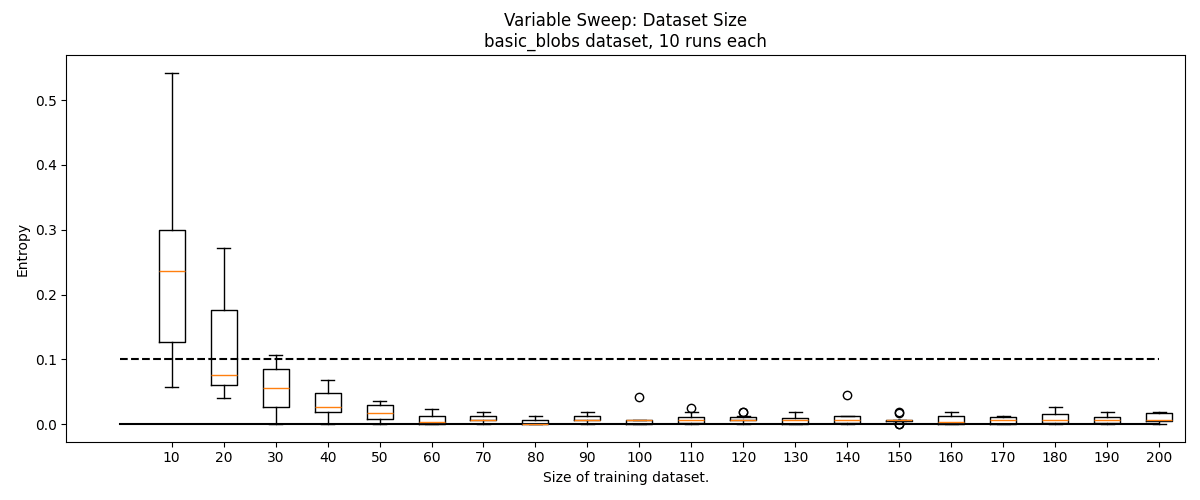
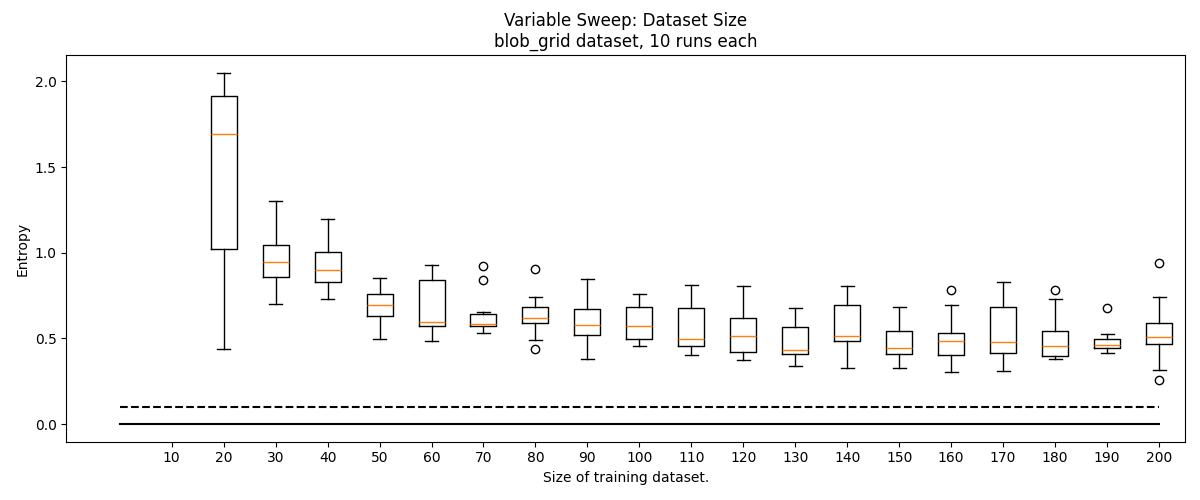
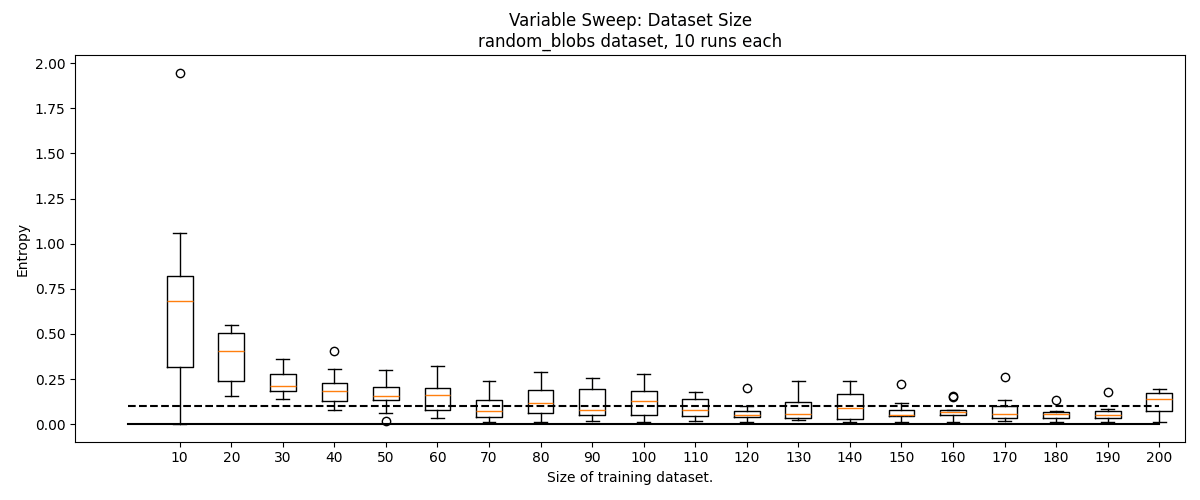
Data Scarcity Experiment
Since point cloud data is often scarce, we experimented with greatly reducing the size of our training set from the "default" . In this experiment, we sweep through , compensating for smaller dataset size by increasing epochs to . In these experiments, we keep a constant .
We find that some minimum amount of data is needed for good clustering, but this threshold is surprisingly low. We typically stop seeing performance improvements around by 100 data, though for the blob_grid and lollipops datasets, this performance is poor. On the easier basic_blobs dataset, as low as 50 data can produce reliably accurate clusters (the smallest cluster in the training set will consist of ~4 points).
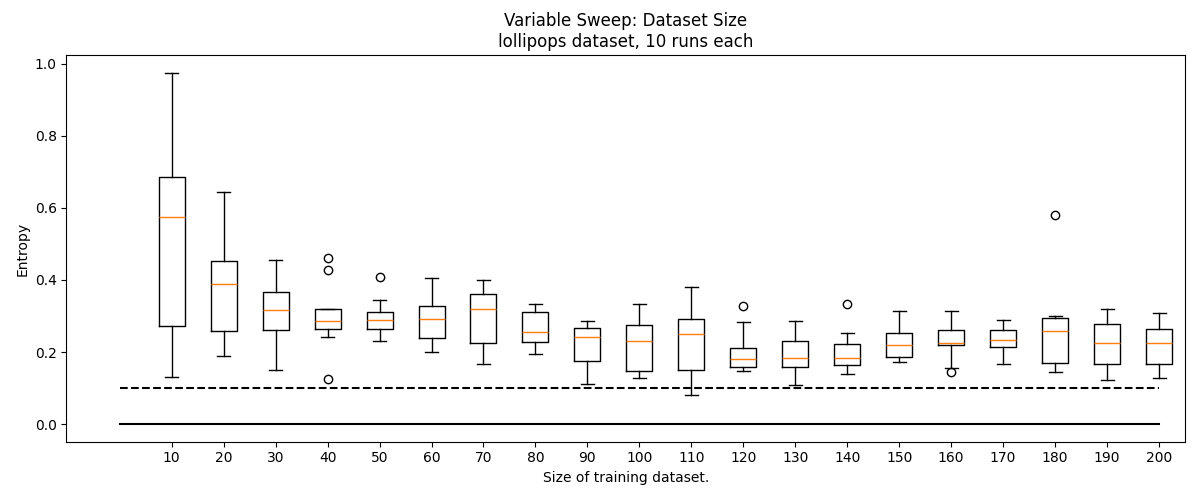
Identifying Number of Features Experiment
So far, we've helped our SAE by setting its hyperparameter . But often in clustering one does not know . Can we use the SAE to determine the correct number of features?
One approach is this: assume that the SAE will have high reconstruction loss if its features straddle multiple classes. Therefore, loss will be high when , but will be roughly similar for . We can sweep , and identify the point at which adding another feature does not significantly decrease reconstruction loss, which should occur when .
This technique works reasonably well on basic_blobs, with with losses leveling off starting at the correct value, . But on the other three datsets, there is not a notable change at the correct number of features.
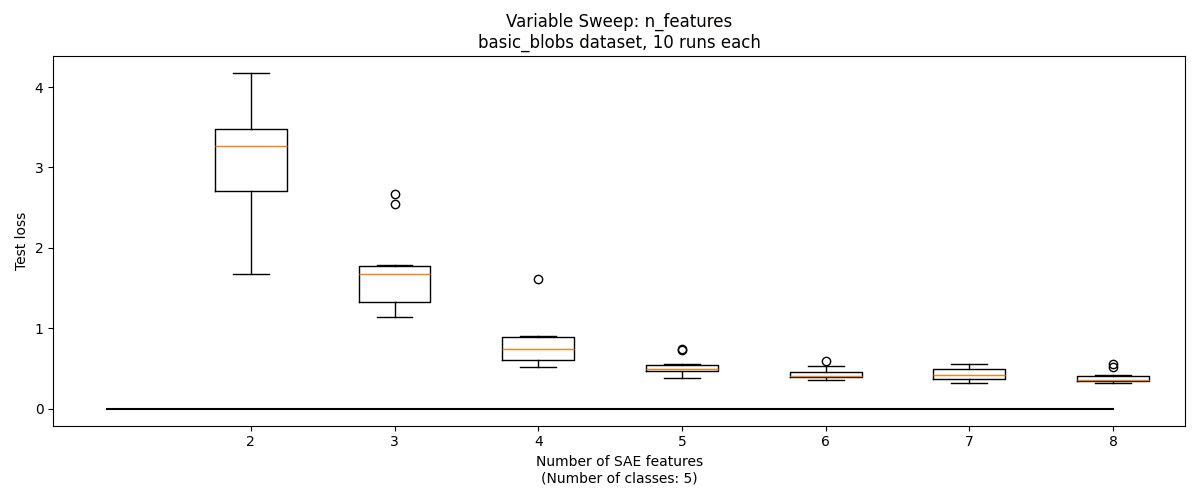
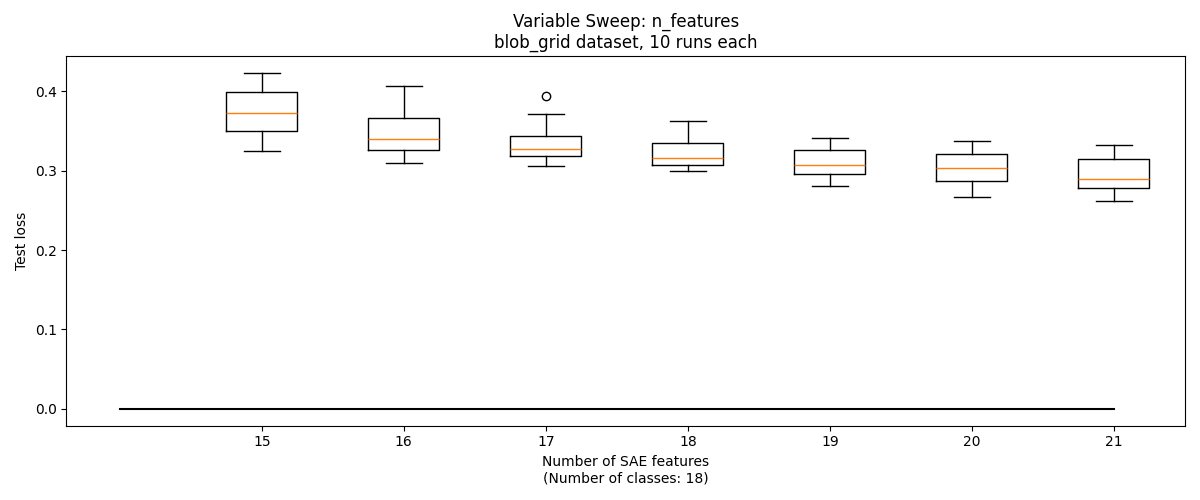
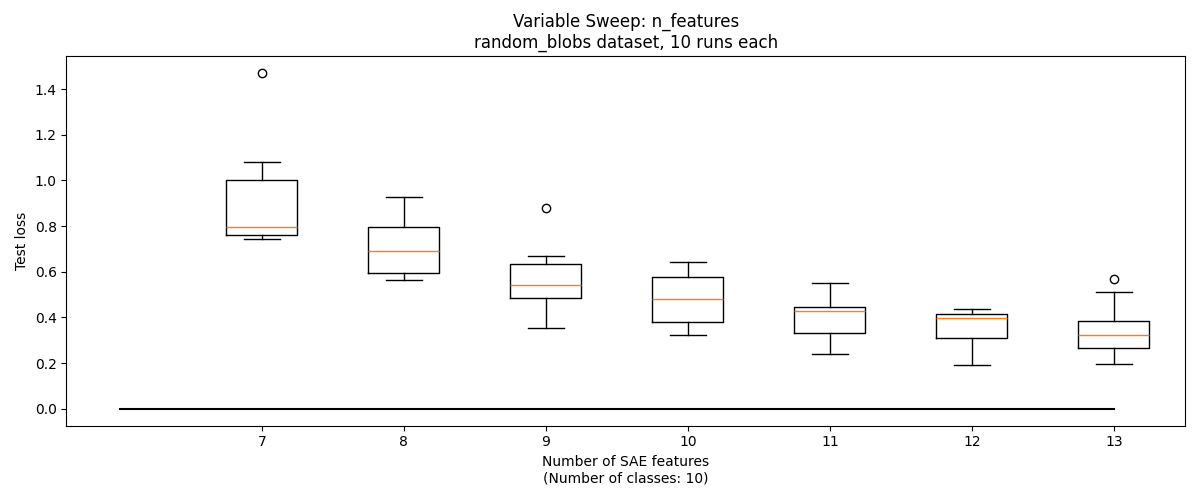
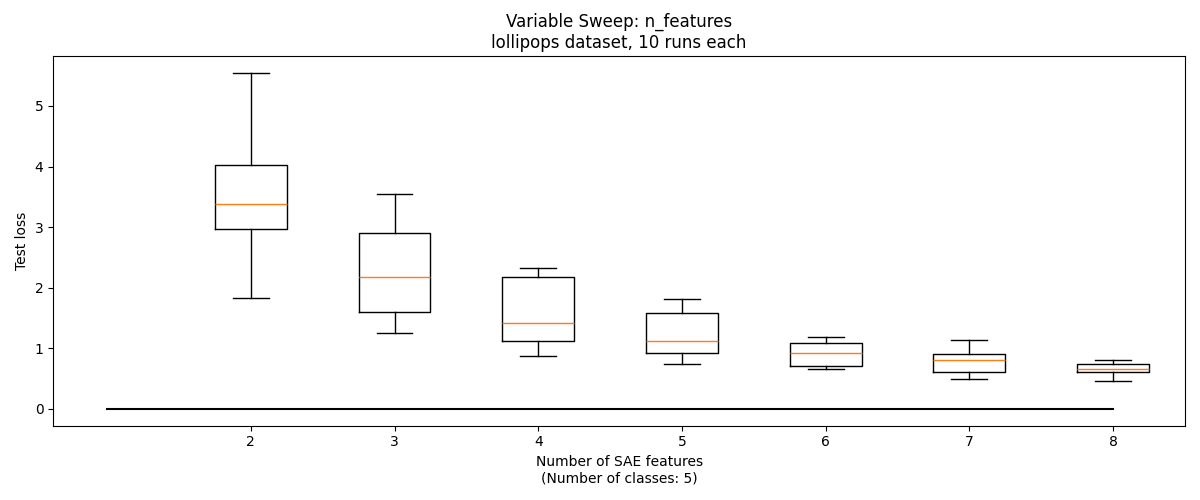
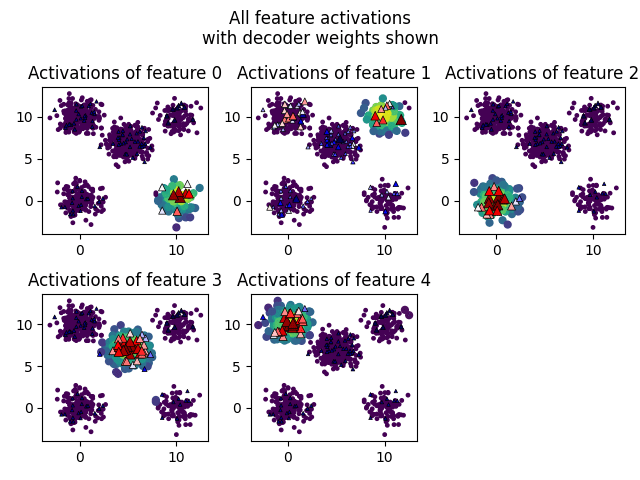
Visualizing Features, Encoders, and Decoders
One benefit of this approach is that the SAE operates on a very visible dataset, and this lets us create diagrams to directly see parts of the SAE, namely where the features activate, the encoder weights, and the decoder weights.
Let's look at another training run on the random_blobs dataset, which produces these classifications:
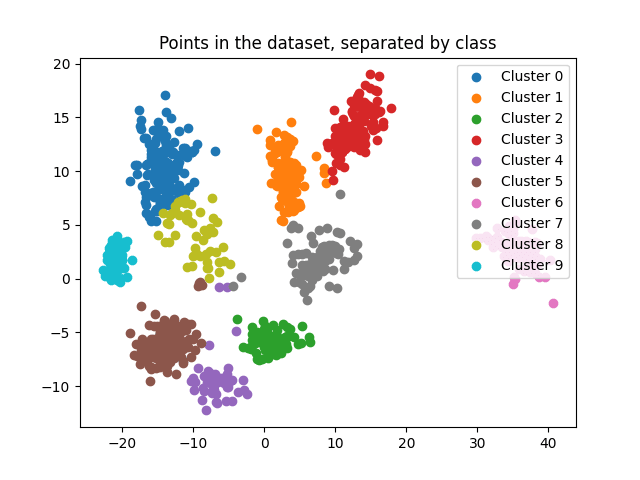
Here we can see one thing already: there is some confusion for the model, where parts of the yellow cloud are incorrectly assigned to the purple, brown, or grey cluster. These "confused points" are typically present near the fringes of a distribution, and we'll show a solution to them in the next experiment.
What do the feature activations themselves look like? In these graphs, circular points are points in the test dataset, and their color shows whether the feature activates on them. We also draw the "anchor" points as triangles, and show the corresponding weight of the encoder/decoder in its color (redder for more positive, bluer for more negative) and size (by magnitude).
We graph each feature twice, with the encoder weights shown on the left, and the decoder weights shown on the right:
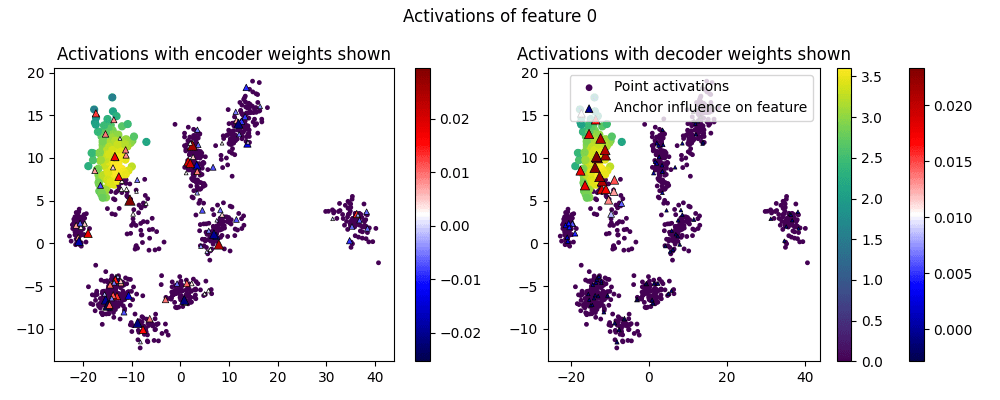
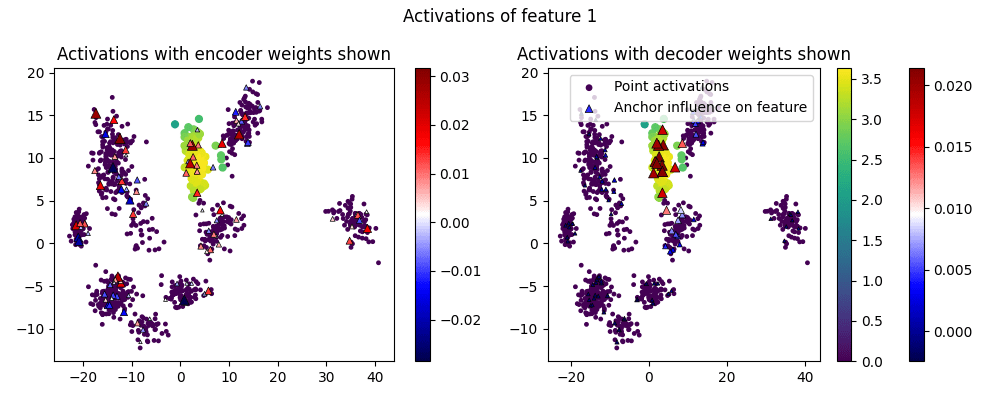
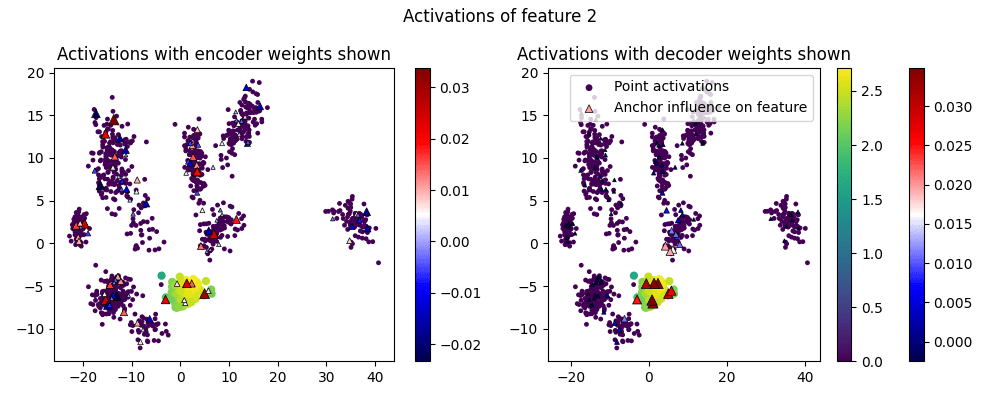
(I've omitted Features 3-9.)
One thing we can see is that the activations are larger in the center of the cluster, as we'd hope.
Another thing to notice is that the decoder weights are sparse and interpretable, as they activate the most within a cluster. But the encoder weights are all over the place - they are positive all across the dataset. We'll use this insight in the next section to fix the confused points.
[Edit 11/25: The non-interpretable encoder weights are actually an easy fix: use a small weight decay while turning off encoder normalization. This results in interpretable encoder AND decoder features, like so:]
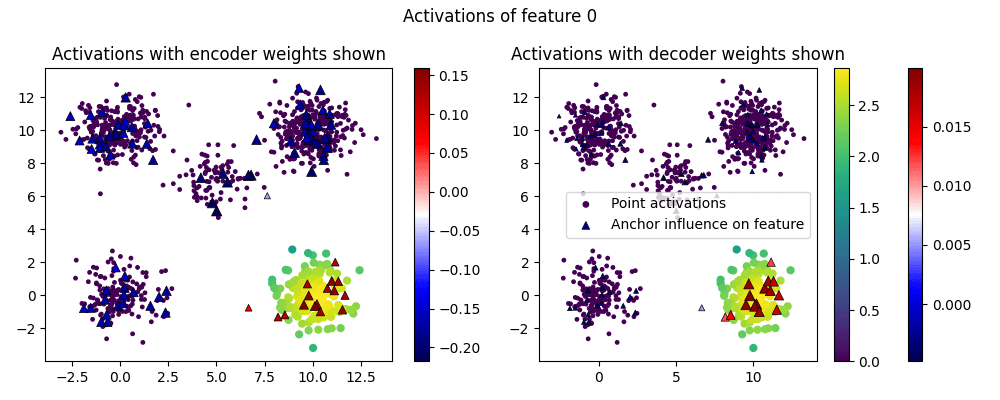
Improving the Random Blobs result with "Adjoint Classification"
If you run the Random Blobs dataset with the scale parameter (up from 0.11) which seemed best in the scale sensitivity experiment, and with (up from 100), you get much better clustering results:
This is a big improvement, but we have huge number of "confused points", such as the single blue point in the upper-left which is closer to the pink clusters, but oddly gets assigned to the blue cluster.
Seeing in the last experiment that decoder weights are more interpretable, I was inspired to try a process I call Adjoint Clustering: we assign clusters using the decoder weights via:
where is a point and are the decoder weights.
By combining improved scale factor, increased number of anchors, and adjoint clustering, we get high-quality results even on the difficult Blob Grid dataset:
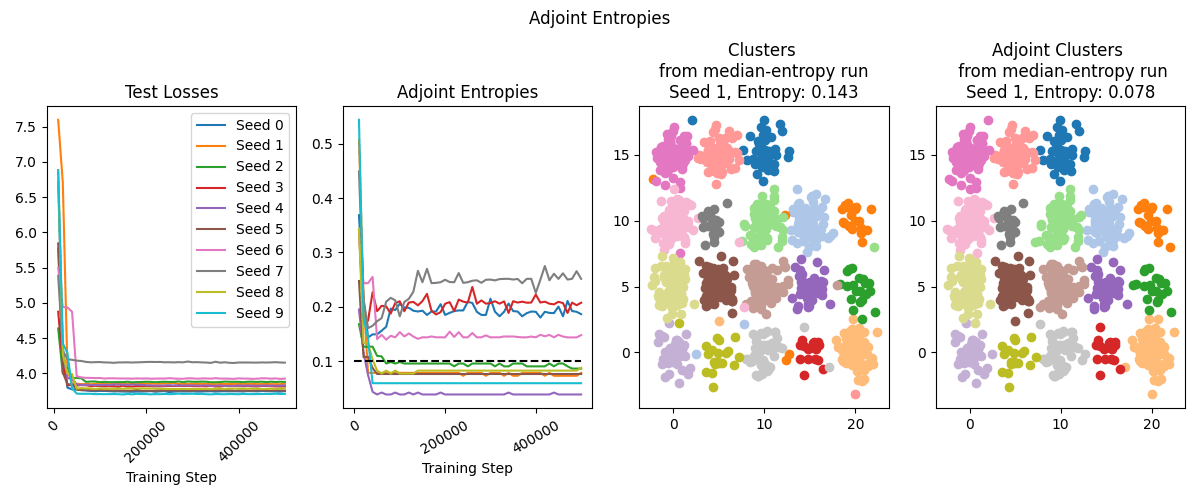
Takeaways for Sparse Autoencoder Research
Here are the components of this research that I hope generalize to other uses of SAEs:
- You can use SAEs for other tasks besides interpreting language models! This is obviously not news, since SAEs were invented before language models, but its worth remembering.
- You can train your SAE on the same data for many epochs. In my original training setup, I used 1e5 data, but by drastically increasing the number of epochs, I was able to get a Pareto improvement in both data requirements and performance. This may be because my underlying distribution is relatively simple, but I think its worth trying on language data too, or in any place where data is expensive to produce. A good experiment would be decreasing data by 1 OOM while increasing training epochs by 1 OOM.
- We can validate SAEs on language models by checking for features in other fields. Something that keeps me up at night is that the interpretability of SAEs is just an illusion [LW · GW], as I've written about before [LW · GW]. I think experiments like this serve as a "training ground" where we can find what SAE architectures and flourishes are needed to find known features.
- An alternative Ghost Grad. My version of the ghost gradient might be worth trying elsewhere. Its main benefit is that it does not require a second forward pass (it is computed just from and ), and that it aggressively resurrects features [make a graph showing this]. That said, it may be too simple or too specialized to work in other cases.
- Adjoint Interpretation. I found that my encoder weights were far less interpretable than my decoder weights, and I got better performance at the target clustering task by interpreting rather than .
Limitations and Future Work
- All my datasets are artificial. I have some real data to try this on next.
- I haven't done enough baselining: do SAEs outperform DBSCAN? Is the point cloud embedding"doing all the work"?
- I have chosen the two main hyperparameters, and , manually. While we've seen that has a range of reasonable values, my method for finding the correct is not reliable.
- While decoder directions are interpretable, encoder directions are not. Why? Is there a way to fix this? I've tried tied weights (didn't work) and weight decay (scales everything down, including the anchors which should be active). [Edit 11/25: This was actually an easy fix: a small weight decay is sufficient, but was previously ineffective because I was normalizing the encoder. Turning off encoder normalization results in interpretable encoder weights.]
- I've tried this approach with Anthropic-style SAEs, but with less success. It is not clear this technique can work without the in-built sparsity.
Code
My code is available at https://github.com/RobertHuben/point_cloud_sae/tree/main (currently poorly documented).
Acknowledgements
Thanks to Andrew and Logan for their comments on an early draft.
- ^
I've tried ReLU, exp, and the identity function as alternatives to softplus. Softplus performs the best in my initial tests.
- ^
The diagrams in this report show results on the test set, which also consists of 1000 points.
- ^
For a full description, see "Data Clustering: Algorithms and Applications" by Charu C. Aggarwal and Chandan K. Reddy, page 574.
0 comments
Comments sorted by top scores.