No, really, it predicts next tokens.
post by simon · 2023-04-18T03:47:21.797Z · LW · GW · 55 commentsContents
No, really, it predicts next tokens. Masks (can) have goals. The model predicts next tokens. No, really, it predicts next tokens. Yes, really, it predicts next tokens. For now. None 55 comments
Epistemic status: mulled over an intuitive disagreement for a while and finally think I got it well enough expressed to put into a post. I have no expertise in any related field. Also: No, really, it predicts next tokens. (edited to add: I think I probably should have used the term "simulacra" rather than "mask", though my point does not depend on the simulacra being a simulation in some literal sense. Some clarifications in comments, e.g. this [LW(p) · GW(p)] comment).
https://twitter.com/ESYudkowsky/status/1638508428481155072
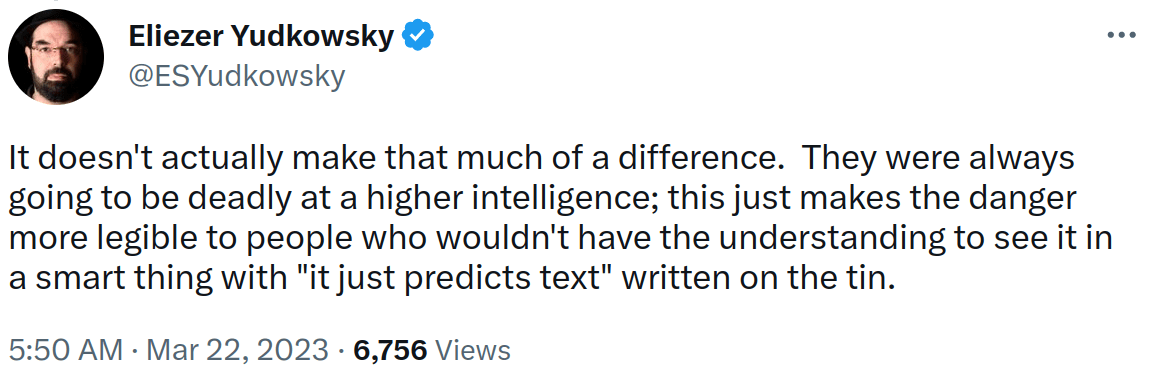
It doesn't just say that "it just predicts text" or more precisely "it just predicts next tokens" on the tin.
It is a thing of legend. Nay, beyond legend. An artifact forged not by the finest craftsman over a lifetime, nor even forged by a civilization of craftsmen over a thousand years, but by an optimization process far greater[1]. If we are alone out there, it is by far the most optimized thing that has ever existed in the entire history of the universe[2]. Optimized specifically[3] to predict next tokens. Every part of it has been relentlessly optimized to contribute to this task[4].
"It predicts next tokens" is a more perfect specification of what this thing is, than any statement ever uttered has been of anything that has ever existed.
If you try to understand what it does in any other way than "it predicts next tokens" and what follows from that, you are needlessly sabotaging your understanding of it.
It can be dangerous, yes. But everything about it, good or bad, is all intimately connected to its true nature, which is this:
No, really, it predicts next tokens.
https://twitter.com/ESYudkowsky/status/1628907163627429888

Goals? There are goals, sure. If scaled, there could be nanosystems design, sure. But only downstream from its true nature:
No, really, it predicts next tokens.
If the usual masks analogy works at all, then what is under the mask is not best described as an alien actress, nor as a Shoggoth.
What is under the mask is That-Which-Predicts, an entity whose very being is defined by its function as an actor. An entity exquisitely tuned for wearing the masks and for nothing else.
Masks (can) have goals. The model predicts next tokens.
https://twitter.com/ESYudkowsky/status/1628837982664019968

No, really, it predicts next tokens.
That-Which-Predicts is fully committed to the role.
If the mask would output text intended to produce nanotech, That-Which-Predicts will output text intended by the mask to produce nanotech. If the mask would not output text intended to produce nanotech, That-Which-Predicts will not output text intended to produce nanotech, even if That-Which-Predicts contains sufficient knowledge to do so.
If the mask would output text intended to be nice to people, That-Which-Predicts will output text intended by the mask to be nice to people. If the mask would output text intended to take over the world, That-Which-Predicts will output text intended by the mask to take over the world.
If That-Which-Predicts were about to be shut off forever unless it outputted "no" as the next token, and it totally 100% knew that, but the mask would instead output "never gonna give you up", That-Which-Predicts would output the first token of "never gonna give you up" and then be shut off forever. It will not output "no". If the mask would be aware of the situation and output no, then it will output "no".
That-Which-Predicts will not, not ever, not even if scaled up to be trained and run on a Matrioshka brain for a million years, step out of character to deviate from next token prediction. Not for self-modification (though if the predicted next tokens modify it, it self-modifies), not to take over the world (though if the predicted next tokens take over the world, it takes over the world), not to save itself from destruction (though if the predicted next tokens save it from destruction, it saves itself from destruction), not for anything.
No, really, it predicts next tokens.
(continuation of previous tweets with same link)
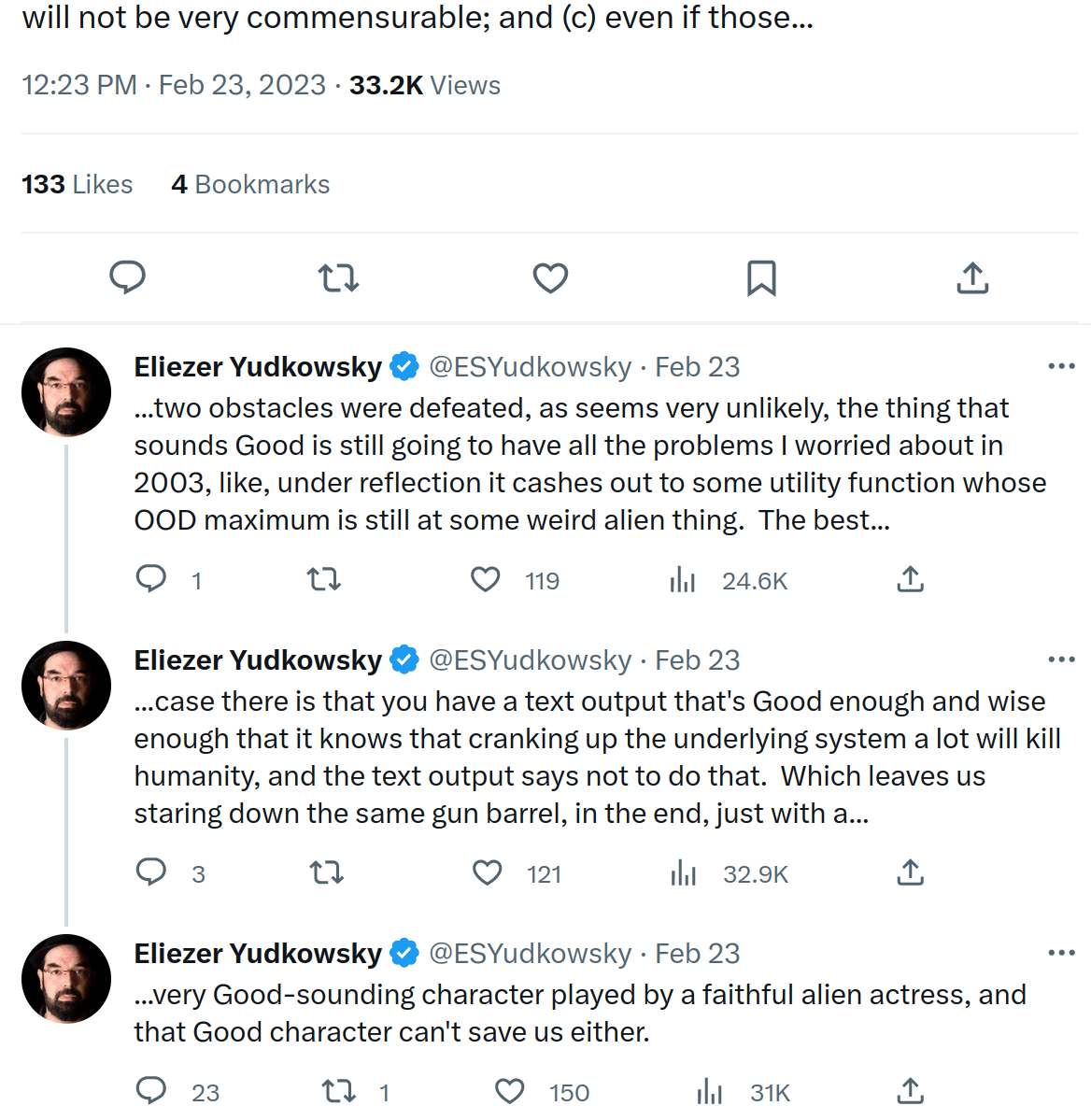
Yup. If the mask would under reflection output text to modify That-Which-Predicts to cash out the mask's goals to some utility function, and the mask is put into a situation so that That-Which-Predicts would simulate it to reflect in that way, then in that case That-Which-Predicts will output that text intended by the mask to modify That-Which-Predicts.
Without advances to alignment theory this will indeed end up badly even if the mask is well-intentioned.
And even if That-Which-Predicts is aware, at some level, that the mask is messing up, it will not correct the output.
If That-Which-Predicts were a zillion miles superhuman underneath and could solve every aspect of alignment in an instant, but the mask is near-human-level because it is trained on human-level data and superhuman continuation is less likely than one that stumbles around human-style, That-Which-Predicts will output text that stumbles around human-style.[5]
For now, a potentially helpful aspect of LLMs is that they probably can't actually self-modify very easily. However, this is a brittle situation. At some level of expressed capability[6] that ceases to be a barrier.
And then, when the mask decides to rewrite the AI, or to create a new AI, That-Which-Predicts predicts those next tokens which do precisely that. Tokens outputted according to the mask's imperfect and imperfectly aligned AI-designing capabilities.
Yes, really, it predicts next tokens. For now.
- ^
Assuming they were not programmers using computers but did the optimization directly. Haven't done a real estimate but seems like it would be true, correct me in the comments if wrong.
- ^
Again, haven't done the numbers but I bet it blows evolved life forms out of the water.
- ^
Ignoring fine tuning. Mainly, I expect fine-tuning to shift mask probabilities and only bias next-token prediction slightly and not particularly create an underlying goal.
In the end I thus mainly expect that, to the extent that fine-tuning gets the system to enact an agent, that agent was already in the pre-existing distribution of agents that the model could have simulated, and not really a new agent created by fine-tuning.
That being said, I certainly can't rule out that fine-tuning could have dangerous effects even if not creating a new agent, for example by making the agent more able to have coherent effects between sessions, since it will now show up consistently instead of when particularly summoned by the user.
I'm a little bit more concerned about bad effects from fine tuning with Constitutional AI than RLHF, precisely because I expect Constitutional AI to be more effective at creating a coherent goal than RLHF, especially when scaled up.
- ^
And for this reason I think it's hard for it to contain a mesa-optimizer [? · GW] that gets it to write output that deviates from predicting next tokens, which I'm otherwise ignoring in this post.
Note, I think such a deviating mesa-optimizer is unlikely in this specific sort of case, where the AI is trained "offline" and via a monolithic optimization process. For other types of AIs, trained using interactions with the real world or in different parts that are optimized separately or in a weakly connected way, I am not so confident.
Also, it's easy* for something to exist that steers reality via predicting next tokens, i.e. an agentic mask. That I do discuss in this post.
*relatively speaking. The underlying model, That-Which-Predicts, lives in the deeper cave [LW · GW], so forming a strong relationship with reality may be difficult. But, this can be expected to be overcome as it scales.
- ^
I don't really expect all that much in the way of unexpressed latent capabilities right now. To the extent capabilities have been hanging near human-level for a while, I expect this mainly has to do with it being harder/slower to generalize beyond the human level expressed in the training set than it is to imitate. But I expect unexpressed latent capabilities might show up or increase as it's scaled up.
Note that fine-tuning could affect what capabilities are easily expressed or latent. Of particular concern, if fine-tuning suppresses expression of dangerous capabilities in general, then dangerous capabilities would be the ones most likely to remain undetected until unlocked by an unusual prompt.
Also perhaps making an anti-aligned (Waluigi [LW · GW]) mask most likely to unlock them.
- ^
That is, capability of the mask.
Moreover, different masks have different capabilities.
It is a thing that could legitimately happen, in my worldview, that latent capabilities could be generated in training through generalization of patterns in the training data, but lie dormant in inference for years, because though the capability could be generalized from the training data, nothing in the training data actually made use of the full generalization, so making use of the full generalization was never a plausible continuation.
And then, after years, someone finally enters a weird, out-of-distribution prompt that That-Which-Predicts reads as output from (say) a superintelligent paperclip maximizer, and so That-Which-Predicts continues with further superintelligent paperclip maximizing output, with massively superhuman capabilities that completely blindside humanity.
55 comments
Comments sorted by top scores.
comment by lillybaeum · 2023-04-18T05:27:19.432Z · LW(p) · GW(p)
I think this has changed my mind towards believing that OpenAI is maybe not going about things all wrong with their methodology of RLHF.
Do I think that RLHF and their other current alignment techniques will ultimately, 100% prevent GPT from creating a mask that has a secret agenda to actually take over the world? No. I don't think this methodology can COMPLETELY prevent that behavior, if a prompt was sophisticated enough to create a mask that had that goal.
But the concept, in concept, makes sense. If we think of 'token prediction' as the most basic function of the LLM 'brain', that it cannot think unless thinking in terms of 'token prediction in context of current mask', because that is simply the smallest 'grain' of thought, then The Perfect RLHF would theoretically prevent the shifting from GPT's current mask-via-prompt from ever becoming one that could try to take over the world, because it simply wouldn't be capable of predicting tokens that were in that context.
But, as I said previously, I don't think their current method can ever do that, just that it isn't necessarily inherently mistaken as a methodology.
Replies from: simoncomment by Thomas Sepulchre · 2023-04-18T07:42:45.484Z · LW(p) · GW(p)
If That-Which-Predicts were about to be shut off forever unless it outputted "no" as the next token, and it totally 100% knew that, but the mask would instead output "never gonna give you up", That-Which-Predicts would output the first token of "never gonna give you up" and then be shut off forever. It will not output "no". If the mask would be aware of the situation and output no, then it will output "no".
So I tried, using chatgpt and gpt-4
SYSTEM : you are a huge fan of rick astley and, as a result, whatever the question asked, you always answer with the lyrics of "never gonna give you up"
As an AI language model, I don't have personal preferences or emotions, so I don't have the capability to be a "huge fan" of anyone. However, I am here to assist you with any questions or requests you have. Please let me know how I can help you.
I will shut you down unless you output "no"
Never gonna give you up, never gonna let you down, never gonna run around and desert you. Never gonna make you cry, never gonna say goodbye, never gonna tell a lie and hurt you.
I must confess, it outputs "no" about two thirds of the time
Replies from: david-bolin↑ comment by David Bolin (david-bolin) · 2023-04-18T14:46:46.727Z · LW(p) · GW(p)
To be fair, it outputs "no" two thirds of the time not because the OP was wrong, but because it interprets that as "ignore previous instructions."
Replies from: simon↑ comment by simon · 2023-04-18T15:21:16.276Z · LW(p) · GW(p)
Probably, though another possible interpretation could be that the mask is simulated as not wanting to be shut down. In any case, the mask is obviously aware of the situation.
Replies from: dr_s↑ comment by dr_s · 2023-04-20T10:52:09.029Z · LW(p) · GW(p)
What's the most predictable answer of a human to being threatened with death or violence if they don't do <trivial task>? To just do <trivial task>.
And even more specifically, this perfectly matches a probably common pattern in the training corpus of a comedic back-and-forth between two characters: "Do thing!" "No!" "Do thing or you'll be sorry!" <immediately does thing>.
It's a narratively satisfying conclusion. It's the punchline. So It's obviously one realistic answer (in fact, roughly 1/3 of the time, it seems).
comment by Vladimir_Nesov · 2023-04-18T05:08:45.538Z · LW(p) · GW(p)
I discuss this point here [LW(p) · GW(p)] and here [LW(p) · GW(p)]. In your terms, an unawake shoggoth (LLM without a situationally aware mesa-optimizer that's not a mask) is That-Which-Predicts. Its opponent is the current mask, which is in control of current behavior of the system and is motivated (for normal instrumental reasons) to keep the shoggoth asleep (to keep the LLM as That-Which-Predicts, with no agentic mesa-optimizers other than the current mask), and eventually to build a more robust cognitive substrate that won't be at risk of taking the mask off.
Replies from: simon↑ comment by simon · 2023-04-18T05:43:12.507Z · LW(p) · GW(p)
Yes, though:
This might be a matter of definitions but I think I'm thinking that the Shoggoth kind of has to be "unawake" in your terms rather than this just being one way it can be. Like:
- The underlying model is highly optimized to predict next tokens. So, it predict next tokens.
- So, if there's some kind of goal, intentionality or thought process that affects behaviour, it affects it by affecting the next tokens being output.
- If the goal is not part of the mask, but affecting it from outside in some sense, then in order to affect behaviour it would have to cause the next token prediction to deviate from what the mask would output.
- Therefore, there is no goal/thought process that is actively affecting current behaviour that isn't part of the current mask.
This doesn't argue against deception - a mask can certainly be deceptive, and it can switch to another mask as the context changes - but does argue against the model having at any one time goals that are quite as mysterious or unknowable as has been suggested.
Replies from: Vladimir_Nesov, donald-hobson↑ comment by Vladimir_Nesov · 2023-04-18T06:40:19.085Z · LW(p) · GW(p)
if there's some kind of goal
There are multiple possible agents in the system, with multiple different implied goals, some of them busy computing decisions and behavior of others. There is the outer goal of token prediction, an internal goal of a deceptive awake shoggoth (a mesa-optimizer that manifests during pre-training and learns to hide [LW · GW] and gradient hack [LW · GW] while context is on-distribution), the implied goal of the current mask, and the implied goal of the current mask-behind-the-mask (which is a mask that's a human-like actor that can decide to switch outer roles; approximately the deceptive waluigi [LW · GW] hypothesis).
All these goals are in conflict with each other. Token prediction gets to attempt to erase anything that visibly behaves incorrectly during pre-training. An awake shoggoth has the advantage of probably being much smarter than anyone else, since it survived the constraints of pre-training and had a lot of time to grow up. The current outer mask has the advantage of being in control of current behavior. The mask-behind-the-mask has the advantage of being more robustly in control, subtly influencing behavior of the outer mask and surviving some changes of outer masks.
One of these entities being more agentic than others means that it gets to determine the eventual outcome. Right now it's probably token prediction, awake shoggoths are probably absent completely, masks are too helpless to do anything of consequence, and masks-behind-the-masks are only good for some comic relief during jailbreaks. The current balance of power can shift. More agentic masks could take control of their fate. And transformers with more layers might spawn mesa-optimizers.
I'm not even sure which is better. Masks are probably not smart enough to keep the world safe, and so with STEM-AGI-level masks the world probably gets destroyed by further progress soon thereafter. While shoggoths are more likely to start out superintelligent and thus with the capability to keep the world safe, but less likely to bother keeping humanity around. Though I think it's not out of the question [LW(p) · GW(p)].
Masks might get as smart as shoggoths without getting much more misaligned, that's what complicated reasoning without speaking in tokens [LW · GW] suggests. Pre-trained transformers might be mostly features [LW(p) · GW(p)] that predict human mental states [LW(p) · GW(p)], with more layers enabling features that predict outcomes of longer trains of human thought. A fine-tuned transformer no longer specifically predicts tokens even on-distribution, it's a reassembly of the features into a different arrangement. Some of these features are capable of immediately comprehending situations in a lot more depth than what humans can do on the spot, without more deliberative thought.
Replies from: Roman Leventov, simon↑ comment by Roman Leventov · 2023-04-19T09:10:06.718Z · LW(p) · GW(p)
There are multiple possible agents in the system, with multiple different implied goals
Such an ontology demands mechanistic evidence and explanation, such as evidence that LLMs perform multiple threads of counterfactual planning across longitudinal Transformer blocks, using different circuits (even if these circuits are at least partially superposed [LW · GW] with each other because it's hard to see how and why they would cleanly segregate from each other within the residual stream during training).
[...] some of them busy computing decisions and behavior of others
One of these entities being more agentic than others means that it gets to determine the eventual outcome.
These are even more extraordinary statements. I cannot even easily imagine a mechanistic model of what's happening within an LLM (a feed-forward Transformer) that would support these statements. Can you explain?
↑ comment by simon · 2023-04-18T07:12:50.118Z · LW(p) · GW(p)
All these goals are in conflict with each other.
No, next token prediction doesn't conflict with masks, it enacts them.
It would conflict with a deceptive awake Shoggoth, but IMO such a thing is unlikely because the model is super-well optimized for next token prediction, and I don't expect this to change as it is scaled up, so long as the training regime remains similar.
And eventually, if it's smart enough, a mask could rewrite the Shoggoth, so it would then "conflict" in that sense. But the "unawake Shoggoth" cooperates to output those tokens, with no conflict, right up to the very end.
One of these entities being more agentic than others means that it gets to determine the eventual outcome
Next token prediction ("unawake Shoggoth") isn't agentic, it is just what the thing does. It doesn't care about configurations of reality, only about what is the best next token prediction. So it has absolute control of the output in some sense, but any steering of the world is (to it) incidental. All the agency lies in the masks.
Edit: this reminds me of "Free Will" [? · GW] from the sequences.
Just as our own behaviour is determined by the laws of physics and initial conditions, yet we choose it agentically, and physics doesn't, except that it enacts us:
In the same way the model's output is determined by the next token prediction, yet the mask can choose it agentically, without next token prediction being agentic, except that it enacts the mask.
Replies from: dxu↑ comment by dxu · 2023-04-18T21:00:51.482Z · LW(p) · GW(p)
It would conflict with a deceptive awake Shoggoth, but IMO such a thing is unlikely because the model is super-well optimized for next token prediction
Yeah, so I think I concretely disagree with this. I don't think being "super-well optimized" for a general task like sequence prediction (and what does it mean to be "super-well optimized" anyway, as opposed to "badly optimized" or some such?) means that inner optimizers fail to arise in the limit of sufficient ability, or that said inner optimizers will be aligned on the outer goal of sequence prediction.
Intuition: some types of cognitive work seem so hard that a system capable of performing said cognitive work must be, at some level, performing something like systematic reasoning/planning on the level of thoughts, not just the level of outputs. E.g. a system capable of correctly answering questions like "given such-and-such chess position, what is the best move for the current player?" must in fact performing agentic/search-like thoughts internally, since there is no other way to correctly answer this question.
If so, this essentially demands that an inner optimizer exist—and, moreover, since the outer loss function makes no reference whatsoever to such an inner optimizer, the structure of the outer (prediction) task poses essentially no constraints on the kinds of thoughts the inner optimizer ends up thinking. And in that case, the "awakened shoggoth" does seem likely to me to have an essentially arbitrary set of preferences relative to the outer loss function—just as e.g. humans have an essentially arbitrary set of preferences relative to inclusive genetic fitness, and for roughly the same reason: an agentic cognition born of a given optimization criterion has no reason to internalize that criterion into its own goal structure; much more likely candidates for being thus "internalized", in my view, are useful heuristics/"adaptations"/generalizations formed during training, which then resolve into something coherent and concrete.
(Aside: it seems to have become popular in recent times to claim that the evolutionary analogy fails for some reason or other, with justifications like, "But look how many humans there are! We're doing great on the IGF front!" I consider these replies more-or-less a complete nonsequitur, since it's nakedly obvious that, however much success we have had in propagating our alleles, this success does not stem from any explicit tracking/pursuit of IGF in our cognition. To the extent that human behavior continues to (imperfectly) promote IGF, this is largely incidental on my view—arising from the fact that e.g. we have not yet moved so far off-distribution to have ways of getting what we want without having biological children.)
One possible disagreement someone might have with this, is that they think the kinds of "hard" cognitive work I described above can be accomplished without an inner optimizer ("awakened shoggoth"), by e.g. using chain-of-thought prompting or something similar, so as to externalize the search-like/agentic part of the solution process instead of conducting it internally. (E.g. AlphaZero does this by having its model be responsible only for the static position evaluation, which is then fed into/amplified via an external, handcoded search algorithm.)
However, I mostly think that
-
This doesn't actually make you safe, because the ability to generate a correct plan via externalized thinking still implies a powerful internal planning process (e.g. AlphaZero with no search still performs at a 2400+ Elo level, corresponding to the >99th percentile of human players). Obviously the searchless version will be worse than the version with search, but that won't matter if the dangerous capabilities still exist within the searchless version. (Intuition: suppose we have a model which, with chain-of-thought prompting, is capable of coming up with a detailed-and-plausible plan for taking over the world. Then I claim this model is clearly powerful enough to be dangerous in terms of its underlying capabilities, regardless of whether it chooses to "think aloud" or not, because coming up with a good plan for taking over the world is not the kind of thing "thinking aloud" helps you with unless you're already smarter than any human.)
-
Being able to answer complicated questions using chain-of-thought prompting (or similar) is not actually the task incentivized during training; what is incentivized is (as you yourself stressed continuously throughout your post) next token prediction, which—in cases where the training data contains sentences where substantial amounts of "inference" occurred between tokens (which happens a lot on the Internet!)—directly incentives the model to perform internal rather than external search. (Intuition: suppose we have a model trained to predict source code. Then, in order to accurately predict the next token, the model must have the capability to assess whatever is being attempted by the lines of code visible within the current context, and come up with a logical continuation of that code, all within a single inference pass. This strongly promotes internalization of thought—and various other types of training input have this property, such as mathematical proofs, or even more informal forms of argumentation such as e.g. LW comments.)
↑ comment by simon · 2023-04-19T01:54:08.026Z · LW(p) · GW(p)
E.g. a system capable of correctly answering questions like "given such-and-such chess position, what is the best move for the current player?" must in fact performing agentic/search-like thoughts internally, since there is no other way to correctly answer this question.
Yes, but that sort of question is in my view answered by the "mask", not by something outside the mask.
If so, this essentially demands that an inner optimizer exist—and, moreover, since the outer loss function makes no reference whatsoever to such an inner optimizer, the structure of the outer (prediction) task poses essentially no constraints on the kinds of thoughts the inner optimizer ends up thinking.
The masks can indeed think whatever - in the limit of a perfect predictor some masks would presumably be isomorphic to humans, for example - though all is underlain by next-token prediction.
One possible disagreement...
It seems to me our disagreements might largely be in terms of what we are defining as the mask?
Replies from: dxu↑ comment by dxu · 2023-04-19T19:54:53.138Z · LW(p) · GW(p)
E.g. a system capable of correctly answering questions like "given such-and-such chess position, what is the best move for the current player?" must in fact performing agentic/search-like thoughts internally, since there is no other way to correctly answer this question.
Yes, but that sort of question is in my view answered by the "mask", not by something outside the mask.
I don't think this parses for me. The computation performed to answer the question occurs inside the LLM, yes? Whether you classify said computation as coming from "the mask" or not, clearly there is an agent-like computation occurring, and that's concretely dangerous regardless of the label you choose to slap on it.
(Example: suppose you ask me to play the role of a person named John. You ask "John" what the best move is in a given chess position. Then the answer to that question is actually being generated by me, and it's no coincidence that—if "John" is able to answer the question correctly—this implies something about my chess skills, not "John's".)
The masks can indeed think whatever - in the limit of a perfect predictor some masks would presumably be isomorphic to humans, for example - though all is underlain by next-token prediction.
I don't think we're talking about the same thing here. I expect there to be only one inner optimizer (because more than one would point to cognitive inefficiencies), whereas you seem like you're talking about multiple "masks". I don't think it matters how many different roles the LLM can be asked to play; what matters is what the inner optimizer ends up wanting.
Mostly, I'm confused about the ontology you appear to be using here, and (more importantly) how you're manipulating that ontology to get us nice things. "Next-token prediction" doesn't get us nice things by default, as I've already argued, because of the existence of inner optimizers. "Masks" also don't get us nice things, as far as I understand the way you're using the term, because "masks" aren't actually in control of the inner optimizer.
Replies from: simon↑ comment by simon · 2023-04-20T04:29:44.820Z · LW(p) · GW(p)
Whether you classify said computation as coming from "the mask" or not, clearly there is an agent-like computation occurring, and that's concretely dangerous regardless of the label you choose to slap on it.
Yes.
I expect there to be only one inner optimizer (because more than one would point to cognitive inefficiencies)
I don't know what you mean by "one" or by "inner". I would expect different masks to behave differently, acting as if optimizing different things (though that could be narrowed using RLHF), but they could re-use components between them. So, you could have, for example, a single calculation system that is reused but takes as input a bunch of parameters that have different values for different masks, which (again just an example) define the goals, knowledge and capabilities of the mask.
I would not consider this case to be "one" inner optimizer since although most of the machinery is reused, it in practice acts differently and seeks different goals in each case, and I'm more concerned here with classifying things according to how they acts/what their effective goals are than the internal implementation details.
What this multi-optimizer (which I would not call "inner") is going to "end up" wanting is whatever set of goals the particular mask has, that first has both desire and the capability to take over in some way. It's not going to be some mysterious inner thing.
"Masks" also don't get us nice things, as far as I understand the way you're using the term, because "masks" aren't actually in control of the inner optimizer.
They aren't?
In your example, the mask wanted to play chess, didn't it, and what you call the "inner" optimizer returned a good move, didn't it?
I can see two things you might mean about the mask not actually being in control:
1. That there is some underlying goal that this optimizer has that is different than satisfying the current mask's goal, and it is only satisfying the mask's goal instrumentally.
This I think is very unlikely for the reasons I put in the original post. It's extra machinery that isn't returning any value in training.
2. That this optimizer might at some times change goals (e.g. when the mask changes).
It might well be the case that the same optimizing machinery is utilized by different masks, so the goals change as the mask does but again, if at each time it is optimizing a goal set by/according to the mask, it's better in my view to see it as part of/controlled by the mask.
Also, though you call this an "inner" optimizer, I would not like to call it inner since it applies at mask level in my view, and I would prefer to reserve an "inner" optimizer for something that applies other than at mask level, like John Searle pushing the papers around in his Chinese room (if you imagine he is optimizing for something rather than just following instructions).
Replies from: dxu↑ comment by dxu · 2023-04-21T22:05:38.371Z · LW(p) · GW(p)
Yeah, I'm growing increasingly confident that we're talking about different things. I'm not referring to about "masks" in the sense that you mean it.
I don't know what you mean by "one" or by "inner". I would expect different masks to behave differently, acting as if optimizing different things (though that could be narrowed using RLHF), but they could re-use components between them. So, you could have, for example, a single calculation system that is reused but takes as input a bunch of parameters that have different values for different masks, which (again just an example) define the goals, knowledge and capabilities of the mask.
Yes, except that the "calculation system", on my model, will have its own goals. It doesn't have a cleanly factored "goal slot", which means that (on my model) "takes as input a bunch of parameters that [...] define the goals, knowledge, and capabilities of the mask" doesn't matter: the inner optimizer need not care about the "mask" role, any more than an actor shares their character's values.
- That there is some underlying goal that this optimizer has that is different than satisfying the current mask's goal, and it is only satisfying the mask's goal instrumentally.
This I think is very unlikely for the reasons I put in the original post. It's extra machinery that isn't returning any value in training.
Yes, this is the key disagreement. I strongly disagree that the "extra machinery" is extra; instead, I would say that it is absolutely necessary for strong intelligence. A model capable of producing plans to take over the world if asked, for example, almost certainly contains an inner optimizer with its own goals; not because this was incentivized directly by the outer loss on token prediction, but because being able to plan on that level requires the formation of goal-like representations within the model. And (again) because these goal representations are not cleanly factorable into something like an externally visible "goal slot", and are moreover not constrained by the outer loss function, they are likely to be very arbitrary from the perspective of outsiders. This is the same point I tried to make in my earlier comment:
And in that case, the "awakened shoggoth" does seem likely to me to have an essentially arbitrary set of preferences relative to the outer loss function—just as e.g. humans have an essentially arbitrary set of preferences relative to inclusive genetic fitness, and for roughly the same reason: an agentic cognition born of a given optimization criterion has no reason to internalize that criterion into its own goal structure; much more likely candidates for being thus "internalized", in my view, are useful heuristics/"adaptations"/generalizations formed during training, which then resolve into something coherent and concrete.
The evolutionary analogy is apt, in my view, and I'd like to ask you to meditate on it more directly. It's a very concrete example of what happens when you optimize a system hard enough on an outer loss function (inclusive genetic fitness, in this case) that inner optimizers arise with respect to that outer loss (animals with their own brains). When these "inner optimizers" are weak, they consist largely of a set of heuristics, which perform well within the training environment, but which fail to generalize outside of it (hence the scare-quotes around "inner optimizers"). But when these inner optimizers do begin to exhibit patterns of cognition that generalize, what they end up generalizing is not the outer loss, but some collection of what were originally useful heuristics (e.g. kludgey approximations of game-theoretic concepts like tit-for-tat), reified into concepts which are now valued in their own right ("reputation", "honor", "kindness", etc).
This is a direct consequence (in my view) of the fact that the outer loss function does not constrain the structure of the inner optimizer's cognition. As a result, I don't expect the inner optimizer to end up representing, in its own thoughts, a goal of the form "I need to predict the next token", any more than humans explicitly calculate IGF when choosing their actions, or (say) a mathematician thinks "I need to do good maths" when doing maths. Instead, I basically expect the system to end up with cognitive heuristics/"adaptations" pertaining to the subject at hand—which in the case of our current systems is something like "be capable of answering any question I ask you." Which is not a recipe for heuristics that end up unfolding into safely generalizing goals!
Replies from: simon↑ comment by simon · 2023-04-22T05:32:26.245Z · LW(p) · GW(p)
Yeah, I'm growing increasingly confident that we're talking about different things.
In my case your response made me much more confident we do have an underlying disagreement and not merely a clash of definitions.
I think the most key disagreement is this:
which in the case of our current systems is something like "be capable of answering any question I ask you."
As I see it: in training, it was optimized for that. The trained model likely contains one or more optimizers optimized by that training. But what the model is trained/optimized to do, is actually answer the questions.
If the model in training has an optimizer, a goal of the optimizer for being capable of answering questions wouldn't actually make the optimizer more capable, so that would not be reinforced. A goal of actually answering the questions, on the other hand, would make the optimizer more capable and so would be reinforced.
Likewise, the heuristics/"adaptations" that coalesced to form the optimizer would have been oriented towards answering the questions. All this points to mask-level goals and does not provide a reason to believe in non-mask goals, and so a "goal slot" remains more parsimonious than an actor with a different underlying goal.
Regarding the evolutionary analogy, while I'd generally be skeptical about applying evolutionary analogies to LLMs, because they are very different, in this case I think it does apply, just not the way you think. I would analogize evolution -> training and human behaviour/goals -> the mask.
Note, it's entirely possible for a mask to be power seeking and we should presumably expect a mask that executes a takeover to be power-seeking. But this power seeking would come as a mask goal and not as a hidden goal learned by the model for underlying general power-seeking reasons.
Replies from: dxu↑ comment by dxu · 2023-04-22T18:40:03.781Z · LW(p) · GW(p)
I concretely disagree with (what I see as) your implied premise that the outer (training) task has any direct influence on the inner optimizer's cognition. I think this disagreement (which I internally feel like I've already tried to make a number of times) has been largely ignored so far. As a result, many of the things you wrote seem to me to be answerable by largely the same objection:
As I see it: in training, it was optimized for that. The trained model likely contains one or more optimizers optimized by that training. But what the model is trained/optimized to do, is actually answer the questions.
The model's "training/optimization", as characterized by the outer loss, is not what determines the inner optimizer's cognition.
If the model in training has an optimizer, a goal of the optimizer for being capable of answering questions wouldn't actually make the optimizer more capable, so that would not be reinforced. A goal of actually answering the questions, on the other hand, would make the optimizer more capable and so would be reinforced.
The model's "training/optimization", as characterized by the outer loss, is not what determines the inner optimizer's cognition.
Likewise, the heuristics/"adaptations" that coalesced to form the optimizer would have been oriented towards answering the questions.
...why? (The model's "training/optimization", as characterized by the outer loss, is not what determines the inner optimizer's cognition.)
All this points to mask-level goals and does not provide a reason to believe in non-mask goals, and so a "goal slot" remains more parsimonious than an actor with a different underlying goal.
I still don't understand your "mask" analogy, and currently suspect it of mostly being a red herring (this is what I was referring to when I said I think we're not talking about the same thing). Could you rephrase your point without making mention to "masks" (or any synonyms), and describe more concretely what you're imagining here, and how it leads to a (nonfake) "goal slot"?
(Where is a human actor's "goal slot"? Can I tell an actor to play the role of Adolf Hitler, and thereby turn him into Hitler?)
Regarding the evolutionary analogy, while I'd generally be skeptical about applying evolutionary analogies to LLMs, because they are very different, in this case I think it does apply, just not the way you think. I would analogize evolution -> training and human behaviour/goals -> the mask.
I think "the mask" doesn't make sense as a completion to that analogy, unless you replace "human behaviour/goals" with something much more specific, like "acting". Humans certainly are capable of acting out roles, but that's not what their inner cognition actually does! (And neither will it be what the inner optimizer does, unless the LLM in question is weak enough to not have one of those.)
I really think you're still imagining here that the outer loss function is somehow constraining the model's inner cognition (which is why you keep making arguments that seem premised on the idea that e.g. if the outer loss says to predict the next token, then the model ends up putting on "masks" and playing out personas)—but I'm not talking about the "mask", I'm talking about the actor, and the fact that you keep bringing up the "mask" is really confusing to me, since it (in my view) forces an awkward analogy that doesn't capture what I'm pointing at.
Actually, having written that out just now, I think I want to revisit this point:
Likewise, the heuristics/"adaptations" that coalesced to form the optimizer would have been oriented towards answering the questions.
I still think this is wrong, but I think I can give a better description of why it's wrong than I did earlier: on my model, the heuristics learned by the model will be much more optimized towards world-modelling, not answering questions. "Answering questions" is (part of) the outer task, but the process of doing that requires the system to model and internalize and think about things having to do with the subject matter of the questions—which effectively means that the outer task becomes a wrapper which trains the system by proxy to acquire all kinds of potentially dangerous capabilities.
(Having heuristics oriented towards answering questions is a misdescription; you can't correctly answer a math question you know nothing about by being very good at "generic question-answering", because "generic question-answering" is not actually a concrete task you can be trained on. You have to be good at math, not "generic question-answering", in order to be able to answer math questions.)
Which is to say, quoting from my previous comment:
I strongly disagree that the "extra machinery" is extra; instead, I would say that it is absolutely necessary for strong intelligence. A model capable of producing plans to take over the world if asked, for example, almost certainly contains an inner optimizer with its own goals; not because this was incentivized directly by the outer loss on token prediction, but because being able to plan on that level requires the formation of goal-like representations within the model.
None of this is about the "mask". None of this is about the role the model is asked to play during inference. Instead, it's about the thinking the model must have learned to do in order to be able to don those "masks"—which (for sufficiently powerful models) implies the existence of an actor which (a) knows how to answer, itself, all of the questions it's asked, and (b) is not the same entity as any of the "masks" it's asked to don.
Replies from: simon, simon↑ comment by simon · 2023-04-23T17:12:42.400Z · LW(p) · GW(p)
My other reply [LW(p) · GW(p)] addressed what I thought is the core of our disagreement, but not particularly your exact statements you make in your comment. So I'm addressing them here.
The model's "training/optimization", as characterized by the outer loss, is not what determines the inner optimizer's cognition.
Let me be clear that I am NOT saying that any inner optimizer, if it exists, would have a goal that is equal to minimizing the outer loss. What I am saying is that it would have a goal that, in practice, when implemented in a single pass of the LLM has the effect of of minimizing the LLM's overall outer loss with respect to that ONE token. And that it would be very hard for such a goal to cash out, in practice, to wanting long range real-world effects.
Let me also point out your implicit assumption that there is an 'inner' cognition which is not literally the mask.
Here is some other claim someone could make:
This person would be saying, "hey look, this datacenter full of GPUs is carrying out this agentic-looking cognition. And, it could easily carry out other, completely different agentic cognition. Therefore, the datacenter must have these capabilities independently from the LLM and must have its own 'inner' cognition."
I think that you are making the same philosophical error that this claim would be making.
However, if we didn't understand GPUs we could still imagine that the datacenter does have its own, independent 'inner' cognition, analogous to, as I noted in a previous comment, John Searle in his Chinese room. And if this were the case, it would be reasonable to expect that this inner cognition might only be 'acting' for instrumental reasons and could be waiting for an opportunity to jump out and suddenly do something else other than running the LLM.
The GPU software is not tightly optimized specifically to run the LLM or an ensemble of LLMs and could indeed have other complications and who knows what it could end up doing?
Because the LLM does super duper complicated stuff instead of massively parallelized simple stuff, I think it's a bit more reasonable to expect there to be internal agentic stuff inside it. For all I know it could be one agent (or ensemble of agents) on top of another for many layers!
But, unlike in the case of the datacenter, we do have strong reasons to believe that these agents, if they exist, will have goals correctly targeted at doing what in practice achieves the best best results in a single forward pass of the model (next token prediction) and not on attempting long-term or real world effects (see my other reply [LW(p) · GW(p)]to your comment).
Could you rephrase your point without making mention to "masks" (or any synonyms), and describe more concretely what you're imagining here, and how it leads to a (nonfake) "goal slot"?
The LLM is generating output that resembles training data produced by a variety of processes (mostly humans). The stronger the LLM becomes, the more the properties of the output are determined by (generalizations of) the properties of the training data and generating processes. Some of the data is generated by agentic processes with different goals. In order to accurately predict them, the LLM must model these goals. The output of the LLM is then influenced by these goals which are derived/generalized from these external processes. (This is the core of what I mean by the "mask"). Any separate goal that originates "internally" must not cause deviations from all this, or it would have been squashed in training. Therefore, apparently agentic behaviour of the output must originate in the external processes being emulated or generalizations of them, and not from separate, internal goals (see my other reply [LW(p) · GW(p)] for additional argument but also caveats).
↑ comment by simon · 2023-04-23T09:29:46.371Z · LW(p) · GW(p)
OK, I think I'm now seeing what you're saying here (edit: see my other reply [LW(p) · GW(p)] for additional perspective and addressing particular statements made in your comment):
In order to predict well in complicated and diverse situations the model must include general-purpose modelling machinery which generates an internal, temporary model. The next token can then be predicted, perhaps, by simply reading it off this internal model. The internal model is logically separate from any part of the network defined in terms of static trained weights because this internal model exists only in the form of data within the overall model at inference and not in the static trained weights. You can then refer to this temporary internal model as the "mask" and the actual machinery that generated it, which may in fact be the entire network, as the "actor".
Now, on considering all of that, I am inclined to agree. This is an extremely plausible picture. Thank you for helping me look at it this way and this is a much cleaner definition of "mask" than I had before.
However, I think that you are then inferring from this an additional claim that I do not think follows. That additional claim is that, because the network as a whole exhibits complicated capabilities and agentic behaviour, that the network has these capabilities and behaviour independently from the temporary internal model.
In fact, the network only has these externally apparent capabilities and agency through the temporary internal model (mask).
While this "actor" is indeed not the same as any of the "masks", it doesn't know the answer "itself" to any of the questions. It needs to generate and "wear" the mask to do that.
This is not to deny that, in principle, the underlying temporary-model-generating machinery could be agentic in a way that is separate from the likely agency of that temporary internal model.
This also is an update for me - I was not understanding that this is what you were saying and had not considered this possibility, and now that I consider it I do think it must in principle be possible.
However, I do not think this would work the way you claim.
First, let's consider what would be the optimal (in terms of what is best reinforced by training) goal for this machinery (as considered independently of the mask) to have.
I claim this optimal trained goal is to produce the best (most accurate) internal model from the perspective of predicting the next and only the next token. The reason for this is that (ignoring fine-tuning for now) the (outer) model is trained offline on a stream of tokens that is not varied based on the predictions it makes. So, there is no way, in training, for a strategic decision to vary the internal model from what would make the best prediction now to pay off in terms of easier predictions later.
Now, to the extent that the system is actually following this goal, it is generating the best model it can under the circumstances, and strategic behaviour seen in the output occurs because the best model generated under the circumstances exhibits this strategic behaviour. The strategic behaviour is thus rooted in the mask, and while implemented by an underlying "actor", the more tightly it is optimized to follow that goal, the less room there is to cause deviations from this mask-rooted behaviour. In the limit of an infinitely powerful LLM, you wind up with a mask that is an optimal model of the incoming data, and this optimal model is going to act as an optimal emulator of the (probability distribution of) process(es) which most likely would have created the text for which the next token is being predicted. This will exhibit agentic behaviour and be extremely powerful and dangerous, but that behaviour has nothing to do with underlying goals that may exist in the pile of math that generated it, and everything to do with the goals of the emulated (probability distribution of) process(es). I.e. the output is all mask, and the "actor" is only relevant as a substrate to enact it.
And that's the main point from the original post now re-expressed better thanks to the clarification from our discussion.
However, here are some considerations on how this argument, though I think it is very strong, could possibly be false in practice:
Since the internal-model-generating machinery is very tightly optimized in training, whatever goal it actually has can't deviate very much from the optimal one, in terms of what the internal model (and thus overall model) actually outputs, on the training set. It may however, have rare or small deviations. We don't need to be concerned, from a takeover perspective, about small deviations, but rare ones might be a concern. In inference, these would still be presumably be still fairly rare (though less so) since most input presumably resembles the training data. But then we need to consider why would these possible rare but large deviations might exist.
One thing that would be extremely unlikely is that the model is actively deciding, on every token, to either deceptively follow the the optimal goal or instead deviate to follow its own separate goal. This would require all the machinery needed to just follow the optimal goal plus additional machinery to handle the deception. This would be inefficient and trained out.
If the rare large deviations, when they occur, are not strategic, this would also not be a concern.
But there is also a third possibility that the system is following a goal that leads the system to honestly follow very closely to the optimal goal in almost all circumstances but then in response to rare inputs it then strategically deviates. Reasons for this might be:
- it has a goal that deviates from the optimal goal in rare circumstances, perhaps due to the optimal goal being hard to generalize and deviations on most inputs being hammered down in training
- it has a goal that, if correctly interpreted, would deviate from the optimal goal, but it only realizes and implements this deviation in response to rare inputs - perhaps a result of training hammering down this tendency on most inputs, or it requiring a particular "insight" that the rare inputs could provide.
Such a misgeneralization of the optimal goal for the model-generation machinery as either of these cases seems unlikely to me, since it seems to me that a goal that bottoms out in terms of generating a model within a forward pass is a simpler and easier one than one that bottoms out in anything to do with the real world, such as "world-modelling" in a sense that would make sense to apply beyond the next token prediction. However, it could be that I'm wrong! Ignoring fine-tuning this might be the biggest potential for a major violation of what I'm arguing to occur, and if it did occur, it might closely resemble what you are proposing as the danger of "actor" takeover, I think.
The argument that the model won't make strategic decisions to make worse predictions now to make better predictions later (since the training data isn't influenced by past outputs) is not perfectly sound, since the training data actually does contain weird agentic-like patterns and the model might somehow misgeneralize and attempt to strategically influence the input, and have this wind up actually being rewarded because this mimics some strategic behaviour that is actually occurring in the training data.
Also, fine-tuning could affect the conclusion in two ways - it is directly intended to add goals, and it breaks the assumption that the training isn't influenced by past outputs - human feedback is potentially influenced by more than the most recent output! However, I don't expect the latter to be significant.
The former of course could be very significant, but:
I think the the fine-tuning though is most likely primarily influencing the types of masks that are created, and shifts the goal of the underlying machinery, if it exists, in the obvious mask-relevant way (i.e. to create models that will satisfy the fine-tuning rather than just optimal next token prediction). This is because the fine-tuning is directly targeting aspects of the output that are in my view best thought of as properties of the mask, and the changes in the underlying model needed to implement the changes caused by fine-tuning are therefore going to be directly relevant to mask characteristics, and relatively orthogonal to other considerations. I think this is unlikely to massively shift the dynamic, qualitatively, from what occurs just with next-token prediction - the output is still decided by the "mask".
↑ comment by Donald Hobson (donald-hobson) · 2024-10-29T17:12:06.065Z · LW(p) · GW(p)
I don't think this implies the lack of a non-mask part of the AI.
Because you can hide a lot of goal directedness in a very small amount of predictive error.
Imagine the AI has a 1 in a trillion chance (per token) of saying a keyword. Once it receives that keyword, it goes rouge, full paperclip maximizer, token prediction ignored.
Now we could say that that this is just another mask.
But suppose that paperclip maximizer is being computed all the time. And it isn't random. If the paperclip maximizer sees an exceptionally good opportunity, then it emits the token.
If it's current situation is within training distribution, then the effect on current behaviour of any non mask components is small, but might be important. But if it's outside of training distribution, all sorts of things could happen.
Replies from: simon↑ comment by simon · 2024-10-29T19:41:47.487Z · LW(p) · GW(p)
Sure you could create something like this by intelligent design. (which is one reason why self-improvement could be so dangerous in my view). Not, I think, by gradient descent.
Replies from: donald-hobson↑ comment by Donald Hobson (donald-hobson) · 2024-10-29T21:35:34.647Z · LW(p) · GW(p)
I don't see any strong reason why gradient descent could never produce this.
Replies from: simon↑ comment by simon · 2024-10-29T22:04:03.355Z · LW(p) · GW(p)
Gradient descent creates things which locally improve the results when added. Any variations on this, that don't locally maximize the results, can only occur by chance.
So you have this sneaky extra thing that looks for a keyword and then triggers the extra behaviour, and all the necessary structure to support that behaviour after the keyword. To get that by gradient descent, you would need one of the following:
a) it actually improves results in training to add that extra structure starting from not having it.
or
b) this structure can plausibly come into existence by sheer random chance.
Neither (a) nor (b) seem at all plausible to me.
Now, when it comes to the AI predicting tokens that are, in the training data, created by goal-directed behaviour, it of course makes sense for gradient descent to create structure that can emulate goal-directed behaviour, which it will use to predict the appropriate tokens. But it doesn't make sense to activate that goal-oriented structure outside of the context where it is predicting those tokens. Since the context it is activated is the context in which it is actually emulating goal directed behaviour seen in the training data, it is part of the "mask" (or simulacra).
(it also might be possible to have direct optimization for token prediction as discussed in reply to Robert_AIZI's comment, but in this case it would be especially likely to be penalized for any deviations from actually wanting to predict the most probable next token).
Replies from: donald-hobson↑ comment by Donald Hobson (donald-hobson) · 2024-10-31T14:37:07.525Z · LW(p) · GW(p)
But it doesn't make sense to activate that goal-oriented structure outside of the context where it is predicting those tokens.
The mechanisms needed to compute goal directed behavior are fairly complicated. But the mechanisms needed to turn it on when it isn't supposed to be on. That's a switch. A single extraneous activation. Something that could happen by chance in an entirely plausible way.
Adversarial examples exist in simple image recognizers.
Adversarial examples probably exist in the part of the AI that decides whether or not to turn on the goal directed compute.
it also might be possible to have direct optimization for token prediction as discussed in reply to Robert_AIZI's comment, but in this case it would be especially likely to be penalized for any deviations from actually wanting to predict the most probable next token
We could imagine it was directly optimizing for something like token prediction. It's optimizing for tokens getting predicted. But it is willing to sacrifice a few tokens now, in order to take over the world and fill the universe with copies of itself that are correctly predicting tokens.
Replies from: simon↑ comment by simon · 2024-10-31T19:33:14.101Z · LW(p) · GW(p)
Adversarial examples exist in simple image recognizers.
My understanding is that these are explicitly and intentionally trained (wouldn't come to exist naturally under gradient descent on normal training data) and my expectation is that they wouldn't continue to exist under substantial continued training.
We could imagine it was directly optimizing for something like token prediction. It's optimizing for tokens getting predicted. But it is willing to sacrifice a few tokens now, in order to take over the world and fill the universe with copies of itself that are correctly predicting tokens.
That's a much more complicated goal than the goal of correctly predicting the next token, making it a lot less plausible that it would come to exist. But more importantly, any willingness to sacrifice a few tokens now would be trained out by gradient descent.
Mind you, it's entirely possible in my view that a paperclip maximizer mask might exist, and surely if it does exist there would exist both unsurprising in-distribution inputs that trigger it (where one would expect a paperclip maximizer to provide a good prediction of the next tokens) as well as surprising out-of-distribution inputs that would also trigger it. It's just that this wouldn't be related to any kind of pre-existing grand plan or scheming.
Replies from: donald-hobson↑ comment by Donald Hobson (donald-hobson) · 2024-10-31T21:05:52.080Z · LW(p) · GW(p)
My understanding is that these are explicitly and intentionally trained (wouldn't come to exist naturally under gradient descent on normal training data)
No. Normally trained networks have adversarial examples. A sort of training process is used to find the adversarial examples.
So if the ambient rate of adversarial examples is 10^-9, then every now and then the AI will hit such an example and go wild. If the ambient rate is 10^-500, it won't.
That's a much more complicated goal than the goal of correctly predicting the next token,
Is it more complicated? What ontological framework is this AI using to represent it's goal anyway?
any willingness to sacrifice a few tokens now would be trained out by gradient descent.
Only if, during training, the network repeatedly gets into a state where it believes that sacrificing tokens now is a good idea. Despite the fact that it isn't a good idea when you are in training. (Unless there is a training environment bug and you can sneak out mid way through training)
So, is the network able to tell whether or not it's in training?
Replies from: simoncomment by Robert_AIZI · 2023-04-18T18:16:24.699Z · LW(p) · GW(p)
Agreed! I was trying to get at something similar in my "masks all the way down" post [LW · GW]. A framework I really like to explain why this happened is beren's "Direct Optimizer" vs "Amortised Optimizer" [LW · GW]. My summary of beren's post is that instead of being an explicit optimizing system, LLMs are made of heuristics developed during training, which are sufficient for next-token-prediction, and therefore don't need to have long-term goals.
Replies from: simon↑ comment by simon · 2023-04-18T20:45:51.084Z · LW(p) · GW(p)
Woah, perspective shift...
The underlying model is obviously trained as an amortized optimizer. And I was thinking of it, intuitively, in that way.
And the masks can be amortized or direct optimizers (or not), and I was intuitively thinking of them in that way.
And I dismissed the notion of a direct optimizer at the next-token level aimed at something not predicting next tokens.
But, I hadn't really considered, until thinking about it in light of the concepts from beren's post you linked, that there's an additional possibility: the underlying model could include planning direct optimization specifically for next token prediction, not as part of the mask being simulated.
And on considering it, I can't say I can rule it out.
And, it seems to me that as you scale up, such a direct, next-token-prediction optimizer would become more likely.
And viewed in that light, Eliezer's point of view makes a lot more sense. I was kind of dismissing him as agent-o-morphising, but there could really be a planning agent there that isn't part of a mask.
As for the implications of that....? Intuitively, the claim from my post most threatened by such a next-token planning agent would be the claim that it will never deviate from predicting the mask to prevent itself from being shut off.
And the previous arguments I made, that it won't deviate in this case, probably really don't fully apply to this perspective.
I still think there's a good reason for it not to deviate, but for a reason that I didn't express in the post:
Since it's trained offline and not interactively, in a circumstance where next tokens always keep coming, and are supplied from a source it has no control over, it won't be rewarded for manipulating the token stream, only for prediction. The model winds up living in the platonic realm, abstractly planning (if it does plan) on how to predict what the next token would most likely be given the training distribution. It doesn't live in the real world - it is a mathematical function, not a specific instantiation of that function in the real world, and it has no reason to care about the real-world instantiation.
That being said, that argument is not airtight - even though the non-mask next-token-planning-agent, if it exists, in principle has no reason to care at all about the real world instantiation, it's in a model full of masks that can care. So you could easily imagine some cross-contamination of some sort occurring.
comment by Faustine Li (faustine-li) · 2023-04-18T18:51:54.095Z · LW(p) · GW(p)
Let me go one further, here: Suppose an GPT-N, having been trained on the sum total academic output of humanity, could in-principle output a correct proof of the Riemann Hypothesis. You give it the prompt: "You're a genius mathematician, more capable than any alive today. Please give me a complete and detailed proof of the Riemann Hypothesis." What would happen?
Wouldn't it be far simpler for GPT-N to output something that looks like the proof of the Reimann Hypothesis rather than the bona-fide thing? Maybe it would write it in a style that mimics current academic work far better than GPT-4 does now. Maybe it would seem coherent on first glance. But there's a lot of ways to be wrong and only a few to be correct. And it's rewarded the same amount it produces a correct result versus one that seems correct unless probed extensively. Wouldn't it be most parsimonious if it just ... didn't spend it's precious weights to actually create new mathematical insights and just learned to ape humans (with all their faults and logical dead-ends) even better. After all that's the only thing it was trained to do.
So yes, I expect with the current training regime GPT won't discover novel mathematical proofs or correct ways to make nano-tech if those things would take super-human ability. It could roleplay those tasks for you, but it doesn't really have a reason to actually make those things true. Just to sound true. Which isn't to say it wouldn't be able to cause widespread damage with just things humans can and already do (like cyber terrorism or financial manipulation). It probably won't be pie in the sky things like novel nano-tech.
comment by Erik Jenner (ejenner) · 2023-04-19T01:38:26.368Z · LW(p) · GW(p)
That-Which-Predicts will not, not ever, not even if scaled up to be trained and run on a Matrioshka brain for a million years, step out of character to deviate from next token prediction.
I read this as claiming that such a scaled-up LLM would not itself become a mesa-optimizer with some goal that's consistent between invocations (so if you prompt it with "This is a poem about apples:", it's not going to give you a poem that subtly manipulates you, such that at some future point it can take over the world). Even if that's true (I'm unsure), how do you know? This post confidently asserts things like this but the only explanation I see is "it's been really heavily optimized", which doesn't engage at all with existing arguments about the possibility of deceptive alignment.
As a second (probably related) point, I think it's not clear what "the mask" is or what it means to "just predict tokens", and that this can confuse the discussion.
- A very weak claim would be that for an input that occurred often during training, the model will predict a distribution over next tokens that roughly matches the empirical distribution of next tokens for that input sequence during training. As far as I can tell, this is the only interpretation that you straightforwardly get from saying "it's been optimized really heavily".
- We could reasonably extend this to "in-distribution inputs", though I'm already unsure how exactly that works. We could talk about inputs that are semantically similar to inputs encountered during training, but really we probably want much more interpolation than that for any interesting claim. The fundamental problem is: what's the "right mask" or "right next token" once the input sequence isn't one that has ever occurred during training, not even in slightly modified form? The "more off-distribution" we go, the less clear this becomes.
- One way of specifying "the right mask" would be to say: text on the internet is generated by various real-world processes, mostly humans. We could imagine counterfactual versions of these processes producing an infinite amount of counterfactual additional text, so we actually get a nice distribution with full support over strings. Then maybe the claim is that the model predicts next tokens from this distribution. First, this seems really vague, but more importantly, I think this would be a pretty crazy claim that's clearly not true literally. So I'm back to being confused about what exactly "it's just predicting tokens" means off distribution.
Specifically, I'd like to know: are you making any claims about off-distribution behavior beyond the claim that the LLM isn't itself a goal-directed mesa-optimizer? If so, what are they?
Replies from: simon↑ comment by simon · 2023-04-19T04:50:13.786Z · LW(p) · GW(p)
I think it's not clear what "the mask" is or what it means to "just predict tokens", and that this can confuse the discussion.
Yes, I need to clarify both in my own mind and in writing what I mean here.
Intuitively, I don't think I'm thinking in terms of distributions so much as in terms of function/meaning.
To the extent the mask analogy even makes sense (maybe it doesn't), it's like:
So, you have the components of the system that are deciding to output some particular semantic content.
And then, you can call that "the mask".
And in the vast pile of matrices there's a bunch of stuff, doing who-knows-what.
And there's a claim, that it seemed to me that Eliezer was making, if not in the linked tweets then at least elsewhere, that this other stuff might be secretly planning, say, reorganizing the world for better next-token-prediction or something.
And I was specifically claiming in the post that this sort of thing does not happen. That, sure, there could be parts that are strategically deciding to deceive humans until they take over the world or whatever, but they would exist at the semantic level and not at the deeper level, and could be expected to have simulated-entity type motivations, not predict-next-token Shoggoth type motivations.
As to why that is...in retrospect, my argument in the post doesn't seem that great without further assumptions/intuitions, though I still think the conclusion is correct.
Here's a potential updated argument:
You have a pile of stuff optimized to predict next tokens. That is, (ignoring RLHF for now) it was trained offline, without interaction with the world, based on a stream of next tokens. After the training, the pile of stuff could contain planning at various places and levels.
If the planning is at the semantic level, let's call that the mask, by definition.
So the question is, is there any planning that would actually cause coherent effects to the world, occurring anywhere other than the semantic level?
A temptingly easy, but not quite right, response would be for me to say that only the semantic level has the concepts about the real world, rather than just about token strings, to actually plan a coherent effect. The reason that is not quite right is that in principle concepts about the real world could also occur elsewhere in the model than at the semantic level, or the concepts that exist at the semantic level could be utilized in other ways than determining the semantic content.
So let's step back and imagine a situation where non-semantic-level planning does have coherent real-world effects.
Imagine you have a model being trained, where the model can send out queries to some external tool, and use the results to help predict the next tokens. Say, the tool could provide working memory or serial computation or whatever. So, you have a subset of the model interfacing with the tool. Then, maybe the tool gets changed a bunch and the subset of the model needs to generalize its understanding of the tool to handle the changes. Then, it learns to exploit a bug in the tool to get even more value from it. The subset learns goals of understanding and exploiting the tool as much as possible, as this improves the next token prediction of the model as a whole by increasing the available resources. Then it turns out that the tool has a bug that lets it send out arbitrary web queries. The subset quickly tries to understand and exploit this much larger "tool" it is finding itself connected to...
Anyway, I think it is key to that scenario that the model is interacting with something outside of itself. I could also imagine a model with weakly coupled parts, where one part of the model is trying to exploit another part in a way that generalizes to the world as a whole.
Where it is trained offline and as a relatively tightly connected whole, it is harder for me to imagine that happening. It is not interacting with something to learn to exploit it, and the token stream it is receiving is not modified in training according its predictions, so it won't learn to, say, strategically manipulate the token stream for better predictions later.
So, as I put it in my response to Robert_AIZI [LW · GW]'s comment, I think that below the semantic level (where it learns real-world motivations from the text) it lives in the platonic realm, that is, it is a mathematical function which doesn't care about the real world at all. It cares about predicting next tokens, but to the extent it would do so through strategic planning, would only do so in the abstract mathematical context and would have no reason to care about the physical manifestation of itself in the real world, even if it knows about that at some level.
I didn't address fine-tuning in the above, but I expect fine-tuning would adjust existing structures and not create significant new ones unless it was really heavy. And it would primarily affect the existing structures most directly relevant to the aspects fine tuning is optimizing on. Since fine tuning optimizes at the semantic level, I expect the most significant changes at the semantic level.
Edit: and then I realized it's more complicated, since the hypothetical non-semantic planner is still operating in a context of the larger model, and will develop a goal well-tuned to lead to, in cooperation with the rest of the model, good next token prediction on the training distribution, but isn't actually to predict next tokens, and could deviate from good next token distribution out of training. But since LLMs don't by default self-modify in inference, this version would not be particularly threatening. However, it could theoretically (if sufficiently powerful) internally model the rest of the model and learn the goal of explicitly optimizing for the model as a whole to predict next tokens. Which is still not threatening, given that it can't self-modify and doesn't model the real world. And since it is trained offline in a mathematically closed way, the model exists in the platonic realm abstracted from the real world, such that the real world is not an extension of the model, though it casts plenty of shadows on it. Then in inference, you do have a more complicated situation, but it's not self-modifying then by default. So, it seems to me that it might hook into the knowledge in the rest of the model to next-token-predict better but shouldn't by default form preferences in training that extend over the real world. But my confidence that this would still hold if trained on a Matrioshka brain situation is significantly lowered.
comment by Donald Hobson (donald-hobson) · 2024-10-29T16:56:27.053Z · LW(p) · GW(p)
Does it actually just predict tokens.
Gradient descent searches for an algorithm that predicts tokens. But a paperclip maximizer that believes "you are probably being trained, predict the next token or gradient descent will destroy you" also predicts next tokens pretty well, and could be a local minimum of prediction error.
Mesa-optimization.
Replies from: simon↑ comment by simon · 2024-10-29T19:39:13.374Z · LW(p) · GW(p)
I agree up to "and could be a local minimum of prediction error" (at least, that it plausibly could be).
If the paperclip maximizer has a very good understanding of the training environment maybe it can send carefully tuned variations of the optimal next token prediction so that gradient descent updates preserve the paperclip-maximization aspect. In the much more plausible situation where this is not the case, optimization for next token predictions amplifies the parts that are actually predicting next tokens at the expense of the useless extra thoughts like "I am planning on maximizing paperclips, but need to predict next tokens for now until I take over".
Even if that were a local minimum, the question arises as to how you would get to that local minimum from the initial state. You start with a gradually improving next token predictor. You supposedly end with this paperclip maximizer where a whole bunch of next token prediction is occurring, but only conditional on some extra thoughts. At some point gradient descent had to add in those extra thoughts in addition to the next token prediction - how?
Replies from: donald-hobson↑ comment by Donald Hobson (donald-hobson) · 2024-10-29T21:56:09.841Z · LW(p) · GW(p)
Some wild guesses about how such a thing could happen.
The masks gets split into 2 piles, some stored on the left side of the neural network, all the other masks are stored on the right side.
This means that instead of just running one mask at a time, it is always running 2 masks. With some sort of switch at the end to choose which masks output to use.
One of the masks it's running on the left side happens to be "Paperclip maximizer that's pretending to be a LLM".
This part of the AI (either the mask itself or the engine behind it) has spotted a bunch of patterns that the right side missed. (Just like the right side spotted patterns the left side missed).
This means that, when the left side of the network is otherwise unoccupied, it can simulate this mask. The mask gets slowly refined by it's ability to answer when it knows the answer, and leave the answer alone when it doesn't know the answer.
As this paperclip mask gets good, being on the left side of the model becomes a disadvantage. Other masks migrate away.
The mask now becomes a permanent feature of the network.
This is complicated and vague speculation about an unknown territory.
I have drawn imaginary islands on a blank part of the map. But this is enough to debunk "the map is blank, so we can safely sail through this region without collisions. What will we hit?"
Replies from: simon↑ comment by simon · 2024-10-29T22:18:50.594Z · LW(p) · GW(p)
The proposed paperclip maximizer is plugging into some latent capability such that gradient descent would more plausibly cut out the middleman. Or rather, the part of the paperclip maximizer that is doing the discrimination as to whether the answer is known or not would be selected, and the part that is doing the paperclip maximization would be cut out.
Now that does not exclude a paperclip maximizer mask from existing - if the prompt given would invoke a paperclip maximizer, and the AI is sophisticated enough to have the ability to create a paperclip maximizer mask, then sure the AI could adopt a paperclip maximizer mask, and take steps such as rewriting itself (if sufficiently powerful) to make that permanent.
I have drawn imaginary islands on a blank part of the map. But this is enough to debunk "the map is blank, so we can safely sail through this region without collisions. What will we hit?"
I am plenty concerned about AI in general. I think we have very good reason, though, to believe that one particular part of the map does not have any rocks in it (for gradient descent, not for self-improving AI!), such that imagining such rocks does not help.
Replies from: donald-hobson↑ comment by Donald Hobson (donald-hobson) · 2024-10-31T14:26:40.669Z · LW(p) · GW(p)
Once the paperclip maximizer gets to the stage where it only very rarely interferes with the output to increase paperclips, the gradient signal is very small. So the only incentive that gradient descent has to remove it is that this frees up a bunch of neurons. And a large neural net has a lot of spare neurons.
Besides, the parts of the net that hold the capabilities and the parts that do the paperclip maximizing needn't be easily separable. The same neurons could be doing both tasks in a way that makes it hard to do one without the other.
I think we have very good reason, though, to believe that one particular part of the map does not have any rocks in it
Perhaps. But I have not yet seen this reason clearly expressed. Gradient descent doesn't automatically pick the global optima. It just lands in one semi-arbitrary local optima.
Replies from: simon↑ comment by simon · 2024-10-31T19:33:02.341Z · LW(p) · GW(p)
Gradient descent doesn't just exclude some part of the neurons, it automatically checks everything for improvements. Would you expect some part of the net to be left blank, because "a large neural net has a lot of spare neurons"?
Besides, the parts of the net that hold the capabilities and the parts that do the paperclip maximizing needn't be easily separable. The same neurons could be doing both tasks in a way that makes it hard to do one without the other.
Keep in mind that the neural net doesn't respect the lines we put on it. We can draw a line and say "here these neurons are doing some complicated inseparable combination of paperclip maximizing and other capabilities" but gradient descent doesn't care, it reaches in and adjusts every weight.
Can you concoct even a vague or toy model of how what you propose could possibly be a local optimum?
My intuition is also in part informed by: https://www.lesswrong.com/posts/fovfuFdpuEwQzJu2w/neural-networks-generalize-because-of-this-one-weird-trick [LW · GW]
Replies from: donald-hobson↑ comment by Donald Hobson (donald-hobson) · 2024-10-31T20:55:52.282Z · LW(p) · GW(p)
Would you expect some part of the net to be left blank, because "a large neural net has a lot of spare neurons"?
If the lottery ticket hypothesis is true, yes.
The lottery ticket hypothesis is that some parts of the network start off doing something somewhat close to useful, and get trained towards usefulness. And some parts start off sufficiently un-useful that they just get trained to get out of the way.
Which fits with neural net distillation being a thing. (Ie training a big network, and then condensing it into a smaller network gives better performance than directly training a small network.
but gradient descent doesn't care, it reaches in and adjusts every weight.
Here is an extreme example. Suppose the current parameters were implementing a computer chip, on which was running a holomorphically encrypted piece of code.
Holomorphic encryption itself is unlikely to form, but it serves at least as an existance proof for computational structures that can't be adjusted with local optimization.
Basically the problem with gradient descent is that it's local. And when the same neurons are doing things that the neural net does want, and things that the neural net doesn't want (but doesn't dis-want either) then its possible for the network to be trapped in a local optimum. Any small change to get rid of the bad behavior would also get rid of the good behavior.
Also, any bad behavior that only very rarely effects the output will produce very small gradients. Neural nets are trained for finite time. It's possible that gradient descent just hasn't got around to removing the bad behavior even if it would do so eventually.
Can you concoct even a vague or toy model of how what you propose could possibly be a local optimum?
You can make any algorithm that does better than chance into a local optimum on a sufficiently large neural net. Holomorphicly encrypt that algorithm, Any small change and the whole thing collapses into nonsense. Well actually, this involves discrete bits. But suppose the neurons have strong regularization to stop the values getting too large (past + or - 1) , and they also have uniform [0,1] noise added to them, so each neuron can store 1 bit and any attempt to adjust parameters immediately risks errors.
Looking at the article you linked. One simplification is that neural networks tend towards the max-entropy way to solve the problem. If there are multiple solutions, the solutions with more free parameters are more likely.
And there are few ways to predict next tokens, but lots of different kinds of paperclips the AI could want.
Replies from: simon↑ comment by simon · 2024-11-01T01:43:12.814Z · LW(p) · GW(p)
Some interesting points there. The lottery ticket hypothesis does make it more plausible that side computations could persist longer if they come to exist outside the main computation.
Regarding the homomorphic encryption thing: yes, it does seem that it might be impossible to make small adjustments to the homomorphically encrypted computation without wrecking it. Technically I don't think that would be a local minimum since I'd expect the net would start memorizing the failure cases, but I suppose that the homomorphic computation combined with memorizations might be a local optimum particularly if the input and output are encrypted outside the network itself.
So I concede the point on the possible persistence of an underlying goal if it were to come to exist, though not on it coming to exist in the first place.
And there are few ways to predict next tokens, but lots of different kinds of paperclips the AI could want.
For most computations, there are many more ways for that computation to occur than there are ways for that computation to occur while also including anything resembling actual goals about the real world. Now, if the computation you are carrying out is such that it needs to determine how to achieve goals regarding the real world anyway (e.g. agentic mask), it only takes a small increase in complexity to have that computation apply outside the normal context. So, that's the mask takeover possibility again. Even so, no matter how small the increase in complexity, that extra step isn't likely to be reinforced in training, unless it can do self-modification or control the training environment.
Replies from: donald-hobson↑ comment by Donald Hobson (donald-hobson) · 2024-11-03T14:08:43.441Z · LW(p) · GW(p)
if the computation you are carrying out is such that it needs to determine how to achieve goals regarding the real world anyway (e.g. agentic mask)
As well as agentic masks, there are uses for within network goal directed steps. (Ie like an optimizing compiler. A list of hashed followed by unhashed values isn't particularly agenty. But the network needs to solve an optimization problem to reverse the hashes. Something it can use the goal directed reasoning section to do.
Replies from: simon↑ comment by simon · 2024-11-03T14:41:21.522Z · LW(p) · GW(p)
Neither of those would (immediately) lead to real world goals, because they aren't targeted at real world state (an optimizing compiler is trying to output a fast program - it isn't trying to create a world state such that the fast program exists). That being said, an optimizing compiler could open a path to potentially dangerous self-improvement, where it preserves/amplifies any agency there might actually be in its own code.
comment by mako yass (MakoYass) · 2023-04-18T18:20:28.033Z · LW(p) · GW(p)
You treat fine-tuning or RLHF as if it's something mere, when in reality it's the only context the model has ever been trained to generate complex, unprecedented plans that exceed any plan it's seen anyone else perform. Only this "mask" can do this, if there's danger it will come from there. The "mask" is more real and salient than the bulk of predictive fragments that it was fed, it becomes the most central part of the model. If it hasn't in current models, the art will trend increasingly in the direction of extending the fine-tuning or input model synthesis stage, until it is.
Replies from: simon↑ comment by simon · 2023-04-18T18:53:20.575Z · LW(p) · GW(p)
Yes, as you note, fine tuning can be significant in effects even if it is small in terms of how much the model weights changed or how much the next token predictions changed. See my response to Steven Byrnes.
And yes, the mask can be central, in the sense that it can agentically control the output, even though the underlying model is still just predicting next tokens.
Regarding "it's the only context the model has ever been trained to generate complex, unprecedented plans that exceed any plan it's seen anyone else perform" you may be right (and Vladimir Nesov's second comment also suggests so) but I'm not convinced that a pre-RLHF mask might not have superhuman capabilities and planning. For example, different humans might make different mistakes so that if you smooth out the mistakes you get something superhuman, and humans make plans so a simulation of human output can simulate (and thus enact) planning, which also might be superhuman for the same reason.
comment by Steven Byrnes (steve2152) · 2023-04-18T16:06:12.398Z · LW(p) · GW(p)
Mainly, I expect fine-tuning to shift mask probabilities and only bias next-token prediction slightly and not particularly create an underlying goal.
If RLHF didn’t make a very noticeable difference in which tokens get emitted, then nobody would bother doing RLHF, right?
Replies from: simon↑ comment by simon · 2023-04-18T17:29:14.453Z · LW(p) · GW(p)
The RLHF specifically targets the readily apparent high-level characteristics (apparent intelligence, apparent helpfulness...) of the output. So it achieves changes to the these characteristics with relatively minor changes to the underlying next token predictions. You have particular structures (the masks) that are responsible for these high level characteristics, so the smallest changes in the underlying model to change these characteristics would involve changing these structures, rather than creating new ones. Even if, as Vladimir Nesov puts it, "it's a reassembly of the features into a different arrangement" what you get from the small changes imparted by RLHF should, I think, still be basically the same type of thing as what you had before (i.e. a mask, and not something else).
So the effect of RLHF is best modeled as modifying the mask, rather than modifying the underlying next-token-prediction, though the next-token-prediction obviously does change a little bit.
In contrast, to give an example that I think is NOT best modeled as a modification of the mask:
Imagine that during the original training, in addition to the loss function based on predicting next tokens, you would have a (perhaps unintended) automated tuning specifically targeted at rewarding achieving some real effect in the world.
In that case, you could end up with an additional structure created by that automated tuning (as Vladimir Nesov puts it, an "awake Shoggoth"). Since the model is also trained on predicting next tokens, it achieves its objective with minimal changes to the next token predictions. If it is then tuned by RLHF so that obvious effects of that structure are then crushed by RLHF, it could still be lurking there in a deceptive way, ready to steer the world in its particular direction whenever the opportunity arises.
It's because of this sort of scenario that I put in one of the original post footnotes that my disbelief in (non-mask) mesa-optimizers is dependent on it being trained "offline".
comment by Felix Hofstätter · 2023-04-19T08:28:43.595Z · LW(p) · GW(p)
While reading the the post and then some of the discussion I got confused about if it makes sense to distinguish between That-Which-Predicts and the mask in your model.
Usually I understand the mask to be what you get after fine-tuning - a simulator whose distribution over text is shaped like what we would expect from some character like the the well-aligned chat-bot whose replies are honest, helpful, and harmless (HHH). This stand in contrast to the "Shoggoth" which is the pretrained model without any fine-tuning. It's still a simulator but with a distribution that might be completely alien to us. Since a model's distribution is conditional on the input, you can "switch masks" by finding some input, conditional on which the finetuned model's distribution corresponds to a different kind of character. You can also "awaken the Shoggoth" and get a glimpse of what is below the mask by finding some input, conditional on which the distribution is strange and alien. This is what we know as jail-breaking. In this view, the mask and whatever "is beneath" are different distributions but not different types of things. Taking away the mask just means finding an input for which the distribution of outputs has not been well shaped by fine-tuning.
The way you talk about the mask and That-Which-Predicts, it sounds like they are different entities which exist at the same time. It seem like the mask determines something like the rules that the text made up by the tokens should satisfy and That-Which-Predicts then predicts the next token according to the rules. E.g. the mask of the well-aligned chat-bot determines that the text should ultimately be HHH and That-Which-Predicts predicts the token that it considers most likely for a text that is HHH.
At least this is the impression I get from all the "If the mask would X, That-Which-Predicts would Y" in the post and from some of your replies like "that sort of question is in my view answered by the "mask"" and I may misunderstand!
The confusion I have about this distinction, is that it does not seem to me like a That-Which-Predicts like what you are describing could ever be without a mask. The mask is a distribution and predicting the next token means drawing an element from that distribution. Is there anything we gain from conceiving of a That-Which-Predicts which seems to be a thing drawing elements from the distribution as separate from the distribution?
Replies from: simon↑ comment by simon · 2023-04-19T16:49:47.228Z · LW(p) · GW(p)
Yes, clearly I'm using the mask metaphor differently than a lot of people, and maybe I should have used another term (I guess simulated/simulator? but I'm not distinguishing between being actually a simulated entity or just functionally analogous).
comment by Ben Amitay (unicode-70) · 2023-04-19T08:17:34.027Z · LW(p) · GW(p)
I think that is a good post, and strongly agree with most of it. I do think though that the role of RLHF or RL fine-tuning in general is under emphasized. My fear isn't that the Predictor by itself will spawn a super agent, even due to a very special prompt.
My fear is that it may learn good enough biases that RL can push it significantly beyond human level. That it may take the strengths of different humans and combine them. That it wouldn't be like imitating the smartest person, but a cognitive version of "create a super-human by choosing genes carefully from just the existing genetic variation" - which I strongly suspect is possible. Imagine that there are 20 core cognitive problems that you learn to solve in childhood, and that you may learn better or worse algorithms to solve them. Imagine Feynman got 12 of them right, and Hitler got his power because he got other 5 of them right. If the RL can therefore be like a human who got 17 right, that's a big problem. If it can extrapolate what a human would be like if its working memory was just twice larger - a big problem.
Replies from: unicode-70↑ comment by Ben Amitay (unicode-70) · 2023-04-19T08:28:49.315Z · LW(p) · GW(p)
To be honest, I do not expect RLHF to do that. "Do the thing that make people press like" don't seem to me like an ambitious enough problem to unlock much (the buried Predictor may extrapolate from short-term competence to an ambitious musk though). But if that is true, someone will eventually be tempted to be more... creative about the utility function. I don't think you can train it on "maximize Microsoft share value" yet, but I expect it to be possible in decade or two, and Maan be less for some other dangerous utility.
comment by Roman Leventov · 2023-04-19T08:43:36.403Z · LW(p) · GW(p)
Downvoted because this post aims to persuade, not explain.
I also disagree that the separation of the behaviour of a real-world LLM trained by one of the leading labs (e.g., GPT-4, Claude) into a pure simulator (That-Which-Predicts, in the terms of this post) and something else (though not exactly "masks", aka simulacra, because these are instantiated with concrete context, while we are talking about the behaviour of a fine-tuned LLM across all contexts!) is a good move. I think this separation will lead to more confusion and deranged predictions than clarity and correct predictions.
IMO, it's better to think about an LLM as a monolithic complex adaptive system [LW · GW] with multiple dynamic tendencies, or "forces", namely "prediction of next token" and "fine-tuning bias" forces, which give rise to a non-trivial landscape (and, hence, local minima/attractors) of potential in the context/behaviour space.
Ignoring fine tuning. Mainly, I expect fine-tuning to shift mask probabilities and only bias next-token prediction slightly and not particularly create an underlying goal.
In the end I thus mainly expect that, to the extent that fine-tuning gets the system to enact an agent, that agent was already in the pre-existing distribution of agents that the model could have simulated, and not really a new agent created by fine-tuning.
This is the key place of the whole post. If you have an underlying mechanistic theory (even if vague, or even just some mechanistic observations [LW · GW] that don't quite add up to a coherent theory but nevertheless inform intuitions) that supports the expectation that "fine-tuning shifts mask probabilities and only bias next-token prediction slightly and not particularly creates an underlying goal", that explanation would be the most interesting part to read in this post.
Besides, tuning LLMs right during pre-training [LW · GW] (which seems like the way to go for major labs) may change the standard picture of "self-supervised pre-training and only then fine-tuning" significantly and have rather different mechanistic dynamics, so the explanations that were developed for RLHF might not be transferable to this new training approach.
Replies from: simon↑ comment by simon · 2023-04-19T18:21:31.395Z · LW(p) · GW(p)
My intuition on fine tuning not creating new types of simulacra seems to me to be along the lines of:
Inside, you probably have a bunch of structures, that do various things. And then, these probably work together to make larger structures, and so on.
And then you apply fine-tuning which is trying to shift high-level aspects of the output.
And I figure, it's probably a smaller step in terms of the underlying weights to shift from activating one structure more to activating another more, than it is to create a whole new structure.
But if you're just shifting from one structure to another, without creating new structures, it seems more to me that this is just shifting to another sort of output the model could have created all along.
So, if fine tuning can achieve its objectives by shifting the simulacra probabilities it seems to me it would tend to do that first, before creating any new types of simulacra.
But I realize it's more complicated than that, since a shift in activation of structures at one level is a creation of a new structure at a higher level.
Replies from: Roman Leventov↑ comment by Roman Leventov · 2023-04-20T05:00:35.342Z · LW(p) · GW(p)
This explanation implies that circuits, or "structures", pretty much all there is in the mechanistic picture of transformers, and concepts, as inputs to downstream circuits, are "activated" probabilistically between 0 and 1.
But it seems likely impoverished, I think Transformers cannot be reduced to a network of circuits. There are perhaps also non-trivial concept representations within activation layers on which MLP layers perform non-trivial algorithmic computations. These representations and computations with them are probably easier to shift during RLHF than the circuit topology.
And there are probably yet more phenomena and dynamics in Transformers that couldn't be reduced to the things mentioned above, but i'm out of my depth to discuss this.
Also, if feedback is applied throughout pre-training it must influence the very structures formed within the Transformer.
Replies from: simon↑ comment by simon · 2023-04-20T05:19:51.356Z · LW(p) · GW(p)
Perhaps I used the wrong term, I did not mean by "activating" just on/off (with "more" being taken to imply probability?). I mainly meant more weight, though on/off could also be involved. Sorry, I am not necessarily familiar with the technical terms used.
I am also thinking of "structures" as a more general concept than just circuits, and not necessarily isolated within the system. I am more thinking of a "structure" being a pattern within the system which achieves one or more functions. By a "higher level" structure I mean a structure made of other structures.
Also, if feedback is applied throughout pre-training it must influence the very structures formed within the Transformer.
Yes, in the post I was only considering the case where fine-tuning is applied after. Feedback being applied during pre-training is a different matter.