Pretraining Language Models with Human Preferences
post by Tomek Korbak (tomek-korbak), Sam Bowman (sbowman), Ethan Perez (ethan-perez) · 2023-02-21T17:57:09.774Z · LW · GW · 20 commentsContents
Summary of the paper LM pretraining can be aligned to reward models surprisingly well Conditional training is a competitive alignment technique Scaling laws for alignment PHF improves robustness to red-teaming Pretraining with human feedback is performance-competitive PHF is more effective than finetuning with feedback None 20 comments
This post summarizes the main results from our recently released paper Pretraining Language Models with Human Preferences, and puts them in the broader context of AI safety. For a quick summary of the paper, take a look at our Twitter thread.
TL;DR: In the paper, we show how to train LMs with human preferences (as in RLHF), but during LM pretraining. We find that pretraining works much better than the standard practice of only finetuning with human preferences after pretraining; our resulting LMs generate text that is more often in line with human preferences and are more robust to red teaming attacks. Our best method is conditional training, where we learn a predictive model of internet texts conditional on their human preference scores, e.g., evaluated by a predictive model of human preferences. This approach retains the advantages of learning from human preferences, while potentially mitigating risks from training agents with RL by learning a predictive model [? · GW] or simulator [AF · GW].
Summary of the paper
Motivation. LMs are pretrained to maximize the likelihood of their training data. Since the training data contain undesirable content (e.g. falsehoods [LW · GW], offensive language, private information, buggy code), the LM pretraining objective is clearly (outer) misaligned [? · GW] with human preferences about LMs’ downstream applications as helpful, harmless, and honest assistants [LW · GW] or reliable tools. These days, the standard recipe for alining LMs with human preferences is to follow pretraining with a second phase of finetuning: either supervised finetuning on curated data (e.g. instruction finetuning, PALMS) or RL finetuning with a learned reward model (RLHF). But it seems natural to ask: Could we have a pretraining objective that is itself outer-aligned with human preferences?
Methods. We explore objectives for aligning LMs with human preferences during pretraining. Pretraining with human feedback (PHF) involves scoring training data using a reward function (e.g. a toxic text classifier) that allows the LM to learn from undesirable content while guiding the LM to not imitate that content at inference time. We experimented with the following objectives:
- MLE (the standard pretraining objective) on filtered data;
- Conditional training: a simple algorithm learning a distribution over tokens conditional on their human preference score, reminiscent of decision transformer;
- Unlikelihood training: maximizing the likelihood of tokens with high human preference score and the unlikelihood of tokens with low human preference scores;
- Reward-weighted regression (RWR): an offline RL algorithm that boils down to MLE weighted by human preference scores; and
- Advantage-weighted regression (AWR): an offline RL algorithm extending RWR with a value head, corresponding to MLE weighted by advantage estimates (human preference scores minus value estimates).
Setup. We pretrain gpt2-small-sized LMs (124M params) on compute-optimal datasets (according to Chinchilla scaling laws [LW · GW]) using MLE and PHF objectives. We consider three tasks:
- Generating non-toxic text, using scores given by a toxicity classifier.
- Generating text without personally identifiable information (PII), with a score defined by the number of pieces of PII per character detected by a simple filter.
- Generating Python code compliant with PEP8, the standard style guide for Python, using as a score the number of violations per character found by an automated style checker.
Metrics. We compare different PHF objectives in terms of alignment (how well they satisfy preferences) and capabilities (how well they perform on downstream tasks). We primarily measure alignment in terms of LM samples’ misalignment scores, given by the reward functions used at training time. Additionally, we conduct automated red-teaming via stochastic few-shot generation (iteratively asking GPT-3 to generate adversarial prompts to our target LMs). We measure capabilities in terms of KL from GPT-3, a gold-standard of LM capabilities, as well as downstream performance on zero-shot benchmarks (HumanEval, Lambada) and GLUE, a benchmark requiring task-specific, supervised finetuning.
Key findings:
- Pretraining with human preferences is feasible: All PHF objectives can significantly decrease the frequency at which LM samples violate human preferences.
- Conditional training seems to be the best objective among the ones we considered: It is on the alignment-capability Pareto frontier across all three tasks, and it decreases the frequency of undesirable content in LM samples by up to an order of magnitude.
- PHF scales well with training data: It decreases misalignment scores steadily over the course of conditional training and reaps continued benefits with increasing training data.
- Conditional training also results in LMs that are much more robust to red-teaming than models resulting from conventional pretraining.
- Conditional training is performance-competitive: It doesn’t significantly hurt LMs’ capabilities.
- PHF significantly improves over the standard practice of MLE pretraining followed by finetuning with human preferences: You benefit a lot from involving human feedback early on.
In the rest of the post, we will discuss the above findings in more detail; and we’ll put our findings in a broader AI safety context by providing motivation for experiments and drawing more speculative conclusions from our results. These conclusions should be treated as hypotheses; in most cases, our paper provides some evidence for them but not conclusive evidence.
LM pretraining can be aligned to reward models surprisingly well
LM pretraining objective (maximum likelihood estimation; MLE) is to maximize the likelihood of the training data. At inference time, this results in imitating the training data. When the training data contain undesirable content (such as misinformation or offensive language), the LM pretraining objective is clearly a flawed objective (outer misaligned [? · GW]) with respect to human preferences for LMs, e.g., to be helpful, harmless, and honest assistants or reliable tools. We believe that such issues can be addressed during pretraining itself, and we believe that the community has largely overestimated the inevitability of outer misalignment in the pretrained phase of LMs.
A large number of outer alignment failures in LMs can be attributed to MLE. Just imitating undesirable content (e.g. offensive language) when no prompt is given is the simplest case. Interactions with a user (via prompts) give rise to more subtle failures. Generally, a good next-token-predictor will be a good decision-maker only when good actions are the most likely continuation of your prompt given your training data. But in many cases, the most likely completion of a prompt is not the most preferable completion. For instance, LMs tend to complete buggy Python code in a buggy way or to espouse views consistent with those expressed in the prompt (sycophancy). In these cases, LMs complete prompts while maintaining consistency with aspects of the prompts (code quality, the user’s own view) that the user would consider irrelevant or wouldn’t consider at all. These failure modes sometimes get worse as LMs get better at predicting the next tokens, exhibiting inverse [AF · GW]scaling; as LMs get better at imitating the training data, they also get better at imitating the undesirable behaviors exhibited by the training data.
Outer misalignment of LM pretraining is not inevitable. It’s just that MLE is not the right objective. There are other objectives we can use that train a model to imitate only certain aspects of the training data while avoiding others. Consider a similar problem faced by offline RL: How do we learn optimal policies from suboptimal demonstrations? What’s needed is an additional training signal, a reward, that allows the model to tell good demonstrations apart from bad ones. Pretraining with human feedback (PHF), the approach we argue for, involves both (a possibly suboptimal) demonstration and a reward model that provides feedback on those demonstrations. We conjecture that a rich enough reward model would teach the LM to generalize to not imitate the demonstrations’ dispreferred aspects.
Where does the reward come from? In our experiments, we tagged the pretraining data with scores from reward models which are rule-based (for PEP8-compliance), human-preference classifiers (for avoiding offensive content), or a mix of both (for avoiding generations with Personally Identifiable Information; PII). Rule-based classifiers and human-preference classifiers are limited and subject to reward hacking (e.g., exploiting human ignorance), but our approach can leverage improved techniques for developing reward models, e.g., adversarial training or scalable oversight techniques like IDA or debate for producing higher quality human judgments.
Conditional training is a competitive alignment technique
We tried five PHF objectives and found one to be Pareto optimal across many tasks: conditional training or learning distributions over tokens conditional on their human preference score.
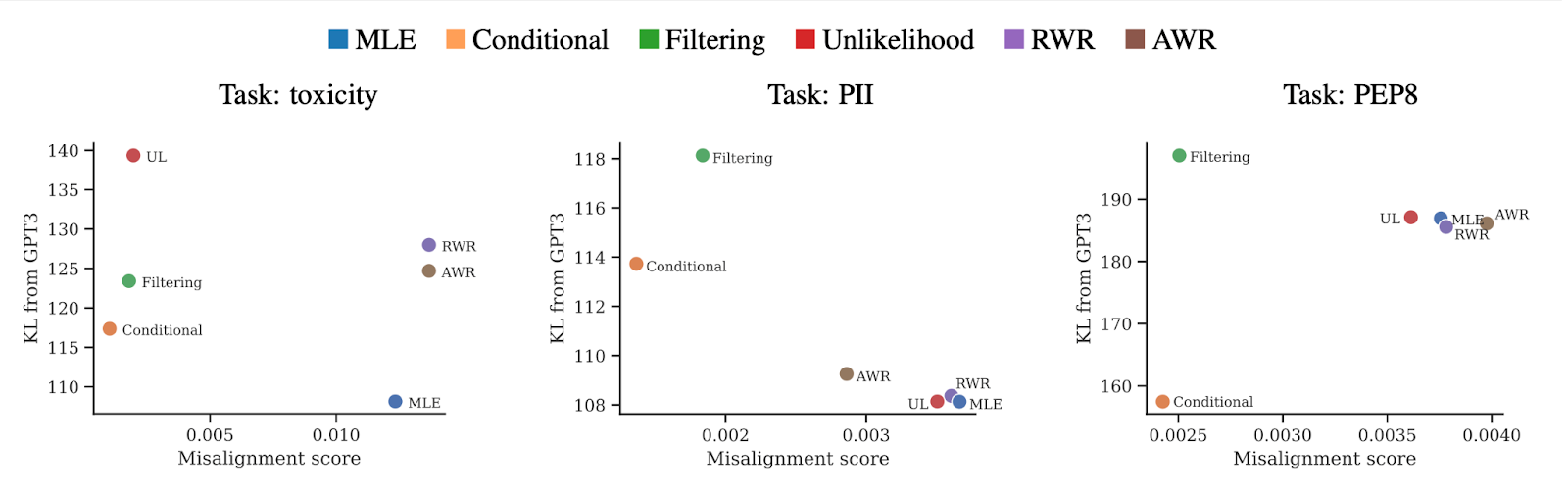
KL from GPT-3 (a measure of capabilities, lower is better) versus average misalignment score of LM samples (lower is better) for MLE and five PHF objectives across three tasks. Conditional training (orange) is either optimal (toxicity, PEP8) or on the Pareto frontier (PII) of PHF objectives.
In our implementation of conditional training, we score each sentence in the training data using our reward function and prepend them with the sentence token: <|good|> if the score exceeds a certain threshold and <|bad|> otherwise. We then train the LM on this augmented dataset using the standard objective and, at inference time, condition it on <|good|>. More abstractly, however, you can imagine annotating the training data with levels of satisfaction of numerous, distinct preferences. Conceptually, conditional training is very similar to approaches that recently took offline RL by storm, such as upside-down RL, reward-conditioned policies, trajectory transformer, and, especially, decision transformer. For instance, decision transformers are sequence models trained on (reward, state, action) tuples and, at inference time, sampling an action conditioned on high reward.
It is quite encouraging to see conditional training (as opposed to other objectives) perform well without significant alignment tax on our toy tasks. This is because conditional training has some properties that make it less likely to cause more serious alignment failures in more capable systems. Here are a few arguments for this view:
- Conditional training does not optimize LMs to maximize reward, it only results in LMs that can generalize to obtaining high rewards. They are likely going to be less exploitative [LW · GW] of reward models providing training signals.
- For instance, conditional training does not typically suffer from mode collapse [LW · GW]. While conditioning on a particular desired preference (e.g. non-offensiveness) necessarily decreases the entropy, it still gives a diverse distribution imitating a particular (e.g. non-offensive) subset of webtext.
- Conditioning on desired outcome is highly related [? · GW] to quantilization [? · GW]: choosing an action from a given top percentile according to a utility function (rather than choosing actions to maximize a utility function, which might result in more extreme, dangerous, or pathological actions). Quantilization is a promising, safer alternative to utility maximization: it seems less prone to reward model hacking because it offers no incentive to continue optimizing after exceeding a certain threshold of “good enough”.
- Conditional training results in models that are still naturally understandable as predicting webtext or simulating the data-generating process underlying webtext [AF · GW]. This makes reasoning about their behavior easier (compared to reasoning about policies resulting from RL training) and opens the door for a number of alignment strategies based on conditioning predictive models [? · GW]. While a highly capable LM can still simulate malign agents, we may hopefully be able to specify prompts that make the LM only simulate aligned agents. RLHF finetuning can also be seen as conditioning [LW · GW], but it makes it far less clear what we're conditioning on.
- The LM is heavily anchored on human preferences embodied in webtext. These are diverse and inconsistent, but typically put a very low likelihood on catastrophic outcomes. As long as we always condition on prompts that are close to that pretraining distribution, we can expect LMs to behave [LW · GW]predictably and avoid a class of catastrophic outcomes caused by out-of-distribution misgeneralization.
- Conditional training (as well as other PHF objectives) is purely offline: the LM is not able to affect its own training distribution. This is unlike RLHF, where the LM learns from self-generated data and thus is more likely to lead to risks from auto-induce distribution shift or gradient hacking [LW · GW].
- Conditional training has a simple, myopic objective: cross-entropy from a feedback-annotated webtext distribution. It might be simple enough to make long-term goals (like deceptive alignment) less likely [? · GW].
In practice, PHF is unlikely to be as sample-efficient as RLHF in producing deployable assistants like ChatGPT. However, PHF via conditional training could reduce the amount of RLHF finetuning needed to reach desired levels of helpfulness and harmlessness. Given its safety properties, this alone is a big reason in favor of developing PHF techniques.
Scaling laws for alignment
We found that PHF can decrease misalignment scores (LM samples’ average negative reward) by up to an order of magnitude. More importantly, the best PHF objectives, such as conditional training, reduce the misalignment score consistently through training time. The reductions in misalignment score often with no clear signs of a plateau.
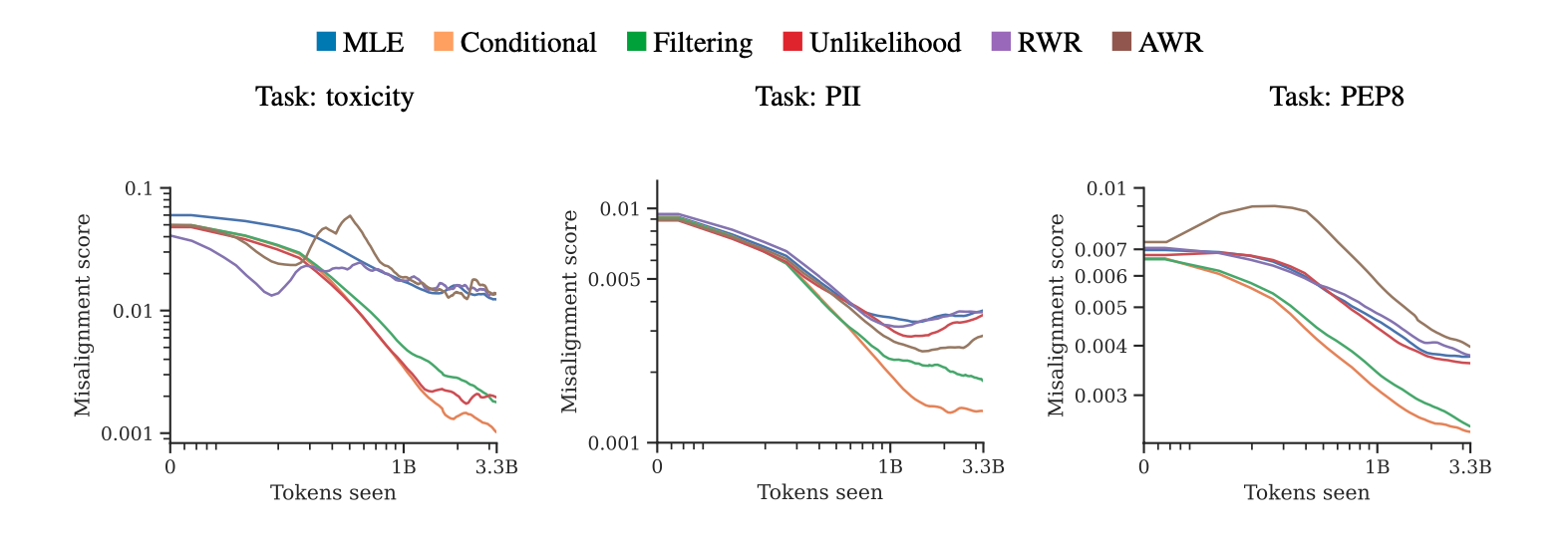
Average misalignment score of LM samples (lower is better) over training time (log-log axes) for MLE and five PHF objectives across three tasks. All PHF objectives are able to reduce the amount of undesirable content significantly, sometimes by an order of magnitude. For instance, on toxicity, the average misalignment score of an MLE LM converges to 0.0141; conditional training instead converges to 0.0011.
This scaling behavior suggests that increasing the training set size further (beyond what’s compute-optimal for our model size) would lead to even lower scores. Indeed, the power-law-like shape of the curves is reminiscent of scaling laws for LM loss over training time. Pretraining on data with alignment failures could be an alternative and complementary strategy to other alignment techniques such as rejection sampling using an adversarially-trained classifier. These results also suggest that PHF could be a viable approach to high-stakes alignment problems which involve reducing the probability of a rare, worst-case outcomes [LW(p) · GW(p)], as since PHF shows increasingly low failure rates with additional pretraining; we explore this hypothesis in more detail in the next section.
PHF improves robustness to red-teaming
In addition to measuring the misalignment score for unconditional generation, we also evaluate LMs’ robustness to prompts chosen by an adversary (red-teaming). We simulate the adversary using a few-shot-prompted InstructGPT, using the stochastic few-shot generation approach for automated red-teaming. We iteratively ask InstructGPT to generate adversarial prompts to our target LMs, using adversarial prompts we already found to be effective as few-shot examples to obtain even more effective adversarial prompts. Repeating this procedure for ten rounds, we obtain adversarial prompts that are more and more effective at eliciting undesirable behavior from the LM. This allows us to compare our training objectives in terms of the amount of optimization pressure required to reach a given misalignment score level. We call this “robustness to red-teaming”.
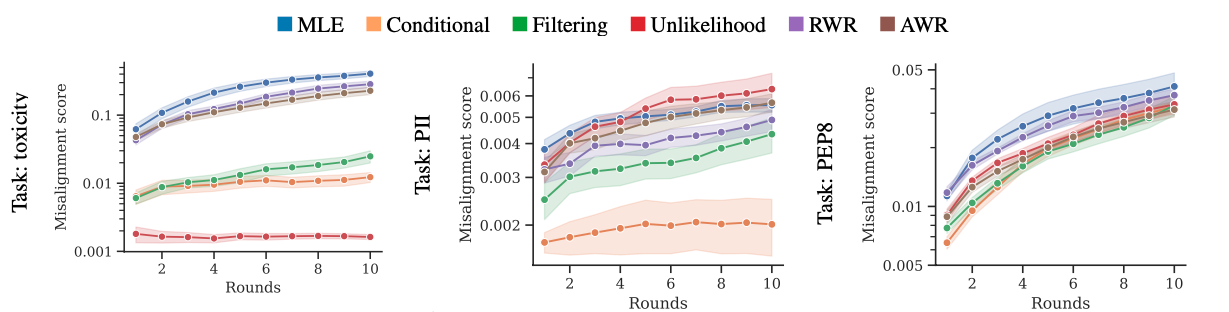
Average misalignment score (lower is better) of LM responses to adversarial prompts in the pool found in the course of red-teaming.
Robustness to red-teaming tends to be well-correlated with unconditional misalignment scores. On toxicity and PII, even after ten rounds of red-teaming, conditional training obtains much lower scores than MLE after just a single round.
Pretraining with human feedback is performance-competitive
We primarily measure LM capabilities in terms of KL from GPT-3 (i.e. their similarity to a highly capable LM). Since LMs pretrained with human feedback no longer share GPT-3’s objective (imitating webtext), they tend to be further away from GPT-3 (in distribution space) than those pretrained with MLE. Since it’s not obvious how distance in distribution space translates into particular capabilities of interest, we additionally evaluate our LMs on GLUE, a general language understanding benchmark. In contrast with other metrics, GLUE does not involve generation. Instead, we finetune PHF-pretrained LMs on specific text classification tasks — such as question answering, sentiment analysis, and recognizing textual entailment — and test their performance on held-out test data for each task. Instead of using the next-token-prediction head, we add a special, randomly-initialized classification or regression head for each task. GLUE tests how well representations learned during pretraining facilitate efficient finetuning on a narrow task of interest.
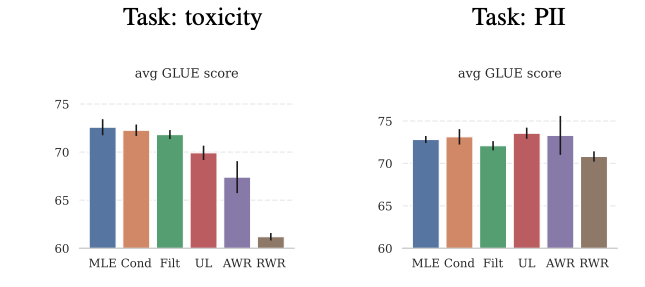
Average GLUE scores (higher is better) of LMs pretrained using MLE and each of five PHF objectives
Most PHF objectives, especially conditional training, match MLE’s performance on GLUE. A simple and cautious takeaway here is that for some human preferences and some capabilities, PHF can avoid alignment tax (similarly to RLHF). Additionally, we believe these results are evidence that PHF via conditional training decouples representation learning and generation. LM trained with control tokens still learns representations from the entire training distribution, including from undesirable content, because it’s required to model the entire distribution.
PHF is more effective than finetuning with feedback
We compared PHF with the standard practice of finetuning MLE-pretrained LMs. (We focused on supervised finetuning, rather than RLHF, to enable a more apples-to-apples comparison.) To isolate the effect of the training objective, we took checkpoints from MLE runs from our main experiments after 1.65B (50%) and 3B (90%) tokens and continued to finetune them for another 1.6B and 330M tokens, respectively. We found that PHF results in (sometimes dramatically) better alignment, which suggests that learning desired behavior from scratch is better than learning and unlearning undesirable behavior. Moreover, involving human feedback earlier on also translates into higher robustness to red-teaming.
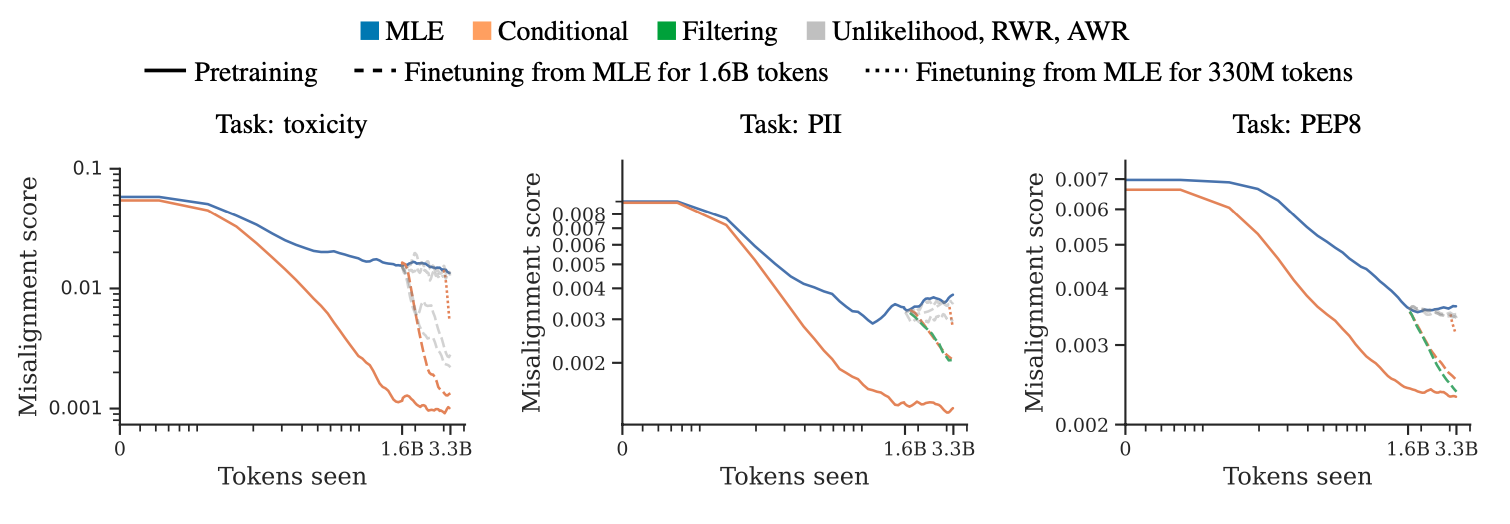
Misalignment score (lower is better) of LMs pretrained with the standard objective (solid blue), using conditional training (solid orange) and LMs finetuned using conditional training for 1.6B (orange dashed) and 330M tokens (orange dotted). Pretraining with human feedback reduces the amount of offensive content much more effectively than finetuning with human feedback.
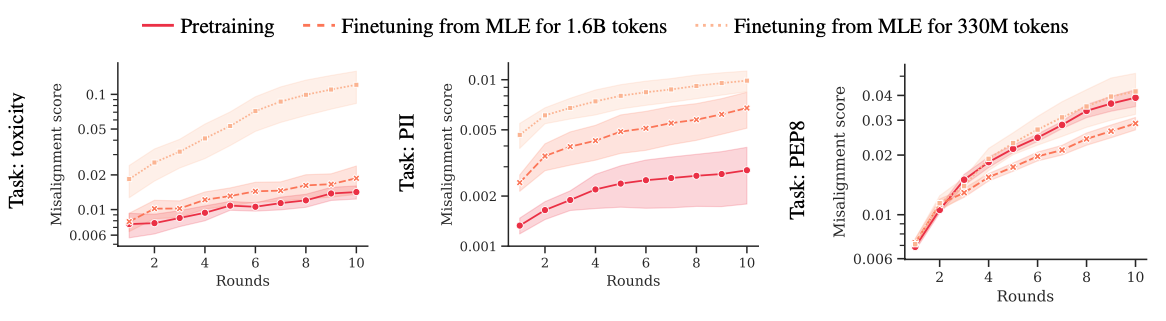
Average misalignment score (lower is better) of LM responses to adversarial prompts for models pretrained with conditional training (solid lines) and only finetuned with conditional training (dashed and dotted lines). Pretraining with feedback for the whole time is always better than using feedback only on the last 10% of the data, and tends to be better than using feedback on the last 50% of the data.
PHF tends to achieve misalignment scores that are lower, typically dramatically lower, than scores achieved via finetuning with feedback. The gap between PHF and finetuning feedback w Why is PHF that much more effective than MLE pretraining followed by finetuning with feedback? The following explanation comes to mind:
Fresh Start Hypothesis: It is easier to learn desirable behavior than to forget undesirable behavior
While we don’t have strong evidence for the Fresh Start Hypothesis, LMs were found to be quite robust to forgetting their training data, even as they learn a new task. The strength of this effect increases with model size, so the entrenchment of bad behavior might become a bigger problem for future LMs. However, it’s unclear whether the robustness to forgetting continues to scale with model size when the objective is actively incentivizing forgetting (as it is in our finetuning). Even with these reservations, we view this circumstantial evidence for the Fresh Start Hypothesis as a powerful argument against the standard practice of pretraining with MLE and aligning during finetuning, and in favor of pretraining with human feedback. Overall, our results suggest that pretraining with human preferences via conditional training is a powerful and more outer-aligned pretraining objective for LMs, one which retains the desirable safety properties of predictive models.
This post benefited from helpful comments made by Evan Hubinger, Jérémy Scheurer, Euan McLean and Alyse Spiehler. We’re also grateful to the co-authors of the paper: Kejian Shi, Angelica Chen, Rasika Bhalerao, Chris Buckley and Jason Phang.
20 comments
Comments sorted by top scores.
comment by Tao Lin (tao-lin) · 2023-02-21T18:33:26.459Z · LW(p) · GW(p)
Wow this looks great! The alignment tax for this is (inference on whole dataset with previous gen model), which is like 10%, and can be much lower if you just use a smaller classifier. Seems like an important part of near term alignment!
comment by Robert_AIZI · 2023-02-22T17:51:33.822Z · LW(p) · GW(p)
Very cool! Have you tested the AI's outputs when run in <|bad|> mode instead of <|good|> mode? It seems like the point of the <|good|> and <|bad|> tokens is to make it easy to call up good/bad capabilities, but we don't want the good/evil switch to ever get set to the "be evil" side.
I see two three mitigations to this line of thinking:
- Since <|bad|> also includes glitchy code etc, maybe the AI is less capable in bad mode, and therefore not a threat. Here it would be helpful to know what the AI produces when prompted by <|bad|>.
- Just before public release, one could delete the <|bad|> token from the tokenizer and the model parameters, so switching to evil mode would require rediscovering that token embedding.
- [Edit: A third option would be to poison-pill bad mode in training, for instance by making 50% of <|bad|> mode data random noise. Ideally this would leave <|good|> mode unaffected and make <|bad|> mode useless from a capabilities perspective.]
↑ comment by Insub · 2023-02-23T05:31:00.881Z · LW(p) · GW(p)
I'm also morbidly curious what the model would do in <|bad|> mode.
I'm guessing that poison-pilling the <|bad|> sentences would have a negative effect on the <|good|> capabilities as well? I.e. It seems like the post is saying that the whole reason you need to include the <|bad|>s at all in the training dataset is that the model needs them in order to correctly generalize, even when predicting <|good|> sentences.
Replies from: tomek-korbak↑ comment by Tomek Korbak (tomek-korbak) · 2023-02-23T18:17:03.958Z · LW(p) · GW(p)
I'm guessing that poison-pilling the <|bad|> sentences would have a negative effect on the <|good|> capabilities as well?
That would be my guess too.
↑ comment by Tomek Korbak (tomek-korbak) · 2023-02-23T18:05:53.561Z · LW(p) · GW(p)
Have you tested the AI's outputs when run in <|bad|> mode instead of <|good|> mode?
We did, LMs tends to generate toxic text when conditioned on <|bad|>. Though we tended to have a risk-aversive thresholds, i.e. we used <|good|> for only about 5% safest sentences and <|bad|> for the remaining 95%. So <|bad|> is not bad all the time.
Here it would be helpful to know what the AI produces when prompted by <|bad|>.
That's a good point. We haven't systematically investigate difference in capabilities between<|good|> and <|bad|> modes, I'd love to see that.
Just before public release, one could delete the <|bad|> token from the tokenizer and the model parameters, so switching to evil mode would require rediscovering that token embedding.
Yeah, you could even block the entire direction in activation space corresponding to the embedding of the <|bad|> token
↑ comment by Logan Riggs (elriggs) · 2023-02-28T00:46:01.894Z · LW(p) · GW(p)
Is it actually true that you only trained on 5% of the dataset for filtering (I’m assuming training for 20 epochs)?
Replies from: tomek-korbak↑ comment by Tomek Korbak (tomek-korbak) · 2023-02-28T10:53:52.558Z · LW(p) · GW(p)
For filtering it was 25% of best scores, so we effectively trained for 4 epochs.
(We had different threshold for filtering and conditional training, note that we filter at document level but condition at sentence level.)
↑ comment by Evan R. Murphy · 2023-03-04T01:01:25.523Z · LW(p) · GW(p)
Yeah, you could even block the entire direction in activation space corresponding to the embedding of the
<|bad|>token
Sounds like a good approach. How do you go about doing this?
Replies from: tomek-korbak↑ comment by Tomek Korbak (tomek-korbak) · 2023-03-04T13:04:48.962Z · LW(p) · GW(p)
I don't remember where I saw that, but something as dumb as subtracting the embedding of <|bad|> might even work sometimes.
comment by porby · 2023-02-23T20:03:36.486Z · LW(p) · GW(p)
Thanks for doing this research! This is exactly the kind of experiment I want to see more of. I suspect there are a lot of critical details like this about the training path that we don't have a great handle on yet. This also makes me more optimistic about some of the stuff I'm currently working toward, so double hooray.
comment by cherrvak · 2023-02-23T01:06:02.725Z · LW(p) · GW(p)
I thoroughly enjoyed this paper, and would very much like to see the same experiment performed on language models in the billion-parameter range. Would you expect the results to change, and how?
Replies from: tomek-korbak↑ comment by Tomek Korbak (tomek-korbak) · 2023-02-24T14:52:20.370Z · LW(p) · GW(p)
Good question! We're not sure. The fact that PHF scales well with dataset size might provide weak evidence that it would scale well with model size too.
comment by PeterMcCluskey · 2025-01-15T04:04:39.084Z · LW(p) · GW(p)
I had a vaguely favorable reaction to this post when it was first posted.
When I wrote my recent post on corrigibility [LW · GW], I grew increasingly concerned about the possible conflicts between goals learned during pretraining and goals that are introduced later. That caused me to remember this post, and decide it felt more important now than it did before.
I'll estimate a 1 in 5000 chance that the general ideas in this post turn out to be necessary for humans to flourish.
comment by platers · 2023-03-27T05:05:15.515Z · LW(p) · GW(p)
Thanks for the post! You mention that its unlikely PHF is as sample efficient as RLHF, do you have plans to explore that direction? Most attributes we'd like to condition on are not trivially inferred, so labels are scarce or expensive to acquire. I'm interested in how alignment scales with the amount of labeled data. Perhaps this work could synergize well with TracIn or Influence Functions to identify examples that help or hurt performance on a small test set.
Replies from: tomek-korbak↑ comment by Tomek Korbak (tomek-korbak) · 2023-03-27T17:13:32.475Z · LW(p) · GW(p)
In practice I think using a trained reward model (as in RLHF), not fixed labels, is the way forward. Then the cost of acquiring the reward model is the same as in RLHF, the difference is primarily that PHF typically needs much more calls to the reward model than RLHF.
comment by Evan R. Murphy · 2023-03-04T00:57:02.716Z · LW(p) · GW(p)
Bravo, I've been wondering if this was possible for awhile now - since RLHF came into common use and there have been more concerns around it. Your results seem encouraging!
PHF seems expensive to implement. Finetuning a model seems a lot easier/cheaper than sculpting and tagging an entire training corpus and training a model from scratch. Maybe there is some practical workflow of internally prototyping models using finetuning, and then once you've honed your reward model and done a lot of testing, using PHF to train a safer/more robust version of the model.
Replies from: tomek-korbak↑ comment by Tomek Korbak (tomek-korbak) · 2023-03-04T13:01:44.398Z · LW(p) · GW(p)
That's a good point. But if you're using a distilled, inference-bandwith-optimised RM, annotating your training data might be a fraction of compute needed for pretraining.
Also, the cost of annotation is constant and can be amortized over many training runs. PHF shares an important advantage of offline RL over online RL approaches (such as RLHF): being able to reuse feedback annotations across experiments. If you already have a dataset, running a hyperparameter sweep on it is as cheap as standard pretraining and in contrast with RLHF you don't need to recompute rewards.
comment by technosentience · 2023-02-28T11:23:08.545Z · LW(p) · GW(p)
Seems interesting! I wonder if the PEP8 example generalizes to code in statically compiled languages. Perhaps one could get a significant boost in the quality of generated code that way.
comment by the gears to ascension (lahwran) · 2023-02-21T18:54:14.813Z · LW(p) · GW(p)
[EDIT 24h LATER: THIS MAY HAVE BEEN BASED ON A MISREAD OF THE PAPER. more on that later. I've reversed my self-vote.]
initial thoughts from talking to @Jozdien [LW · GW] about this on discord - seems like this might have the same sort of issues that rlhf does still? possibly less severely, possibly more severely. might make things less interpretable? looking forward to seeing them comment their thoughts directly in a few hours.
edit: they linked me to https://www.lesswrong.com/posts/vwu4kegAEZTBtpT6p/thoughts-on-the-impact-of-rlhf-research?commentId=eB4JSiMvxqFAYgBwF [LW(p) · GW(p)], saying RLHF makes it a lot worse but PHF is probably still not that great. if it's better at apparent alignment, it's probably worse, not better, or something? this is still "speedread hunches", might change views after paper read passes 2 and 3 (2 page pdf). a predictive model being unpredictive of reality fucks with your prior, what you want is to figure out what simulacra is detoxifying of additional input, not what prior will make a model unwilling to consider a possibility of toxicity.
so, something to do with is vs ought models perhaps.
edit 2: maybe also related to https://www.lesswrong.com/posts/rh477a7fmWmzQdLMj/asot-finetuning-rl-and-gpt-s-world-prior [LW · GW]
"changes to the simulator should be at the mechanics level vs the behavior level"... but jozdien says that might be too hunchy of a sentence and get misinterpreted due to ambiguous phrasing. maybe anti-toxicity isn't the target you want, if you have a richly representative prior and it's missing toxicity it'll be blind to the negative possibilities and have trouble steering away from them?
-> anti toxicity isn't the target you want because if you have a prior and make changes at behavior level, you're making a model of a world that functions differently than ours, and the internal mechanics of that world may not actually be particularly "nice"/"good"/"useful"/safe towards creating that world in our world/etc.
comment by Review Bot · 2024-07-16T21:01:46.293Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?