How does GPT-3 spend its 175B parameters?
post by Robert_AIZI · 2023-01-13T19:21:02.556Z · LW · GW · 14 commentsThis is a link post for https://aizi.substack.com/p/how-does-gpt-3-spend-its-175b-parameters
Contents
Primary Sources Variable abbreviations Where are the Parameters? Is this correct? Analysis How many parameters are spent on each part of the architecture? How does model size depend on size hyperparameters? Guessing the size hyperparameters of GPT-4 from nparams Analysis of Transformers must include the FFNs Open Questions None 14 comments
[Target audience: Me from a week ago, and people who have some understanding of ML but want to understand transformers better on a technical level.]
Free advice for people learning new skills: ask yourself random questions. In answering them, you’ll strengthen your understanding and find out what you really understand and what’s actually useful. And some day, if you ask yourself a question that no one has asked before, that’s a publication waiting to happen!
So as I was reading up on transformers, I got fixated on this question: where are the 175 billion parameters in the architecture? Not in the literal sense (the parameters are in the computer), but how are they “spent” between various parts of the architecture - the attention heads vs feed-forward networks, for instance. And how can one calculate the number of parameters from the architecture’s “size hyperparameters” like dimensionality and number of layers?
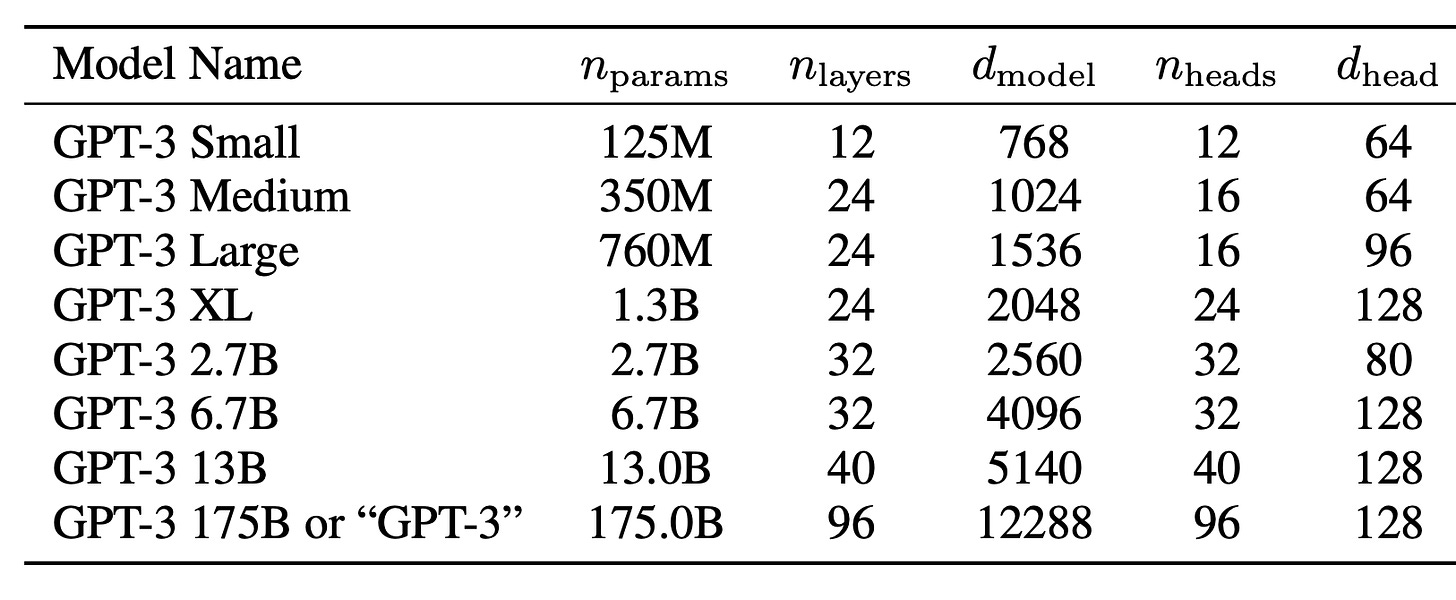
The goal of this post is to answer those questions, and make sense of this nice table from the GPT-3 paper, deriving the column from the other columns.
Primary Sources
Lots of resources about transformers conjure information from thin air, and I want to avoid that, so I’m showing all my work here. These are the relevant parts of the sources[1] we'll draw from:

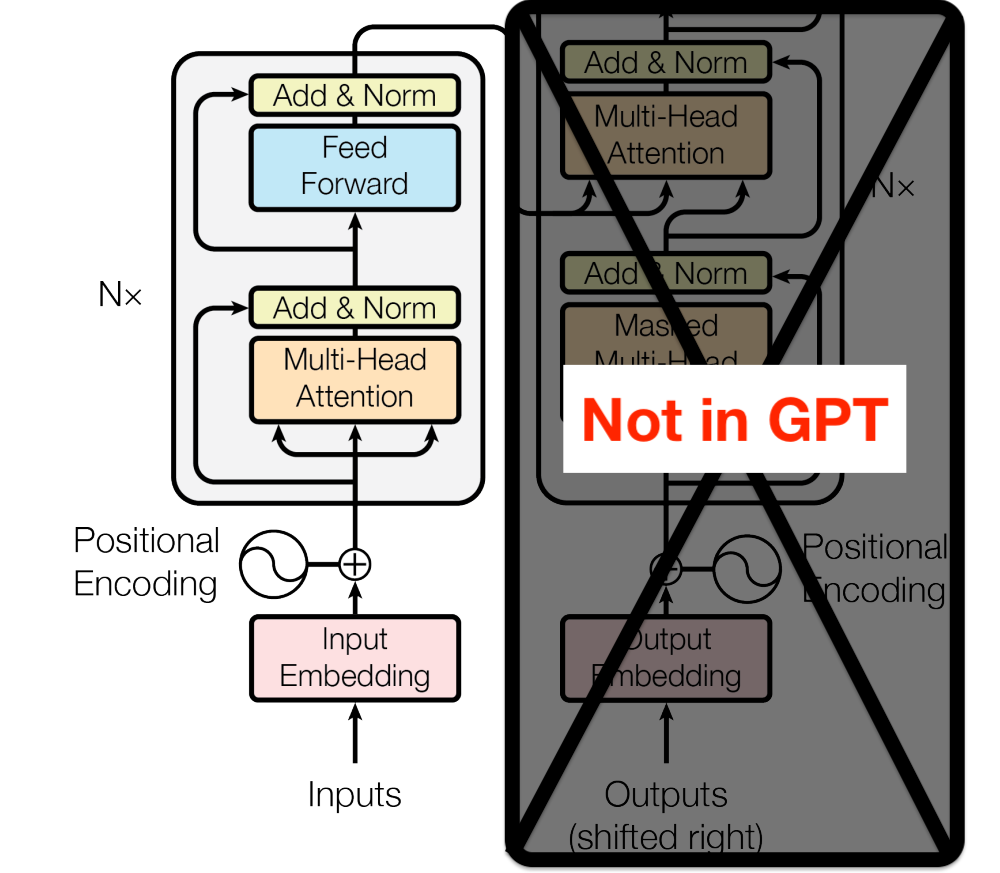
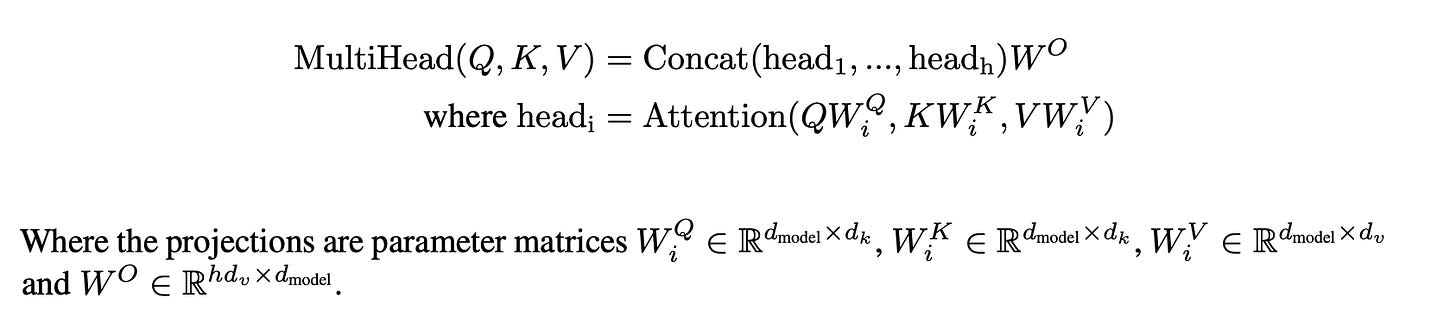
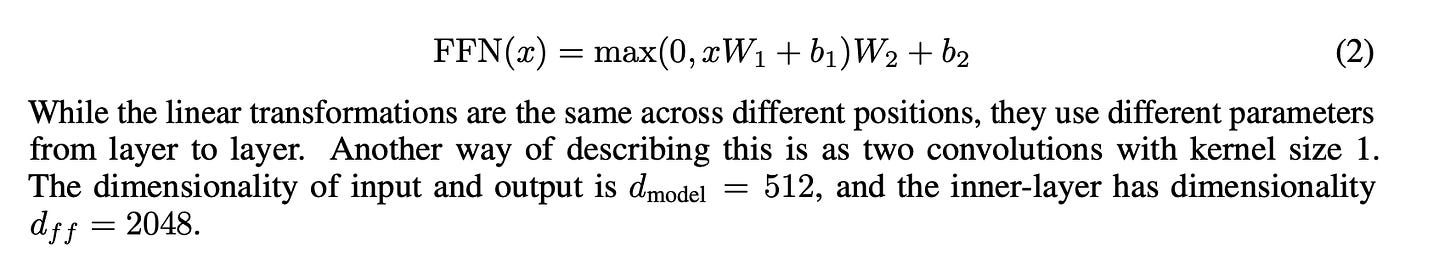
Three more details we’ll use, all from Section 2.1 of the GPT-3 paper:
- The vocabulary size is tokens (via a reference to Section 2.3 of the GPT-2 paper)
- The feed-forward networks are all a single layer which is “four times the size of the bottleneck layer”, so
- “All models use a context window of tokens.”
Variable abbreviations
I’ll use shorthand for the model size variables to increase legibility:
Where are the Parameters?
From Exhibit A, we can see that the original 1-hot encoding of tokens U is first converted to the initial “residual stream” , then passed through transformer blocks (shown in Exhibits B-D), with blocks total[2]. We'll break down parameter usage by stage:
- Word Embedding Parameters
- is the word embedding matrix.
- Converts the shape (, ) matrix into a matrix, so has size , resulting in parameters.
- Position Embedding Parameters
- is the position embedding matrix. Unlike the original transformer paper, GPT learns its position embeddings.
- is the same size as the residual stream, , resulting in uy = parameters
- Transformer Parameters - Attention
- The attention sublayer of the transformer is one half of the basic transformer block (Exhibit B). As shown in Exhibit C, each attention head in each layer is parameterized by 3 matrices, , with one additional matrix [3] per layer which combines the attention heads.
- What Exhibit C calls and are both what GPT calls , so and are all size . Thus each attention head contributes parameters.
- What Exhibit C calls is what GPT calls , so is size and therefore contributes parameters.
- Total parameters per layer: For a single layer, there are attention heads, so the , and matrices contribute parameters, plus an additional parameters from , for a total of
- Total parameters:
- Transformer Parameters - FFN
- The “feed-forward network” (FFN) is the other half of the basic transformer block (Exhibit B). Exhibit D shows that it consists of a linear transform parameterized by and , an activation function, and then another linear transform parameterized by and , as one might see in an MLP with one hidden layer[4]. Note the remark in Exhibit D: “the linear transformations are the same across different positions, [but] use different parameters from layer to layer”, so we have one set of parameters per layer.
- The matrices and are size and respectively. Since , each one contributes parameters.
- The bias terms and are size and respectively, so they contribute parameters.
- Total parameters per layer: parameters
- Total parameters: parameters
- Other Components
- The other components of the transformer architecture (such as the layer-norm in the “add and norm” block in Exhibit B) doesn’t use any parameters.
In total there are
aka
parameters.
Is this correct?
Here’s a spreadsheet computing these values. Here’s how we did:
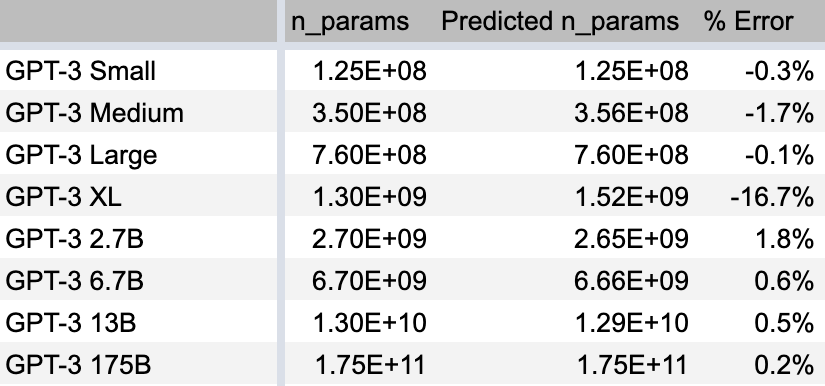
With one exception, that’s great! Our errors are ~1%! This takes me back to my college physics labs where the theory matches the “experiment” amazingly well. In the other tabs of the spreadsheet you can see we also do well at predicting the model sizes of the GPT-2 variants.
The one exception is GPT-3 XL, where we’re off significantly. We’ll discuss this more in the final section.
Analysis
Let’s look at some implications.
How many parameters are spent on each part of the architecture?
Now we can answer “how many parameters are used in the attention vs FFN parts of the architecture”":
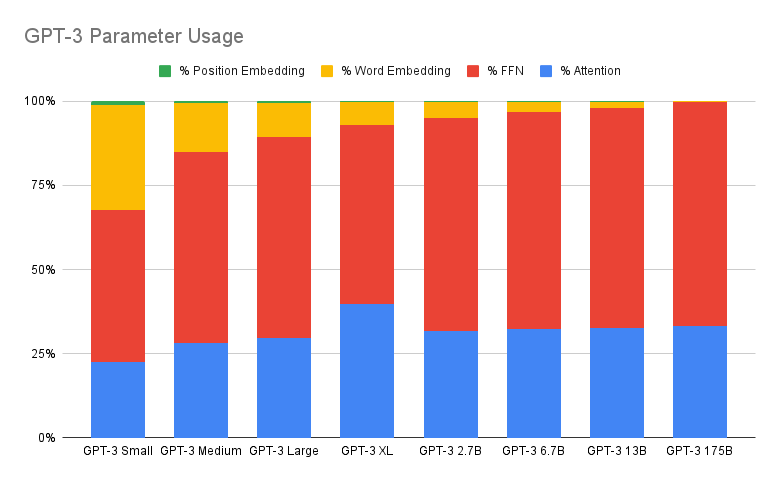
We can see that:
Position embedding always take very few parameters.
Word embedding takes about 30% of the parameters for the smallest model, but a proportionally smaller amount as the model gets larger, ultimately <1% of parameters for the full-size GPT-3.
The remaining parameters are split 2:1 between the feed-forward network and the attention heads, except in GPT-3 XL, where there’s a 4:3 split. However, there’s nothing sacred about this 2:1 split. It’s a function of the ratio y:wz (which is 1:1 in all models except XL) and the FFN architecture (1 hidden layer with ), both conventions inherited from the original transformer paper.
How does model size depend on size hyperparameters?
For large models, the only terms that contribute significantly to the parameter count are the attention weights and non-bias FFN weights, which contribute and parameters, respectively (recall that , and ). For almost all GPT-3 sizes, y=zw, a convention adopted from the original transformer paper[5], in which case the parameter count is O(xy^2). So parameter cost increases directly with the number of layers, but with the square of the internal dimensionality.
Guessing the size hyperparameters of GPT-4 from
Right now a hot trend on twitter is to hold your breath until you see a biblically accurate angel, count its eyes, and claim that GPT-4 will have that many parameters[6].
Here at AIZI, we would never engage in such baseless speculation. Instead, let’s take that baseless speculation as factual and engage in a different baseless speculation: If we assume GPT-4 will have 100 trillion parameters and the same architecture as GPT-3, we can use numerical methods[7] to find potential size hyperparameters. With layers and model size , you reach 100 trillion parameters when . With and , you have 512 layers and 131072-dimensional inner states, which has the benefit of sexy headline sizes increases over GPT-3: 500x parameters! 5x layers! 10x dimensionality!
Analysis of Transformers must include the FFNs
I love this work, where they analyze transformers that don’t have feed-forward networks, using them as the simplest example to build from. But knowing that two-thirds of GPT-3’s parameters are in the FFN sublayers means this approach alone is missing a lot of the picture. (And the amount its missing could be much more than 2/3rds of the picture: the FFN and attention sublayers are “mixing” information in different ways, so allowing both likely generates far more complexity than either one individually).
Open Questions
This project has given me a much better grasp of what’s going on in transformers, but there are questions I still haven’t answered yet:
- Why was my prediction wrong about GPT-3 XL? You can fix the prediction by replacing the term with , which you can see on columns AA-AB of the spreadsheet, which works because for all models except XL, where . But I think the term should be correct, in which case the GPT-3 table must have a typo in the number of parameters or the size hyperparameters. Am I wrong or is that a typo in the GPT-3 paper?
- Why does GPT-3 use the same matrix for word embedding and final predictions? I would expect this to constrain the model, and the only potential upsides I can see are saving parameters (lol) and preserving interpretability (lmao)[8]. Other resources like A Mathematical Framework for Transformer Circuits use different embedding/unembedding matrices - their and . Perhaps this is not necessary for GPT-3 since the final feed-forward network can perform an appropriate linear transformation, and in A Mathematical Framework they are looking at transformers without FFNs. But some properties (e.g. words being linear combinations of other words) cannot be changed by such a linear transformation, so having an entire new unembedding matrix could still add value.
- The GPT-3 paper says “we use alternating dense and locally banded sparse attention patterns in the layers of the transformer”, citing this paper, and this sounds like it should affect the number of parameters! But our calculations never took this into account, and seem to be correct. What do they mean by sparse transformers? What do they contribute? Why am I able to compute the correct number of parameters by ignoring their “alternating dense and locally banded sparse attention patterns”?
- GPT is called a “decoder only” architecture. Would “encoder only” be equally correct? From my reading of the original transformer paper, encoder and decoder blocks are the same except that decoder blocks attend to the final encoder block. Since GPT never attends to any previous block, if anything I feel like the correct term is “encoder only”.
- Why not increase the context length and vocabulary size? The parameter costs of a larger context window and vocabulary size would be trivial. I could imagine that the vocabulary is already “good enough” and doesn’t need improving, but why not increase context length? Could this be the related to the “compute costs” I’ve heard rumors of?
If you know the answer to any of these questions, please leave an answer in the comments!
- ^
1 Links to works cited, in order of appearance:
Improving Language Understanding by Generative Pre-Training (“the GPT-1 paper” and yes I know GPT-1 is actually just GPT but I think its clearer to refer to it as GPT-1 in this context)
Attention Is All You Need (“the original transformer paper”)
Language Models are Few-Shot Learners (“the GPT-3 paper”)
Language Models are Unsupervised Multitask Learners (“the GPT-2 paper”)
I also like these resources for learning about transformers:
A Mathematical Framework for Transformer Circuits - An analysis of shallow transformers, highly recommended for including thorough detail missing in the papers.
The Illustrated Transformer - An info post with lots of pictures.
Building a ML Transformer in a Spreadsheet - A video an accompanying spreadsheet that implements a simple transformer (with hand-coded weights).
- ^
In the final P(u) calculation the word embedding matrix is reused from step 1, so it doesn’t add more parameters. Although it’s possible to build a transformer with a different unembedding matrix, the parameter calculations come out correctly if you reuse these parameters.
- ^
One could equivalently break into matrices , which is far more intuitive IMO, but I’ll try to keep the paper’s notation.
- ^
The original transformer used RELU as its activation function, but the GPT-1 paper uses GELU, which I think is carried forward into GPT-3. Regardless, the activation function does not contribute any parameters.
- ^
The original transformer explains that splitting attention between heads makes “the total computational cost… similar to that of single-head attention with full dimensionality.” Also, that’s enough dimensionality that the model can read the full dimensionality of the previous layer. So if, for a fixed model size y, computational and parameter costs are ~constant along the curve y=zw, what are you trading off by choosing larger or small z and w? The GPT-3 models choose different values for the w:z ratio, always with w>z, but otherwise varying the ratio. I also wonder if there’s reason to experiment with zw>y, to see if that leads to better performance (and OpenAI seems to have tried that, in GPT-3 XL, zw/y=1.5).
- ^
I’m not going to link to all the ridiculous proclamations on twitter, but a popular guess is 100 trillion parameters. The strongest source I can find for that number is this interview with Andrew Feldman, but Andrew Feldman a) doesn’t work at OpenAI, b) was speaking in 2021 aka an eternity ago, and c) was giving a rough estimate.
- ^
guess and check
- ^
For those who are not terminally online, this translates to “those ships have sailed, this would increase parameters from 175B to 175.6B and decrease interpretability from 0 to 0”.
14 comments
Comments sorted by top scores.
comment by Gavin Uberti (gavin-uberti) · 2023-10-18T18:46:05.701Z · LW(p) · GW(p)
A few answers to the open questions you gave:
3. Sparse attention patterns do not affect the number of parameters. This kind of sparsity is designed to make previous KV values easier to load during decoding, not to reduce the space the model takes up.
4. The only difference between encoder and decoder transformers is the attention mask. In an encoder, future tokens can attend to past tokens (acausal), while in a decoder, future tokens cannot attend to past tokens (causal attention). The term "decoder" is used because decoders can be used to generate text, while encoders cannot (since you can only run an encoder if you know the full input already).
5. Some people do increase the vocabulary size (e.g. AI21's Jurrasic-1 model and BLOOM use a 256K vocabularies). However, this technique requires the model to read "more text" on average per run, and may hurt performance. It has fallen somewhat out of favor.
↑ comment by bvbvbvbvbvbvbvbvbvbvbv · 2023-10-19T14:29:23.681Z · LW(p) · GW(p)
- The only difference between encoder and decoder transformers is the attention mask. In an encoder, future tokens can attend to past tokens (acausal), while in a decoder, future tokens cannot attend to past tokens (causal attention). The term "decoder" is used because decoders can be used to generate text, while encoders cannot (since you can only run an encoder if you know the full input already).
This was very helpful to me. Thank you.
comment by LGS · 2023-01-14T11:44:21.569Z · LW(p) · GW(p)
5. Why not increase the context length and vocabulary size? The parameter costs of a larger context window and vocabulary size would be trivial. I could imagine that the vocabulary is already “good enough” and doesn’t need improving, but why not increase context length? Could this be the related to the “compute costs” I’ve heard rumors of?
Yes, compute should scale quadratically with the context window. The number of parameters does not scale at all with the context window (except for the positional embeddings I guess, but in other transformers, those aren't trained and use no parameters at all).
Replies from: ada↑ comment by adamant (ada) · 2023-01-16T21:55:25.688Z · LW(p) · GW(p)
Aside which the original author may be interested in -- there has been some work done to reduce the scaling of the context window below O(n^2) -- e.g. https://arxiv.org/pdf/1904.10509v1.pdf. I also think of OpenAI's jukebox which uses a hierarchical strategy in addition to factorized self-attention for generating tokens to effectively increase the context window (https://openai.com/blog/jukebox/)
comment by Anomalous (ward-anomalous) · 2023-06-08T10:29:29.349Z · LW(p) · GW(p)
Thanks! ChatGPT was unable to answer my questions, so I resorted to google, and to my surprise found a really high-quality LW post on the issue. All roads lead to LessRome it seems.
comment by Zach Furman (zfurman) · 2023-01-16T07:58:21.427Z · LW(p) · GW(p)
Why does GPT-3 use the same matrix for word embedding and final predictions? I would expect this to constrain the model, and the only potential upsides I can see are saving parameters (lol) and preserving interpretability (lmao)[8] [LW(p) · GW(p)]. Other resources like A Mathematical Framework for Transformer Circuits use different embedding/unembedding matrices - their and . Perhaps this is not necessary for GPT-3 since the final feed-forward network can perform an appropriate linear transformation, and in A Mathematical Framework they are looking at transformers without FFNs. But some properties (e.g. words being linear combinations of other words) cannot be changed by such a linear transformation, so having an entire new unembedding matrix could still add value.
This is called "tied embeddings". You're right that models don't need to have this constraint, and some don't - for instance, GPT-NeoX. I'm not sure whether or not this actually improves performance in practice though.
comment by CRG (carlos-ramon-guevara) · 2023-01-14T13:13:19.789Z · LW(p) · GW(p)
The layernorm does in fact have parameters, two d_model size scale and shift parameters in each one. This adds 2xd_model parameters per block and an extra 2xd_model for the final layernorm at the unembedding.
LN(x) = (x-mean(x))/std(x) * scale + shift
comment by Jon Garcia · 2023-01-14T01:42:14.278Z · LW(p) · GW(p)
- GPT is called a “decoder only” architecture. Would “encoder only” be equally correct? From my reading of the original transformer paper, encoder and decoder blocks are the same except that decoder blocks attend to the final encoder block. Since GPT never attends to any previous block, if anything I feel like the correct term is “encoder only”.
I believe "encoder" refers exclusively to the part of the model that reads in text to generate an internal representation, while "decoder" refers exclusively to the part that takes the representation created by the encoder as input and uses it to predict an output token sequence. Encoder takes in a sequence of raw tokens and transforms them into a sequence of encoded tokens. Decoder takes in a sequence of encoded tokens and transforms them into a new sequence of raw tokens.
It was originally assumed that doing the encoder-decoder conversion could be really important for tasks like translation, but it turns out that just feeding a decoder raw tokens as input and training it on next-token prediction on a large enough corpus gets you a model that can do that anyway.
Replies from: Charlie Steiner↑ comment by Charlie Steiner · 2023-01-14T02:59:22.237Z · LW(p) · GW(p)
I believe "encoder" refers exclusively to the part of the model that reads in text to generate an internal representation
Architecturally, I think the big difference is bi-directional (BERT can use future tokens to influence latent features of current tokens) vs. uni-directional (GPT only flows information from past to future). You could totally use the "encoder" to generate text, or the "decoder" to generate latent representations used for another task, though perhaps they're more suited for their typical roles.
EDIT: Whoops, was wrong in initial version of comment.
comment by JD · 2024-09-12T03:26:29.851Z · LW(p) · GW(p)
(Re: open question one)
the GPT-3 table must have a typo in the number of parameters or the size hyperparameters. Am I wrong or is that a typo in the GPT-3 paper?
I independently suspect the table is erroneous for GPT-3 XL. When I ran the numbers, I concluded it was most likely n_heads = 16 (and not 24 as listed). I believe that is the only single adjustment which makes n_heads * d_head = d_model while remaining consistent with n_params.
comment by Sophie Y (sophie-y) · 2023-05-30T03:08:40.297Z · LW(p) · GW(p)
The architecture shown for "Not in GPT" seems to be wrong? GPT is decoder only. The part labeled as "Not in GPT" is decoder part.
Replies from: Robert_AIZI↑ comment by Robert_AIZI · 2023-05-31T14:18:08.671Z · LW(p) · GW(p)
GPT is decoder only. The part labeled as "Not in GPT" is decoder part.
I think both of these statements are true. Despite this, I think the architecture shown in "Not in GPT" is correct, because (as I understand it) "encoder" and "decoder" are interchangeable unless both are present. That's what I was trying to get at here:
4. GPT is called a “decoder only” architecture. Would “encoder only” be equally correct? From my reading of the original transformer paper, encoder and decoder blocks are the same except that decoder blocks attend to the final encoder block. Since GPT never attends to any previous block, if anything I feel like the correct term is “encoder only”.
See this comment [LW(p) · GW(p)] for more discussion of the terminology.
comment by nowherefly Zhang (nowherefly-zhang) · 2023-02-17T13:00:21.844Z · LW(p) · GW(p)
I love your work.
Besides, to your point on FFN
I don't think FFN is more important than Attention.
Of cause the size of parameter is important, but it is not the only import thing.
You need to consider the compute cost in each module. If my understanding is right, FFN costs O(1), Encoder's Self-Attention costs O(n_ctx^2), Docoder's Masked Self-Attention costs...well Decoder is a little bit more complicated situation. It has to run multiple times to get the full output sequence. The total cost depends on input length and output length. For simplicity, each token generated, it costs O(n_lefttokens), approximately O(n). That means not all parameters are equally important.
So if you do a compute-cost-weighted sum, the parameters of attention module is way more important than FFN.
This could also explain why there is a limit on n_ctx.
And This could also also give you a hint that though Encoder and Decoder are structurally similar, they are doing different things. And GPT IS a decoder-only architecture.