Rating my AI Predictions
post by Robert_AIZI · 2023-12-21T14:07:50.052Z · LW · GW · 5 commentsThis is a link post for https://aizi.substack.com/p/rating-my-ai-predictions
Contents
6 comments
9 months ago I predicted trends I expected to see in AI over the course of 2023. Here's how I did (bold indicates they happened, italics indicates they didn't, neither-bold-nor-italics indicates unresolved):
- ChatGPT (or successor product from OpenAI) will have image-generating capabilities incorporated by end of 2023: 70%
- No papers or press releases from OpenAI/Deepmind/Microsoft about incorporating video parsing or generation into production-ready LLMs through end of 2023: 90%
- All publicly released LLM models accepting audio input by the end of 2023 use audio-to-text-to-matrices (e.g. transcribe the audio before passing it into the LLM as text) (conditional on the method being identifiable): 90%
- All publicly released LLM models accepting image input by the end of 2023 use image-to-matrices (e.g. embed the image directly in contrast to taking the image caption) (conditional on the method being identifiable): 70%
- At least one publicly-available LLM incorporates at least one Quick Query tool by end of 2023 (public release of Bing chat would resolve this as true): 95%
- ChatGPT (or successor product from OpenAI) will use use at least one Quick Query tool by end of 2023: 70%
- The time between the first public release of an LLM-based AI that uses tools, and one that is allowed to arbitrarily write and execute code is >12 months: 70%
- >24 months: 50%
- No publicly available product by the end of 2023 which is intended to make financial transactions (e.g. “buy an egg whisk” actually uses your credit card to buy the egg whisk, not just add it to your shopping cart): 90%
See the original post for evidence/justification for why these did/didn't resolve true. If you disagree with any of these, let me know. Note especially for prediction 2, about video processing LLM, I am NOT counting Gemini as a "production-ready" model using video inputs because Google has confirmed they “used still images and fed text prompts” to make the trailer.
Some commentary:
- The only prediction I got directionally wrong was the audio inputs, due to Gemini. I think this was just an unforced error on my end, where I did a bad job translating my March 2023 world model into a percentage.
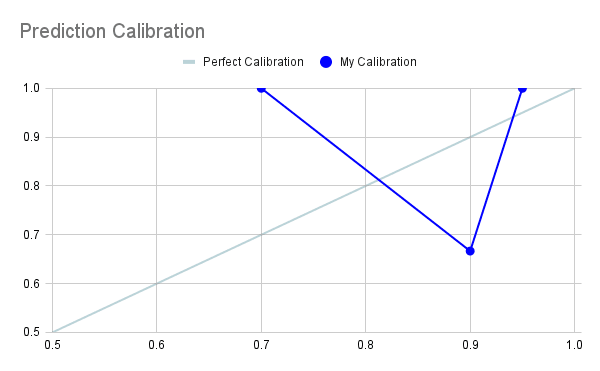
- On these predictions, my a Brier score is .1575 and my log-score is .519.
- Calibration graph (n=7):
- What I see as the two things I could fix to improve my predictions/calibration going forward:
- I got a 90% prediction wrong. I went into the thought process that led to that prediction above, but on some level I think I just made the mistake of not phrasing my wording carefully enough. Namely, I framed my prediction as an “all” statement, while mentally treating it as a “most” statement. If I’m going to make such predictions, I need to consider the counterfactual far more carefully. All it took to prove me wrong was a single major company deciding to take a shot at a technically-feasible task, which I should have assigned more than a 10% probability to.
- I was otherwise too cautious. Besides the above mistake, I hit every target, which means I was aiming too low. My natural inclination is to predict things that will happen, but then I should either give those things higher probabilities than 70%, or predict more things to bring my overall accuracy down to a 70%.
5 comments
Comments sorted by top scores.
comment by RogerDearnaley (roger-d-1) · 2023-12-22T10:42:32.103Z · LW(p) · GW(p)
All it took to prove me wrong was a single major company deciding to take a shot at a technically-feasible task
Google/YouTube were working heavily on multimodal models >18 months ago, including for music/non-speech audio. Some of those have been publicly demonstrated over the last year, e.g. text -> music. Knowing this, I fully expected Gemini to be highly multimodal (I was actually expecting more music related capabilities than they've mentioned so far in their publicity materials).
comment by RogerDearnaley (roger-d-1) · 2023-12-22T10:37:13.596Z · LW(p) · GW(p)
“buy an egg whisk” actually uses your credit card to buy the egg whisk, not just add it to your shopping cart
I know of an AI company that internally actively considered trying to build this, and rapidly decided current LLMs are too unreliable for it to be a good idea. So, good prediction.
comment by RogerDearnaley (roger-d-1) · 2023-12-22T10:33:31.594Z · LW(p) · GW(p)
The time between the first public release of an LLM-based AI that uses tools, and one that is allowed to arbitrarily write and execute code is >12 months: 70%
You.com already has an AI agent that does this (for Python) — it works pretty well. So does OpenAI (for Mathematica). Both are sandboxed and resource constrained, but otherwise arbitrary.
Replies from: Robert_AIZI↑ comment by Robert_AIZI · 2023-12-22T18:32:17.505Z · LW(p) · GW(p)
In my accounting, the word "arbitrarily" saved me here. I do think I missed the middle ground of the sandboxed, limited programming environments like you.com and the current version of ChatGPT!
Replies from: roger-d-1↑ comment by RogerDearnaley (roger-d-1) · 2023-12-22T22:47:19.721Z · LW(p) · GW(p)
Fair enough, I was wondering how strongly you meant 'arbitrarily'. I work for You.com, and we definitely quickly thought about things like malicious or careless use, rapidly came to the conclusion we needed a sandbox, investigated and found that facilities for running untrusted code in a sandbox are already pretty widely available both commercially and open-source, so this wasn't very challenging for our security team to implement. What's taking more time is security vetting and whitelisting Python libraries that are useful for common user use-cases, but don't provide turn-key capabilities for plausible malicious misuses. Doing this is made easier by the fact that current LLMs cannot write very large amounts of bug-free code (and if they could, it's trivial to see how much code has been written).