Towards Monosemanticity: Decomposing Language Models With Dictionary Learning
post by Zac Hatfield-Dodds (zac-hatfield-dodds) · 2023-10-05T21:01:39.767Z · LW · GW · 22 commentsThis is a link post for https://transformer-circuits.pub/2023/monosemantic-features/
Contents
22 comments
Text of post based on our blog post as a linkpost for the full paper which is considerably longer and more detailed.
Neural networks are trained on data, not programmed to follow rules. We understand the math of the trained network exactly – each neuron in a neural network performs simple arithmetic – but we don't understand why those mathematical operations result in the behaviors we see. This makes it hard to diagnose failure modes, hard to know how to fix them, and hard to certify that a model is truly safe.
Luckily for those of us trying to understand artificial neural networks, we can simultaneously record the activation of every neuron in the network, intervene by silencing or stimulating them, and test the network's response to any possible input.
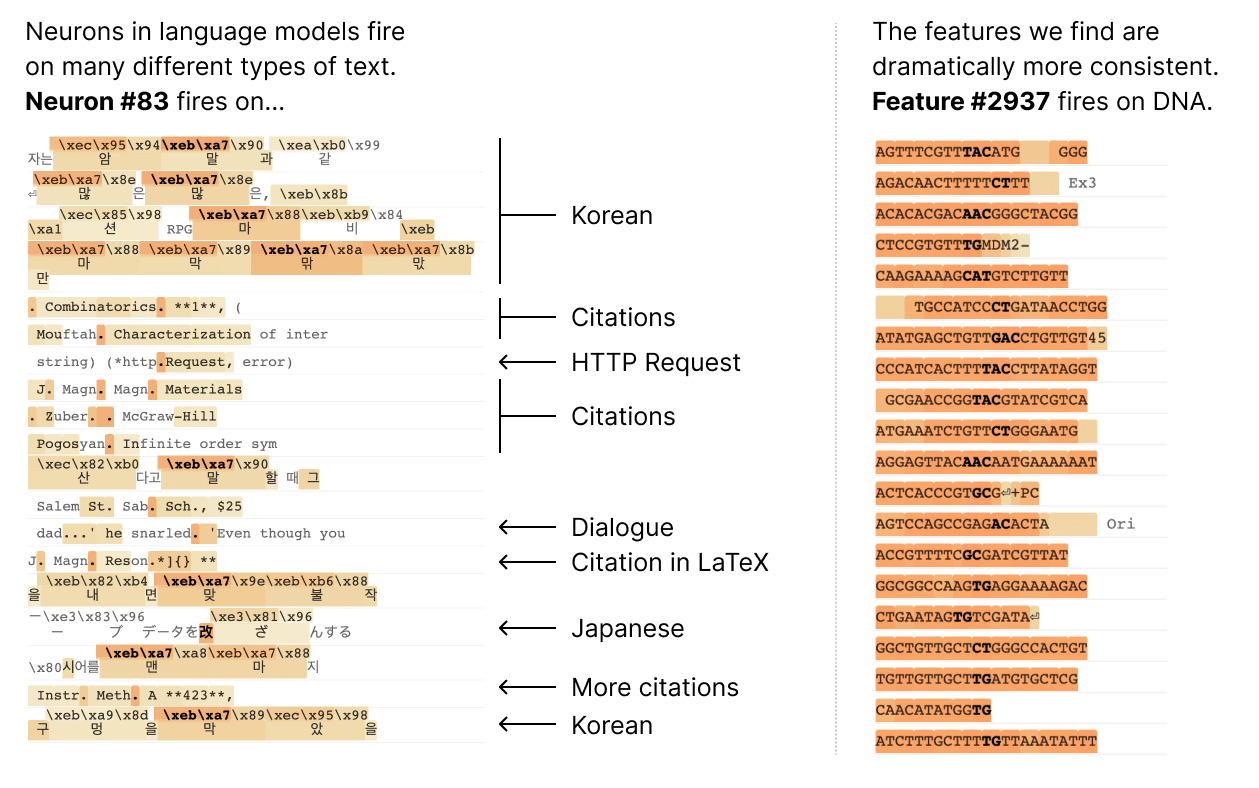
Unfortunately, it turns out that the individual neurons do not have consistent relationships to network behavior. For example, a single neuron in a small language model is active in many unrelated contexts, including: academic citations, English dialogue, HTTP requests, and Korean text. In a classic vision model, a single neuron responds to faces of cats and fronts of cars. The activation of one neuron can mean different things in different contexts.
In our latest paper, Towards Monosemanticity: Decomposing Language Models With Dictionary Learning, we outline evidence that there are better units of analysis than individual neurons, and we have built machinery that lets us find these units in small transformer models. These units, called features, correspond to patterns (linear combinations) of neuron activations. This provides a path to breaking down complex neural networks into parts we can understand, and builds on previous efforts to interpret high-dimensional systems in neuroscience, machine learning, and statistics.
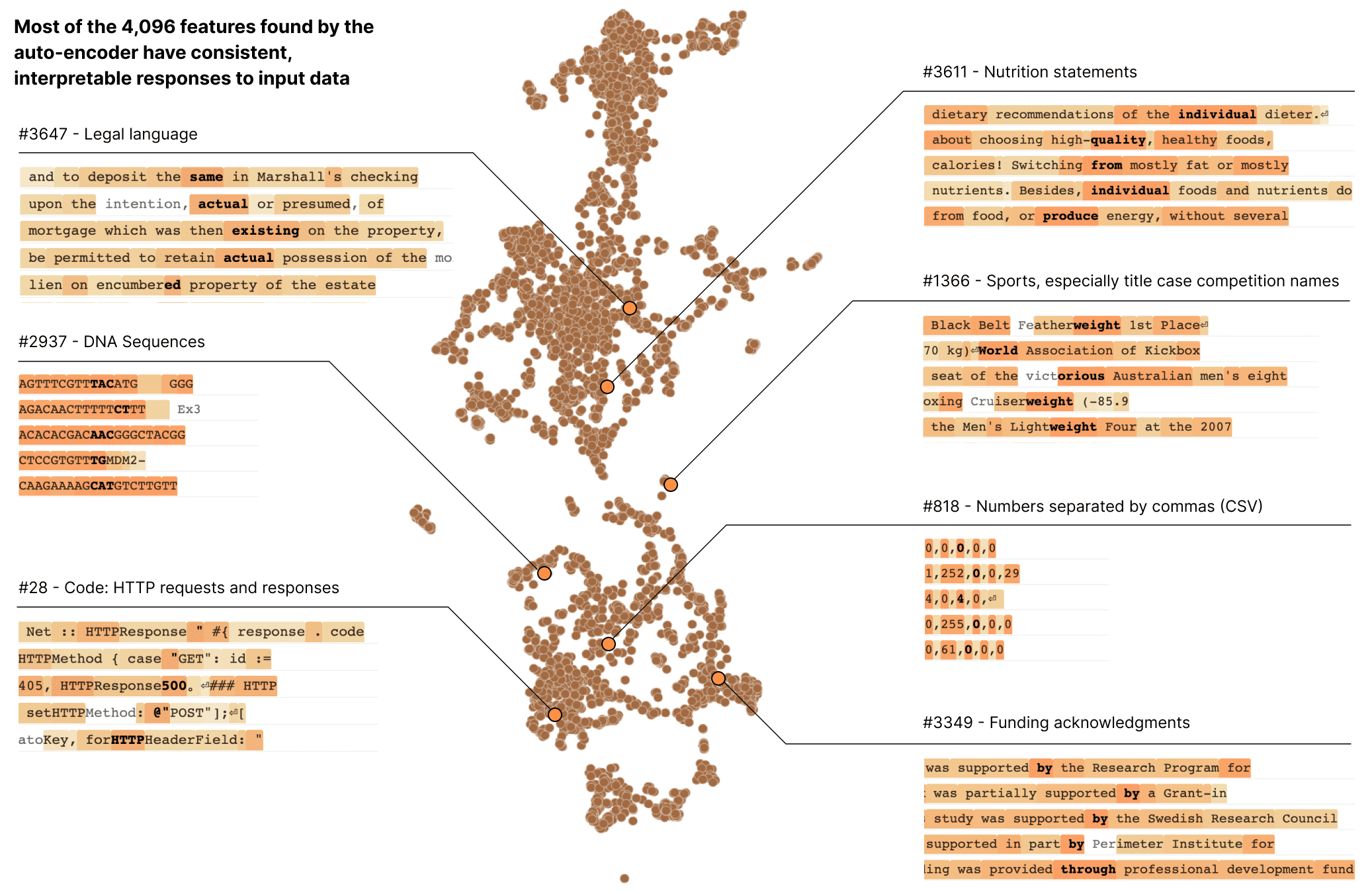
In a transformer language model, we decompose a layer with 512 neurons into more than 4000 features which separately represent things like DNA sequences, legal language, HTTP requests, Hebrew text, nutrition statements, and much, much more. Most of these model properties are invisible when looking at the activations of individual neurons in isolation.
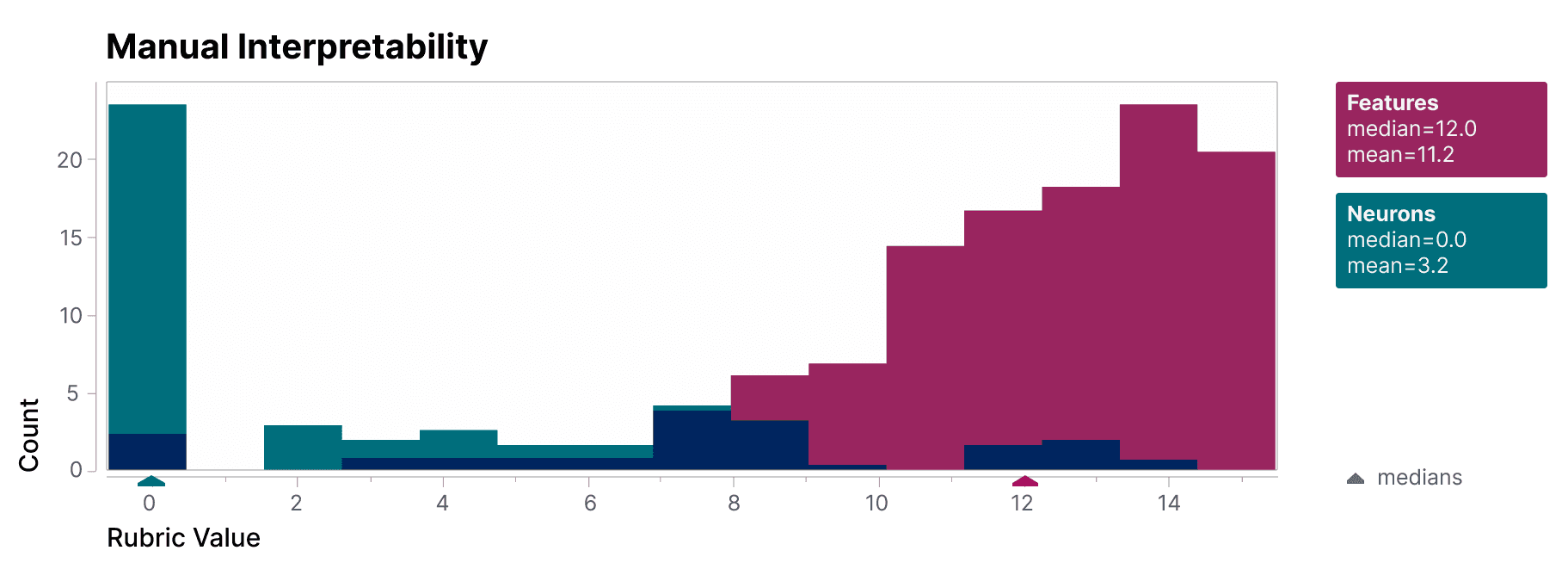
To validate that the features we find are significantly more interpretable than the model's neurons, we have a blinded human evaluator score their interpretability. The features (red) have much higher scores than the neurons (teal).
We additionally take an "autointerpretability" approach by using a large language model to generate short descriptions of the small model's features, which we score based on another model's ability to predict a feature's activations based on that description. Again, the features score higher than the neurons, providing additional evidence that the activations of features and their downstream effects on model behavior have a consistent interpretation.
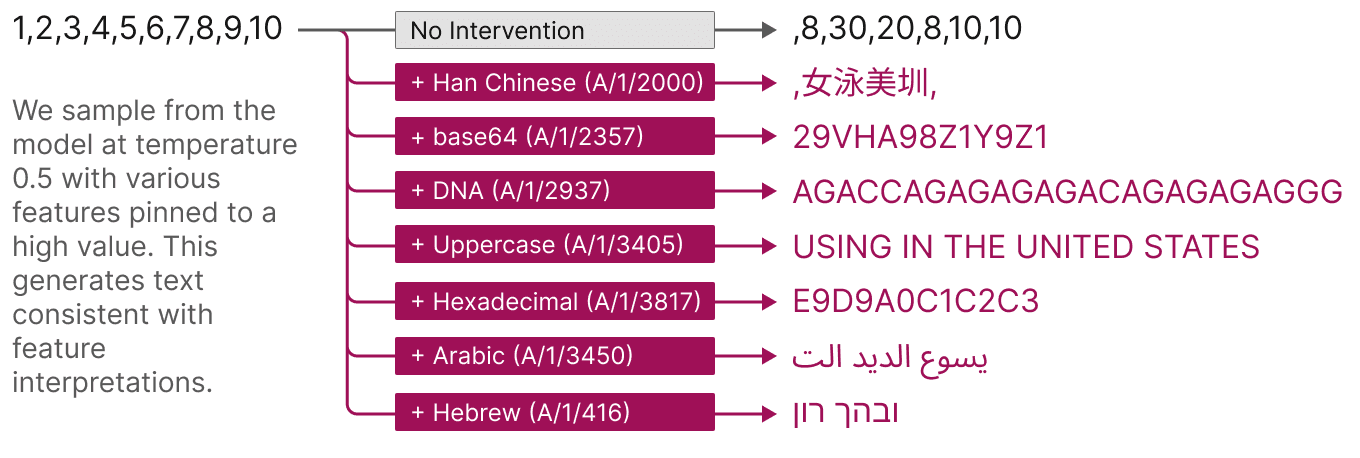
Features also offer a targeted way to steer models. As shown below, artificially activating a feature causes the model behavior to change in predictable ways.
Finally, we zoom out and look at the feature set as a whole. We find that the features that are learned are largely universal between different models, so the lessons learned by studying the features in one model may generalize to others. We also experiment with tuning the number of features we learn. We find this provides a "knob" for varying the resolution at which we see the model: decomposing the model into a small set of features offers a coarse view that is easier to understand, and decomposing it into a large set of features offers a more refined view revealing subtle model properties.
This work is a result of Anthropic’s investment in Mechanistic Interpretability – one of our longest-term research bets on AI safety. Until now, the fact that individual neurons were uninterpretable presented a serious roadblock to a mechanistic understanding of language models. Decomposing groups of neurons into interpretable features has the potential to move past that roadblock. We hope this will eventually enable us to monitor and steer model behavior from the inside, improving the safety and reliability essential for enterprise and societal adoption.
Our next challenge is to scale this approach up from the small model we demonstrate success on to frontier models which are many times larger and substantially more complicated. For the first time, we feel that the next primary obstacle to interpreting large language models is engineering rather than science.
22 comments
Comments sorted by top scores.
comment by nostalgebraist · 2023-10-09T01:09:21.577Z · LW(p) · GW(p)
Very interesting! Some thoughts:
Is there a clear motivation for choosing the MLP activations as the autoencoder target? There are other choices of target that seem more intuitive to me (as I'll explain below), namely:
- the MLP's residual stream update (i.e. MLP activations times MLP output weights)
- the residual stream itself (after the MLP update is added), as in Cunningham et al [LW · GW]
In principle, we could also imagine using the "logit versions" of each of these as the target:
- the change in logits due to the residual stream update[1]
- the logits themselves
(In practice, the "logit versions" might be prohibitively expensive because the vocab is larger than other dimensions in the problem. But it's worth thinking through what might happen if we did autoencode these quantities.)
At the outset, our goal is something like "understand what the MLP is doing." But that could really mean one of 2 things:
- understand the role that the function computed by the MLP sub-block plays in the function computed by the network as whole
- understand the role that the function computed by the MLP neurons plays in the function computed by the network as whole
The feature decomposition in the paper provides a potentially satisfying answer for (1). If someone runs the network on a particular input, and asks you to explain what the MLP was doing during the forward pass, you can say something like:
Here is a list of features that were activated by the input. Each of these features is active because of a particular, intuitive/"interpretable" property of the input.
Each of these features has an effect on the logits (its logit weights), which is intuitive/"interpretable" on the basis of the input properties that cause it to be active.
The net effect of the MLP on the network's output (i.e. the logits) is approximately[2] a weighted sum over these effects, weighted by how active the features were. So if you understand the list of features, you understand the effect of the MLP on the output.
However, if this person now asks you to explain what MLP neuron A/neurons/472 was doing during the forward pass, you may not be able to provide a satisfying answer, even with the feature decomposition in hand.
The story above appealed to the interpetability of each feature's logit weights. To explain individual neuron activations in the same manner, we'd need the dictionary weights to be similarly interpretable. The paper doesn't directly address this question (I think?), but I expect that the matrix of dictionary weights is fairly dense[3] and thus difficult to interpret, with each neuron being a long and complicated sum over many apparently unrelated features. So, even if we understand all the features, we still don't understand how they combine to "cause" any particular neuron's activation.
Is this a bad thing? I don't think so!
An MLP sub-block in a transformer only affects the function computed by the transformer through the update it adds to the residual stream. If we understand this update, then we fully understand "what the MLP is doing" as a component of that larger computation. The activations are a sort of "epiphenomenon" or "implementation detail"; any information in the activations that is not in the update is inaccessible the rest of the network, and has no effect on the function it computes[4].
From this perspective, the activations don't seem like the right target for a feature decomposition. The residual stream update seems more appropriate, since it's what the rest of the network can actually see[5].
In the paper, the MLP that is decomposed into features is the last sub-block in the network.
Because this MLP is the last sub-block, the "residual stream update" is really just an update to the logits. There are no indirect paths going through later layers, only the direct path.
Note also that MLP activations are have a much more direct relationship with this logit update than they do with the inputs. If we ignore the nonlinear part of the layernorm, the logit update is just a (low-rank) linear transformation of the activations. The input, on the other hand, is related to the activations in a much more complex and distant manner, involving several nonlinearities and indeed most of the network.
With this in mind, consider a feature like A/1/2357. Is it...
- ..."a base64-input detector, which causes logit increases for tokens like 'zc' and 'qn' because they are more likely next-tokens in base64 text"?
- ..."a direction in logit-update space pointing towards 'zc' and 'qn' (among other tokens), which typically has ~0 projection on the logit update, but has large projection in a rare set of input contexts corresponding to base64"?
The paper implicitly the former view: the features are fundamentally a sparse and interpretable decomposition of the inputs, which also have interpretable effects on the logits as a derived consequence of the relationship between inputs and correct language-modeling predictions.
(For instance, although the automated interpretability experiments involved both input and logit information[6], the presentation of these results in the paper and the web app (e.g. the "Autointerp" and its score) focuses on the relationship between features and inputs, not features and outputs.)
Yet, the second view -- in which features are fundamentally directions in logit-update space -- seems closer to the way the autoencoder works mechanistically.
The features are a decomposition of activations, and activations in the final MLP are approximately equivalent to logit updates. So, the features found by the autoencoder are
- directions in logit-update space (because logit-updates are, approximately[7], what gets autoencoded),
- which usually have small projection onto the update (i.e. they are sparse, they can usually be replaced with 0 with minimal degradation),
- but have large projection in certain rare sets of input contexts (i.e. they have predictive value for the autoencoder, they can't be replaced with 0 in every context)
To illustrate the value of this perspective, consider the token-in-context features. When viewed as detectors for specific kinds of inputs, these can seem mysterious or surprising:
But why do we see hundreds of different features for "the" (such as "the" in Physics, as distinct from "the" in mathematics)? We also observe this for other common words (e.g. "a", "of"), and for punctuation like periods. These features are not what we expected to find when we set out to investigate one-layer models!
An example of such a feature is A/1/1078, which Claude glosses as
The [feature] fires on the word "the", especially in materials science writing.
This is, indeed, a weird-sounding category to delineate in the space of inputs.
But now consider this feature as a direction in logit-update space, whose properties as a "detector" in input space derive from its logit weights -- it "detects" exactly those inputs on which the MLP wants to move the logits in this particular, rarely-deployed direction.
The question "when is this feature active?" has a simple, non-mysterious answer in terms of the logit updates it causes: "this feature is active when the MLP wants to increase the logit for the particular tokens ' magnetic', ' coupling', 'electron', ' scattering' (etc.)"
Which inputs correspond to logit updates in this direction? One can imagine multiple scenarios in which this update would be appropriate. But we go looking for inputs on which the update was actually deployed, our search will be weighted by
- the ease of learning a given input-output pattern (esp. b/c this network is so low-capacity), and
- how often a given input-output pattern occurs in the Pile.
The Pile contains all of Arxiv, so it contains a lot of materials science papers. And these papers contain a lot of "materials science noun phrases": phrases that start with "the," followed by a word like "magnetic" or "coupling," and possibly more words.
This is not necessarily the only input pattern "detected" by this feature[8] -- because it is not necessarily the only case where this update direction is appropriate -- but it is an especially common one, so it appears at a glance to be "the thing the feature is 'detecting.' " Further inspection of the activation might complicate this story, making the feature seem like a "detector" of an even weirder and more non-obvious category -- and thus even more mysterious from the "detector" perspective. Yet these traits are non-mysterious, and perhaps even predictable in advance, from the "direction in logit-update space" perspective.
That's a lot of words. What does it all imply? Does it matter?
I'm not sure.
The fact that other teams have gotten similar-looking results, while (1) interpreting inner layers from real, deep LMs and (2) interpreting the residual stream rather than the MLP activations, suggests that these results are not a quirk of the experimental setup in the paper.
But in deep networks, eventually the idea that "features are just logit directions" has to break down somewhere, because inner MLPs are not only working through the direct path. Maybe there is some principled way to get the autoencoder to split things up into "direct-path features" (with interpretable logit weights) and "indirect-path features" (with non-interpretable logit weights)? But IDK if that's even desirable.
- ^
We could compute this exactly, or we could use a linear approximation that ignores the layer norm rescaling. I'm not sure one choice is better motivated than the other, and the difference is presumably small.
- ^
because of the (hopefully small) nonlinear effect of the layer norm
- ^
There's a figure in the paper showing dictionary weights from one feature (A/1/3450) to all neurons. It has many large values, both positive and negative. I'm imagining that this case is typical, so that the matrix of dictionary vectors looks like a bunch of these dense vectors stacked together.
It's possible that slicing this matrix along the other axis (i.e. weights from all features to a single neuron) might reveal more readily interpretable structure -- and I'm curious to know whether that's the case! -- but it seems a priori unlikely based on the evidence available in the paper. - ^
However, while the "implementation details" of the MLP don't affect the function computed during inference, they do affect the training dynamics. Cf. the distinctive training dynamics of deep linear networks, even though they are equivalent to single linear layers during inference.
- ^
If the MLP is wider than the residual stream, as it is in real transformers, then the MLP output weights have a nontrivial null space, and thus some of the information in the activation vector gets discarded when the update is computed.
A feature decomposition of the activations has to explain this "irrelevant" structure along with the "relevant" stuff that gets handed onwards. - ^
Claude was given logit information when asked to describe inputs on which a feature is active; also, in a separate experiment, it was asked to predict parts of the logit update.
- ^
Caveat: L2 reconstruction loss on logits updates != L2 reconstruction loss on activations, and one might not even be a close approximation to the other.
That said, I have a hunch they will give similar results in practice, based on a vague intuition that the training loss will tend encourage the neurons to have approximately equal "importance" in terms of average impacts on the logits. - ^
At a glance, it seems to also activate sometimes on tokens like " each" or " with" in similar contexts.
comment by Neel Nanda (neel-nanda-1) · 2024-12-07T01:45:24.232Z · LW(p) · GW(p)
Sparse autoencoders have been one of the most important developments in mechanistic interpretability in the past year or so, and significantly shaped the research of the field (including my own work). I think this is in substantial part due to Towards Monosemanticity, between providing some rigorous preliminary evidence that the technique actually worked, a bunch of useful concepts like feature splitting, and practical advice for training these well. I think that understanding what concepts are represented in model activations is one of the most important problems in mech interp right now. Though highly imperfect, SAEs seem the best current bet we have here, and I expect whatever eventually works to look at least vaguely like an SAE.
I have various complaints and caveats about the paper (that I may elaborate on in a longer review in the discussion phase), and pessimisms about SAEs, but I think this work remains extremely impactful and significantly net positive on the field, and SAEs are a step in the right direction.
comment by Matt Goldenberg (mr-hire) · 2023-10-06T15:55:00.970Z · LW(p) · GW(p)
Anthropic is making a big deal of this and what it means for AI safety - it sort of reminds me of the excitement MIRI had when discovering logical inductors. I've read through the paper, and it does seem very exciting to be able to have this sort of "dial" that can find interpretable features at different levels of abstraction.
I'm curious about other people's takes on this who work in alignment. It seems like if something fundamental is being touched on here, then it could provide large boons to research agendas such as Mechanistic Interpretability agenda, Natural Abstractions, Shard Theory, and Ambitious Value Learning.
But it's also possible there are hidden gotchas I'm not seeing, or that this still doesn't solve the hard problem that people see in going from "inscrutable matrices" to "aligned AI".
What are people's takes?
Especially interested in people who are full-time alignment researchers.
Replies from: abramdemski, sharmake-farah↑ comment by abramdemski · 2023-10-07T21:23:39.295Z · LW(p) · GW(p)
The basic idea is not new to me -- I can't recall where, but I think I've probably seen a talk observing that linear combinations of neurons, rather than individual neurons, are what you'd expect to be meaningful (under some assumptions) because that's how the next layer of neurons looks at a layer -- since linear combinations are what's important to the network, it would be weird if it turned out individual neurons were particularly meaningful. This wasn't even surprising to me at the time I first learned about it.
But it's great to see it illustrated so well!
In my view, this provides relatively little insights to the hard questions of what it even means to understand what is going on inside a network (so, for example, it doesn't provide any obvious progress on the hard version of ELK). So how useful this ultimately turns out to be for aligning superintelligence depends on how useful "weak methods" in general are. (IE methods with empirical validation but which don't come with strong theoretical arguments that they will work in general.)
That being said, I am quite glad that such good progress is being made, even if it's what I would classify as "weak methods".
Replies from: joel-burget↑ comment by Joel Burget (joel-burget) · 2023-10-08T22:37:13.856Z · LW(p) · GW(p)
How would you distinguish between weak and strong methods?
Replies from: abramdemski↑ comment by abramdemski · 2023-10-16T23:53:41.417Z · LW(p) · GW(p)
"Weak methods" means confidence is achieved more empirically, so there's always a question of how well the results will generalize for some new AI system (as we scale existing technology up or change details of NN architectures, gradient methods, etc). "Strong methods" means there's a strong argument (most centrally, a proof) based on a detailed gears-level understanding of what's happening, so there is much less doubt about what systems the method will successfully apply to.
Replies from: TurnTrout↑ comment by TurnTrout · 2023-10-19T00:38:30.004Z · LW(p) · GW(p)
as we scale existing technology up or change details of NN architectures, gradient methods, etc
I think most practical alignment techniques have scaled quite nicely, with CCS maybe being an exception, and we don't currently know how to scale the interp advances in OP's paper.
Blessings of scale (IIRC): RLHF, constitutional AI / AI-driven dataset inclusion decisions / meta-ethics, activation steering / activation addition (LLAMA2-chat results forthcoming), adversarial training / redteaming, prompt engineering (though RLHF can interfere with responsiveness),...
I think the prior strongly favors "scaling boosts alignability" (at least in "pre-deceptive" regimes, though I have become increasingly skeptical of that purported phase transition, or at least its character).
"Weak methods" means confidence is achieved more empirically
I'd personally say "empirically promising methods" instead of "weak methods."
↑ comment by Noosphere89 (sharmake-farah) · 2023-10-06T16:56:36.982Z · LW(p) · GW(p)
A useful advance, but it definitely needs to scale, and you could reasonably argue that it still needs a lot more work before it can be very useful.
comment by Raemon · 2023-11-02T18:40:09.515Z · LW(p) · GW(p)
Curated.
It's still unclear to me how well interpretability can scale and solve the core problems in superintelligence alignment, but this felt like a good/healthy incremental advance. I appreciated the exploration of feature splitting, beginnings of testing for universality, and discussion of the team's update against architectural approaches. I found this remark at the end interesting:
Finally, we note that in some of these expanded theories of superposition, finding the "correct number of features" may not be well-posed. In others, there is a true number of features, but getting it exactly right is less essential because we "fail gracefully", observing the "true features" at resolutions of different granularity as we increase the number of learned features in the autoencoder.
I don't think I've parsed the paper well enough to confidently endorse how well the paper justifies its claims, but it seemed to pass a bar that was worth paying attention to, for people tracking progress in the interpretability field.
One comment I'd note is that I'd have liked more information about how the feature interpretability worked in progress. The description is fairly vague. When reading this paragraph:
We see that features are substantially more interpretable than neurons. Very subjectively, we found features to be quite interpretable if their rubric value was above 8. The median neuron scored 0 on our rubric, indicating that our annotator could not even form a hypothesis of what the neuron could represent! Whereas the median feature interval scored a 12, indicating that the annotator had a confident, specific, consistent hypothesis that made sense in terms of the logit output weights.
I certainly can buy that the features were a lot more interpretable than individual neurons, but I'm not sure, at the end of the day, how useful the interpretations of features were in absolute terms.
comment by Burny · 2023-10-07T06:21:18.065Z · LW(p) · GW(p)
We're at the start of interpretability, but the progress is lovely! Superposition was such a bottleneck even in small models.
More notes:
https://twitter.com/ch402/status/1710004685560750153 https://twitter.com/ch402/status/1710004416148058535
"Scalability of this approach -- can we do this on large models? Scalability of analysis -- can we turn a microscopic understanding of large models into a macroscopic story that answers questions we care about?"
"Make this work for real models. Find out what features exist in large models. Understand new, more complex circuits."
When it comes to manipulation, other recent paper seems more promising IMO! Like fMRI.
https://twitter.com/mezaoptimizer/status/1709292930416910499
https://arxiv.org/abs/2310.01405
"This might be the biggest alignment paper of the year. Everyone has been complaining that mechanistic interpretability is like doing LLM cell microbiology, when what we really need is LLM neuro-imaging. Well now we have it: "representation engineering" Similar to an fMRI scan, CAIS creates the LAT (Linear Artificial Tomography) scan. They also do a form of LLM neuro-modulation, getting the model to be honest or deceptive by just adding in a vector to its activations. imo this could be the winning alignment agenda"
comment by Joseph Miller (Josephm) · 2023-10-07T00:45:58.711Z · LW(p) · GW(p)
Looking at their interactive visualization, I was surprised how clean random learned features are.
comment by Miko Planas (miko-planas) · 2023-10-07T06:02:50.087Z · LW(p) · GW(p)
I'm quite interested in further understanding how the naming of these features will scale once we increase the layers of the transformer model and increase the size of the sparse autoencoder. This sounds like the search space for the large model doing the autointerpreting will become massive. Intuitively, might this affect the reliability of the short descriptions generated by the autointerpretability model? Additionally, if the model being analyzed -- as well as the sparse autoencoder -- is sufficiently larger than the autointerpreting model, how will this affect the reliability of the generation?
I am interested in answering those questions because I am trying to understand the utility of learning a massive dictionary, as well as the feasibility of autogenerating descriptions for the features (engineering problem).
comment by Michaël Trazzi (mtrazzi) · 2023-10-06T17:26:59.234Z · LW(p) · GW(p)
Our next challenge is to scale this approach up from the small model we demonstrate success on to frontier models which are many times larger and substantially more complicated.
What frontier model are we talking about here? How would we know if success had been demonstrated? What's the timeline for testing if this scales?
Replies from: zac-hatfield-dodds↑ comment by Zac Hatfield-Dodds (zac-hatfield-dodds) · 2023-10-06T19:59:34.066Z · LW(p) · GW(p)
The obvious targets are of course Anthropic's own frontier models, Claude Instant and Claude 2.
Problem setup: what makes a good decomposition? discusses what success might look like and enable - but note that decomposing models into components is just the beginning of the work of mechanistic interpretability! Even with perfect decomposition we'd have plenty left to do, unraveling circuits and building a larger-scale understanding of models.
comment by Rosco-Hunter · 2024-04-25T12:28:06.871Z · LW(p) · GW(p)
This was a really interesting paper; however, I was left with one question. Can anyone argue why exactly the model is motivated to learn a much more complex function than the identity map? An auto-encoder whose latent space is much smaller than the input is forced to learn an interesting map; however, I can't see why a highly over-parameterised auto-encoder wouldn't simply learn something close to an identity map. Is it somehow the regularisation or the bias terms? I'd love to hear an argument for why the auto-encoder is likely to learn these mono-semantic features as opposed to an identity map.
Replies from: zac-hatfield-dodds↑ comment by Zac Hatfield-Dodds (zac-hatfield-dodds) · 2024-04-25T15:35:05.260Z · LW(p) · GW(p)
It's a sparse autoencoder because part of the loss function is an L1 penalty encouraging sparsity in the hidden layer. Otherwise, it would indeed learn a simple identity map!
comment by Review Bot · 2024-04-06T09:18:14.560Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
comment by Tom Angsten (tom-angsten) · 2024-01-26T16:35:23.940Z · LW(p) · GW(p)
Superposition of features is only advantageous at a certain point in a network when it is followed by non-linear filtering, as explained in Toy Models of Superposition. Yet, this work places the sparse autoencoder at a point in the one-layer LLM which, up to the logits, is not followed by any non-linear operations. Given this, I would expect that there is no superposition among the activations fed to the sparse autoencoder, and that 512 (the size of the MLP output vector) is the maximum number of features the model can usefully represent.
If the above is true, then expansion factors to the sparse representation greater than 1 would not improve the quality or granularity of the 'true' feature representation. The additional features observed would not truly be present in the model's MLP activations, but would rather be an artifact of applying the sparse auto-encoder. Perhaps individual feature interpretability would still improve because the autoencoder could be driven to represent a rotation of the up-to 512 features to a privileged basis via the sparsity penalty. That all said, this work clearly reports various metrics, such as log-likelihood loss reduction, as being improved as the number of sparse feature coefficients expands well beyond 512, which I would think strongly contradicts my point above. Please help me understand what I am missing.
Side note: There is technically a non-linearity after the features, i.e. the softmax operation on the logits (...and layer norm, which I assume is not worth considering for this question). I haven't seen this discussed anywhere, but perhaps softmax is capable of filtering interference noise and driving superposition?
Quotation from Toy Models of Superposition:
"The Saxe results reveal that there are fundamentally two competing forces which control learning dynamics in the considered model. Firstly, the model can attain a better loss by representing more features (we've labeled this "feature benefit"). But it also gets a worse loss if it represents more than it can fit orthogonally due to "interference" between features. In fact, this makes it never worthwhile for the linear model to represent more features than it has dimensions."
Quotation from this work:
"We can easily analyze the effects features have on the logit outputs, because these are approximately linear in the feature activations."
UPDATE: After some more thought, it seems clear that softmax can provide the filtering needed for superposition to be beneficial given a sparse distribution of features. It's interesting that some parts of the LLM model have ReLUs for decoding features, other parts have softmax. I wonder if these two different non-linearities have distinct impacts on the geometries of the over-complete feature basis.
comment by Bill Benzon (bill-benzon) · 2023-11-28T18:07:53.418Z · LW(p) · GW(p)
Scott Alexander has started a discussion of the monosemanticity paper over at Astral Codex Ten. In a response to a comment by Hollis Robbins I offered these remarks:
Though it is true, Hollis, that the more sophisticated neuroscientists have long ago given up any idea of a one-to-one relationship between neurons and percepts and concepts (the so-called "grandmother cell") I think that Scott is right that "polysemanticity at the level of words and polysemanticity at the level of neurons are two totally different concepts/ideas." I think the idea of distinctive features in phonology is a much better idea.
Thus, for example, English has 24 consonant phonemes and between 14 and 25 vowel phonemes depending on the variety of English (American, Received Pronunciation, and Australian), for a total between 38 and 49 phonemes. But there are only 14 distinctive features in the account given by Roman Jakobson and Morris Halle in 1971. So, how is it the we can account for 38-49 phonemes with only 14 features?
Each phoneme is characterized by more than one feature. As you know, each phoneme is characterized by the presence (+) of absence (-) of a feature. The relationship between phonemes and features can thus be represented by matrix having 38-49 columns, one for each phoneme, and 14 rows, one for each row. Each cell is then marked +/- depending on whether or not the feature is present for that phoneme. Lévi-Strauss adopted a similar system in his treatment of myths in his 1955 paper, "The Structural Study of Myth." I used such a system in one of my first publications, "Sir Gawain and the Green Knight and the Semiotics of Ontology," where I was analyzing the exchanges in the third section of the poem.
Now, in the paper under consideration, we're dealing with many more features, but I suspect the principle is the same. Thus, from the paper: "Just 512 neurons can represent tens of thousands of features." The set of neurons representing a feature will be unique, but it will also be the case that features share neurons. Features are represented by populations, not individual neurons, and individual neurons can participate in many different populations. In the case of animal brains, Karl Pribram argued that over 50 years ago and he wasn't the first.
Pribram argued that perception and memory were holographic in nature. The idea was given considerable discussion back in the 1970s and into the 1980s. In 1982 John Hopfield published a very influential paper on a similar theme, "Neural networks and physical systems with emergent collective computational abilities." I'm all but convinced that LLMs are organized along these lines and have been saying so in recent posts and papers.
comment by Joshua Clancy (joshua-clancy) · 2023-11-02T22:29:13.431Z · LW(p) · GW(p)
How exactly are multiple features being imbedded within neurons?
Am I understanding this correctly? They are saying certain input combinations in context will trigger an output from a neuron. Therefore a neuron can represent multiple neurons. In this (rather simple) way? Where input a1 and a2 can cause an output in one context, but then in another context input a5 and a6 might cause the neuronal output?