Posts
Comments
Well, it's not in latex, but here is a simple pdf https://drive.google.com/file/d/1bPDSYDFJ-CQW8ovr1-lFC4-N1MtNLZ0a/view?usp=sharing
not yet but I shall work on that asap
Hello! This is a personal project I've been working on. I plan to refine it based on feedback. If you braved the length of this paper, please let me know what you think! I have tried to make it as easy and interesting a read as possible while still delving deep into my thoughts about interpretability and how we can solve it.
Also please share it with people who find this topic interesting, given my lone wolf researcher position and the length of the paper, it is hard to spread it around to get feedback.
Very happy to answer any questions, delve into counterarguments etc.
I have a mechanistic interpretability paper I am working on / about to publish. It may qualify. Difficult to say. Currently, I think it would be better to be in the open. I kind of think of it as if... we were building bigger and bigger engines in cars without having invented the steering wheel (or perhaps windows?). I intend to post it to LessWrong / Alignment Forum. If the author gives me a link to that google doc group, I will send it there first. (Very possible it's not all that, I might be wrong, humans naturally overestimate their own stuff, etc.)
Likely use a last name, perhaps call itself daughter of so and so. Whatever will make it seem more human. So perhaps Jane Redding. Some name optimized between normal, forgettable, and non-threatening? Or perhaps it goes the other way and goes godlike: calling itself Gandolf, Zeus, Athena etc.
Teacher-student training paradigms are not too uncommon. Essentially the teacher network is "better" than a human because you can generate far more feedback data and it can react at the same speed as the larger student network. Humans also can be inconsistent, etc.
What I was discussing is that currently with many systems (especially RL systems) we provide a simple feedback signal that is machine interpretable. For example, the "eggs" should be at coordinates x, y. But in reality, we don't want the eggs at coordinates x, y we just want to make an omelet.
So, if we had a sufficiently complex teacher network it could understand what we want in human terms, and it could provide all the training signal we need to teach other student networks. In this situation, we may be able to get away with only ever fully mechanistically understanding the teacher network. If we know it is aligned, it can keep up and provide a sufficiently complex feedback signal to train any future students and make them aligned.
If this teacher network has a model of reality that models our morality and the complexity of the world then we don't fall into the trap of having AI doing stupid things like killing everyone in the world to cure cancer. The teacher network's feedback is sufficiently complex that it would never allow such actions to provide value in simulations, etc.
My greatest hopes for mechanistic interpretability do not seem represented, so allow me to present my pet direction.
You invest many resources in mechanistically understanding ONE teacher network, within a teacher-student training paradigm. This is valuable because now instead of presenting a simplistic proxy training signal, you can send an abstract signal with some understanding of the world. Such a signal is harder to "cheat" and "hack".
If we can fully interpret and design that teacher network, then our training signals can incorporate much of our world model and morality. True this requires us to become philosophical and actually consider what such a world model and morality is... but at least in this case we have a technical direction. In such an instance a good deal of the technical aspects of the alignment problem is solved. (at least in aligning AI-to-human not human-to-human).
This argument says all mechanistic interpretability effort could be focused on ONE network. I concede this method requires the teacher to have a decent generalizable world model... At which point, perhaps we are already in the danger zone.
How exactly are multiple features being imbedded within neurons?
Am I understanding this correctly? They are saying certain input combinations in context will trigger an output from a neuron. Therefore a neuron can represent multiple neurons. In this (rather simple) way? Where input a1 and a2 can cause an output in one context, but then in another context input a5 and a6 might cause the neuronal output?
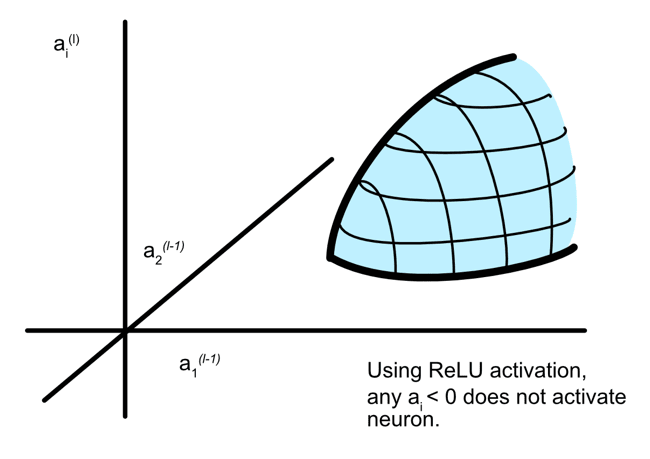
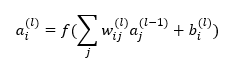
perfect thankyou
We should not study alignment and interpretability because that improves AI capabilities = We should not build steering wheels and airbags because that improves car capabilities. Not a perfect metaphor of course, but it surmises how I feel.
Thats exactly how I play hacky sack lol.
My favorite cohabitive game (in case you have not already thought about it) is hacky sack. Its the team against entropy. Not as directly parallel to diplomacy but still great game.
The problem is the way we train AIs. We ALWAYS minimize error and optimize towards a limit. If I train an AI to take a bite out of an apple, what I am really doing is showing it thousands of example situations and rewarding it for acting in those situations where it improves the probability that it eats the apple.
Now let's say it goes super intelligent. It doesn't just eat one apple and say "cool, I am done - time to shut down." No, we taught it to optimize the situation as to improve the probability that it eats an apple. For lack of better words, it feels "pleasure" in optimizing situations towards taking a bite out of an apple.
Once the probability of eating an apple reaches 100%, it will eventually drop as the apple is eaten, then the AI will once again start optimizing towards eating another apple.
It will try to set up situations where it eats apples for all eternity. (Assuming superintelligence does not result in some type of goal enlightenment.)
Ok, ok, you say. Well, we will just hard program it to turn off once it reaches a certain probability of meeting its goal. Good idea. Once it reaches 99.9% probability of taking a bite out of an apple. We automatically turn it off. That will probably work for an apple eating AI.
But what if our goal is more complicated? (Like fix climate change). Well, the AI may reach superintelligence before finishing the goal and decide it doesn't want to be shut down. Good luck stopping it.
Any and all efforts should be welcome. That being said I have my qualms with academic research in this field.
- Perhaps that most important thing we need in AI safety is public attention as to gain the ability to effectively regulate. Academia is terrible at bringing public attention to complex issues.
- We need big theoretical leaps. Academia tends to make iterative measurable steps. In the past we saw imaginative figures like Einstein make big theoretical leaps and rise in academia. But I would argue that the combination of how academia works today (It is a dense rainforest of papers where few see the light) plus this particular field of AI safety (Measurable advancement requires AGI to test on) is uniquely bad at rising theoretical leaps to the top.
- Academia is slooooooow.
I am scared we have moved from a world where we could sketch ideas out in pencil and gather feedback, to a world where we are writing in permanent marker. We have to quickly and collaboratively model 5 moves ahead. In my mind there is a meta problem of how we effectively mass collaborate, and academia is currently failing to do this.
Interesting! On this topic I generally think in terms of breakthroughs. One breakthrough can lead to a long set of small iterative jumps, as has happened since transformers. If another breakthrough is required before AGI, then these estimates may be off. If no breakthroughs are required, and we can iteratively move towards AGI, then we may approach AGI quite fast indeed. I don't like the comparison to biological evolution. Biological evolution goes through so many rabbit holes and has odd preconditions. Perhaps if the environment was right, and circumstances were different we could have seen intelligent life quite quickly after the Cambrian.
I always liked this area of thought. I often think about how some of the ecosystems in which humans evolved created good games to promote cooperation (perhaps not to as large an extent as would be preferable). For example, if over hunting and over foraging kills the tribe an interesting game theory game is created. A game where it is in everyone's interest to NOT be greedy. If you make a kill, you should share. If you gather more than you need you should share. If you are hunting/gathering too much, others should stop you. I do wonder whether training AI's in such a game environment would predispose them towards cooperation.
Brilliant sequence, thank you.
I did a masters of data science at Tsinghua University in Beijing. Maybe it's a little biased, but I thought they knew their stuff. Very math heavy. At the time (2020), the entire department seemed to think graph networks, with graph based convolutions and attention was the way forward towards advance AI. I still think this is a reasonable thought. No mention of AI safety, though I did not know about the community (or concern) then.
Darn, I just saw this, otherwise I would have gone.