Should we publish mechanistic interpretability research?
post by Marius Hobbhahn (marius-hobbhahn), LawrenceC (LawChan) · 2023-04-21T16:19:40.514Z · LW · GW · 40 commentsContents
The basic case for publishing Capabilities externalities of mechanistic interpretability Other possible reasons why publishing could be net negative Misc. considerations Counterfactual considerations Differential publishing Preliminary suggestions Opinions Richard Stephen Casper Lucius Neel Nate Soares None 40 comments
TL;DR: Multiple people have raised concerns about current mechanistic interpretability research having capabilities externalities. We discuss to which extent and which kind of mechanistic interpretability research we should publish. The core question we want to explore with this post is thus to which extent the statement “findings in mechanistic interpretability can increase capabilities faster than alignment” is true and should be a consideration. For example, foundational findings in mechanistic interpretability may lead to a better understanding of NNs which often straightforwardly generates new hypotheses to advance capabilities.
We argue that there is no general answer and the publishing decision primarily depends on how easily the work advances alignment in relation to how much it can be used to advance capabilities. We recommend a differential publishing process where work with high capabilities potential is initially only circulated with a small number of trusted people and organizations and work with low capabilities potential is published widely.
Related work: A note about differential technological development [AF · GW], Current themes in mechanistic interpretability research [AF · GW], Thoughts on AGI organization and capabilities work [AF · GW], Dan Hendrycks’s take [AF(p) · GW(p)], etc.
We have talked to lots of people about this question and lost track of who to thank individually. In case you talked to either Marius or Lawrence about this, thank you!
The basic case for publishing
Let’s revisit the basic cases for publishing.
- Alignment is probably hard. To get even close to a solution, it likely requires many people working together, coordinating their work and patching together different approaches. If the work isn’t public, this becomes much harder and thus a solution to alignment becomes less likely.
- More people can engage with the work and build on it. Especially people who want to get into the field or are less connected might not be able to access documents that are only shared in small circles.
- It gives more legitimacy to the work of organisations and individuals. For people who are not yet established in the field, publishing their work is the most obvious way to get noticed by an organisation. For academics, publications are the most relevant resource for their careers and organisations can generate more legitimacy by publishing their work (e.g. for grantmakers or other organisations they want to interact with).
- It is a form of movement building. If work on mechanistic interpretability is regularly shown on ML conferences and is available on arxiv, it is more likely that people outside of the alignment field notice that the field exists and get interested in it.
- Publication leads to accountability and feedback. If you know you will publish something, you put more effort into explaining it well and ensuring that your findings are robust. Furthermore, it provides a possibility for other researchers to engage with your work and give you feedback for improvement or future research directions.
In addition, mechanistic interp seems especially well suited for publication in classic academic venues since it is less speculative than other AI safety work and overlaps with established academic fields.
Thus, publication seems robustly positive as long as it doesn’t advance capabilities more than alignment (which is often hard to predict in advance). The crux of this post, therefore, lies mainly in the possible negative externalities of publications and how they trade off against the alignment benefits.
Capabilities externalities of mechanistic interpretability
The primary reason to think that mechanistic interpretability has large capabilities is that understanding a system better makes improvements easier. Historically a lot of applications were a downstream effect of previous foundational research. This seems true for a lot of scientific advances in general, e.g. improved understanding of biology lead to better medicine, but also for ML applications in particular. We decompose the capabilities externalities into multiple different paths.
- Direct insights: Interpretability work might directly produce an insight that increases capabilities, e.g. an attempt to make a network more interpretable might make it more capable. Empirically, all attempts to make networks more interpretable we are aware of have not yet made networks more efficient/capable. (That being said, some work like the SoLU paper does show that some gains in interpretability can come at near zero loss in capabilities).
- Motivation for new insight: Interpretability work can generate an insight that is then used as a motivation for capabilities work. Two recent capability papers (see here and here) have cited the induction heads work by Anthropic as a core motivation (confirmed by authors).
- Supporting capabilities work: Interpretability tools can often speed up the iterations of capability work. For example, if you would be able to reliably detect if a network has learned a specific concept or understand the circuit responsible for that behavior, you might be able to iterate much faster with fine-tuning the model to have that property. In general, better and more detailed evaluations from interpretability decrease the time of iterations.
It’s worth noting that historically, most capability advances were not the result of a detailed understanding of NNs--rather, they were the result of a mix of high-level insights and trial and error. In particular, it seems that existing work interpreting concrete networks has been counterfactually responsible for very few capability gains (other than the two cases cited above).
Unfortunately, we think it’s likely that the potential capability implications of interpretability are proportional to its usefulness for alignment, i.e. better interpretability tools are both better for safety and also increase capabilities more since they yield better insights. Thus, the historic lack of capabilities advances from mechanistic interpretability potentially just indicate that interpretability is too far behind the state of the art to be useful at the moment. But that could change once it catches up.
Other possible reasons why publishing could be net negative
We think these are much less relevant than the capabilities externalities but still worth mentioning.
- Leaking the alignment test set. If we develop powerful tools and benchmarks to detect deception in real-world models, organizations might start to train against these tools and benchmarks. Thus, they might overfit to the specific subset of ideas we came up with but their models are not robust against the kinds of deception we haven’t thought of. It’s important to keep some amount of safety or alignment evaluations “in reserve”, so as to get a better sense of how the models will perform in deployment.
- General hype around AI. Just like GPT-N creates hype around AI, understanding the inner workings of NNs can be fascinating and gets more people excited about the field of AI. However, we think the hype coming from mechanistic interpretability is much smaller than from other work. Furthermore, hype about mechanistic interpretability could even move some researchers from generic capabilities work to interpretability.
- Future AIs might read some of our work. Future models will likely be able to browse the internet and understand the content that describes how they work and how we measure their safety. While there are ways to prevent that, e.g. filtering the content that AIs can read, we should expect none of these filters to be entirely bullet-proof.
Misc. considerations
- It’s hard/impossible to reverse a publication decision. Once an insight is published on the internet it is very hard/impossible to take back. Some people might have downloaded the post or they can find the article with help of the wayback machine. Even if we were able to successfully remove all of the information from the internet, someone might just remember the method and reimplement it from scratch.
- Most people don’t care about alignment Most people who work on ML do not care about alignment but they either directly care about improving the capabilities of ML systems or they are otherwise incentivized to do so (e.g. publications, job opportunities, etc.). Therefore, if you publish to a large audience (e.g. Twitter or ML conference), most of the people who read your work will care more about advancing capabilities than alignment (the alignment people might read it more carefully though).
- Impactful findings are heavy-tailed. Most insights are unlikely to lead to major advances--neither for alignment nor for capabilities. However, some findings have disproportionately large effects. For example, the original transformer paper likely had major consequences for the entire field of AI. The upsides are also heavy-tailed which makes this argument hard to evaluate in practice. For example, a major breakthrough in understanding superposition could both lead to huge leaps in our ability to understand the computations of LLMs but could also lead to more efficient architectures [1]that e.g reduce the compute cost of transformers by an OOM.
The main takeaway from this section is that a small number of publishing decisions will carry most of the impact. For example, if you publish 5 minor things and it goes well (i.e. doesn’t lead to harm), you should not conclude that a major publication will also go well.[2]
Counterfactual considerations
The previous considerations were presented in a vacuum, i.e. we presented effects that are plausibly negative. However, the alternative world could be even worse and we thus look at counterfactual considerations.
- Interpretability might be very important to alignment and it’s thus worth taking the trade-off. Even if it is true that mechanistic interpretability can lead to additional capabilities, it might still be better on net to publish them. If we believe, for example, that deception is the problem that will ultimately lead to catastrophic failures and that understanding the internal cognition of models is necessary to solve deception. Additionally, interpretability might be especially well-suited for fieldbuilding. Under these assumptions, it might be more important to spread information about interpretability even if they carry some risk because the counterfactual would be worse.
- Capabilities that rely on a better understanding of the model are better for alignment. Let’s say, for example, that mechanistic interpretability leads to a breakthrough in understanding superposition in transformers. Assume that, as a result, transformers would be more compute-efficient but also more interpretable. A world in which we build more efficient and more interpretable models might be better than a world in which we create capabilities through scale and trial and error. However, these more interpretable architectures would likely be quickly combined or modified in trial-and-error ways that reduce their interpretability.
Differential publishing
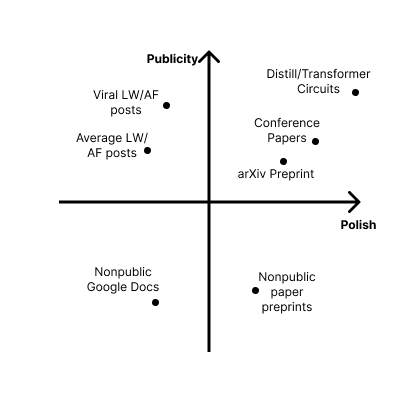
Obviously, publishing can mean very different things. In order of increasing effort and readership size, publishing can mean:
- Publishing to the floating google doc economy: This means sending a google doc or private preprint that describe your findings to a small circle of people who you expect to benefit from seeing the research and trust to use it confidentially. This inner circle usually does not include people who are new to the field.
- Posting on LW/AF: While not everyone who reads LW/AF cares about alignment, it is most likely the public venue with the highest ratio of people who are about alignment vs. who don’t.
- Publishing to Arxiv: If you want to be recognized by anyone in academia, your paper has to be at least on arxiv. Blog posts, no matter how good, usually do not count as research in traditional academia.
- Submitting to a conference: A publication on a top conference will give you reputation among academics and your readership is likely much wider and more heterogeneous than on LW/AF.
A caveat: while the average LW/AF post has relatively low readership and a high alignment/non-alignment ratio, viral LW/AF posts can reach a wide audience. For example, after its tweet thread went viral, Neel Nanda’s grokking work [AF · GW] was widely circulated amongst the academic interpretability community. Given the hit-based nature of virality, there isn’t a particular place to put it on the hierarchy, but it’s worth noting that Twitter threads can sometimes greatly increase the publicity of a post.
Preliminary suggestions
- Be cautious by default, it’s hard to unpublish. Assume you had a very foundational insight about how NNs work. You are excited and publish it somewhere on the internet. Through two corners you hear that people at BrainMind™ saw your idea and use it to make their current models more capable. There is no way to unpublish, the internet remembers.
- Which reach do you want to have with that post? Most of the direct alignment benefits for any project come from a relatively small community of alignment-oriented researchers who work on similar topics. All of the other benefits are either more vague, e.g. building a community of people who do interpretability, or more personal, e.g. the need for citations in an academic career.
- Assess the trade-off. Different projects imply different policies. Intuitively more foundational insights have higher potential downsides because they can lead to major changes in architectures or training regimes. Detection-focused techniques such as probing, seem to carry less risk because they usually don’t have major implications and projects that find more evidence for a previous finding (e.g. “we found another circuit”) carry very low risk.
- In case you’re unsure, ask someone who is more senior. Assessing a specific project is hard, especially if you’re less senior. Thus, reaching out to someone who has more expertise or reading through the opinions below, might give you a sense of the different considerations.
- Don’t worry too much about it if it’s your first project and unmentored. Sometimes people who want to get started in the field are paralyzed because they think their project might be infohazardous. We think it is very unlikely that the first project people try (especially without mentorship) has the potential to cause a lot of harm. In case you’re really convinced that there is cause for concern, reach out to someone more senior.
Opinions
Different people have very different opinions about this question and it seems hard to combine them. Thus, we decided to ask multiple people in the alignment scene about their stance on this question.
Richard
It seems really straightforwardly good to me to publish (almost all) mechanistic interpretability work; it’s so far down the list of things we should be worrying about that by default I assume that objections to it are more strongly motivated by deontological rather than impact considerations. I’m generally skeptical of applying new deontological rules to decisions this complex; but even if we’re focusing on deontology, there are much bigger priorities to consider (e.g. EA’s relationship to AI labs).
Stephen Casper
I enjoyed these thoughts, and there are a few overarching thoughts I have on it.
Is mechanistic interpretability the best category to ask this question about? On one hand, this may be a special case of a broader point involving research in the science of ML. Worries about risks from basic research insights do not seem unique to interpretability. On the other hand, different types of (mechanistic) interpretability research seem likely to have very different implications for safety vs. risky capabilities.
Interpretability tools often trade off with capabilities. In these cases, it might be extra important to publish. For example, disentanglement techniques, adversarial training, modularity techniques, bottlenecking, compression, etc. are all examples of things that tend to harm a network’s performance on the task while making them more interpretable. There are exceptions to this like model editing tools and some architectures. But overall, it seems that in most existing examples, more interpretable models are less capable.
Mechanistic interpretability may not be the elephant in the room. In general, lots of mechanistic interpretability work might not be very relevant for engineers [? · GW] – either for safety or capabilities. There’s a good chance this type of research might not be key either way, especially on short timelines. Meanwhile, RLHF is currently changing the world, and this has now prompted hasty retrospectives about whether it was net good, bad, or ok. At a minimum, mechanistic interpretability is not the only alignment-relevant work that all of these questions should be asked about.
If work is too risky to publish, it may often be good to avoid working on it at all. Pivotal acts could be great. And helping more risk-averse developers of TAI be more competitive seems good. But infohazardous work comes with inherent risks from misuse and copycatting. Much of the time, it may be useful to prioritize work that is more robustly good. And when risky things are worked on, it should be by people who are divested from potential windfalls resulting from it.
Lucius
I strongly agree that this is a thing we should be thinking about. That mechanistic interpretability has failed to meaningfully enhance capabilities so far is, I think, largely owed to current interpretability being really bad. The field has barely figured out the first thing about NN insides yet. I think the level of understanding needed for proper alignment and deception detection is massively above what we currently have. To give a rough idea, I think you probably need to understand LLMs well enough to be able to code one up by hand in C, without using any numerical optimisation, and have it be roughly as good as GPT-2. I would expect that level of insight to have a high risk of leading to massive capability improvements, since I see little indication that current architectures, which were found mostly through not-very-educated guesswork, are anywhere near the upper limit of what the hardware and data sets allow.
I would go further and suggest that we need to plan for what happens if we have some success and see fundamental insights that seem crucial for alignment, but might also be used to make a superintelligence. How do you keep researching and working with collaborators safely in that information environment? There does not currently exist much of an infrastructure for different orgs and researchers to talk to another under some level of security and trust. If not proper NDAs and vetting, at least the early establishment of stronger ecosystem norms around secrecy, and the normalization of legally non-binding, honor based NDAs might be in order. If we don’t do it now, it might become a roadblock that eats up valuable time later, near the end, when time is even more precious.
Neel
TLDR: I care most about how we prioritise research and how we shape the culture of the field. I want mech interp to be a large and thriving field, but one that prizes genuine scientific understanding and steerability of systems, and not a field where the goal is to make a number go up, or where capabilities advancements feel intrinsically high status. Thinking through whether to publish something does matter on the margin and should be done, but it's a lower order bit - most research that could directly cause harm if published is probably just not worth doing! And getting good at interpretability seems really important, in a way that makes me pretty opposed to secrecy or paralysis. I'm concerned about direct effects on capabilities (a la induction heads, or even more directly producing relevant ideas), but think that worrying about indirectly accelerating capabilities via eg field-building or producing fundamental insights about models that someone then builds on, is too hard and paralysing to be worthwhile. People new to the field tend to worry about this way too much, and should chill out.
—
I think these are important, but hard and thorny questions, and it's easy to end paralysed, or to avoid significant positive impact by being too conservative here. But also worth trying to carefully think through.
The most important question to me is not publication norms, but what research we do in the first place, and the norms in the field of what good research looks like. To me this is the highest leverage thing, especially as the field is small yet growing fast. My vision for the field of mechanistic interpretability is one that prizes rigorous, scientific understanding of models. And I personally judge by how well it tracked truth and taught me things about models, rather than whether it made models better. I'll feel pretty sad if we build a field of mech interp where the high-status thing to do is to push hard on making models better.
To me this is a much more important question than publication norms - if you do research that's net bad to publish, probably it would have been better to do something else with a clearer net win for alignment, all other things being the same. This can be hard to tell ahead of time, so I think this is worth thinking through before publishing, but that's a lower-order bit.
At a high level, I think that getting good at interpretability seems crucial to alignment going well (whether via mech interp or some other angle of attack), and we aren't very good at it yet! Further, it's a very hard problem, yet with lots of surface area to get traction on it, and I would like there to be a large and thriving field of mech interp. This includes significant effort from academia and outside the alignment community, which means having people who are excited about capabilities advancement. This means accepting that "do no harm" is an unrealistically high standard, and I mostly want to go full steam ahead on doing great mech interp work and publishing it and making it easy to build upon. I think that tracking the indirect effects here is hard and likely ineffective and unhelpful. Though I do think that "would this result directly help a capabilities researcher, in a way that does not result in interpretability understanding" is a question worth thinking about
I mostly think that interpretability so far has had fairly little impact on capabilities or alignment, but mostly because we aren't very good at it! If the ambitious claims of really understanding a system hold, then I expect this to be valuable for both, (in a way that's pretty correlated) though it seems far better on net than most capabilities work! We should plan for success - if we remain this bad at interpretability we should just give up and do something else. So to me the interesting question is how much there are research directions that push much harder on capabilities than alignment.
One area that's particularly interesting to me is using interpretability to make systems more steerable, like interpretability-assisted RLHF. This seems like it easily boosts capabilities and alignment, but IMO is a pretty important thing to practice and test, and see what it takes to get good at this in practice (or if it just breaks the interpretability techniques and makes the failures more subtle!).
Using mech interp to analyse fundamental scientific questions in deep learning like superposition is more confusing to me. I would mostly guess it's harmless (eg I would be pretty surprised if my grokking work is directly useful for capabilities!). For some specific questions like superposition, I think that better understanding this is one of the biggest open problems in mech interp, and well worth the capabilities externalities!
A final note is that these thoughts are aimed more at established researchers, and how we should think as we grow the field. I often see people new to the field, working independently without a mentor, who are very stressed about this. I think this is highly unproductive - an unmentored first project is probably not going to produce good research, let alone accidentally produce a real capabilities advance, and you should prioritise learning and seeing how much you enjoy the research.
Nate Soares
Depending on when this document is circulated, I either have a post in my drafts folder on this topic, or I have recently posted my thoughts on this topic [LW · GW]. I agree that the situation is pretty thorny. If the choice were all up to me and I had magic coordination powers, I'd create a large and thriving interpretability community that was committed to research closure relative to the larger world, while sharing research freely within the community, and while committing not to use the fruits of that research for capabilities advancements (until humanity understands intelligence well enough to use that knowledge wisely).
- ^
This likely depends a lot on how the “solution to superposition” looks like. A sparse coding scheme is less likely to be capabilities advancing than a fundamental insight into transformers that allows us to decode superposed features everywhere in the network.
- ^
Note that this goes both ways – just because mech interp. has not been particularly useful for alignment right now, does not mean that future work won’t!
40 comments
Comments sorted by top scores.
comment by Mark Xu (mark-xu) · 2023-04-21T17:52:49.531Z · LW(p) · GW(p)
Naively there are so few people working on interp, and so many people working on capabilities, that publishing is so good for relative progress. So you need a pretty strong argument that interp in particular is good for capabilities, which isn't borne out empirically and also doesn't seem that strong.
In general, this post feels like it's listing a bunch of considerations that are pretty small, and the 1st order consideration is just like "do you want people to know about this interpretability work", which seems like a relatively straightfoward "yes".
I also seperately think that LW tends to reward people for being "capabilities cautious" more than is reasonable, and once you've made the decision to not specifically work towards advancing capabilities, then the capabilities externalities of your research probably don't matter ex ante.
Replies from: Lblack, habryka4, marius-hobbhahn, lahwran↑ comment by Lucius Bushnaq (Lblack) · 2023-04-21T18:58:25.634Z · LW(p) · GW(p)
So you need a pretty strong argument that interp in particular is good for capabilities, which isn't borne out empirically and also doesn't seem that strong.
I think current interpretability has close to no capabilities externalities because it is not good yet, and delivers close to no insights into NN internals. If you had a good interpretability tool, which let you read off and understand e.g. how AlphaGo plays games to the extent that you could reimplement the algorithm by hand in C, and not need the NN anymore, then I would expect this to yield large capabilities externalities. This is the level of interpretability I aim for, and the level I think we need to make any serious progress on alignment.
If your interpretability tools cannot do things even remotely like this, I expect they are quite safe. But then I also don't think they help much at all with alignment. There's a roughly proportional relationship between your understanding of the network, and both your ability to align it and make it better, is what I'm saying. I doubt there's many deep insights to be had that further the former without also furthering the latter. Maybe some insights further one a bit more than the other, but I doubt you'd be able to figure out which ones those are in advance. Often, I expect you'd only know years after the insight has been published and the field has figured out all of what can be done with it.
I think it's all one tech tree, is what I'm saying. I don't think neural network theory neatly decomposes into a "make strong AGI architecture" branch and a "aim AGI optimisation at a specific target" branch. Just like quantum mechanics doesn't neatly decompose into a "make a nuclear bomb" branch and a "make a nuclear reactor" branch. In fact, in the case of NNs, I expect aiming strong optimisation is probably just straight up harder than creating strong optimisation.
By default, I think if anyone succeeds at solving alignment, they probably figured out most of what goes into making strong AGI along the way. Even just by accident. Because it's lower in the tech tree.
↑ comment by habryka (habryka4) · 2023-04-21T19:48:32.247Z · LW(p) · GW(p)
I also seperately think that LW tends to reward people for being "capabilities cautious" more than is reasonable, and once you've made the decision to not specifically work towards advancing capabilities, then the capabilities externalities of your research probably don't matter ex ante.
But isn't most of the interpretability research happening from people who have not made this commitment? Anthropic, which is currently the biggest publisher of interp-research, clearly does not have a commitment to not work towards advancing capabilities, and it seems important to have thought about what things Anthropic works on do maybe substantially increase capabilities (and which things they should hold off on).
I also separately don't buy that just because you aren't aiming to specifically work towards advancing capabilities that therefore publishing any of your work is fine. Gwern seems to not be aiming specifically towards advancing capabilities, but nevertheless seems to have had a pretty substantial effect on capability work, at least based on talking to a bunch of researchers in DL who cite Gwern as having been influential on them.
Replies from: rohinmshah, mark-xu, jskatt↑ comment by Rohin Shah (rohinmshah) · 2023-04-22T06:23:15.525Z · LW(p) · GW(p)
Why are you considering Anthropic as a unified whole here? Sure, Anthropic as a whole is probably doing some work that is directly aimed towards advancing capabilities, but this just doesn't seem true of the interp team. (I guess you could imagine that the only reason the interp team exists at Anthropic is that Anthropic believes interp is great for advancing capabilities, but this seems pretty unlikely to me.)
(Note that the criterion is "not specifically work towards advancing capabilities", as opposed to "try not to advance capabilities".)
Replies from: habryka4, JamesPayor↑ comment by habryka (habryka4) · 2023-04-22T17:50:04.694Z · LW(p) · GW(p)
I have found much more success modeling intentions and institutional incentives at the organization level than the team level.
My guess is the interpretability team is under a lot of pressure to produce insights that would help the rest of the org with capabilities work. In-general I've found arguments of the type of "this team in this org is working towards totally different goals than the rest of the org" to have a pretty bad track record, unless you are talking about very independent and mostly remote teams.
Replies from: T3t↑ comment by RobertM (T3t) · 2023-04-22T22:15:34.154Z · LW(p) · GW(p)
My guess is the interpretability team is under a lot of pressure to produce insights that would help the rest of the org with capabilities work
I would be somewhat surprised if this was true, assuming you mean a strong form of this claim (i.e. operationalizing "help with capabilities work" as relying predominantly on 1st-order effects of technical insights, rather than something like "help with capabilities work by making it easier to recruit people", and "pressure" as something like top-down prioritization of research directions, or setting KPIs which rely on capabilities externalities, etc).
I think it's more likely that the interpretability team(s) operate with approximately full autonomy with respect to their research directions, and to the extent that there's any shaping of outputs, it's happening mostly at levels like "who are we hiring" and "org culture".
Replies from: habryka4↑ comment by habryka (habryka4) · 2023-04-23T01:07:19.228Z · LW(p) · GW(p)
The pressure here looks more like "I want to produce work that the people around me are excited about, and the kind of thing they are most excited about is stuff that is pretty directly connected to improving capabilities", whereby I include "getting AIs to perform a wider range of economically useful tasks" as "improving capabilities".
I definitely don't think this is the only pressure the team is under! There are lots of pressures that are acting on them, and my current guess is that it's not the primary pressure, but I would be surprised if it isn't quite substantial.
↑ comment by James Payor (JamesPayor) · 2023-04-23T00:02:25.146Z · LW(p) · GW(p)
I don't think that the interp team is a part of Anthropic just because they might help with a capabilities edge; seems clear they'd love the agenda to succeed in a way that leaves neural nets no smarter but much better understood. But I'm sure that it's part of the calculus that this kind of fundamental research is also worth supporting because of potential capability edges. (Especially given the importance of stuff like figuring out the right scaling laws in the competition with OpenAI.)
(Fwiw I don't take issue with this sort of thing, provided the relationship isn't exploitative. Like if the people doing the interp work have some power/social capital, and reason to expect derived capabilities to be used responsibly.)
↑ comment by Mark Xu (mark-xu) · 2023-04-21T20:40:19.682Z · LW(p) · GW(p)
I think it's probably reasonable to hold off on publishing interpretability if you strongly suspect that it also advances capabilities. But then that's just an instance of a general principle of "maybe don't advance capabilities", and the interpretability part was irrelevant. I don't really buy that interpretability is particularly likely to increase capabilities that you should have a sense of general caution around this. If you have a specific sense that e.g. working on nuclear fission could produce a bomb, then maybe you shouldn't publish (as has historically happen with e.g. research on graphene as a neutron modulator I think), but generically not publishing physics stuff because "it might be used to build a bomb, vaguely" seems like it basically won't matter.
I think Gwern is an interesting case, but also idk what Gwern was trying to do. I would also be surprised if Gwerns effect was "pretty substantial" by my lights (e.g. I don't think Gwern explained > 1% or even probably 0.1% variance in capabilities, and by the time you're calling 1000 things "pretty substantial effects on capabilities" idk what "pretty substantial" means).
Replies from: habryka4↑ comment by habryka (habryka4) · 2023-04-21T21:02:38.865Z · LW(p) · GW(p)
I think Gwern is an interesting case, but also idk what Gwern was trying to do. I would also be surprised if Gwerns effect was "pretty substantial" by my lights (e.g. I don't think Gwern explained > 1% or even probably 0.1% variance in capabilities, and by the time you're calling 1000 things "pretty substantial effects on capabilities" idk what "pretty substantial" means).
This feels a bit weird. Almost no individual explains 0.1% of the variance in capabilities. In-general it seems like the effect size of norms and guidelines like the ones discussed in the OP could make on the order of 10% difference in capability speeds, which depending on your beliefs about p(doom) can go into the 0.1% to 1% increase or decrease in the chance of literally everyone going extinct. It also seems pretty reasonable for someone to think this kind of stuff doesn't really matter at all, though I don't currently think that.
I don't really buy that interpretability is particularly likely to increase capabilities that you should have a sense of general caution around this.
Hmm, I don't know why you don't buy this. If I was trying to make AGI happen as fast as possible I would totally do a good amount of interpretability research and would probably be interested in hiring Chris Olah and other top people in the field. Chris Olah's interpretability work is one of the most commonly used resources in graduate and undergraduate ML classes, so people clearly think it helps you get better at ML engineering, and honestly, if I was trying to develop AGI as fast as possible I would find it a lot more interesting and promising to engage with than 95%+ of academic ML research.
I also bet that if we were to run a survey on what blogposts and papers top ML people would recommend that others should read to become better ML engineers, you would find a decent number of Chris Olah's publications in the top 10 and top 100.
I don't understand why we should have a prior that interpretability research is inherently safer than other types of ML research?
Replies from: mark-xu, arthur-conmy↑ comment by Mark Xu (mark-xu) · 2023-04-21T21:47:00.308Z · LW(p) · GW(p)
I don't really want to argue about language. I'll defend "almost no individual has a pretty substantial affect on capabilities." I think publishing norms could have a pretty substantial effect on capabilities, and also a pretty substantial effect on interpretability, and currently think the norms suggested have a tradeoff that's bad-on-net for x-risk.
Chris Olah's interpretability work is one of the most commonly used resources in graduate and undergraduate ML classes, so people clearly think it helps you get better at ML engineering
I think this is false, and that most ML classes are not about making people good at ML engineering. I think Olah's stuff is disproportionately represented because it's interesting and is presented well, and also that classes really love being like "rigorous" or something in ways that are random. Similarly, probably like proofs of the correctness of backprop are common in ML classes, but not that relevant to being a good ML engineer?
I also bet that if we were to run a survey on what blogposts and papers top ML people would recommend that others should read to become better ML engineers, you would find a decent number of Chris Olah's publications in the top 10 and top 100.
I would be surprised if lots of ML engineers thought that Olah's work was in the top 10 best things to read to become a better ML engineer. I less beliefs about top 100. I would take even odds (and believe something closer to 4:1 or whatever), that if you surveyed good ML engineers and ask for top 10 lists, not a single Olah interpretability piece would be in the top 10 most mentioned things. I think most of the stuff will be random things about e.g. debugging workflow, how deal with computers, how to use libraries effectively, etc. If anyone is good at ML engineering and wants to chime in, that would be neat.
I don't understand why we should have a prior that interpretability research is inherently safer than other types of ML research?
Idk, I have the same prior about trying to e.g. prove various facts about ML stuff, or do statistical learning theory type things, or a bunch of other stuff. It's just like, if you're not trying to eek out more oomph from SGD, then probably the stuff you're doing isn't going to allow you to eek out more oomph from SGD, because it's kinda hard to do that and people are trying many things.
Replies from: habryka4↑ comment by habryka (habryka4) · 2023-04-21T22:55:28.482Z · LW(p) · GW(p)
I don't really want to argue about language. I'll defend "almost no individual has a pretty substantial affect on capabilities." I think publishing norms could have a pretty substantial effect on capabilities, and also a pretty substantial effect on interpretability, and currently think the norms suggested have a tradeoff that's bad-on-net for x-risk.
Yep, makes sense. No need to argue about language. In that case I do think Gwern is a pretty interesting datapoint, and seems worth maybe digging more into.
I would be surprised if lots of ML engineers thought that Olah's work was in the top 10 best things to read to become a better ML engineer. I less beliefs about top 100. I would take even odds (and believe something closer to 4:1 or whatever), that if you surveyed good ML engineers and ask for top 10 lists, not a single Olah interpretability piece would be in the top 10 most mentioned things. I think most of the stuff will be random things about e.g. debugging workflow, how deal with computers, how to use libraries effectively, etc. If anyone is good at ML engineering and wants to chime in, that would be neat.
I would take a bet at 2:1 in my favor for the top 10 thing. Top 10 is a pretty high bar, so I am not at even odds.
Idk, I have the same prior about trying to e.g. prove various facts about ML stuff, or do statistical learning theory type things, or a bunch of other stuff. It's just like, if you're not trying to eek out more oomph from SGD, then probably the stuff you're doing isn't going to allow you to eek out more oomph from SGD, because it's kinda hard to do that and people are trying many things.
Hmm, yeah, I do think I disagree with the generator here, but I don't feel super confident and this perspective seems at least plausible to me. I don't believe it with enough probability to make me think that there is negligible net risk, and I feel like I have a relatively easy time coming up with counterexamples from science and other industries (the nuclear scientists working on nuclear fission did indeed not work on making weapons, and many people were working on making weapons).
Not sure how much it's worth digging more into this here.
↑ comment by Arthur Conmy (arthur-conmy) · 2023-04-21T22:30:42.194Z · LW(p) · GW(p)
Which sorts of works are you referring to on Chris Olah's blog? I see mostly vision interpretability work (which has not helped with vision capabilities), RNN stuff (which essentially does not help capabilities because of transformers) and one article on back-prop, which is more engineering-adjacent but probably replaceable (I've seen pretty similar explanations in at least one publicly available Stanford course).
Replies from: habryka4↑ comment by habryka (habryka4) · 2023-04-21T23:13:47.027Z · LW(p) · GW(p)
I've seen a lot of the articles here used in various ML syllabi: https://distill.pub/
The basic things studied here transfer pretty well to other architectures. Understanding the hierarchical nature of features transfer from vision to language, and indeed when I hear people talk about how features are structured in LLMs, they often use language borrowed from what we know about how they are structured in vision (i.e. having metaphorical edge-detectors/syntax-detectors that then feed up into higher level concepts, etc.)
↑ comment by JakubK (jskatt) · 2023-04-23T03:58:02.919Z · LW(p) · GW(p)
Anthropic, which is currently the biggest publisher of interp-research, clearly does not have a commitment to not work towards advancing capabilities
This statement seems false based on this comment from Chris Olah [LW(p) · GW(p)].
Replies from: habryka4↑ comment by habryka (habryka4) · 2023-04-23T04:34:44.257Z · LW(p) · GW(p)
I am not sure what you mean. Anthropic clearly is aiming to make capability advances. The linked comment just says that they aren't seeking capability advances for the sake of capability advances, but want some benefit like better insight into safety, or better competitive positioning.
Replies from: jskatt↑ comment by JakubK (jskatt) · 2023-04-26T22:26:30.656Z · LW(p) · GW(p)
Oh I see; I read too quickly. I interpreted your statement as "Anthropic clearly couldn't care less about shortening timelines," and I wanted to show that the interpretability team seems to care.
Especially since this post is about capabilities externalities from interpretability research, and your statement introduces Anthropic as "Anthropic, which is currently the biggest publisher of interp-research." Some readers might conclude corollaries like "Anthropic's interpretability team doesn't care about advancing capabilities."
Replies from: habryka4↑ comment by habryka (habryka4) · 2023-04-26T22:51:55.149Z · LW(p) · GW(p)
Makes sense, sorry for the confusion.
↑ comment by Marius Hobbhahn (marius-hobbhahn) · 2023-04-21T20:18:56.627Z · LW(p) · GW(p)
Just to get some intuitions.
Assume you had a tool that basically allows to you explain the entire network, every circuit and mechanism, etc. The tool spits out explanations that are easy to understand and easy to connect to specific parts of the network, e.g. attention head x is doing y. Would you publish this tool to the entire world or keep it private or semi-private for a while?
↑ comment by Mark Xu (mark-xu) · 2023-04-21T20:29:50.569Z · LW(p) · GW(p)
I think this case is unclear, but also not central because I'm imagining the primary benefit of publishing interp research as being making interp research go faster, and this seems like you've basically "solved interp", so the benefits no longer really apply?
Replies from: mark-xu↑ comment by Mark Xu (mark-xu) · 2023-04-21T20:41:12.388Z · LW(p) · GW(p)
Similarly, if you thought that you should publish capabilities research to accelerate to AGI, and you found out how to build AGI, then whether you should publish is not really relevant anymore.
↑ comment by the gears to ascension (lahwran) · 2023-04-22T08:14:26.786Z · LW(p) · GW(p)
agreed, but also, interpretability is unusually impactful capabilities work
comment by Daniel Murfet (dmurfet) · 2023-04-21T20:59:11.896Z · LW(p) · GW(p)
The set of motivated, intelligent people with the relevant skills to do technical alignment work in general, and mechanistic interpretability in particular, has a lot of overlap with the set of people who can do capabilities work. That includes many academics, and students in masters and PhD programs. One way or another they're going to publish, would you rather it be alignment/interpretability work or capabilities work?
It seems to me that speeding up alignment work by several orders of magnitude is unlikely to happen without co-opting a significant number of existing academics, labs and students in related fields (including mathematics and physics in addition to computer science). This is happening already, within ML groups but also physics (Max Tegmark's students) and mathematics (e.g. some of my students at the University of Melbourne).
I have colleagues in my department publishing stacks of papers in CVPR, NeurIPS etc., which this community might call capabilities work. If I succeeded in convincing them to do some alignment or mechanistic interpretability work, they would do it because it was intrinsically interesting or likely to be high status. They would gravitate towards the kinds of work that are dual-use. Relative to the status quo that seems like progress to me, but I'm genuinely interested in the opinion of people here. Real success in this recruitment would, among other things, dilute the power of LW norms to influence things like publishing.
On balance it seems to me beneficial to aggressively recruit academics and their students into alignment and interpretability.
comment by James Payor (JamesPayor) · 2023-04-21T22:08:45.927Z · LW(p) · GW(p)
To throw in my two cents, I think it's clear that whole classes of "mechansitic interpretability" work are about better understanding architectures in ways that, if the research is successful, make it easier to improve their capabilities.
And I think this points strongly against publishing this stuff, especially if the goal is to "make this whole field more prestigious real quick". Insofar as the prestige is coming from folks who work on AI capabilities, that's drinking from a poisoned well (since they'll grant the most prestige to the work that helps them accelerate).
One relevant point I don't see discussed is that interpretability research is trying to buy us "slack", but capabilities research consumes available "slack" as fuel until none is left.
What do I mean by this? Sometimes we do some work and are left with more understanding and grounding about what our neural nets are doing. The repeated pattern then seems to be that this helps someone design a better architecture or scale things up, until we're left with a new more complicated network. Maybe because you helped them figure out a key detail about gradient flow in a deep network, or let them quantize the network better so they can run things faster, or whatnot.
Idk how to point at this thing properly, my examples aren't great. I think I did a better job talking about this over here on twitter recently, if anyone is interested.
But anyhow I support folks doing their research without broadcasting their ideas to people who are trying to do capabilities work. It seems nice to me if there was mostly research closure. And I think I broadly see people overestimating the benefits publishing their work relative to keeping it within a local cluster.
Replies from: neel-nanda-1, Owain_Evans↑ comment by Neel Nanda (neel-nanda-1) · 2023-04-22T11:48:10.983Z · LW(p) · GW(p)
And I think I broadly see people overestimating the benefits publishing their work relative to keeping it within a local cluster.
I'm surprised by this claim, can you say more? My read is weakly that people in interp under publish to wider audiences (eg getting papers into conferences), though maybe that people overpublish blog posts? (Or that I try too hard to make things go viral on Twitter lol)
Replies from: sharmake-farah, JamesPayor↑ comment by Noosphere89 (sharmake-farah) · 2023-04-22T18:48:30.238Z · LW(p) · GW(p)
I disagree with James Payor on people overestimating publishing interpretability work, and I think it's the opposite: People underestimate how good publishing interpretability work is, primarily because a lot of people on LW view interpretability work as being solved by a single clean insight, when this is usually not the case.
To quote 1a3orn:
One way that people think about the situation, which I think leads them to underestimate the costs of secrecy, is that they think about interpretability as a mostly theoretical research program. If you think of it that way, then I think it disguises the costs of secrecy.
But an addition, to a research program, interpretability is in part about producing useful technical artifacts for steering DL, i.e., standard interpretability tools. And technology becomes good because it is used.
It improves through tinkering, incremental change, and ten thousand slight changes in which each increase improves some positive quality by 10% individually. Look at what the first cars looked like and how many transformations they went through to get to where they are now. Or look it the history of the gun. Or, what is relevant for our causes, look at the continuing evolution of open source DL libraries from TF to PyTorch to PyTorch 2. This software became more powerful and more useful because thousands of people have contributed, complained, changed one line of documentation, added boolean flags, completely refactored, and so on and so forth.
If you think of interpretability being "solved" through the creation one big insight -- I think it becomes more likely that interpretability could be closed without tremendous harm. But if you think of it being "solved" through the existence of an excellent torch-shard-interpret package used by everyone who uses PyTorch, together with corresponding libraries for Jax, then I think the costs of secrecy become much more obvious.
Would this increase capabilities? Probably! But I think a world 5 years hence, where capabilities has been moved up 6 months relative to zero interpretability artifacts, but where everyone can look relatively easily into the guts of their models and in fact does so look to improve them, seems preferable to a world 6 months delayed but without these libraries.
I could be wrong about this being the correct framing. And of course, these frames must mix somewhat. But the above article seem to assume the research-insight framing, which I think is not obviously correct.
In general, I think interpretability research is net positive because capabilities will probably differentially progress towards more understandable models, where we are in a huge bottleneck right now for alignment.
Replies from: JamesPayor↑ comment by James Payor (JamesPayor) · 2023-04-23T00:30:05.459Z · LW(p) · GW(p)
I think the issue is that when you get more understandable base components, and someone builds an AGI out of those, you still don't understand the AGI.
That research is surely helpful though if it's being used to make better-understood things, rather than enabling folk to make worse-understood more-powerful things.
I think moving in the direction of "insights are shared with groups the researcher trusts" should broadly help with this.
Replies from: JamesPayor↑ comment by James Payor (JamesPayor) · 2023-04-23T01:05:20.045Z · LW(p) · GW(p)
Hm I should also ask if you've seen the results of current work and think it's evidence that we get more understandable models, moreso than we get more capable models?
↑ comment by James Payor (JamesPayor) · 2023-04-23T00:23:21.900Z · LW(p) · GW(p)
I'm perhaps misusing "publish" here, to refer to "putting stuff on the internet" and "raising awareness of the work through company Twitter" and etc.
I mostly meant to say that, as I see it, too many things that shouldn't be published are being published, and the net effect looks plausibly terrible with little upside (though not much has happened yet in either direction).
The transformer circuits work strikes me this way, so does a bunch of others.
Also, I'm grateful to know your read! I'm broadly interested to hear this and other raw viewpoints, to get a sense of how things look to other people.
Replies from: neel-nanda-1↑ comment by Neel Nanda (neel-nanda-1) · 2023-04-23T12:13:44.324Z · LW(p) · GW(p)
Interesting, thanks for the context. I buy that this could be bad, but I'm surprised that you see little upside - the obvious upside esp for great work like transformer circuits is getting lots of researchers nerdsniped and producing excellent and alignment relevant interp work. Which seems huge if it works
Replies from: JamesPayor↑ comment by James Payor (JamesPayor) · 2023-04-23T23:40:52.238Z · LW(p) · GW(p)
I want to say that I agree the transformer circuits work is great, and that I like it, and am glad I had the opportunity to read it! I still expect it was pretty harmful to publish.
Nerdsniping goes both ways: you also inspire things like the Hyena work trying to improve architectures based on components of what transformers can do.
I think indiscriminate hype and trying to do work that will be broadly attention-grabbing falls on the wrong side, likely doing net harm. Because capabilities improvements seem empirically easier than understanding them, and there's a lot more attention/people/incentives for capabilities.
I think there are more targeted things that would be better for getting more good work to happen. Like research workshops or unconferences, where you choose who to invite, or building community with more aligned folk who are looking for interesting and alignment-relevant research directions. This would come with way less potential harm imo as a recruitment strategy.
↑ comment by Owain_Evans · 2023-04-22T18:35:00.402Z · LW(p) · GW(p)
Can you describe how the "local cluster" thing would work outside of keeping it within a single organization? I'd also be very interested in some case studies where people tried this.
Replies from: JamesPayor↑ comment by James Payor (JamesPayor) · 2023-04-23T00:09:53.210Z · LW(p) · GW(p)
I mostly do just mean "keeping it within a single research group" in the absence of better ideas. And I don't have a better answer, especially not for independent folk or small orgs.
I wonder if we need an arxiv or LessWrong clone where you whitelist who you want to discuss your work with. And some scheme for helping independents find each other, or find existing groups they trust. Maybe with some "I won't use this for capabilities work without the permission of the authors" legal docs as well.
This isn't something I can visualize working, but maybe it has components of an answer.
comment by sudo · 2023-04-21T16:37:08.448Z · LW(p) · GW(p)
Strong upvoted.
I’m excited about people thinking carefully about publishing norms. I think this post existing is a sign of something healthy.
Re Neel: I think that telling junior mech interp researchers to not worry too much about this seems reasonable. As a (very) junior researcher, I appreciate people not forgetting about us in their posts :)
comment by Arthur Conmy (arthur-conmy) · 2023-04-21T22:46:01.026Z · LW(p) · GW(p)
Thank you for providing this valuable synthesis! In reference to:
4. It is a form of movement building.
Based on my personal interactions with more experienced academics, many seem to view the objectives of mechanistic interpretability as overly ambitious (see Footnote 3 in https://distill.pub/2020/circuits/zoom-in/ as an example). This perception may deter them from engaging in interpretability research. In general, it appears that advancements in capabilities are easier to achieve than alignment improvements. Together with the emphasis on researcher productivity in the ML field, as measured by factors like h-index, academics are incentivized to select more promising research areas.
By publishing mechanistic interpretability work, I think the perception of the field's difficulty can be changed for the better, thereby increasing the safety/capabilities ratio of the ML community's output. As the original post acknowledges, this approach could have negative consequences for various reasons.
comment by Max H (Maxc) · 2023-04-21T20:36:21.859Z · LW(p) · GW(p)
Another consideration: mechanistic interpretability might resolve some longstanding disagreements about the nature and difficulty of alignment, but not make the actual problem any easier. So, in the world where alignment turns out to be hard, interpretability research might make AI governance more effective and more possible.
I think this is a consideration mostly in favor of doing and publishing interpretability research, at least for now. But if interpretability ever advances to the point where interpretability results on their own are enough to update previously-skeptical LWers towards higher p(doom), it's probably worth re-evaluating.
comment by JakubK (jskatt) · 2023-04-23T03:51:12.990Z · LW(p) · GW(p)
Thus, we decided to ask multiple people in the alignment scene about their stance on this question.
Richard
Any reason you're not including people's last names? To a newcomer this would be confusing. "Who is Richard?"
Replies from: marius-hobbhahn↑ comment by Marius Hobbhahn (marius-hobbhahn) · 2023-04-23T15:02:53.069Z · LW(p) · GW(p)
People could choose how they want to publish their opinion. In this case, Richard chose the first name basis. To be fair though, there aren't that many Richards in the alignment community and it probably won't be very hard for you to find out who Richard is.
comment by Joshua Clancy (joshua-clancy) · 2024-02-18T02:02:09.758Z · LW(p) · GW(p)
I have a mechanistic interpretability paper I am working on / about to publish. It may qualify. Difficult to say. Currently, I think it would be better to be in the open. I kind of think of it as if... we were building bigger and bigger engines in cars without having invented the steering wheel (or perhaps windows?). I intend to post it to LessWrong / Alignment Forum. If the author gives me a link to that google doc group, I will send it there first. (Very possible it's not all that, I might be wrong, humans naturally overestimate their own stuff, etc.)
comment by RussellThor · 2023-04-22T05:49:24.557Z · LW(p) · GW(p)
"Most people who work on ML do not care about alignment" I am a bit surprised by this, if it was true, are you sure it still is?