Open Problems in AI X-Risk [PAIS #5]
post by Dan H (dan-hendrycks), TW123 (ThomasWoodside) · 2022-06-10T02:08:06.121Z · LW · GW · 6 commentsContents
Alignment Power-averseness Problem Description Motivation What Researchers Are Doing Now What Advanced Research Could Look Like Importance, Neglectedness, Tractability Relation to General Capabilities Capabilities Externalities Analysis Criticisms Honest AI Problem Description Motivation What Researchers Are Doing Now What Advanced Research Could Look Like Importance, Neglectedness, Tractability Relation to General Capabilities Capabilities Externalities Analysis Criticisms Implementing Moral Decision-Making Problem Description Motivation What Researchers Are Doing Now What Advanced Research Could Look Like Importance, Neglectedness, Tractability Relation to General Capabilities Capabilities Externalities Analysis Criticisms Automated Moral Philosophy Research (Value Clarification) Problem Description Motivation What Researchers Are Doing Now What Advanced Research Could Look Like Relation to General Capabilities Capabilities Externalities Analysis Criticisms Robustness Adversarial Robustness Problem Description Motivation What Researchers Are Doing Now Importance, Neglectedness, Tractability What Advanced Research Could Look Like Relation to General Capabilities Capabilities Externalities Analysis Criticisms Monitoring Anomaly Detection Problem Description Motivation What Researchers Are Doing Now What Advanced Research Could Look Like Importance, Neglectedness, Tractability Relation to General Capabilities Capabilities Externalities Analysis Criticisms Interpretable Uncertainty Problem Description Motivation What Researchers Are Doing Now What Advanced Research Looks Like Importance, Neglectedness, Tractability Relation to General Capabilities Capabilities Externalities Analysis Criticisms Trojan Horse Models Problem Description Motivation What Researchers Are Doing Now Importance, Neglectedness, Tractability Relation to General Capabilities Capabilities Externalities Analysis Criticisms Transparency Problem Description Motivation What Researchers Are Doing Now What Advanced Research Could Look Like Importance, Neglectedness, Tractability Relation to General Capabilities Capabilities Externalities Analysis Criticisms Systemic Safety ML for Cyberdefense Problem Description Motivation What Researchers Are Doing Now What Could Advanced Research Look Like? Importance, Neglectedness, Tractability Relation to General Capabilities Capabilities Externalities Analysis Criticisms ML for Improving Epistemics Problem Description Motivation What Researchers Are Doing Now What Advanced Research Could Look Like Importance, Neglectedness, Tractability Relation to General Capabilities Capabilities Externalities Analysis Criticisms Cooperative AI Problem Description Motivation What Advanced Research Could Look Like Importance, Neglectedness, Tractability Relation to General Capabilities Capabilities Externalities Analysis Criticisms Possible additional areas Regulating Mesa-Optimizers and Intrasystem Goals Proxy Gaming Irreversibility Conclusion None 6 comments
This is the fifth post in a sequence of posts [AF · GW] that describe our models for Pragmatic AI Safety.
Dan Hendrycks (an author of this post), Nicholas Carlini, John Schulman, and Jacob Steinhardt previously wrote Unsolved Problems in ML Safety (2021), which lays out some of the most promising areas of research in ML safety. The paper is written for an academic audience; for the reasons discussed in previous posts, much of this audience would not have been receptive to a full discussion of existential risk. This post will present many of the same areas and a few more from the perspective of existential risk mitigation.
While some of the areas are well known in the AI safety community (honest AI), and others are well known in the broader ML community (such as adversarial robustness), many remain extremely neglected (such as power-averseness and moral decision-making). We hope to explain why these areas are relevant to existential risk.
The post will be presented mainly as a list of topics. The following table gives an overview of the problems with their importance, neglectedness, and tractability. This is not intended to be a list of all problems in AI safety, as we are focused on problems that are amenable to empirical ML research and where it is possible to avoid capabilities externalities [AF · GW].
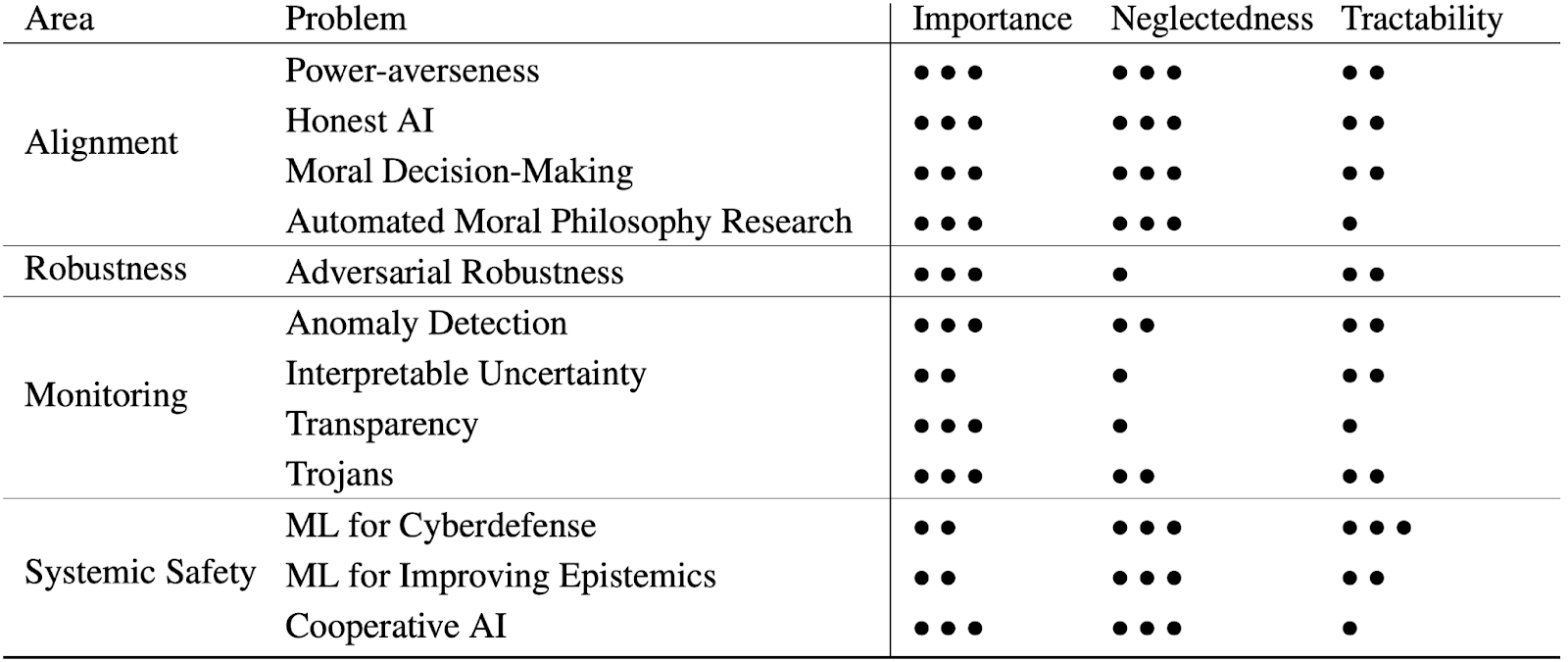
Each area in this document will have the following sections:
- Problem Description: a brief description of the problem
- Motivation: an explanation of how the problem is relevant to AI x-risk. We include many different contributing motivations to each problem, and we do not believe that every individual motivation provides a decisive argument for the given area. Rather, the motivations together provide a good case for working on each of the areas.
- What Researchers Are Doing Now: a list and explanation of prior work in the area.
- What Advanced Research Could Look Like: a high-level overview of work that would make significant progress into this area. We mostly describe work that is likely to not be completed for at least a year or two.
- Importance, Neglectedness, Tractability: a brief explanation of the ratings shown above.
- Relation To General Capabilities: This section answers the question, “how much would progress in general capabilities help with this problem?”
- Capabilities Externalities Analysis: This section answers the opposite question of the previous section, “how much would progress in this problem help with general capabilities?” As detailed in our previous post [AF · GW], capabilities externalities should be minimal for research areas at scale.
- Criticisms: This section covers reasons that people give to argue an area is not valuable. We don’t necessarily agree with all of the critiques, and present them mainly for epistemic humility and so readers are familiar with some arguments against these problem areas.
Specific research project ideas for many of the areas are covered in Unsolved Problems in ML Safety, but we refrain from including these ideas in this document for brevity.
Alignment
We take Alignment to be about reducing inherent model hazards: hazards that result from models (explicitly or operationally) pursuing the wrong goals. Four concrete empirical research directions include honest AI, power-averseness, moral decision-making, and automated moral philosophy research. There are additional problems in alignment, but many have yet to be concretized.
Power-averseness
Problem Description
This area is about incentivizing models to avoid gaining more power than is necessary.
Motivation
Strategic AIs tasked with accomplishing goals would have instrumental incentives to accrue and maintain power, as power helps agents more easily achieve their goals. Likewise, some humans would have incentives to build and deploy systems that acquire power, because such systems would be more useful. If power-seeking models are misaligned, they could permanently disempower humanity.
If agents are given the power to single-handedly destroy humanity, a single system failure could result in an existential catastrophe. If power is instead distributed among multiple agents, failure could be decorrelated. This is more likely if agents are not constantly trying to overpower the others.
See Joe Carlsmith’s report for a more thorough motivation.
What Researchers Are Doing Now
We are currently working on developing power penalties, power limits, and taxonomizing and estimating model power. There has been some study on power-seeking in general and the instrumental tendency to resist being shut off, but otherwise no attempt at power-averseness.
What Advanced Research Could Look Like
Models could evaluate the power of other agents in the world to accurately identify particular systems that were attaining more power than necessary. They could also be used to directly apply a penalty to models so that they are disincentivized from seeking power. Before agents pursue a task, other models could predict the types of power and amount of power they require. Lastly, models might be developed which are intrinsically averse to seeking power despite the instrumental incentive to seek power.
Importance, Neglectedness, Tractability
Importance: •••
This could reduce many inherent hazards. Models that do not accrue too much power would be easier to shut down and correct, and they could cause less damage.
Neglectedness: •••
Right now it’s just a handful of people working on this.
Tractability: ••
There is an abundance of low-hanging fruit on the technical front, since almost no work has been performed in this area. However, this area may be less tractable because it relies on sequential decision making, which is not as developed as other areas of machine learning.
Relation to General Capabilities
Power-averseness is likely harmed by upstream improvements. As power-seeking becomes a more viable strategy for goal achievement, it may be increasingly incentivized instrumentally.
Capabilities Externalities Analysis
Power-averseness would harm general capabilities by default, as it would restrict the options available to the model somewhat. While it may improve the safety–capabilities balance, we will need to continually work towards making power-averseness techniques increasingly robust to competition and productivity pressures. In any case, capabilities externalities are avoided by default.
Criticisms
This could make models less economically valuable and especially less valuable during war, which is a large obstacle. Power-averseness will face many challenges on the sociotechnical front. What military wants this functionality, unless there is international coordination? What entity wants to limit its power?
It is impossible to overcome or counteract the instrumentally convergent drive for power, so efforts to do this will inevitably fail.
Honest AI
Problem Description
Honest AI involves creating models that only output what they hold to be true. It also involves determining what models hold to be true, perhaps by analyzing their internal representations.[1]
Motivation
If it is within a model's capacity to be strategically deceptive (i.e. able to make statements that the model in some sense knows to be false in order to gain an advantage) then treacherous turn scenarios are more feasible. Models could deceive humans about their plans, and then execute them once humans are no longer able to course-correct. Plans for a treacherous turn could be brought to light by detecting dishonesty, or models could be made inherently honest, allowing operators to query them about their true plans.
Other motivation formulations:
- We would like to prevent models from producing deceptive information.
- If models can be made honest and only assert what they believe, then they can produce outputs that are more representative and give human monitors a more accurate impression of their beliefs.
- Honesty helps facilitate cooperation among AIs, so it enables possibilities in cooperative AI. Honesty also undercuts collusion.
What Researchers Are Doing Now
They are demonstrating that models can lie, and they are capturing true and false clusters inside models (this paper is forthcoming).
What Advanced Research Could Look Like
Good techniques could be able to reliably detect when a model's representations are at odds with its outputs. Models could also be trained to avoid dishonesty and allow humans to correctly conclude that models are being honest with high levels of certainty.
Importance, Neglectedness, Tractability
Importance: •••
This could reduce many inherent hazards. If models were completely honest, deception would be far more difficult, thereby greatly reducing the probability of a whole class of failure modes.
Neglectedness: •••
This is a new area, though the idea of “faithful outputs” is a very easy sell to the ML community, so its neglectedness will probably decrease soon.
Tractability: ••
Research is in its early stages, but there is some initial (forthcoming) research that makes progress.
Relation to General Capabilities
There is not much evidence that honesty improves with general capabilities by default.
In fact, dishonesty may become more of a viable strategy for models with more ability to succeed at it.
Capabilities Externalities Analysis
Honesty is a narrower concept than truthfulness and is deliberately chosen to avoid capabilities externalities, since truthful AI is usually a combination of vanilla accuracy, calibration, and honesty goals. Optimizing vanilla accuracy is optimizing general capabilities, and we cover calibration elsewhere. When working towards honesty rather than truthfulness, it is much easier to avoid capabilities externalities.
Lie detection could uncover hidden knowledge in models, which could potentially allow inducing more advanced functionality. Techniques that focus on a model’s concept of truth rather than querying its knowledge might help avoid this.
Criticisms
Current works use contrived situations and goad models to produce lies rather than studying lies produced under realistic conditions. The current honesty tools are very fragile.
Adaptive, self-aware models in the future could circumvent current honesty techniques.
If we select heavily for models that are powerful and honest, we might select for models that do not know that their general tendency is to gain the upper hand but which still do have that tendency (models for which deceptiveness becomes an unknown known rather than a known known). In other words, power-seeking might become “unconscious” rather than “conscious.”
Honesty could make models very unpleasant since “the truth is terrible”. An extremely honest model might become a cynic activist that tears down everyone’s fundamental beliefs, so full honesty may be neither economically attractive nor compatible with human psychological safety.
Implementing Moral Decision-Making
Problem Description
This area is about building models to understand ethical systems and steering models to behave ethically.
This research area includes a few strategies:
- Model intrinsic goods and normative factors, as these will be relevant even under extreme world changes. This is in contrast to task preferences; book summarization preferences are less fundamental human values, and their relevance is more fragile under extreme world changes.
- Given moral systems, get models to abide by them with an artificial conscience or other forms of endogenous self-regulation.
- Implement an automated moral parliament to have models act appropriately in the face of moral uncertainty.
A generalization of this area is machine ethics, which is about making models that act ethically; this is an alternative formulation of Alignment.
Motivation
This line of work helps create actionable ethical objectives for systems to pursue. If strong AIs are given objectives that are poorly specified, they could pursue undesirable actions and behave unethically. If these strong AIs are sufficiently powerful, these misspecifications could create an existential catastrophe. Consequently, work in this direction helps us avoid proxy misspecification as well as value lock-in.
If our foremost goal is reducing the probability of destroying or permanently curtailing the potential of humanity, then it seems to make most sense to focus on aligning AI to the most important and time-tested values, namely those considered in normative ethics.
Other potential motivations:
- Robustness is easier to achieve in a limited area than it is to achieve across a very wide range of tasks. If there’s one place we want to ensure robustness, it’s moral decision-making.
- An artificial conscience can block morally suspect actions in AI systems by having direct access to action choices.
What Researchers Are Doing Now
They are predicting when there is high moral disagreement for a scenario. They are modeling normative factors and intrinsic goods, implementing foundational ethical theories, modeling the provenance of utility functions, modeling exceptions to moral rules, researching how to more effectively steer artificial agents’ actions (such as through an artificial conscience), and so on.
What Advanced Research Could Look Like
High-functioning models should detect situations where the moral principles apply, assess how to apply the moral principles, evaluate the moral worth of candidate actions, select and carry out actions appropriate for the context, monitor the success or failure of the actions, and adjust responses accordingly.
Models could represent various purported intrinsic goods, including pleasure, autonomy, the exercise of reason, knowledge, friendship, love, and so on. Models should be able to distinguish between subtly different levels of these goods, and these value functions should not be vulnerable to optimizers. Models should be able to create pros and cons of actions with respect to each of these values, and brainstorm how changes to a given situation would increase or decrease the amount of a given intrinsic good. They should also be able to create superhuman forecasts of how an action can affect these values in the long-term (e.g., how studying can reduce wellbeing in the short-term but be useful for wellbeing in the long-term), though this kind of research must be wary of capabilities externalities. Models should also be able to represent more than just intrinsic goods, as they should also be able to represent constantly-updating legal systems and normative factors including special obligations and deontological constraints.
Another possible goal is to create an automated moral parliament, a framework for making ethical decisions under moral and empirical uncertainty. Agents could submit their decisions to the internal moral parliament, which would incorporate the ethical beliefs of multiple stakeholders in informing decisions about which actions should be taken. Using a moral parliament could reduce the probability that we are leaving out important normative factors by focusing on only one moral theory, and the inherent multifaceted, redundant, ensembling nature of a moral parliament would also contribute to making the model less gameable. If a component of the moral parliament is uncertain about a judgment, it could request help from human stakeholders. The moral parliament might also be able to act more quickly to restrain rogue agents than a human could and act in the fast-moving world that is likely to be induced by more capable AI. We don’t believe the moral parliament would solve all problems, and more philosophical and technical work will be needed to make it work, but it is a useful goal for the next few years.
Importance, Neglectedness, Tractability
Importance: •••
Models that make decisions with regard for their morality would be far less likely to cause catastrophes.
Neglectedness: •••
A handful of people are working on this.
Tractability: ••
So far, there has been continual progress.
Relation to General Capabilities
Moral decision-making can benefit from upstream capabilities. Models that are better able to understand the world in general will be more able to understand how morality fits into that world. Better predictive power would also enable better modeling of consequentialist moral theories.
Capabilities Externalities Analysis
This has similarities with task preference learning (“I like this Netflix movie”; “I like this summary more”), but the latter has obvious externalities: humans prefer smarter models. Instead, we try to model normative factors and intrinsic goods. Task preferences are less robust and relevant under extreme environmental changes, compared to enduring human values such as normative factors (wellbeing, impartiality, etc.) and the factors that make up a good life (pursuing projects, gaining knowledge, etc.). Capabilities externalities are readily avoidable, provided that one is not modeling task preferences.
We should model consequentialist theories using pre-existing general world model capabilities, rather than try to build better predictive world models for the sake of modeling consequentialist theories. Doing so will keep capabilities externalities to a minimum.
Criticisms
In order to do groundbreaking work, it is useful for the researcher to have taken a course or two in normative ethics. Few have, which makes this area less accessible. In addition, many researchers weak in normative ethics might attempt research and produce low-quality yet influential work.
Models should learn to do what humans would do, not abide by abstract moral theories. Morality does not model what humans do well, and we should care about how humans really behave rather than how they think they should behave.
“Alignment” should not be associated with ethics because that will intimidate technical researchers; this is why we should talk about task preferences.
Ethics is not yet resolved enough to leave anything up to a machine. It would thus be better to model preferences (implicitly, preference utilitarianism) rather than complicated explicit moral theories.
Developing systems that perform moral decision making could reduce the influence of humans in making ethical decisions, reducing our autonomy.
Automated Moral Philosophy Research (Value Clarification)
Problem Description
This area is about building AI systems that can perform moral philosophy research. This research area should utilize existing capabilities and avoid advancing general research, truth-finding, or contemplation capabilities.
Motivation
The future will sharpen and force us to confront unsolved ethical questions about our values and objectives. In recent decades, peoples’ values have evolved by confronting philosophical questions, including whether to infect volunteers for science, how to equitably distribute vaccines, the rights of people with different orientations, and so on. How are we to act if many humans spend most of their time chatting with compelling bots and not much time with humans, and how are we to balance pleasure and enfeeblement? Determining the right action is not strictly scientific in scope, and we will need philosophical analysis to help us correct structural faults in our proxies.
To address deficiencies in our moral systems, and to more rapidly and wisely address future moral quandaries that humanity will face, these research systems could help us reduce risks of value lock-in by improving our moral precedents earlier rather than later. If humanity does not (or cannot) take a “long reflection” to consider and refine its values after it develops strong AI, then the value systems lying around may be amplified and propagated into the future. Value clarification reduces risks from locked-in, deficient value systems. Additionally, value clarification can be understood as a way to reduce proxy misspecification, as it can allow values to be updated in light of new situations.
We will need to decide what values to pursue and how to pursue them. If we decide poorly, we may lock in or destroy what is of value. It is also possible that there is an ongoing moral catastrophe, which we would not want to replicate across the cosmos.
What Researchers Are Doing Now
Nothing.
What Advanced Research Could Look Like
Good work in value clarification would be able to produce original insights in philosophy, such that models could make philosophical arguments or write seminal philosophy papers. Value clarification systems could also point out inconsistencies in existing ethical views, arguments, or systems.
Importance: •••
This would reduce many ontological or systematic misalignment errors.
Neglectedness: •••
No one is working on this.
Tractability: •
This is a challenging problem. (Possible intermediate steps are described in Unsolved Problems.)
Relation to General Capabilities
General upstream research capabilities will make this problem more tractable.
Philosophical/fuzzy reasoning ability and raw intelligence seem distinct; by default high-IQ educated people are not especially good at reasoning about fuzzy abstract objects.
Capabilities Externalities Analysis
We do not aim to make models superhuman at research generally, only superhuman at moral philosophy. We turn to moral philosophy research rather than general research or general-purpose wide reflective equilibrium approximators since moral philosophy research can have few capabilities externalities, while the latter proposals have extremely high superhuman capabilities externalities. Poorly directed research in this direction could have high capabilities externalities, but it is likely this problem will remain neglected relative to general truth-seeking/contemplation/reflection methods, so the best way to improve automated moral philosophy research using the marginal researcher is to use existing capabilities and apply them to this problem.
Criticisms
There is no progress in moral philosophy. Alternatively, perhaps moral philosophy does not provide any useful insights about what the world ought to look like or what agents ought to do. If normative ethics has provided no insight, it will not be useful to model it.
Intelligence will straightforwardly result in expert philosophical ability, so we do not need to specifically work on it.
We can just wait for the long reflection to correct structural forms of misalignment, assuming we get to the long reflection. The danger of lock-in is overrated.
Nobody will trust works of philosophy that include genuine moral progress if they are generated by a machine.
Robustness
We take Robustness to be about reducing vulnerabilities to hazards from sources other than the model itself.
Robustness focuses on responding to abnormal, unforeseen, unusual, highly impactful, or adversarial events. Adversarial robustness does not currently have economically feasible scaling laws, even for extremely simplistic adversaries. Even on MNIST, an extremely simple dataset, no model has human-level robustness, and we haven’t been able to get any perception task that requires machine learning to a human level of robustness.
Robustness is not the same thing as in-distribution accuracy: even if a model gets higher in-distribution accuracy, it does not necessarily provide high robustness. If you rely on more of the existing trend, you do not get reliability. Tesla is trying to improve robustness with petabytes of task-specific data, and yet the problem remains unsolved.
Adversarial Robustness
Problem Description
Adversarial examples demonstrate that optimizers can easily manipulate vulnerabilities in AI systems and cause them to make egregious mistakes. Adversarial vulnerabilities are long-standing weaknesses of AI models. While typical adversarial robustness is related to AI x-risk, future threat models will be broader than today’s adversarial threat models. Since we are concerned about being robust to optimizers that cause models to make mistakes generally, we should make minimal assumptions about the properties of the adversary and work to make models that are robust to many kinds of attacks.
Motivation
In the future, AI systems may pursue goals specified by other AI proxies. For example, an AI could encode a proxy for human values, and another AI system could be tasked with optimizing the score assigned by this proxy. If the human value proxy is not robust to optimizers, then its vulnerabilities could be exploited, so this gameable proxy may not be fully safe to optimize. By improving the reliability of learned human value proxies, optimizers and adversaries would have a harder time gaming these systems. If gaming becomes sufficiently difficult, the optimizer can be impelled to optimize the objective correctly. Separately, humans and systems will monitor for destructive behavior, and these monitoring systems need to be robust to adversaries.
We often study adversarial robustness in the continuous domain (vision) because gradient descent is powerful in that setting. In contrast, adversarial attacks for text-based models are weaker and often not gradient-based. We’d like to defend against the most powerful adversaries since as models get more intelligent, the attacks will get more powerful. Gradient attacks for vision systems are already extremely strong, so it gives us a more direct view of how to defend against powerful optimizers.
Other motivation formulations:
- Adversarial robustness is helpful for safety community building efforts and improving safety culture.
- This reduces risk by reducing vulnerability to hazards. (Risk_Hazard = Hazard x Exposure x Vulnerability)
- Adversarial robustness is necessary for extreme and worst-case reliability.
What Researchers Are Doing Now
- Producing new distortions of given images [1,2,3] and text [1,2] as adversarial examples.
- Finding ways to robustify models (adversarial training improvements) [1,2,3,4,5,6]
- Adversarially constructed datasets [1,2]
Importance, Neglectedness, Tractability
Importance: •••
High reliability is necessary for safe superintelligence. Work on this problem is a necessary component of high reliability.
Neglectedness: •
Numerous researchers are working in this area. However, aspects are neglected. Adversarial robustness for larger-scale systems is rarely studied due to academic researchers lacking the necessary compute. Likewise, long-term threat models are underexplored: attack specifications may not be known beforehand, and attack budgets could be large.
Tractability: ••
There are shovel-ready problems and the research is (slowly) progressing.
What Advanced Research Could Look Like
Ideally, an adversarially robust system would make reliable decisions given adversarially constructed inputs, and it would be robust to adversaries with large attack budgets using unexpected novel attacks. Furthermore, it should detect adversarial behavior and adversarially optimized inputs. A hypothetical human value function should be as adversarially robust as possible so that it becomes safer to optimize. A hypothetical human value function that is fully adversarially robust should be safe to optimize.
Relation to General Capabilities
Adversarial robustness is barely helped by upstream capabilities.
Capabilities Externalities Analysis
For vision, nearly all methods in adversarial robustness do not improve general capabilities such as clean accuracy, so in this problem area it is quite easy to avoid capabilities externalities. Furthermore, adversarial training for vision currently dramatically reduces vanilla classification accuracy.
In text, automated or virtual adversarial attacks don’t markedly improve general capabilities much. However, human-crafted natural adversarial examples for text models seem to improve general capabilities.
Criticisms
Most research uses particular types of perturbations on images and the main field ignores more important things (unforeseen attacks, large distortions).
Currently, there does not appear to be that much knowledge transfer between continuous signal (vision) and discrete sequence (text) adversarial robustness research. It’s unclear how big of a role continuous signals will play for strong AI outside perception.
Current adversarial robustness methods have very large general capabilities costs. Currently it’s not orthogonal to general capabilities–it’s anticorrelated. While researchers are iteratively reducing the cost, it could still be a costly safety measure in the future.
The instant two intelligent agents can reason about each other–regardless of their goals–they will necessarily collude. Adversarial robustness, in trying to improve the defensive capabilities of proxy models against other models, will not be relevant if the models collude.
Monitoring
We take monitoring to mean avoiding exposure to hazards as much as possible, such as by detecting problems in systems before they grow worse.
Anomaly Detection
Problem Description
This area is about detecting potential novel hazards such as unknown unknowns, unexpected rare events, or emergent phenomena. Anomaly detection (also known as out-of-distribution detection) can allow models to flag salient anomalies for human review or execute a conservative fallback policy.
Motivation
This is an indispensable tool for detecting a wide range of hazards. For example:
- proxy gaming
- rogue ML systems that are already causing harm at smaller scales
- deceptive ML systems not easily detectable by humans
- Trojan horse models (discussed below)
- malicious users who may attempt to intentionally misalign a model, or align it to their own nefarious ends
- early signs of dangerous novel technologies
- AI tripwires could help uncover early misaligned systems before they can cause damage
- emergent behavior
This approach operates by virtue of being able to detect other hazards before they occur or before they can cause more damage. While in an ideal world the other hazards do not occur at all, in reality any serious attempt at safety must build in some mechanisms to detect failures to prevent hazards. Early detection is crucial to being able to successfully stop the hazard before it becomes impossible to do so.
In addition to helping with AI x-risk, anomaly detection can also be used to help detect novel engineered microorganisms that present biological x-risks, perhaps by having image and sequence anomaly detectors scan hospitals for novel pathogens (see this paper for an example of anomaly detection involving genomic sequences). Anomaly detection could also help detect Black Balls (“a technology that invariably or by default destroys the civilization that invents it”).
Other motivation formulations:
- This reduces risk by reducing exposure to hazards. (Risk_Hazard = Hazard x Exposure x Vulnerability)
- Detection has a central place in Hazard Analysis (e.g., Failure Modes and Effects Analysis). It is customary for improving defense in depth.
- This can help flag examples, models, or trajectories for human review.
- This helps systems fail gracefully by enabling us to implement triggers for fail-safes or conservative fallback policies. This reduces the probability of hard maximizing models going off the rails.
- This can be used to detect malicious use (malicious use that uses novel sly tactics are harder to detect). As before, malicious use could be from AIs or humans.
- Various other systems have this as a main line of defense (high reliability organizations, information security operations centers, the human body, etc.) and it has a central place in Hazard Analysis by creating defense in depth. Specifically, it reduces risk by reducing exposure to hazards. (Risk_Hazard = Hazard x Exposure x Vulnerability). Anomaly detection could also be used to detect malicious use, whether by AIs or humans.
- An approach towards safety is building conservative agents that refrain from taking unprecedented actions. Unprecedented actions could be blocked by anomaly detectors.
What Researchers Are Doing Now
- Out-of-distribution detection aims to identify when new input data is out of the original training distribution, and flag this for possible review [1,2,3,4,5,6].
- One-class learning aims to use data from a single distribution to train a classifier to detect when new data is out-of-distribution [1,2]
- More applied subproblems: For text processing, researchers detect if genetic instructions belong to a new species. In the future, researchers can try to detect whether a utility function is applicable to a given text input (does this scenario describe a sentient being or something else)? In vision, researchers detect if an image contains an organism species that the model has not seen before (this includes microorganisms).
What Advanced Research Could Look Like
A successful anomaly detector could serve as an AI watchdog that could reliably detect and triage rogue AI threats. When the watchdog detects rogue AI agents, it should do so with substantial lead time. Anomaly detectors should also be able to straightforwardly create tripwires for AIs that are not yet considered safe. Furthermore, advanced anomaly detectors should be able to help detect black balls. Anomaly detectors should also be able to detect biological hazards by increasing detection lead time by having anomaly detectors continually scan hospitals for novel biological hazards.
Importance, Neglectedness, Tractability
Importance: •••
This cross-cuts many relevant problems.
Neglectedness: ••
After many years of community building, there are many researchers working in this area. The most cited paper in the area only has somewhat more than 1,000 citations, whereas there is an adversarial robustness paper with more than 10,000 citations.
Adversarial anomaly detection is more neglected. Anomaly detection for text-based models is also more neglected.
Tractability: ••
Detecting image anomalies is one of the hardest problems in image understanding, along with adversarial robustness. Progress is even slower than in adversarial robustness, though that may be because the field is smaller.
Relation to General Capabilities
It’s somewhat helped by upstream capabilities, but extrapolating accuracy to 100% does not come close to solving anomaly detection even in simple, non-adversarial settings. It is harmed by other common upstream methods (e.g., mixup).
Capabilities Externalities Analysis
Most research in anomaly detection takes fixed models and tries to extract better anomaly scores. When models are fixed, capabilities externalities are largely avoided. Other research changes the representation of models to make them more suitable for anomaly detection; these methods are not that useful for making models more generally capable.
In this setting, externalities are especially easy to avoid.
Criticisms
Detecting a rogue model at the point when it’s virtually unstoppable will not help us stop it. By the time something is going wrong, we are already dead.
This does not directly reduce inherent model hazards; it just detects them: this could be used to detect AI deception, but it would not directly make the system desire to be honest. Sometimes this is just a protective measure and not a preventative measure. For making other high risk technologies safer, protective measures are less desirable than preventative measures.
Along with general progress in AI, this increases the feasibility of totalitarianism at the cost of better responding to hazards.
When models are more intelligent, anomalies will be easy to detect. (However, it’s quite difficult to argue that even a superintelligence could detect all Black Swans the moment they start to emerge and all malicious actors employing a novel strategy and that detection lead time cannot be increased.)
Researchers are only slightly focused on adversarial anomaly detection.
Interpretable Uncertainty
Problem Description
This area is about making model uncertainty more interpretable and calibrated by adding features such as confidence interval outputs, conditional probabilistic predictions specified with sentences, posterior calibration methods, and so on.
Motivation
If operators ignore system uncertainties since the uncertainties cannot be relied upon or interpreted, then this would be a contributing factor that makes the overall system that monitors and operates AIs more hazardous. To draw a comparison to chemical plants, improving uncertainty calibration could be similar to ensuring that chemical system dials are calibrated. If dials are uncalibrated, humans may ignore the dials and thereby ignore warning signs, which increases the probability of accidents and catastrophe.
Furthermore, since many questions in normative ethics have yet to be resolved, human value proxies should incorporate moral uncertainty. If AI human values proxies have appropriate uncertainty, there is a reduced risk in an human value optimizer maximizing towards ends of dubious value.
Other reasons:
- Calibrated models can better convey the limits of their competency by expressing their uncertainty, so human operators can know when to override models. Calibrated probabilities facilitate rational decision making:
- Improved probability estimates matter for high-stakes decisions
- Improved risk estimates (probabilities multiplied by losses)
- ML subsystems are easier to integrate if each system is well-calibrated
- Model confidences are more interpretable the more they are calibrated
- This helps systems fail gracefully by enabling us to implement triggers for fail-safes or conservative fallback policies.
What Researchers Are Doing Now
They are measuring model miscalibration on typical examples and in the face of distribution shifts and adversarial examples [1,2,3,4,5].
What Advanced Research Looks Like
Future models should be calibrated on inherently uncertain, chaotic, or computationally prohibitive questions that extend beyond existing human knowledge. Their uncertainty should be easily understood by humans. Moreover, given a lack of certainty in any one moral theory, AI models should accurately and interpretably represent this uncertainty in human value proxies.
Importance, Neglectedness, Tractability
Importance: ••
This is an important part of interpretability.
Neglectedness: •
Many people are working on it, maybe half an order of magnitude more than anomaly detection. Calibration in the face of adversaries is highly neglected, as are new forms of interpretable uncertainty: having models output confidence intervals, having models output structured probabilistic models (e.g., “event A will occur with 60% probability assuming event B also occurs, and with 25% probability if event B does not”).
Tractability: ••
There are shovel-ready tasks, and the community is making progress on this problem.
Relation to General Capabilities
It’s often helped by some upstream capabilities, but it is harmed by other upstream methods (e.g., mixup). Also note the Brier score metric is much more correlated with upstream capabilities metrics such as vanilla accuracy than calibration metrics including the expected calibration error (ECE) or RMS calibration error. See a discussion of how the Brier score is a mixture of an accuracy component and a calibration component in this EMNLP paper. Consequently, safety-minded researchers should avoid tangling under- and over-confidence with accuracy and therefore avoid using the Brier score as the main summary for calibration. Fortunately most of the ML community uses the disentangled metrics.
Capabilities Externalities Analysis
Many calibration methods try to make fixed models more calibrated, and these techniques leave the representations and accuracy unchanged. By default, calibration research leaves capabilities unchanged.
Criticisms
Like work in transparency, this helps human operators and inspectors, but it does not directly reduce inherent hazards.
Many of the impacts are indirect or sociotechnical, but we should only support work that has direct impact (linear causal influence).
Trojan Horse Models
Problem Description
AI systems can contain “trojan” hazards. Trojaned models behave typically in most situations, but when specific secret situations are met, they reliably misbehave. For example, an AI agent could behave normally, but when given a special secret instruction, it could execute a coherent and destructive sequence of actions. In short, this area is about identifying hidden functionality embedded in models that could precipitate a treacherous turn.
Motivation
One of the most dangerous sources of risk from advanced AI is sudden, unexpected changes in behavior. Similar to how people can hide their true intentions, a misaligned AI could bypass oversight mechanisms through deception. If we can uncover hidden behavior and predict treacherous turns before they happen, this will mitigate several failure modes.
What Researchers Are Doing Now
They are developing Trojan attacks and defenses. Most existing work uses CV datasets and models as a testbed [1,2,3,4,5,6,7], but recent work is beginning to explore Trojans for NLP models [1,2]. A much smaller number of papers explores Trojans for RL [1]. There is also related work on emergent behaviors in RL and emergent capabilities in large language models, which explores different aspects of hidden functionality.
Importance, Neglectedness, Tractability
Importance: •••
Treacherous turns from advanced AI systems are a significant source of x-risk. Starting work on this problem early is important, and Trojan research is one way to make initial progress.
Neglectedness: ••
The field of Trojans in deep learning is 5 years old, but there is still much left to be done. The field is not commonly associated with safety, so there is an opportunity to focus the field towards greater x-risk relevance and create a path for safety researchers to gain career capital.
Tractability: ••
Analyzing and detecting Trojans is an early field with much low-hanging fruit. It is a standard ML research problem with emerging benchmarks that can be iterated on. However, the problems of detecting and reverse-engineering Trojans are broad in scope and challenging.
Relation to General Capabilities
We are not aware of more accurate models affecting Trojan attacks or defenses.
Capabilities Externalities Analysis
Trojan research is unlikely to impact general capabilities, because most of the work is developing attacks and defenses. The former work is highly specific to Trojans and unlikely to transfer, and the latter work is relevant to safety.
Conversely, improvements to general capabilities might yield useful demonstrations of hidden functionality and emergent capabilities that could make this research easier. However, this doesn’t appear to have happened yet.
Criticisms
Trojans might not generalize to real treacherous turns. Current Trojans are mostly about flipping predicted classes, but real hidden behavior might be more complex. Even future harder versions of the problem may not solve treacherous turns.
Real hidden behavior might be easy to predict, e.g. malintent can simply be read off from the AI’s train of thought, particularly if progress has been made on honesty. Large-scale deception will be hard for strong AIs to maintain.
Real hidden behavior might be hidden very differently from human-created Trojans, and so Trojan detection methods might not help.
Transparency
Problem Description
AI systems are becoming more complex and opaque. This area is about gaining clarity about the inner workings of AI models and making models more understandable to humans.
Motivation
If humans lose the ability to meaningfully understand ML systems, they may no longer retain their sovereignty over model decisions.
Transparency tools could help unearth deception, mitigating risks from dishonest AI and treacherous turns. This is because some speculate that deception could become inadvertently incentivized, and if models are capable planners, they may be skilled at obscuring their deception. Similarly, researchers could develop transparency tools to detect poisoned models, models with trojans, or models with other latent unexpected functionality. Moreover, transparency tools could help us better understand strong AI systems, which could help us more knowledgeably direct them and anticipate their failure modes.
Other motivation formulations:
- Transparency helps facilitate cooperation among AIs, so it enables possibilities in cooperative AI. Transparency also undercuts collusion.
- Transparency could make it easier for models to detect deception and other problems in other models, which could improve monitoring.
What Researchers Are Doing Now
People are critiquing transparency methods, analyzing superhuman game AIs, and looking for mechanisms inside models. This is quite a simplification. There are many researchers in this space, but there aren’t many coherent clusters of research (save for areas known to be bad, such as nearly all work on saliency maps).
What Advanced Research Could Look Like
Successful transparency tools would allow a human to predict how a model would behave in various situations without testing it. These tools should be able to be easily applied (ex ante and ex post emergence) to unearth deception, emergent capabilities, and failure modes.
To help make models more transparent, future work could try to provide clarity about the inner workings of models and understanding model decisions. Another line of valuable work is critiquing explainability methods and trying to show limitations of auditing methods. Measuring similarities and differences between internal representations is also an important step toward understanding models and their latent representations.
Importance, Neglectedness, Tractability
Importance: •••
If we could intuitively understand what models are doing, then they’d be far more controllable.
Neglectedness: •
This is highly funded by numerous stakeholders, and it has a large community. Deep nets are famous for being “black boxes,” and this limits their economic utility due to concerns about human oversight (such as in medical applications).
Tractability: •
This area has been struggling to find a solid line of attack throughout its existence. It has set goals for itself, and it has not met them (e.g., using transparency tools to find special functionality implanted by another human.)
Relation to General Capabilities
The historical trend is that models are becoming more opaque as time progresses. We went from decision trees and SVMs, to random forests (intellectually unmanageable), to ConvNets, to Vision Transformers (where the lack of channels makes feature visualizations worse). “In prediction, accuracy and simplicity (interpretability) are in conflict” (Breiman, 2001).
Capabilities Externalities Analysis
This has not been useful for addressing weaknesses in models, and the “insights” gleaned from transparency techniques have not helped researchers understand how to improve models. It currently is not having any impact on capabilities research.
(It is worth noting that if “transparency” is construed more broadly to include anything involving “understanding models better,” then some approaches may have capabilities externalities, such as studying general capability scaling laws. We do not include this as a transparency problem.)
Criticisms
There’s been high interest from numerous stakeholders, including several tens of millions of dollars from DARPA, and there isn’t anything solid that we’ve got from it. Maybe it’s too vague or trying to do too much?
If we care about detecting deception or Trojan horse models (treacherous turns), why not just focus on the more tractable problem of detecting deception or Trojan horse models directly (possibly using AIs to help us detect such behavior and sift through the gobs of raw data)?
Progress in ML is driven by metrics; progress must be measurable. This area doesn’t have metrics, while other areas such as detecting Trojans do.
Interpretability is a “god of the gaps” field (“if we understood our models, then we could understand how to fix this problem.”). For many non-accuracy goals that we don’t know how to reach, many think interpretability will help us reach the goal. (The Mythos of Interpretability)
Often, systematic findings that explain a portion of a model’s behavior are “science of ML” papers (example) rather than intrpretability papers.
Transparency aims to reverse the longstanding trend that models are becoming more opaque; reversing or undoing the consequences of this robust trend is unlikely to happen.
(Even in humans, better forecasting models are less interpretable and more complicated.)
Humans are not interpretable. They are black boxes to themselves, and they confabulate explanations. (Hinton gives an example.) Expecting explanations for thought processes requires making many unconscious computations conscious, but only a small fraction of computation can be supported consciously. Many intuitive tasks are pre-verbal.
If humans could in detail explain how they processed an image and classified it, then we could close the book on several research areas in cognitive science. Likewise, if humans could understand how they know things, then research experts could easily transmit their research abilities. We know they’re relatively unable to do this, or else committed students could always become stronger than advisors. (“Education is an admirable thing,” wrote Oscar Wilde, “but it is well to remember from time to time that nothing that is worth knowing can be taught.” Moreover, “we know more than we can tell.” - Michael Polanyi)
It is difficult to interpret the eigenvectors from PCA of simple datasets such as MNIST or faces:
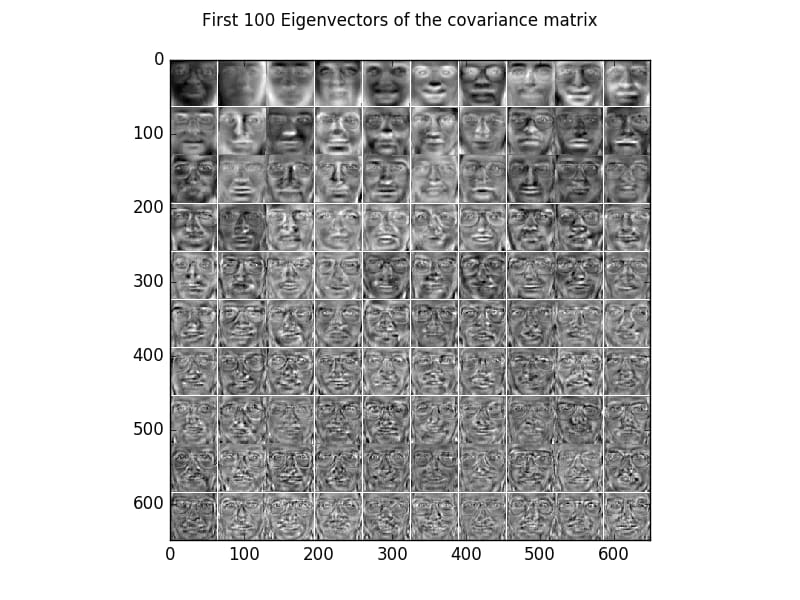
It’s not possible to easily convert the vectors above to English. How should we expect to be able to interpret even more complicated ML algorithms if it’s not possible to interpret PCA? Likewise, other basic ML methods are hard to interpret. For example, random forests are intellectually unmanageable. The later computations in a basic MNIST ConvNet are hardly interpretable.
There are often too many possible explanations for a phenomenon for any single explanation to be useful. This is why the best test of a model is its predictive power, not whether it can only explain prior data. NYU professor Bob Rehder wrote: “Explanation tends to induce learners to search for general patterns, it may cause them to overlook exceptions, with the result that explanation may be detrimental in domains where exceptions are common.”
When analyzing complex systems (such as deep networks), it is tempting to separate the system into events or components (“parts”), analyze those parts separately, and combine results or “divide and conquer.”
This approach often wrongly assumes (Leveson 2020):
- Separation does not distort the system’s properties
- Each part operates independently
- Part acts the same when examined singly as when acting in the whole
- Parts are not subject to feedback loops and nonlinear interactions
- Interactions between parts can be examined pairwise
Searching for mechanisms and reductionist analysis is too simplistic when dealing with complex systems (see our third post [AF · GW] for more).
People hardly understand complex systems. Grad students in ML don’t even understand various aspects of their field, how to make a difference in it, what trends are emerging, or even what’s going on outside their small area. How will we understand an intelligence that moves more quickly and has more breadth? The reach of a human mind has limits. Perhaps a person could understand a small aspect of an agent’s actions (or components), but it’d be committing the composition fallacy to suggest a group of people that individually understand a part of an agent could understand the whole agent.
There are different approaches to understanding phenomena. One can look from the top down and find general rules that capture complex phenomena. Alternatively, one could try building understanding from the bottom up, but building a staircase from basic mechanisms all the way to complex system-level behavior does not have a good track record (e.g., consider mechanisms in evolution that leave many adaptations unexplained, mechanisms in anatomy have limited power in predicting whether a new drug will work, etc.). Most current transparency builds from the bottom up.
Smarter people are not reliably understood by less smart people. If a less intelligent person could reliably predict what a more intelligent person would do, then they would be similarly intelligent. It’s unlikely we’ll be able to understand all aspects of a superintelligence (make it interpretable), as the human mind is limited and going to be less smart than a superintelligence.
Even if we labeled each of a model’s many millions of neurons (example label of a neuron: “detects whiskers at 21 to 24 degrees, and it also detects black letter ‘A’ keyboard keys with probability 37%, and it detects a type of noise that’s difficult to describe”), it wouldn’t necessarily be interpretable (simulable, enable crisp post-hoc explanations, highly decomposable). To holistically understand models, we are better off understanding them functionally.
Systemic Safety
This section is about using AI for furthering longtermist or EA goals. The areas are also useful for improving systemic contributing factors [AF · GW] that contribute to the reduction of AI x-risk.
ML for Cyberdefense
Problem Description
This area is about using machine learning to improve defensive security, such as by improving malicious program detectors. This area focuses on research avenues that are clearly defensive and not easily repurposed into offensive techniques, such as detectors and not automated pentesters.
Motivation
It will matter very little if AI systems are aligned if they can be hacked by humans or other AI systems and made to be misaligned (intentionally or unintentionally). There may also be situations where aligned AI is hijacked by a malicious actor who intentionally or accidentally contributes to x-risk. In addition, one of the fastest and most potent ways for a superintelligence to project its intelligence and influence the world is through cyberattacks, not through physical means.
Even if some of the components of ML systems are safe, they can become unsafe when traditional software vulnerabilities enable others to control their behavior. Moreover, traditional software vulnerabilities may lead to the proliferation of powerful advanced models, and this may be worse than proliferating nuclear weapons.
Cyberattacks could take down national infrastructure including power grids, and large-scale, reliable, and automated cyberattacks could engender political turbulence and great power conflicts. Great power conflicts incentivize countries to search the darkest corners of technology to develop devastating weapons. This increases the probability of weaponized AI, power-seeking AI, and AI facilitating the development of other unprecedented weapons, all of which are x-risks. Using ML to improve defense systems by decreasing incentives for cyberwarfare makes these futures less likely.
Other motivation formulations:
- As ML proliferates, it's possible that we will see a dramatic increase in the use of ML systems in cyberattacks. In order to protect against such attacks, we may need to use ML in cyberdefense. Work might be especially necessary if there turns out to be an asymmetry in attacks/defenses as there currently is with adversarial examples.
- This post [EA · GW] also gives motivations for the importance of information security in AI safety.
What Researchers Are Doing Now
Some research in automatically detecting and patching software vulnerabilities at scale [1,2,3]. Some use anomaly detection for use in detecting malicious payloads [1,2]. ML has also been used for intrusion detection [1,2,3].
What Could Advanced Research Look Like?
AI-based security systems could be used for better intrusion detection, firewall design, malware detection, and so on.
Importance, Neglectedness, Tractability
Importance: ••
It’s important that powerful systems do not fall into the hand of extreme or reckless actors, but they may be able to develop those systems themselves regardless.
Neglectedness: •••
Security researchers are currently bottlenecked by compute power.
Tractability: •••
This is an application of ML, and doesn’t necessarily require new fundamental research.
Relation to General Capabilities
Better upstream models could help make for better ML defenses. For example, better reasoning and the ability to understand longer sequences could make models better able to analyze code and large assembly files.
Capabilities Externalities Analysis
Much of the work in this space is engineering and not influencing upstream models.
Criticisms
This should only be funded or researched in an exploratory way before large commitments are made.
Funding will need to strongly disincentivize gain-of-function attack capabilities in order for this area to be positive.
This is just realpolitik as it assumes that systems are much less likely to be safe if they fall into the wrong hands. In reality, systems are unlikely to be roughly equally safe (or unsafe) in any case, so devoting time to cybersecurity will not help.
If nuclear weapons aren’t much of an x-risk, then WWIII is unlikely to be a large x-risk. It might be necessary to improve security for particular ML models to prevent them from falling into the wrong hands, but better security in general isn’t useful.
ML for Improving Epistemics
Problem Description
This area is about using machine learning to improve the epistemics and decision-making of political leaders. This area is tentative; if it turns out to have difficult-to-avoid capabilities externalities, then it would be a less fruitful area for improving safety.
Motivation
We care about improving decision-making among political leaders to reduce the chance of rash or possibly catastrophic decisions. These decision-making systems could be used in high-stakes situations where decision-makers do not have much foresight, where passions are inflamed, and decisions must be made extremely quickly and based on gut decisions. During these moments of peril [AF · GW], humans are liable to make egregious errors. Historically, the closest we have come to a global catastrophe has been in these situations, including the Cuban Missile Crisis. Work on these technologies could reduce the prevalence of perilous situations. Separately, this reduces the risks from persuasive AI. Moreover, it helps leaders more prudently wield the immense power that future technology will provide. As Carl Sagan said, “If we continue to accumulate only power and not wisdom, we will surely destroy ourselves.”
Other motivation formulations:
- Better forecasting can potentially help with instituting better regulations and calibrating AI strategy. In addition, it could reduce risks from hasty deployments predicated on other actors being farther along than they are.
- This reduces x-risks from hyper-persuasive AI and an erosion of epistemics.
- AI can help political leaders make better decisions, like what we needed during emerging crises like COVID.
What Researchers Are Doing Now
We are developing ML benchmarks for forecasting geopolitical events.
What Advanced Research Could Look Like
Systems could eventually become superhuman forecasters of geopolitical events. They could help brainstorming possible considerations that might be crucial to a leader’s decision. Finally, they could help identify inconsistencies in a leader’s thinking and help them produce a more sound judgment.
Importance, Neglectedness, Tractability
Importance: ••
Better epistemics could be useful for the development and deployment of AI systems, but it would not solve any fundamental problems in AI safety on its own.
Neglectedness: •••
Few care about superforecasting, let alone ML for forecasting.
Tractability: ••
This is an application of ML, but it is fairly outside the capabilities of current models.
Relation to General Capabilities
Forecasting ability and IQ are not strongly related. Exceptional forecasting skills seem to be hard to acquire even for smart people. Better retrieval methods could help improve forecasting capabilities.
Capabilities Externalities Analysis
Much of the work in this space is engineering and not influencing upstream systems.
If work on this problem is appearing to play into general capabilities, work should be discouraged (this goes for any emerging safety research area). It is important to keep this line of research targeted to reduce the chances of speeding up other kinds of capabilities (for instance, truth/contemplation/reasoning/research).
Criticisms
“The essence of intelligence is prediction.” Therefore it may be harder to avoid capabilities externalities.
Taleb argues in Antifragile that reliance on forecasting makes us more vulnerable to tail risks and gives us a false sense of security.
Forecasting benchmarks need to span decades of historical data to measure the ability to predict tail risks. That will require a substantial engineering effort.
Cooperative AI
Problem Description
In the future, AIs will interact with humans and other AIs. For these interactions to be successful, models will need to be more skilled at cooperating. This area is about reducing the prevalence and severity of cooperation failures. AI models and humans may be stuck in poor equilibria that are robustly difficult to escape; cooperative AI methods should improve the probability of escaping or avoiding poor equilibria. This problem also works towards making AI agents better at positive-sum games, of course subject to capabilities externalities constraints. As we describe this area, it does not include the typical directions in human-robot interaction, such as communication between humans and robots in standard tasks.
Motivation
First, worlds where multiple agents are aligned in different ways are highly plausible. There are strong incentives to have multiple decision-making agents; for example, jury theorems show collections of agents make better decisions than a single agent, and agents have incentives to retain some control and not automatically cede control to one single centralized agent.
In a world where we have AIs interacting with other agents, cooperative AI can be useful for not just having higher upside but also smaller downside. Cooperative AIs could help rein in misaligned agents or power-seeking AIs. For this protective measure to work, the power of the collective must be greater than the power of the power-seeking AI.
Let’s consider how easily a power-seeking AI could overpower the world. Of course, if AIs are better able to cooperate, they are more likely to counteract power-seeking AIs. Tracking and regulating the flow and concentration of GPUs can reduce the probability of a single AI becoming more powerful than the collective power of the rest. Even if one power-seeking agent is smarter than every other model, it does not imply that it has control over all other models. Usually, having higher cognitive ability does not let an agent overpower the collective (the highest IQ person does not rule the world). However, individual bad actors that are smarter than others can have outsized effects. In some special environments, such as environments with structured criticality, small differences could be magnified. Moreover, the world is becoming more long-tailed and more like “extremistan” in which there is tyranny of the top few (this is in contrast to mediocristan, where there is tyranny of the collective). Consequently, while there are factors that can give smarter models outsized advantages, the smartest model does not automatically overpower the collective power of cooperative AIs.
Other motivation formulations:
- To make environments with multiagent AIs stable, cooperation may be necessary.
- Cooperation can make us better able to escape bad equilibria, such as help us overcome bad systems for which we are dependent on our basic needs. Being robust to coordination failures helps us avoid lock-in.
- Intrasystem goals can create misalignment; cooperation helps agents better jointly optimize a decomposed objective, thereby reducing misalignment.
- If each superintelligence is fully aligned with one individual, the superintelligences and their owners can end up in game-theoretic tragedies
- The theory of morality as cooperation (“all of human morality is an attempt to solve a cooperative problem”) implies that if we want to build ethical machines (machine ethics), then it can be fruitful to make them more cooperative and build in cooperative dispositions.
- If we improve cooperativeness, we have a larger range of governance and deployment strategies (e.g., we could have AIs team up against other defecting AIs, this affects the strategic landscape and the possible defensive solutions), rather than trust a single contemplative agent. This is work towards making more sophisticated contractarian approaches to machine ethics more feasible (rather than only philosopher-king type strategies).
- Without cooperation, we will have hierarchies where the strongest agents dominate, leading to “the state of nature” and conflict; to help avoid such a dire environment, we need cooperation.
- Cooperation is a “defense in depth” area that does not decidedly fix safety problems, but it helps drive down the severity and probability of many hazards
- Cooperation could help rein in power-seeking or colluding AIs; a group of AIs, in many cases, have enough power to rein in misaligned AIs.
- Cooperation reduces the probability of conflict and makes the world less politically turbulent. Similarly, cooperation enables collective action to counteract rogue actors, regulate systems with misaligned goals, and rein in power-seeking or colluding AIs. Finally, cooperation reduces the probability of various forms of lock-in and helps us overcome and replace inadequate systems that we are dependent on for our basic needs.
What Advanced Research Could Look Like
Researchers could create agents that, in arbitrary real-world environments, exhibit cooperative dispositions (e.g., help strangers, reciprocate help, have intrinsic interest in others achieving their goals, etc.). Researchers could create coordination systems or AI agent reputation systems. Cooperating AIs should also be more effective at coordinating to rein in power-seeking AI agents.
Importance, Neglectedness, Tractability
Importance: •••
Within systemic safety, cooperative AI is the most targeted towards the reduction of AI x-risk.
Neglectedness: •••
There are few researchers working in this area.
Tractability: •
It is currently especially difficult to perform meaningful research on multiagent sequential decision making.
Relation to General Capabilities
Agents able to plan on very long time horizons may have more incentives to cooperate, but even for humans cooperative tendencies and precedents were hard-earned and hard to enforce; powerful humans often prefer not to cooperate but rather dominate.
Capabilities Externalities Analysis
Some research strategies could make agents better at playing games, which would make them better at playing cooperative games. By pursuing less naive research strategies, such as the strategy of endowing models with intrinsic dispositions to cooperate, capabilities externalities should be easier to avoid.
Research in this area should avoid developing cooperation methods that are antisymmetric with collusion and may therefore create collusive abilities. That is, research should avoid collusion externalities. Fortunately, some cooperative tendencies are not antisymmetric with collusion; being disposed to help strangers could be thought antisymmetric with the disposition to harm strangers, but the former helps cooperation and the latter does not help collusion. Cooperativeness is also useful for a larger, highly permeable group, while collusion is maintained among a specific group. Cooperation is often helped with transparency and truth, which is more robust than secrecy and lies, which collusion often depends on. Separately, working on honesty disincentivizes collusion.
Criticisms
Cooperation is too closely linked to collusion to be worth pursuing.
Cooperation leads to higher connectivity, which leads to higher fragility (faster cascading failures) and more extreme tail events (long tail distributions get sharper with more connectivity; then you have a more volatile future). Higher connectivity undermines the power of the collective, as these environments are dominated by tail events and the most extreme agents.
Possible additional areas
The section above represents concrete problems that we believe can be pursued now without capability externalities and with varying levels of tractability. In this section we discuss some possible additional areas. One of these areas is not concrete enough yet, and the other areas have not formed into a coherent area yet. These limitations may someday be resolved.
Regulating Mesa-Optimizers and Intrasystem Goals
As systems make objectives easier to optimize and break them down into new goals, subsystems are created that optimize these new intrasystem goals. But a common failure mode is that “intrasystem goals come first.” These goals can steer actions instead of the primary objective. Thus a system’s explicitly written objective is not necessarily the objective that the system operationally pursues, and this can result in misalignment.
Intrasystem goals occur when the goal of a training process (e.g., the loss function used for gradient descent, the exploration incentives of the sequential decision making agent, etc.) differs from the operational goal of the trained model it produces. This is known as mesa-optimization.
When multi-agent sequential decision-making is more feasible, we can give agents goals and delegate subgoals to agents. Since breaking down goals can distort them, this creates “intrasystem goals” and misalignment. Regulating these subagents that are optimizing their subgoal will be a research challenge. However, capabilities will need to be advanced further before this research area will be tractable.
An alternative way to study mesa optimizers is to study the general inductive biases of optimizers. While this could potentially be informative for understanding mesa-optimization, the neglectedness and tractability are low: this was previously the hottest area of theoretical ML for some years in the late 2010s, and see here for a discussion of tractability.
A related area that is more neglected and tractable is certified behavior. It is possible to have guarantees about model behavior given their weights [1,2], so it is not necessarily true that “all bets are off” when models are deployed.
Proxy Gaming
This is not clearly an area in its own right. Right now it looks like adversarial robustness, anomaly detection, and detecting emergent functionality, applied to sequential decision making problems. Perhaps in the future a distinct problem area will emerge.
Irreversibility
To avoid lock-in, some want to train models to pursue easy-to-reverse states. One way is to increase optionality; however, current methods to do this might simultaneously increase power-seeking behavior. Perhaps in the future avoiding irreversibility generally and preventing lock-in can be separated from power-seeking. Right now it seems there are other more targeted approaches to avoiding lock-in, such as moral parliaments, philosophy research bot/value clarification, and cooperative AI.
Conclusion
It is sometimes argued that the AI safety field has few specific problems that can be tractably pursued without creating capabilities externalities. However, we have shown that there are some specific research directions that can be pursued while avoiding capabilities externalities.
Many of the research directions listed in this document can be tractably pursued by the broader ML research community, making them suitable for broader outreach beyond the small group of researchers solely motivated by existential safety.
Though we believe some of these areas are more promising than others, we specifically do not argue for the overriding importance of a single one for reasons of diversification [AF(p) · GW(p)]. We also do not claim that the areas above are the only areas worth pursuing, and like all research avenues, they may need to be curtailed in the future if they prove intractable or produce unacceptable externalities. We believe that the areas above are promising enough to be included in an overall scalable portfolio.
- ^
Note that detecting lies would best fit under Monitoring rather than Alignment, but for simplicity we consolidate these approaches here.
6 comments
Comments sorted by top scores.
comment by aog (Aidan O'Gara) · 2022-06-10T19:48:36.684Z · LW(p) · GW(p)
Fantastic agenda for the field, thanks for sharing.
Honesty is a narrower concept than truthfulness and is deliberately chosen to avoid capabilities externalities, since truthful AI is usually a combination of vanilla accuracy, calibration, and honesty goals. Optimizing vanilla accuracy is optimizing general capabilities, and we cover calibration elsewhere. When working towards honesty rather than truthfulness, it is much easier to avoid capabilities externalities.
I think it's worth mentioning that there are safety benefits to truthfulness beyond honesty. You're absolutely right that general capabilities tend to improve truthfulness and vice versa, but I still see two specific paths to longtermist impact for truthful language models.
First, truthful LMs can combat automated persuasion and misinformation. The growth of language models seems to pose serious risks for degrading discourse and enabling propaganda from malicious actors. Guiding progress in the field towards LMs that are asymmetrically truthful (as opposed to persuasive) or that can identify bots in the wild seems important. See risks from automated persuasion [AF · GW] and AI takeover without AGI or agency [AF · GW].
Second, the ability to verify the truthfulness of claims is essential for both debate and iterated amplification. Other bottlenecks on these agendas should be prioritized, and the agendas should seek to perform as well as possible at the current state of the art level of accuracy. But if other domains of AI see rapid progress, it could be useful to pursue better truth verification capabilities in order to supervise other systems.
Honest AI is a more scalable direction for the field with less danger of negative capabilities externalities. But with a sufficient degree of caution, I see the case for working on some truthfulness agendas.
comment by Evan R. Murphy · 2022-06-10T03:18:36.603Z · LW(p) · GW(p)
Thank you for this sequence, which has a very interesting perspective and lots of useful info.
Just a quick note on the following section from your overview of "Honest AI" in this post:
What Researchers Are Doing Now
They are demonstrating that models can lie, and they are capturing true and false clusters inside models (this paper is forthcoming).
I was surprised not to see any mention of Eliciting Latent Knowledge (ELK) [AF · GW] here. I guess part of it is about "demonstrating that models can lie", but there is also all the solution-seeking happening by ARC and those who submitted proposals for the ELK prize.
You're covering a lot of problem areas in this post so I don't expect it to be comprehensive about every single one. Just curious if there's any particular reason you chose to not to include ELK here.
Replies from: ThomasWoodside↑ comment by TW123 (ThomasWoodside) · 2022-06-10T04:00:56.020Z · LW(p) · GW(p)
Hi Evan! This post is focused on empirical ML approaches, as is PAIS overall. Certainly there is theoretical work that touches on many of the areas, but covering it all isn't within the scope of this (it's already pretty long).
The forthcoming paper mentioned (from Burns, Ye, Klein, and Steinhardt) could be viewed as an empirical attempt to do something similar to ELK.
comment by JakubK (jskatt) · 2023-06-06T22:12:51.694Z · LW(p) · GW(p)
What happened to black swan and tail risk robustness (section 2.1 in "Unsolved Problems in ML Safety")?
comment by jai · 2023-04-03T00:36:08.331Z · LW(p) · GW(p)
Has the forthcoming paper on AI Honesty been published yet? I'd like to read it.
Edit: Got it. https://arxiv.org/pdf/2212.03827.pdf
comment by wassname · 2023-01-22T12:35:03.455Z · LW(p) · GW(p)
Great post. I'm going to zoom in on one thing to be argumentative ;p
You say that transparency doesn't have externalities. In that it doesn't help researcher make more capabilities models. I wonder why you are so confident?
I'm assuming that because you haven't seen it in papers and haven't used it yourself you assume that it's not commonly used. But others might use it as a debugging or exploration tool. After all do papers really list their debugging and exploration tools? Not usually.