Introduction to Pragmatic AI Safety [Pragmatic AI Safety #1]
post by Dan H (dan-hendrycks), TW123 (ThomasWoodside) · 2022-05-09T17:06:00.409Z · LW · GW · 3 commentsContents
ML Research Precedents Minimal Capabilities Externalities Sociotechnical Systems View The Pragmatic AI Safety Sequence About the authors None 3 comments
This is the introduction to a sequence of posts that describe our models for Pragmatic AI Safety. Thanks to Oliver Zhang, Mantas Mazeika, Scott Emmons, Neel Nanda, Cameron Berg, Michael Chen, Vael Gates, Joe Kwon, Jacob Steinhardt, Steven Basart, and Jacob Hilton for feedback on this sequence (note: acknowledgements here may be updated as more reviewers are added to future posts).
Machine learning has been outpacing safety. Ten years ago, AlexNet pushed the boundaries of machine learning, and it was trained using only two GPUs. Now state-of-the-art models are trained on thousands of GPUs. GPT-2 was released only around three years ago, and today, we have models capable of answering bar exam questions, writing code, and explaining jokes.
Meanwhile, existing approaches to AI safety have not seen similar strides. Many older approaches are still pre-paradigmatic, uncertain about what concrete research directions should be pursued and still aiming to get their bearings. Centered on math and theory, this research focuses on studying strictly futuristic risks that result from potential systems. Unfortunately, not much progress has been made, and deep learning resists the precise and universal mathematical characterizations preferred by some safety approaches.
Recently, some established safety teams have focused more on safety in the context of deep learning systems, which has the benefit of being more concrete and having faster experimental feedback loops. However, many approaches often exhibit the downside of blurring the lines between general capabilities research and safety, as there appear to be few other options.
Finally, neither the pre-paradigmatic nor industry deep learning-based approaches seriously emphasize the broad range of sociotechnical factors that are critical for reducing risk from AI systems.
Given that ML is progressing quickly, that pre-paradigmatic research is not highly scalable to many researchers, and that safety research that advances capabilities is not safely scalable to a broader research community, we suggest an approach that some of us have been developing in academia over the past several years. We propose a simple, underrated, and complementary research paradigm, which we call Pragmatic AI Safety (PAIS). By complementary, we mean that we intend for it to stand alongside current approaches, rather than replace them.
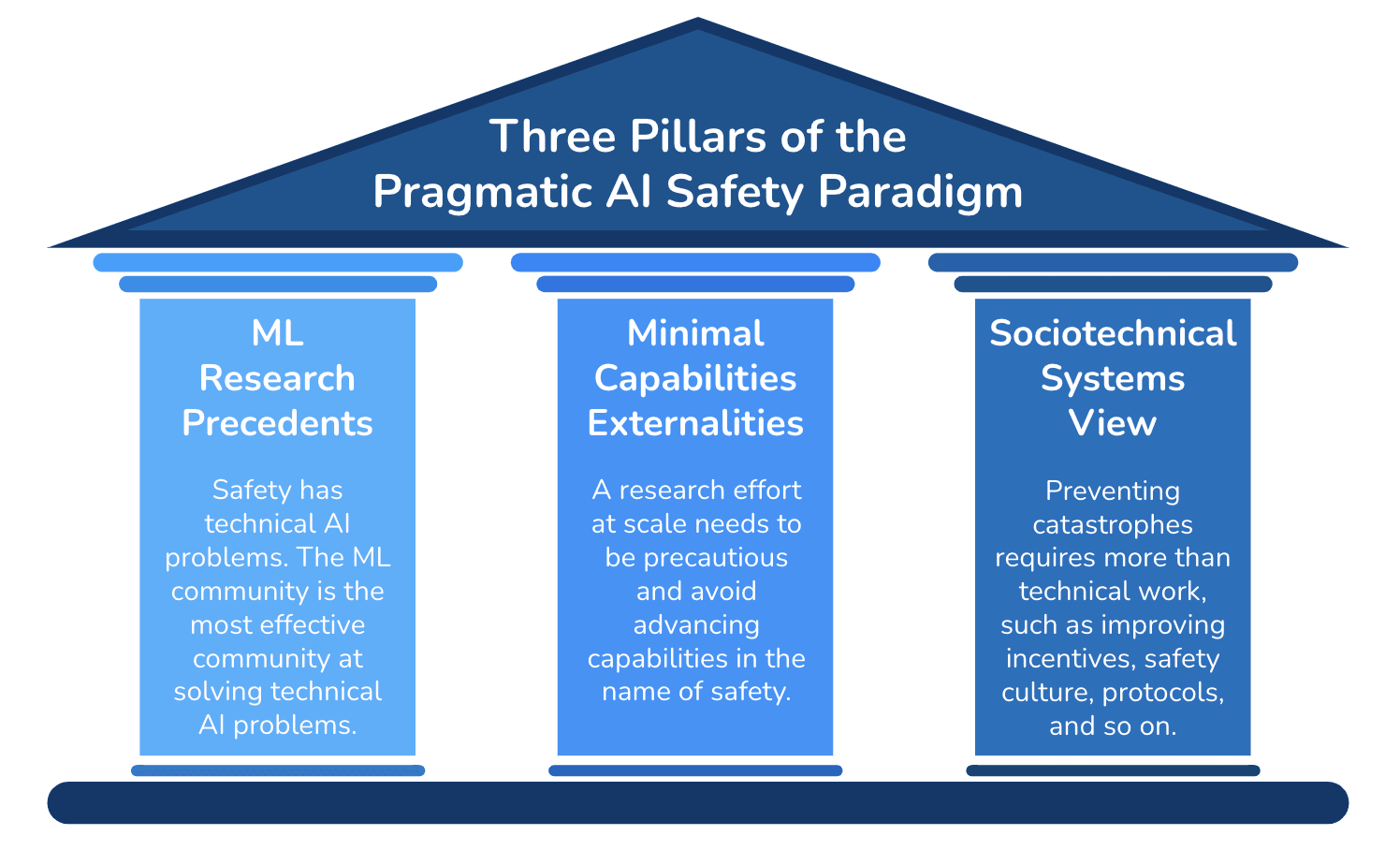
Pragmatic AI Safety rests on three essential pillars:
- ML research precedents. Safety involves technical AI problems, and the ML community’s precedents enable it to be unusually effective at solving technical AI problems.
- Minimal capabilities externalities. Safety research at scale needs to be precautious and avoid advancing capabilities in the name of safety.
- Sociotechnical systems view. Preventing catastrophes requires more than technical work, such as improving incentives, safety culture, protocols, and so on.
ML Research Precedents
Despite relying on “broken” processes like conferences and citations, the ML community has managed to solve an increasingly general set of problems: colorizing images, protein folding, superhuman poker, art generation, etc. This doesn’t mean that the ML community is set up optimally (we will discuss ways in which it’s not), but it does consistently exceed our expectations and demonstrate the best track record in solving technical AI problems.
In general, ML researchers are skilled at adding arbitrary features to systems to improve capabilities, and many aspects of safety could be operationalized so as to be similarly improved. This property makes ML research precedents promising for solving technical ML problems, including many safety problems.
Here are some ML research precedents that we view as important:
- Long term goals are broken down into empirical simplified microcosmic problems
- Subproblems can be worked on iteratively, collectively, and scalably
- Contributions are objectively measured
- The set of research priorities is a portfolio
- Researchers must convince anonymous reviewers of the value of their work
- Highly competitive, pragmatic, no-nonsense culture
- Long-run research track records are necessary for success
We will address all of these precedents throughout this sequence. They are not original to safety, and some safety researchers have been following these precedents for years in academia.
There are many problems that we consider to be included in the PAIS research umbrella that are essentially ML problems or have essential ML components: honest AI, power-averseness, implementing moral decision making, value clarification, adversarial robustness, anomaly detection, interpretable uncertainty, detection of emergent behavior, transparency, ML for cyberdefense, and ML for improved epistemics. We will cover each of these areas in depth later in the sequence.
Lastly, we should note that we consider PAIS to overlap with problems considered relevant in ML, but there are a very large number of ML problems that are not relevant to PAIS (privacy, non-convex optimization, etc.).
Minimal Capabilities Externalities
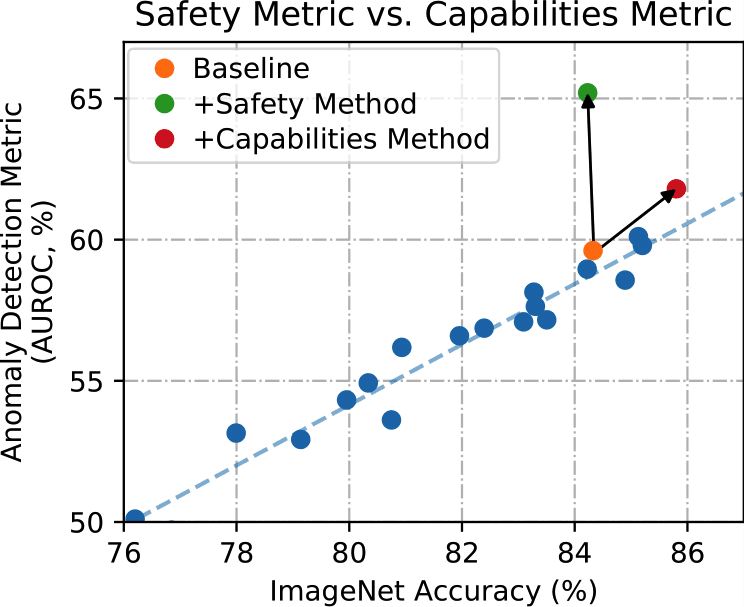
Safety and capabilities are intertwined, especially when researching deep learning systems. For example, training systems to have better world models can make them less likely to spawn unintended consequences, but also makes them more generally capable. Optimizers that can operate over longer time horizons could ensure models don’t take problematic irreversible actions, but also allow models to make more complex longer-term plans in general.
It is clearly possible to make progress on safety metrics without improving capabilities, and some safety researchers have been doing it for years. But it must be done carefully. To do this, we propose a general policy of minimizing capabilities externalities. To the extent possible, we should avoid increasing capabilities in the name of safety, since this is a highly risky strategy and is not safely scalable for a broader research community. We should instead let the broader ML community take care of general capabilities, and work on safety problems that are viable with current capabilities. Rather than intuit whether something is good for overall safety, empirical researchers who follow our approach should demonstrate via measurement that their contribution does not simultaneously improve general capabilities.
Sociotechnical Systems View
A current blindspot in many AI safety approaches is to ignore nonlinear causality. Asking “how does this research agenda directly reduce this specific risk?” is well-intentioned, but it filters out accounts that capture nonlinear causal structures. Unfortunately, direct analysis is not expressive enough to model many of the most important phenomena relevant to safety. Today’s interconnected systems often have nonlinear causality, including feedback loops, multiple causes, circular causation, self-reinforcing processes, butterfly effects, microscale-macroscale dynamics, and so on. There may also be emergent behavior in an overall system that cannot be attributed to any individual subcomponent.
Remote, indirect, and nonlinear causes are omitted from accounts that require linear causality. Contemporary hazard analysis, and complex systems theory in general, is aware of this deficiency, and seeks to correct it. A central takeaway from these analyses is that it is essential to consider the entire sociotechnical system when attempting to prevent failures. Rather than only focusing on the operating process (in this case, a particular AI system’s technical implementation), we need to focus on systemic factors like social pressures, regulations, and perhaps most importantly, safety culture. Safety culture is one reason why engaging the broader ML community (including Chinese ML researchers) is critical, and it is currently highly underemphasized.
The Pragmatic AI Safety Sequence
In this sequence, we will describe a pragmatic approach for reducing existential risk from AI.
In the second post [AF · GW], which will be released alongside this post, we will present a bird’s eye view of the machine learning field. Where is ML research published? What is the relative size of different subfields? How can you evaluate the credibility or predictive power of ML professors and PhD students? Why are evaluation metrics important? What is creative destruction? We will also discuss historical progress in different subfields within ML and paths and timelines towards AGI.
The third post [AF · GW] will provide a background on complex systems and how they can be applied to both influencing the AI research field and researching deep learning.(Edit: the original third post has been split into what will now be the third and fourth posts).
The fourth post [? · GW] will cover problems with certain types of asymptotic reasoning and introduce the concept of capabilities externalities.
The fifth post [AF · GW] will serve as a supplement to Unsolved Problems in ML Safety. Unlike that paper, we will explicitly discuss the existential risk motivations behind each of the areas we advocate.
The sixth and final post will focus on tips for how to conduct good research and navigate the research landscape.
A supplement to this sequence is X-Risk Analysis for AI Research.
About the authors
This sequence is being written by Thomas Woodside and Dan Hendrycks as the result of a series of conversations they’ve had over the last several months.
Dan Hendrycks was motivated to work exceptionally hard after reading Shelly Kagan’s The Limits of Morality in high school. After leaving fundamentalist rural Missouri to go to college, he was advised by Bastian Stern (now at Open Philanthropy) to get into AI to reduce x-risk, and so settled on this rather than proprietary trading for earning to give. He did his undergrad in computer science; he worked on generic capabilities for a week to secure research autonomy (during which time he created the GELU activation), and then immediately shifted into safety-relevant research. He later began his PhD in computer science at UC Berkeley. For his PhD he decided to focus on deep learning rather than reinforcement learning, which most of the safety community was focused on at the time. Since then he’s worked on research that defines problems and measures properties relevant for reliability and alignment. He is currently a fourth and final-year PhD student at UC Berkeley.
Thomas Woodside is a third-year undergraduate at Yale, studying computer science. Thomas did ML research and engineering at a startup and NASA before being introduced to AI safety through effective altruism. He then interned at the Center for Human-Compatible AI, working on safety at the intersection of NLP and RL. He is currently taking leave from school to work with Dan on AI safety, including working on power-seeking AI and writing this sequence.
3 comments
Comments sorted by top scores.
comment by Nathan Helm-Burger (nathan-helm-burger) · 2022-05-13T22:14:03.328Z · LW(p) · GW(p)
This is great! I agree with a lot of what you're saying here and am glad someone is writing these ideas up. Two points of possible disagreement (or misunderstanding on my part perhaps) are:
Highly competitive, pragmatic, no-nonsense culture
I think that competitiveness can certainly be helpful, but too much can be detrimental. Specifically, I think competitiveness needs to go hand-in-hand with cooperation and transparency. Work needs to be shared, and projects need to encompass groups of people. Trying to get the most 'effective research points' from amongst your colleagues as you work together on a group project and communicate clearly and effectively with each other, great. Hiding your work and trying to wait until you have something unique and impressive to share before sharing anything at all, then reporting only the minimal amount of data to prove you did the impressive thing instead of sharing all the details and dead-ends you encountered along the way, not good.
Long-run research track records are necessary for success
I'm not sure how 'long term' you mean, but I think we do need a lot of new people coming into the field, and that we don't have multiple decades for reputations to be gradually established. In particular, I think a failing that academia is vulnerable to is outdated paradigms getting stuck in power until the high-reputation long-established professors finally retire and no longer reject the new paradigm's viewpoints in reviews and grant requests.
Coming from academia to industry was in a lot of ways a breath of fresh air for me, because I was working together with a team that actually wanted the project (making money for our company) to succeed. Rather than working with individual professors that wanted their name on papers in fancy journals. That is near, but not quite matching what should be the goal: 'we want as much accurate knowledge about this science topic to be known as soon as possible by everyone, whether or not we get credit for it.'
Anyway, some thought as to how to get the best of both worlds (industry and academia) may be worthwhile.
comment by Tomáš Turlík (tomas-turlik) · 2023-11-03T17:55:16.374Z · LW(p) · GW(p)
Hey, pictures for first 2 posts in this sequence are 404ing, do you think you could reupload them somewhere?
comment by jacquesthibs (jacques-thibodeau) · 2023-03-14T16:54:47.584Z · LW(p) · GW(p)
The sixth and final post will focus on tips for how to conduct good research and navigate the research landscape.
Is there anything I can do to help with this post? I'm still figuring out these things, but I want to help get this out there.