Renormalization Redux: QFT Techniques for AI Interpretability
post by Lauren Greenspan (LaurenGreenspan), Dmitry Vaintrob (dmitry-vaintrob) · 2025-01-18T03:54:28.652Z · LW · GW · 12 commentsContents
Introduction: Why QFT? Renormalization in physics and ML Some Current Applications Another Call to Action Some paths forward None 12 comments
Introduction: Why QFT?
In a previous post [LW · GW], Lauren offered a take on why a physics way of thinking is so successful at understanding AI systems. In this post, we look in more detail at the potential of Quantum field theory (QFT) to be expanded into a more comprehensive framework for this purpose. Interest in this area has been steadily increasing[1], but efforts have yet to condense into a larger-scale, coordinated effort. In particular, a lot of the more theoretical, technically detailed work remains opaque to anyone not well-versed in physics, meaning that insights[2] are largely disconnected from the AI safety community. The most accessible of these is Principles of Deep Learning theory (which we abbreviate “PDLT”), a nearly 500 page book that lays the groundwork for these ideas[3]. While there has been some AI safety research that has incorporated QFT-inspired threads[4], we see untapped potential for cross-disciplinary collaborations to unify these disparate directions. With this post – one of several in a series linking physics and AI– we explain some of the high-level ideas we find important, with the goal of generating ideas to be developed later. In particular, we want to encourage more of a dialogue between the physics and AI safety communities to generate a tighter feedback loop between (theoretical) idea generation and AI safety’s epistemic goals and methods (namely: strong empirics).
AI interpretability researchers are increasingly realizing that NN’s are less like exact programs and more like big collections of shallow, stochastically interacting heuristics. QFT – a theoretical framework for describing systems with many interacting degrees of freedom – is well suited to study phenomena of this shape, as it captures the collective behavior of particle interactions at varying levels of abstraction set by the scale of the field theory. Briefly, there is a particular scaling limit of neural networks (corresponding roughly to infinite width[5]) in which the neurons become non-interacting, and can be modeled by a system of independent particles, known as a free QFT. The width can be thought of as the parameter governing the scale of interactions between neurons, as it governs how sparse (overparameterized) the network is. In the field theory description, we can do a perturbative expansion in this scale parameter to add more complex interactions (higher order moments) between particles.
The theoretical framework of a QFT for AI has stayed close to the idealized limit, but some simple QFT-inspired experiments still perform reasonably well at providing mechanistic solutions[6]. Interestingly, these examples indicate that the ‘infinite’ width approximation is a good approximation even at realistic (small) widths (maybe everything is[7] Gaussian after all).
Neural networks exhibit complexities that mirror particle interactions in QFT, opening the door for a systematic understanding of its stoachasticity, redundancy, and competing scales. It is unlikely that a “fully reductivist” application of current theoretical techniques will automatically capture sophisticated data relationships learned by state-of-the-art models. However, we are optimistic that an extension of theoretical QFT methods – and corresponding new experimental techniques – will provide insight that extends to real-world settings.
Renormalization in physics and ML
In QFT, a particle interaction can be pictorially represented by a Feynman diagram. In the one below, two particles collide, two particles emerge, and a mess of intermediate interactions at an infinite range of energies can happen in between. How important each latent interaction is depends on scale: they can either damp out quickly, leading to a finite number of important Feynman diagrams, or they become exponentially louder. These divergences are considered ‘unphysical’; they don’t match up with our observations, indicating a problem with the theoretical description. What this means is that the QFT is not appropriately parametrized – or renormalized – given the scale of interactions we care about. A solution to this problem comes from one of the most powerful techniques in QFT called renormalization: at each scale, the unimportant degrees of freedom are systematically left out, resulting in a coarse-grained effective field theory (EFT) which represents the physics at that scale.
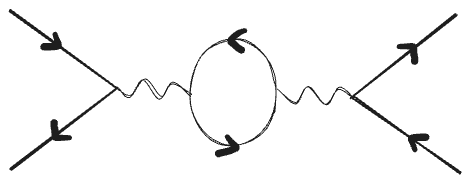
In an analogous picture below[8], a neural network’s input can be run through many different feature interactions to achieve the same output. As anyone who has done causal scrubbing can likely attest, the number of these input-output pathways can quickly blow up, turning into an unholy mess of constructively and destructively interfering phenomena. Renormalization effectively cancels out the irrelevant noise to leave only the meaningful pathways, leading to an effective coarse-graining of the features.
One renormalization technique is known as the renormalization group (RG) flow. The RG flow provides a recipe for renormalization by iteratively filtering out information that doesn’t describe the empirical world at a given scale (i.e. long range, short range). The process defines a parameterized ‘flow’ along the space of models as your scale changes, and can lead to fixed points that describe new or interesting behavior like phase transitions. Different QFTs generally make different predictions but can flow to the same fixed point, demonstrating the nice feature of universality: many microscopic distributions can be described by the same macroscopic theory.
In short: renormalization makes a theory predictable at a fixed scale by ensuring its observables match with empirical results, and the RG flow offers a way to interpolate between theories at different scales. The need for renormalization points to the theoretical description’s inability to adequately describe reality, and the corresponding techniques turn this supposed bug into a way to discover important properties of complex systems.
Some Current Applications
In AI safety, one goal is to correctly interpret what an AI system is doing, but it is often difficult to find a mechanistic description that matches the AI’s reality, given the complexity of even simple real-world tasks. Perhaps further application of QFT techniques like the RG flow will offer a path to alignment while closing the theory-practice gap. To date, most applications of QFT to NNs have focused on a theoretical exploration of networks at infinite width. Taking this limit directly takes us into the so-called “NTK regime”, where all parameters become either ‘frozen’ or Gaussian, meaning they do not interact. Moreover, the network becomes linear, limiting its ability to learn arbitrary functions of the input. In this limit, the network cannot learn new features because its parameters remain close to their initialization.
From this simplified starting point, renormalization leads to a re-tuning of the scale governing the infinite width behavior. In the PDLT book, this is the ratio of hyperparameters w/d, where 1 << depth << width. The width is still considered to be a large parameter, imposing enough sparsity in parameter space that they don’t interact, but tuning the depth turns on what looks like an RG flow through the network’s layers[9]. At every layer, you get a new, effective description of the network features, having marginalized out the low-level features that are irrelevant at that scale. Heuristically, this is similar to curve detectors coarse graining into cat detectors in CNNs. At the end of training, you can reach a stable fixed point corresponding to a QFT that matches the ‘physics’ of the neural network ontology. Importantly, these methods still apply (with some caveats) when neurons are allowed to interact, corresponding to corrections in 1/w where non-Gaussianities become relevant[10].
Halverson et al[11] considers a different, though related parametrization than NTK known as the Neural Network Gaussian Processs (NNGP) limit. This work also aims to construct a precise framework between QFT and neural networks with EFTs and renormalization as core tenets, but treats the RG flow in a different direction to PDLT – tied to a scale parameter describing the input space rather than the feature space[12]. Heuristically, if an input image has a ‘natural’ range of pixel brightness (meaning it is not too high contrast) the function the neural network finds to describe that image should be similarly limited to match the input resolution.
Another Call to Action
Application of QFT techniques to neural networks sometimes seems like a compromise between waving your hands and theoretical rigor[13]. The examples from the last section provide promising proof of concepts while also pointing out some gaps in our understanding that prevent us from coming up with a full QFT framework for AI systems. The fact that there are different ways to conceptualize an RG flow highlights at least three scales of interest in neural networks: the width, the depth, and some characteristic scale of the data distribution. We are not completely sure how to interpret the relationships between these parameters (for example, the initial interaction strength 1/w and the RG cutoff scale d/w) in real-world networks, since terms in the per-layer expansion may become important as the depth is tuned. In order words: Each non gaussian term (new field in the effective field theory at the RG scale) has a strength of its interaction that generally changes with this scale.
It is likely that the ‘physics’ of AI systems are governed by many competing scales that will be difficult to parse without a better sense of what ‘physical’ means for AI systems. Regarding neural network ‘fields’: are they best thought of as particles colliding in a detector, or spins confined to a lattice? Are the interactions between them local (and what defines ‘local’ for NNs?)? What is the natural cutoff? In condensed matter systems, there is a ‘natural’ cutoff given at high energy by the lattice spacing of your system (or at long distances, something like the size of the material). These questions generate parameters for measuring the strength of our understanding. We hope to be able to answer them in the future.
While we’re not the first to say that this could be important, we want to point out some ways in which mechanistic interpretability could leverage QFT techniques. As we will explain in a later post, physicists consistently use renormalization as a way to “fix an ansatz interpretation” of a physical system. Namely, when interpreting experimental data or simplifying a complicated model (such as a lattice model) at macroscopic scales, renormalization techniques allow you to:
- “throw away” overly granular interactions that can be ignored at coarser scales because they don’t match what we see in nature. For AI systems, renormalization can result in cleaner abstractions of neural networks. This is an example of theory being led by empirics.
- discover ‘new physics’. In order for the standard model observables to be renormalizable (finite after renormalization), the theory needed an extra field – the Higgs Boson – at a certain energy scale. In neural networks, this is like the discovery of an important feature ‘pathway’ that prevents the network from being dominated by noise. To name another example, critical points of the RG flow may also allow us to shed light on emergent phenomena in neural networks. These are examples of empirics being led by theory.
In pursuing research combining QFT and mechanistic interpretability, theory and experiment can both iterate toward an adequate description of neural network behavior and model internals.
Some paths forward
In this section, we present some wildly speculative research questions. We welcome feedback in the hopes of discovering QFT techniques for AI interpretability that are both doable and impactful.
There is some hope that real-world networks are not too far from the ideal, and the ratio d/w may be small enough that interesting empirical settings will converge to the theoretical limit to first or second order. Perhaps we can continue to nudge the idealized model toward the real-world, incrementally building up the framework to apply to different notions of scales and non-stochastic initializations.
However, the stronger hope is that this framework is general: NNs are QFTs, even when treated non-perturbatively at finite width. It could be that the starting point of “NTK theory” is just too weak to take us very far in interpreting state-of-the-art neural nets, and that jumping into a new conceptualization of the RG flow with an interpretability mentally will help build the ‘right’ QFT for AI systems. If this can be done (for example, by studying local interactions between SAE features and its extensions), perhaps we can use renormalization techniques to universally subtract out ‘unphysical’ noise from destructive interference, leaving only an EFT that represents the features we want in a more computationally compatible way.
To say more about computational compatibility, it may be possible to probe the relationship between ‘human interpretable’ (SAE) features and features from computational mechanics, which are built on natural units of computation. The latter are also non-linear, so it could be that they would agree with effective features at the right level of abstraction (maybe this could be a definition for what the ‘right level of abstraction’ is). Moreover, computational mechanics has a built in data scale – the degree of resolution that defines how ‘zoomed in’ you are to the fractal simplex [LW · GW]. It would be great if this could shed light on, for example, how different scales (input, feature…) are organized in a neural network field theory, or help us distinguish aspects of NNs that are model agnostic from those that are architecture dependent[14].
- ^
Anecdotally, many physicists (mainly high energy theorists) I have met think this is a promising idea. Among these, many come to the same conclusions somewhat independently, given that the basic insight is pretty low hanging fruit (i.e. Gaussian statistics are universal). On one hand, academic consensus is a signal that this idea at least deserves some further thought. On the other, there is probably some academic bias at play here, and high energy theorists are particularly tempted by the promise of applying their ideas in realistic, useful settings.
- ^
- ^
- ^
- ^
There are a lot of names used to describe this limit, and they are not all the same (infinite width, large N, NTK, NNGP, lazy…). We think this leads to a certain amount of ‘talking past one another’ between research groups, and hope to help unite the masses in this direction by getting everyone on the same page.
- ^
- ^
Roughly, globally, if you squint…
- ^
From this paper.
- ^
If we understand correctly, learning in this way can be thought of as ‘unfreezing’ the previous layers, similar to an analogous recovery of optimal initialization scale found by work on tensor programs.
- ^
In physics speak, turning on finite width corrections leads to a “weakly interacting” or perturbative QFT.
- ^
Berman et al. follow a similar story, running empirical experiments on MNIST. Their results are promising – in particular the renormalized interpretations have significantly better prediction properties than the unrenormalized NTK limit they are “fixing”. However note that these results are unlikely to scale to models significantly beyond MNIST, namely models which require rich learning. MNIST and similar basic vision classifiers have the oh-so-physical property of being empirically learnable by Gaussian learning – see for example this paper.
- ^
They also give a nice pictorial representation of Feynman diagrams, which could help make this work more accessible to researchers outside of physics (the way Feynman diagrams made particle physics more accessible to experimentalists who had never studied QFT).
- ^
This is not a criticism. Maybe this is the sweet spot of physics, and more work needs to be done to understand the corollaries for the AI universe.
- ^
A similar separation can also be found between terms in the NN kernel.
12 comments
Comments sorted by top scores.
comment by Simon Pepin Lehalleur (SPLH) · 2025-01-18T09:26:42.391Z · LW(p) · GW(p)
Thanks a lot for writing this! Some clarifying questions:
- In this context, is QFT roughly a shorthand for "statistical field theory, studied via the mathematical methods of Euclidean QFT"? Or do you expect intuitions from specifically quantum phenomena to play a role?
- There is a community of statistical physicists who use techniques from statistical mechanics of disordered systems and phase transitions to study ML theory, mostly for simple systems (linear models, shallow networks) and simple data distributions (Gaussian data, student-teacher model with a similarly simple teacher). What do you think of this approach? How does it relate to what you have in mind?
- Would this approach, at least when applied to the whole network, rely on an assumption that trained DNNs inherit from their initialization a relatively high level of "homogeneity" and relatively limited differentiation, compared say to biological organisms? For instance, as a silly thought experiment, suppose you had the same view into a tiger as you have a DNN: something like all the chemical-level data as a collection of time-series indexed by (spatially randomized) voxels, and you want to understand the behaviour of the tiger as function of the environment. How would you expect a QFT-based approach to proceed? What observables would it encoder first? Would it be able to go beyond the global thermodynamics of the tiger and say something about cell and tissue differentiation? How would it "put the tiger back together"? (Those are not gotcha questions - I don't really know if any existing interpretability method would get far in this setting!)
↑ comment by Dmitry Vaintrob (dmitry-vaintrob) · 2025-01-18T10:55:36.753Z · LW(p) · GW(p)
Thanks for the questions!
- Yes, "QFT" stands for "Statistical field theory" :). We thought that this would be more recognizable to people (and also, at least to some extent, statistical is a special case of quantum [LW · GW]). We aren't making any quantum proposals.
-
- We're following (part of) this community, and interested in understanding and connecting the different parts better. Most papers in the "reference class" we have looked at come from (a variant of) this approach. (The authors usually don't assume Gaussian inputs or outputs, but just high width compared to depth and number of datapoints -- this does make them "NTK-like", or at least perturbatively Gaussian, in a suitable sense).
- Neither of us thinks that you should think of AI as being in this regime. One of the key issues here is that Gaussian models can not model any regularities of the data beyond correlational ones (and it's a big accident that MNIST is learnable by Gaussian methods). But we hope that what AIs learn can largely be well-described by a hierarchical collection of different regimes where the "difference", suitably operationalized, between the simpler interpretation and the more complicated one is well-modeled by a QFT-like theory (in a reference class that includes perturbatively Gaussian models but is not limited to them). In particular one thing that we'd expect to occur in certain operationalizations of this picture is that once you have some coarse interpretation that correctly captures all generalizing behaviors (but may need to be perturbed/suitably denoised to get good loss), the last and finest emergent layer will be exactly something in the perturbatively Gaussian regime.
- Note that I think I'm more bullish about this picture and Lauren is more nuanced (maybe she'll comment about this). But we both think that it is likely that having good understanding of perturbatively Gaussian renormalization would be useful for "patching in the holes", as it were, of other interpretability schemes. A low-hanging fruit here is that whenever you have a discrete feature-level interpreatation of a model, instead of just directly measuring the reconstruction loss you should at minimum model the difference model-interpretation as a perturbative Gaussian (corresponding to assuming the difference has "no regularity beyond correlation information").
- We don't want to assume homogeneity, and this is mostly covered by 2b-c above. I think the main point we want to get across is that it's important and promising to try to go beyond the "homogeneity" picture -- and to try to test this in some experiments. I think physics has a good track record here. Not on the level of tigers, but for solid-state models like semiconductors. In this case you have:
- The "standard model" only has several-particle interactions (corresponding to the "small-data limit").
- By applying RG techniques to a regular metallic lattice (with initial interactions from the standard model), you end up with a good new universality class of QFT's (this now contains new particles like phonons and excitons which are dictated by the RG analysis at suitable scales). You can be very careful and figure out the renormalization coupling parameters in this class exactly, but much more realistically and easily you just get them from applying a couple of measurements. On an NN level, "many particles arranged into a metallic pattern" corresponds to some highly regular structure in the data (again, we think "particles" here should correspond to datapoints, at least in the current RLTC paradigm).
- The regular metal gives you a "background" theory, and now we view impurities as a discrete random-feature theory on top of this background. Physicists can still run RG on this theory by zooming out and treating the impurities as noise, but in fact you can also understand the theory on a fine-grained level near an impurity by a more careful form of renormalization, where you view the nearest several impurities as discrete sources and only coarsegrain far-away impurities as statistical noise. At least for me, the big hope is that this last move is also possible for ML systems. In other words, when you are interpreting a particular behavior of a neural net, you can model it as a linear combination of a few messy discrete local circuits that apply in this context (like the complicated diagram from Marks et al below) plus a correctly renormalized background theory associated to all other circuits (plus corrections from other layers plus ...)
↑ comment by Simon Pepin Lehalleur (SPLH) · 2025-01-18T14:37:20.481Z · LW(p) · GW(p)
On 1., you should consider that, for people who don't know much about QFT and its relationship with SFT (like, say, me 18 months ago), it is not at all obvious that QFT can be applied beyond quantum systems!
In my case, the first time I read about "QFT for deep learning" I dismissed it automatically because I assumed it would involve some far-fetched analogies with quantum mechanics.
↑ comment by Simon Pepin Lehalleur (SPLH) · 2025-01-18T13:06:44.634Z · LW(p) · GW(p)
but in fact you can also understand the theory on a fine-grained level near an impurity by a more careful form of renormalization, where you view the nearest several impurities as discrete sources and only coarsegrain far-away impurities as statistical noise.
Where could I read about this?
Replies from: dmitry-vaintrobcomment by Tahp · 2025-01-19T22:04:14.670Z · LW(p) · GW(p)
Field theorist here. You talk about renormalization as a thing which can smooth over unimportant noise, which basically matches my understanding, but you haven't explicitly named your regulator. A regulator may be a useful concept to have in interpretability, but I have no idea if it is common in the literature.
In QFT, our issue is that we go to calculate things that are measurable and finite, but we calculate horrible infinities. Obviously those horrible infinities don't match reality, and they often seem to be coming from some particular thing we don't care about that much in our theory, so we find a way to poke it out of the theory. (To be clear, this means that our theories are wrong, and we're going to modify them until they work.) The tool by which you remove irrelevant things which cause divergences is called a regulator. A typical regulator is a momentum cutoff. You go to do the integral over all real momenta which your Feynman diagram demands, and you find that it's infinite, but if you only integrate the momenta up to a certain value, the integral is finite. Of course, now you have a bunch of weird constants sitting around which depend of the value of the cutoff. This is where renormalization comes in. You notice that there are a bunch of parameters, which are generally coupling constants, and these parameters have unknown values which you have to go out into the universe and measure. If you cleverly redefine those constants to be some "bare constant" added to a "correction" which depends on the cutoff, you can do your cutoff integral and set the "correction" to be equal to whatever it needs to be to get rid of all the terms which depend on your cutoff. (edit for clarity: This is the thing that I refer to when I say "renormalization." Cleverly redefining bare parameters to get rid of unphysical effects of a regulator.) By this two step dance, you have taken your theoretical uncertainty about what happens at high momenta and found a way to wrap it up in the values of your coupling constants, which are the free parameters which you go and measure in the universe anyway. Of course, now your coupling constants are different if you choose a different regulator or a different renormalization scheme to remove it, but physicists have gotten used to that.
So you can't just renormalize, you need to define a regulator first. You can even justify your regulator. It is a typical justification for a momentum cutoff that you're using a perturbative theory which is only valid at low energy scales. So what's the regulator for AI interpretability? Why are you justified in regulating in this way? It seems like you might be pointing at regulators when you talk about 1/w and d/w, but you might also be talking about orders in a perturbation expansion, which is a different thing entirely.
Replies from: dmitry-vaintrob↑ comment by Dmitry Vaintrob (dmitry-vaintrob) · 2025-01-19T23:06:19.956Z · LW(p) · GW(p)
This is where this question of "scale" comes in. I want to add that (at least morally/intuitively) we are also thinking about discrete systems like lattices, and then instead of a regulator you have a coarsegraining or a "blocking transformation", which you have a lot of freedom to choose. For example in PDLT, the object that plays the role of coarsegraining is the operation that takes a probability distribution on neurons and applies a single-layer NN to it.
Replies from: Tahp↑ comment by Tahp · 2025-01-20T01:58:52.020Z · LW(p) · GW(p)
I consider the lattice to be a regulator as well, but, semantics aside, thank you for the example.
Replies from: LaurenGreenspan↑ comment by Lauren Greenspan (LaurenGreenspan) · 2025-01-20T16:50:19.227Z · LW(p) · GW(p)
For me, this question of the relevant scale(s) is the main point of introducing this work. d/w is one example of a cutoff, and one associated with the data distribution is another, but more work needs to be done to understand how to relate potentially different theoretical descriptions (for example, how these two cutoffs work together). We also mention the 'lattice as regulator' as a natural cut-off for physical systems, and hope to find similarly natural scales in real-world AI systems.
comment by tailcalled · 2025-01-18T19:46:52.597Z · LW(p) · GW(p)
The way I (computer scientist who dabbles in physics, so YMMV I might be wrong) understand the physics here:
- Feynmann diagrams are basically a Taylor expansion of a physical system in terms of the strength of some interaction,
- To avoid using these Taylor expansions for everything, one tries to modify the parameters of the model to take a summary of the effects into account; for instance one distinguishes between the "bare mass", which doesn't take various interactions into account, versus the "effective mass", which does,
- Sometimes e.g. the Taylor series don't converge (or some integrals people derived from the Taylor expansions don't converge), but you know what the summary parameters turn out to be in the real world, and so you can just pretend the calculations do converge into whatever gives the right summary parameters (which makes sense if we understand the model is just an approximation given what's known and at some point the model breaks down).
Meanwhile, for ML:
- Causal scrubbing is pretty related to Taylor expansions, which makes it pretty related to Feynmann diagrams,
- However, it lacks any model for the non-interaction/non-Taylor-expanded effects, and so there's no parameters that these Taylor expansions can be "absorbed into",
- While Taylor expansions can obviously provide infinite detail, nobody has yet produced any calculations for causal scrubbing that fail to converge rather than simply being unreasonably complicated. This is partly because without the model above, there's not many calculations that are worth running.
I've been thinking about various ideas for Taylor expansions and approximations for neural networks, but I kept running in circles, and the main issue I've ended up with is this:
In order to eliminate noise, we need to decide what really matters and what doesn't really matter. However, purely from within the network, we have no principled way of doing so. The closest we get is what affects the token predictions for the network, but even that contains too may unimportant parameters, because if e.g. the network goes off on a tangent but then returns to the main topic, maybe that tangent didn't matter and we're fine with the approximation discarding it.
As a simplified version of this objection, consider that the token probabilities are not the final output of the network, but instead the tokens are sampled and fed back into the network, which means that really the final layer of the network is connected back to the first layer through a non-differentiable function. (The non-differentiability interferes with any interpretability method based on derivatives....)
What we really want to know is the impacts of the network in real-world scenarios, but it's hard to notice main consequences of the network, and even if we could, it's hard to set up measurable toy models of them. Once we had such toy models, it's unclear whether we'd even need elaborate techniques for interpreting them. If for instance Claude is breaking a generation of young nerds by praising any nonsensical thing they say by responding "Very insightful!", that doesn't really need any advanced interpretability techniques to be understood.
comment by Joel Burget (joel-burget) · 2025-01-18T15:55:06.465Z · LW(p) · GW(p)
Both link to the same PDF.
comment by Mitchell_Porter · 2025-01-18T09:14:59.355Z · LW(p) · GW(p)
In "The Autodidactic Universe", the authors try to import concepts from machine learning into physics. In particular, they want to construct physical models in which "the Universe learns its own physical laws". In my opinion they're not very successful, but one might wish to see whether their physicalized ML concepts can be put to work back in ML, in the context of a program like yours.