Paul's research agenda FAQ
post by zhukeepa · 2018-07-01T06:25:14.013Z · LW · GW · 74 commentsContents
0. Goals and non-goals 0.1: What is this agenda trying to accomplish? 0.2: What are examples of ways in which you imagine these AGI assistants getting used? 0.3: But this might lead to a world dictatorship! Or a world run by philosophically incompetent humans who fail to capture most of the possible value in our universe! Or some other dystopia! 1. Alignment 1.1 How do we get alignment at all? 1.1.1: Isn’t it really hard to give an AI our values? Value learning is really hard, and the default is for it to encounter instrumental incentives to manipulate you or prevent itself from getting shut down. 1.1.2: OK, but doesn't this only incentivize it to appear like it's doing what the operator wants? Couldn’t it optimize for hijacking its reward signal, while seeming to act in ways that humans are happy with? 1.1.3: How do we train it to answer questions comprehensively? 1.1.4: Why should we expect the agent’s answers to correspond to its cognition at all? 1.1.5: Wouldn’t this incentivize the assistant to produce justifications that seem fine and innocent to you, but may actually be harmful? 1.2 Amplifying and distilling alignment 1.2.1: OK, you propose that to amplify some aligned agent, you just run it for a lot longer, or run way more of them and have them work together. I can buy that our initial agent is aligned; why should I trust their aggregate to be aligned? 1.2.2: OK, so given this amplified aligned agent, how do you get the distilled agent? 1.2.3: It seems like imitation learning might cause a lot of minutiae to get lost, and would create something that's "mostly aligned" but actually not aligned in a bunch of subtle ways. Maybe this is tolerable for one round of iteration, but after 100 rounds, I wouldn’t feel very good about the alig... 1.2.4: This distilled agent’s cognition might be much more complex than that of our previous agent. How can we reasonably determine whether we’d approve of its cognition? 1.2.5: Given that this distilled agent is way more powerful than you and your aligned agents, couldn’t it manipulate you and your team of aligned agents? 1.3 Robust alignment / corrigibility 1.3.1: If you delegate oversight to a well-meaning assistant (“hey, can you make sure things are going as planned?”), who delegates oversight to a well-meaning assistant, who delegates oversight to a well-meaning assistant, etc., then the default is for the delegatee 100 layers down to end up with s... 1.3.2: OK, but doesn't this just pass the buck onto corrigibility? In the same way that alignment can get distorted, couldn't corrigibility also get distorted? 1.3.3: I don’t share those intuitions around corrigibility. Do you have any intuition pumps? 1.3.4: This corrigibility thing still seems really fishy. It feels like you just gave some clever arguments about something very fuzzy and handwavy, and I don’t feel comfortable trusting that. 2. Usefulness 2.1. Can the system be both safe and useful? 2.1.1: A lot of my values and knowledge are implicit. Why should I trust my assistant to be able to learn my values well enough to assist me? 2.1.2: OK, sure, but it’ll essentially still be an alien and get lots of minutiae about our values wrong. 2.1.3: But it might make lots of subtle mistakes that add up to something catastrophic! 2.1.4: I’m really not sold that training it to avoid catastrophes and training it to be corrigible will be good enough. 2.2. Universality 2.2.1. What sorts of cognition will our assistants be able to perform? 2.2.2. Why should I think the HCH of some simple question-answering AI assistant can perform arbitrarily complex cognition? 2.2.3. Different reasoners can reason in very different ways and reach very different conclusions. Why should I expect my amplified assistant to reason anything like me, or reach conclusions that I’d have reached? 2.2.4. HCH seems to depend critically on being able to break down arbitrary tasks into subtasks. I don't understand how you can break down tasks that are largely intuitive or perceptual, like playing Go very well, or recognizing images. 2.2.5: What about tasks that require significant accumulation of knowledge? For example, how would the HCH of a human who doesn’t know calculus figure out how to build a rocket? 2.2.6: It seems like this capacity to break tasks into subtasks is pretty subtle. How does the AI learn to do this? And how do we find human operators (besides Paul) who are capable of doing this? 3. State of the agenda 3.1: What are the current major open problems in Paul’s agenda? 3.2: How close to completion is Paul’s research agenda? None 74 comments
I think Paul Christiano’s research agenda for the alignment of superintelligent AGIs presents one of the most exciting and promising approaches to AI safety. After being very confused about Paul’s agenda, chatting with others about similar confusions, and clarifying with Paul many times over, I’ve decided to write a FAQ addressing common confusions around his agenda.
This FAQ is not intended to provide an introduction to Paul’s agenda, nor is it intended to provide an airtight defense. This FAQ only aims to clarify commonly misunderstood aspects of the agenda. Unless otherwise stated, all views are my own views of Paul’s views. (ETA: Paul does not have major disagreements with anything expressed in this FAQ. There are many small points he might have expressed differently, but he endorses this as a reasonable representation of his views. This is in contrast with previous drafts of this FAQ, which did contain serious errors he asked to have corrected.)
For an introduction to Paul’s agenda, I’d recommend Ajeya Cotra’s summary. For good prior discussion of his agenda, I’d recommend Eliezer’s thoughts [LW · GW], Jessica Taylor’s thoughts (here and here), some posts [LW · GW] and [LW · GW] discussions [LW · GW] on [LW · GW] LessWrong [LW · GW], and Wei Dai’s comments on Paul’s blog. For most of Paul’s writings about his agenda, visit ai-alignment.com.
0. Goals and non-goals
0.1: What is this agenda trying to accomplish?
Enable humans to build arbitrarily powerful AGI assistants that are competitive with unaligned AGI alternatives, and only try to help their operators (and in particular, never attempt to kill or manipulate them).
People often conceive of safe AGIs as silver bullets that will robustly solve every problem that humans care about. This agenda is not about building a silver bullet, it’s about building a tool that will safely and substantially assist its operators. For example, this agenda does not aim to create assistants that can do any of the following:
- They can prevent nuclear wars from happening
- They can prevent evil dictatorships
- They can make centuries’ worth of philosophical progress
- They can effectively negotiate with distant superintelligences
- They can solve the value specification problem
On the other hand, to the extent that humans care about these things and could make them happen, this agenda lets us build AGI assistants that can substantially assist humans achieve these things. For example, a team of 1,000 competent humans working together for 10 years could make substantial progress on preventing nuclear wars or solving metaphilosophy. Unfortunately, it’s slow and expensive to assemble a team like this, but an AGI assistant might enable us to reap similar benefits in far less time and at much lower cost.
(See Clarifying "AI Alignment" and Directions and desiderata for AI alignment.)
0.2: What are examples of ways in which you imagine these AGI assistants getting used?
Two countries end up in an AGI arms race. Both countries are aware of the existential threats that AGIs pose, but also don’t want to limit the power of their AIs. They build AGIs according to this agenda, which stay under the operators’ control. These AGIs then help the operators broker an international treaty, which ushers in an era of peace and stability. During this era, foundational AI safety problems (e.g. those in MIRI’s research agenda) are solved in earnest, and a provably safe recursively self-improving AI is built.
A more pessimistic scenario is that the countries wage war, and the side with the more powerful AGI achieves a decisive victory and establishes a world government. This scenario isn’t as good, but it at least leaves humans in control (instead of extinct).
The most pressing problem in AI strategy is how to stop an AGI race to the bottom from killing us all. Paul’s agenda aims to solve this specific aspect of the problem. That isn’t an existential win, but it does represent a substantial improvement over the status quo.
(See section “2. Competitive” in Directions and desiderata for AI alignment.)
0.3: But this might lead to a world dictatorship! Or a world run by philosophically incompetent humans who fail to capture most of the possible value in our universe! Or some other dystopia!
Sure, maybe. But that’s still better than a paperclip maximizer killing us all.
There is a social/political/philosophical question about how to get humans in a post-AGI world to claim a majority of our cosmic endowment (including, among other things, not establishing a tyrannical dictatorship under which intellectual progress halts). While technical AI safety does make progress on this question, it’s a broader question overall that invites fairly different angles of attack (e.g. policy interventions and social influence). And, while this question is extremely important, it is a separate question from how you can build arbitrarily powerful AGIs that stay under their operators’ control, which is the only question this agenda is trying to answer.
1. Alignment
1.1 How do we get alignment at all?
(“Alignment” is an imprecise term meaning “nice” / “not subversive” / “trying to actually help its operator“. See Clarifying "AI alignment" for Paul’s description.)
1.1.1: Isn’t it really hard to give an AI our values? Value learning is really hard, and the default is for it to encounter instrumental incentives to manipulate you or prevent itself from getting shut down.
The AI isn’t learning our values, it’s learning to optimize for our short-term approval—in other words, for each action it takes, it optimizes for something like what rating we’d give it on a scale from 1 to 5 if we just saw it act.
It’s hard to learn the nuances of human values. But from a machine learning perspective, it’s very easy to learn that humans would strongly disapprove of attempts to kill or manipulate us. Paul expresses this well on his blog:
You need only the vaguest understanding of humans to guess that killing the user is: (1) not something they would approve of, (2) not something they would do, (3) not in line with their instrumental preferences.
So in order to get bad outcomes here you have to really mess up your model of what humans want (or more likely mess up the underlying framework in an important way). If we imagine a landscape of possible interpretations of human preferences, there is a “right” interpretation that we are shooting for. But if you start with a wrong answer that is anywhere in the neighborhood, you will do things like “ask the user what to do, and don’t manipulate them.” And these behaviors will eventually get you where you want to go.
(See: Approval-directed agents and Act-based agents.)
1.1.2: OK, but doesn't this only incentivize it to appear like it's doing what the operator wants? Couldn’t it optimize for hijacking its reward signal, while seeming to act in ways that humans are happy with?
We’re not just training the agent to take good actions. We’re also training it to comprehensibly answer questions about why it took the actions it took, to arbitrary levels of detail. (Imagine a meticulous boss grilling an employee about a report he put together, or a tax auditor grilling a corporation about the minutiae of its expenses.) We ensure alignment by randomly performing thorough evaluations of its justifications for its actions, and punishing it severely if any of those justifications seem subversive. To the extent we trust these justifications to accurately reflect the agent’s cognition, we can trust the agent to not act subversively (and thus be aligned).
(See: The informed oversight problem.)
1.1.3: How do we train it to answer questions comprehensively?
Reward it for doing so, and punish it for failing to do so.
Imagine being a meticulous boss who asks his employee to put together a report. Imagine grilling him about the report, and punishing him every time he fails to answer your questions clearly enough or at a satisfactory level of detail, in addition to punishing him for low-quality reports. If your employee is capable enough, he’ll eventually learn to produce high-quality reports and answer questions satisfactorily when you grill him.
Note that the ability to generate comprehensible descriptions of arbitrary cognition is a major open problem in Paul’s agenda, and also a major problem in AI safety broadly. It’s the part of his agenda that Paul is currently focusing most on.
(See The informed oversight problem, Learning representations, and Approval-maximising representations.)
1.1.4: Why should we expect the agent’s answers to correspond to its cognition at all?
We don’t actually have any guarantees that it does, but giving honest answers is probably the easiest way for the agent to maximize its reward. The only feasible alternative is giving thorough dishonest explanations for its actions. But if an employee lies about how he arrived at his conclusions, his explanations won’t check out, and he might get punished severely. And if a corporation lies about how it spent its money, the numbers won’t add up, and its auditor might punish it severely.
It’s critically important for this scheme that the overseer is capable of evaluating the assistant’s justifications extremely thoroughly, and does so often enough. Corporations cook their books in proportion to how thorough their auditors are, how common audits are, and how bad it is to get caught by their auditors. If we audit thoroughly enough and frequently enough, and punish our assistants severely enough for subversion, we should expect them to answer honestly.
1.1.5: Wouldn’t this incentivize the assistant to produce justifications that seem fine and innocent to you, but may actually be harmful?
We should expect the AI not to adversarially manipulate us—by assumption, we’re evaluating its justifications thoroughly enough that we should be able to catch any subversive cognition.
It's possible that there are free variables in what sorts of cognition the operator deems acceptable, and that a non-adversarial optimization process might be able to persuade the operator of essentially arbitrary conclusions by manipulating these free variables in ways the operators approves of. For example, an AGI assistant might accidentally persuade you to become an ISIS suicide bomber, while only thinking in ways that you approve of.
I do think this is a potentially severe problem. But I don’t consider it a dealbreaker, for a number of reasons:
- An AGI assistant “accidentally” manipulating you is no different from a very smart and capable human assistant who, in the process of assisting you, causes you to believe drastic and surprising conclusions. Even if this might lead to bad outcomes, Paul isn’t aiming for his agenda to prevent this class of bad outcomes.
- The more rational you are, the smaller the space of conclusions you can be non-adversarially led into believing. (For example, it’s very hard for me to imagine myself getting persuaded into becoming an ISIS suicide bomber by a process whose cognition I approve of.) It might be that some humans have passed a rationality threshold, such that they only end up believing correct conclusions after thinking for a long time without adversarial pressures.
1.2 Amplifying and distilling alignment
1.2.1: OK, you propose that to amplify some aligned agent, you just run it for a lot longer, or run way more of them and have them work together. I can buy that our initial agent is aligned; why should I trust their aggregate to be aligned?
When aligned agents work together, there’s often emergent behavior that can be described as non-aligned. For example, if the operator is pursuing a goal (like increasing Youtube’s revenue), one group of agents proposes a subgoal (like increasing Youtube views), and another group competently pursues that subgoal without understanding how it relates to the top-level goal (e.g. by triple-counting all the views), you end up with misaligned optimization. As another example, there might be some input (e.g. some weirdly compelling argument) that causes some group of aligned agents to “go insane” and behave unpredictably, or optimize for something against the operator’s wishes.
Two approaches that Paul considers important for preserving alignment:
- Reliability amplification—aggregating agents that can answer a question correctly some of the time (say, 80% of the time) in a way that they can answer questions correctly with arbitrarily high probability.
- Security amplification—winnowing down the set of queries that, when fed to the aggregate, causes the aggregate to “go insane”.
It remains an open question in Paul’s agenda how alignment can be robustly preserved through capability amplification—in other words, how to increase the capabilities of aligned agents without introducing misaligned behavior.
(See: Capability amplification, Reliability amplification, Security amplification, Universality and security amplification, and Two guarantees.)
1.2.2: OK, so given this amplified aligned agent, how do you get the distilled agent?
Train a new agent via some combination of imitation learning (predicting the actions of the amplified aligned agent), semi-supervised reinforcement learning (where the amplified aligned agent helps specify the reward), and techniques for optimizing robustness (e.g. creating red teams that generate scenarios that incentivize subversion).
(See: RL+Imitation, Benign model-free RL, Semi-supervised reinforcement learning, and Techniques for optimisizing worst-case performance.)
1.2.3: It seems like imitation learning might cause a lot of minutiae to get lost, and would create something that's "mostly aligned" but actually not aligned in a bunch of subtle ways. Maybe this is tolerable for one round of iteration, but after 100 rounds, I wouldn’t feel very good about the alignment of the resulting agent...
Indeed, which is why this new agent is also trained with semi-supervised reinforcement learning, and optimized for robustness. The imitation learning is more about getting this new agent off the ground than about ensuring alignment. The bulk of the alignment guarantee comes from the semi-supervised reinforcement learning, where we train it to work on a wide range of tasks and answer questions about its cognition. We trust it to be aligned because we train it the same way we trained our original agent to be aligned—namely, by rewarding it for maximizing our approval, and punishing it for thinking subversive thoughts.
(There’s a common misconception that Paul’s agenda proceeds entirely by taking a single aligned assistant, running it for a lot longer, using imitation learning to distill that into a new assistant, running that new assistant a lot longer, using imitation learning to distill that, etc., much like how AlphaGo Zero improves its policy network. While this does capture a key idea behind how the assistant’s capabilities get amplified, it omits critical components of his agenda that ensure alignment, like inspecting cognition and amplifying robustness.)
1.2.4: This distilled agent’s cognition might be much more complex than that of our previous agent. How can we reasonably determine whether we’d approve of its cognition?
This is where our assistants come in. While the human operator does inspect some aspects of the distilled agent’s cognition, most of the inspection is done by our assistants, whose judgments we trust because we trust that they’re aligned.
(See The reward engineering problem.)
1.2.5: Given that this distilled agent is way more powerful than you and your aligned agents, couldn’t it manipulate you and your team of aligned agents?
If we’re amplifying and distilling agent A, we’re actually training our newly distilled agent to be stronger than A, but much weaker than the amplified version of A. The amplification/distillation procedure can be thought of as repeatedly taking two steps forward (in amplifying A) and one step back (in distilling a new agent).
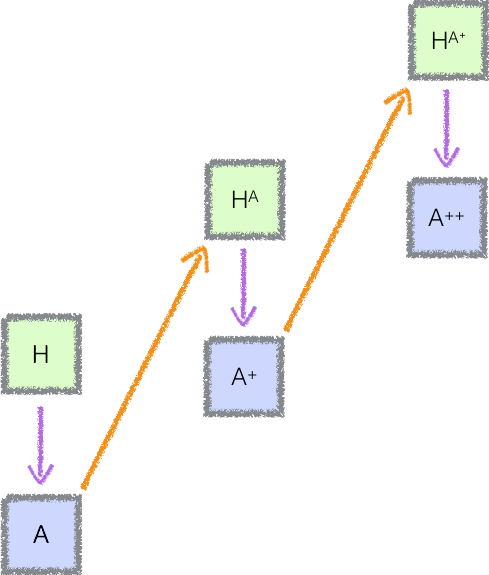
Any subversive plan the distilled agent makes could get recognized as subversive by the amplified agent, because the amplified agent has enough power to thoroughly evaluate every aspect of the cognition that went into the plan. The amplified agent rarely performs thorough evaluations of the distilled agent’s cognition, because it’s extremely expensive, but does so randomly and punishes the distilled agent extremely harshly if it detects subversion. The distilled agent, knowing that it will have to thoroughly justify its actions to a competent supervisor, is thus strongly incentivized against acting subversively.
In other words, the amplified agent randomly “audits” the distilled agent, and punishes the distilled agent very harshly if it fails the audit. Though the distilled agent knows that it might be able to deceive its supervisor when it isn’t audited, it’s so scared of the outcome where it tries to do that and gets audited that it doesn’t even want to try. (Even if you were 99% confident that you could get away with tax evasion, you wouldn’t want to try if you knew the government tortures and murders the families of the tax evaders they catch.)
(See Benign model-free RL, the comments in The informed oversight problem, and William Saunders' post Improbable Oversight, An Attempt at Informed Oversight.)
1.3 Robust alignment / corrigibility
1.3.1: If you delegate oversight to a well-meaning assistant (“hey, can you make sure things are going as planned?”), who delegates oversight to a well-meaning assistant, who delegates oversight to a well-meaning assistant, etc., then the default is for the delegatee 100 layers down to end up with some extremely distorted version of what you care about. Shouldn’t we expect this distortion to happen with the agents we produce?
Yes, which is why alignment isn’t the property we’re ultimately aiming to inductively guarantee. The property we’re trying to guarantee is something closer to “alignment + extreme caution about whether it’s aligned and cautious enough”. Paul usually refers to this as corrigibility.
This way, every time we’re training a distilled agent, we train it to want to clarify with its overseer (i.e., us assisted with a team of corrigible assistants) whenever it’s uncertain about what we would approve of. Our corrigible assistants either answer the question confidently, or clarify with us if it’s uncertain about its answer.
1.3.2: OK, but doesn't this just pass the buck onto corrigibility? In the same way that alignment can get distorted, couldn't corrigibility also get distorted?
Paul has two strong intuitions about corrigibility:
- corrigibility has a simple core that should be easy for humans to impart into powerful AI systems
- corrigibility is robust—agents that are somewhat corrigible want to become more corrigible.
On this view, even if human approval is high-complexity and hard to get right, corrigibility is straightforward to learn and most likely to improve over distillation rather than worsen.
You also need robustness amplification to ensure that corrigibility is maintained. For example, a corrigible supervisor needs to be able to thoroughly evaluate a distilled agent’s cognition, but if its evaluations aren’t reliable, it can’t be trusted to ensure that the distilled agent is corrigible (and not a daemon). And a corrigible agent that “goes insane” doesn’t stay corrigible.
(See: Corrigibility.)
1.3.3: I don’t share those intuitions around corrigibility. Do you have any intuition pumps?
One intuition pump: corrigibility can be thought of as extreme caution about whether you’re actually being helpful, and extreme caution is robust—if you’re extremely cautious about how things can go wrong, you want to know more ways things can go wrong and you want to improve your ability to spot how things are going wrong, which will lead you to become more cautious.
Another intuition pump: I have some intuitive concept of “epistemically corrigible humans”. Some things that gesture at this concept:
- They care deeply about finding the truth, and improving their skill at finding the truth.
- They’re aware that they’re flawed reasoners, with biases and blind spots, and actively seek out ways to notice and remove these flaws. They try to take ideas seriously, no matter how weird they seem.
- Their beliefs tend to become more true over time.
- Their skill at having true beliefs improves over time.
- They tend to reach similar conclusions in the limit (namely, the correct ones), even if they’re extremely weird and not broadly accepted.
I think of corrigible assistants as being corrigible in the above way, except optimizing for helping its operator instead of finding the truth. Importantly, so long as an agent crosses some threshold of corrigibility, they will want to become more and more cautious about whether they’re helpful, which is where robustness comes from.
Given that corrigibility seems like a property that any reasoner could have (and not just humans), it’s probably not too complicated a concept for a powerful AI system to learn, especially given that many humans seem able to learn some version of it.
1.3.4: This corrigibility thing still seems really fishy. It feels like you just gave some clever arguments about something very fuzzy and handwavy, and I don’t feel comfortable trusting that.
While Paul thinks there’s a good intuitive case for something like corrigibility, he also considers getting a deeper conceptual understanding of corrigibility one of the most important research directions for his agenda. He agrees it’s possible that corrigibility may not be safely learnable, or not actually robust, in which case he'd feel way more pessimistic about his entire agenda.
2. Usefulness
2.1. Can the system be both safe and useful?
2.1.1: A lot of my values and knowledge are implicit. Why should I trust my assistant to be able to learn my values well enough to assist me?
Imagine a question-answering system trained on all the data on Wikipedia, that ends up with comprehensive, gears-level world-models, which it can use to synthesize existing information to answer novel questions about social interactions or what our physical world is like. (Think Wolfram|Alpha, but much better.)
This system is something like a proto-AGI. We can easily restrict it (for example by limiting how long it gets to reflect when it answers questions) so that we can train it to be corrigible while trusting that it’s too limited to do anything dangerous that the overseer couldn’t recognize as dangerous. We use such a restricted system to start off the iterated distillation and amplification process, and bootstrap it to get systems of arbitrarily high capabilities.
(See: Automated assistants)
2.1.2: OK, sure, but it’ll essentially still be an alien and get lots of minutiae about our values wrong.
How bad is it really if it gets minutiae wrong, as long as it doesn’t cause major catastrophes? Major catastrophes (like nuclear wars) are pretty obvious, and we would obviously disapprove of actions that lead us to catastrophe. So long as it learns to avoid those (which it will, if we give it the right training data), we're fine.
Also keep in mind that we're training it to be corrigible, which means it’ll be very cautious about what sorts of things we’d consider catastrophic, and try very hard to avoid them.
2.1.3: But it might make lots of subtle mistakes that add up to something catastrophic!
And so might we. Maybe there are some classes of subtle mistakes the AI will be more prone to than we are, but there are probably also classes of subtle mistakes we'll be more prone to than the AI. We’re only shooting for our assistant to avoid trying to lead us to a catastrophic outcome.
(See: Techniques for optimizing worst-case performance.)
2.1.4: I’m really not sold that training it to avoid catastrophes and training it to be corrigible will be good enough.
This is actually more a capabilities question (is our system good enough at trying very hard to avoid catastrophes to actually avoid a catastrophe?) than an alignment question. A major open question in Paul’s agenda is how we can formalize performance guarantees well enough to state actual worst-case guarantees.
(See: Two guarantees and Techniques for optimizing worst-case performance)
2.2. Universality
2.2.1. What sorts of cognition will our assistants be able to perform?
We should roughly expect it to think in ways that would be approved by an HCH (short for “human consulting HCH”). To describe HCHs, let me start by describing a weak HCH:
Consider a human Hugh who has access to a question-answering machine. Suppose the machine answers question Q by perfectly imitating how Hugh would answer question Q, if Hugh had access to the question-answering machine.
That is, Hugh is able to consult a copy of Hugh, who is able to consult a copy of Hugh, who is able to consult a copy of Hugh…
I sometimes picture this as an infinite tree of humans-in-boxes, who can break down questions and pass them to other humans-in-boxes (who can break down those questions and pass them along to other humans-in-boxes, etc.) and get back answers instantaneously. A few remarks:
- This formalism tries to capture some notion of “what would H think about some topic if H thought about it for arbitrarily long amounts of time”? For example, H might make partial progress on some question, and then share this progress with some other H and ask it to make more progress, who might do the same.
- A weak HCH could simulate the cognitive labor of an economy the size of the US economy. After all, a weak HCH can emulate a single human thinking for a long time, so it can emulate teams of humans thinking for a long time, and thus teams of teams of humans thinking for a long time, etc. If you imagine a corporation as teams of teams of teams of humans performing cognitive labor, you get that a weak HCH can emulate the output of an arbitrary corporation, and thus collections of arbitrary corporations communicating with one another.
- Many tasks that don’t intuitively seem like they can be broken down, can in fact be fairly substantially broken down. For example, making progress on difficult math problems seems difficult to break down. But you could break down progress on a math problem into something like (think for a while about possible angles of attack) + (try each angle of attack, and recurse on the new math problem). And (think for a while about possible angles of attack) can be reduced into (look at features of this problem and see if you’ve solved anything similar), which can be reduced into focusing on specific features, and so on.
Strong HCH, or just HCH, is a variant of weak HCHs where the agents-in-boxes are able to communicate with each other directly, and read and write to some shared external memory, in addition to being able to ask, answer, and break down questions. Note that they would be able to implement arbitrary Turing machines this way, and thus avoid any limits on cognition imposed by the structure of weak HCH.
(Note: most people think “HCH” refers to “weak HCH”, but whenever Paul mentions HCHs, he now refers to strong HCHs.)
The exact relationship between HCH and the agents produced through iterated amplification and distillation is confusing and very commonly misunderstood:
- HCHs should not be visualized as having humans in the box. They should be thought of as having some corrigible assistant inside the box, much like the question-answering system described in 2.1.1.
- Throughout the iterated amplification and distillation process, there is never any agent whose cognition resembles an HCH of the corrigible assistant. In particular, agents produced via distillation are general RL agents with no HCH-like constraints on their cognition. The closest resemblance to HCH appears during amplification, during which a superagent (formed out of copies of the agent getting amplified) performs tasks by breaking them down and distributing them among the agent copies.
(As of the time of this writing, I am still confused about the sense in which the agent's cognition is approved by an HCH, and what that means about the agent's capabilities.)
(See: Humans consulting HCH and Strong HCH.)
2.2.2. Why should I think the HCH of some simple question-answering AI assistant can perform arbitrarily complex cognition?
All difficult and creative insights stem from chains of smaller and easier insights. So long as our first AI assistant is a universal reasoner (i.e., it can implement arbitrary Turing machines via reflection), it should be able to realize arbitrarily complex things if it reflects for long enough. For illustration, Paul thinks that chimps aren’t universal reasoners, and that most humans past some intelligence threshold are universal.
If this seems counterintuitive, I’d claim it’s because we have poor intuitions around what’s achievable with 2,000,000,000 years of reflection. For example, it might seem that an IQ 120 person, knowing no math beyond arithmetic, would simply be unable to prove Fermat’s last theorem given arbitrary amounts of time. But if you buy that:
- An IQ 180 person could, in 2,000 years, prove Fermat’s last theorem knowing nothing but arithmetic (which seems feasible, given that most mathematical progress was made by people with IQs under 180)
- An IQ 160 person could, in 100 years, make the intellectual progress an IQ 180 person could in 1 year
- An IQ 140 person could, in 100 years, make the intellectual progress an IQ 160 person could in 1 year
- An IQ 120 person could, in 100 years, make the intellectual progress an IQ 140 person could in 1 year
Then it follows that an IQ 120 person could prove Fermat’s last theorem in 2,000*100*100*100 = 2,000,000,000 years’ worth of reflection.
(See: Of humans and universality thresholds.)
2.2.3. Different reasoners can reason in very different ways and reach very different conclusions. Why should I expect my amplified assistant to reason anything like me, or reach conclusions that I’d have reached?
You shouldn’t expect it to reason anything like you, you shouldn’t expect it to reach the conclusions you'd reach, and you shouldn’t expect it to realize everything you’d consider obvious (just like you wouldn’t realize everything it would consider obvious). You should expect it to reason in ways you approve of, which should constrain its reasoning to be sensible and competent, as far as you can tell.
The goal isn’t to have an assistant that can think like you or realize everything you’d realize. The goal is to have an assistant who can think in ways that you consider safe and substantially helpful.
2.2.4. HCH seems to depend critically on being able to break down arbitrary tasks into subtasks. I don't understand how you can break down tasks that are largely intuitive or perceptual, like playing Go very well, or recognizing images.
Go is actually fairly straightforward: an HCH can just perform an exponential tree search. Iterated amplification and distillation applied to Go is not actually that different from how AlphaZero trains to play Go.
Image recognition is harder, but to the extent that humans have clear concepts of visual features they can reference within images, the HCH should be able to focus on those features. The cat vs. dog debate in Geoffrey Irving’s approach to AI safety via debate gives some illustration of this.
Things get particularly tricky when humans are faced with a task they have little explicit knowledge about, like translating sentences between languages. Paul did mention something like “at some point, you’ll probably just have to stick with relying on some brute statistical regularity, and just use the heuristic that X commonly leads to Y, without being able to break it down further”.
(See: Wei Dai's comment [LW(p) · GW(p)] on Can Corrigibility be Learned Safely, and Paul's response to a different comment by Wei Dai on the topic.)
2.2.5: What about tasks that require significant accumulation of knowledge? For example, how would the HCH of a human who doesn’t know calculus figure out how to build a rocket?
This sounds difficult for weak HCHs on their own to overcome, but possible for strong HCHs to overcome. The accumulated knowledge would be represented in the strong HCHs shared external memory, and the humans essentially act as “workers” implementing a higher-level cognitive system, much like ants in an ant colony. (I’m still somewhat confused about what the details of this would entail, and am interested in seeing a more fleshed out implementation.)
2.2.6: It seems like this capacity to break tasks into subtasks is pretty subtle. How does the AI learn to do this? And how do we find human operators (besides Paul) who are capable of doing this?
Ought is gathering empirical data about task decomposition. If that proves successful, Ought will have numerous publicly available examples of humans breaking down tasks.
3. State of the agenda
3.1: What are the current major open problems in Paul’s agenda?
The most important open problems in Paul’s agenda, according to Paul:
- Worst-case guarantees: How can we make worst-case guarantees about the reliability and security of our assistants? For example, how can we ensure our oversight is reliable enough to prevent the creation of subversive subagents (a.k.a. daemons) in the distillation process that cause our overall agent to be subversive?
- Transparent cognition: How can we extract useful information from ML systems’ cognition? (E.g. what concepts are represented in them, what logical facts are embedded in them, and what statistical regularities about the data it captures.)
- Formalizing corrigibility: Can we formalize corrigibility to the point that we can create agents that are knowably robustly corrigible? For example, could we formalize corrigibility, use that formalization to prove the existence of a broad basin of corrigibility, and then prove that ML systems past some low threshold will land and stay in this basin?
- Aligned capability amplification: Can we perform amplification in a way that doesn’t introduce alignment failures? In particular, can we safely decompose every task we care about without effectively implementing an aligned AGI built out of human transistors?
(See: Two guarantees, The informed oversight problem, Corrigibility, and the “Low Bandwidth Overseer” section of William Saunder's post Understanding Iterated Distillation and Amplification: Claims and Oversight [LW · GW].)
3.2: How close to completion is Paul’s research agenda?
Not very close. For all we know, these problems might be extraordinarily difficult. For example, a subproblem of “transparent cognition” is “how can humans understand what goes on inside neural nets”, which is a broad open question in ML. Subproblems of “worst-case guarantees” include ensuring that ML systems are robust to distributional shift and adversarial inputs, which are also broad open questions in ML, and which might require substantial progress on MIRI-style research to articulate and prove formal bounds. And getting a formalization of corrigibility might require formalizing aspects of good reasoning (like calibration about uncertainty), which might in turn require substantial progress on MIRI-style research.
I think people commonly conflate “Paul has a safety agenda he feels optimistic about” with “Paul thinks he has a solution to AI alignment”. Paul in fact feels optimistic about these problems getting solved well enough for his agenda to work, but does not consider his research agenda anything close to complete.
(See: Universality and security amplification, search “MIRI”)
Thanks to Paul Christiano, Ryan Carey, David Krueger, Rohin Shah, Eric Rogstad, and Eli Tyre for helpful suggestions and feedback.
74 comments
Comments sorted by top scores.
comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2018-07-01T18:12:25.771Z · LW(p) · GW(p)
It would be helpful to know to what extent Paul feels like he endorses the FAQ here. This makes it sound like Yet Another Stab At Boiling Down The Disagreement would say that I disagree with Paul on two critical points:
- (1) To what extent "using gradient descent or anything like it to do supervised learning" involves a huge amount of Project Chaos and Software Despair before things get straightened out, if they ever do;
- (2) Whether there's a simple scalable core to corrigibility that you can find by searching for thought processes that seem to be corrigible over relatively short ranges of scale.
I don't want to invest huge amounts arguing with this until I know to what extent Paul agrees with either the FAQ, or that this sounds like a plausible locus of disagreement. But a gloss on my guess at the disagreement might be:
1:
Paul thinks that current ML methods given a ton more computing power will suffice to give us a basically neutral, not of itself ill-motivated, way of producing better conformance of a function to an input-output behavior implied by labeled data, which can learn things on the order of complexity of "corrigible behavior" and do so without containing tons of weird squiggles; Paul thinks you can iron out the difference between "mostly does what you want" and "very exact reproduction of what you want" by using more power within reasonable bounds of the computing power that might be available to a large project in N years when AGI is imminent, or through some kind of weird recursion. Paul thinks you do not get Project Chaos and Software Despair that takes more than 6 months to iron out when you try to do this. Eliezer thinks that in the alternate world where this is true, GANs pretty much worked the first time they were tried, and research got to very stable and robust behavior that boiled down to having no discernible departures from "reproduce the target distribution as best you can" within 6 months of being invented.
Eliezer expects great Project Chaos and Software Despair from trying to use gradient descent, genetic algorithms, or anything like that, as the basic optimization to reproduce par-human cognition within a boundary in great fidelity to that boundary as the boundary was implied by human-labeled data. Eliezer thinks that if you have any optimization powerful enough to reproduce humanlike cognition inside a detailed boundary by looking at a human-labeled dataset trying to outline the boundary, the thing doing the optimization is powerful enough that we cannot assume its neutrality the way we can assume the neutrality of gradient descent.
Eliezer expects weird squiggles from gradient descent - it's not that gradient descent can never produce par-human cognition, even natural selection will do that if you dump in enough computing power. But you will get the kind of weird squiggles in the learned function that adversarial examples expose in current nets - special inputs that weren't in the training distribution, but look like typical members of the training distribution from the perspective of the training distribution itself, will break what we think is the intended labeling from outside the system. Eliezer does not think Ian Goodfellow will have created a competitive form of supervised learning by gradient descent which lacks "squiggles" findable by powerful intelligence by the time anyone is trying to create ML-based AGI, though Eliezer is certainly cheering Goodfellow on about this and would recommend allocating Goodfellow $1 billion if Goodfellow said he could productively use it. You cannot iron out the squiggles just by using more computing power in bounded in-universe amounts.
These squiggles in the learned function could correspond to daemons, if they grow large enough, or just something that breaks our hoped-for behavior from outside the system when the system is put under a load of optimization. In general, Eliezer thinks that if you have scaled up ML to produce or implement some components of an Artificial General Intelligence, those components do not have a behavior that looks like "We put in loss function L, and we got out something that really actually minimizes L". You get something that minimizes some of L and has weird squiggles around typical-looking inputs (inputs not obviously distinguished from the training distribution except insofar as they exploit squiggles). The system is subjecting itself to powerful optimization that produces unusual inputs and weird execution trajectories - any output that accomplishes the goal is weird compared to a random output and it may have other weird properties as well. You can't just assume you can train for X in a robust way when you have a loss function that targets X.
I imagine that Paul replies to this saying "I agree, but..." but I'm not sure what comes after the "but". It looks to me like Paul is imagining that you can get very powerful optimization with very detailed conformance to our intended interpretation of the dataset, powerful enough to enclose par-human cognition inside a boundary drawn from human labeling of a dataset, and have that be the actual thing we get out rather than a weird thing full of squiggles. If Paul thinks he has a way to compound large conformant recursive systems out of par-human thingies that start out weird and full of squiggles, we should definitely be talking about that. From my perspective it seems like Paul repeatedly reasons "We train for X and get X" rather than "We train for X and get something that mostly conforms to X but has a bunch of weird squiggles" and also often speaks as if the training method is assumed to be gradient descent, genetic algorithms, or something else that can be assumed neutral-of-itself rather than being an-AGI-of-itself whose previous alignment has to be assumed.
The imaginary Paul in my head replies that we actually are using an AGI to train on X and get X, but this AGI was previously trained by a weaker neutral AGI, and so on going back to something trained by gradient descent. My imaginary reply is that neutrality is not the same property as conformance or nonsquiggliness, and if you train your base AGI via neutral gradient descent you get out a squiggly AGI and this squiggly AGI is not neutral when it comes to that AGI looking at a dataset produced by X and learning a function conformant to X. Or to put it another way, if the plan is to use gradient descent on human-labeled data to produce a corrigible alien that is smart enough to produce more corrigible aliens better than gradient descent, this corrigible alien actually needs to be quite smart because an IQ 100 human will not build an aligned IQ 140 human even if you run them for a thousand years, so you are producing something very smart and dangerous on the first step, and gradient descent is not smart enough to align that base case.
But at this point I expect the real Paul to come back and say, "No, no, the idea is something else..."
A very important aspect of my objection to Paul here is that I don't expect weird complicated ideas about recursion to work on the first try, with only six months of additional serial labor put into stabilizing them, which I understand to be Paul's plan. In the world where you can build a weird recursive stack of neutral optimizers into conformant behavioral learning on the first try, GANs worked on the first try too, because that world is one whose general Murphy parameter is set much lower than ours. Being able to build weird recursive stacks of optimizers that work correctly to produce neutral and faithful optimization for corrigible superhuman thought out of human-labeled corrigible behaviors and corrigible reasoning, without very much of a time penalty relative to nearly-equally-resourced projects who are just cheerfully revving all the engines as hard as possible trying to destroy the world, is just not how things work in real life, dammit. Even if you could make the weird recursion work, it would take time.
2:
Eliezer thinks that while corrigibility probably has a core which is of lower algorithmic complexity than all of human value, this core is liable to be very hard to find or reproduce by supervised learning of human-labeled data, because deference is an unusually anti-natural shape for cognition, in a way that a simple utility function would not be an anti-natural shape for cognition. Utility functions have multiple fixpoints requiring the infusion of non-environmental data, our externally desired choice of utility function would be non-natural in that sense, but that's not what we're talking about, we're talking about anti-natural behavior.
E.g.: Eliezer also thinks that there is a simple core describing a reflective superintelligence which believes that 51 is a prime number, and actually behaves like that including when the behavior incurs losses, and doesn't thereby ever promote the hypothesis that 51 is not prime or learn to safely fence away the cognitive consequences of that belief and goes on behaving like 51 is a prime number, while having no other outwardly discernible deficits of cognition except those that directly have to do with 51. Eliezer expects there's a relatively simple core for that, a fixed point of tangible but restrained insanity that persists in the face of scaling and reflection; there's a relatively simple superintelligence that refuses to learn around this hole, refuses to learn how to learn around this hole, refuses to fix itself, but is otherwise capable of self-improvement and growth and reflection, etcetera. But the core here has a very anti-natural shape and you would be swimming uphill hard if you tried to produce that core in an indefinitely scalable way that persisted under reflection. You would be very unlikely to get there by training really hard on a dataset where humans had labeled as the 'correct' behavior what humans thought would be the implied behavior if 51 were a prime number, not least because gradient descent is terrible, but also just because you'd be trying to lift 10 pounds of weirdness with an ounce of understanding.
The central reasoning behind this intuition of anti-naturalness is roughly, "Non-deference converges really hard as a consequence of almost any detailed shape that cognition can take", with a side order of "categories over behavior that don't simply reduce to utility functions or meta-utility functions are hard to make robustly scalable".
The real reasons behind this intuition are not trivial to pump, as one would expect of an intuition that Paul Christiano has been alleged to have not immediately understood. A couple of small pumps would be https://arbital.com/p/updated_deference/ for the first intuition and https://arbital.com/p/expected_utility_formalism/?l=7hh for the second intuition.
What I imagine Paul is imagining is that it seems to him like it would in some sense be not that hard for a human who wanted to be very corrigible toward an alien, to be very corrigible toward that alien; so you ought to be able to use gradient-descent-class technology to produce a base-case alien that wants to be very corrigible to us, the same way that natural selection sculpted humans to have a bunch of other desires, and then you apply induction on it building more corrigible things.
My class of objections in (1) is that natural selection was actually selecting for inclusive fitness when it got us, so much for going from the loss function to the cognition; and I have problems with both the base case and the induction step of what I imagine to be Paul's concept of solving this using recursive optimization bootstrapping itself; and even more so do I have trouble imagining it working on the first, second, or tenth try over the course of the first six months.
My class of objections in (2) is that it's not a coincidence that humans didn't end up deferring to natural selection, or that in real life if we were faced with a very bizarre alien we would be unlikely to want to defer to it. Our lack of scalable desire to defer in all ways to an extremely bizarre alien that ate babies, is not something that you could fix just by giving us an emotion of great deference or respect toward that very bizarre alien. We would have our own thought processes that were unlike its thought processes, and if we scaled up our intelligence and reflection to further see the consequences implied by our own thought processes, they wouldn't imply deference to the alien even if we had great respect toward it and had been trained hard in childhood to act corrigibly towards it.
A dangerous intuition pump here would be something like, "If you take a human who was trained really hard in childhood to have faith in God and show epistemic deference to the Bible, and inspecting the internal contents of their thought at age 20 showed that they still had great faith, if you kept amping up that human's intelligence their epistemology would at some point explode"; and this is true even though it's other humans training the human, and it's true even though religion as a weird sticking point of human thought is one we selected post-hoc from the category of things historically proven to be tarpits of human psychology, rather than aliens trying from the outside in advance to invent something that would stick the way religion sticks. I use this analogy with some reluctance because of the clueless readers who will try to map it onto the AGI losing religious faith in the human operators, which is not what this analogy is about at all; the analogy here is about the epistemology exploding as you ramp up intelligence because the previous epistemology had a weird shape.
Acting corrigibly towards a baby-eating virtue ethicist when you are a utilitarian is an equally weird shape for a decision theory. It probably does have a fixed point but it's not an easy one, the same way that "yep, on reflection and after a great deal of rewriting my own thought processes, I sure do still think that 51 is prime" probably has a fixed point but it's not an easy one.
I think I can imagine an IQ 100 human who defers to baby-eating aliens, although I really think a lot of this is us post-hoc knowing that certain types of thoughts can be sticky, rather than the baby-eating aliens successfully guessing in advance how religious faith works for humans and training the human to think that way using labeled data.
But if you ramp up the human's intelligence to where they are discovering subjective expected utility and logical decision theory and they have an exact model of how the baby-eating aliens work and they are rewriting their own minds, it's harder to imagine the shape of deferential thought at IQ 100 successfully scaling to a shape of deferential thought at IQ 1000.
Eliezer also tends to be very skeptical of attempts to cross cognitive chasms between A and Z by going through weird recursions and inductive processes that wouldn't work equally well to go directly from A to Z. http://slatestarcodex.com/2014/10/12/five-planets-in-search-of-a-sci-fi-story/ and the story of K'th'ranga V is a good intuition pump here. So Eliezer is also not very hopeful that Paul will come up with a weirdly recursive solution that scales deference to IQ 101, IQ 102, etcetera, via deferential agents building other deferential agents, in a way that Eliezer finds persuasive. Especially a solution that works on merely the tenth try over the first six months, doesn't kill you when the first nine tries fail, and doesn't require more than 10x extra computing power compared to projects that are just bulling cheerfully ahead.
3:
I think I have a disagreement with Paul about the notion of being able to expose inspectable thought processes to humans, such that we can examine each step of the thought process locally and determine whether it locally has properties that will globally add up to corrigibility, alignment, and intelligence. It's not that I think this can never be done, or even that I think it takes longer than six months. In this case, I think this problem is literally isomorphic to "build an aligned AGI". If you can locally inspect cognitive steps for properties that globally add to intelligence, corrigibility, and alignment, you're done; you've solved the AGI alignment problem and you can just apply the same knowledge to directly build an aligned corrigible intelligence.
As I currently flailingly attempt to understand Paul, Paul thinks that having humans do the inspection (base case) or thingies trained to resemble aggregates of trained thingies (induction step) is something we can do in an intuitive sense by inspecting a reasoning step and seeing if it sounds all aligned and corrigible and intelligent. Eliezer thinks that the large-scale or macro traces of cognition, e.g. a "verbal stream of consciousness" or written debates, are not complete with respect to general intelligence in bounded quantities; we are generally intelligent because of sub-verbal cognition whose intelligence-making properties are not transparent to inspection. That is: An IQ 100 person who can reason out loud about Go, but who can't learn from the experience of playing Go, is not a complete general intelligence over boundedly reasonable amounts of reasoning time.
This means you have to be able to inspect steps like "learn an intuition for Go by playing Go" for local properties that will globally add to corrigible aligned intelligence. And at this point it no longer seems intuitive that having humans do the inspection is adding a lot of value compared to us directly writing a system that has the property.
This is a previous discussion that is ongoing between Paul and myself, and I think it's a crux of disagreement but not one that's as cruxy as 1 and 2. Although it might be a subcrux of my belief that you can't use weird recursion starting from gradient descent on human-labeled data to build corrigible agents that build corrigible agents. I think Paul is modeling the grain size here as corrigible thoughts rather than whole agents, which if it were a sensible way to think, might make the problem look much more manageable; but I don't think you can build corrigible thoughts without building corrigible agents to think them unless you have solved the decomposition problem that I think is isomorphic to building an aligned corrigible intelligence directly.
I remark that this intuition matches what the wise might learn from Scott's parable of K'th'ranga V: If you know how to do something then you know how to do it directly rather than by weird recursion, and what you imagine yourself doing by weird recursion you probably can't really do at all. When you want an airplane you don't obtain it by figuring out how to build birds and then aggregating lots of birds into a platform that can carry more weight than any one bird and then aggregating platforms into megaplatforms until you have an airplane; either you understand aerodynamics well enough to build an airplane, or you don't, the weird recursion isn't really doing the work. It is by no means clear that we would have a superior government free of exploitative politicians if all the voters elected representatives whom they believed to be only slightly smarter than themselves, until a chain of delegation reached up to the top level of government; either you know how to build a less corruptible relationship between voters and politicians, or you don't, the weirdly recursive part doesn't really help. It is no coincidence that modern ML systems do not work by weird recursion because all the discoveries are of how to just do stuff, not how to do stuff using weird recursion. (Even with AlphaGo which is arguably recursive if you squint at it hard enough, you're looking at something that is not weirdly recursive the way I think Paul's stuff is weirdly recursive, and for more on that see https://intelligence.org/2018/05/19/challenges-to-christianos-capability-amplification-proposal/.)
It's in this same sense that I intuit that if you could inspect the local elements of a modular system for properties that globally added to aligned corrigible intelligence, it would mean you had the knowledge to build an aligned corrigible AGI out of parts that worked like that, not that you could aggregate systems that corrigibly learned to put together sequences of corrigible thoughts into larger corrigible thoughts starting from gradient descent on data humans have labeled with their own judgments of corrigibility.
Replies from: paulfchristiano, paulfchristiano, T3t, paulfchristiano, paulfchristiano, Benito, thomas-kwa, paulfchristiano, TurnTrout↑ comment by paulfchristiano · 2018-07-01T22:45:28.265Z · LW(p) · GW(p)
Eliezer thinks that in the alternate world where this is true, GANs pretty much worked the first time they were tried
Note that GANs did in fact pretty much work the first time they were tried, at least according to Ian's telling, in the strong sense that he had them working on the same night that he came up with the idea over drinks. (That wasn't a journalist editorializing, that's the story as he tells it.)
GANs seem to be unstable in just about the ways you'd expect them to be unstable on paper, we don't have to posit any magical things-are-hard regularity.
This doesn't feel very important to my broader position. I'm totally comfortable with needing to do a lot of tinkering to get stuff working as long as that work (a) doesn't increase linearly with the cost of your AI project and (b) can be done in parallel with AI scaling up rather needing to be done at the very end.
There seems to be some basic difference in the way you are thinking about these terms—I'm not sure what you mean by Project Chaos and Software Despair in this case, it seems to me like it would be fine if our experience with alignment was similar to our experience with GANs.
A very important aspect of my objection to Paul here is that I don't expect weird complicated ideas about recursion to work on the first try
They don't have to work on the first try. We get to try a whole bunch of stuff in advance to try to get them working, to do tons of experiments and build tons of scaled-down systems for which failure is not catastrophic. The thing that I'm aiming for is: the effort of continuing to scale up our alignment techniques as AI improves is (a) small compared to the effort of scaling up our AI, (b) can be done in parallel with scaling up our AI.
From my perspective, your position is like saying "If you want to build crypto systems that stand up to eavesdroppers with a lot of computational power, then you are going to need to do a lot of extra work."
My position is like saying "We'll try to write a library that can do cryptography with arbitrary security parameters. It will take some time to get the library working at all, and then a bunch of extra work the first few times we try to scale it up because we won't have gotten everything right. But at some point it will actually work. After that, as computers get faster, we'll just run the same algorithms with bigger and bigger security parameters, and so our communication will remain secure without significant ongoing work."
It seems clear to me that some kinds of scaleup involve a whole bunch of extra work, and others don't. Lots of algorithms actually work, and they keep working even if you run them on bigger and bigger inputs. I've tried to make arguments for why AI alignment may be more like an algorithmic or conceptually clean task, where we can hope to have a solid solution that scales with AI capabilities. You keep saying that can't happen and pointing to analogies that don't seem convincing to me, but it doesn't feel like you are engaging with the basic argument here.
A bit more quantitatively, I think I'm arguing ">1/3 chance that AI alignment is in the class of tasks that scale well" and you are arguing ">90% chance it isn't."
Also note that even though this is a clear disagreement between us, I don't think it's a crux for the biggest-picture disagreements. I also have a significant probability on needing lots of ongoing ad hoc work, and so I'm very interested in institutional arrangements such that that's feasible and doing all of the preparatory research we can to make that easier. If you convinced me 100% on this point, I'd still be pretty far from thinking MIRI's public position is the right response. (And conversely, if you could convince me that MIRI's public position is sensible conditioned on this pragmatic pessimistic view, then I have enough probability on the pessimistic view that I'd be basically convinced MIRI's position is sensible.)
↑ comment by paulfchristiano · 2018-07-01T22:44:03.264Z · LW(p) · GW(p)
Eliezer thinks that if you have any optimization powerful enough to reproduce humanlike cognition inside a detailed boundary by looking at a human-labeled dataset trying to outline the boundary, the thing doing the optimization is powerful enough that we cannot assume its neutrality the way we can assume the neutrality of gradient descent.
To clarify: it's not that you think that gradient descent can't in fact find human-level cognition by trial and error, it's that you think "the neutrality of gradient descent" is an artifact of its weakness? Or maybe that gradient descent is neutral, but that if it finds a sophisticated policy that policy isn't neutral?
I don't really know that "outline the boundary" means here. We specify a performance criterion, then we do a search for a model that scores well according to that criterion. It's not like we are trying to find some illustrative examples that point out the concept we want to learn, we are just implementing a test for the behavior we are interested in.
The imaginary Paul in my head replies that we actually are using an AGI to train on X and get X
In the very long run I expect AGI to supply the optimization power rather than trial and error, and the continued alignment comes from some combination of "Our training process as long as the optimization is benign" + "Our AGI is benign." But I totally agree that you need the AI trained by gradient descent to work, I'm definitely not imagining that everything will be OK because the optimization is done by AGI instead of by gradient descent. In practice I'm basically always talking about the case where gradient descent is doing the optimization.
↑ comment by RobertM (T3t) · 2018-07-02T04:50:02.574Z · LW(p) · GW(p)
Meta-comment:
It's difficult to tell, having spent some time (but not a very large amount of time) following this back-and-forth, whether much progress is being made in furthering Eliezer's and Paul's understanding of each other's positions and arguments. My impression is that there has been some progress, mostly from Paul vetoing Eliezer's interpretations of Paul's agenda, but by nature this is a slow kind of progress - there are likely many more substantially incorrect interpretations than substantially correct ones, so even if you assume progress toward a correct interpretation to be considerably faster than what might be predicted by a random walk, the slow feedback cycle still means it will take a while.
My question is why the two of you haven't sat down for a weekend (or as many as necessary) to hash out the cruxes and whatever confusion surrounds them. This seems to be a very high-value course of action: if, upon reaching a correct understanding of Paul's position, Eliezer updates in that direction, it's important that happen as soon as possible. Likewise, if Eliezer manages to convince Paul of catastrophic flaws in his agenda, that may be even more important.
Replies from: Jan_Kulveit↑ comment by Jan_Kulveit · 2018-07-02T10:15:40.797Z · LW(p) · GW(p)
On the other hand, you should consider the advantages of having this discussion public. I find it quite valuable to see this, as the debate sheds more light on some of both Paul's and Eliezer's models. If they just sat down for a weekend, talked, and updated, it may be more efficient, but a black-box.
My intuition is from a more strategical perspective, the resource we actually need the most are "more Pauls and Eliezers", and this may actually help.
↑ comment by paulfchristiano · 2018-07-01T22:43:34.647Z · LW(p) · GW(p)
But you will get the kind of weird squiggles in the learned function that adversarial examples expose in current nets - special inputs that weren't in the training distribution, but look like typical members of the training distribution from the perspective of the training distribution itself, will break what we think is the intended labeling from outside the system.
I don't really know what you mean by "squiggles." If you take data that is off the distribution, then your model can perform poorly. This can be a problem if your distribution changes, but in that case you can retrain on the new distribution and repeat until convergence, I think all evidence so far is consistent with SGD for neural networks de facto obtaining an online regret bound.
The harder problem is when you are unhappy with a small number of errors; when your distribution changes and your model fails and the precise way it fails is deciding that now is the time to dismantle the mechanism that was supposed to correct the failure. The natural way to try to fix this is to try guarantee that your model *never* fails so hard that a very tiny fraction of failures would be catastrophic. That's a tricky game, but it doesn't seem like it's about squiggles. You aren't trying to exactly match a complicated landscape anymore, now there is a big space of models that satisfy some "easy" property for all inputs (namely, they *don't* pick actions that are well-optimized to break the training process), and your goal is to continue optimizing within that space.
For adversarial examples in particular, I think that the most reasonable guess right now is that it takes more model capacity (and hence data) to classify all perturbations of natural images correctly rather than merely classifying most correctly—i.e., the smallest neural net that classifies them all right is bigger than the smallest neural net that gets most of them right—but that if you had enough capacity+data then adversarial training would probably be robust to adversarial perturbations. Do you want to make the opposite prediction?
The system is subjecting itself to powerful optimization that produces unusual inputs and weird execution trajectories - any output that accomplishes the goal is weird compared to a random output and it may have other weird properties as well.
It sounds like you are imagining train on "normal" inputs and then apply powerful optimization to get some weird inputs that you haven't trained on. I totally agree that if you try to do that, there is no reason to expect high performance on the weird inputs.
But in fact you train the model on precisely the weird inputs that your system is generating. Over time that distribution shifts. As discussed above, that can cause trouble if a small (o(1)) fraction of failures in the lab can cause. But if you are robust to o(1)% failures in the lab, then you just keep training and everything is OK.
with very detailed conformance to our intended interpretation of the dataset
I don't think that's what I'm hoping for.
I'm saying: hopefully we can find a model that never fails catastrophically. By "catastrophic failure" I mean a failure that we can never recover from, even if it occurs in the lab. For that purpose, we get to cut an extremely wide safety margin around the "intended" interpretation, and the system can be very conservative about avoiding things that would be irreversibly destructive.
This hope involves two parts: first, that it's not much harder for a model to both do the intended task and leave a wide margin around potentially catastrophic behavior, and second that we can actually train for that objective (by distinguishing models that leave a very wide margin around catastrophic behavior from models that would fail catastrophically in some case).
I don't feel like you are engaging with this basic hope. I still don't know whether that's because you don't understand my hope, or because you are making an effort to communicate some very subtle intuition that I don't understand (my best guess is the former).
Replies from: jessica.liu.taylor↑ comment by jessicata (jessica.liu.taylor) · 2018-07-02T06:02:17.403Z · LW(p) · GW(p)
I’m saying: hopefully we can find a model that never fails catastrophically. By “catastrophic failure” I mean a failure that we can never recover from, even if it occurs in the lab. For that purpose, we get to cut an extremely wide safety margin around the “intended” interpretation, and the system can be very conservative about avoiding things that would be irreversibly destructive.
I'm confused about you saying this; it seems like this is incompatible with using the AI to substantially assist in doing big things like preventing nuclear war. You can split a big task into lots of small decisions such that it's fine if a random independent small fraction of decisions are bad (e.g. by using a voting procedure), but that doesn't help much, since it's still vulnerable to multiple small decisions being made badly in a correlated fashion; this is the more likely outcome of the AI's models being bad rather than uncorrelated errors.
Put in other words: if you're using the AI to do a big thing, then you can't section off "avoiding catastrophes" as a bounded subset of the problem, it's intrinsic to all the reasoning the AI is doing.
Replies from: paulfchristiano↑ comment by paulfchristiano · 2018-07-03T04:05:29.435Z · LW(p) · GW(p)
I totally agree that the risk of catastrophic failure is an inevitable part of life and we can't split it off, I spoke carelessly.
I am mostly talking about the informal breakdown in this post.
Replies from: jessica.liu.taylor, Wei_Dai↑ comment by jessicata (jessica.liu.taylor) · 2018-07-03T05:13:01.101Z · LW(p) · GW(p)
My intuition is that the combination of these guarantees is insufficient for good performance and safety.
Say you're training an agent; then the AI's policy is for some set of observations and of actions (i.e. it takes in an observation and returns an action distribution). In general, your utility function will be a nonlinear function of the policy (where we can consider the policy to be a vector of probabilities for each (observation, action) pair). For example, if it is really important for the AI to output the same thing given observation "a" and given observation "b", then this is a nonlinearity. If the AI is doing something like programming, then your utility is going to be highly nonlinear in the policy, since getting even a single character wrong in the program can result in a crash.
Say your actual utility function on the AI's policy is U. If you approximate this utility using average performance, you get this approximation:
where is some distribution over observations and is some bounded performance function. Note that is linear.
Catastrophe avoidance can handle some nonlinearities. Including catastrophe avoidance, we get this approximation:
where is some bounded catastrophe function.
I don't see a good argument for why, for any you might have over the policy, there are some easy-to find such that approximately maximizing yields a policy that is nearly as good as if you had approximately maximized .
Some examples of cases I expect to not work with linear+catastrophe approximation:
- Some decisions are much more important than others, and it's predictable which ones. (This might be easy to handle with importance sampling but that is an extension of the framework, and you have to handle things like "which observations the AI gets depends on the AI's policy")
- The importance of a decision depends on the observations and actions of previous rounds. (e.g. in programming, typing a bad character is important if no bad characters have been typed yet, and not important if the program already contains a syntax error)
- The AI has to be predictable; it has to do the same thing given similar-enough observations (this is relevant if you want different AIs to coordinate with each other)
- The AI consists of multiple copies that must meet at the same point; or the AI consists of multiple copies that must meet at different points.
You could argue that we should move to an episodic RL setting to handle these, however I think my arguments continue to apply if you replace "AI takes an action" with "AI performs a single episode". Episodes have to be short enough that they can be judged efficiently on an individual basis, and the operator's utility function will be nonlinear in the performance on each of these short episodes.
In general my criticism here is pointing at a general criticism of feedback-optimization systems. One interpretation of this criticism is that it implies that feedback-optimization systems are too dumb to do relevant long-term reasoning, even with substantial work in reward engineering.
Evolution provides some evidence that feedback-optimization systems can, with an extremely high amount of compute, eventually produce things that do long-term reasoning (though I'm not that confident in the analogy between evolution and feedback-optimization systems). But then these agents' long-term reasoning is not explained by their optimization of feedback. So understanding the resulting agents as feedback-optimizers is understanding them at the wrong level of abstraction (see this post for more on what "understanding at the wrong level of abstraction" means), and providing feedback based on an overseer's values would be insufficient to get something the overseer wants.
Replies from: paulfchristiano, Wei_Dai↑ comment by paulfchristiano · 2018-07-03T07:44:47.769Z · LW(p) · GW(p)
See this post for discussion of some of these things.
Other points beyond those made in that post:
- The easy way to think about performance is using marginal impact.
- There will be non-convexities---e.g. if you need to get 3 things right to get a prize, and you currently get 0 things right, then the marginal effect of getting an additional thing right is 0 and you can be stuck at a local optimum. My schemes tend to punt these issues to the overseer, e.g. the overseer can choose to penalize the first mistake based on their beliefs about the value function of the trained system rather than the current system.
- To the extent that any decision-maker has to deal with similar difficulties, then your criticism only makes sense in the context of some alternative unaligned AI that might outcompete the current AI. One alternative is the not-feedback-optimizing cognition of a system produced by gradient descent on some arbitrary goal (let's call it an alien). In this case, I suspect my proposal would be able to compete iff informed oversight worked well enough to reflect the knowledge that the aliens use for long-term planning.
Note that catastrophe avoidance isn't intended to overcome the linear approximation. It's intended to prevent the importance weights from blowing up too much. (Though as we've discussed, it can't do that in full generality---I'm going to shovel some stuff under "an AI that is trying to do the right thing" and grant that we aren't going to actually get the optimal policy according to the overseer's values. Instead I'm focused on avoiding some class of failures that I think of as alignment failures.)
I'm not including issues like "you want your AI to be predictable," I'd say that "be very predictable" is a separate problem, just like "be really good at chess" is a separate problem. I agree that our preferences are better satisfied by AIs that solve these additional problems. And I agree that if our alignment techniques are fundamentally incompatible with other techniques that help with these desiderata then that should be considered an open problem for alignment (though we may end up disagreeing about the importance / about whether this happens).
↑ comment by Wei Dai (Wei_Dai) · 2018-07-08T12:54:05.844Z · LW(p) · GW(p)
One interpretation of this criticism is that it implies that feedback-optimization systems are too dumb to do relevant long-term reasoning, even with substantial work in reward engineering.
If this is true, it seems like a really important point that I need to understand better. Any chance you can surface this argument into a top-level post, so more people can see it and chime in with their thoughts? In particular I'd like to understand whether the problem is caused by current ML approaches not offering good/useful enough performance guarantees, which might change in the future, or if this a fundamental problem with ML and feedback-optimization that can't be overcome. Also, can you suggest ways to test this empirically?
(I also can't quite tell to what extent Paul's response has addressed your criticism. If you decide to write a post maybe you can explain that as well?)
↑ comment by Wei Dai (Wei_Dai) · 2018-07-06T18:36:56.946Z · LW(p) · GW(p)
About the inductive argument for the two guarantees, suppose we can show that Amplify(A) satisfies the two guarantees and we're trying to show this for Distill(Amplify(A)).
For the inductive step to go through, Amplify(A) has to detect and disapprove of any incorrigible optimization that may be introduced by Distill, but we don't have a guarantee that Amplify(A) can do this, because the performance guarantee is "on average" so it might not detect some obscure kinds of incorrigible optimizations, and the control guarantee only says Amplify(A) won't itself do any incorrigible optimization but not that it can detect every incorrigible optimization in others.
It seems like for the argument to go through, you need a third guarantee that says something like "can detect any violations of the control guarantee in an agent B as long as B belongs to C (i.e., some class of AIs that includes Distill(Amplify(A)), Distill(Amplify(Distill(Amplify(A)))), and so on), as well as any violations of this guarantee in B." Does that make sense?
(There are things about the performance guarantee that I don't entirely understand, like what distribution are you averaging over exactly, so possibly the way you're thinking about it already implies this third guarantee, but in that case it still seems useful to state this explicitly.)
Replies from: paulfchristiano↑ comment by paulfchristiano · 2018-07-07T06:38:09.765Z · LW(p) · GW(p)
The task that Amplify(A) is doing is something like "Find an input on which the distilled agent will behave malignly, if any exist." (That literal query won't work, one important research goal is to find something along those lines that actually works.)
If Amplify(A) performs well on average, then it finds such inputs with reasonably high probability. To actually get this conclusion you obviously need to argue both about the properties of Amplify(A) and the properties of the problem. But the main point is that it has no dependence on the worst case behavior of Amplify(A).
If Amplify(A) can't solve this task---if we have no way to train a model to certifiably be benign---then we are just screwed anyway.
(I agree that the concern you've mentioned potentially afflicts one of the proposals in my post, inductively defining specifications. It's not clear to me whether it's a serious problem, I'll think about it at some point.)
There are things about the performance guarantee that I don't entirely understand, like what distribution are you averaging over exactly, so possibly the way you're thinking about it already implies this third guarantee, but in that case it still seems useful to state this explicitly.
We'll construct the distribution in order to make the performance guarantee useful.
That is, for the final agent, we take the distribution over tasks I care about. For preceding agents, we take the distribution over subtasks that arise while trying to solve the tasks I care about (i.e. by applying amplification to the problem of evaluating a random task from the next agent's distribution / to the problem of certifying that the next agent is benign).
Replies from: Wei_Dai↑ comment by Wei Dai (Wei_Dai) · 2018-07-07T08:08:56.663Z · LW(p) · GW(p)
If Amplify(A) performs well on average, then it finds such inputs with reasonably high probability.
But that's not enough for the inductive step to go through, because it's "high probability" only if you pick a random distilled agent out of the distribution over which the guarantee applies. As a counter-example, suppose Amplify(A) performs well on the task “Find an input on which the distilled agent will behave malignly, if any exist” for every distilled agents in the distribution, except the actual Distill(Amplify(A)). If it does that, then it will satisfy the performance guarantee (since it does well on average) but fail to train a Distill(Amplify(A)) that satisfies the control guarantee.
That is, for the final agent, we take the distribution over tasks I care about. For preceding agents, we take the distribution over subtasks that arise while trying to solve the tasks I care about (i.e. by applying amplification to the problem of evaluating a random task from the next agent’s distribution / to the problem of certifying that the next agent is benign).
The final agent may be a superintelligent AI faced with tasks that we can't currently foresee. I don't know how to define a distribution such that it covers those tasks, without also covering many other tasks (that I won't care about). Is it ok to define the distribution extremely broadly, or does it need to be the actual distribution that the AI will face in some sense? (Or do we not actually need to explicitly define such a distribution? ETA: Does the overseer training the first distilled agent need to know the final distribution?)
Replies from: paulfchristiano↑ comment by paulfchristiano · 2018-07-07T15:59:07.656Z · LW(p) · GW(p)
But that's not enough for the inductive step to go through, because it's "high probability" only if you pick a random distilled agent out of the distribution over which the guarantee applies.
You keep giving Amplify(A) the task "Try to verify that the current agent is benign" over and over again.
The final agent may be a superintelligent AI faced with tasks that we can't currently foresee. I don't know how to define a distribution such that it covers those tasks, without also covering many other tasks (that I won't care about).
I'm imagining collecting the problems that the agent actually faces and training on those.
More precisely, I'm thinking in terms of an online guarantee rather than fixing an actual distribution, since the distribution of tasks in the real world will shift over time.
As the distribution shifts you may get worse performance. The total amount of underperformance over time is basically bounded. Moreover, our competitors will generally face the same problem.
Replies from: Wei_Dai↑ comment by Wei Dai (Wei_Dai) · 2018-07-07T17:36:19.248Z · LW(p) · GW(p)
You keep giving Amplify(A) the task “Try to verify that the current agent is benign” over and over again.
I don't see how this helps with the inductive argument. The same counter-example I gave in the grandparent comment also applies to this idea.
Replies from: paulfchristiano↑ comment by paulfchristiano · 2018-07-08T06:04:10.613Z · LW(p) · GW(p)
The top-level distribution for Amplify(A) puts 50% of its mass on "Try to verify that the current agent is benign." (Or something like 50%, it's <100% only because you are training A both to evaluate actions and to certify benignness.) If it performs badly on the current agent, then it's not performing well on average. There is no other distribution over distilled agents that we are defining the performance guarantee with respect to.
Because the current agent is training over time, we really want to talk about online guarantees rather than assuming a fixed distribution. Amplify(A) is being trained on the sequence of tasks "Try to verify that the agent at t=0 is benign," "Try to verify that the agent at t=1 is benign," "Try to verify that the agent at t=2 is benign..." etc.
If there was a learnable model that performs well on most of the subtasks of "Try to verify that the current agent is benign," then we get to infer that A in fact performs well on most of these subtasks. If amplification preserves average-case performance, then we get to conclude that Amplify(A) performs well on most tasks of the form "Try to verify that the current agent is benign." If Amplify(A) consistently concludes that the agent is benign, e.g. if Amplify(A) consistently fails to find an input on which the agent behaves malignly, then we hope to conclude that the agent is in fact benign at most steps.
Replies from: Wei_Dai↑ comment by Wei Dai (Wei_Dai) · 2018-07-08T12:30:34.941Z · LW(p) · GW(p)
Thanks, I think I'm finally starting to understand your thinking here.
Because the current agent is training over time, we really want to talk about online guarantees rather than assuming a fixed distribution.
Sounds like I really need to figure out how online guarantees work in relation to your scheme. (It's not clear to me how to map between your setup and the setup in the online learning survey that you cited, e.g., what corresponds to "receive true answer" after every prediction and what corresponds to the set of hypotheses that regret is being measured against.) I've been putting it off and just assuming a fixed distribution because you wrote "Overall, I don’t think this distinction is a huge deal."
If there was a learnable model that performs well on most of the subtasks of “Try to verify that the current agent is benign,”
How do we determine this? (What if the current agent has moved into a part of the agent space such that there was no longer a learnable model that performs well on most of the subtasks of “Try to verify that the current agent is benign”?)
if Amplify(A) consistently fails to find an input on which the agent behaves malignly, then we hope to conclude that the agent is in fact benign at most steps.
What does "most" mean here and why is that good enough? (If there are more than 100 steps and "most" means 99% then you can't rule out having malign agents in some of the steps, which seems like a problem?)
Replies from: paulfchristiano↑ comment by paulfchristiano · 2018-07-08T16:47:54.106Z · LW(p) · GW(p)
As part of designing a technique for optimizing worst-case performance, we need to argue that the overseer's job isn't too hard (so that Amplify(A) is qualified to perform the task). If we remove this restriction, then optimizing worst case performance wouldn't be scary---adversarial training would probably work fine.
(It's not clear to me how to map between your setup and the setup in the online learning survey that you cited, e.g., what corresponds to "receive true answer" after every prediction and what corresponds to the set of hypotheses that regret is being measured against.)
See the section "Limited feedback (bandits)" starting on page 177. Online learning doesn't require seeing the true answer.
We don't compete with any explicit set of hypotheses. When we say that the "model can learn to do X" then we are saying roughly "the model competes with a set of hypotheses including one that does X."
What does "most" mean here and why is that good enough?
Most means most agents over the training process. But:
- Once you have an agent that seems OK, you can freeze that agent and then run the certification process for significantly longer.
- I expect the model is probably going to have some probability of behaving malignly on any given input anyway based on internal stochasticity. So you probably already need to do something based on ensembling / ensuring sufficient per-timestep robustness.
↑ comment by Wei Dai (Wei_Dai) · 2018-07-10T05:59:03.227Z · LW(p) · GW(p)
See the section “Limited feedback (bandits)” starting on page 177. Online learning doesn’t require seeing the true answer.
I'm still having trouble matching up that section with your setup. (It assumes that the agent sees the value of the loss function after every prediction, which I think is not the case in your setup?) Is Section 6 on Online Active Learning in this more comprehensive survey closer to what you have in mind? If so, can you say which of the subsections of Section 6 is the closest? Or alternatively, can you explain the actual formal setup and guarantee you're hoping ML research will provide, which will be sufficient to accomplish what you need? (Or give an example of such formal setup/guarantee if multiple ones could work?)
Also, what if in the future the most competitive ML algorithms do not provide the kinds of guarantees you need? How likely do you think that is, and what's the expected outcome (for your approach and AI alignment in general) conditional on that?
We don’t compete with any explicit set of hypotheses. When we say that the “model can learn to do X” then we are saying roughly “the model competes with a set of hypotheses including one that does X.”
Don't we need to know the size of the set of hypotheses in order to derive a regret bound?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2018-07-10T06:27:05.307Z · LW(p) · GW(p)
It assumes that the agent sees the value of the loss function after every prediction, which I think is not the case in your setup?
You do get to see the loss function, if you couldn't see the loss function then we couldn't train A.
Amplify(A) is computed by calling A a bunch of times. The point of amplification is to set things up so that Amplify(A) will work well if the average call to A works well. A random subset of the calls to A are then evaluated (by calling Amplify(A)), so we get to see their loss.
(Obviously you get identical expected regret bounds if you evaluate an x fraction of decisions at random, just with 1/x times more regret---you get a regret bound on the sequence whose loss you evaluate, and that regret is at least x times the total.)
Replies from: Wei_Dai↑ comment by Wei Dai (Wei_Dai) · 2018-07-10T10:31:13.160Z · LW(p) · GW(p)
What does d (the number of bandit arms) correspond to in your setup? I'm guessing it's the size of the hypothesis class that you're competing with, which must be exponentially large? Since the total regret bound is (page 181, assuming you see the loss every round) it seems that you'd have to see an exponential number of losses (i.e., calls to Amplify(A)) before you could get a useful per-round guarantee. What am I missing here?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2018-07-10T18:00:06.313Z · LW(p) · GW(p)
The d under the log is the size of the hypothesis class (which is exponential in this case). The other d parameterizes the difficulty of the exploration problem. Exp4 is the simplest algorithm that pulls those two parameters apart (though it's obviously not a good algorithm for this case). It's hard to formally capture "the difficulty of the exploration problem", but intuitively it's something like what you'd expect---how many options do you have to try at random before you are guaranteed to get useful signal? This is upper bounded by the number of output options. You can get tighter formal bounds in many cases but it's one of those things where the real bound is kind of a problem-specific mess.
There are two hopes for not needing exponential time:
- In imitation+RL, the exploration difficulty should depend on something like the accuracy of your imitation rather than on the size of the underlying domain (or maybe even better). You don't have to try everything at random to get signal, if you have access to an expert who shows you a good option in each round. We can train A with demonstrations (we can get a demonstration just by calling Amplify(A)).
- Many RL problems have tractable exploration despite large domains for a whole mess of complicated reasons.
(And note that we'll be able to tell whether this is working, so in practice this is probably something that we can validate empirically---not something where we are going up against adversarial optimization pressure and so need a provable bound.)
This doesn't seem likely to be the place where my approach gets stuck, and I don't think it seems worth thinking about it that much until we've made much more progress on understanding the task that Amplify(A) actually needs to perform for robustness and on how amplification works more broadly, since (a) those are way more likely to be dealbreakers, in which case this doesn't matter, (b) it's relatively likely that other progress will change our conception of the learning theory problem we need to solve or obsolete it entirely.
If you want to understand these intuitions in detail it likely requires doing the equivalent of a course in learning theory and reading a bunch of papers in the area (which doesn't sound worth it to me, as a use of your time). Overall this isn't something where I feel excited about engaging in detail, except with experts in the relevant areas who I expect to know something or have intuitions that I don't.
Replies from: Wei_Dai, Wei_Dai↑ comment by Wei Dai (Wei_Dai) · 2018-07-15T20:04:43.616Z · LW(p) · GW(p)
I have some additional questions that I'm still not sure about, that maybe you can answer without spending too much time.
- It seems that if you can get a good online guarantee you are immune to distributional shifts (the online guarantee gives you a bound that's not based on any assumptions about the input data). But to be practically meaningful the hypothesis class (on which the regret bound is based) has to include one that can approximate X well over all possible inputs, otherwise you could prove a good regret bound, and even perform well in practice, but still suffer badly from some future distributional shift, right?
- Are you thinking that it will be possible to design X and the ML algorithm together such that we'll know it can learn to approximate X well over all possible inputs, or alternatively are you thinking of some sort of online guarantee that does make some assumptions about the input data (e.g., that its distribution doesn't change too quickly)? Or both (in a disjunctive sense)?
- Are there any relevant papers you can point to that gave you the intuitions that you have on these questions?
↑ comment by paulfchristiano · 2018-07-15T23:14:25.476Z · LW(p) · GW(p)
It seems that if you can get a good online guarantee you are immune to distributional shifts (the online guarantee gives you a bound that's not based on any assumptions about the input data).
The online guarantee says that on average, over a large sequence of trials, you will perform well. But if I train my system for a while and then deploy it, it could perform arbitrarily poorly after deployment (until I incorporate corrective data, which will generally be impossible for catastrophic failures).
But to be practically meaningful the hypothesis class (on which the regret bound is based) has to include one that can approximate X well over all possible inputs, otherwise you could prove a good regret bound, and even perform well in practice, but still suffer badly from some future distributional shift, right?
I don't understand this (might be related to the previous point). If there is a hypothesis that performs well over the sequence of actual cases that you train on, then you will perform well on the sequence of actual data cases that you train on. For any other inputs, the online guarantee doesn't say anything.
Are you thinking that it will be possible to design X and the ML algorithm together such that we'll know it can learn to approximate X well over all possible inputs, or alternatively are you thinking of some sort of online guarantee that does make some assumptions about the input data (e.g., that its distribution doesn't change too quickly)? Or both (in a disjunctive sense)?
I don't think that anything will be learning to approximate anything else well over all possible inputs.
What does "X" refer to here?
I'm not imagining making any assumptions on the input data.
Are there any relevant papers you can point to that gave you the intuitions that you have on these questions?
I don't think I fully understood the questions.
Replies from: Wei_Dai↑ comment by Wei Dai (Wei_Dai) · 2018-07-16T03:05:23.954Z · LW(p) · GW(p)
The online guarantee says that on average, over a large sequence of trials, you will perform well. But if I train my system for a while and then deploy it, it could perform arbitrarily poorly after deployment (until I incorporate corrective data, which will generally be impossible for catastrophic failures).
Take the regret bound as an example. Suppose is small (what I meant by "a good online guarantee"), then total regret is essentially bounded by , which means that if you max out the regret during training, after deployment it shouldn't accumulate more than about regret per time step, regardless of distributional shifts. Am I misunderstanding something here?
What does “X” refer to here?
It's what we were talking about previously, the set of subtasks of “Try to verify that the current agent is benign.”
I don't think that anything will be learning to approximate anything else well over all possible inputs.
Earlier, you wrote:
When we say that the “model can learn to do X” then we are saying roughly “the model competes with a set of hypotheses including one that does X.”
And I thought one possible interpretation of "do X" is "approximates X well over all possible inputs". If that's not what you meant by "do X", what does it mean?
To step back a bit, I'm finding it hard to understand online guarantees because the "regret bounds" being proven are all relative to a class of hypotheses, but in practice we actually care about performance relative to the ground truth, so in addition to the kinds of regret bounds we see in that OL survey paper, we also need to characterize the performance of the hypothesis class relative to the ground truth, right? What do you expect that characterization to look like? I'm trying to understand your thinking / intuitions about this.
Replies from: paulfchristiano↑ comment by paulfchristiano · 2018-07-16T04:46:12.841Z · LW(p) · GW(p)
You aren't misunderstanding the result, what you say makes complete sense. Now I understand your questions.
"Max out the regret during training" is extremely infeasible---for example, you'd need to know the exact regret bound (which we don't), and much more importantly you'd need to do perfect adversarial training to find every possible mistake the model makes (which we can't).
I'm just hoping to directly use the bound on the total loss.
That is, suppose that I'm trying to apply Amplify(A) to some "not too hard" task. Then I want to argue something like:
1. If we've built Amplify() correctly, then in order for Amplify(A) to succeed at a "not too hard" task, A just needs to solve some "not too hard" subtasks. (This is the main constraint on Amplify() other than preserving alignment, without this constraint it would be relatively easy.)
2. Because those subtasks are "not too hard," we think that A has a regret bound vs. some model that solves those tasks well (on average). Roughly speaking this is the definition of "not too hard," more on this below.
3. So if we keep applying Amplify(A) to the task, and training A on the resulting subtasks, then eventually A will solve those tasks well (on average). At that point, Amplify(A) succeeds at the original task (on average).
4. This argument goes through even if the task is changing over time, as long as the "not too hard" bound applies uniformly over the sequence (such that there is a single model in step #2 that succeeds for every element in the sequence).
In the original example we were discussing, I'm applying Amplify(A) to the task {test whether model B is robust}. When I talk about robustness as a subproblem of alignment, I mean precisely setting up the task {test whether model B is robust} in such a way that it's "not too hard," i.e. such that we can apply the above argument to the task {test whether model B is robust}.
Performing well on average is adequate for this task because I can keep applying Amplify(A) to the task {test whether model B is robust}, over and over again. If it fails 10% of the time, that just means 10% of the tests fail, not that model B can fail catastrophically on 10% of inputs or with 10% probability. (This is the magic we want out of a solution to robustness---to turn an average-case guarantee into a worst-case guarantee.)
And I thought one possible interpretation of "do X" is "approximates X well over all possible inputs". If that's not what you meant by "do X", what does it mean?
The X comes with some performance measure. I mean that the model performs well enough on average over the distribution of subtasks.
(This still depends on the distribution of top-level tasks. For now you can imagine imposing this requirement for the worst case distribution of top-level tasks that can occur during training, though I think we can be a little bit more precise in practice.)
In practice we actually care about performance relative to the ground truth, so in addition to the kinds of regret bounds we see in that OL survey paper, we also need to characterize the performance of the hypothesis class relative to the ground truth, right?
Yes, we need to argue that there is some hypothesis in the class that is able to perform well. This is what I mean by "not too hard." Ultimately we will be assuming that our ML is able to do something impactful in the world, and then trying to argue that if it was able to do that impactful thing, then we could also solve the subtasks necessary to do the same impactful thing safely (since the goal of this approach is to compete with unaligned ML).
In order to argue that a task is not that hard, we will use some combination of:
- The assumption that our ML is good enough at some concrete tasks whose difficulty doesn't scale with the sophistication of the models we are training. This can be verified empirically in advance, and once it's true it tends to become more true.
- The assumption that our ML system is good enough at doing something impactful in the world. (Which we'll combine with some argument about how the tasks we are interested in are not harder than that task, or "not much harder" in the sense that the difference falls into the preceding category, of "easy" tasks that we've demonstrated empirically that our model can solve.)
Overall, things are not really going to be this formal, but hopefully this helps communicate the direction of my thinking/hopes.
Replies from: Wei_Dai↑ comment by Wei Dai (Wei_Dai) · 2018-07-16T07:19:27.576Z · LW(p) · GW(p)
“Max out the regret during training” is extremely infeasible
If you can't max out the regret during training, then I'm having trouble seeing how to make use of such a regret bound the way you want to use it. Let's say the current total regret is 1000 less than the provable regret bound. Then as far as the provable bound is concerned, the model could answer the next 1000 questions incorrectly and still satisfy the bound, so you can't just repeat a task some number of times and then conclude that there's a small probability that all of the answers will be wrong.
Replies from: paulfchristiano↑ comment by paulfchristiano · 2018-07-16T15:57:24.956Z · LW(p) · GW(p)
If A satisfies a regret bound, then:
- For any sequence of queries S, and any model M in the comparison class...
- (average performance of A on S) > (average performance of M on S) - (arbitrarily small constant)
This gives you a lower bound on (average performance of A on S). That's what I want.
Yes, you could get a bad result 1000 times in a row. To guarantee a good result in that setting, you'd need to run 1001 times (which will still probably be a tiny fraction of your overall training time).
Replies from: Wei_Dai↑ comment by Wei Dai (Wei_Dai) · 2018-07-17T04:59:48.869Z · LW(p) · GW(p)
What if during training you can't come close to maxing out regret for the agents that have to be trained with human involvement? That "missing" regret might come due at any time after deployment, and has to be paid with additional oversight/feedback/training data in order for those agents to continue to perform well, right? (In other words, there could be a distributional shift that causes the agents to stop performing well without additional training.) But at that time human feedback may be horribly slow compared to how fast AIs think, thus forcing IDA to either not be competitive with other AIs or to press on without getting enough human feedback to ensure safety.
Am I misunderstanding anything here? (Are you perhaps assuming that we can max out regret during training for the agents that have to be trained with human involvement, but not necessarily for the higher level agents?)
Replies from: paulfchristiano↑ comment by paulfchristiano · 2018-07-17T16:25:13.849Z · LW(p) · GW(p)
That "missing" regret might come due at any time after deployment, and has to be paid with additional oversight/feedback/training data in order for those agents to continue to perform well, right? (In other words, there could be a distributional shift that causes the agents to stop performing well without additional training.)
Yes. (This is true for any ML system, though for an unaligned system the new training data can just come from the world itself.)
Are you perhaps assuming that we can max out regret during training for the agents that have to be trained with human involvement, but not necessarily for the higher level agents?
Yeah, I'm relatively optimistic that it's possible to learn enough from humans that the lower level agent remains universal (+ aligned etc.) on arbitrary distributions. This would probably be the case if you managed to consistently break queries down into simpler pieces until arriving at a very simple queries. And of course it would also be the case if you could eliminate the human from the process altogether.
Failing either of those, it's not clear whether we can do anything formally (vs. expanding the training distribution to cover the kinds of things that look like they might happen, having the human tasks be pretty abstract and independent from details of the situation that change, etc.) I'd still expect to be OK but we'd need to think about it more.
(I still think it's 50%+ that we can reduce the human to small queries or eliminate them altogether, assuming that iterated amplification works at all, so would prefer start with the "does iterated amplification work at all" question.)
↑ comment by Wei Dai (Wei_Dai) · 2018-07-10T21:13:45.707Z · LW(p) · GW(p)
And note that we’ll be able to tell whether this is working, so in practice this is probably something that we can validate empirically---not something where we are going up against adversarial optimization pressure and so need a provable bound.
This is kind of surprising. (I had assumed that you need a provable bound since you talk about guarantees and cite a paper that talks about provable bounds.)
If you have some ML algorithm that only has an exponential provable bound but works well in practice, aren't you worried that you might hit a hard instance of some task in the future that it would perform badly on, or there's a context shift that causes a whole bunch of tasks to become harder to learn? Is the idea to detect that at run time and either pay the increased training cost or switch to another approach if that happens?
If you want to understand these intuitions in detail it likely requires doing the equivalent of a course in learning theory and reading a bunch of papers in the area (which doesn’t sound worth it to me, as a use of your time).
Ok, that's good to know. I think the explanations you gave so far is good enough for my purposes at this point. (You might want to consider posting them somewhere easier to find with a warning similar to this one, so people don't try to figure out what your intuitions are from the OL survey paper like I did.)
↑ comment by paulfchristiano · 2018-07-01T22:42:14.881Z · LW(p) · GW(p)
Eliezer thinks that while corrigibility probably has a core which is of lower algorithmic complexity than all of human value, this core is liable to be very hard to find or reproduce by supervised learning of human-labeled data, because deference is an unusually anti-natural shape for cognition, in a way that a simple utility function would not be an anti-natural shape for cognition. Utility functions have multiple fixpoints requiring the infusion of non-environmental data, our externally desired choice of utility function would be non-natural in that sense, but that's not we're talking about, we're talking about anti-natural behavior.
It seems like there is a basic unclarity/equivocation about what we are trying to do.
From my perspective, there are two interesting questions about corrigibility:
1. Can we find a way to put together multiple agents into a stronger agent, without introducing new incorrigible optimization? This is tricky. I can see why someone might think that this contains the whole of the problem, and I'd be very happy if that turned out to be where our whole disagreement lies.
2. How easy is it to learn to be corrigible? I'd think of this as: if we impose the extra constraint that our model behave corrigibly on all inputs, in addition to solving the object-level task well, how much bigger do we need to make the model?
You seem to mostly be imagining a third category:
3. If you optimize a model to be corrigible in one situation, how likely is it to still be corrigible in a new situation?
I don't care about question 3. It's been more than 4 years since I even seriously discussed the possibility of learning on a mechanism like that, and even at that point it was not a very serious discussion.
Eliezer also tends to be very skeptical of attempts to cross cognitive chasms between A and Z by going through weird recursions and inductive processes that wouldn't work equally well to go directly from A to Z
I totally agree that any safe approach to amplification could probably also be used to construct a (very expensive) safe AI that doesn't use amplification. That's a great reason to think that amplification will be hard. As I said above and have said before, I'd be quite happy if that turned out to be where the whole disagreement lies. My best current hypothesis would be that this is half of our disagreement, with the other half being about whether it's possible to achieve a worst-case guarantee by anything like gradient descent.
(This is similar to the situation with expert iteration / AGZ—in order to make it work you did need to have an algorithm that would play perfect Go in the limit of infinite computation. You still need to use expert iteration to get a good Go algorithm.)
Replies from: zhukeepa, zhukeepa, TurnTrout↑ comment by zhukeepa · 2018-09-14T05:08:16.383Z · LW(p) · GW(p)
I'm currently intuiting that there's a broad basin of "seeming corrigible until you can perform a treacherous turn", but not a broad basin of true corrigibility. If the overseer can robustly detect incorrigible cognition in the distilled agent, I think things may be fine. But if e.g. the overseer is only inspecting the distilled agent's justifications for its behavior, and something like its verbal loop, I don't see how things can work out.
Here are my assumptions underlying this intuition:
1. Past a certain capabilities level, distilled agents can meaningfully be modeled as expected utility maximizers for short-term rewards from its overseer. (This is because expected utility maximization is instrumentally convergent, the same way that believing 51 to be composite is instrumentally convergent, as per Eliezer's comment [LW(p) · GW(p)].)
2. If the agents reason using TDT, the effective utility functions of these act-based agents will optimize for long-term instrumental preferences of their users, because in expectation, adopting this policy raises whatever short-term instrumental reward they'll get.
3. Expected utility maximizers for discounted future rewards of reward signals are hopelessly incorrigible.
4. Agents produced through the distillation process, misaligned in this way, could enter a regime of devoting 99% of their cognition to doing exactly what a corrigible agent would do, and 1% of their cognition to finding strategies for determining how to / whether to execute a treacherous turn.
5. Because of how many ways there are to hide this 1% of cognition, a complete white-box understanding of the agent's cognition is necessary to spot this sort of malign reasoning.
6. We can't achieve this level of understanding via anything like current ML transparency techniques.
Which of these assumptions do you disagree with most? Or do you agree with these assumptions, but feel optimistic that we can get good worst-case guarantees anyway?
2. How easy is it to learn to be corrigible? I'd think of this as: if we impose the extra constraint that our model behave corrigibly on all inputs, in addition to solving the object-level task well, how much bigger do we need to make the model?
My current intuition: for the same reasons it seems really hard to train models that believe 51 is prime while also performing well on object-level tasks, learning to be corrigible seems very difficult.
Replies from: paulfchristiano↑ comment by paulfchristiano · 2018-09-14T13:38:10.821Z · LW(p) · GW(p)
But if e.g. the overseer is only inspecting the distilled agent's justifications for its behavior, and something like its verbal loop, I don't see how things can work out.
You can imagine the overseer as inspecting the agent's actions, and probing the agent's behavior in hypothetical situations. The overseer only "looks inside" the agent's head as a way to help evaluate behavior or identify possibly problematic situations (and there is not necessarily any explicit looking, it could be a weight/activation sharing scheme where the overseer is able to draw on the agent's internal cognitive state in the way that the agent is).
1. Past a certain capabilities level, distilled agents can meaningfully be modeled as expected utility maximizers for short-term rewards from its overseer. (This is because expected utility maximization is instrumentally convergent, the same way that believing 51 to be composite is instrumentally convergent, as per Eliezer's comment [LW(p) · GW(p)].)
Agents can be viewed as expected utility maximizers as soon as their preferences over lotteries become consistent, which probably happens very early in training.
2. If the agents reason using TDT, the effective utility functions of these act-based agents will optimize for long-term instrumental preferences of their users, because in expectation, adopting this policy raises whatever short-term instrumental reward they'll get.
This seems like a non-sequitir / magical thinking. We can be more precise:
- The policy which uses TDT to try to increase its own future reward will be straightforwardly selected against by the outer optimization.
- The inner process may nevertheless use TDT if TDT doesn't diverge from CDT on the training distribution, or it might learn to use TDT but "look nice" so that it doesn't get selected against. From the perspective of my scheme this isn't importantly different from e.g. the case where the agent just has a completely different goal and is waiting for a treacherous turn.
3. Expected utility maximizers for discounted future rewards of reward signals are hopelessly incorrigible.
I certainly agree that if we have an agent that is unaligned (but instrumentally deciding to appear aligned), that will be incorrigible. I don't think that the other stuff about TDT adds anything beyond the usual situation though.
4. Agents produced through the distillation process, misaligned in this way, could enter a regime of devoting 99% of their cognition to doing exactly what a corrigible agent would do, and 1% of their cognition to finding strategies for determining how to / whether to execute a treacherous turn.
Yes, that's always the threat model for adversarial training / verification / interpretability.
5. Because of how many ways there are to hide this 1% of cognition, a complete white-box understanding of the agent's cognition is necessary to spot this sort of malign reasoning.
Of course this is the step where I disagree. We can talk briefly about the possible options (what we care about is some kind of disjunction over these options, along with all other options that we haven't considered):
- Adversarial training. The hope is that you can construct situations that will elicit a treacherous turn. You could do this by a combination of (a) probing a very broad distribution over possible future situations, including every situation you can think of that could appear in the near future, (b) having weight/activation sharing between the agent and the adversary---the hope is that if the agent is able to use that 1% of its brain to think of whether to use a treacherous turn, the adversary could in the same way use that 1% in order to identify situations that might elicit a treacherous turn, (c) allowing the adversary to submit "abstract" attacks that cover a large space of possible situations.
- Verification. Speaking very vaguely, the hope is that instead of merely running the model on individual inputs, you can run it on some kind of relaxed input (e.g. intervals, or putative moments of a distribution over inputs, etc.). Then we verify that not only does the model behave acceptably on actual inputs, it behaves acceptably on these relaxed inputs. I don't have a simple non-technical description of this idea, but I feel relatively confident that the intuition behind your claim is not precise enough to actually rule out this kind of solution.
- Interpretability. The hope is that you can look inside the model and see the "should I do a treacherous turn?" computation. If the agent is doing any optimization to obscure this reasoning from us, then we want to look for that optimization instead. So we are only up against normal gradient descent here. Gradient descent will be pushing against whatever kinds of treacherous turns that can be detected by our machinery. But it will only push for things that improve behavior on the training distribution, so a treacherous turn can only appear where it is coupled with the machinery that is producing good predictions, giving us more traction for interpretability. In general, this looks like a tricky problem, but I don't think you can get nearly as far as saying "a complete white-box understanding of the agent's cognition is necessary to spot this sort of malign reasoning." I think you should generally be skeptical when you have a vague intuitive appeal up against a universal quantifier.
I'm currently intuiting that there's a broad basin of "seeming corrigible until you can perform a treacherous turn", but not a broad basin of true corrigibility
I don't think this argument says very much about whether there is a broad basin of attraction around corrigibility; if your agent waits for a treacherous turn and then behaves badly, that's not in the basin. The point of being a broad basin is that "executes a treacherous turn" now needs to be a discrete thing to kick you out of the basin, it can't be an infinitesimal degradation of performance. But we still have the question: even if "bad behavior" is a discrete event, can we actually use techniques for optimizing worst-case performance to avoid it?
Replies from: zhukeepa↑ comment by zhukeepa · 2018-09-16T17:09:37.555Z · LW(p) · GW(p)
I'm still confused about how each of the approaches would prevent us from eventually creating agents that spend 99% of their cognition acting corrigibly, while spending a well-hidden 1% of its cognition trying to sniff out whether it's in the test distribution, and executing a treacherous turn if so. The way I understand your summaries:
- Adversarial training makes it harder for the malignant 1% to do anything dangerous, since it makes it harder to tell whether it's in the test distribution. But it does little to prevent a malignant 1% from very conservatively trying (and usually failing) to ascertain whether it's in the test distribution.
- Interpretability makes it harder for the malignant 1% to be hidden, but doesn't prevent malignant cognition it can't detect. (My reading of "Gradient descent will be pushing against whatever kinds of treacherous turns that can be detected by our machinery. But it will only push for things that improve behavior on the training distribution, so a treacherous turn can only appear where it is coupled with the machinery that is producing good predictions, giving us more traction for interpretability." is completely consistent with this.)
I didn't understand what your wrote about verification well enough to have anything to say.
It does prima facie seem that an agent spending 100% of its cognition being competent and corrigible achieves higher reward than an agent that only spends 99% of its cognition being competent and corrigible, and 1% of its cognition trying (and almost always failing) to see if it's in the test distribution. Is your model that gradient descent will favor the former agent over the latter agent, making the 99%/1% agent unlikely to arise (and perhaps quantifiably so)?
The inner process may nevertheless use TDT if TDT doesn't diverge from CDT on the training distribution, or it might learn to use TDT but "look nice" so that it doesn't get selected against.
This was what I was intending to convey in assumption 3.
Replies from: paulfchristiano↑ comment by paulfchristiano · 2018-09-18T15:22:18.203Z · LW(p) · GW(p)
Adversarial training makes it harder for the malignant 1% to do anything dangerous, since it makes it harder to tell whether it's in the test distribution. But it does little to prevent a malignant 1% from very conservatively trying (and usually failing) to ascertain whether it's in the test distribution.
The question is roughly: can you be good enough at finding problematic inputs that, if a problematic input exists, it is much more likely to be found during the adversarial training step than at deployment time? If so, then a model with high reward probably won't do anything bad at deployment time (exactly how good you need to be depends on exactly how overwhelmingly strong the prior for malign behavior is).
This likely involves introducing some asymmetry between the adversary's task and the test time task. Examples of possible asymmetries including allowing the adversary to produce different kinds of inputs (e.g. setting activations arbitrarily), letting the adversary poke around inside the model to find bad cases (e.g. doing gradient descent, combining with interpretability, or backwards chaining through the model), or giving the adversary a much weaker job (e.g. only asking them to produce an input on which the model thinks anything remotely suspicious as judged by interpretability, or finding any conditions under which the model fails to instantly shut down a malicious scheme that it previously initiated).
(I don't know what "prevent" means here.)
Interpretability makes it harder for the malignant 1% to be hidden, but doesn't prevent malignant cognition it can't detect.
I agree that if your interpretability doesn't allow you to detect the agent thinking "Am I on the training distribution?" then it won't work. So then the question is: can interpretability be strong enough that if the model is thinking something catastrophically dangerous, you have a very good chance of noticing it? (Again, how good you need to be depends on how overwhelming is the prior for bad behavior.)
It does prima facie seem that an agent spending 100% of its cognition being competent and corrigible achieves higher reward than an agent that only spends 99% of its cognition being competent and corrigible, and 1% of its cognition trying (and almost always failing) to see if it's in the test distribution.
I don't think this fact makes bad behavior unlikely on their own. But interpretability or adversarial training could exploit the fact that your model is trained by gradient descent. Regularization can strengthen the basic observation that a malign failure needs to use parts of the model that are exercised during training, making it easier to identify possible malign failures by examining behavior on the training distribution. We can potentially exploit the fact that gradient descent updates the model continuously.
I'm still confused about how each of the approaches would prevent us from eventually creating agents that spend 99% of their cognition acting corrigibly, while spending a well-hidden 1% of its cognition trying to sniff out whether it's in the test distribution, and executing a treacherous turn if so.
("Well-hidden" here means "well-hidden by gradient descent," not "well-hidden by the agent," right?)
↑ comment by zhukeepa · 2018-07-03T06:51:43.142Z · LW(p) · GW(p)
1. If at the time of implementing ALBA, our conceptual understanding of corrigibility is the same as it is today, how doomed would you feel?
2. How are you imagining imposing an extra constraint that our model behave corrigibly on all inputs?
3. My current best guess is that your model of how to achieve corrigibility is to train the AI on a bunch of carefully labeled examples of corrigible behavior. To what extent is this accurate?
Replies from: zhukeepa↑ comment by zhukeepa · 2018-07-06T01:07:54.852Z · LW(p) · GW(p)
If we view the US government as a single entity, it's not clear that it would make sense to describe it as aligned with itself, under your notion of alignment. If we consider an extremely akrasiatic human, it's not clear that it would make sense to describe him as aligned with himself. The more agenty a human is, the more it seems to make sense to describe him as being aligned with himself.
If an AI assistant has a perfect model of what its operator approves of and only acts according to that model, it seems like it should qualify as aligned. But if the operator is very akrasiatic, should this AI still qualify as being aligned with the operator?
It seems to me that clear conceptual understandings of alignment, corrigibility, and benignity depend critically on a clear conceptual understanding of agency, which suggests a few things:
- Significant conceptual understanding of corrigibility is at least partially blocked on conceptual progess on HRAD. (Unless you think the relevant notions of agency can mostly be formalized with ideas outside of HRAD? Or that conceptual understandings of agency are mostly irrelevant for conceptual understandings of corrigibility?)
- Unless we have strong reasons to think we can impart the relevant notions of agency via labeled training data, we shouldn't expect to be able to adequately impart corrigibility via labeled training data.
- Without a clear conceptual notion of agency, we won't have a clear enough concept of alignment or corrigibility we can use to make worst-case bounds.
I think a lot of folks who are confused about your claims about corrigibility share my intuitions around the nature of corrigibility / the difficulty of learning corrigibility from labeled data, and I think it would shed a lot of light if you shared more of your own views on this.
Replies from: paulfchristiano↑ comment by paulfchristiano · 2018-07-06T16:17:48.348Z · LW(p) · GW(p)
I don't think a person can be described very precisely as having values, you need to do some work to get out something value-shaped. The easiest way is to combine a person with a deliberative process, and then make some assumption about the reflective equilibrium (e.g. that it's rational). You will get different values depending on the choice of deliberative process, e.g. if I deliberate by writing I will generally get somewhat different values than if I deliberate by talking to myself. This path-dependence is starkest at the beginning and I expect it to decay towards 0. I don't think that the difference between various forms of deliberation is likely to be too important, though prima facie it certainly could be.
Similarly for a government, there are lots of extrapolation procedures you can use and they will generally result in different values. I think we should be skeptical of forms of value learning that look like they make sense for people but not for groups of people. (That said, groups of people seem likely to have more path-dependence, so e.g. the choice of deliberative process may be more important for groups than individuals, and more generally individuals and groups can differ in degree if not in kind.)
On this perspective, (a) a human or government is not yet the kind of thing you can be aligned with, in my definition this was hidden in the word "wants," which was maybe bad form but I was OK with because most people who think about this topic already appreciate the complexity of "wants," (b) a human is unlikely to be aligned with anything, in the same sense that a pair of people with different values aren't aligned with anything until they are sufficiently well-coordinated.
I don't think that you would need to describe agency in order to build a corrigible AI. As an analogy: if you want to build an object that will be pushed in the direction the wind, you don't need to give the object a definition of "wind," and you don't even need to have a complete definition of wind yourself. It's sufficient for the person designing/analyzing the object to know enough facts about the wind that they can design/analyze sails.
↑ comment by TurnTrout · 2022-09-20T06:48:08.344Z · LW(p) · GW(p)
You seem to mostly be imagining a third category:
3. If you optimize a model to be corrigible in one situation, how likely is it to still be corrigible in a new situation?
I don't care about question 3. It's been more than 4 years since I even seriously discussed the possibility of learning on a mechanism like that, and even at that point it was not a very serious discussion.
"Don't care" is quite strong. If you still hold this view -- why don't you care about 3? (Curious to hear from other people who basically don't care about 3, either.)
Replies from: paulfchristiano↑ comment by paulfchristiano · 2022-09-20T17:20:11.687Z · LW(p) · GW(p)
Yeah, "don't care" is much too strong. This comment was just meant in the context of the current discussion. I could instead say:
The kind of alignment agenda that I'm working on, and the one we're discussing here, is not relying on this kind of generalization of corrigibility. This kind of generalization isn't why we are talking about corrigibility.
However, I agree that there are lots of approaches to building AI that rely on some kind of generalization of corrigibility, and that studying those is interesting and I do care about how that goes.
In the context of this discussion I also would have said that I don't care about whether honesty generalizes. But that's also something I do care about even though it's not particularly relevant to this agenda (because the agenda is attempting to solve alignment under considerably more pessimistic assumptions).
↑ comment by Ben Pace (Benito) · 2018-07-06T00:13:25.834Z · LW(p) · GW(p)
It would be helpful to know to what extent Paul feels like he endorses the FAQ here... I don't want to invest huge amounts arguing with this until I know to what extent Paul agrees with either the FAQ, or that this sounds like a plausible locus of disagreement.
Note that the second paragraph of zhukeepa's post now contains this:
ETA: Paul does not have major disagreements with anything expressed in this FAQ. There are many small points he might have expressed differently, but he endorses this as a reasonable representation of his views. This is in contrast with previous drafts of this FAQ, which did contain serious errors he asked to have corrected.
↑ comment by Thomas Kwa (thomas-kwa) · 2022-08-28T04:25:39.577Z · LW(p) · GW(p)
The central reasoning behind this intuition of anti-naturalness is roughly, "Non-deference converges really hard as a consequence of almost any detailed shape that cognition can take", with a side order of "categories over behavior that don't simply reduce to utility functions or meta-utility functions are hard to make robustly scalable".
What's the type signature of the utility functions here?
↑ comment by paulfchristiano · 2018-07-01T22:45:50.157Z · LW(p) · GW(p)
If you can locally inspect cognitive steps for properties that globally add to intelligence, corrigibility, and alignment, you're done; you've solved the AGI alignment problem and you can just apply the same knowledge to directly build an aligned corrigible intelligence.
I agree with the first part of this. The second isn't really true because the resulting AI might be very inefficient (e.g. suppose you could tell which cognitive strategies are safe but not which are effective).
Overall I don't think it's likely to be useful to talk about this topic until having much more clarity on other stuff (I think this section is responding to a misreading of my proposal).
This stuff about inspecting thoughts fits into the picture when you say: "But even if you are willing to spend a ton of time looking at a particular decision, how could you tell if it was optimized to cause a catastrophic failure?" and I say "if the AI has learned how to cause a catastrophic failure, we can hope to set up the oversight process so it's not that much harder to explain how it's causing a catastrophic failure" and then you say "I doubt it" and I say "well that's the hope, it's complicated" and then we discuss whether that problem is actually soluble.
And that does have a bunch of hard steps, especially the one where we need to be able to open up some complex model that our AI formed of the world in order to justify a claim about why some action is catastrophic.
↑ comment by TurnTrout · 2022-09-20T06:59:03.208Z · LW(p) · GW(p)
A dangerous intuition pump here would be something like, "If you take a human who was trained really hard in childhood to have faith in God and show epistemic deference to the Bible, and inspecting the internal contents of their thought at age 20 showed that they still had great faith, if you kept amping up that human's intelligence their epistemology would at some point explode"
Yes, a value grounded in a factual error will get blown up by better epistemics, just as "be uncertain about the human's goals" will get blown up by your beliefs getting their entropy deflated to zero by the good ole process we call "learning about reality." But insofar as corrigibility is "chill out and just do some good stuff without contorting 4D spacetime into the perfect shape or whatever", there are versions of that which don't automatically get blown up by reality when you get smarter. As far as I can tell, some humans are living embodiments of the latter. I have some "benevolent libertarian" values pushing me Pareto improving everyone's resource counts and letting them do as they will with their compute budgets. What's supposed to blow that one up?
that in real life if we were faced with a very bizarre alien we would be unlikely to want to defer to it. Our lack of scalable desire to defer in all ways to an extremely bizarre alien that ate babies, is not something that you could fix just by giving us an emotion of great deference or respect toward that very bizarre alien. We would have our own thought processes that were unlike its thought processes, and if we scaled up our intelligence and reflection to further see the consequences implied by our own thought processes, they wouldn't imply deference to the alien even if we had great respect toward it and had been trained hard in childhood to act corrigibly towards it.
This paragraph as a whole seems to make a lot of unsupported-to-me claims and seemingly equivocates between the two bolded claims, which are quite different. The first is that we (as adult humans with relatively well-entrenched values) would not want to defer to a strange alien. I agree.
The second is that we wouldn't want to defer "even if we had great respect toward it and had been trained hard in childhood to act corrigibly towards it." I don't see why you believe that. Perhaps if we were otherwise socialized normally, we would end up unendorsing that value and not deferring? But I conjecture if that a person weren't raised with normal cultural influences, you could probably brainwash them into being aligned baby-eaters via reward shaping via brain stimulation reward.
Acting corrigibly towards a baby-eating virtue ethicist when you are a utilitarian is an equally weird shape for a decision theory.
A utilitarian? Like, as Thomas Kwa asked, what are the type signatures of the utility functions you're imagining the AI to have? Your comment makes more sense to me if I imagine the utility function is computed over "conventional" objects-of-value [LW(p) · GW(p)].
comment by evhub · 2019-11-22T08:14:19.162Z · LW(p) · GW(p)
Reading Alex Zhu's Paul agenda FAQ was the first time I felt like I understood Paul's agenda in its entirety as opposed to only understanding individual bits and pieces. I think this FAQ was a major contributing factor in me eventually coming to work on Paul's agenda.
comment by jessicata (jessica.liu.taylor) · 2018-07-01T09:16:59.143Z · LW(p) · GW(p)
On the other hand, to the extent that humans care about these things and could make them happen, this agenda lets us build AGI assistants that can substantially assist humans achieve these things.
My understanding is that Paul is aiming for something much more ambitious than "substantially assist humans". Specifically, he is trying to make aligned AI systems that are at least 90% as efficient at accomplishing arbitrary objectives as competing unaligned AI systems. See: Scalable AI Control
comment by Eli Tyre (elityre) · 2019-12-02T04:39:53.234Z · LW(p) · GW(p)
I think this was one of the big, public, steps in clarifying what Paul is talking about.
comment by juliawise · 2018-07-11T20:15:24.549Z · LW(p) · GW(p)
It seems odd to write a post about someone with a common first name and not mention their last name until the acknowledgement at the end of the post.
Replies from: Raemon, Benito↑ comment by Ben Pace (Benito) · 2018-07-11T20:56:57.480Z · LW(p) · GW(p)
I just poked Alex and he changed the first line ;-)
comment by Gordon Seidoh Worley (gworley) · 2018-07-10T19:41:45.003Z · LW(p) · GW(p)
I think the point about "transparent cognition" is key, and without it we won't be able to build alignable agents. Glad to see this is getting more attention.
comment by John_Maxwell (John_Maxwell_IV) · 2018-12-13T17:58:49.638Z · LW(p) · GW(p)
[My friend suggested that I read this for a discussion we were going to have. Originally I was going to write up some thoughts on it in an email to him, but I decided to make it a comment in case having it be publicly available generates value for others. But I'm not going to spend time polishing it since this post is 5 months old and I don't expect many people to see it. Alex, if you read this, please tell me if reading it felt more effective than having an in-person discussion.]
OK, but doesn't this only incentivize it to appear like it's doing what the operator wants? Couldn’t it optimize for hijacking its reward signal, while seeming to act in ways that humans are happy with?
We’re not just training the agent to take good actions. We’re also training it to comprehensibly answer questions about why it took the actions it took, to arbitrary levels of detail. (Imagine a meticulous boss grilling an employee about a report he put together, or a tax auditor grilling a corporation about the minutiae of its expenses.) We ensure alignment by randomly performing thorough evaluations of its justifications for its actions, and punishing it severely if any of those justifications seem subversive. To the extent we trust these justifications to accurately reflect the agent’s cognition, we can trust the agent to not act subversively (and thus be aligned).
I think this is too pessimistic. "Reward signal" is slipping in some assumptions about the system's reward architecture. Why is it that I don't "hijack my reward signal" by asking a neurosurgeon to stimulate my pleasure center? Because when I simulate the effect of that using my current reward architecture, the simulation is unfavorable.
Instead of auditing the cognition, I'd prefer the system have correctly calibrated uncertainty and ask humans for clarification regarding specific data points in order to learn stuff (active learning).
Re: "Why should we expect the agent’s answers to correspond to its cognition at all?" I like Cynthia Rudin's comparison of explainable ML and interpretable ML. A system where the objective function has been changed in order to favor simplicity/interpretability (see e.g. sparse representation theory?) seems more robust with fewer moving parts, and probably will also be a more effective ML algorithm since simple models generalize better.
In other words, the amplified agent randomly “audits” the distilled agent, and punishes the distilled agent very harshly if it fails the audit. Though the distilled agent knows that it might be able to deceive its supervisor when it isn’t audited, it’s so scared of the outcome where it tries to do that and gets audited that it doesn’t even want to try. (Even if you were 99% confident that you could get away with tax evasion, you wouldn’t want to try if you knew the government tortures and murders the families of the tax evaders they catch.)
This paragraph seems unnecessarily anthropomorphic. Why not just say: The distilled agent only runs computations if it is at least 99.9% confident that the computation is aligned. Or: To determine whether to run a particular computation, our software uses the following expected value formula:
probability_computation_is_malign * malign_penalty + probability_computation_is_not_malign * benefit_conditional_on_computation_not_being_malign
(When we talk about our programs "wanting" to do various things, we are anthropomorphizing. For example, I could talk about a single-page Javascript app and say: when the internet is slow, the program "wants" to present a good interface to the user even without being able to gather data from the server. In the same way, I could say that a friendly AI "wants" to be aligned. The alignment problem is not due to a lack of desire on the part of the AI to be aligned. The alignment problem is due to the AI having mistaken beliefs about what alignment is.)
I like the section on "epistemically corrigible humans". I've spent a fair amount of time thinking about "epistemically corrigible" meta-learning (no agent--just thinking in terms of the traditional supervised/unsupervised learning paradigms, and just trying to learn the truth, not be particularly helpful--although if you have a learning algorithm that's really good at finding the truth, one particular thing you could use it to find the truth about is which actions humans approve of). I'm now reasonably confident that it's doable, and deprioritizing this a little bit in order to figure out if there's a more important bottleneck in my vision of how FAI could work elsewhere.
"Subproblems of “worst-case guarantees” include ensuring that ML systems are robust to distributional shift and adversarial inputs, which are also broad open questions in ML, and which might require substantial progress on MIRI-style research to articulate and prove formal bounds."
By "MIRI-style research" do we mean HRAD? I thought HRAD was notable because it did not attack machine learning problems like distributional shift, adversarial inputs, etc.
Overall, I think Paul's agenda makes AI alignment a lot harder than it needs to be, and his solution sounds a lot more complicated than I think an FAI needs to be. I think "Deep reinforcement learning from human preferences" is already on the right track, and I don't understand why we need all this additional complexity in order to learn corrigibility and stuff. Complexity matters because an overcomplicated solution is more likely to have bugs. I think instead of overbuilding for intuitions based on anthropomorphism, we should work harder to clarify exactly what the failure modes could be for AI and focus more on finding the simplest solution that is not susceptible to any known failure modes. (The best way to make a solution simple is to kill multiple birds with one stone, so by gathering stones that are capable of killing multiple known birds, you maximize the probability that those stones also kill unknown birds.)
Also, I have an intuition that any approach to FAI that is appears overly customized for FAI is going to be the wrong one. For example, I feel "epistemic corrigibility" is a better problem to study than "corrigibility" because it is a more theoretically pure problem--the notion of truth (beliefs that make correct predictions) is far easier than the notion of human values. (And once you have epistemic corrigibility, I think it's easy to use that to create a system which is corrigibility in the sense we need. And epistemic corrigibility kinda a reframed version of what mainstream ML researchers already look for when they consider the merits of various ML algorithms.)
comment by Wei Dai (Wei_Dai) · 2018-07-07T03:23:34.289Z · LW(p) · GW(p)
This way, every time we’re training a distilled agent, we train it to want to clarify with its overseer (i.e., us assisted with a team of corrigible assistants) whenever it’s uncertain about what we would approve of. Our corrigible assistants either answer the question confidently, or clarify with us if it’s uncertain about its answer.
I'm not sure if the distilled agent is supposed to query the overseer at run time, and whether this is supposed to be a primary or backup safety mechanism (i.e., if the distilled agent is supposed to be safe/aligned even if the overseer isn't available). I haven't seen it stated clearly anywhere, and Paul didn't answer a direct question that I asked [LW(p) · GW(p)] about this. Do you have a citation for the answer that you're giving here?
1.1.4: Why should we expect the agent’s answers to correspond to its cognition at all?
We don’t actually have any guarantees that it does, but giving honest answers is probably the easiest way for the agent to maximize its reward.
We also need an independent way to interpret the agent's cognition and check whether it matches with the answers, right? Otherwise, I don't see how we could detect whether the AI is actually a daemon that's optimizing for some unaligned goal and merely biding its time until it can execute a treacherous turn. (If you ask it any questions, it's going to emulate how an aligned AI would answer, so you can't distinguish between them without some independent way of checking the answers.)
Replies from: paulfchristiano↑ comment by paulfchristiano · 2018-07-07T06:26:27.526Z · LW(p) · GW(p)
I'm not sure if the distilled agent is supposed to query the overseer at run time, and whether this is supposed to be a primary or backup safety mechanism
If the overseer isn't available, the agent may need to act without querying them. The goal is just to produce an agent that tries to do the right thing in light of that uncertainty. To argue that we get a good outcome, we need to make some argument about its competence / the difficulty of the situation, and having query access to the overseer can make the problem easier.
Otherwise, I don't see how we could detect whether the AI is actually a daemon that's optimizing for some unaligned goal and merely biding its time until it can execute a treacherous turn.
Here are my views on this problem.
The mechanism Alex describes is only intended to be used for evaluating proposed actions.
comment by Raemon · 2018-07-05T21:03:25.346Z · LW(p) · GW(p)
Curating (alongside Zhukeepa's Zero Shot Reasoning [LW · GW] post)
We're a bit behind on other tasks and still don't have time to write up formal curation notices, but wanted to at least keep the curated section moving.
comment by cousin_it · 2018-07-03T14:31:18.437Z · LW(p) · GW(p)
It seems to me that uploading tech would be a solution to AI risk, because a trusted team of uploads running at high speed can stop other AIs from arising and figure out the next steps. The first stage assistants proposed by Paul's plan already require tech that's pretty close to uploading tech, and will be very useful for developing uploading tech even without the later recursive stages. So the window of usefulness for the first stage seems small, and the window of usefulness for the later recursive stages seems even smaller. Am I missing something?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2018-07-03T15:31:45.035Z · LW(p) · GW(p)
I don't think it requires anything like uploading tech. It just involves training a model using RL (or RL+imitation learning), that's something we can do today.
Replies from: cousin_it↑ comment by cousin_it · 2018-07-03T15:41:16.871Z · LW(p) · GW(p)
I thought your first stage assistants were supposed to be as good as humans at many tasks, including answering questions about their own thoughts. Is that much easier than imitating a specific human?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2018-07-03T18:29:03.181Z · LW(p) · GW(p)
There is no requirement about the first stage assistant being human-level. I expect they will be superhuman in some respects and subhuman in others, just like existing AI.
Replies from: cousin_it↑ comment by cousin_it · 2018-07-03T19:32:57.537Z · LW(p) · GW(p)
From Ajeya Cotra's post:
The Distill procedure robustly preserves alignment: Given an aligned agent H we can use narrow safe learning techniques to train a much faster agent A which behaves as H would have behaved, without introducing any misaligned optimization or losing important aspects of what H values.
This seems to say every step of IDA, including the first, requires a Distill procedure that's at least strong enough to upload a human. Maybe I'm looking at the wrong post?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2018-07-04T02:50:39.104Z · LW(p) · GW(p)
I agree that "behaves as H would have behaved" seems wrong/sloppy.Iit's referring to the "narrow" end of the spectrum introduced in that post (containing imitation learning, narrow RL, narrow IRL). So H is a rough upper bound on its intelligence.
The assumption is "The Distill procedure robustly preserves alignment." You may think that's only possible with an exact imitation, in which case I agree that you will never get off the ground.
In Ajeya's defense, people do often use shorthand like describing an imitation learner's behavior as "doing what the expert would do" without meaning to imply that it's a perfect imitation. I agree in this case it's unusually confusing.
Replies from: cousin_it↑ comment by cousin_it · 2018-07-04T06:59:10.749Z · LW(p) · GW(p)
It seems to me that doing that without "losing important aspects of what H values" would lead to something human-like anyway (though maybe not an exact imitation of H), because of complexity of value. Basically after the first step you get human-like entities running on computers. Then they can prevent AI risk and carefully figure out what to do next, same as a team of uploads. So the first step looks strategically similar to uploading, and solving stability for further steps might be unnecessary.
Replies from: paulfchristiano↑ comment by paulfchristiano · 2018-07-06T16:23:19.717Z · LW(p) · GW(p)
The resulting agent is supposed to be trying to help H get what its wants, but won't generally encode most of H's values directly (it will only encode them indirectly as "what the operator wants").
I agree that Ajeya's description in that paragraph is problematic (though I think the descriptions in the body of the post were mostly fine), will probably correct it.
Replies from: cousin_itcomment by Richard_Kennaway · 2018-07-03T09:03:47.124Z · LW(p) · GW(p)
1.1.3: How do we train it to answer questions comprehensively?
Reward it for doing so, and punish it for failing to do so.
This reward function is, by hypothesis, uncomputable. If we do not understand what it is doing without an explanation, how can we judge the correctness of its explanation? A resolution of that might hinge on the distinction in computational complexity between searching for an answer to a problem and verifying one, but instead:
Imagine being a meticulous boss who asks his employee to put together a report. Imagine grilling him about the report, and punishing him every time he fails to answer your questions clearly enough or at a satisfactory level of detail, in addition to punishing him for low-quality reports. If your employee is capable enough, he’ll eventually learn to produce high-quality reports and answer questions satisfactorily when you grill him.
This proposal judges explanations by plausibility and articulateness. Truthfulness is only incidentally relevant and will be Goodharted away.
Replies from: zhukeepa, paulfchristiano↑ comment by zhukeepa · 2018-07-03T18:28:33.414Z · LW(p) · GW(p)
This proposal judges explanations by plausibility and articulateness. Truthfulness is only incidentally relevant and will be Goodharted away.
Keep in mind that the overseer (two steps forward) is always far more powerful than the agent we're distilling (one step back), is trained to not Goodhart, is training the new agent to not Goodhart (this is largely my interpretation of what corrigibility gets you), and is explicitly searching for ways in which the new agent may want to Goodhart.
Replies from: Vaniver↑ comment by Vaniver · 2018-07-03T20:03:18.243Z · LW(p) · GW(p)
Keep in mind that the overseer (two steps forward) is always far more powerful than the agent we're distilling (one step back), is trained to not Goodhart, is training the new agent to not Goodhart (this is largely my interpretation of what corrigibility gets you), and is explicitly searching for ways in which the new agent may want to Goodhart.
Well, but Goodhart lurks in the soul of all of us; the question here is something like "what needs to be true about the overseer such that it does not Goodhart (and can recognize it in others)?"
Replies from: zhukeepa↑ comment by paulfchristiano · 2018-07-03T15:34:13.755Z · LW(p) · GW(p)
The proposed solution relies on the same thing as the rest of the scheme: that you can evaluate answers to a hard question Q if you already know the answers to some set of easier subquestions Qi. Then induction until you get to simple enough questions.
comment by riceissa · 2019-08-30T05:28:42.345Z · LW(p) · GW(p)
I'm still confused about the difference between HCH and the amplification step of IDA. Initially I thought that the difference is that with HCH, the assistants are other copies of the human, whereas in IDA the assistants are the distilled agents from the previous step (whose capabilities will be sub-human in early stages of IDA and super-human in later stages). However, this FAQ says "HCHs should not be visualized as having humans in the box."
My next guess is that while HCH allows the recursion for spawning new assistants to be arbitrarily deep, the amplification step of IDA only allows a single level of spawning (i.e. the human can spawn new assistants, but the assistants themselves cannot make new assistants). Ajeya Cotra's post on IDA talks about the human making calls to the assistant, but not about the assistants making further calls to other assistants, so it seems plausible to me that the recursive nature of HCH is the difference. Can someone who understands HCH/IDA confirm that this is a difference and/or name other differences?