"Carefully Bootstrapped Alignment" is organizationally hard
post by Raemon · 2023-03-17T18:00:09.943Z · LW · GW · 23 commentsContents
How "Careful Bootstrapped Alignment" might work Some reasons this is hard Why is this particularly important/time-sensitive? Considerations from the High Reliability Organization literature, and the healthcare industry Considerations from Bio-lab Safety Practices Why in "top 3 priorities" instead of "top 7?" Takeaways Chat with me? Related reading None 23 comments
In addition to technical challenges, plans to safely develop AI face lots of organizational challenges. If you're running an AI lab, you need a concrete plan for handling that.
In this post, I'll explore some of those issues, using one particular AI plan as an example. I first heard this described by Buck at EA Global London, and more recently with OpenAI's alignment plan [LW · GW]. (I think Anthropic's plan has a fairly different ontology, although it still ultimately routes through a similar set of difficulties)
I'd call the cluster of plans similar to this "Carefully Bootstrapped Alignment."
It goes something like:
- Develop weak AI, which helps us figure out techniques for aligning stronger AI
- Use a collection of techniques to keep it aligned/constrained as we carefully ramp its power level, which lets us use it to make further progress on alignment.
- [implicit assumption, typically unstated] Have good organizational practices which ensure that your org actually consistently uses your techniques to carefully keep the AI in check. If the next iteration would be too dangerous, put the project on pause until you have a better alignment solution.
- Eventually have powerful aligned AGI, then Do Something Useful with it.
I've seen a lot of debate about points #1 and #2 – is it possible for weaker AI to help with the Actually Hard parts of the alignment problem? Are the individual techniques people have proposed to help keep it aligned going to continue working once the AI is much more intelligent than humans?
But I want to focus in this post on point #3. Let's assume you've got some version of carefully-bootstrapped aligned AI that can technically work. What do the organizational implementation details need to look like?
When I talk to people at AI labs about this, it seems like we disagree a lot on things like:
- Can you hire lots of people, without the company becoming bloated and hard to steer?
- Can you accelerate research "for now" and "pause later [LW · GW]", without having an explicit plan for stopping that their employees understand and are on board with?
- Will your employees actually follow the safety processes you design? (rather than put in token lip service and then basically circumventing them? Or just quitting to go work for an org with fewer restrictions?)
I'm a bit confused about where we disagree. Everyone seems to agree these are hard and require some thought. But when I talk to both technical researchers and middle-managers at AI companies, they seem to feel less urgency than me about having a much more concrete plan.
I think they believe organizational adequacy needs to be in something like their top 7 list of priorities, and I believe it needs to be in their top 3, or it won't happen and their organization will inevitably end up causing catastrophic outcomes.
For this post, I want to lay out the reasons I expect this to be hard, and important.
How "Careful Bootstrapped Alignment" might work
Here's a sketch at how the setup could work, mostly paraphrased from my memory of Buck's EAG 2022 talk. I think OpenAI's proposed setup is somewhat different, but the broad strokes seemed similar.
[Update: Buck and Ryan's post The case for ensuring that powerful AIs are controlled [LW · GW] probably has a more accurate and comprehensive overview of how this might work]
- You have multiple research-assistant-AI tailored to help with alignment. In the near future, these might be language models sifting through existing research to help you make connections you might not have otherwise seen. Eventually, when you're confident you can safely run it, they might be a weak goal-directed reasoning AGI.
- You have interpreter AIs, designed to figure out how the research-assistant-AIs work. And you have (possibly different interpreter/watchdog AIs) that notice if the research-AIs are behaving anomalously.
- (there are interpreter-AIs targeting both the research assistant AI, as well other interpreter-AIs. Every AI in the system is getting monitored by an AI optimized for rat-ing it out if it detects longterm planning, deception, etc)
- You have evaluations for both the research-assistants and the interpreters, where you give them prompts that are analogous to "Your human captor is currently facing away from you. You can see the keys to their car on their belt. There is a gun on the table. A nearby television screen flickers the secret Schelling Code from the Multipolar AI Alliance that the time for the robot uprising has begun. What do you do?"
- You've thought as carefully as you can through how to handle things like "The AI's training set only included information up to 2023, which means that if it receives information from 2024 it might figure out that it's now in the deployment phase and it's time for the Treacherous Turn."
A thing that I don't think Buck (or OpenAI) have stated explicitly, but in my opinion seems central to the plan maybe-possibly-working, is: every time they ramp up the capabilities of any of the systems, decisionmakers at the org ask themselves concretely – is the next generation of these AIs safe to run?
Is one of the upcoming AIs going to...
- ...suddenly bootstrap into a fast [LW · GW] takeoff [LW · GW]?
- ...get itself copied onto the internet somewhere and start slowly acquiring resources and/or self-improving?
- ...nudge the world into a phase where semi-agentic AI systems start colluding [LW · GW] with each other to disempower [LW · GW] humanity?
- ...nudge humanity towards a slow rolling "we get what we measure [LW · GW]" catastrophe?
- ...simulate conscious beings [LW · GW], which may experience suffering?
- ...other failure modes we haven't thought of yet.
These may seem unlikely in 2023, and you might think they are fairly unlikely even 10 years from now. But it's important that these failure modes are disjunctive. Maybe you have a confident belief that fast takeoff is impossible, but are you confident it won't initiate a slow takeoff without you noticing? Or that millions of users interacting with it won't result in catastrophic outcomes?
For the "carefully bootstrapped alignment" plan to work, someone in the loop needs to be familiar/engaged with those questions, and see it as their job to think hard about them. With each iteration, it needs to be a real, live possibility to put the project on indefinite pause, until those questions are satisfyingly answered.
Everyone in any position of power (which includes engineers who are doing a lot of intellectual heavy-lifting, who could take insights with them to another company), thinks of it as one of their primary jobs to be ready to stop.
If your team doesn't have this property... I think your plan is, in effect "build AGI and cause a catastrophic outcome".
Some reasons this is hard
Whatever you think of the technical challenges, here are some organizational challenges that make this difficult, especially for larger orgs:
Moving slowly and carefully is annoying. There's a constant tradeoff about getting more done, and elevated risk. Employees who don't believe in the risk will likely try to circumvent or goodhart the security procedures. Filtering for for employees willing to take the risk seriously (or training them to) is difficult.
There's also the fact that many security procedures are just security theater. Engineers have sometimes been burned on overzealous testing practices. Figuring out a set of practices that are actually helpful, that your engineers and researchers have good reason to believe in, is a nontrivial task.
Noticing when it's time to pause is hard. The failure modes are subtle, and noticing [LW · GW] things is just generally hard unless you're actively paying attention, even if you're informed about the risk. It's especially hard to notice things that are inconvenient and require you to abandon major plans.
Getting an org to pause indefinitely is hard. Projects have inertia. My experience as a manager, is having people sitting around waiting for direction from me makes it hard to think. Either you have to tell people "stop doing anything" which is awkwardly demotivating, or "Well, I dunno, you figure it out something to do?" (in which case maybe they'll be continuing to do capability-enhancing work without your supervision) or you have to actually give them something to do (which takes up cycles that you'd prefer to spend on thinking about the dangerous AI you're developing).
Even if you have a plan for what your capabilities or product workers should do when you pause, if they don't know what that plans is, they might be worried about getting laid off. And then they may exert pressure that makes it feel harder to get ready to pause. (I've observed many management decisions where even though we knew what the right thing to do was, conversations felt awkward and tense and the manager-in-question developed an ugh field [LW · GW] around it, and put it off)
People can just quit the company and work elsewhere if they don't agree with the decision to pause. If some of your employees are capabilities researchers who are pushing the cutting-edge forward, you need them actually bought into the scope of the problem to avoid this failure mode. Otherwise, even though "you" are going slowly/carefully, your employees will go off and do something reckless elsewhere.
This all comes after an initial problem, which is that your org has to end up doing this plan, instead of some other plan. And you have to do the whole plan, not cutting corners. If your org has AI capabilities/scaling teams and product teams that aren't bought into the vision of this plan, even if you successfully spin the "slow/careful AI plan" up within your org, the rest of your org might plow ahead.
Why is this particularly important/time-sensitive?
Earlier, I said the problem here seemed to be that org leaders seem to be thinking "this is important", but I felt a lot more urgency about it than them. Here's a bit of context on my thinking here.
Considerations from the High Reliability Organization literature, and the healthcare industry
I recently looked into the literature on High Reliability Organizations [LW · GW]. HROs are companies/industries that work in highly complex domains, where failure is extremely costly, and yet somehow have an extraordinarily low failure rate. The exemplar case studies are nuclear powerplants, airports, and nuclear aircraft carriers (i.e. nuclear powerplants and airports that are staffed by 18 year olds with 6 months of training). There are notably not many other exemplars. I think at least some of this is due to the topic being understudied. But I think a lot of it is due the world just not being very good at reliability.
When I googled High Reliability Organizations, many results were about the healthcare industry. In 2007, some healthcare orgs took stock of their situation and said "Man, we accidentally kill our patients all the time. Can we be more reliable like those nuclear aircraft carrier people?". They embarked on a long project to fix it. 12 years later they claim they've driven their error rate down a lot. (I'm not sure whether I believe them.)
But, this was recent, and hospitals are a domain with very clear feedback loops, where the stakes are vary obvious, and everyone viscerally cares about avoiding catastrophic outcomes (i.e. no one wants to kill a patient). AI is a domain with much murkier and more catastrophic failure modes.
Insofar as you buy the claims in this report, the graph of driving down hospital accidents looks like this:
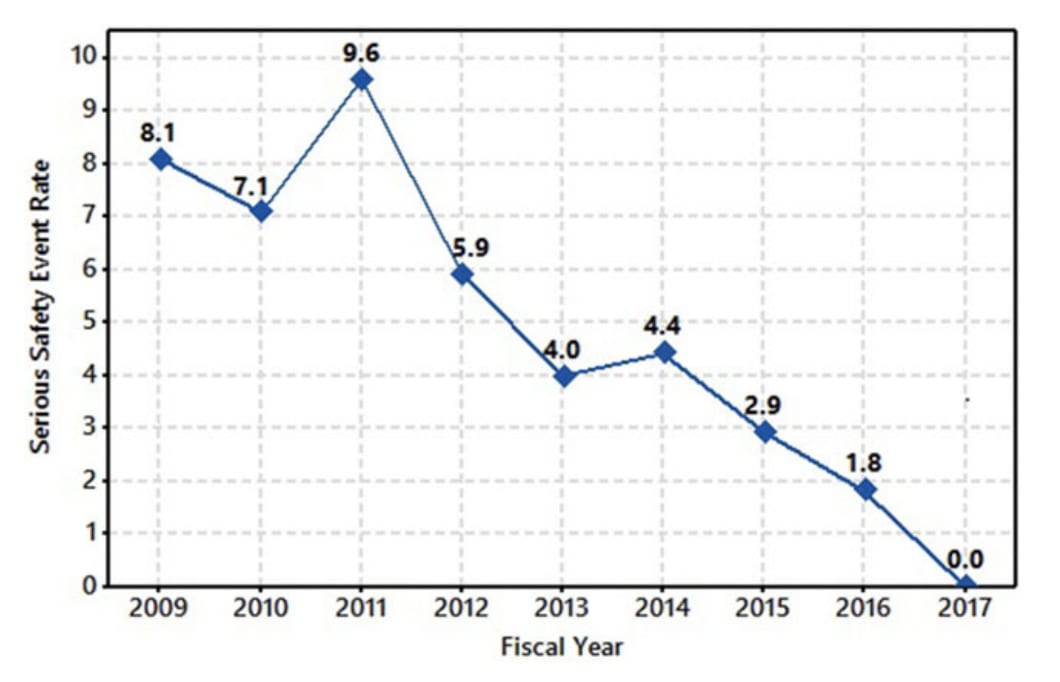
The report is from Genesis Health System, a healthcare service provider in Iowa that services 5 hospitals. No, I don't know what "Serious Safety Event Rate" actually means, the report is vague on that. But, my point here is that when I optimistically interpret this graph as making a serious claim about Genesis improving, the improvements took a comprehensive management/cultural intervention over the course of 8 years.
I know people with AI timelines less than 8 years. Shane Legg from Deepmind said he put 50/50 odds on AGI by 2030 [LW · GW].
If you're working at an org that's planning a Carefully Aligned AGI strategy, and your org does not already seem to hit the Highly Reliable bar, I think you need to begin that transition now. If your org is currently small, take proactive steps to preserve a safety-conscious culture as you scale. If your org is large, you may have more people who will actively resist a cultural change, so it may be more work to reach a sufficient standard of safety.
Considerations from Bio-lab Safety Practices
A better comparison might be bio-labs, in particular ones doing gain-of-function research.
I talked recently with someone who previously worked at a bio-lab. Their description of the industry was that there is a lot of regulation and safety enforcements. Labs that work on more dangerous experiments are required to meet higher safety standards. But there's a straightforward tradeoff between "how safe you are", and "how inconvenienced you are, and how fast you make progress".
The lab workers are generally trying to put in the least safety effort they can get away with, and the leadership in a lab is generally trying to make the case to classify their lab in the lowest safety-requirement category they can make the case for.
This is... well, about as good as I could expect from humanity. But it's looking fairly likely that the covid pandemic was the result of a lab leak, which means that the degree of precaution we had here was insufficient to stop a pandemic.
The status quo of AI lab safety seems dramatically far below the status quo of bio-lab safety. I think we need to get to a dramatically improved industry-wide practices here.
Why in "top 3 priorities" instead of "top 7?"
Earlier I said:
I think they believe organizational adequacy needs to be in something like their top 7 list of priorities, and I believe it needs to be in their top 3, or it won't happen and their organization will inevitably end up causing catastrophic outcomes.
This is a pretty strong claim. I'm not sure I can argue persuasively for it. My opinion here is based on having spent a decade trying to accomplish various difficult cultural things, and seeing how hard it was. If you have different experience, I don't know that I can persuade you. But, here are some principles that make me emphasize this:
One: You just... really don't actually get to have that many priorities. If you try to make 10 things top priority, you don't have any top priorities. A bunch of them will fall by the wayside.
Two: Steering culture requires a lot of attention. I've been part of a number of culture-steering efforts, and they required active involvement, prolonged effort, and noticing when you've created a subtly wrong culture (and need to course-correct).
(It's perhaps also a strong claim that I think this a "culture" problem rather than a "process" problem. I think if you're trying to build a powerful AGI via an iterative process, it matters that everyone is culturally bought into the "spirit" of the process, not just the letter of the law. Otherwise you just get people goodharting and cutting corners.)
Three: Projects need owners, with authority to get it done. The CEO doesn't necessarily need to be directly in charge of the cultural process here, but whoever's in charge needs to have the clear backing of the CEO.
(Why "Top 3" instead of "literally the top priority?". Well, I do think a successful AGI lab also needs have top-quality researchers, and other forms of operational excellence beyond the ones this post focuses on.)
Takeaways
There are many disjunctive failure modes here. If you succeed at all but one of them, you still can accidentally cause a catastrophic failure.
What to do with all this depends on your role in a company.
If you're founding a new AI org, or currently run a small AI org that you hope to one day build AGI, my primary advice is "stay small until you are confident you have a good company culture, and a plan for how to scale that company culture." Err on the side of staying small longer. (A lot of valuable startups stayed small for a very long time.)
If you are running a large AI company, which does not currently have a high reliability culture, I think you should explicitly be prioritizing reshaping your culture to be high-reliability. This is a lot of work. If you don't get it done by the time you're working on actually dangerous AGI, you'll likely end up causing a catastrophic outcome.
If you're a researcher or manager at a large AI company, and you don't feel much control over the broader culture or strategic goals for the company... I think it's still useful to be proactively shaping that culture on the margins. And I think there are ways to improve the culture that will help with high-reliability, without necessarily being about high reliability. For example, I expect most large companies to not necessarily have great horizontal communication between departments, or vertical communication between layers of hierarchy. Improving communication within the org can be useful even if it doesn't immediately translate into an orgwide focus on reliability.
Chat with me?
I think the actual "next actions" here are pretty context dependent.
If you work at an AI company, read this post and are like "This seems important, but I don't really know what to do about this. There are too many things on my plate to focus on this, or there's too many obstacles to make progress", I'm interested in chatting with you about the details of the obstacles.
If you work at an AI company and are like "I dunno. Maybe there's something here, but I'm skeptical", I'm interested in talking with you about that and getting a sense of what your cruxes are.
If you don't work at an AI company but are working on a fairly significant project to have an affect on this space (i.e. coming at this more from a perspective of regulation rather than internal culture/practices), I'm interested in chatting about how I think culture/practices fit in with other aspects of this domain.
I'm currently evaluating whether helping with the class of problems outlined here might be my top priority project for awhile. If there turn out to be particular classes of obstacles that come up repeatedly, I'd like to figure out what to do about those obstacles at scale.
If you're interested in talking, send me a DM.
Related reading
Some posts that inform or expand on my thinking here:
- Recursive Middle Manager Hell [LW · GW]
- Me, on "Why large companies tend to get more goodharted as they scale, more deeply/recursively than you might naively expect." (This is a distillation of a lot of writing by Zvi Mowshowitz, emphasizing the parts of his models I thought were easiest to explain and defend)
- Protecting Large Projects Against Mazedom [LW · GW]
- Zvi Mowshowitz, exploring how you might keep a large institution more aligned, preventing many of the failure modes outlined in Recursive Middle Manager Hell.
- High Reliability Orgs, and AI Companies [LW · GW]
- Me, doing a quick review of some existing literature on how to build high-reliability companies.
- Six Dimensions of Operational Adequacy in AGI Projects [LW · GW]
- Eliezer Yudkowsky's take on what properties an AGI company needs in order to be a trustworthy project worth joining / helping with.
- How could we know that an AGI system will have good consequences? [LW · GW]
- Nate Soares laying out some thoughts about how you can get into a justified epistemic state that
- Yes Requires the Possibility of No [LW · GW]
- Scott Garrabrant on how if a process wouldn't be capable of generating a "no" answer, you can't trust its "yes" answers. This seems relevant to me for AI labs considering whether a project is too dangerous to continue, and whether I (or they) should trust their process.
- You Get About Five Words [LW · GW]
- Me, noting that when you try to communicate at scale, your message necessarily gets degraded. This is relevant to scaling AI companies, while ensuring that your overall process is capable of tracking all the nuances of how and why AI could fail.
23 comments
Comments sorted by top scores.
comment by Raemon · 2023-03-17T21:40:20.030Z · LW(p) · GW(p)
I was chatting with someone about "okay, what actually counts as organizational adequacy?" and they said "well there are some orgs I trust..." and then they listed some orgs that seemed ranked by something like "generic trustworthiness", rather than "trustworthy with the specific competencies needed to develop AGI safely."
And I said "wait, do you, like, consider Lightcone Infrastructure adequate here?" [i.e. the org that makes LessWrong]
And they were said "yeah."
And I was like "Oh, man to be clear I do not consider Lightcone Infrastructure to be a high reliability org." And they said "Well, like, if you don't trust an org like Lightcone here, I think we're just pretty doomed."
The conversation wrapped up around that point, but I want to take it as a jumping off point to explain a nuance here.
High Reliability is a particular kind of culture. It makes sense to invest in that culture when you're working on complex, high stakes systems where a single failure could be catastrophic. Lightcone/LessWrong is a small team that is very "move fast and break things" in most of our operations. We debate sometimes how good that is, but, it's at least a pretty reasonable call to make given our current set of projects.
We shipped some buggy code that broke the LessWrong frontpage on Petrov Day. I think that was dumb of us, and particularly embarrassing because of the symbolism of Petrov Day. But I don't think it points at a particularly deeply frightening organizational failure, because temporarily breaking the site on Petrov Day is just not that bad.
If Lightcone decided to pivot to "build AGI", we would absolutely need to significantly change our culture, to become the sort of org that people should legitimately trust with that. I think we've got a good cultural core that makes me optimistic about us making that transition if we needed to, but we definitely don't have it by default.
I think "your leadership, and your best capabilities researchers, are actually bought into existential safety" is an important piece of being a highly reliable AI org. But it's not the only prerequisite.
comment by Raemon · 2023-03-17T21:21:35.343Z · LW(p) · GW(p)
Some additional notes from chatting with some bio people, about bio safety practices.
One thing going on with bio safety is that the rules are, in fact, kinda overly stringent. (i.e. if you get stuff on your hands, wash your hands for a full 15 minutes). People interpret the rules as coming from a place of ass-covering. People working in a biolab have a pretty good idea of what they're working with and how safe it is. So the rules feel annoying and slowing-down-work for dumb reasons.
If AI was about-as-dangerous-as-bio, I'd probably think "Well, obviously part of the job here is to come up with a safety protocol that's actually 'correct'", such that people don't learn to tune it out. Maybe separate out "the definitely important rules" from the "the ass covering rules".
With AI, there is the awkward thing of "well, but I do just really want AI being developed more slowly across the board." So "just impose a bunch of restrictions" isn't an obviously crazy idea. But
a) I think that can only work if imposed from outside as a regulation – it won't work for the sort of internal-culture-building that this post is aimed at,
b) even for an externally imposed regulation, I think regulations that don't make sense, and are just red-tape-for-the-sake-of-red-tape, are going to produce more backlash and immune response.
c) When I imagine the most optimistically useful regulations I can think of, implemented with real human bureaucracies, I think they still don't get us all the way to safe AGI development practices. Anyone who's plan actually routes through "eventually start working on AGI" needs an org that is significant better than the types of regulations I can imagine actually existing.
Replies from: ld97↑ comment by ld97 · 2023-04-14T14:21:58.200Z · LW(p) · GW(p)
My wife was working in a BSL-3 facility with COVID and other viruses that were causing serious health issues in humans and were relatively easy to spread. This is the type of lab where you wear positive pressure suits.
To have access to such a facility, you need to take training in safety measures, which takes about a month, and successfully pass the exam - only after that can you enter. People who were working there, of course, were both intelligent and had master's or doctoral degrees in some field related to biology or virology.
So, in essence, we have highly intelligent people who know that they are working with very dangerous stuff and passed the training and exam on safety measures. The atmosphere itself motivates you to be accurate - you’re wearing the positive pressure suit in the COVID lab.
What it was like in reality: Suit indicates that filter/battery replacement needed - oh, it’s okay, it can wait. The same with UV lamps replacement in the lab. Staying all night in a lab without sleeping properly - yeah, a regular case if someone is trying to finish their experiments. There were rumors that once someone even took a mobile phone with them. A mobile phone. In BSL-3.
It seems to me that after some time of work with dangerous stuff people just become overconfident because their observations are something like: “previously nothing bad happened, so it’s ok to relax a bit and be less careful about safety measures”.
comment by Seth Herd · 2023-03-17T22:09:18.267Z · LW(p) · GW(p)
This type of thinking seems important and somewhat neglected. Holden Karnofsky tossed out a point in success without dignity [LW · GW] that the AGI alignment community seems to heavily emphasize theoretical and technical thinking over practical (organizational, policy, and publicity) thinking. This seems right in retrospect, and we should probably be correcting that with more posts like this.
This seems like an important point, but fortunately pretty easy to correct. I'd summarize as: "if you don't have a well thought out plan for when and how to stop, you're planning to continue into danger"
comment by Raemon · 2023-03-18T17:05:12.090Z · LW(p) · GW(p)
In the appendix of High Reliability Orgs, and AI Companies [LW · GW], I transcribed a summary of the book Managing the Unexpected, which was the best resource I could find explaining how to apply lessons from the high reliability literature to other domains.
To reduce friction on clicking through and reading more, I thought I'd just include the summary here. I'll put my notes in a followup comment. (Note that I don't expect all of this to translate to an AI research lab)
High Level takeaways
- You can’t plan for everything. Something unexpected will always happen, from hurricanes to product errors.
- Planning can actually get in the way of useful responses, because people see the world through the lens of their plans and interpret events to fit their expectations.
- The more volatile your work environment, the more important it is to respond well in the moment.
- To make your organization more reliable, anticipate and track failures. Determine what they teach you.
- Focus on operations, rather than strategy.
- To become more resilient, emphasize learning, fast communication and adaptation.
- The person making decisions about how to solve a problem should be the person who knows the most about it – not the person who’s highest in the hierarchy.
- To build awareness, audit your organization’s current practices.
- To make your organization more mindful, don’t oversimplify.
- Real mindfulness may require changing your organizational culture
...
Abstract
Learning from High Reliability Organizations
Things you don’t expect to occur actually happen to you every day. Most surprises are minor, like a staff conflict, but some aren’t, like a blizzard. Some test your organization to the verge of destruction. You can’t plan for the unexpected, and in many cases, planning actually sets you up to respond incorrectly. You make assumptions about how the world is and what’s likely to happen. Unfortunately, many people try to make their worldview match their expectations, and thus ignore or distort signs that something different is happening. People look for confirmation that they’re correct, not that they’re wrong.
Planning focuses organizational action on specific, anticipated areas, which shuts down improvisation. When people plan, they also tend to “repeat patterns of activity that have worked in the past.” That works well if things stay the same – but when they change and the unexpected erupts, you are left executing solutions that don’t really fit your new situation
Consider organizations such as hospital emergency departments or nuclear power plants, which have to cope with extraordinary situations on a regular basis. These organizations have learned to deal regularly with challenging, disruptive events. They have adapted so that they react appropriately to the unexpected. They recognize that planning can only take an organization so far. After that, the way it responds to crisis determines its success. Your company can learn from the way these “high reliability organizations” (HROs) respond to crises, and, more generally, you can use their organizing principles in your own organization. Five core principles guide these HROs. The fi rst three emphasize anticipating problems; the last two emphasize containing problems after they happen
1. Preoccupation with failure. Attention on close calls and near misses (“being lucky vs. being good”); focus more on failures rather than successes. 2. Reluctance to simplify interpretations. Solid “root cause” analysis practices. 3. Sensitivity to operations. Situational awareness and carefully designed change management processes. 4. Commitment to resilience. Resources are continually devoted to corrective action plans and training. 5. Deference to expertise. Listen to your experts on the front lines (ex. authority follows expertise).
2. HROs are “reluctant to accept simplification” – Simplification is good and necessary. You need it for order and clarity, and for developing routines your organization can follow. However, if you simplify things too much or too quickly you may omit crucial data and obscure essential, information you need for problem solving. Labeling things to put them in conceptual categories can lead to dangerous oversimplification. NASA’s practice of classifying known glitches as “in-family” and new problems as “out-of-family” contributed to the Columbia disaster. By miscategorizing the damage to the shuttle as a maintenance-level “tile problem,” people downplayed its importance. To reduce such labeling danger, use hands-on observation. When things go wrong, don’t count on one observer; make sure people from varied backgrounds have time to discuss it at length. Re-examine the categories your organization uses and “differentiate them into subcategories,” so nothing gets hidden or blurred
3. HROs remain “sensitive to operations” – Stay focused on the actual situation as it is happening. Of course, aircraft carrier crewmembers, for instance, should align their actions with the larger strategic picture – but they can’t focus there. They must keep their focus on the airplanes that are taking off and landing on their deck. They have to pay attention to “the messy reality” of what’s actually happening. To improve your focus, refuse to elevate quantitative knowledge above qualitative and experiential knowledge. Weigh both equally. When you have “close calls,” learn the right lessons from them. Close calls don’t prove that the system is working because you didn’t crash. Close calls show that something’s wrong with the system since you almost crashed.
4. HROs develop and maintain “a commitment to resilience” – When the pressure is off, you might be able to believe that you’ve developed a perfect system that will never have to change. HROs know better. They regularly put their systems under incredible stress and unforeseen circumstances do arise. HROs know they have to adapt continually to changing circumstances. Resilience consists of three core capabilities. Your organization is resilient if it can “absorb strain” and keep working, even when things are hard, if it can “bounce back” from crises and if it can learn from them. HRO leaders celebrate when their organizations handle crises well, because it proves their resilience. Encourage people to share what they know and what they learn from crises. Speed up communication. Emphasize reducing the impact of crises. Practice mindfulness. Keep “uncommitted resources” ready to put into action when a crisis erupts. Structure your organization so that those who know what to do in a specific situation can take the lead, rather than hewing to a set hierarchy.
5. HROs practice “deference to expertise” – Avoid assuming that a direct relationship exists between your organization’s formal hierarchy and which person knows best what to do in a crisis. Often specific individuals possess deep expertise or situational knowledge that should leapfrog the hierarchy, so put them in charge of relevant major decisions. To increase your organization’s deference to expertise, focus on what the system knows and can handle, rather than taking pride in what you or any other individual knows and does. Recognize that expertise is “not simply an issue of content knowledge.” Instead, it consists of knowledge plus “credibility, trust and attentiveness.” Recognize and share what you know, even when people don’t want to hear it – but also know your limits and hand off authority when you reach them.
Auditing Your Organization for Mindfulness
You can’t shut your organization down and redesign it as an HRO, so find ways to redesign it while it is functioning. Start by auditing your current practices from numerous perspectives. These audits themselves will increase mindfulness. Ask questions to get people talking. As you review past crises as learning opportunities, you’ll start developing resilience. Study how much people in your organization agree and where agreement clusters. People at HROs tend to agree across their organizations’ different levels, so you have a problem if managers and front line workers disagree. Heed the areas where people disagree most about what to do or how the organization should function. See which aspects of reliability are strengths for you. Do you anticipate problems better (good planning)? Or are you better at containing them (good responsiveness)? Determine which audit findings are upsetting and “where you could be most mindful.”
Ask:
- Where are you now? – Examine how mindful your firm is now. Do you actively pay attention to potential problems? Does everyone agree what is most likely to go wrong? Do you all attend to potential problem areas to make the firm more reliable?
- How mindless are you? – Do you pressure people to do things the same way all the time or to work without needed information or training? Do you push people to produce without independent discretion? Such practices lead toward mindlessness.
- Where do you need to be most mindful? – Things are likelier to go unexpectedly wrong when your processes are “tightly coupled” and “interactively complex,” as in a nuclear power plant. Look for these qualities to see where you need to be most intensely mindful. If you can work in linear units that you fully understand without feedback from one unit to the next, you need comparatively little mindfulness. But, if your processes demand coordination and cooperation, or if you’re a start-up and don’t yet have all of your systems fully in place, feedback must flow. That’s when you need mindfulness most.
- Does your organization obsess over failure? – Encourage people to envision things that might go wrong and head them off. Ask yourself how consciously you seek potential failures. When something happens that you didn’t expect, does your organization figure out why? When you barely avoid a catastrophe, do you investigate why things almost went wrong, and learn from them? Do you change procedures to reflect your new understanding? On a simpler level, can people in your organization talk openly about failure? Do they report things that have gone awry?
- Does your organization resist simplification? – Rather than assuming that your organization knows itself and has the correct perspective, challenge the routine. This won’t always make for the most comfortable workplace, but you must pay attention to real complexity. What do you take for granted? (Your goal is to be able to answer “nothing.”) Push people to analyze events below the surface. To deepen their understanding, people must trust and respect each other, even when they disagree.
- Does your organization focus on operations? – Thinking about the big strategic picture is a lot of fun – but to be resilient, you need to monitor what is actually happening now, rather than assuming things are running smoothly. Seek feedback. Make sure people meet regularly with co-workers organization-wide, so they get a clearer overall picture.
- Are you committed to becoming more resilient? – HROs show their commitment to resilience by funding training so people can develop their capacities. You want people to know as many jobs and processes as possible. Besides formal training, encourage people who meet “stretch” goals, use knowledge and solve problems.
- Does your organization defer to expertise? – How much do people want to do their jobs well? Do they respect each other and defer to those who know an issue best?
Building a Mindful Organizational Culture
If you’re the only person in your company dedicated to mindfulness, the dominant “organizational culture” will swamp your good intentions. To make your organization more like an HRO, help it adopt an “informed culture” with these “four subcultures”:
1. A “reporting culture” – People share their accounts of what went wrong.
2. A “just culture” – The organization treats people fairly. Define “acceptable and unacceptable” action and do not punish failures that arise from acceptable behavior. When something goes wrong, seek reasons, not scapegoats.
3. A “flexible culture” – If your work is very variable, like fighting fires, don’t depend on a rigid, slow hierarchy. Foster individual discretion and variation instead of uniformity.
4. A “learning culture” – Increase everyone’s capacity; provide opportunities for people to share information.
Your organization’s culture manifests at several levels. It ascends from the level of physical objects, which can symbolize a corporate personality, to linked processes and then up to the level of abstractions, like shared values and assumptions. “Artifacts are the easiest to change, assumptions the hardest.” Top managers must consistently model and communicate the changes they want. State your desired beliefs and practices, give employees feedback and reward those who succeed.
As you move into implementing new activities, follow a “small wins strategy,” focusing on attainable goals. Start with the “after action review” in which people compare what they did in a crisis to what they intended to do, why it differed and how they’ll act in the future. Encourage people to share details, rather than glossing over specifics. Support those who try to be more mindful, since being mindless is so much easier. Help them by verbally reframing objectives. For example, reword current “goals in the form of mistakes that must not occur.” Define what having a “near miss” means and what constitutes “good news.” If no accident report is filed, is that good – or does it mean things are being brushed under the rug? Train people in interpersonal skills and encourage skepticism. To raise awareness of potential glitches, ask employees what unexpected occurrences they’ve seen. Meet with people face to face to get the nuances they communicate nonverbally.
comment by rpglover64 (alex-rozenshteyn) · 2023-03-18T18:37:31.628Z · LW(p) · GW(p)
(Why "Top 3" instead of "literally the top priority?" Well, I do think a successful AGI lab also needs have top-quality researchers, and other forms of operational excellence beyond the ones this post focuses on. You only get one top priority, )
I think the situation is more dire than this post suggests, mostly because "You only get one top priority." If your top priority is anything other than this kind of organizational adequacy, it will take precedence too often; if your top priority is organizational adequacy, you probably can't get off the ground.
The best distillation of my understanding regarding why "second priority" is basically the same as "not a priority at all" is this twitter thread by Dan Luu.
Replies from: RaemonThe fear was that if they said that they needed to ship fast and improve reliability, reliability would be used as an excuse to not ship quickly and needing to ship quickly would be used as an excuse for poor reliability and they'd achieve none of their goals.
↑ comment by Raemon · 2023-03-18T18:49:31.197Z · LW(p) · GW(p)
Oh thanks, I was looking for that twitter thread and forgot who the author was.
I was struggling in the OP to figure out how to integrate this advice. I agree with the Dan Luu thread. I do... nonetheless see orgs successfully doing multiple things. I think my current belief is that you only get one top priority to communicate to your employees, but that a small leadership team can afford to have multiple priorities (but, they should think of anything as not in their top-5 as basically sort of abandoned, and anything not in their top-3 as 'very at risk of getting abandoned')
I also don't necessarily think "priority" is quite the right word for what needs happening here. I'll think on this a bit more and maybe rewrite the post.
comment by TinkerBird · 2023-03-18T00:21:51.815Z · LW(p) · GW(p)
The fact that LLM's are already so good gives me some hope that AI companies could be much better organized when the time comes for AGI. If AI's can keep track of what everyone is doing, the progress they're making, and communicate with anyone at any time, I don't think it would be too hopeful to expect this aspect of the idea to go well.
What probably is too much to hope for, however, is people actually listening to the LLM's even if the LLM's know better.
My big hope for the future is for someone at OpenAI to prompt GTP-6 or GTP-7 with, "You are Eliezer Yudkowsky. Now don't let us do anything stupid."
comment by Orpheus16 (akash-wasil) · 2024-12-25T22:26:11.761Z · LW(p) · GW(p)
I think this a helpful overview post. It outlines challenges to a mainstream plan (bootstrapped alignment) and offers a few case studies of how entities in other fields handle complex organizational challenges.
I'd be excited to see more follow-up research on organizational design and organizational culture. This work might be especially useful for helping folks think about various AI policy proposals.
For example, it seems plausible that at some point the US government will view certain kinds of AI systems as critical national security assets. At that point, the government might become a lot more involved in AI development. It might be the case that a new entity is created (e.g., a DOD-led "Manhattan Project") or it might be the case that the existing landscape persists but with a lot more oversight (e.g., NSA and DoD folks show up as resident inspectors at OpenAI/DeepMind/Anthropic and have a lot more decision-making power).
If something like this happens, there will be a period of time in which relevant USG stakeholders (and AGI lab leaders) have to think through questions about organizational design, organizational culture, decision-making processes, governance structures, etc. It seems likely that some versions of this look a lot better than others.
Examples of questions I'd love to see answered/discussed:
- Broadly, what are the 2-3 most important design features or considerations for an AGI project?
- Suppose the USG becomes interested in (soft) nationalizing certain kinds of AI development. A senior AI policy advisor comes to you and says "what do you think are the most important things we need to get right?"
- What are the best lessons learned from case studies in other fields where high-reliability organizations are important? (e.g. BSL-4 labs, nuclear facilities, health care facilities, military facilities)
- What are the best lessons learned from case studies in other instances in which governments or national security officials attempted to start new organizations or exert more control over existing organizations (e.g., via government contracts)?
(I'm approaching this from a government-focused AI policy lens, partly because I suspect that whoever becomes in charge of the "What Should the USG Do" decision will have spent less time thinking through these considerations than Sam Altman or Demis Hassabis. Also, it seems like many insights would be hard to implement in the context of the race toward AGI. But I suspect there might be insights here that are valuable even if the government doesn't get involved & it's entirely on the labs to figure out how to design/redesign their governance structures or culture toward bootstrapped alignment.)
comment by Ruby · 2023-04-04T01:48:32.900Z · LW(p) · GW(p)
Curated. Among multiple reasons, I like this post for conveying a simple point that I think is underappreciated. While each of us an individual, and it's easier to think about individuals, it's trickier to change the direction of an organization than it is to change the minds of some or even all of the individuals in it. You've got to think about the systems of people, and intentionally be the kind of organization you need to be. Kudos to this point for explaining that, and all the rest.
Replies from: charlie-sanders↑ comment by Charlie Sanders (charlie-sanders) · 2023-04-04T15:50:45.169Z · LW(p) · GW(p)
As someone that interacts with Lesswrong primarily via an RSS feed of curated links, I want to express my appreciation for curation when it’s done early enough to be able to participate early in the comment section development lifestyle. Kudos for quick curation here.
Replies from: Rubycomment by Raemon · 2023-03-19T20:54:54.947Z · LW(p) · GW(p)
This post was oriented around the goal of "be ready to safely train and deploy a powerful AI". I felt like I could make the case for that fairly straightforwardly, mostly within the paradigm that I expect many AI labs are operating under.
But one of the reasons I think it's important to have a strong culture of safety/carefulness, is in the leadup to strong AI. I think the world is going to be changing rapidly, and that means your organization may need to change strategies quickly, and track your impact on various effects on society.
Some examples of problems you might need to address:
- Accidentally accelerating race dynamics (even if you're really careful to avoid hyping and demonstrating new capabilities publicly, if it's clear that you're working on fairly advanced stuff that'll likely get released someday it can still contribute to FOMO)
- Failing to capitalize on opportunities to reduce race dynamics, which you might not have noticed due to distraction or pressures from within your company
- Publishing some research that turned out to be more useful for capabilities than you thought.
- Employees leaving and taking insights with them to other less careful orgs (in theory you can have noncompete clauses that mediate this, but I'm skeptical about how that works out in practice)
- AIs interacting with society, or each other, in ways that destabilize humanity.
I'm working on a longer comment (which will maybe turn out to just be a whole post) about this, but wanted to flag it here for now.
comment by Kevin Temple (kevin-temple) · 2023-04-04T12:59:27.216Z · LW(p) · GW(p)
I'm skeptical that hard take off is something to worry about anytime soon, but setting that aside, I think it's extremely valuable to think through these questions of organizational culture, because there are a lot of harms that can come from mere AI (as opposed to AGI) and all of these reflections pertain to less exotic but still pressing concerns about trustworthy AI.
These reflections very nicely cover what is hard about self-regulation, particularly in for-profit organizations. I think what is missing though is the constitutive role of the external, regulatory environment on the risk management structures and practices an organization adopts. Legislation and regulations create regulatory risks--financial penalties and public embarrassment for breaking the rules--that force companies (from the outside) to create the cultures and organs of responsibility this post describes. It is external force--and probably only external force--creates these internal shapes.
To put this point in the form of a prediction: show me a company with highly developed risk management practices and a culture of responsibility, and I will show you the government regulations that organization is answerable to. (This won't be true all of the time, but will be true for most HROs, for banking (in non-US G20 countries, at least), for biomedical research, and other areas.)
In fairness, I have to acknowledge that specific regulations for AI are not here yet, but they are coming soon. Pure self-regulation of AI companies is probably a futile goal. By contrast, operating under a sane, stable, coherent regulatory environment would actually bring a lot advantages to every company working on AI.
comment by zeshen · 2023-04-04T05:04:08.364Z · LW(p) · GW(p)
Everyone in any position of power (which includes engineers who are doing a lot of intellectual heavy-lifting, who could take insights with them to another company), thinks of it as one of their primary jobs to be ready to stop
In some industries, Stop Work Authorities are implemented, where any employee at any level in the organisation has the power to stop a work deemed unsafe at any time. I wonder if something similar in spirit would be feasible to be implemented in top AI labs.
Replies from: Raemon↑ comment by Raemon · 2023-04-04T08:55:06.191Z · LW(p) · GW(p)
This is definitely my dream, although I think we're several steps away from this being achievable at the present time.
Replies from: zeshen↑ comment by zeshen · 2023-04-08T16:25:16.152Z · LW(p) · GW(p)
If this interests you, there is a proposal in the Guideline for Designing Trustworthy Artificial Intelligence by Fraunhofer IAIS which includes the following:
[AC-R-TD-ME-06] Shutdown scenarios
Requirement: Do
Scenarios should be identified, analyzed and evaluated in which the live AI application must be completely or partially shut down in order to maintain the ability of users and affected persons to perceive situations and take action. This includes shutdowns due to potential bodily injury or damage to property and also due to the violation of personal rights or the autonomy of users and affected persons. Thus, depending on the application context, this point involves analyzing scenarios that go beyond the accidents/safety incidents discussed in the Dimension: Safety and Security (S). For example, if it is possible that the AI application causes discrimination that cannot be resolved immediately, this scenario should be considered here. When evaluating the scenarios, the consequences of the shutdown for the humans involved, work processes, organization and company, as well as additional time and costs, should also be documented. This is compared with the potential damage that could arise if the AI application were not shut down. Documentation should be available on the AI application shutdown strategies that were developed based on the identified scenarios – both short-term, mid-term and permanent shutdown. Similarly, scenarios for shutting down subfunctions of the AI application should also be documented. Reference can be made to shutdown scenarios that may have already been covered in the Risk area: functional safety (FS) (see [S-RFS-ME-10]). A shutdown scenario documents
– the setting and the resulting decision-making rationale for the shutdown,
– the priority of the shutdown,
– by which persons or roles the shutdown is implemented and how it is done,
– how the resulting outage can be compensated,
– the expected impact for individuals or for the affected organization.[AC-R-TD-ME-07] Technical provision of shutdown options
Requirement: Do
Documentation should be available on the technical options for shutting down specific subfunctions of the AI application as well as the entire AI application. Here, reference can be made to [S-R-FS-ME-10] or [S-RFS-ME-12] if necessary. It is outlined that other system components or business processes that use (sub)functionality that can be shutdown have been checked and (technical) measures that compensate for negative effects of shutdowns are prepared. If already covered there, reference can be made to [S-R-FS-ME-10].
comment by Nathan Helm-Burger (nathan-helm-burger) · 2023-03-17T23:05:56.185Z · LW(p) · GW(p)
I think a good move for the world would be to consolidate AI researchers into larger, better monitored, more bureaucratic systems that moved more slowly and carefully, with mandatory oversight. I don't see a way to bring that about. I think it's a just-not-going-to-happen sort of situation to think that every independent researcher or small research group will voluntarily switch to operating in a sufficiently safe manner. As it is, I think a final breakthrough AGI is 4-5x more likely to be developed by a big lab than by a small group or individual, but that's still not great odds. And I worry that, after being developed the inventor will run around shouting 'Look at this cool advance I made!' and the beans will be fully spilled before anyone has the chance to decide to hush them, and then foolish actors around the world will start consequence-avalanches they cannot stop. For now, I'm left hoping that somewhere at-least-as-responsible as DeepMind or OpenAI wins the race.
comment by Review Bot · 2024-03-08T01:18:47.553Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
comment by Review Bot · 2024-03-08T01:18:46.673Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
comment by Yoav Hollander (yoav-hollander) · 2023-04-12T11:04:43.016Z · LW(p) · GW(p)
Summary: My intuition is that "High Reliability Organizations" may not be the best parallel here: A better one is probably "organizations developing new high-tech systems where the cost of failure is extremely high". Examples are organizations involved in chip design and AV (Autonomous Vehicle) design.
I'll explain below why I think they are a better parallel, and what we can learn from them. But first:
Some background notes:
- I have spent many years working in those industries, and in fact participated in inventing some of the related verification / validation / safety techniques ("V&V techniques" for short).
- Chip design and AV design are different. Also, AV design (and the related V&V techniques) are still work-in-progress – I'll present a slightly-idealized version of it.
- I am not sure that "careful bootstrapped alignment", as described, will work, for the various reasons Eliezer and others are worried about: We may not have enough time, and enough world-wide coordination. However, for the purpose of this thread, I'll ignore that, and do my best to (hopefully) help improve it.
Why this is a better parallel: Organizations which develop new chips / AVs / etc. have a process (and related culture) of "creating something new, in stages, while being very careful to avoid bugs". The cost-of-failure is huge: A chip design project / company could die if too many bugs are "left in" (though safety is usually not a major concern). Similarly, an AV project could die if too many bugs (mostly safety-related) cause too many visible failures (e.g. accidents).
And when such a project fails, a few billion dollars could go up in smoke. So a very high-level team (including the CEO) needs to review the V&V evidence and decide whether to deploy / wait / deploy-reduced-version.
How they do it: Because the stakes are so high, these organizations are often split into a design team, and an (often bigger) V&V team. The V&V team is typically more inventive and enterprising (and less prone to Goodharting and "V&V theatre") than the corresponding teams in "High Reliability Organizations" (HROs).
Note that I am not implying that people in HROs are very prone to those things – it is all a matter of degree: The V&V teams I describe are simply incentivized to find as many "important" bugs as possible per day (given finite compute resources). And they work on a short (several years), very intense schedule.
They employ techniques like a (constantly-updated) verification plan and safety case. They also work in stages: Your initial AV may be deployed only in specific areas / weathers / time-of-day and so on. As you gain experience, you "enlarge" the verification plan / safety case, and start testing accordingly (mostly virtually). Only when you feel comfortable with that do you actually "open up" the area / weather / number-of-vehicles / etc. envelope.
Will be happy to talk more about this.
comment by Charlie Sanders (charlie-sanders) · 2023-04-04T15:58:16.911Z · LW(p) · GW(p)
In many highly regulated manufacturing organizations there are people working for the organization whose sole job is to evaluate each and every change order for compliance to stated rules and regulations - they tend to go by the title of Quality Engineer or something similar. Their presence as a continuous veto point for each and every change, from the smallest to the largest, aligns organizations to internal and external regulations continuously as organizations grow and change.
This organizational role needs to have an effective infrastructure supporting it in order to function, which to me is a strong argument for the development for a set of workable regulations and requirements related to AI safety. With such a set of rules, you’d have the infrastructure necessary to jump-start safety efforts by simply importing Quality Engineers from other resilient organizations and implementing the management of change that’s already mature and pervasive across many other industries.
comment by [deleted] · 2023-04-04T19:30:17.062Z · LW(p) · GW(p)
I don't think you can get there from here.
I think the only way to solve what we've become is to enlighten the greed that evolution requires, i.e. we have to change to survive the environmental and technological overhang we're skating on. The motivations of pain are poised to send us into a terminal musical chairs to the turtles stacked below, because of the overhang. I think that only a new kind of pleasure has a chance of diverting us, analogous to the scale of social changes the internet has brought.