Google's PaLM-E: An Embodied Multimodal Language Model
post by SandXbox (PandaFusion) · 2023-03-07T04:11:18.183Z · LW · GW · 7 commentsThis is a link post for https://palm-e.github.io/
Contents
7 comments
Abstract:
Large language models have been demonstrated to perform complex tasks. However, enabling general inference in the real world, e.g. for robotics problems, raises the challenge of grounding. We propose embodied language models to directly incorporate real-world continuous sensor modalities into language models and thereby establish the link between words and percepts. Input to our embodied language model are multi-modal sentences that interleave visual, continuous state estimation, and textual input encodings. We train these encodings end-to-end, in conjunction with a pre-trained large language model, for multiple embodied tasks, including sequential robotic manipulation planning, visual question answering, and captioning. Our evaluations show that PaLM-E, a single large embodied multimodal model, can address a variety of embodied reasoning tasks, from a variety of observation modalities, on multiple embodiments, and further, exhibits positive transfer: the model benefits from diverse joint training across internet-scale language, vision, and visual-language domains. Our largest model, PaLM-E-562B with 562B parameters, in addition to being trained on robotics tasks, is a visual-language generalist with state-of-the-art performance on OK-VQA, and retains generalist language capabilities with increasing scale.
7 comments
Comments sorted by top scores.
comment by Kaj_Sotala · 2023-03-07T12:30:37.572Z · LW(p) · GW(p)
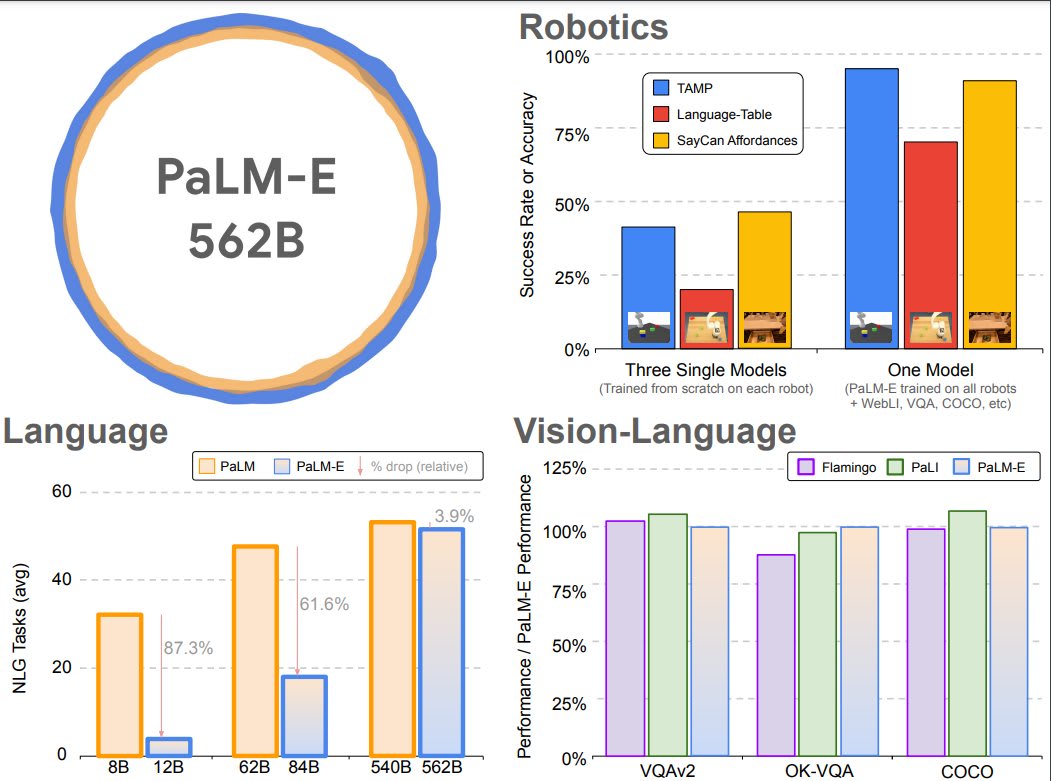
Unlike GATO, which was a bunch of models thrown into the same network but where they did not significantly learn from each other, this model exhibits significant transfer learning.
Replies from: crossgventuresAmong works that output actions, perhaps most similar is the approach proposed in Gato (Reed et al., 2022) which, like PaLM-E, is a generalist multi-embodiment agent. In contrast to Gato, we demonstrate positive transfer across different tasks where the model benefits from diverse joint training across multiple domains. [...]
Tab. 1 shows results for 3-5 objects when training on 1% of the dataset, which corresponds to only 320 examples for each of the two planning tasks. Here we see that there are significant differences between the input representations, especially for the planning tasks. First, pre-training the LLM is beneficial in the low data regime for state inputs. Second, both ViT variants (ViT+TL, ViT-4B) do not perform well in solving the planning tasks for this little data. However, if we co-train on all other robot environments as well as general vision-language datasets (ViT-4B generalist), then the performance of the ViT-4B more than doubles. This shows a significant transfer effect between different robot embodiments and tasks. Finally, using OSRT as the input representation leads to the best performance here, demonstrating the strengths of 3D-aware object representations. We also observe another instance of transfer here: when we remove the TAMP VQA data and only train on the 640 planning tasks examples, there is a (slight) drop in performance. The state-of-the art vision-language model PaLI (Chen et al., 2022) that was not trained on robot data is not able to solve the tasks. We only evaluated it on q2 (objects left/right/center on the table) and q3 (vertical object relations), since those most resemble typical VQA tasks. [...]
Generalist vs specialist models – transfer. As summarized in Fig. 3, we have shown several instances of transfer in this work, meaning that PaLM-E trained on different tasks and datasets at the same time leads to significantly increased performance relative to models trained separately on the different tasks alone. In Fig. 4, co-training on the “full mixture” achieves more than double the performance. In Tab. 9, we see significant improvements in performance if we add LLM/ViT pre-training, and training on the full mixture instead of the mobile manipulation data alone. For the Language-Table experiment in Tab. 2, we observe analogous behaviour.
Data efficiency. Compared to available massive language or vision-language datasets, robotics data is significantly less abundant. As discussed in the last paragraph, our model exhibits transfer, which aids PaLM-E to solve robotics tasks from very few training examples in the robotics domain, e.g. between 10 and 80 for Language Table or 320 for TAMP. The OSRT results show another instance of data-efficiency by using a geometric input representation.
↑ comment by CrossGVentures (crossgventures) · 2023-03-07T23:48:44.886Z · LW(p) · GW(p)
Shit this stuff might happen stupid quick, this is big.
comment by Lone Pine (conor-sullivan) · 2023-03-08T06:56:32.643Z · LW(p) · GW(p)
I honestly now believe that AGI already exists. This model may not have been it, and we will debate for hundreds of years* about whether the threshold was transformers or MLPs or multimodal, and which first model was really the first, in the same way we still debate which electronic computer was truly the first. But I do believe that it is here.
We do not have human-level machine intelligence (HLMI) yet. These systems still have a lot of limitations, in particular the context window and lack of memory. They are very limited in some domains such as robotics. However, it seems unlikely to me that we are not already in the takeoff.
* (assuming the debate doesn't get abruptly stopped)
Replies from: ben-livengood, kevin-imes↑ comment by Ben Livengood (ben-livengood) · 2023-03-08T15:41:03.361Z · LW(p) · GW(p)
I agree it looks like the combination of multimodal learning and memory may be enough to reach AGI, and there's an existing paper with a solution for memory. Human-level is such a hard thing to judge and so my threshold is basically human-level coding ability because that's what allows recursive self-improvement which is where I predict at least 90% of the capability gain toward superhuman AGI will happen. I assume all the pieces are running in data centers now, presumably just not hooked together in precisely the right way (but an AGI model being trained by DeepMind right now would not surprise me much). I will probably update to a year sooner from median ~2026 to ~2025 for human-level coding ability and from there it's almost certainly a fast takeoff (months to a few years) given how many orders of magnitude faster current LLMs are than humans at generating tokens which tightens the iteration loop on serial tasks. Someone is going to want to see how intelligent the AGI is and ask it to "fix a few bugs" even if it's not given an explicit goal of self improvement. I hedge that median both because I am not sure if the next few multimodal models will have enough goal stability to pursue a long research program (memory will probably help but isn't the whole picture of an agent) and because I'm not sure the big companies won't balk somewhere along the path, but Llama 65B is out in the open now and close enough to GPT-3 and PaLM to give (rich) nerds in their basements the ability to do significant capability research.
Replies from: Capybasilisk↑ comment by Capybasilisk · 2023-03-08T22:52:29.399Z · LW(p) · GW(p)
and there’s an existing paper with a solution for memory
Could you link this?
↑ comment by Kevin Imes (kevin-imes) · 2023-03-08T23:33:45.879Z · LW(p) · GW(p)
The only reasonable debate at this point seems to me to be exponential vs superexponential.
When somebody tells you to buy into the S&p 500 what's their reasoning? After a century or two of reliable exponential growth the most conservative prediction is for that trend to continue (barring existential catastrophe). We are in our second or third century of dramatic recursive technology improvement. AI is clearly a part of this virtuous cycle, so the safest money looks like it'd be on radical change.
I appreciate the perspectives of the Gary Marcuses of the world, but I've noticed they tend more towards storytelling ("Chinese room, doesn't know what it's saying"). The near-term singularity crowd tends to point at thirty different graphs of exponential curves and shrug. This is of course an overgeneralization (there are plenty of statistically-grounded arguments against short horizons), but it's hard to argue we're in an S curve when the rate of change is still accelerating. Harder still to argue that AI isn't/won't get spooky when it writes better than most Americans and is about to pass the coffee test.
Forgive my hypocrisy, but I'll do a bit of storytelling myself. As a music ed major, I was taught by nearly every one of my professors to make knowledge transfers and to teach my students to transfer. Research on exercise science, psychology, film criticism, the experience of stubbing a toe; all of it can be used to teach music better if you know how to extract the useful information. To me this act of transfer is the boson of wisdom. If palm-e can use its internal model of a bag of chips to grab it for you out of the cabinet... Google doesn't seem to be out of line to claim palm is transferring knowledge. The Chinese room argument seems to be well and truly dead.


{kind=link}
{kind=link}