"Existential risk from AI" survey results
post by Rob Bensinger (RobbBB) · 2021-06-01T20:02:05.688Z · LW · GW · 7 commentsContents
Methods Results Background and predictions Respondents' comments Footnotes None 8 comments
I sent a two-question survey to ~117 people working on long-term AI risk, asking about the level of existential risk from "humanity not doing enough technical AI safety research" and from "AI systems not doing/optimizing what the people deploying them wanted/intended".
44 people responded (~38% response rate). In all cases, these represent the views of specific individuals, not an official view of any organization. Since some people's views may have made them more/less likely to respond, I suggest caution in drawing strong conclusions from the results below. Another reason for caution is that respondents added a lot of caveats to their responses (see the anonymized spreadsheet), which the aggregate numbers don't capture.
I don’t plan to do any analysis on this data, just share it; anyone who wants to analyze it is of course welcome to.
If you'd like to make your own predictions before seeing the data, I made a separate spoiler-free post for that [LW · GW].
Methods
You can find a copy of the survey here. The main questions (including clarifying notes) were:
1. How likely do you think it is that the overall value of the future will be drastically less than it could have been, as a result of humanity not doing enough technical AI safety research?
2. How likely do you think it is that the overall value of the future will be drastically less than it could have been, as a result of AI systems not doing/optimizing what the people deploying them wanted/intended?
_________________________________________
Note A: "Technical AI safety research" here means good-quality technical research aimed at figuring out how to get highly capable AI systems to produce long-term outcomes that are reliably beneficial.
Note B: The intent of question 1 is something like "How likely is it that our future will be drastically worse than the future of an (otherwise maximally similar) world where we put a huge civilizational effort into technical AI safety?" (For concreteness, we might imagine that human whole-brain emulation tech lets you gather ten thousand well-managed/coordinated top researchers to collaborate on technical AI safety for 200 subjective years well before the advent of AGI; and somehow this tech doesn't cause any other changes to the world.)
The intent of question 1 *isn't* "How likely is it that our future will be astronomically worse than the future of a world where God suddenly handed us the Optimal, Inhumanly Perfect Program?". (Though it's fine if you think the former has the same practical upshot as the latter.)
Note C: We're asking both 1 and 2 in case they end up getting very different answers. E.g., someone might give a lower answer to 1 than to 2 if they think there's significant existential risk from AI misalignment even in worlds where humanity put a major civilizational effort (like the thousands-of-emulations scenario) into technical safety research.
I also included optional fields for "Comments / questions / objections to the framing / etc." and "Your affiliation", and asked respondents to
Check all that apply:
☐ I'm doing (or have done) a lot of technical AI safety research.
☐ I'm doing (or have done) a lot of governance research or strategy analysis related to AGI or transformative AI.
I sent the survey out to two groups directly: MIRI's research team, and people who recently left OpenAI (mostly people suggested by Beth Barnes of OpenAI). I sent it to five other groups through org representatives (who I asked to send it to everyone at the org "who researches long-term AI topics, or who has done a lot of past work on such topics"): OpenAI, the Future of Humanity Institute (FHI), DeepMind, the Center for Human-Compatible AI (CHAI), and Open Philanthropy.
The survey ran for 23 days (May 3–26), though it took time to circulate and some people didn't receive it until May 17.
Results

Each point is a response to Q1 (on the horizontal axis) and Q2 (on the vertical axis). Circles denote (pure) technical safety researchers, squares (pure) strategy researchers; diamonds marked themselves as both, triangles as neither. In four cases, shapes are superimposed because 2–3 respondents gave the same pair of answers to Q1 and Q2. One respondent (a "both" with no affiliation specified) was left off the chart because they gave interval answers: [0.1, 0.5] and [0.1, 0.9].
Purple represents OpenAI, red FHI, green CHAI or UC Berkeley, orange MIRI, blue Open Philanthropy, and black "no affiliation specified". No respondents marked DeepMind as their affiliation.
Separating out the technical safety researchers (left) and the strategy researchers (right):
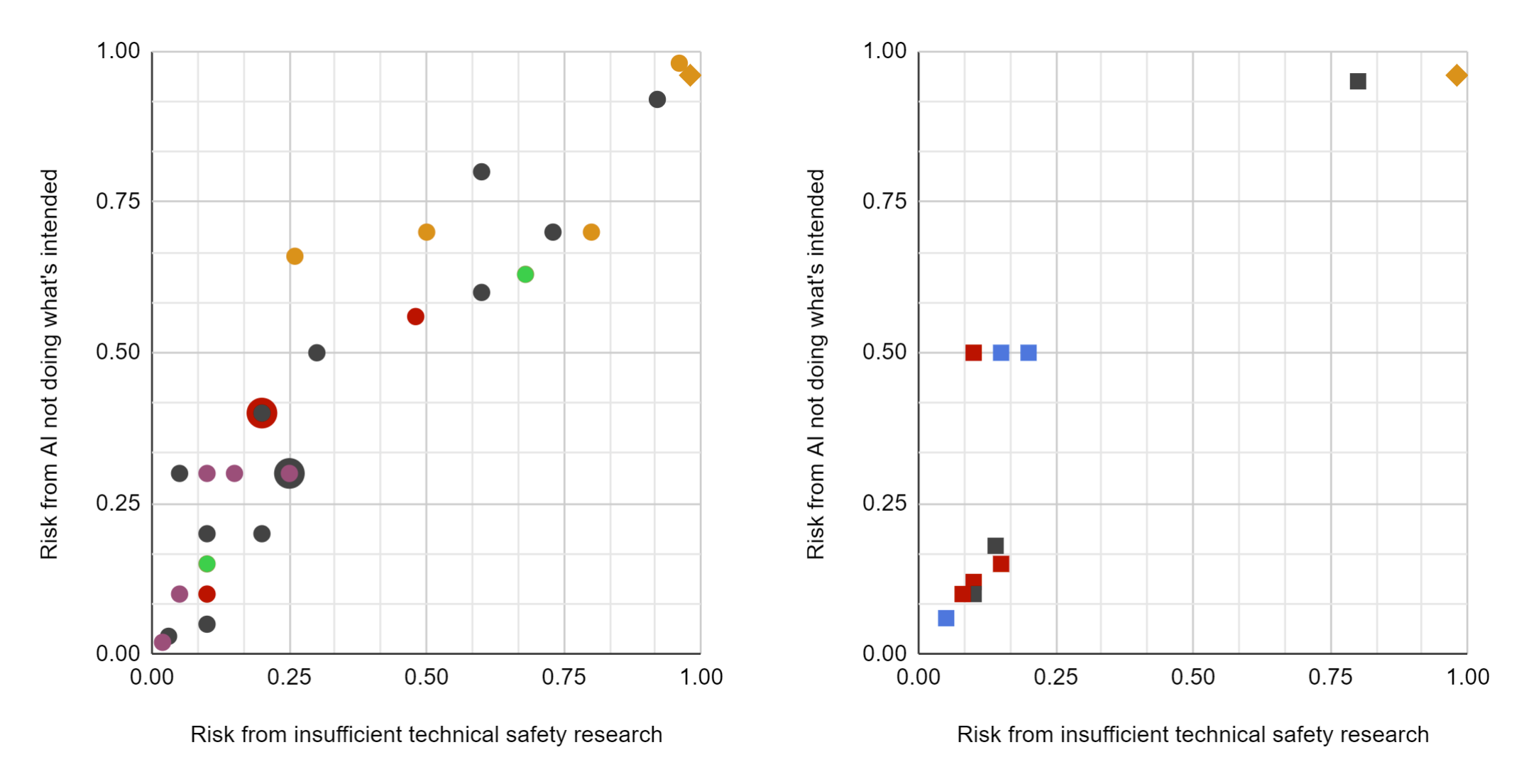
Overall, the mean answer of survey respondents was (~0.3, ~0.4), and the median answer was (0.2, 0.3).
Background and predictions
I'd been considering running a survey like this for a little while, and decided to pull the trigger after a conversation on the EA Forum [EA · GW] in which I criticized an analysis that assigned low probability to a class of AI risk scenarios. In the EA Forum conversation, I quoted a prediction of mine (generated in 2017 via discussion with a non-MIRI researcher I trust):
I think that at least 80% of the AI safety researchers at MIRI, FHI, CHAI, OpenAI, and DeepMind would currently assign a >10% probability to this claim: "The research community will fail to solve one or more technical AI safety problems, and as a consequence there will be a permanent and drastic reduction in the amount of value in our future."
This is (I think) reasonably close to Q1 in the survey. Looking only at people who identified themselves as MIRI/FHI/CHAI/OpenAI/DM (so, excluding Open Phil and ‘no affiliation specified’) and as technical safety or strategy researchers, 11 / 19 = ~58% gave >10% probability to question 1, which is a far cry from my predicted 80+%. I expect this at least partly reflects shifts in the field since 2017, though I think it also casts some doubt on my original claim (and certainly suggests I should have hedged more in repeating it today). Restricting to technical safety researchers, the number is 10 / 15 = ~67%.
Note that respondents who were following the forum discussion might have been anchored in some way by that discussion, or might have had a social desirability effect from knowing that the survey-writer puts high probability on AI risk. It might also have made a difference that I work at MIRI.
Respondents' comments
A large number of respondents noted that their probability assignments were uncertain or unstable, or noted that they might give a different probability if they spent more time on the question. More specific comments included...
(Caveat: I'm choosing the bins below arbitrarily, and I'm editing out meta statements and uncertainty-flagging statements; see the spreadsheet for full answers.)
... from respondents whose highest probability was < 25%:
- 0.1, 0.05: "[...] The first is higher than the second because we're thinking a really truly massive research effort -- it seems quite plausible that (a) coordination failures could cause astronomical disvalue relative to coordination successes and (b) with a truly massive research effort, we could fix coordination failures, even when constrained to do it just via technical AI research. I don't really know what probability to assign to this (it could include e.g. nuclear war via MAD dynamics, climate change, production web, robust resistance to authoritarianism, etc and it's hard to assign a probability to all of those things, and that a massive research effort could fix them when constrained to work via technical AI research)."
- 0.1, 0.12: "(2) is a bit higher than (1) because even if we 'solve' the necessary technical problems, people who build AGI might not follow what the technical research says to do"
- 0.2, 0.2: "'Drastically less than it could have been' is confusing, because it could be 'the future is great, far better than the present, but could have been drastically better still' or alternatively 'we destroy the world / the future seems to have very negative utility'. I'm sort of trying to split the difference in my answer. If it was only the latter, my probability would be lower, if the former, it would be higher. Also, a world where there was tremendous effort directed at technical AI safety seems like a world where there would be far more effort devoted to governance/ethics, and I'm not sure how practically to view this as a confounder."
- 0.019, 0.02: "Low answers to the above should not be taken to reflect a low base rate of P(humans achieve AGI); P(humans achieve AGI) is hovering at around 0.94 for me. [...]"
... from respondents whose highest probability was 25–49%:
- 0.25, 0.3: "`1` and `2` seem like they should be close together for me, because in your brain emulation scenario it implies that our civ has a large amount of willingness to sacrifice competitiveness/efficiency of AI systems (by pausing everything and doing this massive up-front research project). This slack seems like it would let us remove the vast majority of AI x-risk."
- 0.15, 0.3: "I think my answer to (1) changes quite a lot based on whether 'technical AI safety research' is referring only to research that happens before the advent of AGI, separate from the process of actually building it.
In the world where the first AGI system is built over 200 years by 10,000 top technical researchers thinking carefully about how to make it safe, I feel a lot more optimistic about our chances than the world where 10,000 researchers do research for 200 years, then hand some kind of blueprint to the people who are actually building AGI, who may or may not actually follow the blueprint.
I'm interpreting this question as asking about the latter scenario (hand over blueprint). If I interpreted it as the former, my probability would be basically the same as for Q2."
... from respondents whose highest probability was 50–74%:
- 0.2, 0.5: "[...] Deployment-related work seems really important to me, and I take that to be excluded from technical research, hence the large gap."
- 0.68, 0.63: "It's a bit ambiguous whether Q1 covers failures to apply technical AI safety research. Given the elaboration, I'm taking 1 to include the probability that some people do enough AI safety research but others don't know/care/apply it correctly. [...]"
- 0.15, 0.5: "On the answer to 2, I'm counting stuff like 'Human prefs are so inherently incoherent and path-dependent that there was never any robust win available and the only thing any AI could possibly do is shape human prefs into something arbitrary and satisfy those new preferences, resulting in a world that humans wouldn't like if they had taken a slightly different path to reflection and cognitive enhancement than the one the AI happened to lead them down.' I guess that's not quite a central example of 'the value of the future [being] drastically less than it could have been'? [...]"
- 0.1, 0.5: "[...] I think there is some concern that a lot of ways in which 2 is true might be somewhat vacuous: to get to close-to-optimal futures we might need advanced AI capabilities, and these might only get us there if AI systems broadly optimize what we want. So this includes e.g. scenarios in which we never develop sufficiently advanced AI. Even if we read 'AI systems not doing/optimizing what the people deploying them wanted' as presupposing the existence of AI systems, there may be vacuous ways in which non-advanced AI systems don't do what people want, but the key reason is not their 'misalignment' but simply their lack of sufficiently advanced capabilities.
I think on the most plausible narrow reading of 2, maybe my answer is more like 15%." - 0.26, 0.66: "The difference between the numbers is because (i) maybe we will solve alignment but the actor to build TAI will implement the solution poorly or not at all (ii) maybe alignment always comes at the cost of capability and competition will lead to doom (iii) maybe solving alignment is impossible"
- 0.5, 0.5: "[...] My general thoughts: might be more useful to discuss concrete trajectories AI development could follow, and then concrete problems to solve re safety. Here's one trajectory:
1. AI tech gets to the point where it's useful enough to emulate smart humans with little resource costs: AI doesn't look like an 'optimised function for a loss function', rather it behaves like a human who's just very interested in a particular topic (e.g. someone who's obsessed with mathematics, some human interaction, and nothing else).
2. Governments use this to replicate many researchers in research fields, resulting in a massive acceleration of science development.
3. We develop technology which drastically changes the human condition and scarcity of resources: e.g. completely realistic VR worlds, drugs which make people feel happy doing whatever they're doing while still functioning normally, technology to remove the need to sleep and ageing, depending on what is empirically possible.
Dangers from this trajectory: 1. the initial phase of when AI is powerful, but we haven't reached (3), and so there's a chance individual actors could do bad things. 2. Some may think that certain variations of how (3) ends up may be bad for humanity; for example, if we make a 'happiness drug', it might be unavoidable that everyone will take it, but it might also make humanity content by living as monks." - 0.5, 0.7: "For my 0.5 answer to question 1, I'm not imagining an ideal civilizational effort, but am picturing things being 'much better' in the way of alignment research. [...]"
- 0.48, 0.56: "I’m interpreting 'not doing what the people deploying them wanted/intended' as intended to mean 'doing things that are systematically bad for the overall value of the future', but this is very different from what it literally says. The intentions of people deploying AI systems may very well be at odds with the overall value of the future, so the latter could actually benefit from the AI systems not doing what the people deploying them wanted. If I take this phrase at its literal meaning then my answer to question 2 is more like 0.38."
- 0.73, 0.7: "2 is less likely than 1 because I put some weight on x-risk from AI issues other than alignment that have technical solutions."
... from respondents whose highest probability was > 74%:
- 0.6, 0.8: "What are the worlds being compared in question 2? One in which AI systems (somehow manage to) do what the people deploying them wanted/intended vs the default? Or <the former> vs one in which humanity makes a serious effort to solve AI alignment? I answered under the first comparison.
My answer to question 1 might increase if I lean more on allowing 'technical' to include philosophy (e.g., decision theory, ethics, metaphysics, content) and social science (e.g., sociology, economics)." - 0.8, 0.7: "I think that there's a lot riding on how you interpret 'what the people deploying them wanted/intended' in the second question—e.g. does it refer to current values or values after some reflection process?"
- 0.98, 0.96: "I think there's a large chance that the deployers will take an attitude of 'lol we don't care whatevs', but I'm still counting this as 'not doing what they intended' because I expect that the back of their brains will still have expected something other than instant death and empty optimizers producing paperclips. If we don't count this fatality as 'unintended', the answer to question 2 might be more like 0.85.
The lower probability to 2 reflects the remote possibility of deliberately and successfully salvaging a small amount of utility that is still orders of magnitude less than could have been obtained by full alignment, in which possible worlds case 1 would be true and case 2 would be false." - 0.2, 0.9: "[...] I think the basket of things we need a major effort on in order to clear this hurdle is way way broader than technical AI safety research (and inclusive of a massive effort into technical AI safety research), so 1 is a lot lower than 2 because I think 'doing enough technical AI safety research' is necessary but not sufficient [...]"
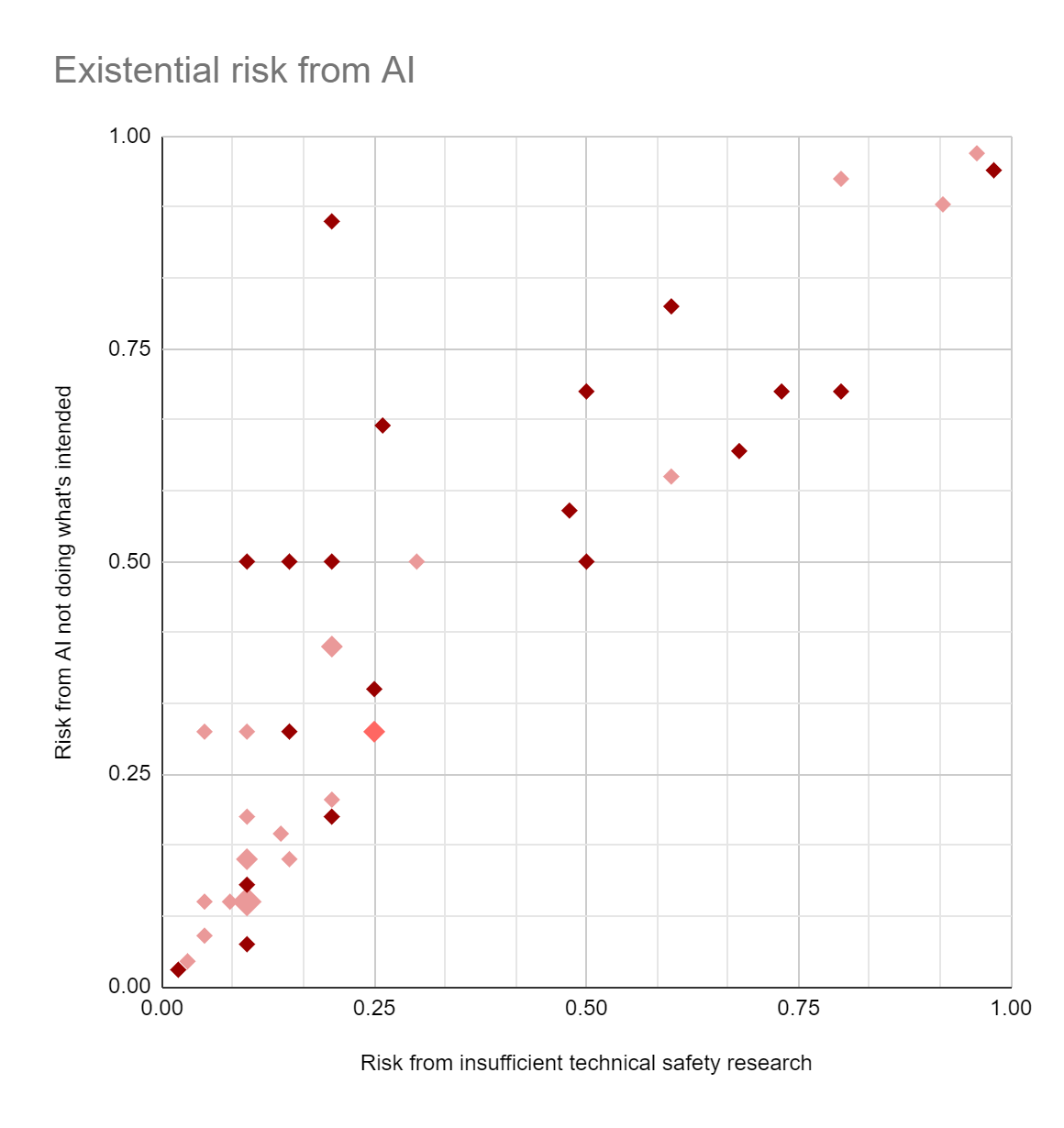
After collecting most of the comments above, I realized that people who gave high x-risk probabilities in this survey tended to leave a lot more non-meta comments; I'm not sure why. Maroon below is "left a non-meta comment", pink is "didn't", red is a {pink, maroon} pair:
Thank you to everyone who participated in the survey or helped distribute it. Additional thanks to Paul Christiano, Evan Hubinger, Rohin Shah, and Carl Shulman for feedback on my question phrasing, though I didn't take all of their suggestions and I'm sure their ideal version of the survey would have looked different.
Footnotes
Changes to the spreadsheet: I redacted respondents’ names, standardized their affiliation input, and randomized their order. I interpreted ‘80’ and ‘70’ in one response, and ‘15’ and ‘15’ in another, as percentages.
I’d originally intended to only survey technical safety researchers and only send the survey to CHAI/DeepMind/FHI/MIRI/OpenAI, but Rohin Shah suggested adding Open Philanthropy and including strategy and forecasting researchers. I’d also originally intended to only ask question #1, but Carl Shulman proposed that I include something like question #2 as well. I think both recommendations were good ones.
The "117 recipients" number is quite approximate, because:
- (a) CHAI's representative gave me a number from memory, which they thought might be off by 1 or 2 people.
- (b) FHI's representative erred on the side of sharing it with a relatively large group, of whom he thought "5-8 people might either self-select into not counting or are people you would not want to count. (Though I would guess that there is decent correlation between the two, which was one reason why I erred on being broad.)"
- (c) Beth from OpenAI shared it in a much larger (85-person) Slack channel; but she told people to only reply if they met my description. OpenAI's contribution to my "117 recipients" number is based on Beth's guess about how many people in the channel fit the description.
Response rates were ~identical for people who received the survey at different times (ignoring any who might have responded but didn't specify an affiliation):
- May 3–4: ~30%
- May 10: ~29%
- May 15–17: ~28%
Overlapping answers:
- (0.2, 0.4) from an FHI technical safety researcher and an affiliation-unspecified technical safety researcher.
- (0.25, 0.3) OpenAI tech safety and affiliation-unspecified tech safety.
- (0.1, 0.15) CHAI tech safety and FHI general staff.
- (0.1, 0.1) FHI tech safety, affiliation-unspecified strategy, FHI general staff.
In case it's visually unclear, I'll note that in the latter case, there are also two FHI strategy researchers who gave numbers very close to (0.1, 0.1).
I checked whether this might have caused MIRI people to respond at a higher rate. 17/117 people I gave the survey to work at MIRI (~15%), whereas 5/27 of respondents who specified an affiliation said they work at MIRI (~19%).
7 comments
Comments sorted by top scores.
comment by Rohin Shah (rohinmshah) · 2021-06-13T21:00:17.078Z · LW(p) · GW(p)
Planned summary for the Alignment Newsletter:
This post reports on the results of a survey sent to about 117 people working on long-term AI risk (of which 44 responded), asking about the magnitude of the risk from AI systems. I’d recommend reading the exact questions asked, since the results could be quite sensitive to the exact wording, and as an added bonus you can see the visualization of the responses. In addition, respondents expressed _a lot_ of uncertainty in their qualitative comments. And of course, there are all sorts of selection effects that make the results hard to interpret.
Keeping those caveats in mind, the headline numbers are that respondents assigned a median probability of 20% to x-risk caused due to a lack of enough technical research, and 30% to x-risk caused due to a failure of AI systems to do what the people deploying them intended, with huge variation (for example, there are data points at both ~1% and ~99%).
Planned opinion:
I know I already harped on this in the summary, but these numbers are ridiculously non-robust, and involve tons of selection biases. You probably shouldn’t conclude much from them about how much risk from AI there really is. Don’t be the person who links to this survey with the quote “experts predict 30% chance of doom from AI”.
comment by Josh Jacobson (joshjacobson) · 2021-06-02T18:58:03.862Z · LW(p) · GW(p)
I redid the visualization of this on Tableau so it'd be colorblind-friendly and more filterable: https://public.tableau.com/app/profile/josh3425/viz/RevisualizationofRobBensingersSurveyResultGraph/Dashboard1
Replies from: RobbBB↑ comment by Rob Bensinger (RobbBB) · 2021-06-02T19:10:37.842Z · LW(p) · GW(p)
Thanks, Josh!
comment by A Ray (alex-ray) · 2021-06-04T00:24:56.702Z · LW(p) · GW(p)
Thanks for doing this research and sharing the results.
I'm curious if you or MIRI plan to do more of this kind of survey research in the future, or its just a one-off project.
↑ comment by Rob Bensinger (RobbBB) · 2021-06-04T00:58:32.697Z · LW(p) · GW(p)
One-off, though Carlier, Clarke, and Schuett have a similar survey coming out in the next week [EA(p) · GW(p)].
comment by steven0461 · 2021-06-02T00:34:21.311Z · LW(p) · GW(p)
A few of the answers seem really high. I wonder if anyone interpreted the questions as asking for P(loss of value | insufficient alignment research) and P(loss of value | misalignment) despite Note B.
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2021-06-13T20:59:43.885Z · LW(p) · GW(p)
I know at least one person who works on long-term AI risk who I am confident really does assign this high a probability to the questions as asked. I don't know if this person responded to the survey, but still, I expect that the people who gave those answers really did mean them.