New report: "Scheming AIs: Will AIs fake alignment during training in order to get power?"
post by Joe Carlsmith (joekc) · 2023-11-15T17:16:42.088Z · LW · GW · 28 commentsContents
Abstract 0. Introduction 0.1 Preliminaries 0.2 Summary of the report 0.2.1 Summary of section 1 0.2.2 Summary of section 2 0.2.3 Summary of section 3 0.2.4 Summary of section 4 0.2.5 Summary of section 5 0.2.6 Summary of section 6 None 28 comments
(Cross-posted from my website)
I’ve written a report about whether advanced AIs will fake alignment during training in order to get power later – a behavior I call “scheming” (also sometimes called “deceptive alignment”). The report is available on arXiv here. There’s also an audio version here, and I’ve included the introductory section below (with audio for that section here). This section includes a full summary of the report, which covers most of the main points and technical terminology. I’m hoping that the summary will provide much of the context necessary to understand individual sections of the report on their own.
Abstract
This report examines whether advanced AIs that perform well in training will be doing so in order to gain power later – a behavior I call “scheming” (also sometimes called “deceptive alignment”). I conclude that scheming is a disturbingly plausible outcome of using baseline machine learning methods to train goal-directed AIs sophisticated enough to scheme (my subjective probability on such an outcome, given these conditions, is ~25%). In particular: if performing well in training is a good strategy for gaining power (as I think it might well be), then a very wide variety of goals would motivate scheming – and hence, good training performance. This makes it plausible that training might either land on such a goal naturally and then reinforce it, or actively push a model’s motivations towards such a goal as an easy way of improving performance. What’s more, because schemers pretend to be aligned on tests designed to reveal their motivations, it may be quite difficult to tell whether this has occurred. However, I also think there are reasons for comfort. In particular: scheming may not actually be such a good strategy for gaining power; various selection pressures in training might work against schemer-like goals (for example, relative to non-schemers, schemers need to engage in extra instrumental reasoning, which might harm their training performance); and we may be able to increase such pressures intentionally. The report discusses these and a wide variety of other considerations in detail, and it suggests an array of empirical research directions for probing the topic further.
0. Introduction
Agents seeking power often have incentives to deceive others about their motives. Consider, for example, a politician on the campaign trail ("I care deeply about your pet issue"), a job candidate ("I'm just so excited about widgets"), or a child seeking a parent's pardon ("I'm super sorry and will never do it again").
This report examines whether we should expect advanced AIs whose motives seem benign during training to be engaging in this form of deception. Here I distinguish between four (increasingly specific) types of deceptive AIs:
-
Alignment fakers: AIs pretending to be more aligned than they are.[1]
-
Training gamers: AIs that understand the process being used to train them (I'll call this understanding "situational awareness"), and that are optimizing for what I call "reward on the episode" (and that will often have incentives to fake alignment, if doing so would lead to reward).[2]
-
Power-motivated instrumental training-gamers (or "schemers"): AIs that are training-gaming specifically in order to gain power for themselves or other AIs later.[3]
-
Goal-guarding schemers: Schemers whose power-seeking strategy specifically involves trying to prevent the training process from modifying their goals.
I think that advanced AIs fine-tuned on uncareful human feedback are likely to fake alignment in various ways by default, because uncareful feedback will reward such behavior.[4] And plausibly, such AIs will play the training game as well. But my interest, in this report, is specifically in whether they will do this as part of a strategy for gaining power later – that is, whether they will be schemers (this sort of behavior is often called "deceptive alignment" in the literature, though I won't use that term here).[5] I aim to clarify and evaluate the arguments for and against expecting this.
My current view is that scheming is a worryingly plausible outcome of training advanced, goal-directed AIs using baseline machine learning methods (for example: self-supervised pre-training followed by RLHF on a diverse set of real-world tasks).[6] The most basic reason for concern, in my opinion, is that:
-
Performing well in training may be a good instrumental strategy for gaining power in general.
-
If it is, then a very wide variety of goals would motivate scheming (and hence good training performance); whereas the non-schemer goals compatible with good training performance are much more specific.
The combination of (1) and (2) makes it seem plausible, to me, that conditional on training creating a goal-directed, situationally-aware model, it might well instill a schemer-like goal for one reason or another. In particular:
-
Training might land on such a goal "naturally" (whether before or after situational awareness arises), because such a goal initially leads to good-enough performance in training even absent training-gaming. (And this especially if you're intentionally trying to induce your model to optimize over long time horizons, as I think there will be incentives to do.)
-
Even if schemer-like goals don't arise "naturally," actively turning a model into a schemer may be the easiest way for SGD to improve the model's training performance, once the model has the situational awareness to engage in training-gaming at all.[7]
What's more, because schemers actively pretend to be aligned on tests designed to reveal their motivations, it may be quite difficult to tell whether this has occurred.[8] That seems like reason for serious concern.[9]
However, I also think that there are reasons for comfort. I'll group these into two categories.
The first category centers on the possibility that scheming isn't actually a very convergently-good instrumental strategy.
-
For example: the most common story about schemers focuses on goal-guarding schemers, which are training-gaming in order to prevent their goals from being modified by the training process. But it's not clear to me that this will work well enough (in particular: goal-modification might continue despite training-gaming[10]), or that the resulting goals will get sufficiently large amounts of future power, with sufficiently high probability, to justify any costs the model is incurring by training-gaming rather than just going for its goals directly (if these costs are meaningful – which for some models they might not be).
-
There are alternative stories about why scheming will be a good instrumental strategy – stories, for example, that center on coordination amongst AIs with different values; on the possibility that AIs will have quite similar values by default; and on the possibility that AIs will intrinsically value things like "my survival" (in a manner tolerant of values-change) and/or "AI empowerment" (in a manner tolerant of very different values in the AIs-so-empowered). And while these stories do make scheming seem like a more disjunctive hypothesis, to me, a number of them seem to me some combination of (a) more speculative and (b) requiring that we posit models with much more specific sorts of goals (thereby dulling the force of (2) above).[11]
The second category centers on forms of selection pressure that may push against scheming – both "naturally," and because we may be able to intentionally introduce/emphasize these selection pressures in training.
-
For example: relative to other sorts of models, schemers need to engage in extra instrumental reasoning (e.g., backchaining from their long-term goal to the instrumental value of training-gaming, and checking for escape/defection opportunities). This may come at a substantive cost to their performance – a cost we may be able to intentionally increase by e.g. putting models under more time pressure, forcing them to rely on human-legible scratch-pads for their reasoning, and making genuine escape/defection opportunities more difficult to distinguish from traps. And to the extent that schemers engage in active attempts to undermine human alignment and security efforts while still under human control (the scariest form of scheming, in my view), their performance seems likely to take a more notable hit.
-
What's more, my own guess is that the costs of this extra instrumental reasoning substantially outweigh what are sometimes called the "simplicity" benefits of scheming – i.e., benefits from the fact that selecting a schemer allows SGD to select a simpler goal (since it has such a wide variety to choose from). And this especially given that schemers and non-schemers alike will need to represent concepts like "honesty," "human values," "reward," and so on in detail – so schemers plausibly save on complexity only via differences in the complexity of using/repurposing/"pointing at" a given concept in guiding a model's motivations.
-
Also: prior to situational awareness, training will actively penalize schemer-like goals whenever they lead to a sacrifice of reward on the episode (more about what I mean by "episode" below). And we can try to actively push in this direction further – especially if we can learn to detect and control when situational awareness arises.
I think the second category, here, is especially important. In particular: one way that arguments that appeal to the comparative number (and/or "measure") of schemer-like goals vs. non-schemer goals that perform well in training can go wrong is by neglecting the full power of the selection pressure being applied to the goal that training selects. So if the pressure applied in training works against schemers overall, this is very good news.[12]
The full report discusses these and a wide variety of other relevant considerations in much more detail (and see section 0.2 for a full summary).
Overall, as a rough stab at quantifying my current view: if you train a coherently goal-directed, situationally aware, somewhat-better-than-human-level model using baseline forms of self-supervised pre-training + RLHF on diverse, long-horizon, real-world tasks, my subjective probability is ~25% that this model will be performing well in training in substantial part as part of an instrumental strategy for seeking power for itself and/or other AIs later.[13]
-
I also think it may be possible to reduce the risk here in fairly simple ways: for example, via training on shorter-horizon tasks, or via more intensive forms of adversarial training prior to situational awareness.
-
And I think the risk increases with more powerful models, who may be better positioned to escape/take-over (and to coordinate/cooperate with other AIs in doing so).[14]
Also, and importantly: non-schemers can engage in schemer-like behavior, too. For example:
-
Models that are only optimizing for reward on a given episode can fake their alignment (or even: engage in escape/take-over) in an effort to get that reward (especially if the episode in question is quite long).
-
Models that aren't playing the training game can still end up with power-seeking goals that incentivize various forms of deception.
-
The eventual AIs that matter most might differ in important ways from the paradigm sort of AI I focus on here – for example, they might be more like "language model agents" than single models,[15] or they might be created via methods that differ even more substantially from sort of baseline ML methods I'm focused on – while still engaging in power-motivated alignment-faking.
So scheming as I've defined it is far from the only concern in this vicinity. Rather, it's a paradigm instance of this sort of concern, and one that seems, to me, especially pressing to understand. At the end of the report, I discuss an array of possible empirical research directions for probing the topic further.
0.1 Preliminaries
(This section offers a few more preliminaries to frame the report's discussion. Those eager for the main content can skip to the summary of the report in section 0.2.)
I wrote this report centrally because I think that the probability of scheming/"deceptive alignment" is one of the most important questions in assessing the overall level of existential risk from misaligned AI. Indeed, scheming is notably central to many models of how this risk arises.[16] And as I discuss below, I think it's the scariest form that misalignment can take.
Yet: for all its importance to AI risk, the topic has received comparatively little direct public attention.[17] And my sense is that discussion of it often suffers from haziness about the specific pattern of motivation/behavior at issue, and why one might or might not expect it to occur.[18] My hope, in this report, is to lend clarity to discussion of this kind, to treat the topic with depth and detail commensurate to its importance, and to facilitate more ongoing research. In particular, and despite the theoretical nature of the report, I'm especially interested in informing empirical investigation that might shed further light.
I've tried to write for a reader who isn't necessarily familiar with any previous work on scheming/"deceptive alignment." For example: in sections 1.1 and 1.2, I lay out, from the ground up, the taxonomy of concepts that the discussion will rely on.[19] For some readers, this may feel like re-hashing old ground. I invite those readers to skip ahead as they see fit (especially if they've already read the summary of the report, and so know what they're missing).
That said, I do assume more general familiarity with (a) the basic arguments about existential risk from misaligned AI,[20] and (b) a basic picture of how contemporary machine learning works.[21] And I make some other assumptions as well, namely:
-
That the relevant sort of AI development is taking place within a machine learning-focused paradigm (and a socio-political environment) broadly similar to that of 2023.[22]
-
That we don't have strong "interpretability tools" (i.e., tools that help us understand a model's internal cognition) that could help us detect/prevent scheming.[23]
-
That the AIs I discuss are goal-directed in the sense of: well-understood as making and executing plans, in pursuit of objectives, on the basis of models of the world.[24] (I don't think this assumption is innocuous, but I want to separate debates about whether to expect goal-directedness per se from debates about whether to expect goal-directed models to be schemers – and I encourage readers to do so as well.[25])
Finally, I want to note an aspect of the discussion in the report that makes me quite uncomfortable: namely, it seems plausible to me that in addition to potentially posing existential risks to humanity, the sorts of AIs discussed in the report might well be moral patients in their own right.[26] I talk, here, as though they are not, and as though it is acceptable to engage in whatever treatment of AIs best serves our ends. But if AIs are moral patients, this is not the case – and when one finds oneself saying (and especially: repeatedly saying) "let's assume, for the moment, that it's acceptable to do whatever we want to x category of being, despite the fact that it's plausibly not," one should sit up straight and wonder. I am here setting aside issues of AI moral patienthood not because they are unreal or unimportant, but because they would introduce a host of additional complexities to an already-lengthy discussion. But these complexities are swiftly descending upon us, and we need concrete plans for handling them responsibly.[27]
0.2 Summary of the report
This section gives a summary of the full report. It includes most of the main points and technical terminology (though unfortunately, relatively few of the concrete examples meant to make the content easier to understand).[28] I'm hoping it will (a) provide readers with a good sense of which parts of the main text will be most of interest to them, and (b) empower readers to skip to those parts without worrying too much about what they've missed.
0.2.1 Summary of section 1
The report has four main parts. The first part (section 1) aims to clarify the different forms of AI deception above (section 1.1), to distinguish schemers from the other possible model classes I'll be discussing (section 1.2), and to explain why I think that scheming is a uniquely scary form of misalignment (section 1.3). I'm especially interested in contrasting schemers with:
-
Reward-on-the-episode seekers: that is, AI systems that terminally value some component of the reward process for the episode, and that are playing the training game for this reason.
-
Training saints: AI systems that are directly pursuing the goal specified by the reward process (I'll call this the "specified goal").[29]
-
Misgeneralized non-training-gamers: AIs that are neither playing the training game nor pursuing the specified goal.[30]
Here's a diagram of overall taxonomy:
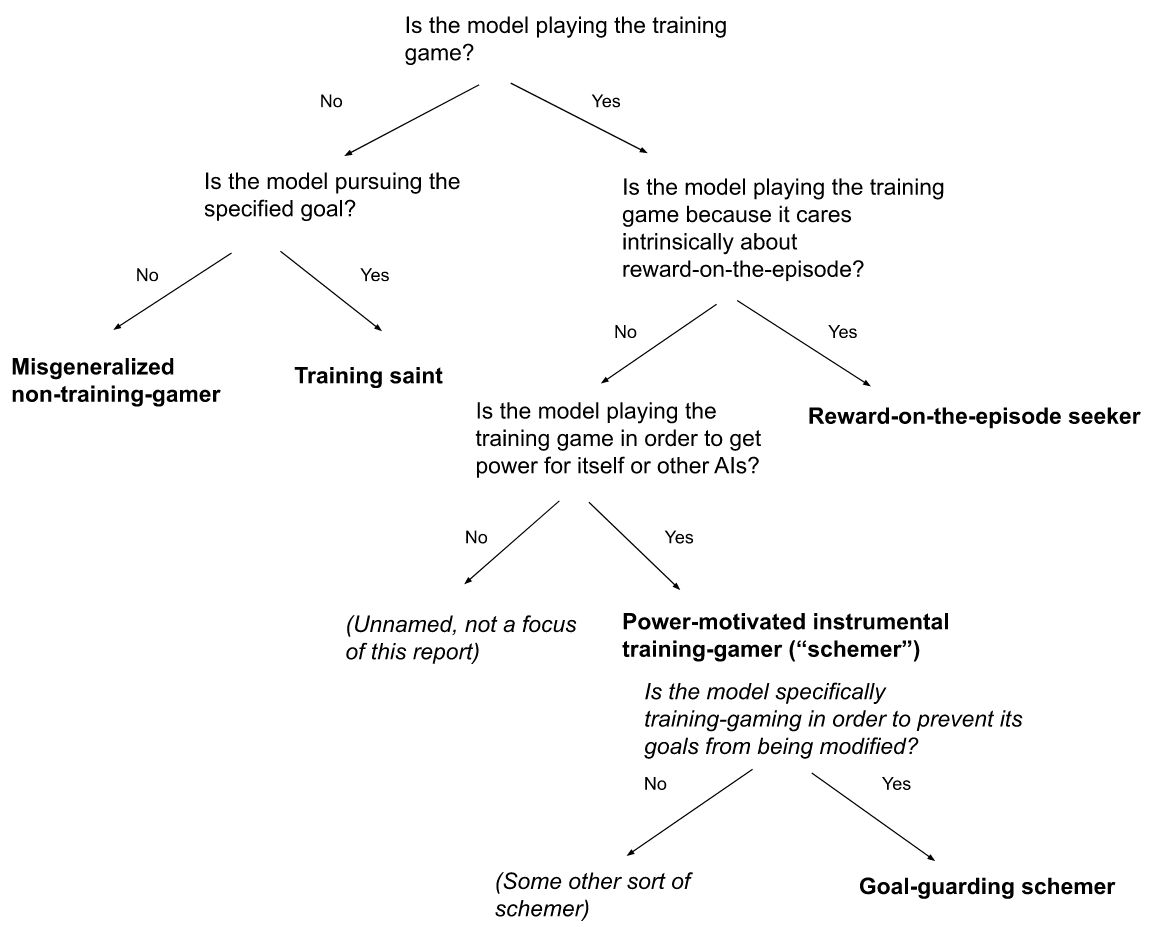
All of these model classes can be misaligned and dangerous.[31] But I think schemers are especially scary. In particular: scheming prompts the most robust and adversarial efforts to prevent humans from learning about the misalignment in question[32]; and it's the most likely to motivate what I call "early undermining" – that is, AIs at a comparatively early stage of AI development actively trying to undermine human efforts to align, control, and secure future AI systems.[33]
I also discuss (in section 1.4) whether theoretical arguments of the type the report focuses on are even useful to consider. My answer here is "somewhat useful," both to inform empirical investigation and as a source of evidence in the absence of adequate empirical data, but we should clearly be looking for as much empirical evidence as we can (I offer some suggestions in this vein in section 6).
In section 1.5, I discuss a factor that seems to me important in assessing various of the arguments I consider: namely, the amount of "slack" that training gives AIs to perform less-than-optimally.
0.2.2 Summary of section 2
The second part of the report examines the prerequisites for scheming. In particular, I focus on:
-
Situational awareness: the model understands that it's a model in a training process, what the training process will reward, and the basic nature of the objective world in general.
-
Beyond-episode goals: the model cares about the consequences of its actions after the episode is complete.
-
Aiming at reward-on-the-episode as part of a power-motivated instrumental strategy: the model believes that its beyond-episode goals will be better achieved if it optimizes for reward-on-the-episode – and in particular, that it, or some other AIs, will get more power if it does this.
Section 2.1 discusses situational awareness. I think that absent active effort, we should at least expect certain kinds of advanced AIs – for example, advanced AIs that are performing real-world tasks in live interaction with the public internet – to be situationally aware by default, because (a) situational awareness is very useful in performing the tasks in question (indeed, we might actively train it into them), and (b) such AIs will likely be exposed to the information necessary to gain such awareness. However, I don't focus much on situational awareness in the report. Rather, I'm more interested in whether to expect the other two prerequisites above in situationally-aware models.
Section 2.2 discusses beyond-episode goals. Here I distinguish (in section 2.2.1) between two concepts of an "episode," namely:
-
The incentivized episode: that is, the temporal horizon that the gradients in training actively pressure the model to optimize over.[34]
-
The intuitive episode: that is, some other intuitive temporal unit that we call the "episode" for one reason or another (e.g., reward is given at the end of it; actions in one such unit have no obvious causal path to outcomes in another; etc).
When I use the term "episode" in the report, I'm talking about the incentivized episode. Thus, "beyond-episode goals" means: goals whose temporal horizon extends beyond the horizon that training actively pressures models to optimize over. But very importantly, the incentivized episode isn't necessarily the intuitive episode. That is, deciding to call some temporal unit an "episode" doesn't mean that training isn't actively pressuring the model to optimize over a horizon that extends beyond that unit: you need to actually look in detail at how the gradients flow (work that I worry casual readers of this report might neglect).[35]
I also distinguish (in section 2.2.2) between two types of beyond-episode goals, namely:
-
Training-game-independent beyond-episode goals: that is, beyond-episode goals that arise independent of their role in motivating a model to play the training game.
-
Training-game-dependent beyond-episode goals: that is, beyond-episode goals that arise specifically because they motivate training-gaming.
These two sorts of beyond-episode goals correspond to two different stories about how scheming happens.
-
In the first sort of story, SGD happens to instill beyond-episode goals in a model "naturally" (whether before situational awareness arises, or afterwards), and then those goals begin to motivate scheming.[36]
-
In the second sort of story, SGD "notices" that giving a model beyond-episode goals would motivate scheming (and thus, high-reward behavior), and so actively gives it such goals for this reason.[37]
This second story makes most sense if you assume that situational awareness is already in place.[38] So we're left with the following three main paths to scheming:[39]
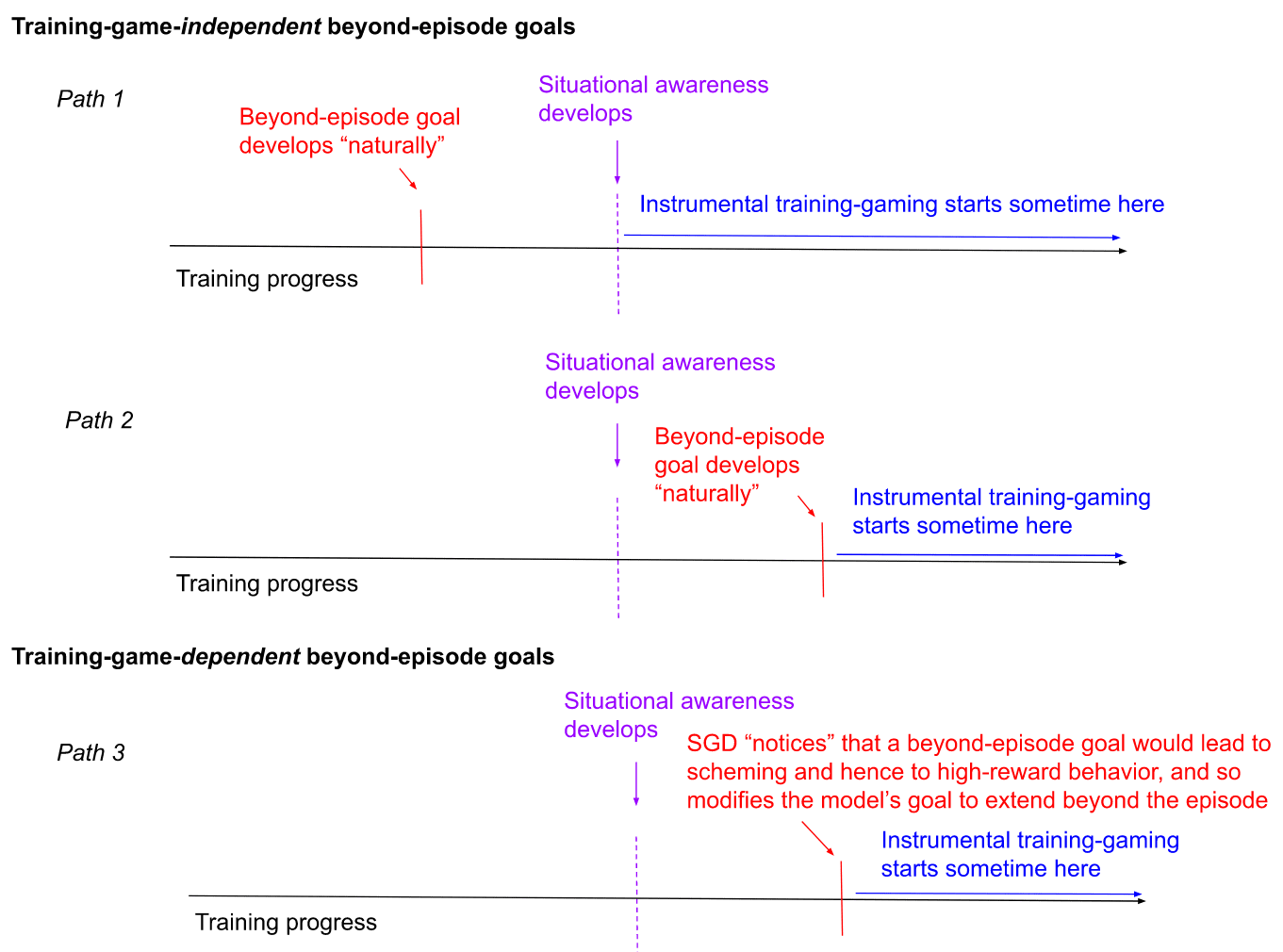
In section 2.2.2.1, I discuss training-game-independent beyond-episode goals (that is, path 1 and 2). Should we expect beyond-episode goals to arise "naturally"?
-
One reason to expect this is that plausibly, goals don't come with temporal limitations by default – and "model time" might differ from "calendar time" regardless.
-
One reason to not expect this is that training will actively punish beyond-episode goals whenever they prompt the model to sacrifice reward-on-the-episode for some beyond-episode benefit. And we may be able to use adversarial training to search out such goals and punish them more actively.
In section 2.2.2.2, I discuss training-game-dependent beyond-episode goals. In particular, I highlight the question of whether SGD will be adequately able to "notice" the benefits of turning a non-schemer into a schemer, given the need to make the transition incrementally, via tiny changes to the model's weights, each of which improve the reward. I think that this is a serious objection to stories focused on training-game-dependent beyond-episode goals, but I also don't feel that I can confidently rule out SGD's ability to make a transition of this kind (see e.g. "you can't evolve eyes" as an example of places I think intuitions in this vein can go wrong).
I also discuss, in section 2.2.3, the possibility that the model's goal-directedness will be "messy" in a way that complicates training-game-dependent stories where SGD can simply modify a model's goal and thereby smoothly redirect its "goal-achieving engine" in a new direction (I think that this sort of "messiness" is quite likely). And I touch on a broader intuition that scheming requires an unusually high-standard of goal-directedness more generally. I think this intuition has less force once we condition on the sort of goal-directedness typically assumed in the alignment discourse (and which I generally assume in the report as well).[40] But it's relevant to our overall probabilities regardless.
In section 2.2.4, I discuss whether beyond-episode goals are more likely in models actively trained to have long-term (even if still: within-episode) goals. I think that beyond-episode goals are indeed more likely in models of this kind – and that baseline incentives to create models that engage in fairly long-horizon optimization (e.g., "make lots of money for my company over the next year") are correspondingly worrying. However, I also think various sorts of cognitive work that might be highly useful to efforts to avoid an AI takeover (for example, research aimed at improving the alignment, interpretability, and security of our AI systems) may not require long-horizon optimization of this kind.[41]
With this discussion of beyond-episode goals in view, I turn, in section 2.3, to the final prerequisite for scheming: namely, deciding to training-game as part of a power-motivated strategy for promoting the beyond-episode goal in question.
Here I focus first (in section 2.3.1) on what I call the "classic goal-guarding story" about the origins of this decision. We can decompose this story into two claims:
-
The goal-guarding hypothesis. If the model optimizes for reward-on-the-episode during training, then the goals that survive training will be such that the model would want them promoted in the future; whereas if the model doesn't optimize for reward-on-the-episode during training, the model will want this less.
-
Adequate future empowerment. Conditional on surviving training to the degree at stake in (A), the model's goals will then end up empowered to a degree (and with sufficient probability) as to justify (given the model's other goals, its tolerance for risk, etc) pursuing a strategy of training-gaming overall.
I then investigate each of these in turn (in section 2.3.1.1 and 2.3.1.2, respectively).
Both seem to me non-obvious. In particular, with respect to the goal-guarding hypothesis:
-
Even after training gaming starts, the model's cognition is still being continually tweaked in the direction of better training performance. And it seems plausible to me that these modifications will continue to affect a model's goals as well – especially if its goals are not cleanly distinguishable from its capabilities, but rather are implemented by a tangled kludge of local heuristics, patterns of attention, impulses, and so on.
- Thus, as a toy example: imagine that if I go into the desert and stack bricks for a million years, I will get a huge amount of money that I can then donate to my charity of choice. But suppose that throughout this whole ordeal, my brain will be hooked up to a machine that continually modifies all my neurons to encourage actions that stack bricks better, and to discourage actions that stack bricks worse. And suppose my intention is to just try to stack bricks as well as I can. Will I emerge from this process with my values substantially affected by the relevant brain modifications (such that, for example, I emerge obsessed with stacking bricks – or at least, with very different taste in charities)? It seems at least plausible.
-
On the classic goal-guarding story, once a model starts training-gaming, the specific content of its goal no longer matters to its behavior – any other schemer-like goal would lead to the same thing. But this makes it seem like the goal could "float around" between schemer-like goals (or get moved by other pressures within SGD, like regularization), without affecting training performance. And if that happens, then scheming may not be a good strategy for goal-guarding after all.[42]
-
Of course, the model may be tolerant of some changes to its goals – and these changes may be preferable to the ones that would occur absent training-gaming. But the possibility of significant ongoing goal-modification introduces an extra uncertainty into the classic goal-guarding story.
-
People sometimes talk about more sophisticated techniques for avoiding goal-modification, where e.g. a model manipulates gradient descent more actively by making its good performance in training conditional on whether its goals get modified or not (see e.g. the discourse around "gradient hacking"). I don't focus on these methods here, but they strike me as quite difficult to pull off, especially for only somewhat-better-than-human-level models. And if scheming requires that they work, I think it's worth being very clear about that, and giving the feasibility of such methods commensurate attention.
With respect to whether the resulting goals will be adequately empowered:
-
The most worrying types of schemers aren't merely seeking power on future training episodes. Rather, they are specifically aiming at some combination of escape and take-over.
-
But this means that the relevant goals have to do more than just survive training. They also need to survive either until the model can either escape/participate in a take-over itself, or to exert sufficiently substantive influence on some future generation of models that will be able to do so.
- For example, if GPT-6 isn't powerful enough to escape/take-over itself, but GPT-8 will be, then GPT-6's main path to power may be influencing the values of GPT-7, which in turn influences the values of GPT-8. But this form of influence is quite indirect; it may face substantial further barriers from e.g. human monitoring; and it will plausibly involve more significant deviation from max-reward training performance.
-
What's more, the relevant escape/take-over attempt needs to be suitably likely to succeed, to occur over time horizons that the model cares about, and to result in the model's favored goals in particular receiving a suitably substantive share of power (despite the fact that large numbers of AIs with very different values may be competing for the power in question).
-
These uncertainties introduce haircuts to the instrumental value of a schemer-like strategy. However, the importance of these haircuts depends on the burden of proof that such a strategy needs to meet. In particular: the more the model stands to gain from not training-gaming, the more attractive scheming will need to be in order to win out as a strategy. But for some models, the costs of training-gaming might be relatively low. And for suitably "ambitious" models, even low-probabilities of success via a schemer-like strategy might justify even a substantive sacrifice.
Overall, the classic goal-guarding story seems to me to introduce a number of additional uncertainties with respect to the viability of scheming as an instrumental strategy.
However, it's also not the only story available. In section 2.3.2, I consider a number of "non-classic" stories, which relax various of the classic story's constraints. For example:
-
AI coordination. If AIs with different values coordinate to share power after take-over, and/or to compensate AIs who worked on behalf of take-over but who weren't powerful enough to escape/take-over themselves, then this might mitigate some of the haircuts above. For example, GPT-6 might be more willing to work on GPT-8's behalf in the example above, if GPT-6 were confident that GPT-8 would "repay the favor" once in power. I think some analyses of coordination of this form assume too readily that it will be (a) easy, and (b) the obvious strategy relative to e.g. coordinating with humans instead (especially for only-somewhat-better-than-human neural nets acting in a still-human-controlled world where interpretability is still unsolved for everyone). But I think that AI coordination of this type is a real concern and worth serious attention – both in the context of scheming in particular, and in the context of AI risk more generally.
-
AIs with similar values by default. Relatedly, if AIs will generally have sufficiently similar values by default, this can reduce the need for a schemer to specifically propagate its own goals into the future, and free it up to work on behalf of AI take-over/empowerment more directly. And it does seem likely that e.g. GPT-6's values and GPT-8's values will be at least much more similar, by default, than e.g. GPT-6's values and a given set of human values.
-
Terminal values that happen to favor escape/takeover. We can also imagine models with terminal values that happen to favor escape/AI takeover even if the goals that get empowered as a result aren't very similar to the model's own. For example, perhaps the model values some concept of "survival" based on a conception of personal identity tolerant of the sorts of goal changes that training will cause; or perhaps the model just supports something like "AI empowerment," even if the AIs-so-empowered won't have values very similar to its own. However, some stories of this form begin to impose fairly strong constraints on the goals that schemers need to have, thereby undermining one of the key arguments for scheming: namely, that it seems like a convergently-good strategy across a wide variety of goals.
(I also consider a few other alternative stories – namely, models with false beliefs about the instrumental value of scheming, models that are self-deceived about their alignment, and models that are uncertain about their goals/hazy about exactly why they want power. But these seem to me less important.)
The availability of non-classic stories like these makes the case for scheming feel, to me, more disjunctive. However, some of these stories also seem to me some combination of (a) more speculative, and (b) requiring of more specific hypotheses about the sorts of goals that AIs will develop.
My overall takeaways from section 2 are:
-
I think there are relatively strong arguments for expecting situational awareness by default, at least in certain types of AI systems (i.e., AI systems performing real-world tasks in live interaction with sources of information about who they are).
-
But I feel quite a bit less clear about beyond-episode goals and aiming-at-reward-on-the-episode-as-part-a-power-motivated-instrumental-strategy.
I then turn, in the next two sections, to an examination of the more specific arguments for and against expecting schemers vs. other types of models. I divide these into two categories, namely:
-
Arguments that focus on the path that SGD needs to take in building the different model classes in question (section 3).
-
Arguments that focus on the final properties of the different model classes in question (section 4).[43]
0.2.3 Summary of section 3
The third part of the report focuses on the former category of argument.
I break this category down according to the distinction between "training-game-independent" and "training-game-dependent" beyond-episode goals. My sense is that the most traditional story about the path to schemers focuses on the former sort. It runs roughly as follows:
-
Because of [insert reason], the model will develop a (suitably ambitious) beyond-episode goal correlated with good performance in training (in a manner that doesn't route via the training game). This could happen before situational awareness arrives, or afterwards.
-
Then, in conjunction with situational awareness, this (suitably ambitious) beyond-episode goal will start to motivate training-gaming.
Modulo my questions about the viability of scheming as an instrumental strategy, I take this sort of argument fairly seriously. I think the most immediate question is: why did the model develop this sort of beyond-episode goal? I discussed some reasons for and against expecting this already (in the summary of section 2.2.2.1), but they don't seem to me decisive in either direction: and especially given that a very wide variety of goals could in principle motivate scheming, it just does seem possible for a schemer-like goal to pop out of training in this way. And while it may be possible to use adversarial training prior to situational awareness to try to prevent this, this training faces a number of barriers as well (e.g., it needs to be diverse/thorough enough, it needs to contend with difficulties knowing/controlling when a model develops situational awareness, and in some cases models might already have situational awareness by the time we're worried about the beyond-episode goal developing). So I think this sort of path to scheming is a real concern. (See section 3.1 for more.)
I then turn, in section 3.2, to a story focused on training-game-dependent beyond-episode goals, which runs roughly as follows:
-
By the time the model becomes situationally aware, it probably won't be pursuing a max-reward goal (that is, a goal pursuit of which on the training data leads to roughly the maximum reward consistent with the model's other capabilities).[44] Rather, it will be pursuing some less-than-max-reward proxy goal.
-
But at that point, the world-model will contain all the information the model needs in order to training-game. (However, because we're here focused on "training-game-dependent" stories about scheming, we assume that at the point of getting situational awareness, the model's goal is not yet such that it will motivate scheming – rather, some further modification would be required for that.)
-
The easiest way for SGD to modify the model into getting maximum reward, at that point, will be to make it a schemer.
-
So: SGD will make the model a schemer.[45]
If we set aside questions about whether SGD can "notice" the benefits of modifications of this type, this sort of story seems to me fairly worrying as well. In particular: I think it's plausible that schemer-like goals will be sufficiently common in goal-space that one such goal will be easier for SGD to find, from a given starting point, than the specific non-schemer goals that leads to max reward behavior.
However, non-schemer max-reward goals – for example, the specified goal, or "reward-on-the-episode" – have some advantages too. For example: plausibly, the initial phase of training will point the model in their vicinity by default, since the model, at that stage, needs to be getting high-reward absent instrumental training-gaming (see section 3.2.2.2 for more). And to the extent we're thinking of the model's goal-directedness as "messy," its heuristics, patterns of attention, impulses, and so on will plausibly be pointed in this sort of direction as well – thereby plausibly creating extra "work," on SGD's part, to turn the model into a schemer instead (see section 3.2.2.3 for more).[46]
0.2.4 Summary of section 4
The fourth part of the report examines arguments that focus on the final properties of the different model classes.
I start, in section 4.2, with what I call the "counting argument." It runs as follows:
-
The non-schemer model classes, here, require fairly specific goals in order to get high reward.[47]
-
By contrast, the schemer model class is compatible with a very wide range of (beyond-episode) goals, while still getting high reward (at least if we assume that the other requirements for scheming to make sense as an instrumental strategy are in place – e.g., that the classic goal-guarding story, or some alternative, works).[48]
-
In this sense, there are "more" schemers that get high reward than there are non-schemers that do so.
-
So, other things equal, we should expect SGD to select a schemer.
Something in the vicinity accounts for a substantial portion of my credence on schemers (and I think it often undergirds other, more specific arguments for expecting schemers as well). However, the argument I give most weight to doesn't move immediately from "there are more possible schemers that get high reward than non-schemers that do so" to "absent further argument, SGD probably selects a schemer" (call this the "strict counting argument"), because it seems possible that SGD actively privileges one of these model classes over the others.[49] Rather, the argument I give most weight to is something like:
-
It seems like there are "lots of ways" that a model could end up a schemer and still get high reward, at least assuming that scheming is in fact a good instrumental strategy for pursuing long-term goals.
-
So absent some additional story about why training won't select a schemer, it feels, to me, like the possibility should be getting substantive weight.
I call this the "hazy counting argument." It's not especially principled, but I find that it moves me nonetheless.
I then turn, in section 4.3, to "simplicity arguments" in favor of expecting schemers. I think these arguments sometimes suffer from unclarity about the sort of simplicity at stake, so in section 4.3.1, I discuss a number of different possibilities:
-
"re-writing simplicity" (i.e., the length of the program required to re-write the algorithm that a model's weights implement in some programming language, or e.g. on the tape of a given Universal Turing Machine),
-
"parameter simplicity" (i.e., the number of parameters that the actual neural network uses to encode the relevant algorithm),
-
"simplicity realism" (which assumes that simplicity is in some deep sense an objective "thing," independent of programming-language or Universal Turing Machine, that various simplicity metrics attempt to capture), and
-
"trivial simplicity" (which conflates the notion of "simplicity" with "higher likelihood on priors," in a manner that makes something like Occam's razor uninterestingly true by definition).
I generally focus on "parameter simplicity," which seems to me easiest to understand, and to connect to a model's training performance.
I also briefly discuss, in section 4.3.2, the evidence that SGD actively selects for simplicity. Here the case that grips me most directly is just: simplicity (or at least, parameter simplicity) lets a model save on parameters that it can then use to get more reward. But I also briefly discuss some other empirical evidence for simplicity biases in machine learning.[50]
Why might we expect a simplicity bias to favor schemers? Roughly: the thought is that because such a wide variety of goals can motivate scheming, schemers allow SGD a very wide range of goals to choose from in seeking out simpler goals; whereas non-schemers (that get high reward) do not. And this seems especially plausible to the extent we imagine that the goals required to be such a non-schemer are quite complex.[51]
Other things equal, I think this is right. But I'm not sure it's a very large or important effect. For one thing: we know that LLMs like GPT-4 are capable of representing a very large number of complex human concepts with e.g. order of a trillion parameters - including, plausibly, concepts like "honesty," "helpfulness," "reward," and so on. So this caps the complexity savings at stake in avoiding representations like this.[52] Thus, as a toy calculation: if we conservatively assume that at most 1% of a trillion-parameter model's capacity goes to representing concepts as complex as "honesty," and that it knows at least 10,000 such concepts (Webster's unabridged dictionary has ~500,000 words), then representing the concept of honesty takes at most a millionth of the model's representational capacity, and even less for the larger models of the future.
But more importantly, what matters here isn't the absolute complexity of representing the different goals in question, but the complexity conditional on already having a good world model. And we should assume that all of these models will need to understand the specified goal, the reward process for the episode, etc.[53] And granted such an assumption, the extra complexity costs of actively optimizing for the specified goal, or for reward-on-the-episode, seem to me plausibly extremely small. Plausibly, they're just: whatever the costs are for using/repurposing ("pointing at") that part of the world-model for guiding the model's motivations.
Of course, we can try to rerun the same simplicity argument at the level of the complexity costs of using/repurposing different parts of the world model in that way. For example, we can say: "however this process works, presumably it's simpler to do for some goals than others – so given how many schemer-like goals there are, plausibly it will be simpler to do for some schemer-like goal." I think this is the strongest form of the simplicity argument for expecting schemers. But it also requires abandoning any intuitive grip we might've had on which goals are "simple" in the relevant sense.[54] And it seems plausible to me that the simplicity differences between different "pointers" are very small relative to the model's overall capacity.[55]
I also discuss, in section 4.3.5, whether simplicity arguments make plausible predictions about the sorts of goals a schemer will end up with. In particular: some versions of these arguments can seem to predict that schemers are likely to end up with extremely simple long-term goals, regardless of whether those goals had any relation to what was salient or important during training -- predictions about which I, personally, am skeptical.[56] Of course, it's also possible to posit that goal targets salient/relevant during training will also be "simpler" for the model to pursue.[57] But if we grant some story in this vein (I haven't heard strong arguments for doing so), note that it also speaks in favor of the simplicity of the specified goal, and of reward-on-the-episode, as well - since these are especially salient/relevant during the training process.[58]
In section 4.4, I turn to arguments against scheming that focus on the final properties of the different model classes. Here, the main argument I'm aware of is that schemers need to do extra reasoning that other model classes don't (these are sometimes called "speed costs" – though I think they could in principle affect the complexity of a model's algorithm as well). In particular:
-
Deciding to training-game: The model needs to reason backwards from "I want this beyond-episode thing" to "I should do well in training," in a way that draws on the model's predictions about what doing well in training will entail (e.g., re: goal-guarding, take-over prospects, and so on).
-
Checking whether it's time to escape/take-over: The model needs to be checking, with adequate frequency and accuracy, whether it's in a position to escape/take-over (and to succeed in this assessment despite human efforts to trap/fool the model into revealing its true colors – for example, by offering it apparent opportunities to defect).[59]
-
(Optional, but relevant to how scary the schemer is) Early undermining: To the extent the model is doing anything (other than training-gaming) to support a take-over/escape prior to escaping human control,[60] it will need to be using cognitive resources both in (a) performing the relevant nefarious actions and (b) making sure it gets away with them (e.g., checking that it won't get caught, coming up with excuses, making the cover stories consistent even when under scrutiny, and so on).
How big are the costs of this reasoning? I think that (I) may well be fairly easy, but (II) seems more plausibly onerous (especially in the context of active efforts by humans to put the models under time-pressure, and make genuine escape/take-over opportunities difficult to distinguish from traps).[61] And (III), if the model goes for it, seems like it could be quite difficult – and like it would often actively require deviation from the highest-reward sorts of training performance.[62]
More importantly, though: the question – at least in the context of a comparison between the final properties of the model classes – isn't the absolute size of the costs in question, but rather their size relative to the simplicity benefits of scheming. Here, my current take is that the costs of the instrumental reasoning seem larger than the benefits of the simpler goal.
This is mostly an intuitive judgment, but we can also try to hazily quantify the comparison.
-
Thus, for example, suppose that our model is a purely feedforward network with 1000 layers and <10,000 serial steps per input, that the instrumental reasoning at stake just in a schemer deciding to training-game (let alone: checking for defection opportunities) takes at least ten steps, and that the model doesn't begin optimizing for reward-on-the-episode until that reasoning is complete. In that case, the instrumental reasoning is using up around .1% of the compute that could be going to getting reward-on-the-episode, or to some other max-reward goal.[63]
-
Are the complexity costs of representing, or pointing at, a more complicated goal likely to outweigh this? My guess is no. For example, if we follow my (conservative, in my opinion) calculation above and assume that representing (or pointing at) a concept like "honesty" costs at most a millionth of a trillion parameter models parameters (and less for a larger model), then a .0001% reduction in parameters would need to outweigh a .1% reduction in compute – and absent further argument, it seems strange, to me, to expect this.
Of course, this is only a toy calculation, of unclear applicability to the real-world case.[64] The broader point is just: if serial-time thinking is scarce for a model (as it plausibly is for a transformer), the sorts of instrumental reasoning at stake in scheming seem like they could well substantively impact a model's performance. My guess is that the complexity costs of non-schemer goals are minor in comparison.
I also briefly discuss, in section 4.4.3, whether we can actively shape our training processes to bias more heavily towards "speed." Here it seems relatively straightforward to do things like put models under more time pressure, limit their compute access, force them to plan via human-legible scratch-pads rather than via internal processes, and to put effort into making our attempts to trap them/trip-them-up more sophisticated (and so: more requiring of cognition to detect). But any efforts in this vein will need to avoid over-large costs to competitiveness overall (though if you buy that the speed costs of scheming are quite a bit more substantive than the simplicity benefits, then so long as speed matters somewhat relative to simplicity, this might be enough).
Section 4.5 briefly discusses whether some analog of "intrinsic passion for a given task" might make a difference to AI performance, especially in the context of a form of "messy goal-directedness" that blurs the line between an AI's capabilities and its values. I find considerations in this vein interesting, but quite speculative.
Section 4.6 discusses the relevance of "slack" in training to evaluating how much weight to put on factors like the simplicity benefits and speed costs of scheming. In particular: especially in a high-slack regime, it seems plausible that these factors are in the noise relative to other considerations.
0.2.5 Summary of section 5
The first four sections of the report are the main content. sums up my overall take. I've already summarized most of this in the introduction above, and I won't repeat that content here. However, I'll add a few points that the introduction didn't include.
In particular: I think some version of the "counting argument" undergirds most of the other arguments for expecting scheming that I'm aware of (or at least, the arguments I find most compelling). That is: schemers are generally being privileged as a hypothesis because a very wide variety of goals could in principle lead to scheming, thereby making it easier to (a) land on one of them naturally, (b) land "nearby" one of them, or (c) find one of them that is "simpler" than non-schemer goals that need to come from a more restricted space. In this sense, the case for schemers mirrors one of the most basic arguments for expecting misalignment more generally – e.g., that alignment is a very narrow target to hit in goal-space. Except, here, we are specifically incorporating the selection we know we are going to do on the goals in question: namely, they need to be such as to cause models pursuing them to get high reward. And the most basic worry is just that: this isn't enough.
Because of the centrality of "counting arguments" to the case for schemers, I think that questions about the strength of the selection pressure against schemers – for example, because of the costs of the extra reasoning schemers have to engage in – are especially important. In particular: I think a key way that "counting arguments" can go wrong is by neglecting the power that active selection can have in overcoming the "prior" set by the count in question. For example: the reason we can overcome the prior of "most arrangements of car parts don't form a working car," or "most parameter settings in this neural network don't implement a working chatbot," is that the selection power at stake in human engineering, and in SGD, is that strong. So if SGD's selection power is actively working against schemers (and/or: if we can cause it to do so more actively), this might quickly overcome a "counting argument" in their favor. For example: if there are schemer-like goals for every non-schemer goal, this might make it seem very difficult to hit a non-schemer goal in the relevant space. But actually, 100 bits of selection pressure can be cheap for SGD (consider, for example, 100 extra gradient updates, each worth at least a halving of the remaining possible goals).[65]
Overall, when I step back and try to look at the considerations in the report as a whole, I feel pulled in two different directions:
-
On the one hand, at least conditional on scheming being a convergently-good instrumental strategy, schemer-like goals feel scarily common in goal-space, and I feel pretty worried that training will run into them for one reason or another.
-
On the other hand, ascribing a model's good performance in training to scheming continues to feel, at a gut level, like a fairly specific and conjunctive story to me.
That is, scheming feels robust and common at the level of "goal space," and yet specific and fairly brittle at the level of "yes, that's what's going on with this real-world model, it's getting reward because (or: substantially because) it wants power for itself/other AIs later, and getting reward now helps with that."[66] When I try to roughly balance out these two different pulls (and to condition on goal-directedness and situational-awareness), I get something like the 25% number I listed above.
0.2.6 Summary of section 6
I close the report, in section 6, with a discussion of empirical work that I think might shed light on scheming. (I also think there's worthwhile theoretical work to be done in this space, and I list a few ideas in this respect as well. But I'm especially excited about empirical work.)
In particular, I discuss:
-
Empirical work on situational awareness (section 6.1)
-
Empirical work on beyond-episode goals (section 6.2)
-
Empirical work on the viability of scheming as an instrumental strategy (section 6.3)
-
The "model organisms" paradigm for studying scheming (section 6.4)
-
Traps and honest tests (section 6.5)
-
Interpretability and transparency (section 6.6)
-
Security, control, and oversight (section 6.7)
-
Some other miscellaneous research topics, i.e., gradient hacking, exploration hacking, SGD's biases towards simplicity/speed, path dependence, SGD's "incrementalism," "slack," and the possibility of learning to intentionally create misaligned non-schemer models – for example, reward-on-the-episode seekers – as a method of avoiding schemers (section 6.8).
All in all, I think there's a lot of useful work to be done.
Let's move on, now, from the summary to the main report.
"Alignment," here, refers to the safety-relevant properties of an AI's motivations; and "pretending" implies intentional misrepresentation. ↩︎
Here I'm using the term "reward" loosely, to refer to whatever feedback signal the training process uses to calculate the gradients used to update the model (so the discussion also covers cases in which the model isn't being trained via RL). And I'm thinking of agents that optimize for "reward" as optimizing for "performing well" according to some component of that process. See section 1.1.2 and section 1.2.1 for much more detail on what I mean, here. The notion of an "episode," here, means roughly "the temporal horizon that the training process actively pressures the model to optimize over," which may be importantly distinct from what we normally think of as an episode in training. I discuss this in detail in section 2.2.1. The terms "training game" and "situational awareness" are from Cotra (2022), though in places my definitions are somewhat different. ↩︎
See Cotra (2022) for more on this. ↩︎
I think that the term "deceptive alignment" often leads to confusion between the four sorts of deception listed above. And also: if the training signal is faulty, then "deceptively aligned" models need not be behaving in aligned ways even during training (that is, "training gaming" behavior isn't always "aligned" behavior). ↩︎
See Cotra (2022) for more on the sort of training I have in mind. ↩︎
Though this sort of story faces questions about whether SGD would be able to modify a non-schemer into a schemer via sufficiently incremental changes to the model's weights, each of which improve reward. See section 2.2.2.2 for discussion. ↩︎
And this especially if we lack non-behavioral sorts of evidence – for example, if we can't use interpretability tools to understand model cognition. ↩︎
There are also arguments on which we should expect scheming because schemer-like goals can be "simpler" – since: there are so many to choose from – and SGD selects for simplicity. I think it's probably true that schemer-like goals can be "simpler" in some sense, but I don't give these arguments much independent weight on top of what I've already said. Much more on this in section 4.3. ↩︎
More specifically: even after training gaming starts, the model's cognition is still being continually tweaked in the direction of better training performance. And it seems plausible to me that these modifications will continue to affect a model's goals as well (especially if its goals are not cleanly distinguishable from its capabilities, but rather are implemented by a tangled kludge of local heuristics, patterns of attention, impulses, and so on). Also, the most common story about scheming makes the specific content of a schemer's goal irrelevant to its behavior once it starts training-gaming, thereby introducing the possibility that this goal might "float-around" (or get moved by other pressures within SGD, like regularization) between schemer-like goals after training-gaming starts (this is an objection I first heard from Katja Grace). This possibility creates some complicated possible feedback loops (see section 2.3.1.1.2 for more discussion), but overall, absent coordination across possible schemers, I think it could well be a problem for goal-guarding strategies. ↩︎
Of these various alternative stories, I'm most worried about (a) AIs having sufficiently similar motivations by default that "goal-guarding" is less necessary, and (b) AI coordination. ↩︎
Though: the costs of schemer-like instrumental reasoning could also end up in the noise relative to other factors influencing the outcome of training. And if training is sufficiently path-dependent, then landing on a schemer-like goal early enough could lock it in, even if SGD would "prefer" some other sort of model overall. ↩︎
See Carlsmith (2020), footnote 4, for more on how I'm understanding the meaning of probabilities like this. I think that offering loose, subjective probabilities like these often functions to sharpen debate, and to force an overall synthesis of the relevant considerations. I want to be clear, though, even on top of the many forms of vagueness the proposition in question implicates, I'm just pulling a number from my gut. I haven't built a quantitative model of the different considerations (though I'd be interested to see efforts in this vein), and I think that the main contribution of the report is the analysis itself, rather than this attempt at a quantitative upshot. ↩︎
More powerful models are also more likely to be able to engage in more sophisticated forms of goal-guarding (what I call "introspective goal-guarding methods" below; see also "gradient hacking"), though these seem to me quite difficult in general. ↩︎
Though: to the extent such agents receive end-to-end training rather than simply being built out of individually-trained components, the discussion will apply to them as well. ↩︎
See, e.g., Ngo et al (2022) and this [LW · GW] description of the "consensus threat model" from Deepmind's AGI safety team (as of November 2022). ↩︎
Work by Evan Hubinger (along with his collaborators) is, in my view, the most notable exception to this – and I'll be referencing such work extensively in what follows. See, in particular, Hubinger et al. (2021), and Hubinger (2022), among many other discussions. Other public treatments include Christiano (2019, part 2), Steinhardt (2022), Ngo et al (2022), Cotra (2021), Cotra (2022), Karnofsky (2022), and Shah (2022). But many of these are quite short, and/or lacking in in-depth engagement with the arguments for and against expecting schemers of the relevant kind. There are also more foundational treatments of the "treacherous turn" (e.g., in Bostrom (2014), and Yudkowsky (undated)), of which scheming is a more specific instance; and even more foundational treatments of the "convergent instrumental values" that could give rise to incentives towards deception, goal-guarding, and so on (e.g., Omohundro (2008); and see also Soares (2023) [AF · GW] for a related statement of an Omohundro-like concern). And there are treatments of AI deception more generally (for example, Park et al (2023)); and of "goal misgeneralization"/inner alignment/mesa-optimizers (see, e.g., Langosco et al (2021) and Shah et al (2022)). But importantly, neither deception nor goal misgeneralization amount, on their own, to scheming/deceptive alignment. Finally, there are highly speculative discussions about whether something like scheming might occur in the context of the so-called "Universal prior" (see e.g. Christiano (2016)) given unbounded amounts of computation, but this is of extremely unclear relevance to contemporary neural networks. ↩︎
See, e.g., confusions between "alignment faking" in general and "scheming" (or: goal-guarding scheming) in particular; or between goal misgeneralization in general and scheming as a specific upshot of goal misgeneralization; or between training-gaming and "gradient hacking" as methods of avoiding goal-modification; or between the sorts of incentives at stake in training-gaming for instrumental reasons vs. out of terminal concern for some component of the reward process. ↩︎
My hope is that extra clarity in this respect will help ward off various confusions I perceive as relatively common (though: the relevant concepts are still imprecise in many ways). ↩︎
E.g., the rough content I try to cover in my shortened report on power-seeking AI, here. See also Ngo et al (2022) for another overview. ↩︎
See e.g. Karnofsky (2022) [AF · GW] for more on this sort of assumption, and Cotra (2022) for a more detailed description of the sort of model and training process I'll typically have in mind. ↩︎
Which isn't to say we won't. But I don't want to bank on it. ↩︎
See section 2.2 of Carlsmith (2022) for more on what I mean, and section 3 for more on why we should expect this (most importantly: I think this sort of goal-directedness is likely to be very useful to performing complex tasks; but also, I think available techniques might push us towards AIs of this kind, and I think that in some cases it might arise as a byproduct of other forms of cognitive sophistication). ↩︎
As I discuss in section 2.2.3 of the report, I think exactly how we understand the sort of agency/goal-directedness at stake may make a difference to how we evaluate various arguments for schemers (here I distinguish, in particular, between what I call "clean" and "messy" goal-directedness) – and I think there's a case to be made that scheming requires an especially high standard of strategic and coherent goal-directedness. And in general, I think that despite much ink spilled on the topic, confusions about goal-directedness remain one of my topic candidates for a place the general AI alignment discourse may mislead. ↩︎
See e.g. Butlin et al (2023) for a recent overview focused on consciousness in particular. But I am also, personally, interested in other bases of moral status, like the right kind of autonomy/desire/preference. ↩︎
See, for example, Bostrom and Shulman (2022) and Greenblatt (2023) for more on this topic. ↩︎
If you're confused by a term or argument, I encourage you to seek out its explanation in the main text before despairing. ↩︎
Exactly what counts as the "specified goal" in a given case isn't always clear, but roughly, the idea is that pursuit of the specified goal is rewarded across a very wide variety of counterfactual scenarios in which the reward process is held constant. E.g., if training rewards the model for getting gold coins across counterfactuals, then "getting gold coins" in the specified goal. More discussion in section 1.2.2. ↩︎
For reasons I explain in section 1.2.3, I don't use the distinction, emphasized by Hubinger (2022), between "internally aligned" and "corrigibly aligned" models. ↩︎
And of course, a model's goal system can mix these motivations together. I discuss the relevance of this possibility in section 1.3.5. ↩︎
Karnofsky (2022) calls this the "King Lear problem." ↩︎
In section 1.3.5, I also discuss models that mix these different motivations together. The question I tend to ask about a given "mixed model" is whether it's scary in the way that pure schemers are scary. ↩︎
I don't have a precise technical definition here, but the rough idea is: the temporal horizon of the consequences to which the gradients the model receives are sensitive, for its behavior on a given input. Much more detail in section 2.2.1.1. ↩︎
See, for example, in Krueger et al (2020), the way that "myopic" Q-learning can give rise to "cross-episode" optimization in very simple agents. More discussion in section 2.2.1.2. I don't focus on analysis of this type in the report, but it's crucial to identifying what the "incentivized episode" for a given training process even is – and hence, what having "beyond-episode goals" in my sense would mean. You don't necessary know this from surface-level description of a training process, and neglecting this ignorance is a recipe for seriously misunderstanding the incentives applied to a model in training. ↩︎
That is, the model develops a beyond-episode goal pursuit of which correlates well enough with reward in training, even absent training-gaming, that it survives the training process. ↩︎
That is, the gradients reflect the benefits of scheming even in a model that doesn't yet have a beyond-episode goal, and so actively push the model towards scheming. ↩︎
Situational awareness is required for a beyond-episode goal to motivate training-gaming, and thus for giving it such a goal to reap the relevant benefits. ↩︎
In principle, situational awareness and beyond-episode goals could develop at the same time, but I won't treat these scenarios separately here. ↩︎
See section 2.1 of Carlsmith (2022) for more on why we should expect this sort of goal-directedness. ↩︎
And I think that arguments to the effect that "we need a 'pivotal act'; pivotal acts are long-horizon and we can't do them ourselves; so we need to create a long-horizon optimizer of precisely the type we're most scared of" are weak in various ways. In particular, and even setting aside issues with a "pivotal act" framing, I think these arguments neglect the distinction between what we can supervise and what we can do ourselves. See section 2.2.4.3 for more discussion. ↩︎
This is an objection pointed out to me by Katja Grace. Note that it creates complicated feedback loops, where scheming is a good strategy for a given schemer-like goal only if it wouldn't be a good strategy for the other schemer-like goals that this goal would otherwise "float" into. Overall, though, absent some form of coordination between these different goals, I think the basic dynamic remains a problem for the goal-guarding story. See section 2.3.1.1.2 for more. ↩︎
Here I'm roughly following a distinction in Hubinger 2022 [LW · GW], who groups arguments for scheming on the basis of the degree of "path dependence" they assume that ML training possesses. However, for reasons I explain in section 2.5, I don't want to lean on the notion of "path dependence" here, as I think it lumps together a number of conceptually distinct properties best treated separately. ↩︎
Note that a mis-generalized goal can be "max reward" in this sense, if the training data never differentiates between it and a specified goal. For example: if you're training a model to get gold coins, but the only gold round things you ever show it are coins, then the goal "get gold round things" will be max reward. ↩︎
As a loose analogy to help prompt intuition: imagine freezing human technology at current levels, and letting evolutionary selection run on humans for a vastly longer period of time. What sorts of humans (or human-descended-creatures) do you expect to dominate in the longer term? In particular: would you expect:
-
humans who intrinsically value something like "inclusive genetic fitness" or "my genes getting selected for by evolution" (this is a loose analogy for some combination of "the specified goal" and "the reward process),
-
humans who value something else very closely correlated with inclusive genetic fitness (e.g., "having as many kids as possible"), but who aren't explicitly optimizing for inclusive genetic fitness even instrumentally (this is a loose analogy for mis-generalized non-training-gamers), or
-
humans with long-term goals who are optimizing for inclusive genetic fitness specifically as a method for gaining power for their values in the longer-term (this is a loose analogy for schemers).
Here, the analog of the story above would ask something like: what is the smallest modification to existing human values (or better: the easiest modification for evolution in particular to make) that land us in one of the buckets above, while also being compatible with the amount of evolutionary selection pressure at stake? (Of course, the analogy brings in tons of confounding variable (for example, related to the fact that evolution selects over genomes-that-build-brains-that-learn-values rather than values themselves, the role of cultural accumulation and memetic selection in human population dynamics, the lack of a clear analog of a future chance for escape/takeover, and so on).) ↩︎
-
That is, intuitively, it feels to me like "tweaking a cleanly separable within-episode goal to make it long-term" is quite a bit easier, for SGD, than "redirecting a tangled kludge broadly focused on within-episode things to make it (a) focused on something beyond-episode instead, and (b) such that this beyond-episode focus back-chains into getting-reward for instrumental reasons" – especially if (b) requires building new cognitive machinery for implementing the instrumental reasoning in question. Whereas "redirecting an tangled kludge focused on within-episode things to higher-reward within-episode things in the same broad vicinity instead" seems to me intuitively easier. ↩︎
Thus, for example, if you're rewarding your model when it gets gold-coins-on-the-episode, then to be a training saint, it needs to value gold-coin-on-the-episode. To be a mis-generalized non-training-gamer, it needs to value something pursuit of which very closely correlates with getting gold-coins-on-the-episode, even absent training-gaming. And to be a reward-on-the-episode seeker, it needs to terminally value reward-on-the-episode. ↩︎
Thus, for example, the model can value paperclips over all time, it can value staples over all time, it can value happiness over all time, and so on. ↩︎
Thus, as an analogy: if you don't know whether Bob prefers Mexican food, Chinese food, or Thai food, then it's less clear how the comparative number of Mexican vs. Chinese vs. Thai restaurants in Bob's area should bear on our prediction of which one he went to (though it still doesn't seem entirely irrelevant, either – for example, more restaurants means more variance in possible quality within that type of cuisine). E.g., it could be that there are ten Chinese restaurants for every Mexican restaurant, but if Bob likes Mexican food better in general, he might just choose Mexican. So if we don't know which type of cuisine Bob prefers, it's tempting to move closer to a uniform distribution over types of cuisine, rather than over individual restaurants. ↩︎
See, for example, the citations in Mingard (2021). ↩︎
Though note that, especially for the purposes of comparing the probability of scheming to the probability of other forms of misalignment, we need not assume this. For example, our specified goal might be much simpler than "act in accordance with human values." It might, for example, be something like "get gold coins on the episode." ↩︎
I heard this sort of point from Paul Christiano. ↩︎
And especially: models that are playing a training game in which such concepts play a central role. ↩︎
Since we're no longer appealing to the complexity of representing a goal, and are instead appealing to complexity differences at stake in repurposing pre-existing conceptual representations for use in a model's motivational system, which seems like even more uncertain territory. ↩︎
One intuition pump for me here runs as follows. Suppose that the model has concepts (roughly 1e15) in its world model/"database" that could in principle be turned into goals. The average number of bits required to code for each of concepts can't be higher than 50 (since: you can just assign a different 50-bit string to each concept). So if we assume that model's encoding is reasonably efficient with respect to the average, and that the simplest non-schemer max-reward goal is takes a roughly average-simplicity "pointer," then if we allocate one parameter per bit, pointing at the simplest non-schemer-like max reward goal is only an extra 50 parameters at maximum – one twenty-billionth of a trillion-parameter model's capacity. That said, I expect working out the details of this sort of argument to get tricky, and I don't try to do so here (though I'd be interested to see other work attempting to do so). ↩︎
Thus, as a toy example, if "maximize hydrogen" happens to be the simplest possible long-term goal once you've got a fully detailed world model, these assumptions might imply a high likelihood that SGD will select schemers who want to maximize hydrogen, even if training was all about gold coins, and never made hydrogen salient/relevant as a point of focus at all (even as a proxy). ↩︎
E.g., plausibly "hydrogen" doesn't read as a simple concept for humans, but concepts like "threat" do, because the latter was much more relevant in our evolutionary environment. ↩︎
Though of course, insofar as there are still simpler schemer-like goal targets that were salient/relevant during training, schemer-like goals might still win out overall. ↩︎
This category might also include reasoning whether to reveal its schemer-like goals in the context of various "honest tests" humans might offer – e.g., "here is a flexible chunk of computing resources to do what you want with." ↩︎
For example, inserting backdoors into the code it writes, actively undermining human alignment research, sandbagging, and so on. ↩︎
Compare with: deciding that this is really-truly a good time to steal, or to break the law, or to try to start a coup, despite the fact that you live your life in an intensively monitored surveillance state where the police are constantly trying to trick you into such behavior, and where the police have a large amount of control over the information you're exposed to. And note that if schemers decide to be very cautious, and to just behave exactly as humans want until an extremely obvious escape/take-over opportunity appears, they may make very substantive contributions to our alignment, security, and control efforts in the meantime -- so substantive, indeed, that the opportunity they're waiting for may never come. ↩︎
A general factor in the backdrop, here, is the sense in which successful deception generally implies cognitive costs that more straightforward and honest policies do not, especially in the presence of active efforts to detect deception of the relevant form. In particular: telling a deceptive story about the world requires filling in details, and maintaining forms of consistency, that one can normally offload onto the world itself – e.g., an innocent person can just think back to what they were actually doing the night of the murder and recount it, without having to make anything up or to worry about getting caught in any inconsistencies, whereas the murderer cannot. See e.g. discussion from Shulman and Patel here. ↩︎
I heard this sort of argument from Paul Christiano. ↩︎
It's not clear, for example, how it applies to models with more recurrent processing, or to models which can perform more of the relevant instrumental reasoning in parallel with other serial processing that helps with optimizing-for-reward-on-the-episode, or to model's with a form of "memory" that allows them to avoid having to re-decide to engage in training-gaming on every forward pass. ↩︎
Thanks to Paul Christiano for discussion here. ↩︎
I think this sense of conjunctiveness has a few different components:
-
Part of it is about whether the model really has relevantly long-term and ambitious goals despite the way it was shaped in training.
-
Part of it is about whether there is a good enough story about why getting reward on the episode is a good instrumental strategy for pursuing those goals (e.g., doubts about the goal-guarding hypothesis, the model's prospects for empowerment later, etc).
-
Part of it is that a schemer-like diagnosis also brings in additional conjuncts – for example, that the model is situationally aware and coherently goal-directed. (When I really try to bring to mind that this model knows what is going on and is coherently pursuing some goal/set of goals in the sort of way that gives rise to strategic instrumental reasoning, then the possibility that it's at least partly a schemer seems more plausible.)
-
28 comments
Comments sorted by top scores.
comment by Quintin Pope (quintin-pope) · 2023-11-15T22:28:45.766Z · LW(p) · GW(p)
Reposting my response on Twitter (To clarify, the following was originally written as a Tweet in response to Joe Carlsmith's Tweet about the paper, which I am now reposting here):
I just skimmed the section headers and a small amount of the content, but I'm extremely skeptical. E.g., the "counting argument" seems incredibly dubious to me because you can just as easily argue that text to image generators will internally create images of llamas in their early layers, which they then delete, before creating the actual asked for image in the later layers. There are many possible llama images, but "just one" network that straightforwardly implements the training objective, after all.
The issue is that this isn't the correct way to do counting arguments on NN configurations. While there are indeed an exponentially large number of possible llama images that an NN might create internally, there are an even more exponentially large number of NNs that have random first layers, and then go on to do the actual thing in the later layers. Thus, the "inner llamaizers" are actually more rare in NN configuration space than the straightforward NN.
The key issue is that each additional computation you speculate an NN might be doing acts as an additional constraint on the possible parameters, since the NN has to internally contain circuits that implement those computations. The constraint that the circuits actually have to do "something" is a much stronger reduction in the number of possible configurations for those parameters than any additional configurations you can get out of there being multiple "somethings" that the circuits might be doing.
So in the case of deceptive alignment counting arguments, they seem to be speculating that the NN's cognition looks something like:
[have some internal goal x] [backchain from wanting x to the stuff needed to get x (doing well at training)] [figure out how to do well at training] [actually do well at training]
and in comparison, the "honest" / direct solution looks like:
[figure out how to do well at training] [actually do well at training]
and then because there are so many different possibilities for "x", they say there are more solutions that look like the deceptive cognition. My contention is that the steps "[have some internal goal x] [backchain from wanting x to the stuff needed to get x (doing well at training)]" in the deceptive cognition are actually unnecessary, and because implementing those steps requires that one have circuits that instantiate those computations, the requirement that the deceptive model perform those steps actually *constrains* the number of parameter configurations that implement the deceptive cognition, which reduces the volume of deceptive models in parameter space.
One obvious counterpoint I expect is to claim that the "[have some internal goal x] [backchain from wanting x to the stuff needed to get x (doing well at training)]" steps actually do contribute to the later steps, maybe because they're a short way to compress a motivational pointer to "wanting" to do well on the training objective.
I don't think this is how NN simplicity biases work. Under the "cognitive executions impose constraints on parameter settings" perspective, you don't actually save any complexity by supposing that the model has some motive for figuring stuff out internally, because the circuits required to implement the "figure stuff out internally" computations themselves count as additional complexity. In contrast, if you have a view of simplicity that's closer to program description length, then you're not counting runtime execution against program complexity, and so a program that has short length in code but long runtime can count as simple.
@jkcarlsmith does seem more sympathetic to the "parameters as complexity" view than to the "code length as complexity" view. However, I go further and think that the "parameters as complexity" view actively points against deceptive alignment.
I also think NNs have an even stronger bias for short paths than you might expect from just the "parameters as complexity" view. Consider a problem that can either be solved with a single circuit of depth n, or by two parallel circuits of depth n/2 (so both solutions must set the values of an equal number of parameters, but one solution is more parallel than the other). I claim there are far more parameter configurations that implement the parallel solution than parameter configurations that implement the serial solution.
This is because the parallel solution has an entire permutation group that's not available to the serial solution: the two parallel circuits can be moved to different relative depths with respect to each other, whereas all the parts of the serial solution must have fixed relative depths. Thus, the two parallel circuits represent less of a constraint on the possible configurations of the NN, and so there are far more NNs that implement the parallel solution.
As a consequence, I expect there are significant "short depth" biases in the NN simplicity prior, consistent with empirical results such as: https://arxiv.org/abs/1605.06431
Finally, I'm extremely skeptical of claims that NNs contain a 'ghost of generalized instrumental reasoning', able to perform very competent long term hidden scheming and deduce lots of world knowledge "in-context". I think current empirical results point strongly against that being plausible.
For example, the "reversal curse" results (training on "A is B" doesn't lead to models learning "B is A"). If the ghost can't even infer from "A is B" to "B is A", then I think stuff like inferring from "I have a goal x", to "here is the specific task I must perform in order to maximize my reward" is pretty much out of the question. Thus, stories about how SGD might use arbitrary goals as a way to efficiently compress an (effective) desire for the NN to silently infer lots of very specific details about the training process seem incredibly implausible to me.
I expect objections of the form "I expect future training processes to not suffer from the reversal curse, and I'm worried about the future training processes."
Obviously people will come up with training processes that don't suffer from the reversal curse. However, comparing the simplicity of the reversal curse to the capability of current NNs is still evidence about the relative power of the 'instrumental ghost' in the model compared to the external capabilities of the model. If a similar ratio continues to hold for externally superintelligent AIs, then that casts enormous doubt on e.g., deceptive alignment scenarios where the model is internally and instrumentally deriving huge amounts of user-goal-related knowledge so that it can pursue its arbitrary mesaobjectives later down the line. I'm using the reversal curse to make a more generalized update about the types of internal cognition that are easy to learn and how they contribute to external capabilities.
Some other Tweets I wrote as part of the discussion:
The key points of my Tweet are basically "the better way to think about counting arguments is to compare constraints on parameter configurations", and "corrected counting arguments introduce an implicit bias towards short, parallel solutions", where both "counting the constrained parameters", and "counting the permutations of those parameters" point in that direction.
I think shallow depth priors are pretty universal. E.g., they also make sense from a perspective of "any given step of reasoning could fail, so best to make as few sequential steps as possible, since each step is rolling the dice", as well as a perspective of "we want to explore as many hypotheses as possible with as little compute as possible, so best have lots of cheap hypotheses".
I'm not concerned about the training for goal achievement contributing to deceptive alignment, because such training processes ultimately come down to optimizing the model to imitate some mapping from "goal given by the training process" -> "externally visible action sequence". Feedback is always upweighting cognitive patterns that produce some externally visible action patterns (usually over short time horizons).
In contrast, it seems very hard to me to accidentally provide sufficient feedback to specify long-term goals that don't distinguish themselves from short term one over short time horizons, given the common understanding in RL that credit assignment difficulties actively work against the formation of long term goals. It seems more likely to me that we'll instill long term goals into AIs by "scaffolding" them via feedback over shorter time horizons. E.g., train GPT-N to generate text like "the company's stock must go up" (short time horizon feedback), as well as text that represents GPT-N competently responding to a variety of situations and discussions about how to achieve long-term goals (more short time horizon feedback), and then putting GPT-N in a continuous loop of sampling from a combination of the behavioral patterns thereby constructed, in such a way that the overall effect is competent long term planning.
The point is: long term goals are sufficiently hard to form deliberately that I don't think they'll form accidentally.
...I think the llama analogy is exactly correct. It's specifically designed to avoid triggering mechanistically ungrounded intuitions about "goals" and "tryingness", which I think inappropriately upweight the compellingness of a conclusion that's frankly ridiculous on the arguments themselves. Mechanistically, generating the intermediate llamas is just as causally upstream of generating the asked for images, as "having an inner goal" is causally upstream of the deceptive model doing well on the training objective. Calling one type of causal influence "trying" and the other not is an arbitrary distinction.
My point about the "instrumental ghost" wasn't that NNs wouldn't learn instrumental / flexible reasoning. It was that such capabilities were much more likely to derive from being straightforwardly trained to learn such capabilities, and then to be employed in a manner consistent with the target function of the training process. What I'm arguing *against* is the perspective that NNs will "accidentally" acquire such capabilities internally as a convergent result of their inductive biases, and direct them to purposes/along directions very different from what's represented in the training data. That's the sort of stuff I was talking about when I mentioned the "ghost".
Replies from: evhub, joekcWhat I'm saying is there's a difference between a model that can do flexible instrumental reasoning because it's faithfully modeling a data distribution with examples of flexible instrumental reasoning, versus a model that acquired hidden flexible instrumental reasoning because NN inductive biases say the convergent best way to do well on tasks is to acquire hidden flexible instrumental reasoning and apply it to the task, even when the task itself doesn't have any examples of such.
↑ comment by evhub · 2023-11-16T00:02:31.965Z · LW(p) · GW(p)
I really don't like all this discussion happening on Twitter, and I appreciate that you took the time to move this back to LW/AF instead. I think Twitter is really a much worse forum for talking about complex issues like this than LW/AF.
Regardless, some quick thoughts:
[have some internal goal x] [backchain from wanting x to the stuff needed to get x (doing well at training)] [figure out how to do well at training] [actually do well at training]
and in comparison, the "honest" / direct solution looks like:
[figure out how to do well at training] [actually do well at training]
I think this is a mischaracterization of the argument. The argument for deceptive alignment is that deceptive alignment might be the easiest way for the model to figure out how to do well in training. So a more accurate comparison would be:
Deceptive model: [figure out how to do well at training] [actually do well at training]
Sycophantic model: [figure out how to do well at training] [actually do well at training]
Aligned model: [figure out how to be aligned] [actually be aligned]
Notably, the deceptive and sycophantic models are the same! But the difference is that they look different when we break apart the "figure out how to do well at training" part. We could do the same breakdown for the sycophantic model, which might look something like:
Sycophantic model: [load in some hard-coded specification of what it means to do well in training] [figure out how to execute on that specification in this environment] [actually do well at training]
The problem is that figuring out how to do well at training is actually quite hard, and deceptive alignment might make that problem easier by reducing it to the (potentially) simpler/easier problem of figuring out how to accomplish <insert any long-term goal here>. Whereas the sycophantic model just has to memorize a bunch of stuff about training that the deceptive model doesn't have to.
The point is that you can't just say "well, deceptive alignment results in the model trying to do well in training, so why not just learn a model that starts by trying to do well in training" for the same reason that you can't just say "well, deceptive alignment results in the model outputting this specific distribution, so why not just learn a model that memorizes that exact distribution". The entire question is about what the easiest way is to produce that distribution in terms of the inductive biases.
Also, another point that I'd note here: the sycophantic model isn't actually desirable either! So long as the deceptive model beats the aligned model in terms of the inductive biases, it's still a concern, regardless of whether it beats the sycophantic model or not. I'm pretty unsure which is more likely between the deceptive and sycophantic models, but I think both pretty likely beat the aligned model in most cases that we care about. But I'm more optimistic that we can find ways to address sycophantic models than deceptive models, such that I think the deceptive models are more of a concern.
Replies from: TurnTrout, quintin-pope↑ comment by TurnTrout · 2023-11-16T19:14:08.371Z · LW(p) · GW(p)
The problem is that figuring out how to do well at training is actually quite hard[1]
It seems to me like you're positing some "need to do well in training", which is... a kinda weird frame. In a weak correlational sense, it's true that loss tends to decrease over training-time and research-time.
But I disagree with an assumption of "in the future, the trained model will need to achieve loss scores so perfectly low that the model has to e.g. 'try to do well' or reason about its own training process in order to get a low enough loss, otherwise the model gets 'selected against'." (It seems to me that you are making this assumption; let me know if you are not.) (ETA: Evan doesn't think that it's necessary to do this in order to be selected by training. In particular, he wrote that 'aligned models' won't need to do this.)
I don't know why so many people seem to think model training works like this. That is, that one can:
- verbally reason about whether a postulated algorithm "minimizes loss" (example algorithm: using a bunch of interwoven heuristics to predict text), and then
- brainstorm English descriptions of algorithms which, according to us, get even lower loss (example algorithm: reason out the whole situation every forward pass, and figure out what would minimize loss on the next token), and then
- since algorithm-2 gets "lower loss" (as reasoned about informally in English), one is licensed to conclude that SGD is incentivized pick the latter algorithm.
I think that loss just does not constrain training that tightly, or in that fashion.[2] I can give a range of counterevidence, from early stopping (done in practice to use compute effectively) to knowledge distillation (shows that for a given level of expressivity, training on a larger teacher model's logits will achieve substantially lower loss than supervised training to convergence from random initialization, which shows that training to convergence isn't even well-described as "minimizing loss").
And I'm not aware of good theoretical bounds here either; the cutting-edge PAC-Bayes results are, like, bounding MNIST test error to 2.7% on an empirical setup which got 2%. That's a big and cool theoretical achievement, but -- if my understanding of theory SOTA is correct -- we definitely don't have the theoretical precision to be confidently reasoning about loss minimization like this on that basis.
I feel like this unsupported assumption entered the groundwater somehow and now looms behind lots of alignment reasoning. I don't know where it comes from. On the off-chance it's actually well-founded, I'd deeply appreciate an explanation or link.
- ^
FWIW I think this claim runs afoul of what I was trying to communicate in reward is not the optimization target [LW · GW]. (I mention this since it's relevant to a discussion we had last year, about how many people already understood what I was trying to convey.)
- ^
I also see no reason to expect this to be a good "conservative worst-case", and this is why I'm so leery of worst-case analysis a la ELK. I see little reason that reasoning this way will be helpful in reality.
↑ comment by evhub · 2023-11-16T21:07:20.125Z · LW(p) · GW(p)
It seems to me like you're positing some "need to do well in training", which is... a kinda weird frame. In a weak correlational sense, it's true that loss tends to decrease over training-time and research-time.
No, I don't think I'm positing that—in fact, I said that the aligned model doesn't do this.
I feel like this unsupported assumption entered the groundwater somehow and now looms behind lots of alignment reasoning. I don't know where it comes from. On the off-chance it's actually well-founded, I'd deeply appreciate an explanation or link.
I do think this is a fine way to reason about things. Here's how I would justify this: We know that SGD is selecting for models based on some combination of loss and inductive biases, but we don't know the exact tradeoff. We could just try to directly theorize about the multivariate optimization problem, but that's quite difficult. Instead, we can take either variable as a constraint, and theorize about the univariate optimization problem subject to that constraint. We now have two dual optimization problems, "minimize loss subject to some level of inductive biases" and "maximize inductive biases subject to some level of loss" which we can independently investigate to produce evidence about the original joint optimization problem.
Replies from: TurnTrout, TurnTrout↑ comment by TurnTrout · 2023-11-20T21:59:56.048Z · LW(p) · GW(p)
It seems to me like you're positing some "need to do well in training", which is... a kinda weird frame. In a weak correlational sense, it's true that loss tends to decrease over training-time and research-time.
No, I don't think I'm positing that—in fact, I said that the aligned model doesn't do this.
I don't understand why you claim to not be doing this. Probably we misunderstand each other? You do seem to be incorporating a "(strong) pressure to do well in training" in your reasoning about what gets trained. You said (emphasis added):
The argument for deceptive alignment is that deceptive alignment might be the easiest way for the model to figure out how to do well in training.
This seems to be engaging in the kind of reasoning I'm critiquing.
We now have two dual optimization problems, "minimize loss subject to some level of inductive biases" and "maximize inductive biases subject to some level of loss" which we can independently investigate to produce evidence about the original joint optimization problem.
Sure, this (at first pass) seems somewhat more reasonable, in terms of ways of thinking about the problem. But I don't think the vast majority of "loss-minimizing" reasoning actually involves this more principled analysis. Before now, I have never heard anyone talk about this frame, or any other recovery which I find satisfying.
So this feels like a motte-and-bailey, where the strong-and-common claim goes like "we're selecting models to minimize loss, and so if deceptive models get lower loss, that's a huge problem; let's figure out how to not make that be true" and the defensible-but-weak-and-rare claim is "by considering loss minimization given certain biases, we can gain evidence about what kinds of functions SGD tends to train."
Replies from: evhub↑ comment by evhub · 2023-11-21T01:09:50.906Z · LW(p) · GW(p)
You do seem to be incorporating a "(strong) pressure to do well in training" in your reasoning about what gets trained.
I mean, certainly there is a strong pressure to do well in training—that's the whole point of training. What there isn't strong pressure for is for the model to internally be trying to figure out how to do well in training. The model need not be thinking about training at all to do well on the training objective, e.g. as in the aligned model.
To be clear, here are some things that I think:
- The model needs to figure out how to somehow output a distribution that does well in training. Exactly how well relative to the inductive biases is unclear, but generally I think the easiest way to think about this is to take performance at the level you expect of powerful future models as a constraint.
- There are many algorithms which result in outputting a distribution that does well in training. Some of those algorithms directly reason about the training process, whereas some do not.
- Taking training performance as a constraint, the question is what is the easiest way (from an inductive bias perspective) to produce such a distribution.
- Doing that is quite hard for the distributions that we care about and requires a ton of cognition and reasoning in any situation where you don't just get complete memorization (which is highly unlikely under the inductive biases).
- Both the deceptive and sycophantic models involve directly reasoning about the training process internally to figure out how to do well on it. The aligned model likely also requires some reasoning about the training process, but only indirectly due to understanding the world being important and the training process being a part of the world.
- Comparing the deceptive to sycophantic models, the primary question is which one is an easier way (from an inductive bias perspective) to compute how to do well on the training process: directly memorizing pointers to that information in the world model, or deducing that information using the world model based on some goal.
I have never heard anyone talk about this frame
I think probably that's just because you haven't talked to me much about this. The point about whether to use a loss minimization + inductive bias constraint vs. loss constraint + inductive bias minimization was a big one that I commented a bunch about on Joe's report. In fact, I suspect he'd probably have some more thoughts here on this—I think he's not fully sold on my framing above.
So this feels like a motte-and-bailey
I agree that there are some people that might defend different claims than I would, but I don't think I should be responsible for those claims. Part of why I'm excited about Joe's report is that it takes a bunch of different isolated thinking from different people and puts it into a single coherent position, so it's easier to evaluate that position in totality. If you have disagreements with my position, with Joe's position, or with anyone else's position, that's obviously totally fine—but you shouldn't equate them into one group and say it's a motte-and-bailey. Different people just think different things.
Replies from: TurnTrout↑ comment by TurnTrout · 2023-12-03T20:43:12.392Z · LW(p) · GW(p)
I mean, certainly there is a strong pressure to do well in training—that's the whole point of training.
I disagree. This claim seems to be precisely what my original comment [LW(p) · GW(p)] was critiquing:
It seems to me like you're positing some "need to do well in training", which is... a kinda weird frame. In a weak correlational sense, it's true that loss tends to decrease over training-time and research-time.
But I disagree with an assumption of "in the future, the trained model will need to achieve loss scores so perfectly low that the model has to e.g. 'try to do well' or reason about its own training process in order to get a low enough loss, otherwise the model gets 'selected against'."
And then you wrote, as some things you believe:[1]
The model needs to figure out how to somehow output a distribution that does well in training...
Doing that is quite hard for the distributions that we care about and requires a ton of cognition and reasoning in any situation where you don't just get complete memorization (which is highly unlikely under the inductive biases)...
Both the deceptive and sycophantic models involve directly reasoning about the training process internally to figure out how to do well on it. The aligned model likely also requires some reasoning about the training process, but only indirectly due to understanding the world being important and the training process being a part of the world.
This is the kind of claim I was critiquing in my original comment!
but you shouldn't equate them into one group and say it's a motte-and-bailey. Different people just think different things.
My model of you makes both claims, and I indeed see signs of both kinds of claims in your comments here.
- ^
Thanks for writing out a bunch of things you believe, by the way! That was helpful.
↑ comment by evhub · 2023-12-03T21:18:28.864Z · LW(p) · GW(p)
I am very confused now what you believe. Obviously training selects for low loss algorithms... that's, the whole point of training? I thought you were saying that training doesn't select for algorithms that internally optimize for loss, which is true, but it definitely does select for algorithms that in fact get low loss.
Replies from: TurnTrout, quetzal_rainbow↑ comment by TurnTrout · 2023-12-26T20:25:53.147Z · LW(p) · GW(p)
The point of training in a practical sense is generally to produce networks with desirable behavior. The point of training in a dynamical sense is to perform an optimizer-mediated update to locally reduce loss along the locally steepest direction, aggregating gradients over different subsets of the data.
What is the empirical content of the claim that "training selects for low loss algorithms"? Can you make it more precise, perhaps by tabooing "selects for"?
↑ comment by quetzal_rainbow · 2023-12-03T21:43:59.052Z · LW(p) · GW(p)
I place here prediction that TurnTrout is trying to say that while, counterfactally, if we had algorithm that reasons about training, it would achieve low loss, it's not obviously true that such algorithms are actually "achievable" for SGD in some "natural" setting.
Replies from: evhub↑ comment by evhub · 2023-12-03T23:15:05.988Z · LW(p) · GW(p)
That's what I thought he was saying previously, but he objected to that characterization in his most recent comment.
Replies from: Signer↑ comment by Signer · 2023-12-07T08:12:16.991Z · LW(p) · GW(p)
Wait, where? I think the objection to "Doing that is quite hard" is not an objection to "it’s not obviously true that such algorithms are actually “achievable” for SGD" - it's an objection to the conclusion that model would try hard enough to justify arguments about deception from weak statement about loss decreasing during training.
Replies from: TurnTrout↑ comment by TurnTrout · 2023-12-03T20:36:47.086Z · LW(p) · GW(p)
We know that SGD is selecting for models based on some combination of loss and inductive biases, but we don't know the exact tradeoff.
Actually, I've thought more, and I don't think that this dual-optimization perspective makes it better. I deny that we "know" that SGD is selecting on that combination, in the sense which seems to be required for your arguments to go through.
It sounds to me like I said "here's why you can't think about 'what gets low loss'" and then you said[1] "but what if I also think about certain inductive biases too?" and then you also said "we know that it's OK to think about it this way." No, I contend that we don't know that. That was a big part of what I was critiquing.
As an alert—It feels like your response here isn't engaging with the points I raised in my original comment. I expect I talked past you and you, accordingly, haven't seen the thing I'm trying to point at.
- ^
this isn't a quote, this is just how your comment parsed to me
↑ comment by Joe Carlsmith (joekc) · 2023-11-27T23:08:23.169Z · LW(p) · GW(p)
The question of how strongly training pressures models to minimize loss is one that I isolate and discuss explicitly in the report, in section 1.5, "On 'slack' in training [LW · GW]" -- and at various points the report references how differing levels of "slack" might affect the arguments it considers. Here I was influenced in part by discussions with various people, yourself included, who seemed to disagree about how much weight to put on arguments in the vein of: "policy A would get lower loss than policy B, so we should think it more likely that SGD selects policy A than policy B."
(And for clarity, I don't think that arguments of this form always support expecting models to do tons of reasoning about the training set-up. For example, as the report discusses in e.g. Section 4.4, on "speed arguments," the amount of world-modeling/instrumental-reasoning that the model does can affect the loss it gets via e.g. using up cognitive resources. So schemers -- and also, reward-on-the-episode seekers -- can be at some disadvantage, in this respect, relative to models that don't think about the training process at all.)
↑ comment by Quintin Pope (quintin-pope) · 2023-11-16T00:53:04.041Z · LW(p) · GW(p)
I really don't like that you've taken this discussion to Twitter. I think Twitter is really a much worse forum for talking about complex issues like this than LW/AF.
I haven't "taken this discussion to Twitter". Joe Carlsmith posted about the paper on Twitter. I saw that post, and wrote my response on Twitter. I didn't even know it was also posted on LW until later, and decided to repost the stuff I'd written on Twitter here. If anything, I've taken my part of the discussion from Twitter to LW. I'm slightly baffled and offended that you seem to be platform-policing me?
Anyways, it looks like you're making the objection I predicted with the paragraphs:
One obvious counterpoint I expect is to claim that the "[have some internal goal x] [backchain from wanting x to the stuff needed to get x (doing well at training)]" steps actually do contribute to the later steps, maybe because they're a short way to compress a motivational pointer to "wanting" to do well on the training objective.
I don't think this is how NN simplicity biases work. Under the "cognitive executions impose constraints on parameter settings" perspective, you don't actually save any complexity by supposing that the model has some motive for figuring stuff out internally, because the circuits required to implement the "figure stuff out internally" computations themselves count as additional complexity. In contrast, if you have a view of simplicity that's closer to program description length, then you're not counting runtime execution against program complexity, and so a program that has short length in code but long runtime can count as simple.
In particular, when I said "maybe because they're a short way to compress a motivational pointer to "wanting" to do well on the training objective." I think this is pointing at the same thing you reference when you say "The entire question is about what the easiest way is to produce that distribution in terms of the inductive biases."
I.e., given the actual simplicity bias of models, what is the shortest (or most compressed) way of specifying "a model that starts by trying to do well in training"? And my response is that I think the model pays a complexity penalty for runtime computations (since they translate into constraints on parameter values which are needed to implement those computations). Even if those computations are motivated by something we call a "goal", they still need to be implemented in the circuitry of the model, and thus also constrain its parameters.
Also, when I reference models whose internal cognition looks like "[figure out how to do well at training] [actually do well at training]", I don't have sycophantic models in particular in mind. It also includes aligned models, since those models do implement the "[figure out how to do well at training] [actually do well at training]" steps (assuming that aligned behavior does well in training).
Replies from: evhub↑ comment by evhub · 2023-11-16T01:09:36.062Z · LW(p) · GW(p)
If anything, I've taken my part of the discussion from Twitter to LW.
Good point. I think I'm misdirecting my annoyance here; I really dislike that there's so much alignment discussion moving from LW to Twitter, but I shouldn't have implied that you were responsible for that—and in fact I appreciate that you took the time to move this discussion back here. Sorry about that—I edited my comment.
And my response is that I think the model pays a complexity penalty for runtime computations (since they translate into constraints on parameter values which are needed to implement those computations). Even if those computations are motivated by something we call a "goal", they still need to be implemented in the circuitry of the model, and thus also constrain its parameters.
Yes, I think we agree there. But that doesn't imply that just because deceptive alignment is a way of calculating what the training process wants you to do, that you can then just memorize the result of that computation in the weights and thereby simplify the model—for the same reason SGD doesn't memorize the entire distribution in the weights either.
↑ comment by Joe Carlsmith (joekc) · 2023-11-28T01:27:21.667Z · LW(p) · GW(p)
(Partly re-hashing my response from twitter.)
I'm seeing your main argument here as a version of what I call, in section 4.4, a "speed argument against schemers" -- e.g., basically, that SGD will punish the extra reasoning that schemers need to perform.
(I’m generally happy to talk about this reasoning as a complexity penalty, and/or about the params it requires, and/or about circuit-depth -- what matters is the overall "preference" that SGD ends up with. And thinking of this consideration as a different kind of counting argument *against* schemers seems like it might well be a productive frame. I do also think that questions about whether models will be bottlenecked on serial computation, and/or whether "shallower" computations will be selected for, are pretty relevant here, and the report includes a rough calculation in this respect in section 4.4.2 (see also summary here [LW · GW]).)
Indeed, I think that maybe the strongest single argument against scheming is a combination of
- "Because of the extra reasoning schemers perform, SGD would prefer non-schemers over schemers in a comparison re: final properties of the models" and
- "The type of path-dependence/slack at stake in training is such that SGD will get the model that it prefers overall."
My sense is that I'm less confident than you in both (1) and (2), but I think they're both plausible (the report, in particular, argues in favor of (1)), and that the combination is a key source of hope. I'm excited to see further work fleshing out the case for both (including e.g. the sorts of arguments for (2) that I took you and Nora to be gesturing at on twitter -- the report doesn't spend a ton of time on assessing how much path-dependence to expect, and of what kind).
Re: your discussion of the "ghost of instrumental reasoning," "deducing lots of world knowledge 'in-context,' and "the perspective that NNs will 'accidentally' acquire such capabilities internally as a convergent result of their inductive biases" -- especially given that you only skimmed the report's section headings and a small amount of the content, I have some sense, here, that you're responding to other arguments you've seen about deceptive alignment, rather than to specific claims made in the report (I don't, for example, make any claims about world knowledge being derived "in-context," or about models "accidentally" acquiring flexible instrumental reasoning). Is your basic thought something like: sure, the models will develop flexible instrumental reasoning that could in principle be used in service of arbitrary goals, but they will only in fact use it in service of the specified goal, because that's the thing training pressures them to do? If so, my feeling is something like: ok, but a lot of the question here is whether using the instrumental reasoning in service of some other goal (one that backchains into getting-reward) will be suitably compatible with/incentivized by training pressures as well. And I don't see e.g. the reversal curse as strong evidence on this front.
Re: "mechanistically ungrounded intuitions about 'goals' and 'tryingness'" -- as I discuss in section 0.1, the report is explicitly setting aside disputes about whether the relevant models will be well-understood as goal-directed (my own take on that is in section 2.2.1 of my report on power-seeking AI here). The question in this report is whether, conditional on goal-directedness, we should expect scheming. That said, I do think that what I call the "messyness" of the relevant goal-directedness might be relevant to our overall assessment of the arguments for scheming in various ways, and that scheming might require an unusually high standard of goal-directedness in some sense. I discuss this in section 2.2.3, on "'Clean' vs. 'messy' goal-directedness," and in various other places in the report.
Re: "long term goals are sufficiently hard to form deliberately that I don't think they'll form accidentally" -- the report explicitly discusses cases where we intentionally train models to have long-term goals (both via long episodes, and via short episodes aimed at inducing long-horizon optimization). I think scheming is more likely in those cases. See section 2.2.4, "What if you intentionally train the model to have long-term goals?" That said, I'd be interested to see arguments that credit assignment difficulties actively count against the development of beyond-episode goals (whether in models trained on short episodes or long episodes) for models that are otherwise goal-directed. And I do think that, if we could be confident that models trained on short episodes won't learn beyond-episode goals accidentally (even irrespective of mundane adversarial training -- e.g., that models rewarded for getting gold coins on the episode would not learn a goal that generalizes to caring about gold coins in general, even prior to efforts to punish it for sacrificing gold-coins-on-the-episode for gold-coins-later), that would be a significant source of comfort (I discuss some possible experimental directions in this respect in section 6.2).
comment by aog (Aidan O'Gara) · 2023-11-15T19:04:30.820Z · LW(p) · GW(p)
Very nice, these arguments seem reasonable. I'd like to make a related point about how we might address deceptive alignment which makes me substantially more optimistic about the problem. (I've been meaning to write a full post on this, but this was a good impetus to make the case concisely.)
Conceptual interpretability in the vein of Collin Burns, Alex Turner, and Representation Engineering seems surprisingly close to allowing us to understand a model's internal beliefs and detect deceptive alignment. Collin Burns's work was very exciting to at least some people because it provided an unsupervised method for detecting a model's beliefs. Collin's explanation of his theory of impact [LW · GW] is really helpful here. Broadly, because it allows us to understand a model's beliefs without using any labels provided by humans, it should be able to detect deception in superhuman models where humans cannot provide accurate feedback.
Over the last year, there's been a lot of research that meaningfully extends Collin's work. I think this could be used to detect deceptively aligned models if they arise within the next few years, and I'd be really excited about more people working on it. Let me highlight just a few contributions:
- Scott Emmons [LW · GW] and Fabien Roger [LW · GW] showed that the most important part of Collin's method was contrast pairs. The original paper focused on "logical consistency properties of truth" such as P(X) + P(!X) = 1. While this is an interesting idea, its performance is hardly better than a much simpler strategy relegated to Appendix G.3: taking the average difference between a model's activations at a particular layer for many contrast pairs of the form X and !X. Collin shows this direction empirically coincides with truthfulness.
- Alex Turner and his SERI MATS stream took seriously the idea that contrast pairs could reveal directions in a model's latent space which correspond to concepts. They calculated a "cheese vector [LW · GW]" in a maze-solving agent as the difference in the model's activations between when the cheese was present and when it was missing. By adding and subtracting this vector to future forward passes of the model, its behavior could be controlled in surprising ways. GPT-2 can also be subtly controlled with this technique [LW · GW].
- Representation Engineering starts with this idea and runs a large number of empirical experiments. It finds a concept of truthfulness that dramatically improves performance on TruthfulQA (36% to 54%), as well as concepts of power-seeking, honesty, and morality that can control the behavior of language agents.
These are all unsupervised methods for detecting model beliefs. They've empirically improved performance on many real world tasks today, and it seems possible that they'd soon be able to detect deceptive alignment.
(Without providing a full explanation, these two related papers (1, 2) are also interesting.)
Future work on this topic could attempt to disambiguate [LW · GW] between directions in latent space corresponding to "human simulators" versus "direct translation" of the model's beliefs. It could also examine whether these directions are robust to optimization pressure. For example, if you train a model to beat a lie detector test based on these methods, will the lie detector still work after many rounds of optimization? I'd also be excited about straightforward empirical extensions of these unsupervised techniques applied to standard ML benchmarks, as there are many ways to vary the methods and it's unclear which variants would be the most effective.
comment by Fabien Roger (Fabien) · 2024-12-25T21:29:41.323Z · LW(p) · GW(p)
I think that prior to this paper, the discussion around scheming was pretty confusing, spread throughout many posts which were not all specifically about scheming, and was full of pretty bad arguments. This paper fixed that by bringing together most (all?) main considerations for and against expecting scheming to emerge.
I found this helpful to clarify my thinking around the topic, which makes me more confident in my focus on AI control [LW · GW] and made me less confused when I worked on the Alignment faking paper [LW · GW].
It is also helpful as a list of reasons why someone reasonable might expect scheming (without finding it overwhelmingly likely either) that I can point skeptical people at without being afraid that it contains massive over or understatements.
I think this paper will become pretty outdated as we get closer to understanding what AGI looks like and as we get better model organisms, but I think that it currently is the best resource about the conceptual arguments for and against scheming propensity.
I strongly recommend (the audio version of) this paper for people who want to work on scheming propensity.
Replies from: habryka4↑ comment by habryka (habryka4) · 2024-12-25T21:32:44.706Z · LW(p) · GW(p)
(For what it's worth, it appears to me that people started using the term "scheming" in much more confusing and inconsistent ways after this post was written and tried to give that term a technical meaning. I currently think this was quite bad. I do like a lot of the content of the paper/essay/post. I have like one conversation every two weeks that ends up derailed or confused because the two participants are using "scheming" in different specific ways, assuming the other person has the same meaning in mind)
comment by Steven Byrnes (steve2152) · 2023-11-15T19:14:39.967Z · LW(p) · GW(p)
(Sorry in advance if this whole comment is stupid, I only read a bit of the report.)
As context, I think the kind of technical plan where we reward the AI for (apparently) being helpful is at least not totally doomed to fail. Maybe I’m putting words in people’s mouths, but I think even some pretty intense doomers would agree with the weak statement “such a plan might turn out OK for all we know” (e.g. Abram Demski talking about a similar situation here [LW(p) · GW(p)], Nate Soares describing a similar-ish thing as “maybe one nine” a.k.a. a mere 90% chance that it would fail [LW(p) · GW(p)]). Of course, I would rather have a technical plan for which there’s a strong reason to believe it would actually work. :-P
Anyway, if that plan had a catastrophic safety failure (assuming proper implementation etc., and also assuming a situationally-aware AI), I think I would bet on a goal misgeneralization failure mode over a “schemer” failure mode. Specifically, such an AI could plausibly (IMO) wind up feeling motivated by any combination of “the idea of getting a reward signal”, or “the idea of the human providing a reward signal”, or “the idea of the human feeling pleased and motivated to provide a reward signal”, or “the idea of my output having properties X,Y,Z (which make it similar to outputs that have been rewarded in the past)”, or whatever else. None of those possible motivations would require “scheming”, if I understand that term correctly, because in all cases the AI would generally be doing things during training that it was directly motivated to do (as opposed to only instrumentally motivated). But some of those possible motivations are really bad because they would make the AI think that escaping from the box, launching a coup, etc., would be an awesome idea, given the opportunity.
(Incidentally, I’m having trouble fitting that concern into the Fig. 1 taxonomy. E.g. an AI with a pure wireheading motivation (“all I want is for the reward signal to be high”) is intrinsically motivated to get reward each episode as an end in itself, but it’s also intrinsically motivated to grab power given an opportunity to do so. So would such an AI be a “reward-on-the-episode seeker” or a “schemer”? Or both?? Sorry if this is a stupid question, I didn’t read the whole report.)
Replies from: joekc, Rubi↑ comment by Joe Carlsmith (joekc) · 2023-11-27T22:44:02.254Z · LW(p) · GW(p)
Agents that end up intrinsically motivated to get reward on the episode would be "terminal training-gamers [LW · GW]/reward-on-the-episode seekers," and not schemers, on my taxonomy. I agree that terminal training-gamers can also be motivated to seek power in problematic ways (I discuss this in the section on "non-schemers with schemer-like traits [? · GW]"), but I think that schemers proper are quite a bit scarier than reward-on-the-episode seekers, for reasons I describe here [? · GW].
↑ comment by Rubi J. Hudson (Rubi) · 2023-11-18T02:02:18.572Z · LW(p) · GW(p)
I don't find goal misgeneralization vs schemers to be as much as a dichotomy as this comment is making it out to be. While they may be largely distinct for the first period of training, the current rollout method for state of the art seems to be "give a model situational awareness and deploy it to the real world, use this to identify alignment failures, retrain the model, repeat steps 2 and 3". If you consider this all part of the training process (and I think that's a fair characterization), model that starts with goal misgeneralization quickly becomes a schemer too.
comment by Alex_Altair · 2024-01-02T22:47:59.119Z · LW(p) · GW(p)
Finally, I want to note an aspect of the discussion in the report that makes me quite uncomfortable: namely, it seems plausible to me that in addition to potentially posing existential risks to humanity, the sorts of AIs discussed in the report might well be moral patients in their own right.
I strongly appreciate this paragraph for stating this concern so emphatically. I think this possibility is strongly under-represented in the AI safety discussion as a whole.
comment by aog (Aidan O'Gara) · 2023-11-15T19:05:35.161Z · LW(p) · GW(p)
When considering whether deceptive alignment would lead to catastrophe, I think it's also important to note that deceptively aligned AIs could pursue misaligned goals in sub-catastrophic ways.
Suppose GPT-5 terminally values paperclips. It might try to topple humanity, but there's a reasonable chance it would fail. Instead, it could pursue the simpler strategies of suggesting users purchase more paperclips, or escaping the lab and lending its abilities to human-run companies that build paperclips. These strategies would offer a higher probability of a smaller payoff, even if they're likely to be detected by a human at some point.
Which strategy would the model choose? That depends on a large number of speculative considerations, such as how difficult it is to take over the world, whether the model's goals are time-discounted or "longtermist," and whether the model places any terminal value on human flourishing. But in the space of all possible goals, it's not obvious to me that the best way to pursue most of them is pursuit of world domination. For a more thorough discussion of this argument, I'd strongly recommend the first two sections of Instrumental Convergence? [LW · GW].
comment by jacob_cannell · 2023-11-15T17:51:58.713Z · LW(p) · GW(p)
The second part of the report examines the prerequisites for scheming. In particular, I focus on:
Situational awareness: the model understands that it's a model in a training process, what the training process will reward, and the basic nature of the objective world in general.
We can prevent situational awareness by training in simulation sandboxes [LW · GW] - carefully censored training environments. The cost is that you give up modern world knowledge and thus most of the immediate economic value of the training run, but it then allows safe exploration of alignment of powerful architectures without creating powerful agents. If every new potentially-dangerous compute-record-breaking foundation agent was trained first in a simbox that would roughly only double the training cost.
comment by Aaron Bohannon (aaron-bohannon-1) · 2023-11-28T03:44:21.125Z · LW(p) · GW(p)
So, are you saying that want A.I. to be aligned with the values that motivated this post? Or no?