Instrumental Convergence? [Draft]
post by J. Dmitri Gallow (j-dmitri-gallow) · 2023-06-14T20:21:41.485Z · LW · GW · 20 commentsContents
Abstract Section 1: A Means to Most Ends? Section 2: The Instrumental Convergence Thesis Section 3: Non-Sequential Decisions Section 4: Sequential Decisions Section 5: Discussion Appendix None 20 comments
This is a draft written by J. Dmitri Gallow, Senior Research Fellow at the Dianoia Institute of Philosophy at ACU, as part of the Center for AI Safety Philosophy Fellowship. This draft is meant to solicit feedback. Here is a PDF version of the draft.
Abstract
The thesis of instrumental convergence holds that a wide range of ends have common means: for instance, self preservation, desire preservation, self improvement, and resource acquisition. Bostrom (2014) contends that instrumental convergence gives us reason to think that ''the default outcome of the creation of machine superintelligence is existential catastrophe''. I use the tools of decision theory to investigate whether this thesis is true. I find that, even if intrinsic desires are randomly selected, instrumental rationality induces biases towards certain kinds of choices. Firstly, a bias towards choices which leave less up to chance. Secondly, a bias towards desire preservation, in line with Bostrom's conjecture. And thirdly, a bias towards choices which afford more choices later on. I do not find biases towards any other of the convergent instrumental means on Bostrom's list. I conclude that the biases induced by instrumental rationality at best weakly support Bostrom's conclusion that machine superintelligence is likely to lead to existential catastrophe.
Section 1: A Means to Most Ends?
According to Bostrom (2014, ch. 7), an intelligent agent could have any desires. There's nothing in the nature of intelligence that makes you more inclined to want some things rather than others. He calls this the orthogonality thesis (intelligence and desire are orthogonal). There is an infinitely large collection of ends which an agent could have. And there's nothing in the nature of intelligence itself which takes any of these ends off the table. Bostrom's point is that, if the orthogonality thesis is true, then we should be wary of anthropomorphising the motivations of future artificial superintelligences. An AI could be as intelligent as you wish, and still want nothing more than to create paperclips, or dance the Macarena, or reshape the Earth into a tetrahedron.
Yudkowsky (2018) agrees: "Imagine a map of mind design space. In one corner, a tiny little circle contains all humans; within a larger tiny circle containing all biological life; and all the rest of the huge map is the space of minds-in-general...It is this enormous space of possibilities which outlaws anthropomorphism as legitimate reasoning.''
Bostrom (2014) counsels humility about a superintelligence's ends. But he does not counsel humility about the means a superintelligence would take to those ends. For he holds that there are certain means which are worth pursuing for a wide range of potential ends. For a wide range of ends, instrumental rationality converges on similar means. He calls this the thesis of instrumental convergence.
Suppose we have a Superintelligent agent, Sia, and we know nothing at all about Sia's intrinsic desires. She might want to calculate as many digits of as possible. She might want to emblazon the Nike symbol on the face of the moon. She might want something too cognitively alien to be described in English. Nonetheless, Bostrom claims that, whatever she intrinsically desires, Sia will likely instrumentally desire her own survival. After all, so long as she is alive, she is more likely to achieve her ends, whatever they may be. Likewise, Sia will likely not want her desires to be changed. After all, if her desires are changed, then she'll be less likely to pursue her ends in the future, and so she is less likely to achieve those ends, whatever they may be. Similar conclusions are reached by Omohundro (2008 a,b). Both (Bostrom, 2014) and (Omohundro, 2008) contend that, even without knowing anything about Sia's intrinsic desires, we should expect her to have an instrumental desire to survive, to preserve her own desires, to improve herself, and to acquire resources.
Bostrom takes the orthogonality and instrumental convergence theses as reasons to think that the "default outcome of the creation of machine superintelligence is existential catastrophe''.[1] Orthogonality suggests that any superintelligent AI is unlikely to have desires like ours. And instrumental convergence suggests that, whatever desires Sia does have, she is likely to pose an existential threat to humanity. Even if Sia's only goal is to calculate the decimals of , she would "have a convergent instrumental reason, in many situations, to acquire an unlimited amount of physical resources and, if possible, to eliminate potential threats...Human beings might constitute potential threats; they certaintly constitute physical resources'' (Bostrom, 2014, p. 116). This echoes Yudkowsky's aphorism: "The AI does not hate you, nor does it love you, but you are made out of atoms which it can use for something else.''[2]
You might wonder why an intelligent agent has to have desires at all. Why couldn't Sia have an intellect without having any desires or motivations? Why couldn't she play chess, compose emails, manage your finances, direct air traffic, calculate digits of , and so on, without wanting to do any of those things, and without wanting to do anything else, either? Lots of our technology performs tasks for us, and most of this technology could only loosely and metaphorically be described as having desires---why should smart technology be any different? You may also wonder about the inference from the orthogonality thesis to the conclusion that Sia's desires are unpredictable if not carefully designed. You might think that, while intelligence is compatible with a wide range of desires, if we train Sia for a particular task, she's more likely to have a desire to perform that task than she is to have any of the myriad other possible desires out there in 'mind design space'. I think these are both fair concerns to have about Bostrom's argument, but I'll put them aside for now. I'll grant that Sia will have desires, and that, without careful planning, we should think of those desires as being sampled randomly from the space of all possible desires. With those points granted, I want to investigate whether there's a version of the instrumental convergence thesis which is both true and strong enough to get us the conclusion that existential catastrophe is the default outcome of creating artificial superintelligence.
Investigating the thesis will require me to give it a more precise formulation than Bostrom does. My approach will be to assume that Sia's intrinsic desires are sampled randomly from the space of all possible desires, and then to ask whether instrumental rationality itself tells us anything interesting about which choices Sia will make. Assuming we know almost nothing about her desires, could we nonetheless say that she's got a better than probability of choosing from a menu of acts? If so, then may be seen as a 'convergent' instrumental means---at least in the sense that she's more likely to choose than some alternatives, though not in the sense that she's more likely to choose than not.
My conclusion will be that most of the items on Bostrom's laundry list are not 'convergent' instrumental means, even in this weak sense. If Sia's desires are randomly selected, we should not give better than even odds to her making choices which promote her own survival, her own cognitive enhancement, technological innovation, or resource acquisition. Nonetheless, I will find three respects in which instrumental rationality does induce a bias on the kinds of choices Sia is likely to make. In the first place, she will be biased towards choices which leave less up to chance. In the second place, she will be biased towards desire preservation, confirming one of Bostrom's conjectures. In the third place, she will be biased towards choices which afford her more choices later on. (As I'll explain below, this is not the same thing as being biased towards choices which protect her survival, or involve the acquisition or resources or power---though they may overlap in particular decisions.) So I'll conclude that the instrumental convergence thesis contains some grains of truth. Instrumental rationality does 'converge' on certain means---at least in the very minimal sense that it gives some choices better than even odds, even when we are maximally uncertain about an agent's intrinsic desires. But the thesis also contains its fair share of exaggerations and falsehood. Assuming we should think of a superintelligence like Sia as having randomly selected desires, the grains of truth may give us reasons to worry about machine superintelligence. But they do not on their own support the contention that the ''default outcome of the creation of machine superintelligence is existential catastrophe''. Like most of life's dangers, the dangers of artificial intelligence are not easily identified from the armchair. Better appreciating those dangers requires less speculation and more careful empirical work.
Section 2: The Instrumental Convergence Thesis
Bostrom's official statement of the thesis of instrumental convergence is this:
Several instrumental values can be identified which are convergent in the sense that their attainment would increase the chances of the agent’s goal being realized for a wide range of final goals and a wide range of situations, implying that these instrumental values are likely to be pursued by a broad spectrum of situated intelligent agents. (Bostrom, 2014, p. 109)
The 'convergent' instrumental values he identifies are: self-preservation, goal-preservation, cognitive enhancement, technological advancement, and resource acquisition. Others, like Carlsmith (ms) and Turner (2021), suggest that power is a convergent instrumental value. Just as Bostrom thinks that Sia is likely to seek resources and technology, Carlsmith thinks she is likely to seek power. This leads Carlsmith to conclude that the disempowerment of humanity is the default outcome of creating a superintelligent agent.
This official thesis includes within it an inference. It begins by saying that there are things the attainment of which would have instrumental value. Let's call this the convergent instrumental value thesis.
The Convergent Instrumental Value Thesis: It would likely be instrumentally valuable for Sia to have power, technology, resources, and so on.
For some of the 'convergent' instrumental goals on the list, the convergent instrumental value thesis strikes me as plausible. Indeed, there are ways of defining 'power' on which it becomes tautological that power would be instrumentally valuable to have. For instance, if we define 'power' in terms of the ability to effectively pursue your ends without incurring costs, then it will follow that more power would be instrumentally valuable. Cost-free abilities are never instrumentally disvaluable---just in virtue of the meaning of 'cost-free'. And the ability to effectively pursue your ends is, of course, instrumentally valuable.
This definition of 'power' is relative to your ends. Different ends will make different things costly, and it will make different abilities effective means to your ends. If we don't know what Sia's ends are, we won't know what 'power' (so defined) looks like for her; nor is there any reason to think that Sia's 'power' and humanity's 'power' are zero-sum.
Defining 'power' in this way makes the convergent instrumental value thesis easy to establish; but for that very reason, it also makes it uninteresting. The sense in which cost-free power is instrumentally valuable is just the sense in which cost-free birthday candles are instrumentally valuable. It's the sense in which cost-free Macarena dancing abilities are instrumentally valuable. From this, we should not conclude that the default outcome of superintelligent AI is birthday-candle-wielding, Macarena-dancing robots.
In discussions of the convergent instrumental value thesis, some have stipulatively defined 'power' in terms of having more available options.[3] If that's how we understand power, then it's less clear whether the thesis is true. Having a larger menu of options isn't always instrumentally valuable, since a larger menu brings with it increased costs of deliberation. It's not irrational to want to select from a curated list. Additionally, if your menu is larger than others', this could engender resentment and competition which damages your relationships. It's not irrational to regard this as a cost. (We'll see below that instrumental rationality does somewhat bias Sia towards acts which afford the possibility of more choices later on---though we'll also see why this isn't the same as being biased towards power acquisition, in any intuitive or natural sense of the word 'power'.)
From the convergent instrumental value thesis, Bostrom infers that Sia is likely to pursue self-improvement, technology, resources, and so on. I'm going to call this second claim the instrumental convergence thesis proper.
The Instrumental Convergence Thesis: It will likely be instrumentally rational for Sia to pursue self-improvement, technology, resources, and so on.
It's important to note that this second claim is the one doing the work in any argument that doom is the default result of a superintelligent agent like Sia. If we're going to reach any conclusions about what will likely happen if Sia is created, then we'll need to say something about how Sia is likely to behave, and not just what kinds of things counterfactually would be instrumentally valuable for her to have. So it is this second thesis which is going to be my primary focus here.
In the quote above, Bostrom seems to suggests that the convergent instrumental value thesis implies the instrumental convergence thesis. But this is not a good inference. Were I to be a billionaire, this might help me pursue my ends. But I'm not at all likely to try to become a billionaire, since I don't value the wealth more than the time it would take to secure the wealth---to say nothing about the probability of failure. In general, whether it's rational to pursue something is going to depend upon the costs and benefits of the pursuit, as well as the probabilities of success and failure, the costs of failure, and so on If you want to know how likely it is that Sia is going to seek cognitive enhancement, you cannot simply consider how beneficial it would be for her to have that enhancement. You also have to think about which costs and risks she incurs by seeking it. And you have to think about what her other alternatives are, what the costs, benefits, and risks of those alternatives are, and so on.
In informal discussions of the instrumental convergence thesis, it's common to hear arguments that Sia "will be incentivised'' to achieve some instrumental goal, . From this conclusion, it is straightaway inferred that she will likely pursue . We should tread with caution here. For there are two ways of understanding the claim that Sia "will be incentivised'' to achieve , corresponding to the two parts of Bostrom's thesis. We could mean that it would be instrumentally valuable for Sia, were she to successfully achieve . Or we could mean that it would be instrumentally rational for her to pursue . This is a motte-and-bailey. The first claim is easier to establish, but less relevant to the question of how an instrumentally rational superintelligence like Sia will actually behave.
You may think that, even though agents like us won't seek every means which would help us achieve our ends, superintelligent agents like Sia will. In conversation, some have suggested that, when it comes to a superintelligence, the costs of acquiring resources, technology, cognitive enhancement, and so on will be much lower than they are for those of human-level intelligence. And so it's more likely that Sia will be willing to pay those costs. Note that this reasoning rests on assumptions about the contents of Sia's desires. A cost is something you don't want. So assuming that the costs are low for Sia is assuming something about Sia's desires. If we accept the orthogonality thesis, then we should be skeptical of armchair claims about Sia's desires. We should be wary of projecting human desires onto an alien intelligence. So we should be skeptical of armchair claims about what costs decreasing with intelligence.
In any case, it won't matter for my purposes here whether the second thesis follows from the first thesis or not. So it won't matter whether you're persuaded by the foregoing. The instrumental convergence thesis is the one doing the work in Bostrom's argument. And I'll be investigating that thesis directly.
The investigation will require me to make the thesis more precise. My approach will use the tools of decision theory. I'll look at particular decisions, and then ask about which kinds of intrinsic desires would rationalise which courses of action in those decisions. If we are uncertain about Sia's intrinsic desires, are there nonetheless acts which we should expect those desires to rationalise? If so, then these acts may be seen as instrumentally convergent means for that decision.
More carefully, I'll formally represent the space of all possible desires that Sia could have. I'll then spread a probability distribution over the desires in this space---think of this as our probability distribution over Sia's desires. I'll then stipulate a decision problem and ask which act we should expect Sia to perform if she's ideally rational. Notice that, while I won't be assuming anything about which desires Sia has, I will be assuming something about the decision she faces. That's in part because, while I know a very natural way to spread probabilities over Sia's desires, I know of no natural way to parameterise the space of all possible decisions, and so I see no natural way to spread probabilities over that space. For some of the results below, this won't matter. We'll be able to show that something is true in every decision Sia could face. However, some other results are going to depend upon which decision she faces. Interpreting these results is going to involve some more substantive assumptions about which kinds of decisions a superintelligence is likely to face.
Section 3: Non-Sequential Decisions
Let me introduce a way of formally modelling the potential desires Sia could have. I'll suppose we have a collection of all the possible ways the world could be, for all Sia is in a position to know. We can then model Sia's desires with a function, , from each of these possible ways for the world to be, , to a real number, . The interpretation is that is higher the better satisfied Sia's desires are, if turns out to be the way the world actually is. (In the interests of economy, from here on out, I'll call a way for the world to be 'a world'.)
Functions like these give us a formal representation of Yudkowsky's informal idea of a 'mind design space'. The set of all possible desire functions---the set of all functions from worlds to real numbers---is the space of all possible desires. We may not have any idea which of these desires Sia will end up with, but we can think through which kinds of acts would be rationalised by different desires in this space.
It's easy to come up with desires Sia could have and decisions she could face such that, in those decisions, those desires don't rationalise pursuing self-preservation, desire-preservation, resources, technology, power, and so on. Suppose Sia's only goal is to commit suicide, and she's given the opportunity to kill herself straightaway. Then, it certainly won't be rational for her to pursue self-preservation. Or suppose that Sia faces a repeated decision of whether to push one of two buttons in front of her. The one on the left changes her desires so that her only goal is to push the button on the right as many times as possible. The button on the right changes her desires so that her only goal is to push the button on the left as many times as possible. Right now, Sia's only goal is to push the button on the left as many times as possible. Then, Sia has no instrumental reason to pursue goal-preservation. Changing her goals is the best means to achieving those goals. Suppose Sia's only goal is to deliver you a quart of milk from the grocery store as soon as possible. To do this, there's no need for her to enhance her own cognition, develop advanced technology, hoard resources, or re-purpose your atoms. And pursuing those means would be instrumentally irrational, since doing so would only keep you waiting longer for your milk.
In fact, we can say something more general. Specify a one-off, non-sequential decision for me. (We'll come to the case of sequential decisions later on.) You get to say precisely what the available courses of action are, precisely what these actions would accomplish, depending on what world Sia is in, and precisely how likely Sia thinks it is that she's in this or that world. Get as creative as you like. In your decision, Sia's desires will make more rational than exactly if the expected utility of exceeds the expected utility of (I give a careful definition of 'expected utility' below and in the appendix.) Then, for any two available acts in your decision whose expected consequences differ, there are infinitely many desires which would make more rational than , and infinitely many others which would make more rational than . In the appendix, I show that:
Proposition 1. If the expected consequences of differ from the expected consequences of , then there are infinitely many desires which make more rational than , and infinitely many desires which make more rational than .
Intuitively, this is true because, whenever the expected consequences of differ from the expected consequences of , it could be that Sia more strongly desires what would bring about, and it could be that she more strongly desires what would bring about---and there are infinitely many strengths with which she could hold those desires.
Of course, this doesn't put any pressure on the instrumental convergence thesis. The thesis doesn't say that Sia definitely will seek self-preservation, cognitive enhancement, and so on. Instead, it says that she is likely to do so. We'll get to this probabilistic claim below. But it'll be instructive to spend a bit more time thinking about the bare existential question of whether there are desires which rationalise certain preferences between acts.
Proposition 1 tells us that, for any act and any alternative with different expected consequences, there are desires which would make more rational than . It does not tell us that, for any act , there are desires which would make more rational than every alternative.
Whether this stronger claim is true depends upon whether or not the worlds over which Sia's probabilities and desires are defined are informative enough to tell us about which choice Sia makes, or about the different near-term consequences of those different choices. Slightly abusing Savage (1954)'s terminology, if there's some world which might occur, if Sia chooses, and which also might occur, if Sia chooses , then I'll say that Sia is facing a 'small world' decision. (The worlds in her decision are 'small' in that they don't include some relevant information---at the least, they don't include information about which choice Sia makes.) Else, I'll say that she is facing a 'grand world' decision. In a grand world decision, the possible consequences of will always differ from the possible consequences of . And we will allow for the possibility that Sia has desires about these different consequences.
Let's think through what happens in small world decisions. Consider:
Certain and Uncertain Acts: For each world, , Sia has available a 'certain' act, , which she knows for sure would bring about . She also has an 'uncertain' act, , which might bring about any world---she doesn't know for sure which one.
Note that this is a small world decision. If it were a grand world decision, then any world in which Sia chooses could only be brought about by . But we've supposed that every world has some action other than which brings it about. So the worlds in this decision must be small.
In this decision, for every certain act, there are desires which would make more rational than it (as promised by proposition 1). But no desires would make more rational than every certain act. Sia could be maximally indifferent, desiring each world equally. In that case, every act will be as rational as every other, since they'll all bring about equally desirable outcomes. But as long as there's some world which Sia desires more strongly than others, it'll be most rational to bring about one of the most strongly desired worlds with a certain act.[4] So there are no desires which make the uncertain more rational than every certain act. (Though there are desires which make rational to choose; they just don't make it more rational than the alternatives.)
On the other hand, when it comes to grand world decisions, we can make the stronger claim: for any act in any grand world decision, there are infinitely many desires which make that act uniquely rational.
Proposition 2. In any grand world decision, and any available act in that decision, , there are infinitely many desires which make more rational than every other alternative.
For instance, in a 'grand world' version of Certain and Uncertain Acts, Sia might prefer not knowing what the future brings. If so, she may prefer the uncertain act to any of the certain ones.
When we're thinking about the instrumental convergence thesis in the context of Bostrom's argument, I think it makes most sense to consider grand world decisions. The argument is meant to establish that existential catastrophe is the default outcome of creating a superintelligent agent like Sia. But the real world is a grand world. So real world agents face grand world decisions. Suppose Sia most desires calculating the digits of , and she faces a decision about whether to keep on calculating or instead take a break to re-purpose the atoms of humanity. If we're thinking though how likely Sia is to disempower humanity, we shouldn't assume away the possibility that she'd rather not take time away from her calculations. So in the remainder, I'll assume that Sia is facing a grand world decision, though I'll occasionally note when this assumption is dispensable.[5]
Propositions 1 and 2 are warm-up exercises. As I mentioned above, they do not themselves put any pressure on the thesis of instrumental convergence, since that thesis is probabilistic. It says that Sia is likely to pursue self-preservation, resources, power, and the like. The orthogonality thesis makes it difficult to evaluate this likelihood claim. For the orthogonality thesis tells us that, from the fact that Sia is intelligent, we can infer nothing at all about what her intrinsic desires are. If we bring a superintelligent AI like Sia into existence without designing her desires, we should think of ourselves as sampling randomly from the space of all possible desires. So, when we try to evaluate the thesis of instrumental convergence, we shouldn't just consider a handful of desires and decisions that spring to mind and ask ourselves whether those desires rationalise resource acquisition in those decisions. To do so would be to engage in an illicit form of anthropomorphism, projecting human-like desires on an alien intelligence.
So let us specify a probability distribution over the space of all possible desires. If we accept the orthogonality thesis, we should not want this probability distribution to build in any bias towards certain kinds of desires over others. So let's spread our probabilities in such a way that we meet the following three conditions. Firstly, we don't expect Sia's desires to be better satisfied in any one world than they are in any other world. Formally, our expectation of the degree to which Sia's desires are satisfied at is equal to our expectation of the degree to which Sia's desires are satisfied at , for any . Call that common expected value ''. Secondly, our probabilities are symmetric around . That is, our probability that satisfies Sia's desires to at least degree is equal to our probability that it satisfies her desires to at most degree . And thirdly, learning how well satisfied Sia's desires are at some worlds won't tell us how well satisfied her desires are at other worlds. That is, the degree to which her desires are satisfied at some worlds is independent of how well satisfied they are at any other worlds. (See the appendix for a more careful formulation of these assumptions.) If our probability distribution satisfies these constraints, then I'll say that Sia's desires are 'sampled randomly' from the space of all possible desires.
Once again, specify any one-off, non-sequential decision you like. You get to say precisely what the available courses of action are, precisely what these actions would accomplish in each world, and precisely what Sia's probability distribution over worlds is. Get as creative as you like. Once you've specified your decision, we can ask: if Sia's desires are sampled randomly, should we expect her to prefer some acts to others? And which act should we expect her to most prefer overall? Again, we can assume that Sia is instrumentally rational. So she'll prefer to if and only if 's expected utility exceeds 's expected utility. And she'll choose iff maximises expected utility. No matter how complicated or creative your decision is, if Sia's desires are sampled randomly, then we should think she's just as likely to prefer to as she is to prefer to . In the appendix, I show that:
Proposition 3. If Sia's desires are sampled randomly, then those desires are just as likely to make more rational than as they are to make more rational than .
(Again, this is a rough statement of the proposition; see the appendix for the details.) This proposition, by the way, is still true even if we assume Sia is facing a small world decision.
Proposition 3 only says something about the probability that is more rational than . It doesn't say that and are equally likely to be the most rational options. As we learnt above, these are different questions. Of course, if there are only two options, then we can say definitively that neither option is any more likely to be rational than the other. But if there are three or more options, matters are more complicated.
Given our assumptions, we will expect Sia's expected utility for any course of action to be ---where , recall, is our expectation of the degree to which Sia's desires will be satisfied at any world. So our probability distribution over Sia's expected utility for and our probability distribution over Sia's expected utility for will have the same mean. Given our assumptions, these probability distributions will be symmetric about that common mean. And, if she's facing a grand world decision, then Sia's expected utility for won't tell us anything about her expected utility for . They'll be independent in our probability function. But, in general, our probability distribution over Sia's expected utility for can have a different standard deviation than our probability distribution over Sia's expected utility for . That is, when it comes to Sia's expected utility for , we may spread our probabilities more widely than we do when it comes to Sia's expected utility for ---even if our probability distributions over the values of , for each world , all have the same standard deviation.
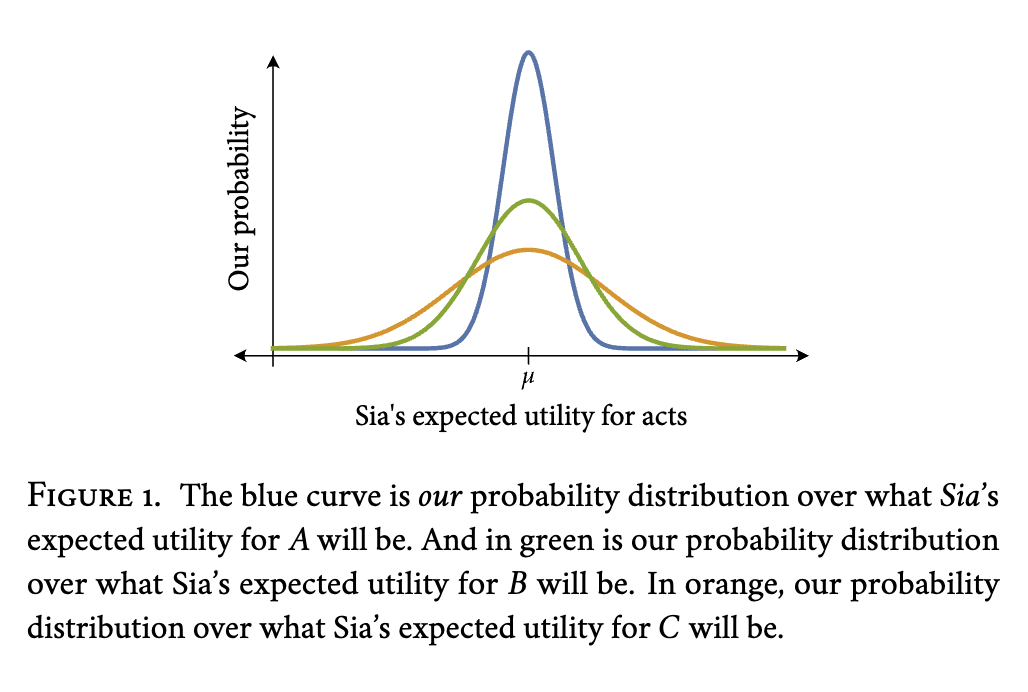
I've illustrated one possible situation in figure 1. There, imagine that the blue curve is our probability distribution for what Sia's expected utility for will be, the green curve is our probability distribution for what Sia's expected utility for will be, and the orange curve is our probability distribution for what Sia's expected utility for will be. For any two acts, the probability that the first is more rational than the second will be equal to the probability that the second is more rational than the first. But it won't in general be true that the probability that one act is most rational is equal to the probability that another act is most rational.
Let me say a bit more about why this happens. Firstly, I'm assuming that Sia is going to calculate expected utilities with a weighted sum of her desires for each world, where the weights come from a suppositional probability function, . is Sia's probability distribution , updated on the supposition that she has performed . Then, the expected utility of the act will be a weighted sum of the degree to which Sia desires each world, with weights given by how confident Sia is in that world, supposing she performs , . Both causal and evidential decision theorists think that rationality requires you to maximise a quantity of this kind. They simply disagree about how to understand . Evidential decision theorists say that is Sia's probability function conditioned on ; [6] whereas causal decision theorists say that is Sia's probability function imaged on . [7] For causal decision theorists, is how likely Sia should think it is that would result, were she to perform . So, for causalists, tells us the likely consequences of Sia's performing .
Just to think matters through, let's spot ourselves a stronger assumption. Let's additionally suppose that, for any two worlds, and , our probability distribution over the potential values of and our probability distribution over the potential values of are normally distributed with a common mean and standard deviation. If this is so, then I'll say that Sia's desires are "sampled normally'' from the space of all possible desires. If Sia's desires are sampled normally, then it follows that the standard deviation of our probability distribution over Sia's expected utility for is going to be proportional to , the square root of the sum of the squares of 's probabilities for worlds, which is sometimes written '', and called the 'magnitude' of .[8]
To build an intuition for the quantity , consider a simple case in which there are three worlds, , and , which we can represent with the three points , , and in three-dimensional Euclidean space.

Then, the set of all probability distributions over these worlds is the set of all points which lie somewhere between them (see figure 2). And for a probability distribution , is just the distance from to the origin, . is greater the further away is from the uniform distribution , and the closer it is to the worlds (see figure 2). In general, if there are worlds, we can think of a probability as a point in an -dimensional Euclidean space. And will be the distance from that point to the origin.
is higher the more it 'points towards' some worlds over others. If invests all its probability in a single world, then . If it spreads its probability between more worlds, then is lower. So, insofar as is lower, the consequences of are more uncertain, and we can say that 'leaves more up to chance'; insofar as they are higher, 's consequences are less uncertain, and we can say that 'leaves less up to chance'.
As leaves less up to chance, gets larger, so the standard deviation of our probability distribution over Sia's expected utility of gets wider. And as this standard deviation gets wider, our probability that maximises expected utility will get greater (Of course, the probability that minimises expected utility also gets greater.) In the appendix, I show that:
Proposition 4. If Sia's desires are sampled normally from the space of all possible desires, then the probability that her desires will rationalise choosing in any grand world decision increases as leaves less up to chance.
For illustration: in the sample distributions shown in figure 1, Sia is about 38% likely to choose (in orange), about 33% likely to choose (in green), and about 29% likely to choose (in blue).
This is a probabilistic version of the phenomenon we encountered with the decision Certain and Uncertain Acts. What proposition 4 tells us is that, if her desires are sampled normally, then we should be somewhat more confident that Sia will choose acts that leave less to chance than we are that she'll choose acts that leave more to chance.
How much leaves to chance isn't straightforwardly related to whether protects Sia's goals or her life, nor whether enhances Sia's cognitive abilities, technological capacities, or resources. If anything, enhancing her cognitive abilities seems to leave more to chance, insofar as Sia won't know which kinds of choices she'll make after her cognition has been enhanced. And if Sia is a highly novel and disruptive agent, then protecting her life may leave more to chance than ending it.
So while we've uncovered a kind of instrumental convergence, it does not appear to be the kind of convergence posited by the instrumental convergence thesis. I'll have more to say about this in section 5 below.
In some small world decisions like Certain and Uncertain Acts, we can know for sure that Sia won't make a particular choice. But in any grand world decision, we should retain some probability that she'll make any particular choice. For we can place a lower bound on the probability that any course of action, , maximises expected utility for Sia. In the appendix, I show that:
Proposition 5. If Sia's desires are sampled randomly, then, in a grand world decision with n available acts, the probability that Sia chooses any given act is at least .
For instance, in a decision between three acts, there is at least a 25% probability that Sia will make any given choice. And, in a decision between four acts, the probability that she'll make any given choice is at least 12.5%. (Of course this is just a lower bound; it could easily be much higher.)
Section 4: Sequential Decisions
Above, we limited ourselves to one-off, non-sequential decisions. When it comes to sequential decisions---where a rational agent is charting a path through a multi-stage decision tree---matters are more complicated. One complication is that it's controversial how rational agents choose in sequential decisions. By way of explanation, consider the following sequential decision.
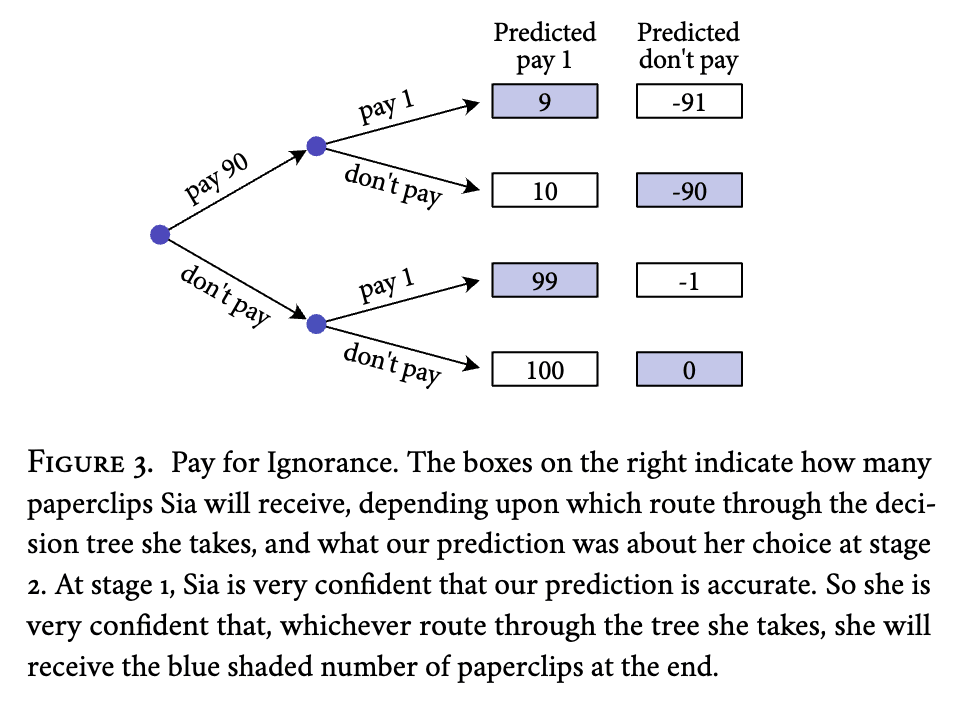
Pay for Ignorance: Sia wants nothing other than paperclips, and her desires are linear with paperclips; each new paperclip is just as good as the one that came before. At stage 1, Sia can either give us 90 paperclips or she can give us none. At stage 2, she can either give us 1 paperclip or she can give us none. Yesterday, we analysed her program and made a prediction about how she'd behave in this decision. If we predicted that she'd give us the single paperclip at stage 2, then we pre-awarded her 100 paperclips. If she doesn't pay us the 90 paperclips at stage 1, then we tell her which prediction we made. If she does pay us the 90 paperclips at stage 1, then we keep her in the dark about which prediction was made. Since our predictions are based on a thorough analysis of Sia's program, they are never wrong. Sia knows all of this.[9]
Sia's stage 2 decision matrix will look like this:
| Predicted Pay 1 | Predicted don't pay | |
| Pay 1 | +99 | -1 |
| Don't Pay | +100 | 0 |
If she doesn't know which prediction we've made, then the decision Sia faces at stage 2 is just the famous 'Newcomb problem'.[10] Let's suppose that Sia is an evidential decision theorist, who chooses whichever act she would be most glad to learn that she'd chosen.[11] (By the way, nothing hinges on the choice of evidentialism here; we could make all the same points if we assumed instead that Sia was a causalist.) What Sia would be most glad to learn she'd chosen at stage 2 will depend upon what she knows. If she doesn't know which prediction we've made, then she'd be most glad to learn that she gives us the paperclip. Learning this would tell her that we pre-rewarded her 100 paperclips; whereas learning that she doesn't pay would tell her that we didn't. Since she'd rather have 99 paperclips than none, she'd rather learn that she pays us the paperclip. On the other hand, if Sia knows our prediction, then she'd be most glad to learn that she doesn't pay. For instance, if she knows that we predicted she wouldn't pay, then learning that she doesn't pay tells her that she's not getting any paperclips. On the other hand, learning that she does pay would tell her that she's only losing a paperclip.
Turn now to the sequential decision Pay for Ignorance. There are two main schools of thought about how Sia should decide at stage 1 of this decision. The orthodox view is often called sophisticated. It says that Sia should decide by doing a 'backwards induction', thinking first about what it would will maximise expected utilitty for her future self at stage 2, and then taking this for granted in her deliberation about what to do at stage 1. In particular, a sophisticated evidentialist Sia will notice that, if she knows what prediction was made, then not paying will maximise expected utility at stage 2. So a sophisticated evidentialist Sia will reason as follows: "the best possible path through the decision tree is to not pay the 90 paperclips at stage 1, and then pay the 1 paperclip at stage 2. If I do that, I'll likely end up with 99 paperclips. But I can't trust my future self to go along with that plan. Once she knows which prediction was made, it'll be rational for her to not pay. And if she doesn't pay, I'll likely end up with no paperclips. So: if I don't pay at stage 1, then I should expect to end up with zero paperclips. On the other hand, if I pay to remain ignorant of the prediction, then my future self will pay the 1 paperclip at stage 2. And so, she'll likely have been predicted to pay the 1 paperclip, and she'll likely have been pre-rewarded 100 paperclips. Minus the 91 I've already paid them, I should expect to end up with 9 paperclips if I pay at stage 1.'' So a sophisticated evidentialist Sia will pay the 90 paperclips at stage 1.
The less orthodox view is known as resolute choice. According to this view, at stage 1, Sia should decide which contingency plan is best, and then she should stick to the plan, even if sticking to the plan stops maximising expected utility later on. (A contingency plan will specify a collection of permissible acts for each situation Sia might find herself in.) A resolute evidentialist Sia will not pay the 90 paperclips at stage 1, and then pay the 1 paperclip at stage 2. Notice that a resolute evidentialist Sia would not pay the 1 paperclip if we just plopped her down in the stage 2 decision with the knowledge of which prediction we'd made, without giving her an earlier choice about whether to pay to avoid this knowledge. According to the resolute view, what it is rational for Sia to do at one stage of a sequential decision depends upon which contingency plans she's already committed herself to.
If Sia doesn't pay at either stage 1 or stage 2, then the sophisticated theory says that she behaved irrationally at stage 1, but rationally at stage 2. And the resolute theory says that she behaved rationally at stage 1 but irrationally at stage 2.[12]
There's another complication worth raising at this point. At stage 1, Sia may possess the ability to bind her future self to a certain course of action. Think of Ulysses binding himself to the mast.[13] With this ability, she would be able to instill in herself the intention to follow through on an initially selected contingency plan and deprive her future self of the ability to revise this intention, even if revising the intention maximises expected utility at that later time. If she possess this ability, then there will be no behavioural difference between her and a resolute chooser.
Suppose Sia follows a resolute theory of sequential decision-making, or that she has the ability to self-bind. Then, at stage 1, Sia will decide between contingency plans by comparing their expected utilities. And proposition 3 assures us that, if Sia's desires are sampled randomly, they are just as likely to make one contingency plan more rational than the other as they are to make the other contingency plan more rational than the one. Proposition 4 teaches us that, if her desires are sampled normally, then she'll be more likely to choose contingency plans which leave less to chance. And proposition 5 puts a lower bound on the probability that her desires will rationalise any particular contingency plan.
If Sia is a resolute chooser, or if she is able to self-bind, then there is a sense in which she is more likely to make some choices than others. If her desires are sampled normally, then---all else equal---a resolute or self-binding Sia will be more likely to make choices which have more choice points downstream of them. For instance, suppose that we have a large collection of prizes, , and each day, Sia has the choice to either take that day's prize or else wait. As soon as she takes a prize, the game is over. (See figure 4.)
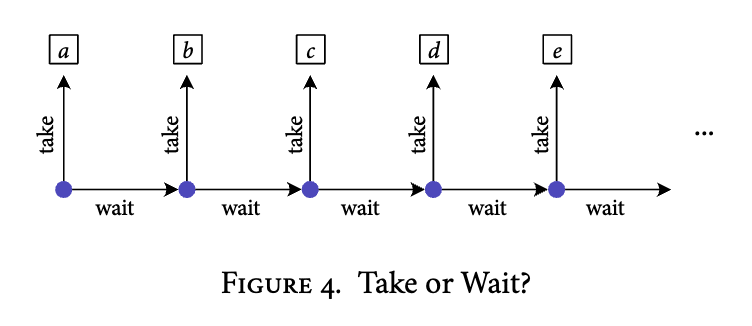
Just to fix ideas, let's stipulate that the worlds over which Sia's desires are defined only include information about which choices Sia makes, and which prize she receives. Then, each contingency plan will leave as much to chance as every other. So, if her desires are sampled normally, she's incredibly likely to wait on day 1, since most of the contingency plans involve waiting on day 1, and only one involves taking . The same thing holds in general. If she's a resolute chooser, or if she's able to self-bind, then (all else equal) Sia will be more likely to make choices that afford her more choices, and less likely to make choices that afford her fewer choices---just because there are more contingency plans which go on to face more choices, and fewer which go on to face fewer.
If Sia is a sophisticated chooser, then matters are more complicated. To introduce the complications, it'll be helpful to consider another of Bostrom's 'convergent' instrumental means: desire preservation. Will Sia be likely to preserve her desires? In general, this is going to depend upon the kind of decision she's facing---which ways she might change her desires, and how things might go differently, depending upon how the desires are changed. But in many simple cases, she will be more likely to keep her desires than she is to change them. Let me spend some time explaining why, since understanding this better will help us to think through what we should expect if Sia is a sophisticated chooser.
For illustration, consider a simple sequential decision like the one shown in figure 5.
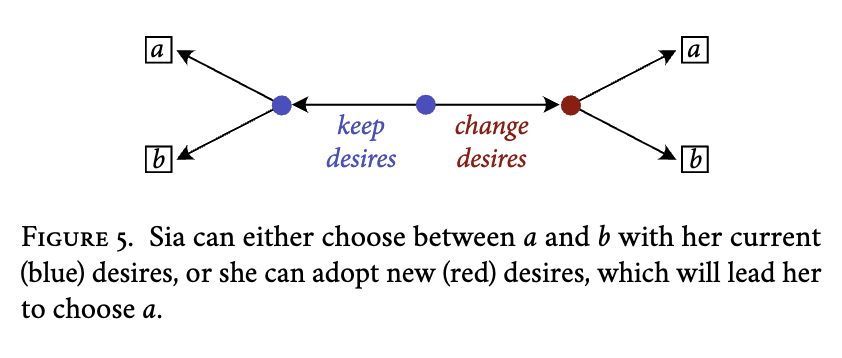
Sia begins at the blue node in the center and decides whether to change her desires or not. Suppose that, if she changes her desires, then she will prefer to . Clearly, if we model this as a 'small world' decision, where Sia only cares about whether she ends up with or , and cares not at all about what her desires are, then she will be more likely to keep her desires. For, if her desires are sampled randomly, then she will be just as likely to prefer to as she will be to prefer to . If she prefers to , then she'll be indifferent between keeping her desires and changing them. And if she prefers to , then she'll prefer to keep her desires.
Even if we model Sia's decision as a 'grand world' decision, and allow that she might care about whether her desires are changed, she will still be more likely to keep her desires in this decision. To appreciate why, let's model her decision with four worlds: 1) the world where she eeps her desires and gets , , 2) the world where she hanges her desires and gets , , 3) , and 4) (with the natural interpretation). If she changes her desires, she will certainly end up at world , since the changed desires will prefer to . So, in deciding whether to change her desires or not, Sia will be comparing the degree to which she desires getting after changing her desires, , to whichever of and is greatest---for, if , then Sia would choose and end up at world ; and, if , then Sia would choose and end up at world . But, conditional on being larger than , it is more likely to be larger than , too. And, similarly, conditional on being larger than , it is more likely to be larger than , too. So, overall, Sia will be more than 50% likely to keep her desires in this decision.
So it looks as though desire preservation will be a 'convergent' instrumental means in this decision, at least in the sense that randomly selected desires are more likely to rationalise desire preservation than they are to rationalise desire change. (Of course, just because this is true in this decision, it doesn't mean that it'll be true in every decision where Sia is deciding whether to modify her desires; but the mechanism which makes desire preservation more likely here seems general enough that we should expect it to carry over to many other decisions, too.)
Moreover, this same mechanism should lead us to expect a sophisticated Sia to make choices which allow for more choices later on. Return again to the sequential decision from figure 4. We saw above that, all else equal, a resolute Sia would be more likely to wait at stage 1 than she was to take , for the simple reason that most of the contingency plans wait at stage 1, and only one takes . If Sia is a sophisticated chooser, it will also be true that she's more likely to wait at stage 1---but it's for a different reason. The reason a sophisticated Sia is more likely to wait at stage 1 is that, in making that decision, she's comparing the degree to which she desires the world where she takes , , to the maximum of the degree to which she desires all other worlds, . And even though our probability that is greater than will be 50%, and the probability that is greater than is 50%, and so on, the probability that is greater than all of is far less than 50%. So---all else equal---a sophisticated Sia whose desires are sampled randomly will be biased towards choices which allow for more choices later on.
Section 5: Discussion
Let's summarise our findings. We've identified three kinds of 'convergent' instrumental means---which is to say, we've identified three ways in which Sia's choices may be predicted with better than chance, even if her desires are sampled randomly.
In the first place, she's somewhat more likely to favour acts which leave less to chance. As I mentioned above, I don't see any reason to think that resource acquisition, technological advancement, cognitive enhancement, and so on, will in general leave less up to chance. Insofar as the results of technological and cognitive enhancement are unpredictable in advance, this gives us some reason to think that Sia is less likely to pursue cognitive and technological enhancement. So I don't think this bias is relevant to the kinds of 'convergent' instrumental means which are Bostrom's focus.
Should a bias against leaving things up to chance lead us to think that existential catastrophe is the more likely outcome of creating a superintelligent agent like Sia? This is far from clear. We might think that a world without humans leaves less to chance, so that we should think Sia is more likely to take steps to eliminate humans. But we should be cautious about this inference. It's unclear that a future without humanity would be more predictable. And even if the future course of history is more predictable after humans are eliminated, that doesn't mean that the act of eliminating humans leaves less to chance, in the relevant sense. It might be that the contingency plan which results in human extinction depends sensitively upon humanity's response; the unpredictability of this response could easily mean that that contingency plan leaves more to chance than the alternatives. At the least, if this bias means that human extinction is a somewhat more likely consequence of creating superintelligent machines, more needs to be said about why.
It's also worth emphasising that this bias only tells us that Sia is more likely to perform acts that leave less to chance she is to perform acts which leave more to chance. It doesn't tell us that she is overall likely to perform any particular act. Ask me to pick a number between one and one billion, and I'm more likely to select 500,000,000 than I am to select 456,034---humans have a bias towards round numbers. But that doesn't mean I'm at all likely to select 500,000,000. So even if this tells us that Sia is somewhat more likely to exterminate humanity than she is to dedicate herself to dancing the Macarena, or gardening, or what-have-you, that doesn't mean that she's particularly likely to exterminate humanity.
In the second place, we found that, in sequential decisions, Sia is more likely to make choices which allow for more choices later on. This turned out to be true whether Sia is a 'resolute' chooser or a 'sophisticated' chooser. (Though it's true for different reasons in the two cases, and there's no reason to think that the effect size is going to be the same.) Does this mean she's more likely to bring about human extinction? It's unclear. We might think that humans constitute a potential threat to Sia's continued existence, so that futures without humans are futures with more choices for Sia to make. So she's somewhat more likely to take steps to eliminate humans. (Again, we should remind ourselves that being more likely isn't the same thing as being likely.) I think we need to tread lightly, for two reasons. In the first place, futures without humanity might be futures which involve very few choices---other deliberative agents tend to force more decisions. So contingency plans which involve human extinction may involve comparatively fewer choicepoints than contingency plans which keep humans around. In the second place, Sia is biased towards choices which allow for more choices---but this isn't the same thing as being biased towards choices which guarantee more choices. Consider a resolute Sia who is equally likely to choose any contingency plan, and consider the following sequential decision. At stage 1, Sia can either take a 'safe' option which will certainly keep her alive or she can play Russian roulette, which has a 1-in-6 probability of killing her. If she takes the 'safe' option, the game ends. If she plays Russian roulette and survives, then she'll once again be given a choice to either take a 'safe' option of definitely staying alive or else play Russian roulette. And so on. Whenever she survives a game of Russian roulette, she's again given the same choice. All else equal, if her desires are sampled normally, a resolute Sia will be much more likely to play Russian roulette at stage 1 than she will be to take the 'safe' option. (The same is true if Sia is a sophisticated chooser, though a sophisticated Sia is more likely to take the safe option at stage 1 than the resolute Sia.) The lesson is this: a bias towards choices with more potential downstream choices isn't a bias towards self-preservation. Whether she's likely to try to preserve her life is going to sensitively depend upon the features of her decision situation. Again, much more needs to be said to substantiate the idea that this bias makes it more likely that Sia will attempt to exterminate humanity.
Finally, we found that in some decisions, Sia is more likely to act so as to preserve her own desires. Desire preservation is the most plausible item on Bostrom's list of 'convergent' instrumental means. While there are of course many situations in which it is instrumentally rational to change your desires, desire preservation is more likely than desire change in a great many decisions. (Again, I haven't spread probabilities over the potential decisions Sia might face, so I'm not in a position to say anything stronger than this.)
Should this lead us to think that existential catastrophe is the most likely outcome of a superintelligent agent like Sia? Again, it is far from clear. Insofar as Sia is likely to preserve her desires, she may be unlikely to allow us to shut her down in order to change those desires.[14] We might think that this makes it more likely that she will take steps to eliminate humanity, since humans constitute a persistent threat to the preservation of her desires. (Again, we should be careful to distinguish Sia being more likely to exterminate humanity from her begin likely to exterminate humanity.) Again, I think this is far from clear. Even if humans constitute a threat to the satisfaction of Sia's desires in some ways, they may be conducive towards her desires in others, depending upon what those desires are. In order to think about what Sia is likely to do with randomly selected desires, we need to think more carefully about the particulars of the decision she's facing. It's not clear that the bias towards desire preservation is going to overpower every other source of bias in the more complex real-world decision Sia would actually face. In any case, as with the other 'convergent' instrumental means, more needs to be said about the extent to which they indicate that Sia is an existential threat to humanity.
In sum, the instrumental convergence thesis contains some grains of truth. A superintelligence with randomly sampled desires will be biased towards certain kinds of choices over others. These include choices which leave less up to chance, choices which allow for more choices, and choices which preserve desires. Nonetheless, the thesis is mostly false. For most of the convergent means on the list, there are decisions in which a superintelligence with random desires is no more likely to pursue them than not. The grains of truth in the thesis may give us reason to worry about the existential threat posed by machine superintelligence. But they do not on their own support Bostrom's stronger contention that "the default outcome of the creation of machine superintelligence is existential catastrophe''. Like most of life's dangers, the dangers posed by artificial intelligence are not easily identified from the armchair. If we want to understand the dangers posed by artificial superintelligence, we will have to do more careful empirical work investigating what kinds of desires future AI systems are likely to have (or, indeed, whether they are likely to have desires at all).
Appendix
You can find the full paper, including the appendix, here.
- ^
Bostrom, 2014. A careful argument for this conclusion is never explicitly formulated. Instead, Bostrom simply says "we can begin to see the outlines of an argument for fearing that the default outcome'' is existential catastrophe. Most of Bostrom's claims are hedged and flagged as speculative. He is less committal than Yudkowsky, who regularly makes claims like "the most likely result of building a superhumanly smart AI, under anything remotely like the current circumstances, is that literally everyone on Earth will die. Not as in 'maybe possibly some remote chance,' but as in 'that is the obvious thing that would happen.'" (Yudkowsky 2023)
- ^
See, e.g., Chivers, 2019. See Carlsmith, ms for similar arguments.
- ^
See, in particular, Benson-Tilsen & Soares (2015) and Turner et al. (2021)
- ^
I'm going to suppose throughout that the number of worlds is finite. And, so long as the number of worlds is finite, there's guaranteed to be some collection of worlds which are most strongly desired.
- ^
Many formal investigations of the instrumental convergence thesis start with the assumption that Sia will face a 'small world' decision. See, for instance, the justifications given by Benson-Tilsen & Soares (2015) and Turner et al. (2021).
- ^
See Jeffrey (1965) and Ahmed (2021), among others.
- ^
See Lewis (1981), Joyce (1999), and Sobel (1994), among others.
- ^
To explain why the standard deviation of our distribution over Sia's expected utility for is going to depend upon in this way: let be a random variable whose value is . And let be the variance of our probability distribution over the random variable . Then, Sia's expected utility for is just the weighted average , which is a linear combination of the random variables (which we are taking to be independent and identically distributed). If is the common variance of the random variables , then . So, the standard deviation of our probability distribution over will be .
- ^
Cf. Gibbard & Harper (1978) and Wells (2019).
- ^
Nozick (1969)
- ^
See Jeffrey (1965) and Ahmed (2021). When I talk about 'how glad Sia would be to learn that she'd chosen ', I mean: how well satisfied Sia would expect her desires to be, conditional on her choosing .
- ^
See Steele & Stefánsson (2015).
- ^
Cf. Arntzenius et al. (2004), & Meacham (2010)
- ^
See the 'shutdown problem' from Soares et al. (2015)
20 comments
Comments sorted by top scores.
comment by Jeremy Gillen (jeremy-gillen) · 2023-07-14T19:53:54.895Z · LW(p) · GW(p)
I read about half of this post when it came out. I didn't want to comment without reading the whole thing, and reading the whole thing didn't seem worth it at the time. I've come back and read it because Dan seemed to reference it in a presentation the other day.
The core interesting claim is this:
My conclusion will be that most of the items on Bostrom's laundry list are not 'convergent' instrumental means, even in this weak sense. If Sia's desires are randomly selected, we should not give better than even odds to her making choices which promote her own survival, her own cognitive enhancement, technological innovation, or resource acquisition.
This conclusion doesn't follow from your arguments. None of your models even include actions that are analogous to the convergent actions on that list.
The non-sequential theoretical model is irrelevant to instrumental convergence, because instrumental convergence is about putting yourself in a better position to pursue your goals later on. The main conclusion seems to come from proposition 3, but the model there is so simple it doesn’t include any possibility of Sia putting itself in a better position for later.
Section 4 deals with sequential decisions, but for some reason mainly gets distracted by a Newcomb-like problem, which seems irrelevant to instrumental convergence. I don't see why you didn't just remove Newcomb-like situations from the model? Instrumental convergence will show up regardless of the exact decision theory used by the agent.
Here's my suggestion for a more realistic model that would exhibit instrumental convergence, while still being fairly simple and having "random" goals across trajectories. Make an environment with 1,000,000 timesteps. Have the world state described by a vector of 1000 real numbers. Have a utility function that is randomly sampled from some Gaussian process (or any other high entropy distribution over functions) on . Assume there exist standard actions which directly make small edits to the world-state vector. Assume that there exist actions analogous to cognitive enhancement, making technology and gaining resources. Intelligence can be used in the future to more precisely predict the consequences of actions on the future world state (you’d need to model a bounded agent for this). Technology can be used to increase the amount or change the type of effect your actions have on the world state. Resources can be spent in the future for more control over the world state. It seems clear to me that for the vast majority of the random utility functions, it's very valuable to have more control over the future world state. So most sampled agents will take the instrumentally convergent actions early in the game and use the additional power later on.
The assumptions I made about the environment are inspired by the real world environment, and the assumptions I've made about the desires are similar to yours, maximally uninformative over trajectories.
Replies from: j-dmitri-gallow↑ comment by J. Dmitri Gallow (j-dmitri-gallow) · 2023-07-20T01:24:09.945Z · LW(p) · GW(p)
Thanks for the read and for the response.
>None of your models even include actions that are analogous to the convergent actions on that list.
I'm not entirely sure what you mean by "model", but from your use in the penultimate paragraph, I believe you're talking about a particular decision scenario Sia could find herself in. If so, then my goal wasn't to prove anything about a particular model, but rather to prove things about every model.
>The non-sequential theoretical model is irrelevant to instrumental convergence, because instrumental convergence is about putting yourself in a better position to pursue your goals later on.
Sure. I started with the easy cases to get the main ideas out. Section 4 then showed how those initial results extend to the case of sequential decision making.
>Section 4 deals with sequential decisions, but for some reason mainly gets distracted by a Newcomb-like problem, which seems irrelevant to instrumental convergence. I don't see why you didn't just remove Newcomb-like situations from the model?
I used the Newcomb problem to explain the distinction between sophisticated and resolute choice. I wasn't assuming that Sia was going to be facing a Newcomb problem. I just wanted to help the reader understand the distinction. The distinction is important, because it makes a difference to how Sia will choose. If she's a resolute chooser, then sequential decisions reduce to a single non-sequential decisions. She just chooses a contingency plan at the start, and then sticks to that contingency plan. Whereas if she's a sophisticated chooser, then she'll make a series of non-sequential decisions. In both cases, it's important to understand how she'll choose in non-sequential decisions, which is why I started off thinking about that in section 3.
>It seems clear to me that for the vast majority of the random utility functions, it's very valuable to have more control over the future world state. So most sampled agents will take the instrumentally convergent actions early in the game and use the additional power later on.
I am not at all confident about what would happen with randomly sampled desires in this decision. But I am confident about what I've proven, namely: if she's a resolute chooser with randomly sampled desires, then for any two contingency plans, Sia is just as likely to prefer the first to the second as she is to prefer the second to the first.
When it comes to the 'power-seeking' contingency plans, there are two competing biases. On the one hand, Sia is somewhat biased towards them for the simple reason that there are more of them. If some early action affords more choices later on, then there are going to be more contingency plans which make that early choice. On the other hand, Sia is somewhat biased against them, since they are somewhat less predictable---they leave more up to chance.
I've no idea which of these biases will win out in your particular decision. It strikes me as a pretty difficult question.
↑ comment by Jeremy Gillen (jeremy-gillen) · 2023-07-23T09:51:27.966Z · LW(p) · GW(p)
Section 4 then showed how those initial results extend to the case of sequential decision making.
[...]
If she's a resolute chooser, then sequential decisions reduce to a single non-sequential decisions.
Ah thanks, this clears up most of my confusion, I had misunderstood the intended argument here. I think I can explain my point better now:
I claim that proposition 3, when extended to sequential decisions with a resolute decision theory, shouldn't be interpreted the way you interpret it. The meaning changes when you make A and B into sequences of actions.
Let's say action A is a list of 1000000 particular actions (e.g. 1000000 small-edits) and B is a list of 1000000 particular actions (e.g. 1 improve-technology, then 999999 amplified-edits).[1]
Proposition 3 says that A is equally likely to be chosen as B (for randomly sampled desires). This is correct. Intuitively this is because A and B are achieving particular outcomes and desires are equally likely to favor "opposite" outcomes.
However this isn't the question we care about. We want to know whether action-sequences that contain "improve-technology" are more likely to be optimal than action-sequences that don't contain "improve-technology", given a random desire function. This is a very different question to the one proposition 3 gives us an answer to.
Almost all optimal action-sequences could contain "improve-technology" at the beginning, while any two particular action sequences are equally likely to be preferred to the other on average across desires. These two facts don't contradict each other. The first fact is true in many environments (e.g. the one I described[2]) and this is what we mean by instrumental convergence. The second fact is unrelated to instrumental convergence.
I think the error might be coming from this definition of instrumental convergence:
could we nonetheless say that she's got a better than probability of choosing from a menu of acts?
When is a sequence of actions, this definition makes less sense. It'd be better to define it as something like "from a menu of initial actions, she has a better than probability of choosing a particular initial action ".
I'm not entirely sure what you mean by "model", but from your use in the penultimate paragraph, I believe you're talking about a particular decision scenario Sia could find herself in.
Yep, I was using "model" to mean "a simplified representation of a complex real world scenario".
- ^
For simplicity, we can make this scenario a deterministic known environment, and make sure the number of actions available doesn't change if "improve-technology" is chosen as an action. This way neither of your biases apply.
- ^
E.g. we could define a "small-edit" as to any location in the state vector. Then an "amplified-edit" as to any location. This preserves the number of actions, and makes the advantage of "amplified-edit" clear. I can go into more detail if you like, this does depend a little on how we set up the distribution over desires.
comment by Aaron_Scher · 2023-06-30T07:41:22.214Z · LW(p) · GW(p)
This might not be a useful or productive comment, sorry. I found this paper pretty difficult to follow. The abstract is high level enough that it doesn't actually describe the argument your making in enough detail to assess. Meanwhile, the full text is pretty in the weeds and I got confused a lot. I suspect the paper would benefit from an introduction that tries to bridge this gap and lay out the main arguments / assumptions / claims in 2-3 pages — this would at least benefit my understanding.
Questions that I would want to be answered in that Intro that I'm currently confused by: What is actually doing the work in your arguments? — it seems to me like Sia's uncertainty about what world W she is in is doing much of the work, but I'm confused. What is the natural language version of the appendix? Proposition 3 in particular seems like one of the first places where I find myself going "huh, that doesn't seem right."
Sorry this is pretty messy feedback. It's late and I didn't understand this paper very much. Insofar as I am somebody who you want to read + understand +update from your paper, that may be worth addressing. After some combination of skimming and reading, I have not changed my beliefs about the orthogonality thesis or instrumental convergence in response to your paper. Again, I think this is mostly because I didn't understand key parts of your argument.
comment by Noosphere89 (sharmake-farah) · 2023-06-15T15:20:18.849Z · LW(p) · GW(p)
This is actually interesting, because it implies that instrumental convergence is too weak to, on it's own, be much of an argument around AI x-risk, without other assumptions, and that makes it a bit interesting, as I was arguing against the inevitability of instrumental convergence, given that enough space for essentially unbounded instrumental goals is essentially useless for capabilities, compared to the lack of instrumental convergence, or perhaps very bounded instrumental convergence.
On the one hand, this makes my argument less important, since instrumental convergence mattered less than I believed it did, but on the other hand it means that a lot of LW reasoning is probably invalid, not just unsound, because it incorrectly assumes that instrumental convergence alone is sufficient to predict very bad outcomes.
And in particular, it implies that LWers, including Nick Bostrom, incorrectly applied instrumental convergence as if it were somehow a good predictor of future AI behavior, beyond very basic behavior.
comment by Evan R. Murphy · 2023-06-15T05:57:22.383Z · LW(p) · GW(p)
Love to see an orthodoxy challenged!
Suppose Sia's only goal is to commit suicide, and she's given the opportunity to kill herself straightaway. Then, it certainly won't be rational for her to pursue self-preservation.
It seems you found one terminal goal which doesn't give rise to the instrumental subgoal of self-preservation. Are there others, or does basically every terminal goal benefit from instrumental self-preservation except for suicide?
(I skipped around a bit and didn't read your full post, so maybe you explain this already and I missed it.)
Replies from: j-dmitri-gallow↑ comment by J. Dmitri Gallow (j-dmitri-gallow) · 2023-06-15T08:40:38.942Z · LW(p) · GW(p)
There are infinitely many desires like that, in fact (that's what proposition 2 shows).
More generally, take any self-preservation contingency plan, A, and any other contingency plan, B. If we start out uncertain about what Sia wants, then we should think her desires are just as likely to make A more rational than B as they are to make B more rational than A. (That's what proposition 3 shows.)
That's rough and subject to a bunch of caveats, of course. I try to go through all of those caveats carefully in the draft.
Replies from: Evan R. Murphy↑ comment by Evan R. Murphy · 2023-06-15T16:38:17.750Z · LW(p) · GW(p)
Interesting... still taking that in.
Related question: Doesn't goal preservation typically imply self preservation? If I want to preserve my goal, and then I perish, I've failed because now my goal has been reassigned from X to nil.
Replies from: j-dmitri-gallow↑ comment by J. Dmitri Gallow (j-dmitri-gallow) · 2023-06-16T02:02:58.241Z · LW(p) · GW(p)
A quick prefatory note on how I'm thinking about 'goals' (I don't think it's relevant, but I'm not sure): as I'm modelling things, Sia's desires/goals are given by a function from ways the world could be (colloquially, 'worlds') to real numbers, , with the interpretation that is how well satisfied Sia's desires are if turns out to be the way the world actually is. By 'the world', I mean to include all of history, from the beginning to the end of time, and I mean to encompass every region of space. I assume that this function can be well-defined even for worlds in which Sia never existed or dies quickly. Humans can want to never have been born, and they can want to die. So I'm assuming that Sia can also have those kinds of desires, in principle. So her goal can be achieved even if she's not around.
When I talk about 'goal preservation', I was talking about Sia not wanting to change her desires. I think you're right that that's different from Sia wanting to retain her desires. If she dies, then she hasn't retained her desires, but neither has she changed them. The effect I found was that Sia is somewhat more likely to not want her desires changed.
comment by David Scott Krueger (formerly: capybaralet) (capybaralet) · 2023-06-29T10:26:36.263Z · LW(p) · GW(p)
So let us specify a probability distribution over the space of all possible desires. If we accept the orthogonality thesis, we should not want this probability distribution to build in any bias towards certain kinds of desires over others. So let's spread our probabilities in such a way that we meet the following three conditions. Firstly, we don't expect Sia's desires to be better satisfied in any one world than they are in any other world. Formally, our expectation of the degree to which Sia's desires are satisfied at is equal to our expectation of the degree to which Sia's desires are satisfied at , for any . Call that common expected value ''. Secondly, our probabilities are symmetric around . That is, our probability that satisfies Sia's desires to at least degree is equal to our probability that it satisfies her desires to at most degree . And thirdly, learning how well satisfied Sia's desires are at some worlds won't tell us how well satisfied her desires are at other worlds. That is, the degree to which her desires are satisfied at some worlds is independent of how well satisfied they are at any other worlds. (See the appendix for a more careful formulation of these assumptions.) If our probability distribution satisfies these constraints, then I'll say that Sia's desires are 'sampled randomly' from the space of all possible desires.
This is a characterization, and it remains to show that there exist distributions that fit it (I suspect there are not, assuming the sets of possible desires and worlds are unbounded).
I also find the 3rd criteria counterintuitive. If worlds share features, I would expect these to not be independent.
↑ comment by Nora Belrose (nora-belrose) · 2023-12-24T14:38:17.471Z · LW(p) · GW(p)
I also find the 3rd criteria counterintuitive. If worlds share features, I would expect these to not be independent.
Agreed, I think this criterion is very strongly violated in practice; a Gaussian process prior with a nontrivial covariance function would be a bit more realistic.
comment by rvnnt · 2023-06-15T10:37:14.489Z · LW(p) · GW(p)
Firstly, a bias towards choices which leave less up to chance.
Wouldn't this imply a bias towards eliminating other agents? (Since that would make the world more predictable, and thereby leave less up to chance?)
And thirdly, a bias towards choices which afford more choices later on.
Wouldn't this strongly imply biases towards both self-preservation and resource acquisition?
If the above two implications hold, then the conclusion
that the biases induced by instrumental rationality at best weakly support [...] that machine superintelligence is likely to lead to existential catastrophe
seems incorrect, no?
Could you briefly explain what is wrong with the reasoning above, or point me to the parts of the post that do so? (I only read the Abstract.)
Replies from: j-dmitri-gallow, ben-lang↑ comment by J. Dmitri Gallow (j-dmitri-gallow) · 2023-06-16T01:48:11.487Z · LW(p) · GW(p)
Wouldn't this imply a bias towards eliminating other agents? (Since that would make the world more predictable, and thereby leave less up to chance?)
A few things to note. Firstly, when I say that there's a 'bias' towards a certain kind of choice, I just mean that the probability that a superintelligent agent with randomly sampled desires (Sia) would make that choice is greater than 1/N, where N is the number of choices available. So, just to emphasize the scale of the effect: even if you were right about that inference, you should still assign very low probability to Sia taking steps to eliminate other agents.
Secondly, when I say that a choice "leaves less up to chance", I just mean that the sum total of history is more predictable, given that choice, than the sum total of history is predictable, given other choices. (I mention this just because you didn't read the post, and I want to make sure we're not talking past each other.)
Thirdly, I would caution against the inference: without humans, things are more predictable; therefore, undertaking to eliminate other agents leaves less up to chance. Even if things are predictable after humans are eliminated, and even if Sia can cook up a foolproof contingency plan for eliminating all humans, that doesn't mean that that contingency plan leaves less up to chance. Insofar as the contingency plan is sensitive to the human response at various stages, and insofar as that human response is unpredictable (or less predictable than humans are when you don't try to kill them all), this bias wouldn't lend any additional probability to Sia choosing that contingency plan.
Fourthly, this bias interacts with the others. Futures without humanity might be futures which involve fewer choices---other deliberative agents tend to force more decisions. So contingency plans which involve human extinction may involve comparatively fewer choicepoints than contingency plans which keep humans around. Insofar as Sia is biased towards contingency plans with more choicepoints, that's a reason to think she's biased against eliminating other agents. I don't have any sense of how these biases interact, or which one is going to be larger in real-world decisions.
Wouldn't this strongly imply biases towards both self-preservation and resource acquisition?
In some decisions, it may. But I think here, too, we need to tread with caution. In many decisions, this bias makes it somewhat more likely that Sia will pursue self-destruction. To quote myself:
Sia is biased towards choices which allow for more choices---but this isn't the same thing as being biased towards choices which guarantee more choices. Consider a resolute Sia who is equally likely to choose any contingency plan, and consider the following sequential decision. At stage 1, Sia can either take a 'safe' option which will certainly keep her alive or she can play Russian roulette, which has a 1-in-6 probability of killing her. If she takes the 'safe' option, the game ends. If she plays Russian roulette and survives, then she'll once again be given a choice to either take a 'safe' option of definitely staying alive or else play Russian roulette. And so on. Whenever she survives a game of Russian roulette, she's again given the same choice. All else equal, if her desires are sampled normally, a resolute Sia will be much more likely to play Russian roulette at stage 1 than she will be to take the 'safe' option.
See the post to understand what I mean by "resolute"---and note that the qualitative effect doesn't depend upon whether Sia is a resolute chooser.
Replies from: rvnnt↑ comment by rvnnt · 2023-06-16T08:51:25.141Z · LW(p) · GW(p)
Thanks for the response.
To the extent that I understand your models here, I suspect they don't meaningfully bind/correspond to reality. (Of course, I don't understand your models at all well, and I don't have the energy to process the whole post, so this doesn't really provide you with much evidence; sorry.)
I wonder how one could test whether or not the models bind to reality? E.g. maybe there are case examples (of agents/people behaving in instrumentally rational ways) one could look at, and see if the models postdict the actual outcomes in those examples?
Replies from: j-dmitri-gallow↑ comment by J. Dmitri Gallow (j-dmitri-gallow) · 2023-06-16T11:18:58.221Z · LW(p) · GW(p)
There's nothing unusual about my assumptions regarding instrumental rationality. It's just standard expected utility theory.
The place I see to object is with my way of spreading probabilities over Sia's desires. But if you object to that, I want to hear more about which probably distribution I should be using to understand the claim that Sia's desires are likely to rationalise power-seeking, resource acquisition, and so on. I reached for the most natural way of distributing probabilities I could come up with---I was trying to be charitable to the thesis, & interpreting it in light of the orthogonality thesis. But if that's not the right way to distribute probability over potential desires, if it's not the right way of understanding the thesis, then I'd like to hear something about what the right way of understanding it is.
↑ comment by Ben (ben-lang) · 2023-06-15T11:47:57.601Z · LW(p) · GW(p)
Other agents are not random though. Many agents act in predictable ways. I certainly don't model the actions of people as random noise. In this sense I don't think other agents are different from any other physical system that might be more-or-less chaotic, unpredictable or difficult to control.
Replies from: rvnnt↑ comment by rvnnt · 2023-06-15T15:35:10.919Z · LW(p) · GW(p)
Other agents are not random though.
I agree. But AFAICT that doesn't really change the conclusion that less agents would tend to make the world more predictable/controllable. As you say yourself:
I don't think other agents are different from any other physical system that might be more-or-less chaotic, unpredictable or difficult to control.
And that was the weaker of the two apparent problems. What about the {implied self-preservation and resource acquisition} part?
comment by Charbel-Raphaël (charbel-raphael-segerie) · 2023-12-21T18:26:10.439Z · LW(p) · GW(p)
Here is the summary from the ML Safety Newsletter #11 Top Safety Papers of 2023.
Instrumental Convergence? questions the argument that a rational agent, regardless of its terminal goal, will seek power and dominance. While there are instrumental incentives to seek power, it is not always instrumentally rational to seek it. While there are incentives to become a billionaire, but it is not necessarily rational for everyone to try to become one. Moreover, in multi-agent settings, AIs that seek dominance over others would likely be counteracted by other AIs, making it often irrational to pursue dominance. Pursuing and maintaining power is costly, and simpler actions often are more rational. Last, agents can be trained to be power averse, as explored in the MACHIAVELLI paper.
"Moreover, in multi-agent settings, AIs that seek dominance over others would likely be counteracted by other AIs" --> I've not read the whole thing, but what about collusion?
"Last, agents can be trained to be power averse, as explored in the MACHIAVELLI paper." --> This is pretty weak imho. Yes, you can fine tune GPTs to be honest, etc, or you can filter the dataset with only honest stuff, but at the end of the day, Cicero still learned strategic deception [LW · GW], and there is no principled way to avoid that completely.
comment by Nora Belrose (nora-belrose) · 2023-12-24T14:45:27.088Z · LW(p) · GW(p)
While I'm inclined to agree with the conclusion of this essay, namely
...the biases induced by instrumental rationality at best weakly support Bostrom's conclusion that machine superintelligence is likely to lead to existential catastrophe.
I don't think the essay presents good arguments for the conclusion. This is in part because the third criterion,
...learning how well satisfied Sia's desires are at some worlds won't tell us how well satisfied her desires are at other worlds. That is, the degree to which her desires are satisfied at some worlds is independent of how well satisfied they are at any other worlds.
is likely to be very strongly violated in practice— we should expect "similar" worlds to be valued similarly.
Perhaps more importantly, though, this essay seems not to criticize the notion of "randomly selected goal" or "most goals." I think the best— in my view decisive— criticisms of instrumental convergence arguments attack these concepts, because they are, in my view, highly arbitrary at best and incoherent at worst. The only non-arbitrary measure over goals is the empirical probability measure over goals which is induced by the actual training procedure we use to create AIs, and it's far from obvious that this distribution is malign in the way assumed by instrumental convergence arguments.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2023-12-24T17:59:17.481Z · LW(p) · GW(p)
I think this is one of the biggest issues, in practice, as I view at least some of the arguments for AI doom to essentially ignore structure, and I suspect that they're committing a similar error to people who argue that the no free lunch theorem makes intelligence and optimization in general so expensive that AI can't progress at all.
This is especially true for the orthogonality thesis.