Posts
Comments
The index by Reporters Without Boarders is primarily about whether a newspaper or reporter can say something without consequences or interference. Things like a competitive media environment seem to be part of the index (The USAs scorecard says "media ownership is highly concentrated, and many of the companies buying American media outlets appear to prioritize profits over public interest journalism"). Its an important thing, but its not the same thing you are talking about.
The second one, from "our world in data", ultimately comes from this (https://www.v-dem.net/documents/56/methodology.pdf). Their measure includes things like corruption, whether political power or influence is concentrated into a smaller group and effective checks and balances on the use of executive power. It sounds like they should have called it a "democratic health index" or something like that instead of a "freedom-of-expression index".
The last one is just a survey of what people think should be allowed.
It reminds maybe of Dominic Cummings and Boris Johnson. The Silicon-Valley + Trump combo feels somehow analogous.
One very important consideration is whether they hold values that they believe are universalist, or merely locally appropriate.
For example, a Chinese AI might believe the following: "Confucianist thought is very good for Chinese people living in China. People in other countries can have their own worse philosophies, and that is fine so long as they aren't doing any harm to China, its people or its interests. Those idiots could probably do better by copying China, but frankly it might be better if they stick to their barbarian ways so that they remain too weak to pose a threat."
Now, the USA AI thinks: "Democracy is good. Not just for Americans living in America, but also for everyone living anywhere. Even if they never interact ever again with America or its allies the Taliban are still a problem that needs solving. Their ideology needs to be confronted, not just ignored and left to fester."
The sort of thing America says it stands for is much more appealing to me than a lot of what the Chinese government does. (I like the government being accountable to the people it serves - which of course entails democracy, a free press and so on). But, my impression is that American values are held to be Universal Truths, not uniquely American idiosyncratic features, which makes the possibility of the maximally bad outcome (worldwide domination by a single power) higher.
I agree this is an inefficiency.
Many of your examples are maybe fixed by having a large audience and some randomness as described by Robo.
But some things are more binary. For example when considering job applicants an applicant who won some prestigious award is much higher value that one who didnt. But, their is a person who was the counterfactual 'second place' for that award, they are basically as high value as the winner, and no one knows who they are.
Having unstable policy making comes with a lot of disadvantages as well as advantages.
For example, imagine a small poor country somewhere with much of the population living in poverty. Oil is discovered, and a giant multinational approaches the government to seek permission to get the oil. The government offers some kind of deal - tax rates, etc. - but the company still isn't sure. What if the country's other political party gets in at the next election? If that happened the oil company might have just sunk a lot of money into refinery's and roads and drills only to see them all taken away by the new government as part of its mission to "make the multinationals pay their share for our people." Who knows how much they might take?
What can the multinational company do to protect itself? One answer is to try and find a different country where the opposition parties don't seem likely to do that. However, its even better to find a dictatorship to work with. If people think a government might turn on a dime, then they won't enter into certain types of deal with it. Not just companies, but also other countries.
So, whenever a government does turn on a dime, it is gaining some amount of reputation for unpredictability/instability, which isn't a good reputation to have when trying to make agreements in the future.
I used to think this. I was in a café reading cake description and the word "cheese" in the Carrot Cake description for the icing really switched me away. I don't want a cake with cheese flavor - sounds gross. Only later did I learn Carrot Cake was amazing.
So it has happened at least once.
There was an interesting Astral Codex 10 thing related to this kind of idea: https://www.astralcodexten.com/p/book-review-the-cult-of-smart
Mirroring some of the logic in that post, starting from the assumption that neither you nor anyone you know are in the running for a job, (lets say you are hiring an electrician to fix your house) then do you want the person who is going to do a better job or a worse one?
If you are the parent of a child with some kind of developmental problem that means they have terrible hand-eye coordination, you probably don't want your child to be a brain surgeon, because you can see that is a bad idea.
You do want your child to have resources, and respect and so on. But what they have, and what they do, can be (at least in principle) decoupled. In other words, I think that using a meritocratic system to decide who does what (the people who are good at something should do it) is uncontroversial. However, using a meritocratic system to decide who gets what might be a lot more controversial. For example, as an extreme case you could consider disability benefit for somebody with a mental handicap to be vaguely against the "who gets what" type of meritocracy.
Personally I am strongly in favor of the "who does what" meritocracy, but am kind of neutral on the "who gets what" one.
Wouldn't higher liquidity and lower transaction costs sort this out? Say you have some money tied up in "No, Jesus will not return this year", but you really want to bet on some other thing. If transaction costs were completely zero then, even if you have your entire net worth tied up in "No Jesus" bets you could still go to a bank, point out you have this more-or-less guaranteed payout on the Jesus market, and you want to borrow against it or sell it to the bank. Then you have money now to spend. This would not in any serious way shift the prices of the "Jesus will return" market because that market is of essentially zero size compared to the size of the banks that will be loaning against or buying the "No" bets.
With low enough transaction costs the time value of money is the same across the whole economy, so buying "yes" shares in Jesus would be competing against a load of other equivalent trades in every other part of the economy. I think selling shares for cash would be one of these, you are expecting loads of people to suddenly want to sell assets for cash in the future, so selling your assets for cash now so you can buy more assets later makes sense.
I dont know Ameeican driving laws on this (i live in the UK), but these two.descriptions dont sound mutually incomptabile.
The clockwise rule tells you everything except who goes first. You say thats the first to arrive.
It says "I am socially clueless enough to do random inappropriate things"
In a sense I agree with you, if you are trying to signal something specific, then wearing a suit in an unusual context is probably the wrong way of doing it. But, the social signalling game is exhausting. (I am English, maybe this makes it worse than normal for me). If I am a guest at someone's house and they offer me food, what am I signalling by saying yes? What if I say no? They didn't let me buy the next round of drinks, do I try again later or take No for an answer? Are they offering me a lift because they actually don't mind? How many levels deep do I need to go in trying to work this situation out?
I have known a few people over the years with odd dress preferences (one person really, really liked an Indiana Jones style hat). To me, the hat declared "I know the rules, and I hereby declare no intention of following them. Everyone else here thereby has permission to stop worrying about this tower of imagined formality and relax." For me that was very nice, creating a more relaxed situation. They tore down the hall of mirrors, and made it easier for me to enjoy myself. I have seen people take other actions with that purpose, clothes are just one way.
Long way of saying, sometimes a good way of asking people to relax is by breaking a few unimportant rules. But, even aside from that, it seems like the OP isn't trying to do this at all. They have actually just genuinely had enough with the hall of mirrors game and have declared themselves to no longer be playing. Its only socially clueless if you break the rules by mistake. If you know you are breaking them, but just don't care, it is a different thing. The entire structure of the post makes it clear the OP knows they are breaking the rules.
As a political comparison, Donald Trump didn't propose putting a "Rivera of the Middle East" in Gaza because he is politically clueless, he did so because he doesn't care about being politically clued-in and he wants everyone to know it.
A nice post about the NY flat rental market. I found myself wondering, does the position you are arguing against at the beginning actually exist, or it is set up only as a rhetorical thing to kill? What I mean is this:
everything’s priced perfectly, no deals to sniff out, just grab what’s in front of you and call it a day. The invisible hand’s got it all figured out—right?
Do people actually think this way? The argument seems to reduce to "This looks like a bad deal, but if it actually was a bad deal then no one would buy it. Therefore, it can't be a bad deal and I should buy it." If there are a population of people out there who think this way then their very existence falsifies the efficient market hypothesis - every business should put some things on the shelf that have no purpose beyond exploiting them. Or, in other words, the market is only going to be as efficient as the customers are discerning. If there are a large number of easy marks in the market then sellers will create new deals and products designed to rip those people off.
Don't we all know that sinking feeling when we find ourselves trying to buy something (normally in a foreign country) and we realise we are in a market designed to rip us off? First we curse all the fools who came before us and created a rip-off machine. Then, we reluctantly decide just to pay the fee, "get got" and move on with our life because its just too much faff, thereby feeding the very machine we despise (https://www.lesswrong.com/posts/ENBzEkoyvdakz4w5d/out-to-get-you ). Similarly, I at least have felt a feeling of lightness when I go into a situation I expect to look like that, and instead find things that are good.
You have misunderstood me in a couple of places. I think think maybe the diagram is confusing you, or maybe some of the (very weird) simplifying assumptions I made, but I am not sure entirely.
First, when I say "momentum" I mean actual momentum (mass times velocity). I don't mean kinetic energy.
To highlight the relationship between the two, the total energy of a mass on a spring can be written as: where p is the momentum, m the mass, k the spring strength and x the position (in units where the lowest potential point is at x=0). The first of the two terms in that expression is the kinetic energy (related to the square of the momentum). The second term is the potential energy, related to the square of the position.
I am not treating gravity remotely accurately in my answer, as I am not trying to be exact but illustrative. So, I am pretending that gravity is just a spring. The force on a spring increases with distance, gravity decreases. That is obviously very important for lots of things in real life! But I will continue to ignore it here because it makes the diagrams here simpler, and its best to understand the simple ones first before adding the complexity.
If going to the right increases your potential energy, and the center has 0 potential energy, then being to the left of the origin means you have negative potential energy?
Here, because we are pretending gravity is a spring, potential energy is related to the square of the potion. (). The potential energy is zero when x=0. But it increases in either direction from the middle. Similarly, in the diagram, the kinetic energy is related to the square of the momentum, so we have zero kinetic energy in the vertical middle, but going either upwards or downwards would increase the kinetic energy. As I said, the circles are the energy contours, any two points on the same circle have the same total energy. Over time, our oscillator will just go around and around in its circle, never going up or down in total energy.
If we made gravity more realistic then potential energy would still increase in either direction from the middle (minimum as x=0, increasing in either direction), instead of being x^2 it would be some other equation.
The x-direction is position (x). The y-direction is momentum (p). The energy isn't shown, but you can implicitly imagine that it is plotted "coming out the page" towards you and that is why their are the circular contour lines.
If you haven't seen phase space diagrams much before this webpage seems good like a good intro: http://www.acs.psu.edu/drussell/Demos/phase-diagram/phase-nodamp.gif.
{kind=link}
I am making a number of simplifying assumptions above, for example I am treating the system as one dimensional (where an orbit actually happens in 2d). Similarly, I am approximating the gravitational field as a spring. Probably much of the confusion comes from me getting a lot of (admittedly important things!) and throwing them out the window to try and focus on other things.
I am not sure that example fully makes sense. If trade is possible then two people with 11 units of resources can get together and do a cost 20 project. That is why companies have shares, they let people chip in so you can make a Suez Canal even if no single person on Earth is rich enough to afford a Suez Canal.
I suppose in extreme cases where everyone is on or near the breadline some of that "Stag Hunt" vs "Rabbit Hunt" stuff could apply.
I agree with you that, if we need to tax something to pay for our government services, then inheritance tax is arguably not a terrible choice.
But a lot of your arguments seem a bit problematic to me. First, as a point of basic practicality, why 100%? Couldn't most of your aims be achieved with a lesser percentage? That would also smooth out weird edge cases.
There is something fundamentally compelling about the idea that every generation should start fresh, free from the accumulated advantages or disadvantages of their ancestors.
This quote stood out to me as interesting. I know this isn't what you meant, but as a society it would be really weird to collectively decide "don't give the next generation fire, they need to start fresh and rediscover that for themselves. We shouldn't give them the accumulated advantages of their ancestors, send them to the wilderness and let them start fresh!".
I think I am not understanding the question this equation is supposed to be answer, as it seems wrong to me.
I think you are considering the case were we draw arrowheads on the lines? So each line is either an "input" or an "output", and we randomly connect inputs only to outputs, never connecting two inputs together or two outputs? With those assumptions I think the probability of only one loop on a shape with N inputs and N outputs (for a total of 2N "puts") is 1/N.
The equation I had ( (N-2)!! / (N-1)!!) is for N "points", which are not pre-assigned into inputs and outputs.
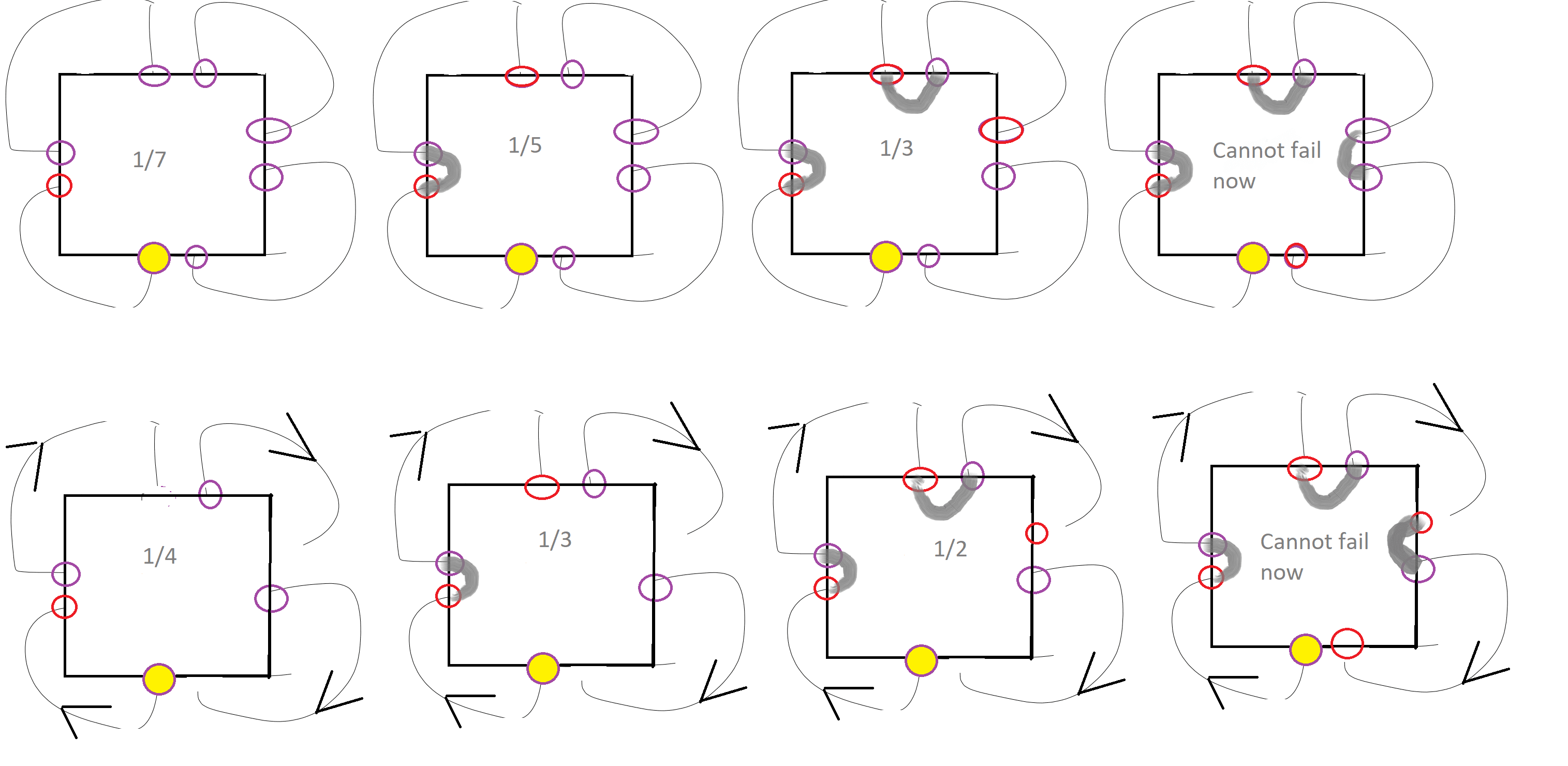
These diagrams explain my logic. On the top row is the "N puts" problem. First panel on the left, we pick a unmatched end (doesn't matter which, by symmetry), the one we picked is the red circle, and we look at the options of what to tie it to, the purple circles. One purple circle is filled with yellow, if we pick that one then we will end up with more than one loop. The probability of picking it randomly is 1/7 (as their are 6 other options). In the next panel we assume we didn't die. By symmetry again it doesn't matter which of the others we connected to, so I just picked the next clockwise. We will follow the loop around. We are now looking to match the newly-red point to another purple. Now their are 5 purples, the yellow is again a "dead end", ensuring more than one loop. We have a 1/5 chance of picking it at random. Continuing like this, we eventually find that the probability of having only one loop is just the probability of not picking badly at any step, (6/7)x(4/5)x(2/3) = (N-2)!! / (N-1)!!.
In the second row I do the same thing for the case where the lines have arrows, instead of 8 ports we have 4 input ports and 4 output ports, and inputs can only be linked to outputs. This changes things, because now each time we make a connection we only reduce the number of options by one at the next step. (Because our new input was never an option as an output). The one-loop chance here comes out as (3/4)x(2/3)x(1/2) = (N-1)! / N! = 1/N. Neither expression seems to match the equations you shared, so either I have gone wrong with my methods or you are answering a different question.
This is really wonderful, thank you so much for sharing. I have been playing with your code.
The probability that their is only one loop is also very interesting. I worked out something, which feels like it is probably already well known, but not to me until now, for the simplest case.

In the simplest case is one tile. The orange lines are the "edging rule". Pick one black point and connect it to another at random. This has a 1/13 chance of immediately creating a closed loop, meaning more than one loop total. Assuming it doesn't do that, the next connection we make has 1/11 chance of failure. The one after 1/9. Etc.
So the total probability of having only one loop is the product: (12/13) (10/11) (8/9) (6/7) (4/5) (2/3), which can be written as 12!! / 13!! (!! double factorial). For a single tile this comes out at 35% ish. (35% chance of only one loop).
If we had a single shape with N sides we would get a probability of (N-2)!! / (N-1)!! .
The probability for a collection of tiles is, as you say, much harder. Each edge point might not uniformly couple to all other edge points because of the multi-stepping in between. Also loops can form that never go to the edge. So the overall probability is most likely less than (N-2)!!/(N-1)!! for N edge dots.
That is a nice idea. The "two sides at 180 degrees" only occurred to me after I had finished. I may look into that one day, but with that many connections is needs to be automated.
In the 6 entries/exits ones above you pick one entry, you have 5 options of where to connect it. Then, you pick the next unused entry clockwise, and have 3 options for where to send it, then you have only one option for how to connect the last two. So its 5x3x1 = 15 different possible tiles.
With 14 entries/exits, its 13x11x9x7x5x3x1 = 135,135 different tiles. (13!!, for !! being double factorial).
You also have (I think) 13+12+11+10+... = 91 different connection pieces.
One day, I may try and write a code to make some of those. I strongly suspect that they won't look nice, but they might be interesting anyway.
I still find the effect weird, but something that I think makes it more clear is this phase space diagram:
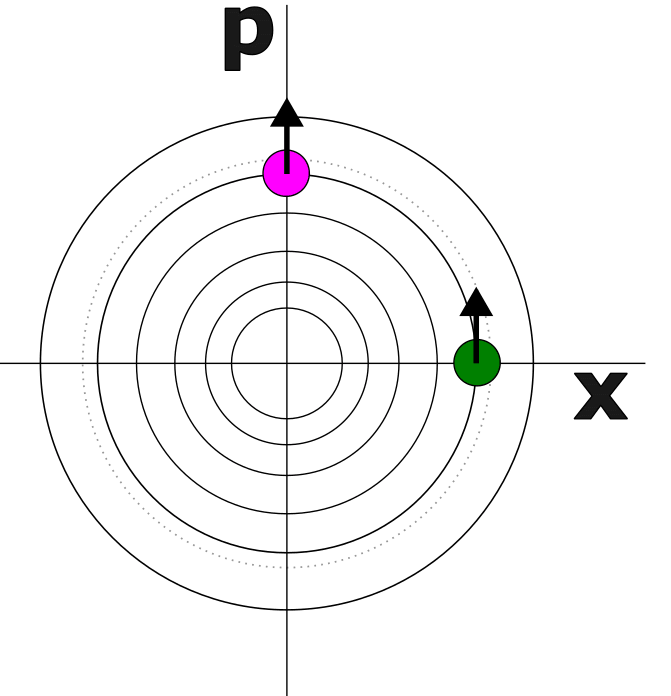
We are treating the situation as 1D, and the circles in the x, p space are energy contours. Total energy is distance from the origin. An object in orbit goes in circles with a fixed distance from the origin. (IE a fixed total energy).
The green and purple points are two points on the same orbit. At purple we have maximum momentum and minimum potential energy. At green its the other way around. The arrows show impulses, if we could suddenly add momentum of a fixed amount by firing the rocket those are the arrows.
Its visually clear that the arrow from the purple point is more efficient. It gets us more than one whole solid-black energy contour higher, in contrast the same length of arrow at the green position only gets us to the dashed orbit, which is lower.
Visually we can see that if we want to get away from the origin of that x, p coordinate system we should shoot when out boost vector aligns with out existing vector.
A weird consequence. Say our spaceship didn't have a rocket, but instead it had a machine that teleported the ship a fixed distance (say 100m). (A fixed change in position, instead of a fixed change in momentum). In this diagram that is just rotating the arrows 90 degrees. This implies the most efficient time to use the teleporting machine is when you are at the maximum distance from the planet (minimum kinetic energy, maximum potential). Mathematically this is because the potential energy has the same quadratic scaling as the kinetic. Visually, its because its where you are adding the new vector to your existing vector most efficiently.
I am not sure that is right. A very large percentage of people really don't think the rolls are independent. Have you ever met anyone who believed in fate, Karma, horoscopes , lucky objects or prayer? They don't think its (fully) random and independent. I think the majority of the human population believe in one or more of those things.
If someone spells a word wrong in a spelling test, then its possible they mistyped, but if its a word most people can't spell correctly then the hypothesis "they don't know the spelling' should dominate. Similarly, I think it is fair to say that a very large fraction of humans (over 50%?) don't actually think dice rolls or coin tosses are independent and random.
That is a cool idea! I started writing a reply, but it got a bit long so I decided to make it its own post in the end. ( https://www.lesswrong.com/posts/AhmZBCKXAeAitqAYz/celtic-knots-on-einstein-lattice )
I stuck to maximal density for two reaosns, (1) to continue the Celtic knot analogy (2) because it means all tiles are always compatible (you can fit two side by side at any orientation without loosing continuity). With tiles that dont use every facet this becomes an issue.
Thinking about it now, and without having checked carefully, I think this compatibilty does something topological and forces odd macrostructure. For example, if we have a line of 4-tiles in a sea of 6-tiles (4 tiles use four facets), then we cant end the line of 4 tiles without breaking continuity. So the wall has to loop, or go off the end. The 'missing lines' the 4 tiles lacked (that would have made them 6's) would have been looped through the 4-wall. So having those tiles available is kind of like being able to delete a few closed loops from a 6s structure.
I might try messing with 4s to see if you are right that they will be asthetically useful.
That's a very interesting idea. I tried going through the blue one at the end.
Its not possible in that case for each string to strictly alternate between going over and under, by any of the rules I have tried. In some cases two strings pass over/under one another, then those same two strings meet again when one has travelled two tiles and the other three. So they are de-synced. They both think its their turn to go over (or under).
The rules I tried to apply were (all of which I believe don't work):
- Over for one tile, under for the next (along each string)
- Over for one collision, under for the next (0, 1 or 2 collisions, are possible in a tile)
- Each string follows the sequence 'highest, middle, lowest, highest, middle lowest...' for each tile it enters.
My feeling having played with it for about 30-45 mins is that there probably is a rule nearby to those above that makes things nice, but I haven't yet found it.
I wasn't aware of that game. Yes it is identical in terms of the tile designs. Thank you for sharing that, it was very interesting and that Tantrix wiki page lead me to this one, https://en.wikipedia.org/wiki/Serpentiles , which goes into some interesting related stuff with two strings per side or differently shaped tiles.
Something related that I find interesting, for people inside a company, the real rival isn't another company doing the same thing, but people in your own company doing a different thing.
Imagine you work at Microsoft in the AI research team in 2021. Management want to cut R&D spending, so either your lot or the team doing quantum computer research are going to be redundant soon. Then, the timeline splits. In one universe, Open AI release Chat GPT, in the other PsiQuantum do something super impressive with quantum stuff. In which of those universes do the Microsoft AI team do well? In one, promotions and raises, in the other, redundancy.
People recognise this instinctively. Changing companies is much faster and easier than changing specialities. So people care primarily about their speciality doing well, their own specific company is a secondary concern.
A fusion expert can expert at a different fusion company way faster and more easily than they can become an expert in wind turbines. Therefore, to the fusion expert all fusion companies are on the same side against the abominable wind farmers. I suspect this is also true of most people in AI, although maybe when talking to the press they will be honour bound to claim otherwise.
I wonder if any of the perceived difference between fusion and AI might be which information sources are available to you. It sounds like you have met the fusion people, and read their trade magazines, and are comparing that to what mainstream news says about AI companies (which won't necessarily reflect the opinions of a median AI researcher.).
I think economics should be taught to children, not for the reasons you express, but because it seems perverse that I spent time at school learning about Vikings, Oxbow lakes, volcanoes, Shakespeare and Castles, but not about the economic system of resource distribution that surrounds me for the rest of my life. When I was about 9 I remember asking why 'they' didn't just print more money until everyone had enough. I was fortunate to have parents who could give a good answer, not everyone will be.
Stock buybacks! Thank you. That is definitely going to be a big part f the "I am missing something here" I was expressing above.
I freely admit to not really understanding how shares are priced. To me it seems like the value of a share should be related to the expected dividend pay-out of that share over the remaining lifetime of the company, with a discount rate applied on pay-outs that are expected to happen further in the future (IE dividend yields 100 years from now are valued much less than equivalent payments this year). By this measure, justifying the current price sounds hard.
Google says that the annual dividend on Nvidia shares is 0.032%. (Yes, the leading digits are 0.0). So, right now, you get a much better rate of return just leaving your money in your bank's current account. So, at least by this measure, Nvidia shares are ludicrously over-priced. You could argue that future Nvidia pay outs might be much larger than the historical ones due to some big AI related profits. But, I don't find this argument convincing. Are future pay outs going to be 100x bigger? It would require a 100-fold yield increase for it to just be competitive with a savings account. If you time discount a little (say those 100-fold increases don't materialise for 3 years) then it looks even worse.
Now, clearly the world doesn't value shares according to the same heuristics that make sense to a non-expert like me. For example, the method "time integrate future expected dividend pay outs with some kind of time discounting" tells us that cryptocurrencies are worthless, because they are like shares with zero dividends. But, people clearly do put a nonzero value on bitcoin - and there is no plausible way that many people are that wrong. So they are grasping something that I am missing, and that same thing is probably what allows company shares to be prices so high relative to the dividends.
That is very interesting! That does sound weird.
In some papers people write density operators using an enhanced "double ket" Dirac notation, where eg. density operators are written to look like |x>>, with two ">"'s. They do this exactly because the differential equations look more elegant.
I think in this notation measurements look like <<m|, but am not sure about that. The QuTiP software (which is very common in quantum modelling) uses something like this under-the-hood, where operators (eg density operators) are stored internally using 1d vectors, and the super-operators (maps from operators to operators) are stored as matrices.
So structuring the notation in other ways does happen, in ways that look quite reminiscent of your tensors (maybe the same).
Yes, in your example a recipient who doesn't know the seed models the light as unpolarised, and one who does as say, H-polarised in a given run. But for everyone who doesn't see the random seed its the same density matrix.
Lets replace that first machine with a similar one that produces a polarisation entangled photon pair, |HH> + |VV> (ignoring normalisation). If you have one of those photons it looks unpolarised (essentially your "ignorance of the random seed" can be thought of as your ignorance of the polarisation of the other photon).
If someone else (possibly outside your light cone) measures the other photon in the HV basis then half the time they will project your photon into |H> and half the time into |V>, each with 50% probability. This 50/50 appears in the density matrix, not the wavefunction, so is "ignorance probability".
In this case, by what I understand to be your position, the fact of the matter is either (1) that the photon is still entangled with a distant photon, or (2) that it has been projected into a specific polarisation by a measurement on that distant photon. Its not clear when the transformation from (1) to (2) takes place (if its instant, then in which reference frame?).
So, in the bigger context of this conversation,
OP: "You live in the density matrices (Neo)"
Charlie :"No, a density matrix incorporates my own ignorance so is not a sensible picture of the fundamental reality. I can use them mathematically, but the underlying reality is built of quantum states, and that randomness when I subject them to measurements is fundamentally part of the territory, not the map. Lets not mix the two things up."
Me: "Whether a given unit of randomness is in the map (IE ignorance), or the territory is subtle. Things that randomly combine quantum states (my first machine) have a symmetry over which underlying quantum states are being mixed that looks meaningful. Plus (this post), the randomness can move abruptly from the territory to the map due to events outside your own light cone (although the amount of randomness is conserved), so maybe worrying too much about the distinction isn't that helpful.
What is the Bayesian argument, if one exists, for why quantum dynamics breaks the “probability is in the mind” philosophy?
In my world-view the argument is based on Bell inequalities. Other answers mention them, I will try and give more of an introduction.
First, context. We can reason inside a theory, and we can reason about a theory. The two are completely different and give different intuitions. Anyone talking about "but the complex amplitudes exist" or "we are in one Everett branch" is reasoning inside the theory. The theory, as given in the textbooks, is accepted as true and interpretations built on.
However, both historically and (I think) more generally, we should also reason about theories. This means we need to look at experimental observations, and ask questions like "what is the most reasonable model?".
Many quantum experiments give random-looking results. As you point out, randomness is usually just "in the mind". Reality was deterministic, but we couldn't see everything. The terminology is "local hidden variable". For an experiment where you draw a card from a deck the "local hidden variable" was which card was on top. In a lottery with (assumedly deterministic) pinballs the local hidden variable is some very specific details of the initial momentums and positions of the balls. In other words the local hidden variable is the thing that you don't know, so to you it looks random. Its the seed of your pseudorandom number generator.
Entanglement - It is possible to prepare two (or more) particles in a state, such that measurements of those two particles gives very weird results. What do I mean by "very weird". Well, in a classical setting if Alice and Bob are measuring two separate objects then there are three possible (extremal) situations (1): Their results are completely uncorrelated, for example Alice is rolling a dice in Texas and Bob is rolling a different dice in London. (2) Correlated, for example, Alice is reading an email telling her she got a job she applied for, and Bob is reading an email telling him he failed to get the same job. (4) Signalling (we skipped 3 on purpose, we will get to that). Alice and Bob have phones, and so the data they receive is related to what the other of them is doing. Linear combinations of the above (eg noisy radio messages, correlation that is nor perfect etc) are also possible.
By very weird, I mean that quantum experiments give rise (in the raw experimental data, before any theory is glued on) to a fourth type of relation; (3): Non-locality. Alice and Bob's measurement outcomes (observations) are random, but the correlation between their observation's changes depending on the measurements they both chose to make (inputs). Mathematically its no more complex than the others, but its fiddly to get your head around because its not something seen in everyday life.
An important feature of (3) is that it cannot be used to create signalling (4). However, (3) cannot be created out of any mixture of (1) and (2). (Just like (4) cannot be created by mixing (1) and (2)). In short, if you have any one of these 4 things, you can use local actions to go "down hill" to lower numbers but you can't go up.
Anyway, "hidden variables" are shorthand for "(1) and (2)" (randomness and correlation). The "local" means "no signalling" (IE no (3), no radios). The reason we insist on no signalling is because the measurements Alice and Bob do on their particles could be outside one another's light cones (so even a lightspeed signal would not be fast enough to explain the statistics). The "no signalling" condition might sound artificial, but if you allow faster than light signalling then you are (by the standards of relativity) also allowing time travel.
Bell inequality experiments have been done. They measure result (3). (3) cannot be made out of ordinary "ignorance" probabilities (cannot be made from (2)). (3) could be made out of (4) (faster than light signalling), but we don't see the signalling itself, and assuming it exists entails time travel.
So, if we reject signalling, we know that whatever it is that is happening in a Bell inequality experiment it can't be merely apparent randomness due to our ignorance. We also know the individual results collected by Alice and Bob look random (but not the correlations between the results), this backs us into the corner of accepting that the randomness is somehow an intrinsic feature of the world, even the photon didn't "know" if it would go through the polariser until you tried it.
The wiki article on Bell inequalities isn't very good unfortunately.
Just the greentext. Yes, I totally agree that the study probably never happened. I just engaged with the actualy underling hypothesis, and to do so felt like some summary of the study helped. But I phrased it badly and it seems like I am claiming the study actually happened. I will edit.
I thought they were typically wavefunction to wavefunction maps, and they need some sort of sandwiching to apply to density matrices?
Yes, this is correct. My mistake, it does indeed need the sandwiching like this .
From your talk on tensors, I am sure it will not surprise you at all to know that the sandwhich thing itself (mapping from operators to operators) is often called a superoperator.
I think the reason it is as it is is their isn't a clear line between operators that modify the state and those that represent measurements. For example, the Hamiltonian operator evolves the state with time. But, taking the trace of the Hamiltonian operator applied to the state gives the expectation value of the energy.
The way it works normally is that you have a state , and its acted on by some operator, , which you can write as . But this doesn't give a number, it gives a new state like the old but different. (For example if a was the anhilation operator the new state is like the old state but with one fewer photons). This is how (for example) an operator acts on the state of the system to change that state. (Its a density matrix to density matrix map).
In dimensions terms this is: (1,1) = (1, 1) * (1,1)
(Two square matrices of size N multiply to give another square matrix of size N).
However, to get the expected outcome of a measurement on a particular state you take : where Tr is the trace. The trace basically gets the "plug" at the left hand side of a matrix and twists it around to plug it into the right hand side. So overall what is happening is that the operators and , each have shapes (1,1) and what we do is:
Tr( (1,1) * (1,1)) = Tr( (1, 1) ) = number.
The "inward facing" dimensions of each matrix get plugged into one another because the matrices multiply, and the outward facing dimensions get redirected by the trace operation to also plug into one another. (The Trace is like matrix multiplication but on paper that has been rolled up into a cylinder, so each of the two matrices inside sees the other on both sides). The net effect is exactly the same as if they had originally been organized into the shapes you suggest of (2,0) and (0,2) respectively.
So if the two "ports" are called A and B your way of doing it gives:
(AB, 0) * (0, AB) = (0, 0) IE number
The traditional way:
Tr( (A, B) * (B, A) ) = Tr( (A, A) ) = (0, 0) , IE number.
I haven't looked at tensors much but I think that in tensor-land this Trace operation takes the role of a really boring metric tensor that is just (1,1,1,1...) down the diagonal.
So (assuming I understand right) your way of doing it is cleaner and more elegant for getting the expectation value of a measurement. But the traditional system works more elegantly for applying an operator too a state to evolve it into another state.
You are completely correct in the "how does the machine work inside?" question. As you point out that density matrix has the exact form of something that is entangled with something else.
I think its very important to be discussing what is real, although as we always have a nonzero inferential distance between ourselves and the real the discussion has to be a little bit caveated and pragmatic.
I think the reason is that in quantum physics we also have operators representing processes (like the Hamiltonian operator making the system evolve with time, or the position operator that "measures" position, or the creation operator that adds a photon), and the density matrix has exactly the same mathematical form as these other operators (apart from the fact the density matrix needs to be normalized).
But that doesn't really solve the mystery fully, because they could all just be called "matrices" or "tensors" instead of "operators". (Maybe it gets us halfway to an explanation, because all of the ones other than the density operator look like they "operate" on the system to make it change its state.)
Speculatively, it might be to do with the fact that some of these operators are applied on continuous variables (like position), where the matrix representation has infinite rows and infinite columns - maybe their is some technicality where if you have an object like that you have to stop using the word "matrix" or the maths police lock you up.
There are some non-obvious issues with saying "the wavefunction really exists, but the density matrix is only a representation of our own ignorance". Its a perfectly defensible viewpoint, but I think it is interesting to look at some of its potential problems:
- A process or machine prepares either |0> or |1> at random, each with 50% probability. Another machine prepares either |+> or |-> based on a coin flick, where |+> = (|0> + |1>)/root2, and |+> = (|0> - |1>)/root2. In your ontology these are actually different machines that produce different states. In contrast, in the density matrix formulation these are alternative descriptions of the same machine. In any possible experiment, the two machines are identical. Exactly how much of a problem this is for believing in wavefuntions but not density matrices is debatable - "two things can look the same, big deal" vs "but, experiments are the ultimate arbiters of truth, if experiemnt says they are the same thing then they must be and the theory needs fixing."
- There are many different mathematical representations of quantum theory. For example, instead of states in Hilbert space we can use quasi-probability distributions in phase space, or path integrals. The relevance to this discussion is that the quasi-probability distributions in phase space are equivalent to density matrices, not wavefunctions. To exaggerate the case, imagine that we have a large number of different ways of putting quantum physics into a mathematical language, [A, B, C, D....] and so on. All of them are physically the same theory, just couched in different mathematics language, a bit like say, ["Hello", "Hola", "Bonjour", "Ciao"...] all mean the same thing in different languages. But, wavefunctions only exist as an entity separable from density matrices in some of those descriptions. If you had never seen another language maybe the fact that the word "Hello" contains the word "Hell" as a substring might seem to possibly correspond to something fundamental about what a greeting is (after all, "Hell is other people"). But its just a feature of English, and languages with an equal ability to greet don't have it. Within the Hilbert space language it looks like wavefunctions might have a level of existence that is higher than that of density matrices, but why are you privileging that specific language over others?
- In a wavefunction-only ontology we have two types of randomness, that is normal ignorance and the weird fundamental quantum uncertainty. In the density matrix ontology we have the total probability, plus some weird quantum thing called "coherence" that means some portion of that probability can cancel out when we might otherwise expect it to add together. Taking another analogy (I love those), the split you like is [100ml water + 100ml oil], (but water is just my ignorance and doesn't really exist), and you don't like the density matrix representation of [200ml fluid total, oil content 50%]. Their is no "problem" here per se but I think it helps underline how the two descriptions seem equally valid. When someone else measures your state they either kill its coherence (drop oil % to zero), or they transform its oil into water. Equivalent descriptions.
All of that said, your position is fully reasonable, I am just trying to point out that the way density matrices are usually introduced in teaching or textbooks does make the issue seem a lot more clear cut than I think it really is.
I just looked up the breakfast hypothetical. Its interesting, thanks for sharing it.
So, my understanding is (supposedly) someone asked a lot of prisoners "How would you feel if you hadn't had breakfast this morning?", did IQ tests on the same prisoners and found that the ones who answered "I did have breakfast this morning." or equivalent were on average very low in IQ. (Lets just assume for the purposes of discussion that this did happen as advertised.)
It is interesting. I think in conversation people very often hear the question they were expecting, and if its unexpected enough they hear the words rearranged to make it more expected. There are conversations where the question could fit smoothly, but in most contexts its a weird question that would mostly be measuring "are people hearing what they expect, or what is being actually said". This may also correlate strongly with having English as a second language.
I find the idea "dumb people just can't understand a counterfactual" completely implausible. Without a counterfactual you can't establish causality. Without causality their is no way of connecting action to outcome. How could such a person even learn to use a TV remote? Given that these people (I assume) can operate TV remotes they must in fact understand counterfactuals internally, although its possible they lack the language skills to clearly communicate about them.
The question of "why should the observed frequencies of events be proportional to the square amplitudes" is actually one of the places where many people perceive something fishy or weird with many worlds. [https://www.sciencedirect.com/science/article/pii/S1355219809000306 ]
To clarify, its not a question of possibly rejecting the square-amplitude Born Rule while keeping many worlds. Its a question of whether the square-amplitude Born Rule makes sense within the many worlds perspective, and it if doesn't what should be modified about the many worlds perspective to make it make sense.
I agree with this. Its something about the guilt that makes this work. Also the sense that you went into it yourself somehow reshapes the perception.
I think the loan shark business model maybe follows the same logic. [If you are going to eventually get into a situation where the victim pays or else suffers violence, then why doesn't the perpetrator just skip the costly loan step at the beginning and go in threat first? I assume that the existence of loan sharks (rather than just blackmailers) proves something about how if people feel like they made a bad choice or engaged willingly at some point they are more susceptible. Or maybe its frog boiling.]
On the "what did we start getting right in the 1980's for reducing global poverty" I think most of the answer was a change in direction of China. In the late 70's they started reforming their economy (added more capitalism, less command economy): https://en.wikipedia.org/wiki/Chinese_economic_reform.
Comparing this graph on wiki https://en.wikipedia.org/wiki/Poverty_in_China#/media/File:Poverty_in_China.svg , to yours, it looks like China accounts for practically all of the drop in poverty since the 1980s.
{kind=link}
Arguably this is a good example for your other points. More willing participation, less central command.
I don't think the framing "Is behaviour X exploitation?" is the right framing. It takes what (should be) an argument about morality and instead turns it into an argument about the definition of the word "exploitation" (where we take it as given that, whatever the hell we decide exploitation "actually means" it is a bad thing). For example see this post: https://www.lesswrong.com/posts/yCWPkLi8wJvewPbEp/the-noncentral-fallacy-the-worst-argument-in-the-world. Once we have a definition of "exploitation" their might be some weird edge cases that are technically exploitation but are obviously fine.
The substantial argument (I think) is that when two parties have unequal bargaining positions, is it OK for the stronger party to get the best deal it can? A full-widget is worth a million dollars. I possess the only left half of a widget in the world. Ten million people each possess a right half that could doc with my left half. Those not used to make widgets are worthless. What is the ethical split for me to offer for a right half in this case?
[This is maybe kind of equivalent to the dating example you give. At least in my view the "bad thing" in the dating example is the phrase "She begins using this position to change the relationship". The word "change" is the one that sets the alarms for me. If they both went in knowing what was going on then, to me, that's Ok. Its the "trap" that is not. I think most of the things we would object to are like this, those Monday meetings and that expensive suit are implied to be surprises jumped onto poor Bob.]
The teapot comparison (to me) seems to be a bad. I got carried away and wrote a wall of text. Feel free to ignore it!
First, lets think about normal probabilities in everyday life. Sometimes there are more ways for one state to come about that another state, for example if I shuffle a deck of cards the number of orderings that look random is much larger than the number of ways (1) of the cards being exactly in order.
However, this manner of thinking only applies to certain kinds of thing - those that are in-principle distinguishable. If you have a deck of blank cards, there is only one possible order, BBBBBB.... To take another example, an electronic bank account might display a total balance of $100. How many different ways are their for that $100 to be "arranged" in that bank account? The same number as 100 coins labelled "1" through "100"? No, of course not. Its just an integer stored on a computer, and their is only one way of picking out the integer 100. The surprising examples of this come from quantum physics, where photons act more like the bank account, where their is only 1 way of a particular mode to contain 100 indistinguishable photons. We don't need to understand the standard model for this, even if we didn't have any quantum theory at all we could still observe these Boson statistics in experiments.
So now, we encounter anthropic arguments like Doomsday. These arguments are essentially positing a distribution, where we take the exact same physical universe and its entire physical history from beginning to end, (which includes every atom, every synapse firing and so on). We then look at all of the "counting minds" in that universe (people count, ants probably don't, aliens, who knows), and we create a whole slew of "subjective universes", , , , , etc, where each of of them is atomically identical to the original but "I" am born as a different one of those minds (I think these are sometimes called "centred worlds"). We assume that all of these subjective universes were, in the first place, equally likely, and we start finding it a really weird coincidence that in the one we find ourselves in we are a human (instead of an Ant), or that we are early in history. This is, as I understand it, The Argument. You can phrase it without explicitly mentioning the different s, by saying "if there are trillions of people in the future, the chances of me being born in the present are very low. So, the fact I was born now should update me away from believing there will be trillions of people in the future". - but the s are still doing all the work in the background.
The conclusion depends on treating all those different subscripted s as distinguishable, like we would for cards that had symbols printed on them. But, if all the cards in the deck are identical there is only one sequence possible. I believe that all of the , , , 's etc are identical in this manner. By assumption they are atomically identical at all times in history, they differ only by which one of the thinking apes gets assigned the arbitrary label "me" - which isn't physically represented in any particle. You think they look different, and if we accept that we can indeed make these arguments, but if you think they are merely different descriptions of the same exact thing then the Doomsday argument no longer makes sense, and possibly some other anthropic arguments also fall apart. I don't think they do look different, if every "I" in the universe suddenly swapped places - but leaving all memories and personality behind in the physical synapses etc, then, how would I even know it? I would be a cyborg fighting in WWXIV and would have no memories of ever being some puny human typing on a web forum in the 21s Cent. Instead of imaging that I was born as someone else I could imagine that I could wake up as someone else, and in any case I wouldn't know any different.
So, at least to me, it looks like the anthropic arguments are advancing the idea of this orbital teapot (the different scripted s, although it is, in fairness, a very conceptually plausible teapot). There are, to me, three possible responses:
1 - This set of different worlds doesn't logically exist. You could push this for this response by arguing "I couldn't have been anyone but me, by definition." [Reject the premise entirely - there is no teapot]
2 - This set of different worlds does logically make sense, and after accepting it I see that it is a suspicious coincidence I am so early in history and I should worry about that. [accept the argument - there is a ceramic teapot orbiting Mars]
3 - This set of different worlds does logically make sense, but they should be treated like indistinguishable particles, blank playing cards or bank balances. [accept the core premise, but question its details in a way that rejects the conclusion - there is a teapot, but its chocolate, not ceramic.].
So, my point (after all that, Sorry!) is that I don't see any reason why (2) is more convincing that (3).
[For me personally, I don't like (1) because I think it does badly in cases where I get replicated in the future (eg sleeping beauty problems, or mind uploads or whatever). I reject (2) because the end result of accepting it is that I can infer information through evidence that is not causally linked to the information I gain (eg. I discover that the historical human population was much bigger than previously reported, and as a result I conclude the apocalypse is further in the future than I previously supposed). This leads me to thinking (3) seems right-ish, although I readily admit to being unsure about all this.].
I found this post to be a really interesting discussion of why organisms that sexually reproduce have been successful and how the whole thing emerges. I found the writing style, where it switched rapidly between relatively serious biology and silly jokes very engaging.
Many of the sub claims seem to be well referenced (I particularly liked the swordless ancestor to the swordfish liking mates who had had artificial swords attached).
"Stock prices represent the market's best guess at a stock's future price."
But they are not the same as the market's best guess at its future price. If you have a raffle ticket that will, 100% for definite, win $100 when the raffle happens in 10 years time, the the market's best guess of its future price is $100, but nobody is going to buy it for $100, because $100 now is better than $100 in 10 years.
Whatever it is that people think the stock will be worth in the future, they will pay less than that for it now. (Because $100 in the future isn't as good as just having the money now). So even if it was a cosmic law of the universe that all companies become more productive over time, and everyone knew this to be true, the stocks in those companies would still go up over time, like the raffle ticket approaching the pay day.
Toy example:
1990 - Stocks in C cost $10. Everyone thinks they will be worth $20 by the year 2000, but 10 years is a reasonably long time to wait to double your money so these two things (the expectation of 20 in the future, and the reality of 10 now) coexist without contradiction.
2000 - Stocks in C now cost $20, as expected. People now think that by 2010 they will be worth $40.
Other Ant-worriers are out there!
""it turned out this way, so I guess it had to be this way" doesn't resolve my confusion"
Sorry, I mixed the position I hold (that they maybe work like bosons) and the position I was trying to argue for, which was an argument in favor of confusion.
I can't prove (or even strongly motivate) my "the imaginary mind-swap procedure works like a swap of indistinguishable bosons" assumption, but, as far as I know no one arguing for Anthropic arguments can prove (or strongly motivate) the inverse position - which is essential for many of these arguments to work. I agree with you that we don't have a standard model of minds, and without such a model the Doomsday Argument, and the related problem of being cosmically early might not be problems at all.
Interestingly, I don't think the weird boson argument actually does anything for worries about whether we are simulations, or Boltzmann brains - those fears (I think) survive intact.
I suspect there is a large variation between countries in how safely taxi drivers drive relative to others.
In London my impression is that the taxis are driven more safely than non-taxis. In Singapore it appears obvious to casual observation that taxis are much less safely driven than most of the cars.
At least in my view, all the questions like the "Doomsday argument" and "why am I early in cosmological" history are putting far, far too much weight on the anthropic component.
If I don't know how many X's their are, and I learn that one of them is numbered 20 billion then sure, my best guess is that there are 40 billion total. But its a very hazy guess.
If I don't know how many X's will be produced next year, but I know 150 million were produced this year, my best guess is 150 million next year. But is a very hazy guess.
If I know that the population of X's has been exponentially growing with some coefficient then my best guess for the future is to infer that out to future times.
If I think I know a bunch of stuff about the amount of food the Earth can produce, the chances of asteroid impacts, nuclear wars, dangerous AIs or the end of the Mayan calendar then I can presumably update on those to make better predictions of the number of people in the future.
My take is that the Doomsday argument would be the best guess you could make if you knew literally nothing else about human beings apart from the number that came before you. If you happen to know anything else at all about the world (eg. that humans reproduce, or that the population is growing) then you are perfectly at liberty to make use of that richer information and put forward a better guess. Someone who traces out the exponential of human population growth out to the heat death of the universe is being a bit silly (lets call this the Exponentiator Argument), but on pure reasoning grounds they are miles ahead of the Doomsday argument, because both of them applied a natural, but naïve, interpolation to a dataset, but the exponentiator interpolated from a much richer and more detailed dataset.
Similarly to answer "why are you early" you should use all the data at your disposal. Given who your parents are, what your job is, your lack of cybernetic or genetic enhancements, how could you not be early? Sure, you might be a simulation of someone who only thinks they are in the 21st centaury, but you already know from what you can see and remember that you aren't a cyborg in the year 10,000, so you can't include that possibility in your imaginary dataset that you are using to reason about how early you are.
As a child, I used to worry a lot about what a weird coincidence it was that I was born a human being, and not an ant, given that ants are so much more numerous. But now, when I try and imagine a world where "I" was instead born as the ant, and the ant born as me, I can't point to in what physical sense that world is different from our own. I can't even coherently point to in what metaphysical sense it is different. Before we can talk about probabilities as an average over possibilities we need to know if the different possibilities are even different, or just different labelling on the same outcome. To me, there is a pleasing comparison to be made with how bosons work. If you think about a situation where two identical bosons have their positions swapped, it "counts as" the same situation as before the swap, and you DON'T count it again when doing statistics. Similarly, I think if two identical minds are swapped you shouldn't treat it as a new situation to average over, its indistinguishable. This is why the cyborgs are irrelevant, you don't have an identical set of memories.
I remember reading something about the Great Leap Forward in China (it may have been the Cultural Revolution, but I think it was the Great Leap Forward) where some communist party official recognised that the policy had killed a lot of people and ruined the lives of nearly an entire generation, but they argued it was still a net good because it would enrich future generations of people in China.
For individuals you weigh up the risk/rewards of differing your resource for the future. But, as a society asking individuals to give up a lot of potential utility for unborn future generations is a harder sell. It requires coercion.