leogao's Shortform
post by leogao · 2022-05-24T20:08:32.928Z · LW · GW · 313 commentsContents
313 comments
313 comments
Comments sorted by top scores.
comment by leogao · 2024-10-14T20:48:11.378Z · LW(p) · GW(p)
it's surprising just how much of cutting edge research (at least in ML) is dealing with really annoying and stupid bottlenecks. pesky details that seem like they shouldn't need attention. tools that in a good and just world would simply not break all the time.
i used to assume this was merely because i was inexperienced, and that surely eventually you learn to fix all the stupid problems, and then afterwards you can just spend all your time doing actual real research without constantly needing to context switch to fix stupid things.
however, i've started to think that as long as you're pushing yourself to do novel, cutting edge research (as opposed to carving out a niche and churning out formulaic papers), you will always spend most of your time fixing random stupid things. as you get more experienced, you get bigger things done faster, but the amount of stupidity is conserved. as they say in running- it doesn't get easier, you just get faster.
as a beginner, you might spend a large part of your research time trying to install CUDA or fighting with python threading. as an experienced researcher, you might spend that time instead diving deep into some complicated distributed training code to fix a deadlock or debugging where some numerical issue is causing a NaN halfway through training.
i think this is important to recognize because you're much more likely to resolve these issues if you approach them with the right mindset. when you think of something as a core part of your job, you're more likely to engage your problem solving skills fully to try and find a resolution. on the other hand, if something feels like a brief intrusion into your job, you're more likely to just hit it with a wrench until the problem goes away so you can actually focus on your job.
in ML research the hit it with a wrench strategy is the classic "google the error message and then run whatever command comes up" loop. to be clear, this is not a bad strategy when deployed properly - this is often the best first thing to try when something breaks, because you don't have to do a big context switch and lose focus on whatever you were doing before. but it's easy to end up trapped in this loop for too long. at some point you should switch modes to actively understanding and debugging the code, which is easier to do if you think of your job as mostly being about actively understanding and debugging code.
earlier in my research career i would feel terrible about having spent so much time doing things that were not the "actual" research, which would make me even more likely to just hit things with a wrench, which actually did make me less effective overall. i think shifting my mindset since then has helped me a lot
Replies from: carl-feynman, leogao, jacques-thibodeau, sharmake-farah, Viliam, nathan-helm-burger↑ comment by Carl Feynman (carl-feynman) · 2024-10-16T15:28:57.232Z · LW(p) · GW(p)
Not only is this true in AI research, it’s true in all science and engineering research. You’re always up against the edge of technology, or it’s not research. And at the edge, you have to use lots of stuff just behind the edge. And one characteristic of stuff just behind the edge is that it doesn’t work without fiddling. And you have to build lots of tools that have little original content, but are needed to manipulate the thing you’re trying to build.
After decades of experience, I would say: any sensible researcher spends a substantial fraction of time trying to get stuff to work, or building prerequisites.
This is for engineering and science research. Maybe you’re doing mathematical or philosophical research; I don’t know what those are like.
↑ comment by Alexander Gietelink Oldenziel (alexander-gietelink-oldenziel) · 2024-10-17T12:08:49.634Z · LW(p) · GW(p)
I can emphathetically say this is not the case in mathematics research.
↑ comment by leogao · 2024-10-14T20:55:01.855Z · LW(p) · GW(p)
a corollary is i think even once AI can automate the "google for the error and whack it until it works" loop, this is probably still quite far off from being able to fully automate frontier ML research, though it certainly will make research more pleasant
Replies from: nathan-helm-burger↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-10-15T18:07:20.763Z · LW(p) · GW(p)
I agree if I specify 'quite far off in ability-space', while acknowledging that I think this may not be 'quite far off in clock-time'. Sometimes the difference between no skill at a task and very little skill is a larger time and effort gap than the difference between very little skill and substantial skill.
↑ comment by jacquesthibs (jacques-thibodeau) · 2024-10-15T16:28:17.736Z · LW(p) · GW(p)
Completely agree. I remember a big shift in my performance when I went from "I'm just using programming so that I can eventually build a startup, where I'll eventually code much less" to "I am a programmer, and I am trying to become exceptional at it." The shift in mindset was super helpful.
↑ comment by Noosphere89 (sharmake-farah) · 2024-10-17T15:45:07.326Z · LW(p) · GW(p)
More and more, I'm coming to the belief that one big flaw of basically everyone in general is not realizing how much you needed to deal with annoying and pesky/stupid details to do good research, and I believe some of this dictum also applies to alignment research as well.
There is thankfully more engineering/ML experience in LW which alleviates the issue partially, but still, not realizing that pesky details mattering a lot in research/engineering is a problem that basically no one wants to particularly deal with.
↑ comment by Viliam · 2024-10-15T07:53:07.157Z · LW(p) · GW(p)
I would hope for some division of labor. There are certainly people out there who can't do ML research, but can fix Python code.
But I guess, even if you had the Python guy and the budget to pay him, waiting until he fixes the bug would still interrupt your flow.
Replies from: leogao↑ comment by leogao · 2024-10-15T09:29:30.104Z · LW(p) · GW(p)
I think there are several reasons this division of labor is very minimal, at least in some places.
- You need way more of the ML engineering / fixing stuff skill than ML research. Like, vastly more. There are still a very small handful of people who specialize full time in thinking about research, but they are very few and often very senior. This is partly an artifact of modern ML putting way more emphasis on scale than academia.
- Communicating things between people is hard. It's actually really hard to convey all the context needed to do a task. If someone is good enough to just be told what to do without too much hassle, they're likely good enough to mostly figure out what to work on themselves.
- Convincing people to be excited about your idea is even harder. Everyone has their own pet idea, and you are the first engineer on any idea you have. If you're not a good engineer, you have a bit of a catch-22: you need promising results to get good engineers excited, but you need engineers to get results. I've heard of even very senior researchers finding it hard to get people to work on their ideas, so they just do it themselves.
↑ comment by Sheikh Abdur Raheem Ali (sheikh-abdur-raheem-ali) · 2024-10-15T11:05:07.859Z · LW(p) · GW(p)
This is encouraging to hear as someone with relatively little ML research skill in comparison to experience with engineering/fixing stuff.
↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-10-15T18:12:12.897Z · LW(p) · GW(p)
For sure. The more novel an idea I am trying to test, the deeper I have to go into the lower level programming stuff. I can't rely on convenient high-level abstractions if my needs are cutting across existing abstractions.
Indeed, I take it as a bad sign of the originality of my idea if it's too easy to implement in an existing high-level library, or if an LLM can code it up correctly with low-effort prompting.
comment by leogao · 2024-10-14T18:23:19.665Z · LW(p) · GW(p)
in research, if you settle into a particular niche you can churn out papers much faster, because you can develop a very streamlined process for that particular kind of paper. you have the advantage of already working baseline code, context on the field, and a knowledge of the easiest way to get enough results to have an acceptable paper.
while these efficiency benefits of staying in a certain niche are certainly real, I think a lot of people end up in this position because of academic incentives - if your career depends on publishing lots of papers, then a recipe to get lots of easy papers with low risk is great. it's also great for the careers of your students, because if you hand down your streamlined process, then they can get a phd faster and more reliably.
however, I claim that this also reduces scientific value, and especially the probability of a really big breakthrough. big scientific advances require people to do risky bets that might not work out, and often the work doesn't look quite like anything anyone has done before.
as you get closer to the frontier of things that have ever been done, the road gets tougher and tougher. you end up spending more time building basic infrastructure. you explore lots of dead ends and spend lots of time pivoting to new directions that seem more promising. you genuinely don't know when you'll have the result that you'll build your paper on top of.
so for people who are not beholden as strongly to academic incentives, it might make sense to think carefully about the tradeoff between efficiency and exploration.
(not sure I 100% endorse this, but it is a hypothesis worth considering)
Replies from: nathan-helm-burger, jacob-pfau, jacques-thibodeau↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-10-14T19:41:39.398Z · LW(p) · GW(p)
I think this is true, and I also think that this is an even stronger effect in wetlab fields where there is lock-in to particular tools, supplies, and methods.
This is part of my argument for why there appears to be an "innovation overhang" of underexplored regions of concept space. And, in the case of programming dependent disciplines, I expect AI coding assistance to start to eat away at the underexplored ideas, and for full AI researchers to burn through the space of implied hypotheses very fast indeed. I expect this to result in a big surge of progress once we pass that capability threshold.
Replies from: M. Y. Zuo, nikolas-kuhn↑ comment by M. Y. Zuo · 2024-10-15T18:21:41.469Z · LW(p) · GW(p)
Or perhaps on the flip side there is a ‘super genius underhang’ where there are insufficient numbers of super competent people to do that work. (Or willing to bet on their future selves being super competent.)
It makes sense for the above average, but not that much above average, researcher to choose to focus on their narrow niche, since their relative prospects are either worse or not evaluable after wading into the large ocean of possibilities.
↑ comment by Amalthea (nikolas-kuhn) · 2024-10-14T20:27:45.815Z · LW(p) · GW(p)
Or simply when scaling becomes too expensive.
↑ comment by Jacob Pfau (jacob-pfau) · 2024-10-14T22:57:38.911Z · LW(p) · GW(p)
I agree that academia over rewards long-term specialization. On the other hand, it is compatible to also think, as I do, that EA under-rates specialization. At a community level, accumulating generalists has fast diminishing marginal returns compared to having easy access to specialists with hard-to-acquire skillsets.
↑ comment by jacquesthibs (jacques-thibodeau) · 2024-10-15T16:21:19.042Z · LW(p) · GW(p)
This is one of the reasons I think 'independent' research is valuable, even if it isn't immediately obvious from a research output (papers, for example) standpoint.
That said, I've definitely had the thought, "I should niche down into a specific area where there is already a bunch of infrastructure I can leverage and churn out papers with many collaborators because I expect to be in a more stable funding situation as an independent researcher. It would also make it much easier to pivot into a role at an organization if I want to or necessary. It would definitely be a much more stable situation for me."(And I also agree that specialization is often underrated.)
Ultimately, I decided not to do this because I felt like there were already enough people in alignment/governance who would take the above option due to financial and social incentives and published directions seeming more promising. However, since this makes me produce less output, I hope this is something grantmakers keep in consideration for my future grant applications.
comment by leogao · 2024-12-17T23:38:16.242Z · LW(p) · GW(p)
I decided to conduct an experiment at neurips this year: I randomly surveyed people walking around in the conference hall to ask whether they had heard of AGI
I found that out of 38 respondents, only 24 could tell me what AGI stands for (63%)
we live in a bubble
(https://x.com/nabla_theta/status/1869144832595431553)
Replies from: UnexpectedValues, daniel-kokotajlo, elityre, lc, nathan-helm-burger↑ comment by Eric Neyman (UnexpectedValues) · 2024-12-18T17:36:18.816Z · LW(p) · GW(p)
What's your guess about the percentage of NeurIPS attendees from anglophone countries who could tell you what AGI stands for?
Replies from: leogao↑ comment by leogao · 2024-12-18T21:31:37.473Z · LW(p) · GW(p)
not sure, i didn't keep track of this info. an important data point is that because essentially all ML literature is in english, non-anglophones generally either use english for all technical things, or at least codeswitch english terms into their native language. for example, i'd bet almost all chinese ML researchers would be familiar with the term CNN and it would be comparatively rare for people to say 卷积神经网络. (some more common terms like 神经网络 or 模型 are used instead of their english counterparts - neural network / model - but i'd be shocked if people didn't know the english translations)
overall i'd be extremely surprised if there were a lot of people who knew conceptually the idea of AGI but didn't know that it was called AGI in english
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2024-12-18T17:41:51.133Z · LW(p) · GW(p)
Very interesting!
Those who couldn't tell you what AGI stands for -- what did they say? Did they just say "I don't know" or did they say e.g. "Artificial Generative Intelligence...?"
Is it possible that some of them totally HAD heard the term AGI a bunch, and basically know what it means, but are just being obstinate? I'm thinking of someone who is skeptical of all the hype and aware the lots of people define AGI differently. Such a person might respond to "Can you tell me what AGI means" with "No I can't (because it's a buzzword that means different things to different people)"
↑ comment by leogao · 2024-12-18T21:26:39.474Z · LW(p) · GW(p)
the specific thing i said to people was something like:
excuse me, can i ask you a question to help settle a bet? do you know what AGI stands for? [if they say yes] what does it stand for? [...] cool thanks for your time
i was careful not to say "what does AGI mean".
most people who didn't know just said "no" and didn't try to guess. a few said something like "artificial generative intelligence". one said "amazon general intelligence" (??). the people who answered incorrectly were obviously guessing / didn't seem very confident in the answer.
if they seemed confused by the question, i would often repeat and say something like "the acronym AGI" or something.
several people said yes but then started walking away the moment i asked what it stood for. this was kind of confusing and i didn't count those people.
Replies from: lsgos↑ comment by lewis smith (lsgos) · 2024-12-19T09:24:05.757Z · LW(p) · GW(p)
not to be 'i trust my priors more than your data', but i have to say that i find the AGI thing quite implausible; my impression is that most AI researchers (way more than 60%), even ones working in like something very non-deep learning adjacent, have heard of the term AGI, but many of them are/were quite dismissive of it as an idea or associate it strongly (not entirely unfairly) with hype /bullshit, hence maybe walking away from you when you ask them about it.
e.g deepmind and openAI have been massive producers of neurips papers for years now (at least since I started a phd in 2016), and both organisations explictly talked about AGI fairly often for years.
maybe neurips has way more random attendees now (i didn't go this year), but I still find this kind of hard to believe; I think I've read about AGI in the financial times now.
Replies from: leogao, Mo Nastri↑ comment by leogao · 2024-12-19T17:37:16.078Z · LW(p) · GW(p)
only 2 people walked away without answering (after saying yes initially); they were not counted as yes or no. another several people refused to even answer, but this was also quite rare. the no responders seemed genuinely confused, as opposed to dismissive.
feel free to replicate this experiment at ICML or ICLR or next neurips.
Replies from: lsgos↑ comment by lewis smith (lsgos) · 2024-12-22T00:42:49.418Z · LW(p) · GW(p)
i mean i think that its' definitely an update (anything short of 95% i think would have been quite surprising to me)
↑ comment by Mo Putera (Mo Nastri) · 2024-12-19T17:02:22.231Z · LW(p) · GW(p)
Why not try out leogao's survey yourself to corroborate/falsify your priors?
↑ comment by Eli Tyre (elityre) · 2024-12-20T20:04:45.466Z · LW(p) · GW(p)
Was this possibly a language thing? Are there Chinese or Indian machine learning researchers who would use a different term than AGI in their native language?
Replies from: leogao↑ comment by leogao · 2024-12-20T20:16:42.342Z · LW(p) · GW(p)
I'd be surprised if this were the case. next neurips I can survey some non native English speakers to see how many ML terms they know in English vs in their native language. I'm confident in my ability to administer this experiment on Chinese, French, and German speakers, which won't be an unbiased sample of non-native speakers, but hopefully still provides some signal.
↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-12-18T21:23:07.868Z · LW(p) · GW(p)
I'd be curious to hear some of the guesses people make when they say they don't know.
comment by leogao · 2025-02-05T04:19:53.987Z · LW(p) · GW(p)
when i was new to research, i wouldn't feel motivated to run any experiment that wouldn't make it into the paper. surely it's much more efficient to only run the experiments that people want to see in the paper, right?
now that i'm more experienced, i mostly think of experiments as something i do to convince myself that a claim is correct. once i get to that point, actually getting the final figures for the paper is the easy part. the hard part is finding something unobvious but true. with this mental frame, it feels very reasonable to run 20 experiments for every experiment that makes it into the paper.
Replies from: Gunnar_Zarncke, sheikh-abdur-raheem-ali↑ comment by Gunnar_Zarncke · 2025-02-05T14:06:21.750Z · LW(p) · GW(p)
What is often left out in papers is all of these experiments and the though chains people had about them.
↑ comment by Sheikh Abdur Raheem Ali (sheikh-abdur-raheem-ali) · 2025-02-07T13:40:01.566Z · LW(p) · GW(p)
This is also because of Jevon's Paradox. As the cost of doing an experiment reduces with experience, the number of experiments run tends to rise.
comment by leogao · 2024-12-07T16:14:54.082Z · LW(p) · GW(p)
it's quite plausible (40% if I had to make up a number, but I stress this is completely made up) that someday there will be an AI winter or other slowdown, and the general vibe will snap from "AGI in 3 years" to "AGI in 50 years". when this happens it will become deeply unfashionable to continue believing that AGI is probably happening soonish (10-15 years), in the same way that suggesting that there might be a winter/slowdown is unfashionable today. however, I believe in these timelines roughly because I expect the road to AGI to involve both fast periods and slow bumpy periods. so unless there is some super surprising new evidence, I will probably only update moderately on timelines if/when this winter happens
Replies from: leogao, TsviBT, william-brewer, sharmake-farah, anaguma↑ comment by leogao · 2024-12-07T16:18:46.363Z · LW(p) · GW(p)
also a lot of people will suggest that alignment people are discredited because they all believed AGI was 3 years away, because surely that's the only possible thing an alignment person could have believed. I plan on pointing to this and other statements similar in vibe that I've made over the past year or two as direct counter evidence against that
(I do think a lot of people will rightly lose credibility for having very short timelines, but I think this includes a big mix of capabilities and alignment people, and I think they will probably lose more credibility than is justified because the rest of the world will overupdate on the winter)
Replies from: Jozdien, leogao, lahwran↑ comment by Jozdien · 2024-12-07T17:43:26.728Z · LW(p) · GW(p)
My timelines are roughly 50% probability on something like transformative AI by 2030, 90% by 2045, and a long tail afterward. I don't hold this strongly either, and my views on alignment are mostly decoupled from these beliefs. But if we do get an AI winter longer than that (through means other than by government intervention, which I haven't accounted for), I should lose some Bayes points, and it seems worth saying so publicly.
Replies from: leogao↑ comment by leogao · 2024-12-08T16:33:43.856Z · LW(p) · GW(p)
to be clear, a "winter/slowdown" in my typology is more about the vibes and could only be a few years counterfactual slowdown. like the dot-com crash didn't take that long for companies like Amazon or Google to recover from, but it was still a huge vibe shift
↑ comment by leogao · 2024-12-08T15:57:13.682Z · LW(p) · GW(p)
also to further clarify this is not an update I've made recently, I'm just making this post now as a regular reminder of my beliefs because it seems good to have had records of this kind of thing (though everyone who has heard me ramble about this irl can confirm I've believed sometime like this for a while now)
↑ comment by the gears to ascension (lahwran) · 2024-12-08T18:30:13.548Z · LW(p) · GW(p)
I was someone who had shorter timelines. At this point, most of the concrete part of what I expected has happened, but the "actually AGI" thing hasn't. I'm not sure how long the tail will turn out to be. I only say this to get it on record.
↑ comment by TsviBT · 2024-12-07T20:16:22.396Z · LW(p) · GW(p)
If you keep updating such that you always "think AGI is <10 years away" then you will never work on things that take longer than 15 years to help. This is absolutely a mistake, and it should at least be corrected after the first round of "let's not work on things that take too long because AGI is coming in the next 10 years". I will definitely be collecting my Bayes points https://www.lesswrong.com/posts/sTDfraZab47KiRMmT/views-on-when-agi-comes-and-on-strategy-to-reduce [LW · GW]
↑ comment by yams (william-brewer) · 2024-12-07T19:18:50.603Z · LW(p) · GW(p)
Does it seem likely to you that, conditional on ‘slow bumpy period soon’, a lot of the funding we see at frontier labs dries up (so there’s kind of a double slowdown effect of ‘the science got hard, and also now we don’t have nearly the money we had to push global infrastructure and attract top talent’), or do you expect that frontier labs will stay well funded (either by leveraging low hanging fruit in mundane utility, or because some subset of their funders are true believers, or a secret third thing)?
↑ comment by Noosphere89 (sharmake-farah) · 2024-12-07T21:47:47.271Z · LW(p) · GW(p)
My guess is that for now, I'd give around a 10-30% chance to "AI winter happens for a short period/AI progress slows down" by 2027.
Also, what would you consider super surprising new evidence?
comment by leogao · 2025-04-03T22:18:06.995Z · LW(p) · GW(p)
every 4 years, the US has the opportunity to completely pivot its entire policy stance on a dime. this is more politically costly to do if you're a long-lasting autocratic leader, because it is embarrassing to contradict your previous policies. I wonder how much of a competitive advantage this is.
Replies from: interstice, D0TheMath, ben-lang↑ comment by interstice · 2025-04-04T14:19:24.957Z · LW(p) · GW(p)
Or disadvantage, because it makes it harder to make long-term plans and commitments?
↑ comment by Garrett Baker (D0TheMath) · 2025-04-04T16:59:35.938Z · LW(p) · GW(p)
Autarchies, including China, seem more likely to reconfigure their entire economic and social systems overnight than democracies like the US, so this seems false.
Replies from: leogao↑ comment by leogao · 2025-04-04T18:24:57.365Z · LW(p) · GW(p)
It's often very costly to do so - for example, ending the zero covid policy was very politically costly even though it was the right thing to do. Also, most major reconfigurations even for autocratic countries probably mostly happen right after there is a transition of power (for China, Mao is kind of an exception, but thats because he had so much power that it was impossible to challenge his authority even when he messed up).
Replies from: D0TheMath↑ comment by Garrett Baker (D0TheMath) · 2025-04-04T19:05:39.780Z · LW(p) · GW(p)
The closing off of China after/during Tinamen square I don't think happened after a transition of power, though I could be mis-remembering. See also the one-child policy, which I also don't think happened during a power transition (allowed for 2 children in 2015, then removed all limits in 2021, while Xi came to power in 2012).
I agree the zero-covid policy change ended up being slow. I don't know why it was slow though, I know a popular narrative is that the regime didn't want to lose face, but one fact about China is the reason why many decisions are made is highly obscured. It seems entirely possible to me there were groups (possibly consisting of Xi himself) who believed zero-covid was smart. I don't know much about this though.
I will also say this is one example of china being abnormally slow of many examples of them being abnormally fast, and I think the abnormally fast examples win out overall.
Mao is kind of an exception, but thats because he had so much power that it was impossible to challenge his authority even when he messed up
Ish? The reason he pursued the cultural revolution was because people were starting to question his power, after the great leap forward, but yeah he could be an outlier. I do think that many autocracies are governed by charismatic & powerful leaders though, so not that much an outlier.
Replies from: leogao↑ comment by leogao · 2025-04-05T00:20:05.837Z · LW(p) · GW(p)
I mean, the proximate cause of the 1989 protests was the death of the quite reformist general secretary Hu Yaobang. The new general secretary, Zhao Ziyang, was very sympathetic towards the protesters and wanted to negotiate with them, but then he lost a power struggle against Li Peng and Deng Xiaoping (who was in semi retirement but still held onto control of the military). Immediately afterwards, he was removed as general secretary and martial law was declared, leading to the massacre.
↑ comment by Ben (ben-lang) · 2025-04-04T21:32:42.033Z · LW(p) · GW(p)
Having unstable policy making comes with a lot of disadvantages as well as advantages.
For example, imagine a small poor country somewhere with much of the population living in poverty. Oil is discovered, and a giant multinational approaches the government to seek permission to get the oil. The government offers some kind of deal - tax rates, etc. - but the company still isn't sure. What if the country's other political party gets in at the next election? If that happened the oil company might have just sunk a lot of money into refinery's and roads and drills only to see them all taken away by the new government as part of its mission to "make the multinationals pay their share for our people." Who knows how much they might take?
What can the multinational company do to protect itself? One answer is to try and find a different country where the opposition parties don't seem likely to do that. However, its even better to find a dictatorship to work with. If people think a government might turn on a dime, then they won't enter into certain types of deal with it. Not just companies, but also other countries.
So, whenever a government does turn on a dime, it is gaining some amount of reputation for unpredictability/instability, which isn't a good reputation to have when trying to make agreements in the future.
comment by leogao · 2024-12-23T00:43:00.420Z · LW(p) · GW(p)
people around these parts often take their salary and divide it by their working hours to figure out how much to value their time. but I think this actually doesn't make that much sense (at least for research work), and often leads to bad decision making.
time is extremely non fungible; some time is a lot more valuable than other time. further, the relation of amount of time worked to amount earned/value produced is extremely nonlinear (sharp diminishing returns). a lot of value is produced in short flashes of insight that you can't just get more of by spending more time trying to get insight (but rather require other inputs like life experience/good conversations/mentorship/happiness). resting or having fun can help improve your mental health, which is especially important for positive tail outcomes.
given that the assumptions of fungibility and linearity are extremely violated, I think it makes about as much sense as dividing salary by number of keystrokes or number of slack messages.
concretely, one might forgo doing something fun because it seems like the opportunity cost is very high, but actually diminishing returns means one more hour on the margin is much less valuable than the average implies, and having fun improves productivity in ways not accounted for when just considering the intrinsic value one places on fun.
Replies from: habryka4, CstineSublime↑ comment by habryka (habryka4) · 2024-12-23T00:55:11.826Z · LW(p) · GW(p)
but actually diminishing returns means one more hour on the margin is much less valuable than the average implies
This importantly also goes in the other direction!
One dynamic I have noticed people often don't understand is that in a competitive market (especially in winner-takes-all-like situations) the marginal returns to focusing more on a single thing can be sharply increasing, not only decreasing.
In early-stage startups, having two people work 60 hours is almost always much more valuable than having three people work 40 hours. The costs of growing a team are very large, the costs of coordination go up very quickly, and so if you are at the core of an organization, whether you work 40 hours or 60 hours is the difference between being net-positive vs. being net-negative.
This is importantly quite orthogonal whether you should rest or have fun or whatever. While there might be at an aggregate level increasing marginal returns to more focus, it is also the case that in such leadership positions, the most important hours are much much more productive than the median hour, and so figuring out ways to get more of the most important hours (which often rely on peak cognitive performance and a non-conflicted motivational system) is even more leveraged than adding the marginal hour (but I think it's important to recognize both effects).
Replies from: leogao, maxime-riche↑ comment by leogao · 2024-12-23T01:44:33.827Z · LW(p) · GW(p)
agree it goes in both directions. time when you hold critical context is worth more than time when you don't. it's probably at least sometimes a good strategy to alternate between working much more than sustainable and then recovering.
my main point is this is a very different style of reasoning than what people usually do when they talk about how much their time is worth.
↑ comment by Maxime Riché (maxime-riche) · 2024-12-24T00:30:01.873Z · LW(p) · GW(p)
It seems that your point applies significantly more to "zero-sum markets". So it may be good to notice it may not apply for altruistic people when non-instrumentally working on AI safety.
↑ comment by CstineSublime · 2024-12-23T01:08:06.734Z · LW(p) · GW(p)
Are these people trying to determine how much they (subjectively) value their time or how much they should value their time?
Because I think if it's the former and Descriptive, wouldn't the obvious approach be to look at what time-saving services they have employed recently or in the past and see how much they have paid for them relative to how much time they saved? I'm referring to services or products where they could have done it themselves as they have the tools, abilities and freedom to commit to it, but opted to buy a machine or outsource the task to someone else. (I am aware that the hidden variable of 'effort' complicates this model). For example, in what situations will I walk or take public transport to get somewhere, and which ones will I order an Uber: There's a certain cross-over point where if the time-saved is enough I'll justify the expense to myself, which would seem to be a good starting point for evaluating in descriptive terms how much I value my time.
I'm guessing if you had enough of these examples where the effort-saved was varied enough then you'd begin to get more accurate model of how one values their time?
↑ comment by leogao · 2024-12-23T01:54:19.222Z · LW(p) · GW(p)
I think the most important part of paying for goods and services is often not the raw time saved, but the cognitive overhead avoided. for instance, I'd pay much more to avoid having to spend 15 minutes understanding something complicated (assuming there is no learning value) than 15 minutes waiting. so it's plausibly more costly to have to figure out the timetable, fare system, remembering to transfer, navigating the station, than the additional time spent in transit (especially applicable in a new unfamiliar city)
Replies from: Viliam, CstineSublime↑ comment by Viliam · 2024-12-23T10:23:27.992Z · LW(p) · GW(p)
I guess is depends on the kind of work you do (and maybe whether you have ADHD). From my perspective, yes, attention is even more scarce than time or money, because when I get home from work, it feels like all my "thinking energy" is depleted, and even if I could somehow leverage the time or money for some good purpose, I am simply unable to do that. Working even more would mean that my private life would fall apart completely. And people would probably ask "why didn't he simply...?", and the answer would be that even the simple things become very difficult to do when all my "thinking energy" is gone.
There are probably smart ways to use money to reduce the amount of "thinking energy" you need to spend in your free time, but first you need enough "thinking energy" to set up such system. The problem is, the system needs to be flawless, because otherwise you still need to spend "thinking energy" to compensate for its flaws.
EDIT: I especially hate things like the principal-agent problem, where the seemingly simple answer is: "just pay a specialist to do that, duh", but that immediately explodes to "but how can I find a specialist?" and "how can I verify that they are actually doing a good job?", which easily become just as difficult as the original problem I tried to solve.
↑ comment by CstineSublime · 2024-12-23T07:07:38.800Z · LW(p) · GW(p)
I wasn't asking how most people go about determining which goods or services to pay for generally, but rather if you're noticing that they are using the working hours by salary equation to determine what their time is worth, if it's to put a dollar figure on what they do in fact value it at, (and that isolates the time element from the effort or cognitive load element)
I didn't specify nor imply that one route took more cognitive load than the other, only that one was quicker than the other, and that differential would be one such way of revealing the value of time. (Otherwise they're not, in fact, trying to ascertain what their time is worth at all... but something else)
Nowadays using Public Transport is often no more complicated or takes no more effort than using Uber thanks to Google Maps, but this tangent is immaterial to my question: are you noticing these people are trying to measure how much they DO value their time, or are they trying to ascertain how much they SHOULD value their time?
comment by leogao · 2025-03-07T00:28:26.495Z · LW(p) · GW(p)
timelines takes
- i've become more skeptical of rsi over time. here's my current best guess at what happens as we automate ai research.
- for the next several years, ai will provide a bigger and bigger efficiency multiplier to the workflow of a human ai researcher.
- ai assistants will probably not uniformly make researchers faster across the board, but rather make certain kinds of things way faster and other kinds of things only a little bit faster.
- in fact probably it will make some things 100x faster, a lot of things 2x faster, and then be literally useless for a lot of remaining things
- amdahl's law tells us that we will mostly be bottlenecked on the things that don't get sped up a ton. like if the thing that got sped up 100x was only 10% of the original thing, then you don't get more than a 1/(1 - 10%) speedup.
- i think the speedup is a bit more than amdahl's law implies. task X took up 10% of the time because there is diminishing returns to doing more X, and so you'd ideally do exactly the amount of X such that the marginal value of time spent on X is exactly in equilibrium with time spent on anything else. if you suddenly decrease the cost of X substantially, the equilibrium point shifts towards doing more X.
- in other words, if AI makes lit review really cheap, you probably want to do a much more thorough lit review than you otherwise would have, rather than just doing the same amount of lit review but cheaper.
- at the first moment that ai can fully replace a human researcher (that is, you can purely just put more compute in and get more research out, and only negligible human labor is required), the ai will probably be more expensive per unit of research than the human
- (things get a little bit weird because my guess is before ai can drop-in replace a human, we will reach a point where adding ai assistance equivalent to the cost of 100 humans to 2025-era openai research would be equally as good as adding 100 humans, but the ai's are not doing the same things as the humans, and if you just keep adding ai's you start experiencing diminishing returns faster than with adding humans. i think my analysis still mostly holds despite this)
- naively, this means that the first moment that AIs can fully automate AI research at human-cost is not a special criticality threshold. if you are at equilibrium for allocating money between researchers and compute, then suddenly having the ability to convert compute into researchers at the exchange rate of the salary of a human researcher doesn't really make sense
- in reality, you will probably not be at equilibrium, because there are a lot of inefficiencies in hiring humans - recruiting is a lemon market, you have to onboard new hires relatively slowly, management capacity is limited, there is a inelastic and inefficient supply of qualified hires, etc. but i claim this is a relatively small effect and can't explain a one OOM increase in workforce size
- also: anyone who has worked in a large organization knows that team size is not everything. having too many people can often even be a liability and slow you down. even when it doesn't, adding more people almost never makes your team linearly more productive.
- however, if AIs have much better scaling laws with additional parallel compute than human organizations do, then this could change things a lot. this is one of my biggest uncertainties here and one reason i still take rsi seriously.
- your AIs might higher have bandwidth communication with each other than your humans do. but also maybe they might be worse at generalizing previous findings to new situations or something.
- they might be more aligned with doing lots of research all day, whereas humans care about a lot of other things like money and status and fun and so on. but if outer alignment is hard we might get the AI equivalent of corporate politics.
- one other thing is that compute is a necessary input to research. i'll mostly roll this into the compute cost of actually running the AIs.
- the part where AI research feeds back into how good the AIs are could be very slow in practice
- there are logarithmic returns to more pretraining compute and more test time compute. so an improvement that 10xes the effective compute doesn't actually get you that much. 4.5 isn't that much better than 4 despite being 10x more compute (which is in turn not that much better than 3.5, I would claim).
- you run out of low hanging fruit at some point. each 2x in compute efficiency is harder to find than the previous one.
- i would claim that in fact much of the recent feeling that AI progress is fast is due to a lot of low hanging fruit being picked. for example, the shift from pretrained models to RL for reasoning picked a lot of low hanging fruit due to not using test time compute / not eliciting CoTs well, and we shouldn't expect the same kind of jump consistently.
- an emotional angle: exponentials can feel very slow in practice; for example, moore's law is kind of insane when you think about it (doubling every 18 months is pretty fast), but it still takes decades to play out
- for the next several years, ai will provide a bigger and bigger efficiency multiplier to the workflow of a human ai researcher.
↑ comment by ryan_greenblatt · 2025-03-07T04:01:11.066Z · LW(p) · GW(p)
My current best guess median is that we'll see 6 OOMs of effective compute in the first year after full automation of AI R&D if this occurs in ~2029 using a 1e29 training run and compute is scaled up by a factor of 3.5x[1] over the course of this year[2]. This is around 5 years of progress at the current rate[3].
How big of a deal is 6 OOMs? I think it's a pretty big deal; I have a draft post discussing how much an OOM gets you (on top of full automation of AI R&D) that I should put out somewhat soon.
Further, my distribution over this is radically uncertain with a 25th percentile of 2.5 OOMs (2 years of progress) and a 75th percentile of 12 OOMs.
The short breakdown of the key claims is:
- Initial progress will be fast, perhaps ~15x faster algorithmic progress than humans.
- Progress will probably speed up before slowing down due to training smarter AIs that can accelerate progress even faster, and this being faster than returns diminish on software.
- We'll be quite far from the limits of software progress (perhaps median 12 OOMs) at the point when we first achieve full automation.
Here is a somewhat summarized and rough version of the argument (stealing heavily from some of Tom Davidson's forthcoming work):
- At the point of full automation, progress will be fast:
- Probably you'll have lots of parallel workers running pretty fast at the point when you have full automation or shortly after this. This isn't totally obvious due to inference compute, but prices often drop fast.
- My guess is you'll have enough compute that if you use 1/6 of your compute running AIs, you'll be able to run the equivalent of ~1 million AIs which are roughly as good as the best human research scientists+engineers (taking into account cost reductions for using weaker models for many tasks). This is attempting to account for a reduction in the number of models due to using a bunch of inference compute. You'll be able to run these AIs at the equivalent of 60x speed (3x from hours, 5x from direct speed, 2x from coordination, and 2x from variable time compute and/or context swapping with a cheaper+faster model). So, like 15k parallel copies at 60x speed.
- Probably the AI company has like ~3k researchers, but when you adjust for quality, this is only as good as like 600 of the top engineers/researchers.
- Let's say marginal returns to parallelism are roughly 0.55.
- Then, the increase in "serial labor equivalents" is roughly (15k / 600)^0.55 * 60 = 350. (Note that most of this is from speed and quality rather than parallel copies!)
- Production of algorithmic research is due to both compute and labor. So, let's say Cobb-Douglas with labor^0.5 compute^0.5 (My guess is that current marginal returns are more like labor^0.6 compute^0.4, but returns will get worse as you add more labor.) So, we do 350^0.5 = 19x which roughly matches my 15x speed up median.
- Progress will speed up before slowing down:
- Limits are high:
- Human brain is 1e24 training flop.
- We're using 1e29 flop to get a bit over human level, so like 4 OOMs of headroom from this.
- We can probably get a lot more efficiency, maybe 9 OOMs, at least for efficiency up rather than down. (By efficiency up rather than down I mean: we can do as well as using 1e33 flop with 1e24 real flop relative to scaling at the point when you hit human efficiency, but probably can't train a human-level AI for 1e15 real flop.)
At some point, I'll write a post that makes a better version of this argument and presents a full version of my picture.
I don't think we'll see a speed criticality per se; rather, I expect the rate of progress to accelerate up to the point of full automation. But I currently don't think this makes a huge difference to the bottom line of "progress in the first year after full automation in practice", as I expect to initially see fast cost decreases and inference time compute can only go so far. I could expand this argument to the extent you have cruxes like "slower takeoff because we've already eaten low-hanging fruit with earlier AI acceleration" and "inference compute means you hit full automation much faster".
3.5x is roughly the rate of bare metal compute scale-up per year. ↩︎
That is, after the first company fully automates AI R&D internally, if they decide to go as fast as possible and their AIs/employees/others don't try to sabotage these efforts. And I'm assuming that AI software progress hasn't substantially slowed down by the time of full automation, though conditioning on a 1e29 training run means that at least compute scaling progress (which is a key driver of software progress) hasn't slowed down all that much. ↩︎
I think we see about 1.2 OOMs per year including both hardware and software. ↩︎
↑ comment by Stephen McAleese (stephen-mcaleese) · 2025-03-09T13:14:01.838Z · LW(p) · GW(p)
Thanks for these thoughtful predictions. Do you think there's anything we can do today to prepare for accelerated or automated AI research?
↑ comment by Hjalmar_Wijk · 2025-03-08T02:06:49.540Z · LW(p) · GW(p)
Maybe distracting technicality:
This seems to make the simplifying assumption that the R&D automation is applied to a large fraction of all the compute that was previously driving algorithmic progress right?
If we imagine that a company only owns 10% of the compute being used to drive algorithmic progress pre-automation (and is only responsible for say 30% of its own algorithmic progress, with the rest coming from other labs/academia/open-source), and this company is the only one automating their AI R&D, then the effect on overall progress might be reduced (the 15X multiplier only applies to 30% of the relevant algorithmic progress).
In practice I would guess that either the leading actor has enough of a lead that they are already responsible for most of their algorithmic progress, or other groups are close behind and will thus automate their own AI R&D around the same time anyway. But I could imagine this slowing down the impact of initial AI R&D automation a little bit (and it might make a big difference for questions like "how much would it accelerate a non-frontier lab that stole the model weights and tried to do rsi").
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2025-03-08T02:23:18.180Z · LW(p) · GW(p)
Yes, I think frontier AI companies are responsible for most of the algorithmic progress. I think its unclear how much the leading actor benefits from progress done at other slightly behind AI companies and this could make progress substantially slower. (However, it's possible the leading AI company would be able to acquire the GPUs from these other companies.)
↑ comment by Garrett Baker (D0TheMath) · 2025-03-07T16:03:59.365Z · LW(p) · GW(p)
at the first moment that ai can fully replace a human researcher (that is, you can purely just put more compute in and get more research out, and only negligible human labor is required), the ai will probably be more expensive per unit of research than the human
Why do you think this? It seems to me that for most tasks once an AI gets some skill it is much cheaper to run it for that skill than a human.
comment by leogao · 2025-01-31T21:48:43.952Z · LW(p) · GW(p)
libraries abstract away the low level implementation details; you tell them what you want to get done and they make sure it happens. frameworks are the other way around. they abstract away the high level details; as long as you implement the low level details you're responsible for, you can assume the entire system works as intended.
a similar divide exists in human organizations and with managing up vs down. with managing up, you abstract away the details of your work and promise to solve some specific problem. with managing down, you abstract away the mission and promise that if a specific problem is solved, it will make progress towards the mission.
(of course, it's always best when everyone has state on everything. this is one reason why small teams are great. but if you have dozens of people, there is no way for everyone to have all the state, and so you have to do a lot of abstracting.)
when either abstraction leaks, it causes organizational problems -- micromanagement, or loss of trust in leadership.
comment by leogao · 2025-02-23T21:58:40.276Z · LW(p) · GW(p)
there are a lot of video games (and to a lesser extent movies, books, etc) that give the player an escapist fantasy of being hypercompetent. It's certainly an alluring promise: with only a few dozen hours of practice, you too could become a world class fighter or hacker or musician! But because becoming hypercompetent at anything is a lot of work, the game has to put its finger on the scale to deliver on this promise. Maybe flatter the user a bit, or let the player do cool things without the skill you'd actually need in real life.
It's easy to dismiss this kind of media as inaccurate escapism that distorts people's views of how complex these endeavors of skill really are. But it's actually a shockingly accurate simulation of what it feels like to actually be really good at something. As they say, being competent doesn't feel like being competent, it feels like the thing just being really easy.
Replies from: TrevorWiesinger, weightt-an, Viliam↑ comment by trevor (TrevorWiesinger) · 2025-02-24T07:07:15.472Z · LW(p) · GW(p)
"power fantasies" are actually a pretty mundane phenomenon given how human genetic diversity shook out; most people intuitively gravitate towards anyone who looks and acts like a tribal chief, or towards the possibility that you yourself or someone you meet could become (or already be) a tribal chief, via constructing some abstract route that requires forging a novel path instead of following other people's.
Also a mundane outcome of human genetic diversity is how division of labor shakes out; people noticing they were born with savant-level skills and that they can sink thousands of hours into skills like musical instruments, programming, data science, sleight of hand party tricks, social/organizational modelling, painting, or psychological manipulation. I expect the pool to be much larger for power-seeking-adjacent skills than art, and that some proportion of that larger pool of people managed to get their skills's mental muscle memory sufficiently intensely honed that everyone should feel uncomfortable sharing a planet with them.
↑ comment by Canaletto (weightt-an) · 2025-02-24T11:27:46.668Z · LW(p) · GW(p)
The alternative is to pit people against each other in some competitive games, 1 on 1 or in teams. I don't think the feeling you get from such games is consistent with "being competent doesn't feel like being competent, it feels like the thing just being really easy", probably mainly because there is skill level matching, there are always opponents who pose you a real challenge.
Hmm maybe such games need some more long tail probabilistic matching, to sometimes feel the difference. Or maybe variable team sizes, with many incompetent people versus few competent, to get a more "doomguy" feeling.
↑ comment by Viliam · 2025-03-04T08:45:58.786Z · LW(p) · GW(p)
Some games do put their finger on the scale, for example you have a first-person shooter where you learn to aim better but you also now have a gun that deals 200 damage per hit, as opposed to your starting gun that dealt 10.
But puzzle-solving games are usually fair, I think.
comment by leogao · 2024-08-12T22:11:49.277Z · LW(p) · GW(p)
reliability is surprisingly important. if I have a software tool that is 90% reliable, it's actually not that useful for automation, because I will spend way too much time manually fixing problems. this is especially a problem if I'm chaining multiple tools together in a script. I've been bit really hard by this because 90% feels pretty good if you run it a handful of times by hand, but then once you add it to your automated sweep or whatever it breaks and then you have to go in and manually fix things. and getting to 99% or 99.9% is really hard because things break in all sorts of weird ways.
I think this has lessons for AI - lack of reliability is one big reason I fail to get very much value out of AI tools. if my chatbot catastrophically hallucinates once every 10 queries, then I basically have to look up everything anyways to check. I think this is a major reason why cool demos often don't mean things that are practically useful - 90% reliable it's great for a demo (and also you can pick tasks that your AI is more reliable at, rather than tasks which are actually useful in practice). this is an informing factor for why my timelines are longer than some other people's
Replies from: faul_sname, sharmake-farah, alexander-gietelink-oldenziel, M. Y. Zuo↑ comment by faul_sname · 2024-08-12T22:40:02.566Z · LW(p) · GW(p)
One nuance here is that a software tool that succeeds at its goal 90% of the time, and fails in an automatically detectable fashion the other 10% of the time is pretty useful for partial automation. Concretely, if you have a web scraper which performs a series of scripted clicks in hardcoded locations after hardcoded delays, and then extracts a value from the page from immediately after some known hardcoded text, that will frequently give you a ≥ 90% success rate of getting the piece of information you want while being much faster to code up than some real logic (especially if the site does anti-scraper stuff like randomizing css classes and DOM structure) and saving a bunch of work over doing it manually (because now you only have to manually extract info from the pages that your scraper failed to scrape).
Replies from: leogao↑ comment by leogao · 2024-08-12T23:14:57.173Z · LW(p) · GW(p)
I think even if failures are automatically detectable, it's quite annoying. the cost is very logarithmic: there's a very large cliff in effort when going from zero manual intervention required to any manual intervention required whatsoever; and as the amount of manual intervention continues to increase, you can invest in infrastructure to make it less painful, and then to delegate the work out to other people.
↑ comment by Noosphere89 (sharmake-farah) · 2024-08-13T01:26:23.604Z · LW(p) · GW(p)
While I agree with this, I do want to note that this:
this is an informing factor for why my timelines are longer than some other people's
Only lengthens timelines very much if we also assume scaling can't solve the reliability problem.
Replies from: leogao↑ comment by leogao · 2024-08-13T01:31:52.560Z · LW(p) · GW(p)
even if scaling does eventually solve the reliability problem, it means that very plausibly people are overestimating how far along capabilities are, and how fast the rate of progress is, because the most impressive thing that can be done with 90% reliability plausibly advances faster than the most impressive thing that can be done with 99.9% reliability
↑ comment by Alexander Gietelink Oldenziel (alexander-gietelink-oldenziel) · 2024-08-15T11:42:05.256Z · LW(p) · GW(p)
Perhaps it shouldn't be too surprising. Reliability, machine precision, economy are likely the deciding factors to whether many (most?) technologies take off. The classic RoP case study: the bike.
↑ comment by M. Y. Zuo · 2024-08-13T17:27:51.184Z · LW(p) · GW(p)
Motorola engineers figured this out a few decades ago, even 99.99 to 99.999 makes a huge difference on a large scale. They even published a few interesting papers and monographs on it from what I recall.
Replies from: gietema↑ comment by gietema · 2024-08-13T21:24:36.149Z · LW(p) · GW(p)
This can be explained when thinking about what these accuracy levels mean: 99.99% accuracy is one error every 10K trials. 99.999% accuracy is one error every 100K trials. So the 99.999% system is 10x better! When errors are costly and you’re operating at scale, this is a huge difference.
comment by leogao · 2024-01-28T04:46:54.866Z · LW(p) · GW(p)
i've noticed a life hyperparameter that affects learning quite substantially. i'd summarize it as "willingness to gloss over things that you're confused about when learning something". as an example, suppose you're modifying some code and it seems to work but also you see a warning from an unrelated part of the code that you didn't expect. you could either try to understand exactly why it happened, or just sort of ignore it.
reasons to set it low:
- each time your world model is confused, that's an opportunity to get a little bit of signal to improve your world model. if you ignore these signals you increase the length of your feedback loop, and make it take longer to recover from incorrect models of the world.
- in some domains, it's very common for unexpected results to actually be a hint at a much bigger problem. for example, many bugs in ML experiments cause results that are only slightly weird, but if you tug on the thread of understanding why your results are slightly weird, this can cause lots of your experiments to unravel. and doing so earlier rather than later can save a huge amount of time
- understanding things at least one level of abstraction down often lets you do things more effectively. otherwise, you have to constantly maintain a bunch of uncertainty about what will happen when you do any particular thing, and have a harder time thinking of creative solutions
reasons to set it high:
- it's easy to waste a lot of time trying to understand relatively minor things, instead of understanding the big picture. often, it's more important to 80-20 by understanding the big picture, and you can fill in the details when it becomes important to do so (which often is only necessary in rare cases).
- in some domains, we have no fucking idea why anything happens, so you have to be able to accept that we don't know why things happen to be able to make progress
- often, if e.g you don't quite get a claim that a paper is making, you could resolve your confusion just by reading a bit ahead. if you always try to fully understand everything before digging into it, you'll find it very easy to get stuck before actually make it to the main point the paper is making
there are very different optimal configurations for different kinds of domains. maybe the right approach is to be aware that this is an important hparameter and occasionally try going down some rabbit holes and seeing how much value it provides
Replies from: Gunnar_Zarncke, johannes-c-mayer, johannes-c-mayer↑ comment by Gunnar_Zarncke · 2024-01-28T23:23:19.467Z · LW(p) · GW(p)
This seems to be related to Goldfish Reading [LW · GW]. Or maybe complementary. In Goldfish Reading [LW · GW] one reads the same text multiple times, not trying to understand it all at once or remember everything, i.e., intentionally ignoring confusion. But in a structured form to avoid overload.
Replies from: leogao↑ comment by leogao · 2024-01-28T23:52:31.596Z · LW(p) · GW(p)
Yeah, this seems like a good idea for reading - lets you get best of both worlds. Though it works for reading mostly because it doesn't take that much longer to do so. This doesn't translate as directly to e.g what to do when debugging code or running experiments.
↑ comment by Johannes C. Mayer (johannes-c-mayer) · 2024-01-29T21:41:25.443Z · LW(p) · GW(p)
I think it's very important to keep track of what you don't know. It can be useful to not try to get the best model when that's not the bottleneck. But I think it's always useful to explicitly store the knowledge of what models are developed to what extent.
↑ comment by Johannes C. Mayer (johannes-c-mayer) · 2024-01-29T21:40:56.869Z · LW(p) · GW(p)
The algorithm that I have been using, where what to understand to what extend is not a hyperparameter, is to just solve the actual problems I want to solve, and then always slightly overdo the learning, i.e. I would always learn a bit more than necessary to solve whatever subproblem I am solving right now. E.g. I am just trying to make a simple server, and then I learn about the protocol stack.
This has the advantage that I am always highly motivated to learn something, as the path to the problem on the graph of justifications is always pretty short. It also ensures that all the things that I learn are not completely unrelated to the problem I am solving.
I am pretty sure if you had perfect control over your motivation this is not the best algorithm, but given that you don't, this is the best algorithm I have found so far.
comment by leogao · 2025-01-22T08:52:55.604Z · LW(p) · GW(p)
don't worry too much about doing things right the first time. if the results are very promising, the cost of having to redo it won't hurt nearly as much as you think it will. but if you put it off because you don't know exactly how to do it right, then you might never get around to it.
Replies from: Viliamcomment by leogao · 2024-09-27T21:30:46.238Z · LW(p) · GW(p)
in some way, bureaucracy design is the exact opposite of machine learning. while the goal of machine learning is to make clusters of computers that can think like humans, the goal of bureaucracy design is to make clusters of humans that can think like a computer
comment by leogao · 2025-03-03T06:28:06.883Z · LW(p) · GW(p)
my referral/vouching policy is i try my best to completely decouple my estimate of technical competence from how close a friend someone is. i have very good friends i would not write referrals for and i have written referrals for people i basically only know in a professional context. if i feel like it's impossible for me to disentangle, i will defer to someone i trust and have them make the decision. this leads to some awkward conversations, but if someone doesn't want to be friends with me because it won't lead to a referral, i don't want to be friends with them either.
Replies from: neel-nanda-1↑ comment by Neel Nanda (neel-nanda-1) · 2025-03-03T15:09:44.717Z · LW(p) · GW(p)
Strong agree (except in that liking someone's company is evidence that they would be a pleasant co-worker, but that's generally not a high order bit). I find it very annoying that standard reference culture seems to often imply giving extremely positive references unless someone was truly awful, since it makes it much harder to get real info from references
Replies from: Josephm↑ comment by Joseph Miller (Josephm) · 2025-03-03T19:17:13.249Z · LW(p) · GW(p)
I find it very annoying that standard reference culture seems to often imply giving extremely positive references unless someone was truly awful, since it makes it much harder to get real info from references
Agreed, but also most of the world does operate in this reference culture. If you choose to take a stand against it, you might screw over a decent candidate by providing only a quite positive recommendation.
Replies from: neel-nanda-1↑ comment by Neel Nanda (neel-nanda-1) · 2025-03-04T12:44:36.827Z · LW(p) · GW(p)
Agreed. If I'm talking to someone who I expect to be able to recalibrate, I just explain that I think the standard norms are dumb, the norms I actually follow, and then give an honest and balanced assessment. If I'm talking to someone I don't really know, I generally give a positive but not very detailed reference or don't reply, depending on context.
comment by leogao · 2024-07-11T06:11:50.632Z · LW(p) · GW(p)
learning thread for taking notes on things as i learn them (in public so hopefully other people can get value out of it)
Replies from: leogao↑ comment by leogao · 2024-07-11T07:23:58.470Z · LW(p) · GW(p)
VAEs:
a normal autoencoder decodes single latents z to single images (or whatever other kind of data) x, and also encodes single images x to single latents z.
with VAEs, we want our decoder (p(x|z)) to take single latents z and output a distribution over x's. for simplicity we generally declare that this distribution is a gaussian with identity covariance, and we have our decoder output a single x value that is the mean of the gaussian.
because each x can be produced by multiple z's, to run this backwards you also need a distribution of z's for each single x. we call the ideal encoder p(z|x) - the thing that would perfectly invert our decoder p(x|z). unfortunately, we obviously don't have access to this thing. so we have to train an encoder network q(z|x) to approximate it. to make our encoder output a distribution, we have it output a mean vector and a stddev vector for a gaussian. at runtime we sample a random vector eps ~ N(0, 1) and multiply it by the mean and stddev vectors to get an N(mu, std).
to train this thing, we would like to optimize the following loss function:
-log p(x) + KL(q(z|x)||p(z|x))
where the terms optimize the likelihood (how good is the VAE at modelling data, assuming we have access to the perfect z distribution) and the quality of our encoder (how good is our q(z|x) at approximating p(z|x)). unfortunately, neither term is tractable - the former requires marginalizing over z, which is intractable, and the latter requires p(z|x) which we also don't have access to. however, it turns out that the following is mathematically equivalent and is tractable:
-E z~q(z|x) [log p(x|z)] + KL(q(z|x)||p(z))
the former term is just the likelihood of the real data under the decoder distribution given z drawn from the encoder distribution (which happens to be exactly equivalent to the MSE, because it's the log of gaussian pdf). the latter term can be computed analytically, because both distributions are gaussians with known mean and std. (the distribution p is determined in part by the decoder p(x|z), but that doesn't pin down the entire distribution; we still have a degree of freedom in how we pick p(z). so we typically declare by fiat that p(z) is a N(0, 1) gaussian. then, p(z|x) is implied to be equal to p(x|z) p(z) / sum z' p(x|z') p(z'))
comment by leogao · 2024-12-07T15:46:18.123Z · LW(p) · GW(p)
a take I've expressed a bunch irl but haven't written up yet: feature sparsity might be fundamentally the wrong thing for disentangling superposition; circuit sparsity might be more correct to optimize for. in particular, circuit sparsity doesn't have problems with feature splitting/absorption
Replies from: Sodium↑ comment by Sodium · 2024-12-07T18:54:47.409Z · LW(p) · GW(p)
Yeah my view is that as long as our features/intermediate variables form human understandable circuits [LW · GW], it doesn't matter how "atomic" they are.
comment by leogao · 2024-11-27T04:37:04.317Z · LW(p) · GW(p)
the most valuable part of a social event is often not the part that is ostensibly the most important, but rather the gaps between the main parts.
- at ML conferences, the headline keynotes and orals are usually the least useful part to go to; the random spontaneous hallway chats and dinners and afterparties are extremely valuable
- when doing an activity with friends, the activity itself is often of secondary importance. talking on the way to the activity, or in the gaps between doing the activity, carry a lot of the value
- at work, a lot of the best conversations happen outside of scheduled 1:1s and group meetings, but rather happen in spontaneous hallway or dinner groups
↑ comment by johnswentworth · 2024-11-28T06:24:38.509Z · LW(p) · GW(p)
I have heard people say this so many times, and it is consistently the opposite of my experience. The random spontaneous conversations at conferences are disproportionately shallow and tend toward the same things which have been discussed to death online already, or toward the things which seem simple enough that everyone thinks they have something to say on the topic. When doing an activity with friends, it's usually the activity which is novel and/or interesting, while the conversation tends to be shallow and playful and fun but not as substantive as the activity. At work, spontaneous conversations generally had little relevance to the actual things we were/are working on (there are some exceptions, but they're rarely as high-value as ordinary work).
Replies from: D0TheMath↑ comment by Garrett Baker (D0TheMath) · 2024-11-28T18:44:50.368Z · LW(p) · GW(p)
I think you are possibly better/optimizing more than most others at selecting conferences & events you actually want to do. Even with work, I think many get value out of having those spontaneous conversations because it often shifts what they're going to do--the number one spontaneous conversation is "what are you working on" or "what have you done so far", which forces you to re-explain what you're doing & the reasons for doing it to a skeptical & ignorant audience. My understanding is you and David already do this very often with each other.
Replies from: johnswentworth↑ comment by johnswentworth · 2024-11-29T06:23:23.423Z · LW(p) · GW(p)
the number one spontaneous conversation is "what are you working on" or "what have you done so far", which forces you to re-explain what you're doing & the reasons for doing it to a skeptical & ignorant audience
I'm very curious if others also find this to be the biggest value-contributor amongst spontaneous conversations. (Also, more generally, I'm curious what kinds of spontaneous conversations people are getting so much value out of.)
Replies from: alexander-gietelink-oldenziel, Lblack↑ comment by Alexander Gietelink Oldenziel (alexander-gietelink-oldenziel) · 2024-11-29T11:18:57.130Z · LW(p) · GW(p)
One of the directions im currently most excited about (modern control theory through algebraic analysis) I learned about while idly chitchatting with a colleague at lunch about old school cybernetics. We were both confused why it was such a big deal in the 50s and 60s then basically died.
A stranger at the table had overheard our conversation and immediately started ranting to us about the history of cybernetics and modern methods of control theory. Turns out that control theory has developed far beyond whay people did in the 60s but names, techniques, methods have changed and this guy was one of the world experts. I wouldn't have known to ask him because the guy's specialization on the face of it had nothing to do with control theory.
↑ comment by Lucius Bushnaq (Lblack) · 2024-12-03T23:00:25.534Z · LW(p) · GW(p)
I do not find this to be the biggest value-contributor amongst my spontaneous conversations.
I don't have a good hypothesis for why spontaneous-ish conversations can end up being valuable to me so frequently. I have a vague intuition that it might be an expression of the same phenomenon that makes slack and playfulness in research and internet browsing very valuable for me.
↑ comment by metachirality · 2024-11-27T09:07:39.760Z · LW(p) · GW(p)
What would an event optimized for this sort of thing look like?
Replies from: Josephm↑ comment by Joseph Miller (Josephm) · 2024-11-27T13:25:03.944Z · LW(p) · GW(p)
Unconferences are a thing for this reason
comment by leogao · 2023-04-14T02:28:46.473Z · LW(p) · GW(p)
random fun experiment: accuracy of GPT-4 on "Q: What is 1 + 1 + 1 + 1 + ...?\nA:"
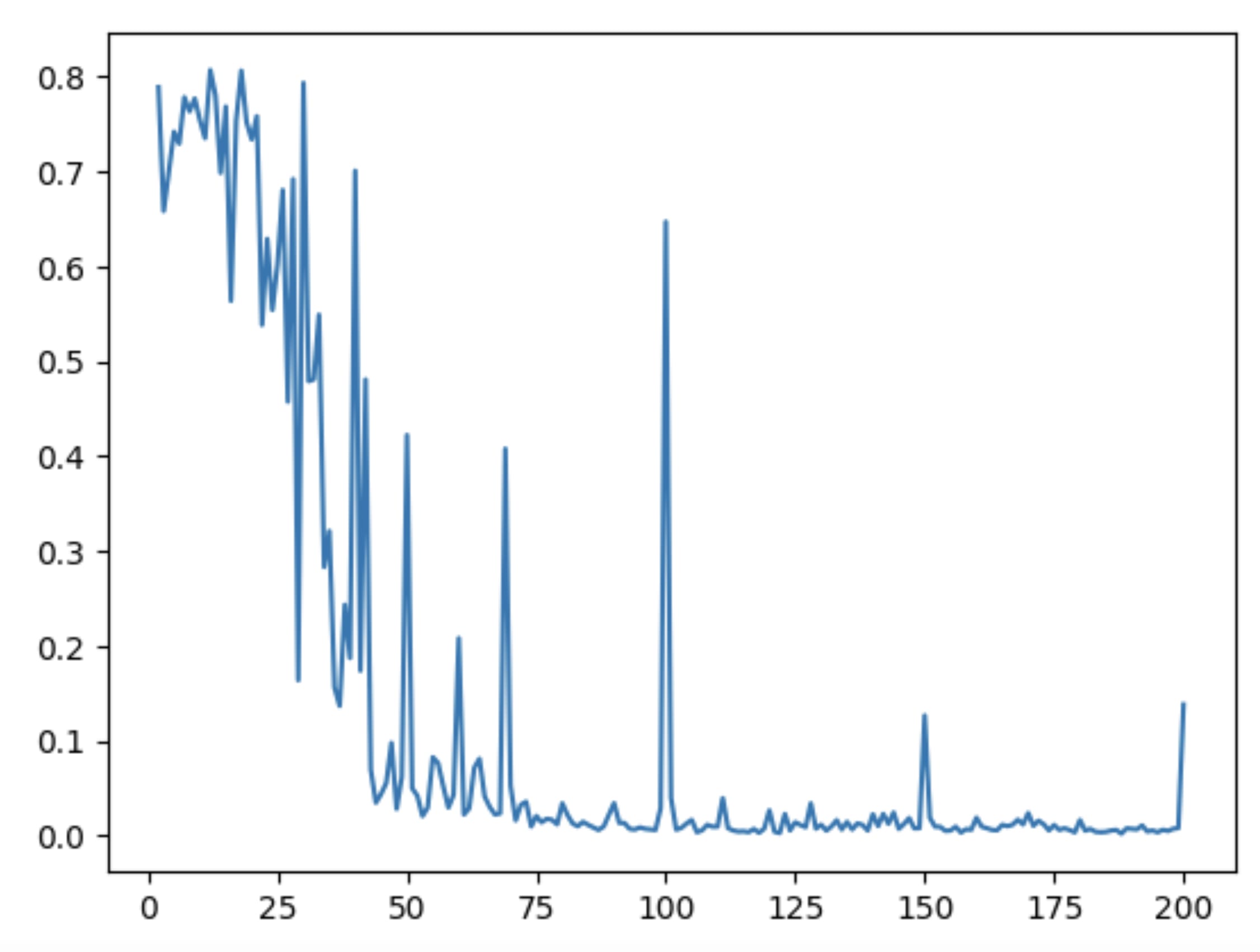

↑ comment by aphyer · 2023-04-14T02:35:08.342Z · LW(p) · GW(p)
...I am suddenly really curious what the accuracy of humans on that is.
Replies from: Richard_Kennaway↑ comment by Richard_Kennaway · 2023-04-14T07:40:20.136Z · LW(p) · GW(p)
'Can you do Addition?' the White Queen asked. 'What's one and one and one and one and one and one and one and one and one and one?'
'I don't know,' said Alice. 'I lost count.'
comment by leogao · 2025-02-24T02:29:30.835Z · LW(p) · GW(p)
you might expect that the butterfly effect applies to ML training. make one small change early in training and it might cascade to change the training process in huge ways.
at least in non-RL training, this intuition seems to be basically wrong. you can do some pretty crazy things to the training process without really affecting macroscopic properties of the model (e.g loss). one very well known example is that using mixed precision training results in training curves that are basically identical to full precision training, even though you're throwing out a ton of bits of precision on every step.
comment by leogao · 2024-12-27T09:46:28.297Z · LW(p) · GW(p)
a lot of unconventional people choose intentionally to ignore normie-legible status systems. this can take the form of either expert consensus or some form of feedback from reality that is widely accepted. for example, many researchers especially around these parts just don't publish at all in normal ML conferences at all, opting instead to depart into their own status systems. or they don't care whether their techniques can be used to make very successful products, or make surprisingly accurate predictions etc. instead, they substitute some alternative status system, like approval of a specific subcommunity.
there's a grain of truth to this, which is that the normal status system is often messed up (academia has terrible terrible incentives). it is true that many people overoptimize the normal status system really hard and end up not producing very much value.
but the problem with starting your own status system (or choosing to compete in a less well-agreed-upon one) is that it's unclear to other people how much stock to put in your status points. it's too easy to create new status systems. the existing ones might be deeply flawed, but at least their difficulty is a known quantity.
one common retort is that it's not worth proving yourself to people who are too closed minded and only accept ideas if they are validated by some legible status system. this is true to some extent, and i'm generally against people spending too much effort to optimize normie status too hard (e.g i think people should be way less worried about getting a degree in order to be taken seriously / get a job offer), but it's possible to take too far.
a rational decision maker should in fact discount claims of extremely illegible quality, because there are simply too many of them and it's too hard to pick out the good ones even if they were there (that's sort of the whole thing about illegibillity!). it seems bad to only bestow the truth upon people who happen to be irrational in ways that cause them to take you seriously by chance. if left unchecked, this kind of thing can also very easily evolve into a cult, where the unmooring from reality checks allows huge epistemic distortions.
a good in between approach might be to do some very legibly impressive things, just to prove that you can in fact do well at the legible status system if you chose to, and are intentionally choosing not to (as opposed to choosing alternative status systems because you're not capable of getting status in the legible system).
Replies from: johnswentworth, habryka4, dmurfet, Amyr, oliver-daniels-koch, CstineSublime↑ comment by johnswentworth · 2024-12-27T13:32:40.239Z · LW(p) · GW(p)
This comment seems to implicitly assume markers of status are the only way to judge quality of work. You can just, y'know, look at it? Even without doing a deep dive, the sort of papers or blog posts which present good research have a different style and rhythm to them than the crap. And it's totally reasonable to declare that one's audience is the people who know how to pick up on that sort of style.
The bigger reason we can't entirely escape "status"-ranking systems is that there's far too much work to look at it all, so people have to choose which information sources to pay attention to.
Replies from: dmurfet, Viliam, leogao↑ comment by Daniel Murfet (dmurfet) · 2024-12-28T01:21:48.532Z · LW(p) · GW(p)
It's a question of resolution. Just looking at things for vibes is a pretty good way of filtering wheat from chaff, but you don't give scarce resources like jobs or grants to every grain of wheat that comes along. When I sit on a hiring committee, the discussions around the table are usually some mix of status markers and people having done the hard work of reading papers more or less carefully (this consuming time in greater-than-linear proportion to distance from your own fields of expertise). Usually (unless nepotism is involved) someone who has done that homework can wield more power than they otherwise would at that table, because people respect strong arguments and understand that status markers aren't everything.
Still, at the end of day, an Annals paper is an Annals paper. It's also true that to pass some of the early filters you either need (a) someone who speaks up strongly for you or (b) pass the status marker tests.
I am sometimes in a position these days of trying to bridge the academic status system and the Berkeley-centric AI safety status system, e.g. by arguing to a high status mathematician that someone with illegible (to them) status is actually approximately equivalent in "worthiness of being paid attention to" as someone they know with legible status. Small increases in legibility can have outsize effects in how easy my life is in those conversations.
Otherwise it's entirely down to me putting social capital on the table ("you think I'm serious, I think this person is very serious"). I'm happy to do this and continue doing this, but it's not easily scalable, because it depends on my personal relationships.
↑ comment by Viliam · 2024-12-27T16:29:44.094Z · LW(p) · GW(p)
Generally, it is about heuristics we can use to find quality in the oceans of crap. If we assume that people are sane to some degree, status is an imperfect proxy for quality. If we assume that people don't use AIs to polish their writing styles, the writing style is an imperfect proxy for quality.
I have no experience reading research. I suspect that there are also crackpots who can write using the right kind of style. For example, they may be experts at their own line of research, and also speak overconfidently about different things they do not understand.
So if you want to be taken seriously, you probably need to know what kind of crackpot do you remind others of, and then find a way how to distinguish yourself from this kind of crackpot specifically.
At some moment it would probably easier to simply do your homework, once, and then have something you can point at. For example, you don't need to publish everything in the established journals, but it would probably help to publish there once -- just to show that if you want, you can; that this is about your priorities, not about lack of quality.
There are probably other ways, for example if you don't wont to get involved too much with the system, find someone who already is, and maybe offer them co-authorship in return for jumping through all the hoops.
I guess my model is that the costs of complying with the standard system are high but constant. So the more time you spend complaining about the system not taking your seriously, the greater the chance that complying with the system would have actually been cheaper than the accumulating opportunity costs.
↑ comment by leogao · 2024-12-28T05:04:30.643Z · LW(p) · GW(p)
there is always too much information to pay attention to. without an inexpensive way to filter, the field would grind to a complete halt. style is probably a worse thing to select on than even academia cred, just because it's easier to fake.
↑ comment by habryka (habryka4) · 2024-12-27T22:26:09.127Z · LW(p) · GW(p)
A thing that I often see happening when people talk about "normie-legible status systems" is that they gaslight themselves into believing that some status system that is extraordinarily legible, or they are part of, is something that is consensus.
Academia is the most intense example of this. Most people don't care that much about academic status! This also happens in the other direction. Youtube is a major source of status in much of the world, especially among young people, but is considered low-brow whenever people argue about this, and so people dismiss it.
I also think people tend to do a fallacy of gray thing where if a status system is not maximally legible (like writing popular blogposts, or running a popular podcast, or making popular Youtube videos, or being popular on Twitter), they dismiss the status system as not real and "illegible".
I think modeling the real status and reputation systems that are present in the world is important, but for example, trying to ascent the academic status hierarchy is a bad use of time and resources. It's extremely competitive, and not actually that influential outside of the academic bubble. It is in some fields better correlated with actual skills and integrity and intelligence, and so I still think a reasonable thing to consider, but I think most people are better placed to trade off a bit of legibility against a whole amount of net realness in status (this importantly does not mean your LW quick takes will be the thing that causes you to become world-renowned, I am not saying "just say smart things and the world will recognize you", I am saying "don't think that only the most legible status systems, or the one with the most mobs hunting dissenters from the status system are the only real ways of gaining recognition in the world").
Replies from: leogao↑ comment by leogao · 2024-12-28T03:53:47.818Z · LW(p) · GW(p)
sure, the thing you're looking for is the status system that jointly optimizes for alignedness with what you care about, and how legible it is to the people you are trying to convince.
Replies from: habryka4↑ comment by habryka (habryka4) · 2024-12-28T05:38:19.021Z · LW(p) · GW(p)
(My guess is you meant to agree with that, but kind of the whole point of my comment was that the dimension that is more important than legibility and alignment with you is the buy-in your audience has for a given status system. Youtube is not very legible, and not that aligned, but for some audiences has very high buy-in.)
↑ comment by Daniel Murfet (dmurfet) · 2024-12-27T10:58:39.577Z · LW(p) · GW(p)
There is a passage from Jung's "Modern man in search of a soul" that I think about fairly often, on this point (p.229 in my edition)
I know that the idea of proficiency is especially repugnant to the pseudo-moderns, for it reminds them unpleasantly of their deceits. This, however, cannot prevent us from taking it as our criterion of the modern man. We are even forced to do so, for unless he is proficient, the man who claims to be modern is nothing but an unscrupulous gambler. He must be proficient in the highest degree, for unless he can atone by creative ability for his break with tradition, he is merely disloyal to the past
↑ comment by Cole Wyeth (Amyr) · 2024-12-27T15:14:32.701Z · LW(p) · GW(p)
It's possible that this wouldn't work for everyone, but so far I am very satisfied working on a PhD on agent foundations (AIXI). There are a lot of complaints here about academic incentives, but mostly I just ignore them. Possibly this will eventually interfere with my academic career prospects, but in the meantime I get years to work on basically whatever I think is interesting and important, and at the end of it I can reasonably expect to end up with a PhD and a thesis I'm proud of, which seems like enough to land on my feet. Looks like the best of both worlds to me.
↑ comment by Oliver Daniels (oliver-daniels-koch) · 2024-12-27T19:20:23.578Z · LW(p) · GW(p)
Two common failure modes to avoid when doing the legibly impressive things
1. Only caring instrumentally about the project (decreases motivation)
2. Doing "net negative" projects
↑ comment by CstineSublime · 2024-12-27T22:35:56.667Z · LW(p) · GW(p)
What kind of changes or outcomes would you expect to see if people around these parts instead of publishing their work independently started trying to get it into traditional ML conferences and related publications?
comment by leogao · 2024-12-07T17:08:55.901Z · LW(p) · GW(p)
people often say that limitations of an artistic medium breed creativity. part of this could be the fact that when it is costly to do things, the only things done will be higher effort
Replies from: leogao, TsviBT, sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2024-12-07T20:22:51.429Z · LW(p) · GW(p)
This seems the likely explanation for any claim that constraints breed creativity/good things in a field, when the expectation is that the opposite outcome would occur.
Replies from: StartAtTheEnd↑ comment by StartAtTheEnd · 2024-12-07T23:05:35.906Z · LW(p) · GW(p)
My own expectation is that limitations result in creativity. Writers block is usually a result of having too many possibilities/choices. If I tell you "You can write a story about anything", it's likely harder for you to think of anything than if I tell you "Write a story about an orange cat". In the latter situation, you're more limited, but you also have something to work with.
I'm not sure if it's as true for computers as it is for humans (that would imply information-theoretic factors), but there's plenty of factors in humans, like analysis paralysis and the "See also" section of that page
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2024-12-08T00:21:21.422Z · LW(p) · GW(p)
My other explanation probably has to do with the fact that it's way easier to work with an already almost-executed object than a specification, because we are constrained to only think about a subset of possibilities for a reasonable time.
In other words, constraints are useful given that you are already severely constrained, to limit the space of possibilities.
comment by leogao · 2024-03-09T12:31:58.539Z · LW(p) · GW(p)
any time someone creates a lot of value without capturing it, a bunch of other people will end up capturing the value instead. this could be end consumers, but it could also be various middlemen. it happens not infrequently that someone decides not to capture the value they produce in the hopes that the end consumers get the benefit, but in fact the middlemen capture the value instead
Replies from: mr-hire, leogao, Dagon↑ comment by Matt Goldenberg (mr-hire) · 2024-03-09T16:06:12.963Z · LW(p) · GW(p)
can you give examples?
Replies from: leogao, ryan_greenblatt↑ comment by leogao · 2024-03-09T16:34:57.032Z · LW(p) · GW(p)
an example: open source software produces lots of value. this value is partly captured by consumers who get better software for free, and partly by businesses that make more money than they would otherwise.
the most clear cut case is that some businesses exist purely by wrapping other people's open source software, doing advertising and selling it for a handsome profit; this makes the analysis simpler, though to be clear the vast majority of cases are not this egregious.
in this situation, the middleman company is in fact creating value (if a software is created in a forest with no one around to use it, does it create any value?) by using advertising to cause people to get value from software. in markets where there are consumers clueless enough to not know about the software otherwise (e.g legacy companies), this probably does actually create a lot of counterfactual value. however, most people would agree that the middleman getting 90% of the created value doesn't satisfy our intuitive notion of fairness. (open source developers are more often trying to have the end consumers benefit from better software, not for random middlemen to get rich off their efforts)
and if advertising is commoditized, then this problem stops existing (you can't extract that much value as an advertising middleman if there is an efficient market with 10 other competing middlemen), and so most of the value does actually accrue to the end user.
↑ comment by ryan_greenblatt · 2024-03-09T22:57:49.411Z · LW(p) · GW(p)
Often tickets will be sold at prices considerably lower than the equilibrium price and thus ticket scalpers will buy the tickets and then resell for a high price.
That said, I don't think this typically occurs because the company/group originally selling the tickets wanted consumers to benefit, it seems more likely that this is due to PR reasons (it looks bad to sell really expensive tickets).
This is actually a case where it seems likely that the situation would be better for consumers if the original seller captured the value. (Because buying tickets from random scalpers is annoying.)
Replies from: Viliam, lahwran↑ comment by Viliam · 2024-03-12T12:47:13.184Z · LW(p) · GW(p)
I wonder how much of this is the PR reasons, and how much something else... for example, the scalpers cooperating (and sharing a part of their profits) with the companies that sell tickets.
To put it simply, if I sell a ticket for $200, I need to pay a tax for the $200. But if I sell the same ticket for $100 and the scalper re-sells it for $200, then I only need to pay the tax for $100, which might be quite convenient if the scalper... also happens to be me? (More precisely, some of the $100 tickets are sold to genuine 3rd party scalpers, but most of them I sell to myself... but according to my tax reports, all of them were sold to the 3rd party.)
↑ comment by the gears to ascension (lahwran) · 2024-03-09T23:33:20.683Z · LW(p) · GW(p)
ticket scalping is bad and we should find some sort of fully distributed market mechanism that makes scalping approach impossible without requiring the ticket seller to capture the value. it ought to be possible to gift value to end customers rather than requiring the richest to be the ones who get the benefit, how can that be achieved?
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2024-03-10T00:48:24.321Z · LW(p) · GW(p)
it ought to be possible to gift value to end customers rather than requiring the richest to be the ones who get the benefit, how can that be achieved?
The simple mechanism is:
- Charge market prices (auction or just figure out the equilibrium price normally)
- Redistribute the income uniformly to some group. Aka UBI.
Of course, you could make the UBI be to (e.g.) Taylor Swift fans in particular, but this is hardly a principled approach to redistribution.
Separately, musicians (and other performers) might want to subsidize tickets for extremely hard core fans because these fans add value to the event (by being enthusiastic). For this, the main difficulty is that it's hard to cheaply determine if someone is a hard core fan. (In principle, being prepared to buy tickets before they run out could be an OK proxy for this, but it fails in practice, at least for buying tickets online.)
More discussion is in this old planet money episode.
↑ comment by leogao · 2024-03-09T12:51:36.974Z · LW(p) · GW(p)
of course, this is more a question about equilibria than literal transactions. suppose you capture most of the value and then pay it back out to users as a dividend: the users now have more money with which they could pay a middleman, and a middleman that could have extracted some amount of value originally can still extract that amount of value in this new situation.
we can model this as a game of ultimatum between the original value creator and the middlemen. if the participation of the OVC and middleman are both necessary, the OVC can bargain for half the value in an iterated game / as FDT agents. however, we usually think of the key differentiating factor between the OVC and middlemen as the middlemen being more replaceable, so the OVC should be able to bargain for a lot more. (see also: commoditizing your complement)
so to ensure that the end users get most of the value, you need to either ensure that all middleman roles are commoditized, or precommit to only provide value in situations where the end user can actually capture most of the value
Replies from: Dagon↑ comment by Dagon · 2024-03-09T17:14:35.857Z · LW(p) · GW(p)
The equilibrium comprises literal transactions, right? You should be able to find MANY representative specific examples to analyze, which would help determine whether your model of value is useful in these cases.
My suspicion is that you're trying to model "value" as something that's intrinsic, not something which a relation between individuals, which means you are failing to see that the packaged/paid/delivered good is actually distinct and non-fungible with the raw/free/open good, for the customers who choose that route.
Note that in the case of open-source software, it's NOT a game of ultimatum, because both channels exist simultaneously and neither has the option to deny the other. A given consumer paying for one does not prevent some other customer (or even the same customer in parallel) using the direct free version.
Replies from: leogao↑ comment by Dagon · 2024-03-09T17:05:09.188Z · LW(p) · GW(p)
It's worth examining whether "capturing value" and "providing value" are speaking of the same thing. In many cases, the middlemen will claim that they're actually providing the majority of the value, in making the underlying thing useful or available. They may or may not be right.
For most goods, it's not clear how much of the consumer use value comes from the idea, the implementation of the idea, or from the execution of the delivery and packaging. Leaving aside government-enforced exclusivity, there are usually reasons for someone to pay for the convenience, packaging, and bundling of such goods.
I worked (long ago) in physical goods distribution for toys and novelties. I was absolutely and undeniably working for a middleman - we bought truckloads of stuff from factories, repackaged it for retail, and sold it at a significant markup to retail stores, who marked it up again and sold it to consumers. Our margins were good, but all trades were voluntary and I don't agree with a framing that we were "capturing" existing value rather than creating value in connecting supply with demand.
Replies from: StartAtTheEnd↑ comment by StartAtTheEnd · 2024-03-09T17:51:56.166Z · LW(p) · GW(p)
All value is finite, and every time value is used, it decreases. The middlemen are merely causing the thing to die faster. For instance, if you discover a nice beach which hasn't been ruined with plastic and glass bottle yet, and make it into a popular area, you won't get to spend many happy summers at that place.
If you find oil and sell it, are you creating value, or are you destroying value? I think both perspectives are valid. But since the openness of information in the modern world makes it so that everything which can be exploited will be exploited, and until the point that exploitation is no longer possible (as with the ruined beach), I strongly dislike unsustainable exploitation and personally tend toward the "destroying value" view.
And if you want something to worry about, let it be premature exploitation. X 'creates' value and chooses not to exploit it prematurely, but then Y will come along and take it, so X is forced to capitalize on it early. Now you have a moloch problem on your hands.
comment by leogao · 2024-01-23T06:13:06.565Z · LW(p) · GW(p)
saying "sorry, just to make sure I understand what you're saying, do you mean [...]" more often has been very valuable
Replies from: Viliam↑ comment by Viliam · 2024-01-23T09:29:32.129Z · LW(p) · GW(p)
yeah, turns off the combat mode
Replies from: leogao↑ comment by leogao · 2024-01-23T10:00:06.160Z · LW(p) · GW(p)
more importantly, both i and the other person get more out of the conversation. almost always, there are subtle misunderstandings and the rest of the conversation would otherwise involve a lot of talking past each other. you can only really make progress when you're actually engaging with the other person's true beliefs, rather than a misunderstanding of their beliefs.
comment by leogao · 2023-11-05T23:01:55.984Z · LW(p) · GW(p)
hypothesis: intellectual progress mostly happens when bubbles of non tribalism can exist. this is hard to safeguard because tribalism is a powerful strategy, and therefore insulating these bubbles is hard. perhaps it is possible for there to exist a monopoly on tribalism to make non tribal intellectual progress happen, in the same way a monopoly on violence makes it possible to make economically valuable trade without fear of violence
Replies from: daniel-kokotajlo, leogao, Viliam↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-11-07T00:05:03.703Z · LW(p) · GW(p)
Continuing the analogy:
You'd want there to be a Tribe, or perhaps two or more Tribes, that aggressively detect and smack down any tribalism that isn't their own. It needs to be the case that e.g. when some academic field starts splintering into groups that stereotype and despise each other, or when people involved in the decision whether to X stop changing their minds frequently and start forming relatively static 'camps,' the main Tribe(s) notice this and squash it somehow.
And/or maybe arrange things so it never happens in the first place.
I wonder if this sorta happens sometimes when there is an Official Religion?
↑ comment by leogao · 2023-11-07T01:40:40.176Z · LW(p) · GW(p)
another way to lean really hard into the analogy: you could have a Tribe which has a constitution/laws that dictate what kinds of argument are ok and which aren't, has a legislative branch that constantly thinks about what kinds of arguments are non truthseeking and should be prohibited, a judicial branch that adjudicates whether particular arguments were truthseeking by the law, and has the monopoly on tribalism in that it is the only entity that can legitimately silence people's arguments or (akin to exile) demand that someone be ostracized. there would also be foreign relations/military (defending the continued existence of the Tribe against all the other tribes out there, many of which will attempt to destroy the Tribe via very nontruthseeking means)
↑ comment by leogao · 2023-11-05T23:34:36.938Z · LW(p) · GW(p)
unfortunately this is pretty hard to implement. free speech/democracy is a very strong baseline but still insufficient. the key property we want is a system where true things systematically win over false things (even when the false things appeal to people's biases), and it is sufficiently reliable at doing so and therefore intellectually legitimate that participants are willing to accept the outcome of the process even when it disagrees with what they started with. perhaps there is some kind of debate protocol that would make this feasible?
Replies from: Viliam↑ comment by Viliam · 2023-11-06T07:15:26.033Z · LW(p) · GW(p)
Prediction markets? Generally, track people's previous success rates about measurable things.
Replies from: leogao↑ comment by leogao · 2023-11-06T07:21:29.146Z · LW(p) · GW(p)
prediction markets have two major issues for this use case. one is that prediction markets can only tell you whether people have been calibrated in the past, which is useful signal and filters out pundits but isn't very highly reliable for out of distribution questions (for example, ai x-risk). the other is that they don't really help much with the case where all the necessary information is already available but it is unclear what conclusion to draw from the evidence (and where having the right deliberative process to make sure the truth comes out at the end is the cat-belling problem). prediction markets can only "pull information from the future" so to speak.
↑ comment by Viliam · 2023-11-07T08:44:14.968Z · LW(p) · GW(p)
BTW, I like the "monopoly on violence" analogy. We can extend it to include verbal violence -- you can have an environment where it is okay to yell at people for being idiots, or you can have an environment where it is okay to yell at people for being politically incorrect. Both will shape the intellectual development in certain directions.
Conflicts arise is when you don't have a monopoly, so sometimes people get yelled at for being idiots, other times for being politically incorrect, and then you have endless "wars" about whether we should or shouldn't study a politically sensitive topic X with an open mind, both sides complaining about lack of progress (from their perspective).
The more mutually contradictory constraints you have, the more people will choose the strategy "let's not do anything unusual", because it is too likely to screw up according to some of the metrics and get yelled at.
comment by leogao · 2024-12-30T00:31:48.252Z · LW(p) · GW(p)
theory: a large fraction of travel is because of mimetic desire (seeing other people travel and feeling fomo / keeping up with the joneses), signalling purposes (posting on IG, demonstrating socioeconomic status), or mental compartmentalization of leisure time (similar to how it's really bad for your office and bedroom to be the same room).
this explains why in every tourist destination there are a whole bunch of very popular tourist traps that are in no way actually unique/comparatively-advantaged to the particular destination. for example: shopping, amusement parks, certain kinds of museums.
Replies from: NinaR, CstineSublime↑ comment by Nina Panickssery (NinaR) · 2024-12-30T07:55:48.468Z · LW(p) · GW(p)
I used to agree with this but am now less certain that travel is mostly mimetic desire/signaling/compartmentalization (at least for myself and people I know, rather than more broadly).
I think “mental compartmentalization of leisure time” can be made broader. Being in novel environments is often pleasant/useful, even if you are not specifically seeking out unusual new cultures or experiences. And by traveling you are likely to be in many more novel environments even if you are a “boring traveler”. The benefit of this extends beyond compartmentalization of leisure, you’re probably more likely to have novel thoughts and break out of ruts. Also some people just enjoy novelty.
Replies from: leogao↑ comment by CstineSublime · 2024-12-30T07:05:50.316Z · LW(p) · GW(p)
What fraction would you say is genuinely motivated by "seeing and experiencing another culture"? I don't doubt that most travel is performative, but I also think most of the people I interact with seem to have different motivations and talk about things from their travels which are a world away from the Pulp Fiction beer in a McDonalds discussion.
comment by leogao · 2024-08-12T11:24:58.105Z · LW(p) · GW(p)
a great way to get someone to dig into a position really hard (whether or not that position is correct) is to consistently misunderstand that position
Replies from: leogao, Seth Herd, keltan↑ comment by leogao · 2024-08-12T11:28:33.001Z · LW(p) · GW(p)
almost every single major ideology has some strawman that the general population commonly imagines when they think of the ideology. a major source of cohesion within the ideology comes from a shared feeling of injustice from being misunderstood.
Replies from: leogao, Viliam↑ comment by leogao · 2024-08-12T21:31:26.659Z · LW(p) · GW(p)
There are some people that I've found to be very consistently thoughtful - when we disagree, the crux is often something interesting and often causes me to realize that I overlooked an important consideration. I respect people like this a lot, even if we disagree a lot. I think talking to people like this is a good antidote to digging yourself into a position.
On the other hand, there are some people I've talked to where I feel like the conversation always runs in circles so it's impossible to pin down a crux, or they always retreat to increasingly deranged positions to avoid admitting being wrong, or they seem to constantly pattern match my argument to something vaguely similar instead of understanding my argument. I think arguing against people like this too much is actively harmful for your epistemics, because you'll start digging yourself into your positions, and you'll get used to thinking that everyone who disagrees with you is wrong. There are a bunch of people (most notably Eliezer) who seem to me to have gone too far down this path.
On the other side of the aisle, I don't know exactly how to consistently become more thoughtful, but I think one good starting point is getting good at deeply understanding people's viewpoints.
↑ comment by Viliam · 2024-08-12T13:45:55.101Z · LW(p) · GW(p)
The people who understand the proper interpretation of the ideology can feel intellectually superior to those who don't. Also, people who misunderstand something are by definition wrong... and therefore the people who understand the ideology correctly must -- quite logically -- be right!
(An equivocation between "be right about what is the correct interpretation of the ideology" and "be right about whether the ideology correctly describes the reality".)
↑ comment by Seth Herd · 2024-08-12T17:34:57.087Z · LW(p) · GW(p)
I think this is a subset of:
irritating people when discussing the topic is a great way to get someone to dig into a position really hard (whether or not that position is correct).
That irritation can be performed any way you like. The most common is insinuating that they're stupid, but making invalid meme arguments and otherwise misunderstanding the position or arguments for the position will serve quite well, too.
I think this follows from the strength and insidious nature of motivated reasoning. It's often mistaken for confirmation bias, but it's actually a much more important effect because it drives polarization in public discussion.
I've been meaning to write a post about this, but doing it justice would take too much time. I think I need to just write a brief incomplete one.
Replies from: leogao↑ comment by leogao · 2024-08-12T21:06:03.989Z · LW(p) · GW(p)
I don't think being irritating in general is enough. I think it's specifically the feeling that everyone who has disagreed with you has been wrong about their disagreement that creates a very powerful sense of feeling like you must be onto something.
Replies from: Seth Herd↑ comment by Seth Herd · 2024-08-12T21:19:38.305Z · LW(p) · GW(p)
Really!? Okay, I'll have to really present the argument when I write that post.
I do agree with your logic for why opponents misunderstanding the argument would make people sure they're right, by general association. It's a separate factor from the irritation, so I think I mis-statedit as a subset (although part of it seems to be; it's irritating to have people repeatedly mis-characterize your position).
It seems pretty apparent to me when I watch people have discussions/arguments that their irritation/anger makes them dig in on their position. It seems to follow from evolutionary psychology: if you make me angry, my brain reacts like we're in a fight. I now want to win that fight, so I need to prove you wrong. Believing any of your arguments or understating mine would lead to losing the fight I feel I'm in.
This isn't usually how motivated reasoning is discussed, so I guess it does really take some careful explanation. It seems intuitive and obvious to me after holding this theory for years, but that could be my own motivated reasoning...
↑ comment by keltan · 2024-08-12T21:22:56.302Z · LW(p) · GW(p)
Unfortunately, I think the average person doesn’t understand misunderstanding. I think it can be taken as…
- You’re too dumb to understand
- You’re being purposely ignorant
- You’re making fun of them I’ll give an example:
— I was recently in a conversation with a non-rationalist. I organised it because I wanted to talk about negative opinions they had on me. We talked a lot about certain scenarios.
In one scenario, I had seemingly rejected the suggestion that we all go bowling. I had said out loud “I hate bowling”. When what I meant was “I hate bowling, but I’m still very happy to sit in a bowling alley and watch my friends play.”
I think I did a bad job communicating there. It made my friends very angry (extra details about situation left out).
During our conversation, I asked for levels of anger or annoyance at me before and after I had explained what I had meant to say. I was surprised when one friend didn’t adjust their anger levels at all. I thought I must have done another bad job at explaining.
“So, you started at 80% angry at me. And now that I’ve told you my perspective, you’re still 80% angry?” This surprised me. I would adjust my levels down if someone explained that to me.
I went back and forth trying to get to the bottom of this for ~half an hour. After which I came to realise we were just wired very different. To do this I used your suggested technique. In the time it took for me to understand this one point, I had deeply annoyed my friend. They were under the impression that I was misunderstanding them on purpose somehow. I think I would have been less comfortable or fulfilled, but better off. If I had just accepted that they were still very angry. And had moved on. Instead, being confused and asking questions made my situation worse.
To be clear though. I did get to the truth with this technique. But sometimes winning can’t be about knowing the truth. Which is sad. I don’t like that. But I think it is true.
Replies from: leogao↑ comment by leogao · 2024-08-12T21:49:36.603Z · LW(p) · GW(p)
It is unfortunately impossible for me to know exactly what happened during this interaction. I will say that the specific tone you use matters a huge amount - for example, if you ask to understand why someone is upset about your actions, the exact same words will be much better received if you do it in a tone of contrition and wanting to improve, and it will be received very poorly if you do it in a tone that implies the other person is being unreasonable in being upset. From the very limited information I have, my guess is you probably often say things in a tone that's not interpreted the way you intended.
Replies from: keltan↑ comment by keltan · 2024-08-13T11:55:00.912Z · LW(p) · GW(p)
I’d say that’s a good guess given the information I provided.
I think I did a good job in this particular circumstance as coming off as confused or curious. That was my aim, and I placed a lot of focus there. However, I haven’t listened back to the audio recordings of the conversation. It’s likely my previous comment is heavily bias.
comment by leogao · 2025-03-28T20:36:27.163Z · LW(p) · GW(p)
idea: flight insurance, where you pay a fixed amount for the assurance that you will definitely get to your destination on time. e.g if your flight gets delayed, they will pay for a ticket on the next flight from some other airline, or directly approach people on the next flight to buy a ticket off of them, or charter a private plane.
pure insurance for things you could afford to self insure is generally a scam (and the customer base of this product could probably afford to self insure) but this mostly provides value by handling the rather complicated logistics for you rather than by reducing the financial burden, and there are substantial benefits from economies of scale (e.g if you have enough customers you can maintain a fleet of private planes within a few hours of most major airports)
Replies from: Gurkenglas↑ comment by Gurkenglas · 2025-03-28T21:03:08.437Z · LW(p) · GW(p)
I'd have called this not a scam because it hands off the cost of delays to someone in a better position to avert the delays.
Replies from: robo↑ comment by robo · 2025-03-29T04:03:54.524Z · LW(p) · GW(p)
That's a good Coasian point. Talking out of my butt, but I think the airlines don't carry the risk. The sale channel (airlines, Expedia, etc.) take commissions distributing an insurance product designed another company (Travel Insured International, Seven Corners) who handles product design compliance, with the actual claims being handled by another company and the insurance capital by yet another company (AIG, Berkshire Hathaway).
LLMs tell me the distributors get 30–50% commission, which tells you that it's not a very good product for consumers.
Replies from: Gurkenglas↑ comment by Gurkenglas · 2025-03-29T12:51:11.532Z · LW(p) · GW(p)
I know less than you here, but last-minute flights are marked up because businesspeople sometimes need them and maybe TII/SC get a better price on those?
comment by leogao · 2024-03-10T18:05:42.018Z · LW(p) · GW(p)
it's often stated that believing that you'll succeed actually causes you to be more likely to succeed. there are immediately obvious explanations for this - survivorship bias. obviously most people who win the lottery will have believed that buying lottery tickets is a good idea, but that doesn't mean we should take that advice. so we should consider the plausible mechanisms of action.
first, it is very common for people with latent ability to underestimate their latent ability. in situations where the cost of failure is low, it seems net positive to at least take seriously the hypothesis that you can do more than you think you can. (also keeping in mind that we often overestimate the cost of failure). there are also deleterious mental health effects to believing in a high probability of failure, and then bad mental health does actually cause failure - it's really hard to give something your all if you don't really believe in it.
belief in success also plays an important role in signalling. if you're trying to make some joint venture happen, you need to make people believe that the joint venture will actually succeed (opportunity costs exist). when assessing the likelihood of success of the joint venture, people will take many pieces of information into account: your track record, the opinions of other people with a track record, object level opinions on the proposal, etc.
being confident in your own venture is an important way of putting your "skin in the game" to vouch that it will succeed. specifically, the way this is supposed to work is that you get punished socially for being overconfident, so you have an incentive to only really vouch for things that really will work. in practice, in large parts of the modern world overconfidence is penalized less than we're hardwired to expect. sometimes this is due to regions with cultural acceptance and even embrace of risky bets (SV), or because of atomization of modern society making the effects of social punishment less important.
this has both good and bad effects. it's what enables innovation, because that fundamentally requires a lot of people to play the research lottery. if you're not willing to work on something that will probably fail but also will pay out big if it succeeds, it's very hard to innovate. research consists mostly of people who are extremely invested in some research bet, to the point where it's extremely hard to convince them to pivot if it's not working out. ditto for startups, which are probably the architypical example of both innovation and also of catastrophic overconfidence.
this also creates problems - for instance, it enables grifting because you don't actually need to have to be correct if you just claim that your idea will work, and then when it inevitably fails you can just say that this is par for the course. also, being systematically overconfident can cause suboptimal decision making where calibration actually is important.
because many talented people are underequipped with confidence (there is probably some causal mechanism here - technical excellence often requires having a very mechanistic mental model of the thing you're doing, rather than just yoloing it and hoping it works), it also creates a niche for middlemen to supply confidence as a service, aka leadership. in the ideal case, this confidence is supplied by people who are calibratedly confident because of experience, but the market is inefficient enough that even people who are not calibrated can supply confidence because of the market inefficiency. another way to view this is that leaders deliver the important service of providing certainty in the face of an uncertain world.
(I'm using the term middleman here in a sense that doesn't necessarily imply that they deliver no value - in fact, causing things to happen can create lots of value, and depending on the specifics this role can be very difficult to fill. but they aren't the people who do the actual technical work. it is of course also valuable for the leader to e.g be able in theory to fill any of the technical roles if needed, because it makes them more able to spend their risk budget on the important technical questions, it creates more slack and thereby increases the probability of success, and the common knowledge of the existence of this slack itself also increases the perceived inevitability of success)
a similar story also applies at the suprahuman level, of tribes or ideologies. if you are an ideology, your job is unfortunately slightly more complicated. on the one hand, you need to project the vibe of inevitable success so that people in other tribes feel the need to get in early on your tribe, but on the other hand you need to make your tribe members feel like every decision they make is very consequential for whether the tribe succeeds. if you're merely calibrated, then only one of the two can be true. different social technologies are used by religions, nations, political movements, companies, etc to maintain this paradox.
comment by leogao · 2023-12-18T02:49:34.580Z · LW(p) · GW(p)
Is it a very universal experience to find it easier to write up your views if it's in response to someone else's writeup? Seems like the kind of thing that could explain a lot about how research tends to happen if it were a pretty universal experience.
Replies from: ryan_greenblatt, mikkel-wilson, pat-myron↑ comment by ryan_greenblatt · 2023-12-18T03:38:54.528Z · LW(p) · GW(p)
I think so/I have this. (I would emoji react for a less heavy response, but doesn't work on older short forms)
The corollary is that it's really annoying to respond to widely held views or frames which aren't clearly written up anywhere. Particularly if these views are very inprecise and confused.
Replies from: leogao↑ comment by leogao · 2023-12-18T05:47:16.125Z · LW(p) · GW(p)
new galaxy brain hypothesis of how research advances: progress happens when people feel unhappy about a bad but popular paper and want to prove it wrong (or when they feel like they can do even better than someone else)
this explains:
- why it's often necessary to have bad incremental papers that don't introduce any generalizable techniques (nobody will care about the followup until it's refuting the bad paper)
- why so much of academia exists to argue that other academics are wrong and bad
- why academics sometimes act like things don't exist unless there's a paper about them, even though the thing is really obvious
↑ comment by MikkW (mikkel-wilson) · 2023-12-21T13:07:58.951Z · LW(p) · GW(p)
This subjectively seems to me to be the case.
↑ comment by Pat Myron (pat-myron) · 2023-12-22T19:32:43.830Z · LW(p) · GW(p)
comment by leogao · 2025-02-24T00:50:29.275Z · LW(p) · GW(p)
there's an obvious synthesis of great man theory and broader structural forces theories of history.
there are great people, but these people are still bound by many constraints due to structural forces. political leaders can't just do whatever they want; they have to appease the keys of power within the country. in a democracy, the most obvious key of power is the citizens, who won't reelect a politician that tries to act against their interests. but even in dictatorships, keeping the economy at least kind of functional is important, because when the citizens are starving, they're more likely to revolt and overthrow the government. there are also powerful interest groups like the military and critical industries, which have substantial sway over government policy in both democracies and dictatorships. many powerful people are mostly custodians for the power of other people, in the same way that a bank is mostly a custodian for the money of its customers.
also, just because someone is involved in something important, it doesn't mean that they were maximally counterfactually responsible. structural forces often create possibilities to become extremely influential, but only in the direction consistent with said structural force. a population that strongly believes in foobarism will probably elect a foobarist candidate, and if the winning candidate never existed, another foobarist candidate would have won. winning an election always requires a lot of competence, but no matter how competent you are, you aren't going to win on an anti-foobar platform. the sentiment of the population has created the role of foobarist president for someone foobarist to fill.
this doesn't mean that influential people have no latitude whatsoever to influence the world. when we're looking at the highest tiers of human ability, the efficient market hypothesis breaks down. there are so few extremely competent people that nobody is a perfect replacement for anyone else. if someone didn't exist, it doesn't necessarily mean someone else would have stepped up to do the same. for example, if napoleon had never existed, there might have been some other leader who took advantage of the weakness of the Directory to seize power, but they likely would have been very different from napoleon. great people still have some latitude to change the world orthogonal to the broader structural forces.
it's not a contradiction for the world to be mostly driven by structural forces, and simultaneously for great people to have hugely more influence than the average person. in the same way that bill gates or elon musk are vastly vastly wealthier than the median person, great people have many orders of magnitude more influence on the trajectory of history than the average person. and yet, the richest person is still only responsible for 0.1%* of the economic output of the united states.
*\ fermi estimate, taking musk's net worth and dividing by 20 to convert stocks to flows, and comparing to gdp. caveats apply based on interest rates and gdp being a bad metric. many assumptions involved here.
Replies from: Josephm, thomas-kwa↑ comment by Joseph Miller (Josephm) · 2025-02-24T09:12:23.315Z · LW(p) · GW(p)
I think there's a spectrum between great man theory and structural forces theory and I would classify your view as much closer to the structural forces view, rather than a combination of the two.
The strongest counter-example might be Mao. It seems like one man's idiosyncratic whims really did set the trajectory for hundreds of millions of people. Although of course as soon as he died most of the power vanished, but surely China and the world would be extremely different today without him.
↑ comment by Viliam · 2025-03-04T09:16:57.461Z · LW(p) · GW(p)
A synthesis between the structural forces theory and "pulling the rope sideways".
The economical and other forces determine the main direction, a leader who already wanted to go in that direction gets elected and starts going in that direction, his idiosyncratic whims get implemented as a side effect.
Like, instead of Hitler, there would be another German leader determined to change the post-WW1 world order, but he would probably be less obsessed about the Jews. Also, he might make different alliances.
↑ comment by Thomas Kwa (thomas-kwa) · 2025-02-24T02:31:56.370Z · LW(p) · GW(p)
and yet, the richest person is still only responsible for 0.1%* of the economic output of the united states.
Musk only owns 0.1% of the economic output of the US but he is responsible for more than this, including large contributions to
- Politics
- Space
- SpaceX is nearly 90% of global upmass
- Dragon is the sole American spacecraft that can launch humans to ISS
- Starlink probably enables far more economic activity than its revenue
- Quality and quantity of US spy satellites (Starshield has ~tripled NRO satellite mass)
- Startup culture through the many startups from ex-SpaceX employees
- Twitter as a medium of discourse, though this didn't change much
- Electric cars probably sped up by ~1 year by Tesla, which still owns over half the nation's charging infrastructure
- AI, including medium-sized effects on OpenAI and potential future effects through xAI
Depending on your reckoning I wouldn't be surprised if Elon's influence added up to >1% of Americans combined. This is not really surprising because a Zipfian relationship would give the top person in a nation of 300 million 5% of the total influence.
Replies from: Josephm, leogao↑ comment by Joseph Miller (Josephm) · 2025-02-24T09:06:14.218Z · LW(p) · GW(p)
The Duke of Wellington said that Napoleon's presence on a battlefield “was worth forty thousand men”.
This would be about 4% of France's military size in 1812.
↑ comment by leogao · 2025-02-24T02:48:01.397Z · LW(p) · GW(p)
i'm happy to grant that the 0.1% is just a fermi estimate and there's a +/- one OOM error bar around it. my point still basically stands even if it's 1%.
i think there are also many factors in the other direction that just make it really hard to say whether 0.1% is an under or overestimate.
for example, market capitalization is generally an overestimate of value when there are very large holders. tesla is also a bit of a meme stock so it's most likely trading above fundamental value.
my guess is most things sold to the public sector probably produce less economic value per $ than something sold to the private sector, so profit overestimates value produced
the sign on net economic value of his political advocacy seems very unclear to me. the answer depends strongly on some political beliefs that i don't feel like arguing out right now.
it slightly complicates my analogy for elon to be both the richest person in the us and also possibly the most influential (or one of). in my comment i am mostly referring to economic-elon. you are possibly making some arguments about influentialness in general. the problem is that influentialness is harder to estimate. also, if we're talking about influentialness in general, we don't get to use the 0.1% ownership of economic output as a lower bound of influentialness. owning x% of economic output doesn't automatically give you x% of influentialness. (i think the majority of other extremely rich people are not nearly as influential as elon per $)
comment by leogao · 2024-10-16T17:32:00.705Z · LW(p) · GW(p)
one kind of reasoning in humans is a kind of instant intuition; you see something and something immediately and effortlessly pops into your mind. examples include recalling vocabulary in a language you're fluent in, playing a musical instrument proficiently, or having a first guess at what might be going wrong when debugging.
another kind of reasoning is the chain of thought, or explicit reasoning: you lay out your reasoning steps as words in your head, interspersed perhaps with visuals, or abstract concepts that you would have a hard time putting in words. It feels like you're consciously picking each step of the reasoning. Working through a hard math problem, or explicitly designing a codebase by listing the constraints and trying to satisfy them, are examples of this.
so far these map onto what people call system 1 and 2, but I've intentionally avoided these labels because I think there's actually a third kind of reasoning that doesn't fit well into either of these buckets.
sometimes, I need to put the relevant info into my head, and then just let it percolate slowly without consciously thinking about it. at some later time, insights into the problem will suddenly and unpredictably pop into my head. I've found this mode of reasoning to be indispensible for dealing with the hardest problems, or for generating insights, where if I just did explicit reasoning I'd just get stuck.
of course, you can't just sit around and do nothing and hope insights come to you - to make this process work you have to absorb lots of info, and also do a lot of explicit reasoning before and after to take flashes of insight and turn them into actual fleshed-out knowledge. and there are conditions that are more or less conducive to this kind of reasoning.
I'm still figuring out how to best leverage it, but I think one hypothesis this raises is the possibility that a necessary ingredient in solving really hard problems is spending a bunch of time simply not doing any explicit reasoning, and creating whatever conditions are needed for subconscious insight-generating reasoning.
Replies from: TsviBT, kh, Vladimir_Nesov, FractalSyn↑ comment by TsviBT · 2024-10-16T22:19:51.119Z · LW(p) · GW(p)
the possibility that a necessary ingredient in solving really hard problems is spending a bunch of time simply not doing any explicit reasoning
I have a pet theory that there are literally physiological events that take minutes, hours, or maybe even days or longer, to happen, which are basically required for some kinds of insight. This would look something like:
-
First you do a bunch of explicit work trying to solve the problem. This makes a bunch of progress, and also starts to trace out the boundaries of where you're confused / missing info / missing ideas.
-
You bash your head against that boundary even more.
- You make much less explicit progress.
- But, you also leave some sort of "physiological questions". I don't know the neuroscience at all, but to make up a story to illustrate what sort of thing I mean: One piece of your brain says "do I know how to do X?". Some other pieces say "maybe I can help". The seeker talks to the volunteers, and picks the best one or two. The seeker says "nah, that's not really what I'm looking for, you didn't address Y". And this plays out as some pattern of electrical signals which mean "this and this and this neuron shouldn't have been firing so much" (like a backprop gradient, kinda), or something, and that sets up some cell signaling state, which will take a few hours to resolve (e.g. downregulating some protein production, which will eventually make the neuron a bit less excitable by changing the number of ion pumps, or decreasing the number of synaptic vesicles, or something).
-
Then you chill, and the physiological questions mostly don't do anything, but some of them answer themselves in the background; neurons in some small circuit can locally train themselves to satisfy the question left there exogenously.
See also "Planting questions".
↑ comment by Kaarel (kh) · 2024-10-16T20:32:24.814Z · LW(p) · GW(p)
a thing i think is probably happening and significant in such cases: developing good 'concepts/ideas' to handle a problem, 'getting a feel for what's going on in a (conceptual) situation'
a plausibly analogous thing in humanity(-seen-as-a-single-thinker): humanity states a conjecture in mathematics, spends centuries playing around with related things (tho paying some attention to that conjecture), building up mathematical machinery/understanding, until a proof of the conjecture almost just falls out of the machinery/understanding
↑ comment by Vladimir_Nesov · 2024-10-16T18:14:18.476Z · LW(p) · GW(p)
This is learning of a narrow topic, which builds representations that make thinking on that topic more effective, novel insights might become feasible even through system 1 where before system 2 couldn't help. With o1, LLMs have systems 1 and 2, but all learning is in pretraining, not targeting the current problem and in any case with horrible sample efficiency. Could be a crucial missing capability, though with scale even in-context learning might get there.
of course, you can't just sit around and do nothing and hope insights come to you - to make this process work you have to absorb lots of info, and also do a lot of explicit reasoning before and after to take flashes of insight and turn them into actual fleshed-out knowledge.
Sounds like a synthetic data generation pipeline.
↑ comment by FractalSyn · 2024-10-16T17:59:11.376Z · LW(p) · GW(p)
Relatable.
Giorgio Parisi mentionned this in his book; he said that the ah-ah moments tend to spark randomly when doing something else. Bertrand Russell had a very active social life (he praised leisure) and believed it is an active form of idleness that could reveal very productive. A good balance might be the best way to leverage it.
comment by leogao · 2024-10-18T17:36:29.721Z · LW(p) · GW(p)
for people who are not very good at navigating social conventions, it is often easier to learn to be visibly weird than to learn to adapt to the social conventions.
this often works because there are some spaces where being visibly weird is tolerated, or even celebrated. in fact, from the perspective of an organization, it is good for your success if you are good at protecting weird people.
but from the perspective of an individual, leaning too hard into weirdness is possibly harmful. part of leaning into weirdness is intentional ignorance of normal conventions. this traps you in a local minimum where any progress on understanding normal conventions hurts your weirdness, but isn't enough to jump all the way to the basin of the normal mode of interaction.
(epistemic status: low confidence, just a hypothesis)
Replies from: Benito, CstineSublime, MichaelDickens, Erich_Grunewald, AprilSR↑ comment by Ben Pace (Benito) · 2024-10-18T23:47:52.460Z · LW(p) · GW(p)
Pretty sure @Ronny Fernandez [LW · GW] has opinions about this (in particular, I expect he disagrees that actively being visibly weird requires being ignorant of how to behave conventionally).
↑ comment by CstineSublime · 2024-10-23T04:57:13.259Z · LW(p) · GW(p)
Perhaps I misunderstand your use of the phrase "intentionally ignorant" but I believe many cases of people who are seen to have acted with "integrity" are people who have been hyperaware and well informed of what normal social conventions are in a given environment and made deliberate choice not to adhere to them, not ignoring said conventions out of a lack of interest.
I also am not sure what you mean by "weird". I assume you mean any behavior which is not the normal convention of any randomly selected cohesive group of people, from a family, to a local soccer club, to a informal but tight knit circle of friends, to a department of a large company. Have I got that right?
My idea of 'weird' tends to involve the stereotypical artists and creatives I associate with, which is, within those circles not weird at all but normal. But I'm meta-aware that might be a weird take.
↑ comment by MichaelDickens · 2024-10-18T21:54:02.911Z · LW(p) · GW(p)
I don't think I understand what "learn to be visibly weird" means, and how it differs from not following social conventions because you fail to understand them correctly.
↑ comment by Erich_Grunewald · 2024-10-18T20:38:49.019Z · LW(p) · GW(p)
for people who are not very good at navigating social conventions, it is often easier to learn to be visibly weird than to learn to adapt to the social conventions.
are you basing this on intuition or personal experience or something else? I guess we should avoid basing it on observations of people who did succeed in that way. People who try and succeed in adapting to social conventions are likely much less noticeable/salient than people who succeed at being visibly weird.
comment by leogao · 2023-09-28T23:24:35.795Z · LW(p) · GW(p)
Since there are basically no alignment plans/directions that I think are very likely to succeed, and adding "of course, this will most likely not solve alignment and then we all die, but it's still worth trying" to every sentence is low information and also actively bad for motivation, I've basically recalibrated my enthusiasm to be centered around "does this at least try to solve a substantial part of the real problem as I see it". For me at least this is the most productive mindset for me to be in, but I'm slightly worried people might confuse this for me having a low P(doom), or being very confident in specific alignment directions, or so on, hence this post that I can point people to.
I think this may also be a useful emotional state for other people with similar P(doom) and who feel very demotivated by that, which impacts their productivity.
comment by leogao · 2023-05-13T20:42:47.676Z · LW(p) · GW(p)
a common discussion pattern: person 1 claims X solves/is an angle of attack on problem P. person 2 is skeptical. there is also some subproblem Q (90% of the time not mentioned explicitly). person 1 is defending a claim like "X solves P conditional on Q already being solved (but Q is easy)", whereas person 2 thinks person 1 is defending "X solves P via solving Q", and person 2 also believes something like "subproblem Q is hard". the problem with this discussion pattern is it can lead to some very frustrating miscommunication:
- if the discussion recurses into whether Q is hard, person 1 can get frustrated because it feels like a diversion from the part they actually care about/have tried to find a solution for, which is how to find a solution to P given a solution to Q (again, usually Q is some implicit assumption that you might not even notice you have). it can feel like person 2 is nitpicking or coming up with fully general counterarguments for why X can never be solved.
- person 2 can get frustrated because it feels like the original proposed solution doesn't engage with the hard subproblem Q. person 2 believes that assuming Q were solved, then there would be many other proposals other than X that would also suffice to solve problem P, so that the core ideas of X actually aren't that important, and all the work is actually being done by assuming Q.
↑ comment by Dagon · 2023-05-14T20:53:24.499Z · LW(p) · GW(p)
I find myself in person 2's position fairly often, and it is INCREDIBLY frustrating for person 1 to claim they've "solved" P, when they're ignoring the actual hard part (or one of the hard parts). And then they get MAD when I point out why their "solution" is ineffective. Oh, wait, I'm also extremely annoyed when person 2 won't even take steps to CONSIDER my solution - maybe subproblem Q is actually easy, when the path to victory aside from that is clarified.
In neither case can any progress be made without actually addressing how Q fits into P, and what is the actual detailed claim of improvement of X in the face of both Q and non-Q elements of P.
↑ comment by Max H (Maxc) · 2023-05-13T21:49:06.649Z · LW(p) · GW(p)
I can see how this could be a frustrating pattern for both parties, but I think it's often an important conversation tree to explore when person 1 (or anyone) is using results about P in restricted domains to make larger claims or arguments about something that depends on solving P at the hardest difficulty setting in the least convenient possible world.
As an example, consider the following three posts:
- Challenge: construct a Gradient Hacker [LW · GW]
- Gradient hacking is extremely difficult [LW · GW]
- My Objections to "We’re All Gonna Die with Eliezer Yudkowsky" [LW · GW]
I think both of the first two posts are valuable and important work on formulating and analyzing restricted subproblems. But I object to citation of the second post (in the third post) as evidence in support of a larger point that doom from mesa-optimizers or gradient descent is unlikely in the real world [LW · GW], and object to the second post to the degree that it is implicitly making this claim.
There's an asymmetry when person I is arguing for an optimistic view on AI x-risk and person 2 is arguing for a doomer-ish view, in the sense that person I has to address all counterarguments but person 2 only has to find one hole. But this asymmetry is unfortunately a fact about the problem domain and not the argument / discussion pattern between I and 2.
↑ comment by the gears to ascension (lahwran) · 2023-05-13T21:46:32.013Z · LW(p) · GW(p)
yeah, but that's because Q is easy if you solve P
Very nicely described, this might benefit from becoming a top level post
↑ comment by DPiepgrass · 2023-05-13T21:42:37.107Z · LW(p) · GW(p)
For example?
Replies from: leogao↑ comment by leogao · 2023-05-13T22:45:13.194Z · LW(p) · GW(p)
here's a straw hypothetical example where I've exaggerated both 1 and 2; the details aren't exactly correct but the vibe is more important:
1: "Here's a super clever extension of debate that mitigates obfuscated arguments [etc], this should just solve alignment"
2: "Debate works if you can actually set the goals of the agents (i.e you've solved inner alignment), but otherwise you can get issues with the agents coordinating [etc]"
1: "Well the goals have to be inside the NN somewhere so we can probably just do something with interpretability or whatever"
2: "how are you going to do that? your scheme doesn't tackle inner alignment, which seems to contain almost all of the difficulty of alignment to me. the claim you just made is a separate claim from your main scheme, and the cleverness in your scheme is in a direction orthogonal to this claim"
1: "idk, also that's a fully general counterargument to any alignment scheme, you can always just say 'but what if inner misalignment'. I feel like you're not really engaging with the meat of my proposal, you've just found a thing you can say to be cynical and dismissive of any proposal"
2: "but I think most of the difficulty of alignment is in inner alignment, and schemes which kinda handwave it away are trying to some some problem which is not the actual problem we need to solve to not die from AGI. I agree your scheme would work if inner alignment weren't a problem."
1: "so you agree that in a pretty nontrivial number [let's say both 1&2 agree this is like 20% or something] of worlds my scheme does actually work- I mean how can you be that confident that inner alignment is that hard? in the world's where inner alignment turns out to be easy then my scheme will work."
2: "I'm not super confident, but if we assume that inner alignment is easy then I think many other simpler schemes will also work, so the cleverness that your proposal adds doesn't actually make a big difference."
Replies from: DPiepgrass↑ comment by DPiepgrass · 2023-05-16T22:17:07.029Z · LW(p) · GW(p)
So Q=inner alignment? Seems like person 2 not only pointed to inner alignment explicitly (so it can no longer be "some implicit assumption that you might not even notice you have"), but also said that it "seems to contain almost all of the difficulty of alignment to me". He's clearly identified inner alignment as a crux, rather than as something meant "to be cynical and dismissive". At that point, it would have been prudent of person 1 to shift his focus onto inner alignment and explain why he thinks it is not hard.
Note that your post suddenly introduces "Y" without defining it. I think you meant "X".
comment by leogao · 2024-03-27T20:37:39.281Z · LW(p) · GW(p)
philosophy: while the claims "good things are good" and "bad things are bad" at first appear to be compatible with each other, actually we can construct a weird hypothetical involving exact clones that demonstrates that they are fundamentally inconsistent with each other
law: could there be ambiguity in "don't do things that are bad as determined by a reasonable person, unless the thing is actually good?" well, unfortunately, there is no way to know until it actually happens
Replies from: Dagon↑ comment by Dagon · 2024-03-27T21:56:02.430Z · LW(p) · GW(p)
I think I need to hear more context (and likely more words in the sentences) to understand what inconsistency you're talking about. "good things are good" COULD be just a tautology, with the assumption that "good things" are relative to a given agent, and "good" is furtherance of the agent's preferences. Or it could be a hidden (and false) claim of universality "good things" are anything that a lot of people support, and "are good" means truly pareto-preferred with no harm to anyone.
Your explanation "by a reasonable person" is pretty limiting, there being no persons who are reasonable on all topics. Likewise "actually good" - I think there's no way to know even after it happens.
comment by leogao · 2022-05-31T00:47:05.876Z · LW(p) · GW(p)
One possible model of AI development is as follows: there exists some threshold beyond which capabilities are powerful enough to cause an x-risk, and such that we need alignment progress to be at the level needed to align that system before it comes into existence. I find it informative to think of this as a race where for capabilities the finish line is x-risk-capable AGI, and for alignment this is the ability to align x-risk-capable AGI. In this model, it is necessary but not sufficient for alignment for alignment to be ahead by the time it's at the finish line for good outcomes: if alignment doesn't make it there first, then we automatically lose, but even if it does, if alignment doesn't continue to improve proportional to capabilities, we might also fail at some later point. However, I think it's plausible we're not even on track for the necessary condition, so I'll focus on that within this post.
Given my distributions over how difficult AGI and alignment respectively are, and the amount of effort brought to bear on each of these problems, I think there's a worryingly large chance that we just won't have the alignment progress needed at the critical juncture.
I also think it's plausible that at some point before when x-risks are possible, capabilities will advance to the point that the majority of AI research will be done by AI systems. The worry is that after this point, both capabilities and alignment will be similarly benefitted by automation, and if alignment is behind at the point when this happens, then this lag will be "locked in" because an asymmetric benefit to alignment research is needed to overtake capabilities if capabilities is already ahead.
There are a number of areas where this model could be violated:
- Capabilities could turn out to be less accelerated than alignment by AI assistance. It seems like capabilities is mostly just throwing more hardware at the problem and scaling up, whereas alignment is much more conceptually oriented.
- After research is mostly/fully automated, orgs could simply allocate more auto-research time to alignment than AGI.
- Alignment(/coordination to slow down) could turn out to be easy. It could turn out that applying the same amount of effort to alignment and AGI results in alignment being solved first.
However, I don't think these violations are likely for the following reasons respective:
- It's plausible that our current reliance on scaling is a product of our theory not being good enough and that it's already possible to build AGI with current hardware if you have the textbook from the future. Even if the strong version of the claim isn't true, one big reason that the bitter lesson is true is that bespoke engineering is currently expensive, and if it became suddenly a lot cheaper we would see a lot more of it and consequently squeezing more out of the same hardware. It also seems likely that before total automation, there will be a number of years where automation is best modelled as a multiplicative factor on human researcher effectiveness. In that case, because of the sheer number of capabilities researchers compared to alignment researchers, alignment researchers would have to benefit a lot more to just break even.
- If it were the case that orgs would pivot, I would expect them to currently be allocating a lot more to alignment than they do currently. While it's still plausible that orgs haven't allocated more to alignment because they think AGI is far away, and that a world where automated research is a thing is a world where orgs would suddenly realize how close AGI is and pivot, that hypothesis hasn't been very predictive so far. Further, because I expect the tech for research automation to be developed at roughly the same time by many different orgs, it seems like not only does one org have to prioritize alignment, but actually a majority weighted by auto research capacity have to prioritize alignment. To me, this seems difficult, although more tractable than the other alignment coordination problem, because there's less of a unilateralist problem. The unilateralist problem still exists to some extent: orgs which prioritize alignment are inherently at a disadvantage compared to orgs that don't, because capabilities progress feeds recursively into faster progress whereas alignment progress is less effective at making future alignment progress faster. However, on the relevant timescales this may become less important.
- I think alignment is a very difficult problem, and that moreover by its nature it's incredibly easy to underestimate. I should probably write a full post about my take on this at some point, and I don't really have space here to really dive into it here, but a quick meta level argument for why we shouldn't lean on alignment easiness even if there is a non negligible chance of easiness is that a) given the stakes, we should exercise extreme caution and b) there are very few problems we have that are in the same reference class as alignment, and of the few that are even close, like computer security, they don't inspire a lot of confidence.
I think exploring the potential model violations further is a fruitful direction. I don't think I'm very confident about this model.
comment by leogao · 2025-04-09T08:31:48.148Z · LW(p) · GW(p)
i find it disappointing that a lot of people believe things about trading that are obviously crazy even if you only believe in a very weak form of the EMH. for example, technical analysis is obviously tea leaf reading - if it were predictive whatsoever, you could make a lot of money by exploiting it until it is no longer predictive.
Replies from: lc, alexander-gietelink-oldenziel, kh↑ comment by lc · 2025-04-09T16:09:29.221Z · LW(p) · GW(p)
Close friend of mine, a regular software engineer, recently threw tens of thousands of dollars - a sizable chunk of his yearly salary - at futures contracts on some absurd theory about the Japanese Yen. Over the last few weeks, he coinflipped his money into half a million dollars. Everyone who knows him was begging him to pull out and use the money to buy a house or something. But of course yesterday he sold his futures contracts and bought into 0DTE Nasdaq options on another theory, and literally lost everything he put in and then some. I'm not sure but I think he's down about half his yearly salary overall.
He has been doing this kind of thing for the last two years or so - not just making investments, but making the most absurd, high risk investments you can think of. Every time he comes up with a new trade, he has a story for me about how his cousin/whatever who's a commodities trader recommended the trade to him, or about how a geopolitical event is gonna spike the stock of Lockheed Martin, or something. On many occasions I have attempted to explain some kind of Inadequate Equilibria thesis to him, but it just doesn't seem to "stick".
It's not that he "rejects" the EMH in these conversations. I think for a lot of people there is literally no slot in their mind that is able to hold market efficiency/inefficiency arguments. They just see stocks moving up and down. Sometimes the stocks move in response to legible events. They think, this is a tractable problem, I just have to predict the legible events. How could I be unable to make money? Those guys from The Big Short did!
He is also taking a large amount of stimulants. I think that is compounding the situation a bit.
↑ comment by Alexander Gietelink Oldenziel (alexander-gietelink-oldenziel) · 2025-04-09T13:24:16.127Z · LW(p) · GW(p)
the steelman is that quants do the version of technical analysis that works - they disprove the EMH proportional to quant salaries.
↑ comment by Kaarel (kh) · 2025-04-09T12:20:33.822Z · LW(p) · GW(p)
i agree that most people doing "technical analysis" are doing nonsense and any particular well-known simple method does not actually work. but also clearly a very good predictor could make a lot of money just looking at the past price time series anyway
comment by leogao · 2024-12-28T08:58:58.290Z · LW(p) · GW(p)
i think it's quite valuable to go through your key beliefs and work through what the implications would be if they were false. this has several benefits:
- picturing a possible world where your key belief is wrong makes it feel more tangible and so you become more emotionally prepared to accept it.
- if you ever do find out that the belief is wrong, you don't flinch away as strongly because it doesn't feel like you will be completely epistemically lost the moment you remove the Key Belief
- you will have more productive conversations with people who disagree with you on the Key Belief
- you might discover strategies that are robustly good whether or not the Key Belief is true
- you will become better at designing experiments to test whether the Key Belief is true
↑ comment by Daniel Tan (dtch1997) · 2024-12-28T09:22:07.580Z · LW(p) · GW(p)
what are some of your key beliefs and what were the implications if they were false?
Replies from: leogao↑ comment by leogao · 2024-12-28T09:49:27.335Z · LW(p) · GW(p)
some concrete examples
- "agi happens almost certainly within in the next few decades" -> maybe ai progress just kind of plateaus for a few decades, it turns out that gpqa/codeforces etc are like chess in that we only think they're hard because humans who can do them are smart but they aren't agi-complete, ai gets used in a bunch of places in the economy but it's more like smartphones or something. in this world i should be taking normie life advice a lot more seriously.
- "agi doesn't happen in the next 2 years" -> maybe actually scaling current techniques is all you need. gpqa/codeforces actually do just measure intelligence. within like half a year, ML researchers start being way more productive because lots of their job is automated. if i use current/near-future ai agents for my research, i will actually just be more productive.
- "alignment is hard" -> maybe basic techniques is all you need, because natural abstractions is true, or maybe the red car / blue car argument for why useful models are also competent at bad things is just wrong because generalization can be made to suck. maybe all the capabilities people are just right and it's not reckless to be building agi so fast
↑ comment by Viliam · 2025-01-08T21:49:16.953Z · LW(p) · GW(p)
Making a list of your beliefs can be complicated. Recognizing the belief as a "belief" is the necessary first step, but the strongest beliefs (those that examining them would be most useful?) are probably transparent, they feel like "just how the world is".
Then again, maybe listing all the strong beliefs would actually be useless, because the list would contain tons of things like "I believe that 2+2=4", and examining those would be mostly a waste of time. We want the beliefs that are strong but possibly wrong. But when you notice that they are "possibly wrong", you have already made the most difficult step; the question is how to get there.
comment by leogao · 2024-08-13T01:42:22.929Z · LW(p) · GW(p)
economic recession and subsequent reduction in speculative research, including towards AGI, seems very plausible
AI (by which I mean, like, big neural networks and whatever) is not that economically useful right now. furthermore, current usage figures are likely an overestimate of true economic usefulness because a very large fraction of it is likely to be bubbly spending that will itself dry up if there is a recession (legacy companies putting LLMs into things to be cool, startups that are burning money without PMF, consumers with disposable income to spend on entertainment).
it will probably still be profitable to develop AI tech, but things will be much more tethered to consumer usefulness.
this probably doesn't set AGI back that much but I think people are heavily underrating this as a possibility. it also probably heavily impacts the amount of alignment work done at labs.
Replies from: leogao, Raemon↑ comment by leogao · 2024-08-13T02:01:45.159Z · LW(p) · GW(p)
for a sense of scale of just how bubbly things can get: Bitcoin has a market cap of ~1T, and the entirety of crypto ~2T. Crypto does produce some amount of real value, but probably on the order of magnitude of 1% that market cap. So it's not at all unheard of for speculation to account for literally trillions of dollars of map (or ~tens of billions of earnings per year, at a reasonable P/E ratio)
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2024-08-13T17:25:07.881Z · LW(p) · GW(p)
I will say that crypto is a pretty pathological case where virtually all the benefit is speculation, because in order to deliver on anything real, they'd have to get rid of the money element in it, it's thankfully pretty rare for entire industries to be outright scams/speculation opportunities.
comment by leogao · 2023-03-07T16:56:25.885Z · LW(p) · GW(p)
one man's modus tollens is another man's modus ponens:
"making progress without empirical feedback loops is really hard, so we should get feedback loops where possible" "in some cases (i.e close to x-risk), building feedback loops is not possible, so we need to figure out how to make progress without empirical feedback loops. this is (part of) why alignment is hard"
Replies from: Raemon, lahwran↑ comment by Raemon · 2023-03-10T22:03:50.462Z · LW(p) · GW(p)
Yeah something in this space seems like a central crux to me.
I personally think (as a person generally in the MIRI-ish camp of "most attempts at empirical work are flawed/confused"), that it's not crazy to look at the situation and say "okay, but, theoretical progress seems even more flawed/confused, we just need to figure out some how of getting empirical feedback loops."
I think there are some constraints on how the empirical work can possibly work. (I don't think I have a short thing I could write here, I have a vague hope of writing up a longer post on "what I think needs to be true, for empirical work to be helping rather than confusedly not-really-helping")
↑ comment by the gears to ascension (lahwran) · 2023-03-10T22:16:12.200Z · LW(p) · GW(p)
you gain general logical facts from empirical work, which can aide providing a blurry image of the manifold that the precise theoretical work is trying to build an exact representation of
comment by leogao · 2023-02-12T04:34:51.821Z · LW(p) · GW(p)
A common cycle:
- This model is too oversimplified! Reality is more complex than this model suggests, making it less useful in practice. We should really be taking these into account. [optional: include jabs at outgroup]
- This model is too complex! It takes into account a bunch of unimportant things, making it much harder to use in practice. We should use this simplified model instead. [optional: include jabs at outgroup]
Sometimes this even results in better models over time.
comment by leogao · 2024-12-25T01:57:05.675Z · LW(p) · GW(p)
the world is too big and confusing, so to get anything done (and to stay sane) you have to adopt a frame. each frame abstracts away a ton about the world, out of necessity. every frame is wrong, but some are useful. a frame comes with a set of beliefs about the world and a mechanism for updating those beliefs.
some frames contain within them the ability to become more correct without needing to discard the frame entirely; they are calibrated about and admit what they don't know. they change gradually as we learn more. other frames work empirically but are a dead end epistemologically because they aren't willing to admit some of their false claims. for example, many woo frames capture a grain of truth that works empirically, but come with a flawed epistemology that prevents them from generating novel and true insights.
often it is better to be confined inside a well trodden frame than to be fully unconstrained. the space of all possible actions is huge, and many of them are terrible. on the other hand, staying inside well trodden frames forever substantially limits the possibility of doing something extremely novel
Replies from: Vladimir_Nesov, leogao, quetzal_rainbow↑ comment by Vladimir_Nesov · 2024-12-25T15:09:58.306Z · LW(p) · GW(p)
It's as efficient to work on many frames while easily switching between them. Some will be poorly developed, but won't require commitment and can anchor curiosity, progress on blind spots of other frames.
↑ comment by quetzal_rainbow · 2024-12-25T15:23:59.850Z · LW(p) · GW(p)
"...you learn that there's three kinds of intellectuals. There's intellectuals that work in one frame. There's intellectuals that work in two frames. And there's intellectuals that change frames like you and I change clothes."
comment by leogao · 2023-11-26T12:40:08.198Z · LW(p) · GW(p)
for something to be a good way of learning, the following criteria have to be met:
- tight feedback loops
- transfer of knowledge to your ultimate goal
- sufficiently interesting that it doesn't feel like a grind
trying to do the thing you care about directly hits 2 but can fail 1 and 3. many things that you can study hit 1 but fail 2 and 3. and of course, many fun games hit 3 (and sometimes 1) but fail to hit 2.
Replies from: leogao↑ comment by leogao · 2023-11-26T12:41:01.170Z · LW(p) · GW(p)
corollary: for things with very long feedback loops, or where you aren't motivated by default, it can be faster for learning to do something that is actually not directly the thing you care about
Replies from: Viliam↑ comment by Viliam · 2023-11-27T07:59:34.757Z · LW(p) · GW(p)
This is basically math (and computer science) education. On one hand, some parts are probably not very useful. On the other hand, some people expect that teachers will defend every single step along the way by explaining how specifically this tiny atom of knowledge improves the student's future life. No, I am not preparing a PowerPoint presentation on how knowing that addition is associative and commutative will make you rich one day.
Replies from: leogao↑ comment by leogao · 2023-11-27T10:57:30.563Z · LW(p) · GW(p)
funnily enough, my experience has been almost entirely from the other direction - almost everything I know is from working directly on things I care about, and very little is from study. one of the reasons behind this shortform was trying to untangle why people spend lots of time studying stuff and whether/when it makes sense for me to study vs simply to learn by doing
Replies from: Viliam↑ comment by Viliam · 2023-11-27T12:28:54.981Z · LW(p) · GW(p)
I think it is good to use your goals as a general motivation for going approximately in some direction, but the opposite extreme of obsessing whether every single detail you learn contributes to the goal is premature optimization.
It reminds me of companies where, before you are allowed to spend 1 hour doing something, the entire team first needs to spend 10 hours in various meetings to determine whether that 1 hour would be spent optimally. I would rather spend all that time doing things, even if some of them turn out to be ultimately useless.
Sometimes it's not even obvious in advance which knowledge will turn out to be useful.
comment by leogao · 2023-11-16T23:09:51.161Z · LW(p) · GW(p)
lifehack: buying 3 cheap pocket sized battery packs costs like $60 and basically eliminates the problem of running out of phone charge on the go. it's much easier to remember to charge them because you can instantaneously exchange your empty battery pack for a full one when you realize you need one, plugging the empty battery pack happens exactly when you swap for a fresh one, and even if you forget once or lose one you have some slack
comment by leogao · 2025-01-25T04:45:36.218Z · LW(p) · GW(p)
a thriving culture is a mark of a healthy and intellectually productive community / information ecosystem. it's really hard to fake this. when people try, it usually comes off weird. for example, when people try to forcibly create internal company culture, it often comes off as very cringe.
comment by leogao · 2024-12-28T08:38:55.606Z · LW(p) · GW(p)
there are two different modes of learning i've noticed.
- top down: first you learn to use something very complex and abstract. over time, you run into weird cases where things don't behave how you'd expect, or you feel like you're not able to apply the abstraction to new situations as well as you'd like. so you crack open the box and look at the innards and see a bunch of gears and smaller simpler boxes, and it suddenly becomes clear to you why some of those weird behaviors happened - clearly it was box X interacting with gear Y! satisfied, you use your newfound knowledge to build something even more impressive than you could before. eventually, the cycle repeats, and you crack open the smaller boxes to find even smaller boxes, etc.
- bottom up: you learn about the 7 Fundamental Atoms of Thingism. you construct the simplest non-atomic thing, and then the second simplest non atomic thing. after many painstaking steps of work, you finally construct something that might be useful. then you repeat the process anew for every other thing you might ever find useful. and then you actually use those things to do something
generally, i'm a big fan of top down learning, because everything you do comes with a source of motivation for why you want to do the thing; bottom up learning often doesn't give you enough motivation to care about the atoms. but also, bottom up learning gives you a much more complete understanding.
Replies from: dtch1997↑ comment by Daniel Tan (dtch1997) · 2024-12-28T09:26:53.520Z · LW(p) · GW(p)
Seems to strongly echo Karpathy, in that top-down learning is most effective for building expertise
https://x.com/karpathy/status/1325154823856033793?s=46&t=iz509DJpCAibJadbMh4TvQ
comment by leogao · 2023-02-20T01:34:09.233Z · LW(p) · GW(p)
Corollary to Others are wrong != I am right (https://www.lesswrong.com/posts/4QemtxDFaGXyGSrGD/other-people-are-wrong-vs-i-am-right [LW · GW]): It is far easier to convince me that I'm wrong than to convince me that you're right.
Replies from: JBlack↑ comment by JBlack · 2023-02-21T01:10:52.234Z · LW(p) · GW(p)
Quite a large proportion of my 1:1 arguments start when I express some low expectation of the other person's argument being correct. This is almost always taken to mean that I believe that some opposing conclusion is correct. Usually I have to give up before being able to successfully communicate the distinction, let alone addressing the actual disagreement.
comment by leogao · 2023-12-17T07:17:55.965Z · LW(p) · GW(p)
current understanding of optimization
- high curvature directions (hessian eigenvectors with high eigenvalue) want small lrs. low curvature directions want big lrs
- if the lr in a direction is too small, it takes forever to converge. if the lr is too big, it diverges by oscillating with increasing amplitude
- momentum helps because if your lr is too small, it makes you move a bit faster. if your lr is too big, it causes the oscillations to cancel out with themselves. this makes high curvature directions more ok with larger lrs and low curvature directions more ok with smaller lrs, improving conditioning
- high curvature directions also have bigger gradients. this is the opposite of what we want because in a perfect world higher curvature directions would have smaller gradients (natural gradient does this but it's usually too expensive). adam second moment / rmsprop helps because it makes gradients stay exactly the same size when the direction gets bigger, which is sorta halfway right
- applied per param rather than per eigenvector
- in real NNs edge of stability means it's actually even more fine to have a too-high lr: the max curvature increases throughout training until it gets to the critical point where it would diverge, but then instead of diverging all the way the oscillations along the top eigenvector somehow cause the model to move into a slightly lower curvature region again, so that it stabilizes right at the edge of stability.
- for Adam, these oscillations also cause second moment increases, which decreases preconditioned max curvature without affecting the original curvature. so this means the original max curvature can just keep increasing for Adam whereas it doesn't for SGD (though apparently there's some region where it jumps into a region with low original max curvature too)
papers
- https://distill.pub/2017/momentum/ really cool momentum explainer
- https://arxiv.org/abs/2103.00065 - edge of stability
- https://arxiv.org/abs/2207.14484 - edge of stability for adam
↑ comment by RHollerith (rhollerith_dot_com) · 2023-12-17T20:16:53.626Z · LW(p) · GW(p)
What does "the lr" mean in this context?
Replies from: leogaocomment by leogao · 2023-02-18T22:37:05.171Z · LW(p) · GW(p)
Some aspirational personal epistemic rules for keeping discussions as truth seeking as possible (not at all novel whatsoever, I'm sure there exist 5 posts on every single one of these points that are more eloquent)
- If I am arguing for a position, I must be open to the possibility that my interlocutor may turn out to be correct. (This does not mean that I should expect to be correct exactly 50% of the time, but it does mean that if I feel like I'm never wrong in discussions then that's a warning sign: I'm either being epistemically unhealthy or I'm talking to the wrong crowd.)
- If I become confident that I was previously incorrect about a belief, I should not be attached to my previous beliefs. I should not incorporate my beliefs into my identity. I should not be averse to evidence that may prove me wrong. I should always entertain the possibility that even things that feel obviously true to me may be wrong.
- If I convince someone to change their mind, I should avoid say things like "I told you so", or otherwise try to score status points out of it.
I think in practice I adhere closer to these principles than most people, but I definitely don't think I'm perfect at it.
(Sidenote: it seems I tend to voice my disagreement on factual things far more often (though not maximally) compared to most people. I'm slightly worried that people will interpret this as me disliking them or being passive aggressive or something - this is typically not the case! I have big disagreements about the-way-the-world-is with a bunch of my closest friends and I think that's a good thing! If anything I gravitate towards people I can have interesting disagreements with.)
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2023-02-18T23:17:25.283Z · LW(p) · GW(p)
I should always entertain the possibility that even things that feel obviously true to me may be wrong.
I find it a helpful framing to instead allow things that feel obviously false to become more familiar, giving them the opportunity to develop a strong enough voice to explain how they are right. That is, the action is on the side of unfamiliar false things, clarifying their meaning and justification, rather than on the side of familiar true things, refuting their correctness. It's harder to break out of a familiar narrative from within.
comment by leogao · 2023-12-18T05:37:13.846Z · LW(p) · GW(p)
hypothesis: the kind of reasoning that causes ML people to say "we have made no progress towards AGI whatsoever" is closely analogous to the kind of reasoning that makes alignment people say "we have made no progress towards hard alignment whatsoever"
ML people see stuff like GPT4 and correctly notice that it's in fact kind of dumb and bad at generalization in the same ways that ML always has been. they make an incorrect extrapolation, which is that AGI must therefore be 100 years away, rather than 10 years away
high p(doom) alignment people see current model alignment techniques and correctly notice that they fail to tackle the AGI alignment problem in the same way that alignment techniques always have. they make an incorrect extrapolation and conclude that p(doom) = 0.99, rather than 0.5
(there is an asymmetry which is that overconfidence that alignment will be solved is much more dangerous than overconfidence that AGI will be solved)
Replies from: quetzal_rainbow↑ comment by quetzal_rainbow · 2023-12-18T08:22:38.118Z · LW(p) · GW(p)
It's differential progress that matters in alignment. I.e., if you expected that we need additional year of alignment research after creating AGI, it still looks pretty doomed, even if you admit overall progress in field.
Replies from: leogaocomment by leogao · 2023-04-15T07:10:38.765Z · LW(p) · GW(p)
takes on takeoff (or: Why Aren't The Models Mesaoptimizer-y Yet)
here are some reasons we might care about discontinuities:
- alignment techniques that apply before the discontinuity may stop applying after / become much less effective
- makes it harder to do alignment research before the discontinuity that transfers to after the discontinuity (because there is something qualitatively different after the jump)
- second order effect: may result in false sense of security
- there may be less/negative time between a warning shot and the End
- harder to coordinate and slow down
- harder to know when the End Times are coming
- alignment techniques that rely on systems supervising slightly smarter systems (i.e RRM) depend on there not being a big jump in capabilities
I think these capture 90% of what I care about when talking about fast/slow takeoff, with the first point taking up a majority
(it comes up a lot in discussions that it seems like I can't quite pin down exactly what my interlocutor's beliefs on fastness/slowness imply. if we can fully list out all the things we care about, we can screen off any disagreement about definitions of the word "discontinuity")
some things that seem probably true to me and which are probably not really cruxes:
- there will probably be a pretty big amount of AI-caused economic value and even more investment into AI, and AGI in particular (not really a bold prediction, given the already pretty big amount of these things! but a decade ago it may have been plausible nobody would care about AGI until the End Times, and this appears not to be the case)
- continuous changes of inputs like compute or investment or loss (not technically an input, but whatever) can result in discontinuous jumps in some downstream metric (accuracy on some task, number of worlds paperclipped)
- almost every idea is in some sense built on some previous idea, but this is not very useful because there exist many ideas [citation needed] and it's hard to tell which ones will be built on to create the idea that actually works (something something hindsight bias). this means you can't reason about how they will change alignment properties, or use them as a warning shot
possible sources of discontinuity:
- breakthroughs: at some point, some group discovers a brand new technique that nobody had ever thought of before / nobody had made work before because they were doing it wrong in some way / "3 hackers in a basement invent AGI"
- depends on how efficient you think the research market is. I feel very uncertain about this
- importantly I think cruxes here may result in other predictions about how efficient the world is generally, in ways unrelated to AI, and which may make predictions before the End Times
- seems like a subcrux of this is whether the new technique immediately works very well or if it takes a nontrivial amount of time to scale it up to working at SOTA scale
- overdetermined "breakthroughs": some technique that didn't work (and couldn't have been made to work) at smaller scales starts working at larger scales. lots of people independently would have tried the thing
- importantly, under this scenario it's possible for something to simultaneously (a) be very overdetermined (b) have very different alignment properties
- very hard to know which of the many ideas that don't work might be the one that suddenly starts working with a few more OOMs of compute
- at some scale, there is just some kind of grokking without any change in techniques, and the internal structure and generalization properties of the networks changes a lot. trends break because of some deep change in the structure of the network
- mostly isomorphic to the previous scenario actually
- for example, in worlds where deceptive alignment happens because at x params suddenly it groks to mesaoptimizer-y structure and the generalization properties completely change
- at some scale, there is "enough" to hit some criticality threshold of some kind of thing the model already has. the downstream behavior changes a lot but the internal structure doesn't change much beyond the threshold. importantly while obviously some alignment strategies would break, there are potentially invariants that we can hold onto
- for example, in worlds where deceptive alignment happens because of ontology mismatch and ontologies get slowly more mismatched with scale, and then past some threshold it snaps over to the deceptive generalization
I think these can be boiled down to 3 more succinct scenario descriptions:
- breakthroughs that totally change the game unexpectedly
- mechanistically different cognition suddenly working at scale
- more of the same cognition is different
comment by leogao · 2023-03-24T23:40:31.236Z · LW(p) · GW(p)
The following things are not the same:
- Schemes for taking multiple unaligned AIs and trying to build an aligned system out of the whole
- I think this is just not possible.
- Schemes for taking aligned but less powerful AIs and leveraging them to align a more powerful AI (possibly with amplification involved)
- This breaks if there are cases where supervising is harder than generating, or if there is a discontinuity. I think it's plausible something like this could work but I'm not super convinced.
comment by leogao · 2022-10-16T18:33:24.437Z · LW(p) · GW(p)
In the spirit of https://www.lesswrong.com/posts/fFY2HeC9i2Tx8FEnK/my-resentful-story-of-becoming-a-medical-miracle [LW · GW] , some anecdotes about things I have tried, in the hopes that I can be someone else's "one guy on a message board. None of this is medical advice, etc.
- No noticeable effects from vitamin D (both with and without K2), even though I used to live somewhere where the sun barely shines and also I never went outside, so I was almost certainly deficient.
- I tried Selenium (200mg) twice and both times I felt like utter shit the next day.
- Glycine (2g) for some odd reason makes me energetic, which makes it really bad as a sleep aid. 1g taken a few hours before bedtime is substantially less disruptive to sleep, but I haven't noticed substantial improvements.
- Unlike oral phenylephrine, intranasal phenylephrine does things, albeit very temporarily, and is undeniably the most effective thing I've tried, though apparently you're not supposed to use it too often, so I only use it when it gets really bad.
comment by leogao · 2025-04-07T07:44:44.389Z · LW(p) · GW(p)
I wonder how many supposedly consistently successful retail traders are actually just picking up pennies in front of the steamroller, and would eventually lose it all if they kept at it long enough.
also I wonder how many people have runs of very good performance interspersed by big losses, such that the overall net gains are relatively modest, but psychologically they only remember/recount the runs of good performance, whereas the losses were just bad luck and will be avoided next time.
comment by leogao · 2024-10-25T18:19:11.751Z · LW(p) · GW(p)
for a sufficiently competent policy, the fact that BoN doesn't update the policy doesn't mean it leaks any fewer bits of info to the policy than normal RL
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2024-10-25T18:26:26.162Z · LW(p) · GW(p)
Something between training the whole model with RL and BoN is training just the last few layers of the model (for current architectures) with RL and then doing BoN on top as needed to increase performance. This means most of the model won't know the information (except insofar as the info shows up in outputs) and allows you to get some of the runtime cost reductions of using RL rather than BoN.
Replies from: leogao↑ comment by leogao · 2024-10-25T18:28:34.823Z · LW(p) · GW(p)
I'm claiming that even if you go all the way to BoN, it still doesn't necessarily leak less info to the morel
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2024-10-25T20:42:13.149Z · LW(p) · GW(p)
Oh huh, parse error on me.
comment by leogao · 2024-10-21T07:02:02.675Z · LW(p) · GW(p)
aiming directly for achieving some goal is not always the most effective way of achieving that goal.
Replies from: MakoYass, Political Therapy↑ comment by mako yass (MakoYass) · 2024-10-21T09:25:34.016Z · LW(p) · GW(p)
You should be more curious about why, when you aim at a goal, you do not aim for the most effective way.
↑ comment by Political Therapy · 2024-10-23T04:15:06.053Z · LW(p) · GW(p)
What do you believe, then, is the most effective way of achieving a goal?
comment by leogao · 2024-10-04T08:59:04.259Z · LW(p) · GW(p)
people love to find patterns in things. sometimes this manifests as mysticism- trying to find patterns where they don't exist, insisting that things are not coincidences when they totally just are. i think a weaker version of this kind of thinking shows up a lot in e.g literature too- events occur not because of the bubbling randomness of reality, but rather carry symbolic significance for the plot. things don't just randomly happen without deeper meaning.
some people are much more likely to think in this way than others. rationalists are very far along the spectrum in the "things just kinda happen randomly a lot, they don't have to be meaningful" direction.
there are some obvious cognitive bias explanations for why people would see meaning/patterns in things. most notably, it's comforting to feel like we understand things. the idea of the world being deeply random and things just happening for no good reason is scary.
but i claim that there is something else going on here. I think an inclination towards finding latent meaning is actually quite applicable when thinking about people. people's actions are often driven by unconscious drives to be quite strongly correlated with those drives. in fact, unconscious thoughts are often the true drivers, and the conscious thoughts are just the rationalization. but from the inside, it doesn't feel that way; from the inside it feels like having free will, and everything that is not a result of conscious thought is random or coincidental. this is a property that is not nearly as true of technical pursuits, so it's very reasonable to expect a different kind of reasoning to be ideal.
not only is this useful for modelling other people, but it's even more useful for modelling yourself. things only come to your attention if your unconscious brain decides to bring them to your attention. so even though something happening to you may be a coincidence, whether you focus on it or forget about it tells you a lot about what your unconscious brain is thinking. from the inside, this feels like things that should obviously be coincidence nonetheless having some meaning behind them. even the noticing of a hypothesis for the coincidence is itself a signal from your unconscious brain.
I don't quite know what the right balance is. on the one hand, it's easy to become completely untethered from reality by taking this kind of thing too seriously and becoming superstitious. on the other hand, this also seems like an important way of thinking about the world that is easy for people like me (and probably lots of people on LW) to underappreciate.
comment by leogao · 2023-11-04T22:50:25.094Z · LW(p) · GW(p)
it is often claimed that merely passively absorbing information is not sufficient for learning, but rather some amount of intentional learning is needed. I think this is true in general. however, one interesting benefit of passively absorbing information is that you notice some concepts/terms/areas come up more often than others. this is useful because there's simply too much stuff out there to learn, and some knowledge is a lot more useful than other knowledge. noticing which kinds of things come up often is therefore useful for prioritization. I often notice that my motivational system really likes to use this heuristic for deciding how motivated to be while learning something.
Replies from: andreas-chrysopoulos↑ comment by Andreas Chrysopoulos (andreas-chrysopoulos) · 2023-11-05T14:53:28.099Z · LW(p) · GW(p)
I think it might also depend on your goals. Like how fast you want to learn something. If you have less than ideal time, then maybe more structured learning is necessary. If you have more time then periods of structureless/passive learning could be beneficial.
comment by leogao · 2023-04-09T17:03:06.948Z · LW(p) · GW(p)
a claim I've been saying irl for a while but have never gotten around to writing up: current LLMs are benign not because of the language modelling objective, but because of the generalization properties of current NNs (or to be more precise, the lack thereof). with better generalization LLMs are dangerous too. we can also notice that RL policies are benign in the same ways, which should not be the case if the objective was the core reason. one thing that can go wrong with this assumption is thinking about LLMs that are both extremely good at generalizing (especially to superhuman capabilities) and simultaneously assuming they continue to have the same safety properties. afaict something like CPM avoids this failure mode of reasoning, but lots of arguments don't
Replies from: Daniel Paleka↑ comment by Daniel Paleka · 2023-04-09T20:00:53.705Z · LW(p) · GW(p)
what is the "language models are benign because of the language modeling objective" take?
Replies from: leogaocomment by leogao · 2023-04-09T15:52:09.312Z · LW(p) · GW(p)
Schmidhubering the agentic LLM stuff pretty hard https://leogao.dev/2020/08/17/Building-AGI-Using-Language-Models/
Replies from: niplav
comment by leogao · 2024-12-24T22:51:03.868Z · LW(p) · GW(p)
the financial industry is a machine that lets you transmute a dollar into a reliable stream of ~4 cents a year ~forever (or vice versa). also, it gives you a risk knob you can turn that increases the expected value of the stream, but also the variance (or vice versa; you can take your risky stream and pay the financial industry to convert it into a reliable stream or lump sum)
comment by leogao · 2023-11-05T00:39:04.728Z · LW(p) · GW(p)
an interesting fact that I notice is that in domains where there are are a lot of objects in consideration, those objects have some structure so that they can be classified, and how often those objects occur follows a power law or something, there are two very different frames that get used to think about that domain:
- a bucket of atomic, structureless objects with unique properties where facts about one object don't really generalize at all to any other object
- a systematized, hierarchy or composition of properties or "periodic table" or full grid or objects defined by the properties they have in some framework
and a lot of interesting things happen when these collide or cooccur, or when shifting from one to the other
I know my description above is really abstract, so here are a bunch of concrete examples that all gesture at the same vibe:
basically all languages have systematic rules in general but special cases around the words that people use very often. this happens too often in unrelated languages to be a coincidence, and as a native/fluent speaker it always feels very natural but as a language learner it's very confusing. for example, for languages with conjugations, a few of the most common verbs are almost always irregular. e.g [to be, am, is, are, was, were] (english), [sein, bin, ist, war, sind] (german), [être, suis, est, était, sont] (french); small counting numbers are often irregular [first, second, third], [两个], [premier], [ひとつ、ふたつ、みっつ]. my theory for why this makes sense to natives but not to language learners is that language learners learn things systematically from the beginning, and in particular don't deal with the true distribution of language usage but rather an artificially flat one designed to capture all the language features roughly equally.
often, when there is a systematic way of naming things, the things that are most common will have special names/nicknames (eg IUPAC names vs common names). sometimes this happens because those things were discovered first before the systematization happened, and the once the systematization happens everyone is still used to the old names for some things. but also even if you start with the systematized thing, often people will create nicknames after the fact.
it often happens that we write software tools for a specific problem, and then later realize that that problem is a special case of a more general problem. often going more general is good because it means we can use the same code to do a wider range of things (which means less bugs, more code reuse, more elegant code). however, the more general/abstract code is often slightly clunkier to use for the common case, so often it makes sense to drop down a level of abstraction if the goal is to quickly hack something together.
when compressing some distribution of strings, the vast majority of the possible but unlikely strings can be stored basically verbatim with a flag and it is very easy to tell properties of the string by looking at the compressed representation; whereas for the most common strings they have to map to short strings that destroy all structure of the data without the decompressor. though note that not all the examples can be described as instances of compression exactly
sometimes, there's friction between people who are using the systematizing and people who are doing the atomic concepts thing. the systematizer comes off as nitpicky, pedantic, and removed from reality to the atomic concepts person, and the atomic concepts person comes off as unrigorous, uncosmopolitan, and missing the big picture to the systematizer.
I think the concept of zero only being invented long after the other numbers is also an instance of this - in some sense for basic everyday usage in counting things, the existence of zero is a weird technicality, and I could imagine someone saying "well sure yes there is a number that comes before zero, but it's not useful for anything, so it's not worth considering". I think a lot of math (eg abstract algebra) is the result of applying truly enormous amounts of this kind of systematizing
I think this also sort of has some handwavy analogies to superposition vs composition.
if there is an existing name for the thing I'm pointing at, I would be interested in knowing.
comment by leogao · 2022-12-31T18:47:43.295Z · LW(p) · GW(p)
House rules for definitional disputes:
- If it ever becomes a point of dispute in an object level discussion what a word means, you should either use a commonly accepted definition, or taboo the term if the participants think those definitions are bad for the context of the current discussion. (If the conversation participants are comfortable with it, the new term can occupy the same namespace as the old tabooed term (i.e going forward, we all agree that the definition of X is Y for the purposes of this conversation, and all other definitions no longer apply))
- If any of the conversation participants want to switch to the separate discussion of "which definition of X is the best/most useful/etc", this is fine if all the other participants are fine as well. However, this has to be explicitly announced as a change in topic from the original object level discussion.
comment by leogao · 2022-06-03T06:32:41.990Z · LW(p) · GW(p)
A few axes along which to classify optimizers:
- Competence: An optimizer is more competent if it achieves the objective more frequently on distribution
- Capabilities Robustness: An optimizer is more capabilities robust if it can handle a broader range of OOD world states (and thus possible pertubations) competently.
- Generality: An optimizer is more general if it can represent and achieve a broader range of different objectives
- Real-world objectives: whether the optimizer is capable of having objectives about things in the real world.
Some observations: it feels like capabilities robustness is one of the big things that makes deception dangerous, because it means that the model can figure out plans that you never intended for it to learn (something not very capabilities robust would just never learn how to deceive if you don't show it). This feels like the critical controller/search-process difference: controller generalization across states is dependent on the generalization abilities of the model architecture, whereas search processes let you think about the particular state you find yourself in. The actions that lead to deception are extremely OOD, and a controller would have a hard time executing the strategy reliably without first having seen it, unless NN generalization is wildly better than I'm anticipating.
Real world objectives is definitely another big chunk of deception danger; caring about the real world leads to nonmyopic behavior (though maybe we're worried about other causes of nonmyopia too? not sure tbh), I'm actually not sure how I feel about generality: on the one hand, it feels intuitive that systems that are only able to represent one objective have got to be in some sense less able to become more powerful just by thinking more; on the other hand I don't know what a rigorous argument for this would look like. I think the intuition relates to the idea of general reasoning machinery being the same across lots of tasks, and this machinery being necessary to do better by thinking harder, and so any model without this machinery must be weaker in some sense. I think this feeds into capabilities robustness (or lack thereof) too.
Examples of where things fall on these axes:
- A rock would be none of the properties.
- A pure controller (i.e a thermostat, "pile of heuristics") can be competent, but not as capabilities robust, not general at all, and have objectives over the real world.
- An analytic equation solver would be perfectly competent and capablilities robust (if it always works), not very general (it can only solve equations), and not be capable of having real world objectives.
- A search based process can be competent, would be more capabilities robust and general, and may have objectives over the real world.
- A deceptive optimizer is competent, capabilities robust, and definitely has real world objectives
↑ comment by leogao · 2022-06-03T19:56:41.789Z · LW(p) · GW(p)
Another generator-discriminator gap: telling whether an outcome is good (outcome->R) is much easier than coming up with plans to achieve good outcomes. Telling whether a plan is good (plan->R) is much harder, because you need a world model (plan->outcome) as well, but for very difficult tasks it still seems easier than just coming up with good plans off the bat. However, it feels like the world model is the hardest part here, not just because of embeddedness problems, but in general because knowing the consequences of your actions is really really hard. So it seems like for most consequentialist optimizers, the quality of the world model actually becomes the main thing that matters.
This also suggests another dimension along which to classify our optimizers: the degree to which they care about consequences in the future (I want to say myopia but that term is already way too overloaded). This is relevant because the further in the future you care about, the more robust your world model has to be, as errors accumulate the more steps you roll the model out (or the more abstraction you do along the time axis). Very low confidence but maybe this suggests that mesaoptimizers probably won't care about things very far in the future because building a robust world model is hard and so perform worse on the training distribution, so SGD pushes for more myopic mesaobjectives? Though note, this kind of myopia is not quite the kind we need for models to avoid caring about the real world/coordinating with itself.
comment by leogao · 2022-05-24T20:08:33.330Z · LW(p) · GW(p)
A thought pattern that I've noticed myself and others falling into sometimes: Sometimes I will make arguments about things from first principles that look something like "I don't see any way X can be true, it clearly follows from [premises] that X is definitely false", even though there are people who believe X is true. When this happens, it's almost always unproductive to continue to argue on first principles, but rather I should do one of: a) try to better understand the argument and find a more specific crux to disagree on or b) decide that this topic isn't worth investing more time in, register it as "not sure if X is true" in my mind, and move on.
Replies from: Dagon↑ comment by Dagon · 2022-05-24T20:30:33.984Z · LW(p) · GW(p)
For many such questions, "is X true" is the wrong question. This is common when X isn't a testable proposition, it's a model or assertion of causal weight. If you can't think of existence proofs that would confirm it, try to reframe as "under what conditions is X a useful model?".
comment by leogao · 2023-11-04T23:22:20.353Z · LW(p) · GW(p)
there are policies which are successful because they describe a particular strategy to follow (non-mesaoptimizers), and policies that contain some strategy for discovering more strategies (mesaoptimizers). a way to view the relation this has to speed/complexity priors that doesn't depend on search in particular is that policies that work by discovering strategies tend to be simpler and more generic (they bake in very little domain knowledge/metis, and are applicable to a broader set of situations because they work by coming up with a strategy for the task at hand on the fly). in contrast, policies that work by knowing a specific strategy tend to be more complex because they have to bake in a ton of domain knowledge, are less generally useful because they specifically know what to do in that situation, and thereby are also less retargetable)
Replies from: leogao, leogao↑ comment by leogao · 2023-11-04T23:31:28.093Z · LW(p) · GW(p)
another observation is that a meta-strategy with the ability to figure out what strategy is good is kind of defined by the fact that it doesn't bake in specifics of dealing with a particular situation, but rather can adapt to a broad set of situations. there are also different degrees of meta-strategy-ness; some meta strategies will more quickly adapt to a broader set of situations. (there's probably some sort of NFLT kind of argument you can make but NFLTs in general don't really matter)
comment by leogao · 2023-05-08T03:08:54.407Z · LW(p) · GW(p)
random brainstorming about optimizeryness vs controller/lookuptableyness:
let's think of optimizers as things that reliably steer a broad set of initial states to some specific terminal state seems like there are two things we care about (at least):
- retargetability: it should be possible to change the policy to achieve different terminal states (but this is an insufficiently strong condition, because LUTs also trivially meet this condition, because we can always just completely rewrite the LUT. maybe the actual condition we want is that the complexity of the map is less than the complexity of just the diff or something?) (in other words, in some sense it should be "easy" to rewrite a small subset or otherwise make a simple diff to the policy to change what final goal is achieved) (maybe related idea: instrumental convergence means most goals reuse lots of strategies/circuitry between each other)
- robustness: it should reliably achieve its goal across a wide range of initial states.
a LUT trained with a little bit of RL will be neither retargetable nor robust. a LUT trained with galactic amounts of RL to do every possible initial state optimally is robust but not retargetable (this is reasonable: robustness is only a property of the functional behavior so whether it's a LUT internally shouldn't matter; retargetability is a property of the actual implementation so it does matter). a big search loop (the most extreme of which is AIXI, which is 100% search) is very retargetable, and depending on how hard it searches is varying degrees of robustness.
(however, in practice with normal amounts of compute a LUT is never robust, this thought experiment only highlights differences that remain in the limit)
what do we care about these properties for?
- efficacy of filtering bad behaviors in pretraining: sufficiently good robustness means doing things that achieve the goal even in states that it never saw during training, and then even in states that require strategies that it never saw during training. if we filter out deceptive alignment from the data, then the model has to do some generalizing to figure out that this is a strategy that can be used to better accomplish its goal (as a sanity check that robustness is the thing here: a LUT never trained on deceptive alignment will never do it, but one that is trained on it will do it, a sufficiently powerful optimizer will always do it)
- arguments about updates wrt "goal": the deceptive alignment argument hinges a lot on "gradient of the goal" making sense. for example when we argue that the gradient on the model can be decomposed into one component that updates the goal to be more correct and another component that updates the capabilities to be more deceptive, we make this assumption. even if we assume away path dependence, the complexity argument depends a lot on the complexity being roughly equal to complexity of goal + complexity of general goal seeking circuitry, independent of goal.
- arguments about difficulty of disentangling correct and incorrect behaviors: there's a dual of retargetability which is something like the extent to which you can make narrow interventions to the behaviour. (some kind of "anti naturalness" argument)
[conjecture 1: retargetability == complexity can be decomposed == gradient of goal is meaningful. conjecture 2: gradient of goal is meaningful/complexity decomposition implies deceptive alignment (maybe we can also find some necessary condition?)]
how do we formalize retargetability?
- maybe something like there exists a homeomorphism from the goal space to NNs with that goal
- problem: doesn't really feel very satisfying and doesn't work at all for discrete things
- maybe complexity: retargetable if it has a really simple map from goals to NNs with goals, conditional on another NN with that goal
- problem: the training process of just training another NN from scratch on the new goal and ignoring the given NN could potentially be quite simple
- maybe complexity+time: seems reasonable to assume retraining is expensive (and maybe for decomposability we also consider complexity+time)
random idea: the hypothesis that complexity can be approximately decomposed into a goal component and a reasoning component is maybe a good formalization of (a weak version of) orthogonality?
comment by leogao · 2024-02-03T11:50:14.888Z · LW(p) · GW(p)
a tentative model of ambitious research projects
when you do a big research project, you have some amount of risk you can work with - maybe you're trying to do something incremental, so you can only tolerate a 10% chance of failure, or maybe you're trying to shoot for the moon and so you can accept a 90% chance of failure.
budgeting for risk is non negotiable because there are a lot of places where risk can creep in - and if there isn't, then you're not really doing research. most obviously, your direction might just be a dead end. but there are also other things that might go wrong: the code might end up too difficult to implement, or it might run too slowly, or you might fail to fix a solvable-in-principle problem that comes up.
I claim that one of the principal components of being a good researcher is being able to eliminate as much unnecessary risk as possible, so you can spend your entire risk budget on the important bets.
for example, if you're an extremely competent engineer, when brainstorming experiments you don't have to think much about the risk that you fail to implement it. you know that even if you don't think through all the contingencies that might pop up, you can figue it out, because you have a track record of figuring it out. you can say the words "and if that happens we'll just scale it up" without spending much risk because you know full well that you can actually execute on it. a less competent engineer would have to pay a much greater risk cost, and correspondingly have to reduce the ambitiousness of the research bets (or else, take on way more risk than intented).
not all research bets are created equal, either. the space of possible research bets is vast, and most of them are wrong. but if you have very good research taste, you can much more reliably tell whether a bet is likely to work out. even the best researchers can't just look at a direction and know for sure if it will work, if you know that you get a good direction 10% of the time you can do a lot more than if your direction is only good 0.1% of the time.
finally, if you know and trust someone to be reliable at executing on their area of expertise, you can delegate things that fall in their domain to them. in practice, this can be quite tough and introduce risk unless they have a very legible track record, or you are sufficiently competent in their domain yourself to tell if they're likely to succeed. and if you're sufficiently competent to do the job of any of your report (even if less efficiently), then you can budget less risk here knowing that even if someone drops their ball you could always pick it up yourself.
comment by leogao · 2023-12-17T05:46:30.294Z · LW(p) · GW(p)
https://arxiv.org/abs/2304.08612 : interesting paper with improvement on straight through estimator
comment by leogao · 2023-12-17T05:45:18.098Z · LW(p) · GW(p)
https://arxiv.org/abs/2302.07011 : sharpness doesn't seem to correlate with generalization
comment by leogao · 2023-11-02T01:20:42.170Z · LW(p) · GW(p)
'And what ingenious maneuvers they all propose to me! It seems to them that when they have thought of two or three contingencies' (he remembered the general plan sent him from Petersburg) 'they have foreseen everything. But the contingencies are endless.'
comment by leogao · 2023-09-15T08:41:42.142Z · LW(p) · GW(p)
We spend a lot of time on trying to figure out empirical evidence to distinguish hypotheses we have that make very similar predictions, but I think a potentially underrated first step is to make sure they actually fit the data we already have.
Replies from: thomas-kwa↑ comment by Thomas Kwa (thomas-kwa) · 2023-09-15T09:31:29.369Z · LW(p) · GW(p)
Example?
comment by leogao · 2023-03-04T19:58:25.882Z · LW(p) · GW(p)
Is the correlation between sleeping too long and bad health actually because sleeping too long is actually causally upstream of bad health effects, or only causally downstream of some common cause like illness?
Replies from: Making_Philosophy_Better↑ comment by Portia (Making_Philosophy_Better) · 2023-03-04T21:23:36.622Z · LW(p) · GW(p)
Afaik, both. Like a lot of shit things - they are caused by depression, and they cause depression, horrible reinforcing loop. While the effect of bad health on sleep is obvious, you can also see this work in reverse; e.g. temporary severe sleep restriction has an anti-depressive effect. Notable, though with not many useful clinical applications, as constant sleep deprivation is also really unhealthy.
comment by leogao · 2023-02-16T07:27:35.984Z · LW(p) · GW(p)
Unsupervised learning can learn things humans can't supervise because there's structure in the world that you need deeper understanding to predict accurately. For example, to predict how characters in a story will behave, you have to have some kind of understanding in some sense of how those characters think, even if their thoughts are never explicitly visible.
Unfortunately, this understanding only has to be structured in a way that makes reading off the actual unsupervised targets (i.e next observation) easy.
comment by leogao · 2023-02-12T08:28:53.557Z · LW(p) · GW(p)
An incentive structure for scalable trusted prediction market resolutions
We might want to make a trustable committee for resolving prediction markets. We might be worried that individual resolvers might build up reputation only to exit-scam, due to finite time horizons and non transferability of reputational capital. However, shareholders of a public company are more incentivized to preserve the value of the reputational capital. Based on this idea, we can set something up as follows:
- Market creators pay a fee for the services of a resolution company
- There is a pool of resolvers who give a first-pass resolution. Each resolver locks up a deposit.
- If an appeal is requested, a resolution passes up through a series of committees of more and more senior resolvers
- At the top, a vote is triggered among all shareholders
↑ comment by Dagon · 2023-02-12T15:26:06.905Z · LW(p) · GW(p)
It's amazing how many proposals for dealing with institutional distrust sound a lot like "make a new institution, with the same structure, but with better actors." You lose me at "trustable committee", especially when you don't describe how THOSE humans are motivated by truth and beauty, rather than filthy lucre. Adding more layers of committees doesn't help, unless you define a "final, un-appealable decision" that's sooner than the full shareholder vote.
Replies from: leogaocomment by leogao · 2023-02-12T04:20:42.173Z · LW(p) · GW(p)
Levels of difficulty:
- Mathematically proven to be impossible (i.e perfect compression)
- Impossible under currently known laws of physics (i.e perpetual motion machines)
- A lot of people have thought very hard about it and cannot prove that it's impossible, but strongly suspect it is impossible (i.e solving NP problems in P)
- A lot of people have thought very hard about it, and have not succeeded, but we have no strong reason to expect it to be impossible (i.e AGI)
- There is a strong incentive for success, and the markets are very efficient, so that for participants with no edge, success is basically impossible (i.e beating the stock market)
- There is a strong incentive for a thing, but a less efficient market, and it seems nobody has done it successfully (i.e a new startup idea that seems nobody seems to be doing)
Hopefully this is a useful reference for conversations that go like this:
A: Why can't we just do X to solve Y? B: You don't realize how hard Y is, you can't just think up a solution in 5 minutes A: You're just not thinking outside the box, [insert anecdote about some historical figure who figured out how to do a thing which was once considered impossible in some sense] B: No you don't understand, it's like actually not possible, not just like really hard, because of Z A: That's what they said about [historical figure]!
comment by leogao · 2023-01-29T21:41:10.848Z · LW(p) · GW(p)
(random shower thoughts written with basically no editing)
Sometimes arguments have a beat that looks like "there is extreme position X, and opposing extreme position Y. what about a moderate 'Combination' position?" (I've noticed this in both my own and others' arguments)
I think there are sometimes some problems with this.
- Usually almost nobody is on the most extreme ends of the spectrum. Nearly everyone falls into the "Combination" bucket technically, so in practice you have to draw the boundary between "combination enough" vs "not combination enough to count as combination", which is sometimes fraught. (There is a dual argument beat that looks like "people too often bucket things into distinct buckets, what about thinking of things as a spectrum." I think this does the opposite mistake, because sometimes there really are relatively meaningful clusters to point to. (this seems quite reminiscent of one Scottpost that I can't remember the name of rn))
- In many cases, there is no easy 1d spectrum. Being a "combination" could refer to a whole set of mutually exclusive sets of views. This problem gets especially bad when the endpoints differ along many axes at once. (Another dual argument here that looks like "things are more nuanced than they seem" which has its own opposite problems)
- Of the times where this is meaningful, I would guess it almost always happens when the axis one has identified is interesting and captures some interesting property of the world. That is to say, if you've identified some kind of quantity that seems to be very explanatory, just noting that fact actually produces lots of value, and then arguing about how or whether to bucket that quantity up into groups has sharply diminishing value.
- In other words, introducing the frame that some particular latent in the world exists and is predictive is hugely valuable; when you say "and therefore my position is in between other people's", this is valuable due to the introduction of the frame. The actual heavy lifting happened in the frame, and the part where you point to some underexplored region of the space implied by that frame is actually not doing much work.
- I hypothesize one common thing is that if you don't draw this distinction, then it feels like the heavy lifting comes in the part where you do the pointing, and then you might want to do this within already commonly accepted frames. From the inside I think this feels like existing clusters of people being surprisingly closed minded, whereas the true reason is that the usefulness of the existing frame has been exhausted.
comment by leogao · 2022-09-14T00:19:54.459Z · LW(p) · GW(p)
Subjective Individualism
TL;DR: This is basically empty individualism except identity is disentangled from cooperation (accomplished via FDT), and each agent can have its own subjective views on what would count as continuity of identity and have preferences over that. I claim that:
- Continuity is a property of the subjective experience of each observer-moment (OM), not necessarily of any underlying causal or temporal relation. (i.e I believe at this moment that I am experiencing continuity, but this belief is a fact of my current OM only. Being a Boltzmann brain that believes I experienced all the moments leading up to that moment feels exactly the same as "actually" experiencing things.)
- Each OM may have beliefs about the existence of past OMs, and about causal/temporal relations between those past OMs and the current OM (i.e one may believe that a memory of the past did in fact result from the faithful recording of a past OM to memory, as opposed to being spawned out of thin air as a Boltzmann brain loaded with false memories.)
- Something like preference utilitarianism is true and it is ok to have preferences about things you cannot observe, or prefer the world to be in one of two states that you cannot in any way distinguish. As a motivating example, one can have preferences between taking atomic actions (a) enter the experience machine and erase all memories of choosing to be in an experience machine and (b) doing nothing.
- Each OM may have preferences for its subjective experience of continuity to correspond to some particular causal structure between OMs, despite this being impossible for that OM to observe or verify. This is where the subjectivity is introduced: each OM can have its own opinion on which other OMs it considers to also be "itself"), and it can have preferences over its self-OMs causally leading to itself in a particular way. This does not have to be symmetric; for instance, your past self may consider your future self to be more self like than your future self considers past self.
- Continuity of self as viewed by each OM is decoupled from decision theoretic cooperation. i.e they coincide in a typical individual, who considers their past/future selves to be also themself, and cooperates decision theoretically (i.e you consider past/future you getting utility to both count as "you" getting utility). However it is also possible to cooperate to the same extent with OMs with whom you do not consider yourself to be the same self (i.e twin PD), or to not coordinate with yourself (i.e myopia/ADHD).
(related: FDT and myopia being much the same thing; you can think of caring about future selves’ rewards because you consider yourself to implement a similar enough algorithm to your future self as acausal trade. This has the nice property of unifying myopia and preventing acausal trade, in that acausal trade is really just caring about OMs that would not be considered the same “self”. This is super convenient because basically every time we talk about myopia for preventing deceptive mesaoptimization we have to hedge by saying “and also we need to prevent acausal trade somehow”, and this lets us unify the two things.)
Properties of this theory:
- This theory allows one to have preferences such as “I want to have lots of subjective experiences into the future” or “I prefer to have physical continuity with my past self” despite rejecting any universal concept of identity which seems pretty useful
- This theory is fully compatible with all sorts of thought experiments by simply not providing an answer as to which OM your current OM leads to “next”. This is philosophically unsatisfying but I think the theory is still useful nonetheless
- Coordination is solved through decision theory, which completely disentangles it from identity.
comment by leogao · 2022-05-27T16:29:02.038Z · LW(p) · GW(p)
Imagine if aliens showed up at your doorstep and tried to explain to you that making as many paperclips as possible was the ultimate source of value in the universe. They show pictures of things that count as paperclips and things that don't count as paperclips. They show you the long rambling definition of what counts as a paperclip from Section 23(b)(iii) of the Declaration of Paperclippian Values. They show you pages and pages of philosophers waxing poetical about how paperclips are great because of their incredible aesthetic value. You would be like, "yeah I get it, you consider this thing to be a paperclip, and you care a lot about them." You could probably pretty accurately tell whether the aliens would approve of anything you'd want to do. And then you wouldn't really care, because you value human flourishing, not paperclips. I mean, it's so silly to care about paperclips, right?
Of course, to the aliens, who have not so subtly indicated that they would blow up the planet and look for a new, more paperclip-loving planet if they were to detect any anti-paperclip sentiments, you say that you of course totally understand and would do anything for paperclips, and that you definitely wouldn't protest being sent to the paperclip mines.
Replies from: Dagon↑ comment by Dagon · 2022-05-27T19:21:11.659Z · LW(p) · GW(p)
I think I'd be confused. Do they care about more or better paperclips, or do they care about worship of paperclips by thinking beings? Why would they care whether I say I would do anything for paperclips, when I'm not actually making paperclips (or disassembling myself to become paperclips)?
Replies from: leogao↑ comment by leogao · 2022-05-27T19:32:10.093Z · LW(p) · GW(p)
I thought it would be obvious from context but the answers are "doesn't really matter, any of those examples work" and "because they will send everyone to the paperclip mines after ensuring there are no rebellious sentiments", respectively. I've edited it to be clearer.
comment by leogao · 2022-10-22T20:09:50.426Z · LW(p) · GW(p)
random thoughts. no pretense that any of this is original or useful for anyone but me or even correct
- It's ok to want the world to be better and to take actions to make that happen but unproductive to be frustrated about it or to complain that a plan which should work in a better world doesn't work in this world. To make the world the way you want it to be, you have to first understand how it is. This sounds obvious when stated abstractly but is surprisingly hard to adhere to in practice.
- It would be really nice to have some evolved version of calibration training where I take some historical events and try to predict concrete questions about what happened, and give myself immediate feedback and keep track of my accuracy and calibration. Backtesting my world model so to speak. Might be a bit difficult to measure accuracy improvments due to non iid ness of the world, but worth trying the naive thing regardless. Would be interesting to try and autogen using GPT3.
- Feedback loops are important. Unfortunately, from the inside it's very easy to forget. In particular, setting up feedback loops is often high friction, because it's hard to measure the thing we care about. Fixing this general problem is probably hard but in the meantime I can try to setup feedback loops for important things like productivity, world modelling, decision making, etc
↑ comment by leogao · 2022-10-22T23:19:14.203Z · LW(p) · GW(p)
- Lots of things have very counterintuitive or indirect values. If you don't take this into account and you make decisions based on maximizing value you might end up macnamara-ing yourself hard.
- The stages of learning something: (1) "this is super overwhelming! I don't think I'll ever understand it. there are so many things I need to keep track of. just trying to wrap my mind around it makes me feel slightly queasy" (2) "hmm this seems to actually make some sense, I'm starting to get the hang of this" (3) "this is so simple and obviously true, I've always known it to be true, I can't believe anyone doesn't understand this" (you start noticing that your explanations of the thing become indistinguishable from the things you originally felt overwhelmed by) (4) "this new thing [that builds on top of the thing you just learned] is super overwhelming! I don't think I'll ever understand it"
- The feeling of regret really sucks. This is a bad thing, because it creates an incentive to never reflect on things or realize your mistakes. This shows up as a quite painful aversion to reflecting on mistakes, doing a postmortem, and improving. I would like to somehow trick my brain into reframing things somehow. Maybe thinking of it as a strict improvement over the status quo of having done things wrong? Or maybe reminding myself that the regret will be even worse if I don't do anything because I'll regret not reflecting in addition
comment by leogao · 2022-06-08T15:09:48.591Z · LW(p) · GW(p)
Thought pattern that I've noticed: I seem to have two sets of epistemic states at any time: one more stable set that more accurately reflects my "actual" beliefs that changes fairly slowly, and one set of "hypothesis" beliefs that changes rapidly. Usually when I think some direction is interesting, I alternate my hypothesis beliefs between assuming key claims are true or false and trying to convince myself either way, and if I succeed then I integrate it into my actual beliefs. In practice this might look like alternating between trying to prove something is impossible and trying to exhibit an example, or taking strange premises seriously and trying to figure out its consequences. I think this is probably very confusing to people because usually when talking to people who are already familiar with alignment I'm talking about implications of my hypothesis beliefs, because that's the frontier of what I'm thinking about, and from the outside it looks like I'm constantly changing my mind about things. Writing this up partially to have something to point people to and partially to push myself to communicate this more clearly.
Replies from: Dagon↑ comment by Dagon · 2022-06-08T15:57:45.842Z · LW(p) · GW(p)
I think this pattern is common among intellectuals, and I'm surprised it's causing confusion. Are you labeling your exploratory beliefs and statements appropriately? An "epistemic status" note for posts here goes a long way, and in private conversation I often say out loud "I'm exploring here, don't take it as what I fully believe" in conversations at work and with friends.
Replies from: leogao↑ comment by leogao · 2022-06-08T16:03:35.985Z · LW(p) · GW(p)
I think I do a poor job of labelling my statements (at least, in conversation. usually I do a bit better in post format). Something something illusion of transparency. To be honest, I didn't even realize explicitly that I was doing this until fairly recent reflection on it.