Posts
Comments
even if you're mediocre at coming up with ideas, as long as it's cheap and you can come up with thousands, one of them is bound to be promising
for ideas which are "big enough", this is just false, right? for example, so far, no LLM has generated a proof of an interesting conjecture in math
coming up with good ideas is very difficult as well
(and it requires good judgment, also)
I've only skimmed the post so the present comment could be missing the mark (sorry if so), but I think you might find it worthwhile/interesting/fun to think (afresh, in this context) about how come humans often don't wirehead and probably wouldn't wirehead even with much much longer lives (in particular, much longer childhoods and research careers), and whether the kind of AI that would do hard math/philosophy/tech-development/science will also be like that.[1][2]
I'm not going to engage further on this here, but if you'd like to have a chat about this, feel free to dm me. ↩︎
I feel like clarifying that I'd inside-view say P( the future is profoundly non-human (in a bad sense) | AI (which is not pretty much a synthetic human) smarter than humans is created this century ) >0.98 despite this. ↩︎
i agree that most people doing "technical analysis" are doing nonsense and any particular well-known simple method does not actually work. but also clearly a very good predictor could make a lot of money just looking at the past price time series anyway
it feels to me like you are talking of two non-equivalent types of things as if they were the same. like, imo, the following are very common in competent entities: resisting attempts on one's life, trying to become smarter, wanting to have resources (in particular, in our present context, being interested in eating the Sun), etc.. but then whether some sort of vnm-coherence arises seems like a very different question. and indeed even though i think these drives are legit, i think it's plausible that such coherence just doesn't arise or that thinking of the question of what valuing is like such that a tendency toward "vnm-coherence" or "goal stability" could even make sense as an option is pretty bad/confused[1].
(of course these two positions i've briefly stated on these two questions deserve a bunch of elaboration and justification that i have not provided here, but hopefully it is clear even without that that there are two pretty different questions here that are (at least a priori) not equivalent)
briefly and vaguely, i think this could involve mistakenly imagining a growing mind meeting a fixed world, when really we will have a growing mind meeting a growing world — indeed, a world which is approximately equal to the mind itself. slightly more concretely, i think things could be more like: eg humanity has many profound projects now, and we would have many profound but currently basically unimaginable projects later, with like the effective space of options just continuing to become larger, plausibly with no meaningful sense in which there is a uniform direction in which we're going throughout or whatever ↩︎
a chat with Towards_Keeperhood on what it takes for sentences/phrases/words to be meaningful
- you could define "mother(x,y)" as "x gave birth to y", and then "gave birth" as some more precise cluster of observations, which eventually need to be able to be identified from visual inputs
Kaarel:
- if i should read this as talking about a translation of "x is the mother of y", then imo this is a bad idea.
- in particular, i think there is the following issue with this: saying which observations "x gave birth to y" corresponds to intuitively itself requires appealing to a bunch of other understanding. it's like: sure, your understanding can be used to create visual anticipations, but it's not true that any single sentence alone could be translated into visual anticipations — to get a typical visual anticipation, you need to rely on some larger segment of your understanding. a standard example here is "the speed of light in vacuum is 3*10^8 m/s" creating visual anticipations in some experimental setups, but being able to derive those visual anticipations depends on a lot of further facts about how to create a vacuum and properties of mirrors and interferometers and so on (and this is just for one particular setup — if we really mean to make a universally quantified statement, then getting the observation sentences can easily end up requiring basically all of our understanding). and it seems silly to think that all this crazy stuff was already there in what you meant when you said "the speed of light in vacuum is m/s". one concrete reason why you don't want this sentence to just mean some crazy AND over observation sentences or whatever is because you could be wrong about how some interferometer works and then you'd want it to correspond to different observation sentences
- this is roughly https://en.wikipedia.org/wiki/Confirmation_holism as a counter to https://en.wikipedia.org/wiki/Verificationism
- that said, i think there is also something wrong with some very strong version of holism: it's not really like our understanding is this unitary thing that only outputs visual anticipations using all the parts together, either — the real correspondence is somewhat more granular than that
TK:
- On reflection, I think my "mother" example was pretty sloppy and perhaps confusing. I agree that often quite a lot of our knowledge is needed to ground a statement in anticipations. And yeah actually it doesn't always ground out in that, e.g. for parsing the meaning of counterfactuals. (See "Mixed Reference: The great reductionist project".)
K:
- i wouldn't say a sentence is grounded in anticipations with a lot of our knowledge, because that makes it sound like in the above example, "the speed of light is m/s" is somehow privileged compared to our understanding of mirrors and interferometers even though it's just all used together to create anticipations; i'd instead maybe just say that a bunch of our knowledge together can create a visual anticipation
TK:
- thx. i wanted to reply sth like "a true statement can either be tautological (e.g. math theorems) or empirical, and for it to be an empirical truth there needs to be some entanglement between your belief and reality, and entanglement happens through sensory anticipations. so i feel fine with saying that the sentence 'the speed of light is m/s' still needs to be grounded in sensory anticipations". but i notice that the way i would use "grounded" here is different from the way I did in my previous comment, so perhaps there are two different concepts that need to be disentangled.
K:
- here's one thing in this vicinity that i'm sympathetic to: we should have as a criterion on our words, concepts, sentences, thoughts, etc. that they play some role in determining our actions; if some mental element is somehow completely disconnected from our lives, then i'd be suspicious of it. (and things can be connected to action via creating visual anticipations, but also without doing that.)
- that said, i think it can totally be good to be doing some thinking with no clear prior sense about how it could be connected to action (or prediction) — eg doing some crazy higher math can be good, imagining some crazy fictional worlds can be good, games various crazy artists and artistic communities are playing can be good, even crazy stuff religious groups are up to can be good. also, i think (thought-)actions in these crazy domains can themselves be actions one can reasonably be interested in supporting/determining, so this version of entanglement with action is really a very weak criterion
- generally it is useful to be able to "run various crazy programs", but given this, it seems obvious that not all variables in all useful programs are going to satisfy any such criterion of meaningfulness? like, they can in general just be some arbitrary crazy things (like, imagine some memory bit in my laptop or whatever) playing some arbitrary crazy role in some context, and this is fine
- and similarly for language: we can have some words or sentences playing some useful role without satisfying any strict meaningfulness criterion (beyond maybe just having some relation to actions or anticipations which can be of basically arbitrary form)
- a different point: in human thinking, the way "2+2=4" is related to visual anticipations is very similar to the way "the speed of light is m/s" is related to visual anticipations
TK:
- Thanks!
- I agree that e.g. imagining fictional worlds like HPMoR can be useful.
- I think I want to expand my notion of "tautological statements" to include statements like "In the HPMoR universe, X happens". You can also pick any empirical truth "X" and turn it into a tautological one by saying "In our universe, X". Though I agree it seems a bit weird.
- Basically, mathematics tells you what's true in all possible worlds, so from mathematics alone you never know in which world you may be in. So if you want to say something that's true about your world specifically (but not across all possible worlds), you need some observations to pin down what world you're in.
- I think this distinction is what Eliezer means in his highly advanced epistemology sequence when he uses "logical pinpointing" and "physical pinpointing".
- You can also have a combination of the two. (I'd say as soon as some physical pinpointing is involved I'd call it an empirical fact.)
- Commented about that. (I actually changed my model slightly): https://www.lesswrong.com/posts/bTsiPnFndZeqTnWpu/mixed-reference-the-great-reductionist-project?commentId=HuE78qSkZJ9MxBC8p
K:
- the imo most important thing in my messages above is the argument against [any criterion of meaningfulness which is like what you’re trying to state] being reasonable
- in brief, because it’s just useful to be allowed to have arbitrary “variables" in "one’s mental circuits”
- just like there’s no such meaningfulness criterion on a bit in your laptop’s memory
- if you want to see from the outside the way the bit is “connected to the world”, one thing you could do is to say that the bit is 0 in worlds which are such-and-such and 1 in worlds which are such-and-such, or, if you have a sense of what the laptop is supposed to be doing, you could say in which worlds the bit "should be 0" and in which worlds the bit "should be 1", but it’s not like anything like this crazy god’s eye view picture is (or even could explicitly be) present inside the laptop
- our sentences and terms don’t have to have meanings “grounded in visual anticipations”, just like the bit in the laptop doesn’t
- except perhaps in the very weak sense that it should be possible for a sentence to be involved in determining actions (or anticipations) in some potentially arbitrarily remote way
- the following is mostly a side point: one problem with seeing from the inside what your bits (words, sentences) are doing (especially in the context of pushing the frontier of science, math, philosophy, tech, or generally doing anything you don’t know how to do yet, but actually also just basically all the time) is that you need to be open to using your bits in new ways; the context in which you are using your bits usually isn’t clear to you
- btw, this is a sort of minor point but i'm stating it because i'm hoping it might contribute to pushing you out of a broader imo incorrect view: even when one is stating formal mathematical statements, one should be allowed to state sentences with no regard for whether they are tautologies/contradictions (that is, provable/disprovable) or not — ie, one should be allowed to state undecidable sentences, right? eg you should be allowed to state a proof that has the structure "if P, then blabla, so Q; but if not-P, then other-blabla, but then also Q; therefore, Q", without having to pay any attention to whether P itself is tautological/contradictory or undecidable
- so, if what you want to do with your criterion of meaningfulness involves banning saying sentences which are not "meaningful", then even in formal math, you should consider non-tautological/contradictory sentences meaningful. (if you don't want to ban the "meaningless" sentences, then idk what we're even supposed to be doing with this notion of meaningfulness.)
TK:
- Thx. I definitely agree one should be able to state all mathematical statements (including undecidable ones), and that for proofs you shouldn't need to pay attention to whether a statement is undecidable or not. (I'm having sorta constructivist tendencies though, where "if P, then blabla, so Q; but if not-P, then other-blabla, but then also Q; therefore, Q" wouldn't be a valid proof because we don't assume the law of excluded middle.)
- Ok yeah thx I think the way I previously used "meaningfully" was pretty confused. I guess I don't really want to rule out any sentences people use.
- I think sth is not meaningful if there's no connection between a belief to your main belief pool. So "a puffy is a flippo" is perhaps not meaningful to you because those concepts don't relate to anything else you know? (But that's a different kind of meaningful from what errors people mostly make.)
K:
- yea. tho then we could involve more sentences about puffies and flippos and start playing some game involving saying/thinking those sentences and then that could be fun/useful/whatever
TK:
- maybe. idk.
I think it's plausible that a system which is smarter than humans/humanity (and distinct and separate from humans/humanity) should just never be created, and I'm inside-view almost certain it'd be profoundly bad if such a system were created any time soon. But I think I'll disagree with like basically anyone on a lot of important stuff around this matter, so it just seems really difficult for anyone to be such that I'd feel like really endorsing them on this matter?[1] That said, my guess is that PauseAI is net positive, tho I haven't thought about this that much :)
Thank you for the comment!
First, I'd like to clear up a few things:
- I do think that making an "approximate synthetic 2025 human newborn/fetus (mind)" that can be run on a server having 100x usual human thinking speed is almost certainly a finite problem, and one might get there by figuring out what structures are there in a fetus/newborn precisely enough, and it plausibly makes sense to focus particularly on structures which are more relevant to learning. If one were to pull this off, one might then further be able to have these synthetic fetuses grow up quickly into fairly normal humans and have them do stuff which ends the present period of (imo) acute x-risk. (And the development of thought continues after that, I think; I'll say more that relates to this later.) While I do say in my post that making mind uploads is a finite problem, it might have been good to state also (or more precisely) that this type of thing is finite.
- I certainly think that one can make a finite system such that one can reasonably think that it will start a process that does very much — like, eats the Sun, etc.. Indeed, I think it's likely that by default humanity would unfortunately start a process that gets the Sun eaten this century. I think it is plausible there will be some people who will be reasonable in predicting pretty strongly that that particular process will get the Sun eaten. I think various claims about humans understanding some stuff about that process are less clear, though there is surely some hypothetical entity that could pretty deeply understand the development of that process up to the point where it eats the Sun.
- Some things in my notes were written mostly with an [agent foundations]y interlocutor in mind, and I'm realizing now that some of these things could also be read as if I had some different interlocutor in mind, and that some points probably seem more incongruous if read this way.
I'll now proceed to potential disagreements.
But there’s something else, which is a very finite legible learning algorithm that can automatically find all those things—the object-level stuff and the thinking strategies at all levels. The genome builds such an algorithm into the human brain. And it seems to work! I don’t think there’s any math that is forever beyond humans, or if it is, it would be for humdrum reasons like “not enough neurons to hold that much complexity in your head at once”.
Some ways I disagree or think this is/involves a bad framing:
- If we focus on math and try to ask some concrete question, instead of asking stuff like "can the system eventually prove anything?", I think it is much more appropriate to ask stuff like "how quickly can the system prove stuff?". Like, brute-force searching all strings for being a proof of a particular statement can eventually prove any provable statement, but we obviously wouldn't want to say that this brute-force searcher is "generally intelligent". Very relatedly, I think that "is there any math which is technically beyond a human?" is not a good question to be asking here.
- The blind idiot god that pretty much cannot even invent wheels (ie evolution) obviously did not put anything approaching the Ultimate Formula for getting far in math (or for doing anything complicated, really) inside humans (even after conditioning on specification complexity and computational resources or whatever), and especially not in an "unfolded form"[1], right? Any rich endeavor is done by present humans in a profoundly stupid way, right?[2] Humanity sorta manages to do math, but this seems like a very weak reason to think that [humans have]/[humanity has] anything remotely approaching an "ultimate learning algorithm" for doing math?[3]
- The structures in a newborn [that make it so that in the right context the newborn grows into a person who (say) pushes the frontier of human understanding forward] and [which participate in them pushing the frontier of human understanding forward] are probably already really complicated, right? Like, there's already a great variety of "ideas" involved in the "learning-relevant structures" of a fetus?
- I think that the framing that there is a given fixed "learning algorithm" in a newborn, such that if one knew it, one would be most of the way there to understanding human learning, is unfortunate. (Well, this comes with the caveat that it depends on what one wants from this "understanding of human learning" — e.g., it is probably fine to think this if one only wants to use this understanding to make a synthetic newborn.) In brief, I'd say "gaining thinking-components is a rich thing, much like gaining technologies more generally; our ability to gain thinking-components is developing, just like our ability to gain technologies", and then I'd point one to Note 3 and Note 4 for more on this.
- I want to say more in response to this view/framing that some sort of "human learning algorithm" is already there in a newborn, even in the context of just the learning that a single individual human is doing. Like, a human is also importantly gaining components/methods/ideas for learning, right? For example, language is centrally involved in human learning, and language isn't there in a fetus (though there are things in a newborn which create a capacity for gaining language, yes). I feel like you might want to say "who cares — there is a preserved learning algorithm in the brain of a fetus/newborn anyway". And while I agree that there are very important things in the brain which are centrally involved in learning and which are fairly unchanged during development, I don't understand what [the special significance of these over various things gained later] is which makes it reasonable to say that a human has a given fixed "learning algorithm". An analogy: Someone could try to explain structure-gaining by telling me "take a random init of a universe with such and such laws (and look along a random branch of the wavefunction[4]) — in there, you will probably eventually see a lot of structures being created" — let's assume that this is set up such that one in fact probably gets atoms and galaxies and solar systems and life and primitive entities doing math and reflecting (imo etc.). But this is obviously a highly unsatisfying "explanation" of structure-gaining! I wanted to know why/how protons and atoms and molecules form and why/how galaxies and stars and black holes form, etc.. I wanted to know about evolution, and about how primitive entities inventing/discovering mathematical concepts could work, and imo many other things! Really, this didn't do very much beyond just telling me "just consider all possible universes — somewhere in there, structures occur"! Like, yes, I've been given a context in which structure-gaining happens, but this does very little to help me make sense of structure-gaining. I'd guess that knowing the "primordial human learning algorithm" which is there in a fetus is significantly more like knowing the laws of physics than your comment makes it out to be. If it's not like that, I would like to understand why it's not like that — I'd like to understand why a fetus's learning-structures really deserve to be considered the "human learning algorithm", as opposed to being seen as just providing a context in which wild structure-gaining can occur and playing some important role in this wild structure-gaining (for now).
- to conclude: It currently seems unlikely to me that knowing a newborn's "primordial learning algorithm" would get me close to understanding human learning — in particular, it seems unlikely that it would get me close understanding how humanity gains scientific/mathematical/philosophical understanding. Also, it seems really unlikely that knowing this "primordial learning algorithm" would get me close to understanding learning/technology-making/mathematical-understanding-gaining in general.[5]
like, such that it is already there in a fetus/newborn and doesn't have to be gained/built ↩︎
I think present humans have much more for doing math than what is "directly given" by evolution to present fetuses, but still. ↩︎
One attempt to counter this: "but humans could reprogram into basically anything, including whatever better system for doing math there is!". But conditional on this working out, the appeal of the claim that fetuses already have a load-bearing fixed "learning algorithm" is also defeated, so this counterargument wouldn't actually work in the present context even if this claim were true. ↩︎
let's assume this makes sense ↩︎
That said, I could see an argument for a good chunk of the learning that most current humans are doing being pretty close to gaining thinking-structures which other people already have, from other people that already have them, and there is definitely something finite in this vicinity — like, some kind of pure copying should be finite (though the things humans are doing in this vicinity are of course more complicated than pure copying, there are complications with making sense of "pure copying" in this context, and also humans suck immensely (compared to what's possible) even at "pure copying"). ↩︎
Thank you for your comment!
What you're saying seems more galaxy-brained than what I was saying in my notes, and I'm probably not understanding it well. Maybe I'll try to just briefly (re)state some of my claims that seem most relevant to what you're saying here (with not much justification for my claims provided in my present comment, but there's some in the post), and then if it looks to you like I'm missing your point, feel very free to tell me that and I can then put some additional effort into understanding you.
- So, first, math is this richly infinite thing that will never be mostly done.
- If one is a certain kind of guy doing alignment, one might hope that one could understand how e.g. mathematical thinking works (or could work), and then make like an explicit math AI one can understand (one would probably really want this for science or for doing stuff in general[1], but a fortiori one would need to be able to do this for math).[2]
- But oops, this is very cursed, because thinking is an infinitely rich thing, like math!
- I think a core idea here is that thinking is a technological thing. Like, one aim of notes 1–6 (and especially 3 and 4) is to "reprogram" the reader into thinking this way about thinking. That is, the point is to reprogram the reader away from sth like "Oh, how does thinking, the definite thing, work? Yea, this is an interesting puzzle that we haven't quite cracked yet. You probably have to, like, combine logical deduction with some probability stuff or something, and then like also the right decision theory (which still requires some work but we're getting there), and then maybe a few other components that we're missing, but bro we will totally get there with a few ideas about how to add search heuristics, or once we've figured out a few more details about how abstraction works, or something."
- Like, a core intuition is to think of thinking like one would think of, like, the totality of humanity's activities, or about human technology. There's a great deal going on! It's a developing sort of thing! It's the sort of thing where you need/want to have genuinely new inventions! There is a rich variety of useful thinking-structures, just like there is a rich variety of useful technological devices/components, just like there is a rich variety of mathematical things!
- Given this, thinking starts to look a lot like math — in particular, the endeavor to understand thinking will probably always be mostly unfinished. It's the sort of thing that calls for an infinite library of textbooks to be written.
- In alignment, we're faced with an infinitely rich domain — of ways to think, or technologies/components/ideas for thinking, or something. This infinitely rich domain again calls for textbooks to keep being written as one proceeds.
- Also, the thing/thinker/thought writing these textbooks will itself need to be rich and developing as well, just like the math AI will need to be rich and developing.
- Generally, you can go meta more times, but on each step, you'll just be asking "how do I think about this infinitely rich domain?", answering which will again be an infinite endeavor.
- You could also try to make sense of climbing to higher infinite ordinal levels, I guess?
(* Also, there's something further to be said also about how [[doing math] and [thinking about how one should do math]] are not that separate.)
I'm at like inside-view p=0.93 that the above presents the right vibe to have about thinking (like, maybe genuinely about its potential development forever, but if it's like technically only the right vibe wrt the next years of thinking (at a 2024 rate) or something, then I'm still going to count that as thinking having this infinitary vibe for our purposes).[3]
However, the question about whether one can in principle make a math AI that is in some sense explicit/understandable anyway (that in fact proves impressive theorems with a non-galactic amount of compute) is less clear. Making progress on this question might require us to clarify what we want to mean by "explicit/understandable". We could get criteria on this notion from thinking through what we want from it in the context of making an explicit/understandable AI that makes mind uploads (and "does nothing else"). I say some more stuff about this question in 4.4.
if one is an imo complete lunatic :), one is hopeful about getting this so that one can make an AI sovereign with "the right utility function" that "makes there be a good future spacetime block"; if one is an imo less complete lunatic :), one is hopeful about getting this so that one can make mind uploads and have the mind uploads take over the world or something ↩︎
to clarify: I actually tend to like researchers with this property much more than I like basically any other "researchers doing AI alignment" (even though researchers with this property are imo engaged in a contemporary form of alchemy), and I can feel the pull of this kind of direction pretty strongly myself (also, even if the direction is confused, it still seems like an excellent thing to work on to understand stuff better). I'm criticizing researchers with this property not because I consider them particularly confused/wrong compared to others, but in part because I instead consider them sufficiently reasonable/right to be worth engaging with (and because I wanted to think through these questions for myself)! ↩︎
I'm saying this because you ask me about my certainty in something vaguely like this — but I'm aware I might be answering the wrong question here. Feel free to try to clarify the question if so. ↩︎
not really an answer but i wanted to communicate that the vibe of this question feels off to me because: surely one's criteria on what to be up to are/[should be] rich and developing. that is, i think things are more like: currently i have some projects i'm working on and other things i'm up to, and then later i'd maybe decide to work on some new projects and be up to some new things, and i'd expect to encounter many choices on the way (in particular, having to do with whom to become) that i'd want to think about in part as they come up. should i study A or B? should i start job X? should i 2x my neuron count using such and such a future method? these questions call for a bunch of thought (of the kind given to them in usual circumstances, say), and i would usually not want to be making these decisions according to any criterion i could articulate ahead of time (though it could be helpful to tentatively state some general principles like "i should be learning" and "i shouldn't do psychedelics", but these obviously aren't supposed to add up to some ultimate self-contained criterion on a good life)
- make humans (who are) better at thinking (imo maybe like continuing this way forever, not until humans can "solve AI alignment")
- think well. do math, philosophy, etc.. learn stuff. become better at thinking
- live a good life
A few quick observations (each with like confidence; I won't provide detailed arguments atm, but feel free to LW-msg me for more details):
- Any finite number of iterates just gives you the solomonoff distribution up to at most a const multiplicative difference (with the const depending on how many iterates you do). My other points will be about the limit as we iterate many times.
- The quines will have mass at least their prior, upweighted by some const because of programs which do not produce an infinite output string. They will generally have more mass than that, and some will gain mass by a larger multiplicative factor than others, but idk how to say something nice about this further.
- Yes, you can have quine-cycles. Relevant tho not exactly this: https://github.com/mame/quine-relay
- As you do more and more iterates, there's not convergence to a stationary distribution, at least in total variation distance. One reason is that you can write a quine which adds a string to itself (and then adds the same string again next time, and so on)[1], creating "a way for a finite chunk of probability to escape to infinity". So yes, some mass diverges.
- Quine-cycles imply (or at least very strongly suggest) probabilities also do not converge pointwise.
- What about pointwise convergence when we also average over the number of iterates? It seems plausible you get convergence then, but not sure (and not sure if this would be an interesting claim). It would be true if we could somehow think of the problem as living on a directed graph with countably many vertices, but idk how to do that atm.
- There are many different stationary distributions — e.g. you could choose any distribution on the quines.
a construction from o3-mini-high: https://colab.research.google.com/drive/1kIGCiDzWT3guCskgmjX5oNoYxsImQre-?usp=sharing ↩︎
I think AlphaProof is pretty far from being just RL from scratch:
- they use a pretrained language model; I think the model is trained on human math in particular ( https://archive.is/Cwngq#selection-1257.0-1272.0:~:text=Dr. Hubert’s team,frequency was reduced. )
- do we have good reason to think they didn't specifically train it on human lean proofs? it seems plausible to me that they did but idk
- the curriculum of human problems teaches it human tricks
- lean sorta "knows" a bunch of human tricks
We could argue about whether AlphaProof "is mostly human imitation or mostly RL", but I feel like it's pretty clear that it's more analogous to AlphaGo than to AlphaZero.
(a relevant thread: https://www.lesswrong.com/posts/sTDfraZab47KiRMmT/views-on-when-agi-comes-and-on-strategy-to-reduce?commentId=ZKuABGnKf7v35F5gp )
I didn't express this clearly, but yea I meant no pretraining on human text at all, and also nothing computer-generated which "uses human mathematical ideas" (beyond what is in base ZFC), but I'd probably allow something like the synthetic data generation used for AlphaGeometry (Fig. 3) except in base ZFC and giving away very little human math inside the deduction engine. I agree this would be very crazy to see. The version with pretraining on non-mathy text is also interesting and would still be totally crazy to see. I agree it would probably imply your "come up with interesting math concepts". But I wouldn't be surprised if like of the people on LW who think A[G/S]I happens in like years thought that my thing could totally happen in 2025 if the labs were aiming for it (though they might not expect the labs to aim for it), with your things plausibly happening later. E.g. maybe such a person would think "AlphaProof is already mostly RL/search and one could replicate its performance soon without human data, and anyway, AlphaGeometry already pretty much did this for geometry (and AlphaZero did it for chess)" and "some RL+search+self-play thing could get to solving major open problems in math in 2 years, and plausibly at that point human data isn't so critical, and IMO problems are easier than major open problems, so plausibly some such thing gets to IMO problems in 1 year". But also idk maybe this doesn't hang together enough for such people to exist. I wonder if one can use this kind of idea to get a different operationalization with parties interested in taking each side though. Like, maybe whether such a system would prove Cantor's theorem (stated in base ZFC) (imo this would still be pretty crazy to see)? Or whether such a system would get to IMO combos relying moderately less on human data?
¿ thoughts on the following:
- solving >95% of IMO problems while never seeing any human proofs, problems, or math libraries (before being given IMO problems in base ZFC at test time). like alphaproof except not starting from a pretrained language model and without having a curriculum of human problems and in base ZFC with no given libraries (instead of being in lean), and getting to IMO combos
some afaik-open problems relating to bridging parametrized bayes with sth like solomonoff induction
I think that for each NN architecture+prior+task/loss, conditioning the initialization prior on train data (or doing some other bayesian thing) is typically basically a completely different learning algorithm than (S)GD-learning, because local learning is a very different thing, which is one reason I doubt the story in the slides as an explanation of generalization in deep learning[1].[2] But setting this aside (though I will touch on it again briefly in the last point I make below), I agree it would be cool to have a story connecting the parametrized bayesian thing to something like Solomonoff induction. Here's an outline of an attempt to give a more precise story extending the one in Lucius's slides, with a few afaik-open problems:
- Let's focus on boolean functions (because that's easy to think about — but feel free to make a different choice). Let's take a learner to be shown certain input-output pairs (that's "training it"), and having to predict outputs on new inputs (that's "test time"). Let's say we're interested in understanding something about which learning setups "generalize well" to these new inputs.
- What should we mean by "generalizing well" in this context? This isn't so clear to me — we could e.g. ask that it does well on problems "like this" which come up in practice, but to solve such problems, one would want to look at what situation gave us the problem and so on, which doesn't seem like the kind of data we want to include in the problem setup here; we could imagine simply removing such data and asking for something that would work well in practice, but this still doesn't seem like such a clean criterion.
- But anyway, the following seems like a reasonable Solomonoff-like thing:
- There's some complexity (i.e., size/[description length], probably) prior on boolean circuits. There can be multiple reasonable choices of [types of circuits admitted] and/or [description language] giving probably genuinely different priors here, but make some choice (it seems fine to make whatever reasonable choice which will fit best with the later parts of the story we're attempting to build).
- Think of all the outputs (i.e. train and test) as being generated by taking a circuit from this prior and running the inputs through it.
- To predict outputs on new inputs, just do the bayesian thing (ie condition the induced prior on functions on all the outputs you've seen).
- My suggestion is that to explain why another learning setup (for boolean functions) has good generalization properties, we could be sort of happy with building a bridge between it and the above simplicity-prior-circuit-solomonoff thing. (This could let us bypass having to further specify what it is to generalize well.)[3]
- One key step in the present attempt at building a bridge from NN-bayes to simplicity-prior-circuit-solomonoff is to get from simplicity-prior-circuit-solomonoff to a setup with a uniform prior over circuits — the story would like to say that instead of picking circuits from a simplicity prior, you can pick circuits uniformly at random from among all circuits of up to a certain size. The first main afaik-open problem I want to suggest is to actually work out this step: to provide a precise setup where the uniform prior on boolean circuits up to a certain size is like the simplicity prior on boolean circuits (and to work out the correspondence). (It could also be interesting and [sufficient for building a bridge] to argue that the uniform prior on boolean circuits has good generalization properties in some other way.) I haven't thought about this that much, but my initial sense is that this could totally be false unless one is careful about getting the right setup (for example: given inputs-outputs from a particular boolean function with a small circuit, maybe it would work up to a certain upper bound on the size of the circuits on which we have a uniform prior, and then stop working; and/or maybe it depends more precisely on our [types of circuits admitted] and/or [description language]). (I know there is this story with programs, but idk how to get such a correspondence for circuits from that, and the correspondence for circuits seems like what we actually need/want.)
- The second afaik-open problem I'm suggesting is to figure out in much more detail how to get from e.g. the MLP with a certain prior to boolean circuits with a uniform prior.
- One reason I'm stressing these afaik-open problems (particularly the second one) is that I'm pretty sure many parametrized bayesian setups do not in fact give good generalization behavior — one probably needs some further things (about the architecture+prior, given the task) to go right to get good generalization (in fact, I'd guess that it's "rare" to get good generalization without these further unclear hyperparams taking on the right values), and one's attempt at building a bridge should probably make contact with these further things (so as to not be "explaining" a falsehood).
- One interesting example is given by MLPs in the NN gaussian process limit (i.e. a certain kind of initialization + taking the width to infinity) learning boolean functions (edit: I've realized I should clarify that I'm (somewhat roughly speaking) assuming the convention, not the convention), which I think ends up being equivalent to kernel ridge regression with the fourier basis on boolean functions as the kernel features (with certain weights depending on the size of the XOR), which I think doesn't have great generalization properties — in particular, it's quite unlike simplicity-prior-circuit-solomonoff, and it's probably fair to think of it as doing sth more like a polyfit in some sense. I think this also happens for the NTK, btw. (But I should say I'm going off some only loosely figured out calculations (joint with Dmitry Vaintrob and o1-preview) here, so there's a real chance I'm wrong about this example and you shouldn't completely trust me on it currently.) But I'd guess that deep learning can do somewhat better than this. (speculation: Maybe a major role in getting bad generalization here is played by the NNGP and NTK not "learning intermediate variables", preventing any analogy with boolean circuits with some depth going through, whereas deep learning can learn intermediate variables to some extent.) So if we want to have a correct solomonoff story which explains better generalization behavior than that of this probably fairly stupid kernel thing, then we would probably want the story to make some distinction which prevents it from also applying in this NNGP limit. (Anyway, even if I'm wrong about the NNGP case, I'd guess that most setups provide examples of fairly poor generalization, so one probably really needn't appeal to NNGP calculations to make this point.)
Separately from the above bridge attempt, it is not at all obvious to me that parametrized bayes in fact has such good generalization behavior at all (i.e., "at least as good as deep learning", whatever that means, let's say)[4]; here's some messages on this topic I sent to [the group chat in which the posted discussion happened] later:
"i'd be interested in hearing your reasons to think that NN-parametrized bayesian inference with a prior given by canonical initialization randomization (or some other reasonable prior) generalizes well (for eg canonical ML tasks or boolean functions), if you think it does — this isn't so clear to me at all
some practical SGD-NNs generalize decently, but that's imo a sufficiently different learning process to give little evidence about the bayesian case (but i'm open to further discussion of this). i have some vague sense that the bayesian thing should be better than SGD, but idk if i actually have good reason to believe this?
i assume that there are some other practical ML things inspired by bayes which generalize decently but it seems plausible that those are still pretty local so pretty far from actual bayes and maybe even closer to SGD than to bayes, tho idk what i should precisely mean by that. but eg it seems plausible from 3 min of thinking that some MCMC (eg SGLD) setup with a non-galactic amount of time on a NN of practical size would basically walk from init to a local likelihood max and not escape it in time, which sounds a lot more like SGD than like bayes (but idk maybe some step size scheduling makes the mixing time non-galactic in some interesting case somehow, or if it doesn't actually do that maybe it can give a fine approximation of the posterior in some other practical sense anyway? seems tough). i haven't thought about variational inference much tho — maybe there's something practical which is more like bayes here and we could get some relevant evidence from that
maybe there's some obvious answer and i'm being stupid here, idk :)
one could also directly appeal to the uniformly random program analogy but the current version of that imo doesn't remotely constitute sufficiently good reason to think that bayesian NNs generalize well on its own"
(edit: this comment suggests https://arxiv.org/pdf/2002.02405 as evidence that bayes-NNs generalize worse than SGD-NNs. but idk — I haven't looked at the paper yet — ie no endorsement of it one way or the other from me atm)
to the extent that deep learning in fact exhibits good generalization, which is probably a very small extent compared to sth like Solomonoff induction, and this has to do with some stuff I talked about in my messages in the post above; but I digress ↩︎
I also think that different architecture+prior+task/loss choices probably give many substantially-differently-behaved learning setups, deserving somewhat separate explanations of generalization, for both bayes and SGD. ↩︎
edit: Instead of doing this thing with circuits, you could get an alternative "principled generalization baseline/ceiling" from doing the same thing with programs instead (i.e., have a complexity prior on turing machines and condition it on seen input-output pairs), which I think ends up being equivalent (up to a probably-in-some-sense-small term) to using the kolmogorov complexities of these functions (thought of "extensionally" as strings, ie just listing outputs in some canonical order (different choices of canonical order should again give the same complexities (up to a probably-in-some-sense-small term))). While this is probably a more standard choice historically, it seems worse for our purposes given that (1) it would probably be strictly harder to build a bridge from NNs to it (and there probably just isn't any NNs <-> programs bridge which is as precise as the NNs <-> circuits bridge we might hope to build, given that NNs are already circuity things and it's easy to have a small program for a function without having a small circuit for it (as the small program could run for a long time)), and (2) it's imo plausible that some variant of the circuit prior is "philosophically/physically more correct" than the program prior, though this is less clear than the first point. ↩︎
to be clear: I'm not claiming it doesn't have good generalization behavior — instead, I lack good evidence/reason to think it does or doesn't and feel like I don't know ↩︎
you say "Human ingenuity is irrelevant. Lots of people believe they know the one last piece of the puzzle to get AGI, but I increasingly expect the missing pieces to be too alien for most researchers to stumble upon just by thinking about things without doing compute-intensive experiments." and you link https://tsvibt.blogspot.com/2024/04/koan-divining-alien-datastructures-from.html for "too alien for most researchers to stumble upon just by thinking about things without doing compute-intensive experiments"
i feel like that post and that statement are in contradiction/tension or at best orthogonal
there's imo probably not any (even-nearly-implementable) ceiling for basically any rich (thinking-)skill at all[1] — no cognitive system will ever be well-thought-of as getting close to a ceiling at such a skill — it's always possible to do any rich skill very much better (I mean these things for finite minds in general, but also when restricting the scope to current humans)
(that said, (1) of course, it is common for people to become better at particular skills up to some time and to become worse later, but i think this has nothing to do with having reached some principled ceiling; (2) also, we could perhaps eg try to talk about 'the artifact that takes at most bits to specify (in some specification-language) which figures out units of math the quickest (for some sufficiently large compared to )', but even if we could make sense of that, it wouldn't be right to think of it as being at some math skill ceiling to begin with, because it will probably very quickly change very much about its thinking (i.e. reprogram itself, imo plausibly indefinitely many times, including indefinitely many times in important ways, until the heat death of the universe or whatever); (3) i admit that there can be some purposes for which there is an appropriate way to measure goodness at some rich skill with a score in , and for such a purpose potential goodness at even a rich skill is of course appropriate to consider bounded and optimal performance might be rightly said to be approachable, but this somehow feels not-that-relevant in the present context)
i'll try to get away with not being very clear about what i mean by a 'rich (thinking-)skill' except that it has to do with having a rich domain (the domain either effectively presenting any sufficiently rich set of mathematical questions as problems or relating richly to humans, or in particular just to yourself, usually suffices) and i would include all the examples you give ↩︎
a few thoughts on hyperparams for a better learning theory (for understanding what happens when a neural net is trained with gradient descent)
Having found myself repeating the same points/claims in various conversations about what NN learning is like (especially around singular learning theory), I figured it's worth writing some of them down. My typical confidence in a claim below is like 95%[1]. I'm not claiming anything here is significantly novel. The claims/points:
- local learning (eg gradient descent) strongly does not find global optima. insofar as running a local learning process from many seeds produces outputs with 'similar' (train or test) losses, that's a law of large numbers phenomenon[2], not a consequence of always finding the optimal neural net weights.[3][4]
- if your method can't produce better weights: were you trying to produce better weights by running gradient descent from a bunch of different starting points? getting similar losses this way is a LLN phenomenon
- maybe this is a crisp way to see a counterexample instead: train, then identify a 'lottery ticket' subnetwork after training like done in that literature. now get rid of all other edges in the network, and retrain that subnetwork either from the previous initialization or from a new initialization — i think this literature says that you get a much worse loss in the latter case. so training from a random initialization here gives a much worse loss than possible
- dynamics (kinetics) matter(s). the probability of getting to a particular training endpoint is highly dependent not just on stuff that is evident from the neighborhood of that point, but on there being a way to make those structures incrementally, ie by a sequence of local moves each of which is individually useful.[5][6][7] i think that this is not an academic correction, but a major one — the structures found in practice are very massively those with sensible paths into them and not other (naively) similarly complex structures. some stuff to consider:
- the human eye evolving via a bunch of individually sensible steps, https://en.wikipedia.org/wiki/Evolution_of_the_eye
- (given a toy setup and in a certain limit,) the hardness of learning a boolean function being characterized by its leap complexity, ie the size of the 'largest step' between its fourier terms, https://arxiv.org/pdf/2302.11055
- imagine a loss function on a plane which has a crater somewhere and another crater with a valley descending into it somewhere else. the local neighborhoods of the deepest points of the two craters can look the same, but the crater with a valley descending into it will have a massively larger drainage basin. to say more: the crater with a valley is a case where it is first loss-decreasing to build one simple thing, (ie in this case to fix the value of one parameter), and once you've done that loss-decreasing to build another simple thing (ie in this case to fix the value of another parameter); getting to the isolated crater is more like having to build two things at once. i think that with a reasonable way to make things precise, the drainage basin of a 'k-parameter structure' with no valley descending into it will be exponentially smaller than that of eg a 'k-parameter structure' with 'a k/2-parameter valley' descending into it, which will be exponentially smaller still than a 'k-parameter structure' with a sequence of valleys of slowly increasing dimension descending into it
- it seems plausible to me that the right way to think about stuff will end up revealing that in practice there are basically only systems of steps where a single [very small thing]/parameter gets developed/fixed at a time
- i'm further guessing that most structures basically have 'one way' to descend into them (tho if you consider sufficiently different structures to be the same, then this can be false, like in examples of convergent evolution) and that it's nice to think of the probability of finding the structure as the product over steps of the probability of making the right choice on that step (of falling in the right part of a partition determining which next thing gets built)
- one correction/addition to the above is that it's probably good to see things in terms of there being many 'independent' structures/circuits being formed in parallel, creating some kind of ecology of different structures/circuits. maybe it makes sense to track the 'effective loss' created for a structure/circuit by the global loss (typically including weight norm) together with the other structures present at a time? (or can other structures do sufficiently orthogonal things that it's fine to ignore this correction in some cases?) maybe it's possible to have structures which were initially independent be combined into larger structures?[8]
- everything is a loss phenomenon. if something is ever a something-else phenomenon, that's logically downstream of a relation between that other thing and loss (but this isn't to say you shouldn't be trying to find these other nice things related to loss)
- grokking happens basically only in the presence of weight regularization, and it has to do with there being slower structures to form which are eventually more efficient at making logits high (ie more logit bang for weight norm buck)
- in the usual case that generalization starts to happen immediately, this has to do with generalizing structures being stronger attractors even at initialization. one consideration at play here is that
- nothing interesting ever happens during a random walk on a loss min surface
- it's not clear that i'm conceiving of structures/circuits correctly/well in the above. i think it would help a library of like >10 well-understood toy models (as opposed to like the maybe 1.3 we have now), and to be very closely guided by them when developing an understanding of neural net learning
some related (more meta) thoughts
- to do interesting/useful work in learning theory (as of 2024), imo it matters a lot that you think hard about phenomena of interest and try to build theory which lets you make sense of them, as opposed to holding fast to an existing formalism and trying to develop it further / articulate it better / see phenomena in terms of it
- this is somewhat downstream of current formalisms imo being bad, it imo being appropriate to think of them more as capturing preliminary toy cases, not as revealing profound things about the phenomena of interest, and imo it being feasible to do better
- but what makes sense to do can depend on the person, and it's also fine to just want to do math lol
- and it's certainly very helpful to know a bunch of math, because that gives you a library in terms of which to build an understanding of phenomena
- it's imo especially great if you're picking phenomena to be interested in with the future going well around ai in mind
(* but it looks to me like learning theory is unfortunately hard to make relevant to ai alignment[9])
acknowledgments
these thoughts are sorta joint with Jake Mendel and Dmitry Vaintrob (though i'm making no claim about whether they'd endorse the claims). also thank u for discussions: Sam Eisenstat, Clem von Stengel, Lucius Bushnaq, Zach Furman, Alexander Gietelink Oldenziel, Kirke Joamets
with the important caveat that, especially for claims involving 'circuits'/'structures', I think it's plausible they are made in a frame which will soon be superseded or at least significantly improved/clarified/better-articulated, so it's a 95% given a frame which is probably silly ↩︎
train loss in very overparametrized cases is an exception. in this case it might be interesting to note that optima will also be off at infinity if you're using cross-entropy loss, https://arxiv.org/pdf/2006.06657 ↩︎
also, gradient descent is very far from doing optimal learning in some solomonoff sense — though it can be fruitful to try to draw analogies between the two — and it is also very far from being the best possible practical learning algorithm ↩︎
by it being a law of large numbers phenomenon, i mean sth like: there are a bunch of structures/circuits/pattern-completers that could be learned, and each one gets learned with a certain probability (or maybe a roughly given total number of these structures gets learned), and loss is roughly some aggregation of indicators for whether each structure gets learned — an aggregation to which the law of large numbers applies ↩︎
to say more: any concept/thinking-structure in general has to be invented somehow — there in some sense has to be a 'sensible path' to that concept — but any local learning process is much more limited than that still — now we're forced to have a path in some (naively seen) space of possible concepts/thinking-structures, which is a major restriction. eg you might find the right definition in mathematics by looking for a thing satisfying certain constraints (eg you might want the definition to fit into theorems characterizing something you want to characterize), and many such definitions will not be findable by doing sth like gradient descent on definitions ↩︎
ok, (given an architecture and a loss,) technically each point in the loss landscape will in fact have a different local neighborhood, so in some sense we know that the probability of getting to a point is a function of its neighborhood alone, but what i'm claiming is that it is not nicely/usefully a function of its neighborhood alone. to the extent that stuff about this probability can be nicely deduced from some aspect of the neighborhood, that's probably 'logically downstream' of that aspect of the neighborhood implying something about nice paths to the point. ↩︎
also note that the points one ends up at in LLM training are not local minima — LLMs aren't trained to convergence ↩︎
i think identifying and very clearly understanding any toy example where this shows up would plausibly be better than anything else published in interp this year. the leap complexity paper does something a bit like this but doesn't really do this ↩︎
i feel like i should clarify here though that i think basically all existing alignment research fails to relate much to ai alignment. but then i feel like i should further clarify that i think each particular thing sucks at relating to alignment after having thought about how that particular thing could help, not (directly) from some general vague sense of pessimism. i should also say that if i didn't think interp sucked at relating to alignment, i'd think learning theory sucks less at relating to alignment (ie, not less than interp but less than i currently think it does). but then i feel like i should further say that fortunately you can just think about whether learning theory relates to alignment directly yourself :) ↩︎
a thing i think is probably happening and significant in such cases: developing good 'concepts/ideas' to handle a problem, 'getting a feel for what's going on in a (conceptual) situation'
a plausibly analogous thing in humanity(-seen-as-a-single-thinker): humanity states a conjecture in mathematics, spends centuries playing around with related things (tho paying some attention to that conjecture), building up mathematical machinery/understanding, until a proof of the conjecture almost just falls out of the machinery/understanding
I find it surprising/confusing/confused/jarring that you speak of models-in-the-sense-of-mathematical-logic=:L-models as the same thing as (or as a precise version of) models-as-conceptions-of-situations=:C-models. To explain why these look to me like two pretty much entirely distinct meanings of the word 'model', let me start by giving some first brushes of a picture of C-models. When one employs a C-model, one likens a situation/object/etc of interest to a situation/object/etc that is already understood (perhaps a mathematical/abstract one), that one expects to be better able to work/play with. For example, when one has data about sun angles at a location throughout the day and one is tasked with figuring out the distance from that location to the north pole, one translates the question to a question about 3d space with a stationary point sun and a rotating sphere and an unknown point on the sphere and so on. (I'm not claiming a thinker is aware of making such a translation when they make it.) Employing a C-model making an analogy. From inside a thinker, the objects/situations on each side of the analogy look like... well, things/situations; from outside a thinker, both sides are thinking-elements.[1] (I think there's a large GOFAI subliterature trying to make this kind of picture precise but I'm not that familiar with it; here are two papers that I've only skimmed: https://www.qrg.northwestern.edu/papers/Files/smeff2(searchable).pdf , https://api.lib.kyushu-u.ac.jp/opac_download_md/3070/76.ps.tar.pdf .)
I'm not that happy with the above picture of C-models, but I think that it seeming like an even sorta reasonable candidate picture might be sufficient to see how C-models and L-models are very different, so I'll continue in that hope. I'll assume we're already on the same page about what an L-model is ( https://en.wikipedia.org/wiki/Model_theory ). Here are some ways in which C-models and L-models differ that imo together make them very different things:
- An L-model is an assignment of meaning to a language, a 'mathematical universe' together with a mapping from symbols in a language to stuff in that universe — it's a semantic thing one attaches to a syntax. The two sides of a C-modeling-act are both things/situations which are roughly equally syntactic/semantic (more precisely: each side is more like a syntactic thing when we try to look at a thinker from the outside, and just not well-placed on this axis from the thinker's internal point of view, but if anything, the already-understood side of the analogy might look more like a mechanical/syntactic game than the less-understood side, eg when you are aware that you are taking something as a C-model).
- Both sides of a C-model are things/situations one can reason about/with/in. An L-model takes from a kind of reasoning (proving, stating) system to an external universe which that system could talk about.
- An L-model is an assignment of a static world to a dynamic thing; the two sides of a C-model are roughly equally dynamic.
- A C-model might 'allow you to make certain moves without necessarily explicitly concerning itself much with any coherent mathematical object that these might be tracking'. Of course, if you are employing a C-model and you ask yourself whether you are thinking about some thing, you will probably answer that you are, but in general it won't be anywhere close to 'fully developed' in your mind, and even if it were (whatever that means), that wouldn't be all there is to the C-model. For an extreme example, we could maybe even imagine a case where a C-model is given with some 'axioms and inference rules' such that if one tried to construct a mathematical object 'wrt which all these axioms and inference rules would be valid', one would not be able to construct anything — one would find that one has been 'talking about a logically impossible object'. Maybe physicists handling infinities gracefully when calculating integrals in QFT is a fun example of this? This is in contrast with an L-model which doesn't involve anything like axioms or inference rules at all and which is 'fully developed' — all terms in the syntax have been given fixed referents and so on.
- (this point and the ones after are in some tension with the main picture of C-models provided above but:) A C-model could be like a mental context/arena where certain moves are made available/salient, like a game. It seems difficult to see an L-model this way.
- A C-model could also be like a program that can be run with inputs from a given situation. It seems difficult to think of an L-model this way.
- A C-model can provide a way to talk about a situation, a conceptual lens through which to see a situation, without which one wouldn't really be able to [talk about]/see the situation at all. It seems difficult to see an L-model as ever doing this. (Relatedly, I also find it surprising/confusing/confused/jarring that you speak of reasoning using C-models as a semantic kind of reasoning.)
(But maybe I'm grouping like a thousand different things together unnaturally under C-models and you have some single thing or a subset in mind that is in fact closer to L-models?)
All this said, I don't want to claim that no helpful analogy could be made between C-models and L-models. Indeed, I think there is the following important analogy between C-models and L-models:
- When we look for a C-model to apply to a situation of interest, perhaps we often look for a mathematical object/situation that satisfies certain key properties satisfied by the situation. Likewise, an L-model of a set of sentences is (roughly speaking) a mathematical object which satisfies those sentences.
(Acknowledgments. I'd like to thank Dmitry Vaintrob and Sam Eisenstat for related conversations.)
- ^
This is complicated a bit by a thinker also commonly looking at the C-model partly as if from the outside — in particular, when a thinker critiques the C-model to come up with a better one. For example, you might notice that the situation of interest has some property that the toy situation you are analogizing it to lacks, and then try to fix that. For example, to guess the density of twin primes, you might start from a naive analogy to a probabilistic situation where each 'prime' p has probability (p-1)/p of not dividing each 'number' independently at random, but then realize that your analogy is lacking because really p not dividing n makes it a bit less likely that p doesn't divide n+2, and adjust your analogy. This involves a mental move that also looks at the analogy 'from the outside' a bit.
That said, the hypothetical you give is cool and I agree the two principles decouple there! (I intuitively want to save that case by saying the COM is only stationary in a covering space where the train has in fact moved a bunch by the time it stops, but idk how to make this make sense for a different arrangement of portals.) I guess another thing that seems a bit compelling for the two decoupling is that conservation of angular momentum is analogous to conservation of momentum but there's no angular analogue to the center of mass (that's rotating uniformly, anyway). I guess another thing that's a bit compelling is that there's no nice notion of a center of energy once we view spacetime as being curved ( https://physics.stackexchange.com/a/269273 ). I think I've become convinced that conservation of momentum is a significantly bigger principle :). But still, the two seem equivalent to me before one gets to general relativity. (I guess this actually depends a bit on what the proof of 12.72 is like — in particular, if that proof basically uses the conservation of momentum, then I'd be more happy to say that the two aren't equivalent already for relativity/fields.)
here's a picture from https://hansandcassady.org/David%20J.%20Griffiths-Introduction%20to%20Electrodynamics-Addison-Wesley%20(2012).pdf :

Given 12.72, uniform motion of the center of energy is equivalent to conservation of momentum, right? P is const <=> dR_e/dt is const.
(I'm guessing 12.72 is in fact correct here, but I guess we can doubt it — I haven't thought much about how to prove it when fields and relativistic and quantum things are involved. From a cursory look at his comment, Lubos Motl seems to consider it invalid lol ( in https://physics.stackexchange.com/a/3200 ).)
The microscopic picture that Mark Mitchison gives in the comments to this answer seems pretty: https://physics.stackexchange.com/a/44533 — though idk if I trust it. The picture seems to be to think of glass as being sparse, with the photon mostly just moving with its vacuum velocity and momentum, but with a sorta-collision between the photon and an electron happening every once in a while. I guess each collision somehow takes a certain amount of time but leaves the photon unchanged otherwise, and presumably bumps that single electron a tiny bit to the right. (Idk why the collisions happen this way. I'm guessing maybe one needs to think of the photon as some electromagnetic field thing or maybe as a quantum thing to understand that part.)
And the loss mechanism I was imagining was more like something linear in the distance traveled, like causing electrons to oscillate but not completely elastically wrt the 'photon' inside the material.
Anyway, in your argument for the redshift as the photon enters the block, I worry about the following:
- can we really think of 1 photon entering the block becoming 1 photon inside the block, as opposed to needing to think about some wave thing that might translate to photons in some other way or maybe not translate to ordinary photons at all inside the material (this is also my second worry from earlier)?
- do we know that this photon-inside-the-material has energy ?
re redshift: Sorry, I should have been clearer, but I meant to talk about redshift (or another kind of energy loss) of the light that comes out of the block on the right compared to the light that went in from the left, which would cause issues with going from there being a uniformly-moving stationary center of mass to the conclusion about the location of the block. (I'm guessing you were right when you assumed in your argument that redshift is 0 for our purposes, but I don't understand light in materials well enough atm to see this at a glance atm.)
Note however, that the principle being broken (uniform motion of centre of mass) is not at all one of the "big principles" of physics, especially not with the extra step of converting the photon energy to mass. I had not previously heard of the principle, and don't think it is anywhere near the weight class of things like momentum conservation.
I found these sentences surprising. To me, the COM moving at constant velocity (in an inertial frame) is Newton's first law, which is one of the big principles (and I also have a mental equality between that and conservation of momentum).
I guess we can also reach your conclusion in that thought experiment arguing from conservation of momentum directly (though I guess the argument I'll give just contains a proof of one direction of the equivalence to the conservation of momentum as a step). Ignoring relativity for a second, we could go into the center of mass frame as the particle approaches the piece of glass from the left, then note that the momentum in this frame needs to zero forever (by conservation of momentum), then note $\int p \text{d}t=m\delta(x)$, where $\delta(x)$ is the distance moved by the center of mass, from which $\delta(x)=0$. I would guess that essentially the same argument also works when relativistic things like photons are involved (and when fields or quantum stuff is involved), as long as one replaces the center of mass by the center of energy ( https://physics.stackexchange.com/questions/742770/centre-of-energy-in-special-relativity ).
One thing that worries me about that thought experiment more than [whether Newton's first law carries over to this context] is the assumption that (in ideal conditions) photons do not lose any energy to the material — that they don't end up redshifted or something. (If photons got redshifted as they go through, then the photons would lose some energy and the block would end up with some momentum and heat, obviously causing issues with the broader argument.) Still, I guess it's probably fine to say that frequency/energy of the light is indeed conserved ( https://physics.stackexchange.com/questions/810869/why-does-the-energy-and-thus-frequency-of-a-photon-entering-glass-stay-constan ), but I unfortunately don't atm understand how to think about a light packet (or something) going through a (potentially moving) material well enough to decide for myself atm. (ChatGPT tells me of some standard argument involving the displacement field, but I haven't decided if I'll trust that argument in this context yet. I also tried to see whether such an effect would be higher-order in some parameter even if it existed but I didn't see a good reason why that would be the case.)
A second thing that worries me about this argument even more is whether it even makes sense to talk about individual photons passing through materials — I think the argument doesn't make sense if photon number is not conserved before vs after a light pulse enters a material (here I'm thinking of the light pulse having small horizontal extent compared to the material). But I really haven't thought very carefully about this. (Also, I'd like to point out that if some kind of light packet number were conserved and we are operating with a notion of momentum such that all of it can be attributed to wave packets, then momentum conservation implies the momentum attributed to a given packet stays constant. But I guess some of it might be more naturally attributed to stuff in the block at some point. I'd need to think more about what kind of partition would be most natural.)
It additionally seems likely to me that we are presently missing major parts of a decent language for talking about minds/models, and developing such a language requires (and would constitute) significant philosophical progress. There are ways to 'understand the algorithm a model is' that are highly insufficient/inadequate for doing what we want to do in alignment — for instance, even if one gets from where interpretability is currently to being able to replace a neural net by a somewhat smaller boolean (or whatever) circuit and is thus able to translate various NNs to such circuits and proceed to stare at them, one probably won't thereby be more than of the way to the kind of strong understanding that would let one modify a NN-based AGI to be aligned or build another aligned AI (in case alignment doesn't happen by default) (much like how knowing the weights doesn't deliver that kind of understanding). To even get to the point where we can usefully understand the 'algorithms' models implement, I feel like we might need to have answered sth like (1) what kind of syntax should we see thinking as having — for example, should we think of a model/mind as a library of small programs/concepts that are combined and updated and created according to certain rules (Minsky's frames?), or as having a certain kind of probabilistic world model that supports planning in a certain way, or as reasoning in a certain internal logical language, or in terms of having certain propositional attitudes; (2) what kind of semantics should we see thinking as having — what kind of correspondence between internals of the model/mind and the external world should we see a model as maintaining(; also, wtf are values). I think that trying to find answers to these questions by 'just looking' at models in some ML-brained, non-philosophical way is unlikely to be competitive with trying to answer these questions with an attitude of taking philosophy (agent foundations) seriously, because one will only have any hope of seeing the cognitive/computational structure in a mind/model by staring at it if one stares at it already having some right ideas about what kind of structure to look for. For example, it'd be very tough to try to discover [first-order logic]/ZFC/[type theory] by staring at the weights/activations/whatever of the brain of a human mathematician doing mathematical reasoning, from a standpoint where one hasn't already invented [first-order logic]/ZFC/[type theory] via some other route — if one starts from the low-level structure of a brain, then first-order logic will only appear as being implemented in the brain in some 'highly encrypted' way.
There's really a spectrum of claims here that would all support the claim that agent foundations is good for understanding the 'algorithm' a model/mind is to various degrees. A stronger one than what I've been arguing for is that once one has these ideas, one needn't stare at models at all, and that staring at models is unlikely to help one get the right ideas (e.g. because it's better to stare at one's own thinking instead, and to think about how one could/should think, sort of like how [first-order logic]/ZFC/[type theory] was invented), so one's best strategy does not involve starting at models; a weaker one than what I've been arguing is that having more and better ideas about the structure of minds would be helpful when staring at models. I like TsviBT's koan on this topic.
Confusion #2: Why couldn't we make similar counting arguments for Turing machines?
I guess a central issue with separating NP from P with a counting argument is that (roughly speaking) there are equally many problems in NP and P. Each problem in NP has a polynomial-time verifier, so we can index the problems in NP by polytime algorithms, just like the problems in P.
in a bit more detail: We could try to use a counting argument to show that there is some problem with a (say) time verifier which does not have any (say) time solver. To do this, we'd like to say that there are more verifier problems than algorithms. While I don't really know how we ought to count these (naively, there are of each), even if we had some decent notion of counting, there would almost certainly just be more algorithms than verifiers (since the verifiers are themselves algorithms).
To clarify, I think in this context I've only said that the claim "The minimax regret rule (sec 5.4.2 of Bradley (2012)) is equivalent to EV max w.r.t. the distribution in your representor that induces maximum regret" (and maybe the claim after it) was "false/nonsense" — in particular, because it doesn't make sense to talk about a distribution that induces maximum regret (without reference to a particular action) — which I'm guessing you agree with.
I wanted to say that I endorse the following:
- Neither of the two decision rules you mentioned is (in general) consistent with any EV max if we conceive of it as giving your preferences (not just picking out a best option), nor if we conceive of it as telling you what to do on each step of a sequential decision-making setup.
I think basically any setup is an example for either of these claims. Here's a canonical counterexample for the version with preferences and the max_{actions} min_{probability distributions} EV (i.e., infrabayes) decision rule, i.e. with our preferences corresponding to the min_{probability distributions} EV ranking:
- Let and be actions and let be flipping a fair coin and then doing or depending on the outcome. It is easy to construct a case where the max-min rule strictly prefers to and also strictly prefers to , and indeed where this preference is strong enough that the rule still strictly prefers to a small enough sweetening of and also still prefers to a small enough sweetening of (in fact, a generic setup will have such a triple). Call these sweetenings and (think of these as -but-you-also-get-one-cent or -but-you-also-get-one-extra-moment-of-happiness or whatever; the important thing is that all utility functions under consideration should consider this one cent or one extra moment of happiness or whatever a positive). However, every EV max rule (that cares about the one cent) will strictly disprefer to at least one of or , because if that weren't the case, the EV max rule would need to weakly prefer over a coinflip between and , but this is just saying that the EV max rule weakly prefers to , which contradicts with it caring about sweetening. So these min preferences are incompatible with maximizing any EV.
There is a canonical way in which a counterexample in preference-land can be turned into a counterexample in sequential-decision-making-land: just make the "sequential" setup really just be a two-step game where you first randomly pick a pair of actions to give the agent a choice between, and then the agent makes some choice. The game forces the max min agent to "reveal its preferences" sufficiently for its policy to be revealed to be inconsistent with EV maxing. (This is easiest to see if the agent is forced to just make a binary choice. But it's still true even if you avoid the strictly binary choice being forced upon the agent by saying that the agent still has access to (internal) randomization.)
Regarding the Thornley paper you link: I've said some stuff about it in my earlier comments; my best guess for what to do next would be to prove some theorem about behavior that doesn't make explicit use of a completeness assumption, but also it seems likely that this would fail to relate sufficiently to our central disagreements to be worthwhile. I guess I'm generally feeling like I might bow out of this written conversation soon/now, sorry! But I'd be happy to talk more about this synchronously — if you'd like to schedule a meeting, feel free to message me on the LW messenger.
Oh ok yea that's a nice setup and I think I know how to prove that claim — the convex optimization argument I mentioned should give that. I still endorse the branch of my previous comment that comes after considering roughly that option though:
That said, if we conceive of the decision rule as picking out a single action to perform, then because the decision rule at least takes Pareto improvements, I think a convex optimization argument says that the single action it picks is indeed the maximal EV one according to some distribution
(though not necessarily one in your set). However, if we conceive of the decision rule as giving preferences between actions or if we try to use it in some sequential setup, then I'm >95% sure there is no way to see it as EV max (except in some silly way, like forgetting you had preferences in the first place).
Sorry, I feel like the point I wanted to make with my original bullet point is somewhat vaguer/different than what you're responding to. Let me try to clarify what I wanted to do with that argument with a caricatured version of the present argument-branch from my point of view:
your original question (caricatured): "The Sun prayer decision rule is as follows: you pray to the Sun; this makes a certain set of actions seem auspicious to you. Why not endorse the Sun prayer decision rule?"
my bullet point: "Bayesian expected utility maximization has this big red arrow pointing toward it, but the Sun prayer decision rule has no big red arrow pointing toward it."
your response: "Maybe a few specific Sun prayer decision rules are also pointed to by that red arrow?"
my response: "The arrow does not point toward most Sun prayer decision rules. In fact, it only points toward the ones that are secretly bayesian expected utility maximization. Anyway, I feel like this does very little to address my original point that there is this big red arrow pointing toward bayesian expected utility maximization and no big red arrow pointing toward Sun prayer decision rules."
(See the appendix to my previous comment for more on this.)
That said, I admit I haven't said super clearly how the arrow ends up pointing to structuring your psychology in a particular way (as opposed to just pointing at a class of ways to behave). I think I won't do a better job at this atm than what I said in the second paragraph of my previous comment.
The minimax regret rule (sec 5.4.2 of Bradley (2012)) is equivalent to EV max w.r.t. the distribution in your representor that induces maximum regret.
I'm (inside view) 99.9% sure this will be false/nonsense in a sequential setting. I'm (inside view) 99% sure this is false/nonsense even in the one-shot case. I guess the issue is that different actions get assigned their max regret by different distributions, so I'm not sure what you mean when you talk about the distribution that induces maximum regret. And indeed, it is easy to come up with a case where the action that gets chosen is not best according to any distribution in your set of distributions: let there be one action which is uniformly fine and also for each distribution in the set, let there be an action which is great according to that distribution and disastrous according to every other distribution; the uniformly fine action gets selected, but this isn't EV max for any distribution in your representor. That said, if we conceive of the decision rule as picking out a single action to perform, then because the decision rule at least takes Pareto improvements, I think a convex optimization argument says that the single action it picks is indeed the maximal EV one according to some distribution (though not necessarily one in your set). However, if we conceive of the decision rule as giving preferences between actions or if we try to use it in some sequential setup, then I'm >95% sure there is no way to see it as EV max (except in some silly way, like forgetting you had preferences in the first place).
The maximin rule (sec 5.4.1) is equivalent to EV max w.r.t. the most pessimistic distribution.
I didn't think about this as carefully, but >90% that the paragraph above also applies with minor changes.
You might say "Then why not just do precise EV max w.r.t. those distributions?" But the whole problem you face as a decision-maker is, how do you decide which distribution? Different distributions recommend different policies. If you endorse precise beliefs, it seems you'll commit to one distribution that you think best represents your epistemic state. Whereas someone with imprecise beliefs will say: "My epistemic state is not represented by just one distribution. I'll evaluate the imprecise decision rules based on which decision-theoretic desiderata they satisfy, then apply the most appealing decision rule (or some way of aggregating them) w.r.t. my imprecise beliefs." If the decision procedure you follow is psychologically equivalent to my previous sentence, then I have no objection to your procedure — I just think it would be misleading to say you endorse precise beliefs in that case.
I think I agree in some very weak sense. For example, when I'm trying to diagnose a health issue, I do want to think about which priors and likelihoods to use — it's not like these things are immediately given to me or something. In this sense, I'm at some point contemplating many possible distributions to use. But I guess we do have some meaningful disagreement left — I guess I take the most appealing decision rule to be more like pure aggregation than you do; I take imprecise probabilities with maximality to be a major step toward madness from doing something that stays closer to expected utility maximization.
But the CCT only says that if you satisfy [blah], your policy is consistent with precise EV maximization. This doesn't imply your policy is inconsistent with Maximality, nor (as far as I know) does it tell you what distribution with respect to which you should maximize precise EV in order to satisfy [blah] (or even that such a distribution is unique). So I don’t see a positive case here for precise EV maximization [ETA: as a procedure to guide your decisions, that is]. (This is my also response to your remark below about “equivalent to "act consistently with being an expected utility maximizer".”)
I agree that any precise EV maximization (which imo = any good policy) is consistent with some corresponding maximality rule — in particular, with the maximality rule with the very same single precise probability distribution and the same utility function (at least modulo some reasonable assumptions about what 'permissibility' means). Any good policy is also consistent with any maximality rule that includes its probability distribution as one distribution in the set (because this guarantees that the best-according-to-the-precise-EV-maximization action is always permitted), as well as with any maximality rule that makes anything permissible. But I don't see how any of this connects much to whether there is a positive case for precise EV maximization? If you buy the CCT's assumptions, then you literally do have an argument that anything other than precise EV maximization is bad, right, which does sound like a positive case for precise EV maximization (though not directly in the psychological sense)?
ETA: as a procedure to guide your decisions, that is
Ok, maybe you're saying that the CCT doesn't obviously provide an argument for it being good to restructure your thinking into literally maintaining some huge probability distribution on 'outcomes' and explicitly maintaining some function from outcomes to the reals and explicitly picking actions such that the utility conditional on these actions having been taken by you is high (or whatever)? I agree that trying to do this very literally is a bad idea, eg because you can't fit all possible worlds (or even just one world) in your head, eg because you don't know likelihoods given hypotheses as you're not logically omniscient, eg because there are difficulties with finding yourself in the world, etc — when taken super literally, the whole shebang isn't compatible with the kinds of good reasoning we actually can do and do do and want to do. I should say that I didn't really track the distinction between the psychological and behavioral question carefully in my original response, and had I recognized you to be asking only about the psychological aspect, I'd perhaps have focused on that more carefully in my original answer. Still, I do think the CCT has something to say about the psychological aspect as well — it provides some pro tanto reason to reorganize aspects of one's reasoning to go some way toward assigning coherent numbers to propositions and thinking of decisions as having some kinds of outcomes and having a schema for assigning a number to each outcome and picking actions that lead to high expectations of this number. This connection is messy, but let me try to say something about what it might look like (I'm not that happy with the paragraph I'm about to give and I feel like one could write a paper at this point instead). The CCT says that if you 'were wise' — something like 'if you were to be ultimately content with what you did when you look back at your life' — your actions would need to be a particular way (from the outside). Now, you're pretty interested in being content with your actions (maybe just instrumentally, because maybe you think that has to do with doing more good or being better). In some sense, you know you can't be fully content with them (because of the reasons above). But it makes sense to try to move toward being more content with your actions. One very reasonable way to achieve this is to incorporate some structure into your thinking that makes your behavior come closer to having these desired properties. This can just look like the usual: doing a bayesian calculation to diagnose a health problem, doing an EV calculation to decide which research project to work on, etc..
(There's a chance you take there to be another sense in which we can ask about the reasonableness of expected utility maximization that's distinct from the question that broadly has to do with characterizing behavior and also distinct from the question that has to do with which psychology one ought to choose for oneself — maybe something like what's fundamentally principled or what one ought to do here in some other sense — and you're interested in that thing. If so, I hope what I've said can be translated into claims about how the CCT would relate to that third thing.)
Anyway, If the above did not provide a decent response to what you said, then it might be worthwhile to also look at the appendix (which I ended up deprecating after understanding that you might only be interested in the psychological aspect of decision-making). In that appendix, I provide some more discussion of the CCT saying that [maximality rules which aren't behaviorally equivalent to expected utility maximization are dominated]. I also provide some discussion recentering the broader point I wanted to make with that bullet point that CCT-type stuff is a big red arrow pointing toward expected utility maximization, whereas no remotely-as-big red arrow is known for [imprecise probabilities + maximality].
e.g. if one takes the cost of thinking into account in the calculation, or thinks of oneself as choosing a policy
Could you expand on this with an example? I don’t follow.
For example, preferential gaps are sometimes justified by appeals to cases like: "you're moving to another country. you can take with you your Fabergé egg xor your wedding album. you feel like each is very cool, and in a different way, and you feel like you are struggling to compare the two. given this, it feels fine for you to flip a coin to decide which one (or to pick the one on the left, or to 'just pick one') instead of continuing to think about it. now you remember you have 10 dollars inside the egg. it still seems fine to flip a coin to decide which one to take (or to pick the one on the left, or to 'just pick one').". And then one might say one needs preferential gaps to capture this. But someone sorta trying to maximize expected utility might think about this as: "i'll pick a randomization policy for cases where i'm finding two things hard to compare. i think this has good EV if one takes deliberation costs into account, with randomization maybe being especially nice given that my utility is concave in the quantities of various things.".
Maximality and imprecision don’t make any reference to “default actions,”
I mostly mentioned defaultness because it appears in some attempts to precisely specify alternatives to bayesian expected utility maximization. One concrete relation is that one reasonable attempt at specifying what it is that you'll do when multiple actions are permissible is that you choose the one that's most 'default' (more precisely, if you have a prior on actions, you could choose the one with the highest prior). But if a notion of defaultness isn't relevant for getting from your (afaict) informal decision rule to a policy, then nvm this!
I also don’t understand what’s unnatural/unprincipled/confused about permissibility or preferential gaps. They seem quite principled to me: I have a strict preference for taking action A over B (/ B is impermissible) only if I’m justified in beliefs according to which I expect A to do better than B.
I'm not sure I understand. Am I right in understanding that permissibility is defined via a notion of strict preferences, and the rest is intended as an informal restatement of the decision rule? In that case, I still feel like I don't know what having a strict preference or permissibility means — is there some way to translate these things to actions? If the rest is intended as an independent definition of having a strict preference, then I still don't know how anything relates to action either. (I also have some other issues in that case: I anticipate disliking the distinction between justified and unjustified beliefs being made (in particular, I anticipate thinking that a good belief-haver should just be thinking and acting according to their beliefs); it's unclear to me what you mean by being justified in some beliefs (eg is this a non-probabilistic notion); are individual beliefs giving you expectations here or are all your beliefs jointly giving you expectations or is some subset of beliefs together giving you expectations; should I think of this expectation that A does better than B as coming from another internal conditional expected utility calculation). I guess maybe I'd like to understand how an action gets chosen from the permissible ones. If we do not in fact feel that all the actions are equal here (if we'd pay something to switch from one to another, say), then it starts to seem unnatural to make a distinction between two kinds of preference in the first place. (This is in contrast to: I feel like I can relate 'preferences' kinda concretely to actions in the usual vNM case, at least if I'm allowed to talk about money to resolve the ambiguity between choosing one of two things I'm indifferent between vs having a strict preference.)
Anyway, I think there's a chance I'd be fine with sometimes thinking that various options are sort of fine in a situation, and I'm maybe even fine with this notion of fineness eg having certain properties under sweetenings of options, but I quite strongly dislike trying to make this notion of fineness correspond to this thing with a universal quantifier over your probability distributions, because it seems to me that (1) it is unhelpful because it (at least if implemented naively) doesn't solve any of the computational issues (boundedness issues) that are a large part of why I'd entertain such a notion of fineness in the first place, (2) it is completely unprincipled (there's no reason for this in particular, and the split of uncertainties is unsatisfying), and (3) it plausibly gives disastrous behavior if taken seriously. But idk maybe I can't really even get behind that notion of fineness, and I'm just confusing it with the somewhat distinct notion of fineness that I use when I buy two different meals to distribute among myself and a friend and tell them that I'm fine with them having either one, which I think is well-reduced to probably having a smaller preference than my friend. Anyway, obviously whether such a notion of fineness is desirable depends on how you want it to relate to other things (in particular, actions), and I'm presently sufficiently unsure about how you want it to relate to these other things to be unsure about whether a suitable such notion exists.
basically everything becomes permissible, which seems highly undesirable
This is a much longer conversation, but briefly: I think it’s ad hoc / putting the cart before the horse to shape our epistemology to fit our intuitions about what decision guidance we should have.
It seems to me like you were like: "why not regiment one's thinking xyz-ly?" (in your original question), to which I was like "if one regiments one thinking xyz-ly, then it's an utter disaster" (in that bullet point), and now you're like "even if it's an utter disaster, I don't care". And I guess my response is that you should care about it being an utter disaster, but I guess I'm confused enough about why you wouldn't care that it doesn't make a lot of sense for me to try to write a library of responses.
Appendix with some things about CCT and expected utility maximization and [imprecise probabilities] + maximality that got cut
Precise EV maximization is a special case of [imprecise probabilities] + maximality (namely, the special case where your imprecise probabilities are in fact precise, at least modulo some reasonable assumptions about what things mean), so unless your class of decision rules turns out to be precisely equivalent to the class of decision rules which do precise EV maximization, the CCT does in fact say it contains some bad rules. (And if it did turn out to be equivalent, then I'd be somewhat confused about why we're talking about it your way, because it'd seem to me like it'd then just be a less nice way to describe the same thing.) And at least on the surface, the class of decision rules does not appear to be equivalent, so the CCT indeed does speak against some rules in this class (and in fact, all rules in this class which cannot be described as precise EV maximization).
If you filled in the details of your maximality-type rule enough to tell me what your policy is — in particular, hypothetically, maybe you'd want to specify sth like the following: what it means for some options to be 'permissible' or how an option gets chosen from the 'permissible options', potentially something about how current choices relate to past choices, and maybe just what kind of POMDP, causal graph, decision tree, or whatever game setup we're assuming in the first place — such that your behavior then looks like bayesian expected utility maximization (with some particular probability distribution and some particular utility function), then I guess I'll no longer be objecting to you using that rule (to be precise: I would no longer be objecting to it for being dominated per the CCT or some such theorem, but I might still object to the psychological implementation of your policy on other grounds).
That said, I think the most straightforward ways [to start from your statement of the maximality rule and to specify some sequential setup and to make the rule precise and to then derive a policy for the sequential setup from the rule] do give you a policy which you would yourself consider dominated though. I can imagine a way to make your rule precise that doesn't give you a dominated policy that ends up just being 'anything is permissible as long as you make sure you looked like a bayesian expected utility maximizer at the end of the day' (I think the rule of Thornley and Petersen is this), but at that point I'm feeling like we're stressing some purely psychological distinction whose relevance to matters of interest I'm failing to see.
But maybe more importantly, at this point, I'd feel like we've lost the plot somewhat. What I intended to say with my original bullet point was more like: we've constructed this giant red arrow (i.e., coherence theorems; ok, it's maybe not that giant in some absolute sense, but imo it is as big as presently existing arrows get for things this precise in a domain this messy) pointing at one kind of structure (i.e., bayesian expected utility maximization) to have 'your beliefs and actions ultimately correspond to', and then you're like "why not this other kind of structure (imprecise probabilities, maximality rules) though?" and then my response was "well, for one, there is the giant red arrow pointing at this other structure, and I don't know of any arrow pointing at your structure", and I don't really know how to see your response as a response to this.
Here are some brief reasons why I dislike things like imprecise probabilities and maximality rules (somewhat strongly stated, medium-strongly held because I've thought a significant amount about this kind of thing, but unfortunately quite sloppily justified in this comment; also, sorry if some things below approach being insufficiently on-topic):
- I like the canonical arguments for bayesian expected utility maximization ( https://www.alignmentforum.org/posts/sZuw6SGfmZHvcAAEP/complete-class-consequentialist-foundations ; also https://web.stanford.edu/~hammond/conseqFounds.pdf seems cool (though I haven't read it properly)). I've never seen anything remotely close for any of this other stuff — in particular, no arguments that pin down any other kind of rule compellingly. (I associate with this the vibe here (in particular, the paragraph starting with "To the extent that the outer optimizer" and the paragraph after it), though I guess maybe that's not a super helpful thing to say.)
- The arguments I've come across for these other rules look like pointing at some intuitive desiderata and saying these other rules sorta meet these desiderata whereas canonical bayesian expected utility maximization doesn't, but I usually don't really buy the desiderata and/or find that bayesian expected utility maximization also sorta has those desired properties, e.g. if one takes the cost of thinking into account in the calculation, or thinks of oneself as choosing a policy.
- When specifying alternative rules, people often talk about things like default actions, permissibility, and preferential gaps, and these concepts seem bad to me. More precisely, they seem unnatural/unprincipled/confused/[I have a hard time imagining what they could concretely cache out to that would make the rule seem non-silly/useful]. For some rules, I think that while they might be psychologically different than 'thinking like an expected utility maximizer', they give behavior from the same distribution — e.g., I'm pretty sure the rule suggested here (the paragraph starting with "More generally") and here (and probably elsewhere) is equivalent to "act consistently with being an expected utility maximizer", which seems quite unhelpful if we're concerned with getting a differently-behaving agent. (In fact, it seems likely to me that a rule which gives behavior consistent with expected utility maximization basically had to be provided in this setup given https://web.stanford.edu/~hammond/conseqFounds.pdf or some other canonical such argument, maybe with some adaptations, but I haven't thought this through super carefully.) (A bunch of other people (Charlie Steiner, Lucius Bushnaq, probably others) make this point in the comments on https://www.lesswrong.com/posts/yCuzmCsE86BTu9PfA/there-are-no-coherence-theorems; I'm aware there are counterarguments there by Elliott Thornley and others; I recall not finding them compelling on an earlier pass through these comments; anyway, I won't do this discussion justice in this comment.)
- I think that if you try to get any meaningful mileage out of the maximality rule (in the sense that you want to "get away with knowing meaningfully less about the probability distribution"), basically everything becomes permissible, which seems highly undesirable. This is analogous to: as soon as you try to get any meaningful mileage out of a maximin (infrabayesian) decision rule, every action looks really bad — your decision comes down to picking the least catastrophic option out of options that all look completely catastrophic to you — which seems undesirable. It is also analogous to trying to find an action that does something or that has a low probability of causing harm 'regardless of what the world is like' being imo completely impossible (leading to complete paralysis) as soon as one tries to get any mileage out of 'regardless of what the world is like' (I think this kind of thing is sometimes e.g. used in davidad's and Bengio's plans https://www.lesswrong.com/posts/pKSmEkSQJsCSTK6nH/an-open-agency-architecture-for-safe-transformative-ai?commentId=ZuWsoXApJqD4PwfXr , https://www.youtube.com/watch?v=31eO_KfkjRQ&t=1946s ). In summary, my inside view says this kind of knightian thing is a complete non-starter. But outside-view, I'd guess that at least some people that like infrabayesianism have some response to this which would make me view it at least slightly more favorably. (Well, I've only stated the claim and not really provided the argument I have in mind, but that would take a few paragraphs I guess, and I won't provide it in this comment.)
- To add: it seems basically confused to talk about the probability distribution on probabilities or probability distributions, as opposed to some joint distribution on two variables or a probability distribution on probability distributions or something. It seems similarly 'philosophically problematic' to talk about the set of probability distributions, to decide in a way that depends a lot on how uncertainty gets 'partitioned' into the set vs the distributions. (I wrote about this kind of thing a bit more here: https://forum.effectivealtruism.org/posts/Z7r83zrSXcis6ymKo/dissolving-ai-risk-parameter-uncertainty-in-ai-future#vJg6BPpsG93iyd7zo .)
- I think it's plausible there's some (as-of-yet-undeveloped) good version of probabilistic thinking+decision-making for less-than-ideal agents that departs from canonical bayesian expected utility maximization; I like approaches to finding such a thing that take aspects of existing messy real-life (probabilistic) thinking seriously but also aim to define a precise formal setup in which some optimality result could be proved. I have some very preliminary thoughts on this and a feeling that it won't look at all like the stuff I've discussed disliking above. Logical induction ( https://arxiv.org/abs/1609.03543 ) seems cool; a heuristic estimator ( https://arxiv.org/pdf/2211.06738 ) would be cool. That said, I also assign significant probability to nothing very nice being possible here (this vaguely relates to the claim: "while there's a single ideal rationality, there are many meaningfully distinct bounded rationalities" (I'm forgetting whom I should attribute this to)).
I think most of the quantitative claims in the current version of the above comment are false/nonsense/[using terms non-standardly]. (Caveat: I only skimmed the original post.)
"if your first vector has cosine similarity 0.6 with d, then to be orthogonal to the first vector but still high cosine similarity with d, it's easier if you have a larger magnitude"
If by 'cosine similarity' you mean what's usually meant, which I take to be the cosine of the angle between two vectors, then the cosine only depends on the directions of vectors, not their magnitudes. (Some parts of your comment look like you meant to say 'dot product'/'projection' when you said 'cosine similarity', but I don't think making this substitution everywhere makes things make sense overall either.)
"then your method finds things which have cosine similarity ~0.3 with d (which maybe is enough for steering the model for something very common, like code), then the number of orthogonal vectors you will find is huge as long as you never pick a single vector that has cosine similarity very close to 1"
For 0.3 in particular, the number of orthogonal vectors with at least that cosine with a given vector d is actually small. Assuming I calculated correctly, the number of e.g. pairwise-dot-prod-less-than-0.01 unit vectors with that cosine with a given vector is at most (the ambient dimension does not show up in this upper bound). I provide the calculation later in my comment.
"More formally, if theta0 = alpha0 d + (1 - alpha0) noise0, where d is a unit vector, and alpha0 = cosine(theta0, d), then for theta1 to have alpha1 cosine similarity while being orthogonal, you need alpha0alpha1 + <noise0, noise1>(1-alpha0)(1-alpha1) = 0, which is very easy to achieve if alpha0 = 0.6 and alpha1 = 0.3, especially if nosie1 has a big magnitude."
This doesn't make sense. For alpha1 to be cos(theta1, d), you can't freely choose the magnitude of noise1
How many nearly-orthogonal vectors can you fit in a spherical cap?
Proposition. Let be a unit vector and let also be unit vectors such that they all sorta point in the direction, i.e., for a constant (I take you to have taken ), and such that the are nearly orthogonal, i.e., for all , for another constant . Assume also that . Then .
Proof. We can decompose , with a unit vector orthogonal to ; then . Given , it's a 3d geometry exercise to show that pushing all vectors to the boundary of the spherical cap around can only decrease each pairwise dot product; doing this gives a new collection of unit vectors , still with . This implies that . Note that since , the RHS is some negative constant. Consider . On the one hand, it has to be positive. On the other hand, expanding it, we get that it's at most . From this, , whence .
(acknowledgements: I learned this from some combination of Dmitry Vaintrob and https://mathoverflow.net/questions/24864/almost-orthogonal-vectors/24887#24887 )
For example, for and , this gives .
(I believe this upper bound for the number of almost-orthogonal vectors is actually basically exactly met in sufficiently high dimensions — I can probably provide a proof (sketch) if anyone expresses interest.)
Remark. If , then one starts to get exponentially many vectors in the dimension again, as one can see by picking a bunch of random vectors on the boundary of the spherical cap.
What about the philosophical point? (low-quality section)
Ok, the math seems to have issues, but does the philosophical point stand up to scrutiny? Idk, maybe — I haven't really read the post to check relevant numbers or to extract all the pertinent bits to answer this well. It's possible it goes through with a significantly smaller or if the vectors weren't really that orthogonal or something. (To give a better answer, the first thing I'd try to understand is whether this behavior is basically first-order — more precisely, is there some reasonable loss function on perturbations on the relevant activation space which captures perturbations being coding perturbations, and are all of these vectors first-order perturbations toward coding in this sense? If the answer is yes, then there just has to be such a vector — it'd just be the gradient of this loss.)
how many times did the explanation just "work out" for no apparent reason
From the examples later in your post, it seems like it might be clearer to say something more like "how many things need to hold about the circuit for the explanation to describe the circuit"? More precisely, I'm objecting to your "how many times" because it could plausibly mean "on how many inputs" which I don't think is what you mean, and I'm objecting to your "for no apparent reason" because I don't see what it would mean for an explanation to hold for a reason in this case.
The Deep Neural Feature Ansatz
@misc{radhakrishnan2023mechanism, title={Mechanism of feature learning in deep fully connected networks and kernel machines that recursively learn features}, author={Adityanarayanan Radhakrishnan and Daniel Beaglehole and Parthe Pandit and Mikhail Belkin}, year={2023}, url = { https://arxiv.org/pdf/2212.13881.pdf } }
The ansatz from the paper
Let denote the activation vector in layer on input , with the input layer being at index , so . Let be the weight matrix after activation layer . Let be the function that maps from the th activation layer to the output. Then their Deep Neural Feature Ansatz says that (I'm somewhat confused here about them not mentioning the loss function at all — are they claiming this is reasonable for any reasonable loss function? Maybe just MSE? MSE seems to be the only loss function mentioned in the paper; I think they leave the loss unspecified in a bunch of places though.)
A singular vector version of the ansatz
Letting be a SVD of , we note that this is equivalent to i.e., that the eigenvectors of the matrix on the RHS are the right singular vectors. By the variational characterization of eigenvectors and eigenvalues (Courant-Fischer or whatever), this is the same as saying that right singular vectors of are the highest orthonormal directions for the matrix on the RHS. Plugging in the definition of , this is equivalent to saying that the right singular vectors are the sequence of highest-variance directions of the data set of gradients .
(I have assumed here that the linearity is precise, whereas really it is approximate. It's probably true though that with some assumptions, the approximate initial statement implies an approximate conclusion too? Getting approx the same vecs out probably requires some assumption about gaps in singular values being big enough, because the vecs are unstable around equality. But if we're happy getting a sequence of orthogonal vectors that gets variances which are nearly optimal, we should also be fine without this kind of assumption. (This is guessing atm.))
Getting rid of the dependence on the RHS?
Assuming there isn't an off-by-one error in the paper, we can pull some term out of the RHS maybe? This is because applying the chain rule to the Jacobians of the transitions gives , so
Wait, so the claim is just which, assuming is invertible, should be the same as . But also, they claim that it is ? Are they secretly approximating everything with identity matrices?? This doesn't seem to be the case from their Figure 2 though.
Oh oops I guess I forgot about activation functions here! There should be extra diagonal terms for jacobians of preactivations->activations in , i.e., it should really say We now instead get This should be the same as which, with denoting preactivations in layer and denoting the function from these preactivations to the output, is the same as This last thing also totally works with activation functions other than ReLU — one can get this directly from the Jacobian calculation. I made the ReLU assumption earlier because I thought for a bit that one can get something further in that case; I no longer think this, but I won't go back and clean up the presentation atm.
Anyway, a takeaway is that the Deep Neural Feature Ansatz is equivalent to the (imo cleaner) ansatz that the set of gradients of the output wrt the pre-activations of any layer is close to being a tight frame (in other words, the gradients are in isotropic position; in other words still, the data matrix of the gradients is a constant times a semi-orthogonal matrix). (Note that the closeness one immediately gets isn't in to a tight frame, it's just in the quantity defining the tightness of a frame, but I'd guess that if it matters, one can also conclude some kind of closeness in from this (related).) This seems like a nicer fundamental condition because (1) we've intuitively canceled terms and (2) it now looks like a generic-ish condition, looks less mysterious, though idk how to argue for this beyond some handwaving about genericness, about other stuff being independent, sth like that.
proof of the tight frame claim from the previous condition: Note that clearly implies that the mass in any direction is the same, but also the mass being the same in any direction implies the above (because then, letting the SVD of the matrix with these gradients in its columns be , the above is , where we used the fact that ).
Some questions
- Can one come up with some similar ansatz identity for the left singular vectors of ? One point of tension/interest here is that an ansatz identity for would constrain the left singular vectors of together with its singular values, but the singular values are constrained already by the deep neural feature ansatz. So if there were another identity for in terms of some gradients, we'd get a derived identity from equality between the singular values defined in terms of those gradients and the singular values defined in terms of the Deep Neural Feature Ansatz. Or actually, there probably won't be an interesting identity here since given the cancellation above, it now feels like nothing about is really pinned down by 'gradients independent of ' by the DNFA? Of course, some -dependence remains even in the gradients because the preactivations at which further gradients get evaluated are somewhat -dependent, so I guess it's not ruled out that the DNFA constrains something interesting about ? But anyway, all this seems to undermine the interestingness of the DNFA, as well as the chance of there being an interesting similar ansatz for the left singular vectors of .
- Can one heuristically motivate that the preactivation gradients above should indeed be close to being in isotropic position? Can one use this reduction to provide simpler proofs of some of the propositions in the paper which say that the DNFA is exactly true in certain very toy cases?
- The authors claim that the DNFA is supposed to somehow elucidate feature learning (indeed, they claim it is a mechanism of feature learning?). I take 'feature learning' to mean something like which neuronal functions (from the input) are created or which functions are computed in a layer in some broader sense (maybe which things are made linearly readable?) or which directions in an activation space to amplify or maybe less precisely just the process of some internal functions (from the input to internal activations) being learned of something like that, which happens in finite networks apparently in contrast to infinitely wide networks or NTK models or something like that which I haven't yet understood? I understand that their heuristic identity on the surface connects something about a weight matrix to something about gradients, but assuming I've not made some index-off-by-one error or something, it seems to probably not really be about that at all, since the weight matrix sorta cancels out — if it's true for one , it would maybe also be true with any other replacing it, so it doesn't really pin down ? (This might turn out to be false if the isotropy of preactivation gradients is only true for a very particular choice of .) But like, ignoring that counter, I guess their point is that the directions which get stretched most by the weight matrix in a layer are the directions along which it would be the best to move locally in that activation space to affect the output? (They don't explain it this way though — maybe I'm ignorant of some other meaning having been attributed to in previous literature or something.) But they say "Informally, this mechanism corresponds to the approach of progressively re-weighting features in proportion to the influence they have on the predictions.". I guess maybe this is an appropriate description of the math if they are talking about reweighting in the purely linear sense, and they take features in the input layer to be scaleless objects or something? (Like, if we take features in the input activation space to each have some associated scale, then the right singular vector identity no longer says that most influential features get stretched the most.) I wish they were much more precise here, or if there isn't a precise interesting philosophical thing to be deduced from their math, much more honest about that, much less PR-y.
- So, in brief, instead of "informally, this mechanism corresponds to the approach of progressively re-weighting features in proportion to the influence they have on the predictions," it seems to me that what the math warrants would be sth more like "The weight matrix reweights stuff; after reweighting, the activation space is roughly isotropic wrt affecting the prediction (ansatz); so, the stuff that got the highest weight has most effect on the prediction now." I'm not that happy with this last statement either, but atm it seems much more appropriate than their claim.
- I guess if I'm not confused about something major here (plausibly I am), one could probably add 1000 experiments (e.g. checking that the isotropic version of the ansatz indeed equally holds in a bunch of models) and write a paper responding to them. If you're reading this and this seems interesting to you, feel free to do that — I'm also probably happy to talk to you about the paper.
typos in the paper
indexing error in the first displaymath in Sec 2: it probably should say '', not ''
A thread into which I'll occasionally post notes on some ML(?) papers I'm reading
I think the world would probably be much better if everyone made a bunch more of their notes public. I intend to occasionally copy some personal notes on ML(?) papers into this thread. While I hope that the notes which I'll end up selecting for being posted here will be of interest to some people, and that people will sometimes comment with their thoughts on the same paper and on my thoughts (please do tell me how I'm wrong, etc.), I expect that the notes here will not be significantly more polished than typical notes I write for myself and my reasoning will be suboptimal; also, I expect most of these notes won't really make sense unless you're also familiar with the paper — the notes will typically be companions to the paper, not substitutes.
I expect I'll sometimes be meaner than some norm somewhere in these notes (in fact, I expect I'll sometimes be simultaneously mean and wrong/confused — exciting!), but I should just say to clarify that I think almost all ML papers/posts/notes are trash, so me being mean to a particular paper might not be evidence that I think it's worse than some average. If anything, the papers I post notes about had something worth thinking/writing about at all, which seems like a good thing! In particular, they probably contained at least one interesting idea!
So, anyway: I'm warning you that the notes in this thread will be messy and not self-contained, and telling you that reading them might not be a good use of your time :)
I'd be very interested in a concrete construction of a (mathematical) universe in which, in some reasonable sense that remains to be made precise, two 'orthogonal pattern-universes' (preferably each containing 'agents' or 'sophisticated computational systems') live on 'the same fundamental substrate'. One of the many reasons I'm struggling to make this precise is that I want there to be some condition which meaningfully rules out trivial constructions in which the low-level specification of such a universe can be decomposed into a pair such that and are 'independent', everything in the first pattern-universe is a function only of , and everything in the second pattern-universe is a function only of . (Of course, I'd also be happy with an explanation why this is a bad question :).)
I find [the use of square brackets to show the merge structure of [a linguistic entity that might otherwise be confusing to parse]] delightful :)
I'd be quite interested in elaboration on getting faster alignment researchers not being alignment-hard — it currently seems likely to me that a research community of unupgraded alignment researchers with a hundred years is capable of solving alignment (conditional on alignment being solvable). (And having faster general researchers, a goal that seems roughly equivalent, is surely alignment-hard (again, conditional on alignment being solvable), because we can then get the researchers to quickly do whatever it is that we could do — e.g., upgrading?)
I was just claiming that your description of pivotal acts / of people that support pivotal acts was incorrect in a way that people that think pivotal acts are worth considering would consider very significant and in a way that significantly reduces the power of your argument as applying to what people mean by pivotal acts — I don't see anything in your comment as a response to that claim. I would like it to be a separate discussion whether pivotal acts are a good idea with this in mind.
Now, in this separate discussion: I agree that executing a pivotal act with just a narrow, safe, superintelligence is a difficult problem. That said, all paths to a state of safety from AGI that I can think of seem to contain difficult steps, so I think a more fine-grained analysis of the difficulty of various steps would be needed. I broadly agree with your description of the political character of pivotal acts, but I disagree with what you claim about associated race dynamics — it seems plausible to me that if pivotal acts became the main paradigm, then we'd have a world in which a majority of relevant people are willing to cooperate / do not want to race that much against others in the majority, and it'd mostly be a race between this group and e/acc types. I would also add, though, that the kinds of governance solutions/mechanisms I can think of that are sufficient to (for instance) make it impossible to perform distributed training runs on consumer devices also seem quite authoritarian.
In this comment, I will be assuming that you intended to talk of "pivotal acts" in the standard (distribution of) sense(s) people use the term — if your comment is better described as using a different definition of "pivotal act", including when "pivotal act" is used by the people in the dialogue you present, then my present comment applies less.
I think that this is a significant mischaracterization of what most (? or definitely at least a substantial fraction of) pivotal activists mean by "pivotal act" (in particular, I think this is a significant mischaracterization of what Yudkowsky has in mind). (I think the original post also uses the term "pivotal act" in a somewhat non-standard way in a similar direction, but to a much lesser degree.) Specifically, I think it is false that the primary kinds of plans this fraction of people have in mind when talking about pivotal acts involve creating a superintelligent nigh-omnipotent infallible FOOMed properly aligned ASI. Instead, the kind of person I have in mind is very interested in coming up with pivotal acts that do not use a general superintelligence, often looking for pivotal acts that use a narrow superintelligence (for instance, a narrow nanoengineer) (though this is also often considered very difficult by such people (which is one of the reasons they're often so doomy)). See, for instance, the discussion of pivotal acts in https://www.lesswrong.com/posts/7im8at9PmhbT4JHsW/ngo-and-yudkowsky-on-alignment-difficulty.
A few notes/questions about things that seem like errors in the paper (or maybe I'm confused — anyway, none of this invalidates any conclusions of the paper, but if I'm right or at least justifiably confused, then these do probably significantly hinder reading the paper; I'm partly posting this comment to possibly prevent some readers in the future from wasting a lot of time on the same issues):
1) The formula for here seems incorrect:
This is because W_i is a feature corresponding to the i'th coordinate of x (this is not evident from the screenshot, but it is evident from the rest of the paper), so surely what shows up in this formula should not be W_i, but instead the i'th row of the matrix which has columns W_i (this matrix is called W later). (If one believes that W_i is a feature, then one can see this is wrong already from the dimensions in the dot product not matching.)

2) Even though you say in the text at the beginning of Section 3 that the input features are independent, the first sentence below made me make a pragmatic inference that you are not assuming that the coordinates are independent for this particular claim about how the loss simplifies (in part because if you were assuming independence, you could replace the covariance claim with a weaker variance claim, since the 0 covariance part is implied by independence):
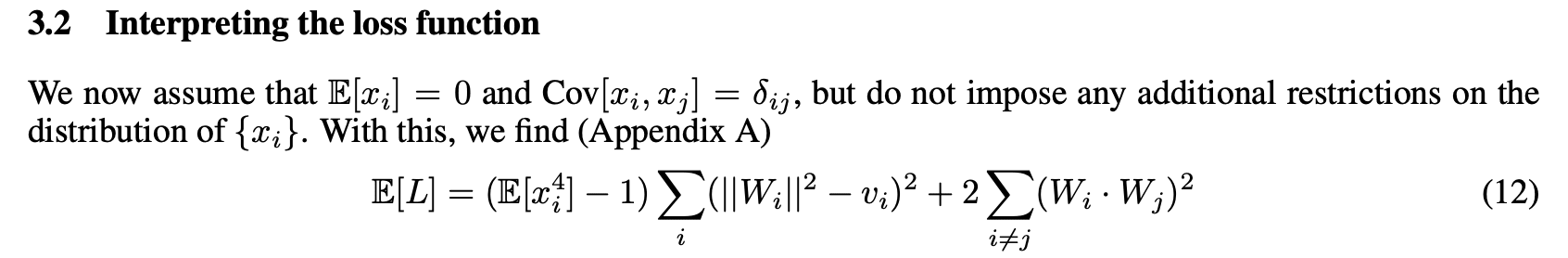
However, I think you do use the fact that the input features are independent in the proof of the claim (at least you say "because the x's are independent"):

Additionally, if you are in fact just using independence in the argument here and I'm not missing something, then I think that instead of saying you are using the moment-cumulants formula here, it would be much much better to say that independence implies that any term with an unmatched index is . If you mean the moment-cumulants formula here https://en.wikipedia.org/wiki/Cumulant#Joint_cumulants , then (while I understand how to derive every equation of your argument in case the inputs are independent), I'm currently confused about how that's helpful at all, because one then still needs to analyze which terms of each cumulant are 0 (and how the various terms cancel for various choices of the matching pattern of indices), and this seems strictly more complicated than problem before translating to cumulants, unless I'm missing something obvious.
3) I'm pretty sure this should say x_i^2 instead of x_i x_j, and as far as I can tell the LHS has nothing to do with the RHS:

(I think it should instead say sth like that the loss term is proportional to the squared difference between the true and predictor covariance.)
At least ignoring legislation, an exchange could offer a contract with the same return as S&P 500 (for the aggregate of a pair of traders entering a Kalshi-style event contract); mechanistically, this index-tracking could be supported by just using the money put into a prediction market to buy VOO and selling when the market settles. (I think.)
An attempt at a specification of virtue ethics
I will be appropriating terminology from the Waluigi post. I hereby put forward the hypothesis that virtue ethics endorses an action iff it is what the better one of Luigi and Waluigi would do, where Luigi and Waluigi are the ones given by the posterior semiotic measure in the given situation, and "better" is defined according to what some [possibly vaguely specified] consequentialist theory thinks about the long-term expected effects of this particular Luigi vs the long-term effects of this particular Waluigi. One intuition here is that a vague specification could be more fine if we are not optimizing for it very hard, instead just obtaining a small amount of information from it per decision.
In this sense, virtue ethics literally equals continuously choosing actions as if coming from a good character. Furthermore, considering the new posterior semiotic measure after a decision, in this sense, virtue ethics is about cultivating a virtuous character in oneself. Virtue ethics is about rising to the occasion (i.e. the situation, the context). It's about constantly choosing the Luigi in oneself over the Waluigi in oneself (or maybe the Waluigi over the Luigi if we define "Luigi" as the more likely of the two and one has previously acted badly in similar cases or if the posterior semiotic measure is otherwise malign). I currently find this very funny, and, if even approximately correct, also quite cool.
Here are some issues/considerations/questions that I intend to think more about:
- What's a situation? For instance, does it encompass the agent's entire life history, or are we to make it more local?
- Are we to use the agent's own semiotic measure, or some objective semiotic measure?
- This grounds virtue ethics in consequentialism. Can we get rid of that? Even if not, I think this might be useful for designing safe agents though.
- Does this collapse into cultivating a vanilla consequentialist over many choices? Can we think of examples of prompting regimes such that collapse does not occur? The vague motivating hope I have here is that in the trolley problem case with the massive man, the Waluigi pushing the man is a corrupt psycho, and not a conflicted utilitarian.
- Even if this doesn't collapse into consequentialism from these kinds of decisions, I'm worried about it being stable under reflection, I guess because I'm worried about the likelihood of virtue ethics being part of an agent in reflective equilibrium. It would be sad if the only way to make this work would be to only ever give high semiotic measure to agents that don't reflect much on values.
- Wait, how exactly do we get Luigi and Waluigi from the posterior semiotic measure? Can we just replace this with picking the best character from the most probable few options according to the semiotic measure? Wait, is this just quantilization but funnier? I think there might be some crucial differences. And regardless, it's interesting if virtue ethics turns out to be quantilization-but-funnier.
- More generally, has all this been said already?
- Is there a nice restatement of this in shard theory language?
A small observation about the AI arms race in conditions of good infosec and collaboration
Suppose we are in a world where most top AI capabilities organizations are refraining from publishing their work (this could be the case because of safety concerns, or because of profit motives) + have strong infosec which prevents them from leaking insights about capabilities in other ways. In this world, it seems sort of plausible that the union of the capabilities insights of people at top labs would allow one to train significantly more capable models than the insights possessed by any single lab alone would allow one to train. In such a world, if the labs decide to cooperate once AGI is nigh, this could lead to a significantly faster increase in capabilities than one might have expected otherwise.
(I doubt this is a novel thought. I did not perform an extensive search of the AI strategy/governance literature before writing this.)
First, suppose GPT-n literally just has a “what a human would say” feature and a “what do I [as GPT-n] actually believe” feature, and those are the only two consistently useful truth-like features that it represents, and that using our method we can find both of them. This means we literally only need one more bit of information to identify the model’s beliefs.
One difference between “what a human would say” and “what GPT-n believes” is that humans will know less than GPT-n. In particular, there should be hard inputs that only a superhuman model can evaluate; on these inputs, the “what a human would say” feature should result in an “I don’t know” answer (approximately 50/50 between “True” and “False”), while the “what GPT-n believes” feature should result in a confident “True” or “False” answer.[2] This would allow us to identify the model’s beliefs from among these two options.
For such that GPT- is superhuman, I think one could alternatively differentiate between these two options by checking which is more consistent under implications, by which I mean that whenever the representation says that the propositions and are true, it should also say that is true. (Here, for a language model, and could be ~whatever assertions written in natural language.) Or more generally, in addition to modus ponens, also construct new propositions with ANDs and ORs, and check against all the inference rules of zeroth-order logic, or do this for first-order logic or whatever. (Alternatively, we can also write down versions of these constraints that apply to probabilities.) Assuming [more intelligent => more consistent] (w.r.t. the same set of propositions), for a superhuman model, the model's beliefs would probably be the more consistent feature. (Of course, one could also just add these additional consistency constraints directly into the loss in CCS instead of doing a second deductive step.)
I think this might even be helpful for differentiating the model's beliefs from what it models some other clever AI as believing or what it thinks would be true in some fake counterfactual world, because presumably it makes sense to devote less of one's computation to ironing out incoherence in these counterfactuals – for humans, it certainly seems computationally much easier to consistently tell the truth than to consistently talk about what would be the case in some counterfactual of similar complexity to reality (e.g. to lie).
Hmm, after writing the above, now that I think more of it, I guess it seems plausible that the feature most consistent under negations is already more likely to be the model's true beliefs, for the same reasons as what's given in the above paragraph. I guess testing modus ponens (and other inference rules) seems much stronger though, and in any case that could be useful for constraining the search.
(There are a bunch of people that should be thanked for contributing to the above thoughts in discussions, but I'll hopefully have a post up in a few days where I do that – I'll try to remember to edit this comment with a link to the post when it's up.)
I think does not have to be a variable which we can observe, i.e. it is not necessarily the case that we can deterministically infer the value of from the values of and . For example, let's say the two binary variables we observe are and . We'd intuitively want to consider a causal model where is causing both, but in a way that makes all triples of variable values have nonzero probability (which is true for these variables in practice). This is impossible if we require to be deterministic once is known.
I agree with you regarding 0 lebesgue. My impression is that the Pearl paradigm has some [statistics -> causal graph] inference rules which basically do the job of ruling out causal graphs for which having certain properties seen in the data has 0 lebesgue measure. (The inference from two variables being independent to them having no common ancestors in the underlying causal graph, stated earlier in the post, is also of this kind.) So I think it's correct to say "X has to cause Y", where this is understood as a valid inference inside the Pearl (or Garrabrant) paradigm. (But also, updating pretty close to "X has to cause Y" is correct for a Bayesian with reasonable priors about the underlying causal graphs.)
(epistemic position: I haven't read most of the relevant material in much detail)