Interpretability: Integrated Gradients is a decent attribution method
post by Lucius Bushnaq (Lblack), jake_mendel, StefanHex (Stefan42), Kaarel (kh) · 2024-05-20T17:55:22.893Z · LW · GW · 7 commentsContents
Context Integrated Gradients Properties of integrated gradients Integrated gradient formula Proof sketch: Integrated Gradients are uniquely consistent under coordinate transformations The problem of choosing a baseline Attributions over datasets Acknowledgements None 7 comments
A short post laying out our reasoning for using integrated gradients as attribution method. It is intended as a stand-alone post based on our LIB papers [1] [2]. This work was produced at Apollo Research.
Context
Understanding circuits in neural networks requires understanding how features interact with other features. There's a lot of features and their interactions are generally non-linear. A good starting point for understanding the interactions might be to just figure out how strongly each pair of features in adjacent layers of the network interacts. But since the relationships are non-linear, how do we quantify their 'strength' in a principled manner that isn't vulnerable to common and simple counterexamples? In other words, how do we quantify how much the value of a feature in layer should be attributed to a feature in layer ?
This is a well-known sort of problem originally investigated in cooperative game theory. A while ago it made its way into machine learning, where people were pretty interested in attributing neural network outputs to their inputs for a while. Lately it's made its way into interpretability in the context of attributing variables in one hidden layer of a neural network to another.
Generally, the way people go about this is setting up a series of 'common-sense' axioms that the attribution method should fulfil in order to be self-consistent and act like an attribution is supposed to act. Then they try to show that there is one unique method that satisfies these axioms. Except that (a) people disagree about what axioms are 'common-sense', and (b) the axioms people maybe agree most on don't quite single out a single method as unique, just a class of methods called path attributions. So no attribution method has really been generally accepted as the canonical 'winner' in the ml context yet. Though some methods are certainly more popular than others.
Integrated Gradients
Integrated gradients is a computationally efficient attribution method (compared to activation patching / ablations) grounded in a series of axioms. It was originally proposed the context of economics (Friedman 2004), and recently used to attribute neural networks outputs to their inputs(Sundararajan et al. 2017). Even more recently, they started being used for internal feature attribution as well (Marks et al. 2024, Redwood Research (unpublished) 2022).
Properties of integrated gradients
Suppose we want to explain to what extent the value of an activation in a layer of a neural network can be 'attributed to' the various components of the activations in layer upstream of .[1] For now, we do this for a single datapoint only. So we want to know how much can be attributed to . We'll write this attribution as .
There is a list of four standard requirements of properties attribution methods should satisfy that single out path attributions as the only kind of attribution methods that can be used to answer this question. Integrated gradients, and other path attribution methods, fulfil all of these (Sundararajan et al. 2017).
- Implementation Invariance: If two different networks have activations , such that for all possible inputs , then the attributions for any in both networks is the same.
- Completeness: The sum over all attributions equals the value of , that is .
- Sensitivity: If does not depend (mathematically) on , the attribution of for is zero.
- Linearity: Let . Then the attribution from to should equal the weighted sum of its attributions for and .
If you add on a fifth requirement that the attribution method behaves sensibly under coordinate transformations, integrated gradients are the only attribution method that satisfies all five axioms:
- Consistency under Coordinate Transformations: If we transform layer into an alternate basis of orthonormal coordinates, where the activation vector is one-hot ( )[2] then the first component should receive the full attribution , and the other components should receive zero attribution.
In other words, all the attribution should go to the direction our activation vector actually lies in. If we go into an alternate basis of coordinates such that one of our coordinate basis vectors lies along , , then the component along should get all the attribution at data point , because the other components aren't even active and thus obviously can't influence anything.
We think that this is a pretty important property for an attribution method to have in the context of interpreting neural network internals. The hidden layers of neural networks don't come with an obvious privileged basis. Their activations are vectors in a vector space, which we can view in any basis we please. So in a sense, any structure in the network internals that actually matters for the computation should be coordinate independent [LW · GW]. If our attribution methods are not well-behaved under coordinate transformations, they can give all kinds of misleading results, for example by taking the network out of the subspace the activations are usually located in [LW · GW].
Property 4 already ensures that the attributions are well-behaved under linear coordinate transformations of the target layer . This 5th axiom ensures they're also well-behaved under coordinate transforms in the starting layer .
We will show below that adding the 5th requirement singles out integrated gradients as the canonical attribution method that satisfies all five requirements.
Integrated gradient formula
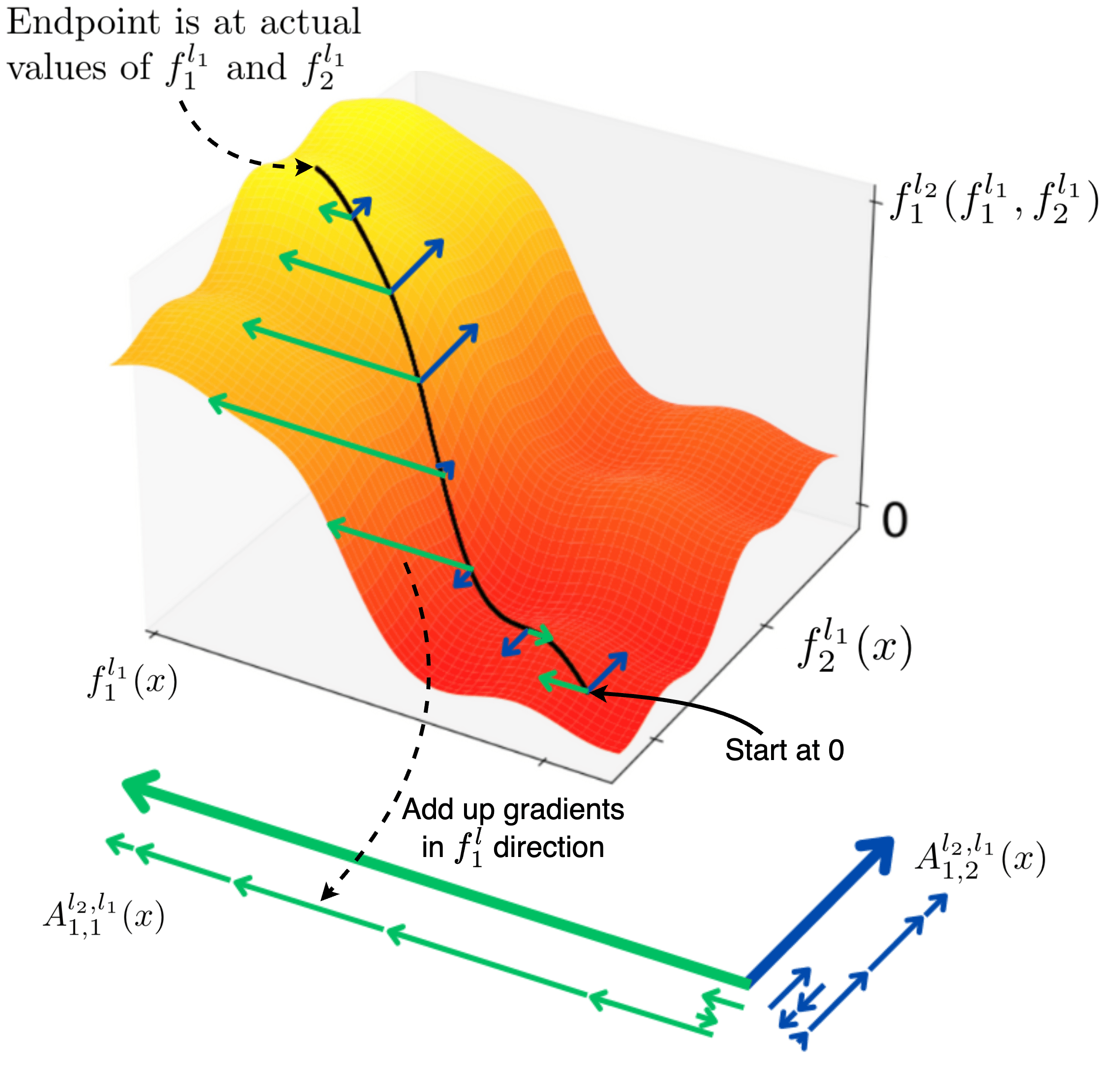
The general integrated gradient formula to attribute the influence of feature in a layer on feature in layer is given by an integral along a straight-line path in layer activation space. To clarify notation, we introduce a function which maps activations from layer to . For example, in an MLP (bias folded in) we might have . Then we can write the attribution from to as
where is a point in the layer activation space, and the path is parameterised by , such that along the curve we have .[2]
Intuitively, this formula asks us to integrate the gradient of with respect to along a straight path from a baseline activation to the actual activation vector , and multiply the result with .
Proof sketch: Integrated Gradients are uniquely consistent under coordinate transformations
Friedman 2004 showed that any attribution method satisfying the first four axioms must be a path attribution of the form
or a convex combination (weighted average with weights ) of these
Each term is a line integral along a monotonous path in the activation space of layer that starts at the baseline and ends at the activation vector .
Claim: The only attribution that also satisfies the fifth axiom is the straight line from to . That is, for all the paths in the sum except for the path parametrised as
Proof sketch: Take as the mapping between layers and , with an orthogonal matrix , and . Then, for any monotonous paths which are not the straight line , at least one direction in layer with will be assigned an attribution .
Since no monotonous paths lead to a negative attribution, the sum over all paths must then also yield an attribution for those , unless for every path in the sum except .
The problem of choosing a baseline
The integrated gradient formula still has one free hyperparameter in it: The baseline . We're trying to attribute the activations in one layer to the activations in another layer. This requires specifying the coordinate origin relative to which the activations are defined.
Zero might look like a natural choice here, but if we are folding the biases into the activations, do we want the baseline for the bias to be zero as well? Or maybe we want the origin to be the expectation value of the activation over the training dataset? But then we'd have a bit of a consistency problem with axiom 2 across layers, because the expectation value of a layer often will not equal its activation at the expectation value of the previous layer, . So, with this baseline the attributions to the activations in a layer would not add up to the activations in layer . In fact, for some activation functions, like sigmoids for example, , so baseline zero potentially has this consistency problem as well.
We don't feel like we have a good framing for picking the baseline in a principled way yet.
Attributions over datasets
We now have a method for how to do attributions on single data points. But when we're searching for circuits, we're probably looking for variables that have strong attributions between each other on average, measured over many data points. But how do we average attributions for different data points into a single attribution over a data set in a principled way?
We don't have a perfect answer to this question. We experimented with applying the integrated gradient definition to functionals, attributing measures of the size of the function to the functions but found counter-examples to those (e.g. cancellation between negative and positive attribution). Thus we decided to simply take the RMS over attributions on single datapoints
This averaged attribution does not itself fulfil axiom 2 (completeness), but it seems workable in practice. We have not found any counterexamples (situations where even though is obviously important for ) for good choices of bases (such as LIB).
Acknowledgements
This work was done as part of the LIB interpretability project [1] [2] at Apollo Research where it benefitted from empirical feedback: the method was implemented by Dan Braun, Nix Goldowsky-Dill, and Stefan Heimersheim. Earlier experiments were conducted by Avery Griffin, Marius Hobbhahn, and Jörn Stöhler.
- ^
The activation vectors here are defined relative to some baseline . This can be zero, but it could also be the mean value over some data set.
- ^
Integrated gradients still leaves us a free choice of baseline relative to which we measure activations. We chose 0 for most of this post for simplicity, but e.g. the dataset mean of the activations also works.
7 comments
Comments sorted by top scores.
comment by ryan_greenblatt · 2024-05-21T03:14:23.839Z · LW(p) · GW(p)
[Not very confident, but just saying my current view.]
I'm pretty skeptical about integrated gradients.
As far as why, I don't think we should care about the derivative at the baseline (zero or the mean).
As far as the axioms, I think I get off the train on "Completeness" which doesn't seem like a property we need/want.
I think you just need to eat that there isn't any sensible way to do something reasonable that gets Completeness.
The same applies with attribution in general (e.g. in decision making).
Replies from: Lblack↑ comment by Lucius Bushnaq (Lblack) · 2024-05-21T07:58:02.356Z · LW(p) · GW(p)
The same applies with attribution in general (e.g. in decision making).
As in, you're also skeptical of traditional Shapley values in discrete coalition games?
"Completeness" strikes me as a desirable property for attributions to be properly normalized. If attributions aren't bounded in some way, it doesn't seem to me like they're really 'attributions'.
Very open to counterarguments here, though. I'm not particularly confident here either. There's a reason this post isn't titled 'Integrated Gradients are the correct attribution method'.
comment by ryan_greenblatt · 2024-05-21T02:59:43.890Z · LW(p) · GW(p)
Integrated gradients is a computationally efficient attribution method (compared to activation patching / ablations) grounded in a series of axioms.
Maybe I'm confused, but isn't integrated gradients strictly slower than an ablation to a baseline?
Replies from: Lblack, Stefan42↑ comment by Lucius Bushnaq (Lblack) · 2024-05-21T09:16:16.274Z · LW(p) · GW(p)
If you want to get attributions between all pairs of basis elements/features in two layers, attributions based on the effect of a marginal ablation will take you forward passes, where is the number of features in a layer. Integrated gradients will take backward passes, and if you're willing to write custom code that exploits the specific form of the layer transition, it can take less than that.
If you're averaging over a data set, IG is also amendable to additional cost reduction through stochastic source techniques.
↑ comment by StefanHex (Stefan42) · 2024-05-21T09:06:17.627Z · LW(p) · GW(p)
Maybe I'm confused, but isn't integrated gradients strictly slower than an ablation to a baseline?
For a single interaction yes (1 forward pass vs integral with n_alpha integration steps, each requiring a backward pass).
For many interactions (e.g. all connections between two layers) IGs can be faster:
- Ablation requires d_embed^2 forward passes (if you want to get the effect of every patch on the loss)
- Integrated gradients requires d_embed * n_alpha forward & backward passes
(This is assuming you do path patching rather than "edge patching", which you should in this scenario.)
Sam Marks makes a similar point in Sparse Feature Circuits, near equations (2), (3), and (4).
comment by tailcalled · 2024-05-20T20:58:29.341Z · LW(p) · GW(p)
We now have a method for how to do attributions on single data points. But when we're searching for circuits, we're probably looking for variables that have strong attributions between each other on average, measured over many data points.
Maybe?
One thing I've been thinking a lot recently is that building tools to interpret networks on individual datapoints might be more relevant than attributing over a dataset. This applies if the goal is to make statistical generalizations since a richer structure on an individual datapoint gives you more to generalize with, but it also applies if the goal is the inverse, to go from general patterns to particulars, since this would provide a richer method for debugging, noticing exceptions, etc..
And basically the trouble a lot of work that attempts to generalize ends up with is that some phenomena are very particular to specific cases, so one risks losing a lot of information by only focusing on the generalizable findings.
Either way, cool work, seems like we've thought about similar lines but you've put in more work.
Replies from: Lblack↑ comment by Lucius Bushnaq (Lblack) · 2024-05-21T11:56:10.814Z · LW(p) · GW(p)
The issue with single datapoints, at least in the context we used this for, which was building interaction graphs for the LIB papers, is that the answer to 'what directions in the layer were relevant for computing the output?' is always trivially just 'the direction the activation vector was pointing in.'
This then leads to every activation vector becoming its own 'feature', which is clearly nonsense. To understand generalisation, we need to see how the network is re-using a small common set of directions to compute outputs for many different inputs. Which means looking at a dataset of multiple activations.
And basically the trouble a lot of work that attempts to generalize ends up with is that some phenomena are very particular to specific cases, so one risks losing a lot of information by only focusing on the generalizable findings.
The application we were interested in here was getting some well founded measure of how 'strongly' two features interact. Not a description of what the interaction is doing computationally. Just some way to tell whether it's 'strong' or 'weak'. We wanted this so we could find modules in the network.
Averaging over data loses us information about what the interaction is doing, but it doesn't necessarily lose us information about interaction 'strength', since that's a scalar quantity. We just need to set our threshold for connection relevance sensitive enough that making a sizeable difference on a very small handful of training datapoints still qualifies.