The Local Interaction Basis: Identifying Computationally-Relevant and Sparsely Interacting Features in Neural Networks
post by Lucius Bushnaq (Lblack), jake_mendel, Dan Braun (dan-braun-1), StefanHex (Stefan42), Nicholas Goldowsky-Dill (nicholas-goldowsky-dill), Kaarel (kh), Avery, Joern Stoehler, debrevitatevitae (cindy-wu), Magdalena Wache, Marius Hobbhahn (marius-hobbhahn) · 2024-05-20T17:53:25.985Z · LW · GW · 4 commentsContents
4 comments
This is a linkpost for our two recent papers:
- An exploration of using degeneracy in the loss landscape for interpretability https://arxiv.org/abs/2405.10927
- An empirical test of an interpretability technique based on the loss landscape https://arxiv.org/abs/2405.10928
This work was produced at Apollo Research in collaboration with Kaarel Hanni (Cadenza Labs), Avery Griffin, Joern Stoehler, Magdalena Wache and Cindy Wu. Not to be confused with Apollo's recent Sparse Dictionary Learning paper [AF · GW].
A key obstacle to mechanistic interpretability is finding the right representation of neural network internals. Optimally, we would like to derive our features from some high-level principle that holds across different architectures and use cases. At a minimum, we know two things:
- We know that the training loss goes down during training. Thus, the features learned during training must be determined by the loss landscape. We want to use the structure of the loss landscape to identify what the features are and how they are represented.
- We know that models generalize, i.e. that they learn features from the training data that allow them to accurately predict on the test set. Thus, we want our interpretation to explain this generalization behavior.
Generalization has been linked to basin [LW · GW] broadness [LW · GW] in the loss landscape in several ways, most notably including singular [LW · GW] learning [? · GW] theory, which introduces the learning [? · GW] coefficient [LW · GW] as a measure of basin broadness that doubles as a measure of generalization error that replaces the parameter count in Occam's razor [LW · GW].
Inspired by both of these ideas, the first paper explores using the structure of the loss landscape to find the most computationally natural representation of a network. We focus on identifying parts of the network that are not responsible for low loss (i.e. degeneracy), inspired by singular learning theory [? · GW]. These degeneracies are an obstacle for interpretability as they mean there exist parameters which do not affect the input-output behavior in the network (similar to the parameters of a Transformer and matrices that do not affect the product ).
We explore 3 different ways neural network parameterisations can be degenerate:
- when activations are linearly dependent
- when gradient vectors are linearly dependent
- when ReLU neurons fire on the same inputs.
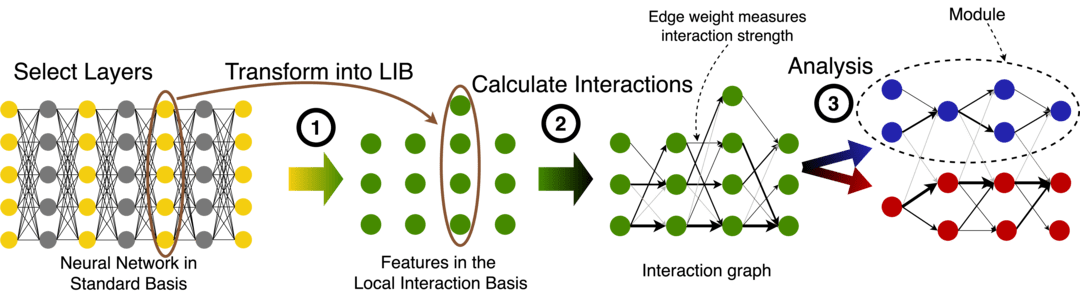
This investigation leads to the interaction basis, and eventually the local interaction basis (LIB) that we test in the second paper. This basis removes computationally irrelevant features and interactions, and sparsifies the remaining interactions between layers.
Finally, we analyse how modularity is connected to degeneracy in the loss landscape. We suggest a preliminary metric for finding the sorts of modules that the neural network prior is biased towards.
The second paper tests how useful the LIB is in toy and language models. In this new basis we calculate integrated gradient based interactions between features, and analyse the graph of all features in a network. We interpret strongly-interacting features, and identify modules in this graph using the modularity metric of the first paper.
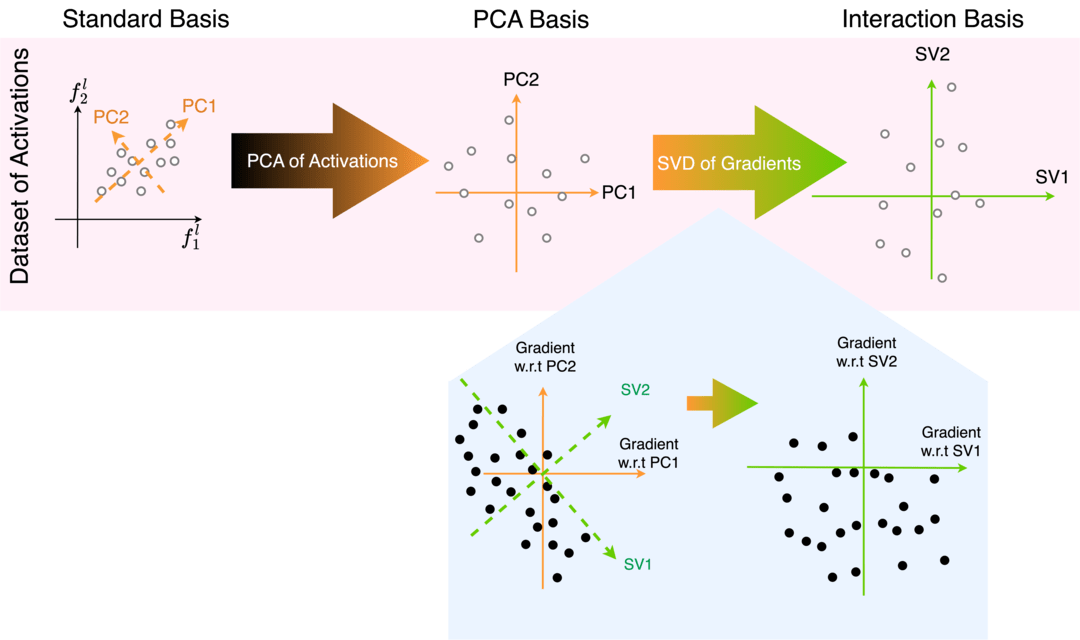
To derive the LIB basis we coordinate-transform the activations of neural networks in two steps: Step 1 is a transformation into the PCA basis, removing activation space directions which don't explain any variance. Step 2 is a transformation of the activations to align the basis with the right singular vectors of the gradient vector dataset. The 2nd step is the key new ingredient which aims to make interactions between adjacent layers sparse, and removes directions which do not affect downstream computation.
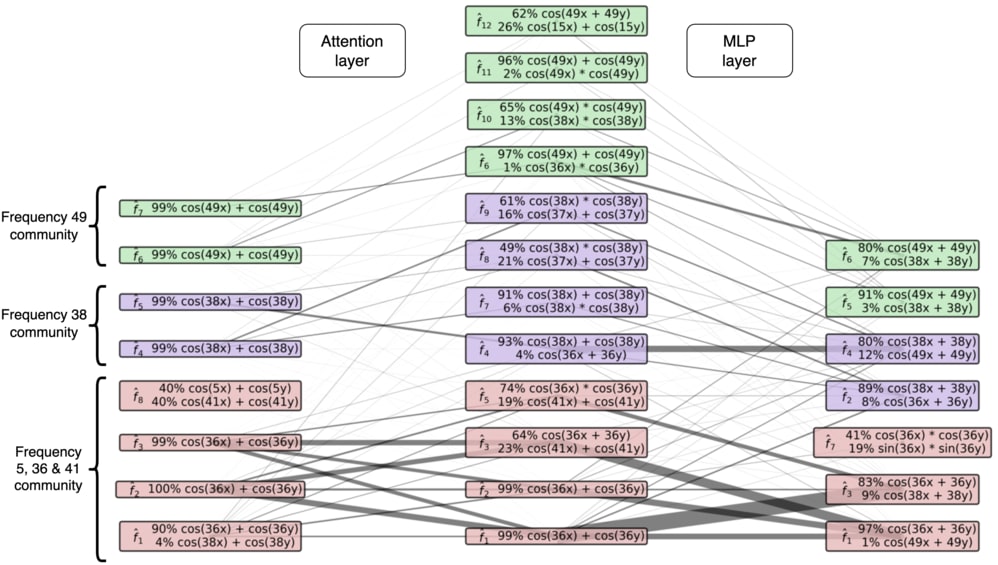
We test LIB on two toy models (modular addition & CIFAR-10), and two language models (Tinystories-1M & GPT2-small). On toy models we successfully find a basis that is more sparsely interacting and contains only computationally-relevant features, and we can identify circuits based on the interaction graphs. See the interaction graph for the modular addition transformer below (cherry picked result).
On language models however, we find that LIB does not help us understand the networks. We find that interaction sparsity, compared to a PCA baseline, increases only slightly (for Tinystories-1M) or not at all (GPT2-small), and can identify no modules or interpretable features.
While this is mostly a negative result, we think there is valuable future work to develop loss landscape inspired techniques for interpretability that makes fewer assumptions than those that went into the derivation of LIB. Most notably, in deriving LIB, we did not assume superposition to be true because we wanted to start with the simplest possible version of the theory, and because we wanted to make a bet that was decorrelated with other research in the field. However, recent advances in sparse dictionary learning suggests that work which relaxes the assumptions of LIB to allow for superposition may find more interpretable features.
4 comments
Comments sorted by top scores.
comment by tailcalled · 2024-05-20T20:45:06.000Z · LW(p) · GW(p)
I was thinking in similar lines, but eventually dropped it because I felt like the gradients would likely miss something if e.g. a saturated softmax prevents any gradient from going through. I find it interesting that experiments also find that the interaction basis didn't work, and I wonder whether any of the failure here is due to saturated softmaxes.
Replies from: Lblack↑ comment by Lucius Bushnaq (Lblack) · 2024-05-21T07:43:00.323Z · LW(p) · GW(p)
I doubt it. Evaluating gradients along an entire trajectory from a baseline gave qualitatively similar results.
A saturated softmax also really does induce insensitivity to small changes. If two nodes are always connected by a saturated softmax, they can't be exchanging more than one bit of information. Though the importance of that bit can be large.
My best guess for why the Interaction Basis didn't work is that sparse, overcomplete representations really are a thing. So in general, you're not going to get a good decomposition of LMs from a Cartesian basis of activation space.
comment by Review Bot · 2024-06-15T01:45:49.068Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2025. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
comment by Charlie Steiner · 2024-06-15T12:23:12.031Z · LW(p) · GW(p)
This was super interesting. I hadn't really thought about the tension between SLT and superposition before, but this is in the middle of it.
Like, there's nothing logically inconsistent with the best local basis for the weights being undercomplete while the best basis for the activations is overcomplete. But if both are true, it seems like the relationship to the data distribution has to be quite special (and potentially fragile).