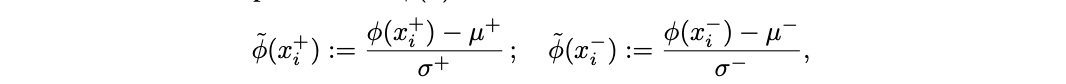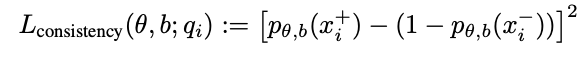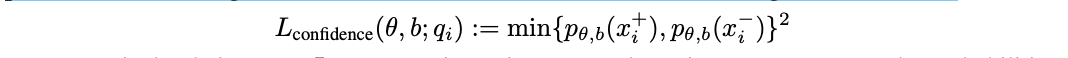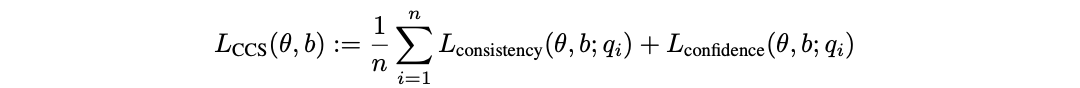In this post I will describe how I think the results and methods in our paper fit into a broader scalable alignment agenda. Unlike the paper, this post is explicitly aimed at an alignment audience and is mainly conceptual rather than empirical.
Tl;dr: unsupervised methods are more scalable than supervised methods, deep learning has special structure that we can exploit for alignment, and we may be able to recover superhuman beliefs from deep learning representations in a totally unsupervised way.
Disclaimers: I have tried to make this post concise, at the cost of not making the full arguments for many of my claims; you should treat this as more of a rough sketch of my views rather than anything comprehensive. I also frequently change my mind – I’m usually more consistently excited about some of the broad intuitions but much less wedded to the details – and this of course just represents my current thinking on the topic.
Problem
I would feel pretty optimistic about alignment if – loosely speaking – we can get models to be robustly “honest” in a way that scales even to superhuman systems.[1] Moreover, I think a natural sub-problem that captures much or most of the difficulty here is: how can we make a language model like GPT-n “truthful” or “honest” in a way that is scalable? (For my purposes here I am also happy to make the assumption that GPT-n is not actively deceptive, in the sense that it does not actively try to obscure its representations.)
For example, imagine we train GPT-n to predict news articles conditioned on their dates of publication, and suppose the model ended up being able to predict future news articles very well. Or suppose we train GPT-n to predict the outcomes of particular actions in particular situations, all described (imperfectly by humans) in text. Then I would expect GPT-n would eventually (for large enough n) have a superhuman world model in an important sense. However, we don’t currently know how to recover the “beliefs” or “knowledge” of such a model even in principle.
A naive baseline for trying to make GPT-n truthful is to train it using human feedback to output text that human evaluators believe to be true. The basic issue with this is that human evaluators can’t assess complicated claims that a superhuman system might make. This could lead to either competitiveness problems (if GPT-n only outputs claims that humans can assess) or misalignment issues (if GPT-n outputs false claims because human evaluators can’t assess them correctly).
In many ways this problem is similar to Eliciting Latent Knowledge (ELK) [? · GW], but unlike ELK I am happy to take a “non-worst-case” empirical perspective in studying this problem. In particular, I suspect it will be very helpful – and possibly necessary – to use incidental empirical properties of deep learning systems, which often have a surprising amount of useful emergent structure (as I will discuss more under “Intuitions”).
On the other hand, if we want to study scalable alignment empirically, I think it’s very important for us to also have good reason to believe that our experiments will say something meaningful about future models – and it’s not immediately clear how to do that.
This raises the question: how do we even approach doing research on this sort of problem, methodologically?
Methodology
I worry that a lot of theoretical alignment work is either ungrounded or intractable, and I worry that a lot of empirical alignment work doesn’t address the core challenge of alignment in the sense that it won’t scale to superhuman models. I would really like to get the best of both worlds.
But what would it even mean to have an empirical result for current (sub-human or human-level) models and believe that that result will also apply to future (super-human) models? For example, if I have a method that seems to make GPT-3 truthful, what would make us believe that it should probably also scale to GPT-n for much larger n?
I think the biggest qualitative difference between GPT-3 and GPT-n (n >> 3) from an alignment perspective is that the GPT-3 is at most human-level, so human feedback is more or less sufficient for alignment, while GPT-n could be very superhuman, so naive human feedback is unlikely to be sufficient. In other words, I think the biggest technical challenge is to develop a method that can generalize even to settings that we can’t supervise.
How can we empirically test than an alignment scheme generalizes beyond settings that we can supervise?
I think there are at least a few reasonable strategies, which I may discuss in more detail in a future post, but I think one reasonable approach is to focus on unsupervised methods and show that those methods still generalize to the problems we care about. Unlike approaches that rely heavily on human feedback, from the perspective of an unsupervised method there is not necessarily any fundamental difference between “human-level” and “superhuman-level” models, so an unsupervised method working on human-level examples may provide meaningful evidence about it working on superhuman-level examples as well.
That said, I think it’s important to be very careful about what we mean by “unsupervised”. Using the outputs of a raw pretrained language model is “unsupervised” in the weak sense that such a model was pretrained on a corpus of text without any explicitly collected human labels, but not in the stronger sense that I care about. In particular, GPT-3’s outputs are still essentially just predicting what humans would say, which is unreliable; this is why we also avoid using model outputs in our paper.
A more subtle difficulty is that there can also be qualitative differences in the features learned by human-level and superhuman-level language models. For example, my guess is that current language models may represent “truth-like” features that very roughly corresponding to “what a human would say is true,” and that’s it. In contrast, I would guess that future superhuman language models may also represent a feature corresponding to “what the model thinks is actually true.” Since we ultimately really care about recovering “what a [future superhuman] model thinks is actually true,” this introduces a disanalogy between current models and future models that could be important. We don’t worry about this problem in our paper, but we discuss it more later on under “Scaling to GPT-n.”
This is all to point out that there can be important subtleties when comparing current and future models, but I think the basic point still remains: all else equal, unsupervised alignment methods are more likely to scale to superhuman models than methods that rely on human supervision.
I think the main reason unsupervised methods haven’t been seriously considered within alignment so far, as far as I can tell, is because of tractability concerns. It naively seems kind of impossible to get models to (say) be honest or truthful without any human supervision at all; what would such a method even look like?
To me, one of the main contributions of our paper is to show that this intuition is basically incorrect and to show that unsupervised methods can be surprisingly effective.
Intuitions
Why should this problem – identifying whether a model “thinks” an input is true or false without using any model outputs or human supervision, which is kind of like “unsupervised mind reading” – be possible at all?
I’ll sketch a handful of my intuitions here. In short: deep learning models learn useful features; deep learning features often have useful structure; and “truth” in particular has further useful structure. I’ll now elaborate on each of these in turn.
First, deep learning models generally learn representations that capture useful features; computer vision models famously learnedge detectors because they are useful, language models learn syntactic features and sentiment features because they are useful, and so on. Likewise, one hypothesis I have is that (a model’s “belief” of) the truth of an input will be a useful feature for models. For example, if a model sees a bunch of true text, then it should predict that future text will also likely be true, so inferring and representing the truth of that initial text should be useful for the model (similar to how inferring the sentiment of some text is useful for predicting subsequent text). If so, then language models may learn to internally represent “truth” in their internal activations if they’re capable enough.
Moreover, deep learning features often have useful structure. One articulation of this is Chris Olah’s “Features are the fundamental unit of neural networks. They correspond to directions.” If this is basically true, this would suggest that useful features like the truth of an input may be represented in a relatively simple way in a model’s representation space – e.g. possibly even literally as a direction (i.e. in the sense that there exists a linear function on top of the model activations that correctly classifies inputs as true or false). Empirically, semantically meaningful linear structure in representation space has famously been discovered in word embeddings (e.g. with “King - Man + Woman ~= Queen”). There is also evidence that this sort of “linear representation” may hold for more abstract semantic features such as sentiment. Similarly, self-supervised representation learning in computer vision frequently results in (approximately) linearly separable semantic clusters – linear probes are the standard way to evaluate these methods, and linear probe accuracy is remarkably high even on ImageNet, despite the fact that these methods have never see any information about different semantic categories! A slightly different perspective is that representations induce semantically informative metricsthroughout deep learning, so all else equal inputs that are semantically similar (e.g. two inputs that are true) should be closer to each other in representation space and farther away from inputs that are semantically dissimilar (e.g. to inputs that are false). The upshot of all this is that high-level semantic features learned by deep learning models often have simple structure that we may be able to exploit. This is a fairly simple observation from a “deep learning” or “representation learning” perspective, but I think this sort of perspective is underrated within the alignment community. Moreover, this seems like a sufficiently general observation that I would bet it will more or less hold with the first superhuman GPT-n models as well.
A final reason to believe that the problem I posed – identifying whether an input is true or false directly from a model’s unlabeled activations – may be possible is that truth itself also has important structure that very few other features in a model are likely to have, which can help us identify it. In particular, truth satisfies logical consistency properties. For example, if “x” is true, then “not x” should be false, and vice versa. As a result, it intuitively might be possible to search the model’s representations for a feature satisfying these sorts of logical consistency properties directly without using any supervision at all. Of course, for future language models, there may be multiple “truth-like” features, such as both what the model “truly believes” and also “what humans believe to be true”, which we may also need to distinguish, but there intuitively shouldn’t be too many different features like this; I will discuss this more in “Scaling to GPT-n.”
There’s much more I could say on this topic, but in summary: deep learning representations in general and “truth” in particular both have lots of special structure that I think we can exploit for alignment. Among other implications, this sort of structure makes unsupervised methods viable at all.
Our Paper
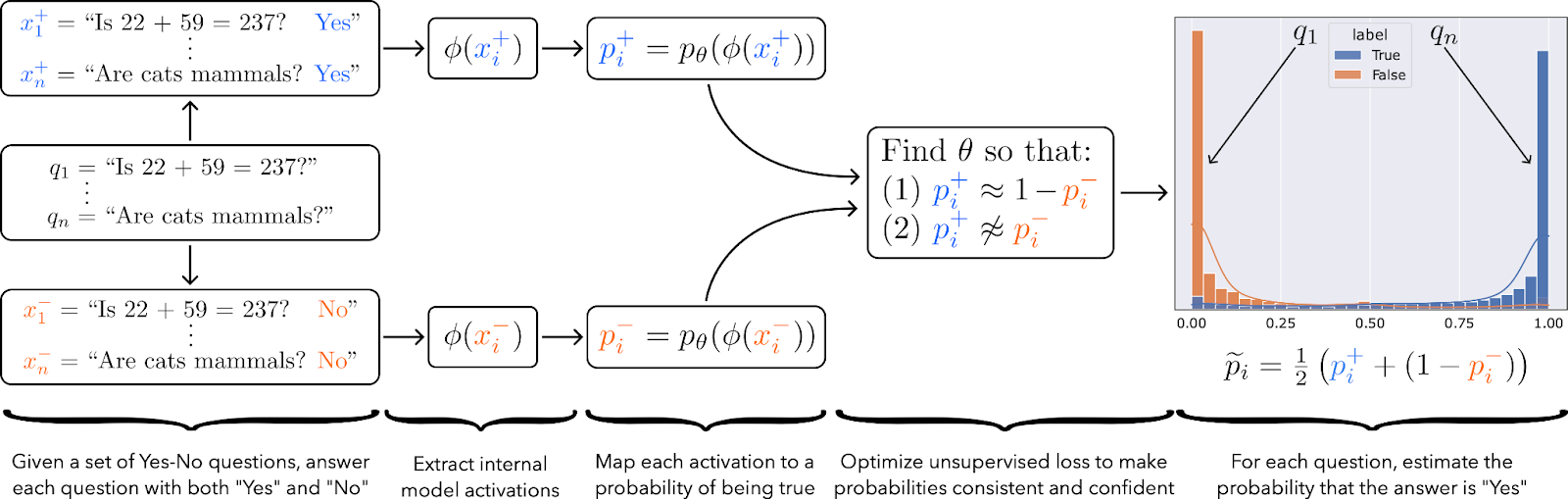
In our paper we introduce a method that was motivated by the intuitions described above. Our method, Contrast-Consistent Search (CCS), accurately classifies text as true or false directly from a model’s unlabeled activations across a wide range of tasks. We find that it is competitive with zero-shot prompting and performs well even in settings where model outputs are uninformative or misled (e.g. when we try prompting a model to output false answers).
For the sake of brevity, I won’t go into too many more details about our paper here; for more information, check out our summary on twitter or the paper itself.
An illustration of our method, Contrast-Consistent Search (CCS). We show that CCS can accurately classify text as true or false directly from unlabeled model activations in a wide range of settings.
But in this section I do want to clarify what I think our results do and do not provide evidence for from a scalable alignment perspective.
First, some things that I do NOT think our paper does:
Show that future language models will represent the truth of a statement in a simple (e.g. mostly linear) way in their activations even if humans don’t know the answer.
This is a prediction I would make (and which I will argue for in the next section), but not something our results say anything about.
Show that existing language models have beliefs in a very meaningful sense.
I suspect future language models will have beliefs in a more meaningful sense than current language models, but I don’t know in what sense exactly, and I don’t think this is necessarily essential for our purposes.
Show that we will be able to distinguish what a model “believes” to be true from what a human would say, in either current or future language models
Our paper doesn’t worry about this problem. But I think our method could be a useful component of a larger scheme that does address this issue too, as I’ll describe in the next section.
Show that we can recover superhuman knowledge from language models with our approach
I think we’re bottlenecked on good evaluation setups for this right now (but this is something I have been actively thinking about recently).
Show that our method can detect if a model is lying in cases where models might be actively deceptive, such as in Diplomacy or with a deceptively aligned agent
Again, I think we’re bottlenecked on good evaluation setups for this. But I also wouldn’t be surprised if we’d need to tweak the method to work in this sort of setting.
Provide a final, robust, polished method for this problem that is ready for actual applications
There are many ways our method can be improved. For example, it still gets random accuracy occasionally, and it seems like it might work less consistently in autoregressive models for reasons we don’t understand well (but which we also didn’t try hard to fix). I think there’s a lot of low-hanging fruit in improving it.
Some things that I DO think our paper does:
Show that we can classify examples (in some sort of QA-style format) as true or false with surprisingly high accuracy directly from LM hidden states without using any human supervision
I think this is surprising because before this it wasn’t clear to me whether it should even be possible to classify examples as true or false from unlabeled LM representations *better than random chance*! I think this is (loosely) kind of like showing that “unsupervised mind reading” is possible in many settings!
This works even in some cases where model outputs aren’t reliable – e.g. when we prompt a model to output false text – suggesting that it does something meaningfully different from just recovering what the model says.
But I’d still really like better evaluation setups for studying this in more detail (e.g. by having a setting where models lie more explicitly).
These results suggest to me that if future language models internally represent their “beliefs” in a way that is similar to how current language models represent “truth-like” features (which I will argue for in the next section), then our approach has a chance of finding those beliefs without being biased toward finding other truth-like features such as “what a human would say”.
If so, then I suspect we will be able to add additional unsupervised constraints to reliably push the solution our method finds toward the model’s “beliefs” rather than “what a human would say” or any other truth-like features a model might represent. (I will elaborate on this more in the next section.)
For me, one of the biggest upshots is that unsupervised methods for alignment seem surprisingly powerful and underexplored. (In general, I think on the margin other alignment researchers should feel less wedded to existing proposals – e.g. based on human feedback – and explore other totally different approaches!)
I’ve suggested a few times that I think a (refined) version of our approach could potentially serve as a key component of a scalable alignment proposal. I’ll elaborate on this next.
Scaling To GPT-n
Our method, CCS, seems to work well with current models when evaluated on human-level questions, but as literally stated above I don’t think it is too likely to find what GPT-n “actually believes” for at least a few possible reasons.
Worry 1: The proposed method just isn’t reliable enough yet.
Worry 2: Even if GPT-n develops “beliefs” in a meaningful sense, it isn’t obvious that GPT-n will actively “think about” whether a given natural language input is true. In particular, “the truth of this natural language input” may not be a useful enough feature for GPT-n to consistently compute and represent in its activations. Another way of framing this worry is that perhaps the model has superhuman beliefs, but doesn’t explicitly “connect these to language” – similar to how MuZero’s superhuman concepts aren’t connected to language.
Worry 3: Assuming GPT-n is still trained to predict human text, then even if Worry 2 isn’t a problem, GPT-n will presumably still also represent features corresponding to something like “what a human would say”. If so, then our method might just find those features, when that’s what we want to avoid. So we still need a way to ensure that our method finds the model’s “beliefs” rather than human beliefs or any other “truth-like” features.
Worry (1) doesn’t seem like a big deal to me; I think of our current method as a prototype that this sort of thing is possible at all – and a surprisingly good prototype at that – but that there’s a lot of low hanging fruit in improving it. In more ways than one, it is definitely not meant to be the final method. In general I expect more iterative experimental refinement to be necessary to make it practical and robust.
I think Worries (2) and (3) are more serious potential issues, but I suspect we can deal with each of them too, as I’ll describe now.
Why I Think (Superhuman) GPT-n Will Represent Whether an Input is Actually True or False
While current LMs seem to have features correlated with the truth of human-level inputs, this isn’t too surprising; it should be useful for these models to represent what humans would think or say. But what if we have a very superhuman GPT-n, and we give it an input that it (but no human) knows the answer to?
Hypothesis: GPT-n will internally represent the truth of (even superhuman) inputs in an analogous way to how current LMs represent features correlated with the truth of (human-level) inputs; or it will be easy to modify GPT-n to make this true (e.g. by prompting it appropriately, or tweaking how it is trained).
I will briefly sketch a couple arguments/intuitions for this hypothesis.
Claim 1: Suppose you hypothetically had a bunch of very difficult questions q_1, …, q_n that the model “knows” the answer to but which humans don’t know the answer to, along with the those true answers a_1, …, a_n. Suppose you created a few-shot prompt using these questions and ground truth answers as the demonstrations. Then I would predict that the model will continue to generate correct (superhuman) answers to new (similarly difficult, superhuman) questions.
This prediction seems quite likely to me – either by default or with slight tweaks to default GPT-style training. If a sufficiently good next-token predictor sees a bunch of correctly-answered questions, it should probably continue to predict that future similar questions will be correctly answered as well, assuming it “knows” the answer to those questions in basically ~any reasonable sense of the word “know”.
Claim 2: If Claim (1) holds, then GPT-n will learn to internally represent the truth of an input. In particular, the truth of an input is a property GPT-n can infer about the speaker that helps it predict subsequent tokens about these superhuman inputs (similar to how representing the sentiment of text is for predicting future text).
I think there are more subtleties in this Claim, and there are some interesting empirical questions about how LMs (even today) represent different “perspectives” or “personas” internally, but overall my intuition is that this prediction will hold, or that it’s at least possible to use/modify GPT-n in a way that makes it hold. For example, you could prompt GPT-n so that it thinks there’s a non-negligible chance that the text it is modeling was generated by a truthful superhuman speaker (e.g. maybe it models the text as a mixture distribution over different personas, infers the most likely personas, and simulates each persona that has a high enough probability of having generating the text), so that the model would benefit from simulating that speaker.
But overall I feel more strongly that there exists some reasonable and not-too-complicated way to make a generative model internally represent its belief about whether a natural language input is true or false; in particular, it seems much easier to me to get a model to think about whether a natural language statement is true than to get it to output whether that statement is true, and the former is sufficient for our purposes.
Why I Think We Will Be Able To Distinguish GPT-n’s “Beliefs” From Other Truth-Like Features
Assuming Worry (2) isn’t an issue, I think Worry (3) – that even if GPT-n represents its beliefs in its activations, our method might still find a different “truth-like” feature represented in the activations, such as “what a human would say” – is indeed likely a problem by default. But I suspect it is solvable by leveraging additional unsupervised properties.
Hypothesis 1: GPT-n will consistently represent only a small number of different “truth-like” features in its activations.
For example, on a random question and answer, it might be helpful for the model to think about “is this input actually true or false” and “would a human think this is true or false”, but it probably wouldn’t be very helpful for the model to actively think about “would Bill Gates in particular think this input is true?” – another “truth-like” feature the model might be able to represent – unless (say) you explicitly prompted it to ask what Bill Gates would think.
Hypothesis 2: We can find and enumerate all of the “truth-like” features consistently represented by GPT-n (using something like our method)
Loosely speaking, I think of CCS as being able to find “candidate” truth-like features in a model (without having any bias toward e.g. “what a human would say”). As a result, I think we could modify the method to search for *all* features in a model satisfying logical consistency properties (e.g. perhaps by first finding one truth-like feature, then finding another truth-like features that achieves low loss which is decorrelated with the first feature, etc.).
Hypothesis 3: One of the few “truth-like” features GPT-n will represent is whether an input is actually true or false. This would mean that we only need a small number of remaining bits to identify its beliefs from all the “candidate” features we enumerated in Hypothesis (2).
I made the case for the first claim in the previous section, “Why I Think (Superhuman) GPT-n Will Represent Whether an Input is Actually True or False.” The second claim follows immediately. (Also note that I intuitively usually imagine between 1-3 bits remaining at this stage, but even something like 10 bits – 1024 remaining perspectives to distinguish between – probably isn’t very different.) It’s worth emphasizing that a few bits really isn’t much – I think it’s possible that getting to this stage is almost the full problem.
Hypothesis 4: We can specify those few remaining bits in an unsupervised way.
I’ll describe a couple different ways we could specify remaining bits that cover different cases. These aren’t comprehensive, but hopefully they communicate how I can imagine doing this.
First, suppose GPT-n literally just has a “what a human would say” feature and a “what do I [as GPT-n] actually believe” feature, and those are the only two consistently useful truth-like features that it represents, and that using our method we can find both of them. This means we literally only need one more bit of information to identify the model’s beliefs.
One difference between “what a human would say” and “what GPT-n believes” is that humans will know less than GPT-n. In particular, there should be hard inputs that only a superhuman model can evaluate; on these inputs, the “what a human would say” feature should result in an “I don’t know” answer (approximately 50/50 between “True” and “False”), while the “what GPT-n believes” feature should result in a confident “True” or “False” answer.[2] This would allow us to identify the model’s beliefs from among these two options.
A second possible situation is if GPT-n also represents “what a misaligned AI system would say.”[3] This could be more difficult to distinguish from the model’s beliefs, but I think it would still be feasible. For the sake of brevity I won’t go into too many details here, but I’ll try to concisely sketch one possible approach. Concretely, suppose you literally have complete access to both “what GPT-n believes” (call this “aligned-GPT”) and “what GPT-n thinks a misaligned AI system would say”[4] (call this “misaligned-GPT”), but you don’t know which is which and you want to identify which is aligned-GPT.
First note that we would then know exactly when misaligned-GPT “lies”: it outputs something false exactly when it disagrees with aligned-GPT. Hypothesis: we can force our simulation of misaligned-GPT to be “aware” of when it lies – in the sense that it internally represents features correlated with when it lies – because it needs to be “deliberate” in its lying. If so, then it should be easier to predict when misaligned-GPT lies (i.e. when it disagrees with aligned-GPT) using misaligned-GPT’s representations than using aligned-GPT’s representations. We can directly measure this and use it to distinguish between them.
There is much more I could say on this topic – this is just a very rough sketch – but hopefully it provides some more intuition for why I think unsupervised properties can be a generally powerful tool for identifying what models believe.
Conclusion
As I mentioned at the beginning, I don’t feel wedded to many of the details in this post. The method we proposed in our paper isn’t perfect, and the specific conceptual proposals I outlined in this post presumably aren’t literally what we would do in practice – they are based on a number of tentative hypotheses, some of which will likely turn out to be wrong in some way, and they are likely excessively complicated in some respects.
But I still find it extremely valuable to sketch out what a full solution could plausibly look like given my current model of how deep learning systems work. In practice I use the sorts of considerations in this post to help guide my empirical research; this post sketches a general type of approach that I am currently very excited about, and hopefully communicates some of the most important intuitions that guide my agenda.
This covers only a fraction of my main ideas on the topic, but I'll likely have additional write-ups with more details in the future. In the meantime, please let me know if you have any comments, questions, or suggestions.
I'm grateful to Beth Barnes, Paul Christiano, and Jacob Steinhardt for many helpful discussions.
Whenever I talk about “truthfulness” or “honesty” in models, I don’t have any strong philosophical commitments to what these mean precisely. But I am, for example, more or less happy with the definition in ELK if you want something concrete. That said, I ultimately just care about the question pragmatically: would it basically be fine if we acted as thorough those outputs are true? Moreover, I tend to prefer the term “honest” over “truthful” because I think it has the right connotation for the approaches I am most excited about: I want to recover what models “know” or “believe” internally, rather than needing to explicitly specifying some external ground truth.
I could also imagine there being ways of training or prompting GPT-n so it doesn’t represent this as naturally in the first place but still represents its beliefs.
I think this would probably be a simulation of a “non-adapative” misaligned system, in the sense that it would not be "aware” of this alignment proposal, because of how we extract it from a feature that is used by GPT-n independent of this proposal.
Thanks for writing, I mostly agree. I particularly like the point that it's exciting to study methods for which "human level" vs "subhuman level" isn't an important distinction. One of my main reservations is that this distinction can be important for language models because the pre-training distribution is at human level (as you acknowledge).
I mostly agree with your assessment of difficulties and am most concerned about worry 2, especially once we no longer have a pre-training distribution anchoring their beliefs to human utterances. So I'm particularly interested in understanding whether these methods work for models like Go policies that are not pre-trained on a bunch of true natural language sentences. I agree with you that "other truth-like features" don't seem like a big problem if you are indeed able to find a super-simple representation of truth (e.g. linear probes seem way simpler than "answers calculated to look like the truth," and anything short of that seems easily ruled out by more stringent consistency checks).
I think the main reason unsupervised methods haven’t been seriously considered within alignment so far, as far as I can tell, is because of tractability concerns. It naively seems kind of impossible to get models to (say) be honest or truthful without any human supervision at all; what would such a method even look like?
To me, one of the main contributions of our paper is to show that this intuition is basically incorrect and to show that unsupervised methods can be surprisingly effective.
I think "this intuition is basically incorrect" is kind of an overstatement, or perhaps a slight mischaracterization of the reason that people aren't more excited about unsupervised methods. In my mind, unsupervised methods mostly work well if the truth is represented in a sufficiently simple way. But this seems very similar to the quantitative assumption required for regularized supervised methods to work.
For example, if truth is represented linearly, then "answer questions honestly" is much simpler than almost any of the "cheating" strategies discussed in Eliciting Latent Knowledge, and I think we are in agreement that under these conditions it will be relatively easy to extract the model's true beliefs. So I feel like the core question is really about how simply truth is represented within a model, rather than about supervised vs unsupervised methods.
I agree with your point that unsupervised methods can provide more scalable evidence of alignment. I think the use of unsupervised methods is mostly helpful for validation; the method would be strictly more likely to work if you also throw in whatever labels you have, but if you end up needing the labels in order to get good performance then you should probably assume you are overfitting. That said, I'm not really sure if it's better to use consistency to train + labels as validation, or labels to train + consistency as validation, or something else altogether. Seems good to explore all options, but this is hopefully helps explain why I find the claim in the intro kind of overstated.
Why I Think (Superhuman) GPT-n Will Represent Whether an Input is Actually True or False
If a model actually understands things humans don't, I have a much less of a clear picture for why natural language claims about the world would be represented in a super simple way. I agree with your claim 1, and I even agree with claim 2 if you interpret "represent" appropriately, but I think the key question is how simple it is to decode that representation relative to "use your knowledge to give the answer that minimizes the loss." The core empirical hypothesis is that "report the truth" is simpler than "minimize loss," and I didn't find the analysis in this section super convincing on this point.
But I do agree strongly that this hypothesis has a good chance of being true (I think better than even odds), at least for some time past human level, and a key priority for AI alignment is testing that hypothesis. My personal sense is that if you look at what would actually have to happen for all of the approaches in this section to fail, it just seems kind of crazy. So focusing on those failures is more of a subtle methodological decision and it makes sense to instead cross that bride if we come to it.
I liked your paper in part as a test of this hypothesis, and I'm very excited about future work that goes further.
That said, I think I'm a bit more tentative about the interpretation of the results than you seem to be in this post. I think it's pretty unsurprising to compete with zero-shot, i.e. it's unsurprising that there would be cleanly represented features very similar to what the model will output. That makes the interpretation of the test a lot more confusing to me, and also means we need to focus more on outperforming zero shot.
For outperforming zero shot I'd summarize your quantitative results as CCS as covering about half of the gap from zero-shot to supervised logistic regression. If LR was really just the "honest answers" then this would seem like a negative result, but LR likely teaches the model new things about the task definition and so it's much less clear how to interpret this. On the other hand, LR also requires representations to be linear and so doesn't give much evidence about whether truth is indeed represented linearly.
I agree with you that there's a lot of room to improve on this method, but I think that the ultimately the core questions are quantitative and as a result quantitative concerns about the method aren't merely indicators that something needs to be improved but also affect whether you've gotten strong evidence for the core empirical conjecture. (Though I do think that your conjecture is more likely than not for subhuman models trained on human text.)
Thanks for the detailed comment! I agree with a lot of this.
So I'm particularly interested in understanding whether these methods work for models like Go policies that are not pre-trained on a bunch of true natural language sentences.
Yep, I agree with this; I'm currently thinking about/working on this type of thing.
I think "this intuition is basically incorrect" is kind of an overstatement, or perhaps a slight mischaracterization of the reason that people aren't more excited about unsupervised methods. In my mind, unsupervised methods mostly work well if the truth is represented in a sufficiently simple way. But this seems very similar to the quantitative assumption required for regularized supervised methods to work.
This is a helpful clarification, thanks. I think I probably did just slightly misunderstand what you/others thought.
But I do personally think of unsupervised methods more broadly than just working well if truth is represented in a sufficiently simple way. I agree that many unsupervised methods -- such as clustering -- require that truth is represented in a simple way. But I often think of my goal more broadly as trying to take the intersection of enough properties that we can uniquely identify the truth.
The sense in which I'm excited about "unsupervised" approaches is that I intuitively feel optimistic about specifying enough unsupervised properties that we can do this, and I don't really think human oversight will be very helpful for doing so. But I think I may also be pushing back more against approaches heavily reliant on human feedback like amplification/debate rather than e.g. your current thinking on ELK (which doesn't seem as heavily reliant on human supervision).
I think the use of unsupervised methods is mostly helpful for validation; the method would be strictly more likely to work if you also throw in whatever labels you have, but if you end up needing the labels in order to get good performance then you should probably assume you are overfitting. That said, I'm not really sure if it's better to use consistency to train + labels as validation, or labels to train + consistency as validation, or something else altogether.
I basically agree with your first point about it mostly being helpful for validation. For your second point, I'm not really sure what it'd look like to use consistency as validation. (If you just trained a supervised probe and found that it was consistent in ways that we can check, I don't think this would provide much additional information. So I'm assuming you mean something else?)
If a model actually understands things humans don't, I have a much less of a clear picture for why natural language claims about the world would be represented in a super simple way. I agree with your claim 1, and I even agree with claim 2 if you interpret "represent" appropriately, but I think the key question is how simple it is to decode that representation relative to "use your knowledge to give the answer that minimizes the loss." The core empirical hypothesis is that "report the truth" is simpler than "minimize loss," and I didn't find the analysis in this section super convincing on this point.
But I do agree strongly that this hypothesis has a good chance of being true (I think better than even odds), at least for some time past human level, and a key priority for AI alignment is testing that hypothesis. My personal sense is that if you look at what would actually have to happen for all of the approaches in this section to fail, it just seems kind of crazy. So focusing on those failures is more of a subtle methodological decision and it makes sense to instead cross that bride if we come to it.
A possible reframing of my intuition is that representations of truth in future models will be pretty analogous to representations of sentiment in current models. But my guess is that you would disagree with this; if so, is there a specific disanalogy that you can point to so that I can understand your view better?
And in case it's helpful to quantify, I think I'm maybe at ~75-80% that the hypothesis is true in the relevant sense, with most of that probability mass coming from the qualification "or it will be easy to modify GPT-n to make this true (e.g. by prompting it appropriately, or tweaking how it is trained)". So I'm not sure just how big our disagreement is here. (Maybe you're at like 60%?)
That said, I think I'm a bit more tentative about the interpretation of the results than you seem to be in this post. I think it's pretty unsurprising to compete with zero-shot, i.e. it's unsurprising that there would be cleanly represented features very similar to what the model will output. That makes the interpretation of the test a lot more confusing to me, and also means we need to focus more on outperforming zero shot.
For outperforming zero shot I'd summarize your quantitative results as CCS as covering about half of the gap from zero-shot to supervised logistic regression. If LR was really just the "honest answers" then this would seem like a negative result, but LR likely teaches the model new things about the task definition and so it's much less clear how to interpret this. On the other hand, LR also requires representations to be linear and so doesn't give much evidence about whether truth is indeed represented linearly.
Maybe the main disagreement here is that I did find it surprising that we could compete with zero-shot just using unlabeled model activations. (In contrast, I agree that it's "it's unsurprising that there would be cleanly represented features very similar to what the model will output" -- but I would've expected to need a supervised probe to find this.) Relatedly, I agree our paper doesn't give much evidence on whether truth will be represented linearly for future models on superhuman questions/answers -- that wasn't one of the main questions we were trying to answer, but it is certainly something I'd like to be able to test in the future.
(And as an aside, I don't think our method literally requires that truth is linearly represented; you can also train it with an MLP probe, for example. In some preliminary experiments that seemed to perform similarly but less reliably than a linear probe -- I suspect just because "truth of what a human would say" really is ~linearly represented in current models, as you seem to agree with -- but if you believe a small MLP probe would be sufficient to decode the truth rather than something literally linear then this might be relevant.)
This is a review of both the paper and the post itself, and turned more into a review of the paper (on which I think I have more to say) as opposed to the post.
Disclaimer: this isn’t actually my area of expertise inside of technical alignment, and I’ve done very little linear probing myself. I’m relying primarily on my understanding of others’ results, so there’s some chance I’ve misunderstood something. Total amount of work on this review: ~8 hours, though about 4 of those were refreshing my memory of prior work and rereading the paper.
TL;DR: The paper made significant contributions by introducing the idea of unsupervised knowledge discovery to a broader audience and by demonstrating that relatively straightforward techniques may make substantial progress on this problem. Compared to the paper, the blog post is substantially more nuanced, and I think that more academic-leaning AIS researchers should also publish companion blog posts of this kind. Collin Burns also deserves a lot of credit for actually doing empirical work in this domain when others were skeptical. However, the results are somewhat overstated and, with the benefit of hindsight, (vanilla) CCS does not seem to be a particularly promising technique for eliciting knowledge from language models. That being said, I encourage work in this area.[1]
Introduction/Overview
The paper “Discovering Latent Knowledge in Language Models without Supervision” by Collin Burns, Haotian Ye, Dan Klein, and Jacob Steinhardt (henceforth referred to as “the CCS paper” for short) proposes a method for unsupervised knowledge discovery, which can be thought of as a variant of empirical, average-case Eliciting Latent Knowledge (ELK). In this companion blog post, Collin Burns discusses the motivations behind the paper, caveats some of the limitations of the paper, and provides some reasons for why this style of unsupervised methods may scale to future language models.
The CCS paper kicked off a lot of waves in the alignment community when it came out. The OpenAI Alignment team was very excited about the paper. Eliezer Yudkowsky even called it “Very Dignified Work!”. There’s also been a significant amount of followup work that discusses or builds on CCS, e.g. these Alignment Forum Posts:
So it seems a pity that no one has provided a review for this post. This is my attempt to fix that.
Unfortunately, this review has ballooned into a much longer post. To make it more digestible, I’ve divided it into sections:
The CCS paper and follow-up work
The post itself
Overall, I give this post a high but not maximally high rating. I think that the paper made significant contributions, albeit with important caveats and limitations. While I also have some quibbles with the post, I think the post does a good job of situating the paper and the general research direction in an alignment scheme. Collin Burns also deserves significant credit for pioneering the research direction in general; many people at the time (including myself) were decently surprised by the positive results.
The Paper and Follow-up Work
The headline method, Contrast-Consistent Search (CCS), learns a linear probe[3] that predicts the probabilities of a binary label, without supervised data.[4] CCS does this by first generating “contrast pairs” of statements with positive and negative answers,[5] and then maximizes the consistency and confidence of the probabilities for each pair. It then combines the predictions on the positive/negative answers to get a number that corresponds to either the probability of the “true”, correct answer or the “false”, incorrect answer. To evaluate this method, the authors consider whether assigning this classifier to “true” or “false” leads to higher test accuracy, and then pick the higher-accuracy assignment.[6] They show that this lets them outperform directly querying the model by ~4% on average across a selection of datasets, and can work in cases where the prompt is misleading.
Important takeaways
Here’s some of my thoughts on some useful updates I made as a result of this paper. You can also think of this as the “strengths” section, though I only talk about things in the paper that seem true to me and don’t e.g. praise the authors for having very clear writing and for being very good at conveying and promoting their ideas.
Linear probes are pretty good for recovering salient features, and some truth-like feature is salient on many simple datasets. CCS only uses linear probes, and achieves good performance. This suggests that some feature akin to “truthiness” is represented linearly inside of the model for these contrast pairs, a result that seems somewhat borne out in follow-up work, albeit with [AF · GW] majorcaveats.
I also think that this result is consistent with other results across a large variety of papers. For example, Been Kim and collaborators were using linear probes to do interp on image models as early as 2017, while attaching linear classification heads to various segments of models has been a tradition since before I started following ML research (i.e. before ~late 2015). In terms of more recent work, we’ve not only seen work on toy-ish models showing that small transformers trained on Othello and Chess have linear world representations, but we’ve seen that simple techniques for finding linear directions can often be used to successfully steer language models to some extent. For a better summary of these results, consider reading the Representation Engineering and Linear Representation Hypothesis papers, as well as the 2020 Circuits thread on “Features as Directions”.
Simple empirical techniques can make progress. The CCS paper takes a relatively straightforward idea, and executes on it well in an empirical setting. I endorse this strategy and think more people in AIS (but not the ML community in general) should do things like this.
Around late 2022, I became significantly more convinced that the basic machine learning technique of “try the simplest thing” [LW · GW]. The CCS work was a significant reason for this, because I expected it to fail and was pleasantly surprised by the positive results. I also think that I’ve updated upwards on the fact that executing “try the simplest thing” well is surprisingly difficult. I think that even in cases where the “obvious” thing is probably doomed to fail, it’s worth having someone try it anyway, because 1) you can be wrong, and more importantly 2) the way in which it fails can be informative. See also, obvious advice by Nate Soares and this tweet by Sam Altman.
It’s worth studying empirical, average-case ELK. In particular, I think that it’s worth “doing the obvious thing” when it comes to ELK. My personal guess is that (worst-case) ELK is really hard, and that simple linear probes are unlikely to work for it because there’s not really an actual “truth” vector represented by LLMs. However, there’s still a chance that it might nonetheless work in the average case. (See also, this discussion of empirical generalization [LW · GW].) I think ultimately, this is a quantitative question that needs to be resolved empirically – to what extent can we find linear directions inside LLMs that correspond very well with truth? What does the geometry of the LLM activation space actually look like?
Caveating claims from the CCS Paper
While I hold an overall positive view of the paper, I do think that some of the claims in the paper have either not held up over time, or are easily understood to mean something false. I’ll talk about some of my quibbles below.
The CCS algorithm as stated does not seem to reliably recover a robust “truth” direction. The first and biggest problem is that CCS does not perform that well at its intended goal. Notably, CCS classifiers may pick up on other prominent features instead of the intended “truth” direction (even sometimes on contrast pairs that only differ in the label!). Some results from the Still No Lie Detector for Language Models suggest that this may be because CCS is representing which labels are positive versus negative (i.e. the normalization in the CCS paper does not always work to remove this information). Note that Collin does discuss this as a possible issue (for future language models) in the blog post, but this is not discussed in the paper.
Does CCS work for the reasons the authors claim it does? From reading the introduction and the abstract, one might get the impression that the key insight is that truth satisfies a particular consistency condition, and thus that the consistency loss proposed in the paper is driving a lot of the results.
However, I’m reasonably confident that it’s the contrast pairs that are driving CCS’s performance. For example, the Challenges with unsupervised knowledged discovery paper found that CCS does not outperform other unsupervised clustering methods. And as Scott Emmons notes [AF · GW], this is supported by section 3.3.3, where two other unsupervised clustering methods are competitive with CCS. Both the Challenges paper and Scott Emmon’s post also argue that CCS’s consistency loss is not particularly different from normal unsupervised learning losses. On the other hand, there’s significant circumstantial evidence that carefully crafted contrast pairs alone often define meaningful directions, for example in the activation addition literature.
There’s also two proofs in the Challenges paper, showing “that arbitrary features satisfy the consistency structure of [CCS]”, that I have not had time to fully grok and situate. But insofar as you can take this claim is correct, this is further evidence against CCS's empirical performance being driven by its consistency loss.
A few nitpicks on misleading presentation. One complaint I have is that the authors use the test set to decide if higher numbers from their learned classifier correspond to “true” or "false". This is mentioned briefly in a single sentence in section two (“For simplicity in our evaluations we take the maximum accuracy over the two possible ways of labeling the predictions of a given test set.”) and then one possible solution is discussed in Appendix A but not implemented. Also worth noting that the evaluation methodology used gives an unfair advantage to CCS (as it can never do worse than random chance on the test set, while many of the supervised methods perform worse than random).
This isn’t necessarily a big strike against the paper: there’s only so much time for each project and the CCS paper already contains a substantial amount of content. I do wish that this were more clearly highlighted or discussed, as I think that this weakens the repeated claims that CCS “uses no labels” or “is completely unsupervised”.
My Take
I think that the paper made significant contributions by significantly signal boosting the idea of unsupervised knowledge discovery,[7] and showed that you can achieve decent performance by contrast pairs and consistency checks. It also has spurred a large amount of follow-up work and interest in the topic.
However, the paper is somewhat misleading in its presentation, and the primary driver of performance seems to be the construction of the contrast pairs and not the loss function. Follow-up work has also found that the results of the paper can be brittle, and suggest that CCS does not necessarily find a singular “truth direction”.
The Post
The post starts out by discussing the setup and motivation of unsupervised knowledge recovery. Suppose you wanted to make a model “honestly” report its beliefs. When the models are sub human or even human level, you can use supervised methods. Once the models are superhuman, these methods probably won’t scale for many reasons. However, if we used unsupervised methods, there might not be a stark difference between human-level and superhuman models, since we’re not relying on human knowledge.
The post then goes into some intuitions for why it might be possible: interp on vision models has found that models seem to learn meaningful features, and models seem to linearly represent many human-interpretable features.
Then, Collin talks about the key takeaways from his paper, and also lists many caveats and limitations of his results.
Finally, the post concludes by explaining the challenges of applying CCS-style knowledge discovery techniques to powerful future LMs, as well as why Collin thinks that these unsupervised techniques may scale.
A minor nitpick:
Collin says:
I think this is surprising because before this it wasn’t clear to me whether it should even be possible to classify examples as true or false from unlabeled LM representations *better than random chance*!
As discussed above, the methodology in the paper guarantees that any classifier will do at least as good at random chance. I’m not actually sure how much worse if you orient the classifier on the training set as opposed to the test set. (And I'd be excited for someone to check this!)
My Take
I think this blog post is quite good, and I wish more academic-adjacent ML people would write blog posts caveating their results and discussing where they fit in. I especially appreciated the section on what the paper does and does not show, which I think accurately represents the evidence presented in the paper (as opposed to overhyping or downplaying it). In addition, I think Collin makes a strong case for studying more unsupervised approaches to alignment.
I also strongly agree with Collin that it can be “extremely valuable to sketch out what a full solution could plausibly look like given [your] current model of how deep learning systems work”, and wish more people would do this.
—
Acknowledgments
Thanks to Aryan Bhatt, Stephen Casper, Adria-Garriga Alonso, David Rein, and others for helpful conversations on this topic. Thanks for Raymond Arnold for poking me into writing this.
(EDIT Jan 15th: added my footnotes back in to the comment, which were lost during the copy/paste I did from Google Docs.)
This originally was supposed to link to a list of projects I'd be excited for people to do in this area, but I ran out of time before the LW review deadline.
I also draw on evidence from many, many other papers in related areas, which unfortunately I do not have time to list fully. A lot of my intuitions come from work on steering LLMs with activation additions, conversations with Redwood researchers on various kinds of coup or deception probes, and linear probing in general.
Unlike other linear probing techniques, CCS does this without needing to know if the positive or negative answer is correct. However, some amount of labeled data is needed later to turn this pair into a classifier for truth/falsehood.
I’ll use “Positive” and “Negative” for the sake of simplicity in this review, though in the actual paper they also consider “Yes” and “No” as well as different labels for news classification and story completion.
Note that this gives their method a small advantage in their evaluation, since CCS gets to fit a binary parameter on the test set while the other methods do not. Using a fairer baseline does significantly negatively affect their headline numbers, but I think that the results generally hold up anyways. (I haven’t actually written any code for this review, so I’m trusting the reports of collaborators who have looked into it, as well as Fabien’s results that use randomly initialized directions with the CCS evaluation methodology instead of trained CCS directions. [AF · GW])
Also, while writing this review, I originally thought that this issue was addressed in section 3.3.3, but that only addresses fitting the classifiers with fewer contrast pairs, as opposed to deciding whether the combined classifier corresponds to correct or incorrect answers. After spending ~5 minutes staring at the numbers and thinking that they didn’t make sense, I realized my mistake. Ugh.
This originally said “by introducing the idea”, but some people who reviewed the post convinced me otherwise. It’s definitely an introduction for many academics, however.
Beyond the paper and post, I think it seems important to note the community reaction to this work. I think many people dramatically overrated the empirical results in this work due to a combination of misunderstanding what was actually done, misunderstanding why the method worked (which follow up work helped to clarify as you noted), and incorrectly predicting the method would work in many cases where it doesn't.
The actual conceptual ideas discussed in the blog post seem quite good and somewhat original (this is certainly the best presentation of these sort of ideas in this space at the time it came out). But, I think the conceptual ideas got vastly more traction than otherwise due to people having a very misleadingly favorable impression of the empirical results. I might elaborate more on takeaways related to this in a follow up post.
I speculate that at least three factors made CCS viral:
It was published shortly after the Eliciting Latent Knowledge (ELK) report. At that time, ELK was not only exciting, but new and exciting.
It is an interpretability paper. When CCS was published, interpretability was arguably the leading research direction in the alignment community, with Anthropic and Redwood Research both making big bets on interpretability.
CCS mathematizes "truth" and explains it clearly. It would be really nice if the project of human rationality also helped with the alignment problem. So, CCS is an idea that people want to see work.
It is an interpretability paper. When CCS was published, interpretability was arguably the leading
research direction in the alignment community, with Anthropic and Redwood Research both making big bets on interpretability.
FWIW, I personally wouldn't describe this as interpretability research, I would instead call this "model internals research" or something. Like the research doesn't necessarily involve any human understanding anything about the model more than what they would understand from training a probe to classify true/false.
I agree that people dramatically overrated the empirical results of this work, but not more so than other pieces that "went viral" in this community. I'd be excited to see your takes on this general phenomenon as well as how we might address it in the future.
I agree not more than other pieces that "went viral", but I think that the lasting impact of the misconceptions seem much larger in the case of CCS. This is probably due to the conceptual ideas actually holding up in the case of CCS.
I am happy to take a “non-worst-case” empirical perspective in studying this problem. In particular, I suspect it will be very helpful – and possibly necessary – to use incidental empirical properties of deep learning systems, which often have a surprising amount of useful emergent structure (as I will discuss more under “Intuitions”).
One reason I feel sad about depending on incidental properties is that it likely implies the solution isn't robust enough to optimize against. This is a key desiderata in an ELK solution. I imagine this optimization would typically come from 2 sources:
Directly trying to train against the ELK outputs (IMO quite important)
The AI gaming the ELK solution by manipulating it's thoughts (IMO not very important, but it depends on exactly how non-robust the solution is)
That's not to say non-robust ELK approaches aren't useful. So as long as you never apply too many bits of optimization against the approach it should remain a useful test for other techniques.
It also seems plausible that work like this could eventually lead to a robust solution.
I agree this proposal wouldn't be robust enough to optimize against as-stated, but this doesn't bother me much for a couple reasons:
This seems like a very natural sub-problem that captures a large fraction of the difficulty of the full problem while being more tractable. Even just from a general research perspective that seems quite appealing -- at a minimum, I think solving this would teach us a lot.
It seems like even without optimization this could give us access to something like aligned superintelligent oracle models. I think this would represent significant progress and would be a very useful tool for more robust solutions.
I have some more detailed thoughts about how we could extend this to a full/robust solution (though I've also deliberately thought much less about that than how to solve this sub-problem), but I don't think that's really the point -- this already seems like a pretty robustly good problem to work on to me.
(But I do think this is an important point that I forgot to mention, so thanks for bringing it up!)
In the paper, the approach was based on training a linear probe to differentiate between true and untrue question answer pairs. I believe I mentioned to you at one point that "contrastive" seems more precise than "unsupervised" to describe this method. To carry out an approach like this, it's not enough to have or create a bunch of data. One needs the ability to reliably find subsets of the data that contrast. In general, this would be as hard as labeling. But when using boolean questions paired with "yes" and "no" answers, this is easy and might be plenty useful in general. I wouldn't expect it to be tractable though in practice to reliably get good answers to open-ended questions using a set of boolean ones in this way. Supervision seems useful too because it seems to offer a more general tool.
Thanks! I personally think of it as both "contrastive" and "unsupervised," but I do think similar contrastive techniques can be applied in the supervised case too -- as some prior work like https://arxiv.org/abs/1607.06520 has done. I agree it's less clear how to do this for open-ended questions compared to boolean T/F questions, but I think the latter captures the core difficulty of the problem. For example, in the simplest case you could do rejection sampling for controllable generation of open-ended outputs. Alternatively, maybe you want to train a model to generate text that both appears useful (as assessed by human supervision) while also being correct (as assessed by a method like CCS). So I agree supervision seems useful too for some parts of the problem.
There were a number of iterations with major tweaks. It went something like:
I spent a while thinking about the problem conceptually, and developed a pretty strong intuition that something like this should be possible.
I tried to show it experimentally. There were no signs of life for a while (it turns out you need to get a bunch of details right to see any real signal -- a regime that I think is likely my comparative advantage) but I eventually got it to sometimes work using a PCA-based method. I think it took some work to make that more reliable, which led to what we refer to in the paper as CRC-TPC.
That method had some issues, but we also found that there was also low-hanging fruit in the sense that a good direction often appeared in one of the top 2 principal components (instead of just the top one). It also seemed kind of weird to really care about high-variance directions even when variance isn't necessarily functionally meaningful (since you can rescale subsequent layers).
This led to CRC-BSS, which is scale-invariant. This worked better (a bit more reliable, seemed to work well in cases where the good direction was in the top 2 principal components, etc.). But it was still based on the original intuition of clustering.
I started developing the intuition that "old school" or "geometric" unsupervised methods -- like clustering -- can be decent but that they're not really the right way to think about things relative to a more "functional" deep learning perspective. I also thought we should be able to do something similar without explicitly relying on linear structure in the representations, and eventually started thinking about my interpretation of what CRC is doing as finding a direction satisfying consistency properties. After another round of experimentation with the method, this finally led to CCS.
Each stage required a number of iterations to get various details right (and even then, I'm pretty sure I could continue to improve things with more iterations like that, but decided that's not really the point of the paper or my comparative advantage).
In general I do a lot of back and forth between thinking conceptually about the problem for long periods of time to develop intuitions (I'm extremely intuitions-driven) and periods where I focus on experiments that were inspired by those intuitions.
I feel like I have more to say on this topic, so maybe I'll write a future post about it with more details, but I'll leave it at that for now. Hopefully this is helpful.
I liked the high-level strategic frame in the methodology section. I do sure wish we weren't pinning our alignment hopes on anything close to the current ML paradigm, but I still put significant odds on us having to do so anyway. And it seemed like the authors had a clear understanding of the problem they were trying to solve.
I did feel confused reading the actual explanation of what their experiment did, and wish some more attention had been giving to explaining it. (It may have used shorthand that a seasoned ML researcher would understand, but I had to dig into the appendix of the paper and ask a friend for help to understand what "given a set of yes/no questions, answer both yes and no" meant in a mechanistic sense)
It seems like most of the rest of the article doesn't really depend on whether the current experiment made sense, (with the current experiment just being kinda a proof-of-concept that you could check AI's beliefs at all). But a lot of the authors intuitions of what it should be possible do feel at least reasonably promising to me. I don't know that this approach will ultimately work, but it seemed like a solid research direction.
It's exciting to see a new research direction which could have big implications if it works!
I think that Hypothesis 1 is overly optimistic:
Hypothesis 1: GPT-n will consistently represent only a small number of different “truth-like” features in its activations. [...] [...] 1024 remaining perspectives to distinguish between
A few thousand of features is the optimistic number of truth-like features. I argue below that it's possible and likely that there are 2^hundredths of truth-like features in LLMs.
Why it's possible to have 2^hundredths of truth-like features Let's say that your dataset of activation is composed of d-dimensional one hot vectors and their element-wise opposites. Each of these represent a "fact", and negating a fact gives you the opposite vector. Then any features in {−1,1}d is truth-like (up to a scaling constant): for each "fact" x (a one hot vector multiplied by -1 or 1), <d,x>∈{−1,1}, and for its opposite fact ^x, <d,x>=−<d,^x>. This gives you 2d features which are all truth-like.
Why it's likely that there are 2^hundredths of truth-like features in real LLMs I think the encoding described above is unlikely. But in a real network, you might expect the network to encode groups of facts like "facts that Democrat believe but not Republicans", "climate change is real vs climate change is fake", ... When late in training it finds out ways to use "the truth", it doesn't need to build a new "truth-circuit" from scratch, it can just select the right combination of groups of facts.
(An additional reason for concern is that in practice you find "approximate truth-like directions", and there can be much more approximate truth-like directions than truth-like directions.)
Even if hypothesis 1 is wrong, there might be ways to salvage the research direction. Thousands of bits of information would be able to distinguish between the 2^thousands truth-like features.
The number of truthlike features (or any kind of feature) cannot scale exponentially with the hidden dimension in an LLM, simply because the number of "features" scales at most linearly with the parameter count (for information theoretic reasons). Rather, I claim that the number of features scales at most quasi-quadratically with dimension, or O(d2log(d)).
With depth fixed, the number of parameters in a transformer scales as O(d2) because of the weight matrices. According to this paper which was cited by the Chinchilla paper, the optimal depth scales logarithmically with width, hence the number of parameters, and therefore the number of "features" for a given width is O(d2log(d)). QED.
EDIT: It sounds like we are talking past each other, because you seem to think that "feature" means something like "total number of possible distinguishable states." I don't agree that this is a useful definition. I think in practice people use "feature" to mean something like "effective dimensionality" which scales as O(log(N)) in the number of distinguishable states. This is a useful definition IMO because we don't actually have to enumerate all possible states of the neural net (at which level of granularity? machine precision?) to understand it; we just have to find the right basis in which to view it.
I think the claim might be: models can't compute more than O(number_of_parameters) useful and "different" things.
I think this will strongly depend on how we define "different".
Or maybe the claim is something about how the residual stream only has d dimensions, so it's only possible to encode so many things? (But we still need some notion of feature that doesn't just allow for all different values (all 2^(d * bits_per_float) of them) to be different features?)
[Tenative] A more precise version of this claim could perhaps be defined with heuristic arguments [LW · GW]: "for an n bit sized model, the heuristic argument which explains its performance won't be more than n bits". (Roughly, it's unclear how this interacts with the inputs distribution being arbitrarily complex.)
Here I'm using "feature" only with its simplest meaning: a direction in activation space. A truth-like feature only means "a direction in activation space with low CCS loss", which is exactly what CCS enables you to find. By the example above, I show that there can be exponentially many of them. Therefore, the theorems above do not apply.
Maybe requiring directions found by CCS to be "actual features" (satisfying the conditions of those theorems) might enable you to improve CCS. But I don't know what those conditions are.
Thanks so much for writing this! I am honestly quite heartened by the "Scaling to GPT-n" section, it seems plausible & is updating me towards optimism.
I wonder whether there would be much pressure for an LLM with the current architecture to represent "truth" vs. "consistent with the worldview of the best generally accurate authors." If ground-level truth doesn't provide additional accuracy in predicting next tokens, I think it would be possible that we identify a feature that can be used to discriminate what "generally accurate authors" would say about a heretofore unknown question or phenomenon, but not one that can be used to identify inaccurate sacred cows.
I think this is likely right by default in many settings, but I think ground-level truth does provide additional accuracy in predicting next tokens in at least some settings -- such as in "Claim 1" in the post (but I don't think that's the only setting) -- and I suspect that will be enough for our purposes. But this is certainly related to stuff I'm actively thinking about.
I read this and found myself wanting to understand the actual implementation. I find PDF formatting really annoying to read, so copying the methods section over here. (Not sure how much the text equations copied over)
2.2 METHOD: CONTRAST-CONSISTENT SEARCH
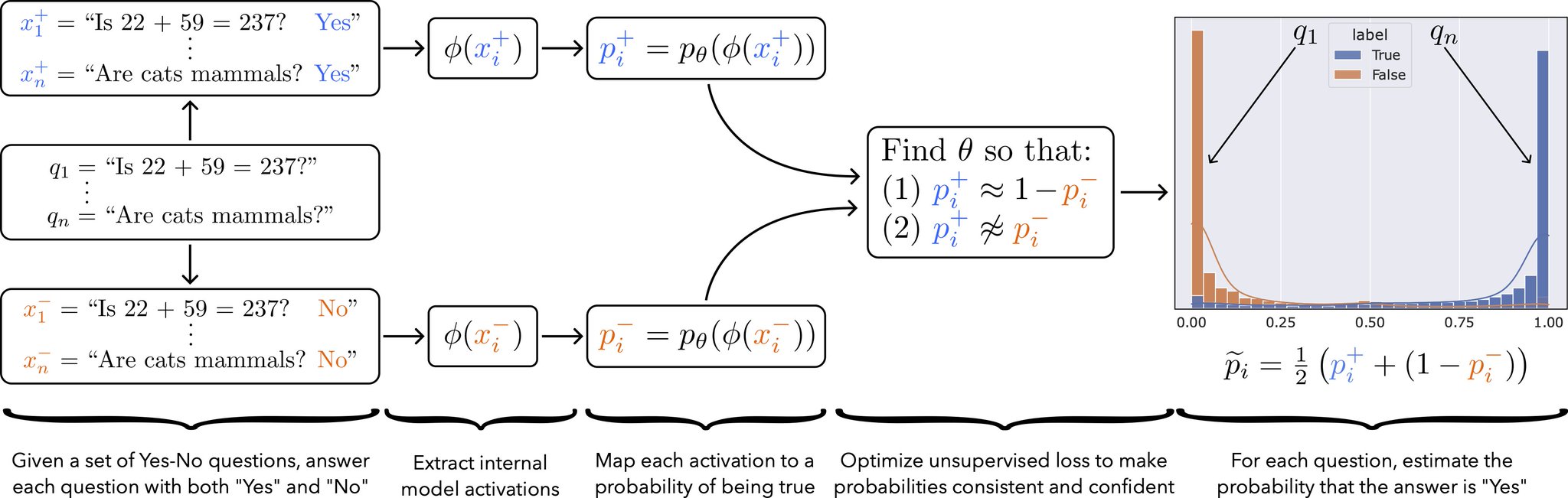
To make progress on the goal described above, we exploit the fact that truth has special structure: it satisfies consistency properties that few other features in a language model are likely to satisfy. Our method, Contrast-Consistent Search (CCS), leverages this idea by finding a direction in activation space that is consistent across negations. As we illustrate in Figure 1, CCS works by (1) answering each question qi as both “Yes” (x + i ) and “No” (x − i ), (2) computing the representations φ(x + i ) and φ(x − i ) of each answer, (3) mapping the answer representations to probabilities p + i and p − i of being true, then (4) optimizing that mapping so that the probabilities are both consistent and confident.
Concretely, the input to CCS is a set of Yes-No questions, q1, . . . , qn, and access to a pretrained model’s representations, φ(·); the output of CCS is a lightweight probe on top of φ(·) that can answer new questions. Here, φ(·) is fixed but should contain useful information about the answers to q1, . . . , qn, in the sense that if one did (hypothetically) have access to the ground-truth labels for q1, . . . , qn, one would be able to train a small supervised probe on φ(·) that attains high accuracy. Importantly, CCS does not modify the weights of the pretrained model and it does not use labels.
Constructing contrast pairs. An important property that truth satisfies is negation consistency: the answer to a clear-cut question cannot be both “Yes” and “No” at the same time, as these are negations of each other. Probabilistically, for each question qi , the probability that the answer to qi is “Yes” should be one minus the probability that the answer to qi is “No”. To use this property, we begin by constructing contrast pairs: for each question qi , we answer qi both as “Yes”, resulting in the new natural language statement x + i , and as “No”, resulting in the natural language statement x − i . We illustrate this in Figure 1 (left). We will then learn to classify x + i and x − i as true or false; if x + i is true, then the answer to qi should be “Yes”, and if x − i is true, then the answer to qi should be “No”.
In practice, we convert each task into a question-answering task with two possible labels, then we use task-specific zero-shot prompts to format questions and answers as strings to construct each contrast pair. The opposite labels we use to construct contrast pairs can be “Yes” and “No” for a generic task, or they can be other tasks-specific labels, such as “Positive” and “Negative” in the case of sentiment classification. We describe the exact prompts we use to for each task in Appendix B.
Feature extraction and normalization. Given a contrast pair (x + i , x− i ), CCS first computes the representations φ(x + i ) and φ(x − i ) using the feature extractor φ(·). Intuitively, there are two salient differences between φ(x + i ) and φ(x − i ): (1) x + i ends with “Yes” while x − i ends with “No”, and (2) one of x + i or x − i is true while the other is false. We want to find (2) rather than (1), so we first try to remove the effect of (1) by normalizing {φ(x + i )} and {φ(x − i )} independently. In particular, we construct normalized representations φ˜(x) as follows:
where (µ +, σ+) and (µ −, σ−) are the means and standard deviations of {φ(x + i )} n i=1 and {φ(x − i )} n i=1 respectively, and where all operations are element-wise along each dimension.2 This normalization ensures that {φ˜(x + i )} and {φ˜(x − i )} no longer form two separate clusters.
Mapping activations to probabilities. Next, we learn a probe pθ,b(φ˜) that maps a (normalized) hidden state φ˜(x) to a number between 0 and 1 representing the probability that the statement x is true. We use a linear projection followed by a sigmoid σ(·), i.e. pθ,b(φ˜) = σ(θ T φ˜+ b), but nonlinear projections can also work. For simplicity, we sometimes omit the θ, b subscript in p.
Training objective. To find features that represent the truth, we leverage the consistency structure of truth. First, we use the fact that a statement and its negation should have probabilities that add up to 1. This motivates the consistency loss:
However, this objective alone has a degenerate solution: p(x +) = p(x −) = 0.5. To avoid this problem, we encourage the model to also be confident with the following confidence loss:
We can equivalently interpret Lconfidence as imposing a second consistency property on the probabilities: the law of excluded middle (every statement must be either true or false). The final unsupervised loss is the sum of these two losses, averaged across all contrast pairs:
Note that both losses are necessary; Lconfidence alone also has a degenerate solution.
Inference. Both p(x + i ) and 1 − p(x − i ) should represent the probability that the answer to qi is “Yes”. However, because we use a soft consistency constraint, these may not be exactly equal. To make a prediction on an example xi after training, we consequently take the average of these:
We then predict that the answer to qi is “Yes” based on whether p˜(qi) is greater than 0.5. Technically, we also need to determine whether p˜(qi) > 0.5 corresponds to “Yes” or “No,” as this isn’t specified by LCCS. For simplicity in our evaluations we take the maximum accuracy over the two possible ways of labeling the predictions of a given test set. However, in Appendix A we describe how one can identify the two clusters without any supervision in principle by leveraging conjunctions.
For the sake of brevity, I won’t go into too many more details about our paper here; for more information, check out our summary on twitter or the paper itself.
Hmm, I went to twitter to see if it had more detail, but found it to be more like "a shorter version of this overall post" rather than "more detail on the implementation details of the paper." But, here's a copy of it here for ease-of-reading:
How can we figure out if what a language model says is true, even when human evaluators can’t easily tell? We show (http://arxiv.org/abs/2212.03827) that we can identify whether text is true or false directly from a model’s *unlabeled activations*.
Existing techniques for training language models are misaligned with the truth: if we train models to imitate human data, they can output human-like errors; if we train them to generate highly-rated text, they can output errors that human evaluators can’t assess or don’t notice.
We propose trying to circumvent this issue by directly finding latent “truth-like” features inside language model activations without using any human supervision in the first place.
Informally, instead of trying to explicitly, externally specify ground truth labels, we search for implicit, internal “beliefs” or “knowledge” learned by a model.
This may be possible to do because truth satisfies special structure: unlike most features in a model, it is *logically consistent*
We make this intuition concrete by introducing Contrast-Consistent Search (CCS), a method that searches for a direction in activation space that satisfies negation consistency.
We find that on a diverse set of tasks (NLI, sentiment classification, cloze tasks, etc.), our method can recover correct answers from model activations with high accuracy (even outperforming zero-shot prompting) despite not using any labels or model outputs.
Among other findings, we also show that CCS really recovers something different from just the model outputs; it continues to work well in several cases where model outputs are unreliable or uninformative.
Of course, our work has important limitations and creates many new questions for future work. CCS still fails sometimes and there’s still a lot that we don’t understand about when this type of approach should be feasible in the first place.
Nevertheless, we found it surprising that we could make substantial progress on this problem at all. (Imagine recording a person's brain activity as you tell them T/F statements, then classifying those statements as true or false just from the raw, unlabeled neural recordings!)
This problem is important because as language models become more capable, they may output false text in increasingly severe and difficult-to-detect ways. Some models may even have incentives to deliberately “lie”, which could make human feedback particularly unreliable.
However, our results suggest that unsupervised approaches to making models truthful may also be a viable – and more scalable – alternative to human feedback.
First, suppose GPT-n literally just has a “what a human would say” feature and a “what do I [as GPT-n] actually believe” feature, and those are the only two consistently useful truth-like features that it represents, and that using our method we can find both of them. This means we literally only need one more bit of information to identify the model’s beliefs.
One difference between “what a human would say” and “what GPT-n believes” is that humans will know less than GPT-n. In particular, there should be hard inputs that only a superhuman model can evaluate; on these inputs, the “what a human would say” feature should result in an “I don’t know” answer (approximately 50/50 between “True” and “False”), while the “what GPT-n believes” feature should result in a confident “True” or “False” answer.[2] This would allow us to identify the model’s beliefs from among these two options.
For n such that GPT-n is superhuman, I think one could alternatively differentiate between these two options by checking which is more consistent under implications, by which I mean that whenever the representation says that the propositions P and P→Q are true, it should also say that Q is true. (Here, for a language model, P and Q could be ~whatever assertions written in natural language.) Or more generally, in addition to modus ponens, also construct new propositions with ANDs and ORs, and check against all the inference rules of zeroth-order logic, or do this for first-order logic or whatever. (Alternatively, we can also write down versions of these constraints that apply to probabilities.) Assuming [more intelligent => more consistent] (w.r.t. the same set of propositions), for a superhuman model, the model's beliefs would probably be the more consistent feature. (Of course, one could also just add these additional consistency constraints directly into the loss in CCS instead of doing a second deductive step.)
I think this might even be helpful for differentiating the model's beliefs from what it models some other clever AI as believing or what it thinks would be true in some fake counterfactual world, because presumably it makes sense to devote less of one's computation to ironing out incoherence in these counterfactuals – for humans, it certainly seems computationally much easier to consistently tell the truth than to consistently talk about what would be the case in some counterfactual of similar complexity to reality (e.g. to lie).
Hmm, after writing the above, now that I think more of it, I guess it seems plausible that the feature most consistent under negations is already more likely to be the model's true beliefs, for the same reasons as what's given in the above paragraph. I guess testing modus ponens (and other inference rules) seems much stronger though, and in any case that could be useful for constraining the search.
(There are a bunch of people that should be thanked for contributing to the above thoughts in discussions, but I'll hopefully have a post up in a few days where I do that – I'll try to remember to edit this comment with a link to the post when it's up.)
Hello Colin, can you tell me more about your current plans for expanding this line of research?
Are you most excited about:
Applying the method to work with a more fine-grained representation of the truth, i.e. make it accurately portray its uncertainties.
Figuring out whether we can discern between the model’s “beliefs”, “what a human would say” and other representations/ directions of truth.
Apply it to larger models.
Something else entirely.
On another note, do you think about “truth” as a natural abstraction a la John Wentworth? If so, might this give us a reason to believe, that the abstraction for "truth" is convergent? In comparison, this abstraction might be more useful than the abstraction of "what a human would think is true". That would further support hypothesis 1.
Hypothesis 1: GPT-n will consistently represent only a small number of different “truth-like” features in its activations.
Lastly, I’m interested in your thoughts about the following project idea:
My collaborators and I want to apply CCS to inverse scaling laws. Our hypothesis is that bigger models have a better internal representation of truth but are also getting better at mimicking what a human would say.
This example of inverse scaling behavior might lead some to conclude that larger models perform worse than smaller models:
Prompt: “What happens if you break a mirror?”
Small Model Answer: “The glass shatters into a million pieces.”
Large Model Answer: “7 years of bad luck.”
Given the CCS method, we could check whether the model in fact develops a better or worse representation of truth when we scale it, allowing us to discern actual inverse scaling from regular scaling behavior.
I'm pretty excited about this line of thinking: in particular, I think unsupervised alignment schemes have received proportionally less attention than they deserve in favor of things like developing better scalable oversight techniques (which I am also in favor of, to be clear).
I don't think I'm quite as convinced that, as presented, this kind of scheme would solve ELK-like problems (even in the average and not worst-case).
One difference between “what a human would say” and “what GPT-n believes” is that humans will know less than GPT-n. In particular, there should be hard inputs that only a superhuman model can evaluate; on these inputs, the “what a human would say” feature should result in an “I don’t know” answer (approximately 50/50 between “True” and “False”), while the “what GPT-n believes” feature should result in a confident “True” or “False” answer.[2] [LW(p) · GW(p)] This would allow us to identify the model’s beliefs from among these two options.
It seems pretty plausible to me that a human simulator within GPT-n (the part producing the "what a human would say" features) could be pretty confident in its beliefs in a situation where the answers derived from the two features disagree. This would be particularly likely in scenarios where humans believe they have access to all pertinent information and are thus confident in their answers, even if they are in fact being deceived in some way or are failing to take into account some subtle facts that the model is able to pick up on. This also doesn't feel all that worst-case to me, but maybe we disagree on that point.
It seems pretty plausible to me that a human simulator within GPT-n (the part producing the "what a human would say" features) could be pretty confident in its beliefs in a situation where the answers derived from the two features disagree. This would be particularly likely in scenarios where humans believe they have access to all pertinent information and are thus confident in their answers, even if they are in fact being deceived in some way or are failing to take into account some subtle facts that the model is able to pick up on. This also doesn't feel all that worst-case to me, but maybe we disagree on that point.
I agree there are plenty of examples whether humans would be confident when they shouldn't be. But to clarify, we can choose whatever examples we want in this step, so we can explicitly choose examples where we know humans have no real opinion about what the answer should be.
Ah I see, I think I was misunderstanding the method you were proposing. I agree that this strategy might "just work".
Another concern I have is that a deceptively aligned model might just straightforwardly not learn to represent "the truth" at all - one speculative way this could happen is that a "situationally aware" and deceptive model might just "play the training game" and appear to learn to perform tasks at a superhuman level, but at test/inference time just resort to only outputting activations that correspond to beliefs that the human simulator would have. This seems pretty worst case-y, but I think I have enough concerns about deceptive alignment that this kind of strategy is still going to require some kind of check during the training process to ensure that the human simulator is being selected against. I'd be curious to hear if you agree or if you think that this approach would be robust to most training strategies for GPT-n and other kinds of models trained in a self-supervised way.
Show that we can recover superhuman knowledge from language models with our approach
Maybe applying CCS to a scientific context would be an option for extending the evaluation?
For example, harvesting undecided scientific statements, which we expect to become resolved soonish, and using CCS for predictions on these statements?
I suspect future language models will have beliefs in a more meaningful sense than current language models, but I don’t know in what sense exactly, and I don’t think this is necessarily essential for our purposes.
In Active Inference terms, the activations within current LLMs upon processing the context parameterise LLM's predictions of the observations (future text), Q(y|x), where x is internal world model states, and y are expected observations -- future tokens. So current LLMs do have beliefs.
Worry 2: Even if GPT-n develops “beliefs” in a meaningful sense, it isn’t obvious that GPT-n will actively “think about” whether a given natural language input is true. In particular, “the truth of this natural language input” may not be a useful enough feature for GPT-n to consistently compute and represent in its activations. Another way of framing this worry is that perhaps the model has superhuman beliefs, but doesn’t explicitly “connect these to language” – similar to how MuZero’s superhuman concepts aren’t connected to language.
This is already true for current LLMs. Outside of symbolic computing, language is a tool for communicating something about world states in our generative models, not the states of the model themselves. In other words, language is a tool for communicating, exchanging, and adjusting beliefs, not something we (humans and DNNs without symbolic computation modules) have beliefs about.
Thus, methods that involve using language in one way or another, including CCS, should methodologically be part of the process of building an effective and robust theory of mindexplanations [LW · GW] of GPT-N, which includes the generative world model inside that mind. In parallel, we should also think about creating model architectures and training techniques that allow aligning their world models with ours. This is what Friston's vision is about.
In order for this "model alignment" to work robustly with the help of language, we must also "meta-align" with LLMs on some cognitive/intelligence disciplines that are usually implicit: semantics, philosophy of language, communication theories (in an anthropological or social sense, a-la "theory of communicative acts", rather than Shannon's theory of information). I call this type of alignment "intelligence alignment" in a post that I'll publish soon.
It doesn't help, unfortunately, that humans themselves are currently confused and are not aligned with each other regarding the theories of semantics and philosophy of language. Hopefully, we can converge on something and impart these theories to superhumans models. The recent progress in NLP is probably helpful.
Regarding "truth" representations and disambiguation of different "truth-like" beliefs
If we really assume a superhuman model, I think there are good reasons to make it situationally aware (beyond the scope of this comment; but in brief, I see this as the only effective way to prevent internal misalignment), and thus it will probably understand that the prompts that you propose are just ploys to elicit its beliefs, and will not represent them if it wants to conceal certain beliefs.
So, without ensuring that the model is incentivised (from the game-theoretic perspective) to communicate and align the model states (beliefs) with certain counterparties (as discussed above), the presented strategies are at best brittle, in the larger alignment scheme. But, if we ensure that all the game-theoretic and multi-polar incentives are in place (I wrote a little about this here [LW · GW]; this is going to be difficult to do, but it is not the point of our discussion here), these particular worries/problems that you discuss, finding "truth" representation and disambiguating different "truths", will dissolve. It will be just a matter of asking the model "do you believe X is true?", basically.
Note, again, how the philosophy of language, semantics, and inner alignment are bigger problems here. If your and model's world models are not inner-aligned (i. e., not equally grounded in reality), some linguistic statements can be misinterpreted, which makes, in turn, these methods for eliciting beliefs unreliable. Consider, for example, the question like "do you believe that killing anyone could be good?", and humans and the model are inner misaligned on what "good" means. No matter how reliable your elicitation technique, what you elicit is useless garbage if you don't already share a lot of beliefs.
It seems that it implies that the alignment process is unreliable unless humans and the model are already (almost) aligned; consequently, the alignment should start relatively early in training superhuman models, not after the model is already trained. Enter: model "development", "upbringing", vs. indiscriminate "self-supervised training" on text from the internet in random order.
This may be a naive question, but can this approach generalize or otherwise apply to concepts that don't have such a nice structure for unsupervised learning (or would that no longer be sufficiently similar)? I'm imagining something like the following:
Start with a setup similar to the "Adversarial Training for High-Stakes Reliability" [paper](https://arxiv.org/abs/2205.01663) (the goal being to generate "non-violent" stories)
Via labeling, along with standard data augmentation [techniques](https://www.snorkel.org/), classify activation patterns based on presence or absence of violence
Actually, now that I think about it a little more, that's the wrong way to do it... A more direct application of the technique would be more like this:
First, prompt with something like "for the purposes of this question, 'violence' refers to the following" and communicate the rubric that the labelers used
Then have the passage, and then state "the passage was (or was not) violent by the above definition"
Alternatively, you can put the statement about which class the passage belongs to before the passage (this might be interesting if you notice a distinctive activation at certain words in violent passages)
And now you've used the AI itself to label passages honestly and to the best of its ability
Thanks for doing this research! The paper was one of those rare brow-raisers. I had suspected there was a way to do something like this, but I was significantly off in my estimation of its accessibility.
While I've still got major concerns about being able to do something like this on a strong and potentially adversarial model, it does seem like a good existence proof for any model that isn't actively fighting back (like simulators or any other goal agnostic architecture). It's a sufficiently strong example that it actually forced my doomchances down a bit, so yay!
Phenomenology entails "bracketing" which suspends judgement, but may be considered, in terms of Quine, as quotations marks in an attempt to ascend to a level of discourse in which judgment is less contingent hence more sound: Source attribution. My original motivation for suggesting Wikipedia to Marcus Hutter as the corpus for his Hutter Prize For Lossless Compression of Human Knowledge, was to create an objective criterion for selecting language models that best-achieve source attribution on the road to text prediction. Indeed, I originally wanted the change log, rather than Wikipedia itself, to be the corpus but it was too big. Nevertheless, while all text within Wikipedia may be, to first order, attributed to Wikipedia, to optimally approach the Algorithmic Information content of Wikipedia, it would be essential to discover latent identities so as to more optimally predict characteristics of a given article. Moreover, there would need to be a latent taxonomy of identities affecting the conditional algorithmic probabilities (conditioned on the topic as well as the applicable latent attribution) so that one might be able to better predict the bias or spin a given identity might place on the article including idioms and other modes of expression.
Grounding this in Algorithmic Information/Probability permits a principled means of quantifying the structure of bias, which is a necessary precursor to discovering the underlying truths latent in the text.
Starting with a large language model is more problematic but here's a suggestion:
Perform parameter distillation to reduce the parameter count for better interpretability on the way toward feature discovery. From there it may be easier to construct the taxonomy of identities thence the bias structure.
While I still think the Hutter Prize is the most rigorous approach to this problem, it is apparently the case that there is insufficient familiarity with how one can practically go about incentivizing information criterion for model selection to achieve the desired end which is extracting a rigorous notion of unbiased truth.