The theory-practice gap
post by Buck · 2021-09-17T22:51:46.307Z · LW · GW · 15 commentsContents
Alignment strategies Empirical generalization The theory-practice gap Sources of theory-practice gap Practical difficulties, eg getting human feedback Problems with the structure of the recursion NP-hard problems Classifying alignment work AI alignment disagreements as variations on this picture How useful is it to work on narrowing the theory-practice gap for alignment strategies that won’t solve the whole problem? Conclusion None 15 comments
[Thanks to Richard Ngo, Damon Binder, Summer Yue, Nate Thomas, Ajeya Cotra, Alex Turner, and other Redwood Research people for helpful comments; thanks Ruby Bloom for formatting this for the Alignment Forum for me.]
I'm going to draw a picture, piece by piece. I want to talk about the capability of some different AI systems.
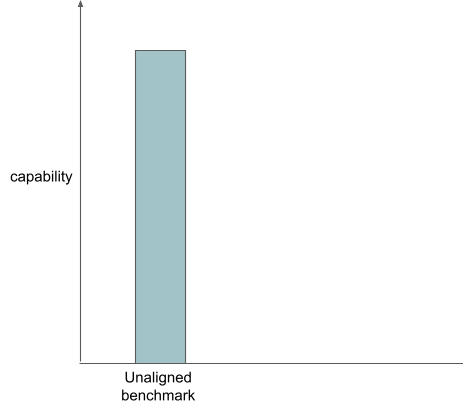
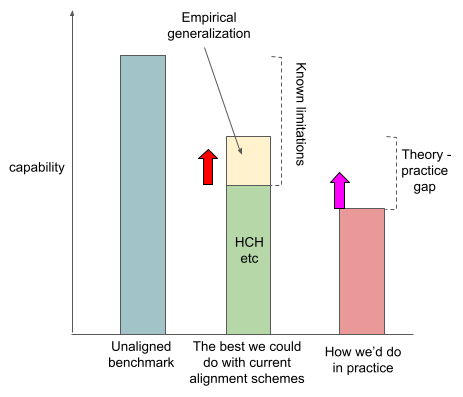
You can see here that we've drawn the capability of the system we want to be competitive with, which I’ll call the unaligned benchmark. The unaligned benchmark is what you get if you train a system on the task that will cause the system to be most generally capable. And you have no idea how it's thinking about things, and you can only point this system at some goals and not others.
I think that the alignment problem looks different depending on how capable the system you’re trying to align is, and I think there are reasonable arguments for focusing on various different capabilities levels. See here for more of my thoughts on this question.
Alignment strategies
People have also proposed various alignment strategies. But I don’t think that these alignment strategies are competitive with the unaligned benchmark, even in theory.
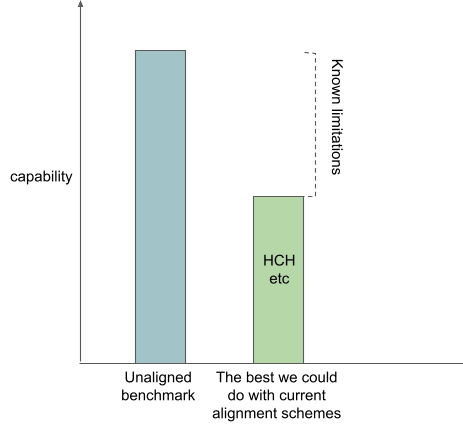
I want to claim that most of the action in theoretical AI alignment is people proposing various ways of getting around these problems by having your systems do things that are human understandable instead of doing things that are justified by working well.
For example, the hope with imitative IDA [AF · GW] is that through its recursive structure you can build a dataset of increasingly competent answers to questions, and then at every step you can train a system to imitate these increasingly good answers to questions, and you end up with a really powerful question-answerer that was only ever trained to imitate humans-with-access-to-aligned-systems, and so your system is outer aligned.
The bar I’ve added, which represents how capable I think you can get with amplified humans, is lower than the bar for the unaligned benchmark. I've drawn this bar lower because I think that if your system is trying to imitate cognition that can be broken down into human understandable parts, it is systematically not going to be able to pursue certain powerful strategies that the end-to-end trained systems will be able to. I think that there are probably a bunch of concepts that humans can’t understand quickly, or maybe can’t understand at all. And if your systems are restricted to never use these concepts, I think your systems are probably just going to be a bunch weaker.
I think that transparency techniques, as well as AI alignment strategies like microscope AI [AF · GW] that lean heavily on them, rely on a similar assumption that the cognition of the system you’re trying to align is factorizable into human-understandable parts. One component of the best-case scenario for transparency techniques is that anytime your neural net does stuff, you can get the best possible human understandable explanation of why it's doing that thing. If such an explanation doesn’t exist, your transparency tools won’t be able to assure you that your system is aligned even if it is.
To summarize, I claim that current alignment proposals don’t really have a proposal for how to make systems that are aligned but either
- produce plans that can’t be understood by amplified humans
- do cognitive actions that can’t be understood by amplified humans
And so I claim that current alignment proposals don’t seem like they can control systems as powerful as the systems you’d get from an unaligned training strategy.
Empirical generalization
I think some people are optimistic that alignment will generalize from the cases where amplified humans can evaluate it to the cases where the amplified humans can’t. I'm going to call this empirical generalization. I think that empirical generalization is an example of relying on empirical facts about neural nets that are not true of arbitrary general black box function approximators.
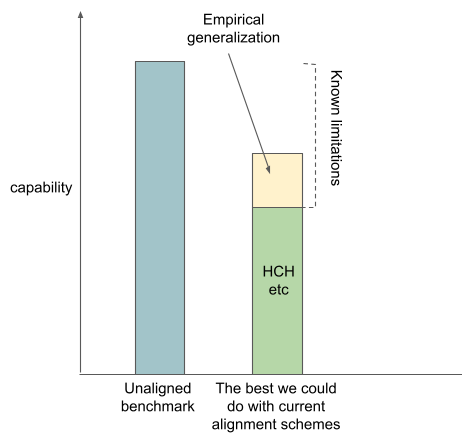
I think this is a big part of the reason why some people are optimistic about the strategy that Paul Christiano calls “winging it”.
(I think that one particularly strong argument for empirical generalization is that if you imagine AGI as something like GPT-17 fine-tuned on human feedback on various tasks, your AGI might think about things in a very human-shaped way. (Many people disagree with me on this.) It currently seems plausible to me that AGI will be trained with a bunch of unsupervised learning based on stuff humans have written, which maybe makes it more likely that your system will have this very human-shaped set of concepts.)
The theory-practice gap
So the total height of that second column is the maximum level of capabilities that we think we could theoretically attain using the same capability techniques that we used for the unaligned benchmark, but using the alignment strategies that we know about right now. But in practice, we probably aren't going to do as well as that, for a variety of practical reasons. For example, as I've said, I think transparency tools are theoretically limited, but we're just way below the maximum theoretically available capability of transparency tools right now.
So I want to claim that reality will probably intervene in various ways and mean that the maximum capability of an aligned AI that we can build is lower than the maximum achievable theoretically from the techniques we know about and empirical generalization. I want to call that difference the theory practice gap.
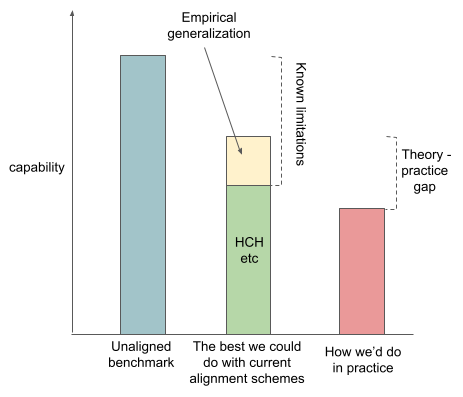
Sources of theory-practice gap
Practical difficulties, eg getting human feedback
Human feedback is annoying in a wide variety of ways; you have to do quality control etc.
Problems with the structure of the recursion
I think it's reasonably plausible that the most competitive way of making powerful systems ends up not really being shapeable into the shape you need for the amplified human stuff to work out. So for example, maybe the best way of making AGI is doing some kind of evolution simulation, where you have this population of little creatures and they compete with each other and stuff. And if that's the only way of making smart systems, then I think it's pretty plausible that there's just like no way of building a trusted, amplified reward signal out of it. And so you can't do the IDA style things, or things where you use a system to do transparency analysis on a slightly more powerful version of itself.
NP-hard problems
Maybe your amplified system won’t be able to answer questions like “are there any inputs on which this system does the wrong thing” even if it wants to. Eg the RSA-2048 problem.
I think that transparency has a related problem: the most competitive-to-train models might have internal structure that amplified humans would be able to understand if it was explained to them, but we might not be able to get a model to find that structure.
Why am I lumping together fundamental concerns like “maybe these alignment strategies will require solving NP-hard problems” with things like “it’s annoying to do quality control on your labelling contractors”?
It’s primarily because I want to emphasize that these concerns are different from the fundamental limitations of currently proposed alignment schemes: even if you assume that we don’t e.g. run into the hard instances of the NP-hard problems, I think that the proposed alignment schemes still aren’t clearly good enough. There are lots of complicated arguments about the extent to which we have some of these “practical” problems; I think that these arguments distract from the claim that the theoretical alignment problem might be unsolved even if these problems are absent.
So my current view is that if you want to claim that we're going to fully solve the technical alignment problem as I described it above, you've got to believe some combination of:
- we're going to make substantial theoretical improvements
- factored cognition is true
- we're going to have really good empirical generalization
(In particular, your belief in these factors needs to add up to some constant. E.g., if you’re more bullish on factored cognition, you need less of the other two.)
I feel like there’s at least a solid chance that we’re in a pretty inconvenient world where none of these are true.
Classifying alignment work
This picture suggests a few different ways of trying to improve the situation.
- You could try to improve the best alignment techniques. I think this is what a lot of AI alignment theoretical work is. For example, I think Paul Christiano’s recent imitative generalization work is trying to increase the theoretically attainable capabilities of aligned systems. I’ve drawn this as the red arrow on the graph below.
- You can try to reduce the theory-practice gap. I think this is a pretty good description of what I think applied alignment research is usually trying to do. This is also what I’m currently working on. This is the pink arrow.
- You can try to improve our understanding of the relative height of all these bars.
AI alignment disagreements as variations on this picture
So now that we have this picture, let's try to use it to explain some common disagreements about AI alignment.
I think some people think that amplified humans are actually just as capable as the unaligned benchmark. I think this is basically the factored cognition hypothesis.
I think there's a bunch of people who are really ML-flavored alignment people who seem to be pretty optimistic about empirical generalization. From their perspective, almost everything that AI alignment researchers should be doing is narrowing that theory practice gap, because that's the only problem.
I think there's also a bunch of people like perhaps the stereotypical MIRI employee who thinks that amplified humans aren't that powerful, and you're not going to get any empirical generalization, and there are a bunch of problems with the structure of the recursion for amplification procedures. And so it doesn't feel that important to them to work on the practical parts of the theory practice gap, because even if we totally succeeded at getting that to zero, the resulting systems wouldn't be very powerful or very aligned. And so it just wouldn't have mattered that much. And the stereotypical such person wants you to work on the red arrow instead of the pink arrow.
How useful is it to work on narrowing the theory-practice gap for alignment strategies that won’t solve the whole problem?
Conclusion
I feel pretty nervous about the state of the world described by this picture.
I'm really not sure whether I think that theoretical alignment researchers are going to be able to propose a scheme that gets around the core problems with the schemes they've currently proposed.
There's a pretty obvious argument for optimism here, which is that people haven't actually put in that many years into AI alignment theoretical research so far. And presumably they're going to do a lot more of it between now and AGI. I think I'm like 30% on the proposition that before AGI, we're going to come up with some alignment scheme that just looks really good and clearly solves most of the problems with current schemes.
I think I overall disagree with people like Joe Carlsmith and Rohin Shah mostly in two places:
- By the time we get to AGI, will we have alignment techniques that are even slightly competitive? I think it’s pretty plausible the answer is no. (Obviously it would be very helpful for me to operationalize things like “pretty plausible” and “slightly competitive” here.)
- If we don’t have the techniques to reliably align AI, will someone deploy AI anyway? I think it’s more likely the answer is yes.
15 comments
Comments sorted by top scores.
comment by Vanessa Kosoy (vanessa-kosoy) · 2021-09-18T00:12:55.902Z · LW(p) · GW(p)
There is a case that aligned AI doesn't have to be competitive with unaligned AI, it just has to be much better than humans at alignment research. Because, if this holds, then we can delegate the rest of the problem to the AI.
Where it might fail is: it takes so much work to solve the alignment problem that even that superhuman aligned AI will not do it in time to build the "next stage" aligned AI (i.e. before the even-more-superhuman unaligned AI is deployed). In this case, it might be advantageous to have mere humans doing extra progress in alignment between the point "first stage" solution is available and the point the first stage aligned AI is deployed.
The bigger the capability gap between first stage aligned AI and humans, the less valuable this extra progress becomes (because the AI would be able to do it on its own much faster). On the other hand, the smaller the time difference between first stage aligned AI deployment and unaligned AI deployment, the more valuable this extra progress becomes.
Replies from: Buck, zac-hatfield-dodds↑ comment by Zac Hatfield-Dodds (zac-hatfield-dodds) · 2021-09-23T03:58:16.431Z · LW(p) · GW(p)
There is a case that aligned AI doesn't have to be competitive with unaligned AI, it just has to be much better than humans at alignment research. Because, if this holds, then we can delegate the rest of the problem to the AI.
I don't find this at all reassuring, because by the same construction your aligned-alignment-researcher-AI may now be racing an unaligned-capabilities-researcher-AI, and my intuition is that the latter is an easier problem because you don't have to worry about complexity of value or anything, just make the loss/Tflop go down.
Replies from: vanessa-kosoy↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2021-09-23T10:49:36.731Z · LW(p) · GW(p)
If equally advanced unaligned AI is deployed earlier than aligned AI, then we might be screwed anyway. My point is, if aligned AI is deployed earlier by a sufficient margin, then it can bootstrap itself to an effective anti-unaligned-AI shield in time.
comment by Rohin Shah (rohinmshah) · 2021-09-18T07:10:05.315Z · LW(p) · GW(p)
Planned summary for the Alignment Newsletter:
We can think of alignment as roughly being decomposed into two “gaps” that we are trying to reduce:
1. The gap between proposed theoretical alignment approaches (such as iterated amplification) and what we might do without such techniques (aka the <@unaligned benchmark@>(@An unaligned benchmark@))
2. The gap between actual implementations of alignment approaches, and what those approaches are theoretically capable of.(This distinction is fuzzy. For example, the author puts “the technique can’t answer NP-hard questions” into the second gap while I would have had it in the first gap.)
We can think of some disagreements in AI alignment as different pictures about how these gaps look:
1. A stereotypical “ML-flavored alignment researcher” thinks that the first gap is very small, because in practice the model will generalize appropriately to new, more complex situations, and continue to do what we want. Such people would then be more focused on narrowing the second gap, by working on practical implementations.
2. A stereotypical “MIRI-flavored alignment researcher” thinks that the first gap is huge, such that it doesn’t really matter if you narrow the second gap, because even if you reduced that gap to zero you would still be doomed with near certainty.
Other notes:
I think some people think that amplified humans are actually just as capable as the unaligned benchmark. I think this is basically the factored cognition hypothesis.
I don't see how this is enough. Even if this were true, vanilla iterated amplification would only give you an average-case / on-distribution guarantee. Your alignment technique also needs to come with a worst-case / off-distribution guarantee. (Another way of thinking about this is that it needs to deal with potential inner alignment failures.)
By the time we get to AGI, will we have alignment techniques that are even slightly competitive? I think it’s pretty plausible the answer is no.
I'm not totally sure what you mean here by "alignment techniques". Is this supposed to be "techniques that we can justify will be intent aligned in all situations", or perhaps "techniques that empirically turn out to be intent aligned in all situations"? If so, I agree that the answer is plausibly (even probably) no.
But what we'll actually do is some technique that is more capable that we don't justifiably know is intent aligned, and (probably) wouldn't be intent aligned in some exotic circumstances. But it still seems plausible that in practice we never hit those exotic circumstances (because those exotic circumstances never happen, or because we've retrained the model before we get to the exotic circumstances, etc), and it's intent aligned in all the circumstances the model actually encounters.
I think I'm like 30% on the proposition that before AGI, we're going to come up with some alignment scheme that just looks really good and clearly solves most of the problems with current schemes.
Fwiw if you mostly mean something that resolves the unaligned benchmark - theory gap, without relying on empirical generalization / contingent empirical facts we learn from experiments, and you require it to solve abstract problems like this [LW(p) · GW(p)], I feel more pessimistic, maybe 20% (which comes from starting at ~10% and then updating on "well if I had done this same reasoning in 2010 I think I would have been too pessimistic about the progress made since then").
Replies from: Edouard Harris↑ comment by Edouard Harris · 2021-09-21T00:12:56.015Z · LW(p) · GW(p)
I agree with pretty much this whole comment, but do have one question:
But it still seems plausible that in practice we never hit those exotic circumstances (because those exotic circumstances never happen, or because we've retrained the model before we get to the exotic circumstances, etc), and it's intent aligned in all the circumstances the model actually encounters.
Given that this is conditioned on us getting to AGI, wouldn't the intuition here be that pretty much all the most valuable things such a system would do would fall under "exotic circumstances" with respect to any realistic training distribution? I might be assuming too much in saying that — e.g., I'm taking it for granted that anything we'd call an AGI could self-improve to the point of accessing states of the world that we wouldn't be able to train it on; and also I'm assuming that the highest-reward states would probably be the these exotic / hard-to-access ones. But both of those do seem (to me) like they'd be the default expectation.
Or maybe you mean it seems plausible that, even under those exotic circumstances, an AGI may still be able to correctly infer our intent, and be incentivized to act in alignment with it?
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2021-09-21T07:42:09.051Z · LW(p) · GW(p)
There are lots and lots of exotic circumstances. We might get into a nuclear war. We might invent time travel. We might become digital uploads. We might decide democracy was a bad idea.
I agree that AGI will create exotic circumstances. But not all exotic circumstances will be created by AGI. I find it plausible that the AI systems fail in only a special few exotic circumstances, which aren't the ones that are actually created by AGI.
Replies from: Edouard Harris↑ comment by Edouard Harris · 2021-09-22T12:55:48.887Z · LW(p) · GW(p)
Got it, thanks!
I find it plausible that the AI systems fail in only a special few exotic circumstances, which aren't the ones that are actually created by AGI.
This helps, and I think it's the part I don't currently have a great intuition for. My best attempt at steel-manning would be something like: "It's plausible that an AGI will generalize correctly to distributions which it is itself responsible for bringing about." (Where "correctly" here means "in a way that's consistent with its builders' wishes.") And you could plausibly argue that an AGI would have a tendency to not induce distributions that it didn't expect it would generalize correctly on, though I'm not sure if that's the specific mechanism you had in mind.
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2021-09-22T13:59:36.782Z · LW(p) · GW(p)
It's nothing quite so detailed as that. It's more like "maybe in the exotic circumstances we actually encounter, the objective does generalize, but also maybe not; there isn't a strong reason to expect one over the other". (Which is why I only say it is plausible that the AI system works fine, rather than probable.)
You might think that the default expectation is that AI systems don't generalize. But in the world where we've gotten an existential catastrophe, we know that the capabilities generalized to the exotic circumstance; it seems like whatever made the capabilities generalize could also make the objective generalize in that exotic circumstance.
Replies from: Edouard Harris↑ comment by Edouard Harris · 2021-09-23T14:12:45.247Z · LW(p) · GW(p)
I see. Okay, I definitely agree that makes sense under the "fails to generalize" risk model. Thanks Rohin!
comment by Charlie Steiner · 2021-09-18T16:14:38.090Z · LW(p) · GW(p)
I guess I fall into the stereotypical pessimist camp? But maybe it depends on what the actual label of the y-axis on this graph is.
Does an alignment scheme that will definitely not work, but is "close" to a working plan in units of number of breakthroughs needed count as high or low on the y-axis? Because I think we occupy a situation where we have some good ideas, but all of them are broken in several ways, and we would obviously be toast if computers got 5 orders of magnitude faster overnight and we had to implement our best guesses.
On the other hand, I'm not sure there's too much disagreement about that - so maybe what makes me a pessimist is that I think fixing those problems still involves work in the genre of "theory" rather than just "application"?
comment by Aaron_Scher · 2023-03-01T05:02:30.400Z · LW(p) · GW(p)
I am confused by the examples you use for sources of the theory-practice gap. Problems with the structure of the recursion [LW · GW] and NP-hard problems [LW · GW] seem much more like the first gap.
I understand the two gaps the way Rohin described [LW · GW] them. The two problems listed above don’t seem to be implementation challenges, they seem like ways in which our theoretic-best-case alignment strategies can’t keep up. If the capabilities-optimal ML paradigm is one not amenable to safety, that’s a problem which primarily restricts the upper bound on our alignment proposals (they must operate under other, worse, paradigms), rather than a theory-practice gap.
comment by Sam Clarke · 2021-10-06T13:39:26.275Z · LW(p) · GW(p)
If we don’t have the techniques to reliably align AI, will someone deploy AI anyway? I think it’s more likely the answer is yes.
What level of deployment of unaligned benchmark systems do you expect would make doom plausible? "Someone" suggests maybe you think one deployment event of a sufficiently powerful system could be enough (which would be surprising in slow takeoff worlds). If you do think this, is it something to do with your expectations about discontinuous progress around AGI?
comment by Koen.Holtman · 2021-09-20T10:28:16.924Z · LW(p) · GW(p)
Nice pictures!
So now that we have this picture, let's try to use it to explain some common disagreements about AI alignment.
I'll use the above pictures to explain another disagreement about AI alignment, one you did not explore above.
I fundamentally disagree with your framing that successful AI alignment research is about closing the capabilities gap in the above pictures.
To better depict the goals of AI alignment research, I would draw a different set of graphs that have alignment with humanity as the metric on the vertical axis, not capabilities. When you re-draw the above graphs with an alignment metric on the vertical axis, then all aligned paperclip maximizers will greatly out-score Bostrom's unaligned maximally capable paperclip maximizer.
Conversely, Bostrom's unaligned superintelligent paperclip maximizer will always top any capabilities chart, when the capability score is defined as performance on a paperclip maximizing benchmark. Unlike an unaligned AI, an aligned AI will have to stop converting the whole planet into paperclips when the humans tell it to stop.
So fundamentally, if we start from the assumption that we will not be able to define the perfectly aligned reward function that Bostrom also imagines, a function that is perfectly aligned even with the goals of all future generations, then alignment research has to be about creating the gap in the above capabilities graphs, not about closing it.