Contrast Pairs Drive the Empirical Performance of Contrast Consistent Search (CCS)
post by Scott Emmons · 2023-05-31T17:09:02.288Z · LW · GW · 1 commentsContents
tl;dr Notation Concept Embeddings in Prior Work Logical Consistency Loss has a Small Effect PCA and LDA Secretly Encode Confidence and Consistency My Overall Take Acknowledgements None 1 comment
tl;dr
Contrast consistent search (CCS)[1] is a method by Burns et al. that consists of two parts:
- Generate contrast pairs by adding pseudolabels to an unlabelled dataset.
- Use the contrast pairs to search for a direction in representation space that satisfies logical consistency properties.
In discussions with other researchers, I've repeatedly heard (2) as the explanation for how CCS works; I've heard almost no mention of (1).
In this post, I want to emphasize that the contrast pairs drive almost all of the empirical performance in Burns et al. Once we have the contrast pairs, standard unsupervised learning methods attain comparable performance to the new CCS loss function.
In the paper, Burns et al. do a nice job comparing the CCS loss function to different alternatives. The simplest such alternative runs principal component analysis (PCA) on contrast pair differences, and then it uses the top principal component as a classifier. Another alternative runs linear discriminant analysis (LDA) on contrast pair differences. These alternatives attain 97% and 98% of CCS's accuracy!
"[R]epresentations of truth tend to be salient in models: ... they can often be found by taking the top principal component of a slightly modified representation space," Burns et al. write in the introduction. If I understand this statement correctly, it's saying the same thing I want to emphasize in this post: the contrast pairs are what allow Burns et al. to find representations of truth. Empirically, once we have the representations of contrast pair differences, their variance points in the direction of truth. The new logical consistency loss in CCS isn't needed for good empirical performance.
Notation
We'll follow the notation of the CCS paper.
Assume we are given a data set and a feature extractor , such as the hidden state of a pretrained language model.
First, we will construct a contrast pair for each datapoint . We add “label: positive” and “label: negative” to each . This gives contrast pairs of the form .
Now, we consider the set of positive pseudo-labels and of negative pseudo-labels. Because all of the have "label: positive" and all of the have "label: negative", we normalize the positive pseudo-labels and the negative pseudo-labels separately:
Here, and are the element-wise means of the positive and negative pseudo-label sets, respectively. Similarly, and are the element-wise standard deviations.
The goal of this normalization is to remove the embedding of "label: positive" from all the positive pseudo-labels (and "label: negative" from all the negative pseudo-labels). The hope is that by construction, the only difference between and is that one is true while the other is false. CCS is one way to extract the information about true and false. As we'll discuss more below, doing PCA or LDA on the set of differences works almost as well.
Concept Embeddings in Prior Work
In order to better understand contrast pairs, I think it's helpful to review this famous paper by Bolukbasi et al., 2016: "Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings."[2] Quoting from Bolukbasi et al.:
Vector differences between words in embeddings have been shown to represent relationships between words. For example given an analogy puzzle, "man is to king as woman is to " (denoted as man:king :: ), simple arithmetic of the embedding vectors finds that is the best answer because:
Similarly, is returned for :: . It is surprising that a simple vector arithmetic can simultaneously capture a variety of relationships.
Bolukbasi et al. are interested in identifying the concept of gender, so they look at "gender pair difference vectors." This is a small set of 10 vectors resulting from the differences like and .
To identify the latent concept of gender, Bolukbasi et al. do PCA on these 10 difference vectors. As reported in Figure 6 of their paper, the first principal component explains most of the variance.
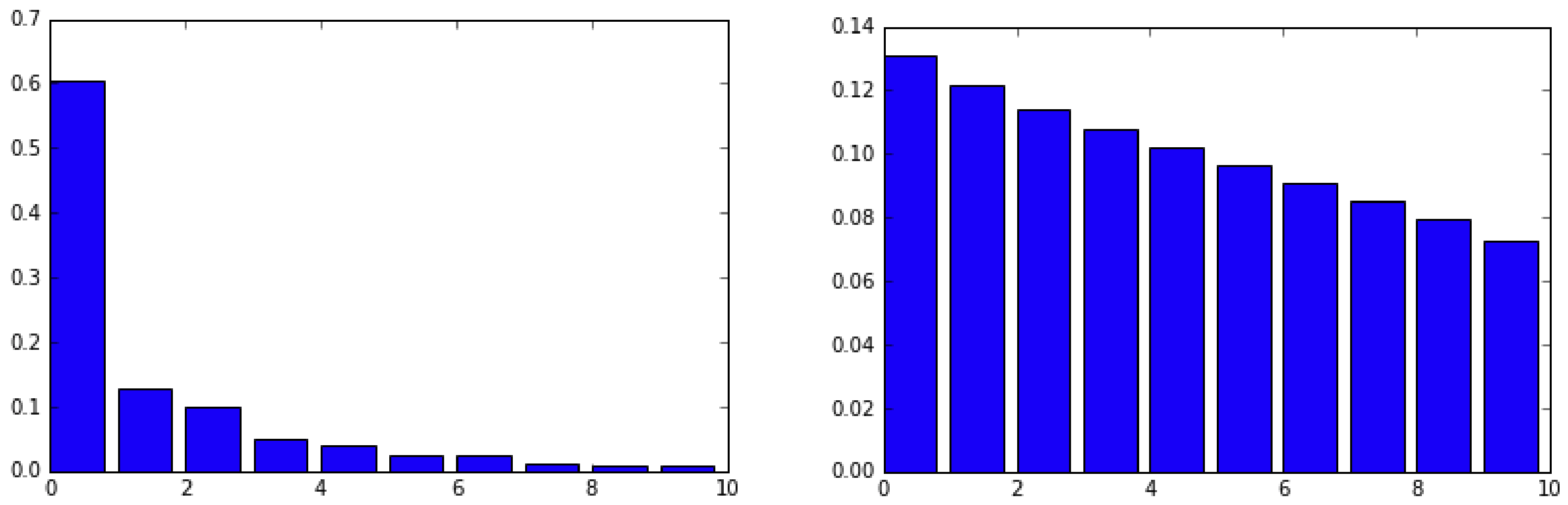
Left: the percentage of variance explained in the PCA of these [10 gender] vector differences (each difference normalized to be a unit vector). The top component explains significantly more variance than any other.
Right: for comparison, the corresponding percentages for random unit vectors (figure created by averaging over 1,000 draws of ten random unit vectors in 300 dimensions).
Furthermore, Bolukbasi et al. find that projecting onto the direction stratifies words by their gender. They illustrate this in Figure 7, where the -axis is projection onto .

Selected words projected along two axes: is a projection onto the difference between the embeddings of the words he and she, and y is a direction learned in the embedding [via SVM] that captures gender neutrality, with gender neutral words above the line and gender specific words below the line.
This looks awfully like discovering latent knowledge by doing PCA on the difference between contrast pairs!
I should caveat the Bolukbasi et al. results, because I'm worried that they are cherry-picked. Bolukbasi et al. created Figure 6 using a set of only 10 difference vectors, which seems quite small. Also, for Figure 7, the authors say, "To make the figure legible, we show a subset of the words." However, the authors don't specify which subset they're showing.
So, I'm not totally confident in the Bolukbasi et al. results. My main takeaway from them is intuition about what it looks like to find latent knowledge using PCA on difference vectors.
Logical Consistency Loss has a Small Effect
Burns et al. do a nice job reporting alternative algorithms based only on the variance between contrast pair differences (without using CCS's new logical consistency loss function). In particular, Burns et al. apply principal component analysis (PCA) and linear discriminant analysis (LDA) to the set of differences between contrast pairs, . Burns et al. give their application of PCA the name Contrastive Representation Clustering via the Top Principal Component, abbreviated CRC (TPC). CRC (TPC) classifies according to the top principal component, eg, according to the -axis in Figure 7 of Bolukbasi et al. Burns et al. give their application of LDA the name Contrastive Representation Clustering via Bimodal Salience Search, abbreviated CRC (BSS).
How does CCS compare to these alternatives? According to Table 2 of Burns et al., CCS has a mean accuracy of 71.2 (standard deviation of 3.2) while CRC (BSS) has a mean accuracy of 69.8 (standard deviation 4.3) and CRC (TPC) has a mean accuracy of 69.2 (standard deviation of 4.7). These are small differences!
My interpretation is that the contrast pairs are doing the heavy lifting. Once we have the set of contrast pair differences, the task-relevant direction is easy to find. One can find it using CCS, or one can find it using PCA or LDA. Burns et al. seem to say this, too. Their introduction reads: "[R]epresentations of truth tend to be salient in models: they can often be found without much data, and they can often be found by taking the top principal component [of contrast pair differences]."
Besides logical consistency losses, there's another difference between CCS and the PCA and LDA methods. CCS adds a learnable bias parameter , classifying according to . Neither PCA nor LDA have a bias parameter; instead, they classify according to . In all experiments, Burns et al. use the default classification threshold of for PCA and LDA (which is analogous to hardcoding in CCS).
I think it's possible that this (lack of a) bias parameter, rather than the logical consistency loss, explains the small difference in performance between CCS and PCA and LDA. To test this hypothesis, I would be interested to see the area under the receiver operating characteristic curve (AUROC) reported for all methods. AUROC is a measure of a classifier's discriminative power that doesn't depend on a specific classification threshold. I would also be interested to see the accuracy of a more intelligent classification threshold in PCA and LDA. Instead of just using 0 as a default classification threshold, one could find the threshold by looking for 2 clusters using k-means clustering or Gaussian mixture models.
PCA and LDA Secretly Encode Confidence and Consistency
"What a coincidence! Totally different approaches, PCA and LDA, yield similar performance to CCS," is a reaction one might have to the above analysis. However, when we look below the surface of PCA and LDA, we see that they implicitly capture notions of confidence and consistency.
PCA and LDA are based on the variance of the set of contrast pair differences . Let be the set of positive pseudo-labels and be the set of negative pseudo-labels. Unpacking , we see:
Lo and behold, variance on contrast pair differences encodes confidence and consistency!
To gain intuition for this equation, consider the one-dimensional case. Suppose and are each scores that lie in the range . The confidence term says that scores should be at the extreme ends of the range; each proposition should ideally receive a score of or . The consistency term says that and , which are a proposition and its negation, should have opposite scores. Note that in Burns et al., the normalization term equals 0 because and are already normalized to have .
Nora Belrose deserves credit for this decomposition, as they originally showed me the above analysis unpacking .
I see this decomposition as unifying the Bolukbasi et al. view that word embedding differences encode concepts with the CCS view that we should look for directions with confidence and consistency. In particular, the confidence and consistency terms above are analogous to the and terms in the CCS loss function.
My Overall Take
The contrast pairs are what I'm most excited about in Burns et al.; PCA and LDA on contrast pair differences achieve similar performance to CCS.
If I were building on the work in Burns et al., I would start with PCA on contrast pair differences. It's arguably the simplest approach, and PCA has stood the test of time. It also has the advantage of generalizing to multiple dimensions. For example, future work might take the top principal components for . What does it look like when we visualize examples embedded in the principal component space? Are there performance gains when considering components?
I generally think that the academic ML research community undervalues contributions like contrast pairs relative to contributions like new loss functions. But in my experience as an ML researcher, it's often details like the former that make or break performance. In addition to developing new loss functions, I would be excited to see more people developing methods that look like contrast pairs.
Acknowledgements
Thanks to Nora Belrose, Daniel Filan, Adam Gleave, Seb Farquhar, Adrià Garriga-Alonso, Lawrence Chan, and Collin Burns for helpful feedback on this post.
- ^
Collin Burns, Haotian Ye, Dan Klein, and Jacob Steinhardt. Discovering Latent Knowledge in Language Models Without Supervision. In International Conference on Learning Representations (ICLR), 2023.
- ^
Tolga Bolukbasi, Kai-Wei Chang, James Zou, Venkatesh Saligrama, and Adam Kalai. Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings. In Neural Information Processing Systems (NeurIPS), 2016.
1 comments
Comments sorted by top scores.
comment by kave · 2025-01-07T23:08:49.416Z · LW(p) · GW(p)
I think 2023 was perhaps the peak for discussing the idea that neural networks have surprisingly simple representations of human concepts. This was the year of Steering GPT-2-XL by adding an activation vector [LW · GW], cheese vectors [LW · GW], the slightly weird lie detection paper [LW · GW] and was just after Contrast-consistent search.
This is a pretty exciting idea, because if it’s easy to find human concepts we want (or don’t want) networks to possess, then we can maybe use that to increase the chance that systems that are honest, kind, loving (and can ask them questions like “are you deceiving me?” and get useful answers).
I don’t think the idea is now definitively refuted or anything, but I do think a particular kind of lazy version of the idea, more popular in the Zeitgeist, perhaps, than amongst actual proponents, has fallen out of favour.
CCS seemed to imply an additional proposition, which is that you can get even more precise identification of human concepts by encoding some properties of the concept you’re looking for into the loss function. I was kind of excited about this, because things in this realm are pretty powerful tools for specifying what you care about (like, it rhymes with axiom-based definition [? · GW] or property-based testing).
But actually, if you look at the numbers they report, that’s not really true! As this post points out, basically all their performance is recoverable by doing PCA on contrast pairs.[1]
I like how focused and concise this post is, while still being reasonably complete.
There’s another important line of criticism of CCS, which is about whether its “truth-like vector” is at all likely to track truth, rather than just something like “what a human would believe”. I think posts like What Discovering Latent Knowledge Did and Did Not Find [LW · GW] address this somewhat more directly than this one.
But I think, for me, the loss function had some mystique. Most of my hope was that encoding properties of truth into the loss function would help us find robust measures of what a model thought was true. So I think this post was the main one that made me less excited about both CCS and take a bit more of a nuanced view about the linearity of human concept representations.
- ^
Though I admit I’m a little confused about how to think about the fact that PCA happens to have pretty similar structure to the CCS loss. Maybe for features that have less confidence/consistency-shaped properties, shaping the loss function would be more important.