Grokking, memorization, and generalization — a discussion
post by
Kaarel (kh),
Dmitry Vaintrob (dmitry-vaintrob) ·
2023-10-29T23:17:30.098Z ·
LW ·
GW ·
11 comments
Contents
11 comments
Intro: Kaarel and Dmitry have been meeting to think about various interpretability and toy model questions. We are both interested in unsupervised and superposition-agnostic interpretability results (Kaarel [LW · GW], Dmitry [LW · GW]). Recently we discussed questions related to grokking, memorization, double descent and so on. Dmitry has been doing a number of experiments on modular addition with Nina Rimsky. (See here [LW · GW] and here [LW · GW]. Another writeup on modular addition circuits based on these experiments is in the works. Note that Nina is also interested in these questions, but couldn’t join today. Dmitry's views here are almost entirely a result of conversations with Nina.) Dmitry is interested in having a better gears-level understanding of grokking and thinks there are some issues with how these are interpreted in the intepretability/alignment community and literature (a view Kaarel partially shares). Kaarel's views on the topic should be attributed in part to previous discussions with Jake Mendel and Simon Skade. The discussion started in a private conversation, and we decided that it might be helpful to continue this as a public discussion. This is our first experiment with LW conversations, so we would like to heartily invite critical feedback about style, format, technical level, etc.
Do you know if anyone has compiled a list of all the quantitative aspects of grokking / double descent that we'd expect a good theory of memorization vs generalization to explain? stuff like the location of interpolation thresholds in various parameters, (claimed) superexponential growth of the time to grok as the data set size decreases
I think there are several interesting questions that are largely distinct here. There's been some work done on all of them, but I'm not sure if I'm up to date on all of it
There's a theory that grokking is directly the competition between a large-basin phenomenon (grokking) and small-basin phenomena (memorization). I think the strongest evidence for this is found in Barak et al on parity learning. There's an attempt at isolating/explaining large generalizing circuits in terms of sparsity (which I think is useful, but doesn’t capture a lot of interesting cases?) in a paper of Merrill, Tsivlis and Shukla, and another reinterpretation, via a linear programming complexity measure, that I prefer, by Liu, Zhong, and Tegmark.
I have some issues with this interpretation (related to what I was telling you in Oxford), but I think after some tests we did with Nina that it's largely correct for modular addition
Within this interpretation, I think there are two related questions that people are interested in: namely,
A. why does grokking sometimes occur after memorization, rather than both of them occurring at the same time (as you'd expect from an ordinary race) and
B. why does phase transition occur (i.e., the phenomenon where grokking seems to occur in quanta of "learning a circuit" and the process of learning a circuit starts with a part where progress is slow/imperceptible, then becomes faster than memorization, then (practically) stops once the weight assigned to the circuit has become large). This can be asked both on the level of offline and online learning dynamics, i.e., both as a function of training time and as a function of number of samples.
I personally am confused about the amount of ink spilled about Question B above, and think that (assuming the “large circuit” hypothesis), the explanation of the phase transition is somewhat obvious. I might be misunderstanding what people actually are thinking here.
Namely as I see it, a generalizing circuit helps reduce overall loss by pushing a particular linear combination of weights. Generally, nontrivial circuits in x-entropy loss (and I think this is somewhat true for other kinds of loss, though I haven't thought about it as much) will tend to want to improve in directions where they have started learning something but aren't to the point of having fully learned the thing. There's a few ways to see that this should happen, but a simple symmetry breaking argument is sufficient: just note that at a noisy configuration, you would expect "learnable directions" to be very noisy, and largely cancel each other out, so the gradient will be predominantly noise from the perspective of the circuits that are eventually learned; but a circuit by itself has a clear learnable direction which isn't noise. Thus once a circuit starts getting learned, it will also become more attractive to learn it, until it is fully learned. This is a phase transition behavior. We observe this also for an individual memorization circuit (though for memorization circuits it's hard to see in the performance over training graphs, since each memorization circuit is tiny and they smooth each other out)
The grokking phase transition is the same phenomenon (once symmetry is broken and there's a clear and un-noisy attractor at a basin, you'll see increased learning towards that basin. If the basin is large and generalizing, you'll naturally see what we observe in grokking). BTW, you can also see the phase transition behavior mathematically using a toy model for a circuit. So in my mind the existence of phase transitions is kind of obvious, kind of a non-issue, and I think that people pay way too much attention to it
Though there is a nice paper which explicitly connects phase transitions (in an MSE context) to phase transitions in physics, and (if I understand correctly), more or less fully explains grokking in e.g. MSE modular addition in a mathematical physics sense (it makes lots of assumptions and approximations -- including the mean field theory approximation, but it seems they are supported empirically). I think I mentioned this paper before: Rubin et al.
This is an investigation of the specific mechanism and mathematical shape of the phase transition -- again, I don't think extra explanation or proof is needed to see that it will exist to some extent
I think Question A. above (why does grokking sometimes occur after memorization/why does it look like it has some unique stochastic behavior that is qualitatively different from memorization) is more interesting
I don't know if it is explained in a way that I find satisfactory. I think omnigrok by Liu et al. has some positions on it. My favorite point of view on it at the moment is the "slingshot mechanism" by Thilak et al. (the paper makes a few assumptions about grokking, like that it happens after memorization, which are false in general, but I don't think any of them are load-bearing)
The idea here is that the thing that causes the weird behaviors like generalization long after memorization is an artifact of the stochastic part of SGD (maybe improved by ADAM) and only happens for sufficiently large learning rates (i.e., not for "smooth" gradient descent). I think the paper that first introduces and studies the relevant SGD phenomenon (though not in the context of grokking) is the "Edge of Stability" paper (Cohen et al.).
In our modular arithmetic experiments, Nina and I have very consistently observed that grokking happens much better and much faster when learning rate starts out comparatively large (within some reasonable bounds, but actually even quite large learning rates of .1 or more will sometimes immediately grok). Also, similar to what the paper predicts, we observe that there is an optimal learning rate (neither too low nor too high) that depends on the architecture and the complexity (i.e., the size of the prime)
However, I'm not 100% sure that this is the only/the correct explanation for the phenomenon of grokking being weird from a statistical process perspective/ behaving long after memorization in certain contexts. There might be some other things going on
Could you say a bit more about what you mean by large-basin phenomena vs small-basin phenomena? Is this just referring to something like the effective parameter count of the model — generalizing solutions are ones with a smaller effective parameter count — or is this referring to actual basins in the loss landscape? (I'm mostly asking because with a regularization term in the loss, it seems plausible to me that memorizing solutions do not correspond to basins at all, strictly speaking. I agree they might correspond to basins if you look at the classification loss alone.) Is this also roughly the same story as the one in Varma et al. and Davies et al.?
Yeah I am using the term "basin" very loosely, almost (but not quite) synonymously with "circuit". In a very noiseless (or, possibly, a very overparametrized) architecture, I would expect every memorization to correspond to a small dip in the loss (in x-entropy loss, the dip is on the order of 1/n where n is the number of samples). So it's sort of a basin (even though it's not a local minimum). This is the point of view we take in the low-hanging fruit [LW · GW] post with Nina. I think that this is similar to the notion of "pattern" in the second paper you shared (Davies et al. -- btw I haven't seen this paper before, thanks for sharing it). And I think that both papers you mention fit into this "large vs. small basin" picture.
Here's a heuristic story of grokking that I sort of like (I think this is roughly the story from the two papers above), but which I think you might not like (?), and I'd be interested in better understanding if/why you think this story is wrong or what this story is missing:
Generalizing circuits are more efficient (in the sense of getting the logits scaled to a particular high value using less weight norm) than memorizing circuits, roughly because in a generalizing circuit, the same weights get reused to push logits to be high for many (or, without label noise, possibly all) data points, whereas if the NN is an ensemble of memorizing circuits, more of the weight norm is wasted on pushing the right logit to be high on each particular data point alone. With weight regularization, and assuming there aren't memorizing local optima (that gradient descent can get stuck in), this implies that a generalizing solution is found eventually. Two parts of this story that I'm not sure how to make very good sense of are: 1) why memorizing circuits are learned initially (though I think that this in fact often doesn't happen in practice, so maybe it's sort of reasonable for us not to have a reason to expect this?) and 2) whether something like this also makes sense without weight decay (I'm aware grokking sometimes happens without weight decay, but I don't have a good sense of the state of empirical evidence on the importance of weight decay for grokking / double descent — for instance, is it the case that weight decay plays a key role in most realistic cases of generalization?).
For instance, this story doesn't depend on the optimizer used (SGD/GD/Adam), and I would currently guess that it's the main cause of most cases of generalization long after getting very low train loss, which I think you might disagree with? I'd be interested in being convinced that I'm wrong here :). I guess it's possible that there's multiple independent phenomena that outwardly look the same, i.e. give the same grokking-like loss curves, and maybe the disagreement here (if there's any) is mostly not about whether any of these make sense, but about which is closest to being the main cause of sudden generalization in realistic cases? (Another thing I'm confused about that seems relevant to mention here is the degree to which e.g. the mechanism behind the sudden gain of some practical capability as one scales up the size of a language model is the same as the mechanism behind a small model grokking on some algorithmic task, but maybe let's leave a discussion of that for later.)
(Another obstacle to making better sense of this story is how to think of multiple circuits living sort of independently in a neural net / contributing to the logits independently — I wanted to mention that I'd also like to understand this better before being happy with the story.)
I think there are a few points here. First, I think the "heuristic story" you mention largely agrees with what I mean by the "competition between large and small circuits" model, and I agree that it seems correct for many toy models including modular addition and the parity paper of Barak et al, and probably is at least partially correct in more general networks. (BTW I think this model for grokking as learning large, more efficient circuits is already introduced in the original paper of Nanda et al, if not in the earlier paper of Power et al.) I also agree with your "two hard parts". I think your second "hard question" corresponds to my question A (and I'll give a rant on the first "hard question" about weight decay momentarily). I think that, in addition to the two questions you mention, people often seem to worry about what I call "Question B", namely, why the existence of a "more efficient" circuit corresponds to something that looks like a phase transition (i.e., a discrete-looking learning event that, e.g. if you look at generalization loss, will start slow, speed up, then complete). I think the key term in your heuristic story that corresponds to this question is "more efficient". If "more efficient" meant that the best way to reduce loss is always to move towards a generalizing (or "grokking") circuit, then we would observe a very different picture where memorization never occurs and the whole grokking story is moot. But in fact, even with very efficient architectures, we do tend to observe memorization happening a little bit before generalization starts. So generalization is (at least under this model, though I think this is true more generally) more efficient in the limit, but very early in training, generalization contributes less to the gradient, and local behavior is mostly dominated by memorization.
I think that when you explain your model, you sort of naturally jump to the same conclusion as me, that if you have a few possible large and efficient circuits then (ignoring everything else that happens, whether it be memorization or something else), you would expect a phase transition-like behavior, where first a noisy symmetry-breaking behavior chooses a large circuit, then this large circuit warms up (slow growth), then it has high growth, then it completes.
I think that it's also kind of obvious why for learning memorization circuits, this will tend to happen much faster. Namely, since each memorization circuit effectively only requires one weight to learn (i.e., its effective dimension is roughly one -- this is a folklore idea, see e.g. our post [LW · GW] or the end of page 4 in this paper, which you told me about, for empirical confirmations), we can think of memorization as a very "small" circuit, and so the initial symmetry breaking of "turning on" such a circuit (in order to then learn it completely) is expected to happen easily and quickly using e.g. a stochastic search.
So in some sense it seems to me that under the model we both are discussing of large, ultimately more efficient circuits vs. small, easy-to-learn circuits, phase transition behavior is an obvious consequence of the model, modulo some kind of symmetry-breaking or "learning shape" argument. But it seems to me that lots of people find this particular behavior surprising, and so I sometimes feel that I'm missing something (maybe my definition of "phase transition" is different from the one normally used in the literature).
About your first "hard question", allow me to engage on a small rant. Namely, there seems to be a persistent myth that grokking (at least in modular addition) only happens with explicit regularization (like weight decay). I know that this isn't what you believe, but I've seen it all over the literature, including the recent Deepmind paper you mentioned. But just to try to address this false meme: This is known to be generally completely false, including in the overparametrized case. For example this is explained in the beginning of the omnigrok paper. In our experiments, if you design the modular addition network efficiently, it will often immediately grok without regularization. In fact in some architectures we tried (involving frozen layers), not regularizing has better behavior than regularizing; in other architectures we worked with, regularizing improves performance (but it's almost never necessary, except in edge cases). If you believe omnigrok (though from what I understand maybe you think there issues with some of the claims there), then the thing that replaces regularization is starting with low weight norm; then usual SGD/whatever optimizer you use is incentivized to find solutions with smaller weight norm just because they're easier to reach/require fewer steps. I think that when we talk about regularization in some kind of context of "efficiency", we should include implicit regularization of this type and any other phenomenon that encourages lower-weight-norm solutions. I would guess that some kind of implicit or explicit regularization is in general necessary or at least useful for grokking, and I don't have enough experience training larger models to predict whether explicit regularization in the form of weight decay helps for grokking more generally.
Finally, you mention that your heuristic story doesn't depend on the optimizer. This is also what I would a priori expect. However, in our experiments, it appears that the optimizer is extremely important. ADAM is significantly better than SGD, and either ADAM or SGD with suitably high learning rate is significantly better than if we reduce the learning rate to be small and comparatively adjust the number of epochs to be large. Both of these effects don't just speed up or slow down learning: both ADAM and large lr improve generalization over memorization in a qualitative way, where memorization local minima are more likely without ADAM/with small lr. Also in Neel Nanda's original experiments, the reasonably high lr seems quite significant. Again, my favorite explanation of this is Thilak et al.'s "slingshot mechanism". I don't completely understand the theory behind it, but my understanding is that it is an "edge of stability" (Cohen et al) effect. The idea here is that larger lr effectively makes high-entropy landscapes (like the memorization landscape) have higher temperature (from the stochastic part of SGD) than flatter, lower-entropy landscapes like the generalization landscape, and this privileges generalization over memorization (even more than just ordinary stochasticity, e.g. via Langevin dynamics, would do).
I think the Barak paper is the only source I know that carefully tries to control lr and experiment with small lr-SGD (i.e., approximating regular GD). I think they sort of get grokking for small networks, but mention that it doesn't work to generalize for most of the examples they consider (and more generally, they also find this effect of larger lr often being better, even if you inversely adjust learning time).
So my general guess is that yes, just appropriate regularization + GD (+ maybe some controlled stochasticity to avoid getting stuck) is sufficient for generalization, but one of my biggest updates from our experiments is just how much learning rate and optimizer parameters matter.
sort of a side point: I think we should clarify what we want to mean by "grokking" — I think we have been using it somewhat differently: it seems to me that you sometimes use it to mean sudden generalization (e.g. when you said that grokking need not happen after memorization), whereas I use it in the sense of going from very poor test performance to very good test performance (long) after reaching perfect train accuracy?
not that this really matters except for ease of parsing this discussion, but I think my sense is what people usually mean by "grokking" (?): "We show that, long after severely overfitting, validation accuracy sometimes suddenly begins to increase from chance level toward perfect generalization. We call this phenomenon ‘grokking’" (from Power et al.)
And I agree that generalization often happens without regularization, and it seems plausible to me that it can often be sudden — I think your explanation in terms of a circuit that is half-formed implying it is very helpful for decreasing loss to push further weight into it makes sense (though I'd appreciate having more detailed/quantitative models of this — e.g., should I think of the circuit as being there in the weights to begin with lottery-ticket-style and undergoing exponential growth for the entire duration that is already nearly finished once it starts to visibly contribute to the loss, or should I think of there being a period of randomly jumping around until we land on a version of the good circuit with tiny weights, followed by a period of pushing weight into the tiny circuit). So I agree that the phase-transition-like loss curve does not seem that surprising — I agree that your Question B seems sort of easy (but I could also just be missing what people find surprising about it)
Right - I agree that I'm using a non-standard definition of grokking. As you say, there are two definitions, one being "large sudden uptick in generalization performance" and the other (which Power et al. originally introduced) being "large sudden uptick in generalization performance long after perfect memorization accuracy". I might be mistaken since I know very little about the history of the question, but I think that originally the two were the same, since the only known upticks in generalization performance occurred in networks after overfitting. I think the simpler definition (without requiring memorization to complete) is becoming more common now. I think it's also better, since from a mechanistic perspective, there's nothing qualitatively different between learning a generalization circuit before or after memorization completes, so this is the definition I use (and yeah, this is confusing and maybe there should be a different term for this).
The phenomenon of "grokking as originally defined", i.e., of generalization long after overfitting, doesn't occur all the time. In most of the architectures we studied with Nina, "grokking" in the sense of rapid generalization improvement occurs long before training loss accuracy goes above 50%. However the fact that it does occur sometimes is surprising (this is my "question A."). In my nomenclature this phenomenon would be a "property of grokking" (that it occurs late) rather than the definition of grokking.
I'm guessing you agree that the degree of outrageousness / truth of claims like "grokking only happens with weight decay" or "grokking can only happen after memorization" depends massively on which of these two definitions one is using? I think it's plausible that mostly when such claims are explicitly made in the literature, people mean to say the less wrong thing? E.g. I doubt that many people would say that (sudden) generalization can't happen in the overparametrized case without regularization, anyway after the canonical Zhang et al.
re the importance of not doing vanilla GD: Is it fair to rephrase what you said as:
"The heuristic story is somewhat wrong because, in fact, vanilla GD does often get stuck in local optima (or maybe would hit a very low-gradient region and then move slowly enough that it can be seen as stuck for practical purposes), at least in toy algorithmic tasks, whereas SGD has an easier time jumping out of these narrow local optima. This is especially true because the "effective stochasticity" is higher in the narrower basins corresponding to memorizing solutions because of something like (1) the gradients for different data pointing in very different directions (which is less true when there's a single circuit that's helpful on all data points — this makes all gradients point "in the direction of this circuit"); in particular, doing a gradient step on input x might break the memorizing circuit on input y; and (1.5) (relatedly) generally sth like: the variance of the gradient computed on a small subset of the inputs at the point θ in parameter space is related to the variance of the full-batch gradient but computed on a point sampled at random from small disk of some constant radius (?) around θ in parameter space, and the latter obviously has higher variance when the loss basin is narrower. (And one can tell a similar story for Adam — the stochasticity is still present, and now one also has some combination of momentum and ~forced constant-size steps to help one escape narrow local optima.)"
Yes, I think your summary of why higher lr in SGD/ADAM matters is exactly correct - at least to the best of my ability to understand the "edge of stability" paper. You have much more experience with the optimizer literature, and I'm curious if you'll come up with nuances/corrections to this point of view if you read some of the literature around the "Edge of Stability" result.
One could ask whether there are theoretical reasons that "vanilla GD with regularization" fails to generalize, I don't feel like I have enough of model to say for sure. I think it could go either way. I.e., it's possible that even with regularization, you would expect vanilla GD to converge to a memorization minimum (there's a simple mathematical argument that, for suitable choices of architecture and hyperparameters, a memorization solution can be fully stable under GD even with regularization - I can sketch it out for you if you're interested). On the other hand, it's possible that when the empirical networks we coded get stuck executing low-lr SGD, this is just because the gradient is very small, and if one were to wait a suitable (and possibly astronomical) amount of time, SGD would eventually converge to a generalizing solution. I think that I have genuine uncertainty about which phenomenon is "theoretically correct" (or whether there is significant dependence on architecture/initialization norm, even for theoretical limit cases), and I wouldn't be prepared to make a bet either way. I think this is an interesting topic to study! I think Rubin et al. may be a step towards understanding this - it sort of follows from their context, at least if you believe their assumptions, that in their MSE (mean-squared error) loss architecture, "vanilla SLGD" will grok with an arbitrarily small step size. I.e., if you introduce noise in a theoretically controlled way rather than through SGD, you'll get a generalizing solution in a suitable limit. Here I should flag that I don't completely understand that paper at the moment.
I'd be quite interested to hear the stuck construction, especially if it seems somewhat realistic (in particular, I think this might be relevant to my disagreements/confusions with omnigrok)
About "outrageousness", I think it's pretty natural that people don't read each other's papers. Intepretability is a very new field with people coming in from a bunch of fields (theoretical physics, academic CS, statistics, and industry to name a few). I think this kind of "stuck meme" phenomenon occurs even in much smaller fields as well. So I don't think it's outrageous or a mark of bad scholarship (in particular, I constantly notice giant blindspots in my understanding of the literature). But first, "grokking as originally defined" (i.e., long after memorization is complete) does occur without regularization: see e.g. the Thilak paper mentioned before, and Gromov. Second, I've seen the explicit claim in papers that the other definition of grokking, i.e., "rapid generalization loss improvement", can't occur without regularizing/ without first overfitting (don't remember exactly where, and don't think it's useful to try to find references to shame people - again, I think it's perfectly normal for such memes to become entrenched). I think the "omnigrok" paper also low-key complains about this persistent belief.
I agree that it was a bit outrageous of me to call these claims outrageous :) (and I also agree with your other points)
For the stuck construction: actually, the original example I wrote down doesn't work. The rough idea is this: instead of regularizing, imagine you're constrained to lie on a sphere. Say you've found a good memorizing point, which is far from any generalizing attractor. Then there may be learnable directions to learn a generalizing circuit, but because of the "warm-up" effect, the loss decrease going in these directions might be smaller than the corresponding loss increase from moving away from your memorizing solution. I'm not sure how plausible this situation is in realistic networks: I suspect you may be right that this happens less than people think (and that you would expect generalization to win even with very low regularizations, just at very slow/astronomical time scales).
Regarding a memorizing circuit having an effective dimension of 1 being the reason that it tends to be learned faster: I think it makes a lot of sense to me that this would happen in the "learning does a random walk until landing on a tiny version of a good circuit, which then gets its weight pushed up" picture, but I understand less well what this would look like in the picture where both circuits are learned simultaneously, from the beginning of training, just with different speeds (I think this is the picture in e.g. Varma et al.). I guess the questions that come up here are:
1) Which picture is "more right"? (Is there a way to think of these as being the same picture?)
2) If the latter picture makes sense, what does the implication from having an effective dimension of 1 to being learned fast look like in it?
3) Is there a better picture-independent/orthogonal way to understand this?
(I think these have significant overlap — free to only address whichever seems most useful.)
my guess at an answer: only having to get 1 parameter right implies that there is likely a full memorizing circuit close to where one starts, which means that gradients toward it are also larger to begin with (+ probably less importantly, one needs to travel a smaller distance)? Or maybe a memorizing circuit having having small effective dimension implies that the "largest generalizing circuit starting off smaller than the largest memorizing circuit" or slightly less vaguely "starts off with a much smaller serial product of weights, causing smaller gradients pushing it up" (+ some quantitative argument for why the benefit of doing an update pushing weight into the generalizing circuit on every data point, vs a particular memorizing circuit only getting boosted when we do a gradient step on that particular data point, tends to initially be dominated by this circuit size / effective parameter count effect)?
(I think Pezehski et al., Kuzborskij et al., Stephenson & Lee might also be helpful, but tbh I've only read the abstracts (h/t Jesse Hoogland for mentioning these once).)
Yes, I feel like all of your models for why memorization happens the way it does make sense, and I think the question of how they combine makes sense and is interesting. The one thing I would definitely predict is that "lottery ticket" phenomena matter, i.e., that the initialization makes certain memorization circuits more immediately learnable than others. I would suspect this is more due to stochasticity in the derivative of logits with respect to the weights (which can make some memorizations faster to learn) than to differences between the logits themselves at initialization.
Thanks for these papers on memorization/double descent - they all look cool, and I'll take a look. There's also the very good "Double descent demystified" paper which looks at linear regression for noisy inputs directly (this is a convex optimization problem I think, so the training dynamics are simple). I think that there are several differences between memorization in our context and the "usual" double descent phenomenon.
First, most theoretical studies of double descent look at MSE loss, where I think the "symmetry breaking" phenomenon is even less pronounced than cross-entropy. In particular, in a pure memorization problem I would expect cross-entropy loss to work a bit more like sequentially learning a series of memorizations, whereas MSE would look a bit more like just flow towards the linear regression result (see also my next comment). Second, we have no label noise (which can results in different behavior in the "Double Descent Demystified" paper), though maybe a combination of stochasticity from SGD and batching can lead to similar effects. And finally, of course the generalizing solution changes the dynamics (since the effective dimension of the generalizing circuit is much smaller than the number of samples we consider). But I agree that it's a good intuition that linear regression and memorization should exhibit some similar behaviors. I don't have a very good sense for this (Nina understands it much better), and would be interested in your/Jake's points of view.
Actually, when sketching out formulas for a comparison of cross-entropy and reply, I realized that there's a nice model for cross-entropy loss early on in training as an for architectures with sufficiently many output classes as a certain ℓ1-metric maximizing flow (and this sort of conflicts with viewing cross-entropy loss as a circuit). Here's a simple but I think useful picture:
Claim. If we assume that the number of output classes, K, is suitably high compared to other hyperparameters (something that is definitely true in modular addition), then loss early in training is, up to an additive constant, close to the sum of the correct logits
Lcross-entropy≈∑xo(x,y∗)+C,
where C is a constant. (Here the sum is over input classes x, the output y∗=y∗(x) is the correct output for the given input, and o(x,y) is the logit.)
Proof The loss per input, x, is the log of
softmaxx=exp(o(x,y∗))∑Ky=1exp(o(x,y)).
Now early in training, terms in the sum in the denominator are close, so changing a single term has a much smaller effect on the softmax than changing the numerator. Thus we can assume that change in the denominator is mostly zero/noise sufficiently early on. Thus we can approximate the loss associated with x as a constant plus log of the numerator, i.e., Lx≈Cx+o(x,y∗). □
This means that, early on, gradient descent will just be trying to increase every logit with roughly equal weight (hence ℓ1). So in fact, for cross-entropy loss the "symmetry breaking" model is sort of broken for memorization, since there is not much competition between different attractors (at least assuming you're overparametrized): loss is just trying to push the correct logits to be as high as possible. There's still a kind of basin behavior, where once a logit is learned, loss associated to that particular input becomes mostly flat (especially if you have regularization). I think this is even worse with MSE loss: since you're taking squares, MSE loss will push logits that are further away from being learned even faster (so in the phase transition picture I gave, instead of having a "warmup" where circuits that are partially learned become more attractive, there is an opposite effect).
That makes sense. I think the conclusion about no symmetry breaking holds independently of the ℓ1 claim though? I.e., in the overparametrized case, assuming gradients computed from individual data points are independent random vectors v1,…,vm (let's say with iid gaussian coordinates or drawn uniformly from a sphere, whatever), one can decrease loss on almost every input (assuming there are fewer data points than params) for a while just by moving in the direction of v1+⋯+vm (or, more precisely, gradient descent will in fact move in this direction).
I guess maybe the additional conclusion from the ℓ1 claim here is that we can think of moving in these directions as not just decreasing loss on the corresponding inputs, but more precisely as mostly just pushing a single logit up?
Also, I think it might still make sense to think of these as circuits — movement in the vidirection builds up a small vi-circuit that memorizes data point i (?)
Agreed that you can view learning data point i as a circuit. In some sense you can call anything a circuit, but I agree that the fact that they're somewhat independent in the overparametrized case makes them more "circuit-like". I also think that with cross-entropy loss, memorizing an input looks more like a circuit than for MSE loss, because the ℓ1 metric is more basis-dependent than the ℓ2 metric (and this becomes even more pronounced beyond early learning, when the basis of logits becomes even more important) - but this is kind of a vague/aesthetic point.
Right, I agree with your more general argument against symmetry-breaking for memorization. I'm realizing that my notion of symmetry breaking is a bit confused: it's an intuition that needs more unpacking. So let me try to formalize it a little. I think a more formal notion of "symmetry breaking" here is a situation where you expect that vectors that move towards all the different possible circuits conflict with each other (usually because there are "too many" possible circuits in some appropriate sense). If you view "learning data point x_i" as a circuit, then you're right, in the overparametrized case, you can move towards all of them simultaneously without expecting conflicts. This complicates my picture of generalizing circuits having symmetry breaking. In most of the networks we trained in our experiments, we used a small embed_dim (this tends to improve efficiency a lot). In our architecture, though there's only one nonlinearity, there is also a hidden_dim, and setting that high enough can make a network with such a "narrow" layer still be overparametrized (and successful at memorizing). But the embed_dim limits the number of learnable generalizing circuits (the maximal number, barring weird superposition effects, is embed_dim/2); on the other hand, the number of possible "types" of generalizing circuits is equal to the number of Fourier modes, which is p−12. So in our architecture, there is clear symmetry breaking in that you can't learn all the different Fourier modes at once (since they don't "fit" in the embed_dim -- in some sense, the model is underparametrized from the point of view of types of generalizing circuits). In other models, like Nanda et al.'s original model, this is actually not the case, so in some sense, you could learn all the Fourier modes without getting conflicts. So I guess in this case you need a more sophisticated symmetry breaking argument. One way to argue that it's bad to learn all Fourier modes simultaneously (i.e., you have symmetry breaking) is to see that regularization (whether explicit or implicit) limits the number of "fully learned" Fourier modes you can have, and partially learned Fourier circuits have much worse loss than fully learned Fourier circuits. This is a bit circular, since it essentially goes back to claiming that Fourier circuits improve loss in a nonlinear way (the original claim about phase transitions). But it's easy to see in mathematical models (e.g., for the MSE case, it follows from the "Droplets of good representations" result).
I've kind of argued myself into a corner, haven't I? :) Maybe the phase transition question ("Question B") shouldn't be considered obvious. Though it seems intuitively unsurprising. It's also very easy to see experimentally. Like here's a visualization we made of the loss per Fourier mode over training for a modular addition circuit:
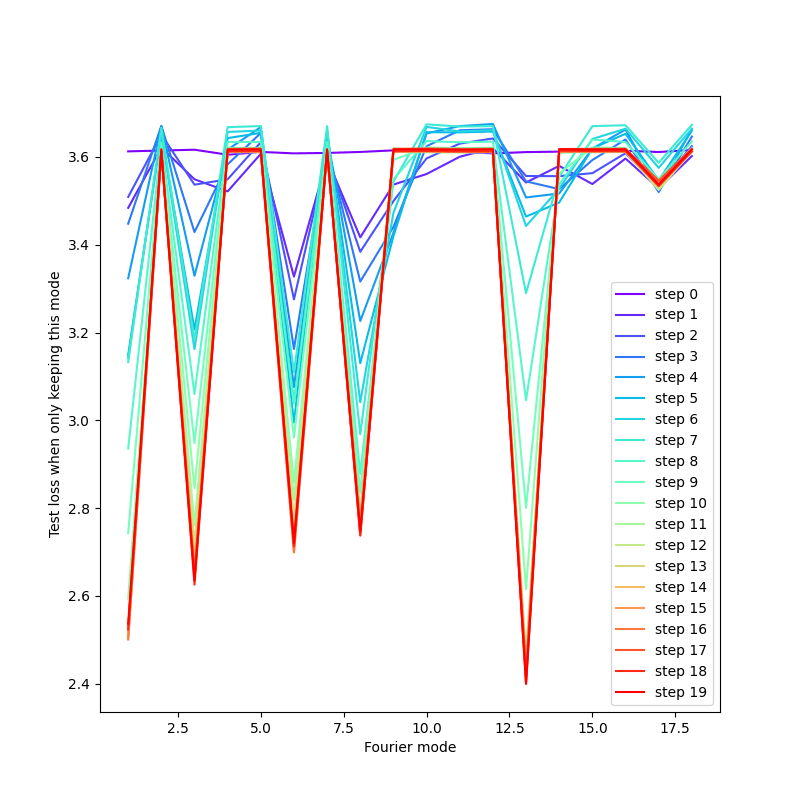
Here you see that starting very early on, modes that start getting "turned on" get more prominent/more relevant for loss while modes that don't start getting "turned on" stabilize to an irrelevant baseline (this is the analog of logits - with memorization, you'd expect all logits to improve early on). Note that here 5 modes are learned, but the embed_dim has room for up to 12, so this symmetry breaking behavior is not just due to the effective underparametrization I mentioned (and similar pictures happen when it would be possible to fit all Fourier modes in the embed_dim, i.e., you have effective overparametrization).
We'll wrap up here, but we're planning to have part 2 of this discussion next week. I think I've learned a lot in this exchange — thank you! Here are some topics that we're hoping to discuss (more) in part 2:
* Rubin et al. (which you've told me is good; I'll also try to find time to read it before we talk again)
* implicit regularizers
* relatedly: my disagreements/confusions with omnigrok
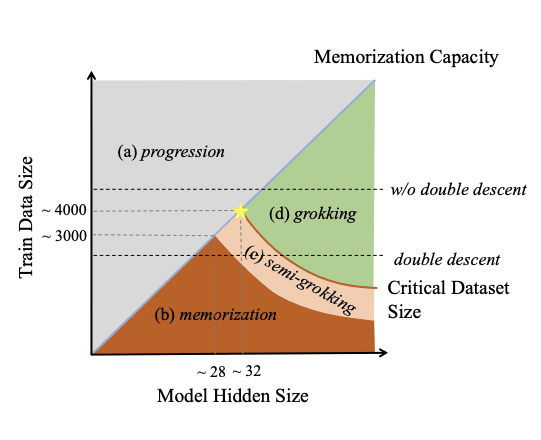
* maybe a bit on double descent in model size, data set size
* SLT connections
* possible issues with the "generalizing circuit vs. memorizing circuit" dichotomy for larger / more complicated networks
* how does any of this connect to the sudden emergence of practical capabilities in (language) models?
* more broadly, how does understanding this stuff (or figuring out deep learning theory in general) get us closer to solving alignment? Should people that care about alignment work on this, or can we trust usual academia to handle this?
Thanks. Chatting with you here has really helped me clarify and find bugs in my thinking about this.
I really like your list of questions! Most of these are all things I've thought very little about and I'm looking forward to hearing your perspectives on these.
Comments sorted by top scores.
comment by kave ·
2023-10-31T01:54:32.858Z · LW(p) · GW(p)
Thanks for writing and sharing this dialogue on LessWrong! I really enjoyed it, and I think the questions about how and when neural networks generalise are very interesting (in particular because of the interplay with questions about when and whether we should expect things to “generalise to agents”).
I thought I’d mention a couple of things that I particularly enjoyed about this dialogue, and share my intuitive story about grokking. I also had some specific questions and clarifications, which I’ll scatter through some sibling comments.
The reasoning transparency around which of your views had evolved in conversation or how much of a given paper you’ve read or (especially!) understood. It’s pretty easy for me to feel like if I’m going to try and join some conversations based on theory papers, I have to read and understand them completely in order to contribute. But seeing you be epistemically resourceful with some papers you were less familiar with relaxed me a bit.
I also like how you were both willing to put yourself out there with respect to your intuitions for grokking. I have felt somewhat similarly to Dmitry with respect to “but like, wouldn’t a generalising circuit just warm up slowly then get locked in? What’s the confusion?”, or Kaarel on “generalising circuits are more efficient”. That then made the questions like “well is this a sigmoid growth curve or a random walk followed by rapid scale up?” or “why does memorisation sometimes happen significantly earlier?” or “why don’t the circuits improve loss linearly such that you learn each of them a bit?” much easier for me to grasp, because I’d been “brought along” the path.
I thought I would throw in my intuitive story as well (which I think is largely similar to the ones in the post). It only really works with regularisation, and I don’t know much about ML, so perhaps I’ll learn why this can’t work.
The initialised network has at least a few “lottery tickets” that more-or-less predict some individual data points. They have good gradients to get locked-in at the beginning. After a few such points are learned, the classification loss is not as concentrated on the generalising solution (which is partially just getting the right answer on data points where we already get the right answer).
In fact, the generalising solution might be partially penalised on the data points where we’ve memorised solutions, as it continues to push on high probability tokens, slightly skewing the distribution (or worse if we’re regressing). But there’s probably still overall positive gradient on the generalising solutions.
As the generalising circuit continues to climb, the memorising circuits are less-and-less valuable, and start to lose out against the regularisation penalty. As the memorising circuits start to decline, the generalising circuit gets stronger gradients as it becomes more necessary.
comment by kave ·
2023-10-31T01:55:36.467Z · LW(p) · GW(p)
just note that at a noisy configuration, you would expect "learnable directions" to be very noisy, and largely cancel each other out, so the gradient will be predominantly noise from the perspective of the circuits that are eventually learned
I think this is saying something like “parameters participate in multiple circuits and the needed value of that parameter across those circuits is randomly distributed”. Is that right?
comment by kave ·
2023-10-31T01:56:16.531Z · LW(p) · GW(p)
I think that when we talk about regularization in some kind of context of "efficiency", we should include implicit regularization of this type and any other phenomenon that encourages lower-weight-norm solutions.
It does seem like small initialisation is a regularisation of a sort, but it seems pretty hard to imagine how it might first allow a memorising solution to be fully learned, and then a generalising solution. Maybe gradient descent in general tends to destroy memorising circuits for reasons like the “edge of stability” stuff Dmitry alludes to. But is the low initial weight norm playing much role there? Maybe there’s a norm-dependent factor?
Replies from: NinaR↑ comment by Nina Panickssery (NinaR) ·
2023-10-31T10:00:28.774Z · LW(p) · GW(p)
It does seem like small initialisation is a regularisation of a sort, but it seems pretty hard to imagine how it might first allow a memorising solution to be fully learned, and then a generalising solution.
"Memorization" is more parallelizable and incrementally learnable than learning generalizing solutions and can occur in an orthogonal subspace of the parameter space to the generalizing solution.
And so one handwavy model I have of this is a low parameter norm initializes the model closer to the generalizing solution than otherwise, and so a higher proportion of the full parameter space is used for generalizing solutions.
The actual training dynamics here would be the model first memorizes a high proportion of the training data while simultaneously learning a lossy/inaccurate version of the generalizing solution in another subspace (the "prioritization" / "how many dimensions are being used" extent of the memorization being affected by the initialization norm). Then, later in training, the generalization can "win out" (due to greater stability / higher performance / other regularization).
Replies from: dmitry-vaintrobcomment by kave ·
2023-10-31T01:55:49.063Z · LW(p) · GW(p)
Is this just referring to something like the effective parameter count of the model — generalizing solutions are ones with a smaller effective parameter count — or is this referring to actual basins in the loss landscape?
Is the difference between “basin” and “effective parameter count” / “circuit” here that the latter is a minimum in a subset of dimensions?
Replies from: dmitry-vaintrob↑ comment by Dmitry Vaintrob (dmitry-vaintrob) ·
2023-10-31T23:07:57.171Z · LW(p) · GW(p)
Noticed thad I didn't answer Kaarel's question there in a satisfactory way. Yeah - "basin" here is meant very informally as a local piece of the loss landscape with lower loss than the rest of the landscape, and surrounding a subspace of weight space corresponding to a circuit being on. Nina and I actually call this a "valley" our "low-hanging fruit [LW · GW]" post.
By "smaller" vs. "larger" basins I roughly mean the same thing as the notion of "efficiency" that we later discuss
comment by kave ·
2023-10-31T01:55:05.779Z · LW(p) · GW(p)
in some sense, the model is underparametrized from the point of view of types of generalizing circuits
That is a pretty interesting idea! I’ll be interested to see if it works out. It seems like it’s possibly in tension with an SLT-like frame, where the multiple representation of generalising circuits is (in my limited understanding from a couple of hours of explanation) is a big part of the picture. Though the details are a little fuzzy.
Replies from: dmitry-vaintrob↑ comment by Dmitry Vaintrob (dmitry-vaintrob) ·
2023-10-31T23:09:23.736Z · LW(p) · GW(p)
Interesting - what SLT prediction do you think is relevant here?
Replies from: kave↑ comment by kave ·
2023-11-01T19:51:03.297Z · LW(p) · GW(p)
To be clear, I have only cursory familiarity with SLT. But my thought is we have something like:
- Claim: the mechanism that favours generalising circuits involves the fact that symmetries mean they are overrepresented in the parameter space
- Claim: generalising algorithms are underrepresented in the parameter space
Which seem to be in tension. Perhaps the synthesis is that only a few of the generalising algorithms are represented, but those that are are represented many times.