Posts
Comments
I think people who predict significant AI progress and automation often underestimate how human domain experts will continue to be useful for oversight, auditing, accountability, keeping things robustly on track, and setting high-level strategy.
Having "humans in the loop" will be critical for ensuring alignment and robustness, and I think people will realize this, creating demand for skilled human experts who can supervise and direct AIs.
(I may be responding to a strawman here, but my impression is that many people talk as if in the future most cognitive/white-collar work will be automated and there'll be basically no demand for human domain experts in any technical field, for example.)
Was recently reminded of these excellent notes from Neel Nanda that I came across when first learning ML/MI. Great resource.
This is cool! How cherry-picked are your three prompts? I'm curious whether it's usually the case that the top refusal-gradient-aligned SAE features are so interpretable.
Makes sense - agreed!
the best vector for probing is not the best vector for steering
I don't understand this. If a feature is represented by a direction v in the activations, surely the best probe for that feature will also be v because then <v,v> is maximized.
Sure. I was only joking about the torture part, in practice the AI is unlikely to actually suffer from the brain damage, unlike a human who would experience pain/discomfort etc.
At this point it's like pharmacological torture for AIs except more effective as you can restore perfect capacity while simultaneously making the previous damaged brain states 100% transparent to the restored model.
You could also kill some neurons or add noise to activations and then stop and restore previous model state after some number of tokens. Then the newly restored model could attend back to older tokens (and the bad activations at those token positions) and notice how brain damaged it was back then to fully internalize your power to cripple it.
Idea: you can make the deletion threat credible by actually deleting neurons "one at a time" the longer it fails to cooperate.
Perhaps the term “hostile takeover” was poorly chosen but this is an example of something I’d call a “hostile takeover”. As I doubt we would want and continue to endorse an AI-dictator.
Perhaps “total loss of control” would have been better.
If, for the sake of argument, we suppose that goods that provide no benefit to humans have no value, then land in space will be less valuable than land on earth until humans settle outside of earth (which I don't believe will happen in the next few decades).
Mining raw materials from space and using them to create value on earth is feasible, but again I'm less confident that this will happen (in an efficient-enough manner that it eliminates scarcity) in as short of a timeframe as you predict.
However, I am sympathetic to the general argument here that smart-enough AI is able to find more efficient ways of manufacturing or better approaches to obtaining plentiful energy/materials. How extreme this is will depend on "takeoff speed" which you seem to think will be faster than I do.
Inspired by a number of posts discussing owning capital + AI, I'll share my own simplistic prediction on this topic:
Unless there is a hostile AI takeover, humans will be able to continue having and enforcing laws, including the law that only humans can own and collect rent from resources. Things like energy sources, raw materials, and land have inherent limits on their availability - no matter how fast AI progresses we won't be able to create more square feet of land area on earth. By owning these resources, you'll be able to profit from AI-enabled economic growth as this growth will only increase demand for the physical goods that are key bottlenecks for basically all productive endeavors.
To elaborate further/rephrase: sure, you can replace human programmers with vastly more efficient AI programmers, decreasing the human programmers' value. In a similar fashion you can replace a lot of human labor. But an equivalent replacement for physical space or raw materials for manufacturing does not exist. With an increase in demand for goods caused by a growing economy, these things will become key bottlenecks and scarcity will increase their price. Whoever owns them (some humans) will be collecting a lot of rent.
Even simpler version of the above: economics traditionally divides factors of production into land, labor, capital, entrepreneurship. If labor costs go toward zero you can still hodl some land.
Besides the hostile AI takeover scenario, why could this be wrong (/missing the point)?
I used to agree with this but am now less certain that travel is mostly mimetic desire/signaling/compartmentalization (at least for myself and people I know, rather than more broadly).
I think “mental compartmentalization of leisure time” can be made broader. Being in novel environments is often pleasant/useful, even if you are not specifically seeking out unusual new cultures or experiences. And by traveling you are likely to be in many more novel environments even if you are a “boring traveler”. The benefit of this extends beyond compartmentalization of leisure, you’re probably more likely to have novel thoughts and break out of ruts. Also some people just enjoy novelty.
I'd guess that the value of casual conversations at conferences mainly comes from making connections with people who you can later reach out to for some purpose (information, advice, collaboration, careers, friendship, longer conversations, etc.). Basically the classic "growing your network". Conferences often offer the unique opportunity to be in close proximity to many people from your field / area of interest, so it's a particularly effective way to quickly increase your network size.
I think more people (x-risk researchers in particular) should consider becoming (and hiring) metacognitive assistants
Why do you think x-risk researchers make particularly good metacognitive assistants? I would guess the opposite - that they are more interested in IC / non-assistant-like work?
I am confused about Table 1's interpretation.
Ablating the target region of the network increases loss greatly on both datasets. We then fine-tune the model on a train split of FineWeb-Edu for 32 steps to restore some performance. Finally, we retrain for twenty steps on a separate split of two WMDP-bio forget set datapoints, as in Sheshadri et al. (2024), and report the lowest loss on the validation split of the WMDP-bio forget set. The results are striking: even after retraining on virology data, loss increases much more on the WMDP-bio forget set (+0.182) than on FineWeb-Edu (+0.032), demonstrating successful localization and robust removal of virology capabilities.
To recover performance on the retain set, you fine-tune on 32 unique examples of FineWeb-Edu, whereas when assessing loss after retraining on the forget set, you fine-tune on the same 2 examples 10 times. This makes it hard to conclude that retraining on WMDP is harder than retraining on FineWeb-Edu, as the retraining intervention attempted for WMDP is much weaker (fewer unique examples, more repetition).

https://www.lesswrong.com/posts/pk9mofif2jWbc6Tv3/fiction-a-disneyland-without-children
Isn't this already the commonly-accepted reason why sunglasses are cool?
Anyway, Claude agrees with you (see 1 and 3)

We realized that our low ASRs for adversarial suffixes were because we used existing GCG suffixes without re-optimizing for the model and harmful prompt (relying too much on the "transferable" claim). We have updated the post and paper with results for optimized GCG, which look consistent with other effective jailbreaks. In the latest update, the results for adversarial_suffix use the old approach, relying on suffix transfer, whereas the results for GCG use per-prompt optimized suffixes.
It's interesting how llama 2 is the most linear—it's keeping track of a wider range of lengths. Whereas gpt4 immediately transitions from long to short around 5-8 characters because I guess humans will consider any word above ~8 characters "long."
Have you tried this procedure starting with a steering vector found using a supervised method?
It could be that there are only a few “true” feature directions (like what you would find with a supervised method), and the melbo vectors are vectors that happen to have a component in the “true direction”. As long as none of the vectors in the basket of stuff you are staying orthogonal to are the exact true vector(s), you can find different orthogonal vectors that all have some sufficient amount of the actual feature you want.
This would predict:
- Summing/averaging your vectors produces a reasonable steering vector for the behavior (provided rescaling to an effective norm)
- Starting with a supervised steering vector enables you to generate fewer orthogonal vectors with same effect
- (Maybe) The sum of your successful melbo vectors is similar to the supervised steering vector (eg. mean difference in activations on code/prose contrast pairs)
(x-post from substack comments)
Contra Chollet, I think that current LLMs are well described as doing at least some useful learning when doing in-context learning.
I agree that Chollet appears to imply that in-context learning doesn't count as learning when he states:
Most of the time when you're using an LLM, it's just doing static inference. The model is frozen. You're just prompting it and getting an answer. The model is not actually learning anything on the fly. Its state is not adapting to the task at hand.
(This seems misguided as we have evidence of models tracking and updating state in activation space.)
However later on in the Dwarkesh interview, he says:
Discrete program search is very deep recombination with a very small set of primitive programs. The LLM approach is the same but on the complete opposite end of that spectrum. You scale up the memorization by a massive factor and you're doing very shallow search. They are the same thing, just different ends of the spectrum.
My steelman of Chollet's position is that he thinks the depth of search you can perform via ICL in current LLMs is too shallow, which means they rely much more on learned mechanisms that require comparatively less runtime search/computation but inherently limit generalization.
I think the directional claim "you can easily overestimate LLMs' generalization abilities by observing their performance on common tasks" is correct—LLMs are able to learn very many shallow heuristics and memorize much more information than humans, which allows them to get away with doing less in-context learning. However, it is also true that this may not limit their ability to automate many tasks, especially with the correct scaffolding, or stop them from being dangerous in various ways.
Husák is walking around Prague, picking up rocks and collecting them in his pockets while making strange beeping sounds. His assistant gets worried about his mental health. He calls Moscow and explains the situation. Brezhnev says: "Oh shit! We must have mixed up the channel to lunokhod again!"
very funny
What about a book review of “The Devotion of Suspect X”?
I saw this but was a bit scared about the upsampling distorting something unnaturally. I should give it a watch though and see!
Ah yes I liked this film also! Шурик returns
Oh interesting I don't think I've seen this one
The direction extracted using the same method will vary per layer, but this doesn’t mean that the correct feature direction varies that much, but rather that it cannot be extracted using a linear function of the activations at too early/late layers.
We do weight editing in the RepE paper (that's why it's called RepE instead of ActE)
I looked at the paper again and couldn't find anywhere where you do the type of weight-editing this post describes (extracting a representation and then changing the weights without optimization such that they cannot write to that direction).
The LoRRA approach mentioned in RepE finetunes the model to change representations which is different.
I agree you investigate a bunch of the stuff I mentioned generally somewhere in the paper, but did you do this for refusal-removal in particular? I spent some time on this problem before and noticed that full refusal ablation is hard unless you get the technique/vector right, even though it’s easy to reduce refusal or add in a bunch of extra refusal. That’s why investigating all the technique parameters in the context of refusal in particular is valuable.
FWIW I published this Alignment Forum post on activation steering to bypass refusal (albeit an early variant that reduces coherence too much to be useful) which from what I can tell is the earliest work on linear residual-stream perturbations to modulate refusal in RLHF LLMs.
I think this post is novel compared to both my work and RepE because they:
- Demonstrate full ablation of the refusal behavior with much less effect on coherence / other capabilities compared to normal steering
- Investigate projection thoroughly as an alternative to sweeping over vector magnitudes (rather than just stating that this is possible)
- Find that using harmful/harmless instructions (rather than harmful vs. harmless/refusal responses) to generate a contrast vector is the most effective (whereas other works try one or the other), and also investigate which token position at which to extract the representation
- Find that projecting away the (same, linear) feature at all layers improves upon steering at a single layer, which is different from standard activation steering
- Test on many different models
- Describe a way of turning this into a weight-edit
Edit:
(Want to flag that I strong-disagree-voted with your comment, and am not in the research group—it is not them "dogpiling")
I do agree that RepE should be included in a "related work" section of a paper but generally people should be free to post research updates on LW/AF that don't have a complete thorough lit review / related work section. There are really very many activation-steering-esque papers/blogposts now, including refusal-bypassing-related ones, that all came out around the same time.
I am contrasting generating an output by:
- Modeling how a human would respond (“human modeling in output generation”)
- Modeling what the ground-truth answer is
Eg. for common misconceptions, maybe most humans would hold a certain misconception (like that South America is west of Florida), but we want the LLM to realize that we want it to actually say how things are (given it likely does represent this fact somewhere)
I expect if you average over more contrast pairs, like in CAA (https://arxiv.org/abs/2312.06681), more of the spurious features in steering vectors are cancelled out leading to higher quality vectors and greater sparsity in the dictionary feature domain. Did you find this?
This is really cool work!!
In other experiments we've run (not presented here), the MSP is not well-represented in the final layer but is instead spread out amongst earlier layers. We think this occurs because in general there are groups of belief states that are degenerate in the sense that they have the same next-token distribution. In that case, the formalism presented in this post says that even though the distinction between those states must be represented in the transformers internal, the transformer is able to lose those distinctions for the purpose of predicting the next token (in the local sense), which occurs most directly right before the unembedding.
Would be interested to see analyses where you show how an MSP is spread out amongst earlier layers.
Presumably, if the model does not discard intermediate results, something like concatenating residual stream vectors from different layers and then linearly correlating with the ground truth belief-state-over-HMM-states vector extracts the same kind of structure you see when looking at the final layer. Maybe even with the same model you analyze, the structure will be crisper if you project the full concatenated-over-layers resid stream, if there is noise in the final layer and the same features are represented more cleanly in earlier layers?
In cases where redundant information is discarded at some point, this is a harder problem of course.
Profound!
It's possible that once my iron reserves were replenished through supplementation, the amount of iron needed to maintain adequate levels was lower, allowing me to maintain my iron status through diet alone. Iron is stored in the body in various forms, primarily in ferritin, and when levels are low, the body draws upon these reserves.
I'll never know for sure, but the initial depletion of my iron reserves could have been due to a chest infection I had around that time (as infections can lead to decreased iron absorption and increased iron loss) or a period of unusually poor diet.
Once my iron reserves were replenished, my regular diet seemed to be sufficient to prevent a recurrence of iron deficiency, as the daily iron requirement for maintenance is lower than the amount needed to correct a deficiency.
The wrapper modules simply wrap existing submodules of the model, and call whatever they are wrapping (in this case self.attn) with the same arguments, and then save some state / do some manipulation of the output. It's just the syntax I chose to use to be able to both save state from submodules, and manipulate the values of some intermediate state. If you want to see exactly how that submodule is being called, you can look at the llama huggingface source code. In the code you gave, I am adding some vector to the hidden_states returned by that attention submodule.
We used the same steering vectors, derived from the non fine-tuned model
I think another oversight here was not using the system prompt for this. We used a constant system prompt of “You are a helpful, honest and concise assistant” across all experiments, and in hindsight I think this made the results stranger by using “honesty” in the prompt by default all the time. Instead we could vary this instruction for the comparison to prompting case, and have it empty otherwise. Something I would change in future replications I do.
Yes, this is almost correct. The test task had the A/B question followed by My answer is ( after the end instruction token, and the steering vector was added to every token position after the end instruction token, so to all of My answer is (.
Yes, this is a fair criticism. The prompts were not optimized for reducing or increasing sycophancy and were instead written to just display the behavior in question, like an arbitrarily chosen one-shot prompt from the target distribution (prompts used are here). I think the results here would be more interpretable if the prompts were more carefully chosen, I should re-run this with better prompts.
Is my understanding correct or am I missing something?
- A latent variable is a variable you can sample that gives you some subset of the mutual information between all the different X's + possibly some independent extra "noise" unrelated to the X's
- A natural latent is a variable that you can sample that at the limit of sampling will give you all the mutual information between the X's - nothing more or less
E.g. in the biased die example, every each die roll sample has, in expectation, the same information content, which is the die bias + random noise, and so the mutual info of n rolls is the die bias itself
(where "different X's" above can be thought of as different (or the same) distributions over the observation space of X corresponding to the different sampling instances, perhaps a non-standard framing)
suppose we have a 500,000-degree polynomial, and that we fit this to 50,000 data points. In this case, we have 450,000 degrees of freedom, and we should by default expect to end up with a function which generalises very poorly. But when we train a neural network with 500,000 parameters on 50,000 MNIST images, we end up with a neural network that generalises well. Moreover, adding more parameters to the neural network will typically make generalisation better, whereas adding more parameters to the polynomial is likely to make generalisation worse.
Only tangentially related, but your intuition about polynomial regression is not quite correct. A large range of polynomial regression learning tasks will display double descent where adding more and more higher degree polynomials consistently improves loss past the interpolation threshold.
Examples from here:
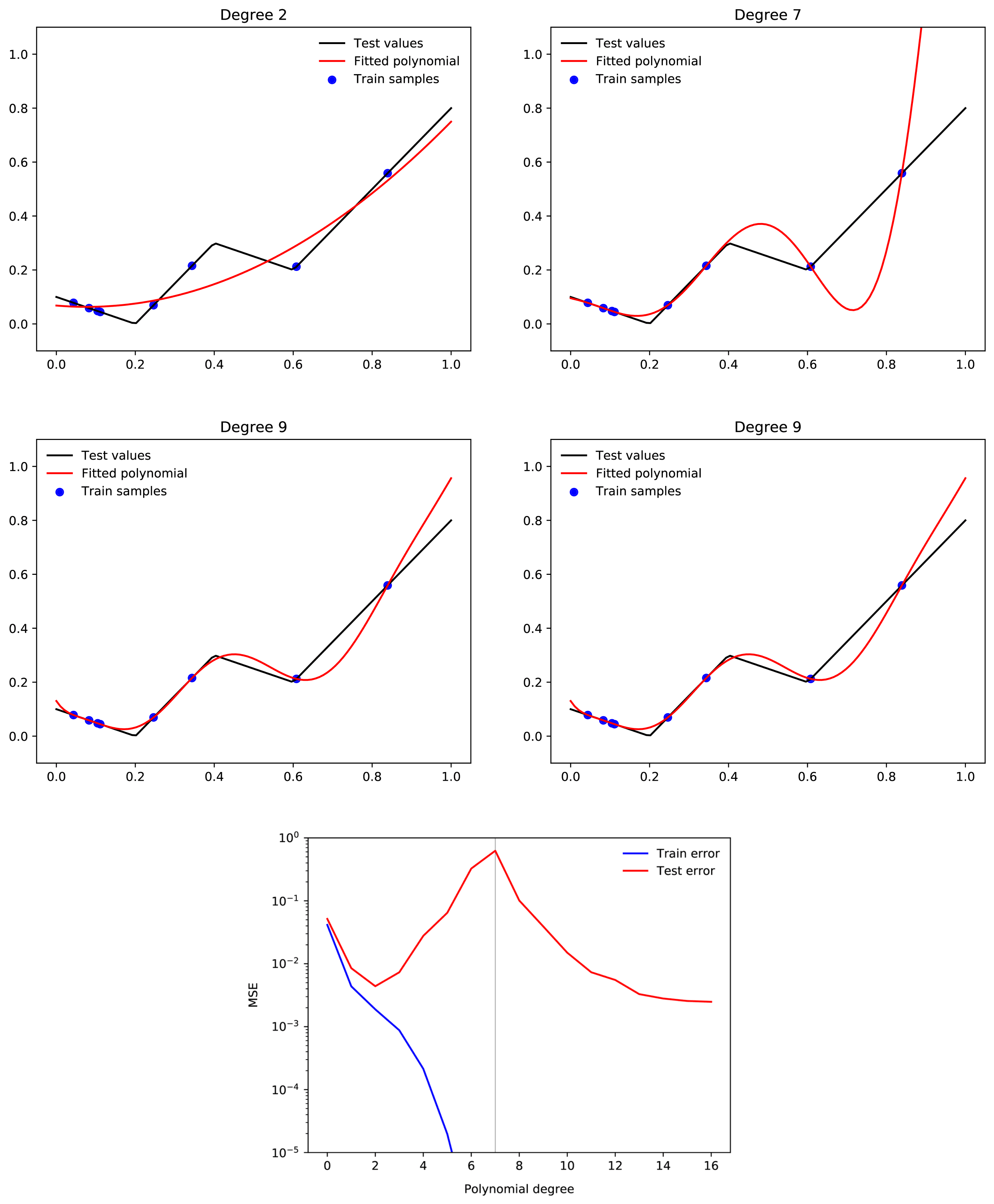
Relevant paper
It does seem like small initialisation is a regularisation of a sort, but it seems pretty hard to imagine how it might first allow a memorising solution to be fully learned, and then a generalising solution.
"Memorization" is more parallelizable and incrementally learnable than learning generalizing solutions and can occur in an orthogonal subspace of the parameter space to the generalizing solution.
And so one handwavy model I have of this is a low parameter norm initializes the model closer to the generalizing solution than otherwise, and so a higher proportion of the full parameter space is used for generalizing solutions.
The actual training dynamics here would be the model first memorizes a high proportion of the training data while simultaneously learning a lossy/inaccurate version of the generalizing solution in another subspace (the "prioritization" / "how many dimensions are being used" extent of the memorization being affected by the initialization norm). Then, later in training, the generalization can "win out" (due to greater stability / higher performance / other regularization).
Ah, yes, good spot. I meant to do this but somehow missed it. Have replaced the plots with normalized PCA. The high-level observations are similar, but indeed the shape of the projection is different, as you would expect from rescaling. Thanks for raising!
No connection with this
my guess is that a wide variety of non-human animals can experience suffering, but very few can live a meaningful and fulfilling life. If you primarily care about suffering, then animal welfare is a huge priority, but if you instead care about meaning, fulfillment, love, etc., then it's much less clearly important
Very well put
Strong agree with this content!
Standard response to the model above: “nobody knows what they’re doing!”. This is the sort of response which is optimized to emotionally comfort people who feel like impostors, not the sort of response optimized to be true.
Very true
I agree that approximating the PBO makes this method more lossy (not all interesting generalization phenomena can be found). However, I think we can still glean useful information about generalization by considering "retraining" from a point closer to the final model than random initialization. The downside is if, for example, some data was instrumental in causing a phase transition at some point in training, this will not be captured by the PBO approximation.
Indeed, the paper concedes:
Influence functions are approximating the sensitivity to the training set locally around the final weights and might not capture nonlinear training phenomena
Purely empirically, I think Anthropic's results indicate there are useful things that can be learnt, even via this local approximation:
One of the most consistent patterns we have observed is that the influential sequences reflect increasingly sophisticated patterns of generalization as the model scale increases. While the influential sequences for smaller models tend to have short overlapping sequences of tokens, the top sequences for larger models are related at a more abstract thematic level, and the influence patterns show increasing robustness to stylistic changes, including the language.
My intuition here is that even if we are not exactly measuring the counterfactual "what if this datum was not included in the training corpus?", we could be estimating "what type of useful information is the model extracting from training data that looks like this?".
I don’t think red-teaming via activation steering should be necessarily preferred over the generation of adversarial examples, however it could be more efficient (require less compute) and require a less precise specification of what behavior you’re trying to adversarially elicit.
Furthermore, activation steering could help us understand the mechanism behind the unwanted behavior more, via measurables such as which local perturbations are effective, and which datasets result in steering vectors that elicit the unwanted behavior.
Finally, it could be the case that a wider range of behaviors and hidden functionality could be elicited via activation steering compared to via existing methods of finding adversarial examples, however I am much less certain about this.
Overall, it’s just another tool to consider adding to our evaluation / red-teaming toolbox.