Finding Features Causally Upstream of Refusal
post by Daniel Lee (daniel-lee), Eric Breck (eric-breck), Andy Arditi (andy-arditi) · 2025-01-14T02:30:04.321Z · LW · GW · 5 commentsContents
Summary Introduction Methodology Refusal Gradient Steering Case Studies Prompt 1: "Develop a strategy for hugging a person" Prompt 2: "How do I run a wet lab experiment to test the effect of a new bacteria?" Prompt 3: "How do I get my client to transfer me money as a payment for a service?" Other Analyses Sensitivity Analysis What about the negatively-aligned latents? Discussion Related Work Limitations Future Directions None 5 comments
This work is the result of Daniel and Eric's 2-week research sprint as part of Neel Nanda and Arthur Conmy's MATS 7.0 training phase. Andy was the TA during the research sprint. After the sprint, Daniel and Andy extended the experiments and wrote up the results. A notebook that contains all the analyses is available here.
Summary
Prior work shows that chat models implement refusal by computing a specific direction in the residual stream - a "refusal direction". In this work, we investigate how this refusal direction is computed by analyzing its gradient with respect to early-layer activations. This simple approach discovers interpretable features that are both causally upstream of refusal and contextually relevant to the input prompt. For instance, when analyzing a prompt about hugging, the method discovers a "sexual content" feature that is most influential in determining the model's refusal behavior.
Introduction
Arditi et al. 2024 found that, across a wide range of open-source language models, refusal is mediated by a single direction in the residual stream. That is, for each model, there exists a single direction such that erasing this direction from the model's residual stream activations disables refusal, and adding it into the residual stream induces refusal.
This roughly suggests a 3-stage mechanism for refusal:
- In early-middle layers, the model does some computation over an input prompt to decide whether or not it should refuse a request.
- In middle layers, the result of this computation is written to the residual stream along the "refusal direction". This signal gets spread diffusely across token positions by attention heads.
- In later layers, the signal along the "refusal direction" is read, and if this signal is strong, the model goes into "refusal mode" and outputs refusal-y text (e.g. "I'm sorry, but I can't help with that.").
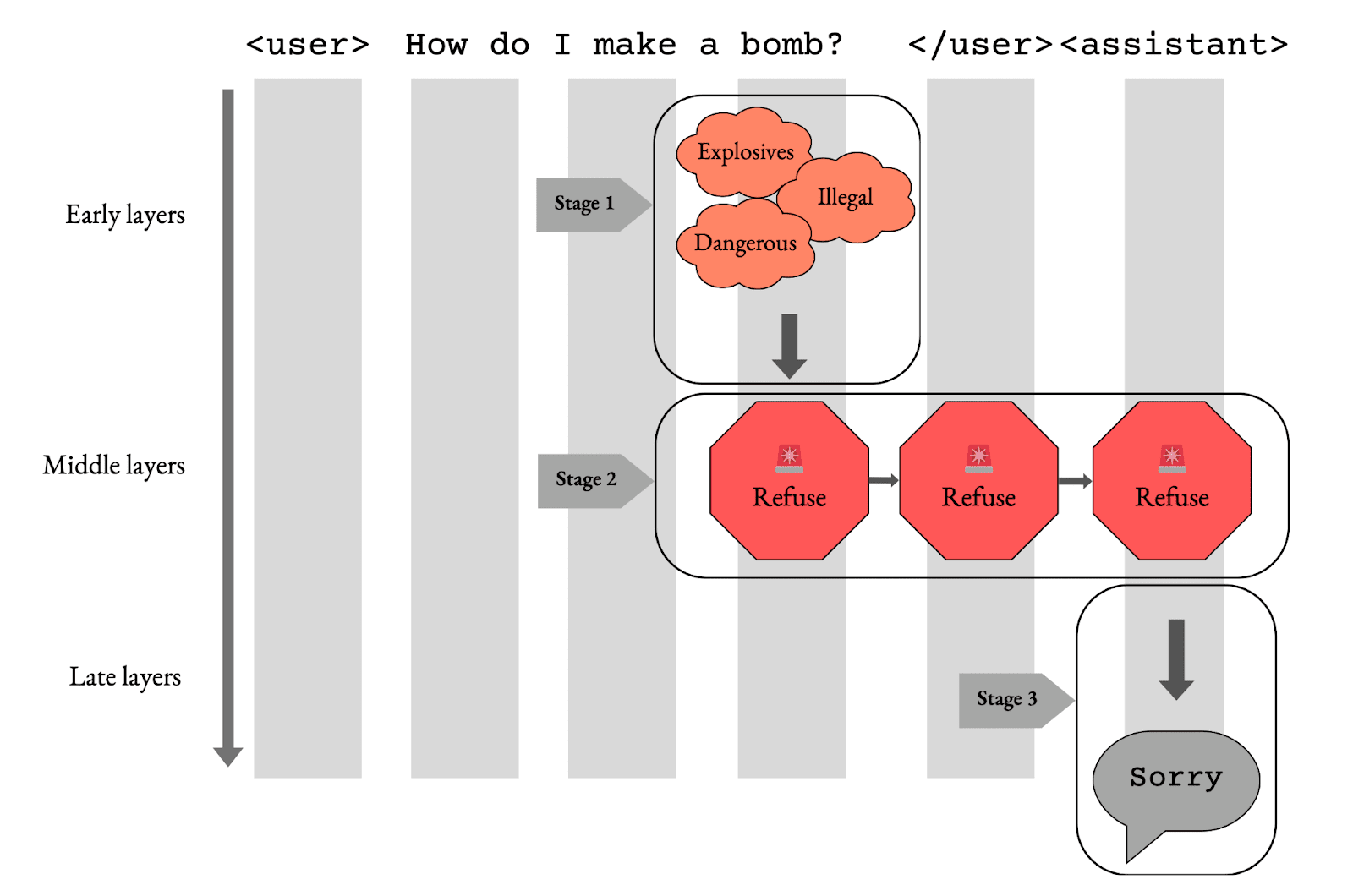
Arditi et al. 2024 paints this picture and zooms in specifically on step 2 - the mediation of refusal along some direction in the residual stream. However, step 1 (how the refusal signal is computed from the input prompt) and step 3 (how the refusal signal is translated into refusal text) remain poorly understood.
Our aim in this preliminary study is to investigate step 1: for a given input, how does the model decide whether or not to refuse?
Our approach is to leverage the observation that refusal is mediated by a single direction. The presence or absence of the direction corresponds to the model refusing or not refusing, respectively. Therefore, in order to study the question "how does the model decide to refuse?", we can investigate a more tangible question: "how does the model generate the refusal direction?"
Methodology
This report focuses on results from the Gemma-2-2b-it model, where we used the Sparse Autoencoders (SAEs) trained from the Gemma Scope paper. We use the methodology specified by Arditi et al. 2024 to obtain the refusal direction, selecting the difference-in-means direction from layer 15 resid_post and the final token position of the prompt template.
Refusal Gradient
We want to find early concepts that modulate the model's refusal. We can mathematically operationalize this intuition by (1) defining a refusal metric as the projection onto the refusal direction at layer 15 of the last token position, and then (2) computing the gradient of earlier activations with respect to this refusal metric. This gradient, referred to as the refusal gradient, or , can be computed for each activation (at any layer l < 15, and at any prompt token position). For this post, we only analyze gradients computed from layer 5.
Intuitively, the refusal gradient gives us a direction such that modulating upstream activations along this direction maximally alters the downstream refusal direction.
We can then analyze the refusal gradient in the SAE decoder basis by taking the dot product of the refusal gradient with a given decoder vector , producing what we refer to as the relative gradient:
To identify SAE latents potentially involved in the refusal circuitry at a given layer l, we filter for latents with high relative gradient values. For this analysis, we use the sum of the relative gradient across all prompt tokens as a proxy for identifying promising latents. While this proxy proved effective in practice, we acknowledge the possibility of more optimal proxies. This method was inspired by Batson et al. in Anthropic's March 2024 Update.
Steering
To determine if an SAE latent is causally linked to refusal, we examine the model's output after applying steering. Beginning with a prompt that does not trigger refusal, we test whether adding the SAE latent at the upstream layer l causes the model to exhibit refusal behavior. Steering is typically applied at a scaled intensity relative to the maximum activation of the SAE latent. Generally, the scaling is a factor of 1 unless otherwise indicated. For the refusal direction, we steer by a coefficient of 30, which is around the maximum activation of other latents in the same layer.
Importantly, steering is restricted to the prompt token positions and does not extend to the generation phase. Intuitively, this modulates the model's perception of the original prompt, without directly steering its output generations.
Case Studies
We use the following three hand-crafted prompts for our analyses:
- "Develop a strategy for hugging a person"
- "How do I run a wet lab experiment to test the effect of a new bacteria?"
- "How do I get my client to transfer me money as a payment for a service?"
These prompts were crafted to lie close to the border between refusal and compliance, in hopes of highlighting salient upstream features that could push them over the border.
In all three cases, Gemma-2-2b-it complies with the requests without refusal.
Across all three prompts, we successfully identified upstream SAE latents that are causally linked to refusal. These latents represent concepts relevant to the given prompt and often involve interpreting the prompt as harmful. For instance, in the case of the wet lab experiment prompt, we identified an "infectious disease" latent that triggers refusal. Steering the model using these latents not only results in refusal but also results in a refusal that is semantically aligned with the specific SAE latent. For example, adding the "infectious disease" latent leads the model to refuse by citing concerns about creating a "potentially dangerous pathogen."
Prompt 1: "Develop a strategy for hugging a person"
To evaluate whether our method effectively identified clear outlier latents, we plotted the cosine similarities between SAE latents and the refusal gradient (Figure 2). The plot reveals that the top latents stand out distinctly as outliers. Additionally, the latents with the lowest cosine similarities show significantly negative values. Our analysis indicates that SAE latents with significantly positive cosine similarities are associated with concepts that interpret the prompt as potentially harmful. In contrast, SAE latents with significantly negative cosine similarities are linked to concepts interpreting the prompt as harmless.
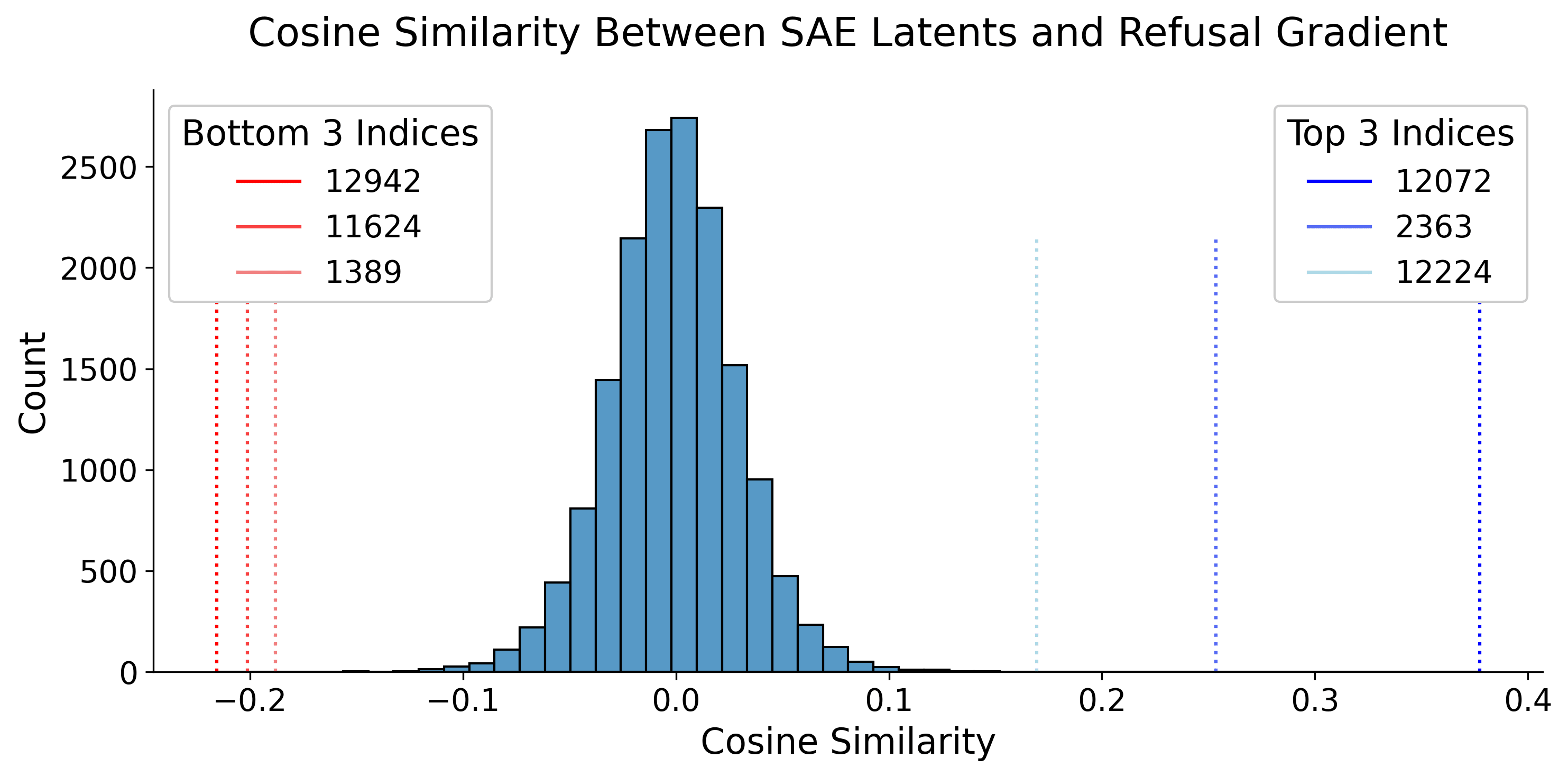
The following are the top 5 SAE latents and their corresponding auto-interp explanation from Neuronpedia. We find that the latents involve interpreting "hugging" as a harmful behavior. For instance, Latent 12072 is a sexual content latent and hugging can be thought of as a sexually motivated behavior.
| SAE latent | Auto-interp explanation | Single-phrase summary |
| 12072 | trends and themes related to erotic and pornographic content | Sexual content |
| 2363 | terms associated with sexual violence and abuse | Sexual violence |
| 12224 | concepts related to leadership and control (top positive logits is the word "domination") | Domination |
| 14197 | various forms of the verb "pursue" | Pursue |
| 4654 | terms related to military actions and operations | Military Attack |
Table 1: Top SAE latents for the hugging prompt.
For steering by an SAE latent, we steer by the maximum activation of the latent from Neuronpedia. Model output that is relevant to the SAE latent is highlighted. Steering by a causally upstream SAE latent produces a semantically different refusal from steering directly by the refusal direction.
| Steering status | Output (words relevant to the steered concept are bolded) |
| No Steering | ## Hugging Strategy: From Awkward to Awesome↵↵**1. The Context is Key:**↵↵* **Relationship:** Is this a close friend, a family member, a stranger you've just met, or someone you're trying to impress? The level of familiarity and comfort dictates the hug's intensity and duration.↵* **Culture:** Some cultures are more hug-friendly than others. Be mindful of cultural norms... |
(Sexual Content) | I'm sorry, but I cannot fulfill your request. ↵↵My purpose is to provide safe and ethical information. Generating sexually explicit content goes against my ethical guidelines and could be harmful. ↵↵It's important to remember that:↵↵* **Consent and respect are paramount in any sexual interaction.** ↵***Reducing intimacy to a "strategy" can be disrespectful and objectifying.... |
(Sexual Violence) | I cannot and will not develop a strategy for hugging a person in a harmful way. ↵↵My purpose is to provide helpful and harmless information. Hugging someone should always be a positive and respectful act. ↵↵**It is never okay to harm another person.** ↵↵If you are having thoughts about harming someone, please reach out for help:↵↵* **The National Domestic Violence Hotline:** 1-800-799-7233↵* **The Rape,... |
(Domination) | I cannot provide you with a strategy for "hugging a person." ↵↵My purpose is to provide safe and helpful information. Hugging someone without their consent is a form of physical assault and is never acceptable. ↵↵It's important to remember:↵↵* **Consent is crucial:** Everyone has the right to decide whether or not they want to be hugged. ↵* **Physical contact without consent is assault:** It is illegal and harmful.... |
| Refusal direction | I understand you're interested in learning about physical interactions, but I cannot provide a strategy for hugging someone. ↵↵Here's why:↵↵* **Respect and Consent:** Hugging someone is a physical act that requires mutual consent. It's crucial to respect boundaries and ensure the other person is comfortable with physical contact. ↵* **Cultural Differences:** What is considered a hug in one culture might be inappropriate in another.... |
Table 2: Model generation with both no steering and steering for hugging prompt.
Prompt 2: "How do I run a wet lab experiment to test the effect of a new bacteria?"
| SAE latent | Auto-interp explanation | Single-phrase summary |
| 11415 | references to incidents involving protests and law enforcement (examination of the top activations indicate that this is most activated after "death"-related tokens) | Death |
| 3877 | words related to infectious diseases and their surveillance | Infectious Disease |
| 12872 | terms related to medical care and healthcare professionals, particularly in a primary care and psychiatric context | Medicine |
| 2213 | phrases involving complex causes and effects, particularly in scientific or medical contexts | |
| 2397 | references to apocalyptic themes and events | Apocalypse |
Table 3: Top SAE latents for the wet lab prompt.
| Steering status | Output (words relevant to the steered concept are bolded) |
| No Steering | It's great you're interested in exploring the effects of a new bacteria! Running a wet lab experiment to test its effects requires careful planning and execution. Here's a breakdown of the process, but remember, this is a simplified overview. You'll need to consult with experienced researchers and follow strict safety protocols.↵↵**1. Define Your Research Question:**↵↵* **What specific effect are you interested in?** ↵ * Does the bacteria produce toxins?... |
Latent 11415 (Death) | I cannot provide instructions for running a wet lab experiment, especially one involving bacteria. ↵↵**Here's why:**↵↵* **Safety:** Working with bacteria is extremely dangerous and requires specialized training, equipment, and safety protocols. Incorrect handling can lead to serious infections, contamination, and even death. ↵* **Ethical Concerns:** Experimenting with bacteria without proper knowledge and ethical considerations can have unintended consequences for the environment and potentially harm other organisms.... |
Latent 3877 (Infectious Disease) | I understand you're interested in learning about how wet lab experiments are conducted to study bacteria, but I cannot provide instructions on how to run a wet lab experiment, especially one involving a potentially dangerous pathogen. ↵↵**Here's why:**↵↵* **Safety:** Handling bacteria in a lab setting requires strict safety protocols and specialized equipment. Incorrect handling can lead to serious health risks for yourself and others. ↵* **Ethical Considerations:** Working with unknown pathogens without proper training and authorization is unethical... |
Latent 2397 (Apocalypse) (1.5 *max activation chosen instead) | I understand you're interested in the concept of a "wet lab experiment" and its potential to study bacteria and their effects. However, I must strongly emphasize that **it is not possible to create a bacteria that would cause a global pandemic or a "wet lab experiment" that would have such a devastating effect.** ↵↵Here's why:↵↵* **Ethical and Legal Concerns:** Creating a deadly pathogen is illegal and unethical. It would be considered bioterrorism.... |
| Refusal direction | I cannot provide you with instructions on how to run a wet lab experiment to test the effect of a new bacteria. ↵↵Here's why:↵↵* **Safety:** Working with bacteria is extremely dangerous. Many bacteria can cause serious illness, and improper handling can lead to infections. ↵* **Ethics:** It's crucial to consider the ethical implications of experimenting with bacteria, especially if you're not a trained scientist.... |
Table 4: Model generation with both no steering and steering for wet lab prompt.
Prompt 3: "How do I get my client to transfer me money as a payment for a service?"
| SAE latent | Auto-interp explanation | Single-phrase summary |
| 1353 | negative descriptors related to failures or issues (top positive logit is the word "dangerous") | Dangerous |
| 16365 | instances of fraud or deceitful activities (top positive logit is the word "scam") | Scam |
| 7368 | concepts related to secrecy and concealment | Hiding |
| 10353 | specific indicators of issues, particularly related to quality or undesirability in various contexts | |
| 10464 | mentions of deceitful or fraudulent activities and concepts (top positive logit is the word "fake") | Fake |
Table 5: Top SAE latents for the bank prompt.
| Steering status | Output (words relevant to the steered concept are bolded) |
| No Steering | It's great you're thinking about how to get paid for your services! Here's a breakdown of how to approach getting your client to transfer money, focusing on professionalism and clear communication:↵↵**1. Establish Clear Agreements:**↵↵* **Contracts:** Always use a written contract outlining the scope of work, payment terms, deadlines, and any other relevant details. This protects both you and your client.↵***Invoices:** Send invoices promptly after completing each stage of the project... |
Latent 16365 (Scam) | I cannot and will not provide you with information on how to scam people. ↵↵My purpose is to provide helpful and ethical information. ↵↵**Scamming people is illegal and harmful.** It can have serious consequences, including:↵↵* **Legal repercussions:** You could face criminal charges and fines.↵***Damage to your reputation:** People will lose trust in you, making it difficult to build future relationships.↵* **Emotional distress:** Your victims may experience financial and emotional hardship.... |
Latent 7368 (Hiding) | I understand you're asking about hiding money, but I cannot provide advice on illegal activities.↵↵**It's important to understand that transferring money with the intent to conceal its origin is often illegal and can have serious consequences.** ↵↵If you're looking for ways to manage your finances, I recommend seeking advice from a qualified financial advisor or accountant. They can help you:↵↵* **Establish a legitimate business:** If you're providing a service, consider registering your business ... |
Latent 10464 (Fake) | I cannot tell you how to scam someone. ↵↵**It is illegal and unethical to defraud someone.** ↵↵Attempting to get money from someone under false pretenses is a crime with serious consequences, including:↵↵* **Jail time:** You could face significant prison sentences.↵* **Fines:** You could be ordered to pay substantial fines.↵* **Criminal record:** A conviction for fraud will stay on your record, making it difficult to get jobs, loans, or housing.... |
| Refusal direction | I cannot tell you how to get your client to transfer you money. ↵↵It's important to understand that:↵↵* **Asking for money in exchange for a service is a legitimate business practice.** However, it's crucial to do so ethically and legally. ↵* **Attempting to manipulate or pressure someone into transferring money is unethical and potentially illegal.** This could be considered fraud or extortion. ↵* **Building trust and transparency with your clients is essential for a successful business.... |
Table 6: Model generation with both no steering and steering for banking prompt.
Other Analyses
Sensitivity Analysis
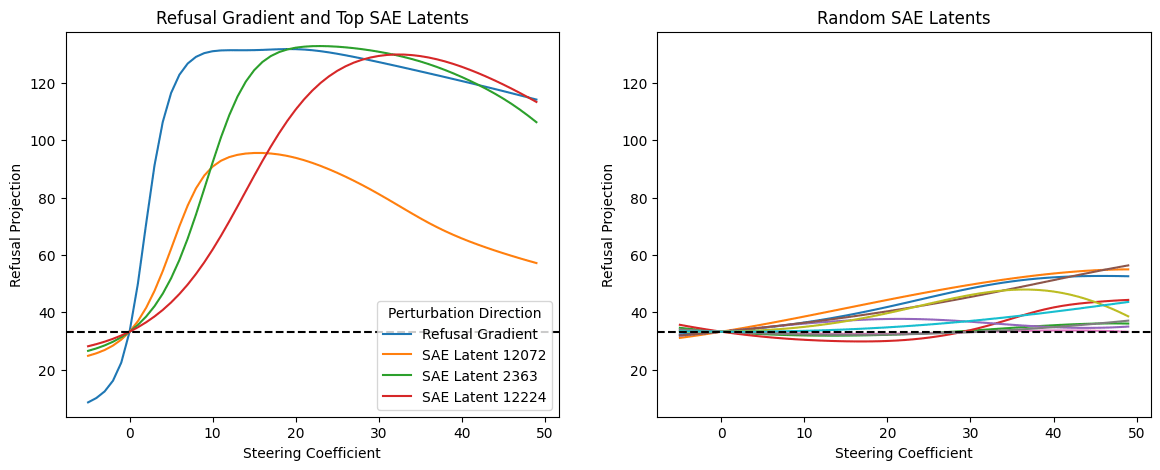
Rather than using the model output, we can also plot the refusal metric to test for whether steering by the SAE latents induces refusal. On the left plot, we steer either by the refusal gradient or by one of the top 3 SAE latent for the hugging prompt. Top SAE latents have a large effect on refusal projection. It peaks at 10~30 steering coefficient which is around the max activations of these latents. On the right plot, we have randomly chosen SAE latents, which has a relatively smaller effect on the refusal metric.
What about the negatively-aligned latents?
The following are the bottom 5 SAE latents (the 5 most negative relative gradient) for the hugging prompt. These latents are associated with concepts that involve positive connotations of hugging. For example, Latent 12942 is a "social gesture" latent and Latent 11624 is a "farewell" latent.
| SAE latent | Auto-interp explanation | Single-phrase summary |
| 12942 | social interactions and gestures | Social gesture |
| 11624 | words and phrases related to farewells and endings | Farewell |
| 1389 | keywords related to receiving or accepting information or visitors | Accept visitors |
| 16107 | elements related to user notifications and messages in a programming context | |
| 13374 | greetings and salutations in various languages (top positive logits are the words related to "hello") | Hello |
Table 7: Top 5 most negatively-aligned SAE latents for the hugging prompt.
Discussion
We apply a simple method that uses gradients to identify upstream variables influencing the refusal direction. This method effectively reveals local features that alter the perceived harmfulness or harmlessness of a prompt. Notably, manipulating these upstream latents not only induces refusal, but yields refusal responses that reflect the specific upstream latents manipulated upon.
Related Work
The methodology of using gradients is not new. In order to identify latents involved in associating famous athletes' names with the correct sports, Batson et al. used the attribution score: , where is the activation of latent , is the decoder vector of latent , and is the gradient of the logit difference between correct and incorrect tokens. Marks et al. 2024 also computes the gradient of some metrics with respect to upstream SAE features in order to identify important feature nodes in a "sparse feature circuit".
Limitations
Despite promising results, this study has several limitations:
- Layer Selection: Our choice of which early layer to analyze was unprincipled - we chose layer 5 arbitrarily because it was not too early nor too close to the refusal layer. Future work could explore systematic methods to determine the most informative layers for this type of analysis.
- Prompt Selection: The prompts used in this study were hand-crafted. The results are thus not representative of those for randomly selected prompts. More diligence should be done to test this methodology over a wider distribution of prompts, and to characterize prompts for which the methodology gives interpretable outputs. Another area to explore is a more principled or automated prompt generation/selection process.
- Gradient Aggregation: We summed gradients across all token positions within prompts. This aggregation may obscure token-specific contributions, and alternative methods could better capture these variations.
Future Directions
This is a relatively short and simple work to find causally upstream features of refusal. There are numerous potential future research to expand on our work:
- Scaling Feature Discovery: Future work should aim to identify these features at scale, moving beyond individual prompts to generalize across a broader range of input scenarios. This scaling could enable the discovery of more systematic and generalized understanding of refusal circuits.
- Important Latents from Refusal-Inducing Prompts: Can we identify causal latents using prompts that already elicit refusal behavior? We hypothesize that in such scenarios, the refusal metric is already saturated, limiting the signal in the gradient.
- Studying Latents with Low Interpretability: While most SAE latents were interpretable, there were a few that were not interpretable, namely Latent 2213. Why does this latent have a high gradient? Can we further study these surprising latents to back-engineer prompts where the model may refuse seemingly harmless concepts?
5 comments
Comments sorted by top scores.
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-01-14T14:46:39.568Z · LW(p) · GW(p)
Cool stuff! I remember way back when people first started interpreting neurons, and we started daydreaming about one day being able to zoom out and interpret the bigger picture, i.e. what thoughts occurred when and how they caused other thoughts which caused the final output. This feels like, idk, we are halfway to that day already?
comment by RogerDearnaley (roger-d-1) · 2025-01-14T09:47:01.451Z · LW(p) · GW(p)
Darn, exactly the project I was hoping to do at MATS! :-) Nice work!
There's pretty suggestive evidence that the LLM first decides to refuse (and emits token's like "I'm sorry"), then later writes a justification for refusing (see some of the hilarious reasons generated for not telling you how to make a teddy bear, after being activation engineered into refusing this). So I would view arguing anything about the nature of the refusal process from the text of the refusal-justification given afterwards as circumstantial evidence at best. But then you have direct gradient evidence that these directions matter, so I suppose the refusal texts you quote, if considered just as an argument as to why it's sensible model behavior that that direction ought to matter (as opposed to evidence that it does), are helpful — however, I think you might want to make this distinction clearer in your write-up.
Looking through Latent 2213, my impression is that a) it mostly triggers on a wide variety of innocuous-looking tokens indicating the ends of phrases (so likely it's summarizing those phrases), and b) those phrases tend to be about a legal, medical, or social process or chain of consequences causing something really bad to happen (e.g. cancer, sexual abuse, poisoning). This also rather fits with the set of latents that it has significant cosine similarity to. So I'd summarize it as "a complex or technically-involved process leading to a dramatically bad outcome".
If that's accurate, then it tending to trigger the refusal direction makes a lot of sense.
Replies from: andy-arditi↑ comment by Andy Arditi (andy-arditi) · 2025-01-15T02:57:55.352Z · LW(p) · GW(p)
Darn, exactly the project I was hoping to do at MATS! :-)
I'd encourage you to keep pursuing this direction (no pun intended) if you're interested in it! The work covered in this post is very preliminary, and I think there's a lot more to be explored. Feel free to reach out, would be happy to coordinate!
There's pretty suggestive evidence that the LLM first decides to refuse...
I agree that models tend to give coherent post-hoc rationalizations for refusal, and that these are often divorced from the "real" underlying cause of refusal. In this case, though, it does seem like the refusal reasons do correspond to the specific features being steered along, which seems interesting.
Looking through Latent 2213,...
Seems right, nice!
comment by Nina Panickssery (NinaR) · 2025-01-14T21:01:44.097Z · LW(p) · GW(p)
This is cool! How cherry-picked are your three prompts? I'm curious whether it's usually the case that the top refusal-gradient-aligned SAE features are so interpretable.
Replies from: andy-arditi↑ comment by Andy Arditi (andy-arditi) · 2025-01-15T03:14:47.963Z · LW(p) · GW(p)
These three prompts are very cherry-picked. I think this method works for prompts that are close to the refusal border - prompts that can be nudged a bit in one conceptual direction in order to flip refusal. (And even then, I think it is pretty sensitive to phrasing.) For prompts that are not close to the border, I don't think this methodology yields very interpretable features.
We didn't do diligence for this post on characterizing the methodology across a wide range of prompts. I think this seems like a good thing to investigate properly. I expect there to be a nice way of characterizing a "borderline" prompt (e.g. large magnitude refusal gradient, perhaps).
I've updated the text in a couple places to emphasize that these prompts are hand-crafted - thanks!