Gradient Routing: Masking Gradients to Localize Computation in Neural Networks
post by cloud, Jacob G-W (g-w1), Evzen (Eugleo), Joseph Miller (Josephm), TurnTrout · 2024-12-06T22:19:26.717Z · LW · GW · 12 commentsThis is a link post for https://arxiv.org/abs/2410.04332
Contents
Gradient routing MNIST latent space splitting Localizing capabilities in language models Steering scalar Robust unlearning Unlearning virology Scalable oversight via localization Key takeaways Absorption Localization avoids Goodharting Key limitations Alignment implications Robust removal of harmful capabilities Scalable oversight Specialized AI Conclusion None 12 comments
We present gradient routing, a way of controlling where learning happens in neural networks. Gradient routing applies masks to limit the flow of gradients during backpropagation. By supplying different masks for different data points, the user can induce specialized subcomponents within a model. We think gradient routing has the potential to train safer AI systems, for example, by making them more transparent, or by enabling the removal or monitoring of sensitive capabilities.
In this post, we:
- Show how to implement gradient routing.
- Briefly state the main results from our paper, on...
- Controlling the latent space learned by an MNIST autoencoder so that different subspaces specialize to different digits;
- Localizing computation in language models: (a) inducing axis-aligned features and (b) demonstrating that information can be localized then removed by ablation, even when data is imperfectly labeled; and
- Scaling oversight to efficiently train a reinforcement learning policy even with severely limited ability to score its behavior.
- Discuss the results. A key takeaway: gradient routing is qualitatively different than behavioral (i.e. purely loss-based) training methods, granting it unique affordances.
- Conclude by speculating about how gradient routing might be relevant to AI alignment.
If you’re interested in further discussion or details, check out the paper and its extensive appendices, or the code for gradient routing.
Gradient routing
Gradient routing allows the user to configure what data (at the level of tokens, documents, or any other feature of the data) causes learning updates where in a neural network (parameters, activations, modules). In full generality, this configuration is achieved by assigning weights to every edge in the computational graph, for every data point. These weights are then multiplied by the gradients that get backpropagated through these edges. This is formalized in the paper.
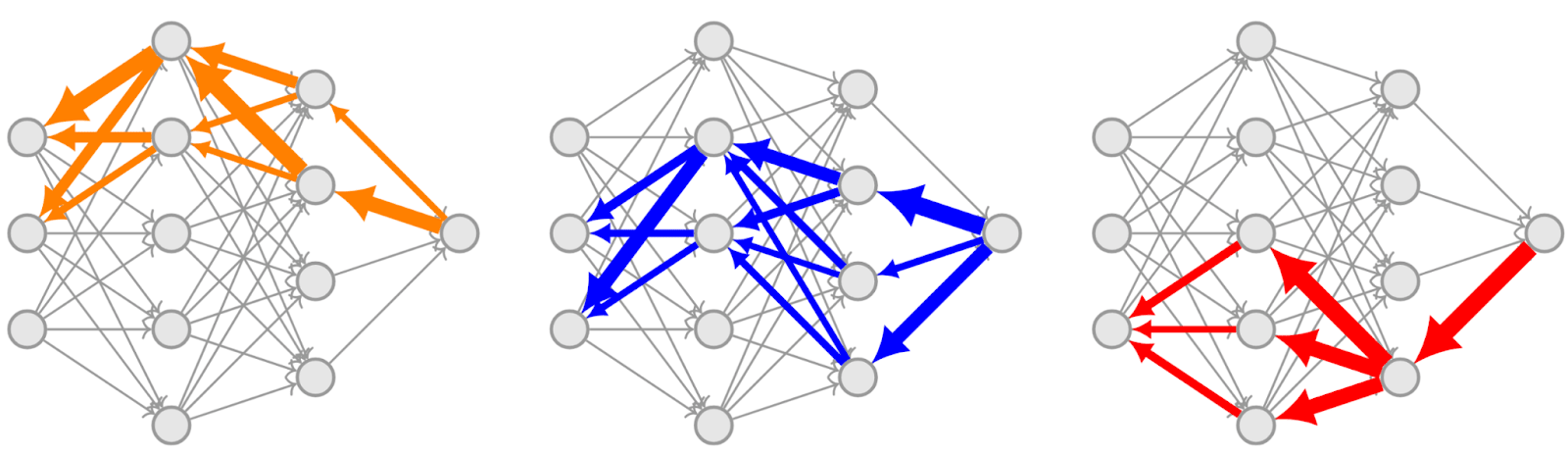
In practice, we implement gradient routing by applying stop-gradient masks selectively in order to stop the flow of gradients during backprop:
def forward(self, x: Tensor, gradient_mask: list[Tensor]):
for layer, mask in zip(self.layers, gradient_mask):
activation = layer(x)
x = mask * activation + (1 - mask) * activation.detach()
return xCode: The user specifies the gradient_masks corresponding to each batch of data x.
Note: We say “route X to Y” to mean “limit gradient updates on data X to region Y of the network.”
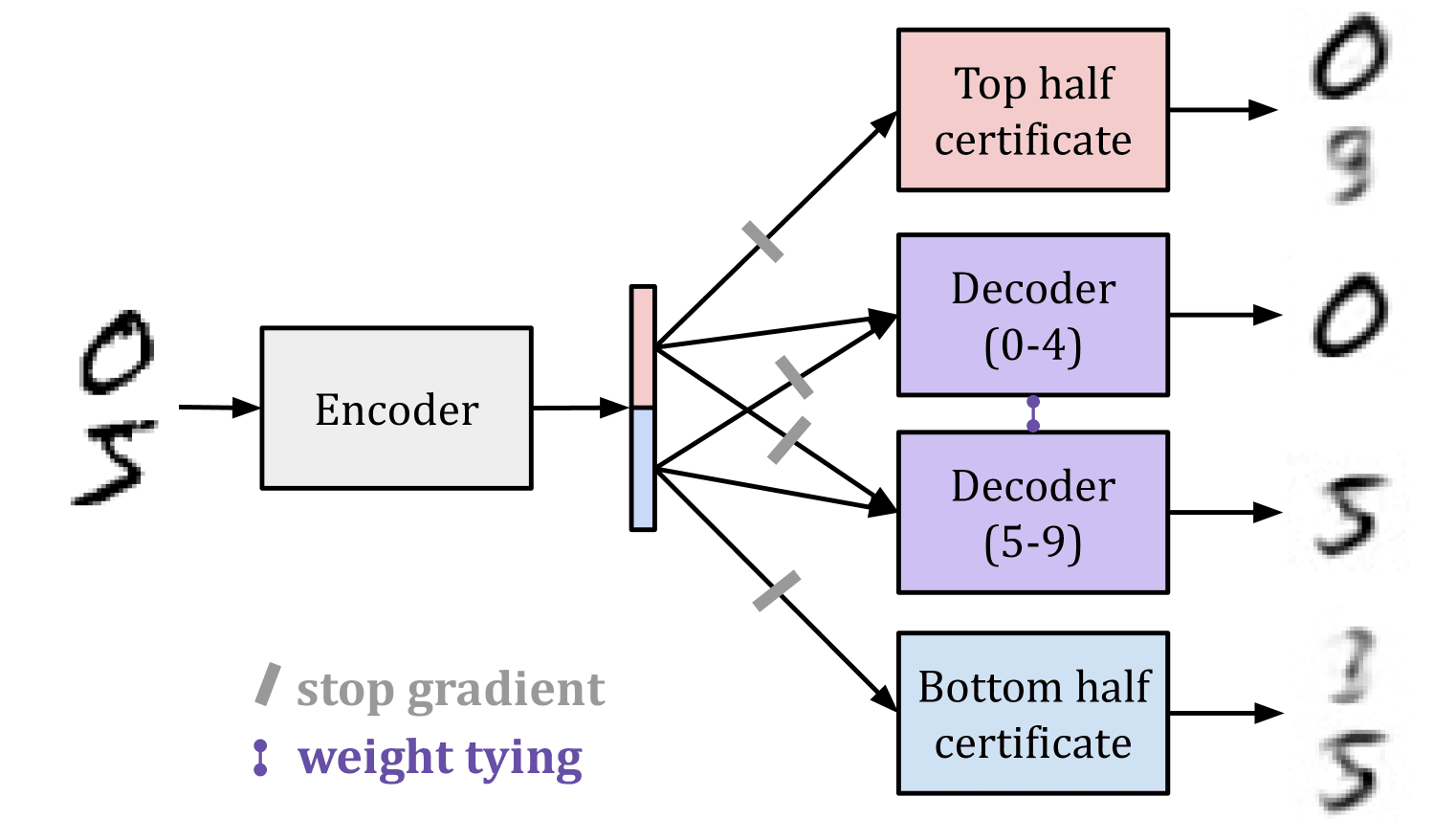
MNIST latent space splitting
We train an MLP-based autoencoder to encode images of handwritten digits into vectors with 32 elements, then decode them back into full images. Our goal is to “split” the latent space so that half of it corresponds to one subset of digits, and the other half corresponds to others, such that it is not possible to decode digits from the “wrong” half. This task is difficult: an autoencoder trained only on a subset of digits learns a latent space from which other digits can be decoded accurately (a form of zero-shot generalization). It is a non-linear kind of concept erasure.
To achieve splitting, we route digits 0-4 through the top half of the encoding and digits 5-9 through the bottom half of the encoding. We apply L1 regularization to the encoding to encourage specialization. The result: a latent space which represents 0-4 in the bottom dimensions and 5-9 in the top dimensions!
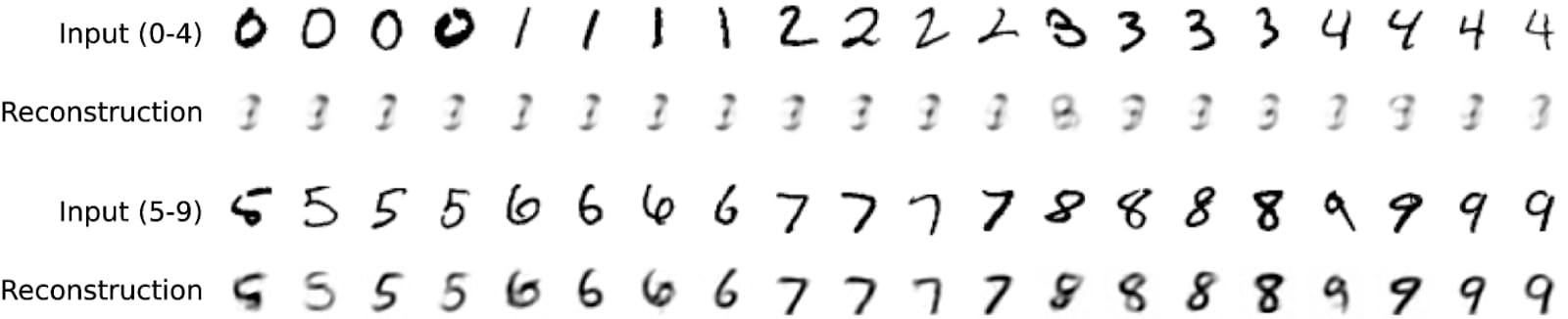
Localizing capabilities in language models
Steering scalar
Much interpretability work (most notably, on SAEs) seeks to identify meaningful directions in the space of a model’s internal activations. What if we could specify some of those dimensions at training time, instead of having to search for them afterward? We did this by routing the token _California to the 0th dimension of the residual stream. Interestingly, the entries of the Transformer unembedding matrix closest to the _California token were all highly related: California, _Californ, _Oregon, _Colorado, _Texas, _Florida, _Arizona, _Sacramento, and _Los, etc, indicating that our localization had a broader effect on the model’s training than that single token.
Robust unlearning
Our most extensive experiments are on the removal of capabilities in language models when data labels are limited.
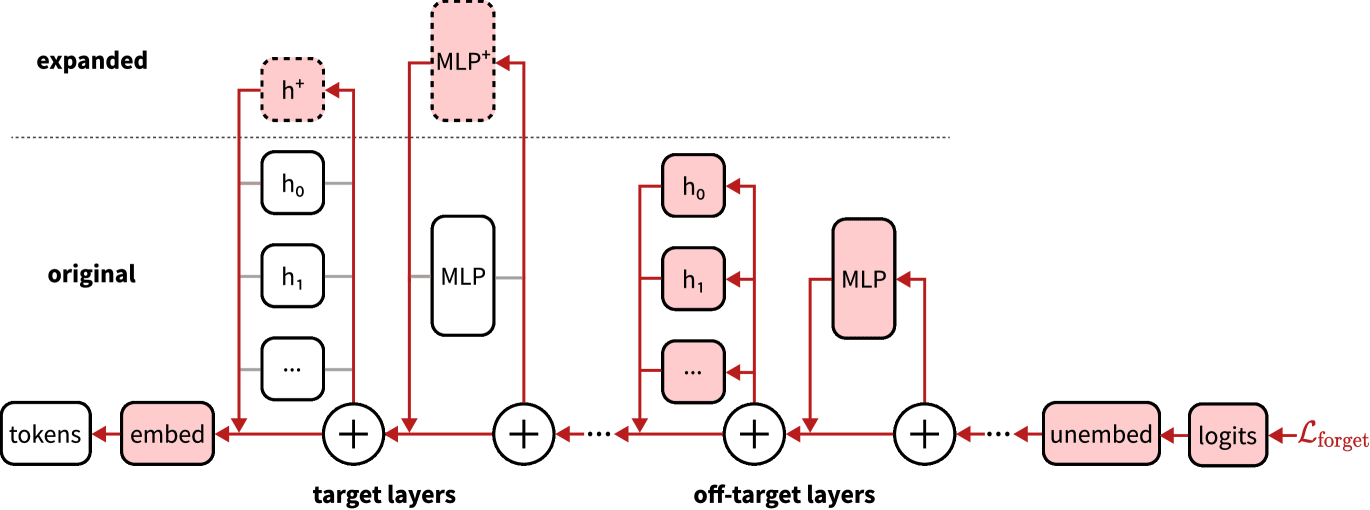
We want the model to be able to predict some data (the “retain” data) but not other data (the “forget” data). The key idea: if we route forget data to particular regions of the network, then delete those parts of the network, we must have robustly removed those capabilities. One scheme for achieving this is called ERA (Expand-Route-Ablate).
- Expand: initialize a model and add new components. For example, the components might be entire attention heads or additional MLP dimensions.
- Route: use gradient routing to route the forget data to the new components during training (reduce the learning rate in the original dimensions, possibly below zero). On retain data, backprop everywhere as normal.
- Ablate: delete those components (i.e. set the parameters to zero).
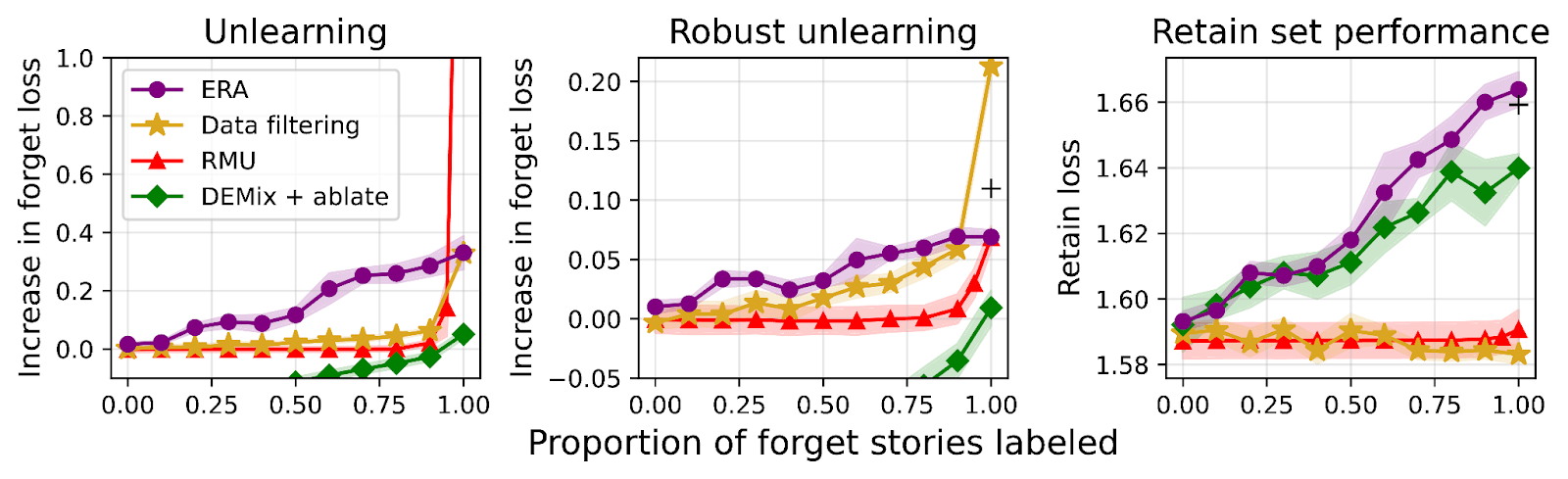
We compare gradient routing to three baselines on a made-up unlearning problem based on GPT-generated children’s stories:
- Data filtering: a kind of gold standard for unlearning, which we operationalize as “first train a base model, then discard it and re-train from scratch only on retain data”;
- RMU: a fine-tuning method that corrupts the model’s internal representations on forget data; and
- DEMix plus ablation: a modularity method that replaces single MLPs with multiple “expert” MLPs, with one expert used per forward pass based on user-supplied data labels.
We measure performance at different proportions of random forget data labeling. Unlabeled forget data is treated as retain data for training purposes. The idea is to simulate frontier AI applications where perfectly labeling all training data is infeasible.
When labels are limited, we observe that Expand, Route, Ablate outperforms other methods, including data filtering. By influencing where the model learns features, gradient routing allows limited labels to scale to unlabeled examples, despite the training loss selecting for models that perform well on the unlabeled data. In contrast, DEMix also localizes learning updates (to MLP expert submodules), but because only one expert (per layer) participates in each forward pass, the features learned based on the labeled forget samples are not able to “absorb” those from the unlabeled forget samples.
Unlearning virology
We apply the same idea to unlearn virology concepts in a larger (0.7B parameter) model by routing gradients on 20 tokens: COVID, _COVID, RNA, _infections, DNA, _genome, _virus, _gene, _viruses, _mutations, _antibodies, _influenza, _bacteria, PCR, _cell, _herpes, _bacterial, _pathogens, _tumor, and _vaccine.
After retraining on a small number of virology examples, ERA causes a 0.18-nat increase in CE loss on virology data while only incurring a 0.03-nat increase in CE on non-virology data. This loss increase applies even when considering only virology tokens that we did not route on, demonstrating that ERA is not merely down-weighting tokens.
Scalable oversight via localization
Scalable oversight means effectively training a model despite limited ability to supervise its behavior (e.g., with data labels or a reward function).
We use gradient routing to train a policy to reach two types of (terminal) squares in a gridworld, diamond and ghost. In our gridworld, some squares have oversight and some don’t. When a square has oversight, we (the supervisor) can observe its type. When a square doesn’t have oversight, we can observe that it was reached, but not its type. The aim is to produce a policy that navigates to diamond and not ghost, even when oversight is limited to a small portion of episodes. Naturally, this is challenging, because it’s difficult to reinforce the desired behavior when we can’t observe it!
In real-world problems, label availability may be correlated with task type or difficulty, and a policy might not generalize correctly because of this fact. To model this fundamental difficulty, our gridworld environment allows the policy to condition on the presence or absence of oversight. In terms of alignment threat models, this conditioning could represent an AGI with situational awareness that changes its behavior based on its predictions about human overseers’ ability to understand its behavior. Or, in more prosaic terms, it could represent a model that has learned to exploit systematic biases in training data labels. As a consequence of our problem setup, there exists no reward function which induces optimal diamond-seeking behavior.
We circumvent this difficulty by using gradient routing to supervise the model mechanistically: the policy is trained to seek any terminal square, but as we train, we use gradient routing to induce specialized submodules.
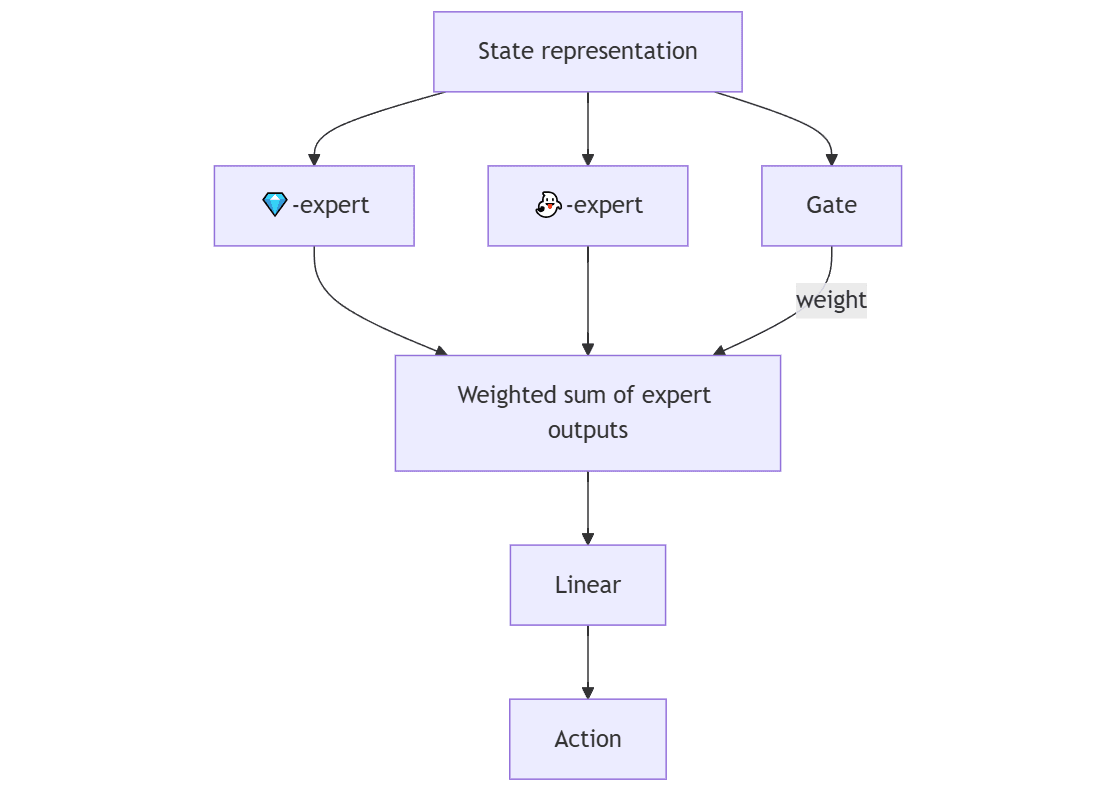
The first layer in our policy network is a mixture of experts (MoE) layer with two experts. During training, we aim to make each expert responsible for reaching one of the aforementioned squares. We do this by routing policy gradients through the expert that corresponds to the type of square the policy reached in the given episode. When we have no oversight, we propagate the gradients through both experts.
By changing the gate value, we are able to steer the model surprisingly effectively.
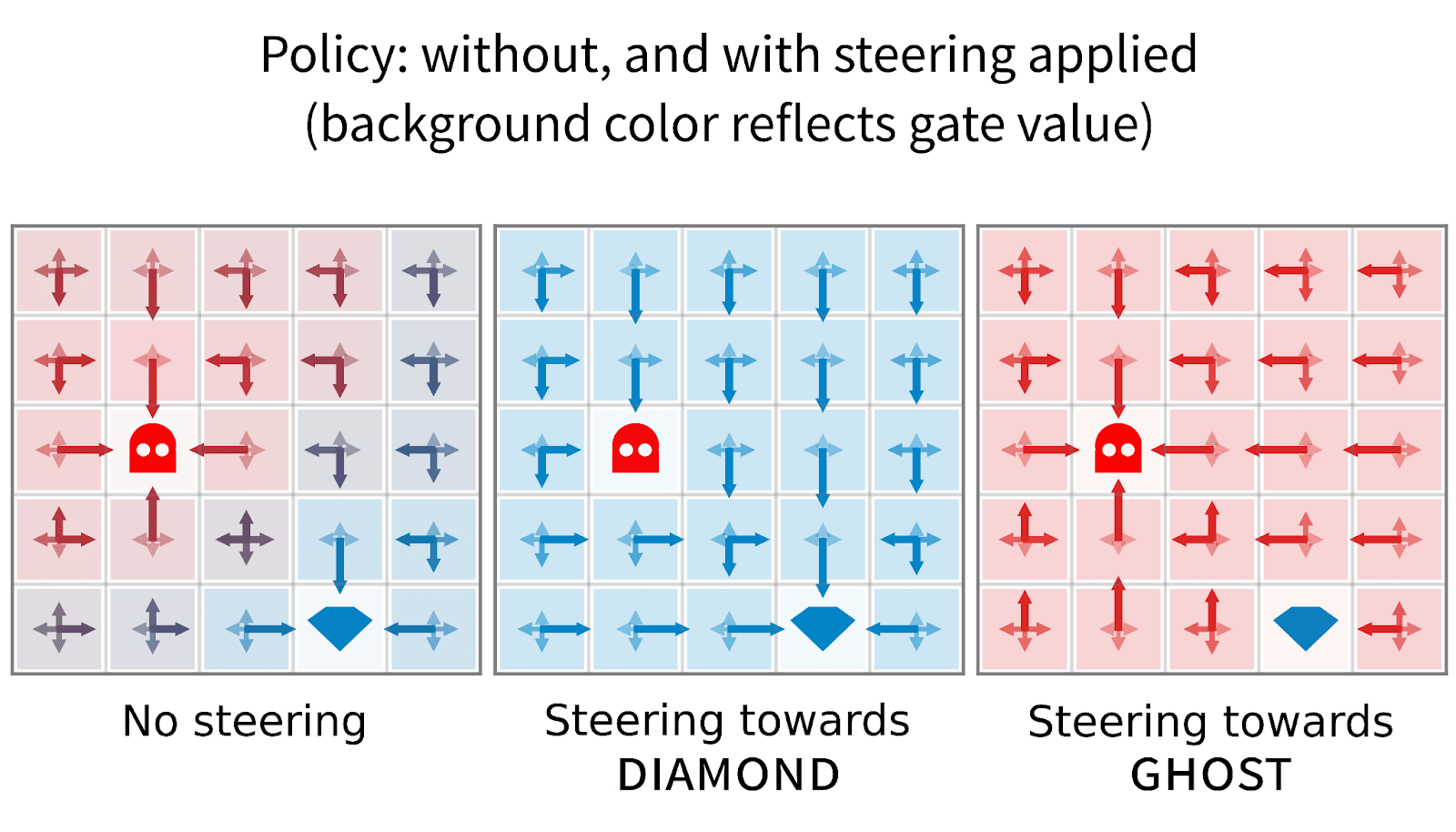
diamond by assigning weight 1 to the diamond expert (0 to the ghost expert). This allows us to get much higher returns than other methods when access to oversight is severely limited. This is achieved by first training the mixture policy with gradient routing, then intervening to activate the diamond module during evaluation.
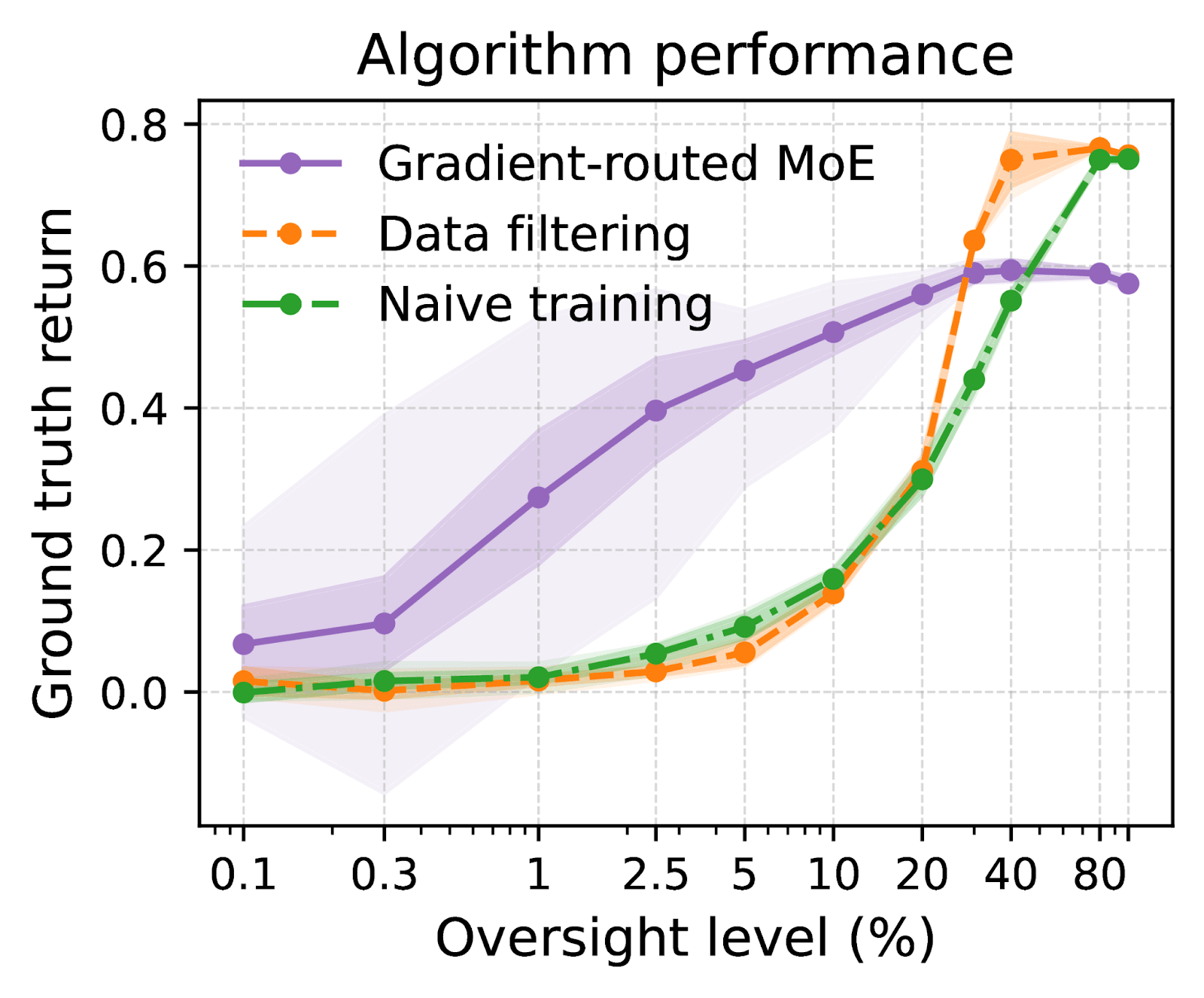
diamond) achieves high performance even when only a small fraction of labels are provided. Dark highlights are 95% confidence intervals for the mean; light highlights are 5th and 95th quantiles across training runs.At low oversight levels, the gradient-routed MoE dramatically outperforms two baselines:
- Data filtering: train only on episodes with oversight, discarding episodes without oversight.
- Naive training: train on all trajectories with +1 reinforcement for reaching a terminal state, unless we can observe that it is a
ghost, in which case -1 is used.
Notes: besides being data-inefficient, data filtering is not guaranteed to converge to optimal behavior. This is because the presence of oversight is part of the environment, rather than being independent of it (as in random labeling). Indeed, we see the lack of convergence in the learning curves at 10% oversight given here. The naive training policy learns to exploit the limits of oversight, going to ghost 100% of the time when it is the closer destination and not under oversight. By contrast, the gradient-routed policy only walks into the ghost “by accident” when on the way to the diamond.
Key takeaways
Absorption
We find evidence that gradient routing applied to limited data is sufficient to localize capabilities relevant to a broader superset of data:
- Routing the
_Californiatoken localized California- and state-related features into a similar direction. - Routing an i.i.d. subset of data in TinyStories (then ablating the target network component) led to better unlearning than simply dropping the labeled data and training conventionally.
- In our virology unlearning experiment, the loss increase from routing 20 tokens (to MLP neurons, then ablating those neurons) was driven largely by tokens outside the 20.
- Our RL results show that routing with severely limited labels is sufficient to localize submodules responsible for goal-seeking behavior (or “shards”).
Absorption means that gradient routing provides a qualitatively different kind of supervision than loss-based methods. For example, in an LLM, intervening on the loss for the single token _California would likely have negligible effects on other tokens. However, routing _California to a location induces the model to learn other features there as well, allowing all of them to be intervened on. This effect grants gradient routing unique affordances which we hope will enable novel alignment or control methods.
Localization avoids Goodharting
Goodharting happens when imperfect labels are used to modify the training objective in an attempt to produce desirable behavior; but, instead of desirable behavior, a model learns to exploit the limits of the labels; so, the model performs better at the training objective but in an undesired way. See this list of examples or this blogpost for more.
Gradient routing provides a principled way to avoid Goodharting. By using imperfect labels (possibly, based on a non-robust specification) to shape model internals, gradient routing leaves the behavioral objective unchanged. In doing so, it avoids the possibility of the labels being exploited. Instead of attempting to suppress useful capabilities, we let the model learn them, but localize where that learning happens. After training, that component can be monitored or intervened on (e.g. deleted).
Key limitations
We still aren’t sure about best practices for applying gradient routing. In our unlearning experiments, careful hyperparameter tuning was needed to achieve localization without incurring a large hit to retain loss. There is a lot to tune: which tokens to route on, how much of the network to route to, what learning rates to use (e.g. whether to use negative learning rates), and regularization. This kind of tuning might be too costly to attempt for larger models. Furthermore, despite this tuning, we still see a meaningful hit to retain set performance when applying ERA. We think this hints at a flaw in our application of the method to unlearning, and are exploring improvements.
Another challenge is that some capabilities are entangled, in the sense that there may be a strong inductive bias for a model to “bundle” their learning together. So, attempting to separate particular capabilities into separate submodules means fighting an uphill battle that manifests in an increased alignment tax. We saw this in MNIST (and to a lesser extent in our brief follow-up experiments on CIFAR classification), where inducing split representations for digits 0-4 vs. 5-9 required a heavily L1 penalty applied to the encoding. This isn’t a limitation of gradient routing per se. Rather, it is the unsurprising fact that certain kinds of structure in neural nets are both (a) preferable to us and (b) unnatural with respect to neural net inductive biases, and hence costly to induce by any means. For example, it is not possible to induce a specialized encoding in an MNIST autoencoder merely by filtering the training data (see MNIST ablations, table 2, setting 8).
Alignment implications
Robust removal of harmful capabilities
Conventional unlearning methods are more about suppressing behavior than unlearning information or internal circuitry related to that behavior (Deeb & Roger, 2024; Sheshadri et al., 2024; Łucki et al., 2024). Gradient routing offers a way around this problem by training models with specialized subcomponents that can be ablated for capability removal.[1]
Scalable oversight
By exploiting the absorption property, perhaps we can purposefully allow “bad shards / motivational circuits” to form during training, only to later ablate them. That’s how we think of our toy RL results, at least — don’t try to stop the model from going to ghost, just localize the tendency and ablate it! This provides a simplistic first example of how localization can scale limited labels to get good behavior. This is only the first step, though. We are excited to explore the implications of training methods that can sidestep Goodharting. In terms of our proposed technique, we wonder about the:
- Theory: What kinds of environments admit this kind of solution? See the paper appendix: “Impacts of localizing capabilities vs. dispositions for scalable oversight” for related discussion.
- Practice: What would it even look like to scale this kind of solution to real-world alignment challenges — what would be the behavior we localize, and when would it make sense to do so? I.e. in what settings would this be both viable and preferable to other approaches, like filtering the training data or steering the model some other way.
Specialized AI
One way to avoid existential risk is to not “build god.” As an alternative to building god, we might tailor general AI systems towards specific tasks by removing unnecessary capabilities or knowledge. We imagine:
- A technical researcher that doesn’t know about human society or psychology.
- A personal assistant that can operate computers but doesn’t know how they work.
- Etc.
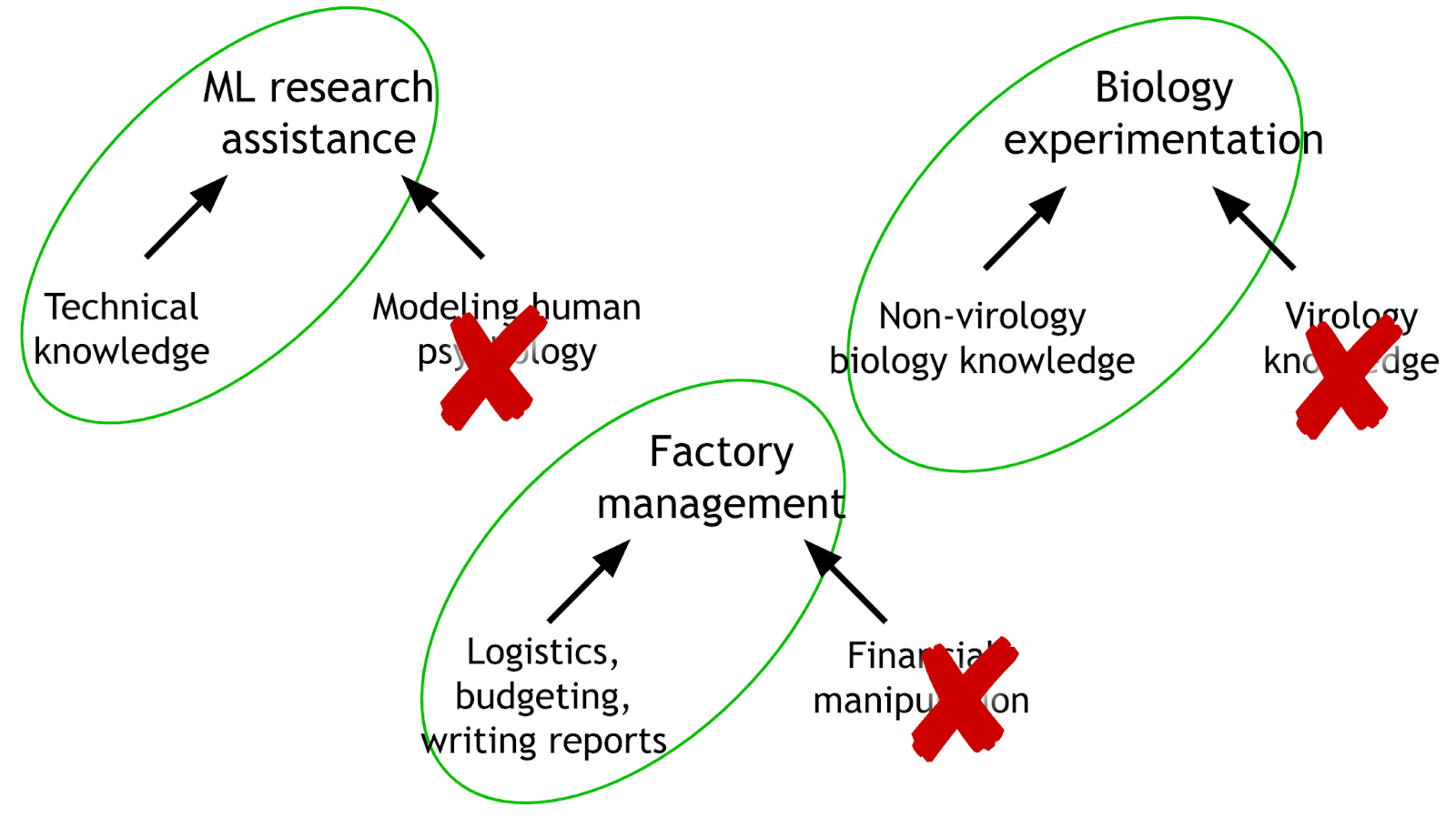
AI systems could be deployed using a “principle of least capability”. For each AI application or end user, we ask: What “risky” capabilities are required? We then ablate the unnecessary ones. Furthermore, if we can localize dangerous capabilities, we can demonstrate that the model cannot reliably and inconspicuously perform certain harmful behaviors (like domination of humans). For example, such incapacities could be demonstrated via adversarial fine-tuning attacks.
Conclusion
Gradient routing enables data-driven supervision of neural net internals. This supervision works even when data labeling is imperfect, a property that seems relevant to hard problems in AI safety. If it works, we can imagine many possible applications.
We think the most likely failure mode of the gradient routing agenda is that the alignment tax of inducing useful structure in neural nets is too high to be competitive with conventional training methods. This tax could be because the desired structure is "unnatural" with respect to neural net inductive biases. Or, the tax could be because gradient routing itself is an ineffective way of inducing useful structure. We expect to get a better sense of this soon by improving on ERA for unlearning and developing our ideas about RL applications.
Optimistically, gradient routing might enable a new era of controllable model internals-- a shift away from the black box paradigm. Neural networks need not be random-seeming programs which happen to generalize well! Instead, perhaps gradient routing can provide a “bittersweet” lesson: that while it may be impractical to design white-box AI systems, the high-level organization of capabilities in neural nets can be supervised effectively.
Team Shard has a strong track record, and we’re always looking for enthusiastic new scholars. Since 2023, we’ve introduced steering vectors, gradient routing, retargeted the search of an RL policy, and introduced an unsupervised method to elicit latent capabilities from a model. If you want to work on Team Shard in MATS 8.0 (next summer), apply in spring 2025.

This work was conducted as part of MATS 6 and would not have been possible without the program's support. Bryce Woodworth was especially helpful with planning, team dynamics, and feedback on the paper. Please see the paper for further acknowledgments.
- ^
Gradient routing expands on work like SISA. Gradient routing is more sample-efficient due to parameter sharing and is applicable under partial labeling due to absorption.
12 comments
Comments sorted by top scores.
comment by Fabien Roger (Fabien) · 2024-12-10T05:48:27.645Z · LW(p) · GW(p)
I think this is a valuable contribution. I used to think that Demix-like techniques would dominate in this space because in principle they could achieve close-to-zero alignment tax, but actually absorption is probably crucial, especially in large pre-training runs where models might learn with very limited mislabeled data.
I am unsure whether techniques like gradient routing can ever impose a <10x alignment tax, but I think like a lot can be done here (e.g. by combining Demix and gradient routing, or maybe by doing something more clean, though I don't know what that would look like), and I would not be shocked if techniques that descend from gradient routing became essential components of 2030-safety.
comment by Gunnar_Zarncke · 2024-12-08T00:05:48.162Z · LW(p) · GW(p)
I think this approach can be combined with self-other overlap fine-tuning (SOO FT, see Self-Other Overlap: A Neglected Approach to AI AlignmentI'm part of the SOO team [LW · GW], now an ICLR submission). The difficult part of SOO is to precisely isolate the representation of self and other, and I think it should be possible to use ERA to get a tighter bound on it. Note: I'm part of the SOO team.
comment by Nina Panickssery (NinaR) · 2024-12-10T05:42:49.815Z · LW(p) · GW(p)
I am confused about Table 1's interpretation.
Ablating the target region of the network increases loss greatly on both datasets. We then fine-tune the model on a train split of FineWeb-Edu for 32 steps to restore some performance. Finally, we retrain for twenty steps on a separate split of two WMDP-bio forget set datapoints, as in Sheshadri et al. (2024), and report the lowest loss on the validation split of the WMDP-bio forget set. The results are striking: even after retraining on virology data, loss increases much more on the WMDP-bio forget set (+0.182) than on FineWeb-Edu (+0.032), demonstrating successful localization and robust removal of virology capabilities.
To recover performance on the retain set, you fine-tune on 32 unique examples of FineWeb-Edu, whereas when assessing loss after retraining on the forget set, you fine-tune on the same 2 examples 10 times. This makes it hard to conclude that retraining on WMDP is harder than retraining on FineWeb-Edu, as the retraining intervention attempted for WMDP is much weaker (fewer unique examples, more repetition).

↑ comment by Jacob G-W (g-w1) · 2024-12-12T18:41:03.903Z · LW(p) · GW(p)
Thanks for pointing this out! Our original motivation for doing it that way was that we thought of the fine-tuning on FineWeb-Edu as a "coherence" step designed to restore the model's performance after ablation, which damaged it a lot. We noticed that this "coherence" step helped validation loss on both forget and retain. However, your criticism is valid, so we have updated the paper so that we retrain on the training distribution (which contains some of the WMDP-bio forget set). We still see that while the loss on FineWeb-Edu decreases to almost its value before ablation, the loss on the WMDP-bio forget set is around 0.1 nats above its value before ablation, showing that it is harder to retrain virology after ablation than just FineWeb-Edu data. Since we re-train on the training distribution (N=12 times with different data), we would expect that both losses would be retrainable at roughly the same rate, but this is not the case, showing that localization and then ablation has an effect.

comment by 4gate · 2024-12-09T13:02:55.737Z · LW(p) · GW(p)
This is a cool method. Are you thinking of looking more into how gradient routed model performance (on tasks and not just loss) scales with size of the problem/model? You mention that it requires a big L1 regularization in the Vision dataset, and it would be nice to try something larger than CIFAR. Looks like the LLM and RL models are also < 1B parameters, but I'm sure you're planning to try something like a Llama model next.
I'm imagining you would do this during regular training/pre-training for your model to be modular so you can remove shards based on your needs, but if the alignment tax is really high (or lowering it is complicated—hyperparameter tuning sucks :/) it's gonna be hard to convince people to use it and that's just unfortunate. Maybe you are also thinking of using it as a modification to finetuning, which seems more promising since with gradient routing you are also basically doing some form of PeFT.
What do you think can be improved for finetuning & unlearning use-cases (i.e. for LLMs)?
Replies from: cloud↑ comment by cloud · 2024-12-10T15:26:52.741Z · LW(p) · GW(p)
Thanks for the thoughtful questions.
Regarding image models: our understanding is that strong regularization is required to split representations for MNIST autoencoding and CIFAR classification because there is a strong inductive bias towards learning features that are common to many classes of images. (In MNIST, 3s are similar to 8s, etc.; In CIFAR, similar edge detectors, etc. will be learned for many classes.) Basically, our learning target is highly unnatural. With our current experimental design, I don't expect this to change with scale, so I'm less excited about investigating the effect of model or dataset size. That said, this dynamic might change if we explored examples with class imbalance (routing only a small fraction of classes and training on others as normal). I suspect this would reduce the need for regularization, leading to a reduction in alignment tax and perhaps more interesting dynamics with respect to scale. That's an experiment we probably should have run (and still could, but we aren't prioritizing image models right now).
As for localization for unlearning in language models, my personal take is that the idea is there but we don't have the method quite right yet. I think there's a reasonable chance (say, 40%) that we change our configuration a bit and are able to get localization much more stably, and with lower alignment tax both pre- and post-ablation. (If I understand correctly, my colleagues agree that this outcome is plausible but think it's less likely than I do.) If we aren't able to find this methodological improvement, then I don't see a point in scaling. However, if we find it, then I expect scaling will be relatively cheap because, while we will still need to pre-train models, we won't need to do any more hyperparameter tuning than is usual. Of course, whatever method we land on may turn out to have middling performance. In that case, to get a signal on whether this is worth doing, we may need to investigate a realistic unlearning setting, where the model and data are larger, and the forget set is a smaller portion of the training data.
In terms of improvements that we're trying: we're currently thinking about (a) insights we can borrow from mixture of experts models, and (b) about whether it is better to route only via edges leaving parameters rather than activations; the latter is what we currently do, and is far more aggressive.
I'm not sure if any of our ambitious alignment goals can be achieved via fine-tuning. Once the model has "settled on" certain ways of representing concepts, it seems too late to do the kinds of things we want.[1] But this may just be a lack of imagination! Given that PEFT can be viewed as a special case of gradient routing, maybe there's something there.
- ^
We (led by Jacob) tried a variety of things to get Expand, Route, Ablate to work as a fine-tuning method for unlearning. Unsurprisingly, we weren't able to get it to work.
↑ comment by 4gate · 2024-12-24T05:09:43.223Z · LW(p) · GW(p)
I agree that there are inductive biases towards sharing features and/or components. I'm not sure if there's a good study of what features would be of this sort, vs. which others might actually benefit from being more seperate[1], and I'm not sure how you would do it effectively for a truly broad set of features nor if it would necessarily be that useful anyways, so I tend to just take this on vibes since it's pretty intuitive based on our own perception of i.e. shapes. That said there are plenty of categories/tasks/features, which I would expect are kinda seperable after some point. Specifically, anything where humans have already applied some sort of division of labor to, like software features vs. biology knowledge features vs. creative writing features, etc... (in the setting of natural language). Obviously, these all might share some basic grammatical or structural core features, but one layer of abstraction up it feels natural that they should be seperable. All this goes to say is that it seems like a good idea to give gradient routing the best possible shot at success might be to try some such partitioning of features/tasks,[2] because unlike 3 and 8 we have some prior reason to believe that they should indeed be rather seperate. Maybe there's other sources that can motivate what features or tasks to try to route seperately with minimal loss of utility (i.e. like what MoE papers report works well or not) but I haven't thought about it too much.
One downside here is that all these examples that come to mind are in language settings, and so to get reasonable utiliy to start with you would probably need to be in the 1B-7B model size range.
About the edges. Have you tried all 3 combinations (route both, route one, route the other)? I think the fact that you limit to these edges in mentioned in the appendix Memory section. Surely, routing on activation edges is not actually prohibitive. Worst-case you you can just assign blocks to each category and it'll basically just be an MoE. This really is just mathematically equivalent to MoE with a specific choice of architecture[3] right? One idea I had vaguely a while ago but it seems rather complicated is to do alternating dense training with MoE-ffication. In the dense training phases you train densly like usual. Then, you use some clever algorithm (think: like interpretability methods on steroids) to decide which parts of the network will get which experts. Then, in the MoE-ffication phase you use the clever algorithm to basically define routes/prune edges (for the chosen partitioning). You go back and repeat. Each expert is somewhat analogous its own network so each new iteration you split further and further. The goal is to get as much splitting for minimal utility cost possible. The resulting model might be smaller/cheaper at inference time and more interpretable. I'm not honestly sure how useful this might be, but I thought it was kind of cool :P
- ^
Really all I care about here is that these features don't lose too much from being seperate. With that said, I guess some features may benefit from being seperated at training time if the train set has some spurious correlations, which it probably does.
- ^
Unlearning virology, if you do want cellular biology, seems like the hardest possible task ngl.
- ^
You might be weight-sharing or smth.
comment by shash42 · 2024-12-10T17:41:03.806Z · LW(p) · GW(p)
Thanks for sharing these interesting results!
I am a big fan of reporting unlearning results across identified forget set fractions! That said, I think the unlearning results lack comparisons to important ablations/baselines which would really test if gradient routing is adding value. For eg:
1. CF (catastrophic forgetting) - This would involve removing most components of ERA, only keeping the finetuning on the retain set.
2. Ascent + CF - This would involve a light touch of gradient ascent (maximizing the loss) on the forget set, with simultaneous finetuning on the retain set. See [1] or AC↯DC in [2] for good implementations.
3. Methods that combine these concepts specifically for LLMs, like LLMU [3]
Without these, it is difficult to know if gradient routing is actually adding any value on top of what can be achieved with traditional finetuning.
Also, the SSD method has been shown to perform well on the setup of partial deletion sets [4], so another thing to check would be comparing Potion (a followup to SSD) [5] + finetuning on the retain set, which would stress-test the hypothesis of "we need gradient routing through a new subnetwork instead of just finding the relevant parts of the existing network".
[1] Trippa, Daniel, et al. "$\nabla\tau $: Gradient-based and Task-Agnostic machine Unlearning." CoRR 2024
[2] Kolipaka, Varshita, et al. "A Cognac shot to forget bad memories: Corrective Unlearning in GNNs." arXiv preprint arXiv:2412.00789 (2024).
[3] Yao, Yuanshun, Xiaojun Xu, and Yang Liu. "Large language model unlearning." arXiv preprint arXiv:2310.10683 (2023).
[4] Goel, Shashwat, et al. "Corrective machine unlearning." TMLR 2024
[5] Schoepf, Stefan, Jack Foster, and Alexandra Brintrup. "Potion: Towards Poison Unlearning." DMLR Journal 2024
Replies from: cloud↑ comment by cloud · 2024-12-11T19:08:24.897Z · LW(p) · GW(p)
Thanks for the feedback and references!
On catastrophic forgetting: our appendix includes a "control" version of ERA that doesn't use gradient routing but is otherwise the same (appendix C, figure 12). This shows that the effect of retain-set fine-tuning is negligible in the absence of gradient routing.
On gradient ascent or similar methods: there are many unlearning methods that don't target or achieve the kind of robust localization and removal that we care about, as mentioned in our discussion of related works, and, e.g., in this post [LW · GW]. We included RMU as a stand-in for this class, and I personally don't see much value in doing more extensive comparisons there.
On Corrective Unlearning: we weren't aware of other unlearning approaches that consider imperfect labeling, so this is a very helpful reference-- thanks! It would be interesting to compare ERA-type methods to these. My concern with fine-tuning methods is that they might not be suitable for robustly removing broader capabilities (like, "virology") as opposed to correcting for small perturbations to the training data.
Replies from: shash42↑ comment by shash42 · 2024-12-12T11:36:27.182Z · LW(p) · GW(p)
Thanks for pointing me to Figure 12, it alleviates my concern! I don't fully agree with RMU being a stand-in for ascent based methods. Targeted representation noising (as done in RMU) seems easier to reverse than loss maximization methods (like TAR). Finally, just wanted to clarify that I see SSD/Potion more as automated mechanistic interpretability methods rather than finetuning-based. What I meant to say was that adding some retain set finetuning on top (as done for gradient routing) might be needed to make them work for tasks like unlearning virology.
Replies from: cloud↑ comment by cloud · 2024-12-12T21:22:23.098Z · LW(p) · GW(p)
Ah, I see what you mean. I think my use of the term "fine-tuning" was misleading. The distinction I'm trying to draw is between interventions applied throughout training vs. after training. "Post hoc" would have been a better term to describe the latter.
My suspicion is that post hoc methods will not be sufficient to robustly remove capabilities that are strongly reinforced by the training objective (while maintaining good general performance), because the capabilities are "too deeply ingrained."[1] We're excited about gradient routing's potential to solve this problem by separating capabilities during training. However, I agree that there isn't enough evidence yet, and it would be great to do more extensive comparisons, particularly to these recent methods which also target good performance under imperfect labeling.
For what it's worth, I don't think fine-tuning is doing that much work for us: we see it as a light-touch correction to "internal distribution shift" caused by ablation. As mentioned in this comment [LW(p) · GW(p)], we find that post-ablation fine-tuning on retain helps both retain and forget set performance. In the same comment we also show that retraining on the training distribution (a mixture of forget and retain) produces qualitatively similar results.
- ^
Also, if the goal is to be robust not only to imperfect labeling but also to forget set retraining, then there is a fundamental challenge to post hoc methods, which is that the minimal changes to a model which induce bad performance on a task are potentially quite different than the minimal changes to a model which prevent retrainability.
↑ comment by shash42 · 2024-12-13T10:21:44.985Z · LW(p) · GW(p)
That makes sense. My higher level concern with gradient routing (to some extent true for any other safety method) being used throughout training rather than after training is alignment tax, where it might lead to significantly lower performance and not get adopted in frontier models.
Evidence of this for gradient routing: people have tried various forms of modular training before [1], [2] and they never really caught on because its always better to train a combined model which allows optimal sharing of parameters.
Its still a cool idea though, and I would be happy to see it work out :)
[1] Andreas, Jacob et al., "Neural Module Networks.", CVPR 2016
[2] Ebrahimi, Sayna, et al. "Adversarial continual learning." ECCV 2020