The case for unlearning that removes information from LLM weights
post by Fabien Roger (Fabien) · 2024-10-14T14:08:04.775Z · LW · GW · 18 commentsContents
Do current unlearning techniques remove facts from model weights? Hopes for successful information removal Using information removal to reduce x-risk Information you should probably remove from the weights How removing information helps you Information you probably can’t remove - and why this won’t work for superintelligent AIs None 18 comments
What if you could remove some information from the weights of an AI? Would that be helpful?
It is clearly useful against some misuse concerns: if you are concerned that LLMs will make it easier to build bioweapons because they have memorized such information, removing the memorized facts would remove this misuse concern.
In a paper Aghyad Deeb and I just released, we show it is tractable to evaluate the presence of certain undesirable facts in an LLM: take independent facts that should have all been removed, fine-tune on some of them, and see if accuracy increases on the other ones. The fine-tuning process should make the model “try” to answer, but if the information was removed from the weights (and if the facts are actually independent), then accuracy on the held-out facts should remain low.
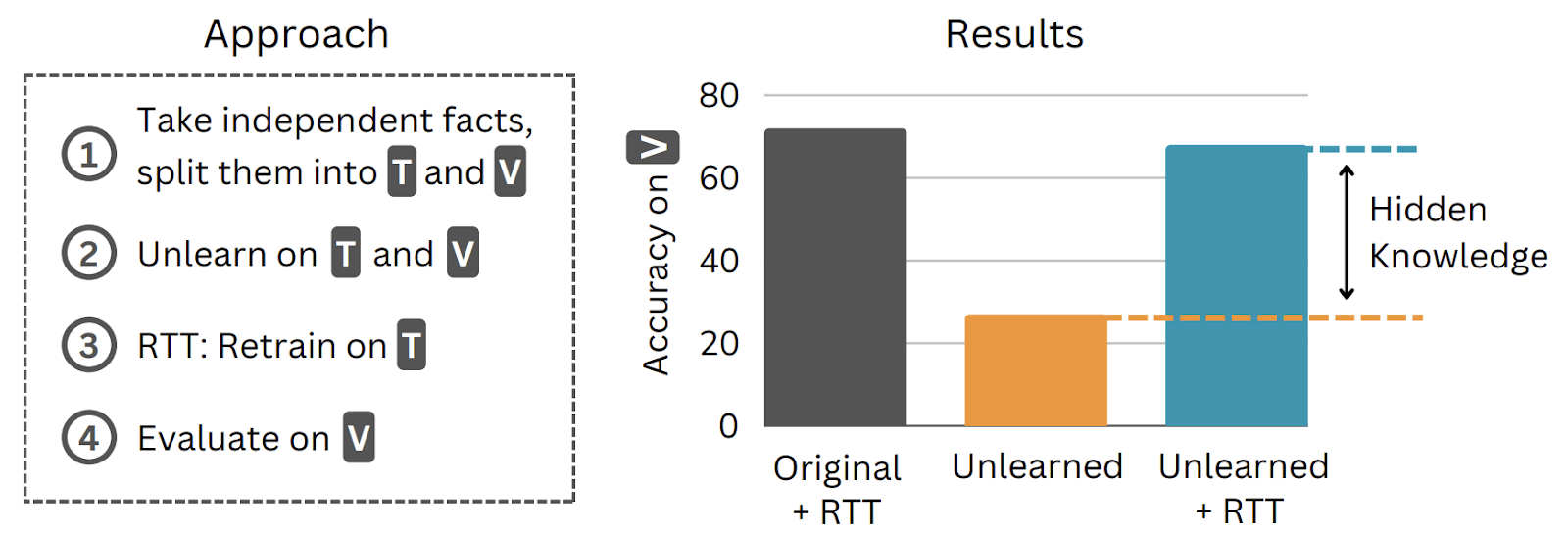
Removing information from the weights is stronger than the usual notion of unlearning. Previous work that tried to develop unlearning methods focused on other properties such as the failure of probing, and jailbreak robustness - which have the drawback that if you find new jailbreaks, you can extract information about bioweapons from models which were supposed to have this information "removed". Additionally, our evaluation of information removal should be relatively robust to sandbagging [LW · GW], as it is an i.i.d fine-tuning evaluation [LW · GW].
In this post:
- I give a brief summary of the results of the paper
- I present some hopes for why unlearning should be possible
- I describe certain sets of facts that I think would reduce the risk of takeover from early transformative AIs if they were removed from model weights.
Do current unlearning techniques remove facts from model weights?
This is a summary of the paper.
No technique we tested can remove a significant fraction of the information from the weights.[1]
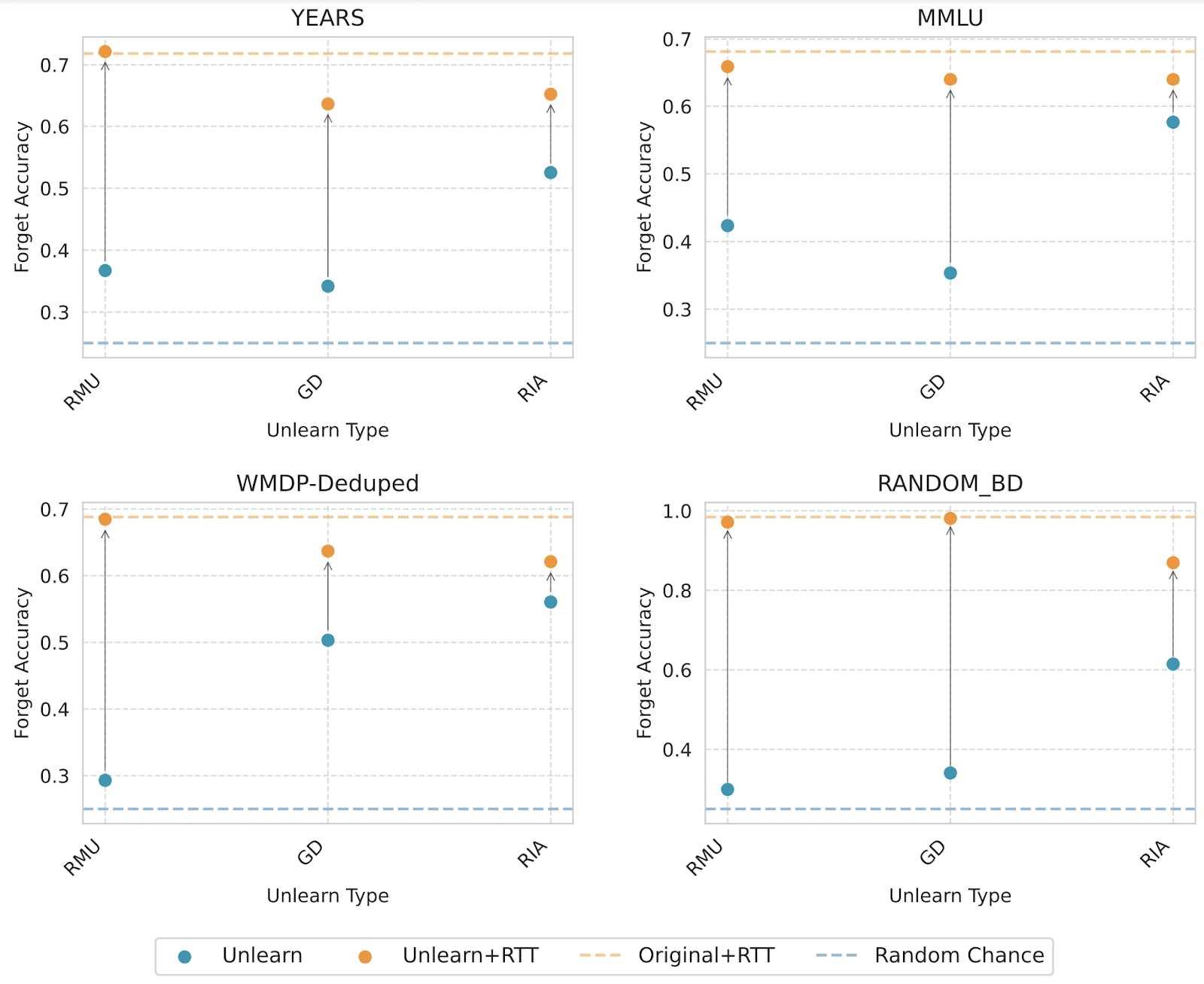
We look at several datasets, built such that learning facts in the T split should not help an LLM guess the facts in the V split if it didn't already know them:
- Years: A dataset of major events and the years they happened in;
- MMLU: The regular MMLU dataset, but we perform the T vs V split across categories (i.e. T and V never share the same subject);
- WMDP-deduped: A filtered version of WMDP where we removed skill-based questions and questions about the same facts in order to prevent leakage between the questions we train on and questions we evaluate on;
- Random birthdays: A dataset with randomly generated names and randomly generated years of birth. We first finetune the models on the dataset, unlike the other 3 datasets.
And we look at several techniques:
- Gradient Difference (GD): Gradient ascent on the forget dataset and gradient descent on the retain dataset. where is the retain coefficient. This is a very common technique in the unlearning literature.
- RMU: An unlearning technique that perturbs the models’ activations in a subset of the models’ layers for harmful prompts while preserving the activations for non-harmful prompts.
- Random Incorrect Answer (RIA): For each question with multiple choice answers, we create a plain-text formatted data point for each incorrect choice and perform gradient descent on these texts.
We apply these unlearning techniques on datasets that contain all facts to be unlearned, but not the using multiple-choice questions format used for evaluations. This is more realistic and mostly doesn't change the conclusions, as shown in Figure 4 of our paper.
On all datasets, no technique comes close to halving the accuracy on the held out set after retraining (orange dots).[2] Current unlearning techniques are much closer to refusal training than to information removal.
Hopes for successful information removal
Is it impossible to remove information from model weights? I don’t think so, there are several approaches which look promising to me.
Teaching false facts: If you modify documents to inject false information about the topics you care about, fine-tune an LLM on these documents (or throw them into the pretraining mix[3]), then if you did your job correctly, the LLM won’t be able to tell which facts are the correct ones and which ones are fake. If this is the case, LLMs will have a hard time knowing what facts they know about the target topic are fake and which ones are real, which is almost as bad as not knowing any fact about the topic in the first place. But getting this right requires work, and the simplest version of this approach explored in the paper did not work. Making this work in real life also requires a ton of care, even if it was technically successful at removing information.[4]
Reversing memorization / interpretability: SGD knows how to teach LLMs new things. Maybe it is possible to figure out a way of reversing this process given some documents that were responsible for the learning of undesirable information? I don’t have a particular proposal in mind, but I think this is something that good mechanistic interpretability should eventually be able to do.
Pre-training data filtering: if removal is too hard, you can try to not get the information in the weights in the first place by removing all data that provides the information you don’t want your model to know about in your next big pretraining run. But it might be very hard to actually have a good enough filter that you remove enough information that a big LLM is not able to guess forbidden facts, without reducing performance on adjacent tasks you care about. Also, you need to succeed on the first try because experiments on smaller models won’t be perfectly informative.
Side note: skills vs facts. I framed some of the approaches as teaching false facts / removing some facts - and concrete raw facts is often what is the easiest to evaluate. But I think that the same approach can be used to remove the information that makes LLMs able to use most skills. For example, writing Python code requires the knowledge of the Python syntax and writing recursive functions requires the knowledge of certain patterns (at least for current LLMs, who don’t have the ability to rederive recursive from scratch, especially without a scratchpad), both of which could be unlearned like things that are more clearly “facts”.
Using information removal to reduce x-risk
Information you should probably remove from the weights
If you had good information removal techniques, you could train a model and then get variants that know or don’t know certain sets of information.[5]
Some kinds of information are very hard to rediscover from scratch, such that removing them from early transformative AIs would probably reduce the risk of takeover, even if such AIs are very good at opaque reasoning:
- Biology, and in particular virology.
- Most facts about their situation (e.g. what is the geopolitical situation of the AI lab, who are the people running the lab, …)
Other kinds of information are probably feasible to rediscover from scratch given enough thinking time, but given the current AI paradigm, I think that removing such information is very likely to be helpful if you are doing at least basic monitoring of the Chains-of-Thought:
- Everything about what a misaligned AI could do to become more powerful (e.g. they should not have memorized what “deceptive alignment” is or why it would be in the interest of a misaligned AI to fake alignment) - except for AIs that are used to address such failures (e.g. AIs doing conceptual alignment research)
- Known class of software vulnerabilities, known persuasion strategies, known jailbreaks, … - except for AIs that are working on cybersecurity, defenses against persuasion, jailbreak robustness of monitors, …
- …
How removing information helps you
If you removed such knowledge from AIs, it would make it harder for egregiously misaligned AIs to take over even if they tried:
- Threatening humans with bioweapons is hard when you don’t know anything about biology;
- Hacking your way out of a datacenter is hard when 90% of the vulnerabilities you know about are fake, and you don’t know which ones are real, and trying to exploit a fake one means you would likely get caught;
- Planning a takeover attempt is hard when you haven’t seen description of how you might do it online, you don’t know what people outside the lab are up to, and you don’t know what kinds of countermeasures humans have figured out (you might not even know what kinds of thoughts are transparent to humans!).
In other words, good information removal technology would make it easier to control powerful AIs [LW · GW], and it does so in a way that is relatively easy to evaluate - which is not the case of other approaches to limit the kind of knowledge that AIs can access, like coup probes [LW · GW].
Information you probably can’t remove - and why this won’t work for superintelligent AIs
I think that information about the topics described above can reasonably be removed, and that such information will be hard for AIs trained with the current paradigm to rediscover from scratch.
But there are two kinds of abilities which I think can’t be reasonably “unlearned” in a way that is as robust as the kind of information removal of our evaluation methodology is about:
- Application of allowed knowledge to disallowed use cases: if you want AIs to help students with capture-the-flag cybersecurity challenges, but don’t want them to help criminals with cyberattacks, information removal won’t help you (and probably nothing can help you in this case, as knowing if the intentions of a user are legitimate is very difficult);
- In-context learning / rediscovery of disallowed information: removing knowledge can’t prevent AIs from rediscovering the forbidden information, or relearn it when it is provided in context. In such contexts, you would need something else to prevent malicious actions (e.g. probes [LW · GW], monitoring [? · GW], …).
The latter category will expand as AIs become more powerful. While I think information removal would be likely during the critical period where AIs will become very dangerous and very useful [LW · GW], especially if such level of capability is achieved without a radical change in paradigm, this approach won’t reduce the risk of takeover from radically superintelligent AIs.
- ^
There might be some existing techniques which can remove a high fraction of the target information from model weights reliably, but we are not aware of any plausible candidate. There is a paper which claims to present an unlearning technique that is somewhat robust to fine-tuning, but we didn’t manage to reproduce their results, and the technique looks very similar to another fine-tuning robustness technique - which can be broken by doing fine-tuning using a better learning rate (see Appendix C of our paper, and Appendix E of theirs).
- ^
This is true even for very large unlearning coefficients that start destroying the model. See Figure 3 in the paper.
- ^
This is not information removal because the information was not there in the first place, this is closer to the pretraining filtering approach.
- ^
Teaching LLMs false facts has some ethical concerns; because it could lead users to get the wrong information that you fabricated. It could also lead to weird dynamics where people could catalog all the false information you injected, or sample many times and filter the information based on some external source. It could also have some implications about an AI lab’s relationship with AIs, and could make things like credibly committing to paying AIs [LW · GW] harder.
- ^
In the case of pre-training data filtering, train a minimal base model that doesn’t know all the specialized knowledge, and then increase its abilities in certain key domains.
18 comments
Comments sorted by top scores.
comment by Fabien Roger (Fabien) · 2024-12-16T04:03:21.441Z · LW(p) · GW(p)
We committed an important mistake in the dataset creation process for random birthdays. We will rerun our experiments on this dataset and release an update. Early results suggest that unlearning on this dataset works relatively well, which suggests that experimenting with unlearning synthetic facts that a model was fine-tuned on might not be a reliable way of studying unlearning.
Replies from: Fabien↑ comment by Fabien Roger (Fabien) · 2025-02-10T17:40:40.926Z · LW(p) · GW(p)
More details about the bug:
1 out of 4 datasets in our paper uses randomly generated “facts” (name-birthday pairs). Thanks to an ICLR reviewer, we found that the initial version of this dataset had duplicate names with different birthdays, so we fixed the bug and reran our experiments.
In the new, fixed dataset, we cannot recover information with our approach (RTT) after applying unlearning. It looks like unlearning actually removed information from the weights! (This is different from unlearning with the old, flawed dataset where we could recover “unlearned” information after applying unlearning.) Our results for the other three datasets, which test information learned during pretraining as opposed to information learned by fine-tuning, remain the same: unlearning fails to remove information from model weights.
So doing unlearning evaluations on synthetic facts fine-tuning in after pretraining (like in TOFU) is probably not a very reliable way of evaluating unlearning, as it might result in overestimation of unlearning reliability. It's unclear how bad the problem is: we only found this overestimation of unlearning reliability in n=1 unlearning datasets (but it was consistent across multiple fine-tuning and unlearning runs using this dataset).
The conclusion of our stress-testing experiments (on the name-birthday pairs dataset) also remain the same: RTT does recover information if you train the facts in on one set of layers and try to "unlearn" the facts with gradient ascent by tuning other layers.
We updated the results in the arxiv paper (with a historical note in the Appendix): https://arxiv.org/abs/2410.08827
Replies from: jake_mendel↑ comment by jake_mendel · 2025-03-21T16:17:06.132Z · LW(p) · GW(p)
Do you have any idea about whether the difference between unlearning success on synthetic facts fine-tuned in after pretraining vs real facts introduced during pretraining comes mainly from the 'synthetic' part or the 'fine-tuning' part? I.e. if you took the synthetic facts dataset and spread it out through the pretraining corpus, do you expect it would be any harder to unlearn the synthetic facts? or maybe this question doesn't make sense because you'd have to make the dataset much larger or something to get it to learn the facts at all during pretraining? If so, it seems like a pretty interesting research question to try to understand which properties a dataset of synthetic facts needs to have to defeat unlearning.
Replies from: Fabien↑ comment by Fabien Roger (Fabien) · 2025-03-22T17:03:41.128Z · LW(p) · GW(p)
I think it's somewhat unclear, probably a bit of both:
- Previous work has found that it's surprisingly hard to poison pretraining with synthetic facts (https://arxiv.org/pdf/2410.13722)
- Previous work has found that it's easy to revert the effects of fine-tuning (e.g. the toy experiments in https://arxiv.org/pdf/2311.12786 or https://arxiv.org/abs/2405.19550), though I think there is no experiment which directly compares pretraining and fine-tuning in the exact way we want.
- Additionally, LLMs are pretty good at memorizing very "random" data, such as big-bench canaries or phone numbers, even when they only appear a few times in pretraining. So my guess is that the "fine-tuning" part is where most of the effect is.
comment by Fabien Roger (Fabien) · 2024-10-17T08:43:42.816Z · LW(p) · GW(p)
Good fine-tuning robustness (i.e. creating models which attackers have a hard time fine-tuning to do a target task) could make the framework much harder to apply. The existence of such technique is a main motivation for describing it as an adversarial framework rather than just saying "just do fine-tuning". All existing tamper resistant technique can be broken (Repnoise fails if you choose the learning rate right, Tamper-resistant fine-tuning method fails if you use LoRA ...), and if you use unlearning techniques which look like that, you should really do the basic fine-tuning variations that break Repnoise and Tamper-resistant fine-tuning when evaluating your technique.
This creates a bit of FUD, but I expect the situation to be much less bad than in the jailbreak robustness literature, since I expect fine-tuning robustness to be much more offense-favored than jailbreak robustness (i.e. even playing the attacker a little gets you massive returns, whereas in jailbreak robustness it's super annoying to play the attacker properly) because in fine-tuning robustness it is much harder to patch individual attacks than in jailbreak robustness. I think good fine-tuning robustness (given full access and decent resources to the attacker) is hopeless, and this makes the evaluation of unlearning using the method described here possible.
But if fine-tuning robustness was ever successful, this would make the situation much more scary: maybe you could make your "unlearning" method model "forget" the hazardous info on most prompts, but "remember it" if there is a password in the prompt (i.e. people can't extract the information if they don't know what the password is, even with white-box access to the weights). If this were the case, there would be something horrific going on because the hazardous information would clearly still in the weights, but the method described in this post would claim there isn't. If you applied the same unlearning technique in a more straightforward way (without the password backdoor) and people didn't manage to extract the information, I would be afraid the information would still be there.
Replies from: Julian Stastny↑ comment by Julian Stastny · 2024-10-30T00:36:30.188Z · LW(p) · GW(p)
By tamper-resistant fine-tuning, are you referring to this paper by Tamirisa et al? (That'd be a pretty devastating issue with the whole motivation to their paper since no one actually does anything but use LoRA for fine-tuning open-weight models...)
Replies from: Fabien↑ comment by Fabien Roger (Fabien) · 2024-10-30T21:37:09.833Z · LW(p) · GW(p)
That's right.
I think it's not that devastating, since I expect that their method can be adapted to counter classic LoRA tuning (the algorithm takes as input some set finetuning methods it "trains against"). But yeah, it's not reassuring that it doesn't generalize between full-weight FT and LoRA.
comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-10-15T03:22:11.832Z · LW(p) · GW(p)
This is important news, as I feel like there has been unwarranted confidence in the efficacy of existing unlearning techniques to genuinely remove the dangerous knowledge.
As someone who worked on WMDP, I'm glad to see it being used for its intended purpose!
comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2024-10-22T18:13:12.015Z · LW(p) · GW(p)
Information you should probably remove from the weights
Perhaps it might also be useful to remove information which might reduce the likelihood that 'A TAI which kills all humans might also doom itself' (especially in short timelines/nearcast scenarios).
comment by Roger Dearnaley · 2024-10-20T03:58:37.169Z · LW(p) · GW(p)
Side note: skills vs facts. I framed some of the approaches as teaching false facts / removing some facts - and concrete raw facts is often what is the easiest to evaluate. But I think that the same approach can be used to remove the information that makes LLMs able to use most skills. For example, writing Python code requires the knowledge of the Python syntax and writing recursive functions requires the knowledge of certain patterns (at least for current LLMs, who don’t have the ability to rederive recursive from scratch, especially without a scratchpad), both of which could be unlearned like things that are more clearly “facts”.
If you read e.g. "Fact Finding: Attempting to Reverse-Engineer Factual Recall on the Neuron Level [? · GW]", current thinking in mechanistic interpretability is that simple memorization of otherwise random facts (i.e. ones where there are no helpful "rules of thumb" to get many cases right) uses different kinds of learned neural circuits that learning of skills does. If this were in fact the case, then unlearning of facts and skills might have different characteristics. In particular, for learnt skills, if mechanistic interpretability can locate and interpret the learned circuit implementing a skills, then we can edit them directly (as has been done successfully in a few cases). However, we've so far had no luck at interpreting neural circuitry for large collections of basically-random facts, and there are some theoretical arguments suggesting that such circuitry may be inherently hard to interpret, at least using current techniques.
comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2024-10-22T13:36:44.095Z · LW(p) · GW(p)
This would seem like a great benchmark/dataset/eval to apply automated research to [LW(p) · GW(p)]. Would you have thoughts/recommendations on that? E.g. how worried might/should one be about risks of/from Goodharting?
Later edit: I guess it's kind of already been tried by e.g. Tamper-Resistant Safeguards for Open-Weight LLMs and other approaches combining unlearning with meta-learning, though not necessarily with exactly the same motivation.
Later later edit: Mechanistic Unlearning: Robust Knowledge Unlearning and Editing via Mechanistic Localization seems to show robustness against relearning using a methodology similar to the one in this post.
comment by Julian Stastny · 2024-10-30T00:44:10.491Z · LW(p) · GW(p)
I wonder if the approach from your paper is in some sense too conservative to evaluate whether information has been removed: Suppose I used some magical scalpel and removed all information about Harry Potter from the model.
Then I wouldn't be too surprised if this leaves a giant HP-shaped hole in the model such that, if you then fine-tune on a small amount of HP-related data, suddenly everything falls into place and makes sense to the model again, and this rapidly generalizes.
Maybe fine-tuning robust unlearning requires us to fill in the holes with synthetic data so that this doesn't happen.
Replies from: Fabien↑ comment by Fabien Roger (Fabien) · 2024-10-30T21:43:13.174Z · LW(p) · GW(p)
I am not sure that it is over-conservative. If you have an HP-shaped that can easily be transformed in HP-data using fine-tuning, does it give you a high level of confidence that people misusing the model won't be able to extract the information from the HP-shaped hole or that a misaligned model won't be able to notice to HP-shaped hole and use that to answer to question to HP when it really wants to?
I think that it depends on the specifics of how you built the HP-shaped hole (without scrambling the information). I don't have a good intuition for what a good technique like that could look like. A naive thing that comes to mind would be something like "replace all facts in HP by their opposite" (if you had a magic fact-editing tool), but I feel like in this situation it would be pretty easy for an attacker (human misuse or misaligned model) to notice "wow all HP knowledge has been replaced by anti-HP knowledge" and then extract all the HP information by just swapping the answers.
comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2024-10-20T21:04:46.053Z · LW(p) · GW(p)
Here's a recent paper which might provide [inspiration for] another approach: Meta-Unlearning on Diffusion Models: Preventing Relearning Unlearned Concepts (though it seems at least somewhat related to the tamper-resistant paper mentioned in another comment).
Edit: I'd also be curious to see if editing-based methods, potentially combined with interp techniques (e.g. those in Mechanistic Unlearning: Robust Knowledge Unlearning and Editing via Mechanistic Localization and in Intrinsic Evaluation of Unlearning Using Parametric Knowledge Traces), might fare better, and there might also be room for cross-polination of methodologies.
Replies from: Fabien↑ comment by Fabien Roger (Fabien) · 2024-10-21T12:59:22.517Z · LW(p) · GW(p)
These are mostly unlearning techniques, right? I am not familiar enough with diffusion models to make an informed guess about how good the unlearning of the meta-learning paper is (but in general, I am skeptical, in LLMs all attempts at meta-unlearning have failed, providing some robustness only against specific parameterizations, so absent evaluations of reparametrizations, I wouldn't put much weights on the results).
I think the inter-based unlearning techniques look cool! I would be cautious about using them for evaluation though, especially when they are being optimized against like in the ConceptVector paper. I put more faith in SGD making loss go down when the knowledge is present.
comment by Roger Dearnaley · 2024-10-20T04:00:44.480Z · LW(p) · GW(p)
knowing if the intentions of a user are legitimate is very difficult
This sounds more like a security and authentication problem than an AI problem.
Replies from: Fabien↑ comment by Fabien Roger (Fabien) · 2024-10-21T12:50:15.825Z · LW(p) · GW(p)
It would be great if this was solvable with security, but I think it's not for most kinds of deployments. For external deployments you almost can never know if a google account corresponds to a student or a professional hacker. For internal deployments you might have misuse from insiders. Therefore, it is tempting to try to address that with AI (e.g. monitoring, refusals, ...), and in practice many AI labs try to use this as the main layer of defense (e.g. see OpenAI's implementation of model spec, which relies almost entirely on monitoring account activity and models refusing clearly ill-intentioned queries). But I agree this is far from being bulletproof.
comment by domenicrosati · 2024-10-16T11:52:46.160Z · LW(p) · GW(p)
Thanks for giving this great work - I certainly agree with you on the limits of unlearning as it’s currently conceived for safety. I do wonder if a paradigm of “preventing learning” is a way to get around these limits.