Does davidad's uploading moonshot work?
post by Bird Concept (jacobjacob), lisathiergart, Anders_Sandberg, davidad, Arenamontanus · 2023-11-03T02:21:51.720Z · LW · GW · 35 commentsContents
Barcoding as blocker (and synchrotrons) End-to-end iteration as blocker (and organoids, holistic processes, and exotica) Using AI to speed up uploading research Training frontier models to predict neural activity instead of next token How to avoid having to spend $100B and and build 100,000 light-sheet microscopes What would General Groves do? Some unanswered questions Appendix: the proposal None 35 comments
davidad [LW · GW] has a 10-min talk out on a proposal about which he says: “the first time I’ve seen a concrete plan that might work to get human uploads before 2040, maybe even faster, given unlimited funding”.
I think the talk is a good watch, but the dialogue below is pretty readable even if you haven't seen it. I'm also putting some summary notes from the talk in the Appendix of this dialoge.
I think of the promise of the talk as follows. It might seem that to make the future go well, we have to either make general AI progress slower, or make alignment progress differentially faster. However, uploading seems to offer a third way: instead of making alignment researchers more productive, we "simply" run them faster. This seems similar to OpenAI’s Superalignment proposal of building an automated alignment scientist -- with the key exception that we might plausibly think a human-originated upload would have a better alignment guarantee than, say, an LLM.
I decided to organise a dialogue on this proposal because it strikes me as “huge if true”, yet when I’ve discussed this with some folks I've found that people generally don't seem that aware of it, and sometimes raise questions/confusions/objections that neither me nor the talk could answer.
I also invited Anders Sandberg, who co-authored the 2008 Whole Brain Emulation roadmap with Nick Bostrom, and co-organised the Foresight workshop on the topic where Davidad presented his plan, and Lisa Thiergart from MIRI, who also gave a talk at the workshop and has previously written about whole brain emulation here on LessWrong [LW · GW].
The dialogue ended up covering a lot of threads at the same time. I split them into six separate sections, that are fairly readable independently.
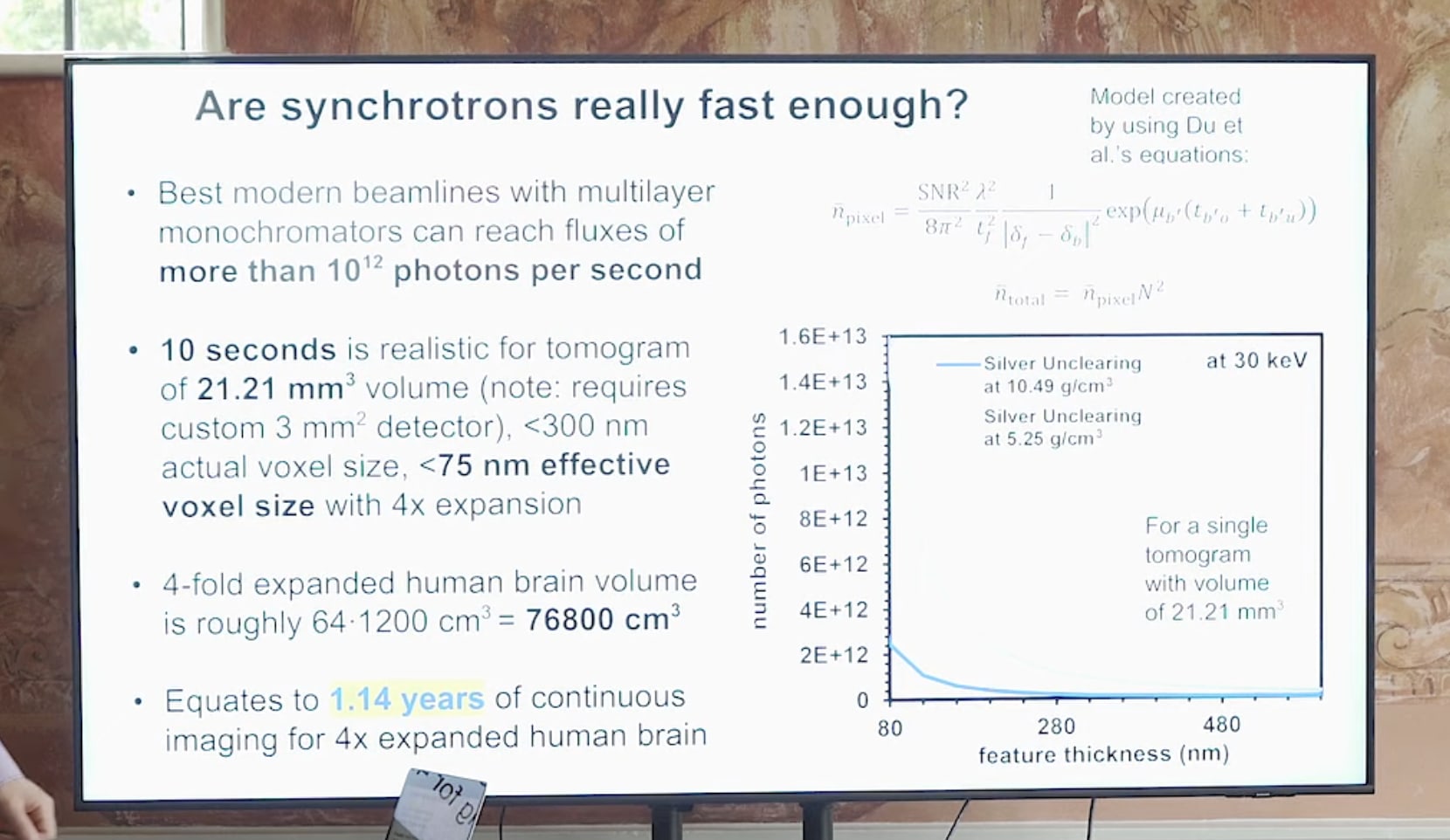
Barcoding as blocker (and synchrotrons)
End-to-end iteration as blocker (and organoids, holistic processes, and exotica)
Using AI to speed up uploading research
Training frontier models to predict neural activity instead of next token
How to avoid having to spend $100B and and build 100,000 light-sheet microscopes

What would General Groves do?
Some unanswered questions
Me (jacobjacob) and Lisa started the dialogue by brainstorming some questions. We didn't get around to answering all of them (and neither did we intend to). Below, I'm copying in the ones that didn't get answered.
Appendix: the proposal
Here's a screenshot of notes from Davidad's talk.


35 comments
Comments sorted by top scores.
comment by TsviBT · 2023-11-03T06:14:16.544Z · LW(p) · GW(p)
all the cognitive information processing
I don't understand what's being claimed here, and feel the urge to get off the boat at this point without knowing more. Most stuff we care about isn't about 3-second reactions, but about >5 minute reactions. Those require thinking, and maybe require non-electrical changes--synaptic plasticity, as you mention. If they do require non-electrical changes, then this reasoning doesn't go through, right? If we make a thing that simulates the electrical circuitry but doesn't simulate synaptic plasticity, we'd expect to get... I don't know, maybe a thing that can perform tasks that are already "compiled into low-level code", so to speak, but not tasks that require thinking? Is the claim that thinking doesn't require such changes, or that some thinking doesn't require such changes, and that subset of thinking is enough for greatly decreasing X-risk?
Replies from: steve2152, davidad, M. Y. Zuo↑ comment by Steven Byrnes (steve2152) · 2023-11-03T14:10:19.996Z · LW(p) · GW(p)
Seconded! I too am confused and skeptical about this part.
Humans can do lots of cool things without editing the synapses in their brain. Like if I say: “imagine an upside-down purple tree, and now answer the following questions about it…”. You’ve never thought about upside-down purple trees in your entire life, and yet your brain can give an immediate snap answer to those questions, by flexibly combining ingredients that are already stored in it.
…And that’s roughly how I think about GPT-4’s capabilities. GPT-4 can also do those kinds of cool things. Indeed, in my opinion, GPT-4 can do those kinds of things comparably well to a human. And GPT-4 already exists and is safe. So that’s not what we need.
By contrast, when I think about what humans can do that GPT-4 can’t do, I think of things that unfold over the course of minutes and hours and days and weeks, and centrally involve permanently editing brain synapses. (See also: “AGI is about not knowing how to do something, and then being able to figure it out.” [LW · GW])
Replies from: jacobjacob↑ comment by Bird Concept (jacobjacob) · 2023-11-04T03:08:36.281Z · LW(p) · GW(p)
Hm, here's a test case:
GPT4 can't solve IMO problems. Now take an IMO gold medalist about to walk into their exam, and upload them at that state into an Em without synaptic plasticity. Would the resulting upload would still be able to solve the exam at a similar level as the full human?
I don't have a strong belief, but my intuition is that they would. I recall once chatting to @Neel Nanda [LW · GW] about how he solved problems (as he is in fact an IMO gold winner), and recall him describing something that to me sounded like "introspecting really hard and having the answers just suddenly 'appear'..." (though hopefully he can correct that butchered impression)
Do you think such a student Em would or would not perform similarly well in the exam?
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2023-11-04T10:56:40.639Z · LW(p) · GW(p)
I don’t have a strong opinion one way or the other on the Em here.
In terms of what I wrote above (“when I think about what humans can do that GPT-4 can’t do, I think of things that unfold over the course of minutes and hours and days and weeks, and centrally involve permanently editing brain synapses … being able to figure things out”), I would say that human-unique “figuring things out” process happened substantially during the weeks and months of study and practice, before the human stepped into the exam room, wherein they got really good at solving IMO problems. And hmm, probably also some “figuring things out” happens in the exam room, but I’m not sure how much, and at least possibly so little that they could get a decent score without forming new long-term memories and then building on them.
I don’t think Ems are good for much if they can’t figure things out and get good at new domains—domains that they didn’t know about before uploading—over the course of weeks and months, the way humans can. Like, you could have an army of such mediocre Ems monitor the internet, or whatever, but GPT-4 can do that too. If there’s an Em Ed Witten without the ability to grow intellectually, and build new knowledge on top of new knowledge, then this Em would still be much much better at string theory than GPT-4 is…but so what? It wouldn’t be able to write groundbreaking new string theory papers the way real Ed Witten can.
↑ comment by davidad · 2023-11-04T02:42:42.388Z · LW(p) · GW(p)
I have said many times that uploads created by any process I know of so far would probably be unable to learn or form memories. (I think it didn't come up in this particular dialogue, but in the unanswered questions section Jacob mentions having heard me say it in the past.)
Eliezer has also said that makes it useless in terms of decreasing x-risk. I don't have a strong inside view on this question one way or the other. I do think if Factored Cognition [? · GW] is true then "that subset of thinking is enough," but I have a lot of uncertainty about whether Factored Cognition is true.
Anyway, even if that subset of thinking is enough, and even if we could simulate all the true mechanisms of plasticity, then I still don't think this saves the world [LW · GW], personally, which is part of why I am not in fact pursuing uploading these days.
↑ comment by M. Y. Zuo · 2023-11-03T18:32:58.160Z · LW(p) · GW(p)
That's a very interesting point, 'synaptic plasticity' is probably a critical difference. At least the recent results in LLMs suggest.
The author not considering, or even mentioning, it also suggests way more work and thought needs to be put into this.
comment by Logan Thrasher Collins (logan-thrasher-collins) · 2023-11-14T01:44:53.210Z · LW(p) · GW(p)
Hello folks! I'm the person who presented the 'expansion x-ray microtomography' approach at the Oxford workshop. I wanted to mention that since that presentation, I've done a lot of additional research into what would be needed to facilitate 1 year imaging of human brain via synchrotron + ExM. I now have estimates for 11-fold expansion to 27 nm voxel size, which is much closer to what is needed for traceability (further expansion could also help if needed). You can find my updated proposal here: https://logancollinsblog.com/2023/02/22/feasibility-of-mapping-the-human-brain-with-expansion-x-ray-microscopy/
In addition, I am currently compiling improved estimates for the speed of other imaging modalities for comparison. I've done a deep dive into the literature and identified the most competitive approaches now available for electron microscopy (EM) and expansion light-sheet fluorescence microscopy (ExLSFM). I expect to make these numbers available in the near future, but I want to go through and revise my analysis paper before posting it. If you are interested in learning more early, feel free to reach out to me!
comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2023-11-03T18:15:52.225Z · LW(p) · GW(p)
I don't think that faster alignment researchers get you to victory, but uploading should also allow for upgrading and while that part is not trivial I expect it to work.
Replies from: kh↑ comment by Kaarel (kh) · 2023-11-03T19:36:23.920Z · LW(p) · GW(p)
I'd be quite interested in elaboration on getting faster alignment researchers not being alignment-hard — it currently seems likely to me that a research community of unupgraded alignment researchers with a hundred years is capable of solving alignment (conditional on alignment being solvable). (And having faster general researchers, a goal that seems roughly equivalent, is surely alignment-hard (again, conditional on alignment being solvable), because we can then get the researchers to quickly do whatever it is that we could do — e.g., upgrading?)
Replies from: Eliezer_Yudkowsky↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2023-11-03T21:19:00.936Z · LW(p) · GW(p)
I currently guess that a research community of non-upgraded alignment researchers with a hundred years to work, picks out a plausible-sounding non-solution and kills everyone at the end of the hundred years.
Replies from: bogdan-ionut-cirstea, SimonF↑ comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2024-10-16T09:40:46.453Z · LW(p) · GW(p)
I'm highly confused about what is meant here. Is this supposed to be about the current distribution of alignment researchers? Is this also supposed to hold for e.g. the top 10 percentile of alignment researchers, e.g. on safety mindset? What about many uploads/copies of Eliezer only?
↑ comment by Simon Fischer (SimonF) · 2023-11-15T12:22:55.370Z · LW(p) · GW(p)
I'm confused by this statement. Are you assuming that AGI will definitely be built after the research time is over, using the most-plausible-sounding solution?
Or do you believe that you understand NOW that a wide variety of approaches to alignment, including most of those that can be thought of by a community of non-upgraded alignment researchers (CNUAR) in a hundred years, will kill everyone and that in a hundred years the CNUAR will not understand this?
If so, is this because you think you personally know better or do you predict the CNUAR will predictably update in the wrong direction? Would it matter if you got to choose the composition of the CNUAR?
comment by aysja · 2023-11-05T03:21:36.341Z · LW(p) · GW(p)
Thanks for making this dialogue! I’ve been interested in the science of uploading for awhile, and I was quite excited about the various C. elegans projects when they started.
I currently feel pretty skeptical, though, that we understand enough about the brain to know which details will end up being relevant to the high-level functions we ultimately care about. I.e., without a theory telling us things like “yeah, you can conflate NMDA receptors with AMPA, that doesn’t affect the train of thought” or whatever, I don’t know how one decides what details are and aren’t necessary to create an upload.
You mention that we can basically ignore everything that isn’t related to synapses or electricity (i.e., membrane dynamics), because chemical diffusion is too long to account for the speed of cognitive reaction times. But as Tsvi pointed out, many of the things we care about occur on longer timescales. Like, learning often occurs over hours, and is sometimes not stored in synapses or membranes—e.g., in C. elegans some of the learning dynamics unfold in the protein circuits within individual neurons (not in the connections between them).[1] Perhaps this is a strange artifact of C. elegans, but at the very least it seems like a warning flag to me; it’s possible to skip over low-level details which seem like they shouldn’t matter, but end up being pretty important for cognition.
That’s just one small example, but there are many possibly relevant details in a brain… Does the exact placement of synapses matter? Do receptor subtypes matter? Do receptor kinematics matter, e.g., does it matter that NMDA is a coincidence detector? Do oscillations matter? Dendritic computation? Does it matter that the Hodgkin-Huxley model assumes a uniform distribution of ion channels? I don’t know! There are probably loads of things that you can abstract away, or conflate, or not even measure. But how can you be sure which ones are safe to ignore in advance?
This doesn't make me bearish on uploading in general, but it does make me skeptical of plans which don't start by establishing a proof of concept. E.g., if it were me, I’d finish the C. elegans simulation first, before moving onto to larger brains. Both because it seems important to establish that the details that you’re uploading in fact map onto the high-level behaviors that we ultimately care about, and because I suspect that you'd sort out many of the kinks in this pipeline earlier on in the project.
- ^
“The temperature minimum is reset by adjustments to the neuron’s internal signaling; this requires protein synthesis and takes several hours” and “Again, reprogramming a signaling pathway within a neuron allows experience to change the balance between attraction and repulsion.” Principles of Neural Design, page 32, under the section “Associative learning and memory.” (As far as I understand, these internal protein circuits are separate from the transmembrane proteins).
comment by the gears to ascension (lahwran) · 2023-11-03T04:29:52.680Z · LW(p) · GW(p)
Are y'all familiar with what Openwater has been up to? my hunch is that it wouldn't give high enough resolution for the things intended here, but I figured it was worth mentioning: it works by doing holographic descattering in infrared through the skull, and apparently has MRI-level resolution. I have wondered if combining it with AI is possible, or if they're already relying on AI to get it to work at all. The summary that first introduced me to it was their ted talk - though there are also other discussions with them on youtube. I didn't find a text document which goes into a ton of detail about their tech but somewhat redundant with the ted talk might be one of the things on their "in the press" list, eg this article.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2023-11-03T13:01:45.348Z · LW(p) · GW(p)
I carefully read all the openwater information and patents during a brief period where I was doing work in a similar technical area (brain imaging via simultaneous use of ultrasound + infrared). …But that was like 2017-2018, and I don’t remember all the details, and anyway they may well have pivoted since then. But anyway, people can hit me up if they’re trying to figure out what exactly Openwater is hinting at in their vague press-friendly descriptions, I’m happy to chat and share hot-takes / help brainstorm.
I don’t think they’re aspiring to measure anything that you can’t already measure with MRI, or else they would have bragged about it on their product page or elsewhere, right? Of course, MRI is super expensive and inconvenient, so what they’re doing is still potentially cool & exciting, even if it doesn’t enable new measurements that were previously impossible at any price. But in the context of this post … if I imagine cheap and ubiquitous fMRI (or EEG, ultrasound, etc.), it doesn’t seem relevant, i.e. I don’t think it would make uploading any easier, at least the way I see things.
comment by wolajacy · 2023-11-04T00:50:31.026Z · LW(p) · GW(p)
This is potentially a naive question, but how well would the imagining deal with missing data? Say that 1% (or whatever the base rate is) of tissue samples would be destroyed during slicing or expansion - would we be able to interpolate those missing pieces somehow? Do we know any bounds on the error would that introduce in the dynamics later?
Replies from: Iliocomment by jbash · 2023-11-03T20:01:38.906Z · LW(p) · GW(p)
Short answer: no.
Even assuming that you can scan whatever's important[1], you're still unlikely to have remotely the computing power to actually run an upload, let alone a lot of uploads, faster than "real time"... unless you can figure out how to optimize them in a bunch of ways. It's not obvious what you can leave out.
It's especially not obvious what you can leave out if you want the strong AGI that you're thereby creating to be "aligned". It's not even clear that you can rely on the source humans to be "aligned", let alone rely on imperfect emulations.
I don't think you're going to get a lot of volunteers for destructive uploading (or actually even for nondestructive uploading). Especially not if the upload is going to be run with limited fidelity. Anybody who does volunteer is probably deeply atypical and potentially a dangerous fanatic. And I think you can assume that any involuntary upload will be "unaligned" by default.
Even assuming you could get good, well-meaning images and run them in an appropriate way[2] , 2040 is probably not soon enough. Not if the kind of computing power and/or understanding of brains that you'd need to do that has actually become available by then. By the time you get your uploads running, something else will probably have used those same capabilities to outpace the uploads.
Regardless of when you got them running, there's not even much reason to have a very strong belief that more or faster "alignment researchers" would to be all that useful or influential, even if they were really trying to be. It seems at least as plausible to me that you'd run them faster and they'd either come up with nothing useful, or with potentially useful stuff that then gets ignored.
We already have a safety strategy that would be 100 percent effective if enacted: don't build strong AGI. The problem is that it's definitely not going to be enacted, or at least not universally. So why would you expect anything these uploads came up with to be enacted universally? At best you might be able to try for a "pivotal event" based on their output... which I emphasize is AGI output. Are you willing to accept that as the default plan?
... and accelerating the timeline for MMAcevedo scenarios does not sound like a great or safe idea.
... which you probably will not get close to doing by 2040, at least not without the assistance of AI entities powerful enough to render the whole strategy moot. ↩︎
... and also assuming you're in a world where the scenarios you're trying to guard against can come true at all... which is a big assumption ↩︎
↑ comment by Bird Concept (jacobjacob) · 2023-11-03T20:36:51.504Z · LW(p) · GW(p)
I don't think you're going to get a lot of volunteers for destructive uploading (or actually even for nondestructive uploading). Especially not if the upload is going to be run with limited fidelity. Anybody who does volunteer is probably deeply atypical and potentially a dangerous fanatic.
Seems falsified by the existence of astronauts?
Replies from: Benito, SimonF, jbash↑ comment by Ben Pace (Benito) · 2023-11-03T20:40:10.336Z · LW(p) · GW(p)
I, for one, would be more willing to risk my life to go to cyberspace than to go to the moon.
Replies from: jacobjacob↑ comment by Bird Concept (jacobjacob) · 2023-11-03T20:56:58.667Z · LW(p) · GW(p)
Separately, I'm kind of awed by the idea of an "uploadonaut": the best and brightest of this young civilisation, undergoing extensive mental and research training to have their minds able to deal with what they might experience post upload, and then courageously setting out on a dangerous mission of crucial importance for humanity.
(I tried generating some Dall-E 1960's style NASA recruitment posters for this, but they didn't come out great. Might try more later)
↑ comment by Simon Fischer (SimonF) · 2023-11-12T19:55:25.255Z · LW(p) · GW(p)
Another big source of potential volunteers: People who are going to be dead soon anyway. I'd probably volunteer if I knew that I'm dying from cancer in a few weeks anyway.
↑ comment by jbash · 2023-11-03T23:29:28.986Z · LW(p) · GW(p)
I don't think they're comparable at all.
Space flight doesn't involve a 100 percent chance of physical death, with an uncertain "resurrection", with a certainly altered and probably degraded mind, in a probably deeply impoverished sensory environment. If you survive space flight, you get to go home afterwards. And if you die, you die quickly and completely.
Still, I didn't say you'd get no volunteers. I said you'd get atypical ones and possible fanatics. And, since you have a an actual use for the uploads, you have to take your volunteers from the pool of people you think might actually be able to contribute. That's seems like an uncomfortably narrow selection.
Replies from: jacobjacob↑ comment by Bird Concept (jacobjacob) · 2023-11-04T03:16:54.723Z · LW(p) · GW(p)
Space flight doesn't involve a 100 percent chance of physical death
I think historically folks have gone to war or on other kinds of missions that had death rates of like, at least, 50%. And folks, I dunno, climb Mount Everest, or figured out how to fly planes before they could figure out how to make them safe.
Some of them were for sure fanatics or lunatics. But I guess I also think there's just great, sane, and in many ways whole, people, who care about things greater than their own personal life and death, and are psychologically consituted to be willing to pursue those greater things.
Replies from: Benito↑ comment by Ben Pace (Benito) · 2023-11-04T17:59:07.882Z · LW(p) · GW(p)
See the 31 climbers in a row who died scaling Nanga Parbat [LW · GW] before the 32nd was successful.
↑ comment by Bird Concept (jacobjacob) · 2023-11-03T20:44:11.878Z · LW(p) · GW(p)
Noting that I gave this a weak downvote as I found this comment to be stating many strong claims but without correspondingly strong (or sometimes not really any) arguments. I am still interested in the reasons you believe these things though (for example, like a fermi on inferece cost at runtime).
Replies from: jbash↑ comment by jbash · 2023-11-03T23:23:39.025Z · LW(p) · GW(p)
OK... although I notice that everybody in the initial post is just assuming you could run the uploads without providing any arguments.
Human brains have probably more than 1000 times as many synapses as current LLMs have weights. All the values describing the synapse behavior have to be resident in some kind of memory with a whole lot of bandwidth to the processing elements. LLMs already don't fit on single GPUs.
Unlike transformers, brains don't pass nice compact contexts from layer to layer, so splitting them across multiple GPU-like devices is going to slow you way down because you have to shuttle such big vectors between them... assuming you can even vectorize most of it at all given the timing and whatnot, and don't have to resort to much discrete message passing.
It's not even clear that you can reduce a biological synapse to a single weight; in fact you probably can't. For one thing, brains don't run "inference" in the way that artificial neural networks do. They run forward "inference-like" things, and at the same time do continuous learning based on feedback systems that I don't think are well understood... but definitely are not back propagation. It's not plausible that a lot of relatively short term tasks aren't dependent on that, so you're probably going to have to do something more like continuously running training than like continuously running inference.
There are definitely also things going on in there that depend on the relative timings of cascades of firing through different paths. There are also chemicals sloshing around that affect the ensemble behavior of whole regions on the scale of seconds to minutes. I don't know about in brains, but I do know that there exist biological synapses that aren't just on or off, either.
You can try to do dedicated hardware, and colocate the "weights" with the computation, but then you run into the problem that biological synapses aren't uniform. Brains actually do have built-in hardware architectures, and I don't believe those can be replicated efficiently with arrays of uniform elements of any kind... at least not unless you make the elements big enough and programmable enough that your on-die density goes to pot. If you use any hardwired heterogeneity and you get it wrong, you have to spin the hardware design, which is Not Cheap (TM). You also lose density because you have to replicate relatively large computing elements instead of only replicating relatively dense memory elements. You do get a very nice speed boost on-die, but I at a wild guess I'd say that's probably a wash with the increased need for off-die communication because of the low density.
If you want to keep your upload sane, or be able to communicate with it, you're also going to have to give it some kind of illusion of a body and some kind of illusion of a comprehensible and stimulating environment. That means simulating an unknown but probably large amount of non-brain biology (which isn't necessarily identical between individuals), plus a not-inconsiderable amount of outside-world physics.
So take a GPT-4 level LLM as a baseline. Assume you want to speed up your upload to be able to fast-talk about as fast as the LLM can now, so that's a wash. Now multiply by 1000 for the raw synapse count, by say 2 for the synapse diversity, by 5? for the continuous learning, by 2 for the extra synapse complexity, and by conservatively 10 for the hardware bandwidth bottlenecks. Add another 50 percent for the body, environment, etc.
So running your upload needs 300,000 times the processing power you need to run GPT-4. Which I suspect is usually run on quad A100s (at maybe $100,000 per "inference machine").
You can't just spend 30 billion dollars and shove 1,200,000 A100s into a chassis; the power, cooling, and interconnect won't scale (nor is there fab capacity to make them). If you packed them into a sphere at say 500 per cubic meter (which allows essentially zero space for cooling or interconnects, both of which get big fast), the sphere would be about 16 meters across and dissipate 300MW (with a speed of light delay from one side to the other of 50ns).
Improved chips help, but won't save you. Moore's law in "area form" is dead and continues to get deader. If you somehow restarted Moore's law in its original, long-since-diverged-from form, and shrank at 1.5x in area per year for the next 17 years, you'd have transistors ten times smaller than atoms (and your power density would be, I don't know, 100 time as high, leading to melted chips). And once you go off-die, you're still using macrosopic wires or fibers for interconnect. Those aren't shrinking... and I'm not sure the dies can get a lot bigger.
Switching to a completely different architecture the way I mentioned above might get back 10X or so, but doesn't help with anything else as long as you're building your system out of a fundamentally planar array of transistors. So you still have a 240 cubic meter, 30MW, order-of-3-billon-dollar machine, and if you get the topology wrong on the first try you get to throw it away and replace it. For one upload. That's not very competitive with just putting 10 or even 100 people in an office.
Basically, to be able to use a bunch of uploads, you need to throw away all current computing technology and replace it with some kind of much more element-dense, much more interconnect-dense, and much less power-dense computing substrate. Something more brain-like, with a 3D structure. People have been trying to do that for decades and haven't gotten anywhere; I don't think it's going to be manufactured in bulk by 2040.
... or you can try to trim the uploads themselves down by factors that end with multiple zeroes, without damaging them into uselessness. That strikes me as harder than doing the scanning... and it also strikes me as something you can't make much progress on until you have mostly finished solving the scanning problem.
It's not that you can't get some kind of intelligence in realistic hardware. You might even be able to get something much smarter than a human. But you're specifically asking to run a human upload, and that doesn't look feasible.
Replies from: steve2152, jacobjacob↑ comment by Bird Concept (jacobjacob) · 2023-11-04T02:54:18.354Z · LW(p) · GW(p)
I have an important appointment this weekend that will take up most of my time, but hope to come back to this after that, but wanted to quickly note:
but definitely are not back propagation.
Why?
Last time I looked into this 6 years ago seemed like an open question and it could plausibly be backprop or at least close enough: https://www.lesswrong.com/posts/QWyYcjrXASQuRHqC5/brains-and-backprop-a-key-timeline-crux [LW · GW]
3yrs ago Daniel Kokotajlo shared some further updates in that direction: https://www.lesswrong.com/posts/QWyYcjrXASQuRHqC5/brains-and-backprop-a-key-timeline-crux?commentId=RvZAPmy6KStmzidPF [LW(p) · GW(p)]
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2023-11-04T11:08:28.080Z · LW(p) · GW(p)
It’s possible that you (jacobjacob) and jbash are actually in agreement that (part of) the brain does something that is not literally backprop but “relevantly similar” to backprop—but you’re emphasizing the “relevantly similar” part and jbash is emphasizing the “not literally” part?
Replies from: jbash↑ comment by jbash · 2023-11-07T00:37:38.345Z · LW(p) · GW(p)
I think that's likely correct. What I mean is that it's not running all the way to the end of a network, computing a loss function at the end of a well defined inference cycle, computing a bunch of derivatives, etc... and also not doing anything like any of that mid-cycle. If you're willing to accept a large class of feedback systems as "essentially back propagation", then it depends on what's in your class. And I surely don't know what it's actually doing.
comment by niknoble · 2023-11-03T17:53:47.571Z · LW(p) · GW(p)
However, uploading seems to offer a third way: instead of making alignment researchers more productive, we "simply" run them faster.
When I think about uploading as an answer to AI, I don't think of it as speeding up alignment research necessarily, but rather just outpacing AI. You won't get crushed by an unaligned AI if you're smarter and faster than it is, with the same kind of access to digital resources.
comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2024-10-16T09:27:28.903Z · LW(p) · GW(p)
(I've only skimmed/talked to Claude about this post, so apologies if this was already discussed/addressed; also: cross-posted from some Slack/Signal groups on WBE and AI safety.)
Computational requirements for various [especially hi-fi] WBE simulation levels might make applicability to automated safety research mostly useless (even supposing the rest of the technical problems were solved, e.g. scanning, synapse tracing, etc.). E.g. looking at table 9 from page 80 of the WBE roadmap and assuming roughly 10^22 FLOP total computational power available worldwide (see e.g. https://wiki.aiimpacts.org/ai_timelines/hardware_and_ai_timelines/computing_capacity_of_all_gpus_and_tpus): if a spiking neural network simulation is required, this would only allow for < 10,000 automated (WBE) safety researchers; not bad, but not a huge gain in numbers either (compared to current numbers of safety researchers). And it gets (much) worse with more detailed levels of simulation: the next level (electrophysiology) would allow for <=1 WBE.
So I think this weakens the appeal of hi-fi WBEs (for which I don't think the arguments were a slamdunk even to begin with) even more.
comment by Review Bot · 2024-08-14T05:27:25.043Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?