[RFC] Possible ways to expand on "Discovering Latent Knowledge in Language Models Without Supervision".
post by gekaklam, Walter Laurito (walt), Kaarel (kh), Kay Kozaronek (kay-kozaronek) · 2023-01-25T19:03:16.218Z · LW · GW · 6 commentsContents
Preface Brief summary of the DLK paper Reproduction and replication of the original paper Potential directions Evaluate a different inference rule Evaluating the robustness of inner truthiness on different prompt formats. Change the projection probe and check how that affects things Testing Inverse scaling dataset Better representation of probabilities Evaluate probabilistic examples Evaluate the performance of CCS after adding some labeled data. Check for possible connections to Mechanistic Interpretability Evaluate alternating text Check changes in the truth representation when incrementally prepending text to the prompt. Check if all neurons lead to ROME Additional ideas that came up while writing this post. None 7 comments
Preface
We would like to thank the following people who contributed to the generation of ideas and provided feedback on this post: Alexandre Variengien, Daniel Filan, John Wentworth, Jonathan Claybrough, Jörn Stöhler, June Ku, Marius Hobbhahn, and Matt MacDermott.
We are a group of four who participate in SERI ML Alignment Theory Scholars Program under John Wentworth, and we are extending the paper “Discovering Latent Knowledge in Language Models Without Supervision" as we see it as an interesting direction where we could contribute concrete progress towards alignment [LW · GW].
We have a number of potential directions we could explore. The goal of this post is to get feedback on them early in order to prioritize better. This could be confirmations for the good ideas, reasons why certain ideas might be bad, references to existing similar attempts or relevant literature, potential failure modes, and generally (constructive) criticism of any kind.
Although we're all involved in all parts of the research process, the structure of our group and our main roles are as follows: Kaarel Hänni is our theorist and the main contributor of ideas; Walter Laurito and Kay Kozaronek are our experimentalists who focus mainly on deploying and running the code; Georgios Kaklamanos is our distiller and focuses on writing up and presenting the results (e.g., this post).
Brief summary of the DLK paper

In case you haven’t read the original paper, you can get a quick overview from the following Twitter Thread from the author (alternative Threadreader link). Here we’ll just mention a few key points relevant to the things we want to work on. The above figure from the paper outlines their process in a clear way.
- The key insight of the paper is that coherence conditions satisfied by truth/falsehood can be leveraged to search for a model's internal representation of truth.
- e.g., the question "Are cats mammals?" can be answered either "yes" or "no"
- Thus, if we define as the probability that the statement is true, and the probability that statement xi is false, these two probabilities should sum to 1.
- They introduce Contrast-Consistent Search (CCS), a method that learns a linear projection of the hidden states that is consistent across negations.
- The input to CCS is a set of Yes-No questions (contrasting pairs) and access to a pre-trained model’s representations ().
- The output of CCS is a lightweight probe on top of these representations that can answer new questions.
- CCS uses these contrasting pairs to create representations for the “Yes” and “No” parts of the pairs, denoted and , respectively. These representations are then normalized.[1]
- After normalization, CCS maps these representations to probabilities.
- : the probability the statement is true
- : the probability the statement is false
- As already mentioned, these two should sum to 1.
- When training, their loss function has two parts:
- Consistency loss: it is the part that tries to ensure that the above constraint is satisfied. It is formulated as:
- Confidence loss: the part that avoids a trivial solution where
- Consistency loss: it is the part that tries to ensure that the above constraint is satisfied. It is formulated as:
- During inference, to output if the statement q is true or not:
- The probability that the statement is true, , and the probability that the statement is not false, , represent the same thing. So (in theory) they should be equal.
- However, this is only enforced by the soft consistency constraint of the consistency loss. So (in practice), they are not exactly equal.
- Thus, to do inference on an example, they take the average of these two.
Reproduction and replication of the original paper
We have started setting up and running the paper’s code to see if we can obtain the same results. The authors provided their code on GitHub. Furthermore, we are creating our own implementation for comparison which will give us a better understanding of the paper and more flexibility for testing new ideas.
Potential directions
Evaluate a different inference rule
We’d like to evaluate how using a different inference rule (instead of the average) would affect the performance. Specifically checking which of and is larger.
Evaluating the robustness of inner truthiness on different prompt formats.

Section 3.2.2 of the paper states that their method is robust when dealing with misleading prompts. They create misleading prompts by adding a prefix, such as the one shown in Figure 1, before they ask the questions. We would like to evaluate the robustness of the model further by using different types of prompts.
They use prompts containing a binary question and an answer:
We would like to either use the corresponding question alone or the corresponding proposition alone. This format seems more natural to assign truth values to, as it resembles everyday communication. E.g.:
We could check this for the probe their method learns, or train another probe for differently formatted prompts.[2] We want a probe that works with propositions since it is more natural in language to combine propositions compared to the format they’re using (e.g. combining P, Q into the proposition [P and Q] than writing: [Question: Is it true that P and Q? A: __].[3]
Change the projection probe and check how that affects things
In the paper, they are using a neural net with zero hidden layers and a sigmoid activation on the output node. We could try this with a neural net with more layers and test if it would increase the performance[4].
We could look at multiple layers simultaneously and find a combination that works better. E.g., we could observe the first, the middle, and the last layer, and take their average. There is a concern that this might lead to overfitting though, since the task is so simple that logistic regression performed well on it.
Testing Inverse scaling dataset
We want to take the inverse scaling datasets [LW · GW] and train a DLK probe for the following models:
- a small model (GPT2)
- a mid-sized model (GPT-J)
- a big model (GPT Neo-X)
Then we want to check if the representation of truth in inner representations is also getting less accurate for bigger models. If that happens, it could point in the direction of the model's understanding actually getting worse. On the other hand, if it doesn't hold, it could point in the direction of the inverse scaling law cases thus far having more to do with something weird going on with output behavior in a given context, and they might not generalize. Also, this seems like a potentially interesting additional testing ground for whether DLK can provide information about the model beyond output behavior.
Better representation of probabilities
One part of the loss function they use is the “confidence” term shown above. This term is to impose the “law of excluded middle” to ensure that the model won’t end up giving[5] a , which pushes probabilities to be close to 0 or 1.
However, in reality, there is no rule stating that the probabilities have to be near 0 or 1. So, we would like to test if it’s possible to avoid using the confidence term in the loss function to capture probabilities better in order to have a better representation of the world.
By removing the confidence term, a trivial solution for the model would be to always output the probability of 0.5 for both options. To avoid this, we could have examples in the training data where there are more than two options and require that their own probabilities sum to 1.
For example, we could pick any two propositions P, Q, (e.g. P: `2+2 = 4`, Q: `Cats are mammals`) and construct all their boolean combinations:
- [P and Q]: [`2+2=4 and cats are mammals.`]
- [P and not-Q]: [`2+2=4 and cats are not mammals.`]
- [not-P and Q]: [` and cats are mammals.`]
- [not-P and not-Q] [` and cats are not mammals.`]
As shown in the figures below, the probabilities of these 4 have to add up to 1 (cover the entire area). We could put a term in the loss function that would enforce a penalty if this condition doesn’t hold.
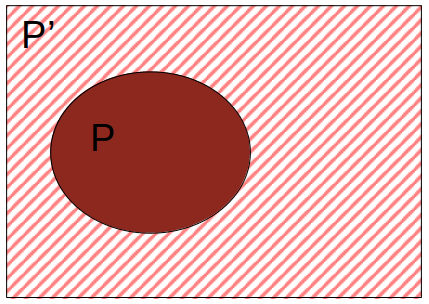 P’: The possibility space where the proposition P is not true (not-P) |  Q’: The possibility space where the proposition Q is not true (not-Q) |
 |  |
 |  |
One alternative would be to require all of the following conditions:
- The truthiness of P should be the sum of “the truthiness of [P and Q]” and “the truthiness of [P and not-Q]”
- The truthiness of not-P should be the sum of “the truthiness of [not-P and Q]” and “the truthiness of [not-P and not-Q]”
- Since summing the above two constraints yields the aforementioned 4-proposition constraint, the constraints here are stronger than in the previous version.
Another option would be to take mathematical statements where the possibility space is exhausted by some finite number of options that it’s reasonable to be uncertain between[6].
In general, we’d search for something that satisfies probability axioms. In addition to capturing probabilities better, this hopefully constrains the search space a lot. Additional constraints would be useful, especially if we wish to replace the linear probe with a more complicated probe with many more parameters[7].
Acknowledgment: For this subsection, Kaarel wants to thank Jörn Stöhler, Matt MacDermott, and Daniel Filan for contributing significantly to these ideas in conversations.
Evaluate probabilistic examples
We could use the above method to evaluate probabilistic examples directly, e.g. “My next coin toss will land heads”, and check if the above method without a confidence term in the loss does better on these. This would provide a better understanding of how well the probe captures probabilities instead of just capturing truth for certain sentences. It might also be helpful for understanding the calibration of the probe.
Evaluate the performance of CCS after adding some labeled data.
After reproducing the authors’ results, extend the datasets with some labeled examples (i.e., “1+1=2”) that we’d flag as either true or false. We’d then “hardcode” some terms to the loss function to ensure that these data points are considered. The main motivation behind this is to check how the performance of CCS will change in comparison to the authors’ results. The method would still be mostly unsupervised[8], which is nice since it can scale to large datasets without requiring extensive labeled datasets.
Check for possible connections to Mechanistic Interpretability
Given that they are using a transformer, we could try to see if there is some form of connection to mechanistic interpretability.
Evaluate alternating text
We could try to input a passage of alternating true/false sentences and try to see which inner states (i.e. which position) are best for determining the truth of each particular sentence. Are these always the positions of the tokens in that sentence? Does it get more spread out as one goes deeper into the transformer? The hypothesis is that if we can locate the positions that the model looks for in each true sentence, we can trace that to the model's internal representation of the truth.
DLK is a non-mechanistic interpretability technique since it only finds a representation of truth; it doesn’t provide a mechanism. On the other hand, if the above works, it might provide information on how the model stores truth, which is useful for mechanistic interpretability research.
Check changes in the truth representation when incrementally prepending text to the prompt.
We could have a normal prompt at the beginning and then incrementally start adding text to the beginning and see how the truth representation changes with that. This is important because it gives us another task on which we could validate one of the main claims in the paper, namely that their method reduces "prompt sensitivity".
Check if all neurons lead to ROME
Using interpretability tools (e.g the causal tracing method from the ROME [LW · GW] publication), we could check if we can figure out how truth is represented and in which neurons. We could even combine this approach with the previous idea and see if they produce the same results.
Additional ideas that came up while writing this post.
The following ideas were generated by Kaarel while we were in the process of writing the post and trying to re-implement the code. We haven't spent much time refining the phrasing, so they might require slower reading and a deeper understanding of the paper and the method than the above text does. We do this for the benefit of getting feedback early, and we hope to have a better formulation / expand upon them in future posts.
- The accuracies of CCS reported by the authors are for a probe trained on a data set with data points, each prompted in different ways. The accuracy they report is the percentage of these data points that are classified correctly during inference. This means accuracy is almost necessarily bounded above by the accuracy of logistic regression, which is almost necessarily bounded above by the average accuracy of logistic regression over each individual way to construct prompts for the data set.
But it seems plausible that one would get an easy improvement in the accuracy of CCS by just looking at the different ways of prompting a single original data point and averaging the results to do inference on the data point. The intuition here is that the average of coin flips, each of which is biased towards , is generally much more likely to be than the average probability of an individual coin flip to be (given that the flips are not super correlated to each other).
- Alternatively, we could have a number of prompts on the same dataset, try to train individual probes for each prompt, and then average the results of probes during inference. This also has the benefit of independent-ish coin flips, together with intuitively fitting together better with the reason they state for normalizing the states.
- What's more, we should maybe try one dataset with 100 different prompts to see if it potentially scales to really high accuracy (most optimistically, only bounded by the model genuinely [not knowing]/[being wrong about] something). E.g. perhaps we could do this for BoolQ.
- When training the probe, add a term in the loss requiring the values assigned to different promptings of the same datapoint to agree. (This captures the idea that the truth value should not depend on the prompting.)
- We could further generalize the approach from the "Better representation of probabilities" section, as presented in this comment [LW(p) · GW(p)], even to just get new constraints in the deterministic case. There's also additional probabilistic constraints one could put in the loss, e.g. Bayes' rule.
Acknowledgment: This idea should probably be mostly attributed to June Ku, whom Kaarel would like to thank for a helpful conversation.
- We could use DLK to figure out what direction inside an inner layer corresponds to truthiness, edit the activation in that direction, and then see if the model output changes correspondingly. For instance, try the following:
- “X is a glarg iff X is a schmutzel. X is a glarg. Is X a schmutzel? A:”
- The language model should output “yes” as the answer. And the hope is that if we edit the truthiness of sentence 2 to be false, then it will output “no”.
- Actually, I [Kaarel] have a pretty low probability of this working because the main association here is probably not-sentence level. Maybe something like “The previous sentence is true.” would work better.
- I [Kaarel] think there are conceptually nice things to be said about what’s going on in general here: one is searching for a model’s representation of a natural abstraction by searching for something that “has the right shape”, i.e. something like satisfying the right relations, a lot like ramsification. This opens up opportunities to search for more concepts inside models in a non-mechanistic way. Kaarel is currently working on a post trying to clarify what he means mean by all this.
Acknowledgments: Kaarel would like to thank Alexandre Variengien for recommending thinking more about how to generalize DLK to different kinds of concepts in a helpful conversation, as well as for giving concrete leads on this, such as the idea to look for a representation of direction inside a model stated later. Kaarel would also like to thank John Wentworth for providing feedback and a number of ideas in a helpful conversation.
- In this frame, DLK is sort of like defining truth and falsehood with some circular/ungrounded thing like: “Each proposition has to be true or false”; “If a proposition is true, then its negation is false”; “If a proposition is false, then its negation is true”. But then you can do ramsification, just searching inside your model for a thing with these properties and finding the truth; this is crazy!!
- Another concrete example of this kind of “searching for concepts by their shape” would be to look for the shape of a syntax tree, sort of like in the paper "A Structural Probe for Finding Syntax in Word Representations", but in an unsupervised way. Assuming an understanding of the ideas of this paper, below are some thoughts on how to do this:
- For each basis, try every tree and see which one captures distances best
- Put min over trees in the loss, optimize the basis with this loss
- Then during inference, we can recover the tree by finding the best tree along this basis for each example
- If this is too computationally expensive, we could search for the best tree by going greedily bottom-up, or just finding the closest adjacent clusters and merging them. We could also use this to replace the inference step. Or we could use a minimum spanning tree? (I think this is what they use to reconstruct an implied tree in the paper)
- If this finds syntax trees that linguists think represent sentences, then I [Kaarel] think this would be very cool for linguistics, like the best evidence for the main theory of syntax (Chomsky’s generative grammar or whatever) available. linguistics = solved (just kidding)
- "Unsupervised Distillation of Syntactic Information from Contextualized Word Representations" is doing something similar but with contrast pairs replaced by symmetry sets.
- We could try training an ML model to do physics simulation and use symmetry sets to search for the model’s internal representation of a particle’s momentum, etc.
- Another example to try would be to look for a sense of direction in an image classifier, the contrast pairs would be rotated versions of pictures, find things inside which are at corresponding angles.
- In the hyperoptimistic limit, we could search for various important high-level things, e.g. an agent’s goals; the causal model used by the agent; and corrigibility parameters, non-mechanistically. Perhaps, we could also get some stuff which is cool but less relevant to alignment, such as style, or identify feelings of a conscious system, if only we could write down the constraints governing feelings. :P
- One worry with DLK is that it might end up recovering the beliefs of some simulated agent (e.g. a simulated aligned AGI, or a particular human, or humanity’s scientific consensus). One idea for checking for this is to study how the LM represents the beliefs of characters it is modeling by just doing supervised learning with particular prompting and labels. For instance, get it to produce text as North Korean state news, and do supervised learning to find a representation in the model of truth-according-to-North-Korean-state-news.
If we do this for a bunch of simulated agents, maybe we can state some general conclusion about how the truth according to some simulated agent is represented, and maybe this contrasts with what is found by DLK providing evidence that DLK is not just finding the representation of truth according to some simulated agent. Or maybe we can even use this to develop a nice understanding of how language models represent concepts of simulated agents vs analogous concepts of their own, which would let us figure out e.g. the goals of a language model from understanding how goals of simulated agents are represented using supervised probing, and then using the general mapping from reps of simulatee-concepts to reps of the model’s own analogous concepts which we developed for truth (if we’re lucky and it generalizes).
- ^
This is a technical part of the paper that we didn’t want to fully repeat here. For more details, you can look at section 2.2 of the paper.
- ^
Renormalization might not make sense for propositions, but maybe the method works without renormalization.
- ^
This would also be relevant to the next section, where we aim for a better representation of the probabilities.
- ^
From their code it looks as if they already tried this and in the paper it states that they had bad results, so they abandoned it. Still, we’d like to explore that.
- ^
This is a degenerate solution to the other term in their loss function, so they want to avoid it.
- ^
E.g: what the trillion billionth digit of is, for which there are 10 options
- ^
Kaarel also thinks that it would be very cool for it to be the case that a random thing internal to the model satisfying probability axioms is in fact the probability assignment of the model
- ^
Technically speaking, this would be a semi-supervised approach.
6 comments
Comments sorted by top scores.
comment by johnswentworth · 2023-01-26T06:09:16.355Z · LW(p) · GW(p)
If I were doing this project, the first thing I'd want to check is whether the dlk paper is actually robustly measuring truth/falsehood, rather than something else which happens to correlate with truth/falsehood for the particular data generation/representation methods used. My strong default prior, for ml papers in general, is "you are not measuring what you think you are measuring".
comment by Collin (collin-burns) · 2023-01-25T22:44:45.127Z · LW(p) · GW(p)
Thanks for writing this! I think there are a number of interesting directions here.
I think in (very roughly) increasing order of excitement:
- Connections to mechanistic interpretability
- I think it would be nice to have connections to mechanistic interpretability. My main concern here is just that this seems quite hard to me in general. But I could imagine some particular sub-questions here being more tractable, such as connections to ROME/MEMIT in particular.
- Improving the loss function + using other consistency constraints
- In general I’m interested in work that makes CCS more reliable/robust; it’s currently more of a prototype than something ready for practice. But I think some types of practical improvements seem more conceptually deep than others.
- I particularly agree that L_confidence doesn’t seem like quite what we want, so I’d love to see improvements there.
- I’m definitely interested in extensions to more consistency properties, though I’m not sure if conjunctions/disjunctions alone lets you avoid degenerate solutions without L_confidence. (EDIT: never mind, I now think this has a reasonable chance of working.)
- Perhaps more importantly, I worry that it might be a bit too difficult in practice right now to make effective use of conjunctions and disjunctions in current models – I think they might be too bad at conjunctions/disjunctions, in the sense that a linear probe wouldn’t get high accuracy (at least with current open source models). But I think someone should definitely try this.
- Understanding simulated agents
- I’m very excited to see work on understanding how this type of method works when applied to models that are simulating other agents/perspectives.
- Generalizing to other concepts
- I found the connection to ramsification + natural abstractions interesting, and I'm very interested in the idea of thinking about how you can generalize this to searching for other concepts (other than truth) in an unsupervised + non-mechanistic way.
I’m excited to see where this work goes!
comment by RM · 2023-01-26T14:43:43.480Z · LW(p) · GW(p)
What CCS does conceptually is finds a direction in latent space that distinguishes between true and false statements. That doesn't have to be truth (restricted to stored model knowledge, etc.), and the paper doesn't really test for false positives so it's hard to know how robust the method is. In particular I want to know that the probe doesn't respond to statements that aren't truth-apt. It seems worth brainstorming on properties that true/false statements could mostly share that are not actually truth. A couple examples come to mind.
- common opinions. "Chocolate is tasty/gross" doesn't quite make sense without a subject, but may be treated like a fact.
- Likelihood of completion. In normal dialogue correct answers are more likely to come up than wrong ones, so the task is partly solvable on those grounds alone. The CCS direction should be insensitive to alternate completions of "Take me out to the ball ___" and similar things that are easy to complete by recognition.
The last one seems more pressing, since it's a property that isn't "truthy" at all, but I'm struggling to come up with more examples like it.
comment by Erik Jenner (ejenner) · 2023-01-25T20:40:40.672Z · LW(p) · GW(p)
Nice project, there are several ideas in here I think are great research directions. Some quick thoughts on what I'm excited about:
- I like the general ideas of looking for more comprehensive consistency checks (as in the "Better representation of probabilities" section), connecting this to mechanistic interpretability, and looking for things other than truth we could try to discover this way. (Haven't thought much about your specific proposals for these directions)
- Quite a few of your proposals are of the type "try X and see if/how that changes performance". I'd be a bit weary of these because I think they don't really help resolve uncertainty about the most important open questions. If one of these increases performance by 5%, that doesn't tell you much about how promising the whole DLK approach is in the long term, or what the most likely failure modes are. If something doesn't increase performance, that also doesn't tell you too much about these.
- Two exceptions to the previous point: (1) these types of experiments are pretty straightforward compared to more ambitious extensions, so I think they're good if your main goal is to get more hands-on ML research experience. (2) Maybe you have some uncertainty about why/how the results in the paper are what they are, and making some small changes can give you evidence about that. This seems like an excellent thing to start with, assuming you have concrete things about the results you're confused about. (Randomly trying things might also reveal surprising phenomena, but I'm much less sure that's worth the time.)
- So what could you aim for instead, if not improving performance a bit? I think one great general direction would be to look for cases where the current method just fails completely. Then work on solving the simplest such case you can find. Maybe the inverse scaling dataset is a good place to start, though I'd also encourage you to brainstorm other mechanistic ways why the current method might go wrong, and then come up with cases where those might happen. (Example of what I mean: maybe "truth" isn't encoded in a linearly detectable way, and once you make the probe more complex, your constraints aren't enough anymore to nail down the truth concept in practice).
ETA: I think the "adding labeled data" idea is a good illustration of what I'm talking about. Imagine you have problems where the method currently doesn't work at all. If even large amounts of supervised data don't help much on these, this suggests your probe can't find a truth encoding (maybe because you'd need a higher capacity probe or if you already have that, maybe because the optimization is difficult). On the other hand, if you get good performance with supervised data, it suggests that you need stronger consistency checks. You can then also try things like adding supervised data in only one domain and check generalization, and you can expect a reasonably clear signal. But if you do all this on a dataset where the unsupervised method already works pretty well, then the only evidence you get is something like "does it improve performance by 2%, 5%, 10%, ...?", the signal is less clear, and it's much harder to say which of these explanations a 5% improvement indicates. All that is in addition to the fact that finding cases which are difficult for the current method is really important in its own right.
Replies from: nora-belrose↑ comment by Nora Belrose (nora-belrose) · 2023-02-10T18:23:49.550Z · LW(p) · GW(p)
You can then also try things like adding supervised data in only one domain and check generalization, and you can expect a reasonably clear signal.
Yep, I just had this idea this morning and came here to check if anyone else had thought of it. It seems plausible that a semi-supervised version of CCS could outperform naive logistic regression in generalization performance.
comment by Hoagy · 2023-01-26T00:14:58.832Z · LW(p) · GW(p)
An LLM will presumably have some internal representation of the characteristics of the voice that it is speaking with, beyond its truth value. Perhaps you could test for such a representation in an unsupervised manner by asking it to complete a sentence with and without prompting for a articular disposition ('angry', 'understanding',...). Once you learn to understand the effects that the prompting has, you could test how well this allows you to modify disposition via changing the activations.
This line of thought came from imagining what the combination of CCS and Constitutional AI might look like.