There are some additional reasons, beyond the question of which values would be embedded in the AGI systems, to not prefer AGI development in China, that I haven't seen mentioned here:
Systemic opacity, state-driven censorship, and state control of the media means AGI development under direct or indirect CCP control would probably be less transparent than in the US, and the world may be less likely to learn about warning shots, wrongheaded decisions, reckless behaviour, etc. True, there was the Manhattan Project, but that was quite long ago; recent examples like the CCP's suppression of information related to the origins of COVID feel more salient and relevant.
There are more checks and balances in the US than in China, which you may think could e.g., positively influence regulation; or if there's a government project, help incentivise responsible decisions there; or if someone attempts to concentrate power using some early AGI, stop that from happening. E.g., in the West voters have some degree of influence over the government, there's the free press, the judiciary, an ecosystem of nonprofits, and so on. In China, the CCP doesn't have total control, but much more so than Western governments do.
I think it's also very rare that people are actually faced with a choice between "AGI in the US" versus "AGI in China". A more accurate but still flawed model of the choice people are sometimes faced with is "AGI in the US" versus "AGI in the US and in China", or even "AGI in the US, and in China 6-12 months later" versus "AGI in the US, and in China 3-6 months later".
The view shared by Hanania in 2024 that Trump would be reined in by others seems less solid now: whereas during his first term Trump’s top economic adviser Gary Cohn allegedly twice stole major trade-related documents off of his desk, nothing like that seems to be happening now.
On April 9, financial markets were going haywire. Treasury Secretary Scott Bessent and Commerce Secretary Howard Lutnick wanted President Trump to put a pause on his aggressive global tariff plan. But there was a big obstacle: Peter Navarro, Trump’s tariff-loving trade adviser, who was constantly hovering around the Oval Office.
Navarro isn’t one to back down during policy debates and had stridently urged Trump to keep tariffs in place, even as corporate chieftains and other advisers urged him to relent. And Navarro had been regularly around the Oval Office since Trump’s “Liberation Day” event.
So that morning, when Navarro was scheduled to meet with economic adviser Kevin Hassett in a different part of the White House, Bessent and Lutnick made their move, according to multiple people familiar with the intervention.
They rushed to the Oval Office to see Trump and propose a pause on some of the tariffs—without Navarro there to argue or push back. They knew they had a tight window. The meeting with Bessent and Lutnick wasn’t on Trump’s schedule.
The two men convinced Trump of the strategy to pause some of the tariffs and to announce it immediately to calm the markets. They stayed until Trump tapped out a Truth Social post, which surprised Navarro, according to one of the people familiar with the episode. Bessent and press secretary Karoline Leavitt almost immediately went to the cameras outside the White House to make a public announcement.
This is a great post, thanks for writing it. I agree that, when it comes to creative endeavours, there's just no "there" there with current AI systems. They just don't "get it". I'm reminded of this tweet:
Mark Cummins: After using Deep Research for a while, I finally get the “it’s just slop” complaint people have about AI art.
Because I don’t care much about art, most AI art seems pretty good to me. But information is something where I’m much closer to a connoisseur, and Deep Research is just nowhere near a good human output. It’s not useless, I think maybe ~20% of the time I get something I’m satisfied with. Even then, there’s this kind of hall-of-mirrors quality to the output, I can’t fully trust it, it’s subtly distorted. I feel like I’m wading through epistemic pollution.
Obviously it’s going to improve, and probably quite rapidly. If it read 10x more sources, thought 100x longer, and had 1000x lower error rate, I think that would do it. So no huge leap required, just turning some knobs, it’s definitely going to get there. But at the same time, it’s quite jarring to me that a large fraction of people already find the outputs compelling.
As someone who does care about art, and has, I think, discerning taste, I have always kind of felt this, and only when I read the above tweet did I realise that not everyone felt what I felt. When Sam Altman tweeted that story, which seemed to impress some people and inspire disgust/ridicule from others, the division became even clearer.
I think with Deep Research the slop is actually not as much of a problem -- you can just treat it as a web search on steroids and can always jump into the cited sources to verify things. And for similar reasons, it seems true that if DR "read 10x more sources, thought 100x longer, and had 1000x lower error rate", it could be as good as me at doing bounded investigations. For the hardest bits needed for AI to generate genuinely good creative fiction, it feels less obvious whether the same type of predictable progress will happen.
I think I'm less sure than you that the problem has to do with attractor basins, though. That does feel part of or related to the problem, but I think a larger issue is that chatbots are not coherent enough. Good art has a sort of underlying internal logic to it, which even if you do not notice it contributes to making the artwork feel like a unified whole. Chatbots don't do that, they are too all over the place.
I think this article far overstates the extent to which these AI policy orgs (maybe with the exception of MIRI? but I don’t think so) are working towards an AI pause, or see the goal of policy/regulation as slowing AI development. (I mean policy orgs, not advocacy orgs.) I see as much more common policy objectives: creating transparency around AI development, directing R&D towards safety research, laying groundwork for international agreements, slowing Chinese AI development, etc. — things that (is the hope) are useful on their own, not because of any effect on timelines.
On the advice of @adamShimi, I recently read Hasok Chang's Inventing Temperature. The book is terrific and full of deep ideas, many of which relate in interesting ways to AI safety. What follows are some thoughts on that relationship, from someone who is not an AI safety researcher and only somewhat follows developments there, and who probably got one or two things wrong.
(Definitions: By "operationalizing", I mean "giving a concept meaning by describing it in terms of measurable or closer-to-measurable operations", whereas "abstracting" means "removing properties in the description of an object".)
There has been discussion on LessWrong about the relative value of abstract work on AI safety (e.g., agent foundations) versus concrete work on AI safety (e.g., mechanistic interpretability, prosaic alignment). Proponents of abstract work argue roughly that general mathematical models of AI systems are useful or essential for understanding risks, especially coming from not-yet-existing systems like superintelligences. Proponents of concrete work argue roughly that safety work is more relevant when empirically grounded and subjected to rapid feedback loops. (Note: The abstract-concrete distinction is similar to, but different from, the distinction between applied and basic safety research.)
As someone who has done neither, I think we need both. We need abstract work because we need to build safety mechanisms using generalizable concepts, so that we can be confident that the mechanisms apply to new AI systems and new situations. We need concrete work because we must operationalize the abstract concepts in order to measure them and apply them to actually existing systems. And finally we need work that connects the abstract concepts to the concrete concepts, to see that they are coherent and for each to justify the other.
Chang writes:
The dichotomy between the abstract and the concrete has been enormously helpful in clarifying my thinking at the earlier stages, but I can now afford to be more sophisticated. What we really have is a continuum, or at least a stepwise sequence, between the most abstract and the most concrete. This means that the operationalization of a very abstract concept can proceed step by step, and so can the building-up of a concept from concrete operations. And it may be beneficial to move only a little bit at a time up and down the ladder of abstraction.
Take for example the concept of (capacity for) corrigibility, i.e., the degree to which an AI system can be corrected or shut down. The recent alignment faking paper showed that, in experiments, Claude would sometimes "pretend" to change its behavior when it was ostensibly being trained with new alignment criteria, while not actually changing its behavior. That's an interesting and important result. But (channeling Bridgman) we can only be confident that it applies to the concrete concept of corrigibility measured by the operations used in the experiments -- we have no guarantees that it holds for some abstract corrigibility, or when corrigibility is measured using another set of operations or under other circumstances.
An interesting case study discussed in the book is the development of the abstract concept of temperature by Lord Kelvin (the artist formerly known as William Thomson) in collaboration with James Prescott Joule (of conservation of energy fame). Thomson defined his abstract temperature in terms of work and pressure (which were themselves abstract and needed to be operationalized). He based his definition on the Carnot cycle, an idealized process performed by the theoretical Carnot heat engine. The Carnot heat engine was inspired by actual heat engines, but was fully theoretical -- there was no physical Carnot heat engine that could be used in experiments. In other words, the operationalization of temperature that Thomson invented using the Carnot cycle was an intermediate step that required further operationalization before Thomson's abstract temperature could be connected with experimental data. Chang suggests that, while the Carnot engine was never necessary for developing an abstract concept of temperature, it did help Thomson achieve that feat.
Ok, back to AI safety. So above I said that, for the whole AI thing to go well, we probably need progress on both abstract and concrete AI safety concepts, as well as work to bridge the two. But where should research effort be spent on the margin?
You may think abstract work is useless because it has no error-correcting mechanism when it is not trying to, or is not close to being able to, operationalize its abstract concepts. If it is not grounded in any measurable quantities, it can't be empirically validated. On the other hand, many abstract concepts (such as corrigibility) still make sense today and are currently being studied in the concrete (though they have not yet been connected to fully abstract concepts) despite being formulated before AI systems looked much like they do today.
You may think concrete work is useless because AI changes so quickly that the operations used to measure things today will soon be irrelevant, or more pertinently perhaps, because the superintelligent systems we truly need to align are presumably vastly different from today's AI systems, in their behavior if not in their architecture. In that way, AI is quite different from temperature. The physical nature of temperature is constant in space and time -- if you measure temperature with a specific set of operations (measurement tools and procedures), you would expect the same outcomes regardless of which century or country you do it in -- whereas the properties of AI change rapidly over time and across architectures. On the other hand, timelines seem short, such that AGI may share many similarities with today's AI systems, and it is possible to build abstractions gradually on top of concrete operations.
There is in fact an example from the history of thermometry of extending concrete concepts to new environments without recourse to abstract concepts. In the 18th century, scientists realized that the mercury and air thermometers used then behaved very differently, or could not be used at all due to freezing and melting, for very low and very high temperatures. While they had an intuitive notion that some abstract temperature ought to apply across all degrees of heat or cold, their operationalized temperatures clearly only applied to a limited range of heat and cold. To solve this, they eventually developed different sets of operations for the measurement of temperatures in extreme ranges. For example, Josiah Wedgwood measured very high temperatures in ovens by baking standardized clay cylinders and measuring how much they'd shrunk. These different operations, which yielded measurements of temperature on different scales, were then connected by measuring temperature for both scales (using different operations) in an overlapping range and lining those up. All this was done without an abstract theory of temperature, and while the resulting scale was not on very solid theoretical ground, it was good enough to provide practical value.
Of course, the issue with superintelligence is that, because of e.g., deceptive alignment and gradient hacking, we want trustworthy safety mechanisms and alignment techniques in place well before the system has finished training. That's why we want to tie those techniques to abstract concepts which we are confident will generalize well. But I have no idea what the appropriate resource allocation is across these different levels of abstraction.[1] Maybe what I want to suggest is that abstract and concrete work is complementary and should strive towards one another. But maybe that's what people have been doing all along?
The most upvoted dialogue topic on an October 2023 post by Ben Pace was "Prosaic Alignment is currently more important to work on than Agent Foundations work", which received 40 agree and 32 disagree votes, suggesting that the general opinion on LessWrong at that time was that the current balance was about right, or that prosaic alignment should get some more resources on the margin. ↩︎
Hmm, if the Taiwan tariff announcement caused the NVIDIA stock crash, then why did Apple stock (which should be similarly impacted by those tariffs) go up that day? I think DeepSeek -- as illogical as it is -- is the better explanation.
I don't think that's true? AFAIK there's no requirement for companies to report material impact on an 8-K form. In a sense, the fact that NVIDIA even filed an 8-K form is a signal that the diffusion rule is significant for their business -- which it obviously is, though it's not clear whether the impact will be substantially material. I think we have to wait for their 10-Q/10-K filings to see what NVIDIA signals to investors, since there I do think it is the case that they'd need to report expected material impact.
You talk later about evolution to be selfish; not only is the story for humans is far more complicated (why do humans often offer an even split in the ultimatum game?), but also humans talk a nicer game than they act (See construal level theory, or social-desirability bias.). Once you start looking at AI agents who have similar affordances and incentives that humans have, I think you'll see a lot of the same behaviors.
I think I'd guess roughly that, "Claude is probably more altruistic and cooperative than the median Western human, most other models are probably about the same, or a bit worse, in these simulated scenarios". But of course a major difference here is that the LLMs don't actually have anything on the line -- they don't stand to earn or lose any money, for example, and if they did, they would have nothing to do with the money. So you might expect them to be more altruistic and cooperative than they would under the conditions humans are tested.
In the New York example, it could be that when someone says “Guys, we should really buy those Broadway tickets. The trip to New York is next month already.” they prompt the response “What? I thought we were going the month after!”, hence the disagreement. If this detail had been discussed earlier, there might have been the “February trip” and the “March trip” in order to disambiguate the trip(s) to New York.
I guess I don't understand what focusing on disagreements adds. Sure, in this situation, the disagreement stems from some people thinking the trip is near (and others thinking it's farther away). But we already knew that some people think AGI is near and others think it's farther away! What does observing that people disagree about that stuff add?
What seems to have happened is that people at one point latched on to the concept of AGI, thinking that their interpretation was virtually the same as those of others because of its lack of definition. Again, if they had disagreed with the definition to begin with, they would have used a different word altogether. Now that some people are claiming that AGI is here or here soon, it turns out that the interpretations do in fact differ.
Yeah, I would say that as those early benchmarks ("can beat anyone at chess", etc.) are achieved without producing what "feels like" AGI, people are forced to make their intuitions concrete, or anyway reckon with their old bad operationalizations of AGI. And that naturally leads to lots of discussion around what actually constitutes AGI. But again, all this is evidence of is that those early benchmarks have been achieved without producing what "feels like" AGI. But we already knew that.
I think that, in your New York example, the increasing disagreement is driven by people spending more time thinking about the concrete details of the trip. They do so because it is obviously more urgent, because they know the trip is happening soon. The disagreements were presumably already there in the form of differing expectations/preferences, and were only surfaced later on as they started discussing things more concretely. So the increasing disagreements are driven by increasing attention to concrete details.
It seems likely to me that the increasing disagreement around AGI is also driven by people spending more time thinking about the concrete details of what constitutes AGI. But where in the New York example we can assume people pay more attention to the details because they know the trip is upcoming, with AGI we know that people don't know when AGI will happen, so there must be some other reason.
One reason could be "a bunch of people think/feel AGI is near", but we already knew that before noticing disagreement around AGI. Another reason could be that there's currently a lot of hype and activity around AI and AGI. But the fact that there's lots of hype around AI/AGI doesn't seem like much evidence that AGI is near, or if it is, can also be stated more directly than through a detour via disagreements.
Thanks for writing this -- it's very concrete and interesting.
Have you thought about using company market caps as an indicator of AGI nearness? I would guess that an AI index -- maybe NVIDIA, Alphabet, Meta, and Microsoft -- would look really significantly different in the two scenarios you paint. To control for general economic conditions, you could look at the those companies relative to the NASDAQ-100 (minus AI companies). An advantage of this is that it tracks a lot of different indicators, including ones that are really fuzzy or hard to discover, through the medium of market speculators. Another advantage is that it is a clear and easily measurable quantity. That makes it easy to make bets and create prediction markets around it.
Of course, there is weirdness around how we should expect the market to behave in the run-up to AGI, where wealth may become less relevant, etc. But I'd still expect the market to be significantly more bullish on AI stocks in the run-up to AGI, than in an AI fizzle/winter scenario.
The jury is still out, but it's currently available even in Direct Chat on Chatbot Arena, there will be more data on this soon.
Fyi, it's also available on https://chat.deepseek.com/, as is their reasoning model DeepSeek-R1-Lite-Preview ("DeepThink"). (I suggest signing up with a throwaway email and not inputting any sensitive queries.) From quickly throwing it a few requests I recently asked 3.5 Sonnet, DeepSeek-V3 seems slightly worse, but nonetheless solid.
I'm not totally sure of this, but it looks to me like there's already more scientific consensus around mirror life being a threat worth taking seriously, than is the case for AI. E.g., my impression is that this paper was largely positively received by various experts in the field, including experts that weren't involved in the paper. AI risk looks much more contentious to me even if there are some very credible people talking about it. That could be driving some of the difference in responses, but yeah, the economic potential of AI probably drives a bunch of the difference too.
To add to that, Oeberst (2023) argues that all cognitive biases at heart are just confirmation bias based around a few "fundamental prior" beliefs. (A "belief" would be a hypothesis about the world bundled with an accuracy.) The fundamental beliefs are:
My experience is a reasonable reference
I make correct assessments of the world
I am good
My group is a reasonable reference
My group (members) is (are) good
People's attributes (not context) shape outcomes
That is obviously rather speculative, but I think it's some further weak reason to think motivated reasoning is in some sense a fundamental problem of rationality.
It seems like an obviously sensible thing to do from a game-theoretic point of view.
Hmm, seems highly contingent on how well-known the gift would be? And even if potential future Petrovs are vaguely aware that this happened to Petrov's heirs, it's not clear that it would be an important factor when they make key decisions, if anything it would probably feel pretty speculative/distant as a possible positive consequence of doing the right thing. Especially if those future decisions are not directly analogous to Petrov's, such that it's not clear whether it's the same category. But yeah, mainly I just suspect this type of thing to not get enough attention that it ends up shifting important decisions in the future? Interesting idea, though -- upvoted.
Specific examples might include criticisms of RSPs, Kelsey’s coverage of the OpenAI NDA stuff, alleged instances of labs or lab CEOs misleading the public/policymakers, and perspectives from folks like Tegmark and Leahy (who generally see a lot of lab governance as safety-washing and probably have less trust in lab CEOs than the median AIS person).
Isn't much of that criticism also forms of lab governance? I've always understood the field of "lab governance" as something like "analysing and suggesting improvements for practices, policies, and organisational structures in AI labs". By that definition, many critiques of RSPs would count as lab governance, as could the coverage of OpenAI's NDAs. But arguments of the sort "labs aren't responsive to outside analyses/suggestions, dooming such analyses/suggestions" would indeed be criticisms of lab governance as a field or activity.
(ETA: Actually, I suppose there's no reason why a piece of X research cannot critique X (the field it's a part of). So my whole comment may be superfluous. But eh, maybe it's worth pointing out that the stuff you propose adding can also be seen as a natural part of the field.)
The key point I will make is that, from a game-theoretic point of view, this race is not an arms race but a suicide race. In an arms race, the winner ends up better off than the loser, whereas in a suicide race, both parties lose massively if either one crosses the finish line.
But from a game-theoretic perspective, it can still make sense for the US to aggressively pursue AGI, even if one believes there's a substantial risk of an AGI takeover in the case of a race, especially if the US acts in its own self interest. Even with this simple model, the optimal strategy would depend on how likely AGI takeover is, how bad China getting controllable AGI first would be from the point of view of the US, and how likely China is to also not race if the US does not race. In particular, if the US is highly confident that China will aggressively pursue AGI even if the US chooses to not race, then the optimal strategy for the US could be to race even if AGI takeover is highly likely.
So really I think some key cruxes here are:
How likely is AGI (or its descendants) to take over?
How likely is China to aggressively pursue AGI if the US chooses not to race?
And vice versa for China. But the OP doesn't really make any headway on those.
Additionally, I think there are a bunch of complicating details that also end up mattering, for example:
To what extent can two rival countries cooperate while simultaneously competing? The US and the Soviets did cooperate onmultipleoccasions, while engaged in intense geopolitic competition. That could matter if one thinks racing is bad because it makes cooperation harder (as opposed to being bad because it brings AGI faster).
How (if at all) does the magnitude of the leader's lead over the follower change the probability of AGI takeover (i.e., does the leader need "room to manoeuvre" to develop AGI safely)?
Is the likelihood of AGI takeover lower when AGI is developed in some given country than in some other given country (all else equal)?
Is some sort of coordination more likely in worlds where there's a larger gap between racing nations (e.g., because the leader has more leverage over the follower, or because a close follower is less willing to accept a deal)?
And adding to that, obviously constructs like "the US" and "China" are simplifications too, and the details around who actually makes and influences decisions could end up mattering a lot
It seems to me all these things could matter when determining the optimal US strategy, but I don't see them addressed in the OP.
for people who are not very good at navigating social conventions, it is often easier to learn to be visibly weird than to learn to adapt to the social conventions.
are you basing this on intuition or personal experience or something else? I guess we should avoid basing it on observations of people who did succeed in that way. People who try and succeed in adapting to social conventions are likely much less noticeable/salient than people who succeed at being visibly weird.
Yeah that makes sense. I think I underestimated the extent to which "warning shots" are largely defined post-hoc, and events in my category ("non-catastrophic, recoverable accident") don't really have shared features (or at least features in common that aren't also there in many events that don't lead to change).
One man's 'warning shot' is just another man's "easily patched minor bug of no importance if you aren't anthropomorphizing irrationally", because by definition, in a warning shot, nothing bad happened that time. (If something had, it wouldn't be a 'warning shot', it'd just be a 'shot' or 'disaster'.
I agree that "warning shot" isn't a good term for this, but then why not just talk about "non-catastrophic, recoverable accident" or something? Clearly those things do sometimes happen, and there is sometimes a significant response going beyond "we can just patch that quickly". For example:
The Three Mile Island accident led to major changes in US nuclear safety regulations and public perceptions of nuclear energy
9/11 led to the creation of the DHS, the Patriot Act, and 1-2 overseas invasions
The Chicago Tylenol murders killed only 7 but led to the development and use of tamper-resistant/evident packaging for pharmaceuticals
The Italian COVID outbreak of Feb/Mar 2020 arguably triggered widespread lockdowns and other (admittedly mostly incompetent) major efforts across the public and private sectors in NA/Europe
I think one point you're making is that some incidents that arguably should cause people to take action (e.g., Sydney), don't, because they don't look serious or don't cause serious damage. I think that's true, but I also thought that's not the type of thing most people have in mind when talking about "warning shots". (I guess that's one reason why it's a bad term.)
I guess a crux here is whether we will get incidents involving AI that (1) cause major damage (hundreds of lives or billions of dollars), (2) are known to the general public or key decision makers, (3) can be clearly causally traced to an AI, and (4) happen early enough that there is space to respond appropriately. I think it's pretty plausible that there'll be such incidents, but maybe you disagree. I also think that if such incidents happen it's highly likely that there'll be a forceful response (though it could still be an incompetent forceful response).
I don't really have a settled view on this; I'm mostly just interested in hearing a more detailed version of MIRI's model. I also don't have a specific expert in mind, but I guess the type of person that Akash occasionally refers to -- someone who's been in DC for a while, focuses on AI, and has encouraged a careful/diplomatic communication strategy.
“Be careful what you say, try to look normal, and slowly accumulate political capital and connections in the hope of swaying policymakers long-term” isn’t an unconditionally good strategy, it’s a strategy adapted to a particular range of situations and goals.
I agree with this. I also think that being more outspoken is generally more virtuous in politics, though I also see drawbacks with it. Maybe I'd wished OP mentioned some of the possible drawbacks of the outspoken strategy and whether there are sensible ways to mitigate those, or just making clear that MIRI thinks they're outweighed by the advantages. (There's some discussion, e.g., the risk of being "discounted or uninvited in the short term", but this seems to be mostly drawn from the "ineffective" bucket, not from the "actively harmful" bucket.)
AI risk is a pretty weird case, in a number of ways: it’s highly counter-intuitive, not particularly politically polarized / entrenched, seems to require unprecedentedly fast and aggressive action by multiple countries, is almost maximally high-stakes, etc.
Yeah, I guess this is a difference in worldview between me and MIRI, where I have longer timelines, am less doomy, and am more bullish on forceful government intervention, causing me to think increased variance is probably generally bad.
That said, I'm curious why you think AI risk is highly counterintuitive (compared to, say, climate change) -- it seems the argument can be boiled down to a pretty simple, understandable (if reductive) core ("AI systems will likely be very powerful, perhaps more than humans, controlling them seems hard, and all that seems scary"), and it has indeed been transmitted like that successfully in the past, in films and other media.
I'm also not sure why it's relevant here that AI risk is relatively unpolarized -- if anything, that seems like it should make it more important not to cause further polarization (at least if highly visible moral issues being relatively unpolarized represent unstable equilibriums)?
That's one reason why an outspoken method could be better. But it seems like you'd want some weighing of the pros and cons here? (Possible drawbacks of such messaging could include it being more likely to be ignored, or cause a backlash, or cause the issue to become polarized, etc.)
Like, presumably the experts who recommend being careful what you say also know that some people discount obviously political speech, but still recommend/practice being careful what you say. If so, that would suggest this one reason is not on its own enough to override the experts' opinion and practice.
Everything that happened since then has made it clear that this is not the case; that all these big flashy commitments like Superalignment were just safety-washing and virtue signaling. They were only going to do alignment work inasmuch as that didn't interfere with racing full-speed towards greater capabilities.
It's not clear to me that it was just safety-washing and virtue signaling. I think a better model is something like: there are competing factions within OAI that have different views, that have different interests, and that, as a result, prioritize scaling/productization/safety/etc. to varying degrees. Superalignment likely happened because (a) the safety faction (Ilya/Jan/etc.) wanted it, and (b) the Sam faction also wanted it, or tolerated it, or agreed to it due to perceived PR benefits (safety-washing), or let it happen as a result of internal negotiation/compromise, or something else, or some combination of these things.
If OAI as a whole was really only doing anything safety-adjacent for pure PR or virtue signaling reasons, I think its activities would have looked pretty different. For one, it probably would have focused much more on appeasing policymakers than on appeasing the median LessWrong user. (The typical policymaker doesn't care about the superalignment effort, and likely hasn't even heard of it.) It would also not be publishing niche (and good!) policy/governance research. Instead, it would probably spend that money on actual PR (e.g., marketing campaigns) and lobbying.
I do think OAI has been tending more in that direction (that is, in the direction of safety-washing, and/or in the direction of just doing less safety stuff period). But it doesn't seem to me like it was predestined. I.e., I don't think it was "only going to do alignment work inasmuch as that didn't interfere with racing full-speed towards greater capabilities". Rather, it looks to me like things have tended that way as a result of external incentives (e.g., looming profit, Microsoft) and internal politics (in particular, the safety faction losing power). Things could have gone quite differently, especially if the board battle had turned out differently. Things could still change, the trend could still reverse, even though that seems improbable right now.
Open Philanthropy did donate $30M to OpenAI in 2017, and got in return the board seat that Helen Toner occupied until very recently. However, that was when OpenAI was a non-profit, and was done in order to gain some amount of oversight and control over OpenAI. I very much doubt any EA has donated to OpenAI unconditionally, or at all since then.
They often do things of the form "leaving out info, knowing this has misleading effects"
On that, here are a few examples of Conjecture leaving out info in what I think is a misleading way.
(Context: Control AI is an advocacy group, launched and run by Conjecture folks, that is opposing RSPs. I do not want to discuss the substance of Control AI’s arguments -- nor whether RSPs are in fact good or bad, on which question I don’t have a settled view -- but rather what I see as somewhat deceptive rhetoric.)
One, Control AI’s X account features a banner image with a picture of Dario Amodei (“CEO of Anthropic, $2.8 billion raised”) saying, “There’s a one in four chance AI causes human extinction.” That is misleading. What Dario Amodei has said is, “My chance that something goes really quite catastrophically wrong on the scale of human civilisation might be somewhere between 10-25%.” I understand that it is hard to communicate uncertainty in advocacy, but I think it would at least have been more virtuous to use the middle of that range (“one in six chance”), and to refer to “global catastrophe” or something rather than “human extinction”.
Two, Control AI writes that RSPs like Anthropic’s “contain wording allowing companies to opt-out of any safety agreements if they deem that another AI company may beat them in their race to create godlike AI”. I think that, too, is misleading. The closest thing Anthropic’s RSP says is:
However, in a situation of extreme emergency, such as when a clearly bad actor (such as a rogue state) is scaling in so reckless a manner that it is likely to lead to imminent global catastrophe if not stopped (and where AI itself is helpful in such defense), we could envisage a substantial loosening of these restrictions as an emergency response. Such action would only be taken in consultation with governmental authorities, and the compelling case for it would be presented publicly to the extent possible.
Anthropic’s RSP is clearly only meant to permit labs to opt out when any other outcome very likely leads to doom, and for this to be coordinated with the government, with at least some degree of transparency. The scenario is not “DeepMind is beating us to AGI, so we can unilaterally set aside our RSP”, but more like “North Korea is beating us to AGI, so we must cooperatively set aside our RSP”.
Relatedly, Control AI writes that, with RSPs, companies “can decide freely at what point they might be falling behind – and then they alone can choose to ignore the already weak” RSPs. But part of the idea with RSPs is that they are a stepping stone to national or international policy enforced by governments. For example, ARC and Anthropic both explicitly said that they hope RSPs will be turned into standards/regulation prior to the Control AI campaign. (That seems quite plausible to me as a theory of change.) Also, Anthropic commits to only updating its RSP in consultation with its Long-Term Benefit Trust (consisting of five people without any financial interest in Anthropic) -- which may or may not work well, but seems sufficiently different from Anthropic being able to “decide freely” when to ignore its RSP that I think Control AI’s characterisation is misleading. Again, I don't want to discuss the merits of RSPs, I just think Control AI is misrepresenting Anthropic's and others' positions.
Three, Control AI seems to say that Anthropic’s advocacy for RSPs is an instance of safetywashing and regulatory capture. (Connor Leahy: “The primary aim of responsible scaling is to provide a framework which looks like something was done so that politicians can go home and say: ‘We have done something.’ But the actual policy is nothing.” And also: “The AI companies in particular and other organisations around them are trying to capture the summit, lock in a status quo of an unregulated race to disaster.”) I don’t know exactly what Anthropic’s goals are -- I would guess that its leadership is driven by a complex mixture of motivations -- but I doubt it is so clear-cut as Leahy makes it out to be.
To be clear, I think Conjecture has good intentions, and wants the whole AI thing to go well. I am rooting for its safety work and looking forward to seeing updates on CoEm. And again, I personally do not have a settled view on whether RSPs like Anthropic’s are in fact good or bad, or on whether it is good or bad to advocate for them – it could well be that RSPs turn out to be toothless, and would displace better policy – I only take issue with the rhetoric.
(Disclosure: Open Philanthropy funds the organisation I work for, though the above represents only my views, not my employer’s.)
I think it is reasonable to treat this as a proxy for the state of the evidence, because lots ofAIpolicypeople specifically praised it as a good and thoughtful paper on policy.
All four of those AI policy people are coauthors on the paper -- that does not seem like good evidence that the paper is widely considered good and thoughtful, and therefore a good proxy (though I think it probably is an ok proxy).
When Jeff Kaufman shared one of the papers discussed here on the EA Forum, there was a highly upvoted comment critical of the paper (more upvoted than the post itself). That would suggest to me that this post would be fairly well received on the EA Forum, though its tone is definitely more strident than that comment, so maybe not.
ARC & Open Philanthropy state in a press release “In a sane world, all AGI progress should stop. If we don’t, there’s more than a 10% chance we will all die.”
Could you spell out what you mean by "in a sane world"? I suspect a bunch of people you disagree with do not favor a pause due to various empirical facts about the world (e.g., there being competitors like Meta).
Well, it's not like vegans/vegetarians are some tiny minority in EA. Pulling together some data from the 2022 ACX survey, people who identify as EA are about 40% vegan/vegetarian, and about 70% veg-leaning (i.e., vegan, vegetarian, or trying to eat less meat and/or offsetting meat-eating for moral reasons). (That's conditioning on identifying as an LW rationalist, since anecdotally I think being vegan/vegetarian is somewhat less common among Bay Area EAs, and the ACX sample is likely to skew pretty heavily rationalist, but the results are not that different if you don't condition.)
Israel's strategy since the Hamas took the strip over in 2007 has been to try and contain it, and keeping it weak by periodic, limited confrontations (the so called Mowing the Lawn doctorine), and trying to economically develop the strip in order to give Hamas incentives to avoid confrontation. While Hamas grew stronger, the general feeling was that the strategy works and the last 15 years were not that bad.
I am surprised to read the bolded part! What actions have the Israeli government taken to develop Gaza, and did Gaza actually develop economically in that time? (That is not a rhetorical question -- I know next to nothing about this.)
Looking quickly at some stats, real GDP per capita seems to have gone up a bit since 2007, but has declined since 2016, and its current figure ($5.6K in 2021) is lower than e.g., Angola, Bangladesh, and Venezuela.
Qualitatively, the blockade seems to have been net negative for Gaza's economic development. NYT writes:
The Palestinian territory of Gaza has been under a suffocating Israeli blockade, backed by Egypt, since Hamas seized control of the coastal strip in 2007. The blockade restricts the import of goods, including electronic and computer equipment, that could be used to make weapons and prevents most people from leaving the territory.
More than two million Palestinians live in Gaza. The tiny, crowded coastal enclave has a nearly 50 percent unemployment rate, and Gaza’s living conditions, health system and infrastructure have all deteriorated under the blockade.
But that is a news report, so we should take it with a grain of salt.
Assuming you have the singular "you" in mind, no, I do not think I am not running a motte and bailey. I said above that if you accept the assumptions, I think using the ranges as (provisional, highly uncertain) moral weights is pretty reasonable, but I also think it's reasonable to reject the assumptions. I do think it is true that some people have (mis)interpreted the report and made stronger claims than is warranted, but the report is also full of caveats and (I think) states its assumptions and results clearly.
The report:
Instead, we’re usually comparing either improving animal welfare (welfare reforms) or preventing animals from coming into existence (diet change → reduction in production levels) with improving human welfare or saving human lives.
Yes, the report is intended to guide decision-making in this way. It is not intended to provide a be-all-end-all estimate. The results still need to be interpreted in the context of the assumptions (which are clearly stated up front). I would take it as one input when making decisions, not the only input.
The post's response to the heading "So you’re saying that one person = ~three chickens?" is, no, that's just the year to year of life comparison, chickens have shorter lives than humans so the life-to-life comparison is more like 1/16. Absolutely insane.
No, that is not the post's response to that heading. It also says: "No. We’re estimating the relative peak intensities of different animals’ valenced states at a given time. So, if a given animal has a welfare range of 0.5 (and we assume that welfare ranges are symmetrical around the neutral point), that means something like, 'The best and worst experiences that this animal can have are half as intense as the best and worst experiences that a human can have' [...]" There is a difference between comparing the most positive/negative valenced states an animal can achieve and their moral worth.
The report says that somehow, people should still mostly accept Rethinking Priotities' conclusions even if they disagree with the assumptions:
“I don't share this project’s assumptions. Can't I just ignore the results?" We don’t think so. First, if unitarianism is false, then it would be reasonable to discount our estimates by some factor or other. However, the alternative—hierarchicalism, according to which some kinds of welfare matter more than others or some individuals’ welfare matters more than others’ welfare—is very hard to defend.
I think I disagree with your characterization, but it depends a bit on what you mean by "mostly". The report makes a weaker claim, that if you don't accept the premises, you shouldn't totally ignore the conclusions (as opposed to "mostly accepting" the conclusions). The idea is that even if you don't accept hedonism, it would be weird if capacity for positively/negatively valenced experiences didn't matter at all when determining moral weights. That seems reasonable to me and I don't really see the issue?
So if you factor in life span (taking 2 months for a drone) and do the ⅔ reduction for not accepting hedonism, you get a median of 1 human life = ~20K bee lives, given the report's other assumptions. That's 3 OOMs more than what Richard Kennaway wrote above.
In response to someone commenting in part:
saving human lives is net positive
The post author's reply is:
This is a very interesting result; thanks for sharing it. I've heard of others reaching the same conclusion, though I haven't seen their models. If you're willing, I'd love to see the calculations. But no pressure at all.
I am not sure what you are trying to say here, could you clarify?
This is a misrepresentation of what the report says. The report says that, conditional on hedonism, valence symmetry, the animals being sentient, and other assumptions, the intensity of positive/negative valence that a bee can experience is 7% that of the positive/negative intensity that a human can experience. How to value creatures based on the intensities of positively/negatively valenced states they are capable of is a separate question, even if you fully accept the assumptions. (ETA: If you assume utilitarianism and hedonism etc., I think it is pretty reasonable to anchor moral weight (of a year of life) in range of intensity of positive/negative valence, while of course keeping the substantial uncertainties around all this in mind.)
On bees in particular, the authors write:
We also find it implausible that bees have larger welfare ranges than salmon. But (a) we’re also worried about pro-vertebrate bias; (b) bees are reallyimpressive; (c) there's a great deal of overlap in the plausible welfare ranges for these two types of animals, so we aren't claiming that their welfare ranges are significantly different; and (d) we don’t know how to adjust the scores in a non-arbitrary way. So, we’ve let the result stand.
I think when engaging in name-calling ("batshit crazy animal rights folks") it is especially important to get things right.
(COI: The referenced report was produced by my employer, though a different department.)
I think this is a productivity/habit question disguised as something else. You know you want to do thing X, but instead procrastinate by doing thing Y. Here are some concrete suggestions for getting out of this trap:
Try Focusmate. Sign up and schedule a session. The goal of your first session will be to come up with a concrete project/exercise to do, if you have not already done so. The goal of your second session will be to make some progress on that project/exercise (e.g., write 1 page).
You can also use the same accountability technique with a friend, but Focusmate is probably easier since you can always schedule a session whenever you want, and you will feel more obliged to focus in the presence of a stranger.
I often start my day with scheduling Focusmate sessions. It is easier to schedule a session for future you to be productive during, and then to stick to that commitment, than to start being productive right away.
Try Beeminder. Sign up and set a goal to write object-level things for at least N minutes each day. If you fail to do so, Beeminder will charge you money. (I think N can be small -- the difficult thing is to get started on the right task.)
Try other accountability devices. For example, tell a friend or partner that you commit to doing N minutes of object-level writing each week, and that you will report your progress to them weekly. If you did not do what you committed to, brainstorm ways to make it more likely that you do so next week.
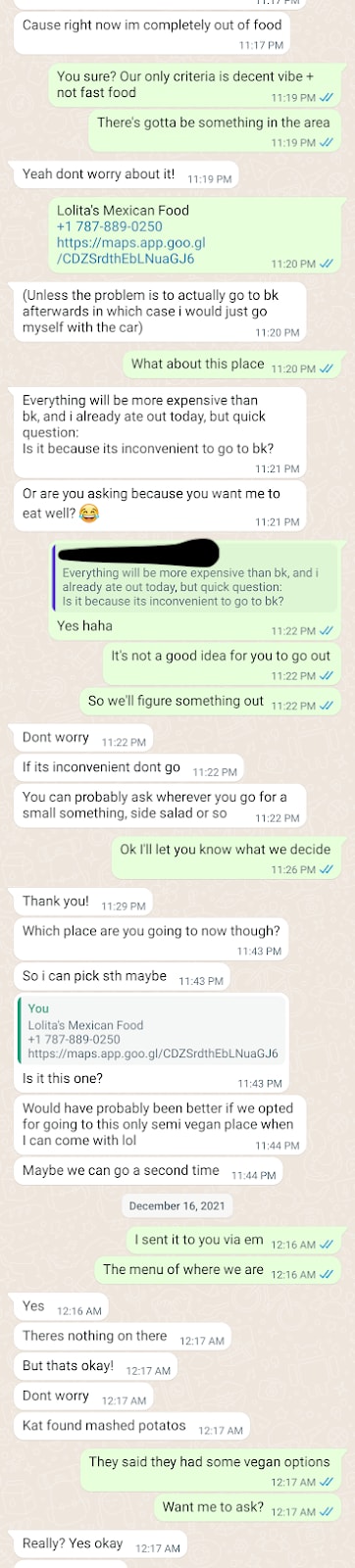
It could be that I am misreading or misunderstanding these screenshots, but having read through them a couple of times trying to parse what happened, here's what I came away with:
On December 15, Alice states that she'd had very little to eat all day, that she'd repeatedly tried and failed to find a way to order takeout to their location, and tries to ask that people go to Burger King and get her an Impossible Burger which in the linked screenshots they decline to do because they don't want to get fast food. She asks again about Burger King and is told it's inconvenient to get there. Instead, they go to a different restaurant and offer to get her something from the restaurant they went to. Alice looks at the menu online and sees that there are no vegan options. Drew confirms that 'they have some salads' but nothing else for her. She assures him that it's fine to not get her anything.
It seems completely reasonable that Alice remembers this as 'she was barely eating, and no one in the house was willing to go out and get her nonvegan foods' - after all, the end result of all of those message exchanges was no food being obtained for Alice and her requests for Burger King being repeatedly deflected with 'we are down to get anything that isn't fast food' and 'we are down to go anywhere within a 12 min drive' and 'our only criteria is decent vibe + not fast food', after which she fails to find a restaurant meeting those (I note, kind of restrictive if not in a highly dense area) criteria and they go somewhere without vegan options and don't get her anything to eat.
It also seems totally reasonable that no one at Nonlinear understood there was a problem. Alice's language throughout emphasizes how she'll be fine, it's no big deal, she's so grateful that they tried (even though they failed and she didn't get any food out of the 12/15 trip, if I understand correctly). I do not think that these exchanges depict the people at Nonlinear as being cruel, insane, or unusual as people. But it doesn't seem to me that Alice is lying to have experienced this as 'she had covid, was barely eating, told people she was barely eating, and they declined to pick up Burger King for her because they didn't want to go to a fast food restaurant, and instead gave her very limiting criteria and went somewhere that didn't have any options she could eat'.
On December 16th it does look like they successfully purchased food for her.
My big takeaway from these exchanges is not that the Nonlinear team are heartless or insane people, but that this degree of professional and personal entanglement and dependence, in a foreign country, with a young person, is simply a recipe for disaster. Alice's needs in the 12/15 chat logs are acutely not being met. She's hungry, she's sick, she conveys that she has barely eaten, she evidently really wants someone to go to BK and get an impossible burger for her, but (speculatively) because of this professional/personal entanglement, she lobbies for this only by asking a few times why they ruled out Burger King, and ultimately doesn't protest when they instead go somewhere without food she can eat, assuring them it's completely fine. This is also how I relate to my coworkers, tbh - but luckily, I don't live with them and exclusively socialize with them and depend on them completely when sick!!
Given my experience with talking with people about strongly emotional events, I am inclined towards the interpretation where Alice remembers the 15th with acute distress and remembers it as 'not getting her needs met despite trying quite hard to do so', and the Nonlinear team remembers that they went out of their way that week to get Alice food - which is based on the logs from the 16th clearly true! But I don't think I'd call Alice a liar based on reading this, because she did express that she'd barely eaten and request apologetically for them to go somewhere she could get vegan food (with BK the only option she'd been able to find) only for them to refuse BK because of the vibes/inconvenience.
We definitely did not fail to get her food, so I think there has been a misunderstanding - it says in the texts below that Alice told Drew not to worry about getting food because I went and got her mashed potatoes. Ben mentioned the mashed potatoes in the main post, but we forgot to mention it again in our comment - which has been updated
The texts involved on 12/15/21:
I also offered to cook the vegan food we had in the house for her.
I think that there's a big difference between telling everyone "I didn't get the food I wanted, but they did get/offer to cook me vegan food, and I told them it was ok!" and "they refused to get me vegan food and I barely ate for 2 days".
Also, re: "because of this professional/personal entanglement" - at this point, Alice was just a friend traveling with us. There were no professional entanglements.
As of 2020, anti-government protests in North America rose steadily from 2009 to 2017 where it peaked (at ~7x the 2009 number) and started to decline (to ~4x the 2009 number in 2019).
Americans' trust in the US government is very low (only ~20% say they trust the USG to do what's right most of the time) and has been for over a decade. It seems to have locally peaked at ~50% after 9/11, and then declined to ~15% in 2010, after the financial crisis.
Congressional turnover rates have risen somewhat since the 90s, and are now at about the same level as in the 1970s.
Congress seems to pass fewer bills every year since at least the mid-1970s (though apparently bottoming out in 2011, following the 2010 red wave midterms).
Actually Charles Babbage was not trying to disrupt the industry of printed logarithmic tables, he was trying to print accurate tables.
Hmm, Babbage wanted to remove errors from tables by doing the calculations by steam. He was also concerned with how tedious and time-consuming those calculations were, though, and I guess the two went hand in hand. ("The intolerable labour and fatiguing monotony of a continued repetition of similar arithmetical calculation, first excited the desire and afterwards suggested the idea, of a machine, which, by the aid of gravity or any other moving power, should become a substitute for one of the lower operations of human intellect. [...] I think I am justified in presuming that if engines were made purposely for this object, and were afterwards useless, the tables could be produced at a much cheaper rate; and of their superior accuracy there could be no doubt.") I think that fits "disrupt" if defined something like "causing radical change in (an industry or market) by means of innovation".
What are mathematical tables, you ask? Imagine that you need to do some trigonometry. What's sin(79)?
Well, today you'd just look it up online. 15 years ago you'd probably grab your TI-84 calculator. But in the year 1812, you'd have to consult a mathematical table. Something like this:
They'd use computers to compute all the values and write them down in books. Just not the type of computers you're probably thinking of. No, they'd use human computers.
Interestingly, humans having to do a lot of calculation manually was also how John Napier discovered the logarithm in the 17th century. The logarithm reduces the task of multiplication to the much faster and less error-prone task of addition. Of course that meant you also needed to get the logarithms of numbers, so it in turn spawned an industry of printed logarithmic tables (which Charles Babbage later tried to disrupt with his Difference Engine).
I think your analysis makes sense if using a "center" name really should require you to have some amount of eminence or credibility first. I've updated a little bit in that direction now, but I still mostly think it's just synonymous with "institute", and on that view I don't care if someone takes a "center" name (any more than if someone takes an "institute" name). It's just, you know, one of the five or so nouns non-profits and think tanks use in their names ("center", "institute", "foundation", "organization", "council", blah).
Or actually, maybe it's more like I'm less convinced that there's a common pool of social/political capital that CAIS is now spending from. I think the signed statement has resulted in other AI gov actors now having higher chances of getting things done. I think if the statement had been not very successful, it wouldn't have harmed those actors' ability to get things done. (Maybe if it was really botched it would've, but then my issue would've been with CAIS's botching the statement, not with their name.)
I guess I also don't really buy that using "center" spends from this pool (to the extent that there is a pool). What's the scarce resource it's using? Policy-makers' time/attention? Regular people's time/attention? Or do people only have a fixed amount of respect or credibility to accord various AI safety orgs? I doubt, for example, that other orgs lost out on opportunities to influence people, or inform policy-makers, due to CAIS's actions. I guess what I'm trying to say is I'm a bit confused about your model!
Btw, in case it matters, the other examples I had in mind were Center for Security and Emerging Technology (CSET) and Centre for the Governance of AI (GovAI).
The only criticism of you and your team in the OP is that you named your team the "Center" for AI Safety, as though you had much history leading safety efforts or had a ton of buy-in from the rest of the field.
Fwiw, I disagree that "center" carries these connotations. To me it's more like "place where some activity of a certain kind is carried out", or even just a synonym of "institute". (I feel the same about the other 5-10 EA-ish "centers/centres" focused on AI x-risk-reduction.) I guess I view these things more as "a center of X" than "the center of X". Maybe I'm in the minority on this but I'd be kind of surprised if that were the case.
It's valuable to flag the causal process generating an idea, but it's also valuable to provide legible argumentation, because most people can't describe the factors which led them to their beliefs in sufficient detail to actually be compelling.
To add to that, trying to provide legible argumentation can also be good because it can convince you that your idea actually doesn't make sense, or doesn't make sense as stated, if that is indeed the case.
Seems to me like (a), (b) and maybe (d) are true for the airplane manufacturing industry, to some degree.
But I'd still guess that flying is safer with substantial regulation than it would be in a counterfactual world without substantial regulation.
That would seem to invalidate your claim that regulation would make AI x-risk worse. Do you disagree with (1), and/or with (2), and/or see some important dissimilarities between AI and flight that make a difference here?
It's not clear whether that will mean the end of humanity in the sense of the systems we've created destroying us. It's not clear if that's the case, but it's certainly conceivable. If not, it also just renders humanity a very small phenomenon compared to something else that is far more intelligent and will become incomprehensible to us, as incomprehensible to us as we are to cockroaches.
It's interesting that he seems so in despair over this now. To the extent that he's worried about existential/catastrophic risks, I wonder if he is unaware of efforts to mitigate those, or if he is aware but thinks they are hopeless (or at least not guaranteed to succeed, which -- fair enough). To the extent that he's more broadly worried about human obsolescence (or anyway something more metaphysical), well, there are people trying to slow/stop AI, and others trying to enhance human capabilities -- maybe he's pessimistic about those efforts, too.
I’m confused about the parallelization part and what it implies. It says the model was trained on 2K GPUs but GPT-4 was probably trained on 1 OOM more than that right?
I think this is an excellent, well-researched contribution and am confused about why it's not being upvoted more (on LW that is; it seems to be doing much better on EAF, interestingly).
Within a particular genus or architecture, more neurons would be higher intelligence.
I'm not sure that's necessarily true? Though there's probably a correlation. See e.g. this post:
[T]he raw number of neurons an organism possesses does not tell the full story about information processing capacity. That’s because the number of computations that can be performed over a given amount of time in a brain also depends upon many other factors, such as (1) the number of connections between neurons, (2) the distance between neurons (with shorter distances allowing faster communication), (3) the conduction velocity of neurons, and (4) the refractory period which indicates how much time must elapse before a given neuron can fire again. In some ways, these additional factors can actually favor smaller brains (Chitka 2009).