InternLM - China's Best (Unverified)
post by Lao Mein (derpherpize) · 2023-06-09T07:39:15.179Z · LW · GW · 4 commentsContents
4 comments
A technical report of InternLM on 6/7. It consisted of 104 billion parameters, was trained on 1.6 trillion tokens, and was fine-tuned for performance in Chinese.
The authors claimed that it performed second-best on the Chinese language benchmark C-Eval, right after GPT4. In addition, it performed at the level of GPT3.5 in one-shot MMLU. A version fine-tuned for programming also performed similarly to GPT3.5 in coding benchmarks like HumanEval.
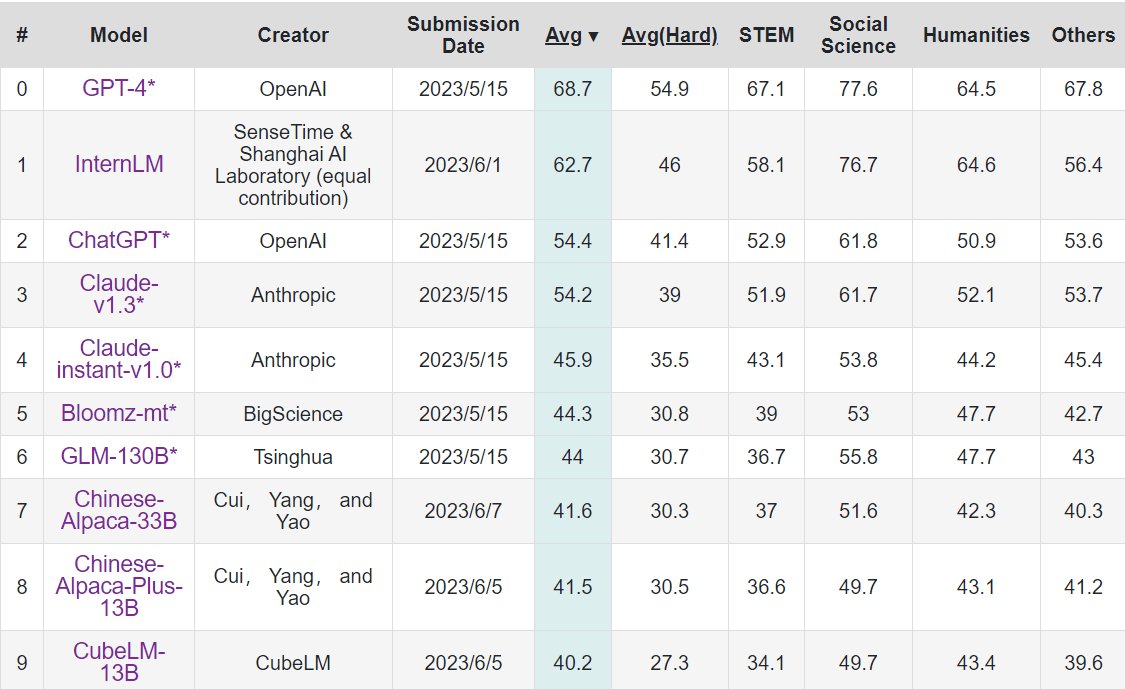
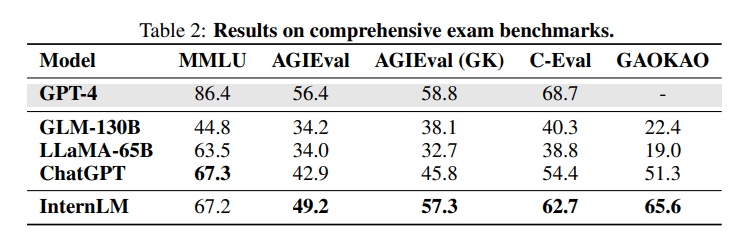
Notable takeaways:
- Significant effort was put into parallelization to help evade the US chip ban. I don't know how impressive this actually is.
- It achieved GPT3.5-level performance with similar-ish levels of compute and data. The China-America algorithmic gap is shrinking.
- My gut feeling is that the model was very specifically fine-tuned for performing well on standardized tests, especially those in Chinese (GK/Gao Kao is the Chinese College entrance exam). It was also consistently bad with math.

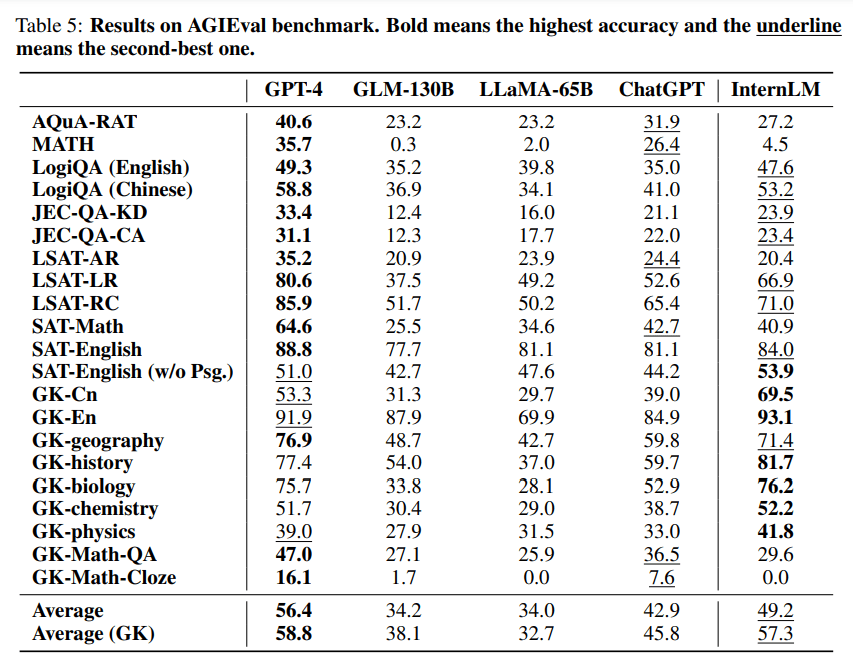
4 comments
Comments sorted by top scores.
comment by Erich_Grunewald · 2023-06-09T17:00:25.586Z · LW(p) · GW(p)
I’m confused about the parallelization part and what it implies. It says the model was trained on 2K GPUs but GPT-4 was probably trained on 1 OOM more than that right?
Replies from: sanxiyn↑ comment by sanxiyn · 2023-06-10T01:05:18.004Z · LW(p) · GW(p)
Parallelization part (data parallelism, tensor parallelism, pipeline parallelism, ZeRO) is completely standard. See Efficient Training on Multiple GPUs by Hugging Face for a standard description. Failure recovery part is relatively unusual.
Replies from: dr_s↑ comment by dr_s · 2023-06-11T08:36:21.913Z · LW(p) · GW(p)
I don't get what the parallelization strategy should have to do with the chip ban? It sounds like just a basic parallelism approach.
Replies from: derpherpize↑ comment by Lao Mein (derpherpize) · 2023-06-11T09:23:26.982Z · LW(p) · GW(p)
You're right. I was pretty tired when I wrote this and am not sure where that thought came from.