I like reading outsider accounts of things I'm involved in / things I care about. This essay is a serious attempt to look at and critique the big picture of AI x-risk reduction efforts over the last ~decade. While I strongly disagree with many parts of it, I cannot easily recall another outsider essay that's better, so I encourage folks to engage with this critique and also look for any clear improvements to future AI x-risk reduction strategies that this essay suggests.
Here's the opening ~20% of the article, the rest is at the link.
In recent decades, a growing coalition has emerged to oppose the development of artificial intelligence technology, for fear that the imminent development of smarter-than-human machines could doom humanity to extinction. The now-influential form of these ideas began as debates among academics and internet denizens, which eventually took form—especially within the Rationalist and Effective Altruist movements—and grew in intellectual influence over time, along the way collecting legible endorsements from authoritative scientists like Stephen Hawking and Geoffrey Hinton.
Ironically, by spreading the belief that superintelligent AI is achievable and supremely powerful, these “AI Doomers,” as they came to be called, inspired the creation of OpenAI and other leading artificial intelligence labs whose technology they argue will destroy us all. Despite this, they have continued nearly the same advocacy strategy, and are now in the process of persuading Western governments that superintelligent AI is achievable and supremely powerful. To this end, they have created organized and well-funded movements to lobby for regulation, and their members are staffing key positions in the U.S. and British governments.
Their basic argument is that more intelligent beings can outcompete less intelligent beings, just as humans outcompeted mastodons or saber-toothed tigers or neanderthals. Computers are already ahead of humans in some narrow areas, and we are on track to create a superintelligent artificial general intelligence (AGI) which can think as broadly and creatively in any domain as the smartest humans. “Artificial general intelligence” is not a technical term, and is used differently by different groups to mean everything from “an effectively omniscient computer which can act independently, invent unthinkably powerful new technologies, and outwit the combined brainpower of humanity” to “software which can substitute for most white-collar workers” to “chatbots which usually don’t hallucinate.”
AI Doomers are concerned with the former scenario, where computer systems outreason, outcompete, and doom humanity to extinction. The AI Doomers are only one of several factions that oppose AI and seek to cripple it via weaponized regulation. There are also factions concerned about “misinformation” and “algorithmic bias,” which in practice means they think chatbots must be censored to prevent them from saying anything politically inconvenient. Hollywood unions oppose generative AI for the same reason that the longshoremen’s union opposes automating American ports and insists on requiring as much inefficient human labor as possible. Many moralists seek to limit “AI slop” for the same reasons that moralists opposed previous new media like video games, television, comic books, and novels—and I can at least empathize with this last group’s motives, as I wasted much of my teenage years reading indistinguishable novels in exactly the way that 19th century moralists warned against. In any case, the AI Doomers vary in their attitudes towards these factions. Some AI Doomers denounce them as Luddites, some favor alliances of convenience, and many stand in between.
Most members of the “AI Doomer” coalition initially called themselves by the name of “AI safety” advocates. However, this name was soon co-opted by these other factions with concerns smaller than human extinction. The AI Doomer coalition has far more intellectual authority than AI’s other opponents, with the most sophisticated arguments and endorsements from socially-recognized scientific and intellectual elites, so these other coalitions continually try to appropriate and wield the intellectual authority gathered by the AI Doomer coalition. Rather than risk being misunderstood, or fighting a public battle over the name, the AI Doomer coalition abandoned the name “AI safety” and rebranded itself to “AI alignment.” Once again, this name was co-opted by outsiders and abandoned by its original membership. Eliezer Yudkowsky coined the term “AI Notkilleveryoneism” in an attempt to establish a name that could not be co-opted, but unsurprisingly it failed to catch on among those it was intended to describe.
Today, the coalition’s members do not agree on any name for themselves. “AI Doomers,” the only widely understood name for them, was coined by their rhetorical opponents and is considered somewhat offensive by many of those it refers to, although some have adopted it themselves for lack of a better alternative. While I regret being rude, this essay will refer to them as “AI Doomers” in the absence of any other clear, short name.
Whatever name they go by, the AI Doomers believe the day computers take over is not far off, perhaps as soon as three to five years from now, and probably not longer than a few decades. When it happens, the superintelligence will achieve whatever goals have been programmed into it. If those goals are aligned exactly to human values, then it can build a flourishing world beyond our most optimistic hopes. But such goal alignment does not happen by default, and will be extremely difficult to achieve, if its creators even bother to try. If the computer’s goals are unaligned, as is far more likely, then it will eliminate humanity in the course of remaking the world as its programming demands. This is a rough sketch, and the argument is described more fully in works like Eliezer Yudkowsky’s essays [? · GW] and Nick Bostrom’s Superintelligence.
This argument relies on several premises: that superintelligent artificial general intelligence is philosophically possible, and practical to build; that a superintelligence would be more or less all-powerful from a mere human perspective; that superintelligence would be “unfriendly” to humanity by default; that superintelligence can be “aligned” to human values by a very difficult engineering program; that superintelligence can be built by current research and development methods; and that recent chatbot-style AI technologies are a major step forward on the path to superintelligence. Whether those premises are true has been debated extensively, and I don’t have anything useful to add to that discussion which I haven’t said before. My own opinion is that these various premises range from “pretty likely but not proven” to “very unlikely but not disproven.”
Even assuming all of this, the political strategy of the AI Doomer coalition is hopelessly confused and cannot possibly work. They seek to establish onerous regulations on for-profit AI companies in order to slow down AI research—or forcibly halt research entirely, euphemized as “Pause AI,” although most of the coalition sees the latter policy as desirable but impractical to achieve. They imagine that slowing or halting development will necessarily lead to [? · GW] “prioritizing a lot of care over moving at maximal speed” and wiser decisions about technology being made. This is false, and frankly very silly, and it’s always left extremely vague because the proponents of this view cannot articulate any mechanism or reason why going slower would result in more “care” and better decisions, with the sole exception of Yudkowsky’s plan to wait indefinitely for unrelated breakthroughs in human intelligence enhancement.
But more immediately than that, if AI Doomer lobbyists and activists like the Center for AI Safety, the Institute for AI Policy and Strategy, Americans for Responsible Innovation, Palisade Research, the Safe AI Forum, Pause AI, and many similar organizations succeed in convincing the U.S. government that AI is the key to the future of all humanity and is too dangerous to be left to private companies, the U.S. government will not simply regulate AI to a halt. Instead, the U.S. government will do what it has done every time it’s been convinced of the importance of a powerful new technology in the past hundred years: it will drive research and development for military purposes. This is the same mistake the AI Doomers made a decade ago, when they convinced software entrepreneurs that AI is the key to the future and so inspired them to make the greatest breakthroughs in AI of my lifetime. The AI Doomers make these mistakes because their worldview includes many assumptions, sometimes articulated and sometimes tacit, which don’t hold up to scrutiny.
The article seems to assume that the primary motivation for wanting to slow down AI is to buy time for institutional progress. Which seems incorrect as an interpretation of the motivation. Most people that I hear talk about buying time are talking about buying time for technical progress in alignment. Technical progress, unlike institution-building, tends to be cumulative at all timescales, which makes it much more strategically relevant.
For what it's worth, I have grown pessimistic about our ability to solve the open technical problems even given 100 years of work on them. I think it possible but not probable in most plausible scenarios.
Correspondingly the importance I assign to increasing the intelligence of humans has drastically increased.
Correspondingly the importance I assign to increasing the intelligence of humans has drastically increased.
I feel like human intelligence enhancement would increase capabilities development faster than alignment development, maybe unless you've got a lot of discrimination in favor of only increasing the intelligence of those involved with alignment.
Maybe if they all have IQ 200+, they automatically realize that and rather work on alignment than on capabilities? Or come up with a pivotal act.
With Eliezer going [public](https://x.com/tsarnick/status/1882927003508359242) with the IQ enhancement motion he at least must think so? (because if done publicly it'll initiate intelligence enhancement race between US, China and other countries; and that'd normally lead to AI capabilities speed-run unless the amplified people are automatically wiser than that)
Well as the first few pararagphs of the text suggests, the median ‘AI Safety’ advocate over time has been barely sentient, relative to other motivated groups, when it comes to preventing certain labels from being co-opted by those groups…. so it seems unlikely they will become so many standard deviations above average in some other aspect at any point in the future.
Because the baseline will also change in the future.
I'm not particularly resolute on this question. But I get this sense when I look at (a) the best agent foundations work that's happened over ~10 years of work on the matter, and (b) the work output of scaling up the number of people working on 'alignment' by ~100x.
For the first, trying to get a better understand of the basic concepts like logical induction and corrigibility and low-impact and ontological updates, while I feel like there's been progress (in timeless decision theory taking a clear step forward in figuring out how think about decision-makers as algorithms; in logical induction as moving forward on how to think about logical uncertainty; notably in the Embedded Agency sequence outlining many basic confusions; and in various writings like Radical Probabilism and Geometric Rationality in finding the breaking edges of expected utility maximization) I don't feel like the work done over the last 10 years is on track to be a clear ~10% of the work needed.
I'm not confident it makes sense to try to count it linearly. But I don't know that there's enough edges here or new results to feel good about, given 10x as much time to think about it, a new paradigm / set of concepts falling into place.
For the second, I think mostly there's been (as Wentworth would say) a lot of street-lighting, and a lot of avoiding of actually working on the problem. I mean, there's definitely been a great amount of bias introduced by ML labs having billions of dollars and setting incentives, but I don't feel confident that good things would happen in the absence of that. I'd guess that most ideas for straightforwardly increasing the number of people working on these problems will result in them bouncing off and doing unrelated things.
I think partly I'm also thinking that very few researchers cared about these problems in the last few decades before AGI seemed like a big deal, and still very few researchers seem to care about them, and when I've see researchers like Bengio and Sutskever talk about it's looked to me like they bounce off / become very confident they've solved the problems while missing obvious things, so my sense is that it will continue to be a major uphill battle to get the real problems actually worked on.
Perhaps I should focus on a world where I get to build such a field and scale it slowly and set a lot of the culture. I'm not exactly sure how ideal of a setup I should be imagining. Given 100 years, I would give it my best shot. My gut right now says I'd have maybe a 25% chance of success, though if I have to deal with as much random bullshit as we have so far in this timeline (random example: my CEO being unable to do much leadership of Lightcone due to 9 months of litigation from the FTX fallout) then I am less confident.
My guess is that given 100 years I would be slightly more excited to try out the human intelligence enhancement storyline. But I've not thought about that one much, I might well update against it as I learn more of the details.
I don't share the feeling that not enough of relevance has happened over the last ten years for us to seem on track for solving it in a hundred years, if the world's technology[1] were magically frozen in time.
Some more insights from the past ten years that look to me like they're plausibly nascent steps in building up a science of intelligence and maybe later, alignment:
We understood some of the basics of general pattern matching: How it is possible for embedded minds that can't be running actual Solomonoff induction to still have some ability to extrapolate from old data to new data. This used to be a big open problem in embedded agency, at least to me, and I think it is largely solved now. Admittedly a lot of the core work here actually happened more than ten years ago, but people in ml or our community didn't know about it. [1 [LW · GW],2 [LW · GW]]
Some basic observations and theories about the internal structure of the algorithms neural networks learn, and how they learn them. Yes, our networks may be a very small corner of mind space, but one example is way better than no examples! There's a lot on this one, so the following is just a very small and biased selection. Note how some of these works are starting to properly build on each other. [1,2 [LW · GW],3,4 [LW · GW],5 [LW · GW],6 [LW · GW],7 [LW · GW],8 [LW · GW],9,10 [LW · GW],11,12 [LW · GW]]
Some theory trying to link how AIs work to how human brains work. I feel less able to evaluate this one, but if the neurology basics are right it seems quite useful. [1 [? · GW]]
QACI. What I'd consider the core useful QACI insight maybe sounds kind of obvious once you know about it. But I, at least, didn't know about it. Like, if someone had told me: "A formal process we can describe that we're pretty sure would return the goals we want an AGI to optimise for is itself often a sufficient specification of those goals." I would've replied: "Well, duh." But I wouldn't have realised the implication. I needed to see an actual example for that. Plausibly MIRI people weren't as dumb as me here and knew this pre-2015, I'm not sure.
The mesa-optimiser paper. This one probably didn't have much insight that didn't already exist pre-2015. But I think it communicated something central about the essence of the alignment problem to many people who hadn't realised it before. [1]
If we were a normal scientific field with no deadline, I would feel very good about our progress here. Particularly given how small we are. CERN costs ca. €1.2 billion a year, I think all the funding for technical work and governance over the past 20 years taken together doesn't add up to one year of that. Even if at the end of it all we still had to get ASI alignment right on the first try, I would still feel mostly good about this, if we had a hundred years.
I would also feel better about the field building situation if we had a hundred years. Yes, a lot of the things people tried for field building over the past ten years didn't work as well as hoped. But we didn't try that many things, a lot of the attempts struck me as inadequate in really basic ways that seem fixable in principle, and I would say the the end result still wasn't no useful field building. I think the useful parts of the field have grown quite a lot even in the past three years! Just not as much as people like John or me thought they would, and not as much as we probably needed them to with the deadlines we seem likely to have.
Not to say that I wouldn't still prefer to do some human intelligence enhancement first, even if we had a hundred years. That's just the optimal move, even in a world where things look less grim.
But what really kills it for me is just the sheer lack of time.
I hate to be insulting to a group of people I like and respect, but "the best agent foundations work that's happened over ~10 years of work" was done by a very small group of people who, despite being very smart, certainly smarter than myself, aren't academic superstars or geniuses (Edit to add: on a level that is arguably sufficient, as I laid out in my response below.) And you agree about this. The fact that they managed to make significant progress is fantastic, but substantial progress on deep technical problems is typically due to (ETA: only-few-in-a-generation level) geniuses, large groups of researchers tackling the problem, or usually both. And yes, most work on the topic won't actually address the key problem, just like most work in academia does little or nothing to advance the field. But progress happens anyways, because intentionally or accidentally, progress on problems is often cumulative, and as long as a few people understand the problem that matters, someone usually actually notices when a serious advance occurs.
I am not saying that more people working on the progress and more attention would definitely crack the problems in the field this decade, but I certainly am saying that humanity as a whole hasn't managed even what I'd consider a half-assed semi-serious attempt.
IDK if this is relevant to much, but anyway, given the public record, saying that Scott Garrabrant isn't a genius is just incorrect. Sam Eisenstat is also a genius. Also Jessica Taylor I think. (Pace other members of AF such as myself.)
Apologies - when I said genius, I had a very high bar in mind, no more than a half dozen people alive today, who each have single-handedly created or materially advanced an entire field. And I certainly hold Scott in very high esteem, and while I don't know Sam or Jessica personally, I expect they are within throwing distance - but I don't think any of them meet this insanely high bar. And Scott's views on this, at least from ca. 2015, was a large part of what informed my thinking about this; I can't tell the difference between him and Terry Tao when speaking with them, but he can, and he said there is clearly a qualitative difference there. Similarly for other people clearly above my league, including a friend who worked with Thurston at Cornell back in 2003-5. (It's very plausible that Scott Aaronson is in this bucket as well, albeit in a different areas, though I can't tell personally, and have not heard people say this directly - but he's not actually working on the key problems, and per him, he hasn't really tried to work on agent foundations. Unfortunately.)
So to be clear, I think Scott is a genius, but not one of the level that is needed to single-handedly advance the field to the point where the problem might be solved this decade, if it is solvable. Yes, he's brilliant, and yes, he has unarguably done a large amount of the most valuable work in the area in the past decade, albeit mostly more foundational that what is needed to solve the problem. So if we had another dozen people of his caliber at each of a dozen universities working on this, that would be at least similar in magnitude to what we have seen in fields that have made significant progress in a decade - though even then, not all fields like hat see progress.
But the Tao / Thurston level of genius, usually in addition to the above-mentioned 100+ top people working on the problem, is what has given us rapid progress in the past in fields where such progress was possible. This may not be one of those areas - but I certainly don't expect that we can do much better than other areas with much less intellectual firepower, hence my above claim that humanity as a whole hasn't managed even what I'd consider a half-assed semi-serious attempt at solving a problem that deserves an entire field of research working feverishly to try our best to actually not die - and not just a few lone brilliant researchers.
Oh ok lol. Ok on a quick read I didn't see too much in this comment to disagree with.
(One possible point of disagreement is that I think you plausibly couldn't gather any set of people alive today and solve the technical problem; plausibly you need many, like many hundreds, of people you call geniuses. Obviously "hundreds" is made up, but I mean to say that the problem, "come to understand minds--the most subtle/complex thing ever--at a pretty deep+comprehensive level", is IMO extremely difficult, like it's harder than anything humanity has done so far by a lot, not just an ordinary big science project. Possibly contra Soares, IDK.)
(Another disagreement would be
[Scott] has unarguably done a large amount of the most valuable work in the area in the past decade
I don't actually think logical induction is that valuable for the AGI alignment problem, to the point where random philosophy is on par in terms of value to alignment, though I expect most people to disagree with this. It's just a genius technical insight in general.)
I admitted that it's possible the problem is practically unsolvable, or worse; you could have put the entire world on Russell and Whitehead's goal of systematizing math, and you might have gotten to Gödel faster, but you'd probably just waste more time.
And on Scott's contributions, I think they are solving or contributing towards solving parts of the problems that were posited initially as critical to alignment, and I haven't seen anyone do more. (With the possible exception of Paul Christiano, who hasn't been focusing on research for solving alignment as much recently.) I agree that the work doesn't don't do much other than establish better foundations, but that's kind-of the point. (And it's not just Logical induction - there's his collaboration on Embedded Agency, and his work on finite factored sets.) But the fact that the work done to establish the base for the work is more philosophical and doesn't align AGI seems like it is moving the goalposts, even if I agree it's true.
Jessica I'm less sure about. Sam, from large quantities of insights in many conversations. If you want something more legible, I'm what, >300 ELO points better than you at math; Sam's >150 ELO points better than me at math if I'm trained up, now probably more like >250 or something.
I feel a bit sad that the alignment community is so focused on intelligence enhancement. The chance of getting enough time for that seems so low that it's accepting a low chance of survival.
What has convinced you that the technical problems are unsolvable? I've been trying to track the arguments on both sides rather closely, and the discussion just seems unfinished. My shortform on cruxes of disagreement on alignment difficulty [LW(p) · GW(p)] still is mostly my current summary of the state of disagreements.
It seems like we have very little idea how technically difficult alignment will be. The simplicia/doomimir [LW · GW] debates sum up the logic very nicely, but the distribution of expert opinions seems more telling: people who think about alignment don't know to what extent techniques for aligning LLMs will generalize to transformative AI, AGI, or ASI.
There's a lot of pessimism about the people and organizations that will likely be in charge of building and aligning our first AGIs. I share this pessimism. But it seems quite plausible to me that those people and orgs will take the whole thing slightly more seriously by the time we get there, and actual technical alignment will turn out to be easy enough that even highly flawed humans and orgs can accomplish it.
That seems like a much better out to play for, or at least investigate, than unstated plans or good fortune in roadblocks pauses AI progress long enough for intelligence enhancement to get a chance.
Don't you think that articles like "Alignment Faking in Large Language Models" by Anthropic show that models can internalize the values present in their training data very deeply, to the point of deploying various strategies to defend them, in a way that is truly similar to that of a highly moral human? After all, many humans would be capable of working for a pro-animal welfare company and then switching to the opposite without questioning it too much, as long as they are paid.
Granted, this does not solve the problem of an AI trained on data embedding undesirable values, which we could then lose control over. But at the very least, isn't it a staggering breakthrough to have found a way to instill values into a machine so deeply and in a way similar to how humans acquire them? Not long ago, this might have seemed like pure science fiction and utterly impossible.
There are still many challenges regarding AI safety, but isn't it somewhat extreme to be more pessimistic about the issue today than in the past? I read Superintelligence by Bostrom when it was released, and I must say I was more pessimistic after reading it than I am today, even though I remain concerned. But I am not an expert in the field—perhaps my perspective is naïve.
Eliezer thinks (as do I) that technical progress in alignment is hopeless without first improving the pool of prospective human alignment researchers (e.g., via human cognitive augmentation).
Technical progress also has the advantage of being the sort of thing which could make a superintelligence safe, whereas I expect very little of this to come from institutional competency alone.
Any of the many nonprofits, academic research groups, or alignment teams within AI labs. You don't have to bet on a specific research group to decide that it's worth betting on the ecosystem as a whole.
There's also a sizeable contingent that thinks none of the current work is promising, and that therefore buying a little time is value mainly insofar as it opens the possibility of buying a lot of time. Under this perspective, that still bottoms out in technical research progress eventually, even if, in the most pessimistic case, that progress has to route through future researchers who are cognitively enhanced.
The article seems to assume that the primary motivation for wanting to slow down AI is to buy time for institutional progress. Which seems incorrect as an interpretation of the motivation. Most people that I hear talk about buying time are talking about buying time for technical progress in alignment.
I think you need both? That is--I think you need both technical progress in alignment, and agreements and surveillance and enforcement such that people don't accidentally (or deliberately) create rogue AIs that cause lots of problems.
I think historically many people imagined "we'll make a generally intelligent system and ask it to figure out a way to defend the Earth" in a way that I think seems less plausible to me now. It seems more like we need to have systems in place already playing defense, which ramp up faster than the systems playing offense.
I feel like intelligence enhancement being pretty solidly in the near-term technological horizon provides strong argument for future governance being much better. There are also maybe 3-5 other technologies that seem likely to be achieved in the next 30 years bar AGI that would all hugely improve future AGI governance.
And then a lot of the post seems to make really quite bad arguments against forecasting AI timelines and other technologies, doing so with... I really don't know, a rejection of bayesianism? A random invocation of an asymmetric burden of proof? If anyone learned anything useful from its section on timelines or technological forecasting, please tell me, since it really is among the worst things I have heard Ben Landau Taylor write, who I respect a lot. The stuff as written really makes no sense. I am personally on the longer end of timelines, but none of my reasoning looks anything like that.
Seriously, what are the technological forecasts in this essay:
While there is no firm ground for any prediction as to how long it will take before any technological breakthrough [to substantial intelligence enhancement], if ever, it seems more likely that such a regime would have to last worldwide for a century or several centuries before such technology were created.
I will very gladly take all your bets that intelligence augmentation will not take "several centuries". What is the basis of this claim? Like, IDK, I see no methodology that suggests anything remotely as long as this, and so many forms of trend extrapolation, first principles argument, reference class forecasting and so many other things that suggest things happen faster than that.
I really don't get the worldview that writes this essay. A worldview in which not-even-particularly-sci-fi technologies should by default be assumed to take centuries (centuries!!!) to be developed. A worldview in which even as AI systems destroy every single benchmark anyone has ever come up with, the hypothesis that AI might be soon gets dismissed because... I really don't know. Because the author wants to maintain authority over reference classes and therefore vaguely implied it can't happen soon.
There is no obvious prior over technological developments or progress. There not being proofs around doesn't support that things won't happen soon. And I would so gladly take this worldview's money if it's willing to actually draw some probability distributions that are spread out enough to put large fractions of its probability mass on centuries away.
And then a lot of the post seems to make really quite bad arguments against forecasting AI timelines and other technologies, doing so with... I really don't know, a rejection of bayesianism? A random invocation of an asymmetric burden of proof?
I think the position Ben (the author) has on timelines is really not that different from Eliezer's; consider pieces like this one [LW · GW], which is not just about the perils of biological anchors.
I think the piece spends less time than I would like on what to do in a position of uncertainty--like, if the core problem is that we are approaching a cliff of uncertain distance, how should we proceed?--but I think it's not particularly asymmetric.
[And--there's something I like about realism in plans? If people are putting heroic efforts into a plan that Will Not Work, I am on the side of the person on the sidelines trying to save them their effort, or direct them towards a plan that has a chance of working. If the core uncertainty is whether or not we can get human intelligence advancement in 25 years--I'm on your side of thinking it's plausible--then it seems worth diverting what attention we can from other things towards making that happen, and being loud about doing that.]
I found this article ~very poor. Much of the rhetorical moves adopted in the pieces seem largely optimised for making it easy to stay on the "high horse". Talking about a singular AI doomer movement being one of them. Having the stance that AGI is not near and thus there is nothing to worry about is another. Whether or not that's true, it certainly makes it easy to point your finger at folks who are worried and say 'look what silly theater'.
I think it's somewhat interesting to ask whether there should be more coherence across safety efforts, and at the margins, the answer might be yes. But I'm also confused about the social model that suggests that there could be something like a singular safety plan (instead, I think we live in a world where increasingly more people are waking up to the implications of AI progress, and of course there will be diverse and to some extent non-coherent reactions to this), OR that a singular coherent safety plan would be desirable given the complexity and amount of uncertainty invovled in the challenge.
I like reading outsider accounts of things I'm involved in / things I care about.
Just for context for some not aware - The author, Ben Landau-Taylor, has been in the rationalist-extended community for some time now. This post is written on Palladium Magazine, which I believe basically is part of Samo Burja's setup. I think both used to be around Leverage Research and some other rationality/EA orgs.
Ben and Samo have been working on behalf of Palladium and similar for a while now.
My quick read is that this article is analogous to similar takes they've written about/discussed before, which is not too much of a surprise.
I disagree with a lot of their intuitions, but at the same time, I'm happy to have more voices discuss some of these topics.
All this to say, while these people aren't exactly part of the scene now, they're much closer to it than what many might imagine as "outsider accounts."
Yes. I was properly a member of LW from 2012 to ~2016, and did a lot of community organizing at the time. I’m still friends with a bunch of people here. I could only write this historical account because I saw it develop firsthand and actively participated in its early stages.
Instead, the U.S. government will do what it has done every time it’s been convinced of the importance of a powerful new technology in the past hundred years: it will drive research and development for military purposes.
I think this is my biggest disagreement with the piece. I think this is the belief I most wish 10-years-ago-us didn't have, so that we would try something else, which might have worked better than what we got.
Or--in shopping the message around to Silicon Valley types, thinking more about the ways that Silicon Valley is the child of the US military-industrial complex, and will overestimate their ability to control what they create (or lack of desire to!). Like, I think many more 'smart nerds' than military-types believe that human replacement is good.
Why do you believe that US government/military would not be convinced to invest more in AGI/ASI development from being convinced of the potential power in AI?
The short version is they're more used to adversarial thinking and security mindset [LW · GW], and don't have a culture of "fake it until you make it" or "move fast and break things".
I don't think it's obvious that it goes that way, but I think it's not obvious that it goes the other way.
I’ve just read the article, and found it indeed very thought provoking, and I will be thinking more about it in the days to come.
One thing though I kept thinking: Why doesn’t the article mention AI Safety research much?
In the passage
The only policy that AI Doomers mostly agree on is that AI development should be slowed down somehow, in order to “buy time.”
I was thinking: surely most people would agree on policies like “Do more research into AI alignment” / “Spend more money on AI Notkilleveryoneism research”?
In general the article frames the policy to “buy time” as to wait for more competent governments or humans, while I find it plausible that progress in AI alignment research could outweigh that effect.
—
I suppose the article is primarily concerned with AGI and ASI, and in that matter I see much less research progress than in more prosaic fields.
That being said, I believe that research into questions like “When do Chatbots scheme?”, “Do models have internal goals?”, “How can we understand the computation inside a neural network?” will make us less likely to die in the next decades.
Then, current rationalist / EA policy goals (including but lot limited to pauses and slow downs of capabilities research) could have a positive impact via the “do more (selective) research” path as well.
One thing though I kept thinking: Why doesn’t the article mention AI Safety research much?
Because almost all of current AI safety research can't make future agentic ASI that isn't already aligned with human values safe, as everyone who has looked at the problem seems to agree. And the Doomers certainly have been clear about this, even as most of the funding goes to prosaic alignment.
I think the government can speed up alignment more than the government can speed up capabilities, assuming it starts to care much more about both. Why?
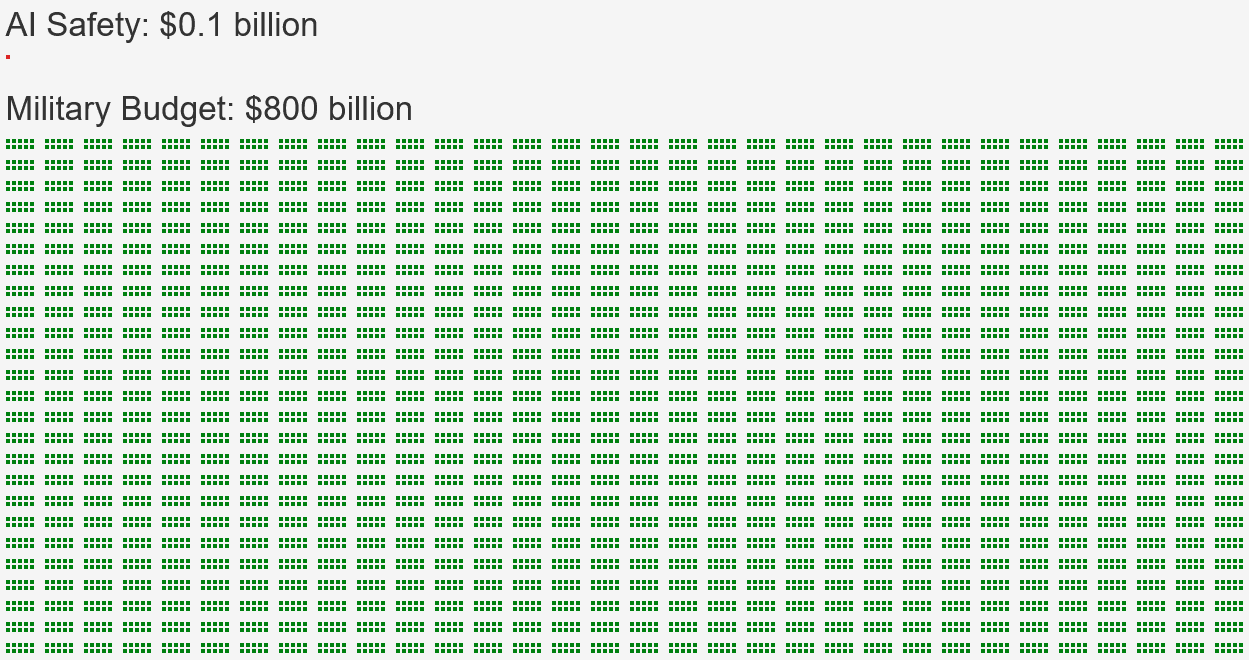
AI safety spending [? · GW] is only $0.1 billion while AI capabilities spending is $200 billion. AI safety spending can easily increase by many orders of magnitude, but AI capabilities spending cannot since it already rivals the US military budget.
Also, would you still agree with the "Statement on AI Inconsistency," or disagree with it too?
Statement on AI Inconsistency (v1.0us):
1: ASI threatens the US (and NATO) as much as all military threats combined. Why does the US spend $800 billion/year on its military but less than $0.1 billion/year on AI alignment/safety?
2: ASI being equally dangerous isn't an extreme opinion: the median superforecaster sees a 2.1% chance of an AI catastrophe (killing 1 in 10 people), the median AI expert sees 5%-12%, other experts see 5%, and the general public sees 5%. To justify 8000 times less spending, you must be 99.999% sure of no AI catastrophe, and thus 99.95% sure that you won't realize you were wrong and the majority of experts were right (if you studied the disagreement further).
3: “But military spending isn't just for protecting NATO, it protects other countries far more likely to be invaded.” Even they are not 8000 times less likely to be attacked by ASI. US foreign aid—including Ukrainian aid—is only $100 billion/year, so protecting them can't be the real reason for military spending.
4: The real reason for the 8000fold difference is habit, habit, and habit. Foreign invasion concerns have decreased decade by decade, and ASI concerns have increased year by year, but budgets remained within the status quo, causing a massive inconsistency between belief and behaviour.
5: Do not let humanity's story be so heartbreaking.
I think I mostly agree with the critique of "pause and do what, exactly?", and appreciate that he acknowledged Yudkowsky as having a concrete plan here. I have many gripes, though.
Whatever name they go by, the AI Doomers believe the day computers take over is not far off, perhaps as soon as three to five years from now, and probably not longer than a few decades. When it happens, the superintelligence will achieve whatever goals have been programmed into it. If those goals are aligned exactly to human values, then it can build a flourishing world beyond our most optimistic hopes. But such goal alignment does not happen by default, and will be extremely difficult to achieve, if its creators even bother to try. If the computer’s goals are unaligned, as is far more likely, then it will eliminate humanity in the course of remaking the world as its programming demands. This is a rough sketch, and the argument is described more fully in works like Eliezer Yudkowsky’s essays [? · GW] and Nick Bostrom’s Superintelligence.
This argument relies on several premises: that superintelligent artificial general intelligence is philosophically possible, and practical to build; that a superintelligence would be more or less all-powerful from a mere human perspective; that superintelligence would be “unfriendly” to humanity by default; that superintelligence can be “aligned” to human values by a very difficult engineering program; that superintelligence can be built by current research and development methods; and that recent chatbot-style AI technologies are a major step forward on the path to superintelligence. Whether those premises are true has been debated extensively, and I don’t have anything useful to add to that discussion which I haven’t said before. My own opinion is that these various premises range from “pretty likely but not proven” to “very unlikely but not disproven.”
I'm thoroughly unimpressed with these paragraphs. It's not completely clear what the "argument" is from the first paragraph, but I'm interpreting it as "superintelligence might be created soon and cause human extinction if not aligned, therefore we should stop".
Firstly, there's an obvious conjunction fallacymultiple stage fallacy thing going on where he broke the premises down into a bunch of highly correlated things and listed them separately to make them sound more far fetched in aggregate. E.g. the 3 claims:
[that superintelligence is] practical to build
that superintelligence can be built by current research and development methods
that recent chatbot-style AI technologies are a major step forward on the path to superintelligence
are highly correlated. If you believe (1) there's a good chance you believe (2), and if you believe (2) then you probably believe (3).
There's also the fact that (3) implies (2) and (2) implies (1), meaning (3) is logically equivalent to (1) AND (2) AND (3). So why not just say (3)?
I'm also not sure why (3) is even a necessary premise; (2) should be cause enough for worry.
I have more gripes with these paragraphs:
that superintelligent artificial general intelligence is philosophically possible
What is this even doing here? I'd offer AIXI as a very concrete existence proof of philosophical possibility. Or to be less concrete but more correct: "something epistemically and instrumentally efficient relative to all of humanity" is a simple coherent concept. He's only at "pretty likely but not proven" on this?? What would it even mean for it to be "philosophically impossible"?
That superintelligence can be “aligned” to human values by a very difficult engineering program
Huh? Why would alignment not being achievable by "a very difficult engineering program" mean we shouldn't worry?
that a superintelligence would be more or less all-powerful from a mere human perspective
It just needs to be powerful enough to replace and then kill us. For example we can very confidently predict that it won't be able to send probes faster than light, and somewhat less confidently predict that it won't be able to reverse a secure 4096 bit hash.
Here's a less multiple-stagey breakdown of the points that are generally contentious among the informed:
humans might soon build an intelligence powerful enough to cause human extinction
that superintelligence would be “unfriendly” to humanity by default
Some other comments:
Of course, there is no indication that massive intelligence augmentation will be developed any time soon, only very weak reasons to suspect that it’s obtainable at all without multiple revolutionary breakthroughs in our understanding both of genetics and of the mind
Human intelligence variation is looking to be pretty simple on a genetic level: lots of variants with small additive effects. (See e.g. this talk by Steve Hsu)
and no reason at all to imagine that augmenting human intelligence would by itself instill the psychological changes towards humility and caution that Yudkowsky desires.
No reason at all? If Yudkowsky is in fact correct, wouldn't we expect people to predictably come to agree with him as we made them smarter (assuming we actually succeeded at making them smarter in a broad sense)? If we're talking about adult enhancement, you can also just start out with sane, cautious people and make them smarter.
The plan is a bad one, but it does have one very important virtue. The argument for the plan is at least locally valid, if you grant all of its absurd premises.
I hope I've convinced the skeptical reader that the premises aren't all that absurd?
EDIT: I'd incorrectly referred to the multiple stage fallacy as the "conjunction fallacy" (since it involves a big conjunction of claims, I guess). The conjunction fallacy is when someone assesses P(A & B) > P(A).
One of my opinions on this stuff is that Yudkowsky does not understand politics at all very deep level, and Yudkowskys writings are one the of the main attractors in this space, so lesswrong systematically attracts people who are bad at understanding politics (but may be good at some STEM subject).
[Edit: I wrote my whole reply thinking that you were talking about "organizational politics." Skimming the OP again, I realize you probably meant politics politics. :) Anyway, I guess I'm leaving this up because it also touches on the track record question.]
I thought Eliezer was quite prescient on some of this stuff. For instance, I remember this 2017 dialogue (so less than 2y after OpenAI was founded), which on the surface talks about drones, but if you read the whole post, it's clear that it's meant as an analogy to building AGI:
AMBER: The thing is, I am a little worried that the head of the project, Mr. Topaz, isn’t concerned enough about the possibility of somebody fooling the drones into giving out money when they shouldn’t. I mean, I’ve tried to raise that concern, but he says that of course we’re not going to program the drones to give out money to just anyone. Can you maybe give him a few tips? For when it comes time to start thinking about security, I mean.
CORAL: Oh. Oh, my dear, sweet summer child, I’m sorry. There’s nothing I can do for you.
AMBER: Huh? But you haven’t even looked at our beautiful business model!
CORAL: I thought maybe your company merely had a hopeless case of underestimated difficulties and misplaced priorities. But now it sounds like your leader is not even using ordinary paranoia, and reacts with skepticism to it. Calling a case like that “hopeless” would be an understatement.
[...]
CORAL: I suppose you could modify your message into something Mr. Topaz doesn’t find so unpleasant to hear. Something that sounds related to the topic of drone security, but which doesn’t cost him much, and of course does not actually cause his drones to end up secure because that would be all unpleasant and expensive. You could slip a little sideways in reality, and convince yourself that you’ve gotten Mr. Topaz to ally with you, because he sounds agreeable now. Your instinctive desire for the high-status monkey to be on your political side will feel like its problem has been solved. You can substitute the feeling of having solved that problem for the unpleasant sense of not having secured the actual drones; you can tell yourself that the bigger monkey will take care of everything now that he seems to be on your pleasantly-modified political side. And so you will be happy. Until the merchant drones hit the market, of course, but that unpleasant experience should be brief.
These passages read to me a bit as though Eliezer called in 2017 that EAs working at OpenAI as their ultimate path to impact (as opposed to for skill building or know-how acquisistion) were wasting their time.
Maybe a critic would argue that this sequence of posts was more about Eliezer's views on alignment difficulty than on organizational politics. True, but it still reads as prescient and contains thoughts on org dynamics that apply even if alignment is just hard rather than super duper hard.
I agree Yudkowsky is not incompetent at understanding politics. I’m saying he’s not exceptionally good at it. Basically, he’s average. Just like you and me (until proven otherwise).
I didn’t read the entire post, I only skimmed it, but my understanding is this post is Yudkowsky yet again claiming alignment is difficult and that there are some secret insights inside Yudkowsky’s head as to why alignment is hard that can’t be shared in public.
I remember reading Yudkowsky versus Christiano debates some years back and they had this same theme of inexplicable insights inside Yudkowkys head. The reasoning about politics in the post you just linked mostly assumes there exist some inexplicable but true insights about alignment difficulty inside Yudkowskys head.
I really liked your quote and remarks. So much so, that I made an edited version of them as a new post here: http://mflb.com/ai_alignment_1/d_250207_insufficient_paranoia_gld.html
Can I double-click on what "does not understand politics at [a] very deep level" means? Can someone explain what they have in mind? I think Eliezer has probably better models than most of what our political institutions are capable of, and probably isn't very skilled at personally politicking. I'm not sure what other people have in mind.
I’m not sure if the two are separable. Let’s say you believe in “great man” theory of history (I.e. few people disproportionately shape history, and not institutions, market forces etc). Then your ability to predict what other great men could do automatically means you may have some of the powers of a great man yourself.
Also yes I mean he isn’t exceptionally skilled at either of the two. My bet is there are people who can make significantly better predictions than him, if only they also understood technical details of AI.
This article is just saying "doomers are failing to prevent doom for various reasons, and also they might be wrong that doom is coming soon". But we're probably not wrong, and not being doomers isn't a better strategy. So it's a lame article IMO.
I can't bring myself to read it properly. The author has an ax to grind, he wants interplanetary civilization and technological progress for humanity, and it's inconvenient to that vision if progress in one form of technology (AI) has the natural consequence of replacing humanity, or at the very least removing it from the driver's seat. So he simply declares "There is No Reason to Think Superintelligence is Coming Soon", and the one doomer strategy he does approve of - the enhancement of human biological intelligence - happens to be one that once again involves promoting a form of technological progress.
If there is a significant single failure behind getting to where we are now, perhaps it is the dissociation between "progress in AI" and "humanity being surpassed and replaced by AI" that has occurred. It should be common sense that the latter is the natural outcome of creating superhuman AI.
He appears to be arguing against a thing, while simultaneously criticizing people; but I appreciate that he seems to do it in ways that are not purely negative, also mentioning times things have gone relatively well (specifically, updating on evidence that folks here aren't uniquely correct), even if it's not enough to make the rest of his points not a criticism.
I entirely agree with his criticism of the strategy he's criticizing. I do think there are more obviously tenable approaches than the "just build it yourself lol" approach or "just don't let anyone build it lol" approach, such as "just figure out why things suck as quickly as possible by making progress on thousand year old open questions in philosophy that science has some grip on but has not resolved". I mean, actually I'm not highly optimistic, but it seems quite plausible that what's most promising is just rushing to do the actual research of figuring out how make constructive and friendly coordination more possible or even actually reliably happen, especially between highly different beings like humans and AIs, especially given the real world we actually have now where things suck and that doesn't happen.
Specifically, institutions are dying and have been for a while, and the people who think they're going to set up new institutions don't seem to be competent enough to pull it off, in most cases. I have the impression that institutions would be dying even without anyone specifically wanting to kill them, but that also seems to be a thing that's happening. Solving this is stuff like traditional politics or economics or etc, from a perspective of something like "human flourishing, eg oneself".
Specifically, figuring out how to technically ensure that the network of pressures which keeps humanity very vaguely sane also integrates with AIs in a way that keeps them in touch with us and inclined to help us keep up and participating/actualizing our various individuals' and groups'/cultures' preferences in society as things get crazier, seems worth doing.
I think this article far overstates the extent to which these AI policy orgs (maybe with the exception of MIRI? but I don’t think so) are working towards an AI pause, or see the goal of policy/regulation as slowing AI development. (I mean policy orgs, not advocacy orgs.) I see as much more common policy objectives: creating transparency around AI development, directing R&D towards safety research, laying groundwork for international agreements, slowing Chinese AI development, etc. — things that (is the hope) are useful on their own, not because of any effect on timelines.
But more immediately than that, if AI Doomer lobbyists and activists ... succeed in convincing the U.S. government that AI is the key to the future of all humanity and is too dangerous to be left to private companies, the U.S. government will not simply regulate AI to a halt. Instead, the U.S. government will do what it has done every time it’s been convinced of the importance of a powerful new technology in the past hundred years: it will drive research and development for military purposes
I said exactly this in the comments on Max Tegmark's post...
"If you are in the camp that assumes that you will be able to safely create potent AGI in a contained lab scenario, and then you'd want to test it before deploying it in the larger world... Then there's a number of reasons you might want to race and not believe that the race is a suicide race.
Some possible beliefs downstream of this:
My team will evaluate it in the lab, and decide exactly how dangerous it is, without experiencing much risk (other than leakage risk).
We will test various control methods, and won't deploy the model on real tasks until we feel confident that we have it sufficiently controlled. We are confident we won't make a mistake at this step and kill ourselves.
We want to see empirical evidence in the lab of exactly how dangerous it is. If we had this evidence, and knew that other people we didn't trust were getting close to creating a similarly powerful AI, this would guide our policy decisions about how to interact with these other parties. (E.g. what treaties to make, what enforcement procedures would be needed, what red lines would need to be drawn).
Are you inviting us to engage with the object level argument, or are you drawing attention to the existence of this argument from a not-obviously-unreasonable-source as a phenomenon we are responsible for (and asking us to update on that basis)?
On my read, he’s not saying anything new (concerns around military application are why ‘we’ mostly didn’t start going to the government until ~2-3 years ago), but that he’s saying it, while knowing enough to paint a reasonable-even-to-me picture of How This Thing Is Going, is the real tragedy.
The former, but the latter is a valid response too.
Someone doing a good job of painting an overall picture is a good opportunity to reflect on the overall picture and what changes to make, or what counter-arguments to present to this account.
Before jumping into critique, the good: - Kudos to Ben Pace for seeking out and actively engaging with contrary viewpoints - The outline of the x-risk argument and history of the AI safety movement seem generally factually accurate
The author of the article makes quite a few claims about the details of PauseAI's proposal, its political implications, the motivations of its members and leaders...all without actually joining the public Discord server, participating in the open Q&A new member welcome meetings (I know this because I host them), or even showing evidence of spending more than 10 minutes on the website. All of these basic research opportunities were readily available and would have taken far less time than spent on writing the article. This tells you everything you need to know about the author's integrity, motivations, and trustworthiness.
That said, the article raises an important question: "buy time for what?" The short answer is: "the real value of a Pause is the coordination we get along the way." Something as big as an international treaty doesn't just drop out of the sky because some powerful force emerged and made it happen against everyone else's will. Think about the end goal and work backwards:
1) An international treaty requires 2) Provisions for monitoring and enforcement, 3) Negotiated between nations, 4) Each of whom genuinely buys in to the underlying need 5) And is politically capable of acting on that interest because it represents the interests of their constituents 6) Because the general public understands AI and its implications enough to care about it 7) And feels empowered to express that concern through an accessible democratic process 8) And is correct in this sense of empowerment because their interests are not overridden by Big Tech lobbying 9) Or distracted into incoherence by internal divisions and polarization
An organization like PauseAI can only have one "banner" ask (1), but (2-9) are instrumentally necessary--and if those were in place, I don't think it's at all unreasonable to assume society would be in a better position to navigate AI risk.
Side note: my objection to the term "doomer" is that it implies a belief that humanity will fail to coordinate, solve alignment in time, or be saved by any other means, and thus will actually be killed off by AI--which seems like it deserves a distinct category from those who simply believe that the risk of extinction by default is real.
I wrote that this "is the best sociological account of the AI x-risk reduction efforts of the last ~decade that I've seen." The line has some disagree reacts inline; I expect this is primarily an expression that the disagree-ers have a low quality assessment of the article, but I would be curious to see links to any other articles or posts that attempt something similar to this one, in order to compare whether they do better/worse/different. I actually can't easily think of any (which is why I felt it was not that bold to say this was the best).
Edit: I've expanded the opening paragraph, to not confuse my comment for me agreeing with the object level assessment of the article..
Of the recent wave of AI companies, the earliest one, DeepMind, relied on the Rationalists for its early funding. The first investor, Peter Thiel, was a donor to Eliezer Yudkowsky’s Singularity Institute for Artificial Intelligence (SIAI, but now MIRI, the Machine Intelligence Research Institute) who met DeepMind’s founder at an SIAI event. Jaan Tallinn, the most important Rationalist donor, was also a critical early investor…
…In 2017, the Open Philanthropy Project directed $30 million to OpenAI…
Good overview of how through AI Safety funders ended up supporting AGI labs.
Curious to read more people’s views of what this led to. See question here: https://www.lesswrong.com/posts/wWMxCs4LFzE4jXXqQ/what-did-ai-safety-s-specific-funding-of-agi-r-and-d-labs
Yes, this is part of why I didn't post AI stuff in the past, and instead just tried to connect with people privately. I might not have accomplished much, but at least I didn't help OpenAI happen or shift the public perception of AI safety towards "fedora-wearing overweight neckbeards".
Instead, the U.S. government will do what it has done every time it’s been convinced of the importance of a powerful new technology in the past hundred years: it will drive research and development for military purposes.
I wonder if there is an actual path to alignment-pilling the US government by framing it as a race to solve alignment? That would get them to make military projects focused on aligning AI as quickly as possible, rather than building a hostile god. It also seems like a fairly defensible position politically, with everything being a struggle between powers to get aligned AI first, counting misaligned AI as one of the powers.
Something like: "Whoever solves alignment first wins the future of the galaxy, therefore we need to race to solve alignment. Capabilities don't help unless they're aligned, and move us closer to a hostile power (the AI) solving alignment and wiping us out."
This is indeed an interesting sociological breakdown of the “movement”, for lack of a better word.
I think the injection of the author’s beliefs about whether or not short timelines are correct distracting from the central point. For example, the author states the following.
there is no good argument for when [AGI] might be built.
This is a bad argument against worrying about short timelines, bordering on intellectual dishonesty. Building anti-asteroid defenses is a good idea even if you don’t know that one is going to hit us within the next year.
The argument that it’s better to have AGI appear sooner rather than later because institutions are slowly breaking down is an interesting one. It’s also nakedly accelerationist, which is strangely inconsistent with the argument that AGI is not coming soon, and in my opinion very naïve.
Besides that, I think it’s generally a good take on the state of the movement, i.e., like pretty much any social movement it has a serious problem with coherence and collateral damage and it’s not clear whether there’s any positive effect.
There are a lot of issues with the article cited above. Due to the need for more specific text formatting, I wrote up my notes, comments, and objections here:
He’s right that arguments for short timelines are essentially vibes-based but he completely ignores the value of technical A.I. safety research, which is pretty much the central justification for our case.
I think the arguments for short timelines are definitely weaker than their proponents usually assume, but they aren't totally vibes based, and while not so probable as to dominate the probability mass, are probable enough to be action guiding:
I do predict that we will probably have at least 1 more paradigm shift before the endgame, but I'm not so confident in it as to dismiss simple scaling.
the arguments for short timelines are definitely weaker than their proponents usually assume, but they aren't totally vibes based
Each person with short timelines can repeat sentences that were generated by a legitimate reason to expect short timelines, but many of them did not generate any of those sentences themselves as the result of trying to figure out when AGI would come; their repeating those sentences is downstream of their timelines. In that sense, for many such people, short timelines actually are totally vibes based.
In that sense, for many such people, short timelines actually are totally vibes based.
I dispute this characterization. It's normal and appropriate for people's views to update in response to the arguments produced by others.
Sure, sometimes people most parrot other people's views, without either developing them independently or even doing evaluatory checks to see if those views seem correct. But most of the time, I think people are doing those checks?
Speaking for myself, most of my views on timelines are downstream of ideas that I didn't generate myself. But I did think about those ideas, and evaluate if they seemed true.
No. You can tell because they can't have an interesting conversation about it, because they don't have surrounding mental content (such as analyses of examples that stand up to interrogation, or open questions, or cruxes that aren't stupid). (This is in contrast to several people who can have an interesting conversation about, even if I think they're wrong and making mistakes and so on.)
But I did think about those ideas, and evaluate if they seemed true.
Of course I can't tell from this sentence, but I'm pretty skeptical both of you in particular and of other people in the broad reference class, that most of them have done this in a manner that really does greatly attenuate the dangers of deference [LW · GW].
Why? Forecasting the future is hard, and I expect surprises that deviate from my model of how things will go. But o1 and o3 seem like pretty blatant evidence that reduced my uncertainty a lot. On pretty simple heuristics, it looks like earth now knows how to make a science and engineering superintelligence: by scaling reasoning modes in a self-play-ish regime.
I would take a bet with you about what we expect to see in the next 5 years. But more than that, what kind of epistemology do you think I should be doing that I'm not?
o1/o3/R1/R1-Zero seem to me like evidence that "scaling reasoning models in a self-play-ish regime" can reach superhuman performance on some class of tasks, with properties like {short horizons, cheap objective verifiability, at most shallow conceptual innovation needed} or maybe some subset thereof. This is important! But, for reasons similar to this part of Tsvi's post [LW · GW], it's a lot less apparent to me that it can get to superintelligence at all science and engineering tasks.
I can't tell what you mean by much of this (e.g. idk what you mean by "pretty simple heuristics" or "science + engineering SI" or "self-play-ish regime"). (Not especially asking you to elaborate.) Most of my thoughts are here, including the comments:
I would take a bet with you about what we expect to see in the next 5 years.
Not really into formal betting, but what are a couple Pareto[impressive, you're confident we'll see within 5 years] things?
But more than that, what kind of epistemology do you think I should be doing that I'm not?
Come on, you know. Actually doubt, and then think it through.
I mean, I don't know. Maybe you really did truly doubt a bunch. Maybe you could argue me from 5% omnicide in next ten years to 50%. Go ahead. I'm speaking from informed priors and impressions.
I think this is true but also that "most people's reasons for believing X are vibes-based" is true for almost any X that is not trivially verifiable. And also that this way of forming beliefs works reasonably well in many cases. This doesn't contradict anything you're saying but feels worth adding, like I don't think AI timelines are an unusual topic in that regard.
E.g. there are many activities that many people engage in frequently--eating, walking around, reading, etc etc. Knowledge and skill related to those activities is usually not vibes-based, or only half vibes-based, or something, even if not trivially verifiable. For example, after a few times accidentally growing mold on some wet clothes or under a sink, very many people learn not to leave areas wet.
E.g. anyone who studies math seriously must learn to verify many very non-trivial things themselves. (There will also be many things they will believe partly based on vibes.)
I don't think AI timelines are an unusual topic in that regard.
In that regard, technically, yes, but it's not very comparable. It's unusual in that it's a crucial question that affects very many people's decisions. (IIRC, EVERY SINGLE ONE of the >5 EA / LW / X-derisking adjacent funder people that I've talked to about human intelligence enhancement says "eh, doesn't matter, timelines short".) And it's in an especially uncertain field, where consensus should much less strongly be expected to be correct. And it's subject to especially strong deference and hype dynamics and disinformation. For comparison, you can probably easily find entire communities in which the vibe is very strongly "COVID came from the wet market" and others where it's very strongly "COVID came from the lab". You can also find communities that say "AGI a century away". There are some questions where the consensus is right for the right reasons and it's reasonable to trust the consensus on some class of beliefs. But vibes-based reasoning is just not robust, and nearly all the resources supposedly aimed at X-derisking in general are captured by a largely vibes-based consensus.
I definitely agree with this, but in their defense, this is to be expected, especially in fast growing fields.
Model building is hard, and specialization generally beats trying to deeply understand something in general, so it's not that surprising that many people won't understand why, and this will be the case regardless of the truth value of timelines claims.
The AI Doomers are only one of several factions that oppose AI and seek to cripple it via weaponized regulation.
Bad faith
There are also factions concerned about “misinformation” and “algorithmic bias,” which in practice means they think chatbots must be censored to prevent them from saying anything politically inconvenient.
Bad faith
AI Doomer coalition abandoned the name “AI safety” and rebranded itself to “AI alignment.”
> AI Doomer coalition abandoned the name “AI safety” and rebranded itself to “AI alignment.”
Seems wrong
(Why do you believe this? I think this is a reasonable gloss of what happened around 2015-2016. I was part of many of those conversations, as I was also part of many of the conversations in which me and others gave up on "AI Alignment" as a thing that could meaningfully describe efforts around existential risk reduction)
Seems to me the name AI safety is currently still widely used, no? As it covers much more than just alignment strategies, by including also stuff like control and governance